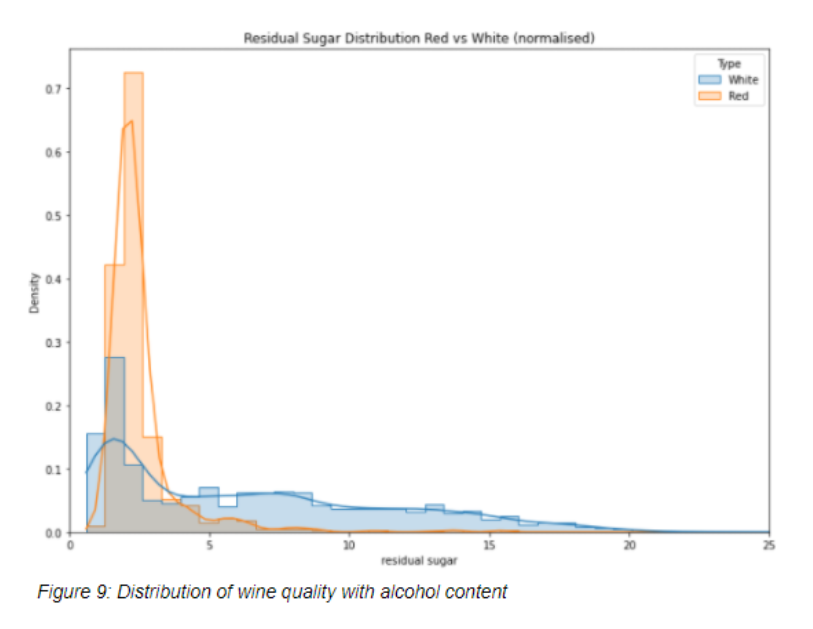
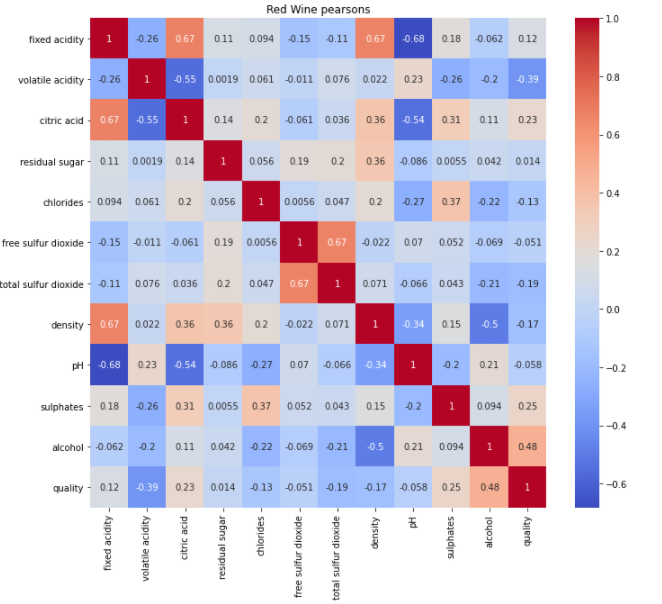
The objective of this study is to explore useful learning models to predict red and white wine quality. First general patterns were analysed; when analysing distribution of quality most scored 5 and 6 dropping off either side, white wines are perceived as generally higher quality. There is a positive correlation between quality and alcohol content in both wines and no significant correlation between quality and sweetness. When analysing correlations, density had a high correlation with alcohol and residual sugar so this was removed for learning, residual Sugar and free sulfur dioxide were also removed for low correlation with quality.
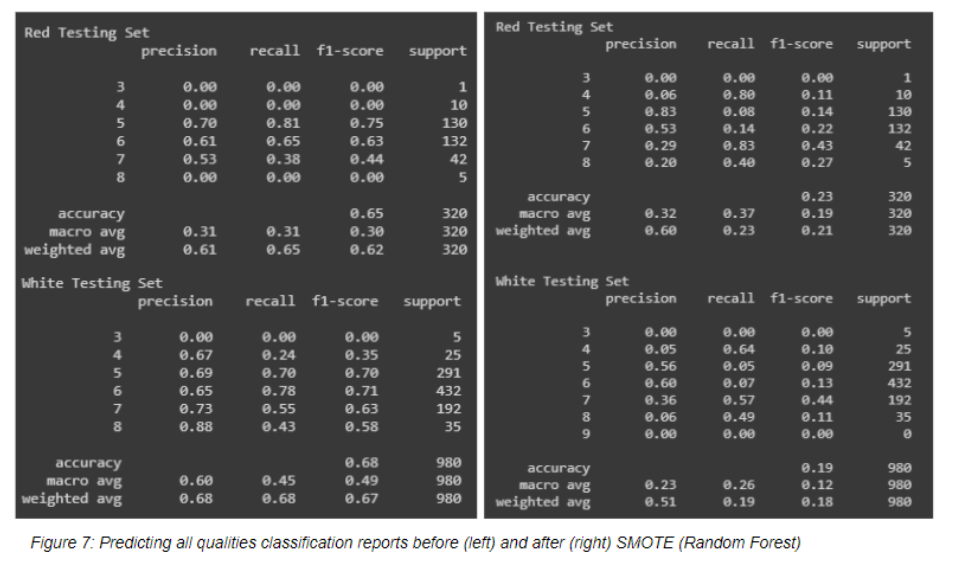
Regarding models, random forest classifier was the most successful classification model with the highest f1 and k-fold scores, however logistic regression performed only a little worse and is less prone to overfitting. The regression models had very low accuracy so would be unsuitable to use however it may be an unsuitable model type in the first place as the outcome set is not highly suitable for treating regressively and there are very few data points for some qualities. Similar problems were found with predicting all qualities as the lack of data points meant low accuracy despite SMOTE. Predicting all quality outcomes proved inaccurate as well especially with low data sample values.
Full report can be found in repository