|
1 | | -# labmlai_annotated_deeplearning_paper_implementation |
2 | | -KOREAN Translation of labmlai/annotated_deep_learning_paper_implementations |
| 1 | +# 가짜연구소에서 진행하는 nn.labml.ai 페이지 번역을 위한 깃헙입니다 |
| 2 | + |
| 3 | + |
| 4 | +[](https://twitter.com/labmlai) |
| 5 | +[](https://github.com/sponsors/labmlai) |
| 6 | + |
| 7 | +# [labml.ai Deep Learning Paper Implementations](https://nn.labml.ai/index.html) |
| 8 | + |
| 9 | +This is a collection of simple PyTorch implementations of |
| 10 | +neural networks and related algorithms. |
| 11 | +These implementations are documented with explanations, |
| 12 | + |
| 13 | +[The website](https://nn.labml.ai/index.html) |
| 14 | +renders these as side-by-side formatted notes. |
| 15 | +We believe these would help you understand these algorithms better. |
| 16 | + |
| 17 | +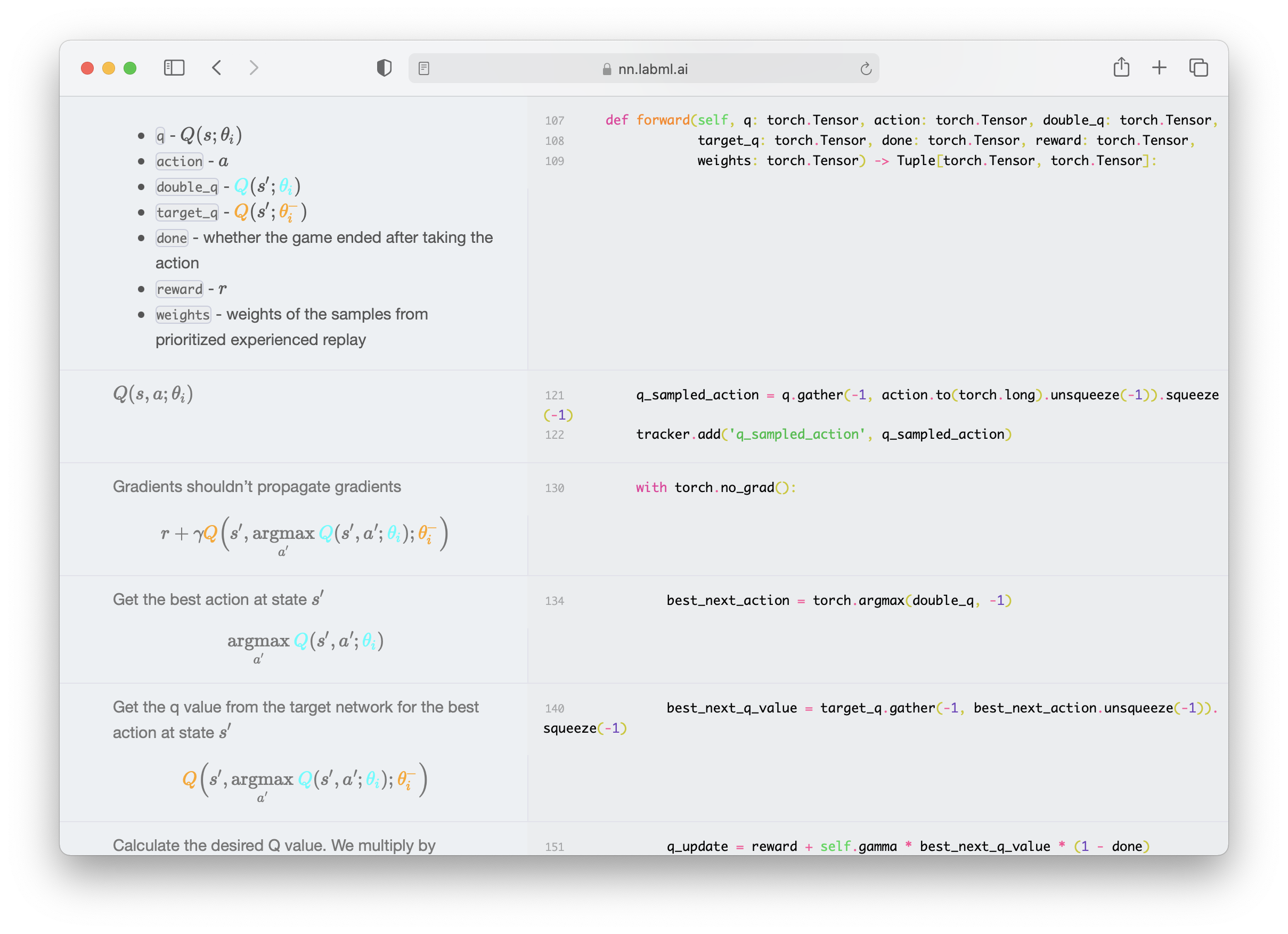 |
| 18 | + |
| 19 | +We are actively maintaining this repo and adding new |
| 20 | +implementations almost weekly. |
| 21 | +[](https://twitter.com/labmlai) for updates. |
| 22 | + |
| 23 | +## Paper Implementations |
| 24 | + |
| 25 | +#### ✨ [Transformers](https://nn.labml.ai/transformers/index.html) |
| 26 | + |
| 27 | +* [Multi-headed attention](https://nn.labml.ai/transformers/mha.html) |
| 28 | +* [Transformer building blocks](https://nn.labml.ai/transformers/models.html) |
| 29 | +* [Transformer XL](https://nn.labml.ai/transformers/xl/index.html) |
| 30 | + * [Relative multi-headed attention](https://nn.labml.ai/transformers/xl/relative_mha.html) |
| 31 | +* [Rotary Positional Embeddings](https://nn.labml.ai/transformers/rope/index.html) |
| 32 | +* [Attention with Linear Biases (ALiBi)](https://nn.labml.ai/transformers/alibi/index.html) |
| 33 | +* [RETRO](https://nn.labml.ai/transformers/retro/index.html) |
| 34 | +* [Compressive Transformer](https://nn.labml.ai/transformers/compressive/index.html) |
| 35 | +* [GPT Architecture](https://nn.labml.ai/transformers/gpt/index.html) |
| 36 | +* [GLU Variants](https://nn.labml.ai/transformers/glu_variants/simple.html) |
| 37 | +* [kNN-LM: Generalization through Memorization](https://nn.labml.ai/transformers/knn) |
| 38 | +* [Feedback Transformer](https://nn.labml.ai/transformers/feedback/index.html) |
| 39 | +* [Switch Transformer](https://nn.labml.ai/transformers/switch/index.html) |
| 40 | +* [Fast Weights Transformer](https://nn.labml.ai/transformers/fast_weights/index.html) |
| 41 | +* [FNet](https://nn.labml.ai/transformers/fnet/index.html) |
| 42 | +* [Attention Free Transformer](https://nn.labml.ai/transformers/aft/index.html) |
| 43 | +* [Masked Language Model](https://nn.labml.ai/transformers/mlm/index.html) |
| 44 | +* [MLP-Mixer: An all-MLP Architecture for Vision](https://nn.labml.ai/transformers/mlp_mixer/index.html) |
| 45 | +* [Pay Attention to MLPs (gMLP)](https://nn.labml.ai/transformers/gmlp/index.html) |
| 46 | +* [Vision Transformer (ViT)](https://nn.labml.ai/transformers/vit/index.html) |
| 47 | +* [Primer EZ](https://nn.labml.ai/transformers/primer_ez/index.html) |
| 48 | +* [Hourglass](https://nn.labml.ai/transformers/hour_glass/index.html) |
| 49 | + |
| 50 | +#### ✨ [Eleuther GPT-NeoX](https://nn.labml.ai/neox/index.html) |
| 51 | +* [Generate on a 48GB GPU](https://nn.labml.ai/neox/samples/generate.html) |
| 52 | +* [Finetune on two 48GB GPUs](https://nn.labml.ai/neox/samples/finetune.html) |
| 53 | +* [LLM.int8()](https://nn.labml.ai/neox/utils/llm_int8.html) |
| 54 | + |
| 55 | +#### ✨ [Diffusion models](https://nn.labml.ai/diffusion/index.html) |
| 56 | + |
| 57 | +* [Denoising Diffusion Probabilistic Models (DDPM)](https://nn.labml.ai/diffusion/ddpm/index.html) |
| 58 | +* [Denoising Diffusion Implicit Models (DDIM)](https://nn.labml.ai/diffusion/stable_diffusion/sampler/ddim.html) |
| 59 | +* [Latent Diffusion Models](https://nn.labml.ai/diffusion/stable_diffusion/latent_diffusion.html) |
| 60 | +* [Stable Diffusion](https://nn.labml.ai/diffusion/stable_diffusion/index.html) |
| 61 | + |
| 62 | +#### ✨ [Generative Adversarial Networks](https://nn.labml.ai/gan/index.html) |
| 63 | +* [Original GAN](https://nn.labml.ai/gan/original/index.html) |
| 64 | +* [GAN with deep convolutional network](https://nn.labml.ai/gan/dcgan/index.html) |
| 65 | +* [Cycle GAN](https://nn.labml.ai/gan/cycle_gan/index.html) |
| 66 | +* [Wasserstein GAN](https://nn.labml.ai/gan/wasserstein/index.html) |
| 67 | +* [Wasserstein GAN with Gradient Penalty](https://nn.labml.ai/gan/wasserstein/gradient_penalty/index.html) |
| 68 | +* [StyleGAN 2](https://nn.labml.ai/gan/stylegan/index.html) |
| 69 | + |
| 70 | +#### ✨ [Recurrent Highway Networks](https://nn.labml.ai/recurrent_highway_networks/index.html) |
| 71 | + |
| 72 | +#### ✨ [LSTM](https://nn.labml.ai/lstm/index.html) |
| 73 | + |
| 74 | +#### ✨ [HyperNetworks - HyperLSTM](https://nn.labml.ai/hypernetworks/hyper_lstm.html) |
| 75 | + |
| 76 | +#### ✨ [ResNet](https://nn.labml.ai/resnet/index.html) |
| 77 | + |
| 78 | +#### ✨ [ConvMixer](https://nn.labml.ai/conv_mixer/index.html) |
| 79 | + |
| 80 | +#### ✨ [Capsule Networks](https://nn.labml.ai/capsule_networks/index.html) |
| 81 | + |
| 82 | +#### ✨ [U-Net](https://nn.labml.ai/unet/index.html) |
| 83 | + |
| 84 | +#### ✨ [Sketch RNN](https://nn.labml.ai/sketch_rnn/index.html) |
| 85 | + |
| 86 | +#### ✨ Graph Neural Networks |
| 87 | + |
| 88 | +* [Graph Attention Networks (GAT)](https://nn.labml.ai/graphs/gat/index.html) |
| 89 | +* [Graph Attention Networks v2 (GATv2)](https://nn.labml.ai/graphs/gatv2/index.html) |
| 90 | + |
| 91 | +#### ✨ [Counterfactual Regret Minimization (CFR)](https://nn.labml.ai/cfr/index.html) |
| 92 | + |
| 93 | +Solving games with incomplete information such as poker with CFR. |
| 94 | + |
| 95 | +* [Kuhn Poker](https://nn.labml.ai/cfr/kuhn/index.html) |
| 96 | + |
| 97 | +#### ✨ [Reinforcement Learning](https://nn.labml.ai/rl/index.html) |
| 98 | +* [Proximal Policy Optimization](https://nn.labml.ai/rl/ppo/index.html) with |
| 99 | + [Generalized Advantage Estimation](https://nn.labml.ai/rl/ppo/gae.html) |
| 100 | +* [Deep Q Networks](https://nn.labml.ai/rl/dqn/index.html) with |
| 101 | + with [Dueling Network](https://nn.labml.ai/rl/dqn/model.html), |
| 102 | + [Prioritized Replay](https://nn.labml.ai/rl/dqn/replay_buffer.html) |
| 103 | + and Double Q Network. |
| 104 | + |
| 105 | +#### ✨ [Optimizers](https://nn.labml.ai/optimizers/index.html) |
| 106 | +* [Adam](https://nn.labml.ai/optimizers/adam.html) |
| 107 | +* [AMSGrad](https://nn.labml.ai/optimizers/amsgrad.html) |
| 108 | +* [Adam Optimizer with warmup](https://nn.labml.ai/optimizers/adam_warmup.html) |
| 109 | +* [Noam Optimizer](https://nn.labml.ai/optimizers/noam.html) |
| 110 | +* [Rectified Adam Optimizer](https://nn.labml.ai/optimizers/radam.html) |
| 111 | +* [AdaBelief Optimizer](https://nn.labml.ai/optimizers/ada_belief.html) |
| 112 | +* [Sophia-G Optimizer](https://nn.labml.ai/optimizers/sophia.html) |
| 113 | + |
| 114 | +#### ✨ [Normalization Layers](https://nn.labml.ai/normalization/index.html) |
| 115 | +* [Batch Normalization](https://nn.labml.ai/normalization/batch_norm/index.html) |
| 116 | +* [Layer Normalization](https://nn.labml.ai/normalization/layer_norm/index.html) |
| 117 | +* [Instance Normalization](https://nn.labml.ai/normalization/instance_norm/index.html) |
| 118 | +* [Group Normalization](https://nn.labml.ai/normalization/group_norm/index.html) |
| 119 | +* [Weight Standardization](https://nn.labml.ai/normalization/weight_standardization/index.html) |
| 120 | +* [Batch-Channel Normalization](https://nn.labml.ai/normalization/batch_channel_norm/index.html) |
| 121 | +* [DeepNorm](https://nn.labml.ai/normalization/deep_norm/index.html) |
| 122 | + |
| 123 | +#### ✨ [Distillation](https://nn.labml.ai/distillation/index.html) |
| 124 | + |
| 125 | +#### ✨ [Adaptive Computation](https://nn.labml.ai/adaptive_computation/index.html) |
| 126 | + |
| 127 | +* [PonderNet](https://nn.labml.ai/adaptive_computation/ponder_net/index.html) |
| 128 | + |
| 129 | +#### ✨ [Uncertainty](https://nn.labml.ai/uncertainty/index.html) |
| 130 | + |
| 131 | +* [Evidential Deep Learning to Quantify Classification Uncertainty](https://nn.labml.ai/uncertainty/evidence/index.html) |
| 132 | + |
| 133 | +#### ✨ [Activations](https://nn.labml.ai/activations/index.html) |
| 134 | + |
| 135 | +* [Fuzzy Tiling Activations](https://nn.labml.ai/activations/fta/index.html) |
| 136 | + |
| 137 | +#### ✨ [Langauge Model Sampling Techniques](https://nn.labml.ai/sampling/index.html) |
| 138 | +* [Greedy Sampling](https://nn.labml.ai/sampling/greedy.html) |
| 139 | +* [Temperature Sampling](https://nn.labml.ai/sampling/temperature.html) |
| 140 | +* [Top-k Sampling](https://nn.labml.ai/sampling/top_k.html) |
| 141 | +* [Nucleus Sampling](https://nn.labml.ai/sampling/nucleus.html) |
| 142 | + |
| 143 | +#### ✨ [Scalable Training/Inference](https://nn.labml.ai/scaling/index.html) |
| 144 | +* [Zero3 memory optimizations](https://nn.labml.ai/scaling/zero3/index.html) |
| 145 | + |
| 146 | +## Highlighted Research Paper PDFs |
| 147 | + |
| 148 | +* [FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/2205.14135.pdf) |
| 149 | +* [Autoregressive Search Engines: Generating Substrings as Document Identifiers](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/2204.10628.pdf) |
| 150 | +* [Training Compute-Optimal Large Language Models](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/2203.15556.pdf) |
| 151 | +* [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/1910.02054.pdf) |
| 152 | +* [PaLM: Scaling Language Modeling with Pathways](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/2204.02311.pdf) |
| 153 | +* [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/dall-e-2.pdf) |
| 154 | +* [STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/2203.14465.pdf) |
| 155 | +* [Improving language models by retrieving from trillions of tokens](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/2112.04426.pdf) |
| 156 | +* [NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/2003.08934.pdf) |
| 157 | +* [Attention Is All You Need](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/1706.03762.pdf) |
| 158 | +* [Denoising Diffusion Probabilistic Models](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/2006.11239.pdf) |
| 159 | +* [Primer: Searching for Efficient Transformers for Language Modeling](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/2109.08668.pdf) |
| 160 | +* [On First-Order Meta-Learning Algorithms](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/1803.02999.pdf) |
| 161 | +* [Learning Transferable Visual Models From Natural Language Supervision](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/2103.00020.pdf) |
| 162 | +* [The Sensory Neuron as a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/2109.02869.pdf) |
| 163 | +* [Meta-Gradient Reinforcement Learning](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/1805.09801.pdf) |
| 164 | +* [ETA Prediction with Graph Neural Networks in Google Maps](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/google_maps_eta.pdf) |
| 165 | +* [PonderNet: Learning to Ponder](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/ponder_net.pdf) |
| 166 | +* [Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/muzero.pdf) |
| 167 | +* [GANs N’ Roses: Stable, Controllable, Diverse Image to Image Translation (works for videos too!)](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/gans_n_roses.pdf) |
| 168 | +* [An Image is Worth 16X16 Word: Transformers for Image Recognition at Scale](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/vit.pdf) |
| 169 | +* [Deep Residual Learning for Image Recognition](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/resnet.pdf) |
| 170 | +* [Distilling the Knowledge in a Neural Network](https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/papers/distillation.pdf) |
| 171 | + |
| 172 | +### Installation |
| 173 | + |
| 174 | +```bash |
| 175 | +pip install labml-nn |
| 176 | +``` |
| 177 | + |
| 178 | +### Citing |
| 179 | + |
| 180 | +If you use this for academic research, please cite it using the following BibTeX entry. |
| 181 | + |
| 182 | +```bibtex |
| 183 | +@misc{labml, |
| 184 | + author = {Varuna Jayasiri, Nipun Wijerathne}, |
| 185 | + title = {labml.ai Annotated Paper Implementations}, |
| 186 | + year = {2020}, |
| 187 | + url = {https://nn.labml.ai/}, |
| 188 | +} |
| 189 | +``` |
| 190 | + |
| 191 | +### Other Projects |
| 192 | + |
| 193 | +#### [🚀 Trending Research Papers](https://papers.labml.ai/) |
| 194 | + |
| 195 | +This shows the most popular research papers on social media. It also aggregates links to useful resources like paper explanations videos and discussions. |
| 196 | + |
| 197 | + |
| 198 | +#### [🧪 labml.ai/labml](https://github.com/labmlai/labml) |
| 199 | + |
| 200 | +This is a library that let's you monitor deep learning model training and hardware usage from your mobile phone. It also comes with a bunch of other tools to help write deep learning code efficiently. |
| 201 | + |
0 commit comments