In the realm of video game development, the creation of unique and engaging characters plays a pivotal role in crafting immersive experiences. This project explores the innovative use of Stable Diffusion, an advanced deep learning model, for the generation of video game characters, enhanced through fine-tuning methodologies like DreamBooth and LoRA. The project focuses on leveraging the generative AI models to automate the creation of highly variative video game characters. By responding to a wide array of descriptive prompts such as 'cyberpunk', 'mythological' and 'post-apocalyptic', this project allows the generation of diverse, thematic character skins, enhancing both creativity and efficiency in game design.
Creating diverse and thematic character skins in video games is a resource-intensive task. It involves many iterations of creating designs and editing them. Sometimes samples can be discarded and new ones have to be created, which requires a lot of ideas and creativity. This project aims to boost the process of creatining drafts by streamlining this process with automated skin generation using AI, responsive to a variety of thematic prompts.
The motivation is deeply connected with evolving needs of the video game industry in the realm of character designing. As games become vast and complex in details more characters are required to populate the in-game world, even smaller companies might have difficulties to allocate resources for quality designs due to the lack of them. Making this resource intensive work of graphical designers more eficient can save a lot of time and efforts. This project sits at the confluence of AI technology and creative game design, with the potential to revolutionize character skin creation. Automating this process will not only save time and resources but also allow for greater creative exploration in game design.
Our approach utilizes the DreamBooth and LoRA techniques, fine-tuned with a dataset of character images. The AI is trained to generate skins based on a wide range of prompts like 'cyberpunk', 'mythological' and 'post-apocalyptic', ensuring versatility and adaptability in design.
DreamBooth - this approach changes all weights of the model associating it with some keywoard the model is trained on. Using this approach the model can learn how to generate many new and different characters and even change the generation style. For example, the base model was trained on realistic images, then generating fictional, art styled characters will produce worse results. However with a lot of fine-tuning with the DreamBooth technique, the model will learn how to produce art styled images. The final model produced is of the size of the original and usually over 4gb.
LoRA(Low Rank Adaptation) - another smaller model is trained, that adds it's weights to the cross attention layer of the base diffusion model to produce results as closest to the images it was trained on. This approach is good at introducing some aspect to the generation. There can be character, style, pose, concept, clothing LoRAs that enhance some detail of the image. This is suitable to generate high-quality images of a certaing character. The LoRA models can weight from 20mb to 300mb which is much smaller than the base models.
Stable Diffusion represents a cutting-edge generative model, but its potential in specific domains like video game character design is yet to be fully explored. The model open-sourceness enables the possibility for customization and fine-tuning, making it a prefect choice for our goal. The choice of DreamBooth and a diverse range of prompts aims to surpass the limitations of traditional AI models in terms of creative freedom and thematic accuracy. DreamBooth fine-tunes the model to understand previously unknown concepts. By combining those concepts the model is capable of creating diverse and unseen representations of the characters. LoRa doesn't fine-tune the base model so it is efficient at learn one aspect, making it impossible to understand multiple characters simultaneously. The base model might not produce quality images when applying known aspects, but which were unseen with other character. This is where LoRAs shine, they are able to introduce new notion to already known by learning it thoroughly. Character LoRAs can enhance the generation of certain characters, pose LoRAs - make the charater stand in a new pose, style LoRA - change the style of the image, clothing LoRAs - make the character dress a specific clothing. Even with two good approaches the exceptional part is that they can be combined, producing unbelievable results.
The project hinges on the fine-tuned DreamBooth model and the comprehensiveness of the dataset. One limitation may be the AI's interpretation accuracy of complex or abstract themes. Another limitation is the resolution of our images which is lower than the standard for stable diffusion and leads to blurryness. Last limitation is the bounded computational resources, with a dataset this size, learning all characters requires a lot of training, this could not be achieved given our resources and time bounds.
The dataset contains a total of 32,000 images with 50 images for each of the 646 characters from 13 games. This was created by web scrapping using BeautifulSoup and Selenium. The images are rgb and the sizes are approximately 200x200 pixels which is smaller than the 512x512 the stable diffusion model was trained on, so the images will be upscaled for training and thus produces a more blurry picture after fine-tuning.
The WebScrapper.ipynb was used to collect images from bing for the dataset. This notebook can be run by executing all its cells. It requires a csv file with columns "Game" and "Character" along with specifying base_dir variable for the save directory. The csv file with the character names can be located in the repository.
The web scraping notebook web-scraping.ipynb can be run to download images for a desired character. The search_prompt variable describes what images to search on google images. Tha variables download_path specifies the image download location and charachter_name under which to save the images.
Use dataset_formater.ipynb to format the dataset in a specific structure. Given a csv file with character names and a directory with images extracts them into a new directory with this structure: "Game name"/"character name"/"images" format. Takes a list of Image_name:labels pairs and creates a directory with the same structure but for text files with image labels in the specified location.
For the model we used: runwayml/stable-diffusion-v1-5 from huggingface and Counterfeit-V3.0.
For the variational auto encoder [vae] we used: stabilityai/sd-vae-ft-mse
For finetuning we used DreamBooth from the diffusers library.
For finetuning we used LoRA from the diffusers library.
Training was done on a system with an RTX 4070 [12 GB of VRAM], 32 GB of RAM on a WSL environment.
The model's architecture:
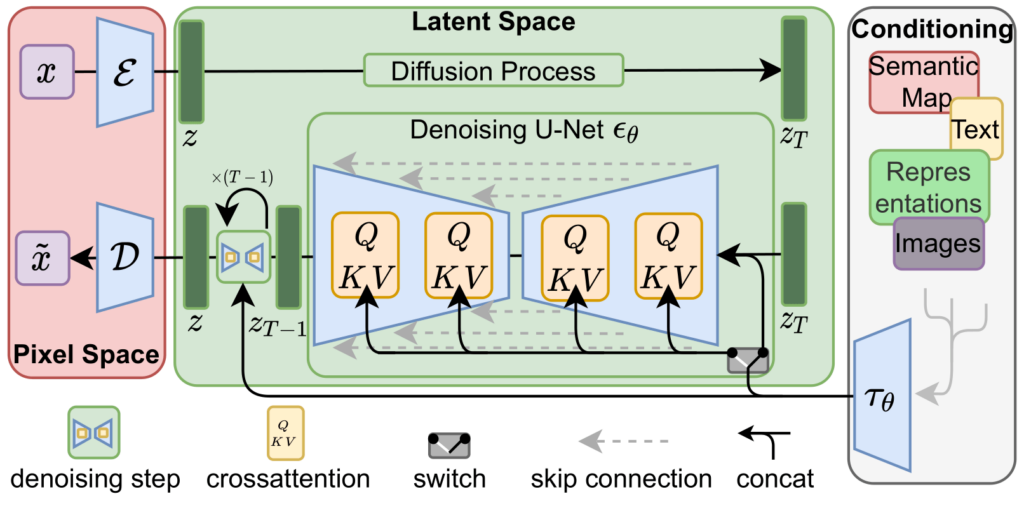
Diffuses the image in a latent space, adds additional parameters like text and denoises the image using a U-net with cross attention layers.
DreamBooth: StableDiffustion v1.5 takes in images of size 512x512 and for our training, we have used the parameters as:
precision - fp16
train_batch_size - 1
use_8bit_adam - TRUE
To keep the VRAM used just under 12GB
LoRa:
precision - fp16 pretrained_model_name_or_path - runwayml/stable-diffusion-v1-5 dataloader_num_workers - 0 resolution - 512 center_crop random_flip train_batch_size - 2 gradient_accumulation_steps - 4 max_train_steps - 15000 learning_rate - 1e-04 max_grad_norm: 1 lr_scheduler: "cosine" lr_warmup_steps - 0 checkpointing_steps - 1000 validation_epochs - 100 rank - 20
The above variables can be customized inside the script file for DreamBooth or LoRA training.
DreamBooth:
Open DB-Finetuning.ipynb notebook and customize the variables as desired. This code utilizes the train_dreambooth.py script from the diffusers library. Customize MODEL_NAME to change the model and OUTPUT_DIR for the output directory. Edit the concepts list to add new concepts to train on. The concept list specifies a dictionaries with the folloeing parameters: instance_prompt - the prompt to associate images with unique words; class_prompt-general propt without any unique words; instance_data_dir - the directory with images we want to teach on; class_data_dir - the directory of images with concepts we want to preserve. Run all the cells to train the model. Run the inference section to generate images using the fine-tuned model, then model_path and promp have to be specified.
LoRA:
A LoRA can be trained by using the lora-train.ipynb notebook, MODEL_NAME, OUTPUT_DIR, DATASET_NAME have to be specified to before running the notebook. DATASET_NAME specifies the name of the dataset as on huggingface hub. To create a custom dataset the 'dataset_path' and 'labels_paths' variables need to point to the images and labels, where labels is a folder of txt files where the name of the file matches the name of the corresponding image. Still, DATASET_NAME has to be correctly pointing to the newly uploaded dataset. Other training parameters can be specified as desired. This code utilizes the training script train_text_to_image_lora.py from the diffusers library. After training the model will be saved to th OUTPUT_DIR location.
Initial results are promising, showing the model's capability to generate unique and thematic skins while adhereing to the prompt instructions. Here is a comparison of generating the character Cypher from Valorant:

The following promt was used to generate the images:
3d, blur censor, blurry, blurry background, blurry foreground, bokeh, cellphone picture, chromatic aberration, concert, cosplay photo, depth of field, female pov, figure, film grain, focused, glowstick, meta, money, motion blur, multiple girls, photo (medium), photo (object), photo background, photo inset, photorealistic, poster (object), pov, pov hands, rainbow, reference inset, shopping, stadium, taking picture, unconventional media, cypher, valorant.
The results produced by different models:
Base stable-diffusion-v1.5:

DreamBooth fine-tuned:

LoRA:

Here we can see the comparison of the generated images. Base stable diffusion generated incoherent noise and didn't know about the character at all. DreamBooth produced a recognizable picture of Cypher that is not precise, still elements of his character could be seen, this is an impressive leap compared to the not fine-tuned model. The LoRA produced result image is the closes to the original character, which shows the high-quality approach of Low Rank Adaptations. However, the image is all pixelated, mostly due to the lower resolution of our data. We can see that both approaches have different results, the DreamBooth fine-tuned model was able to learn the character to a limited extent which migh be because of insufficient training, nevertheless the picture stayed clean, as the model knows how to produce high-quality images. On the other hand, LoRA managed to capture the character in all details but also captured the low resolution of our data.
Furher is a comparison of stable-diffusion-v1.5 to a couterfeitv3.0 model, which was already fully fine-tuned using the DreamBooth technique. This model was trained on different art, anime styled character and is better at producing them.
This is a picture of a character from League of Legends named Ahri:

The following pictures were generated using this prompt: 1girl, ahri, animal ears, bare shoulders, black hair, blurry, blurry foreground, closed eyes, depth of field, detached sleeves, facial mark, fox ears, fox tail, korean clothes, long hair, multiple tails, solo, tail, vastaya, whisker markings
This is a picture of Ahri created by stable-diffusion-v1.5 with Ahri LoRA applied:

This is a picture of Ahri created by couterfeitv3.0 with Ahri LoRA applied:

Comparing the stable-diffusion-v1.5 with counterfeit-v3.0 both models using Ahri Lora we can see how drifferent the image quality is. The base model produces a recognizable but distorted image with a lot of artifacts and in a bad quality, all due to it trying to produce an image in a compeletly different art style and unseen concepts, like a human with fox tails. The other model could produce a good image of a girl with ears and fox tails, however, it didn't look as close as the Ahri character. Subsequently, applying an Ahri LoRA to this model produces exceptional results as seen on the second image. That's the result of counterfeit being able to generate high-quality art images by it's own then the LoRA tweaks the generation to fully create a desired character. Given all the positive, there is one limitation, that counterfeit-v3.0 has difficulties in generating Ahri in a suit as it has only seen chinese dresses. This issue, however, can be fixed by applying a clothing LoRA.
Let's compare counterfeit-v3.0 the model on a character it's familiar with and then with a LoRA applied to it.
Here is the image of Raiden Shogun from the game Genshin Impact:

The folliwing images were generated using this simple prompt to understand the difference in concept learning: 1girl, raiden shogun, genshin impact
This image is generated via counterfeit-v3.0 without Raiden Shogun LoRA:

This image is generated via counterfeit-v3.0 with Raiden Shogun LoRA:

From the results obtained it is evident how the model with Raiden Shogun LoRA understood the character fully and generated a close to the original image. The model without LoRA knew this character, nevertheless the knowledge was not to the extent to reproduce it in full details. This reveals how much applying a LoRA changes the created image, even when knowing a character LoRAs add precision. It's worth mentioning that the more different the training images of a character are the better the results will be, as the model will not memorize certain attributes like pose or weapon. Overall, combinig a fine-tuned model with LoRAs produces the best results.
Parameters were selected so that the model could be trained on the system available. LoRA rank must be chosen > 10 otherwise the model has a small impact on the generation. Enabling random_flip greatly enhances the model generation quality and concept understanding. use_8bit_adam - TRUE - reduces the VRAM requirements and is advised to use with gpus with less than 12gb VRAM. validation_epochs = 100 otherwise the model validates too much interrupting the training.
Overall we achieved a predicted result for this project. We managed to fine-tune the stable-diffusion-v1.5 model using different approaches, although some generated images could not represent the character in details or lacked quality. We expected the DreamBooth fine-tuned model to generate images closer to the original, however this was not observed. This is probably due to the small number of iterations each image was seen by the model, when increasing the fine-tuning would take much more time, but could still be done in the future. The LoRA approach produced excelent results on the counterfeit model, but the base model sometimes produced wrong shapes, artifacts. This is most probable due to the stable-diffusion model being trained on realistic images and applying the LoRA to produce an art of a fictional character clashed with existing knowledge. The reduction in resolution observed in all generations with a LoRA applied is a result of our dataset having a smaller resolution that the base models were trained on. Interestingly, this had a lesser impact on the DreamBooth fine-tuned model. All those disadvantages can be fixed to produce exceptional results. Combining our own DreamBooth trained model with LoRAs could enhance the generations even further. Generating a character and changing their clothing, appearance was possible to some extent, this can be fixed by adding variablity to the dataset.
To conclude, we gathered a dataset of 32,000 character images from different games, explored various diffusion model fine-tuning approaches like DreamBooth and LoRAs. Fine-tuned the stable-diffusion-v1.5 model using the found approaches and compared them. Compared results using LoRAs with the original model and another, art and anime fine-tuned one. Analyzed the results and found places for imrovement. We found out that our DreamBooth fine-tuned stable-diffusion-v1.5 model produces recognizable but not detailed character images due to the lack of training epochs. We realized that our datased reduces the image quality especially when using LoRAs, due to the low resolution of it. When analyzing both approaches we understood that DreamBooth has more variability while LoRAs have a better precision when generating images. The first approach is better and faster at teaching the model a lot of new concepts when the other excels at introducing one. Our comparison revealed that combining DreamBooth and LoRAs will produce the best results, subsequently, we can use them together on our dataset. Finally, we managed to generate various character designs with different skin attributes like clothing, poses, setting. Lastly, agreed on steps for further improvement and exploration.
- The next step is to try different models with this approach.
- Fine-tune the model on a high-resolution dataset.
- Comibne LoRA and our DreamBooth trained model.
- Try training style, clothing, concept LoRAs and compare results.
- Explore the use of LyCORIS for model fine-tuning.
- https://huggingface.co/runwayml/stable-diffusion-v1-5
- https://github.com/ShivamShrirao/diffusers/tree/main/examples/dreambooth
- https://huggingface.co/blog/stable_diffusion
- https://huggingface.co/docs/diffusers/training/lora?installation=PyTorch
- https://github.com/huggingface/diffusers/tree/main/examples/text_to_image
- https://civitai.com/models/4468?modelVersionId=57618
- https://github.com/AUTOMATIC1111/stable-diffusion-webui
- https://huggingface.co/openai/clip-vit-base-patch32
- https://github.com/KichangKim/DeepDanbooru
Alexander Seljuk, Varadh Kaushik, Girish Adari Kumar