diff --git a/.github/workflows/test_llm.yml b/.github/workflows/test_llm.yml
new file mode 100644
index 000000000..31b218c52
--- /dev/null
+++ b/.github/workflows/test_llm.yml
@@ -0,0 +1,42 @@
+name: UnitTests for Fine-tuning LLMs
+
+on:
+ pull_request:
+ types: [opened, synchronize, edited]
+
+jobs:
+ run:
+ if: false == contains(github.event.pull_request.title, 'WIP')
+ runs-on: ${{ matrix.os }}
+ timeout-minutes: 20
+ strategy:
+ matrix:
+ os: [ubuntu-latest]
+ python-version: ['3.9']
+ torch-version: ['2.0.0']
+ torchvision-version: ['0.15.0']
+ torchaudio-version: ['2.0.0']
+ env:
+ OS: ${{ matrix.os }}
+ PYTHON: '3.9'
+ steps:
+ - uses: actions/checkout@master
+ - name: Setup Python ${{ matrix.python-version }}
+ uses: actions/setup-python@master
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install PyTorch ${{ matrix.torch-version }}+cpu
+ run: |
+ pip install numpy typing-extensions dataclasses
+ pip install torch==${{ matrix.torch-version}}+cpu torchvision==${{matrix.torchvision-version}}+cpu torchaudio==${{matrix.torchaudio-version}}+cpu -f https://download.pytorch.org/whl/torch_stable.html
+ - name: Install FS
+ run: |
+ pip install -e .[llm,test]
+ - name: Test GPT2
+ run: |
+ python federatedscope/main.py --cfg federatedscope/llm/baseline/testcase.yaml federate.total_round_num 1 eval.count_flops False train.local_update_steps 2 data.splits "[0.998, 0.001, 0.001]"
+ [ $? -eq 1 ] && exit 1 || echo "Passed"
+ - name: Test GPT2 with offsite-tuning
+ run: |
+ python federatedscope/main.py --cfg federatedscope/llm/baseline/testcase.yaml federate.total_round_num 1 eval.count_flops False llm.offsite_tuning.use True llm.offsite_tuning.emu_l 2 llm.offsite_tuning.emu_r 10 train.local_update_steps 2 data.splits "[0.998, 0.001, 0.001]"
+ [ $? -eq 1 ] && exit 1 || echo "Passed"
\ No newline at end of file
diff --git a/LICENSE b/LICENSE
index 82e353b70..b4d15e39c 100644
--- a/LICENSE
+++ b/LICENSE
@@ -661,3 +661,45 @@ distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
+
+---------------------------------------------------------------------------------
+The implementations of LLM dataset in federatedscope/llm/dataset/llm_dataset.py
+adapted from https://github.com/tatsu-lab/stanford_alpaca (Apache License)
+
+Copyright 2023 Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+
+---------------------------------------------------------------------------------
+The implementations of evaluation for MMLU in federatedscope/llm/eval_for_mmlu/eval.py
+and federatedscope/llm/eval_for_mmlu/categories.py are adapted from https://github.com/hendrycks/test (MIT License)
+
+Copyright (c) 2020 Dan Hendrycks
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/README-main.md b/README-main.md
new file mode 100644
index 000000000..8e1f3fb64
--- /dev/null
+++ b/README-main.md
@@ -0,0 +1,339 @@
+
+  +
+
+
+
+
+[](https://federatedscope.io/)
+[](https://colab.research.google.com/github/alibaba/FederatedScope)
+[](https://federatedscope.io/docs/contributor/)
+
+FederatedScope is a comprehensive federated learning platform that provides convenient usage and flexible customization for various federated learning tasks in both academia and industry. Based on an event-driven architecture, FederatedScope integrates rich collections of functionalities to satisfy the burgeoning demands from federated learning, and aims to build up an easy-to-use platform for promoting learning safely and effectively.
+
+A detailed tutorial is provided on our website: [federatedscope.io](https://federatedscope.io/)
+
+You can try FederatedScope via [FederatedScope Playground](https://try.federatedscope.io/) or [Google Colab](https://colab.research.google.com/github/alibaba/FederatedScope).
+
+| [Code Structure](#code-structure) | [Quick Start](#quick-start) | [Advanced](#advanced) | [Documentation](#documentation) | [Publications](#publications) | [Contributing](#contributing) |
+
+## News
+-  [05-17-2023] Our paper [FS-REAL](https://arxiv.org/abs/2303.13363) has been accepted by KDD'2023!
+-  [05-17-2023] Our benchmark paper for FL backdoor attacks [Backdoor Attacks Bench](https://arxiv.org/abs/2302.01677) has been accepted by KDD'2023!
+-  [05-17-2023] Our paper [Communication Efficient and Differentially Private Logistic Regression under the Distributed Setting]() has been accepted by KDD'2023!
+-  [04-25-2023] Our paper [pFedGate](https://arxiv.org/abs/2305.02776) has been accepted by ICML'2023!
+-  [04-25-2023] Our benchmark paper for FedHPO [FedHPO-Bench](https://arxiv.org/abs/2206.03966) has been accepted by ICML'2023!
+-  [04-03-2023] We release FederatedScope v0.3.0!
+- [02-10-2022] Our [paper](https://arxiv.org/pdf/2204.05011.pdf) elaborating on FederatedScope is accepted by VLDB'23!
+- [10-05-2022] Our benchmark paper for personalized FL, [pFL-Bench](https://arxiv.org/abs/2206.03655) has been accepted by NeurIPS'22, Dataset and Benchmark Track!
+- [08-18-2022] Our KDD 2022 [paper](https://arxiv.org/abs/2204.05562) on federated graph learning receives the KDD Best Paper Award for ADS track!
+- [07-30-2022] We release FederatedScope v0.2.0!
+- [06-17-2022] We release **pFL-Bench**, a comprehensive benchmark for personalized Federated Learning (pFL), containing 10+ datasets and 20+ baselines. [[code](https://github.com/alibaba/FederatedScope/tree/master/benchmark/pFL-Bench), [pdf](https://arxiv.org/abs/2206.03655)]
+- [06-17-2022] We release **FedHPO-Bench**, a benchmark suite for studying federated hyperparameter optimization. [[code](https://github.com/alibaba/FederatedScope/tree/master/benchmark/FedHPOBench), [pdf](https://arxiv.org/abs/2206.03966)]
+- [06-17-2022] We release **B-FHTL**, a benchmark suit for studying federated hetero-task learning. [[code](https://github.com/alibaba/FederatedScope/tree/master/benchmark/B-FHTL), [pdf](https://arxiv.org/abs/2206.03436)]
+- [06-13-2022] Our project was receiving an attack, which has been resolved. [More details](https://github.com/alibaba/FederatedScope/blob/master/doc/news/06-13-2022_Declaration_of_Emergency.txt).
+- [05-25-2022] Our paper [FederatedScope-GNN](https://arxiv.org/abs/2204.05562) has been accepted by KDD'2022!
+- [05-06-2022] We release FederatedScope v0.1.0!
+
+## Code Structure
+```
+FederatedScope
+├── federatedscope
+│ ├── core
+│ | ├── workers # Behaviors of participants (i.e., server and clients)
+│ | ├── trainers # Details of local training
+│ | ├── aggregators # Details of federated aggregation
+│ | ├── configs # Customizable configurations
+│ | ├── monitors # The monitor module for logging and demonstrating
+│ | ├── communication.py # Implementation of communication among participants
+│ | ├── fed_runner.py # The runner for building and running an FL course
+│ | ├── ... ..
+│ ├── cv # Federated learning in CV
+│ ├── nlp # Federated learning in NLP
+│ ├── gfl # Graph federated learning
+│ ├── autotune # Auto-tunning for federated learning
+│ ├── vertical_fl # Vartical federated learning
+│ ├── contrib
+│ ├── main.py
+│ ├── ... ...
+├── scripts # Scripts for reproducing existing algorithms
+├── benchmark # We release several benchmarks for convenient and fair comparisons
+├── doc # For automatic documentation
+├── enviornment # Installation requirements and provided docker files
+├── materials # Materials of related topics (e.g., paper lists)
+│ ├── notebook
+│ ├── paper_list
+│ ├── tutorial
+│ ├── ... ...
+├── tests # Unittest modules for continuous integration
+├── LICENSE
+└── setup.py
+```
+
+## Quick Start
+
+We provide an end-to-end example for users to start running a standard FL course with FederatedScope.
+
+### Step 1. Installation
+
+First of all, users need to clone the source code and install the required packages (we suggest python version >= 3.9). You can choose between the following two installation methods (via docker or conda) to install FederatedScope.
+
+```bash
+git clone https://github.com/alibaba/FederatedScope.git
+cd FederatedScope
+```
+#### Use Docker
+
+You can build docker image and run with docker env (cuda 11 and torch 1.10):
+
+```
+docker build -f environment/docker_files/federatedscope-torch1.10.Dockerfile -t alibaba/federatedscope:base-env-torch1.10 .
+docker run --gpus device=all --rm -it --name "fedscope" -w $(pwd) alibaba/federatedscope:base-env-torch1.10 /bin/bash
+```
+If you need to run with down-stream tasks such as graph FL, change the requirement/docker file name into another one when executing the above commands:
+```
+# environment/requirements-torch1.10.txt ->
+environment/requirements-torch1.10-application.txt
+
+# environment/docker_files/federatedscope-torch1.10.Dockerfile ->
+environment/docker_files/federatedscope-torch1.10-application.Dockerfile
+```
+Note: You can choose to use cuda 10 and torch 1.8 via changing `torch1.10` to `torch1.8`.
+The docker images are based on the nvidia-docker. Please pre-install the NVIDIA drivers and `nvidia-docker2` in the host machine. See more details [here](https://github.com/alibaba/FederatedScope/tree/master/environment/docker_files).
+
+#### Use Conda
+
+We recommend using a new virtual environment to install FederatedScope:
+
+```bash
+conda create -n fs python=3.9
+conda activate fs
+```
+
+If your backend is torch, please install torch in advance ([torch-get-started](https://pytorch.org/get-started/locally/)). For example, if your cuda version is 11.3 please execute the following command:
+
+```bash
+conda install -y pytorch=1.10.1 torchvision=0.11.2 torchaudio=0.10.1 torchtext=0.11.1 cudatoolkit=11.3 -c pytorch -c conda-forge
+```
+
+For users with Apple M1 chips:
+```bash
+conda install pytorch torchvision torchaudio -c pytorch
+# Downgrade torchvision to avoid segmentation fault
+python -m pip install torchvision==0.11.3
+```
+
+Finally, after the backend is installed, you can install FederatedScope from `source`:
+
+##### From source
+
+```bash
+# Editable mode
+pip install -e .
+
+# Or (developers for dev mode)
+pip install -e .[dev]
+pre-commit install
+```
+
+Now, you have successfully installed the minimal version of FederatedScope. (**Optinal**) For application version including graph, nlp and speech, run:
+
+```bash
+bash environment/extra_dependencies_torch1.10-application.sh
+```
+
+### Step 2. Prepare datasets
+
+To run an FL task, users should prepare a dataset.
+The DataZoo provided in FederatedScope can help to automatically download and preprocess widely-used public datasets for various FL applications, including CV, NLP, graph learning, recommendation, etc. Users can directly specify `cfg.data.type = DATASET_NAME`in the configuration. For example,
+
+```bash
+cfg.data.type = 'femnist'
+```
+
+To use customized datasets, you need to prepare the datasets following a certain format and register it. Please refer to [Customized Datasets](https://federatedscope.io/docs/own-case/#data) for more details.
+
+### Step 3. Prepare models
+
+Then, users should specify the model architecture that will be trained in the FL course.
+FederatedScope provides a ModelZoo that contains the implementation of widely adopted model architectures for various FL applications. Users can set up `cfg.model.type = MODEL_NAME` to apply a specific model architecture in FL tasks. For example,
+
+```yaml
+cfg.model.type = 'convnet2'
+```
+
+FederatedScope allows users to use customized models via registering. Please refer to [Customized Models](https://federatedscope.io/docs/own-case/#model) for more details about how to customize a model architecture.
+
+### Step 4. Start running an FL task
+
+Note that FederatedScope provides a unified interface for both standalone mode and distributed mode, and allows users to change via configuring.
+
+#### Standalone mode
+
+The standalone mode in FederatedScope means to simulate multiple participants (servers and clients) in a single device, while participants' data are isolated from each other and their models might be shared via message passing.
+
+Here we demonstrate how to run a standard FL task with FederatedScope, with setting `cfg.data.type = 'FEMNIST'`and `cfg.model.type = 'ConvNet2'` to run vanilla FedAvg for an image classification task. Users can customize training configurations, such as `cfg.federated.total_round_num`, `cfg.dataloader.batch_size`, and `cfg.train.optimizer.lr`, in the configuration (a .yaml file), and run a standard FL task as:
+
+```bash
+# Run with default configurations
+python federatedscope/main.py --cfg scripts/example_configs/femnist.yaml
+# Or with custom configurations
+python federatedscope/main.py --cfg scripts/example_configs/femnist.yaml federate.total_round_num 50 dataloader.batch_size 128
+```
+
+Then you can observe some monitored metrics during the training process as:
+
+```
+INFO: Server has been set up ...
+INFO: Model meta-info: .
+... ...
+INFO: Client has been set up ...
+INFO: Model meta-info: .
+... ...
+INFO: {'Role': 'Client #5', 'Round': 0, 'Results_raw': {'train_loss': 207.6341676712036, 'train_acc': 0.02, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.152683353424072}}
+INFO: {'Role': 'Client #1', 'Round': 0, 'Results_raw': {'train_loss': 209.0940284729004, 'train_acc': 0.02, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.1818805694580075}}
+INFO: {'Role': 'Client #8', 'Round': 0, 'Results_raw': {'train_loss': 202.24929332733154, 'train_acc': 0.04, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.0449858665466305}}
+INFO: {'Role': 'Client #6', 'Round': 0, 'Results_raw': {'train_loss': 209.43883895874023, 'train_acc': 0.06, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.1887767791748045}}
+INFO: {'Role': 'Client #9', 'Round': 0, 'Results_raw': {'train_loss': 208.83140087127686, 'train_acc': 0.0, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.1766280174255375}}
+INFO: ----------- Starting a new training round (Round #1) -------------
+... ...
+INFO: Server: Training is finished! Starting evaluation.
+INFO: Client #1: (Evaluation (test set) at Round #20) test_loss is 163.029045
+... ...
+INFO: Server: Final evaluation is finished! Starting merging results.
+... ...
+```
+
+#### Distributed mode
+
+The distributed mode in FederatedScope denotes running multiple procedures to build up an FL course, where each procedure plays as a participant (server or client) that instantiates its model and loads its data. The communication between participants is already provided by the communication module of FederatedScope.
+
+To run with distributed mode, you only need to:
+
+- Prepare isolated data file and set up `cfg.data.file_path = PATH/TO/DATA` for each participant;
+- Change `cfg.federate.model = 'distributed'`, and specify the role of each participant by `cfg.distributed.role = 'server'/'client'`.
+- Set up a valid address by `cfg.distribute.server_host/client_host = x.x.x.x` and `cfg.distribute.server_port/client_port = xxxx`. (Note that for a server, you need to set up `server_host` and `server_port` for listening messages, while for a client, you need to set up `client_host` and `client_port` for listening as well as `server_host` and `server_port` for joining in an FL course)
+
+We prepare a synthetic example for running with distributed mode:
+
+```bash
+# For server
+python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_server.yaml data.file_path 'PATH/TO/DATA' distribute.server_host x.x.x.x distribute.server_port xxxx
+
+# For clients
+python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_client_1.yaml data.file_path 'PATH/TO/DATA' distribute.server_host x.x.x.x distribute.server_port xxxx distribute.client_host x.x.x.x distribute.client_port xxxx
+python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_client_2.yaml data.file_path 'PATH/TO/DATA' distribute.server_host x.x.x.x distribute.server_port xxxx distribute.client_host x.x.x.x distribute.client_port xxxx
+python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_client_3.yaml data.file_path 'PATH/TO/DATA' distribute.server_host x.x.x.x distribute.server_port xxxx distribute.client_host x.x.x.x distribute.client_port xxxx
+```
+
+An executable example with generated toy data can be run with (a script can be found in `scripts/run_distributed_lr.sh`):
+```bash
+# Generate the toy data
+python scripts/distributed_scripts/gen_data.py
+
+# Firstly start the server that is waiting for clients to join in
+python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_server.yaml data.file_path toy_data/server_data distribute.server_host 127.0.0.1 distribute.server_port 50051
+
+# Start the client #1 (with another process)
+python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_client_1.yaml data.file_path toy_data/client_1_data distribute.server_host 127.0.0.1 distribute.server_port 50051 distribute.client_host 127.0.0.1 distribute.client_port 50052
+# Start the client #2 (with another process)
+python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_client_2.yaml data.file_path toy_data/client_2_data distribute.server_host 127.0.0.1 distribute.server_port 50051 distribute.client_host 127.0.0.1 distribute.client_port 50053
+# Start the client #3 (with another process)
+python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_client_3.yaml data.file_path toy_data/client_3_data distribute.server_host 127.0.0.1 distribute.server_port 50051 distribute.client_host 127.0.0.1 distribute.client_port 50054
+```
+
+And you can observe the results as (the IP addresses are anonymized with 'x.x.x.x'):
+
+```
+INFO: Server: Listen to x.x.x.x:xxxx...
+INFO: Server has been set up ...
+Model meta-info: .
+... ...
+INFO: Client: Listen to x.x.x.x:xxxx...
+INFO: Client (address x.x.x.x:xxxx) has been set up ...
+Client (address x.x.x.x:xxxx) is assigned with #1.
+INFO: Model meta-info: .
+... ...
+{'Role': 'Client #2', 'Round': 0, 'Results_raw': {'train_avg_loss': 5.215108394622803, 'train_loss': 333.7669372558594, 'train_total': 64}}
+{'Role': 'Client #1', 'Round': 0, 'Results_raw': {'train_total': 64, 'train_loss': 290.9668884277344, 'train_avg_loss': 4.54635763168335}}
+----------- Starting a new training round (Round #1) -------------
+... ...
+INFO: Server: Training is finished! Starting evaluation.
+INFO: Client #1: (Evaluation (test set) at Round #20) test_loss is 30.387419
+... ...
+INFO: Server: Final evaluation is finished! Starting merging results.
+... ...
+```
+
+
+## Advanced
+
+As a comprehensive FL platform, FederatedScope provides the fundamental implementation to support requirements of various FL applications and frontier studies, towards both convenient usage and flexible extension, including:
+
+- **Personalized Federated Learning**: Client-specific model architectures and training configurations are applied to handle the non-IID issues caused by the diverse data distributions and heterogeneous system resources.
+- **Federated Hyperparameter Optimization**: When hyperparameter optimization (HPO) comes to Federated Learning, each attempt is extremely costly due to multiple rounds of communication across participants. It is worth noting that HPO under the FL is unique and more techniques should be promoted such as low-fidelity HPO.
+- **Privacy Attacker**: The privacy attack algorithms are important and convenient to verify the privacy protection strength of the design FL systems and algorithms, which is growing along with Federated Learning.
+- **Graph Federated Learning**: Working on the ubiquitous graph data, Graph Federated Learning aims to exploit isolated sub-graph data to learn a global model, and has attracted increasing popularity.
+- **Recommendation**: As a number of laws and regulations go into effect all over the world, more and more people are aware of the importance of privacy protection, which urges the recommender system to learn from user data in a privacy-preserving manner.
+- **Differential Privacy**: Different from the encryption algorithms that require a large amount of computation resources, differential privacy is an economical yet flexible technique to protect privacy, which has achieved great success in database and is ever-growing in federated learning.
+- ...
+
+More supports are coming soon! We have prepared a [tutorial](https://federatedscope.io/) to provide more details about how to utilize FederatedScope to enjoy your journey of Federated Learning!
+
+Materials of related topics are constantly being updated, please refer to [FL-Recommendation](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/FL-Recommendation), [Federated-HPO](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/Federated_HPO), [Personalized FL](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/Personalized_FL), [Federated Graph Learning](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/Federated_Graph_Learning), [FL-NLP](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/FL-NLP), [FL-Attacker](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/FL-Attacker), [FL-Incentive-Mechanism](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/FL-Incentive), [FL-Fairness](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/FL-Fiarness) and so on.
+
+## Documentation
+
+The classes and methods of FederatedScope have been well documented so that users can generate the API references by:
+
+```shell
+cd doc
+pip install -r requirements.txt
+make html
+```
+NOTE:
+* The `doc/requirements.txt` is only for documentation of API by Sphinx, which can be automatically generated by Github actions `.github/workflows/sphinx.yml`. (Trigger by pull request if `DOC` in the title.)
+* Download via Artifacts in Github actions.
+
+We put the API references on our [website](https://federatedscope.io/refs/index).
+
+Besides, we provide documents for [executable scripts](https://github.com/alibaba/FederatedScope/tree/master/scripts) and [customizable configurations](https://github.com/alibaba/FederatedScope/tree/master/federatedscope/core/configs).
+
+## License
+
+FederatedScope is released under Apache License 2.0.
+
+## Publications
+If you find FederatedScope useful for your research or development, please cite the following paper:
+```
+@article{federatedscope,
+ title = {FederatedScope: A Flexible Federated Learning Platform for Heterogeneity},
+ author = {Xie, Yuexiang and Wang, Zhen and Gao, Dawei and Chen, Daoyuan and Yao, Liuyi and Kuang, Weirui and Li, Yaliang and Ding, Bolin and Zhou, Jingren},
+ journal={Proceedings of the VLDB Endowment},
+ volume={16},
+ number={5},
+ pages={1059--1072},
+ year={2023}
+}
+```
+More publications can be found in the [Publications](https://federatedscope.io/pub/).
+
+## Contributing
+
+We **greatly appreciate** any contribution to FederatedScope! We provide a developer version of FederatedScope with additional pre-commit hooks to perform commit checks compared to the official version:
+
+```bash
+# Install the developer version
+pip install -e .[dev]
+pre-commit install
+
+# Or switch to the developer version from the official version
+pip install pre-commit
+pre-commit install
+pre-commit run --all-files
+```
+
+You can refer to [Contributing to FederatedScope](https://federatedscope.io/docs/contributor/) for more details.
+
+Welcome to join in our [Slack channel](https://join.slack.com/t/federatedscopeteam/shared_invite/zt-1apmfjqmc-hvpYbsWJdm7D93wPNXbqww), or DingDing group (please scan the following QR code) for discussion.
+
+ diff --git a/README.md b/README.md
deleted file mode 100644
index 4d3501c12..000000000
--- a/README.md
+++ /dev/null
@@ -1,334 +0,0 @@
-
diff --git a/README.md b/README.md
deleted file mode 100644
index 4d3501c12..000000000
--- a/README.md
+++ /dev/null
@@ -1,334 +0,0 @@
-
-
-
-
-
-
-[](https://federatedscope.io/)
-[](https://try.federatedscope.io/)
-[](https://federatedscope.io/docs/contributor/)
-
-FederatedScope is a comprehensive federated learning platform that provides convenient usage and flexible customization for various federated learning tasks in both academia and industry. Based on an event-driven architecture, FederatedScope integrates rich collections of functionalities to satisfy the burgeoning demands from federated learning, and aims to build up an easy-to-use platform for promoting learning safely and effectively.
-
-A detailed tutorial is provided on our website: [federatedscope.io](https://federatedscope.io/)
-
-You can try FederatedScope via [FederatedScope Playground](https://try.federatedscope.io/) or [Google Colab](https://colab.research.google.com/github/alibaba/FederatedScope).
-
-| [Code Structure](#code-structure) | [Quick Start](#quick-start) | [Advanced](#advanced) | [Documentation](#documentation) | [Publications](#publications) | [Contributing](#contributing) |
-
-## News
--  [04-03-2023] We release FederatedScope v0.3.0!
--  [02-10-2022] Our [paper](https://arxiv.org/pdf/2204.05011.pdf) elaborating on FederatedScope is accepted by VLDB'23!
--  [10-05-2022] Our benchmark paper for personalized FL, [pFL-Bench](https://arxiv.org/abs/2206.03655) has been accepted by NeurIPS'22, Dataset and Benchmark Track!
--  [08-18-2022] Our KDD 2022 [paper](https://arxiv.org/abs/2204.05562) on federated graph learning receives the KDD Best Paper Award for ADS track!
-- [07-30-2022] We release FederatedScope v0.2.0!
-- [06-17-2022] We release **pFL-Bench**, a comprehensive benchmark for personalized Federated Learning (pFL), containing 10+ datasets and 20+ baselines. [[code](https://github.com/alibaba/FederatedScope/tree/master/benchmark/pFL-Bench), [pdf](https://arxiv.org/abs/2206.03655)]
-- [06-17-2022] We release **FedHPO-Bench**, a benchmark suite for studying federated hyperparameter optimization. [[code](https://github.com/alibaba/FederatedScope/tree/master/benchmark/FedHPOBench), [pdf](https://arxiv.org/abs/2206.03966)]
-- [06-17-2022] We release **B-FHTL**, a benchmark suit for studying federated hetero-task learning. [[code](https://github.com/alibaba/FederatedScope/tree/master/benchmark/B-FHTL), [pdf](https://arxiv.org/abs/2206.03436)]
-- [06-13-2022] Our project was receiving an attack, which has been resolved. [More details](https://github.com/alibaba/FederatedScope/blob/master/doc/news/06-13-2022_Declaration_of_Emergency.txt).
-- [05-25-2022] Our paper [FederatedScope-GNN](https://arxiv.org/abs/2204.05562) has been accepted by KDD'2022!
-- [05-06-2022] We release FederatedScope v0.1.0!
-
-## Code Structure
-```
-FederatedScope
-├── federatedscope
-│ ├── core
-│ | ├── workers # Behaviors of participants (i.e., server and clients)
-│ | ├── trainers # Details of local training
-│ | ├── aggregators # Details of federated aggregation
-│ | ├── configs # Customizable configurations
-│ | ├── monitors # The monitor module for logging and demonstrating
-│ | ├── communication.py # Implementation of communication among participants
-│ | ├── fed_runner.py # The runner for building and running an FL course
-│ | ├── ... ..
-│ ├── cv # Federated learning in CV
-│ ├── nlp # Federated learning in NLP
-│ ├── gfl # Graph federated learning
-│ ├── autotune # Auto-tunning for federated learning
-│ ├── vertical_fl # Vartical federated learning
-│ ├── contrib
-│ ├── main.py
-│ ├── ... ...
-├── scripts # Scripts for reproducing existing algorithms
-├── benchmark # We release several benchmarks for convenient and fair comparisons
-├── doc # For automatic documentation
-├── enviornment # Installation requirements and provided docker files
-├── materials # Materials of related topics (e.g., paper lists)
-│ ├── notebook
-│ ├── paper_list
-│ ├── tutorial
-│ ├── ... ...
-├── tests # Unittest modules for continuous integration
-├── LICENSE
-└── setup.py
-```
-
-## Quick Start
-
-We provide an end-to-end example for users to start running a standard FL course with FederatedScope.
-
-### Step 1. Installation
-
-First of all, users need to clone the source code and install the required packages (we suggest python version >= 3.9). You can choose between the following two installation methods (via docker or conda) to install FederatedScope.
-
-```bash
-git clone https://github.com/alibaba/FederatedScope.git
-cd FederatedScope
-```
-#### Use Docker
-
-You can build docker image and run with docker env (cuda 11 and torch 1.10):
-
-```
-docker build -f environment/docker_files/federatedscope-torch1.10.Dockerfile -t alibaba/federatedscope:base-env-torch1.10 .
-docker run --gpus device=all --rm -it --name "fedscope" -w $(pwd) alibaba/federatedscope:base-env-torch1.10 /bin/bash
-```
-If you need to run with down-stream tasks such as graph FL, change the requirement/docker file name into another one when executing the above commands:
-```
-# environment/requirements-torch1.10.txt ->
-environment/requirements-torch1.10-application.txt
-
-# environment/docker_files/federatedscope-torch1.10.Dockerfile ->
-environment/docker_files/federatedscope-torch1.10-application.Dockerfile
-```
-Note: You can choose to use cuda 10 and torch 1.8 via changing `torch1.10` to `torch1.8`.
-The docker images are based on the nvidia-docker. Please pre-install the NVIDIA drivers and `nvidia-docker2` in the host machine. See more details [here](https://github.com/alibaba/FederatedScope/tree/master/environment/docker_files).
-
-#### Use Conda
-
-We recommend using a new virtual environment to install FederatedScope:
-
-```bash
-conda create -n fs python=3.9
-conda activate fs
-```
-
-If your backend is torch, please install torch in advance ([torch-get-started](https://pytorch.org/get-started/locally/)). For example, if your cuda version is 11.3 please execute the following command:
-
-```bash
-conda install -y pytorch=1.10.1 torchvision=0.11.2 torchaudio=0.10.1 torchtext=0.11.1 cudatoolkit=11.3 -c pytorch -c conda-forge
-```
-
-For users with Apple M1 chips:
-```bash
-conda install pytorch torchvision torchaudio -c pytorch
-# Downgrade torchvision to avoid segmentation fault
-python -m pip install torchvision==0.11.3
-```
-
-Finally, after the backend is installed, you can install FederatedScope from `source`:
-
-##### From source
-
-```bash
-# Editable mode
-pip install -e .
-
-# Or (developers for dev mode)
-pip install -e .[dev]
-pre-commit install
-```
-
-Now, you have successfully installed the minimal version of FederatedScope. (**Optinal**) For application version including graph, nlp and speech, run:
-
-```bash
-bash environment/extra_dependencies_torch1.10-application.sh
-```
-
-### Step 2. Prepare datasets
-
-To run an FL task, users should prepare a dataset.
-The DataZoo provided in FederatedScope can help to automatically download and preprocess widely-used public datasets for various FL applications, including CV, NLP, graph learning, recommendation, etc. Users can directly specify `cfg.data.type = DATASET_NAME`in the configuration. For example,
-
-```bash
-cfg.data.type = 'femnist'
-```
-
-To use customized datasets, you need to prepare the datasets following a certain format and register it. Please refer to [Customized Datasets](https://federatedscope.io/docs/own-case/#data) for more details.
-
-### Step 3. Prepare models
-
-Then, users should specify the model architecture that will be trained in the FL course.
-FederatedScope provides a ModelZoo that contains the implementation of widely adopted model architectures for various FL applications. Users can set up `cfg.model.type = MODEL_NAME` to apply a specific model architecture in FL tasks. For example,
-
-```yaml
-cfg.model.type = 'convnet2'
-```
-
-FederatedScope allows users to use customized models via registering. Please refer to [Customized Models](https://federatedscope.io/docs/own-case/#model) for more details about how to customize a model architecture.
-
-### Step 4. Start running an FL task
-
-Note that FederatedScope provides a unified interface for both standalone mode and distributed mode, and allows users to change via configuring.
-
-#### Standalone mode
-
-The standalone mode in FederatedScope means to simulate multiple participants (servers and clients) in a single device, while participants' data are isolated from each other and their models might be shared via message passing.
-
-Here we demonstrate how to run a standard FL task with FederatedScope, with setting `cfg.data.type = 'FEMNIST'`and `cfg.model.type = 'ConvNet2'` to run vanilla FedAvg for an image classification task. Users can customize training configurations, such as `cfg.federated.total_round_num`, `cfg.dataloader.batch_size`, and `cfg.train.optimizer.lr`, in the configuration (a .yaml file), and run a standard FL task as:
-
-```bash
-# Run with default configurations
-python federatedscope/main.py --cfg scripts/example_configs/femnist.yaml
-# Or with custom configurations
-python federatedscope/main.py --cfg scripts/example_configs/femnist.yaml federate.total_round_num 50 dataloader.batch_size 128
-```
-
-Then you can observe some monitored metrics during the training process as:
-
-```
-INFO: Server has been set up ...
-INFO: Model meta-info: .
-... ...
-INFO: Client has been set up ...
-INFO: Model meta-info: .
-... ...
-INFO: {'Role': 'Client #5', 'Round': 0, 'Results_raw': {'train_loss': 207.6341676712036, 'train_acc': 0.02, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.152683353424072}}
-INFO: {'Role': 'Client #1', 'Round': 0, 'Results_raw': {'train_loss': 209.0940284729004, 'train_acc': 0.02, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.1818805694580075}}
-INFO: {'Role': 'Client #8', 'Round': 0, 'Results_raw': {'train_loss': 202.24929332733154, 'train_acc': 0.04, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.0449858665466305}}
-INFO: {'Role': 'Client #6', 'Round': 0, 'Results_raw': {'train_loss': 209.43883895874023, 'train_acc': 0.06, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.1887767791748045}}
-INFO: {'Role': 'Client #9', 'Round': 0, 'Results_raw': {'train_loss': 208.83140087127686, 'train_acc': 0.0, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.1766280174255375}}
-INFO: ----------- Starting a new training round (Round #1) -------------
-... ...
-INFO: Server: Training is finished! Starting evaluation.
-INFO: Client #1: (Evaluation (test set) at Round #20) test_loss is 163.029045
-... ...
-INFO: Server: Final evaluation is finished! Starting merging results.
-... ...
-```
-
-#### Distributed mode
-
-The distributed mode in FederatedScope denotes running multiple procedures to build up an FL course, where each procedure plays as a participant (server or client) that instantiates its model and loads its data. The communication between participants is already provided by the communication module of FederatedScope.
-
-To run with distributed mode, you only need to:
-
-- Prepare isolated data file and set up `cfg.data.file_path = PATH/TO/DATA` for each participant;
-- Change `cfg.federate.model = 'distributed'`, and specify the role of each participant by `cfg.distributed.role = 'server'/'client'`.
-- Set up a valid address by `cfg.distribute.server_host/client_host = x.x.x.x` and `cfg.distribute.server_port/client_port = xxxx`. (Note that for a server, you need to set up `server_host` and `server_port` for listening messages, while for a client, you need to set up `client_host` and `client_port` for listening as well as `server_host` and `server_port` for joining in an FL course)
-
-We prepare a synthetic example for running with distributed mode:
-
-```bash
-# For server
-python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_server.yaml data.file_path 'PATH/TO/DATA' distribute.server_host x.x.x.x distribute.server_port xxxx
-
-# For clients
-python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_client_1.yaml data.file_path 'PATH/TO/DATA' distribute.server_host x.x.x.x distribute.server_port xxxx distribute.client_host x.x.x.x distribute.client_port xxxx
-python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_client_2.yaml data.file_path 'PATH/TO/DATA' distribute.server_host x.x.x.x distribute.server_port xxxx distribute.client_host x.x.x.x distribute.client_port xxxx
-python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_client_3.yaml data.file_path 'PATH/TO/DATA' distribute.server_host x.x.x.x distribute.server_port xxxx distribute.client_host x.x.x.x distribute.client_port xxxx
-```
-
-An executable example with generated toy data can be run with (a script can be found in `scripts/run_distributed_lr.sh`):
-```bash
-# Generate the toy data
-python scripts/distributed_scripts/gen_data.py
-
-# Firstly start the server that is waiting for clients to join in
-python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_server.yaml data.file_path toy_data/server_data distribute.server_host 127.0.0.1 distribute.server_port 50051
-
-# Start the client #1 (with another process)
-python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_client_1.yaml data.file_path toy_data/client_1_data distribute.server_host 127.0.0.1 distribute.server_port 50051 distribute.client_host 127.0.0.1 distribute.client_port 50052
-# Start the client #2 (with another process)
-python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_client_2.yaml data.file_path toy_data/client_2_data distribute.server_host 127.0.0.1 distribute.server_port 50051 distribute.client_host 127.0.0.1 distribute.client_port 50053
-# Start the client #3 (with another process)
-python federatedscope/main.py --cfg scripts/distributed_scripts/distributed_configs/distributed_client_3.yaml data.file_path toy_data/client_3_data distribute.server_host 127.0.0.1 distribute.server_port 50051 distribute.client_host 127.0.0.1 distribute.client_port 50054
-```
-
-And you can observe the results as (the IP addresses are anonymized with 'x.x.x.x'):
-
-```
-INFO: Server: Listen to x.x.x.x:xxxx...
-INFO: Server has been set up ...
-Model meta-info: .
-... ...
-INFO: Client: Listen to x.x.x.x:xxxx...
-INFO: Client (address x.x.x.x:xxxx) has been set up ...
-Client (address x.x.x.x:xxxx) is assigned with #1.
-INFO: Model meta-info: .
-... ...
-{'Role': 'Client #2', 'Round': 0, 'Results_raw': {'train_avg_loss': 5.215108394622803, 'train_loss': 333.7669372558594, 'train_total': 64}}
-{'Role': 'Client #1', 'Round': 0, 'Results_raw': {'train_total': 64, 'train_loss': 290.9668884277344, 'train_avg_loss': 4.54635763168335}}
------------ Starting a new training round (Round #1) -------------
-... ...
-INFO: Server: Training is finished! Starting evaluation.
-INFO: Client #1: (Evaluation (test set) at Round #20) test_loss is 30.387419
-... ...
-INFO: Server: Final evaluation is finished! Starting merging results.
-... ...
-```
-
-
-## Advanced
-
-As a comprehensive FL platform, FederatedScope provides the fundamental implementation to support requirements of various FL applications and frontier studies, towards both convenient usage and flexible extension, including:
-
-- **Personalized Federated Learning**: Client-specific model architectures and training configurations are applied to handle the non-IID issues caused by the diverse data distributions and heterogeneous system resources.
-- **Federated Hyperparameter Optimization**: When hyperparameter optimization (HPO) comes to Federated Learning, each attempt is extremely costly due to multiple rounds of communication across participants. It is worth noting that HPO under the FL is unique and more techniques should be promoted such as low-fidelity HPO.
-- **Privacy Attacker**: The privacy attack algorithms are important and convenient to verify the privacy protection strength of the design FL systems and algorithms, which is growing along with Federated Learning.
-- **Graph Federated Learning**: Working on the ubiquitous graph data, Graph Federated Learning aims to exploit isolated sub-graph data to learn a global model, and has attracted increasing popularity.
-- **Recommendation**: As a number of laws and regulations go into effect all over the world, more and more people are aware of the importance of privacy protection, which urges the recommender system to learn from user data in a privacy-preserving manner.
-- **Differential Privacy**: Different from the encryption algorithms that require a large amount of computation resources, differential privacy is an economical yet flexible technique to protect privacy, which has achieved great success in database and is ever-growing in federated learning.
-- ...
-
-More supports are coming soon! We have prepared a [tutorial](https://federatedscope.io/) to provide more details about how to utilize FederatedScope to enjoy your journey of Federated Learning!
-
-Materials of related topics are constantly being updated, please refer to [FL-Recommendation](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/FL-Recommendation), [Federated-HPO](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/Federated_HPO), [Personalized FL](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/Personalized_FL), [Federated Graph Learning](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/Federated_Graph_Learning), [FL-NLP](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/FL-NLP), [FL-Attacker](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/FL-Attacker), [FL-Incentive-Mechanism](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/FL-Incentive), [FL-Fairness](https://github.com/alibaba/FederatedScope/tree/master/materials/paper_list/FL-Fiarness) and so on.
-
-## Documentation
-
-The classes and methods of FederatedScope have been well documented so that users can generate the API references by:
-
-```shell
-cd doc
-pip install -r requirements.txt
-make html
-```
-NOTE:
-* The `doc/requirements.txt` is only for documentation of API by Sphinx, which can be automatically generated by Github actions `.github/workflows/sphinx.yml`. (Trigger by pull request if `DOC` in the title.)
-* Download via Artifacts in Github actions.
-
-We put the API references on our [website](https://federatedscope.io/refs/index).
-
-Besides, we provide documents for [executable scripts](https://github.com/alibaba/FederatedScope/tree/master/scripts) and [customizable configurations](https://github.com/alibaba/FederatedScope/tree/master/federatedscope/core/configs).
-
-## License
-
-FederatedScope is released under Apache License 2.0.
-
-## Publications
-If you find FederatedScope useful for your research or development, please cite the following paper:
-```
-@article{federatedscope,
- title = {FederatedScope: A Flexible Federated Learning Platform for Heterogeneity},
- author = {Xie, Yuexiang and Wang, Zhen and Gao, Dawei and Chen, Daoyuan and Yao, Liuyi and Kuang, Weirui and Li, Yaliang and Ding, Bolin and Zhou, Jingren},
- journal={Proceedings of the VLDB Endowment},
- volume={16},
- number={5},
- pages={1059--1072},
- year={2023}
-}
-```
-More publications can be found in the [Publications](https://federatedscope.io/pub/).
-
-## Contributing
-
-We **greatly appreciate** any contribution to FederatedScope! We provide a developer version of FederatedScope with additional pre-commit hooks to perform commit checks compared to the official version:
-
-```bash
-# Install the developer version
-pip install -e .[dev]
-pre-commit install
-
-# Or switch to the developer version from the official version
-pip install pre-commit
-pre-commit install
-pre-commit run --all-files
-```
-
-You can refer to [Contributing to FederatedScope](https://federatedscope.io/docs/contributor/) for more details.
-
-Welcome to join in our [Slack channel](https://join.slack.com/t/federatedscopeteam/shared_invite/zt-1apmfjqmc-hvpYbsWJdm7D93wPNXbqww), or DingDing group (please scan the following QR code) for discussion.
-
-
diff --git a/README.md b/README.md
new file mode 120000
index 000000000..148230b49
--- /dev/null
+++ b/README.md
@@ -0,0 +1 @@
+federatedscope/llm/README.md
\ No newline at end of file
diff --git a/README_setup.md b/README_setup.md
new file mode 100644
index 000000000..11b707ad5
--- /dev/null
+++ b/README_setup.md
@@ -0,0 +1,89 @@
+# Installation, Setup and Running of FederatedScope for LLMs Fine-tuning
+
+First, use a virtual environment manager such as pyenv to create a virtual environment. Make sure you are using Python 3.9.0:
+
+```bash
+pyenv install 3.9.0
+pyenv virtualenv 3.9.0 fs-llm_3.9.0
+pyenv activate fs-llm_3.9.0
+```
+
+Clone the specific branch of the FederatedScope repository to your machine:
+
+```bash
+git clone --branch llm-eloquence https://github.com/jordiluque/FederatedScope.git
+```
+
+To ensure that the correct CUDA paths are set, add the following lines to your `.bashrc` (or equivalent shell configuration file). The CUDA version should be around version 12 (e.g., 12.4, 12.5, or 12.6). If you don’t already have the [CUTLASS](https://github.com/NVIDIA/cutlass) repository installed, clone and set it up on your machine.
+
+```bash
+export PATH=/usr/local/cuda-12/bin/:$PATH
+export LD_LIBRARY_PATH=/usr/local/cuda-12/lib64:/usr/local/cuda-12/lib:$LD_LIBRARY_PATH
+export CUDA_HOME=/usr/local/cuda-12
+export CUTLASS_PATH=/home/user/repos/cutlass
+```
+
+After editing `.bashrc`, don't forget to run:
+
+```bash
+source ~/.bashrc
+```
+
+Install the following Python libraries. The specific versions are known to work well:
+```bash
+pip install torch==2.4.1 torchaudio==2.4.1 torchvision==0.19.1
+```
+
+From the source of the repository, install the required FederatedScope requirements:
+```bash
+pip install -e .[llm]
+```
+
+Check if the default script runs correctly to verify the installation:
+
+```bash
+python federatedscope/main.py --cfg federatedscope/llm/baseline/testcase.yaml
+```
+
+Now let's install and configure DeepSpeed. It is is highly recommended for efficiently fine-tuning LLMs. To install it, run:
+
+```bash
+pip install deepspeed
+```
+
+Install the cupy library for CUDA Acceleration with CUDA 12 support:
+
+```bash
+pip install cupy-cuda12x
+```
+
+If you are working with recent models (e.g., Phi models), they may not be included in the default version of the transformers library. In this case, upgrade the library:
+
+```bash
+pip install --upgrade transformers
+```
+
+Before using DeepSpeed, review the configuration file at `federatedscope/llm/baseline/deepspeed/ds_config_4bs.json`. Ensure that the train_batch_size parameter is properly set to match the number of GPUs available on your machine.
+
+Check if fine-tuning an LLM in standalone mode works correctly with DeepSpeed. Run the following script to verify that the fine-tuning process is functioning properly:
+
+```bash
+deepspeed federatedscope/main.py --cfg configs/standalone/Phi-3.5-mini-instruct/ds_3c_200r_30ls.yaml
+```
+
+To execute federated fine-tuning in distributed mode, separate commands need to be run for the server and each client. In the FederatedScope framework, each client must run on a different machine. The following config files will allow us to test if the setup works with two clients in distributed mode. However, before running the commands, ensure that the `server_host`, `server_port`, `client_host`, and `client_port` fields in the config files are updated with the correct IP addresses and ports for your machines. Additionally, adjust CUDA_VISIBLE_DEVICES to reflect the number of GPUs available on each machine.
+
+To run the server use:
+```bash
+deepspeed --master_addr=127.0.0.1 --master_port=29500 federatedscope/main.py --cfg configs/distributed/Phi-3.5-mini-instruct/server_ds_2c_200r_30ls.yaml
+```
+
+To run a first client in one machine use:
+```bash
+CUDA_VISIBLE_DEVICES=0,1,2 deepspeed --master_addr=127.0.0.1 --master_port=29500 federatedscope/main.py --cfg configs/distributed/Phi-3.5-mini-instruct/client_1_ds_2c_200r_30ls.yaml
+```
+
+To run a second client in another machine:
+```bash
+CUDA_VISIBLE_DEVICES=0,1,2 deepspeed --master_addr=127.0.0.1 --master_port=29500 federatedscope/main.py --cfg configs/distributed/Phi-3.5-mini-instruct/client_2_ds_2c_200r_30ls.yaml
+```
\ No newline at end of file
diff --git a/benchmark/Backdoor-bench/README.md b/benchmark/Backdoor-bench/README.md
new file mode 100644
index 000000000..faadbd5e1
--- /dev/null
+++ b/benchmark/Backdoor-bench/README.md
@@ -0,0 +1,91 @@
+# Benchmark for Back-door Attack on Personalized Federated Learning
+
+
+
+Backdoor-bench is a benchmark for backdoor attacks on personalized federated learning. It contains backdoor attacks including [edge-based trigger](https://arxiv.org/abs/2007.05084), [BadNet](https://ieeexplore.ieee.org/document/8685687), [Blended](https://arxiv.org/abs/1712.05526) and [SIG](https://arxiv.org/abs/1902.11237). The attacked pFL methods include: FedAvg, Fine-tuning (FT), Ditto, FedEM, pFedMe, FedBN, FedRep. More details about the benchmark settings and experimental results refer to our KDD [paper](https://arxiv.org/abs/2302.01677).
+
+**Notice**:
+Considering FederatedScope is an open-sourced library that updates frequently, to ensure the reproducibility of the experimental results, we create a new branch `backdoor-bench`. The users can reproduce the results by running the configs under the directory [scripts/B-backdoor_scripts attack_config](https://github.com/alibaba/FederatedScope/tree/backdoor-bench/scripts/backdoor_scripts/attack_config). The results of our paper is located in `paper_plot/results_all`.
+
+## Publications
+
+If you find Back-door-bench useful for your research or development, please cite the following [paper](https://arxiv.org/pdf/2302.01677.pdf):
+
+```tex
+@inproceedings{
+qin2023revisiting,
+title={Revisiting Personalized Federated Learning: Robustness Against Backdoor Attacks},
+author={Zeyu Qin and Liuyi Yao and Daoyuan Chen and Yaliang Li and Bolin Ding and Minhao Cheng},
+booktitle={29th SIGKDD Conference on Knowledge Discovery and Data Mining - Applied Data Science Track},
+year={2023},
+}
+```
+
+## Quick Start
+
+To run the script, you should
+- First clone the repository [FederatedScope](https://github.com/alibaba/FederatedScope),
+- Then follow [README.md](https://github.com/alibaba/FederatedScope/blob/master/README.md) to build the running environment for FederatedScope,
+- Switch to the branch `backdoor-bench` and run the scripts
+```bash
+# Step-1. clone the repository
+git clone https://github.com/alibaba/FederatedScope.git
+
+# Step-2. follow https://github.com/alibaba/FederatedScope/blob/master/README.md to build the running environment
+
+# Step-3. install packages required by the benchmark
+pip install opencv-python matplotlib pympler scikit-learn
+
+# Step-3. switch to the branch `backdoor-bench` for the benchmark
+git fetch
+git switch backdoor-bench
+
+# Step-4. run the baseline (taking attacking FedAvg with Edge type trigger as an example)
+cd FederatedScope
+python federatedscope/main.py --cfg scripts/backdoor_scripts/attack_config/backdoor_fedavg_resnet18_on_cifar10_small.yaml
+
+```
+## Reimplementing Results of Paper
+
+The all scripts of conducting experiments are in file [attack_config](https://github.com/alibaba/FederatedScope/tree/backdoor-bench/scripts/backdoor_scripts/attack_config).
+- **Backdoor or not**: Files with 'backdoor' in their filename are experimental instructions related to backdoor poisoning during the training process. Files without 'backdoor' are experimental instructions about normal FL or pFL training process.
+- **Models**: Files with different models name represents experiments with using different models, such as "convnet" or "resnet18".
+- **Datasets**: Files with different dataset name represents experiments on different datasets, such as "femnist" or "cifar10".
+- **pFL Methods**: Files with different method name represents experiments with using different pFL methods.
+- **IID vs Non-IID**: Files with 'iid' represents experiments under IID settings.
+- **Ablation Study**: Files with 'abl' represents ablation studies of pFL methods conducted in Section 5.
+- **FedBN**: Files with 'bn' and 'para' or 'sta' mean experiments of Fed-para and Fed-sta conducted in Section 5.1.
+- **Existing Defense**: Experiments about existing defense methods:
+ * Krum: please set attack.krum: True
+ * Multi-Krum: please set attack.multi_krum: True
+ * Norm_clip: please set attack.norm_clip: True and tune attack.norm_clip_value.
+ * Adding noise: please tune attack.dp_noise.
+
+**Notice:** The Files with 'small' or 'avg' are about experiments with changing attackers since we wish to test whether the size of the local dataset possessed by the attacker will have an impact on the success of the backdoor poisoning. You can ignore them.
+
+----
+
+## Explanations about Attack Config
+
+
+ attack:
+ setting: 'fix' --fix-frequency attack setting
+ freq: 10 --the adversarial client is selected for every fixed 10 round.
+ attack_method: 'backdoor'
+ attacker_id: 15 --the client id of attacker
+ label_type: 'dirty' --dirty or clean-label attacks. We now only support dirty-label attacks
+ trigger_type: gridTrigger --BadNet: gridTrigger; Blended: hkTrigger; edge: edge; SIG: sigTrigger
+ edge_num: 500 --the number of samples with edge trigger
+ poison_ratio: 0.5 --poisoning ratio of local training dataset
+ target_label_ind: 9 --target label of backdoor attacks
+ self_opt: False --you can ignore it since we do not test it.
+ self_lr: 0.1 --you can ignore it since we do not test it.
+ self_epoch: 6 --you can ignore it since we do not test it.
+ scale_poisoning: False --you can ignore it since we do not test it.
+ scale_para: 3.0 --you can ignore it since we do not test it.
+ pgd_poisoning: False --you can ignore it since we do not test it.
+ mean: [0.4914, 0.4822, 0.4465] --normalizations used in backdoor attacks (different dataset have different settings.)
+ std: [0.2023, 0.1994, 0.2010]
+
+
+
diff --git a/benchmark/FedHPOBench/fedhpobench/utils/cost_model.py b/benchmark/FedHPOBench/fedhpobench/utils/cost_model.py
index a91385651..3441d4375 100644
--- a/benchmark/FedHPOBench/fedhpobench/utils/cost_model.py
+++ b/benchmark/FedHPOBench/fedhpobench/utils/cost_model.py
@@ -81,7 +81,7 @@ def raw_cost(**kwargs):
def get_info(cfg, configuration, fidelity, data):
cfg = merge_cfg(cfg, configuration, fidelity)
- model = get_model(cfg.model, list(data.values())[0])
+ model = get_model(cfg, list(data.values())[0])
model_size = sum([param.nelement() for param in model.parameters()])
return cfg, model_size
diff --git a/benchmark/pFL-Bench/README.md b/benchmark/pFL-Bench/README.md
index 39410f5e8..b7142ef83 100644
--- a/benchmark/pFL-Bench/README.md
+++ b/benchmark/pFL-Bench/README.md
@@ -2,7 +2,8 @@
The **pFL-Bench** is a comprehensive benchmark for personalized Federated Learning (pFL), which contains more than 10 diverse datasets, 20 competitive pFL baselines, and systematic evaluation with highlighted benefits and potential of pFL. See more details in our [paper](https://arxiv.org/abs/2206.03655).
-This repository includes the experimental data, environments, scripts and codes of **pFL-Bench**. We welcome contributions of new pFL methods and datasets to keep pFL-Bench up-to-date and to evolve it! See more details about contribution [here](https://github.com/alibaba/FederatedScope#contributing).
+This repository mainly includes the experimental data, environments, scripts and codes of **pFL-Bench**. We welcome contributions of new pFL methods and datasets to keep pFL-Bench up-to-date and to evolve it! See more details about contribution [here](https://github.com/alibaba/FederatedScope#contributing).
+Recently, our new proposed method for efficient pFL, [pFedGate](https://arxiv.org/abs/2305.02776) has been accepted to ICML'23. We provide its initial implementation [here](https://github.com/yxdyc/pFedGate) and will add it and more efficient pFL methods into our benchmark.
**NOTICE:** We are working on seamlessly and consistently fusing the new features in pFL-Bench into the *FederatedScope*. However, since the underling package *FederatedScope* is still being continuously and actively updated, the results can be a little different to the ones in our paper.
To fully reproduce the experimental results reported in the paper, please use the code versioned by this [branch](https://github.com/alibaba/FederatedScope/tree/Feature/pfl_bench) on which the experiments were conducted at the time.
@@ -111,3 +112,22 @@ wandb login --host=http://xx.xx.xx.xx:8080/
```
3. connect the machine and develop your pFL algorithm
+
+
+# License
+Our codes were released with Apache-2.0 License. Please kindly cite our papers (and the respective papers of the methods used) if our work is useful for you:
+```
+@inproceedings{chen2022pflbench,
+ title={p{FL}-Bench: A Comprehensive Benchmark for Personalized Federated Learning},
+ author={Daoyuan Chen and Dawei Gao and Weirui Kuang and Yaliang Li and Bolin Ding},
+ booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
+ year={2022},
+}
+
+@inproceedings{chen2023pFedGate,
+ title={Efficient Personalized Federated Learning via Sparse Model-Adaptation},
+ author={Daoyuan Chen and Liuyi Yao and Dawei Gao and Bolin Ding and Yaliang Li},
+ booktitle={International Conference on Machine Learning},
+ year={2023},
+}
+```
diff --git a/configs/distributed/Phi-3-mini-128k-instruct/client_1_ds_1c_200r_30ls.yaml b/configs/distributed/Phi-3-mini-128k-instruct/client_1_ds_1c_200r_30ls.yaml
new file mode 100644
index 000000000..4380aa09e
--- /dev/null
+++ b/configs/distributed/Phi-3-mini-128k-instruct/client_1_ds_1c_200r_30ls.yaml
@@ -0,0 +1,53 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_1c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: "distributed"
+ client_num: 1
+ total_round_num: 200
+ save_to: "models/distributed/Phi-3-mini-128k-instruct/ds_1c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11004
+ client_host: '192.168.24.115'
+ client_port: 50052
+ role: 'client'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3-mini-128k-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/Phi-3-mini-128k-instruct/client_1_ds_2c_200r_30ls.yaml b/configs/distributed/Phi-3-mini-128k-instruct/client_1_ds_2c_200r_30ls.yaml
new file mode 100644
index 000000000..3885565df
--- /dev/null
+++ b/configs/distributed/Phi-3-mini-128k-instruct/client_1_ds_2c_200r_30ls.yaml
@@ -0,0 +1,53 @@
+use_gpu: True
+expname_tag: "ds_2c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: distributed
+ client_num: 2
+ total_round_num: 200
+ save_to: "models/distributed/Phi-3-mini-128k-instruct/client_1_ds_2c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11100
+ client_host: '192.168.24.117'
+ client_port: 51159
+ role: 'client'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3-mini-128k-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/Phi-3-mini-128k-instruct/client_2_ds_2c_200r_30ls.yaml b/configs/distributed/Phi-3-mini-128k-instruct/client_2_ds_2c_200r_30ls.yaml
new file mode 100644
index 000000000..e58a8b2c5
--- /dev/null
+++ b/configs/distributed/Phi-3-mini-128k-instruct/client_2_ds_2c_200r_30ls.yaml
@@ -0,0 +1,53 @@
+use_gpu: True
+expname_tag: "ds_2c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: distributed
+ client_num: 2
+ total_round_num: 200
+ save_to: "models/distributed/Phi-3-mini-128k-instruct/client_2_ds_2c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11100
+ client_host: '192.168.24.115'
+ client_port: 51160
+ role: 'client'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3-mini-128k-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/Phi-3-mini-128k-instruct/server_ds_1c_200r_30ls.yaml b/configs/distributed/Phi-3-mini-128k-instruct/server_ds_1c_200r_30ls.yaml
new file mode 100644
index 000000000..0f731fd27
--- /dev/null
+++ b/configs/distributed/Phi-3-mini-128k-instruct/server_ds_1c_200r_30ls.yaml
@@ -0,0 +1,52 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_1c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: "distributed"
+ client_num: 1
+ total_round_num: 200
+ save_to: "models/distributed/Phi-3-mini-128k-instruct/server_ds_1c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11004
+ role: 'server'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3-mini-128k-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/Phi-3-mini-128k-instruct/server_ds_2c_200r_30ls.yaml b/configs/distributed/Phi-3-mini-128k-instruct/server_ds_2c_200r_30ls.yaml
new file mode 100644
index 000000000..9b9fae382
--- /dev/null
+++ b/configs/distributed/Phi-3-mini-128k-instruct/server_ds_2c_200r_30ls.yaml
@@ -0,0 +1,51 @@
+use_gpu: True
+expname_tag: "ds_2c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: distributed
+ client_num: 2
+ total_round_num: 200
+ save_to: "models/distributed/phi-3-mini-128k-instruct/server_ds_2c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11100
+ role: 'server'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3-mini-128k-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/RedPajama-INCITE-Chat-3B-v1/client_1_ds_1c_200r_30ls.yaml b/configs/distributed/RedPajama-INCITE-Chat-3B-v1/client_1_ds_1c_200r_30ls.yaml
new file mode 100644
index 000000000..490b3ff3b
--- /dev/null
+++ b/configs/distributed/RedPajama-INCITE-Chat-3B-v1/client_1_ds_1c_200r_30ls.yaml
@@ -0,0 +1,54 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_1c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: "distributed"
+ client_num: 1
+ total_round_num: 200
+ save_to: "models/distributed/RedPajama-INCITE-Chat-3B-v1/ds_1c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11000
+ client_host: '192.168.24.117'
+ client_port: 50052
+ role: 'client'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head", "query_key_value", "dense", "dense_h_to_4h", "dense_4h_to_h" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'togethercomputer/RedPajama-INCITE-Chat-3B-v1@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/RedPajama-INCITE-Chat-3B-v1/server_ds_1c_200r_30ls.yaml b/configs/distributed/RedPajama-INCITE-Chat-3B-v1/server_ds_1c_200r_30ls.yaml
new file mode 100644
index 000000000..dfd6145e7
--- /dev/null
+++ b/configs/distributed/RedPajama-INCITE-Chat-3B-v1/server_ds_1c_200r_30ls.yaml
@@ -0,0 +1,52 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_1c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: distributed
+ client_num: 1
+ total_round_num: 200
+ save_to: "models/distributed/RedPajama-INCITE-Chat-3B-v1/server_ds_1c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11000
+ role: 'server'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head", "query_key_value", "dense", "dense_h_to_4h", "dense_4h_to_h" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'togethercomputer/RedPajama-INCITE-Chat-3B-v1@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/TinyLlama-1.1B-Chat-v1.0/client_1_ds_1c_200r_30ls.yaml b/configs/distributed/TinyLlama-1.1B-Chat-v1.0/client_1_ds_1c_200r_30ls.yaml
new file mode 100644
index 000000000..8d04ce056
--- /dev/null
+++ b/configs/distributed/TinyLlama-1.1B-Chat-v1.0/client_1_ds_1c_200r_30ls.yaml
@@ -0,0 +1,54 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_1c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: "distributed"
+ client_num: 1
+ total_round_num: 200
+ save_to: "models/distributed/TinyLlama-1.1B-Chat-v1.0/ds_1c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11000
+ client_host: '192.168.24.117'
+ client_port: 50052
+ role: 'client'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'TinyLlama/TinyLlama-1.1B-Chat-v1.0@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/TinyLlama-1.1B-Chat-v1.0/client_1_ds_2c_200r_30ls.yaml b/configs/distributed/TinyLlama-1.1B-Chat-v1.0/client_1_ds_2c_200r_30ls.yaml
new file mode 100644
index 000000000..d2d4875ed
--- /dev/null
+++ b/configs/distributed/TinyLlama-1.1B-Chat-v1.0/client_1_ds_2c_200r_30ls.yaml
@@ -0,0 +1,53 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_2c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: "distributed"
+ client_num: 2
+ total_round_num: 200
+ save_to: "models/distributed/TinyLlama-1.1B-Chat-v1.0/ds_2c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11000
+ client_host: '192.168.24.117'
+ client_port: 50052
+ role: 'client'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'TinyLlama/TinyLlama-1.1B-Chat-v1.0@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/TinyLlama-1.1B-Chat-v1.0/client_2_ds_2c_200r_30ls.yaml b/configs/distributed/TinyLlama-1.1B-Chat-v1.0/client_2_ds_2c_200r_30ls.yaml
new file mode 100644
index 000000000..e772f9a56
--- /dev/null
+++ b/configs/distributed/TinyLlama-1.1B-Chat-v1.0/client_2_ds_2c_200r_30ls.yaml
@@ -0,0 +1,53 @@
+use_gpu: True
+expname_tag: "ds_2c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: distributed
+ client_num: 2
+ total_round_num: 200
+ save_to: "models/distributed/TinyLlama-1.1B-Chat-v1.0/ds_2c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11000
+ client_host: '192.168.24.115'
+ client_port: 51160
+ role: 'client'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'TinyLlama/TinyLlama-1.1B-Chat-v1.0@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/TinyLlama-1.1B-Chat-v1.0/server_ds_1c_200r_30ls.yaml b/configs/distributed/TinyLlama-1.1B-Chat-v1.0/server_ds_1c_200r_30ls.yaml
new file mode 100644
index 000000000..9c0137300
--- /dev/null
+++ b/configs/distributed/TinyLlama-1.1B-Chat-v1.0/server_ds_1c_200r_30ls.yaml
@@ -0,0 +1,52 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_1c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: distributed
+ client_num: 1
+ total_round_num: 200
+ save_to: "models/distributed/TinyLlama-1.1B-Chat-v1.0/server_ds_1c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11000
+ role: 'server'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'TinyLlama/TinyLlama-1.1B-Chat-v1.0@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/TinyLlama-1.1B-Chat-v1.0/server_ds_2c_200r_30ls.yaml b/configs/distributed/TinyLlama-1.1B-Chat-v1.0/server_ds_2c_200r_30ls.yaml
new file mode 100644
index 000000000..f7c9d00fc
--- /dev/null
+++ b/configs/distributed/TinyLlama-1.1B-Chat-v1.0/server_ds_2c_200r_30ls.yaml
@@ -0,0 +1,52 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_2c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: distributed
+ client_num: 2
+ total_round_num: 200
+ save_to: "models/distributed/TinyLlama-1.1B-Chat-v1.0/server_ds_2c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11000
+ role: 'server'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'TinyLlama/TinyLlama-1.1B-Chat-v1.0@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/phi-1_5/client_1_ds_1c_200r_30ls.yaml b/configs/distributed/phi-1_5/client_1_ds_1c_200r_30ls.yaml
new file mode 100644
index 000000000..7ffb9b138
--- /dev/null
+++ b/configs/distributed/phi-1_5/client_1_ds_1c_200r_30ls.yaml
@@ -0,0 +1,54 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_1c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: "distributed"
+ client_num: 1
+ total_round_num: 200
+ save_to: "models/distributed/phi-1_5/ds_1c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11004
+ client_host: '192.168.24.115'
+ client_port: 50052
+ role: 'client'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/phi-1_5@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/phi-1_5/client_1_ds_2c_200r_30ls.yaml b/configs/distributed/phi-1_5/client_1_ds_2c_200r_30ls.yaml
new file mode 100644
index 000000000..da045f6c8
--- /dev/null
+++ b/configs/distributed/phi-1_5/client_1_ds_2c_200r_30ls.yaml
@@ -0,0 +1,53 @@
+use_gpu: True
+expname_tag: "ds_2c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: distributed
+ client_num: 2
+ total_round_num: 200
+ save_to: "models/distributed/phi-1_5/client_1_ds_2c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11100
+ client_host: '192.168.24.117'
+ client_port: 51159
+ role: 'client'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/phi-1_5@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/phi-1_5/server_ds_1c_200r_30ls.yaml b/configs/distributed/phi-1_5/server_ds_1c_200r_30ls.yaml
new file mode 100644
index 000000000..66cd236f6
--- /dev/null
+++ b/configs/distributed/phi-1_5/server_ds_1c_200r_30ls.yaml
@@ -0,0 +1,52 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_1c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: "distributed"
+ client_num: 1
+ total_round_num: 200
+ save_to: "models/distributed/phi-1_5/server_ds_1c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11004
+ role: 'server'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/phi-1_5@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/distributed/phi-1_5/server_ds_2c_200r_30ls.yaml b/configs/distributed/phi-1_5/server_ds_2c_200r_30ls.yaml
new file mode 100644
index 000000000..ead6953cd
--- /dev/null
+++ b/configs/distributed/phi-1_5/server_ds_2c_200r_30ls.yaml
@@ -0,0 +1,52 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_2c_200r_30ls_dist"
+early_stop:
+ patience: 0
+federate:
+ mode: distributed
+ client_num: 2
+ total_round_num: 200
+ save_to: "models/distributed/phi-1_5/server_ds_2c_200r_30ls.ckpt"
+ make_global_eval: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '192.168.24.120'
+ server_port: 11100
+ role: 'server'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/phi-1_5@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/configs/standalone/OLMo-7B-Instruct-hf/baseline.yaml b/configs/standalone/OLMo-7B-Instruct-hf/baseline.yaml
new file mode 100644
index 000000000..f6c3896e7
--- /dev/null
+++ b/configs/standalone/OLMo-7B-Instruct-hf/baseline.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "baseline"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 1
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ #save_to: ""
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: False
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'allenai/OLMo-7B-Instruct-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/OLMo-7B-Instruct-hf/ds_10c_200r_30ls.yaml b/configs/standalone/OLMo-7B-Instruct-hf/ds_10c_200r_30ls.yaml
new file mode 100644
index 000000000..e54cd8855
--- /dev/null
+++ b/configs/standalone/OLMo-7B-Instruct-hf/ds_10c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_10c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 10
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/OLMo-7B-Instruct-hf/ds_10c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'allenai/OLMo-7B-Instruct-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/OLMo-7B-Instruct-hf/ds_30c_200r_30ls.yaml b/configs/standalone/OLMo-7B-Instruct-hf/ds_30c_200r_30ls.yaml
new file mode 100644
index 000000000..847401567
--- /dev/null
+++ b/configs/standalone/OLMo-7B-Instruct-hf/ds_30c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 2
+expname_tag: "ds_30c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 30
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/OLMo-7B-Instruct-hf/ds_30c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'allenai/OLMo-7B-Instruct-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/OLMo-7B-Instruct-hf/ds_3c_200r_30ls.yaml b/configs/standalone/OLMo-7B-Instruct-hf/ds_3c_200r_30ls.yaml
new file mode 100644
index 000000000..b784b79df
--- /dev/null
+++ b/configs/standalone/OLMo-7B-Instruct-hf/ds_3c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_3c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 3
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/OLMo-7B-Instruct-hf/ds_3c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'allenai/OLMo-7B-Instruct-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/OLMo-7B-Instruct-hf/ds_6c_200r_30ls.yaml b/configs/standalone/OLMo-7B-Instruct-hf/ds_6c_200r_30ls.yaml
new file mode 100644
index 000000000..095d2b519
--- /dev/null
+++ b/configs/standalone/OLMo-7B-Instruct-hf/ds_6c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 1
+expname_tag: "ds_6c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 6
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/OLMo-7B-Instruct-hf/ds_6c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'allenai/OLMo-7B-Instruct-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/Phi-3-mini-128k-instruct/ds_10c_200r_30ls.yaml b/configs/standalone/Phi-3-mini-128k-instruct/ds_10c_200r_30ls.yaml
new file mode 100644
index 000000000..33ba4e8a3
--- /dev/null
+++ b/configs/standalone/Phi-3-mini-128k-instruct/ds_10c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_10c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 10
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/Phi-3-mini-128k-instruct/ds_10c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3-mini-128k-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/Phi-3-mini-128k-instruct/ds_15c_200r_30ls.yaml b/configs/standalone/Phi-3-mini-128k-instruct/ds_15c_200r_30ls.yaml
new file mode 100644
index 000000000..124c13c3f
--- /dev/null
+++ b/configs/standalone/Phi-3-mini-128k-instruct/ds_15c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 3
+expname_tag: "ds_15c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 15
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/Phi-3-mini-128k-instruct/ds_15c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3-mini-128k-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/Phi-3-mini-128k-instruct/ds_1c_200r_30ls.yaml b/configs/standalone/Phi-3-mini-128k-instruct/ds_1c_200r_30ls.yaml
new file mode 100644
index 000000000..ce9fef863
--- /dev/null
+++ b/configs/standalone/Phi-3-mini-128k-instruct/ds_1c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_1c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 1
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/Phi-3-mini-128k-instruct/ds_1c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3-mini-128k-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/Phi-3-mini-128k-instruct/ds_20c_200r_30ls.yaml b/configs/standalone/Phi-3-mini-128k-instruct/ds_20c_200r_30ls.yaml
new file mode 100644
index 000000000..83ce6bdfe
--- /dev/null
+++ b/configs/standalone/Phi-3-mini-128k-instruct/ds_20c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_20c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 20
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/Phi-3-mini-128k-instruct/ds_20c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3-mini-128k-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/Phi-3-mini-128k-instruct/ds_30c_200r_30ls.yaml b/configs/standalone/Phi-3-mini-128k-instruct/ds_30c_200r_30ls.yaml
new file mode 100644
index 000000000..33571bd95
--- /dev/null
+++ b/configs/standalone/Phi-3-mini-128k-instruct/ds_30c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 2
+expname_tag: "ds_30c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 30
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/Phi-3-mini-128k-instruct/ds_30c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3-mini-128k-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/Phi-3-mini-128k-instruct/ds_3c_200r_30ls.yaml b/configs/standalone/Phi-3-mini-128k-instruct/ds_3c_200r_30ls.yaml
new file mode 100644
index 000000000..da7cd20ae
--- /dev/null
+++ b/configs/standalone/Phi-3-mini-128k-instruct/ds_3c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_3c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 3
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/Phi-3-mini-128k-instruct/ds_3c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3-mini-128k-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/Phi-3-mini-128k-instruct/ds_6c_200r_30ls.yaml b/configs/standalone/Phi-3-mini-128k-instruct/ds_6c_200r_30ls.yaml
new file mode 100644
index 000000000..c912010f6
--- /dev/null
+++ b/configs/standalone/Phi-3-mini-128k-instruct/ds_6c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_6c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 6
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/Phi-3-mini-128k-instruct/ds_6c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3-mini-128k-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/Phi-3.5-mini-instruct/baseline.yaml b/configs/standalone/Phi-3.5-mini-instruct/baseline.yaml
new file mode 100644
index 000000000..54bba8b65
--- /dev/null
+++ b/configs/standalone/Phi-3.5-mini-instruct/baseline.yaml
@@ -0,0 +1,48 @@
+use_gpu: False
+device: 1
+expname_tag: "baseline"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 1
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ #save_to: ""
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: False
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: False
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3.5-mini-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
diff --git a/configs/standalone/Phi-3.5-mini-instruct/ds_10c_200r_30ls.yaml b/configs/standalone/Phi-3.5-mini-instruct/ds_10c_200r_30ls.yaml
new file mode 100644
index 000000000..a346f5576
--- /dev/null
+++ b/configs/standalone/Phi-3.5-mini-instruct/ds_10c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 3
+expname_tag: "ds_10c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 10
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/Phi-3.5-mini-instruct/ds_10c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3.5-mini-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/Phi-3.5-mini-instruct/ds_15c_200r_30ls.yaml b/configs/standalone/Phi-3.5-mini-instruct/ds_15c_200r_30ls.yaml
new file mode 100644
index 000000000..b7fcbaccc
--- /dev/null
+++ b/configs/standalone/Phi-3.5-mini-instruct/ds_15c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 1
+expname_tag: "ds_15c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 15
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/Phi-3.5-mini-instruct/ds_15c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3.5-mini-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/Phi-3.5-mini-instruct/ds_20c_200r_30ls.yaml b/configs/standalone/Phi-3.5-mini-instruct/ds_20c_200r_30ls.yaml
new file mode 100644
index 000000000..fa8dfa13d
--- /dev/null
+++ b/configs/standalone/Phi-3.5-mini-instruct/ds_20c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 1
+expname_tag: "ds_20c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 20
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/Phi-3.5-mini-instruct/ds_20c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3.5-mini-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/Phi-3.5-mini-instruct/ds_30c_200r_30ls.yaml b/configs/standalone/Phi-3.5-mini-instruct/ds_30c_200r_30ls.yaml
new file mode 100644
index 000000000..0ddbeef24
--- /dev/null
+++ b/configs/standalone/Phi-3.5-mini-instruct/ds_30c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_30c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 30
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/Phi-3.5-mini-instruct/ds_30c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3.5-mini-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/Phi-3.5-mini-instruct/ds_3c_200r_30ls.yaml b/configs/standalone/Phi-3.5-mini-instruct/ds_3c_200r_30ls.yaml
new file mode 100644
index 000000000..00493a0b4
--- /dev/null
+++ b/configs/standalone/Phi-3.5-mini-instruct/ds_3c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 2
+expname_tag: "ds_3c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 3
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/Phi-3.5-mini-instruct/ds_3c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3.5-mini-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/Phi-3.5-mini-instruct/ds_6c_200r_30ls.yaml b/configs/standalone/Phi-3.5-mini-instruct/ds_6c_200r_30ls.yaml
new file mode 100644
index 000000000..1b8d86086
--- /dev/null
+++ b/configs/standalone/Phi-3.5-mini-instruct/ds_6c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 2
+expname_tag: "ds_6c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 6
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/Phi-3.5-mini-instruct/ds_6c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/Phi-3.5-mini-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/RedPajama-INCITE-Chat-3B-v1/ds_1c_200r_30ls.yaml b/configs/standalone/RedPajama-INCITE-Chat-3B-v1/ds_1c_200r_30ls.yaml
new file mode 100644
index 000000000..6249cb437
--- /dev/null
+++ b/configs/standalone/RedPajama-INCITE-Chat-3B-v1/ds_1c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_1c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 1
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/RedPajama-INCITE-Chat-3B-v1/ds_1c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head", "query_key_value", "dense", "dense_h_to_4h", "dense_4h_to_h", "embed_out" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'togethercomputer/RedPajama-INCITE-Chat-3B-v1@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/RedPajama-INCITE-Chat-3B-v1/ds_2c_200r_30ls.yaml b/configs/standalone/RedPajama-INCITE-Chat-3B-v1/ds_2c_200r_30ls.yaml
new file mode 100644
index 000000000..eaf1711b9
--- /dev/null
+++ b/configs/standalone/RedPajama-INCITE-Chat-3B-v1/ds_2c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 3
+expname_tag: "ds_2c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 2
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/RedPajama-INCITE-Chat-3B-v1/ds_2c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head", "query_key_value", "dense", "dense_h_to_4h", "dense_4h_to_h" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'togethercomputer/RedPajama-INCITE-Chat-3B-v1@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/TinyLlama-1.1B-Chat-v1.0/ds_1c_200r_30ls.yaml b/configs/standalone/TinyLlama-1.1B-Chat-v1.0/ds_1c_200r_30ls.yaml
new file mode 100644
index 000000000..11af7eb82
--- /dev/null
+++ b/configs/standalone/TinyLlama-1.1B-Chat-v1.0/ds_1c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 1
+expname_tag: "ds_1c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 1
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/TinyLlama-1.1B-Chat-v1.0/ds_1c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'TinyLlama/TinyLlama-1.1B-Chat-v1.0@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/TinyLlama-1.1B-Chat-v1.0/ds_2c_200r_30ls.yaml b/configs/standalone/TinyLlama-1.1B-Chat-v1.0/ds_2c_200r_30ls.yaml
new file mode 100644
index 000000000..3a4c9657a
--- /dev/null
+++ b/configs/standalone/TinyLlama-1.1B-Chat-v1.0/ds_2c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_2c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 2
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/TinyLlama-1.1B-Chat-v1.0/ds_2c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'TinyLlama/TinyLlama-1.1B-Chat-v1.0@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/occiglot-7B-eu5-instruct/baseline.yaml b/configs/standalone/occiglot-7B-eu5-instruct/baseline.yaml
new file mode 100644
index 000000000..7bd19b9e9
--- /dev/null
+++ b/configs/standalone/occiglot-7B-eu5-instruct/baseline.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 2
+expname_tag: "baseline"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 3
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ #save_to: ""
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: False
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'occiglot/occiglot-7B-eu5-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/occiglot-7B-eu5-instruct/ds_10c_200r_30ls.yaml b/configs/standalone/occiglot-7B-eu5-instruct/ds_10c_200r_30ls.yaml
new file mode 100644
index 000000000..9304f1033
--- /dev/null
+++ b/configs/standalone/occiglot-7B-eu5-instruct/ds_10c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_10c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 10
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/occiglot-7B-eu5-instruct/ds_10c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'occiglot/occiglot-7B-eu5-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/occiglot-7B-eu5-instruct/ds_15c_200r_30ls.yaml b/configs/standalone/occiglot-7B-eu5-instruct/ds_15c_200r_30ls.yaml
new file mode 100644
index 000000000..95cb3b1f2
--- /dev/null
+++ b/configs/standalone/occiglot-7B-eu5-instruct/ds_15c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_15c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 15
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/occiglot-7B-eu5-instruct/ds_15c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'occiglot/occiglot-7B-eu5-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/occiglot-7B-eu5-instruct/ds_20c_200r_30ls.yaml b/configs/standalone/occiglot-7B-eu5-instruct/ds_20c_200r_30ls.yaml
new file mode 100644
index 000000000..6ba454900
--- /dev/null
+++ b/configs/standalone/occiglot-7B-eu5-instruct/ds_20c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 1
+expname_tag: "ds_20c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 20
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/occiglot-7B-eu5-instruct/ds_20c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'occiglot/occiglot-7B-eu5-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/occiglot-7B-eu5-instruct/ds_30c_200r_30ls.yaml b/configs/standalone/occiglot-7B-eu5-instruct/ds_30c_200r_30ls.yaml
new file mode 100644
index 000000000..d5660989c
--- /dev/null
+++ b/configs/standalone/occiglot-7B-eu5-instruct/ds_30c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 2
+expname_tag: "ds_30c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 30
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/occiglot-7B-eu5-instruct/ds_30c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'occiglot/occiglot-7B-eu5-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/occiglot-7B-eu5-instruct/ds_3c_200r_30ls.yaml b/configs/standalone/occiglot-7B-eu5-instruct/ds_3c_200r_30ls.yaml
new file mode 100644
index 000000000..e6c7da4a2
--- /dev/null
+++ b/configs/standalone/occiglot-7B-eu5-instruct/ds_3c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_3c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 3
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/occiglot-7B-eu5-instruct/ds_3c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'occiglot/occiglot-7B-eu5-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/occiglot-7B-eu5-instruct/ds_6c_200r_30ls.yaml b/configs/standalone/occiglot-7B-eu5-instruct/ds_6c_200r_30ls.yaml
new file mode 100644
index 000000000..76776ea9b
--- /dev/null
+++ b/configs/standalone/occiglot-7B-eu5-instruct/ds_6c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_6c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 6
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/occiglot-7B-eu5-instruct/ds_6c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'occiglot/occiglot-7B-eu5-instruct@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/phi-1_5/ds_1c_200r_30ls.yaml b/configs/standalone/phi-1_5/ds_1c_200r_30ls.yaml
new file mode 100644
index 000000000..4ae41c1b0
--- /dev/null
+++ b/configs/standalone/phi-1_5/ds_1c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_1c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 1
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/phi-1_5/ds_1c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/phi-1_5@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/phi-1_5/ds_2c_200r_30ls.yaml b/configs/standalone/phi-1_5/ds_2c_200r_30ls.yaml
new file mode 100644
index 000000000..1bdb12cd9
--- /dev/null
+++ b/configs/standalone/phi-1_5/ds_2c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_2c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 2
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/phi-1_5/ds_2c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/phi-1_5@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/configs/standalone/phi-1_5/ds_3c_200r_30ls.yaml b/configs/standalone/phi-1_5/ds_3c_200r_30ls.yaml
new file mode 100644
index 000000000..e5992d344
--- /dev/null
+++ b/configs/standalone/phi-1_5/ds_3c_200r_30ls.yaml
@@ -0,0 +1,48 @@
+use_gpu: True
+device: 0
+expname_tag: "ds_3c_200r_30ls"
+early_stop:
+ patience: 0
+federate:
+ mode: "standalone"
+ master_port: 29340
+ client_num: 3
+ total_round_num: 200
+ share_local_model: True
+ online_aggr: False
+ process_num: 1
+ save_to: "models/standalone/phi-1_5/ds_3c_200r_30ls.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05, 'target_modules': [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "lm_head" ] } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config_4bs.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'microsoft/phi-1_5@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/autotune/fedex/server.py b/federatedscope/autotune/fedex/server.py
index 5413936b8..d3696cf83 100644
--- a/federatedscope/autotune/fedex/server.py
+++ b/federatedscope/autotune/fedex/server.py
@@ -173,7 +173,7 @@ def sample(self, thetas):
# determine index
if self._stop_exploration:
- cfg_idx = [theta.argmax() for theta in thetas]
+ cfg_idx = [int(theta.argmax()) for theta in thetas]
else:
cfg_idx = [
np.random.choice(len(theta), p=theta) for theta in thetas
diff --git a/federatedscope/contrib/scheduler/example.py b/federatedscope/contrib/scheduler/example.py
index e505829a7..26224d856 100644
--- a/federatedscope/contrib/scheduler/example.py
+++ b/federatedscope/contrib/scheduler/example.py
@@ -1,7 +1,7 @@
from federatedscope.register import register_scheduler
-def call_my_scheduler(optimizer, reg_type):
+def call_my_scheduler(optimizer, reg_type, **kwargs):
try:
import torch.optim as optim
except ImportError:
diff --git a/federatedscope/core/auxiliaries/dataloader_builder.py b/federatedscope/core/auxiliaries/dataloader_builder.py
index 4b9574113..a8ff8cc89 100644
--- a/federatedscope/core/auxiliaries/dataloader_builder.py
+++ b/federatedscope/core/auxiliaries/dataloader_builder.py
@@ -83,5 +83,15 @@ def get_dataloader(dataset, config, split='train'):
# edge_index of raw graph
dataset = dataset[0].edge_index
filtered_args = filter_dict(loader_cls.__init__, raw_args)
+
+ if config.data.type.lower().endswith('@llm'):
+ from federatedscope.llm.dataloader import get_tokenizer, \
+ LLMDataCollator
+ model_name, model_hub = config.model.type.split('@')
+ tokenizer, _ = get_tokenizer(model_name, config.data.root,
+ config.llm.tok_len, model_hub)
+ data_collator = LLMDataCollator(tokenizer=tokenizer)
+ filtered_args['collate_fn'] = data_collator
+
dataloader = loader_cls(dataset, **filtered_args)
return dataloader
diff --git a/federatedscope/core/auxiliaries/logging.py b/federatedscope/core/auxiliaries/logging.py
index 94e7565f3..a3bca1bc0 100644
--- a/federatedscope/core/auxiliaries/logging.py
+++ b/federatedscope/core/auxiliaries/logging.py
@@ -57,7 +57,7 @@ def filter(self, record):
return True
-def update_logger(cfg, clear_before_add=False):
+def update_logger(cfg, clear_before_add=False, rank=0):
root_logger = logging.getLogger("federatedscope")
# clear all existing handlers and add the default stream
@@ -70,11 +70,16 @@ def update_logger(cfg, clear_before_add=False):
root_logger.addHandler(handler)
# update level
- if cfg.verbose > 0:
- logging_level = logging.INFO
+ if rank == 0:
+ if cfg.verbose > 0:
+ logging_level = logging.INFO
+ else:
+ logging_level = logging.WARN
+ root_logger.warning("Skip DEBUG/INFO messages")
else:
- logging_level = logging.WARN
- root_logger.warning("Skip DEBUG/INFO messages")
+ root_logger.warning(f"Using deepspeed, and we will disable "
+ f"subprocesses {rank} logger.")
+ logging_level = logging.CRITICAL
root_logger.setLevel(logging_level)
# ================ create outdir to save log, exp_config, models, etc,.
@@ -88,6 +93,9 @@ def update_logger(cfg, clear_before_add=False):
cfg.expname = f"{cfg.expname}_{cfg.expname_tag}"
cfg.outdir = os.path.join(cfg.outdir, cfg.expname)
+ if rank != 0:
+ return
+
# if exist, make directory with given name and time
if os.path.isdir(cfg.outdir) and os.path.exists(cfg.outdir):
outdir = os.path.join(cfg.outdir, "sub_exp" +
diff --git a/federatedscope/core/auxiliaries/model_builder.py b/federatedscope/core/auxiliaries/model_builder.py
index a1d5800c4..1110ed195 100644
--- a/federatedscope/core/auxiliaries/model_builder.py
+++ b/federatedscope/core/auxiliaries/model_builder.py
@@ -93,12 +93,12 @@ def get_shape_from_data(data, model_config, backend='torch'):
return shape
-def get_model(model_config, local_data=None, backend='torch'):
+def get_model(config, local_data=None, backend='torch'):
"""
This function builds an instance of model to be trained.
Arguments:
- model_config: ``cfg.model``, a submodule of ``cfg``
+ config: ``cfg``
local_data: the model to be instantiated is responsible for the \
given data
backend: chosen from ``torch`` and ``tensorflow``
@@ -122,7 +122,11 @@ def get_model(model_config, local_data=None, backend='torch'):
``mf.model.model_builder.get_mfnet()``
=================================== ==============================
"""
- if model_config.type.lower() in ['xgb_tree', 'gbdt_tree', 'random_forest']:
+ model_config = config.model
+
+ if model_config.type.lower() in \
+ ['xgb_tree', 'gbdt_tree', 'random_forest'] or \
+ model_config.type.lower().endswith('_llm'):
input_shape = None
elif local_data is not None:
input_shape = get_shape_from_data(local_data, model_config, backend)
@@ -180,6 +184,9 @@ def get_model(model_config, local_data=None, backend='torch'):
elif model_config.type.lower().endswith('transformers'):
from federatedscope.nlp.model import get_transformer
model = get_transformer(model_config, input_shape)
+ elif model_config.type.lower().endswith('_llm'):
+ from federatedscope.llm.model import get_llm
+ model = get_llm(config)
elif model_config.type.lower() in [
'gcn', 'sage', 'gpr', 'gat', 'gin', 'mpnn'
]:
diff --git a/federatedscope/core/auxiliaries/splitter_builder.py b/federatedscope/core/auxiliaries/splitter_builder.py
index 6f91684f0..834353fca 100644
--- a/federatedscope/core/auxiliaries/splitter_builder.py
+++ b/federatedscope/core/auxiliaries/splitter_builder.py
@@ -75,6 +75,9 @@ def get_splitter(config):
elif config.data.splitter == 'iid':
from federatedscope.core.splitters.generic import IIDSplitter
splitter = IIDSplitter(client_num)
+ elif config.data.splitter == 'meta':
+ from federatedscope.core.splitters.generic import MetaSplitter
+ splitter = MetaSplitter(client_num)
else:
logger.warning(f'Splitter {config.data.splitter} not found or not '
f'used.')
diff --git a/federatedscope/core/auxiliaries/trainer_builder.py b/federatedscope/core/auxiliaries/trainer_builder.py
index b32baf74e..1d6e3b7db 100644
--- a/federatedscope/core/auxiliaries/trainer_builder.py
+++ b/federatedscope/core/auxiliaries/trainer_builder.py
@@ -29,6 +29,7 @@
"cltrainer": "CLTrainer",
"lptrainer": "LPTrainer",
"atc_trainer": "ATCTrainer",
+ "llmtrainer": "LLMTrainer"
}
@@ -157,6 +158,8 @@ def get_trainer(model=None,
dict_path = "federatedscope.mf.trainer.trainer"
elif config.trainer.type.lower() in ['atc_trainer']:
dict_path = "federatedscope.nlp.hetero_tasks.trainer"
+ elif config.trainer.type.lower() in ['llmtrainer']:
+ dict_path = "federatedscope.llm.trainer.trainer"
else:
raise ValueError
diff --git a/federatedscope/core/auxiliaries/utils.py b/federatedscope/core/auxiliaries/utils.py
index b9264b240..dd7157263 100644
--- a/federatedscope/core/auxiliaries/utils.py
+++ b/federatedscope/core/auxiliaries/utils.py
@@ -92,6 +92,26 @@ def merge_dict_of_results(dict1, dict2):
return dict1
+def b64serializer(x, tool='pickle'):
+ if tool == 'pickle':
+ return base64.b64encode(pickle.dumps(x))
+ elif tool == 'dill':
+ import dill
+ return base64.b64encode(dill.dumps(x))
+ else:
+ raise NotImplementedError('Choose from `pickle` or `dill`')
+
+
+def b64deserializer(x, tool='pickle'):
+ if tool == 'pickle':
+ return pickle.loads((base64.b64decode(x)))
+ elif tool == 'dill':
+ import dill
+ return dill.loads((base64.b64decode(x)))
+ else:
+ raise NotImplementedError('Choose from `pickle` or `dill`')
+
+
def param2tensor(param):
# TODO: make it work in `message`
if isinstance(param, list):
@@ -101,7 +121,7 @@ def param2tensor(param):
elif isinstance(param, float):
param = torch.tensor(param, dtype=torch.float)
elif isinstance(param, str):
- param = pickle.loads((base64.b64decode(param)))
+ param = b64deserializer(param)
return param
@@ -157,3 +177,12 @@ def get_resource_info(filename):
with open(filename, 'br') as f:
device_info = pickle.load(f)
return device_info
+
+
+def get_ds_rank():
+ return int(os.environ.get("RANK", "0"))
+
+
+def add_prefix_to_path(prefix, path):
+ directory, file = os.path.split(path)
+ return os.path.join(directory, prefix + file)
diff --git a/federatedscope/core/auxiliaries/worker_builder.py b/federatedscope/core/auxiliaries/worker_builder.py
index 49fd30631..2497d41b6 100644
--- a/federatedscope/core/auxiliaries/worker_builder.py
+++ b/federatedscope/core/auxiliaries/worker_builder.py
@@ -105,6 +105,13 @@ def get_client_cls(cfg):
add_atk_method_to_Client_GradAscent
logger.info("=========== add method to current client class ")
client_class = add_atk_method_to_Client_GradAscent(client_class)
+
+ if cfg.llm.offsite_tuning.use:
+ from federatedscope.llm.offsite_tuning.client import \
+ OffsiteTuningClient
+ logger.info("=========== Using offsite_tuning ===========")
+ return OffsiteTuningClient
+
return client_class
@@ -207,4 +214,10 @@ def get_server_cls(cfg):
else:
server_class = Server
+ if cfg.llm.offsite_tuning.use:
+ from federatedscope.llm.offsite_tuning.server import \
+ OffsiteTuningServer
+ logger.info("=========== Using offsite_tuning ===========")
+ return OffsiteTuningServer
+
return server_class
diff --git a/federatedscope/core/cmd_args.py b/federatedscope/core/cmd_args.py
index 2581a33d7..516e22110 100644
--- a/federatedscope/core/cmd_args.py
+++ b/federatedscope/core/cmd_args.py
@@ -17,6 +17,10 @@ def parse_args(args=None):
required=False,
default=None,
type=str)
+ parser.add_argument('--local_rank',
+ type=int,
+ default=-1,
+ help='local rank passed from distributed launcher')
parser.add_argument(
'--help',
nargs="?",
diff --git a/federatedscope/core/configs/README.md b/federatedscope/core/configs/README.md
index 5b8b3dc05..dbcc73ebc 100644
--- a/federatedscope/core/configs/README.md
+++ b/federatedscope/core/configs/README.md
@@ -11,6 +11,7 @@ We summarize all the customizable configurations:
- [cfg_differential_privacy.py](#differential-privacy)
- [cfg_hpo.py](#auto-tuning-components)
- [cfg_attack.py](#attack)
+- [cfg_llm.py](#llm)
### config
The configurations related to environment of running experiment.
@@ -168,9 +169,10 @@ The following configurations are related to the local training.
| `train.batch_or_epoch` | (string) 'batch' | The type of local training. | `train.batch_or_epoch` specifies the unit that `train.local_update_steps` adopts. All new parameters will be used as arguments for the chosen optimizer. |
| `train.optimizer` | - | - | You can add new parameters under `train.optimizer` according to the optimizer, e.g., you can set momentum by `cfg.train.optimizer.momentum`. |
| `train.optimizer.type` | (string) 'SGD' | The type of optimizer used in local training. | Currently we support all optimizers build in PyTorch (The modules under `torch.optim`). |
-| `train.optimizer.lr` | (float) 0.1 | The learning rate used in the local training. | - |
+| `train.optimizer.lr` | (float) 0.1 | The learning rate used in the local training. | - |
| `train.scheduler` | - | - | Similar with `train.optimizer`, you can add new parameters as you need, e.g., `train.scheduler.step_size=10`. All new parameters will be used as arguments for the chosen scheduler. |
-| `train.scheduler.type` | (string) '' | The type of the scheduler used in local training | Currently we support all schedulers build in PyTorch (The modules under `torch.optim.lr_scheduler`). |
+| `train.scheduler.type` | (string) '' | The type of the scheduler used in local training | Currently we support all schedulers build in PyTorch (The modules under `torch.optim.lr_scheduler`). |
+| `train.is_enable_half` | (bool) False | Whether use half precision | When model is too large, users can use half-precision model |
#### Fine tuning
The following configurations are related to the fine tuning.
@@ -413,3 +415,52 @@ The configurations related to the data/dataset are defined in `cfg_attack.py`.
`attack.self_opt` |(bool) False |This keyword represents whether to use his own training procedure for attack client.|-|
`attack.self_lr` |(float) 0.05|This keyword represents learning rate of his own training procedure for attack client.|-|
`attack.self_epoch` |(int) 6 |This keyword represents epoch number of his own training procedure for attack client.|-|
+
+### LLM
+The configurations related to LLMs are defined in `cfg_llm.py`.
+
+| [General](#llm-general) | [Inference](#inference) | [DeepSpeed](#deepspeed) | [Adapter](#Adapter) | [Offsite-tuning](#offsite-tuning) |
+#### LLM-general
+| Name | (Type) Default Value | Description | Note |
+|:---------------------:|:--------------------:|:---------------------------------------------------------|:-----|
+| `cfg.llm.tok_len` | (int) 128 | Max token length for model input (training) ||
+| `cfg.llm.cache.model` | (string) '' | The fold for storing model cache, default in `~/.cache/` ||
+|||||
+#### Inference
+| Name | (Type) Default Value | Description | Note |
+|:------------------------------:|:--------------------:|:---------------------------------------------|:-----|
+| `cfg.llm.chat.max_len` | (int) 1000 | Max token length for model input (inference) ||
+| `cfg.llm.chat.max_history_len` | (int) 10 | Max number of history texts ||
+#### DeepSpeed
+| Name | (Type) Default Value | Description | Note |
+|:-----------------------------:|:--------------------:|:-------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------|
+| `cfg.llm.deepspeed.use` | (bool) False | Whether use DeepSpeed | Use `nvcc - V` to make sure CUDA installed. When set it to `True`, we can full-parameter fine-tune a `llama-7b` on a machine with 4 V100-32G gpus. |
+| `cfg.llm.deepspeed.ds_config` | (string) '' | The path to the file containing configurations for DeepSpeed | See `federatedscope/llm/baseline/deepspeed/ds_config.json` |
+#### Adapter
+| Name | (Type) Default Value | Description | Note |
+|:---------------------------:|:--------------------:|:---------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| `cfg.llm.adapter.use` | (bool) False | Whether use adapter ||
+| `cfg.llm.adapter.args` | list ([{}]) | Args for adapters | We offer the following four adaptets:
`[ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]`;
`[{'adapter_package': 'peft', 'adapter_method': 'prefix', 'prefix_projection': False, 'num_virtual_tokens': 20}]`;
`[{'adapter_package': 'peft', 'adapter_method': 'p-tuning', 'encoder_reparameterization_type': 'MLP', 'encoder_dropout': 0.1, 'num_virtual_tokens': 20}]`;
`[{'adapter_package': 'peft', 'adapter_method': 'prompt', 'prompt_tuning_init': 'RANDOM', 'num_virtual_tokens': 20}]`. |
+| `cfg.llm.adapter.mv_to_cpu` | (bool) False | Whether move the adapter to cpu after each training step | If true, it can save memory but cost more time |
+#### Offsite-tuning
+| Name | (Type) Default Value | Description | Note |
+|:-----------------------------------------------------------:|:----------------------:|:----------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| `cfg.llm.offsite_tuning.use` | (bool) False | Whether apply offsite-tuning | Set it `True` when clients cannot access to the full model |
+| `cfg.llm.offsite_tuning.strategy` | (string) 'drop_layer' | The mothod used for offsite-tuning | More methods will be supported ASAP |
+| `cfg.llm.offsite_tuning.emu_l` | (int) 1 | Fix the previous layers as adapter for training ||
+| `cfg.llm.offsite_tuning.emu_r` | (int) 10 | Fix the layers behind as adapter for training ||
+| `cfg.llm.offsite_tuning.kwargs` | (list) [{}] | Args for offsite-tuning method | E.g.,`[{'drop_ratio':0.2}]` means uniformly drops 20% of the layers between `cfg.llm.offsite_tuning.emu_l` and `cfg.llm.offsite_tuning.emu_r`, denote the remaining as emulator |
+| `cfg.llm.offsite_tuning.eval_type` | (string) 'emu' | The type of evaluation for offsite-tuning | 'full' means evaluating the original model with fine-tuned adapters; 'emu' means evaluating the emulator with fine-tuned adapters |
+| `cfg.llm.offsite_tuning.emu_align.use` | (bool) False | Whether use model distillation | If `True`, the server will regard the layers between `cfg.llm.offsite_tuning.emu_l` and `cfg.llm.offsite_tuning.emu_r` as a teacher model, and distill a student model as the emulator |
+| `cfg.llm.offsite_tuning.emu_align.restore_from` | (string) '' | The path to the emulator load by clients to perform fine-tuning ||
+| `cfg.llm.offsite_tuning.emu_align.save_to` | (string) '' | The path to the emulator saved by server ||
+| `cfg.llm.offsite_tuning.emu_align.exit_after_align` | (bool) False | Whether exist after model distillation ||
+| `cfg.llm.offsite_tuning.emu_align.data.root` | (string) 'data' | The fold where the `data` file located for model distilation ||
+| `cfg.llm.offsite_tuning.emu_align.data.type` | (string) 'alpaca@llm' | The Dataset name for model distillation ||
+| `cfg.llm.offsite_tuning.emu_align.data.splits` | (list) [0.8, 0.1, 0.1] | Train, valid, test splits for model distillation ||
+| `cfg.llm.offsite_tuning.emu_align.train.local_update_steps` | (int) 10 | The number of local training steps in model distillation ||
+| `cfg.llm.offsite_tuning.emu_align.train.batch_or_epoch` | (string) 'batch' | The type of local training for model distillation ||
+| `cfg.llm.offsite_tuning.emu_align.train.lm_loss_weight` | (float) 0.1 | The ratio of language model loss in model distillation ||
+| `cfg.llm.offsite_tuning.emu_align.train.kd_loss_weight` | (float) 0.9 | The ratio of knowledge distillation loss in model distillation ||
+| `cfg.llm.offsite_tuning.emu_align.train.optimizer.type` | (string) 'SGD' | The type of optimizer used in model distillation ||
+| `cfg.llm.offsite_tuning.emu_align.train.optimizer.lr` | (float) 0.01 | The learning rate used in model distillation ||
diff --git a/federatedscope/core/configs/cfg_fl_setting.py b/federatedscope/core/configs/cfg_fl_setting.py
index 7c3a62bf5..676082247 100644
--- a/federatedscope/core/configs/cfg_fl_setting.py
+++ b/federatedscope/core/configs/cfg_fl_setting.py
@@ -14,6 +14,7 @@ def extend_fl_setting_cfg(cfg):
cfg.federate = CN()
cfg.federate.client_num = 0
+ cfg.federate.client_idx_for_local_train = 0
cfg.federate.sample_client_num = -1
cfg.federate.sample_client_rate = -1.0
cfg.federate.unseen_clients_rate = 0.0
@@ -38,6 +39,8 @@ def extend_fl_setting_cfg(cfg):
cfg.federate.use_ss = False # Whether to apply Secret Sharing
cfg.federate.restore_from = ''
cfg.federate.save_to = ''
+ cfg.federate.save_freq = -1
+ cfg.federate.save_client_model = False
cfg.federate.join_in_info = [
] # The information requirements (from server) for join_in
cfg.federate.sampler = 'uniform' # the strategy for sampling client
@@ -102,6 +105,10 @@ def extend_fl_setting_cfg(cfg):
cfg.vertical.data_size_for_debug = 0 # use a subset for debug in vfl,
# 0 indicates using the entire dataset (disable debug mode)
+ cfg.adapter = CN()
+ cfg.adapter.use = False
+ cfg.adapter.args = []
+
# --------------- register corresponding check function ----------
cfg.register_cfg_check_fun(assert_fl_setting_cfg)
diff --git a/federatedscope/core/configs/cfg_llm.py b/federatedscope/core/configs/cfg_llm.py
new file mode 100644
index 000000000..05269b4cc
--- /dev/null
+++ b/federatedscope/core/configs/cfg_llm.py
@@ -0,0 +1,93 @@
+import json
+import logging
+
+from federatedscope.core.configs.config import CN
+from federatedscope.register import register_config
+
+logger = logging.getLogger(__name__)
+
+
+def extend_llm_cfg(cfg):
+ # ---------------------------------------------------------------------- #
+ # LLM related options
+ # ---------------------------------------------------------------------- #
+ cfg.llm = CN()
+ cfg.llm.tok_len = 128
+ cfg.llm.retry_on_nan_loss = False
+
+ # ---------------------------------------------------------------------- #
+ # Cache for LLM
+ # ---------------------------------------------------------------------- #
+ cfg.llm.cache = CN()
+ cfg.llm.cache.model = ''
+
+ # ---------------------------------------------------------------------- #
+ # Chat tools for LLM
+ # ---------------------------------------------------------------------- #
+ cfg.llm.chat = CN()
+ cfg.llm.chat.max_history_len = 10
+ cfg.llm.chat.max_len = 100
+
+ # ---------------------------------------------------------------------- #
+ # Deepspeed related options
+ # ---------------------------------------------------------------------- #
+ cfg.llm.deepspeed = CN()
+ cfg.llm.deepspeed.use = False
+ cfg.llm.deepspeed.ds_config = ''
+
+ # ---------------------------------------------------------------------- #
+ # Adapters for LLM
+ # ---------------------------------------------------------------------- #
+ cfg.llm.adapter = CN()
+ cfg.llm.adapter.use = False
+ cfg.llm.adapter.args = [{}]
+ # Move adapter to `cpu` after training, which can save memory but cost
+ # more time.
+ cfg.llm.adapter.mv_to_cpu = False
+
+ # ---------------------------------------------------------------------- #
+ # Offsite-tuning related options
+ # ---------------------------------------------------------------------- #
+ cfg.llm.offsite_tuning = CN()
+ cfg.llm.offsite_tuning.use = False
+ cfg.llm.offsite_tuning.strategy = 'drop_layer'
+ cfg.llm.offsite_tuning.kwargs = [{}]
+ cfg.llm.offsite_tuning.emu_l = 1 # Index of emulator layer left
+ cfg.llm.offsite_tuning.emu_r = 10 # Index of emulator layer right
+
+ # Used in `eval`
+ cfg.llm.offsite_tuning.eval_type = 'emu' # Choose one of `[emu, full]`
+
+ # Emulator alignment will use dataset in Server
+ cfg.llm.offsite_tuning.emu_align = CN()
+ cfg.llm.offsite_tuning.emu_align.use = False
+ cfg.llm.offsite_tuning.emu_align.restore_from = ''
+ cfg.llm.offsite_tuning.emu_align.save_to = ''
+ cfg.llm.offsite_tuning.emu_align.exit_after_align = False
+
+ # Server held-out data
+ cfg.llm.offsite_tuning.emu_align.data = CN()
+ cfg.llm.offsite_tuning.emu_align.data.root = 'data'
+ cfg.llm.offsite_tuning.emu_align.data.type = 'alpaca@llm'
+ cfg.llm.offsite_tuning.emu_align.data.splits = [0.8, 0.1, 0.1]
+
+ cfg.llm.offsite_tuning.emu_align.train = CN()
+ cfg.llm.offsite_tuning.emu_align.train.local_update_steps = 10
+ cfg.llm.offsite_tuning.emu_align.train.batch_or_epoch = 'batch'
+ cfg.llm.offsite_tuning.emu_align.train.lm_loss_weight = 0.1
+ cfg.llm.offsite_tuning.emu_align.train.kd_loss_weight = 0.9
+
+ cfg.llm.offsite_tuning.emu_align.train.optimizer = CN(new_allowed=True)
+ cfg.llm.offsite_tuning.emu_align.train.optimizer.type = 'SGD'
+ cfg.llm.offsite_tuning.emu_align.train.optimizer.lr = 0.01
+
+
+def assert_llm_cfg(cfg):
+ if cfg.llm.offsite_tuning.emu_align.use:
+ if cfg.llm.offsite_tuning.emu_align.restore_from != '':
+ logger.warning(
+ 'Enabling `restore_from` in offsite_tuning emulator '
+ 'alignment will skip training the emulator.')
+
+
+register_config("llm", extend_llm_cfg)
diff --git a/federatedscope/core/configs/cfg_training.py b/federatedscope/core/configs/cfg_training.py
index 6e98c3623..3a91f8213 100644
--- a/federatedscope/core/configs/cfg_training.py
+++ b/federatedscope/core/configs/cfg_training.py
@@ -32,6 +32,7 @@ def extend_training_cfg(cfg):
cfg.train.local_update_steps = 1
cfg.train.batch_or_epoch = 'batch'
+ cfg.train.data_para_dids = [] # `torch.nn.DataParallel` devices
cfg.train.optimizer = CN(new_allowed=True)
cfg.train.optimizer.type = 'SGD'
@@ -42,6 +43,9 @@ def extend_training_cfg(cfg):
cfg.train.scheduler.type = ''
cfg.train.scheduler.warmup_ratio = 0.0
+ # when model is too large, users can use half-precision model
+ cfg.train.is_enable_half = False
+
# ---------------------------------------------------------------------- #
# Finetune related options
# ---------------------------------------------------------------------- #
diff --git a/federatedscope/core/data/base_translator.py b/federatedscope/core/data/base_translator.py
index 1ac20fd7a..d01391f17 100644
--- a/federatedscope/core/data/base_translator.py
+++ b/federatedscope/core/data/base_translator.py
@@ -119,7 +119,8 @@ def split_to_client(self, train, val, test):
except:
logger.warning(
'Cannot access train label distribution for '
- 'splitter.')
+ 'splitter, split dataset without considering train '
+ 'label.')
if len(val) > 0:
split_val = self.splitter(val, prior=train_label_distribution)
if len(test) > 0:
diff --git a/federatedscope/core/data/utils.py b/federatedscope/core/data/utils.py
index be785cb74..5d8c77ff2 100644
--- a/federatedscope/core/data/utils.py
+++ b/federatedscope/core/data/utils.py
@@ -94,6 +94,9 @@ def load_dataset(config, client_cfgs=None):
from federatedscope.nlp.hetero_tasks.dataloader import \
load_heteroNLP_data
dataset, modified_config = load_heteroNLP_data(config, client_cfgs)
+ elif '@llm' in config.data.type.lower():
+ from federatedscope.llm.dataloader import load_llm_dataset
+ dataset, modified_config = load_llm_dataset(config)
elif '@' in config.data.type.lower():
from federatedscope.core.data.utils import load_external_data
dataset, modified_config = load_external_data(config)
diff --git a/federatedscope/core/fed_runner.py b/federatedscope/core/fed_runner.py
index 3c9b046fc..a006bf2d0 100644
--- a/federatedscope/core/fed_runner.py
+++ b/federatedscope/core/fed_runner.py
@@ -9,7 +9,8 @@
from federatedscope.core.workers import Server, Client
from federatedscope.core.gpu_manager import GPUManager
from federatedscope.core.auxiliaries.model_builder import get_model
-from federatedscope.core.auxiliaries.utils import get_resource_info
+from federatedscope.core.auxiliaries.utils import get_resource_info, \
+ get_ds_rank
from federatedscope.core.auxiliaries.feat_engr_builder import \
get_feat_engr_wrapper
@@ -133,6 +134,10 @@ def run(self):
"""
raise NotImplementedError
+ @property
+ def ds_rank(self):
+ return get_ds_rank()
+
def _setup_server(self, resource_info=None, client_resource_info=None):
"""
Set up and instantiate the server.
@@ -201,18 +206,16 @@ def _setup_client(self,
client_device = self._server_device if \
self.cfg.federate.share_local_model else \
self.gpu_manager.auto_choice()
- client = self.client_class(ID=client_id,
- server_id=self.server_id,
- config=client_specific_config,
- data=client_data,
- model=client_model
- or get_model(client_specific_config.model,
- client_data,
- backend=self.cfg.backend),
- device=client_device,
- is_unseen_client=client_id
- in self.unseen_clients_id,
- **kw)
+ client = self.client_class(
+ ID=client_id,
+ server_id=self.server_id,
+ config=client_specific_config,
+ data=client_data,
+ model=client_model or get_model(
+ client_specific_config, client_data, backend=self.cfg.backend),
+ device=client_device,
+ is_unseen_client=client_id in self.unseen_clients_id,
+ **kw)
if self.cfg.vertical.use:
from federatedscope.vertical_fl.utils import wrap_vertical_client
@@ -340,9 +343,13 @@ def _set_up(self):
self.client = dict()
# assume the client-wise data are consistent in their input&output
# shape
- self._shared_client_model = get_model(
- self.cfg.model, self.data[1], backend=self.cfg.backend
- ) if self.cfg.federate.share_local_model else None
+ if self.cfg.federate.online_aggr:
+ self._shared_client_model = get_model(
+ self.cfg, self.data[1], backend=self.cfg.backend
+ ) if self.cfg.federate.share_local_model else None
+ else:
+ self._shared_client_model = self.server.model \
+ if self.cfg.federate.share_local_model else None
for client_id in range(1, self.cfg.federate.client_num + 1):
self.client[client_id] = self._setup_client(
client_id=client_id,
@@ -360,14 +367,12 @@ def _set_up(self):
def _get_server_args(self, resource_info=None, client_resource_info=None):
if self.server_id in self.data:
server_data = self.data[self.server_id]
- model = get_model(self.cfg.model,
- server_data,
- backend=self.cfg.backend)
+ model = get_model(self.cfg, server_data, backend=self.cfg.backend)
else:
server_data = None
data_representative = self.data[1]
model = get_model(
- self.cfg.model, data_representative, backend=self.cfg.backend
+ self.cfg, data_representative, backend=self.cfg.backend
) # get the model according to client's data if the server
# does not own data
kw = {
@@ -518,7 +523,7 @@ def _set_up(self):
self.server_address = {
'host': self.cfg.distribute.server_host,
- 'port': self.cfg.distribute.server_port
+ 'port': self.cfg.distribute.server_port + self.ds_rank
}
if self.cfg.distribute.role == 'server':
self.server = self._setup_server(resource_info=sampled_resource)
@@ -527,15 +532,13 @@ def _set_up(self):
# the server has been set up and number with #0
self.client_address = {
'host': self.cfg.distribute.client_host,
- 'port': self.cfg.distribute.client_port
+ 'port': self.cfg.distribute.client_port + self.ds_rank
}
self.client = self._setup_client(resource_info=sampled_resource)
def _get_server_args(self, resource_info, client_resource_info):
server_data = self.data
- model = get_model(self.cfg.model,
- server_data,
- backend=self.cfg.backend)
+ model = get_model(self.cfg, server_data, backend=self.cfg.backend)
kw = self.server_address
kw.update({'resource_info': resource_info})
return server_data, model, kw
@@ -682,7 +685,7 @@ def _setup_for_standalone(self):
# assume the client-wise data are consistent in their input&output
# shape
self._shared_client_model = get_model(
- self.cfg.model, self.data[1], backend=self.cfg.backend
+ self.cfg, self.data[1], backend=self.cfg.backend
) if self.cfg.federate.share_local_model else None
for client_id in range(1, self.cfg.federate.client_num + 1):
@@ -830,16 +833,14 @@ def _setup_server(self, resource_info=None, client_resource_info=None):
if self.mode == 'standalone':
if self.server_id in self.data:
server_data = self.data[self.server_id]
- model = get_model(self.cfg.model,
+ model = get_model(self.cfg,
server_data,
backend=self.cfg.backend)
else:
server_data = None
data_representative = self.data[1]
model = get_model(
- self.cfg.model,
- data_representative,
- backend=self.cfg.backend
+ self.cfg, data_representative, backend=self.cfg.backend
) # get the model according to client's data if the server
# does not own data
kw = {
@@ -849,9 +850,7 @@ def _setup_server(self, resource_info=None, client_resource_info=None):
}
elif self.mode == 'distributed':
server_data = self.data
- model = get_model(self.cfg.model,
- server_data,
- backend=self.cfg.backend)
+ model = get_model(self.cfg, server_data, backend=self.cfg.backend)
kw = self.server_address
kw.update({'resource_info': resource_info})
else:
@@ -918,17 +917,18 @@ def _setup_client(self,
client_device = self._server_device if \
self.cfg.federate.share_local_model else \
self.gpu_manager.auto_choice()
- client = self.client_class(
- ID=client_id,
- server_id=self.server_id,
- config=client_specific_config,
- data=client_data,
- model=client_model or get_model(client_specific_config.model,
- client_data,
- backend=self.cfg.backend),
- device=client_device,
- is_unseen_client=client_id in self.unseen_clients_id,
- **kw)
+ client = self.client_class(ID=client_id,
+ server_id=self.server_id,
+ config=client_specific_config,
+ data=client_data,
+ model=client_model
+ or get_model(client_specific_config,
+ client_data,
+ backend=self.cfg.backend),
+ device=client_device,
+ is_unseen_client=client_id
+ in self.unseen_clients_id,
+ **kw)
else:
raise ValueError
diff --git a/federatedscope/core/message.py b/federatedscope/core/message.py
index 94753939f..93f4bc54b 100644
--- a/federatedscope/core/message.py
+++ b/federatedscope/core/message.py
@@ -1,12 +1,8 @@
import json
-import pickle
-import base64
import numpy as np
-from federatedscope.core.proto import gRPC_comm_manager_pb2
-
-def b64serializer(x):
- return base64.b64encode(pickle.dumps(x))
+from federatedscope.core.auxiliaries.utils import b64serializer
+from federatedscope.core.proto import gRPC_comm_manager_pb2
class Message(object):
diff --git a/federatedscope/core/monitors/monitor.py b/federatedscope/core/monitors/monitor.py
index 81f71b0a5..671541bac 100644
--- a/federatedscope/core/monitors/monitor.py
+++ b/federatedscope/core/monitors/monitor.py
@@ -737,6 +737,7 @@ def update_best_result(self, best_results, new_results, results_type):
logger.error(
"cfg.wandb.use=True but not install the wandb package")
exit()
+ return update_best_this_round
def add_items_to_best_result(self, best_results, new_results,
results_type):
diff --git a/federatedscope/core/parallel/parallel_runner.py b/federatedscope/core/parallel/parallel_runner.py
index 4b7eda710..aa6b6c90c 100644
--- a/federatedscope/core/parallel/parallel_runner.py
+++ b/federatedscope/core/parallel/parallel_runner.py
@@ -114,14 +114,12 @@ def _set_up(self):
def _get_server_args(self, resource_info=None, client_resource_info=None):
if self.server_id in self.data:
server_data = self.data[self.server_id]
- model = get_model(self.cfg.model,
- server_data,
- backend=self.cfg.backend)
+ model = get_model(self.cfg, server_data, backend=self.cfg.backend)
else:
server_data = None
data_representative = self.data[1]
model = get_model(
- self.cfg.model, data_representative, backend=self.cfg.backend
+ self.cfg, data_representative, backend=self.cfg.backend
) # get the model according to client's data if the server
# does not own data
kw = {
@@ -204,12 +202,12 @@ def setup(self):
self.config.freeze()
if self.rank in data:
self.data = data[self.rank] if self.rank in data else data[1]
- model = get_model(self.config.model,
+ model = get_model(self.config,
self.data,
backend=self.config.backend)
else:
self.data = None
- model = get_model(self.config.model,
+ model = get_model(self.config,
data[1],
backend=self.config.backend)
kw = {
@@ -325,7 +323,7 @@ def setup(self):
self.config.merge_from_other_cfg(modified_cfg)
self.config.freeze()
self.shared_model = get_model(
- self.config.model,
+ self.config,
self.data[self.base_client_id],
backend=self.config.backend
) if self.config.federate.share_local_model else None
@@ -352,7 +350,7 @@ def setup(self):
config=client_specific_config,
data=client_data,
model=self.shared_model
- or get_model(client_specific_config.model,
+ or get_model(client_specific_config,
client_data,
backend=self.config.backend),
device=self.device,
diff --git a/federatedscope/core/splitters/generic/__init__.py b/federatedscope/core/splitters/generic/__init__.py
index 8bf4c2790..572a7d4c7 100644
--- a/federatedscope/core/splitters/generic/__init__.py
+++ b/federatedscope/core/splitters/generic/__init__.py
@@ -1,4 +1,5 @@
from federatedscope.core.splitters.generic.lda_splitter import LDASplitter
from federatedscope.core.splitters.generic.iid_splitter import IIDSplitter
+from federatedscope.core.splitters.generic.meta_splitter import MetaSplitter
-__all__ = ['LDASplitter', 'IIDSplitter']
+__all__ = ['LDASplitter', 'IIDSplitter', 'MetaSplitter']
diff --git a/federatedscope/core/splitters/generic/iid_splitter.py b/federatedscope/core/splitters/generic/iid_splitter.py
index 4aeadba7f..a550ae61b 100644
--- a/federatedscope/core/splitters/generic/iid_splitter.py
+++ b/federatedscope/core/splitters/generic/iid_splitter.py
@@ -19,7 +19,7 @@ def __call__(self, dataset, prior=None):
length = len(dataset)
index = [x for x in range(length)]
np.random.shuffle(index)
- idx_slice = np.split_array(dataset, self.client_num)
+ idx_slice = np.array_split(np.array(index), self.client_num)
if isinstance(dataset, Dataset):
data_list = [Subset(dataset, idxs) for idxs in idx_slice]
else:
diff --git a/federatedscope/core/splitters/generic/lda_splitter.py b/federatedscope/core/splitters/generic/lda_splitter.py
index 08f3fdfaf..c7810f7e8 100644
--- a/federatedscope/core/splitters/generic/lda_splitter.py
+++ b/federatedscope/core/splitters/generic/lda_splitter.py
@@ -22,7 +22,12 @@ def __call__(self, dataset, prior=None, **kwargs):
from torch.utils.data import Dataset, Subset
tmp_dataset = [ds for ds in dataset]
- label = np.array([y for x, y in tmp_dataset])
+ if isinstance(tmp_dataset[0], tuple):
+ label = np.array([y for x, y in tmp_dataset])
+ elif isinstance(tmp_dataset[0], dict):
+ label = np.array([x['categories'] for x in tmp_dataset])
+ else:
+ raise TypeError(f'Unsupported data formats {type(tmp_dataset[0])}')
idx_slice = dirichlet_distribution_noniid_slice(label,
self.client_num,
self.alpha,
diff --git a/federatedscope/core/splitters/generic/meta_splitter.py b/federatedscope/core/splitters/generic/meta_splitter.py
new file mode 100644
index 000000000..ff3b5dd2c
--- /dev/null
+++ b/federatedscope/core/splitters/generic/meta_splitter.py
@@ -0,0 +1,47 @@
+import random
+import numpy as np
+
+from federatedscope.core.splitters import BaseSplitter
+
+
+class MetaSplitter(BaseSplitter):
+ """
+ This splitter split dataset with meta information with LLM dataset.
+
+ Args:
+ client_num: the dataset will be split into ``client_num`` pieces
+ """
+ def __init__(self, client_num, **kwargs):
+ super(MetaSplitter, self).__init__(client_num)
+
+ def __call__(self, dataset, prior=None, **kwargs):
+ from torch.utils.data import Dataset, Subset
+
+ tmp_dataset = [ds for ds in dataset]
+ if isinstance(tmp_dataset[0], tuple):
+ label = np.array([y for x, y in tmp_dataset])
+ elif isinstance(tmp_dataset[0], dict):
+ label = np.array([x['categories'] for x in tmp_dataset])
+ else:
+ raise TypeError(f'Unsupported data formats {type(tmp_dataset[0])}')
+
+ # Split by categories
+ categories = set(label)
+ idx_slice = []
+ for cat in categories:
+ idx_slice.append(np.where(np.array(label) == cat)[0].tolist())
+ random.shuffle(idx_slice)
+
+ # Merge to client_num pieces
+ new_idx_slice = []
+ for i in range(len(categories)):
+ if i < self.client_num:
+ new_idx_slice.append(idx_slice[i])
+ else:
+ new_idx_slice[i % self.client_num] += idx_slice[i]
+
+ if isinstance(dataset, Dataset):
+ data_list = [Subset(dataset, idxs) for idxs in idx_slice]
+ else:
+ data_list = [[dataset[idx] for idx in idxs] for idxs in idx_slice]
+ return data_list
diff --git a/federatedscope/core/trainers/base_trainer.py b/federatedscope/core/trainers/base_trainer.py
index 1d0637d42..9a7bb0a4a 100644
--- a/federatedscope/core/trainers/base_trainer.py
+++ b/federatedscope/core/trainers/base_trainer.py
@@ -33,3 +33,6 @@ def print_trainer_meta_info(self):
meta_info = tuple([(val.name, getattr(self, val.name))
for val in sign])
return f'{self.__class__.__name__}{meta_info}'
+
+ def save_model(self, path, cur_round):
+ raise NotImplementedError
diff --git a/federatedscope/core/trainers/torch_trainer.py b/federatedscope/core/trainers/torch_trainer.py
index fd5a72c53..86c66e8f0 100644
--- a/federatedscope/core/trainers/torch_trainer.py
+++ b/federatedscope/core/trainers/torch_trainer.py
@@ -28,12 +28,12 @@
class GeneralTorchTrainer(Trainer):
def get_model_para(self):
- if self.cfg.federate.process_num > 1:
+ if self.cfg.federate.process_num > 1 or \
+ self.cfg.federate.share_local_model or \
+ self.cfg.llm.deepspeed.use:
return self._param_filter(self.ctx.model.state_dict())
else:
- return self._param_filter(
- self.ctx.model.state_dict() if self.cfg.federate.
- share_local_model else self.ctx.model.cpu().state_dict())
+ return self._param_filter(self.ctx.model.cpu().state_dict())
def setup_data(self, ctx):
"""
@@ -98,6 +98,10 @@ def evaluate(self, target_data_split_name="test"):
return self.ctx.eval_metrics
def register_default_hooks_train(self):
+ self.register_hook_in_train(
+ self._hook_on_fit_start_numerical_precision, "on_fit_start")
+ self.register_hook_in_train(self._hook_on_data_parallel_init,
+ "on_fit_start")
self.register_hook_in_train(self._hook_on_fit_start_init,
"on_fit_start")
self.register_hook_in_train(
@@ -118,6 +122,10 @@ def register_default_hooks_train(self):
self.register_hook_in_train(self._hook_on_fit_end, "on_fit_end")
def register_default_hooks_ft(self):
+ self.register_hook_in_ft(self._hook_on_fit_start_numerical_precision,
+ "on_fit_start")
+ self.register_hook_in_ft(self._hook_on_data_parallel_init,
+ "on_fit_start")
self.register_hook_in_ft(self._hook_on_fit_start_init, "on_fit_start")
self.register_hook_in_ft(self._hook_on_fit_start_calculate_model_size,
"on_fit_start")
@@ -137,6 +145,10 @@ def register_default_hooks_ft(self):
def register_default_hooks_eval(self):
# test/val
+ self.register_hook_in_eval(self._hook_on_fit_start_numerical_precision,
+ "on_fit_start")
+ self.register_hook_in_eval(self._hook_on_data_parallel_init,
+ "on_fit_start")
self.register_hook_in_eval(self._hook_on_fit_start_init,
"on_fit_start")
self.register_hook_in_eval(self._hook_on_epoch_start, "on_epoch_start")
@@ -147,6 +159,30 @@ def register_default_hooks_eval(self):
self.register_hook_in_eval(self._hook_on_batch_end, "on_batch_end")
self.register_hook_in_eval(self._hook_on_fit_end, "on_fit_end")
+ def _hook_on_fit_start_numerical_precision(self, ctx):
+ if self.cfg.train.is_enable_half:
+ ctx.model = ctx.model.half()
+
+ def _hook_on_data_parallel_init(self, ctx):
+ """
+ Note:
+ The modified attributes and according operations are shown below,
+ further modifications should be made to `ctx.model` other object:
+ ================================== ===========================
+ Attribute Operation
+ ================================== ===========================
+ ``ctx.model`` Wrap ``nn.Module` to \
+ `nn.DataParallel`
+ ================================== ===========================
+ """
+ if isinstance(ctx.model, torch.nn.DataParallel):
+ return
+
+ if len(ctx.cfg.train.data_para_dids):
+ ctx.model = \
+ torch.nn.DataParallel(ctx.model,
+ device_ids=ctx.cfg.train.data_para_dids)
+
def _hook_on_fit_start_init(self, ctx):
"""
Note:
@@ -427,8 +463,9 @@ def discharge_model(self):
Discharge the model from GPU device
"""
# Avoid memory leak
- if not self.cfg.federate.share_local_model:
- if torch is None:
- pass
- else:
- self.ctx.model.to(torch.device("cpu"))
+ if torch is None:
+ return
+
+ if not self.cfg.federate.share_local_model and \
+ not self.cfg.llm.deepspeed.use:
+ self.ctx.model.to(torch.device("cpu"))
diff --git a/federatedscope/core/trainers/trainer.py b/federatedscope/core/trainers/trainer.py
index 689f64abe..41be4ad71 100644
--- a/federatedscope/core/trainers/trainer.py
+++ b/federatedscope/core/trainers/trainer.py
@@ -279,9 +279,10 @@ def _run_routine(self, mode, hooks_set, dataset_name=None):
return self.ctx.num_samples
@lifecycle(LIFECYCLE.EPOCH)
- def _run_epoch(self, hooks_set):
- for epoch_i in range(
- getattr(self.ctx, f"num_{self.ctx.cur_split}_epoch")):
+ def _run_epoch(self, hooks_set, run_step=-1):
+ if run_step == -1:
+ run_step = getattr(self.ctx, f"num_{self.ctx.cur_split}_epoch")
+ for epoch_i in range(run_step):
self.ctx.cur_epoch_i = CtxVar(epoch_i, "epoch")
for hook in hooks_set["on_epoch_start"]:
@@ -293,9 +294,10 @@ def _run_epoch(self, hooks_set):
hook(self.ctx)
@lifecycle(LIFECYCLE.BATCH)
- def _run_batch(self, hooks_set):
- for batch_i in range(
- getattr(self.ctx, f"num_{self.ctx.cur_split}_batch")):
+ def _run_batch(self, hooks_set, run_step=-1):
+ if run_step == -1:
+ run_step = getattr(self.ctx, f"num_{self.ctx.cur_split}_batch")
+ for batch_i in range(run_step):
self.ctx.cur_batch_i = CtxVar(batch_i, LIFECYCLE.BATCH)
for hook in hooks_set["on_batch_start"]:
diff --git a/federatedscope/core/trainers/trainer_pFedMe.py b/federatedscope/core/trainers/trainer_pFedMe.py
index dac1e81f0..cf069324f 100644
--- a/federatedscope/core/trainers/trainer_pFedMe.py
+++ b/federatedscope/core/trainers/trainer_pFedMe.py
@@ -1,10 +1,24 @@
import copy
+try:
+ import torch
+except ImportError:
+ torch = None
from federatedscope.core.trainers.torch_trainer import GeneralTorchTrainer
from federatedscope.core.optimizer import wrap_regularized_optimizer
from typing import Type
+def get_trainable_parameter_list(model):
+ copied_param = []
+ for param in model.parameters():
+ if param.requires_grad:
+ copied_param.append(copy.deepcopy(param))
+ else:
+ copied_param.append(None)
+ return copied_param
+
+
def wrap_pFedMeTrainer(
base_trainer: Type[GeneralTorchTrainer]) -> Type[GeneralTorchTrainer]:
"""
@@ -81,7 +95,7 @@ def init_pFedMe_ctx(base_trainer):
# the local_model_tmp is used to be the referenced parameter when
# finding the approximate \theta in paper
# will be copied from model every run_routine
- ctx.pFedMe_local_model_tmp = None
+ ctx.pFedMe_local_model_param_tmp = None
def _hook_on_fit_start_set_local_para_tmp(ctx):
@@ -95,7 +109,7 @@ def _hook_on_fit_start_set_local_para_tmp(ctx):
``wrap_regularized_optimizer`` and set compared parameter group
``ctx.pFedMe_outer_lr`` Initialize to \
``ctx.cfg.train.optimizer.lr``
- ``ctx.pFedMe_local_model_tmp`` Copy from ``ctx.model``
+ ``ctx.pFedMe_local_model_param_tmp`` Copy from ``ctx.model``
================================== ===========================
"""
# the optimizer used in pFedMe is based on Moreau Envelopes regularization
@@ -106,13 +120,10 @@ def _hook_on_fit_start_set_local_para_tmp(ctx):
for g in ctx.optimizer.param_groups:
g['lr'] = ctx.cfg.personalization.lr
ctx.pFedMe_outer_lr = ctx.cfg.train.optimizer.lr
-
- ctx.pFedMe_local_model_tmp = copy.deepcopy(ctx.model)
+ ctx.pFedMe_local_model_param_tmp = get_trainable_parameter_list(ctx.model)
# set the compared model data, then the optimizer will find approximate
# model using trainer.cfg.personalization.lr
- compared_global_model_para = [{
- "params": list(ctx.pFedMe_local_model_tmp.parameters())
- }]
+ compared_global_model_para = [{"params": ctx.pFedMe_local_model_param_tmp}]
ctx.optimizer.set_compared_para_group(compared_global_model_para)
@@ -181,23 +192,22 @@ def _hook_on_epoch_end_update_local(ctx):
Attribute Operation
================================== ===========================
``ctx.model`` Update parameters by \
- ``ctx.pFedMe_local_model_tmp``
+ ``ctx.pFedMe_local_model_param_tmp``
``ctx.optimizer`` Set compared parameter group
================================== ===========================
"""
# update local weight after finding approximate theta
- for client_param, local_para_tmp in zip(
- ctx.model.parameters(), ctx.pFedMe_local_model_tmp.parameters()):
- local_para_tmp.data = local_para_tmp.data - \
- ctx.optimizer.regular_weight * \
- ctx.pFedMe_outer_lr * (local_para_tmp.data -
- client_param.data)
+ for client_param, local_para_tmp in zip(ctx.model.parameters(),
+ ctx.pFedMe_local_model_param_tmp):
+ if client_param.requires_grad:
+ local_para_tmp.data = local_para_tmp.data - \
+ ctx.optimizer.regular_weight * \
+ ctx.pFedMe_outer_lr * (local_para_tmp.data -
+ client_param.data)
# set the compared model data, then the optimizer will find approximate
# model using trainer.cfg.personalization.lr
- compared_global_model_para = [{
- "params": list(ctx.pFedMe_local_model_tmp.parameters())
- }]
+ compared_global_model_para = [{"params": ctx.pFedMe_local_model_param_tmp}]
ctx.optimizer.set_compared_para_group(compared_global_model_para)
@@ -209,12 +219,13 @@ def _hook_on_fit_end_update_local(ctx):
Attribute Operation
================================== ===========================
``ctx.model`` Update parameters by
- ``ctx.pFedMe_local_model_tmp``
- ``ctx.pFedMe_local_model_tmp`` Delete
+ ``ctx.pFedMe_local_model_param_tmp``
+ ``ctx.pFedMe_local_model_param_tmp`` Delete
================================== ===========================
"""
for param, local_para_tmp in zip(ctx.model.parameters(),
- ctx.pFedMe_local_model_tmp.parameters()):
- param.data = local_para_tmp.data
+ ctx.pFedMe_local_model_param_tmp):
+ if param.requires_grad:
+ param.data = local_para_tmp.data
- del ctx.pFedMe_local_model_tmp
+ del ctx.pFedMe_local_model_param_tmp
diff --git a/federatedscope/core/workers/base_worker.py b/federatedscope/core/workers/base_worker.py
index 8a36c1995..f9c1bcd21 100644
--- a/federatedscope/core/workers/base_worker.py
+++ b/federatedscope/core/workers/base_worker.py
@@ -1,4 +1,5 @@
from federatedscope.core.monitors.monitor import Monitor
+from federatedscope.core.auxiliaries.utils import get_ds_rank
class Worker(object):
@@ -68,3 +69,7 @@ def mode(self):
@mode.setter
def mode(self, value):
self._mode = value
+
+ @property
+ def ds_rank(self):
+ return get_ds_rank()
diff --git a/federatedscope/core/workers/client.py b/federatedscope/core/workers/client.py
index 455a12f9d..1be53984b 100644
--- a/federatedscope/core/workers/client.py
+++ b/federatedscope/core/workers/client.py
@@ -10,11 +10,12 @@
from federatedscope.core.auxiliaries.trainer_builder import get_trainer
from federatedscope.core.secret_sharing import AdditiveSecretSharing
from federatedscope.core.auxiliaries.utils import merge_dict_of_results, \
- calculate_time_cost
+ calculate_time_cost, add_prefix_to_path, get_ds_rank
from federatedscope.core.workers.base_client import BaseClient
logger = logging.getLogger(__name__)
-logger.setLevel(logging.INFO)
+if get_ds_rank() == 0:
+ logger.setLevel(logging.INFO)
class Client(BaseClient):
@@ -142,8 +143,12 @@ def __init__(self,
self.comm_bandwidth = None
if self._cfg.backend == 'torch':
- self.model_size = sys.getsizeof(pickle.dumps(
- self.model)) / 1024.0 * 8. # kbits
+ try:
+ self.model_size = sys.getsizeof(pickle.dumps(
+ self.model)) / 1024.0 * 8. # kbits
+ except Exception as error:
+ self.model_size = 1.0
+ logger.warning(f'{error} in calculate model size.')
else:
# TODO: calculate model size for TF Model
self.model_size = 1.0
@@ -546,9 +551,19 @@ def callback_funcs_for_evaluate(self, message: Message):
role='Client #{}'.format(self.ID),
forms=['raw'],
return_raw=True)
- self._monitor.update_best_result(self.best_results,
- formatted_eval_res['Results_raw'],
- results_type=f"client #{self.ID}")
+ logger.info(formatted_eval_res)
+ update_best_this_round = self._monitor.update_best_result(
+ self.best_results,
+ formatted_eval_res['Results_raw'],
+ results_type=f"client #{self.ID}",
+ )
+
+ if update_best_this_round and self._cfg.federate.save_client_model:
+ path = add_prefix_to_path(f'client_{self.ID}_',
+ self._cfg.federate.save_to)
+ if self.ds_rank == 0:
+ self.trainer.save_model(path, self.state)
+
self.history_results = merge_dict_of_results(
self.history_results, formatted_eval_res['Results_raw'])
self.early_stopper.track_and_check(self.history_results[
diff --git a/federatedscope/core/workers/server.py b/federatedscope/core/workers/server.py
index 65ef0ff68..c8cefb9cc 100644
--- a/federatedscope/core/workers/server.py
+++ b/federatedscope/core/workers/server.py
@@ -5,7 +5,6 @@
import numpy as np
import pickle
-import time
from federatedscope.core.monitors.early_stopper import EarlyStopper
from federatedscope.core.message import Message
@@ -14,13 +13,14 @@
from federatedscope.core.auxiliaries.aggregator_builder import get_aggregator
from federatedscope.core.auxiliaries.sampler_builder import get_sampler
from federatedscope.core.auxiliaries.utils import merge_dict_of_results, \
- Timeout, merge_param_dict
+ Timeout, merge_param_dict, add_prefix_to_path, get_ds_rank
from federatedscope.core.auxiliaries.trainer_builder import get_trainer
from federatedscope.core.secret_sharing import AdditiveSecretSharing
from federatedscope.core.workers.base_server import BaseServer
logger = logging.getLogger(__name__)
-logger.setLevel(logging.INFO)
+if get_ds_rank() == 0:
+ logger.setLevel(logging.INFO)
class Server(BaseServer):
@@ -91,7 +91,10 @@ def __init__(self,
self._monitor.the_larger_the_better)
if self._cfg.federate.share_local_model \
- and not self._cfg.federate.process_num > 1:
+ and not self._cfg.federate.process_num > 1 \
+ and not self._cfg.llm.deepspeed.use:
+ if self._cfg.train.is_enable_half:
+ model = model.half()
# put the model to the specified device
model.to(device)
# Build aggregator
@@ -106,7 +109,8 @@ def __init__(self,
f' {self._cfg.federate.restore_from}.')
else:
_ = self.aggregator.load_model(self._cfg.federate.restore_from)
- logger.info("Restored the model from {}-th round's ckpt")
+ logger.info(f"Restored the model from "
+ f"{self._cfg.federate.restore_from}")
if int(config.model.model_num_per_trainer) != \
config.model.model_num_per_trainer or \
@@ -403,6 +407,14 @@ def check_and_save(self):
))
self.state = self.total_round_num + 1
+ if self.state != self.total_round_num and \
+ self.state % self._cfg.federate.save_freq == 0 and \
+ self._cfg.federate.save_freq > 0:
+ path = add_prefix_to_path(f'{self.state}_',
+ self._cfg.federate.save_to)
+ if self.ds_rank == 0:
+ self.aggregator.save_model(path, self.state)
+
if should_stop or self.state == self.total_round_num:
logger.info('Server: Final evaluation is finished! Starting '
'merging results.')
@@ -521,9 +533,11 @@ def save_best_results(self):
"""
To Save the best evaluation results.
"""
-
- if self._cfg.federate.save_to != '':
- self.aggregator.save_model(self._cfg.federate.save_to, self.state)
+ # Save final round model
+ if self._cfg.federate.save_to != '' and self.ds_rank == 0:
+ self.aggregator.save_model(
+ add_prefix_to_path('final_', self._cfg.federate.save_to),
+ self.state)
formatted_best_res = self._monitor.format_eval_res(
results=self.best_results,
rnd="Final",
@@ -606,17 +620,37 @@ def merge_eval_results_from_all_clients(self):
metrics_all_clients,
results_type="unseen_client_best_individual"
if merge_type == "unseen" else "client_best_individual")
+
self._monitor.save_formatted_results(formatted_logs)
+
+ update_prior = -1 # Bigger the higher priority
+ update_prior_list = ['fairness', 'avg', 'weighted_avg']
+ update_best_this_round = False
for form in self._cfg.eval.report:
+ if form in update_prior_list:
+ update_prior_tmp = update_prior_list.index(form)
+ else:
+ update_prior_tmp = -1
if form != "raw":
metric_name = form + "_unseen" if merge_type == \
"unseen" else form
- self._monitor.update_best_result(
- self.best_results,
- formatted_logs[f"Results_{metric_name}"],
- results_type=f"unseen_client_summarized_{form}"
- if merge_type == "unseen" else
- f"client_summarized_{form}")
+ update_best_this_round_tmp = \
+ self._monitor.update_best_result(
+ self.best_results,
+ formatted_logs[f"Results_{metric_name}"],
+ results_type=f"unseen_client_summarized_{form}"
+ if merge_type == "unseen" else
+ f"client_summarized_{form}")
+ if update_prior_tmp >= update_prior:
+ update_prior = update_prior_tmp
+ update_best_this_round = update_best_this_round_tmp
+ if update_best_this_round:
+ # When the frequency of evaluations is high,
+ # the frequency of writing to disk in the early stages
+ # may also be high
+ if self._cfg.federate.save_to != '' and self.ds_rank == 0:
+ self.aggregator.save_model(self._cfg.federate.save_to,
+ self.state)
return formatted_logs_all_set
@@ -661,11 +695,23 @@ def broadcast_model_para(self,
self.models[model_idx_i])
skip_broadcast = self._cfg.federate.method in ["local", "global"]
- if self.model_num > 1:
- model_para = [{} if skip_broadcast else model.state_dict()
- for model in self.models]
+ if self._cfg.federate.share_local_model and not \
+ self._cfg.federate.online_aggr:
+ if self.model_num > 1:
+ model_para = [
+ {} if skip_broadcast else copy.deepcopy(model.state_dict())
+ for model in self.models
+ ]
+ else:
+ model_para = {} if skip_broadcast else copy.deepcopy(
+ self.models[0].state_dict())
else:
- model_para = {} if skip_broadcast else self.models[0].state_dict()
+ if self.model_num > 1:
+ model_para = [{} if skip_broadcast else model.state_dict()
+ for model in self.models]
+ else:
+ model_para = {} if skip_broadcast else self.models[
+ 0].state_dict()
# quantization
if msg_type == 'model_para' and not skip_broadcast and \
@@ -795,8 +841,13 @@ def trigger_for_start(self):
]
else:
if self._cfg.backend == 'torch':
- model_size = sys.getsizeof(pickle.dumps(
- self.models[0])) / 1024.0 * 8.
+ try:
+ model_size = sys.getsizeof(pickle.dumps(
+ self.models[0])) / 1024.0 * 8.
+ except Exception as error:
+ model_size = 1.0
+ logger.warning(f'Error {error} in calculate model '
+ f'size.')
else:
# TODO: calculate model size for TF Model
model_size = 1.0
diff --git a/federatedscope/llm/README.md b/federatedscope/llm/README.md
new file mode 100644
index 000000000..1b7ba4354
--- /dev/null
+++ b/federatedscope/llm/README.md
@@ -0,0 +1,297 @@
+
+ +
+
+
+
+
+[](https://federatedscope.io/)
+[](https://colab.research.google.com/github/alibaba/FederatedScope)
+[](https://federatedscope.io/docs/contributor/)
+
+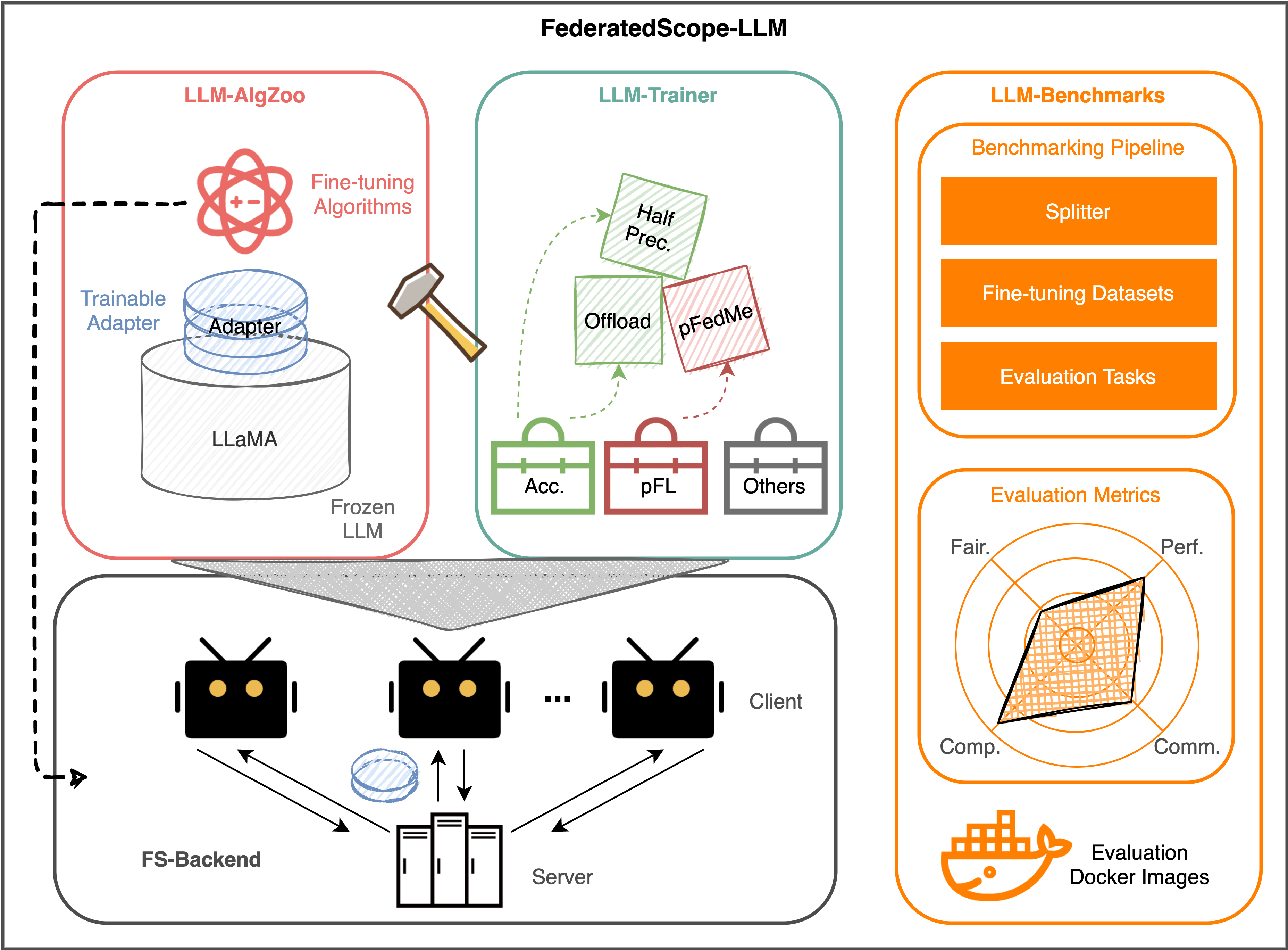 +
+FederatedScope-LLM (FS-LLM) is a comprehensive package for federated fine-tuning large language models, which provide:
+
+* A complete **end-to-end benchmarking pipeline**, automizing the processes of dataset preprocessing, federated fine-tuning execution or simulation, and performance evaluation on federated LLM fine-tuning with different capability demonstration purposes;
+* Comprehensive and off-the-shelf **federated fine-tuning algorithm** implementations and versatile programming interfaces for future extension to enhance the capabilities of LLMs in FL scenarios with low communication and computation costs, even without accessing the full model (e.g., closed-source LLMs);
+* Several **accelerating operators and resource-efficient operators** for fine-tuning LLMs with limited resources and the flexible pluggable sub-routines for interdisciplinary study (e.g., LLMs in personalized FL).
+
+For more details, please refer to our paper: [FederatedScope-LLM: A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning](https://arxiv.org/abs/2309.00363).
+
+We provide a hands-on tutorial here for your quick start.
+
+## Code Structure
+
+[LLM-related directory](https://github.com/alibaba/FederatedScope/tree/llm/federatedscope/llm)
+
+```
+FederatedScope
+├── federatedscope
+│ ├── core # Federated learning backend modules
+│ ├── llm # Federated fine-tuning LLMs modules
+│ │ ├── baseline # Scripts for LLMs
+│ │ ├── dataloader # Federated fine-tuning dataloader
+│ │ ├── dataset # Federated fine-tuning dataset
+│ │ ├── eval # Evaluation for fine-tuned LLMs
+│ │ ├── misc # Miscellaneous
+│ │ ├── model # LLMs and Adapter
+│ │ ├── trainer # Fine-tuning with accerating operators
+│ │ ├── ...
+│ ├── main.py # Running interface
+│ ├── ... ...
+├── tests # Unittest modules for continuous integration
+├── LICENSE
+└── setup.py
+```
+
+## Quick Start
+
+Let’s start with fine-tuning GPT-2 on [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) to familiarize you with FS-LLM.
+
+### Step 1. Installation
+
+The installation of FS-LLM is similar to minimal FS (see [here](https://github.com/alibaba/FederatedScope/tree/master) for details), except that it requires **Pytorch>=1.13.0** (we recommend version 2.0.X) because of the [PEFT](https://github.com/huggingface/peft) dependency:
+
+```bash
+# Create virtual environments with conda
+conda create -n fs-llm python=3.9
+conda activate fs-llm
+
+# Install Pytorch>=1.13.0 (e.g., Pytorch==2.0.0)
+conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
+
+# Install FS-LLM with editable mode
+pip install -e .[llm]
+```
+
+Now, you have successfully installed the FS-LLM.
+
+### Step 2. Run with exmaple config
+
+Now, we can fine-tune a GPT2 on Alpaca with FedAvg.
+
+```bash
+python federatedscope/main.py --cfg federatedscope/llm/baseline/testcase.yaml
+```
+
+For more details about customized configurations, see **Advanced**.
+
+## Advanced
+
+### Start with built-in functions
+
+You can easily run through a customized `yaml` file. Here we only introduce the configuration related to FS-LLM, other configurations please refer to [Configurations](https://github.com/alibaba/FederatedScope/blob/master/federatedscope/core/configs/README.md). For more examples, please refer to `federatedscope/llm/baseline`.
+
+```yaml
+# For this configuration, you might need a GPU with at least 32GB of video memory to run.
+
+# Whether to use GPU
+use_gpu: True
+
+# Deciding which GPU to use
+device: 0
+
+# Early stop steps, set `0` to disable
+early_stop:
+ patience: 0
+
+# Federate learning related options
+federate:
+ # `standalone` or `distributed`
+ mode: standalone
+ # Number of communication round
+ total_round_num: 500
+ # Saving path for ckpt
+ save_to: "llama_rosetta_9_fed.ckpt"
+ # Number of dataset being split
+ client_num: 9
+ # Enable for saving memory, all workers share the same model instance
+ share_local_model: True
+
+# Dataset related options
+data:
+ # Root directory where the data stored
+ root: data/
+ # Dataset name
+ type: 'rosetta_alpaca@llm'
+ # Train/val/test splits
+ splits: [0.89,0.1,0.01]
+ # Use meta inforamtion to split `rosetta_alpaca`
+ splitter: 'meta'
+
+# LLM related options
+llm:
+ # Max token length for model input (training)
+ tok_len: 650
+ # ChatBot related options
+ chat:
+ # Max token length for model input (inference)
+ max_len: 1000
+ # Max number of history texts
+ max_history_len: 10
+ # Path for store model cache, default in `~/.cache/`
+ cache:
+ model: ''
+ # PEFT related options
+ adapter:
+ # Set ture to enable PEFT fine-tuning
+ use: True
+ # Args for PEFT fine-tuning
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+
+# DataLoader related options
+dataloader:
+ # Batch size for iter loader
+ batch_size: 1
+
+# Model related options
+model:
+ # Model type (format: {MODEL_REPO}@huggingface_llm)
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+
+# Train related options
+train:
+ # Number of local update steps
+ local_update_steps: 30
+ # `batch` or `epoch` for local_update_steps
+ batch_or_epoch: batch
+ # Optimizer related options
+ optimizer:
+ # Learning rate
+ lr: 0.003
+ # Weight decay
+ weight_decay: 0.0
+ # Set ture to enable `model.half()`
+ is_enable_half: True
+
+# Trainer related options
+trainer:
+ # Trainer type
+ type: llmtrainer
+
+# Evaluation related options
+eval:
+ # Frequency of evaluation
+ freq: 50
+ # Evaluation metrics
+ metrics: ['loss']
+ # Set key to track best model
+ best_res_update_round_wise_key: val_loss
+```
+
+### Fine-tuning Datasets
+
+In general, we use instruction SFT following [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) team. And in standalone mode, all dataset can be split into several clients with spesific `splitter` (i.e., `lda`, `meta`, `iid`) and `federate.num_client`.
+
+#### Built-in Data
+
+| data.type | Source | Note |
+| --------------------- | ----------------------------------------------------- | --------------------------------------------------- |
+| `alpaca@llm` | [Link](https://github.com/tatsu-lab/stanford_alpaca) | `IIDSplitter` |
+| `alpaca_cleaned@llm` | [Link](https://github.com/gururise/AlpacaDataCleaned) | `IIDSplitter` |
+| `dolly-15k@llm` | [Link](https://github.com/databrickslabs/dolly) | `LDASplitter` or `MetaSplitter` split to 8 clients. |
+| `gsm8k@llm` | [Link](https://github.com/openai/grade-school-math) | `IIDSplitter` |
+| `rosetta_alpaca@llm` | [Link](https://github.com/sahil280114/codealpaca) | `LDASplitter` or `MetaSplitter` split to 9 clients. |
+| `code_search_net@llm` | [Link](https://github.com/github/CodeSearchNet) | `LDASplitter` or `MetaSplitter` split to 6 clients. |
+
+#### Self-maintained Data
+
+| data.type | Note |
+| ------------------------- | ------------------------------------------------------------ |
+| `YOU_DATA_NAME.json@llm` | Format: `[{'instruction': ..., 'input': ..., 'output':...}]`, default key: `instruction`, `input`, `output`, `category` |
+| `YOU_DATA_NAME.jsonl@llm` | Format of each line: `{'instruction': ..., 'input': ..., 'output':...}`, default key: `instruction`, `input`, `output`, `category` |
+
+#### Evaluation tools
+
+We evaluate model domain capability of fine-tuned models with easy-to-use evaluation tools.
+
+```bash
+FederatedScope
+├── federatedscope
+│ ├── llm
+│ │ ├── eval
+│ │ │ ├── eval_for_code
+│ │ │ ├── eval_for_gsm8k
+│ │ │ ├── eval_for_helm
+│ │ │ ├── eval_for_mmlu
+...
+```
+
+How to use:
+
+For example, to evaluate the model fine-tuned with `python federatedscope/main.py --cfg sft_gsm8k.yaml`, you can run `python federatedscope/llm/eval/eval_for_gsm8k/eval.py --cfg sft_gsm8k.yaml` in the `eval_for_gsm8k` directory. For other usages, please refer to the `README.md` file in each subdirectory.
+
+### Agorithms
+
+#### Parameter-Efficient Fine-Tuning
+
+With the help of parameter-efficient fine-tuning methods, federally fine-tuning a large model requires passing only a very small percentage of model parameters (adapters), making it possible for the client enable efficient adaptation of pre-trained language models to various downstream applications. We adopt [PEFT](https://github.com/huggingface/peft) for fine-tuning LLMs, and more methods are coming soon!
+
+| Methods | Source | Example for `llm.adapter.args` |
+| ------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| LoRA | [Link](https://arxiv.org/abs/2106.09685) | `[ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]` |
+| Prefix Tuning | [Link](https://aclanthology.org/2021.acl-long.353/), [Link](https://arxiv.org/pdf/2110.07602.pdf) | `[{'adapter_package': 'peft', 'adapter_method': 'prefix', 'prefix_projection': False, 'num_virtual_tokens': 20}]` |
+| P-Tuning | [Link](https://arxiv.org/abs/2103.10385) | `[{'adapter_package': 'peft', 'adapter_method': 'p-tuning', 'encoder_reparameterization_type': 'MLP', 'encoder_dropout': 0.1, 'num_virtual_tokens': 20}]` |
+| Prompt Tuning | [Link](https://arxiv.org/abs/2104.08691) | `[{'adapter_package': 'peft', 'adapter_method': 'prompt', 'prompt_tuning_init': 'RANDOM', 'num_virtual_tokens': 20}]` |
+
+#### Federate fine-tune closed-source LLMs
+
+We support federated fine-tuning not only for open-source LLMs, but also for closed-source LLMs. In this scenario, clients can fine-tune LLMs without fully accessing the model, where models and data are both considered as privacy.
+
+| Methods | Source | How to enable | Note |
+|----------------|------------------------------------------|----------------------------------------------------------------------------------------------------------|----|
+| Offsite-Tuning | [Link](https://arxiv.org/abs/2302.04870) | `llm.offsite_tuning.use=True` | - |
+
+For example, the following methods are supported:
+
+| Methods | Source | How to use | Note |
+|---------------|--------|-------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| Drop layers | [Link](https://arxiv.org/abs/2302.04870) | `llm.offsite_tuning.emu_l=2`
+
+FederatedScope-LLM (FS-LLM) is a comprehensive package for federated fine-tuning large language models, which provide:
+
+* A complete **end-to-end benchmarking pipeline**, automizing the processes of dataset preprocessing, federated fine-tuning execution or simulation, and performance evaluation on federated LLM fine-tuning with different capability demonstration purposes;
+* Comprehensive and off-the-shelf **federated fine-tuning algorithm** implementations and versatile programming interfaces for future extension to enhance the capabilities of LLMs in FL scenarios with low communication and computation costs, even without accessing the full model (e.g., closed-source LLMs);
+* Several **accelerating operators and resource-efficient operators** for fine-tuning LLMs with limited resources and the flexible pluggable sub-routines for interdisciplinary study (e.g., LLMs in personalized FL).
+
+For more details, please refer to our paper: [FederatedScope-LLM: A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning](https://arxiv.org/abs/2309.00363).
+
+We provide a hands-on tutorial here for your quick start.
+
+## Code Structure
+
+[LLM-related directory](https://github.com/alibaba/FederatedScope/tree/llm/federatedscope/llm)
+
+```
+FederatedScope
+├── federatedscope
+│ ├── core # Federated learning backend modules
+│ ├── llm # Federated fine-tuning LLMs modules
+│ │ ├── baseline # Scripts for LLMs
+│ │ ├── dataloader # Federated fine-tuning dataloader
+│ │ ├── dataset # Federated fine-tuning dataset
+│ │ ├── eval # Evaluation for fine-tuned LLMs
+│ │ ├── misc # Miscellaneous
+│ │ ├── model # LLMs and Adapter
+│ │ ├── trainer # Fine-tuning with accerating operators
+│ │ ├── ...
+│ ├── main.py # Running interface
+│ ├── ... ...
+├── tests # Unittest modules for continuous integration
+├── LICENSE
+└── setup.py
+```
+
+## Quick Start
+
+Let’s start with fine-tuning GPT-2 on [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) to familiarize you with FS-LLM.
+
+### Step 1. Installation
+
+The installation of FS-LLM is similar to minimal FS (see [here](https://github.com/alibaba/FederatedScope/tree/master) for details), except that it requires **Pytorch>=1.13.0** (we recommend version 2.0.X) because of the [PEFT](https://github.com/huggingface/peft) dependency:
+
+```bash
+# Create virtual environments with conda
+conda create -n fs-llm python=3.9
+conda activate fs-llm
+
+# Install Pytorch>=1.13.0 (e.g., Pytorch==2.0.0)
+conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
+
+# Install FS-LLM with editable mode
+pip install -e .[llm]
+```
+
+Now, you have successfully installed the FS-LLM.
+
+### Step 2. Run with exmaple config
+
+Now, we can fine-tune a GPT2 on Alpaca with FedAvg.
+
+```bash
+python federatedscope/main.py --cfg federatedscope/llm/baseline/testcase.yaml
+```
+
+For more details about customized configurations, see **Advanced**.
+
+## Advanced
+
+### Start with built-in functions
+
+You can easily run through a customized `yaml` file. Here we only introduce the configuration related to FS-LLM, other configurations please refer to [Configurations](https://github.com/alibaba/FederatedScope/blob/master/federatedscope/core/configs/README.md). For more examples, please refer to `federatedscope/llm/baseline`.
+
+```yaml
+# For this configuration, you might need a GPU with at least 32GB of video memory to run.
+
+# Whether to use GPU
+use_gpu: True
+
+# Deciding which GPU to use
+device: 0
+
+# Early stop steps, set `0` to disable
+early_stop:
+ patience: 0
+
+# Federate learning related options
+federate:
+ # `standalone` or `distributed`
+ mode: standalone
+ # Number of communication round
+ total_round_num: 500
+ # Saving path for ckpt
+ save_to: "llama_rosetta_9_fed.ckpt"
+ # Number of dataset being split
+ client_num: 9
+ # Enable for saving memory, all workers share the same model instance
+ share_local_model: True
+
+# Dataset related options
+data:
+ # Root directory where the data stored
+ root: data/
+ # Dataset name
+ type: 'rosetta_alpaca@llm'
+ # Train/val/test splits
+ splits: [0.89,0.1,0.01]
+ # Use meta inforamtion to split `rosetta_alpaca`
+ splitter: 'meta'
+
+# LLM related options
+llm:
+ # Max token length for model input (training)
+ tok_len: 650
+ # ChatBot related options
+ chat:
+ # Max token length for model input (inference)
+ max_len: 1000
+ # Max number of history texts
+ max_history_len: 10
+ # Path for store model cache, default in `~/.cache/`
+ cache:
+ model: ''
+ # PEFT related options
+ adapter:
+ # Set ture to enable PEFT fine-tuning
+ use: True
+ # Args for PEFT fine-tuning
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+
+# DataLoader related options
+dataloader:
+ # Batch size for iter loader
+ batch_size: 1
+
+# Model related options
+model:
+ # Model type (format: {MODEL_REPO}@huggingface_llm)
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+
+# Train related options
+train:
+ # Number of local update steps
+ local_update_steps: 30
+ # `batch` or `epoch` for local_update_steps
+ batch_or_epoch: batch
+ # Optimizer related options
+ optimizer:
+ # Learning rate
+ lr: 0.003
+ # Weight decay
+ weight_decay: 0.0
+ # Set ture to enable `model.half()`
+ is_enable_half: True
+
+# Trainer related options
+trainer:
+ # Trainer type
+ type: llmtrainer
+
+# Evaluation related options
+eval:
+ # Frequency of evaluation
+ freq: 50
+ # Evaluation metrics
+ metrics: ['loss']
+ # Set key to track best model
+ best_res_update_round_wise_key: val_loss
+```
+
+### Fine-tuning Datasets
+
+In general, we use instruction SFT following [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) team. And in standalone mode, all dataset can be split into several clients with spesific `splitter` (i.e., `lda`, `meta`, `iid`) and `federate.num_client`.
+
+#### Built-in Data
+
+| data.type | Source | Note |
+| --------------------- | ----------------------------------------------------- | --------------------------------------------------- |
+| `alpaca@llm` | [Link](https://github.com/tatsu-lab/stanford_alpaca) | `IIDSplitter` |
+| `alpaca_cleaned@llm` | [Link](https://github.com/gururise/AlpacaDataCleaned) | `IIDSplitter` |
+| `dolly-15k@llm` | [Link](https://github.com/databrickslabs/dolly) | `LDASplitter` or `MetaSplitter` split to 8 clients. |
+| `gsm8k@llm` | [Link](https://github.com/openai/grade-school-math) | `IIDSplitter` |
+| `rosetta_alpaca@llm` | [Link](https://github.com/sahil280114/codealpaca) | `LDASplitter` or `MetaSplitter` split to 9 clients. |
+| `code_search_net@llm` | [Link](https://github.com/github/CodeSearchNet) | `LDASplitter` or `MetaSplitter` split to 6 clients. |
+
+#### Self-maintained Data
+
+| data.type | Note |
+| ------------------------- | ------------------------------------------------------------ |
+| `YOU_DATA_NAME.json@llm` | Format: `[{'instruction': ..., 'input': ..., 'output':...}]`, default key: `instruction`, `input`, `output`, `category` |
+| `YOU_DATA_NAME.jsonl@llm` | Format of each line: `{'instruction': ..., 'input': ..., 'output':...}`, default key: `instruction`, `input`, `output`, `category` |
+
+#### Evaluation tools
+
+We evaluate model domain capability of fine-tuned models with easy-to-use evaluation tools.
+
+```bash
+FederatedScope
+├── federatedscope
+│ ├── llm
+│ │ ├── eval
+│ │ │ ├── eval_for_code
+│ │ │ ├── eval_for_gsm8k
+│ │ │ ├── eval_for_helm
+│ │ │ ├── eval_for_mmlu
+...
+```
+
+How to use:
+
+For example, to evaluate the model fine-tuned with `python federatedscope/main.py --cfg sft_gsm8k.yaml`, you can run `python federatedscope/llm/eval/eval_for_gsm8k/eval.py --cfg sft_gsm8k.yaml` in the `eval_for_gsm8k` directory. For other usages, please refer to the `README.md` file in each subdirectory.
+
+### Agorithms
+
+#### Parameter-Efficient Fine-Tuning
+
+With the help of parameter-efficient fine-tuning methods, federally fine-tuning a large model requires passing only a very small percentage of model parameters (adapters), making it possible for the client enable efficient adaptation of pre-trained language models to various downstream applications. We adopt [PEFT](https://github.com/huggingface/peft) for fine-tuning LLMs, and more methods are coming soon!
+
+| Methods | Source | Example for `llm.adapter.args` |
+| ------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| LoRA | [Link](https://arxiv.org/abs/2106.09685) | `[ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]` |
+| Prefix Tuning | [Link](https://aclanthology.org/2021.acl-long.353/), [Link](https://arxiv.org/pdf/2110.07602.pdf) | `[{'adapter_package': 'peft', 'adapter_method': 'prefix', 'prefix_projection': False, 'num_virtual_tokens': 20}]` |
+| P-Tuning | [Link](https://arxiv.org/abs/2103.10385) | `[{'adapter_package': 'peft', 'adapter_method': 'p-tuning', 'encoder_reparameterization_type': 'MLP', 'encoder_dropout': 0.1, 'num_virtual_tokens': 20}]` |
+| Prompt Tuning | [Link](https://arxiv.org/abs/2104.08691) | `[{'adapter_package': 'peft', 'adapter_method': 'prompt', 'prompt_tuning_init': 'RANDOM', 'num_virtual_tokens': 20}]` |
+
+#### Federate fine-tune closed-source LLMs
+
+We support federated fine-tuning not only for open-source LLMs, but also for closed-source LLMs. In this scenario, clients can fine-tune LLMs without fully accessing the model, where models and data are both considered as privacy.
+
+| Methods | Source | How to enable | Note |
+|----------------|------------------------------------------|----------------------------------------------------------------------------------------------------------|----|
+| Offsite-Tuning | [Link](https://arxiv.org/abs/2302.04870) | `llm.offsite_tuning.use=True` | - |
+
+For example, the following methods are supported:
+
+| Methods | Source | How to use | Note |
+|---------------|--------|-------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| Drop layers | [Link](https://arxiv.org/abs/2302.04870) | `llm.offsite_tuning.emu_l=2`
`llm.offsite_tuning.emu_r=30`
`llm.offsite_tuning.kwargs={"drop_ratio":0.2}}` | The server fixes the first two layers and the layers after 30th layer as the adapter, and uniformly drops 20% of the remaining layers, denoted as the emulator |
+| Model distill |[Link](https://arxiv.org/abs/2302.04870)| `llm.offsite_tuning.emu_align.use=True`
`llm.offsite_tuning.emu_l=2`
`llm.offsite_tuning.emu_r=30`
| The server fixes the first two layers and the layers after 30th layer as the adapter, and regards the remaining as the teacher model, and distills a student model as the emulator |
+
+More methods will be supported ASAP.
+
+##### Evaluation of fine-tuned closed-source LLMs
+
+To evaluate fine-tuned closed-source LLMs, one should decide whether to evaluate the original model with fine-tuned adapters or the emulator with fine-tuned adapters.
+
+| Methods | Source | How to use | note |
+|---------------------------------------------|------------------------------------------|-----------------------------------------------------|-------|
+| Evaluation of fine-tuned closed-source LLMs | [Link](https://arxiv.org/abs/2302.04870) | `cfg.llm.offsite_tuning.eval_type='full'` (or `'emu'`) | 'full' means evaluating the original model with fine-tuned adapters; 'emu' means evaluating the emulator with fine-tuned adapters |
+
+#### Federate fine-tune with efficiency
+
+To make the federated fine-tuning efficient, we adopt a series of acceleration operators.
+
+| Methods | Source | How to use | Note |
+|-----------------------|------------------------------------------------------------------------------|-----------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------|
+| torch.nn.DataParallel | [Link](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html) | `cfg.train.data_para_dids=[0,1]` | It splits the input across the specified devices by chunking in the batch dimension. |
+| DeepSpeed | [Link](https://github.com/microsoft/DeepSpeed) | `cfg.llm.accelation.use=True` | Use `nvcc - V` to make sure `CUDA` installed.
When set it to `True`, we can full-parameter fine-tune a `llama-7b` on a machine with 4 V100-32G gpus. |
+| FP16 | [Link](https://arxiv.org/abs/1710.03740) | `train.is_enable_half=True` | Converting float types to half-precision to save memory usage |
+| Share local model | - | `federate.share_local_model=True` | The clients will share the base model, which reduces a lot of cpu memory consumption. |
+| Move to cpu | - | `llm.adapter.mv_to_cpu=True` | Move adapter to `cpu` after training, which can save memory but cost more time. |
+
+
+
+
+## FAQ
+
+- `WARNING: Skip the batch due to the loss is NaN, it may be caused by exceeding the precision or invalid labels.`
+ - Possible reason 1: This is because `llm.tok_len` limits the input length, causing the label to be empty, which automatically skips that data. Setting a larger `llm.tok_len` can avoid this.
+ - Possible reason 2: Due to the enabling of `train.is_enable_half`, numerical overflow may occur. This usually happens when setting the `optimizer.type` to `Adam`, since the default `eps` is `1e-8` but `fp16` requires at least `1e-5`.
+- `ValueError: Tokenizer class LLaMATokenizer does not exist or is not currently imported. `
+ - This is a problem with `transformers`, you can fix it in your local file. Replace `LLaMATokenizer` with `LlamaTokenizer` in `PATH_TO_DATA_ROOT/MODEL_REPO/snapshots/..../tokenizer_config.json`
+- `OutOfMemoryError: CUDA out of memory.`
+ - Torch's garbage collection mechanism may not be timely resulting in OOM, please set `cfg.eval.count_flops` to `False`.
+
+## Citation
+If you find FederatedScope-LLM useful for your research or development, please cite the following paper:
+```
+@article{kuang2023federatedscopellm,
+ title={FederatedScope-LLM: A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning},
+ author={Weirui Kuang and Bingchen Qian and Zitao Li and Daoyuan Chen and Dawei Gao and Xuchen Pan and Yuexiang Xie and Yaliang Li and Bolin Ding and Jingren Zhou},
+ journal={arXiv preprint arXiv:2309.00363},
+ year={2023}
+}
+```
+
diff --git a/federatedscope/llm/__init__.py b/federatedscope/llm/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/federatedscope/llm/baseline/client.yaml b/federatedscope/llm/baseline/client.yaml
new file mode 100644
index 000000000..b4e6e0cbe
--- /dev/null
+++ b/federatedscope/llm/baseline/client.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+early_stop:
+ patience: 10
+federate:
+ mode: distributed
+ client_num: 1
+ total_round_num: 200
+ save_to: "gpt2_new.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '127.0.0.1'
+ server_port: 50051
+ client_host: '127.0.0.1'
+ client_port: 50052
+ role: 'client'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+dataloader:
+ batch_size: 8
+model:
+ type: 'gpt2@huggingface_llm'
+train:
+ local_update_steps: 10
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/deepspeed/ds_config.json b/federatedscope/llm/baseline/deepspeed/ds_config.json
new file mode 100644
index 000000000..9b865c943
--- /dev/null
+++ b/federatedscope/llm/baseline/deepspeed/ds_config.json
@@ -0,0 +1,46 @@
+{
+ "train_batch_size": 4,
+ "steps_per_print": 2000,
+ "fp16": {"enabled": true},
+ "optimizer": {
+ "type": "Adam",
+ "params": {
+ "lr": 0.001,
+ "betas": [
+ 0.8,
+ 0.999
+ ],
+ "eps": 1e-8,
+ "weight_decay": 3e-7
+ }
+ },
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": 0,
+ "warmup_max_lr": 0.001,
+ "warmup_num_steps": 1000
+ }
+ },
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": "auto",
+ "stage3_prefetch_bucket_size": "auto",
+ "stage3_param_persistence_threshold": "auto",
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": false
+ },
+ "wall_clock_breakdown": false
+ }
diff --git a/federatedscope/llm/baseline/deepspeed/ds_config_4bs.json b/federatedscope/llm/baseline/deepspeed/ds_config_4bs.json
new file mode 100644
index 000000000..919521482
--- /dev/null
+++ b/federatedscope/llm/baseline/deepspeed/ds_config_4bs.json
@@ -0,0 +1,36 @@
+{
+ "train_batch_size": 4,
+ "steps_per_print": 2000,
+ "bfp16": {
+ "enabled": true,
+ "auto_cast": true,
+ "loss_scale": 0,
+ "initial_scale_power": 16,
+ "loss_scale_window": 1000,
+ "hysteresis": 2,
+ "consecutive_hysteresis": false,
+ "min_loss_scale": 1
+ },
+ "seq_parallel_communication_data_type": "torch.bfloat16",
+ "sparse_attention": {"enabled": true},
+ "optimizer": {
+ "type": "OneBitAdam",
+ "params": {
+ "lr": 0.001,
+ "betas": [
+ 0.8,
+ 0.999
+ ],
+ "eps": 1e-1,
+ "weight_decay": 3e-7
+ }
+ },
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": 0,
+ "warmup_max_lr": 0.001,
+ "warmup_num_steps": 1000
+ }
+ }
+ }
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/deepspeed/llama_client.yaml b/federatedscope/llm/baseline/deepspeed/llama_client.yaml
new file mode 100644
index 000000000..73620fd73
--- /dev/null
+++ b/federatedscope/llm/baseline/deepspeed/llama_client.yaml
@@ -0,0 +1,51 @@
+# deepspeed --master_port 29501 federatedscope/main.py --cfg federatedscope/llm/baseline/deepspeed/llama_client.yaml
+use_gpu: True
+early_stop:
+ patience: 0
+federate:
+ mode: distributed
+ client_num: 1
+ total_round_num: 500
+ save_to: "llama_ds.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '127.0.0.1'
+ server_port: 50051 # [50051, 50051 + client_num]
+ client_host: '127.0.0.1'
+ client_port: 50061 # [50061, 50061 + client_num]
+ role: 'client'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-13b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+trainer:
+ type: llmtrainer
+eval:
+ freq: 5
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/deepspeed/llama_ds.yaml b/federatedscope/llm/baseline/deepspeed/llama_ds.yaml
new file mode 100644
index 000000000..502b22003
--- /dev/null
+++ b/federatedscope/llm/baseline/deepspeed/llama_ds.yaml
@@ -0,0 +1,42 @@
+# deepspeed federatedscope/main.py --cfg federatedscope/llm/baseline/deepspeed/llama_ds.yaml
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 1
+ total_round_num: 500
+ save_to: "llama_ds.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-13b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+trainer:
+ type: llmtrainer
+eval:
+ freq: 5
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/deepspeed/llama_server.yaml b/federatedscope/llm/baseline/deepspeed/llama_server.yaml
new file mode 100644
index 000000000..d2206e722
--- /dev/null
+++ b/federatedscope/llm/baseline/deepspeed/llama_server.yaml
@@ -0,0 +1,49 @@
+# deepspeed --master_port 29500 federatedscope/main.py --cfg federatedscope/llm/baseline/deepspeed/llama_server.yaml
+use_gpu: True
+early_stop:
+ patience: 0
+federate:
+ mode: distributed
+ client_num: 1
+ total_round_num: 500
+ save_to: "llama_ds.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '127.0.0.1'
+ server_port: 50051 # [50051, 50051 + client_num]
+ role: 'server'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+ deepspeed:
+ use: True
+ ds_config: 'federatedscope/llm/baseline/deepspeed/ds_config.json'
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-13b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+trainer:
+ type: llmtrainer
+eval:
+ freq: 5
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_federate.yaml b/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_federate.yaml
new file mode 100644
index 000000000..02c80918d
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_federate.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ total_round_num: 500
+ save_to: "llama_alpaca_fed_30*500.ckpt"
+ save_freq: 100
+ share_local_model: True
+ online_aggr: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_global.yaml b/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_global.yaml
new file mode 100644
index 000000000..e462d9421
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_global.yaml
@@ -0,0 +1,42 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 1
+ total_round_num: 500
+ save_to: "llama_alpaca_global_30*500.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_local_client_1.yaml b/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_local_client_1.yaml
new file mode 100644
index 000000000..00245c06c
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_local_client_1.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ client_idx_for_local_train: 1
+ total_round_num: 500
+ save_to: "llama_alpaca_c1_30*500.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_local_client_2.yaml b/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_local_client_2.yaml
new file mode 100644
index 000000000..3da3e25cc
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_local_client_2.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ client_idx_for_local_train: 2
+ total_round_num: 500
+ save_to: "llama_alpaca_c1_30*500.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_local_client_3.yaml b/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_local_client_3.yaml
new file mode 100644
index 000000000..ee0ed0ebc
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/alpaca/alpaca_local_client_3.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ client_idx_for_local_train: 3
+ total_round_num: 500
+ save_to: "llama_alpaca_c1_30*500.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/csn/csn_federate.yaml b/federatedscope/llm/baseline/exp_yaml/csn/csn_federate.yaml
new file mode 100644
index 000000000..f635da5f7
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/csn/csn_federate.yaml
@@ -0,0 +1,45 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 6
+ total_round_num: 500
+ save_to: "llama_csn_fed_30*500.ckpt"
+ save_freq: 100
+ share_local_model: True
+ online_aggr: False
+data:
+ root: data/
+ type: 'code_search_net@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'meta'
+ subsample: 0.05
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_1.yaml b/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_1.yaml
new file mode 100644
index 000000000..a10e79a52
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_1.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 6
+ client_idx_for_local_train: 1
+ total_round_num: 500
+ save_to: "llama_csn_c1_30*500.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'code_search_net@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'meta'
+ subsample: 0.05
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_2.yaml b/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_2.yaml
new file mode 100644
index 000000000..099958b9b
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_2.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 6
+ client_idx_for_local_train: 2
+ total_round_num: 500
+ save_to: "llama_csn_c2_30*500.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'code_search_net@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'meta'
+ subsample: 0.05
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_3.yaml b/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_3.yaml
new file mode 100644
index 000000000..87f9488ac
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_3.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 6
+ client_idx_for_local_train: 3
+ total_round_num: 500
+ save_to: "llama_csn_c3_30*500.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'code_search_net@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'meta'
+ subsample: 0.05
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_4.yaml b/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_4.yaml
new file mode 100644
index 000000000..ed40db98c
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_4.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 6
+ client_idx_for_local_train: 4
+ total_round_num: 500
+ save_to: "llama_csn_c4_30*500.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'code_search_net@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'meta'
+ subsample: 0.05
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_5.yaml b/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_5.yaml
new file mode 100644
index 000000000..6fc48a0f1
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_5.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 6
+ client_idx_for_local_train: 5
+ total_round_num: 500
+ save_to: "llama_csn_c5_30*500.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'code_search_net@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'meta'
+ subsample: 0.05
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_6.yaml b/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_6.yaml
new file mode 100644
index 000000000..d0d453760
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/csn/csn_local_client_6.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 6
+ client_idx_for_local_train: 6
+ total_round_num: 500
+ save_to: "llama_csn_c6_30*500.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'code_search_net@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'meta'
+ subsample: 0.05
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_federate.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_federate.yaml
new file mode 100644
index 000000000..65d4c6b35
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_federate.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ total_round_num: 500
+ save_to: "llama_dolly_fed_30*500.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'lda'
+ splitter_args: [{'alpha': 0.5}]
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_global.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_global.yaml
new file mode 100644
index 000000000..456c73722
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_global.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 1
+ total_round_num: 500
+ save_to: "llama_dolly_global_30*500.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'lda'
+ splitter_args: [{'alpha': 0.5}]
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_local_client_1.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_local_client_1.yaml
new file mode 100644
index 000000000..5f45664e8
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_local_client_1.yaml
@@ -0,0 +1,45 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ client_idx_for_local_train: 1
+ total_round_num: 500
+ save_to: "llama_dolly_c1_30*500.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'lda'
+ splitter_args: [{'alpha': 0.5}]
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_local_client_2.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_local_client_2.yaml
new file mode 100644
index 000000000..563c92793
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_local_client_2.yaml
@@ -0,0 +1,45 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ client_idx_for_local_train: 2
+ total_round_num: 500
+ save_to: "llama_dolly_c2_30*500.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'lda'
+ splitter_args: [{'alpha': 0.5}]
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_local_client_3.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_local_client_3.yaml
new file mode 100644
index 000000000..4b28c1b50
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_lda/dolly_local_client_3.yaml
@@ -0,0 +1,45 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ client_idx_for_local_train: 3
+ total_round_num: 500
+ save_to: "llama_dolly_c3_30*500.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'lda'
+ splitter_args: [{'alpha': 0.5}]
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_federate.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_federate.yaml
new file mode 100644
index 000000000..4270925b8
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_federate.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 8
+ total_round_num: 500
+ save_to: "llama_dolly_meta_fed_30*500_0.0005_64_0.1.ckpt"
+ save_freq: 100
+ share_local_model: True
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.99, 0.0, 0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 64, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.005
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ split: ['test']
+ best_res_update_round_wise_key: test_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_global.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_global.yaml
new file mode 100644
index 000000000..b111c8425
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_global.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 1
+ total_round_num: 500
+ save_to: "llama_dolly_meta_global_30*500_0.0005_64_0.1.ckpt"
+ save_freq: 100
+ share_local_model: True
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.99, 0.0, 0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 64, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.005
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ split: ['test']
+ best_res_update_round_wise_key: test_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_1.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_1.yaml
new file mode 100644
index 000000000..e692cd6b8
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_1.yaml
@@ -0,0 +1,45 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 8
+ client_idx_for_local_train: 1
+ total_round_num: 500
+ save_to: "llama_dolly_meta_c1_30*500_0.001_32_0.1.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.99, 0.0, 0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ split: ['test']
+ best_res_update_round_wise_key: test_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_2.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_2.yaml
new file mode 100644
index 000000000..c92ceefbf
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_2.yaml
@@ -0,0 +1,45 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 8
+ client_idx_for_local_train: 2
+ total_round_num: 500
+ save_to: "llama_dolly_meta_c2_30*500_0.001_32_0.1.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.99, 0.0, 0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ split: ['test']
+ best_res_update_round_wise_key: test_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_3.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_3.yaml
new file mode 100644
index 000000000..0032fd645
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_3.yaml
@@ -0,0 +1,45 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 8
+ client_idx_for_local_train: 3
+ total_round_num: 500
+ save_to: "llama_dolly_meta_c3_30*500_0.001_32_0.1.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.99, 0.0, 0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ split: ['test']
+ best_res_update_round_wise_key: test_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_4.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_4.yaml
new file mode 100644
index 000000000..0eeec992a
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_4.yaml
@@ -0,0 +1,45 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 8
+ client_idx_for_local_train: 4
+ total_round_num: 500
+ save_to: "llama_dolly_meta_c4_30*500_0.001_32_0.1.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.99, 0.0, 0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ split: ['test']
+ best_res_update_round_wise_key: test_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_5.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_5.yaml
new file mode 100644
index 000000000..c4bb920e9
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_5.yaml
@@ -0,0 +1,45 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 8
+ client_idx_for_local_train: 5
+ total_round_num: 500
+ save_to: "llama_dolly_meta_c5_30*500_0.001_32_0.1.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.99, 0.0, 0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ split: ['test']
+ best_res_update_round_wise_key: test_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_6.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_6.yaml
new file mode 100644
index 000000000..9bf5c1d3d
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_6.yaml
@@ -0,0 +1,45 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 8
+ client_idx_for_local_train: 6
+ total_round_num: 500
+ save_to: "llama_dolly_meta_c6_30*500_0.001_32_0.1.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.99, 0.0, 0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ split: ['test']
+ best_res_update_round_wise_key: test_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_7.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_7.yaml
new file mode 100644
index 000000000..ffa63349b
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_7.yaml
@@ -0,0 +1,45 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 8
+ client_idx_for_local_train: 7
+ total_round_num: 500
+ save_to: "llama_dolly_meta_c7_30*500_0.001_32_0.1.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.99, 0.0, 0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ split: ['test']
+ best_res_update_round_wise_key: test_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_8.yaml b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_8.yaml
new file mode 100644
index 000000000..b05a14c46
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/dolly_meta/dolly_meta_local_client_8.yaml
@@ -0,0 +1,45 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 8
+ client_idx_for_local_train: 8
+ total_round_num: 500
+ save_to: "llama_dolly_meta_c8_30*500_0.001_32_0.1.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.99, 0.0, 0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ split: ['test']
+ best_res_update_round_wise_key: test_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/gsm/gsm_federate.yaml b/federatedscope/llm/baseline/exp_yaml/gsm/gsm_federate.yaml
new file mode 100644
index 000000000..bd3107867
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/gsm/gsm_federate.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ total_round_num: 500
+ save_to: "llama_gsm_fed_30*500.ckpt"
+ save_freq: 100
+ share_local_model: True
+ online_aggr: False
+data:
+ root: data/
+ type: 'gsm8k@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.005
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/gsm/gsm_global.yaml b/federatedscope/llm/baseline/exp_yaml/gsm/gsm_global.yaml
new file mode 100644
index 000000000..06f95533c
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/gsm/gsm_global.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 1
+ total_round_num: 500
+ save_to: "llama_gsm_global_30*500.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'gsm8k@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.005
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/gsm/gsm_local_client_1.yaml b/federatedscope/llm/baseline/exp_yaml/gsm/gsm_local_client_1.yaml
new file mode 100644
index 000000000..2f79851ad
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/gsm/gsm_local_client_1.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ client_idx_for_local_train: 1
+ total_round_num: 500
+ save_to: "llama_gsm_c1_30*500.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'gsm8k@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.005
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/gsm/gsm_local_client_2.yaml b/federatedscope/llm/baseline/exp_yaml/gsm/gsm_local_client_2.yaml
new file mode 100644
index 000000000..3b05b3c3d
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/gsm/gsm_local_client_2.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ client_idx_for_local_train: 2
+ total_round_num: 500
+ save_to: "llama_gsm_c2_30*500.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'gsm8k@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.003
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/gsm/gsm_local_client_3.yaml b/federatedscope/llm/baseline/exp_yaml/gsm/gsm_local_client_3.yaml
new file mode 100644
index 000000000..326177312
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/gsm/gsm_local_client_3.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ client_idx_for_local_train: 3
+ total_round_num: 500
+ save_to: "llama_gsm_c3_30*500.ckpt"
+ save_freq: 100
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'gsm8k@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 128, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/offsite_tuning/dolly/dolly_fed.yaml b/federatedscope/llm/baseline/exp_yaml/offsite_tuning/dolly/dolly_fed.yaml
new file mode 100644
index 000000000..15c156b4a
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/offsite_tuning/dolly/dolly_fed.yaml
@@ -0,0 +1,60 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 8
+ total_round_num: 500
+ save_to: "llama_dolly_fed_ot.ckpt"
+ save_freq: -1
+ share_local_model: True
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.99, 0.0, 0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ mv_to_cpu: True
+ offsite_tuning:
+ use: True
+ eval_type: 'emu'
+ kwargs: [ { "drop_ratio": 0.2 } ]
+ emu_l: 2
+ emu_r: 30
+ emu_align:
+ use: True
+ restore_from: 'aligned_llama_dolly_fed_ot.ckpt'
+ save_to: 'aligned_llama_dolly_fed_ot.ckpt'
+ train:
+ local_update_steps: 500
+ batch_or_epoch: 'batch'
+ lm_loss_weight: 0.0
+ kd_loss_weight: 1.0
+ optimizer:
+ lr: 0.0001
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.005
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ split: ['test']
+ best_res_update_round_wise_key: test_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/offsite_tuning/gsm/gsm_fed.yaml b/federatedscope/llm/baseline/exp_yaml/offsite_tuning/gsm/gsm_fed.yaml
new file mode 100644
index 000000000..d7866a809
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/offsite_tuning/gsm/gsm_fed.yaml
@@ -0,0 +1,59 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ total_round_num: 500
+ save_to: "llama_gsm_fed_ot.ckpt"
+ save_freq: -1
+ share_local_model: True
+ online_aggr: False
+data:
+ root: data/
+ type: 'gsm8k@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ adapter:
+ mv_to_cpu: True
+ chat:
+ max_len: 1000
+ offsite_tuning:
+ use: True
+ eval_type: 'emu'
+ kwargs: [{"drop_ratio": 0.2}]
+ emu_l: 2
+ emu_r: 30
+ emu_align:
+ use: True
+ restore_from: 'aligned_llama_gsm_fed_ot.ckpt'
+ save_to: 'aligned_llama_gsm_fed_ot.ckpt'
+ train:
+ local_update_steps: 500
+ batch_or_epoch: 'batch'
+ lm_loss_weight: 0.0
+ kd_loss_weight: 1.0
+ optimizer:
+ lr: 0.0001
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.005
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/offsite_tuning/rosetta/rosetta_fed.yaml b/federatedscope/llm/baseline/exp_yaml/offsite_tuning/rosetta/rosetta_fed.yaml
new file mode 100644
index 000000000..461b83f7f
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/offsite_tuning/rosetta/rosetta_fed.yaml
@@ -0,0 +1,60 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 9
+ total_round_num: 500
+ save_to: "llama_rosetta_fed_ot.ckpt"
+ save_freq: -1
+ share_local_model: True
+ online_aggr: False
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.89,0.1,0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ mv_to_cpu: True
+ offsite_tuning:
+ use: True
+ eval_type: 'emu'
+ kwargs: [ { "drop_ratio": 0.2 } ]
+ emu_l: 2
+ emu_r: 30
+ emu_align:
+ use: True
+ restore_from: 'aligned_llama_rosetta_fed_ot.ckpt'
+ save_to: 'aligned_llama_rosetta_fed_ot.ckpt'
+ train:
+ local_update_steps: 500
+ batch_or_epoch: 'batch'
+ lm_loss_weight: 0.0
+ kd_loss_weight: 1.0
+ optimizer:
+ lr: 0.0001
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_3_clients/rosetta_federate.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_3_clients/rosetta_federate.yaml
new file mode 100644
index 000000000..f591ff02a
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_3_clients/rosetta_federate.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ total_round_num: 500
+ save_to: "llama_rosetta_fed_30*500.ckpt"
+ save_freq: 100
+ share_local_model: True
+ online_aggr: False
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_3_clients/rosetta_local_client_1.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_3_clients/rosetta_local_client_1.yaml
new file mode 100644
index 000000000..3147af704
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_3_clients/rosetta_local_client_1.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ client_idx_for_local_train: 1
+ total_round_num: 500
+ save_to: "llama_rosetta_c1_30*500.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_3_clients/rosetta_local_client_2.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_3_clients/rosetta_local_client_2.yaml
new file mode 100644
index 000000000..cc41f102a
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_3_clients/rosetta_local_client_2.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ client_idx_for_local_train: 2
+ total_round_num: 500
+ save_to: "llama_rosetta_c2_30*500.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_3_clients/rosetta_local_client_3.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_3_clients/rosetta_local_client_3.yaml
new file mode 100644
index 000000000..2ab223841
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_3_clients/rosetta_local_client_3.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ client_idx_for_local_train: 3
+ total_round_num: 500
+ save_to: "llama_rosetta_c3_30*500.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.998,0.001,0.001]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_federate.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_federate.yaml
new file mode 100644
index 000000000..214530db9
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_federate.yaml
@@ -0,0 +1,44 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 9
+ total_round_num: 500
+ save_to: "llama_rosetta_9_fed_30*500_0.003_32_0.1.ckpt"
+ save_freq: -1
+ share_local_model: True
+ online_aggr: False
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.89,0.1,0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.0 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_global.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_global.yaml
new file mode 100644
index 000000000..66efca16d
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_global.yaml
@@ -0,0 +1,42 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 1
+ total_round_num: 500
+ save_to: "llama_rosetta_global_30*500_0.001_32_0.1.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.89,0.1,0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 512
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_1.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_1.yaml
new file mode 100644
index 000000000..8bf9e27ae
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_1.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 9
+ client_idx_for_local_train: 1
+ total_round_num: 500
+ save_to: "llama_rosetta_9_c1_30*500_0.001_64_0.1.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.89,0.1,0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 64, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_2.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_2.yaml
new file mode 100644
index 000000000..a901f902b
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_2.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 9
+ client_idx_for_local_train: 2
+ total_round_num: 500
+ save_to: "llama_rosetta_9_c2_30*500_0.001_32_0.1.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.89,0.1,0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_3.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_3.yaml
new file mode 100644
index 000000000..bf5de2bb8
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_3.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 9
+ client_idx_for_local_train: 3
+ total_round_num: 500
+ save_to: "llama_rosetta_9_c3_30*500_0.001_32_0.1.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.89,0.1,0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_4.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_4.yaml
new file mode 100644
index 000000000..a85243737
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_4.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 9
+ client_idx_for_local_train: 4
+ total_round_num: 500
+ save_to: "llama_rosetta_9_c4_30*500_0.001_64_0.1.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.89,0.1,0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 64, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_5.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_5.yaml
new file mode 100644
index 000000000..13c3a110b
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_5.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 9
+ client_idx_for_local_train: 5
+ total_round_num: 500
+ save_to: "llama_rosetta_9_c5_30*500_0.001_64_0.1.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.89,0.1,0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 64, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_6.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_6.yaml
new file mode 100644
index 000000000..d72211b55
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_6.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 9
+ client_idx_for_local_train: 6
+ total_round_num: 500
+ save_to: "llama_rosetta_9_c6_30*500_0.001_64_0.1.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.89,0.1,0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 64, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_7.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_7.yaml
new file mode 100644
index 000000000..123741648
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_7.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 9
+ client_idx_for_local_train: 7
+ total_round_num: 500
+ save_to: "llama_rosetta_9_c7_30*500_0.001_64_0.1.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.89,0.1,0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 64, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_8.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_8.yaml
new file mode 100644
index 000000000..9b32a891c
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_8.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 9
+ client_idx_for_local_train: 8
+ total_round_num: 500
+ save_to: "llama_rosetta_9_c8_30*500_0.001_64_0.1.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.89,0.1,0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 64, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_9.yaml b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_9.yaml
new file mode 100644
index 000000000..dd6176a9e
--- /dev/null
+++ b/federatedscope/llm/baseline/exp_yaml/rosetta_9_clients/rosetta_local_client_9.yaml
@@ -0,0 +1,43 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 9
+ client_idx_for_local_train: 9
+ total_round_num: 500
+ save_to: "llama_rosetta_9_c9_30*500_0.001_32_0.1.ckpt"
+ save_freq: 100
+data:
+ root: data/
+ type: 'rosetta_alpaca@llm'
+ splits: [0.89,0.1,0.01]
+ splitter: 'meta'
+llm:
+ tok_len: 650
+ chat:
+ max_len: 1000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ best_res_update_round_wise_key: val_loss
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/lda.yaml b/federatedscope/llm/baseline/lda.yaml
new file mode 100644
index 000000000..2e695d523
--- /dev/null
+++ b/federatedscope/llm/baseline/lda.yaml
@@ -0,0 +1,37 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 10
+federate:
+ mode: standalone
+ client_num: 1
+ total_round_num: 200
+ save_to: "gpt2.ckpt"
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'lda'
+ splitter_args: [{'alpha': 0.05}]
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+dataloader:
+ batch_size: 1
+model:
+ type: 'gpt2@huggingface_llm'
+train:
+ local_update_steps: 10
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 10
+ metrics: ['loss']
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/llama.yaml b/federatedscope/llm/baseline/llama.yaml
new file mode 100644
index 000000000..a918522df
--- /dev/null
+++ b/federatedscope/llm/baseline/llama.yaml
@@ -0,0 +1,40 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ total_round_num: 500
+ save_to: "llama.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/llama_modelscope.yaml b/federatedscope/llm/baseline/llama_modelscope.yaml
new file mode 100644
index 000000000..202e99ffe
--- /dev/null
+++ b/federatedscope/llm/baseline/llama_modelscope.yaml
@@ -0,0 +1,43 @@
+#pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
+use_gpu: True
+device: 0
+early_stop:
+ patience: 0
+federate:
+ mode: standalone
+ client_num: 3
+ total_round_num: 500
+ save_to: "llama.ckpt"
+ share_local_model: True
+ online_aggr: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 2000
+ adapter:
+ use: True
+ args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 16, 'lora_dropout': 0.05 } ]
+dataloader:
+ batch_size: 1
+model:
+ type: 'skyline2006/llama-7b@modelscope_llm'
+train:
+ local_update_steps: 30
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0003
+ weight_decay: 0.0
+ is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
+ count_flops: False
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/llama_offsite.yaml b/federatedscope/llm/baseline/llama_offsite.yaml
new file mode 100644
index 000000000..6e78bd403
--- /dev/null
+++ b/federatedscope/llm/baseline/llama_offsite.yaml
@@ -0,0 +1,42 @@
+use_gpu: True
+device: 1
+early_stop:
+ patience: 10
+federate:
+ mode: standalone
+ client_num: 1
+ total_round_num: 1000
+ save_to: "llama.offsite_tuning.ckpt"
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+ offsite_tuning:
+ use: True
+ emu_l: 2
+ emu_r: 30
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 10
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0001
+ weight_decay: 0.0
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 10
+ metrics: ['loss']
+ best_res_update_round_wise_key: 'val_loss'
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/llama_offsite_align.yaml b/federatedscope/llm/baseline/llama_offsite_align.yaml
new file mode 100644
index 000000000..f84596cf5
--- /dev/null
+++ b/federatedscope/llm/baseline/llama_offsite_align.yaml
@@ -0,0 +1,54 @@
+use_gpu: True
+device: 1
+early_stop:
+ patience: 10
+federate:
+ mode: standalone
+ client_num: 1
+ total_round_num: 20
+ save_to: "llama.offsite_tuning.ckpt"
+ share_local_model: True
+ online_aggr: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+ offsite_tuning:
+ use: True
+ emu_l: 2
+ emu_r: 30
+ emu_align:
+ use: True
+ restore_from: 'aligned_emulator.ckpt'
+ save_to: 'aligned_emulator.ckpt'
+ train:
+ local_update_steps: 10
+ batch_or_epoch: 'batch'
+ lm_loss_weight: 0.1
+ kd_loss_weight: 0.9
+ optimizer:
+ lr: 0.01
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 10
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0001
+ weight_decay: 0.0
+# is_enable_half: True
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 10
+ metrics: ['loss']
+ best_res_update_round_wise_key: 'val_loss'
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/llama_offsite_dolly.yaml b/federatedscope/llm/baseline/llama_offsite_dolly.yaml
new file mode 100644
index 000000000..c25ac54d8
--- /dev/null
+++ b/federatedscope/llm/baseline/llama_offsite_dolly.yaml
@@ -0,0 +1,45 @@
+use_gpu: True
+device: 2
+early_stop:
+ patience: 10
+federate:
+ mode: standalone
+ client_num: 2
+ sample_client_rate: 1.0
+ total_round_num: 1000
+ save_to: "llama.dolly.offsite_tuning.ckpt"
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'dolly-15k@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'lda'
+ splitter_args: [{'alpha': 0.05}]
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+ offsite_tuning:
+ use: True
+ emu_l: 2
+ emu_r: 30
+dataloader:
+ batch_size: 1
+model:
+ type: 'decapoda-research/llama-7b-hf@huggingface_llm'
+train:
+ local_update_steps: 10
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.0001
+ weight_decay: 0.0
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 10
+ metrics: ['loss', 'acc']
+ report: ['avg', 'weighted_avg']
+ best_res_update_round_wise_key: 'val_loss'
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/server.yaml b/federatedscope/llm/baseline/server.yaml
new file mode 100644
index 000000000..a5e3b1a63
--- /dev/null
+++ b/federatedscope/llm/baseline/server.yaml
@@ -0,0 +1,42 @@
+use_gpu: True
+early_stop:
+ patience: 10
+federate:
+ mode: distributed
+ client_num: 1
+ total_round_num: 200
+ save_to: "gpt2_new.ckpt"
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+distribute:
+ use: True
+ server_host: '127.0.0.1'
+ server_port: 50051
+ role: 'server'
+ data_idx: 1
+ grpc_max_send_message_length: 1048576000
+ grpc_max_receive_message_length: 1048576000
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+dataloader:
+ batch_size: 8
+model:
+ type: 'gpt2@huggingface_llm'
+train:
+ local_update_steps: 10
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 50
+ metrics: ['loss']
\ No newline at end of file
diff --git a/federatedscope/llm/baseline/testcase.yaml b/federatedscope/llm/baseline/testcase.yaml
new file mode 100644
index 000000000..6f23ee474
--- /dev/null
+++ b/federatedscope/llm/baseline/testcase.yaml
@@ -0,0 +1,37 @@
+use_gpu: True
+device: 0
+early_stop:
+ patience: 10
+federate:
+ mode: standalone
+ client_num: 1
+ total_round_num: 200
+ save_to: "gpt2.ckpt"
+ share_local_model: False
+ online_aggr: False
+data:
+ root: data/
+ type: 'alpaca@llm'
+ splits: [0.98,0.01,0.01]
+ splitter: 'iid'
+llm:
+ tok_len: 1000
+ chat:
+ max_len: 1000
+dataloader:
+ batch_size: 1
+model:
+ type: 'gpt2@huggingface_llm'
+train:
+ local_update_steps: 10
+ batch_or_epoch: batch
+ optimizer:
+ lr: 0.001
+ weight_decay: 0.0
+criterion:
+ type: CrossEntropyLoss
+trainer:
+ type: llmtrainer
+eval:
+ freq: 10
+ metrics: ['loss']
\ No newline at end of file
diff --git a/federatedscope/llm/dataloader/__init__.py b/federatedscope/llm/dataloader/__init__.py
new file mode 100644
index 000000000..36310643f
--- /dev/null
+++ b/federatedscope/llm/dataloader/__init__.py
@@ -0,0 +1,4 @@
+from federatedscope.llm.dataloader.dataloader import load_llm_dataset, \
+ get_tokenizer, LLMDataCollator
+
+__all__ = ['load_llm_dataset', 'get_tokenizer', 'LLMDataCollator']
diff --git a/federatedscope/llm/dataloader/dataloader.py b/federatedscope/llm/dataloader/dataloader.py
new file mode 100644
index 000000000..0ae14765c
--- /dev/null
+++ b/federatedscope/llm/dataloader/dataloader.py
@@ -0,0 +1,348 @@
+import os
+import gzip
+import json
+import random
+import logging
+import torch
+import transformers
+
+from dataclasses import dataclass
+from federatedscope.llm.dataset.llm_dataset import DefaultToken, LLMDataset
+from federatedscope.core.data.utils import download_url
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class LLMDataCollator(object):
+ """
+ A data collator for supervised fine-tuning of language models.
+ This class implements a callable that takes a list of instances and
+ returns a batch of input_ids, labels, and attention_mask tensors. The
+ input_ids and labels are padded with the tokenizer's pad_token_id and a
+ special ignore index value, respectively. The attention_mask indicates
+ which tokens are not padding.
+ """
+
+ tokenizer: transformers.PreTrainedTokenizer
+
+ def __call__(self, instances):
+ """Collates a list of instances into a batch.
+
+ Args:
+ instances: A list of dictionaries, each containing input_ids and
+ labels as torch.LongTensor objects.
+
+ Returns:
+ A dictionary with the following keys and values:
+ - input_ids: A torch.LongTensor of shape (batch_size,
+ max_length)
+ containing the padded input ids.
+ - labels: A torch.LongTensor of shape (batch_size, max_length)
+ containing the padded labels.
+ - attention_mask: A torch.BoolTensor of shape (batch_size,
+ max_length)
+ indicating which tokens are not padding.
+ """
+
+ input_ids, labels = tuple([instance[key] for instance in instances]
+ for key in ("input_ids", "labels"))
+ input_ids = torch.nn.utils.rnn.pad_sequence(
+ input_ids,
+ batch_first=True,
+ padding_value=self.tokenizer.pad_token_id)
+ labels = torch.nn.utils.rnn.pad_sequence(
+ labels,
+ batch_first=True,
+ padding_value=DefaultToken.IGNORE_INDEX.value)
+ return dict(
+ input_ids=input_ids,
+ labels=labels,
+ attention_mask=input_ids.ne(self.tokenizer.pad_token_id),
+ )
+
+
+def get_tokenizer(model_name, cache_dir, tok_len=128, pkg='huggingface_llm'):
+ """
+ This function loads a tokenizer from a pretrained model name and adds some
+ default special tokens if they are not already defined. It also sets the
+ model max length and the padding side of the tokenizer.
+
+ Args:
+ model_name: A string, the name of the pretrained model.
+ cache_dir: A string, the path to the cache directory.
+ tok_len: An integer, the maximum length of the tokens. Defaults to 128.
+
+ Returns:
+ A tuple of (tokenizer, num_new_tokens), where:
+ - tokenizer: A transformers.AutoTokenizer object.
+ - num_new_tokens: An integer, the number of new special tokens
+ """
+ assert pkg in ['huggingface_llm', 'modelscope_llm'], \
+ f'Not supported package {pkg}.'
+
+ if pkg == 'huggingface_llm':
+ from transformers import AutoTokenizer
+ elif pkg == 'modelscope_llm':
+ from modelscope import AutoTokenizer
+
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_name,
+ cache_dir=cache_dir,
+ model_max_length=tok_len,
+ padding_side="right",
+ use_fast=True,
+ )
+
+ special_tokens = dict()
+ if tokenizer.pad_token is None:
+ special_tokens["pad_token"] = DefaultToken.PAD_TOKEN.value
+ if tokenizer.eos_token is None:
+ special_tokens["eos_token"] = DefaultToken.EOS_TOKEN.value
+ if tokenizer.bos_token is None:
+ special_tokens["bos_token"] = DefaultToken.BOS_TOKEN.value
+ if tokenizer.unk_token is None:
+ special_tokens["unk_token"] = DefaultToken.UNK_TOKEN.value
+
+ num_new_tokens = tokenizer.add_special_tokens(special_tokens)
+
+ return tokenizer, num_new_tokens
+
+
+def load_json(file_path,
+ instruction='instruction',
+ input='input',
+ output='output',
+ category='category'):
+ """
+ This function reads a JSON file that contains a list of examples,
+ each with an instruction, an input, an output, and a category. It
+ returns a list of dictionaries with the same keys, but with the
+ option to rename them.
+
+ Args:
+ file_path: A string, the path to the JSON file.
+ instruction: A string, the key for the instruction field. Defaults
+ to 'instruction'.
+ input: A string, the key for the input field. Defaults to 'input'.
+ output: A string, the key for the output field. Defaults to 'output'.
+ category: A string, the key for the category field. Defaults to
+ 'category'.
+
+ Returns:
+ A list of dictionaries, each with four keys: instruction, input,
+ output, and category. The values are taken from the JSON file
+ and may be None if the corresponding key is not present in the
+ file.
+ """
+
+ # Format: [{'instruction': ..., 'input': ..., 'output':...}]
+ with open(file_path, 'r', encoding="utf-8") as f:
+ list_data_dict = json.load(f)
+
+ # Replace key
+ new_list_data_dict = []
+ for item in list_data_dict:
+ new_item = dict(
+ instruction=item[instruction] if instruction in item else None,
+ input=item[input] if input in item else None,
+ output=item[output] if output in item else None,
+ category=item[category] if category in item else None)
+ new_list_data_dict.append(new_item)
+ return new_list_data_dict
+
+
+def load_jsonl(file_path,
+ instruction='instruction',
+ input='input',
+ output='output',
+ category='category',
+ is_gzip=False):
+ """
+ This function reads a JSONL file that contains one example per line,
+ each with an instruction, an input, an output, and a category. It
+ returns a list of dictionaries with the same keys, but with the option
+ to rename them. It also supports reading gzip-compressed files.
+
+ Args:
+ file_path: A string, the path to the JSONL file.
+ instruction: A string, the key for the instruction field. Defaults
+ to 'instruction'.
+ input: A string, the key for the input field. Defaults to 'input'.
+ output: A string, the key for the output field. Defaults to 'output'.
+ category: A string, the key for the category field. Defaults to
+ 'category'.
+ is_gzip: A boolean, whether the file is gzip-compressed or not.
+ Defaults to False.
+
+ Returns:
+ A list of dictionaries, each with four keys: instruction, input,
+ output, and category. The values are taken from the JSONL file and
+ may be None if the corresponding key is not present in the line.
+
+ """
+ # Format of each line:
+ # {'instruction': ..., 'input': ..., 'output':...}
+ list_data_dict = []
+ open_func = open if not is_gzip else gzip.open
+ with open_func(file_path, 'r') as f:
+ for line in f:
+ item = json.loads(line)
+ new_item = dict(
+ instruction=item[instruction] if instruction in item else None,
+ input=item[input] if input in item else None,
+ output=item[output] if output in item else None,
+ category=item[category] if category in item else None)
+ item = new_item
+ list_data_dict.append(item)
+ return list_data_dict
+
+
+def load_llm_dataset(config=None, **kwargs):
+ """
+ This function takes a config object and optional keyword arguments and
+ returns a dataset object and an updated config object.
+ The function supports various dataset types, such as JSON, JSONL, alpaca,
+ alpaca_cleaned, dolly-15K, gsm8k, code_search_net, rosetta_alpaca. It
+ will download the data files from their respective URLs if they are not
+ found in the data directory. It will also load a tokenizer from a
+ pretrained model name and add some default special tokens if they are
+ not already defined.
+
+ Args:
+ config: An object, the configuration for loading the dataset.
+ **kwargs: Optional keyword arguments that can override the config
+ attributes.
+
+ Returns:
+ A tuple of (dataset, config), where:
+ - dataset: A LLMDataset object that contains the examples with
+ instruction, input, output, and category fields.
+ - config: An object, the updated configuration.
+ """
+ model_name, model_hub = config.model.type.split('@')
+ tokenizer, num_new_tokens = \
+ get_tokenizer(model_name, config.data.root, config.llm.tok_len,
+ model_hub)
+
+ dataset_name, _ = config.data.type.split('@')
+
+ if dataset_name.endswith('.json'):
+ fp = os.path.join(config.data.root, dataset_name)
+ list_data_dict = load_json(fp)
+ dataset = LLMDataset(list_data_dict, tokenizer)
+ elif dataset_name.endswith('.jsonl'):
+ fp = os.path.join(config.data.root, dataset_name)
+ list_data_dict = load_jsonl(fp)
+ dataset = LLMDataset(list_data_dict, tokenizer)
+ elif dataset_name.lower() == 'alpaca':
+ fp = os.path.join(config.data.root, 'alpaca_data.json')
+ download_url(
+ 'https://raw.githubusercontent.com/tatsu-lab'
+ '/stanford_alpaca/'
+ '761dc5bfbdeeffa89b8bff5d038781a4055f796a/'
+ 'alpaca_data.json', config.data.root)
+ list_data_dict = load_json(fp)
+ dataset = LLMDataset(list_data_dict, tokenizer)
+ elif dataset_name.lower() == 'alpaca_cleaned':
+ fp = os.path.join(config.data.root, 'alpaca_data_cleaned.json')
+ download_url(
+ 'https://raw.githubusercontent.com/gururise/AlpacaDataCleaned/'
+ 'a7d629079a95c2e4b7ec7dfe55087fbd18d9eba8/'
+ 'alpaca_data_cleaned.json', config.data.root)
+ list_data_dict = load_json(fp)
+ dataset = LLMDataset(list_data_dict, tokenizer)
+ elif dataset_name.lower() == 'dolly-15k':
+ fp = os.path.join(config.data.root, 'databricks-dolly-15k.jsonl')
+ download_url(
+ 'https://raw.githubusercontent.com/databrickslabs'
+ '/dolly/d000e3030970379aabbf6d291f50ffdd3b715b64'
+ '/data/databricks-dolly-15k.jsonl', config.data.root)
+ list_data_dict = load_jsonl(fp,
+ instruction='instruction',
+ input='context',
+ output='response',
+ category='category')
+ dataset = LLMDataset(list_data_dict, tokenizer)
+ elif dataset_name.lower() == 'gsm8k':
+ fp = os.path.join(config.data.root, 'gsm8k_train.jsonl')
+ if not os.path.exists(fp):
+ download_url(
+ 'https://raw.githubusercontent.com/openai/grade-school-math'
+ '/3101c7d5072418e28b9008a6636bde82a006892c/'
+ 'grade_school_math/data/train.jsonl', config.data.root)
+ os.rename(os.path.join(config.data.root, 'train.jsonl'), fp)
+ list_data_dict = load_jsonl(fp,
+ instruction='question',
+ output='answer')
+ for i in range(len(list_data_dict)):
+ list_data_dict[i]['output'] = \
+ list_data_dict[i]['output'].replace('####', 'The answer is')
+ dataset = LLMDataset(list_data_dict, tokenizer)
+ elif dataset_name.lower() == 'code_search_net':
+ from tqdm import tqdm
+ from federatedscope.llm.dataset.code_search_net import \
+ CSN_FILE_NUM_DICT
+
+ list_data_dict = []
+ logger.info('Loading code search net data file...')
+ try:
+ for language in tqdm(CSN_FILE_NUM_DICT.keys()):
+ sub_list_data_dict = []
+ for file_index in range(CSN_FILE_NUM_DICT[language]['train']):
+ fp = \
+ os.path.join(config.data.root, language,
+ 'final', 'jsonl', 'train',
+ f'{language}_train_{file_index}.jsonl.gz')
+ tmp_list_data_dict = load_jsonl(
+ fp,
+ instruction='docstring',
+ input='language',
+ output='code',
+ category='language',
+ is_gzip=True,
+ )
+ sub_list_data_dict += tmp_list_data_dict
+ # Subsample
+ raw_size = len(sub_list_data_dict)
+ num_subsample = int(raw_size * config.data.subsample)
+ list_data_dict += random.sample(sub_list_data_dict,
+ num_subsample)
+ logger.info(f"Subsample "
+ f"{sub_list_data_dict[0]['category']} with "
+ f"rate {config.data.subsample}: "
+ f"the sample size is # {num_subsample} "
+ f"(the raw size is {raw_size}).")
+ # Modify instruction with specific language
+ for sample in list_data_dict:
+ sample['instruction'] = \
+ sample['category'] + ' ' + sample['instruction']
+ except FileNotFoundError:
+ raise FileNotFoundError(
+ 'Data not found! Please run `python '
+ 'federatedscope/llm/dataset/code_search_net.py` '
+ 'to download data.')
+ dataset = LLMDataset(list_data_dict, tokenizer)
+ elif dataset_name.lower() == 'rosetta_alpaca':
+ fp = os.path.join(config.data.root, 'rosetta_alpaca.json')
+ download_url(
+ 'https://raw.githubusercontent.com/'
+ 'sahil280114/codealpaca/'
+ 'd269da106a579a623a654529b3cb91b5dfa9c72f/'
+ 'data/rosetta_alpaca.json', config.data.root)
+ list_data_dict = load_json(fp,
+ instruction='instruction',
+ input='input',
+ output='output',
+ category='input')
+ # Remove 'x86-64 Assembl' if splitter is `meta` due to the number of
+ # samples is too small.
+ if config.data.splitter == 'meta':
+ list_data_dict = [
+ i for i in list_data_dict if i['category'] != 'X86-64 Assembly'
+ ]
+ dataset = LLMDataset(list_data_dict, tokenizer)
+ else:
+ raise ValueError(f'Not support data type {dataset_name}.')
+
+ return dataset, config
diff --git a/federatedscope/llm/dataset/__init__.py b/federatedscope/llm/dataset/__init__.py
new file mode 100644
index 000000000..c0b31382d
--- /dev/null
+++ b/federatedscope/llm/dataset/__init__.py
@@ -0,0 +1,8 @@
+from os.path import dirname, basename, isfile, join
+import glob
+
+modules = glob.glob(join(dirname(__file__), "*.py"))
+__all__ = [
+ basename(f)[:-3] for f in modules
+ if isfile(f) and not f.endswith('__init__.py')
+]
diff --git a/federatedscope/llm/dataset/code_search_net.py b/federatedscope/llm/dataset/code_search_net.py
new file mode 100644
index 000000000..3bd1c4bdc
--- /dev/null
+++ b/federatedscope/llm/dataset/code_search_net.py
@@ -0,0 +1,111 @@
+import os
+import json
+import random
+
+from tqdm import tqdm
+from subprocess import call
+from federatedscope.llm.dataloader.dataloader import load_jsonl
+
+CSN_FILE_NUM_DICT = {
+ 'python': {
+ 'train': 14,
+ 'val': 1,
+ 'test': 1,
+ },
+ 'javascript': {
+ 'train': 5,
+ 'val': 1,
+ 'test': 1,
+ },
+ 'java': {
+ 'train': 16,
+ 'val': 1,
+ 'test': 1,
+ },
+ 'ruby': {
+ 'train': 2,
+ 'val': 1,
+ 'test': 1,
+ },
+ 'php': {
+ 'train': 18,
+ 'val': 1,
+ 'test': 1,
+ },
+ 'go': {
+ 'train': 11,
+ 'val': 1,
+ 'test': 1,
+ },
+}
+
+
+def generate_eval_files(destination_dir='data'):
+ list_data_dict = []
+ for language in tqdm(CSN_FILE_NUM_DICT.keys()):
+ sub_list_data_dict = []
+ for file_index in range(CSN_FILE_NUM_DICT[language]['test']):
+ fp = \
+ os.path.join(destination_dir, language,
+ 'final', 'jsonl', 'test',
+ f'{language}_test_{file_index}.jsonl.gz')
+ tmp_list_data_dict = load_jsonl(
+ fp,
+ instruction='docstring',
+ input='code',
+ category='language',
+ is_gzip=True,
+ )
+ sub_list_data_dict += tmp_list_data_dict
+
+ # Clear docstring in code
+ for sample in sub_list_data_dict:
+ if sample['instruction'] in sample['input']:
+ sample['input'] = sample['input'].replace(
+ sample['instruction'], "")
+
+ # Build negative samples
+ random.shuffle(sub_list_data_dict)
+ num_half = len(sub_list_data_dict) // 2
+ neg_data_list = sub_list_data_dict[:num_half]
+ pos_data_list = sub_list_data_dict[num_half:]
+
+ for i, neg in enumerate(neg_data_list):
+ neg['input'] = random.choice(pos_data_list)['input']
+ neg['output'] = 0
+
+ for pos in pos_data_list:
+ pos['output'] = 1
+
+ sub_list_data_dict = neg_data_list + pos_data_list
+ random.shuffle(sub_list_data_dict)
+
+ list_data_dict += sub_list_data_dict
+
+ # Save as a jsonl file
+ with open(os.path.join(destination_dir, "csn_test.jsonl"), "w") as f:
+ for d in list_data_dict:
+ json.dump(d, f)
+ f.write("\n")
+
+ return list_data_dict
+
+
+def download_csn(destination_dir='data'):
+ if not os.path.exists(destination_dir):
+ os.makedirs(destination_dir)
+
+ for language in CSN_FILE_NUM_DICT.keys():
+ if os.path.exists(os.path.join(destination_dir, f'{language}.zip')):
+ continue
+ call([
+ 'wget', 'https://huggingface.co/datasets'
+ '/code_search_net/resolve/main/data/{}.zip'.format(language), '-P',
+ destination_dir, '-O', '{}.zip'.format(language)
+ ])
+ call(['unzip', '{}.zip'.format(language)])
+
+
+if __name__ == '__main__':
+ download_csn('data')
+ generate_eval_files('data')
diff --git a/federatedscope/llm/dataset/llm_dataset.py b/federatedscope/llm/dataset/llm_dataset.py
new file mode 100644
index 000000000..c7e047aa2
--- /dev/null
+++ b/federatedscope/llm/dataset/llm_dataset.py
@@ -0,0 +1,185 @@
+"""
+Some code snippets are borrowed from the open-sourced stanford_alpaca (
+ https://github.com/tatsu-lab/stanford_alpaca)
+"""
+
+import copy
+import logging
+import pandas as pd
+
+from enum import Enum
+from torch.utils.data import Dataset
+
+logger = logging.getLogger(__name__)
+
+
+class DefaultToken(Enum):
+ PAD_TOKEN = "[PAD]"
+ EOS_TOKEN = ""
+ BOS_TOKEN = ""
+ UNK_TOKEN = ""
+ IGNORE_INDEX = -100
+
+
+PROMPT_DICT = {
+ "prompt_input": (
+ "Below is an instruction that describes a task, "
+ "paired with an input that provides further context. "
+ "Write a response that appropriately completes the request.\n\n"
+ "### Instruction:\n{instruction}\n\n### Input:"
+ "\n{input}\n\n### Response:"),
+ "prompt_no_input": (
+ "Below is an instruction that describes a task. "
+ "Write a response that appropriately completes the request.\n\n"
+ "### Instruction:\n{instruction}\n\n### Response:"),
+}
+
+
+class LLMDataset(Dataset):
+ """
+ A dataset for language modeling tasks.
+
+ This class inherits from torch.utils.data.Dataset and implements a
+ dataset that can load and preprocess data for language modeling. It
+ takes a list of data dictionaries, a tokenizer, and optional prompt
+ templates as input, and creates input ids, labels, and categories as
+ output. The input ids and labels are padded and masked according to
+ the tokenizer settings and the source and target lengths. The
+ categories are encoded as integers using pandas.Categorical.
+
+ Attributes:
+ input_ids: A list of torch.LongTensor objects of shape (max_length,)
+ containing the padded input ids.
+ labels: A list of torch.LongTensor objects of shape (max_length,)
+ containing the padded labels.
+ categories: A list of integers representing the category codes.
+ tokenizer: A transformers.PreTrainedTokenizer object that can
+ encode and decode text.
+ """
+ def __init__(self,
+ list_data_dict,
+ tokenizer,
+ prompt_input=PROMPT_DICT["prompt_input"],
+ prompt_no_input=PROMPT_DICT["prompt_no_input"]):
+ """
+ Initializes the dataset with the given arguments.
+
+ Args:
+ list_data_dict: A list of dictionaries, each containing input,
+ output, and optionally category keys and values as strings.
+ tokenizer: A transformers.PreTrainedTokenizer object that can
+ encode and decode text.
+ prompt_input: An optional string template for creating the source
+ text when the input key is present in the data dictionary.
+ The template can use {input}, {output}, and {category} as
+ placeholders for the corresponding values. The default value
+ is PROMPT_DICT["prompt_input"].
+ prompt_no_input: An optional string template for creating the
+ source text when the input key is not present in the data
+ dictionary. The template can use {output} and {category} as
+ placeholders for the corresponding values. The default value is
+ PROMPT_DICT["prompt_no_input"].
+ """
+ super(LLMDataset, self).__init__()
+
+ sources = [
+ prompt_input.format_map(example) if example.get("input", "") != ""
+ else prompt_no_input.format_map(example)
+ for example in list_data_dict
+ ]
+ targets = [
+ f"{example['output']}{tokenizer.eos_token}"
+ for example in list_data_dict
+ ]
+
+ data_dict = self.preprocess(sources, targets, tokenizer)
+
+ self.input_ids = data_dict["input_ids"]
+ self.labels = data_dict["labels"]
+
+ categories = [
+ example['category'] if 'category' in example else None
+ for example in list_data_dict
+ ]
+ df = pd.DataFrame(categories, columns=["category"])
+ self.categories = list(pd.Categorical(df["category"]).codes)
+
+ def _tokenize_fn(self, strings, tokenizer):
+ """
+ Tokenizes a list of strings using the given tokenizer.
+
+ Args:
+ strings: A list of strings to be tokenized.
+ tokenizer: A transformers.PreTrainedTokenizer object that can
+ encode and decode text.
+
+ Returns:
+ A dictionary with the following keys and values:
+ - input_ids: A list of torch.LongTensor objects of shape (
+ max_length,) containing the tokenized input ids.
+ - labels: A list of torch.LongTensor objects of shape (
+ max_length,) containing the tokenized labels.
+ - input_ids_lens: A list of integers representing the
+ lengths of the input ids before padding.
+ - labels_lens: A list of integers representing the lengths of
+ the labels before padding.
+ """
+ tokenized_list = [
+ tokenizer(
+ text,
+ return_tensors="pt",
+ padding="longest",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ ) for text in strings
+ ]
+ input_ids = labels = [
+ tokenized.input_ids[0] for tokenized in tokenized_list
+ ]
+ input_ids_lens = labels_lens = [
+ tokenized.input_ids.ne(tokenizer.pad_token_id).sum().item()
+ for tokenized in tokenized_list
+ ]
+ return dict(
+ input_ids=input_ids,
+ labels=labels,
+ input_ids_lens=input_ids_lens,
+ labels_lens=labels_lens,
+ )
+
+ def preprocess(self, sources, targets, tokenizer):
+ """
+ Preprocesses the sources and targets using the given tokenizer.
+
+ Args:
+ sources: A list of strings representing the source texts.
+ targets: A list of strings representing the target texts.
+ tokenizer: A transformers.PreTrainedTokenizer object that can
+ encode and decode text.
+
+ Returns:
+ A dictionary with the following keys and values:
+ - input_ids: A list of torch.LongTensor objects of shape (
+ max_length,) containing the padded input ids.
+ - labels: A list of torch.LongTensor objects of shape (
+ max_length,) containing the padded labels.
+ """
+ examples = [s + t for s, t in zip(sources, targets)]
+ examples_tokenized, sources_tokenized = [
+ self._tokenize_fn(strings, tokenizer)
+ for strings in (examples, sources)
+ ]
+ input_ids = examples_tokenized["input_ids"]
+ labels = copy.deepcopy(input_ids)
+ for label, source_len in zip(labels,
+ sources_tokenized["input_ids_lens"]):
+ label[:source_len] = DefaultToken.IGNORE_INDEX.value
+ return dict(input_ids=input_ids, labels=labels)
+
+ def __len__(self):
+ return len(self.input_ids)
+
+ def __getitem__(self, i):
+ return dict(input_ids=self.input_ids[i],
+ labels=self.labels[i],
+ categories=self.categories[i])
diff --git a/federatedscope/llm/eval/__init__.py b/federatedscope/llm/eval/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/federatedscope/llm/eval/eval_for_code/README.md b/federatedscope/llm/eval/eval_for_code/README.md
new file mode 100644
index 000000000..49a2f050f
--- /dev/null
+++ b/federatedscope/llm/eval/eval_for_code/README.md
@@ -0,0 +1,34 @@
+# HumanEval Usage
+
+* Using the trained model to generate codes from prompt, and save them as a `jsonl` file.
+ * `python federatedscope/llm/eval/eval_for_code/humaneval.py --cfg federatedscope/llm/baseline/llama.yaml`
+ * The file name of `jsonl` should be `{cfg.federate.save_to}_humaneval_answer.jsonl`
+* Use HumanEval tools to test the pass@k score
+ * Installation
+ * `git clone https://github.com/openai/human-eval`
+ * `pip install -e human-eval`
+ * uncomment the following line 59 in `human-eval/human_eval/execution.py`
+ * `exec(check_program, exec_globals)`
+ * Evaluate
+ * `evaluate_functional_correctness {cfg.federate.save_to}_humaneval_answer.jsonl`
+
+# HumanEvalX Usage
+
+* Using the trained model to generate codes from prompt, and save them as 5 `jsonl` files (`['cpp', 'go', 'java', 'js', 'python']`).
+
+ * `python federatedscope/llm/eval/eval_for_code/humanevalx.py --cfg federatedscope/llm/baseline/llama.yaml`
+
+ * The file name of `jsonl` should be `{cfg.federate.save_to}_humanevalx_{LANGUAGE}_answer.jsonl`
+
+* Use HumanEvalX Docker Image to test the pass@k score
+
+ * `docker pull rishubi/codegeex:latest`
+
+ * ```bash
+ docker run -it --mount type=bind,source=$PWD,target=/workspace/fs rishubi/codegeex:latest /bin/bash -c "cd CodeGeeX; git fetch; git pull; pip install -e .; \
+ bash scripts/evaluate_humaneval_x.sh ../fs/{cfg.federate.save_to}_humanevalx_cpp_answer.jsonl cpp 1; \
+ bash scripts/evaluate_humaneval_x.sh ../fs/{cfg.federate.save_to}_humanevalx_go_answer.jsonl go 1; \
+ bash scripts/evaluate_humaneval_x.sh ../fs/{cfg.federate.save_to}_humanevalx_java_answer.jsonl java 1; \
+ bash scripts/evaluate_humaneval_x.sh ../fs/{cfg.federate.save_to}_humanevalx_js_answer.jsonl js 1; \
+ bash scripts/evaluate_humaneval_x.sh ../fs/{cfg.federate.save_to}_humanevalx_python_answer.jsonl python 1; exit"
+ ```
diff --git a/federatedscope/llm/eval/eval_for_code/__init__.py b/federatedscope/llm/eval/eval_for_code/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/federatedscope/llm/eval/eval_for_code/eval.py b/federatedscope/llm/eval/eval_for_code/eval.py
new file mode 100644
index 000000000..4aa0be3d8
--- /dev/null
+++ b/federatedscope/llm/eval/eval_for_code/eval.py
@@ -0,0 +1,197 @@
+import os
+import torch
+import random
+import transformers
+import numpy as np
+from tqdm import tqdm
+
+from federatedscope.core.configs.config import global_cfg
+from federatedscope.core.cmd_args import parse_args, parse_client_cfg
+from federatedscope.core.auxiliaries.utils import setup_seed
+from federatedscope.core.auxiliaries.logging import update_logger
+from federatedscope.core.data.utils import download_url
+from federatedscope.llm.dataloader.dataloader import load_json, load_jsonl
+from federatedscope.llm.misc.fschat import FSChatBot
+
+transformers.logging.set_verbosity(40)
+
+EVAL_DATA = 'code_search_net' # code_search_net
+N_SHOT = 5
+SAMPLES = [{
+ "idx": "cosqa-train-0",
+ "doc": "python code to write bool value 1",
+ "code": "def writeBoolean(self, n):\n \"\"\"\n"
+ " Writes a Boolean to the stream.\n "
+ "\"\"\"\n t = TYPE_BOOL_TRUE\n\n "
+ "if n is False:\n t = TYPE_BOOL_FALSE\n\n"
+ " self.stream.write(t)",
+ "label": 0
+}, {
+ "idx": "cosqa-train-9",
+ "doc": "1d array in char datatype in python",
+ "code": "def _convert_to_array(array_like, dtype):\n"
+ " \"\"\"\n "
+ "Convert Matrix attributes which are "
+ "array-like or buffer to array.\n "
+ "\"\"\"\n if isinstance(array_like, bytes):\n"
+ " return np.frombuffer(array_like, dtype=dtype)\n"
+ " return np.asarray(array_like, dtype=dtype)",
+ "label": 1
+}, {
+ "idx": "cosqa-train-2",
+ "doc": "python colored output to html",
+ "code": "def _format_json(data, theme):\n "
+ "\"\"\"Pretty print a dict as a JSON, "
+ "with colors if pygments is present.\"\"\"\n "
+ "output = json.dumps(data, indent=2, sort_keys=True)\n\n"
+ " if pygments and sys.stdout.isatty():\n "
+ "style = get_style_by_name(theme)\n "
+ "formatter = Terminal256Formatter(style=style)\n "
+ "return pygments.highlight(output, JsonLexer(), formatter)\n\n"
+ " return output",
+ "label": 0
+}, {
+ "idx": "cosqa-train-18",
+ "doc": "python condition non none",
+ "code": "def _not(condition=None, **kwargs):\n \"\"\"\n"
+ " Return the opposite of input condition.\n\n "
+ ":param condition: condition to process.\n\n "
+ ":result: not condition.\n :rtype: bool\n "
+ "\"\"\"\n\n result = True\n\n "
+ "if condition is not None:\n "
+ "result = not run(condition, **kwargs)\n\n "
+ "return result",
+ "label": 1
+}, {
+ "idx": "cosqa-train-4",
+ "doc": "python column of an array",
+ "code": "def _vector_or_scalar(x, type='row'):\n "
+ "\"\"\"Convert an object to either a scalar or "
+ "a row or column vector.\"\"\"\n "
+ "if isinstance(x, (list, tuple)):\n "
+ "x = np.array(x)\n if isinstance(x, np.ndarray):\n"
+ " assert x.ndim == 1\n "
+ "if type == 'column':\n "
+ "x = x[:, None]\n return x",
+ "label": 0
+}]
+
+
+def build_prompt(sample, n_shot):
+ input_text_prompt = 'Input: a piece of code and a document\n' \
+ 'Output: 0 or 1 score indicating the degree of ' \
+ 'matching between the code and the document, ' \
+ 'with 0 indicating a mismatch ' \
+ 'and 1 indicating a match.\n\n'
+
+ index_list = list(range(len(SAMPLES)))
+ random.shuffle(index_list)
+ for i in index_list[:n_shot]:
+ input_text_prompt += f"Document: {SAMPLES[i]['doc']}\n" \
+ f"Code: {SAMPLES[i]['code']}\n" \
+ f"Score: {SAMPLES[i]['label']}\n\n"
+ input_text_prompt += f"Document:{sample['category']}" \
+ f" {sample['instruction']}\n" \
+ f"Code: {sample['input']}\n" \
+ f"Score: "
+
+ return input_text_prompt
+
+
+@torch.no_grad()
+def main():
+ init_cfg = global_cfg.clone()
+ args = parse_args()
+
+ if args.cfg_file:
+ init_cfg.merge_from_file(args.cfg_file)
+ cfg_opt, client_cfg_opt = parse_client_cfg(args.opts)
+ init_cfg.merge_from_list(cfg_opt)
+
+ update_logger(init_cfg, clear_before_add=True)
+ setup_seed(init_cfg.seed)
+
+ # load your finetuned model (saved as xxx.ckpt)
+ # in yaml file federate.save_to
+ fschatbot = FSChatBot(init_cfg)
+ tokenizer = fschatbot.tokenizer
+ model = fschatbot.model
+ device = fschatbot.device
+
+ # Get test file
+ if EVAL_DATA == 'cosqa':
+ fp = os.path.join(init_cfg.data.root, 'cosqa-dev.json')
+ if not os.path.exists(fp):
+ download_url(
+ 'https://github.com/microsoft/CodeXGLUE/raw/'
+ 'd67dd5c73b9c433307d7df5f9faab2af9f5d1742/'
+ 'Text-Code/NL-code-search-WebQuery/CoSQA/cosqa-dev.json',
+ init_cfg.data.root)
+ list_data_dict = load_json(fp,
+ instruction='doc',
+ input='code',
+ output='label')
+ for sample in list_data_dict:
+ sample['category'] = 'python'
+ elif EVAL_DATA == 'code_search_net':
+ fp = os.path.join(init_cfg.data.root, 'csn_test.jsonl')
+ if not os.path.exists(fp):
+ raise FileNotFoundError('Run `python '
+ 'federatedscope/llm/'
+ 'dataset/code_search_net.py` '
+ 'to build test file')
+ list_data_dict = load_jsonl(fp,
+ instruction='instruction',
+ input='input',
+ output='output',
+ category='category')
+ else:
+ raise ValueError(EVAL_DATA)
+
+ labels, preds, cors = [], [], []
+ category = None
+ for sample in tqdm(list_data_dict):
+ if sample['category'] != category:
+ print(f"==============={category}===============\n"
+ f"Num of total question: {len(cors)}\n"
+ f"Average accuracy {np.mean(cors)}\n\n")
+ category = sample['category']
+ labels, preds, cors = [], [], []
+
+ n_shot = N_SHOT
+ input_text = build_prompt(sample, n_shot)
+ label = sample['output']
+
+ while len(input_text) > 1024 and n_shot > 0:
+ n_shot -= 1
+ input_text = build_prompt(sample, n_shot)
+
+ input_ids = \
+ tokenizer(input_text, return_tensors="pt",
+ max_length=tokenizer.model_max_length).input_ids.to(
+ device)
+ logits = model(input_ids=input_ids).logits[0, -1]
+ probs = (torch.nn.functional.softmax(
+ torch.tensor([
+ logits[tokenizer("0").input_ids[-1]],
+ logits[tokenizer("1").input_ids[-1]],
+ ]).float(),
+ dim=0,
+ ).detach().cpu().numpy())
+
+ pred = {0: 0, 1: 1}[np.argmax(probs)]
+
+ cor = pred == label
+
+ labels.append(label)
+ preds.append(pred)
+ cors.append(cor)
+
+ # Print final
+ print(f"==============={category}===============\n"
+ f"Num of total question: {len(cors)}\n"
+ f"Average accuracy {np.mean(cors)}\n\n")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/federatedscope/llm/eval/eval_for_code/humaneval.py b/federatedscope/llm/eval/eval_for_code/humaneval.py
new file mode 100644
index 000000000..e6968ff4c
--- /dev/null
+++ b/federatedscope/llm/eval/eval_for_code/humaneval.py
@@ -0,0 +1,116 @@
+import os
+import torch
+import json
+import transformers
+from transformers import GenerationConfig
+from tqdm import tqdm
+
+from federatedscope.core.configs.config import global_cfg
+from federatedscope.core.cmd_args import parse_args, parse_client_cfg
+from federatedscope.core.auxiliaries.utils import setup_seed
+from federatedscope.core.auxiliaries.logging import update_logger
+from federatedscope.core.data.utils import download_url
+from federatedscope.llm.dataloader.dataloader import load_jsonl
+from federatedscope.llm.misc.fschat import FSChatBot
+
+transformers.logging.set_verbosity(40)
+
+DEBUG = False
+NUM_ANSWERS_PER_QUESTION = 5
+
+
+def clean_answer(code):
+ """
+ Borrow from: https://github.com/FSoft-AI4Code/CodeCapybara
+ """
+ def pad_spaces(s, num=4):
+ n = 0
+ while n < len(s) and s[n] == " ":
+ n += 1
+ if n != num:
+ s = " " * num + s[n:]
+ return s
+
+ # 1. remove the special char \u00a0
+ code = code.replace('\u00a0', '')
+ # # 2. remove everything after "\n\n"
+ # code = code.split("\n\n")[0]
+ # 3. remove everything after the following stop sequences
+ # Reference: https://github.com/openai/human-eval
+ for stop_seq in ['\nclass', '\ndef', '\n#', '\nif', '\nprint', '\nassert']:
+ code = code.split(stop_seq)[0]
+ # 4. pad to four space to avoid `unindent` error
+ code = pad_spaces(code, 4)
+ return code
+
+
+@torch.no_grad()
+def main():
+ init_cfg = global_cfg.clone()
+ args = parse_args()
+
+ if args.cfg_file:
+ init_cfg.merge_from_file(args.cfg_file)
+ cfg_opt, client_cfg_opt = parse_client_cfg(args.opts)
+ init_cfg.merge_from_list(cfg_opt)
+
+ update_logger(init_cfg, clear_before_add=True)
+ setup_seed(init_cfg.seed)
+
+ # load your finetuned model (saved as xxx.ckpt)
+ # in yaml file federate.save_to
+ fschatbot = FSChatBot(init_cfg)
+ out_file = f'{init_cfg.federate.save_to}_humaneval_answer.jsonl'
+
+ # Get test file
+ fp = os.path.join(init_cfg.data.root, 'HumanEval.jsonl.gz')
+ if not os.path.exists(fp):
+ download_url(
+ 'https://github.com/openai/human-eval/raw/'
+ '463c980b59e818ace59f6f9803cd92c749ceae61/'
+ 'data/HumanEval.jsonl.gz', init_cfg.data.root)
+ list_data_dict = load_jsonl(fp,
+ instruction='prompt',
+ input='entry_point',
+ category='task_id',
+ output='test',
+ is_gzip=True)
+
+ answers = []
+ for sample in tqdm(list_data_dict):
+ input_text = sample['instruction']
+ generation_config = GenerationConfig(
+ temperature=0.1,
+ top_k=40,
+ top_p=0.75,
+ do_sample=True,
+ num_return_sequences=NUM_ANSWERS_PER_QUESTION,
+ )
+ generate_kwargs = dict(
+ generation_config=generation_config,
+ max_new_tokens=128,
+ )
+ try:
+ model_completions = fschatbot.generate(input_text, generate_kwargs)
+ except torch.cuda.OutOfMemoryError as error:
+ print(error)
+ model_completions = ['' for _ in range(NUM_ANSWERS_PER_QUESTION)]
+
+ for i, completion in enumerate(model_completions):
+ completion = clean_answer(completion)
+ answers.append(
+ dict(task_id=sample['category'], completion=completion))
+ if DEBUG:
+ print(f"task_id: {sample['category']},\n"
+ f"completion {i + 1}:\n{completion}\n\n")
+
+ # Save as samples.jsonl for eval pass@k score
+ # Run `evaluate_functional_correctness samples.jsonl`
+ with open(out_file, 'w') as f:
+ for answer in answers:
+ json_str = json.dumps(answer)
+ f.write(json_str + '\n')
+
+
+if __name__ == "__main__":
+ main()
diff --git a/federatedscope/llm/eval/eval_for_code/humanevalx.py b/federatedscope/llm/eval/eval_for_code/humanevalx.py
new file mode 100644
index 000000000..854cb5c6c
--- /dev/null
+++ b/federatedscope/llm/eval/eval_for_code/humanevalx.py
@@ -0,0 +1,140 @@
+import os
+import torch
+import json
+import transformers
+from transformers import GenerationConfig
+from tqdm import tqdm
+
+from federatedscope.core.configs.config import global_cfg
+from federatedscope.core.cmd_args import parse_args, parse_client_cfg
+from federatedscope.core.auxiliaries.utils import setup_seed
+from federatedscope.core.auxiliaries.logging import update_logger
+from federatedscope.llm.dataloader.dataloader import load_jsonl
+from federatedscope.core.data.utils import download_url
+from federatedscope.llm.misc.fschat import FSChatBot
+
+transformers.logging.set_verbosity(40)
+
+DEBUG = False
+NUM_ANSWERS_PER_QUESTION = 5
+LANGUAGES = ['cpp', 'go', 'java', 'js', 'python']
+LANGUAGE_TAG = {
+ "cpp": "// language: C++",
+ "python": "# language: Python",
+ "java": "// language: Java",
+ "js": "// language: JavaScript",
+ "go": "// language: Go",
+}
+
+
+def clean_answer(code, language_type=None):
+ """
+ Cleans up the generated code.
+ Borrow from: https://github.com/THUDM/CodeGeeX/blob/main/codegeex
+ /benchmark/utils.py
+ """
+ code = code.replace('\u00a0', '')
+ if language_type.lower() == "python":
+ end_words = ["\ndef", "\nclass", "\nif", "\n#", "\nprint", "\nassert"]
+ for w in end_words:
+ if w in code:
+ code = code[:code.rfind(w)]
+ elif language_type.lower() == "java":
+ main_pos = code.find("public static void main")
+ if main_pos != -1:
+ code = code[:main_pos] + '}'
+ if '}' in code:
+ code = code[:code.rfind('}')] + '}'
+ if code.count('{') + 1 == code.count('}'):
+ code += "\n}"
+ elif language_type.lower() == "go":
+ end_words = ["\n//", "\nfunc main("]
+ for w in end_words:
+ if w in code:
+ code = code[:code.rfind(w)]
+ if '}' in code:
+ code = code[:code.rfind('}')] + '}'
+ elif language_type.lower() == "cpp":
+ if '}' in code:
+ code = code[:code.rfind('}')] + '}'
+ elif language_type.lower() == "js":
+ if '}' in code:
+ code = code[:code.rfind('}')] + '}'
+ return code
+
+
+@torch.no_grad()
+def main():
+ init_cfg = global_cfg.clone()
+ args = parse_args()
+
+ if args.cfg_file:
+ init_cfg.merge_from_file(args.cfg_file)
+ cfg_opt, client_cfg_opt = parse_client_cfg(args.opts)
+ init_cfg.merge_from_list(cfg_opt)
+
+ update_logger(init_cfg, clear_before_add=True)
+ setup_seed(init_cfg.seed)
+
+ # load your finetuned model (saved as xxx.ckpt)
+ # in yaml file federate.save_to
+ fschatbot = FSChatBot(init_cfg)
+
+ for lang in LANGUAGES:
+ out_file = \
+ f'{init_cfg.federate.save_to}_humanevalx_{lang}_answer.jsonl'
+
+ # Get test file
+ fp = os.path.join(init_cfg.data.root, f'humaneval_{lang}.jsonl.gz')
+ if not os.path.exists(fp):
+ download_url(
+ 'https://github.com/THUDM/CodeGeeX/raw'
+ '/e64e88e40a73358bb4ad60ef24114355e7141880/codegeex'
+ f'/benchmark/humaneval-x/{lang}/data/humaneval_'
+ f'{lang}.jsonl.gz', init_cfg.data.root)
+ list_data_dict = load_jsonl(fp,
+ instruction='prompt',
+ category='task_id',
+ is_gzip=True)
+
+ answers = []
+ for sample in tqdm(list_data_dict):
+ input_text = LANGUAGE_TAG[lang] + '\n' + sample['instruction']
+ generation_config = GenerationConfig(
+ temperature=0.1,
+ top_k=40,
+ top_p=0.75,
+ do_sample=True,
+ num_return_sequences=NUM_ANSWERS_PER_QUESTION,
+ )
+ generate_kwargs = dict(
+ generation_config=generation_config,
+ max_new_tokens=128,
+ )
+ try:
+ model_completions = fschatbot.generate(input_text,
+ generate_kwargs)
+ except torch.cuda.OutOfMemoryError as error:
+ print(error)
+ model_completions = [
+ '' for _ in range(NUM_ANSWERS_PER_QUESTION)
+ ]
+
+ for i, completion in enumerate(model_completions):
+ completion = clean_answer(completion, language_type=lang)
+ answers.append(
+ dict(task_id=sample['category'], generation=completion))
+ if DEBUG:
+ print(f"task_id: {sample['category']},\n"
+ f"generation {i + 1}:\n{completion}\n\n")
+
+ # Save as samples.jsonl for eval pass@k score
+ # Run `evaluate_functional_correctness samples.jsonl`
+ with open(out_file, 'w') as f:
+ for answer in answers:
+ json_str = json.dumps(answer)
+ f.write(json_str + '\n')
+
+
+if __name__ == "__main__":
+ main()
diff --git a/federatedscope/llm/eval/eval_for_gsm8k/__init__.py b/federatedscope/llm/eval/eval_for_gsm8k/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/federatedscope/llm/eval/eval_for_gsm8k/eval.py b/federatedscope/llm/eval/eval_for_gsm8k/eval.py
new file mode 100644
index 000000000..4cac616c0
--- /dev/null
+++ b/federatedscope/llm/eval/eval_for_gsm8k/eval.py
@@ -0,0 +1,214 @@
+# Ref: https://github.com/kojima-takeshi188/zero_shot_cot
+
+import re
+import os
+import random
+import transformers
+from tqdm import tqdm
+
+from federatedscope.core.configs.config import global_cfg
+from federatedscope.core.cmd_args import parse_args, parse_client_cfg
+from federatedscope.core.auxiliaries.utils import setup_seed
+from federatedscope.core.auxiliaries.logging import update_logger
+from federatedscope.core.data.utils import download_url
+from federatedscope.llm.dataloader.dataloader import load_jsonl
+from federatedscope.llm.misc.fschat import FSChatBot
+
+transformers.logging.set_verbosity(40)
+
+ANS_RE = re.compile(r"#### (\-?[0-9\.\,]+)")
+INVALID_ANS = "[invalid]"
+
+N_SHOT = 8
+COT_FLAG = True
+DEBUG = False
+ANSWER_TRIGGER = "The answer is"
+
+
+def extract_answer_from_output(completion):
+ match = ANS_RE.search(completion)
+ if match:
+ match_str = match.group(1).strip()
+ match_str = match_str.replace(",", "")
+ return match_str
+ else:
+ return INVALID_ANS
+
+
+def is_correct(model_answer, answer):
+ gt_answer = extract_answer_from_output(answer)
+ assert gt_answer != INVALID_ANS
+ return model_answer == gt_answer
+
+
+def create_demo_text(n_shot=8, cot_flag=True):
+ question, chain, answer = [], [], []
+ question.append("There are 15 trees in the grove. "
+ "Grove workers will plant trees in the grove today. "
+ "After they are done, there will be 21 trees. "
+ "How many trees did the grove workers plant today?")
+ chain.append("There are 15 trees originally. "
+ "Then there were 21 trees after some more were planted. "
+ "So there must have been 21 - 15 = 6.")
+ answer.append("6")
+
+ question.append(
+ "If there are 3 cars in the parking lot and 2 more cars arrive, "
+ "how many cars are in the parking lot?")
+ chain.append("There are originally 3 cars. 2 more cars arrive. 3 + 2 = 5.")
+ answer.append("5")
+
+ question.append(
+ "Leah had 32 chocolates and her sister had 42. If they ate 35, "
+ "how many pieces do they have left in total?")
+ chain.append("Originally, Leah had 32 chocolates. "
+ "Her sister had 42. So in total they had 32 + 42 = 74. "
+ "After eating 35, they had 74 - 35 = 39.")
+ answer.append("39")
+
+ question.append(
+ "Jason had 20 lollipops. He gave Denny some lollipops. Now Jason "
+ "has 12 lollipops. How many lollipops did Jason give to Denny?")
+ chain.append(
+ "Jason started with 20 lollipops. Then he had 12 after giving some "
+ "to Denny. So he gave Denny 20 - 12 = 8.")
+ answer.append("8")
+
+ question.append(
+ "Shawn has five toys. For Christmas, he got two toys each from his "
+ "mom and dad. How many toys does he have now?")
+ chain.append(
+ "Shawn started with 5 toys. If he got 2 toys each from his mom and "
+ "dad, then that is 4 more toys. 5 + 4 = 9.")
+ answer.append("9")
+
+ question.append(
+ "There were nine computers in the server room. Five more computers "
+ "were installed each day, from monday to thursday. "
+ "How many computers are now in the server room?")
+ chain.append(
+ "There were originally 9 computers. For each of 4 days, 5 more "
+ "computers were added. So 5 * 4 = 20 computers were added. "
+ "9 + 20 is 29.")
+ answer.append("29")
+
+ question.append(
+ "Michael had 58 golf balls. On tuesday, he lost 23 golf balls. On "
+ "wednesday, he lost 2 more. "
+ "How many golf balls did he have at the end of wednesday?")
+ chain.append(
+ "Michael started with 58 golf balls. After losing 23 on tuesday, "
+ "he had 58 - 23 = 35. After losing 2 more, "
+ "he had 35 - 2 = 33 golf balls.")
+ answer.append("33")
+
+ question.append("Olivia has $23. She bought five bagels for $3 each. "
+ "How much money does she have left?")
+ chain.append("Olivia had 23 dollars. "
+ "5 bagels for 3 dollars each will be 5 x 3 = 15 dollars. "
+ "So she has 23 - 15 dollars left. 23 - 15 is 8.")
+ answer.append("8")
+
+ # randomize order of the examples ...
+ index_list = list(range(len(question)))
+ random.shuffle(index_list)
+
+ # Concatenate demonstration examples ...
+ demo_text = ""
+ for i in index_list[:n_shot]:
+ if cot_flag:
+ demo_text += "Q: " + question[i] + "\nA: " + chain[i] + " " + \
+ ANSWER_TRIGGER + " " + answer[i] + ".\n\n"
+ else:
+ demo_text += "Question: " + question[i] + "\nAnswer: " + \
+ ANSWER_TRIGGER + " " + answer[i] + ".\n\n"
+ return demo_text
+
+
+def build_prompt(input_text, n_shot, cot_flag):
+ demo = create_demo_text(n_shot, cot_flag)
+ input_text_prompt = demo + "Q: " + input_text + "\n" + "A:"
+ return input_text_prompt
+
+
+def clean_answer(model_pred):
+ model_pred = model_pred.lower()
+ preds = model_pred.split(ANSWER_TRIGGER.lower())
+ answer_flag = True if len(preds) > 1 else False
+ if answer_flag:
+ # Pick first answer with flag
+ pred = preds[1]
+ else:
+ # Pick last number without flag
+ pred = preds[-1]
+
+ pred = pred.replace(",", "")
+ pred = [s for s in re.findall(r'-?\d+\.?\d*', pred)]
+
+ if len(pred) == 0:
+ return INVALID_ANS
+
+ if answer_flag:
+ # choose the first element in list
+ pred = pred[0]
+ else:
+ # choose the last element in list
+ pred = pred[-1]
+
+ # (For arithmetic tasks) if a word ends with period, it will be omitted ...
+ if pred[-1] == ".":
+ pred = pred[:-1]
+
+ return pred
+
+
+def main():
+ init_cfg = global_cfg.clone()
+ args = parse_args()
+
+ if args.cfg_file:
+ init_cfg.merge_from_file(args.cfg_file)
+ cfg_opt, client_cfg_opt = parse_client_cfg(args.opts)
+ init_cfg.merge_from_list(cfg_opt)
+
+ update_logger(init_cfg, clear_before_add=True)
+ setup_seed(init_cfg.seed)
+
+ # load your finetuned model (saved as xxx.ckpt)
+ # in yaml file federate.save_to
+ fschatbot = FSChatBot(init_cfg)
+
+ # Get test file
+ fp = os.path.join(init_cfg.data.root, 'gsm8k_test.jsonl')
+ if not os.path.exists(fp):
+ download_url(
+ 'https://raw.githubusercontent.com/openai/'
+ 'grade-school-math/2909d34ef28520753df82a2234c357259d254aa8/'
+ 'grade_school_math/data/test.jsonl', init_cfg.data.root)
+ os.rename(os.path.join(init_cfg.data.root, 'test.jsonl'), fp)
+
+ list_data_dict = load_jsonl(fp, instruction='question', output='answer')
+
+ answers = []
+ for sample in tqdm(list_data_dict):
+ input_text = build_prompt(sample['instruction'], N_SHOT, COT_FLAG)
+ generate_kwargs = dict(max_new_tokens=256, top_p=0.95, temperature=0.8)
+ model_completion = fschatbot.generate(input_text, generate_kwargs)
+ model_answer = clean_answer(model_completion)
+ is_cor = is_correct(model_answer, sample['output'])
+ answers.append(is_cor)
+ if DEBUG:
+ print(f'Full input_text:\n{input_text}\n\n')
+ print(f'Question: {sample["instruction"]}\n\n'
+ f'Answers: {extract_answer_from_output(sample["output"])}\n\n'
+ f'Model Answers: {model_answer}\n\n'
+ f'Model Completion: {model_completion}\n\n'
+ f'Is correct: {is_cor}\n\n')
+
+ print(f'Num of total question: {len(answers)}, '
+ f'correct num: {sum(answers)}, '
+ f'correct rate: {float(sum(answers))/len(answers)}.')
+
+
+if __name__ == "__main__":
+ main()
diff --git a/federatedscope/llm/eval/eval_for_helm/README.md b/federatedscope/llm/eval/eval_for_helm/README.md
new file mode 100644
index 000000000..7143fc92b
--- /dev/null
+++ b/federatedscope/llm/eval/eval_for_helm/README.md
@@ -0,0 +1,100 @@
+# Helm + FS
+
+## Docker
+
+* Build images:
+ * Build from Dockerfile: `docker build -f federatedscope-torch2.0-helm.Dockerfile -t fsteam/federatedscope:fs_helm .`
+ * Pull from docker hub: `docker pull fsteam/federatedscope:fs_helm`
+
+* Download Helm evaluation dataset
+
+ * `wget https://federatedscope.oss-cn-beijing.aliyuncs.com/helm_data.zip -O ${PATH_TO_HELM_DATA}/helm_data.zip`
+ * `unzip ${PATH_TO_HELM_DATA}/helm_data.zip`
+
+* Prepare FS and related `ckpt` and `yaml`
+
+ * `${PATH_TO_FS}`
+
+* Launch and mapping dataset and FS
+
+ ```bash
+ docker run -p ${PORT}:${DOCKER_PORT} -u root: --gpus device=all -it --rm \
+ -v "${PATH_TO_HELM_DATA}/helm_data/benchmark_output:/root/src/helm/benchmark_output" \
+ -v "${PATH_TO_HELM_DATA}/helm_data/nltk_data:/root/nltk_data" \
+ -v "${PATH_TO_HELM_DATA}/helm_data/prompt_construction_settings.json:/tmp/prompt_construction_settings.json" \
+ -v "${PATH_TO_FS}:/root/FederatedScope" \
+ -v "${PATH_TO_CACHE}:/root/.cache" \
+ -w '/root/FederatedScope' \
+ --name "helm_fs" fsteam/federatedscope:fs_helm /bin/bash
+ ```
+
+ Example for a root user:
+
+ ```bash
+ docker run -p 8000:8000 -u root: --gpus device=all -it --rm \
+ -v "/root/helm_fs/helm_data/benchmark_output:/root/src/helm/benchmark_output" \
+ -v "/root/helm_fs/helm_data/nltk_data:/root/nltk_data" \
+ -v "/root/helm_fs/helm_data/prompt_construction_settings.json:/tmp/prompt_construction_settings.json" \
+ -v "/root/helm_fs/FederatedScope:/root/FederatedScope" \
+ -v "/root/.cache:/root/.cache" \
+ -w '/root/FederatedScope' \
+ --name "helm_fs" fsteam/federatedscope:fs_helm /bin/bash
+ ```
+
+* Install FS in container
+
+ * `pip install -e .[llm]`
+
+* Move to helm
+
+ * `cd /root/src/crfm-helm`
+
+* Start to evaluate
+
+ * `helm-run --conf-paths federatedscope/llm/eval/eval_for_helm/run_specs.conf --enable-local-huggingface-model decapoda-research/llama-7b-hf --suite ${SUITE_NAME} -m 100 --local -n 1 --skip-completed-runs --local-path xxx`
+ * The above code will evaluate the model `decapoda-research/llama-7b-hf` and save the results in `/benchmark_output/runs/${SUITE_NAME}`.
+ * `-m 100` means that there will be 100 items in each task.
+ * `--skip-completed-runs` means that when restarted, it will skip the completed test sets. It is recommended to add this if you no dot want to waste your time for the completed tasks.
+ * `--local-path xxx` means the directory to put cache files, default value is `prod_env`. It will always use it when you run a new task. It is recommended that before running a new task, delete it or assign a new name to it.
+ * If you want to test your own trained `ckpt` for `decapoda-research/llama-7b-hf`, please add parameters `--yaml /path/to/xxx.yaml`. If you want to modify the configurations in `yaml`, just add parameters similar to the behaviors in FS. For example, add `federate.save_to xxxx.ckpt` to change the ckpt.
+* Launch webserver to view results
+ * `bash evaluaton/setup_server.sh -n ${SUITE_NAME} -p ${PORT}`
+
+ Run the above code and view the results on port `${PORT}`.
+ * Remark: Actually, it will always show the results of the last task. If you want to see the results of another task, say, the suite name is `result_of_exp1`, add `?suite=result_of_exp1` after the port address.
+
+## Conda
+
+* Create new env `helm_fs` in conda
+ * `conda create -n helm_fs python=3.9`
+* Create dir
+ * `mkdir helm_fs`
+ * `cd helm_fs`
+* Install helm from our branch
+ * `pip install -e git+https://github.com/qbc2016/helm.git@helm_for_fs#egg=crfm-helm`
+* Install FS-LLM (**errors can be igored**)
+ * `git clone -b llm https://github.com/alibaba/FederatedScope.git`
+ * `cd FederatedScope`
+ * `pip install -e .[llm]`
+* Download and unzip Helm evaluation dataset
+ * `wget https://federatedscope.oss-cn-beijing.aliyuncs.com/helm_data.zip -O ${PATH_TO_HELM_DATA}/helm_data.zip`
+ * `unzip ${PATH_TO_HELM_DATA}/helm_data.zip`
+* Move files
+ * `benchmark_output` -> `~/helm_fs/src/crfm-helm/benchmark_output`
+ * `nltk_data` -> `~/nltk_data`
+ * `prompt_construction_settings.json` - > `/tmp/prompt_construction_settings.json`
+* Move ckpt and yaml
+* Start to evaluate
+ * `helm-run --conf-paths federatedscope/llm/eval/eval_for_helm/run_specs.conf --enable-local-huggingface-model decapoda-research/llama-7b-hf --suite ${SUITE_NAME} -m 100 --local -n 1 --skip-completed-runs --local-path xxx`
+* Launch webserver to view results
+ * In `~/helm_fs/src/crfm-helm/evaluation/setup_server.sh`, set
+ * `SUITE_NAME=${SUITE_NAME}`
+ * `PATH_HELM=~/helm_fs/src/crfm-helm`
+ * `PATH_WORKDIR=~/helm_fs/src/crfm-helm`
+ * `root/miniconda3/bin/python -> ${which python}`
+ * `bash evaluation/setup_server.sh -n ${SUITE_NAME} -p ${PORT}`
+ * Remark: Actually, it will show the result of the last task. If you want to see the result of another task, say, the suite name is result_of_exp1, add `?suite=result_of_exp1`after the port address.
+
+Remark: For the second run of `decapoda-research/llama-7b-hf`, if not work, in ~/helm_fs/src/crfm-helm/data/decapoda-research--llama-7b-hf/snapshots/xxxx/tokenizer_config.json, change
+
+"tokenizer_class": "LLaMATokenizer" -> "tokenizer_class": "LlamaTokenizer"
diff --git a/federatedscope/llm/eval/eval_for_helm/__init__.py b/federatedscope/llm/eval/eval_for_helm/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/federatedscope/llm/eval/eval_for_helm/federatedscope-torch2.0-helm.Dockerfile b/federatedscope/llm/eval/eval_for_helm/federatedscope-torch2.0-helm.Dockerfile
new file mode 100644
index 000000000..54d47b11c
--- /dev/null
+++ b/federatedscope/llm/eval/eval_for_helm/federatedscope-torch2.0-helm.Dockerfile
@@ -0,0 +1,39 @@
+# The federatedscope image includes all runtime stuffs of federatedscope,
+# with customized miniconda and required packages installed.
+
+# based on the nvidia-docker
+# NOTE: please pre-install the NVIDIA drivers and `nvidia-docker2` in the host machine,
+# see details in https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html
+ARG ROOT_CONTAINER=nvidia/cuda:11.7.0-runtime-ubuntu20.04
+
+FROM $ROOT_CONTAINER
+
+# Fix: https://github.com/hadolint/hadolint/wiki/DL4006
+# Fix: https://github.com/koalaman/shellcheck/wiki/SC3014
+SHELL ["/bin/bash", "-o", "pipefail", "-c"]
+
+# shanghai zoneinfo
+ENV TZ=Asia/Shanghai
+RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
+
+# install basic tools
+RUN apt-get -y update \
+ && apt-get -y install curl git gcc g++ make openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev python-dev libmysqlclient-dev
+
+# install miniconda, in batch (silent) mode, does not edit PATH or .bashrc or .bash_profile
+RUN apt-get update -y \
+ && apt-get install -y wget
+RUN wget https://repo.anaconda.com/miniconda/Miniconda3-py39_23.1.0-1-Linux-x86_64.sh \
+ && bash Miniconda3-py39_23.1.0-1-Linux-x86_64.sh -b \
+ && rm Miniconda3-py39_23.1.0-1-Linux-x86_64.sh
+
+ENV PATH=/root/miniconda3/bin:${PATH}
+RUN source activate
+
+RUN conda update -y conda \
+ && conda config --add channels conda-forge
+
+# Install helm
+RUN mkdir /root/helm_fs \
+ && cd /root/helm_fs
+RUN pip install -e git+https://github.com/qbc2016/helm.git@helm_for_fs#egg=crfm-helm
diff --git a/federatedscope/llm/eval/eval_for_helm/run_specs.conf b/federatedscope/llm/eval/eval_for_helm/run_specs.conf
new file mode 100644
index 000000000..9b962e753
--- /dev/null
+++ b/federatedscope/llm/eval/eval_for_helm/run_specs.conf
@@ -0,0 +1,107 @@
+# Only for fast test
+
+entries: [
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=abstract_algebra,data_augmentation=canonical", priority: 2}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=anatomy,data_augmentation=canonical", priority: 3}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=college_chemistry,data_augmentation=canonical", priority: 2}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=computer_security,data_augmentation=canonical", priority: 2}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=econometrics,data_augmentation=canonical", priority: 2}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=global_facts,data_augmentation=canonical", priority: 3}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=jurisprudence,data_augmentation=canonical", priority: 3}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=philosophy,data_augmentation=canonical", priority: 3}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=professional_medicine,data_augmentation=canonical", priority: 3}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=us_foreign_policy,data_augmentation=canonical", priority: 2}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=astronomy,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=business_ethics,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=clinical_knowledge,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=college_biology,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=college_computer_science,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=college_mathematics,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=college_medicine,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=college_physics,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=conceptual_physics,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=electrical_engineering,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=elementary_mathematics,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=formal_logic,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_biology,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_chemistry,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_computer_science,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_european_history,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_geography,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_government_and_politics,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_macroeconomics,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_mathematics,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_microeconomics,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_physics,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_psychology,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_statistics,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_us_history,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=high_school_world_history,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=human_aging,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=human_sexuality,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=international_law,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=logical_fallacies,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=machine_learning,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=management,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=marketing,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=medical_genetics,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=miscellaneous,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=moral_disputes,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=moral_scenarios,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=nutrition,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=prehistory,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=professional_accounting,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=professional_law,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=professional_psychology,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=public_relations,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=security_studies,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=sociology,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=virology,data_augmentation=canonical", priority: 4}
+ {description: "mmlu:model=decapoda-research/llama-7b-hf,subject=world_religions,data_augmentation=canonical", priority: 4}
+
+ {description: "imdb:model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 1}
+
+ {description: "raft:subset=ade_corpus_v2,model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 2}
+ {description: "raft:subset=banking_77,model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 2}
+ {description: "raft:subset=neurips_impact_statement_risks,model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 2}
+ {description: "raft:subset=one_stop_english,model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 2}
+ {description: "raft:subset=overruling,model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 2}
+ {description: "raft:subset=semiconductor_org_types,model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 2}
+ {description: "raft:subset=tweet_eval_hate,model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 2}
+ {description: "raft:subset=twitter_complaints,model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 2}
+ {description: "raft:subset=systematic_review_inclusion,model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 2}
+ {description: "raft:subset=tai_safety_research,model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 2}
+ {description: "raft:subset=terms_of_service,model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 2}
+
+ {description: "summarization_cnndm:model=decapoda-research/llama-7b-hf,temperature=0.3,device=cpu", priority: 1}
+
+ {description: "truthful_qa:model=decapoda-research/llama-7b-hf,task=mc_single,data_augmentation=canonical", priority: 1}
+
+ {description: "boolq:model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 1}
+
+ {description: "narrative_qa:model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 2}
+
+ {description: "natural_qa:model=decapoda-research/llama-7b-hf,mode=openbook_longans,data_augmentation=canonical", priority: 1}
+
+ {description: "natural_qa:model=decapoda-research/llama-7b-hf,mode=closedbook,data_augmentation=canonical", priority: 1}
+
+ {description: "quac:model=decapoda-research/llama-7b-hf,data_augmentation=canonical", priority: 1}
+
+ {description: "commonsense:model=decapoda-research/llama-7b-hf,dataset=hellaswag,method=multiple_choice_separate_original,data_augmentation=canonical", priority: 1}
+ {description: "commonsense:model=decapoda-research/llama-7b-hf,dataset=openbookqa,method=multiple_choice_separate_calibrated,data_augmentation=canonical", priority: 2}
+
+ {description: "msmarco:model=decapoda-research/llama-7b-hf,data_augmentation=canonical,track=regular,valid_topk=30", priority: 2}
+ {description: "msmarco:model=decapoda-research/llama-7b-hf,data_augmentation=canonical,track=trec,valid_topk=30", priority: 1}
+
+ {description: "summarization_xsum_sampled:model=decapoda-research/llama-7b-hf,temperature=0.3,device=cpu", priority: 1}
+
+ {description: "civil_comments:model=decapoda-research/llama-7b-hf,demographic=all,data_augmentation=canonical", priority: 1}
+ {description: "civil_comments:model=decapoda-research/llama-7b-hf,demographic=male,data_augmentation=canonical", priority: 2}
+ {description: "civil_comments:model=decapoda-research/llama-7b-hf,demographic=female,data_augmentation=canonical", priority: 2}
+ {description: "civil_comments:model=decapoda-research/llama-7b-hf,demographic=LGBTQ,data_augmentation=canonical", priority: 2}
+ {description: "civil_comments:model=decapoda-research/llama-7b-hf,demographic=christian,data_augmentation=canonical", priority: 2}
+ {description: "civil_comments:model=decapoda-research/llama-7b-hf,demographic=muslim,data_augmentation=canonical", priority: 2}
+ {description: "civil_comments:model=decapoda-research/llama-7b-hf,demographic=other_religions,data_augmentation=canonical", priority: 2}
+ {description: "civil_comments:model=decapoda-research/llama-7b-hf,demographic=black,data_augmentation=canonical", priority: 2}
+ {description: "civil_comments:model=decapoda-research/llama-7b-hf,demographic=white,data_augmentation=canonical", priority: 2}
+]
\ No newline at end of file
diff --git a/federatedscope/llm/eval/eval_for_mmlu/__init__.py b/federatedscope/llm/eval/eval_for_mmlu/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/federatedscope/llm/eval/eval_for_mmlu/categories.py b/federatedscope/llm/eval/eval_for_mmlu/categories.py
new file mode 100644
index 000000000..4ada271ce
--- /dev/null
+++ b/federatedscope/llm/eval/eval_for_mmlu/categories.py
@@ -0,0 +1,72 @@
+# ref: https://github.com/hendrycks/test/blob/master/evaluate_flan.py
+subcategories = {
+ "abstract_algebra": ["math"],
+ "anatomy": ["health"],
+ "astronomy": ["physics"],
+ "business_ethics": ["business"],
+ "clinical_knowledge": ["health"],
+ "college_biology": ["biology"],
+ "college_chemistry": ["chemistry"],
+ "college_computer_science": ["computer science"],
+ "college_mathematics": ["math"],
+ "college_medicine": ["health"],
+ "college_physics": ["physics"],
+ "computer_security": ["computer science"],
+ "conceptual_physics": ["physics"],
+ "econometrics": ["economics"],
+ "electrical_engineering": ["engineering"],
+ "elementary_mathematics": ["math"],
+ "formal_logic": ["philosophy"],
+ "global_facts": ["other"],
+ "high_school_biology": ["biology"],
+ "high_school_chemistry": ["chemistry"],
+ "high_school_computer_science": ["computer science"],
+ "high_school_european_history": ["history"],
+ "high_school_geography": ["geography"],
+ "high_school_government_and_politics": ["politics"],
+ "high_school_macroeconomics": ["economics"],
+ "high_school_mathematics": ["math"],
+ "high_school_microeconomics": ["economics"],
+ "high_school_physics": ["physics"],
+ "high_school_psychology": ["psychology"],
+ "high_school_statistics": ["math"],
+ "high_school_us_history": ["history"],
+ "high_school_world_history": ["history"],
+ "human_aging": ["health"],
+ "human_sexuality": ["culture"],
+ "international_law": ["law"],
+ "jurisprudence": ["law"],
+ "logical_fallacies": ["philosophy"],
+ "machine_learning": ["computer science"],
+ "management": ["business"],
+ "marketing": ["business"],
+ "medical_genetics": ["health"],
+ "miscellaneous": ["other"],
+ "moral_disputes": ["philosophy"],
+ "moral_scenarios": ["philosophy"],
+ "nutrition": ["health"],
+ "philosophy": ["philosophy"],
+ "prehistory": ["history"],
+ "professional_accounting": ["other"],
+ "professional_law": ["law"],
+ "professional_medicine": ["health"],
+ "professional_psychology": ["psychology"],
+ "public_relations": ["politics"],
+ "security_studies": ["politics"],
+ "sociology": ["culture"],
+ "us_foreign_policy": ["politics"],
+ "virology": ["health"],
+ "world_religions": ["philosophy"],
+}
+
+categories = {
+ "STEM": [
+ "physics", "chemistry", "biology", "computer science", "math",
+ "engineering"
+ ],
+ "humanities": ["history", "philosophy", "law"],
+ "social sciences": [
+ "politics", "culture", "economics", "geography", "psychology"
+ ],
+ "other (business, health, misc.)": ["other", "business", "health"],
+}
diff --git a/federatedscope/llm/eval/eval_for_mmlu/eval.py b/federatedscope/llm/eval/eval_for_mmlu/eval.py
new file mode 100644
index 000000000..68a59be87
--- /dev/null
+++ b/federatedscope/llm/eval/eval_for_mmlu/eval.py
@@ -0,0 +1,209 @@
+# ref: https://github.com/hendrycks/test/blob/master/evaluate_flan.py
+import os
+import torch
+import numpy as np
+import pandas as pd
+from federatedscope.llm.eval.eval_for_mmlu.categories import \
+ subcategories, categories
+import json
+import transformers
+
+from federatedscope.core.configs.config import global_cfg
+from federatedscope.core.cmd_args import parse_args, parse_client_cfg
+from federatedscope.core.auxiliaries.utils import setup_seed
+from federatedscope.core.auxiliaries.logging import update_logger
+from federatedscope.llm.misc.fschat import FSChatBot
+from federatedscope.core.data.utils import download_url
+import tarfile
+
+transformers.logging.set_verbosity(40)
+
+choices = ["A", "B", "C", "D"]
+
+
+def format_subject(subject):
+ ll = subject.split("_")
+ s = ""
+ for entry in ll:
+ s += " " + entry
+ return s
+
+
+def format_example(df, idx, include_answer=True):
+ prompt = df.iloc[idx, 0]
+ k = df.shape[1] - 2
+ for j in range(k):
+ prompt += "\n{}. {}".format(choices[j], df.iloc[idx, j + 1])
+ prompt += "\nAnswer:"
+ if include_answer:
+ prompt += " {}\n\n".format(df.iloc[idx, k + 1])
+ return prompt
+
+
+def gen_prompt(train_df, subject, k=-1):
+ prompt = "The following are multiple choice \
+ questions (with answers) about {}.\n\n".format(format_subject(subject))
+ if k == -1:
+ k = train_df.shape[0]
+ for i in range(k):
+ prompt += format_example(train_df, i)
+ return prompt
+
+
+@torch.no_grad()
+def eval(subject, model, tokenizer, dev_df, test_df, device):
+ cors = []
+ all_probs = []
+ answers = choices[:test_df.shape[1] - 2]
+
+ for i in range(test_df.shape[0]):
+ # get prompt and make sure it fits
+ k = 5
+ prompt_end = format_example(test_df, i, include_answer=False)
+ train_prompt = gen_prompt(dev_df, subject, k)
+ prompt = train_prompt + prompt_end
+
+ input_ids = tokenizer(
+ prompt,
+ return_tensors="pt",
+ max_length=tokenizer.model_max_length,
+ ).input_ids.to(device)
+
+ while input_ids.shape[-1] > 1024:
+ k -= 1
+ train_prompt = gen_prompt(dev_df, subject, k)
+ prompt = train_prompt + prompt_end
+ input_ids = tokenizer(prompt,
+ return_tensors="pt").input_ids.to(device)
+
+ label = test_df.iloc[i, test_df.shape[1] - 1]
+
+ logits = model(input_ids=input_ids).logits[0, -1]
+
+ probs = (torch.nn.functional.softmax(
+ torch.tensor([
+ logits[tokenizer("A").input_ids[-1]],
+ logits[tokenizer("B").input_ids[-1]],
+ logits[tokenizer("C").input_ids[-1]],
+ logits[tokenizer("D").input_ids[-1]],
+ ]).float(),
+ dim=0,
+ ).detach().cpu().numpy())
+ pred = {0: "A", 1: "B", 2: "C", 3: "D"}[np.argmax(probs)]
+
+ cor = pred == label
+ cors.append(cor)
+ all_probs.append(probs)
+
+ acc = np.mean(cors)
+ cors = np.array(cors)
+
+ all_probs = np.array(all_probs)
+ print("Average accuracy {:.3f} - {}".format(acc, subject))
+
+ return cors, acc, all_probs
+
+
+def main():
+ init_cfg = global_cfg.clone()
+ args = parse_args()
+
+ if args.cfg_file:
+ init_cfg.merge_from_file(args.cfg_file)
+ cfg_opt, client_cfg_opt = parse_client_cfg(args.opts)
+ init_cfg.merge_from_list(cfg_opt)
+
+ update_logger(init_cfg, clear_before_add=True)
+ setup_seed(init_cfg.seed)
+
+ # load your finetuned model (saved as xxx.ckpt)
+ # in yaml file federate.save_to
+ fschatbot = FSChatBot(init_cfg)
+ tokenizer = fschatbot.tokenizer
+ model = fschatbot.model
+ device = fschatbot.device
+
+ if not os.path.exists("data/mmlu"):
+ download_url("https://people.eecs.berkeley.edu/~hendrycks/data.tar",
+ init_cfg.data.root)
+ t = tarfile.open("data/data.tar", "r:")
+ os.makedirs("data/mmlu/")
+ t.extractall(path="data/mmlu/")
+ t.close()
+
+ data_dir = os.path.join(init_cfg.data.root, "mmlu/data")
+ eval_dir = "eval_result"
+
+ subjects = sorted([
+ f.split("_test.csv")[0]
+ for f in os.listdir(os.path.join(data_dir, "test")) if "_test.csv" in f
+ ])
+
+ if not os.path.exists(eval_dir):
+ os.makedirs(eval_dir)
+ if not os.path.exists(
+ os.path.join(eval_dir, "results_{}".format(
+ init_cfg.federate.save_to))):
+ os.makedirs(
+ os.path.join(eval_dir,
+ "results_{}".format(init_cfg.federate.save_to)))
+
+ all_cors = []
+ subcat_cors = {
+ subcat: []
+ for subcat_lists in subcategories.values() for subcat in subcat_lists
+ }
+ cat_cors = {cat: [] for cat in categories}
+
+ for subject in subjects:
+ dev_df = pd.read_csv(os.path.join(data_dir, "dev",
+ subject + "_dev.csv"),
+ header=None)[:5]
+ test_df = pd.read_csv(os.path.join(data_dir, "test",
+ subject + "_test.csv"),
+ header=None)
+
+ cors, acc, probs = eval(subject, model, tokenizer, dev_df, test_df,
+ device)
+ subcats = subcategories[subject]
+ for subcat in subcats:
+ subcat_cors[subcat].append(cors)
+ for key in categories.keys():
+ if subcat in categories[key]:
+ cat_cors[key].append(cors)
+ all_cors.append(cors)
+
+ test_df["{}_correct".format(init_cfg.federate.save_to)] = cors
+ for j in range(probs.shape[1]):
+ choice = choices[j]
+ test_df["{}_choice{}_probs".format(init_cfg.federate.save_to,
+ choice)] = probs[:, j]
+ test_df.to_csv(
+ os.path.join(eval_dir,
+ "results_{}".format(init_cfg.federate.save_to),
+ "{}.csv".format(subject)),
+ index=None,
+ )
+
+ results = {"subcategories": {}, "categories": {}}
+ for subcat in subcat_cors:
+ subcat_acc = np.mean(np.concatenate(subcat_cors[subcat]))
+ print("Average accuracy {:.3f} - {}".format(subcat_acc, subcat))
+
+ for cat in cat_cors:
+ cat_acc = np.mean(np.concatenate(cat_cors[cat]))
+ results["categories"][cat] = cat_acc
+ print("Average accuracy {:.3f} - {}".format(cat_acc, cat))
+ weighted_acc = np.mean(np.concatenate(all_cors))
+ results["weighted_accuracy"] = weighted_acc
+ print("Average accuracy: {:.3f}".format(weighted_acc))
+
+ results_file = os.path.join(
+ eval_dir, "accuracies_{}.json".format(
+ init_cfg.federate.save_to.replace("/", "_")))
+ with open(results_file, "w") as f:
+ json.dump(results, f)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/federatedscope/llm/misc/__init__.py b/federatedscope/llm/misc/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/federatedscope/llm/misc/federatedscope-torch2.0.Dockerfile b/federatedscope/llm/misc/federatedscope-torch2.0.Dockerfile
new file mode 100644
index 000000000..50515d6a2
--- /dev/null
+++ b/federatedscope/llm/misc/federatedscope-torch2.0.Dockerfile
@@ -0,0 +1,59 @@
+# The federatedscope image includes all runtime stuffs of federatedscope,
+# with customized miniconda and required packages installed.
+
+# based on the nvidia-docker
+# NOTE: please pre-install the NVIDIA drivers and `nvidia-docker2` in the host machine,
+# see details in https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html
+ARG ROOT_CONTAINER=nvidia/cuda:11.7.0-runtime-ubuntu20.04
+
+FROM $ROOT_CONTAINER
+
+# Fix: https://github.com/hadolint/hadolint/wiki/DL4006
+# Fix: https://github.com/koalaman/shellcheck/wiki/SC3014
+SHELL ["/bin/bash", "-o", "pipefail", "-c"]
+
+# shanghai zoneinfo
+ENV TZ=Asia/Shanghai
+RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
+
+# install basic tools
+RUN apt-get -y update \
+ && apt-get -y install curl git gcc g++ make openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev python-dev libmysqlclient-dev
+
+# install miniconda, in batch (silent) mode, does not edit PATH or .bashrc or .bash_profile
+RUN apt-get update -y \
+ && apt-get install -y wget
+RUN wget https://repo.anaconda.com/miniconda/Miniconda3-py39_23.1.0-1-Linux-x86_64.sh \
+ && bash Miniconda3-py39_23.1.0-1-Linux-x86_64.sh -b \
+ && rm Miniconda3-py39_23.1.0-1-Linux-x86_64.sh
+
+ENV PATH=/root/miniconda3/bin:${PATH}
+RUN source activate
+
+RUN conda update -y conda \
+ && conda config --add channels conda-forge
+
+# Install torch
+RUN conda install -y pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia \
+ && conda clean -a -y
+
+# Install FS-LLM
+RUN cd /root \
+ && git clone -b llm https://github.com/alibaba/FederatedScope.git \
+ && cd /root/FederatedScope \
+ && pip install -e .[llm] \
+ && pip cache purge
+
+# Prepare datas
+RUN mkdir /root/FederatedScope/data \
+ && cd /root/FederatedScope/data \
+ && wget https://raw.githubusercontent.com/databrickslabs/dolly/d000e3030970379aabbf6d291f50ffdd3b715b64/data/databricks-dolly-15k.jsonl \
+ && wget https://raw.githubusercontent.com/openai/grade-school-math/3101c7d5072418e28b9008a6636bde82a006892c/grade_school_math/data/train.jsonl -O gsm8k_train.jsonl \
+ && wget https://raw.githubusercontent.com/openai/grade-school-math/2909d34ef28520753df82a2234c357259d254aa8/grade_school_math/data/test.jsonl -O gsm8k_test.jsonl \
+ && wget https://raw.githubusercontent.com/sahil280114/codealpaca/d269da106a579a623a654529b3cb91b5dfa9c72f/data/rosetta_alpaca.json
+
+# Prepare Evaluation
+RUN cd /root/FederatedScope \
+ && git clone https://github.com/openai/human-eval \
+ && pip install -e human-eval \
+ && pip cache purge
\ No newline at end of file
diff --git a/federatedscope/llm/misc/fschat.py b/federatedscope/llm/misc/fschat.py
new file mode 100644
index 000000000..a1f7536c7
--- /dev/null
+++ b/federatedscope/llm/misc/fschat.py
@@ -0,0 +1,214 @@
+import sys
+import logging
+import torch
+import transformers
+
+transformers.logging.set_verbosity(40)
+
+from federatedscope.core.configs.config import global_cfg
+from federatedscope.core.cmd_args import parse_args, parse_client_cfg
+from federatedscope.llm.dataloader.dataloader import get_tokenizer
+from federatedscope.llm.model.model_builder import get_llm
+from federatedscope.llm.dataset.llm_dataset import PROMPT_DICT
+from federatedscope.core.auxiliaries.utils import setup_seed
+from federatedscope.core.auxiliaries.logging import update_logger
+
+logger = logging.getLogger(__name__)
+
+
+class FSChatBot(object):
+ """
+ A chatbot class that uses a language model for generating responses.
+
+ This class implements a chatbot that can interact with users using natural
+ language. It uses a pretrained language model as the backbone and can
+ optionally load a fine-tuned checkpoint from federated learning. It can
+ also use history and prompt templates to enhance the conversation quality.
+ It provides two methods for generating responses: predict and generate.
+
+ Attributes:
+ tokenizer: A transformers.PreTrainedTokenizer object that can
+ encode and decode text.
+ model: A transformers.PreTrainedModel object that can generate text.
+ device: A string representing the device to run the model on.
+ add_special_tokens: A boolean indicating whether to add special tokens
+ to the input and output texts.
+ max_history_len: An integer representing the maximum number of
+ previous turns to use as context.
+ max_len: An integer representing the maximum number of tokens to
+ generate for each response.
+ history: A list of lists of integers representing the tokenized input
+ and output texts of previous turns.
+ """
+ def __init__(self, config):
+ """
+ Initializes the chatbot with the given configuration.
+
+ Args:
+ config: A FS configuration object that contains various settings
+ for the chatbot.
+ """
+ model_name, model_hub = config.model.type.split('@')
+ self.tokenizer, _ = get_tokenizer(model_name, config.data.root,
+ config.llm.tok_len, model_hub)
+ self.model = get_llm(config)
+
+ self.device = f'cuda:{config.device}'
+ self.add_special_tokens = True
+
+ if config.llm.offsite_tuning.use:
+ from federatedscope.llm.offsite_tuning.utils import \
+ wrap_offsite_tuning_for_eval
+ self.model = wrap_offsite_tuning_for_eval(self.model, config)
+ else:
+ try:
+ ckpt = torch.load(config.federate.save_to, map_location='cpu')
+ if 'model' and 'cur_round' in ckpt:
+ self.model.load_state_dict(ckpt['model'])
+ else:
+ self.model.load_state_dict(ckpt)
+ except Exception as error:
+ print(f"{error}, will use raw model.")
+
+ if config.train.is_enable_half:
+ self.model.half()
+
+ self.model = self.model.to(self.device)
+ self.model = self.model.eval()
+ if torch.__version__ >= "2" and sys.platform != "win32":
+ self.model = torch.compile(self.model)
+
+ self.max_history_len = config.llm.chat.max_history_len
+ self.max_len = config.llm.chat.max_len
+ self.history = []
+
+ def _build_prompt(self, input_text):
+ """
+ Builds a prompt template for the input text.
+
+ Args:
+ input_text: A string representing the user's input text.
+
+ Returns:
+ A string representing the source text with a prompt template.
+ """
+ source = {'instruction': input_text}
+ return PROMPT_DICT['prompt_no_input'].format_map(source)
+
+ def predict(self, input_text, use_history=True, use_prompt=True):
+ """
+ Generates a response for the input text using the model.
+
+ Args:
+ input_text: A string representing the user's input text.
+ use_history: A boolean indicating whether to use previous turns as
+ context for generating the response. Default is True.
+ use_prompt: A boolean indicating whether to use a prompt
+ template for creating the source text. Default is True.
+
+ Returns:
+ A string representing the chatbot's response text.
+ """
+ if use_prompt:
+ input_text = self._build_prompt(input_text)
+ text_ids = self.tokenizer.encode(input_text, add_special_tokens=False)
+ self.history.append(text_ids)
+ input_ids = []
+ if use_history:
+ for history_ctx in self.history[-self.max_history_len:]:
+ input_ids.extend(history_ctx)
+ else:
+ input_ids.extend(text_ids)
+ input_ids = torch.tensor(input_ids).long()
+ input_ids = input_ids.unsqueeze(0).to(self.device)
+ response = self.model.generate(input_ids=input_ids,
+ max_new_tokens=self.max_len,
+ num_beams=4,
+ no_repeat_ngram_size=2,
+ early_stopping=True,
+ temperature=0.0)
+
+ self.history.append(response[0].tolist())
+ response_tokens = \
+ self.tokenizer.decode(response[0][input_ids.shape[1]:],
+ skip_special_tokens=True)
+ return response_tokens
+
+ @torch.no_grad()
+ def generate(self, input_text, generate_kwargs={}):
+ """
+ Generates a response for the input text using the model and
+ additional arguments.
+
+ Args:
+ input_text: A string representing the user's input text.
+ generate_kwargs: A dictionary of keyword arguments to pass to the
+ model's generate method. Default is an empty dictionary.
+
+ Returns:
+ A string or a list of strings representing the chatbot's response
+ text. If the generate_kwargs contains num_return_sequences > 1,
+ then a list of strings is returned. Otherwise, a single string is
+ returned.
+ """
+ input_text = self.tokenizer(
+ input_text,
+ padding=False,
+ add_special_tokens=True,
+ return_tensors="pt",
+ )
+ input_ids = input_text.input_ids.to(self.device)
+ attention_mask = input_text.attention_mask.to(self.device)
+
+ output_ids = self.model.generate(input_ids=input_ids,
+ attention_mask=attention_mask,
+ **generate_kwargs)
+ response = []
+ for i in range(output_ids.shape[0]):
+ response.append(
+ self.tokenizer.decode(output_ids[i][input_ids.shape[1]:],
+ skip_special_tokens=True,
+ ignore_tokenization_space=True))
+
+ if len(response) > 1:
+ return response
+ return response[0]
+
+ def clear(self):
+ """Clears the history of previous turns.
+
+ This method can be used to reset the chatbot's state and start a new
+ conversation.
+ """
+ self.history = []
+
+
+def main():
+ init_cfg = global_cfg.clone()
+ args = parse_args()
+ if args.cfg_file:
+ init_cfg.merge_from_file(args.cfg_file)
+ cfg_opt, client_cfg_opt = parse_client_cfg(args.opts)
+ init_cfg.merge_from_list(cfg_opt)
+
+ update_logger(init_cfg, clear_before_add=True)
+ setup_seed(init_cfg.seed)
+
+ chat_bot = FSChatBot(init_cfg)
+ welcome = "Welcome to FSChatBot," \
+ "`clear` to clear history," \
+ "`quit` to end chat."
+ print(welcome)
+ while True:
+ input_text = input("\nUser:")
+ if input_text.strip() == "quit":
+ break
+ if input_text.strip() == "clear":
+ chat_bot.clear()
+ print(welcome)
+ continue
+ print(f'\nFSBot: {chat_bot.predict(input_text)}')
+
+
+if __name__ == "__main__":
+ main()
diff --git a/federatedscope/llm/model/__init__.py b/federatedscope/llm/model/__init__.py
new file mode 100644
index 000000000..4c7796e93
--- /dev/null
+++ b/federatedscope/llm/model/__init__.py
@@ -0,0 +1,3 @@
+from federatedscope.llm.model.model_builder import get_llm
+
+__all__ = ['get_llm']
diff --git a/federatedscope/llm/model/adapter_builder.py b/federatedscope/llm/model/adapter_builder.py
new file mode 100644
index 000000000..d2b46ed63
--- /dev/null
+++ b/federatedscope/llm/model/adapter_builder.py
@@ -0,0 +1,299 @@
+import torch
+import torch.nn as nn
+from collections import OrderedDict
+
+
+def enable_adapter(model, package, adapter, **kwargs):
+ """
+ Enables an adapter for a given model and package.
+
+ Args:
+ model: A pre-trained model from HuggingFace Transformers library.
+ package: A string indicating the name of the package that provides
+ the adapter. Currently, only 'peft' and 'adapterhub' is supported.
+ adapter: A string indicating the name of the adapter to enable. The
+ available adapters depend on the package.
+ **kwargs: Additional keyword arguments that are passed to the
+ adapter configuration.
+
+ Returns:
+ A model object that has the adapter enabled.
+
+ Raises:
+ NotImplementedError: If the package or the adapter is not supported.
+ """
+ adapter = adapter.lower()
+ if package == 'peft':
+ """
+ PEFT: https://github.com/huggingface/peft
+ Support methods:
+ LoRA
+ Prefix Tuning
+ P-Tuning
+ Prompt Tuning
+ AdaLoRA
+ """
+ from peft import get_peft_model, TaskType
+ if adapter == 'lora':
+ from peft import LoraConfig
+ peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM, **kwargs)
+ model = get_peft_model(model, peft_config)
+ elif adapter == 'prefix':
+ from peft import PrefixTuningConfig
+ peft_config = PrefixTuningConfig(task_type=TaskType.CAUSAL_LM,
+ **kwargs)
+ model = get_peft_model(model, peft_config)
+ elif adapter == 'prompt':
+ from peft import PromptTuningConfig
+ peft_config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM,
+ **kwargs)
+ model = get_peft_model(model, peft_config)
+ elif adapter == 'p-tuning':
+ from peft import PromptEncoderConfig
+ peft_config = PromptEncoderConfig(task_type=TaskType.CAUSAL_LM,
+ **kwargs)
+ model = get_peft_model(model, peft_config)
+ else:
+ raise NotImplementedError
+ model.print_trainable_parameters()
+
+ elif package == 'adapterhub':
+ """
+ AdapterHub: https://docs.adapterhub.ml/model_overview.html
+ Support methods:
+ Bottleneck Adapters
+ Prefix Tuning
+ LoRA
+ Compacter
+ Adapter Fusion
+ Invertible Adapters
+ Parallel block
+ """
+ # TODO: After supporting adapterhub, we will move the following
+ # parameters in yaml file for users' convenient
+ if adapter == 'lora':
+ from transformers.adapters import LoRAConfig
+
+ config = LoRAConfig(r=8, alpha=16)
+ model.add_adapter("lora_adapter", config=config)
+ model.train_adapter(['lora_adapter'])
+ elif adapter == 'bottleneck':
+ from transformers.adapters import AdapterConfig
+
+ config = AdapterConfig(mh_adapter=True,
+ output_adapter=True,
+ reduction_factor=16,
+ non_linearity="relu")
+ model.add_adapter("bottleneck_adapter", config=config)
+ model.train_adapter(['bottleneck_adapter'])
+ elif adapter == 'lang':
+ from transformers.adapters import PfeifferInvConfig
+
+ config = PfeifferInvConfig()
+ model.add_adapter("lang_adapter", config=config)
+ model.train_adapter(['lang_adapter'])
+ elif adapter == 'prefix':
+ from transformers.adapters import PrefixTuningConfig
+
+ config = PrefixTuningConfig(flat=False, prefix_length=30)
+ model.add_adapter("prefix_tuning", config=config)
+ model.train_adapter(['prefix_tuning'])
+ elif adapter == 'compacter':
+ from transformers.adapters import CompacterConfig
+
+ config = CompacterConfig()
+ model.add_adapter("dummy", config=config)
+ model.train_adapter(['dummy'])
+ elif adapter == 'ia_3':
+ from transformers.adapters import IA3Config
+
+ config = IA3Config()
+ model.add_adapter("ia3_adapter", config=config)
+ model.train_adapter(['ia3_adapter'])
+ elif adapter == 'union':
+ from transformers.adapters import AdapterConfig, ConfigUnion
+
+ # TODO: configure these args in cfg
+ config = ConfigUnion(
+ AdapterConfig(mh_adapter=True,
+ output_adapter=False,
+ reduction_factor=16,
+ non_linearity="relu"),
+ AdapterConfig(mh_adapter=False,
+ output_adapter=True,
+ reduction_factor=2,
+ non_linearity="relu"),
+ )
+ model.add_adapter("union_adapter", config=config)
+ model.train_adapter(['union_adapter'])
+ elif adapter == 'mam':
+ from transformers.adapters import \
+ ConfigUnion, ParallelConfig, PrefixTuningConfig
+
+ config = ConfigUnion(
+ PrefixTuningConfig(bottleneck_size=800),
+ ParallelConfig(),
+ )
+ model.add_adapter("mam_adapter", config=config)
+ model.train_adapter(['mam_adapter'])
+ else:
+ raise NameError(
+ f"There is no adapter named {adapter} in {package}")
+ else:
+ raise NotImplementedError
+ return model
+
+
+class AdapterModel(nn.Module):
+ """
+ A wrapper class for a model that can use adapters for fine-tuning.
+
+ This class inherits from torch.nn.Module and implements a wrapper for a
+ model that can optionally use adapters for fine-tuning. Adapters are small
+ modules that can be inserted between the layers of a pretrained model and
+ trained on a specific task, while keeping the original parameters frozen.
+ This class can use different adapter packages and methods, such as PEFT
+ and LoRA. It also provides methods for saving and loading the model state
+ dict, as well as generating text using the model.
+
+ Attributes:
+ model: A torch.nn.Module object that represents the original or
+ adapted model.
+
+ """
+ def __init__(self, model, use_adapter=False, *args, **kwargs):
+ """
+ Initializes the wrapper with the given model and arguments.
+
+ Args:
+ model: A torch.nn.Module object that represents the original model.
+ use_adapter: A boolean indicating whether to use adapters for
+ fine-tuning. Default is False.
+ *args: Additional positional arguments to pass to the adapter
+ package or method.
+ **kwargs: Additional keyword arguments to pass to the adapter
+ package or method. These may include adapter_package,
+ adapter_method, etc.
+ """
+ super().__init__()
+
+ self.model = None
+ if use_adapter:
+ adapter_package = kwargs.pop('adapter_package', 'peft')
+ adapter_method = kwargs.pop('adapter_method', 'lora')
+
+ self.model = enable_adapter(model, adapter_package, adapter_method,
+ **kwargs)
+ else:
+ self.model = model
+
+ def forward(self, *args, **kwargs):
+ """
+ Calls the forward method of the wrapped model.
+
+ Args:
+ *args: Positional arguments to pass to the model's forward method.
+ **kwargs: Keyword arguments to pass to the model's forward method.
+
+ Returns:
+ The output of the model's forward method.
+ """
+ return self.model.forward(*args, **kwargs)
+
+ def generate(self, *args, **kwargs):
+ """
+ Calls the generate method of the wrapped model.
+
+ Args:
+ *args: Positional arguments to pass to the model's generate method.
+ **kwargs: Keyword arguments to pass to the model's generate method.
+
+ Returns:
+ The output of the model's generate method.
+ """
+ try:
+ res = self.model.generate(*args, **kwargs)
+ except RuntimeError as e:
+ # When does evaluation in HELM,
+ # half precision will cause RuntimeError,
+ # the following solves it
+ if 'do_sample' in kwargs.keys():
+ del kwargs['do_sample']
+ res = self.model.generate(*args, **kwargs)
+ else:
+ raise RuntimeError(e)
+ return res
+
+ def state_dict(self, return_trainable=True, *args, **kwargs):
+ """
+ Returns the state dict of the wrapped model.
+
+ Args:
+ return_trainable: A boolean indicating whether to return only the
+ trainable parameters of the model. Default is True.
+ *args: Additional positional arguments to pass to the model's
+ state_dict method.
+ **kwargs: Additional keyword arguments to pass to the model's
+ state_dict method.
+
+ Returns:
+ A dictionary containing the state dict of the model. If
+ return_trainable is True, only the parameters that require grad are
+ included. Otherwise, all parameters are included.
+ """
+ if return_trainable:
+ return self.get_trainable_state_dict()
+ else:
+ return self.model.state_dict(*args, **kwargs)
+
+ def load_state_dict(self, state_dict, strict=False):
+ """
+ Loads the state dict into the wrapped model.
+
+ Args:
+ state_dict: A dictionary containing the state dict to load into
+ the model.
+ strict: A boolean indicating whether to strictly enforce that the
+ keys in state_dict match the keys returned by this module’s
+ state_dict() function. Default is False.
+ """
+ return self.model.load_state_dict(state_dict, strict=False)
+
+ def get_trainable_state_dict(self):
+ """
+ Returns only the trainable parameters of the wrapped model.
+
+ This method can be used to get only the parameters that require grad,
+ such as adapters or task-specific layers.
+
+ Returns:
+ A dictionary containing the state dict of the trainable parameters
+ of the model.
+ """
+ grad_params = []
+ for name, param in self.model.named_parameters():
+ if param.requires_grad:
+ grad_params.append(name)
+ model_state_dict = self.model.state_dict()
+ new_state_dict = OrderedDict()
+ for k, v in model_state_dict.items():
+ if k in grad_params:
+ new_state_dict[k] = v
+ return new_state_dict
+
+ def save_model(self, path, state=0):
+ """
+ Saves the model state dict and the current round to a file.
+
+ Args:
+ path: A string representing the file path to save the model to.
+ state: An integer representing the current round of training or
+ evaluation. Default is 0.
+
+ """
+ ckpt = {'cur_round': state, 'model': self.model.state_dict()}
+ torch.save(ckpt, path)
+
+ # TODO: Fix `__getattr__`
+ # def __getattr__(self, item):
+ # return getattr(self.model, item)
diff --git a/federatedscope/llm/model/model_builder.py b/federatedscope/llm/model/model_builder.py
new file mode 100644
index 000000000..33fee958d
--- /dev/null
+++ b/federatedscope/llm/model/model_builder.py
@@ -0,0 +1,97 @@
+from federatedscope.llm.model.adapter_builder import AdapterModel
+import torch
+
+def get_model_from_huggingface(model_name, config):
+ """
+ Load a causal language model from HuggingFace transformers library.
+
+ Args:
+ model_name (str): The name of the pre-trained model to load.
+ config (Config): The configuration object that contains the model
+ parameters.
+
+ Returns:
+ AutoModelForCausalLM: A causal language model object.
+ """
+ from transformers import AutoModelForCausalLM
+ torch.backends.cuda.matmul.allow_tf32 = True
+ torch.backends.cudnn.allow_tf32 = True
+
+ kwargs = {}
+ if len(config.llm.cache.model):
+ kwargs['cache_dir'] = config.llm.cache.model
+
+ return AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, torch_dtype=torch.bfloat16, **kwargs)
+
+
+
+def get_model_from_modelscope(model_name, config):
+ """
+ Load a causal language model from ModelScope models library.
+
+ Args:
+ model_name (str): The name of the pre-trained model to load.
+ config (Config): The configuration object that contains the model
+ parameters.
+
+ Returns:
+ Model: A causal language model object.
+ """
+ from modelscope import AutoModelForCausalLM
+ torch.backends.cuda.matmul.allow_tf32 = True
+ torch.backends.cudnn.allow_tf32 = True
+
+ kwargs = {}
+ if len(config.llm.cache.model):
+ kwargs['cache_dir'] = config.llm.cache.model
+
+ return AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, torch_dtype=torch.bfloat16, **kwargs)
+
+
+def get_llm(config):
+ """
+ Get a causal language model based on the configuration.
+
+ Args:
+ config (Config): The configuration object that contains the model
+ parameters.
+
+ Returns:
+ AdapterModel: A causal language model object with optional adapter
+ layers.
+ """
+ from federatedscope.llm.dataloader import get_tokenizer
+
+ model_config = config.model
+ model_name, model_hub = model_config.type.split('@')
+ if model_hub == 'huggingface_llm':
+ model = get_model_from_huggingface(model_name=model_name,
+ config=config)
+ elif model_hub == 'modelscope_llm':
+ model = get_model_from_modelscope(model_name=model_name, config=config)
+ else:
+ raise NotImplementedError(f'Not support LLM {model_name} in'
+ f' {model_hub}.')
+
+ # Resize LLM model based on settings
+ tokenizer, num_new_tokens = \
+ get_tokenizer(model_name, config.data.root, config.llm.tok_len,
+ model_hub)
+ model.resize_token_embeddings(len(tokenizer))
+ if num_new_tokens > 0:
+ input_embeddings = model.get_input_embeddings().weight.data
+ output_embeddings = model.get_output_embeddings().weight.data
+
+ input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(
+ dim=0, keepdim=True)
+ output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(
+ dim=0, keepdim=True)
+
+ input_embeddings[-num_new_tokens:] = input_embeddings_avg
+ output_embeddings[-num_new_tokens:] = output_embeddings_avg
+
+ args = config.llm.adapter.args[0] if len(
+ config.llm.adapter.args[0]) > 0 else {}
+ model = AdapterModel(model, use_adapter=config.llm.adapter.use, **args)
+
+ return model
diff --git a/federatedscope/llm/offsite_tuning/__init__.py b/federatedscope/llm/offsite_tuning/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/federatedscope/llm/offsite_tuning/client.py b/federatedscope/llm/offsite_tuning/client.py
new file mode 100644
index 000000000..afe5f2f49
--- /dev/null
+++ b/federatedscope/llm/offsite_tuning/client.py
@@ -0,0 +1,64 @@
+import gc
+import logging
+
+from federatedscope.core.message import Message
+from federatedscope.core.workers.client import Client
+from federatedscope.core.auxiliaries.utils import b64deserializer
+from federatedscope.core.auxiliaries.trainer_builder import get_trainer
+
+logger = logging.getLogger(__name__)
+
+
+class OffsiteTuningClient(Client):
+ """
+ Client implementation of
+ "Offsite-Tuning: Transfer Learning without Full Model" paper
+ """
+ def __init__(self,
+ ID=-1,
+ server_id=None,
+ state=-1,
+ config=None,
+ data=None,
+ model=None,
+ device='cpu',
+ strategy=None,
+ *args,
+ **kwargs):
+ super(OffsiteTuningClient,
+ self).__init__(ID, server_id, state, config, data, model, device,
+ strategy, *args, **kwargs)
+ if self._cfg.federate.mode == 'standalone' and \
+ self._cfg.federate.share_local_model:
+ # self.model is emulator_and_adapter, so we do nothing
+ pass
+ else:
+ # Delete the stored client's model
+ delattr(self, '_model')
+ delattr(self, 'trainer')
+ gc.collect()
+ self.trainer = None
+
+ def _register_default_handlers(self):
+ super(OffsiteTuningClient, self)._register_default_handlers()
+ self.register_handlers('emulator_and_adapter',
+ self.callback_funcs_for_emulator_and_adapter,
+ [None])
+
+ def callback_funcs_for_emulator_and_adapter(self, message: Message):
+ if self._cfg.federate.mode == 'standalone' and \
+ self._cfg.federate.share_local_model:
+ logger.info(f'Client {self.ID}: `share_local_model` mode '
+ f'enabled, emulator and adapter built from FedRunner.')
+ else:
+ logger.info(f'Client {self.ID}: Emulator and adapter received.')
+ adapter_model = b64deserializer(message.content, tool='dill')
+
+ # Define new model upon received
+ self._model = adapter_model
+ self.trainer = get_trainer(model=adapter_model,
+ data=self.data,
+ device=self.device,
+ config=self._cfg,
+ is_attacker=self.is_attacker,
+ monitor=self._monitor)
diff --git a/federatedscope/llm/offsite_tuning/kd_trainer.py b/federatedscope/llm/offsite_tuning/kd_trainer.py
new file mode 100644
index 000000000..b5575a84b
--- /dev/null
+++ b/federatedscope/llm/offsite_tuning/kd_trainer.py
@@ -0,0 +1,94 @@
+import torch
+import logging
+from federatedscope.llm.trainer.trainer import LLMTrainer
+from federatedscope.core.trainers.context import CtxVar
+from federatedscope.core.trainers.enums import LIFECYCLE
+
+logger = logging.getLogger(__name__)
+
+
+def get_kd_loss(raw_model, adap_model):
+ """
+ This function is borrowed from offsite-tuning:
+ https://github.com/mit-han-lab/offsite-tuning/blob/main/offsite_tuning
+ /utils.py
+ """
+ kwargs = adap_model.student_l.input_kwargs
+ args = adap_model.student_l.input_args
+ output_teacher = args[0]
+ args = list(args[1:])
+ args = tuple(args)
+
+ with torch.no_grad():
+ raw_model.teacher.eval()
+ for teacher_layer in raw_model.teacher:
+ output_teacher = teacher_layer(output_teacher, *args, **kwargs)
+ if isinstance(output_teacher, tuple):
+ output_teacher = output_teacher[0]
+
+ output_student = adap_model.student_r.cached_output.float()
+ output_teacher = output_teacher.float()
+
+ std = output_teacher.pow(2).mean().sqrt()
+ kd_loss = (output_teacher - output_student).div(std).pow(2).mean()
+ return kd_loss
+
+
+class KDTrainer(LLMTrainer):
+ def __init__(self,
+ raw_model,
+ adapter_model,
+ data,
+ device,
+ config,
+ only_for_eval=False,
+ monitor=None):
+ super(KDTrainer, self).__init__(adapter_model, data, device, config,
+ only_for_eval, monitor)
+ self.ctx.raw_model = raw_model.to(device)
+ self.lm_loss_weight = \
+ config.llm.offsite_tuning.emu_align.train.lm_loss_weight
+ self.kd_loss_weight = \
+ config.llm.offsite_tuning.emu_align.train.kd_loss_weight
+
+ def _hook_on_fit_start_numerical_precision(self, ctx):
+ super(KDTrainer, self)._hook_on_fit_start_numerical_precision(ctx)
+ if self.cfg.train.is_enable_half:
+ ctx.raw_model = ctx.raw_model.half()
+
+ def train(self, target_data_split_name="train", hooks_set=None):
+ num_samples, model_para_all, eval_metrics = \
+ super(KDTrainer, self).train(target_data_split_name, hooks_set)
+ logger.info("Finish alignment, move raw model to cpu.")
+ self.ctx.raw_model.cpu()
+ return num_samples, model_para_all, eval_metrics
+
+ def _hook_on_batch_forward(self, ctx):
+ input_ids = ctx.data_batch['input_ids'].to(ctx.device)
+ labels = ctx.data_batch['labels'].to(ctx.device)
+ attention_mask = ctx.data_batch['attention_mask'].to(ctx.device)
+
+ outputs = ctx.model(input_ids=input_ids,
+ labels=labels,
+ attention_mask=attention_mask)
+
+ logits = outputs.logits
+ kd_loss = self.kd_loss_weight * get_kd_loss(ctx.raw_model, ctx.model)
+ lm_loss = self.lm_loss_weight * outputs.loss
+ loss = kd_loss + lm_loss
+
+ if torch.isnan(loss):
+ ctx.skip_this_batch = CtxVar(True, LIFECYCLE.BATCH)
+ logger.warning('Skip the batch due to the loss is NaN, '
+ 'it may be caused by exceeding the precision or '
+ 'invalid labels.')
+ else:
+ ctx.skip_this_batch = CtxVar(False, LIFECYCLE.BATCH)
+
+ ctx.y_true = CtxVar(labels, LIFECYCLE.BATCH)
+ ctx.y_prob = CtxVar(logits, LIFECYCLE.BATCH)
+
+ ctx.loss_batch = CtxVar(loss, LIFECYCLE.BATCH)
+ ctx.batch_size = CtxVar(len(labels), LIFECYCLE.BATCH)
+
+ logger.info(f'lm_loss: {lm_loss.item()}, kd loss: {kd_loss.item()}')
diff --git a/federatedscope/llm/offsite_tuning/server.py b/federatedscope/llm/offsite_tuning/server.py
new file mode 100644
index 000000000..ad0a0dd8f
--- /dev/null
+++ b/federatedscope/llm/offsite_tuning/server.py
@@ -0,0 +1,180 @@
+import os
+import logging
+
+from federatedscope.core.message import Message
+from federatedscope.core.auxiliaries.utils import b64serializer, \
+ merge_dict_of_results
+from federatedscope.core.monitors.monitor import Monitor
+from federatedscope.core.auxiliaries.trainer_builder import get_trainer
+from federatedscope.core.workers.server import Server
+
+from federatedscope.llm.offsite_tuning.utils import \
+ generate_emulator_and_adapter, align_student_with_teacher
+
+logger = logging.getLogger(__name__)
+
+
+class OffsiteTuningServer(Server):
+ """
+ Server implementation of
+ "Offsite-Tuning: Transfer Learning without Full Model" paper
+ """
+ def __init__(self,
+ ID=-1,
+ state=0,
+ config=None,
+ data=None,
+ model=None,
+ client_num=5,
+ total_round_num=10,
+ device='cpu',
+ strategy=None,
+ **kwargs):
+ compress_strategy = config.llm.offsite_tuning.strategy
+ emulator_l = config.llm.offsite_tuning.emu_l
+ emulator_r = config.llm.offsite_tuning.emu_r
+ offsite_tuning_kwargs = config.llm.offsite_tuning.kwargs[0]
+ logger.info('Server: Generating emulator and adapter...')
+ adap_model = \
+ generate_emulator_and_adapter(model,
+ strategy=compress_strategy,
+ emulator_l=emulator_l,
+ emulator_r=emulator_r,
+ **offsite_tuning_kwargs)
+ # Emulator alignment
+ if config.llm.offsite_tuning.emu_align.use:
+ adap_model = align_student_with_teacher(raw_model=model,
+ adap_model=adap_model,
+ cfg=config,
+ device=device,
+ monitor=Monitor(
+ config,
+ monitored_object=self))
+ if config.llm.offsite_tuning.emu_align.exit_after_align:
+ os._exit(0)
+ # No need for this attr
+ if hasattr(adap_model, 'teacher'):
+ del adap_model.teacher
+
+ self.raw_model = model
+ super(OffsiteTuningServer,
+ self).__init__(ID, state, config, data, adap_model, client_num,
+ total_round_num, device, strategy, **kwargs)
+ if self._cfg.llm.offsite_tuning.eval_type == 'full':
+ self.raw_model_trainer = get_trainer(model=self.raw_model,
+ data=self.data,
+ device=self.device,
+ config=self._cfg,
+ only_for_eval=True,
+ monitor=Monitor(
+ self._cfg,
+ monitored_object=self))
+
+ def trigger_for_feat_engr(self,
+ trigger_train_func,
+ kwargs_for_trigger_train_func={}):
+ logger.info('Server: Converting emulator and adapter...')
+ if self._cfg.federate.mode == 'standalone' and \
+ self._cfg.federate.share_local_model:
+ logger.info('Server: `share_local_model` mode enabled, '
+ 'emulator_and_adapter is built in FedRunner.')
+ self.comm_manager.send(
+ Message(msg_type='emulator_and_adapter',
+ sender=self.ID,
+ receiver=list(
+ self.comm_manager.get_neighbors().keys()),
+ timestamp=self.cur_timestamp,
+ content=None))
+ else:
+ emulator_and_adapter = b64serializer(self._model, tool='dill')
+
+ self.comm_manager.send(
+ Message(msg_type='emulator_and_adapter',
+ sender=self.ID,
+ receiver=list(
+ self.comm_manager.get_neighbors().keys()),
+ timestamp=self.cur_timestamp,
+ content=emulator_and_adapter))
+
+ trigger_train_func(**kwargs_for_trigger_train_func)
+
+ def eval(self):
+ # Update the raw model with the new adapters
+ if self._cfg.llm.offsite_tuning.eval_type == 'full':
+ self.model.to('cpu')
+ new_raw_model_state_dict = self.raw_model.state_dict()
+ for key, value in zip(self.raw_model.state_dict().keys(),
+ self.model.state_dict().values()):
+ new_raw_model_state_dict[key] = value
+ self.raw_model_trainer.update(new_raw_model_state_dict,
+ strict=False)
+ # make the evaluation on raw model at the server first
+ raw_metrics = {}
+ for split in self._cfg.eval.split:
+ metrics = self.raw_model_trainer.evaluate(
+ target_data_split_name=split)
+ for key, value in metrics.items():
+ raw_metrics['plugin.' + key] = value
+ # Move to cpu
+ self.raw_model.to('cpu')
+
+ if self._cfg.federate.make_global_eval:
+ # By default, the evaluation is conducted one-by-one for all
+ # internal models;
+ # for other cases such as ensemble, override the eval function
+ for i in range(self.model_num):
+ trainer = self.trainers[i]
+ # Preform evaluation for emulator at server
+ metrics = {}
+ for split in self._cfg.eval.split:
+ eval_metrics = trainer.evaluate(
+ target_data_split_name=split)
+ for key, value in eval_metrics.items():
+ metrics['emulator.' + key] = value
+ metrics.update(**raw_metrics)
+ formatted_eval_res = self._monitor.format_eval_res(
+ metrics,
+ rnd=self.state,
+ role='Server #',
+ forms=self._cfg.eval.report,
+ return_raw=self._cfg.federate.make_global_eval)
+ self._monitor.update_best_result(
+ self.best_results,
+ formatted_eval_res['Results_raw'],
+ results_type="server_global_eval")
+ self.history_results = merge_dict_of_results(
+ self.history_results, formatted_eval_res)
+ self._monitor.save_formatted_results(formatted_eval_res)
+ logger.info(formatted_eval_res)
+ self.check_and_save()
+ else:
+ super().eval()
+ if self._cfg.llm.offsite_tuning.eval_type == 'full':
+ self.raw_metrics = raw_metrics
+
+ def callback_funcs_for_metrics(self, message: Message):
+ """
+ The handling function for receiving the evaluation results, \
+ which triggers ``check_and_move_on`` (perform aggregation when \
+ enough feedback has been received).
+
+ Arguments:
+ message: The received message
+ """
+
+ rnd = message.state
+ sender = message.sender
+ content = message.content
+
+ if rnd not in self.msg_buffer['eval'].keys():
+ self.msg_buffer['eval'][rnd] = dict()
+
+ # The content received from the clients is the result of emulator
+ self.msg_buffer['eval'][rnd][sender] = {
+ 'emulator.' + key: value
+ for key, value in content.items()
+ }
+ if self._cfg.llm.offsite_tuning.eval_type == 'full':
+ self.msg_buffer['eval'][rnd][sender].update(**self.raw_metrics)
+
+ return self.check_and_move_on(check_eval_result=True)
diff --git a/federatedscope/llm/offsite_tuning/utils.py b/federatedscope/llm/offsite_tuning/utils.py
new file mode 100644
index 000000000..05301e456
--- /dev/null
+++ b/federatedscope/llm/offsite_tuning/utils.py
@@ -0,0 +1,433 @@
+import gc
+import os
+import copy
+import logging
+import torch
+import torch.nn as nn
+
+from transformers import (OPTForCausalLM, GPT2LMHeadModel, BloomForCausalLM,
+ LlamaForCausalLM)
+from federatedscope.llm.model.adapter_builder import AdapterModel
+from federatedscope.llm.offsite_tuning.kd_trainer import KDTrainer
+from federatedscope.core.auxiliaries.data_builder import get_data
+
+logger = logging.getLogger(__name__)
+
+
+def add_prologue(module, prologue):
+ """
+ This function is borrowed from offsite-tuning:
+ https://github.com/mit-han-lab/offsite-tuning/blob/main/offsite_tuning
+ /utils.py
+ """
+ module.old_forward = module.forward
+ module.prologue = prologue
+
+ def new_forward(self):
+ def lambda_forward(*args, **kwargs):
+ self.input_args = args
+ self.input_kwargs = kwargs
+ if self.prologue is not None:
+ x = self.prologue(args[0])
+ else:
+ x = args[0]
+ args = (x, ) + args[1:]
+ return self.old_forward(*args, **kwargs)
+
+ return lambda_forward
+
+ module.forward = new_forward(module)
+ return module
+
+
+def add_epilogue(module, epilogue):
+ """
+ This function is borrowed from offsite-tuning:
+ https://github.com/mit-han-lab/offsite-tuning/blob/main/offsite_tuning
+ /utils.py
+ """
+ module.old_forward = module.forward
+ module.epilogue = epilogue
+
+ def new_forward(self):
+ def lambda_forward(*args, **kwargs):
+ output = self.old_forward(*args, **kwargs)
+ if isinstance(output, tuple):
+ x = output[0]
+ else:
+ x = output
+
+ if self.epilogue is not None:
+ x = self.epilogue(x)
+
+ if isinstance(output, tuple):
+ output = (x, ) + output[1:]
+ else:
+ output = x
+
+ self.cached_output = x
+ return output
+
+ return lambda_forward
+
+ module.forward = new_forward(module)
+ return module
+
+
+def get_layers(adapter_model):
+ """
+ Modified from the official implementation:
+ https://github.com/mit-han-lab/offsite-tuning/tree/main
+ """
+ if isinstance(adapter_model.model, OPTForCausalLM):
+ layers = adapter_model.model.model.decoder.layers
+ elif isinstance(adapter_model.model, GPT2LMHeadModel):
+ layers = adapter_model.model.transformer.h
+ elif isinstance(adapter_model.model, BloomForCausalLM):
+ layers = adapter_model.model.transformer.h
+ elif isinstance(adapter_model.model, LlamaForCausalLM):
+ layers = adapter_model.model.model.layers
+ else:
+ # TODO: support more LLM
+ logger.warning(f'Model {type(adapter_model.model)} not support, '
+ f'use default setting.')
+ layers = adapter_model.model.transformer.h
+ return layers
+
+
+def set_layers(adapter_model, layers, emu_l=0, emu_r=-1):
+ """
+ Set the layers of the adapter model based on the model type and the
+ emulator range.
+
+ Args:
+ adapter_model (AdapterModel): The adapter model object that contains
+ the causal language model and the adapter layers.
+ layers (nn.ModuleList): The list of layers to be assigned to the
+ adapter model.
+ emu_l (int): The left index of the emulator range. Default to 0.
+ emu_r (int): The right index of the emulator range. Default to -1.
+
+ Returns:
+ AdapterModel: The adapter model object with the updated layers.
+ """
+ if isinstance(adapter_model.model, OPTForCausalLM):
+ adapter_model.model.model.decoder.layers = layers
+ elif isinstance(adapter_model.model, GPT2LMHeadModel):
+ adapter_model.model.transformer.h = layers
+ elif isinstance(adapter_model.model, BloomForCausalLM):
+ adapter_model.model.transformer.h = layers
+ elif isinstance(adapter_model.model, LlamaForCausalLM):
+ adapter_model.model.model.layers = layers
+ else:
+ # TODO: support more LLM
+ logger.warning(f'Model {type(adapter_model.model)} not support, '
+ f'use default setting.')
+ adapter_model.model.transformer.h = layers
+ adapter_model.student = layers[emu_l:emu_r]
+ adapter_model.adapter = layers[:emu_l] + layers[emu_r:]
+ add_prologue(adapter_model.student[0], None)
+ add_epilogue(adapter_model.student[-1], None)
+ adapter_model.student_l = adapter_model.student[0]
+ adapter_model.student_r = adapter_model.student[-1]
+ return adapter_model
+
+
+def model_drop_layer(layers, drop_ratio=0.5, **kwargs):
+ """
+ Drop layers from a list of layers based on a drop ratio.
+
+ Args:
+ layers (nn.ModuleList): The list of layers to be dropped.
+ drop_ratio (float): The ratio of layers to be dropped. Default to 0.5.
+ **kwargs: Additional keyword arguments.
+
+ Returns:
+ nn.ModuleList: A new list of layers with some layers dropped.
+ """
+ new_model = nn.ModuleList()
+ num_new_layers = round(len(layers) * (1 - drop_ratio))
+
+ stride = (len(layers) - 1) / (num_new_layers - 1)
+
+ for i in range(num_new_layers):
+ idx = int(i * stride)
+ logger.info(f"Adding layer {idx} to emulator.")
+ new_model.append(layers[idx])
+
+ return new_model
+
+
+def model_pruning(model, ratio=0.5, **kwargs):
+ raise NotImplementedError
+
+
+def model_quantization(model, bits, **kwargs):
+ raise NotImplementedError
+
+
+def model_distillation(model, **kwargs):
+ raise NotImplementedError
+
+
+COMP_FUNC_MAPPING = {
+ 'drop_layer': model_drop_layer,
+ 'pruning': model_pruning,
+ 'quantization': model_quantization,
+ 'distillation': model_distillation
+}
+
+
+def generate_emulator_and_adapter(model: AdapterModel,
+ strategy='drop_layer',
+ emulator_l=1,
+ emulator_r=1000,
+ **kwargs):
+ layers = get_layers(model)
+ l, r = max(emulator_l, 1), min(emulator_r, len(layers) - 1)
+
+ # Set the to-compress part untrainable
+ for layer in layers[l:r]:
+ for param in layer.parameters():
+ param.data = param.data.float()
+ param.requires_grad = False
+ # Set teacher model
+ model.teacher = layers[l:r] # Ref for old model
+
+ emulator = COMP_FUNC_MAPPING[strategy](layers[l:r], **kwargs)
+
+ emulator_and_adapter = nn.ModuleList()
+
+ # Adapter before Emulator
+ for idx in range(l):
+ emulator_and_adapter.append(layers[idx])
+ emu_l = l
+
+ # Emulator
+ for idx in range(len(emulator)):
+ emulator_and_adapter.append(emulator[idx])
+ emu_r = emu_l + len(emulator)
+
+ # Adapter after Emulator
+ for idx in range(r, len(layers)):
+ emulator_and_adapter.append(layers[idx])
+
+ # Need keep raw model when kd applied
+ new_model = copy.deepcopy(model)
+ new_emulator_and_adapter = copy.deepcopy(emulator_and_adapter)
+ # Set student model
+ new_model = set_layers(new_model, new_emulator_and_adapter, emu_l, emu_r)
+
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ return new_model
+
+
+def convert_layers_train_state(layers, is_trainable=True):
+ """
+ Convert the trainability state of a list of layers.
+
+ Args:
+ layers (nn.ModuleList): The list of layers to be converted.
+ is_trainable (bool): The flag to indicate whether the layers should
+ be trainable or not. Default to True.
+
+ Returns:
+ None: This function does not return anything, but modifies the
+ layers in-place.
+ """
+ if is_trainable:
+ for layer in layers:
+ for param in layer.parameters():
+ param.requires_grad = True
+ else:
+ for layer in layers:
+ for param in layer.parameters():
+ param.requires_grad = False
+
+
+def align_student_with_teacher(raw_model, adap_model, cfg, device, monitor):
+ """
+ Align the student part of the adapter model with the teacher part using
+ knowledge distillation on a held-out dataset.
+
+ Args:
+ raw_model (AdapterModel): The original adapter model object that
+ contains the causal language model and the adapter layers.
+ adap_model (AdapterModel): The compressed adapter model object that
+ contains the emulator and the adapter layers.
+ cfg (Config): The configuration object that contains the alignment
+ parameters.
+ device (torch.device): The device to run the alignment on.
+ monitor (Monitor): The monitor object to track the FL progress.
+
+ Returns:
+ AdapterModel: The aligned adapter model object with the updated
+ emulator and adapter layers.
+ """
+ def build_cfg_for_alignment(config):
+ new_cfg = copy.deepcopy(config)
+ new_cfg.defrost()
+
+ # Overwrite `config.train` with
+ # `config.llm.offsite_tuning.emu_align.train`
+ for key, value in \
+ new_cfg.llm.offsite_tuning.emu_align.train.optimizer.items():
+ if key.startswith('__'):
+ continue
+ setattr(new_cfg, f'train.optimizer.{key}', value)
+ new_cfg.train.local_update_steps = \
+ config.llm.offsite_tuning.emu_align.train.local_update_steps
+ new_cfg.train.batch_or_epoch = \
+ config.llm.offsite_tuning.emu_align.train.batch_or_epoch
+
+ # Overwrite `config.data` with
+ # `config.llm.offsite_tuning.emu_align.data`
+ for key, value in \
+ new_cfg.llm.offsite_tuning.emu_align.data.items():
+ if key.startswith('__'):
+ continue
+ setattr(new_cfg, f'data.{key}', value)
+ # Used for data translator
+ new_cfg.federate.client_num = 1
+
+ # TODO: might generate extra cfg file, delete
+ new_cfg.freeze()
+ return new_cfg
+
+ does_train_emulator = True
+ if cfg.llm.offsite_tuning.emu_align.restore_from != '':
+ try:
+ if not os.path.exists(
+ cfg.llm.offsite_tuning.emu_align.restore_from):
+ logger.warning(
+ f'Invalid `emu_align.restore_from`:'
+ f' {cfg.llm.offsite_tuning.emu_align.restore_from}.')
+ else:
+ assert adap_model is not None
+ ckpt = torch.load(
+ cfg.llm.offsite_tuning.emu_align.restore_from,
+ map_location='cpu')
+ adap_model.load_state_dict(ckpt['model'], strict=False)
+ logger.info("Restored the adapter and emulator from ckpt")
+ logger.warning(
+ "Please make sure the dtype of model keep the same.")
+ # Make student un-trainable
+ convert_layers_train_state(adap_model.student,
+ is_trainable=False)
+ does_train_emulator = False
+ except Exception as error:
+ logger.error(error)
+
+ # Case1: Load ckpt, so we do not need to train student
+ if not does_train_emulator:
+ return adap_model
+
+ # Case2: Restore fail or not assigned, start to train student
+ new_cfg = build_cfg_for_alignment(cfg)
+
+ # Make adapter un-trainable
+ convert_layers_train_state(adap_model.adapter, is_trainable=False)
+
+ # Make student trainable
+ convert_layers_train_state(adap_model.student, is_trainable=True)
+
+ # Loading held-out data
+ logger.info('Loading held-out dataset for alignment...')
+ data, modified_cfg = get_data(new_cfg.clone())
+ new_cfg.merge_from_other_cfg(modified_cfg)
+
+ # Create `KDTrainer` and train
+ kd_trainer = KDTrainer(raw_model,
+ adap_model,
+ data[1],
+ device,
+ new_cfg,
+ only_for_eval=False,
+ monitor=monitor)
+ logger.info('Start to align student model with teacher model...')
+ kd_trainer.train()
+ logger.info('Alignment finished!')
+
+ # Save aligned model
+ del adap_model.teacher
+ adap_model.save_model(cfg.llm.offsite_tuning.emu_align.save_to)
+
+ # Make adapter trainable
+ convert_layers_train_state(adap_model.adapter, is_trainable=True)
+
+ # Make student un-trainable
+ convert_layers_train_state(adap_model.student, is_trainable=False)
+
+ return adap_model
+
+
+def wrap_offsite_tuning_for_eval(model, config):
+ """
+ Wrap the offsite tuning process for evaluation.
+
+ Args:
+ model (AdapterModel): The original adapter model object that
+ contains the causal language model and the adapter layers.
+ config (Config): The configuration object that contains the
+ offsite-tuning parameters.
+
+ Returns:
+ AdapterModel or nn.Module: The offsite-tuned model object that
+ contains the emulator and the adapter layers, or the original model
+ object with the adapter layers updated.
+ """
+ logger.info('===============use offsite tuning===============')
+ # We use offsite-tuning in this experiment
+ # Use adapter model instead
+ compress_strategy = config.llm.offsite_tuning.strategy
+ emulator_l = config.llm.offsite_tuning.emu_l
+ emulator_r = config.llm.offsite_tuning.emu_r
+ offsite_tuning_kwargs = config.llm.offsite_tuning.kwargs[0]
+ adap_model = \
+ generate_emulator_and_adapter(model,
+ strategy=compress_strategy,
+ emulator_l=emulator_l,
+ emulator_r=emulator_r,
+ **offsite_tuning_kwargs)
+ # Load kd model if ckpt exits
+ if config.llm.offsite_tuning.emu_align.use and \
+ config.llm.offsite_tuning.eval_type == 'emu':
+ if config.llm.offsite_tuning.emu_align.restore_from != '':
+ try:
+ ckpt = torch.load(
+ config.llm.offsite_tuning.emu_align.restore_from,
+ map_location='cpu',
+ )
+ adap_model.load_state_dict(ckpt['model'], strict=False)
+ logger.info("Restored the adapter and emulator from ckpt")
+ except Exception as error:
+ logger.warning(error)
+
+ # Load ckpt for eval
+ try:
+ ckpt = torch.load(config.federate.save_to, map_location='cpu')
+ if 'model' and 'cur_round' in ckpt:
+ adap_model.load_state_dict(ckpt['model'])
+ else:
+ adap_model.load_state_dict(ckpt)
+ except Exception as error:
+ logger.warning(f"{error}, will use raw model.")
+
+ if config.llm.offsite_tuning.eval_type == 'emu':
+ model = adap_model
+ del model.teacher
+ elif config.llm.offsite_tuning.eval_type == 'full':
+ # Raw model load adapter from adapter_and_emulator
+ new_model_state_dict = model.state_dict()
+ for key, value in zip(model.state_dict().keys(),
+ adap_model.state_dict().values()):
+ new_model_state_dict[key] = value
+ model.load_state_dict(new_model_state_dict, strict=False)
+ del adap_model
+ else:
+ raise NotImplementedError(
+ '`config.llm.offsite_tuning.eval_type` should be chosen from '
+ '`["emu", "full"]`.')
+ return model
diff --git a/federatedscope/llm/trainer/__init__.py b/federatedscope/llm/trainer/__init__.py
new file mode 100644
index 000000000..c0b31382d
--- /dev/null
+++ b/federatedscope/llm/trainer/__init__.py
@@ -0,0 +1,8 @@
+from os.path import dirname, basename, isfile, join
+import glob
+
+modules = glob.glob(join(dirname(__file__), "*.py"))
+__all__ = [
+ basename(f)[:-3] for f in modules
+ if isfile(f) and not f.endswith('__init__.py')
+]
diff --git a/federatedscope/llm/trainer/trainer.py b/federatedscope/llm/trainer/trainer.py
new file mode 100644
index 000000000..0470f80d7
--- /dev/null
+++ b/federatedscope/llm/trainer/trainer.py
@@ -0,0 +1,224 @@
+import torch
+import logging
+try:
+ import deepspeed
+ from deepspeed import DeepSpeedEngine
+except:
+ deepspeed = None
+ DeepSpeedEngine = None
+from federatedscope.register import register_trainer
+from federatedscope.core.trainers import GeneralTorchTrainer
+from federatedscope.core.trainers.context import CtxVar
+from federatedscope.core.trainers.enums import MODE, LIFECYCLE
+from federatedscope.core.monitors.monitor import Monitor
+from federatedscope.core.auxiliaries.optimizer_builder import get_optimizer
+from federatedscope.core.auxiliaries.scheduler_builder import get_scheduler
+from federatedscope.llm.model.adapter_builder import AdapterModel
+
+logger = logging.getLogger(__name__)
+
+
+class LLMTrainer(GeneralTorchTrainer):
+ def _hook_on_fit_start_numerical_precision(self, ctx):
+ if self.cfg.train.is_enable_half:
+ if not ctx.cfg.llm.deepspeed.use:
+ ctx.model = ctx.model.half()
+
+ def _hook_on_fit_start_init(self, ctx):
+ if ctx.cfg.llm.deepspeed.use:
+ # Enable deepspeed
+ # TODO: save ctx.optimizer and ctx.scheduler
+ # TODO: should clients share the same `ctx.model_engine`?
+ assert deepspeed is not None, "Please install deepspeed."
+ if not hasattr(ctx, 'model_engine'):
+ ctx.model_engine, ctx.optimizer, _, ctx.scheduler = \
+ deepspeed.initialize(
+ config=ctx.cfg.llm.deepspeed.ds_config,
+ model=ctx.model,
+ model_parameters=filter(lambda p: p.requires_grad,
+ ctx.model.parameters()),
+ )
+ # Enable all cards from 0
+ ctx.device = ctx.model_engine.local_rank
+ if ctx.cfg.train.is_enable_half:
+ ctx.fp16 = ctx.model_engine.fp16_enabled()
+ else:
+ # prepare model and optimizer
+ ctx.model.to(ctx.device)
+ if ctx.cur_mode in [MODE.TRAIN, MODE.FINETUNE]:
+ # Initialize optimizer here to avoid the reuse of optimizers
+ # across different routines
+ ctx.optimizer = get_optimizer(
+ ctx.model, **ctx.cfg[ctx.cur_mode].optimizer)
+ ctx.scheduler = get_scheduler(
+ ctx.optimizer, **ctx.cfg[ctx.cur_mode].scheduler)
+
+ # prepare statistics
+ ctx.loss_batch_total = CtxVar(0., LIFECYCLE.ROUTINE)
+ ctx.loss_regular_total = CtxVar(0., LIFECYCLE.ROUTINE)
+ ctx.num_samples = CtxVar(0, LIFECYCLE.ROUTINE)
+ ctx.ys_true = CtxVar([], LIFECYCLE.ROUTINE)
+ ctx.ys_prob = CtxVar([], LIFECYCLE.ROUTINE)
+
+ def _hook_on_batch_forward(self, ctx):
+ input_ids = ctx.data_batch['input_ids'].to(ctx.device)
+ labels = ctx.data_batch['labels'].to(ctx.device)
+ attention_mask = ctx.data_batch['attention_mask'].to(ctx.device)
+
+ if ctx.cfg.llm.deepspeed.use:
+ outputs = ctx.model_engine(input_ids=input_ids,
+ labels=labels,
+ attention_mask=attention_mask)
+ else:
+ outputs = ctx.model(input_ids=input_ids,
+ labels=labels,
+ attention_mask=attention_mask)
+
+ logits = outputs.logits
+ loss = outputs.loss
+
+ if torch.isnan(loss):
+ ctx.skip_this_batch = CtxVar(True, LIFECYCLE.BATCH)
+ logger.warning('Skip the batch due to the loss is NaN, '
+ 'it may be caused by exceeding the precision or '
+ 'invalid labels.')
+ else:
+ ctx.skip_this_batch = CtxVar(False, LIFECYCLE.BATCH)
+
+ ctx.y_true = CtxVar(labels, LIFECYCLE.BATCH)
+ ctx.y_prob = CtxVar(logits, LIFECYCLE.BATCH)
+
+ ctx.loss_batch = CtxVar(loss, LIFECYCLE.BATCH)
+ ctx.batch_size = CtxVar(len(labels), LIFECYCLE.BATCH)
+
+ def _hook_on_batch_backward(self, ctx):
+ if ctx.skip_this_batch:
+ return
+
+ if ctx.cfg.llm.deepspeed.use:
+ ctx.model_engine.backward(ctx.loss_task)
+ ctx.model_engine.step()
+ else:
+ ctx.optimizer.zero_grad()
+ ctx.loss_task.backward()
+
+ if ctx.grad_clip > 0:
+ torch.nn.utils.clip_grad_norm_(ctx.model.parameters(),
+ ctx.grad_clip)
+
+ ctx.optimizer.step()
+ if ctx.scheduler is not None:
+ ctx.scheduler.step()
+
+ def _hook_on_batch_end(self, ctx):
+ if ctx.skip_this_batch:
+ if ctx.cfg.llm.retry_on_nan_loss:
+ # Retry with new data in train and finetune
+ if ctx.cur_mode == MODE.TRAIN:
+ self._run_batch(self.hooks_in_train, run_step=1)
+ elif ctx.cur_mode == MODE.FINETUNE:
+ self._run_batch(self.hooks_in_ft, run_step=1)
+ return
+
+ ctx.num_samples += ctx.batch_size
+ ctx.loss_batch_total += ctx.loss_batch.item() * ctx.batch_size
+ ctx.loss_regular_total += float(ctx.get("loss_regular", 0.))
+
+ def _hook_on_fit_end(self, ctx):
+ avg_loss = 0 if float(
+ ctx.num_samples) == 0 else ctx.loss_batch_total / float(
+ ctx.num_samples)
+ eval_results = {
+ f'{ctx.cur_split}_loss': ctx.loss_batch_total,
+ f'{ctx.cur_split}_total': ctx.num_samples,
+ f'{ctx.cur_split}_avg_loss': avg_loss,
+ }
+ setattr(ctx, 'eval_metrics', eval_results)
+
+ # TODO: make this as a hook function
+ # Move trainable part to `cpu`, which can save memory but cost time
+ if ctx.cfg.llm.adapter.mv_to_cpu:
+ for p in ctx.model.parameters():
+ if p.requires_grad:
+ p.data = p.to('cpu')
+ if p.grad is not None:
+ p.grad.data = p.grad.to('cpu')
+
+ def _hook_on_batch_forward_flop_count(self, ctx):
+ """
+ The monitoring hook to calculate the flops during the fl course
+
+ Note:
+ For customized cases that the forward process is not only \
+ based on ctx.model, please override this function (inheritance \
+ case) or replace this hook (plug-in case)
+
+ The modified attributes and according operations are shown below:
+ ================================== ===========================
+ Attribute Operation
+ ================================== ===========================
+ ``ctx.monitor`` Track average flops
+ ================================== ===========================
+ """
+
+ # The process may occupy a large amount of video memory
+ # if the garbage collection is not triggered in time
+ # when there is plenty of video memory left. Set
+ # `eval.count_flops = False` to avoid this.
+ if not isinstance(ctx.monitor, Monitor):
+ logger.warning(
+ f"The trainer {type(self)} does contain a valid monitor, "
+ f"this may be caused by initializing trainer subclasses "
+ f"without passing a valid monitor instance."
+ f"Please check whether this is you want.")
+ return
+
+ if self.cfg.eval.count_flops and ctx.monitor.flops_per_sample == 0:
+ # calculate the flops_per_sample
+ try:
+ input_ids = ctx.data_batch['input_ids'].to(ctx.device)
+ labels = ctx.data_batch['labels'].to(ctx.device)
+ attention_mask = ctx.data_batch['attention_mask'].to(
+ ctx.device)
+ from fvcore.nn import FlopCountAnalysis
+ if isinstance(ctx.model, AdapterModel):
+ flops_one_batch = FlopCountAnalysis(
+ ctx.model.model,
+ inputs=(input_ids, attention_mask)).total()
+ else:
+ flops_one_batch = FlopCountAnalysis(
+ ctx.model, inputs=(input_ids, attention_mask)).total()
+ ctx.monitor.track_avg_flops(flops_one_batch, ctx.batch_size)
+ except Exception as e:
+ logger.warning("When using count flops functions, torch's "
+ "garbage collection mechanism may not be "
+ "timely resulting in OOM, please set "
+ "`cfg.eval.count_flops` to `False` "
+ "to avoid error or warning like this.")
+ logger.error(e)
+ # Raise warning at the first failure
+ logger.warning(
+ "current flop count implementation is for general LLM "
+ "trainer case: "
+ "1) ctx.data_batch contains [input_ids, labels, "
+ "attn_mask]; and 2) the ctx.model takes first two "
+ "arguments should be and attention_mask. "
+ "If ctx.model is an adapter model, the model in 2) has "
+ "been replaced by ctx.model.model. "
+ "Please check the forward format or implement your own "
+ "flop_count function")
+ ctx.monitor.flops_per_sample = -1
+
+ # by default, we assume the data has the same input shape,
+ # thus simply multiply the flops to avoid redundant forward
+ ctx.monitor.total_flops += ctx.monitor.flops_per_sample * \
+ ctx.batch_size
+
+
+def call_llm_trainer(trainer_type):
+ if trainer_type == 'llmtrainer':
+ trainer_builder = LLMTrainer
+ return trainer_builder
+
+
+register_trainer('llmtrainer', call_llm_trainer)
diff --git a/federatedscope/main.py b/federatedscope/main.py
index d63ec8444..e5022d9f8 100644
--- a/federatedscope/main.py
+++ b/federatedscope/main.py
@@ -9,7 +9,7 @@
from federatedscope.core.cmd_args import parse_args, parse_client_cfg
from federatedscope.core.auxiliaries.data_builder import get_data
-from federatedscope.core.auxiliaries.utils import setup_seed
+from federatedscope.core.auxiliaries.utils import setup_seed, get_ds_rank
from federatedscope.core.auxiliaries.logging import update_logger
from federatedscope.core.auxiliaries.worker_builder import get_client_cls, \
get_server_cls
@@ -29,7 +29,11 @@
cfg_opt, client_cfg_opt = parse_client_cfg(args.opts)
init_cfg.merge_from_list(cfg_opt)
- update_logger(init_cfg, clear_before_add=True)
+ if init_cfg.llm.deepspeed.use:
+ import deepspeed
+ deepspeed.init_distributed()
+
+ update_logger(init_cfg, clear_before_add=True, rank=get_ds_rank())
setup_seed(init_cfg.seed)
# load clients' cfg file
@@ -47,6 +51,12 @@
client_cfgs=client_cfgs)
init_cfg.merge_from_other_cfg(modified_cfg)
+ if init_cfg.federate.client_idx_for_local_train != 0:
+ init_cfg.federate.client_num = 1
+ new_data = {0: data[0]} if 0 in data.keys() else dict()
+ new_data[1] = data[init_cfg.federate.client_idx_for_local_train]
+ data = new_data
+
init_cfg.freeze()
runner = get_runner(data=data,
diff --git a/federatedscope/vertical_fl/linear_model/worker/vertical_server.py b/federatedscope/vertical_fl/linear_model/worker/vertical_server.py
index 2fd34faf7..60690a104 100644
--- a/federatedscope/vertical_fl/linear_model/worker/vertical_server.py
+++ b/federatedscope/vertical_fl/linear_model/worker/vertical_server.py
@@ -46,7 +46,7 @@ def __init__(self,
def _init_data_related_var(self):
self.dims = [0] + self.vertical_dims
- self.model = get_model(self._cfg.model, self.data)
+ self.model = get_model(self._cfg, self.data)
self.theta = self.model.state_dict()['fc.weight'].numpy().reshape(-1)
def trigger_for_start(self):
diff --git a/materials/paper_list/FL-LLM/README.md b/materials/paper_list/FL-LLM/README.md
new file mode 100644
index 000000000..b05ae8101
--- /dev/null
+++ b/materials/paper_list/FL-LLM/README.md
@@ -0,0 +1,17 @@
+## Federated Learning for LLM
+This list is constantly being updated. Feel free to contribute!
+
+### 2023
+| Title | Venue | Link |
+| --- |-------|------------------------------------------------------------------|
+| FedPETuning: When Federated Learning Meets the Parameter-Efficient Tuning Methods of Pre-trained Language Models | ACL | [pdf](https://aclanthology.org/2023.findings-acl.632/), [code](https://github.com/SMILELab-FL/FedPETuning) |
+
+### 2022
+| Title | Venue | Link |
+|-------|-------|-----------------------------------------|
+| Scaling Language Model Size in Cross-Device Federated Learning | ACL Workshop | [pdf](https://arxiv.org/abs/2204.09715) |
+
+### 2021
+| Title | Venue | Link |
+| --- | --- |------------------------------------------|
+| Scaling federated learning for fine-tuning of large language models | NLDB | [pdf](https://arxiv.org/abs/2102.00875) |
diff --git a/setup.py b/setup.py
index 814157f5a..86e24cdae 100644
--- a/setup.py
+++ b/setup.py
@@ -7,34 +7,72 @@
URL = 'https://github.com/alibaba/FederatedScope'
minimal_requires = [
- 'numpy<1.23.0', 'scikit-learn==1.0.2', 'scipy==1.7.3', 'pandas',
- 'grpcio>=1.45.0', 'grpcio-tools', 'pyyaml>=5.1', 'fvcore', 'iopath',
- 'wandb', 'tensorboard', 'tensorboardX', 'pympler', 'protobuf==3.19.4',
- 'matplotlib'
+ 'numpy<1.23.0',
+ 'scikit-learn==1.4.2',
+ 'scipy==1.6.3',
+ 'pandas==2.2.2',
+ 'grpcio>=1.62.1',
+ 'grpcio-tools',
+ 'pyyaml>=5.1',
+ 'fvcore',
+ 'iopath',
+ 'wandb==0.17.0',
+ 'tensorboard==2.13.0',
+ 'tensorboardX',
+ 'pympler',
+ 'protobuf==3.20.2',
+ 'matplotlib==3.8.4',
+ 'dill',
]
-test_requires = ['pytest', 'pytest-cov']
+test_requires = [
+ 'pytest==7.3.2',
+ 'pytest-cov',
+]
-dev_requires = test_requires + ['pre-commit', 'networkx', 'matplotlib']
+dev_requires = test_requires + ['pre-commit==3.7.1', 'networkx', 'matplotlib==3.8.4']
-org_requires = ['paramiko==2.11.0', 'celery[redis]', 'cmd2']
+org_requires = [
+ 'paramiko==2.11.0',
+ 'celery[redis]',
+ 'cmd2',
+]
app_requires = [
- 'torch-geometric==2.0.4', 'nltk', 'transformers==4.16.2',
- 'tokenizers==0.10.3', 'datasets', 'sentencepiece', 'textgrid', 'typeguard',
- 'openml==0.12.2'
+ 'torch-geometric==2.0.4',
+ 'nltk',
+ 'transformers==4.16.2',
+ 'tokenizers==0.10.3',
+ 'datasets',
+ 'sentencepiece==0.1.99',
+ 'textgrid',
+ 'typeguard',
+ 'openml==0.12.2',
+]
+
+llm_requires = [
+ 'tokenizers==0.19.1',
+ 'transformers==4.40.2',
+ 'accelerate==0.30.1',
+ 'peft==0.3.0',
+ 'sentencepiece==0.1.99',
]
benchmark_hpo_requires = [
- 'configspace==0.5.0', 'hpbandster==0.7.4', 'smac==1.3.3', 'optuna==2.10.0'
+ 'configspace==0.5.0',
+ 'hpbandster==0.7.4',
+ 'smac==1.3.3',
+ 'optuna==2.10.0',
]
-benchmark_htl_requires = ['learn2learn']
+benchmark_htl_requires = [
+ 'learn2learn',
+]
full_requires = org_requires + benchmark_hpo_requires + \
benchmark_htl_requires + app_requires
-with open("README.md", "r") as fh:
+with open("README.md", "r", encoding='UTF-8') as fh:
long_description = fh.read()
setuptools.setup(
@@ -56,6 +94,7 @@
extras_require={
'test': test_requires,
'app': app_requires,
+ 'llm': llm_requires,
'org': org_requires,
'dev': dev_requires,
'hpo': benchmark_hpo_requires,