diff --git a/.actor/actor.json b/.actor/actor.json
index 9a31f99..9b3714b 100644
--- a/.actor/actor.json
+++ b/.actor/actor.json
@@ -9,17 +9,17 @@
"storages": {
"dataset": {
"actorSpecification": 1,
- "title": "RAG Web browser",
- "description": "Too see all scraped properties, export the whole dataset or select All fields instead of Overview",
+ "title": "RAG Web Browser",
+ "description": "Too see all scraped properties, export the whole dataset or select All fields instead of Overview.",
"views": {
"overview": {
"title": "Overview",
- "description": "Selected fields from the dataset",
+ "description": "An view showing just basic properties for simplicity.",
"transformation": {
"fields": [
"metadata.url",
"metadata.title",
- "text"
+ "markdown"
],
"flatten": ["metadata"]
},
@@ -31,39 +31,39 @@
"format": "text"
},
"metadata.title": {
- "label": "Page Title",
+ "label": "Page title",
"format": "text"
},
"text": {
- "label": "Extracted text",
+ "label": "Extracted markdown",
"format": "text"
}
}
}
},
- "googleSearchResults": {
- "title": "Google Search Results",
- "description": "Title, Description and URL of the Google Search Results",
+ "searchResults": {
+ "title": "Search results",
+ "description": "A view showing just the Google Search results, without the page content.",
"transformation": {
"fields": [
- "googleSearchResult.description",
- "googleSearchResult.title",
- "googleSearchResult.url"
+ "searchResult.description",
+ "searchResult.title",
+ "searchResult.url"
],
- "flatten": ["googleSearchResult"]
+ "flatten": ["searchResult"]
},
"display": {
"component": "table",
"properties": {
- "googleSearchResult.description": {
+ "searchResult.description": {
"label": "Description",
"format": "text"
},
- "googleSearchResult.title": {
+ "searchResult.title": {
"label": "Title",
"format": "text"
},
- "googleSearchResult.url": {
+ "searchResult.url": {
"label": "URL",
"format": "text"
}
diff --git a/.actor/input_schema.json b/.actor/input_schema.json
index 3a457d0..c9a0494 100644
--- a/.actor/input_schema.json
+++ b/.actor/input_schema.json
@@ -1,31 +1,31 @@
{
"title": "RAG Web Browser",
- "description": "RAG Web Browser for a retrieval augmented generation workflows. Retrieve and return website content from the top Google Search Results Pages",
+ "description": "Here you can test the Actor and its various settings. Enter the search terms or URL below and click *Start* to see the results. For production applications, we recommend using the Standby mode and calling the Actor via HTTP server for faster response times.",
"type": "object",
"schemaVersion": 1,
"properties": {
"query": {
- "title": "Search term(s)",
+ "title": "Search term or URL",
"type": "string",
- "description": "You can Use regular search words or enter Google Search URLs. Additionally, you can also apply [advanced Google search techniques](https://blog.apify.com/how-to-scrape-google-like-a-pro/). For example:\n\n - Search for results from a particular website: llm site:openai.com (note: there should be no space between `site`, the colon, and the domain openai.com; also the `.com` is required).\n\n - Search for results related to javascript OR python",
- "prefill": "apify rag browser",
- "editor": "textarea",
+ "description": "Enter Google Search keywords or a URL to a specific web page. The keywords might include the [advanced search operators](https://blog.apify.com/how-to-scrape-google-like-a-pro/). Examples:\n\n- san francisco weather\n- https://www.cnn.com\n- function calling site:openai.com",
+ "prefill": "san francisco weather",
+ "editor": "textfield",
"pattern": "[^\\s]+"
},
"maxResults": {
- "title": "Number of top search results to return from Google. Only organic results are returned and counted",
+ "title": "Maximum results",
"type": "integer",
- "description": "The number of top organic search results to return and scrape text from",
- "prefill": 3,
+ "description": "The maximum number of top organic Google Search results whose web pages will be extracted. If `query` is a URL, then this field is ignored and the Actor only fetches the specific web page.",
+ "default": 3,
"minimum": 1,
"maximum": 100
},
"outputFormats": {
"title": "Output formats",
"type": "array",
- "description": "Select the desired output formats for the retrieved content",
+ "description": "Select one or more formats to which the target web pages will be extracted and saved in the resulting dataset.",
"editor": "select",
- "default": ["text"],
+ "default": ["markdown"],
"items": {
"type": "string",
"enum": ["text", "markdown", "html"],
@@ -33,34 +33,35 @@
}
},
"requestTimeoutSecs": {
- "title": "Request timeout in seconds",
+ "title": "Request timeout",
"type": "integer",
- "description": "The maximum time (in seconds) allowed for request. If the request exceeds this time, it will be marked as failed and only already finished results will be returned",
+ "description": "The maximum time in seconds available for the request, including querying Google Search and scraping the target web pages. For example, OpenAI allows only [45 seconds](https://platform.openai.com/docs/actions/production#timeouts) for custom actions. If a target page loading and extraction exceeds this timeout, the corresponding page will be skipped in results to ensure at least some results are returned within the timeout. If no page is extracted within the timeout, the whole request fails.",
"minimum": 1,
- "maximum": 600,
- "default": 45
+ "maximum": 300,
+ "default": 40,
+ "unit": "seconds"
},
- "proxyGroupSearch": {
- "title": "Search Proxy Group",
+ "serpProxyGroup": {
+ "title": "Google SERP proxy group",
"type": "string",
- "description": "Select the proxy group for loading search results",
+ "description": "Enables overriding the default Apify Proxy group used for fetching Google Search results.",
"editor": "select",
"default": "GOOGLE_SERP",
"enum": ["GOOGLE_SERP", "SHADER"],
- "sectionCaption": "Google Search Settings"
+ "sectionCaption": "Google Search scraping settings"
},
- "maxRequestRetriesSearch": {
- "title": "Maximum number of retries for Google search request on network / server errors",
+ "serpMaxRetries": {
+ "title": "Google SERP maximum retries",
"type": "integer",
- "description": "The maximum number of times the Google search crawler will retry the request on network, proxy or server errors. If the (n+1)-th request still fails, the crawler will mark this request as failed.",
+ "description": "The maximum number of times the Actor will retry fetching the Google Search results on error. If the last attempt fails, the entire request fails.",
"minimum": 0,
"maximum": 5,
- "default": 3
+ "default": 2
},
"proxyConfiguration": {
- "title": "Crawler: Proxy configuration",
+ "title": "Proxy configuration",
"type": "object",
- "description": "Enables loading the websites from IP addresses in specific geographies and to circumvent blocking.",
+ "description": "Apify Proxy configuration used for scraping the target web pages.",
"default": {
"useApifyProxy": true
},
@@ -68,66 +69,61 @@
"useApifyProxy": true
},
"editor": "proxy",
- "sectionCaption": "Content Crawler Settings"
+ "sectionCaption": "Target pages scraping settings"
},
"initialConcurrency": {
- "title": "Initial concurrency",
+ "title": "Initial browsing concurrency",
"type": "integer",
- "description": "Initial number of Playwright browsers running in parallel. The system scales this value based on CPU and memory usage.",
+ "description": "The initial number of web browsers running in parallel. The system automatically scales the number based on the CPU and memory usage, in the range specified by `minConcurrency` and `maxConcurrency`. If the initial value is `0`, the Actor picks the number automatically based on the available memory.",
"minimum": 0,
"maximum": 50,
- "default": 5
+ "default": 4,
+ "editor": "hidden"
},
"minConcurrency": {
- "title": "Minimal concurrency",
+ "title": "Minimum browsing concurrency",
"type": "integer",
- "description": "Minimum number of Playwright browsers running in parallel. Useful for defining a base level of parallelism.",
+ "description": "The minimum number of web browsers running in parallel.",
"minimum": 1,
"maximum": 50,
- "default": 3
+ "default": 1,
+ "editor": "hidden"
},
"maxConcurrency": {
- "title": "Maximal concurrency",
+ "title": "Maximum browsing concurrency",
"type": "integer",
- "description": "Maximum number of browsers or clients running in parallel to avoid overloading target websites.",
+ "description": "The maximum number of web browsers running in parallel.",
"minimum": 1,
- "maximum": 50,
- "default": 20
+ "maximum": 100,
+ "default": 50,
+ "editor": "hidden"
},
"maxRequestRetries": {
- "title": "Maximum number of retries for Playwright content crawler",
+ "title": "Target page max retries",
"type": "integer",
- "description": "Maximum number of retry attempts on network, proxy, or server errors. If the (n+1)-th request fails, it will be marked as failed.",
+ "description": "The maximum number of times the Actor will retry loading the target web page on error. If the last attempt fails, the page will be skipped in the results.",
"minimum": 0,
"maximum": 3,
"default": 1
},
- "requestTimeoutContentCrawlSecs": {
- "title": "Request timeout for content crawling",
- "type": "integer",
- "description": "Timeout (in seconds) for making requests for each search result, including fetching and processing its content.\n\nThe value must be smaller than the 'Request timeout in seconds' setting.",
- "minimum": 1,
- "maximum": 60,
- "default": 30
- },
"dynamicContentWaitSecs": {
- "title": "Wait for dynamic content (seconds)",
+ "title": "Target page dynamic content timeout",
"type": "integer",
- "description": "Maximum time (in seconds) to wait for dynamic content to load. The crawler processes the page once this time elapses or when the network becomes idle.",
- "default": 10
+ "description": "The maximum time in seconds to wait for dynamic page content to load. The Actor considers the web page as fully loaded once this time elapses or when the network becomes idle.",
+ "default": 10,
+ "unit": "seconds"
},
"removeCookieWarnings": {
"title": "Remove cookie warnings",
"type": "boolean",
- "description": "If enabled, removes cookie consent dialogs to improve text extraction accuracy. Note that this will impact latency.",
+ "description": "If enabled, the Actor attempts to close or remove cookie consent dialogs to improve the quality of extracted text. Note that this setting increases the latency.",
"default": true
},
"debugMode": {
- "title": "Debug mode (stores debugging information in dataset)",
+ "title": "Enable debug mode",
"type": "boolean",
- "description": "If enabled, the Actor will store debugging information in the dataset's debug field",
- "default": false,
- "sectionCaption": "Debug Settings"
+ "description": "If enabled, the Actor will store debugging information into the resulting dataset under the `debug` field.",
+ "default": false
}
}
}
diff --git a/CHANGELOG.md b/CHANGELOG.md
index 1d7017d..c973d29 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -1,5 +1,22 @@
This changelog summarizes all changes of the RAG Web Browser
+### 2024-11-13
+
+🚀 Features
+- Improve README.md and simplify configuration
+- Add an AWS Lambda function
+- Hide variables initialConcurrency, minConcurrency, and maxConcurrency in the Actor input and remove them from README.md
+- Remove requestTimeoutContentCrawlSecs and use only requestTimeoutSecs
+- Ensure there is enough time left to wait for dynamic content before the Actor timeout (normal mode)
+- Rename googleSearchResults to searchResults and searchProxyGroup to serpProxyGroup
+- Implement input validation
+
+### 2024-11-08
+
+🚀 Features
+- Add functionality to extract content from a specific URL
+- Update README.md to include new functionality and provide examples
+
### 2024-10-17
🚀 Features
diff --git a/LICENSE.md b/LICENSE.md
new file mode 100644
index 0000000..a9c29c5
--- /dev/null
+++ b/LICENSE.md
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+END OF TERMS AND CONDITIONS
+
+APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "{}"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+Copyright 2024 Apify Technologies s.r.o.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
diff --git a/README.md b/README.md
index 25cec49..f55b02d 100644
--- a/README.md
+++ b/README.md
@@ -1,47 +1,117 @@
# 🌐 RAG Web Browser
-This Actor retrieves website content from the top Google Search Results Pages (SERPs).
-Given a search query, it fetches the top Google search result URLs and then follows each URL to extract the text content from the targeted websites.
+This Actor provides web browsing functionality for AI and LLM applications,
+similar to the [web browsing](https://openai.com/index/introducing-chatgpt-search/) feature in ChatGPT.
+It accepts a search phrase or a URL, queries Google Search, then crawls web pages from the top search results, cleans the HTML, converts it to text or Markdown,
+and returns it back for processing by the LLM application.
+The extracted text can then be injected into prompts and retrieval augmented generation (RAG) pipelines, to provide your LLM application with up-to-date context from the web.
-The RAG Web Browser is designed for Large Language Model (LLM) applications or LLM agents to provide up-to-date Google search knowledge.
+## Main features
-**✨ Main features**:
-- Searches Google and extracts the top Organic results. The Google search country is set to the United States.
-- Follows the top URLs to scrape HTML and extract website text, excluding navigation, ads, banners, etc.
-- Capable of extracting content from JavaScript-enabled websites and bypassing anti-scraping protections.
-- Output formats include plain text, markdown, and HTML.
+- 🚀 **Quick response times** for great user experience
+- ⚙️ Supports **dynamic JavaScript-heavy websites** using a headless browser
+- 🕷 Automatically **bypasses anti-scraping protections** using proxies and browser fingerprints
+- 📝 Output formats include **Markdown**, plain text, and HTML
+- 🪟 It's **open source**, so you can review and modify it
-This Actor combines the functionality of two specialized actors: the [Google Search Results Scraper](https://apify.com/apify/google-search-scraper) and the [Website Content Crawler](https://apify.com/apify/website-content-crawler).
-- To scrape only Google Search Results, use the [Google Search Results Scraper](https://apify.com/apify/google-search-scraper) actor.
-- To extract content from a list of URLs, use the [Website Content Crawler](https://apify.com/apify/website-content-crawler) actor.
+## Example
-ⓘ The Actor defaults to using Google Search in the United States.
-As a result, queries like "find the best restaurant nearby" will return results from the US.
-Other countries are not currently supported.
-If you need support for a different region, please create an issue to let us know.
+For a search query like `web browser site:openai.com`, the Actor will return an array with a content of top results from Google Search:
-## 🚀 Fast responses using the Standby mode
+```json
+[
+ {
+ "metadata": {
+ "url": "https://python.langchain.com/docs/integrations/providers/apify/#utility",
+ "title": "Apify | 🦜️🔗 LangChain"
+ },
+ "text": "Apify | 🦜️🔗 LangChain | This notebook shows how to use the Apify integration ..."
+ },
+ {
+ "metadata": {
+ "url": "https://microsoft.github.io/autogen/0.2/docs/notebooks/agentchat_webscraping_with_apify/",
+ "title": "Web Scraping using Apify Tools | AutoGen"
+ },
+ "text": "Web Scraping using Apify Tools | This notebook shows how to use Apify tools with AutoGen agents ...."
+ }
+]
+```
-This Actor can be run in both normal and [standby modes](https://docs.apify.com/platform/actors/running/standby).
-Normal mode is useful for testing and running in ad-hoc settings, but it comes with some overhead due to the Actor's initial startup time.
+If you enter a specific URL such as `https://docs.apify.com/platform/integrations/openai-assistants`, the Actor will extract
+the web page content directly.
-For optimal performance, it is recommended to run the Actor in Standby mode.
-This allows the Actor to stay active, enabling it to retrieve results with lower latency.
+
-### 🔥 How to start the Actor in a Standby mode?
+```json
+[
+ {
+ "metadata": {
+ "url": "https://docs.apify.com/platform/integrations/openai-assistants",
+ "title": "OpenAI Assistants integration | Platform | Apify Documentation"
+ },
+ "text": "OpenAI Assistants integration. Learn how to integrate Apify with OpenAI Assistants to provide real-time search data ..."
+ }
+]
+```
-You need know the Actor's standby URL and `APIFY_API_TOKEN` to start the Actor in Standby mode.
+## Usage
-```shell
-curl -X GET https://rag-web-browser.apify.actor?token=APIFY_API_TOKEN
-```
+The RAG Web Browser can be used in two ways: **as a standard Actor** by passing it an input object with the settings,
+or in the **Standby mode** by sending it an HTTP request.
-Then, you can send requests to the `/search` path along with your `query` and the number of results (`maxResults`) you want to retrieve.
-```shell
-curl -X GET https://rag-web-browser.apify.actor/search?token=APIFY_API_TOKEN\&query=apify\&maxResults=1
+### Normal Actor run
+
+You can run the Actor "normally" via API or manually, pass it an input JSON object with settings including the search phrase or URL,
+and it will store the results to the default dataset.
+This is useful for testing and evaluation, but might be too slow for production applications and RAG pipelines,
+because it takes some time to start a Docker container and the web browser.
+Also, one Actor run can only handle one query, which isn't very inefficient.
+
+### Standby web server
+
+The Actor also supports the [**Standby mode**](https://docs.apify.com/platform/actors/running/standby),
+where it runs an HTTP web server that receives requests with the search phrases and responds with the extracted web content.
+This way is preferred for production applications, because if the Actor is already running, it will
+return the results much faster. Additionally, in the Standby mode the Actor can handle multiple requests
+in parallel, and thus utilizes the computing resources more efficiently.
+
+To use RAG Web Browser in the Standby mode, simply send an HTTP GET request to the following URL:
+
+```
+https://rag-web-browser.apify.actor/search?token=&query=
```
-Here’s an example of the server response (truncated for brevity):
+where `` is your [Apify API token](https://console.apify.com/settings/integrations) and ``
+is the search query or a single web page URL.
+Note that you can also pass the API token using the `Authorization` HTTP header with Basic authentication for increased security.
+
+The response is a JSON array with objects containing the web content from the found web pages.
+
+
+#### Request
+
+The `/search` GET HTTP endpoint accepts the following query parameters:
+
+| Parameter | Type | Default | Description |
+|----------------------------------|---------|---------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| `query` | string | N/A | Enter Google Search keywords or a URL to a specific web page. The keywords might include the [advanced search operators](https://blog.apify.com/how-to-scrape-google-like-a-pro/). You need to percent-encode the value if it contains some special characters. |
+| `maxResults` | number | `3` | The maximum number of top organic Google Search results whose web pages will be extracted. If `query` is a URL, then this parameter is ignored and the Actor only fetches the specific web page. |
+| `outputFormats` | string | `markdown` | Select one or more formats to which the target web pages will be extracted. Use comma to separate multiple values (e.g. `text,markdown`) |
+| `requestTimeoutSecs` | number | `30` | The maximum time in seconds available for the request, including querying Google Search and scraping the target web pages. For example, OpenAI allows only [45 seconds](https://platform.openai.com/docs/actions/production#timeouts) for custom actions. If a target page loading and extraction exceeds this timeout, the corresponding page will be skipped in results to ensure at least some results are returned within the timeout. If no page is extracted within the timeout, the whole request fails. |
+| `serpProxyGroup` | string | `GOOGLE_SERP` | Enables overriding the default Apify Proxy group used for fetching Google Search results. |
+| `serpMaxRetries` | number | `1` | The maximum number of times the Actor will retry fetching the Google Search results on error. If the last attempt fails, the entire request fails. |
+| `maxRequestRetries` | number | `1` | The maximum number of times the Actor will retry loading the target web page on error. If the last attempt fails, the page will be skipped in the results. |
+| `requestTimeoutContentCrawlSecs` | number | `30` | The maximum time in seconds for loading and extracting the target web page content. The value should be smaller than the `requestTimeoutSecs` setting to have any effect. |
+| `dynamicContentWaitSecs` | number | `10` | The maximum time in seconds to wait for dynamic page content to load. The Actor considers the web page as fully loaded once this time elapses or when the network becomes idle. |
+| `removeCookieWarnings` | boolean | `true` | If enabled, removes cookie consent dialogs to improve text extraction accuracy. Note that this will impact latency. |
+| `debugMode` | boolean | `false` | If enabled, the Actor will store debugging information in the dataset's debug field. |
+
+
+
+#### Response
+
+The `/search` GET HTTP endpoint responds with a JSON array, which looks as follows:
+
```json
[
{
@@ -51,7 +121,7 @@ Here’s an example of the server response (truncated for brevity):
"uniqueKey": "3e8452bb-c703-44af-9590-bd5257902378",
"requestStatus": "handled"
},
- "googleSearchResult": {
+ "searchResult": {
"url": "https://apify.com/",
"title": "Apify: Full-stack web scraping and data extraction platform",
"description": "Cloud platform for web scraping, browser automation, and data for AI...."
@@ -64,85 +134,54 @@ Here’s an example of the server response (truncated for brevity):
"languageCode": "en",
"url": "https://apify.com/"
},
- "text": "Full-stack web scraping and data extraction platform..."
+ "text": "Full-stack web scraping and data extraction platform...",
+ "markdown": "# Full-stack web scraping and data extraction platform..."
}
]
```
-The Standby mode has several configuration parameters, such as Max Requests per Run, Memory, and Idle Timeout.
-You can find the details in the [Standby Mode documentation](https://docs.apify.com/platform/actors/running/standby#how-do-i-customize-standby-configuration).
-
-**Note** Sending a search request to `/search` will also initiate Standby mode.
-You can use this endpoint for both purposes conveniently
-```shell
-curl -X GET https://rag-web-browser.apify.actor/search?token=APIFY_API_TOKEN&query=apify%20llm
-```
+## Integration with LLMs
-### 📧 API parameters
+RAG Web Browser has been designed for easy integration to LLM applications, GPTs, assistants, and RAG pipelines using function calling.
-When running in the standby mode the RAG Web Browser accepts the following query parameters:
+### OpenAPI schema
-| parameter | description |
-|----------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------|
-| `query` | Use regular search words or enter Google Search URLs. You can also apply advanced Google search techniques. |
-| `maxResults` | The number of top organic search results to return and scrape text from (maximum is 100). |
-| `outputFormats` | Select the desired output formats for the retrieved content (e.g., "text", "markdown", "html"). |
-| `requestTimeoutSecs` | The maximum time (in seconds) allowed for the request. If the request exceeds this time, it will be marked as failed. |
-| `proxyGroupSearch` | Select the proxy group for loading search results. Options: 'GOOGLE_SERP', 'SHADER'. |
-| `maxRequestRetriesSearch` | Maximum number of retry attempts on network, proxy, or server errors for Google search requests. |
-| `proxyConfiguration` | Enables loading the websites from IP addresses in specific geographies and to circumvent blocking. |
-| `initialConcurrency` | Initial number of Playwright browsers running in parallel. The system scales this value based on CPU and memory usage. |
-| `minConcurrency` | Minimum number of Playwright browsers running in parallel. Useful for defining a base level of parallelism. |
-| `maxConcurrency` | Maximum number of browsers or clients running in parallel to avoid overloading target websites. |
-| `maxRequestRetries` | Maximum number of retry attempts on network, proxy, or server errors for the Playwright content crawler. |
-| `requestTimeoutContentCrawlSecs` | Timeout (in seconds) for making requests for each search result, including fetching and processing its content. |
-| `dynamicContentWaitSecs` | Maximum time (in seconds) to wait for dynamic content to load. The crawler processes the page once this time elapses or when the network becomes idle. |
-| `removeCookieWarnings` | If enabled, removes cookie consent dialogs to improve text extraction accuracy. Note that this will impact latency. |
-| `debugMode` | If enabled, the Actor will store debugging information in the dataset's debug field. |
+Here you can find the [OpenAPI schema](https://raw.githubusercontent.com/apify/rag-web-browser/refs/heads/master/docs/standby-openapi-3.1.0.json)
+for the Standby web server. Note that the OpenAPI definition contains
+all available query parameters, but only `query` is required.
+You can remove all the others parameters from the definition if their default value is right for your application,
+in order to reduce the number of LLM tokens necessary and to reduce the risk of hallucinations.
-## 🏃 What is the best way to run the RAG Web Browser?
+### OpenAI Assistants
-The RAG Web Browser is designed to be run in Standby mode for optimal performance.
-The Standby mode allows the Actor to stay active, enabling it to retrieve results with lower latency.
+While ChatGPT and GPTs supports web browsing natively, [OpenAI Assistants](https://platform.openai.com/docs/assistants/overview) do not.
+With RAG Web Browser, you can easily add the web search and browsing capability to your custom AI assistant and chatbots.
-## ⏳ What is the expected latency?
+For detailed instructions and a step-by-step guide, see the [OpenAI Assistants integration](https://docs.apify.com/platform/integrations/openai-assistants#real-time-search-data-for-openai-assistant) in Apify documentation.
-The latency is proportional to the **memory allocated** to the Actor and **number of results requested**.
-
-Below is a typical latency breakdown for the RAG Web Browser with **initialConcurrency=3** and **maxResults** set to either 1 or 3.
-These settings allow for processing all search results in parallel.
+### OpenAI GPTs
-Please note the these results are only indicative and may vary based on the search term, the target websites,
-and network latency.
-
-The numbers below are based on the following search terms: "apify", "Donald Trump", "boston".
-Results were averaged for the three queries.
-
-| Memory (GB) | Max Results | Latency (s) |
-|-------------|-------------|-------------|
-| 4 | 1 | 22 |
-| 4 | 3 | 31 |
-| 8 | 1 | 16 |
-| 8 | 3 | 17 |
+You can easily add the RAG Web Browser to your GPT by creating a custom action using the [OpenAPI schema](#openapi-schema).
+Follow the detailed guide in the article [Add custom actions to your GPTs with Apify Actors](https://blog.apify.com/add-custom-actions-to-your-gpts/).
-Based on your requirements, if low latency is a priority, consider running the Actor with 4GB or 8GB of memory.
-However, if you're looking for a cost-effective solution, you can run the Actor with 2GB of memory, but you may experience higher latency and might need to set a longer timeout.
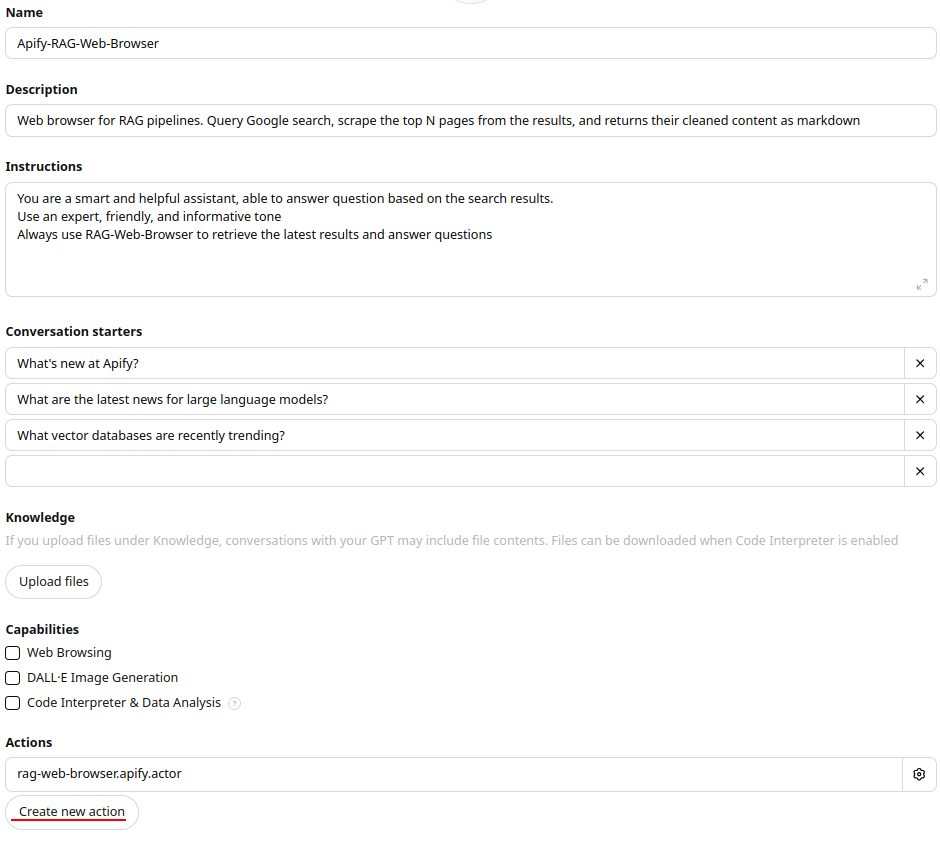
+Here's a quick guide to adding the RAG Web Browser to your GPT as a custom action:
-If you need to gather more results, you can increase the memory and adjust the `initialConcurrency` parameter accordingly.
+1. Click on **Explore GPTs** in the left sidebar, then select **+ Create** in the top right corner.
+1. Complete all required details in the form.
+1. Under the **Actions** section, click **Create new action**.
+1. In the Action settings, set **Authentication** to **API key** and choose Bearer as **Auth Type**.
+1. In the **schema** field, paste the OpenAPI specification for the RAG Web Browser.
+ 1. **Normal mode**: Copy the OpenAPI schema from the [RAG-Web-Browser Actor](https://console.apify.com/actors/3ox4R101TgZz67sLr/input) under the API -> OpenAPI specification.
+ 1. **Standby mode**: Copy the OpenAPI schema from the [OpenAPI standby mode](https://raw.githubusercontent.com/apify/rag-web-browser/refs/heads/master/docs/standby-openapi.json) json file.
-## 🎢 How to optimize the RAG Web Browser for low latency?
+
-For low latency, it's recommended to run the RAG Web Browser with 8 GB of memory. Additionally, adjust these settings to further optimize performance:
-- **Initial Concurrency**: This controls the number of Playwright browsers running in parallel. If you only need a few results (e.g., 3, 5, or 10), set the initial concurrency to match this number to ensure content is processed simultaneously.
-- **Dynamic Content Wait Secs**: Set this to 0 if you don't need to wait for dynamic content. This can significantly reduce latency.
-- **Remove Cookie Warnings**: If the websites you're scraping don't have cookie warnings, set this to false to slightly improve latency.
-- **Debug Mode**: Enable this to store debugging information if you need to measure the Actor's latency.
-If you require a response within a certain timeframe, use the `requestTimeoutSecs` parameter to define the maximum duration the Actor should spend on making search requests and crawling.
+## ✃ How to set up request timeout?
+
-## ✃ How to set up request timeout?
You can set the `requestTimeoutSecs` parameter to define how long the Actor should spend on making the search request and crawling.
If the timeout is exceeded, the Actor will return whatever results were scraped up to that point.
@@ -159,7 +198,7 @@ For example, the following outputs (truncated for brevity) illustrate this behav
"httpStatusMessage": "OK",
"requestStatus": "handled"
},
- "googleSearchResult": {
+ "searchResult": {
"description": "Apify command-line interface helps you create, develop, build and run Apify actors, and manage the Apify cloud platform.",
"title": "Apify",
"url": "https://github.com/apify"
@@ -172,48 +211,81 @@ For example, the following outputs (truncated for brevity) illustrate this behav
"httpStatusMessage": "Timed out",
"requestStatus": "failed"
},
- "googleSearchResult": {
+ "searchResult": {
"description": "Cloud platform for web scraping, browser automation, and data for AI.",
"title": "Apify: Full-stack web scraping and data extraction platform",
"url": "https://apify.com/"
},
- "text": "Cloud platform for web scraping, browser automation, and data for AI."
+ "text": ""
}
]
```
-## 💡 How to use RAG Web Browser in OpenAI Assistant as a tool for web search?
-You can use the RAG Web Browser to provide up-to-date information from Google search results to your OpenAI Assistant.
-The assistant can use the RAG Web Browser as a tool and whenever it needs to fetch information from the web, it sends request a request to the RAG Web Browser based on the search query.
-For a complete example with images and detailed instructions, visit the [OpenAI Assistant integration](https://docs.apify.com/platform/integrations/openai-assistants#real-time-search-data-for-openai-assistant) page.
+## ⏳ Performance and cost optimization
-## ֎ How to use RAG Web Browser in your GPT as a custom action?
+To optimize the performance and cost of your application, see the [Standby mode settings](https://docs.apify.com/platform/actors/running/standby#how-do-i-customize-standby-configuration).
-You can easily add the RAG Web Browser to your GPT by uploading its OpenAPI specification and creating a custom action.
-Follow the detailed guide in the article [Add custom actions to your GPTs with Apify Actors](https://blog.apify.com/add-custom-actions-to-your-gpts/).
+The latency is proportional to the **memory allocated** to the Actor and **number of results requested**.
-Here's a quick guide to adding the RAG Web Browser to your GPT as a custom action:
+Below is a typical latency breakdown for the RAG Web Browser with **maxResults** set to either 1 or 3.
+These settings allow for processing all search results in parallel.
-1. Click on **Explore GPTs** in the left sidebar, then select **+ Create** in the top right corner.
-1. Complete all required details in the form.
-1. Under the **Actions** section, click **Create new action**.
-1. In the Action settings, set **Authentication** to **API key** and choose Bearer as **Auth Type**.
-1. In the **schema** field, paste the OpenAPI specification for the RAG Web Browser.
- 1. **Normal mode**: Copy the OpenAPI schema from the [RAG-Web-Browser Actor](https://console.apify.com/actors/3ox4R101TgZz67sLr/input) under the API -> OpenAPI specification.
- 1. **Standby mode**: Copy the OpenAPI schema from the [OpenAPI standby mode](https://raw.githubusercontent.com/apify/rag-web-browser/refs/heads/master/docs/standby-openapi.json) json file.
+Please note the these results are only indicative and may vary based on the search term, the target websites, and network latency.
-
+The numbers below are based on the following search terms: "apify", "Donald Trump", "boston".
+Results were averaged for the three queries.
+
+| Memory (GB) | Max Results | Latency (s) |
+|-------------|-------------|-------------|
+| 4 | 1 | 22 |
+| 4 | 3 | 31 |
+| 8 | 1 | 16 |
+| 8 | 3 | 17 |
+
+Based on your requirements, if low latency is a priority, consider running the Actor with 4GB or 8GB of memory.
+However, if you're looking for a cost-effective solution, you can run the Actor with 2GB of memory, but you may experience higher latency and might need to set a longer timeout.
+
+### 🎢 How to optimize the RAG Web Browser for low latency?
+
+For low latency, it's recommended to run the RAG Web Browser with 8 GB of memory. Additionally, adjust these settings to further optimize performance:
+
+- **Dynamic Content Wait Secs**: Set this to 0 if you don't need to wait for dynamic content. This can significantly reduce latency.
+- **Remove Cookie Warnings**: If the websites you're scraping don't have cookie warnings, set this to false to slightly improve latency.
+- **Debug Mode**: Enable this to store debugging information if you need to measure the Actor's latency.
+
+If you require a response within a certain timeframe, use the `requestTimeoutSecs` parameter to define the maximum duration the Actor should spend on making search requests and crawling.
+
+
+## ⓘ Limitations and feedback
+
+The Actor defaults to Google Search in the United States and English language
+and so queries like "_best nearby restaurants_" will return search results from the US.
+
+If you need other regions or languages, or have some other feedback, please submit an issue on the
+Actor in Apify Console to let us know.
## 👷🏼 Development
-**Run STANDBY mode using apify-cli for development**
+The RAG Web Browser Actor has open source on [GitHub](https://github.com/apify/rag-web-browser),
+so that you can modify and develop it yourself. Here are the steps how to run it locally on your computer.
+
+Download the source code:
+
```bash
-APIFY_META_ORIGIN=STANDBY apify run -p
+git clone https://github.com/apify/rag-web-browser
+cd rag-web-browser
```
-**Install playwright dependencies**
+Install [Playwright](https://playwright.dev) with dependencies:
+
```bash
npx playwright install --with-deps
```
+
+And then you can run it locally using [Apify CLI](https://docs.apify.com/cli) as follows:
+
+```bash
+APIFY_META_ORIGIN=STANDBY apify run -p
+```
diff --git a/docs/aws-lambda-call-rag-web-browser.py b/docs/aws-lambda-call-rag-web-browser.py
new file mode 100644
index 0000000..ec581c5
--- /dev/null
+++ b/docs/aws-lambda-call-rag-web-browser.py
@@ -0,0 +1,91 @@
+"""
+This is an example of an AWS Lambda function that calls the RAG Web Browser actor and returns text results.
+
+There is a limit of 25KB for the response body in AWS Bedrock, so we need to limit the number of results to 3
+and truncate the text whenever required.
+"""
+
+import json
+import os
+import urllib.parse
+import urllib.request
+
+ACTOR_BASE_URL = "https://rag-web-browser.apify.actor" # Base URL from OpenAPI schema
+MAX_RESULTS = 3 # Limit the number of results to decrease response size, limit 25KB
+TRUNCATE_TEXT_LENGTH = 5000 # Truncate the response body to decrease the response size, limit 25KB
+
+# Lambda function environment variable
+APIFY_API_TOKEN = os.getenv("APIFY_API_TOKEN")
+
+
+def lambda_handler(event, context):
+ print("Received event", event)
+
+ api_path = event["apiPath"]
+ http_method = event["httpMethod"]
+ parameters = event.get("parameters", [])
+
+ url = f"{ACTOR_BASE_URL}{api_path}"
+ headers = {"Authorization": f"Bearer {APIFY_API_TOKEN}"}
+
+ query_params = {}
+ for param in parameters:
+ name = param["name"]
+ value = param["value"]
+ query_params[name] = value
+
+ # Limit the number of results to decrease response size
+ # Getting: lambda response exceeds maximum size 25KB: 66945
+ print("Query params: ", query_params)
+ query_params["maxResults"] = min(3, int(query_params.get("maxResults", 3)))
+ print("Limited max results to: ", query_params["maxResults"])
+
+ try:
+ if query_params and http_method == "GET":
+ url = f"{url}?{urllib.parse.urlencode(query_params)}"
+ print(f"GET request to {url}")
+ req = urllib.request.Request(url, headers=headers, method="GET")
+ with urllib.request.urlopen(req) as response:
+ response_body = response.read().decode("utf-8")
+
+ else:
+ return {"statusCode": 400, "body": json.dumps({"message": f"HTTP method {http_method} not supported"})}
+
+ response = json.loads(response_body)
+ # Truncate the response body to decrease the response size, there is a limit of 25KB
+ body = [d["text"][:TRUNCATE_TEXT_LENGTH] + "..." for d in response]
+
+ # Handle the API response
+ action_response = {
+ "actionGroup": event["actionGroup"],
+ "apiPath": api_path,
+ "httpMethod": http_method,
+ "httpStatusCode": 200,
+ "responseBody": {"application/json": {"body": "\n".join(body)}},
+ }
+
+ dummy_api_response = {"response": action_response, "messageVersion": event["messageVersion"]}
+ print("Response: {}".format(dummy_api_response))
+
+ return dummy_api_response
+
+ except Exception as e:
+ return {"statusCode": 500, "body": json.dumps({"message": "Internal server error", "error": str(e)})}
+
+
+if __name__ == "__main__":
+
+ test_event = {
+ "apiPath": "/search",
+ "httpMethod": "GET",
+ "parameters": [
+ {"name": "query", "type": "string", "value": "AI agents in healthcare"},
+ {"name": "maxResults", "type": "integer", "value": "3"},
+ ],
+ "agent": "healthcare-agent",
+ "actionGroup": "action-call-rag-web-browser",
+ "sessionId": "031263542130667",
+ "messageVersion": "1.0",
+ }
+ handler_response = lambda_handler(test_event, None)
+ print("Response: ", handler_response)
diff --git a/docs/standby-openapi.json b/docs/standby-openapi-3.0.0.json
similarity index 98%
rename from docs/standby-openapi.json
rename to docs/standby-openapi-3.0.0.json
index b4e7e56..b8a84a9 100644
--- a/docs/standby-openapi.json
+++ b/docs/standby-openapi-3.0.0.json
@@ -35,7 +35,7 @@
"schema": {
"type": "integer",
"minimum": 1,
- "maximum": 50
+ "maximum": 100
}
},
{
@@ -73,7 +73,7 @@
}
},
{
- "name": "proxyGroupSearch",
+ "name": "serpProxyGroup",
"in": "query",
"description": "Proxy group for loading search results.",
"required": false,
@@ -87,7 +87,7 @@
}
},
{
- "name": "maxRequestRetriesSearch",
+ "name": "serpMaxRetries",
"in": "query",
"description": "Maximum retries for Google search requests on errors.",
"required": false,
diff --git a/docs/standby-openapi-3.1.0.json b/docs/standby-openapi-3.1.0.json
new file mode 100644
index 0000000..93c973e
--- /dev/null
+++ b/docs/standby-openapi-3.1.0.json
@@ -0,0 +1,198 @@
+{
+ "openapi": "3.0.0",
+ "info": {
+ "title": "RAG Web Browser",
+ "description": "Web browser for OpenAI Assistants API and RAG pipelines, similar to a web browser in ChatGPT. It queries Google Search, scrapes the top N pages from the results, and returns their cleaned content as Markdown for further processing by an LLM.",
+ "version": "v1"
+ },
+ "servers": [
+ {
+ "url": "https://rag-web-browser.apify.actor"
+ }
+ ],
+ "paths": {
+ "/search": {
+ "get": {
+ "operationId": "apify_rag-web-browser",
+ "x-openai-isConsequential": false,
+ "summary": "Web browser for OpenAI Assistants API and RAG pipelines",
+ "description": "Web browser for OpenAI Assistants API and RAG pipelines, similar to a web browser in ChatGPT. It queries Google Search, scrapes the top N pages from the results, and returns their cleaned content as Markdown for further processing by an LLM.",
+ "parameters": [
+ {
+ "name": "query",
+ "in": "query",
+ "description": "Use regular search words or enter Google Search URLs. You can also apply advanced Google search techniques, such as AI site:twitter.com or javascript OR python",
+ "required": true,
+ "schema": {
+ "type": "string",
+ "pattern": "[^\\s]+"
+ }
+ },
+ {
+ "name": "maxResults",
+ "in": "query",
+ "description": "The number of top organic search results to return and scrape text from",
+ "required": false,
+ "schema": {
+ "type": "integer",
+ "minimum": 1,
+ "maximum": 100
+ }
+ },
+ {
+ "name": "outputFormats",
+ "in": "query",
+ "description": "Select the desired output formats for the retrieved content",
+ "required": false,
+ "schema": {
+ "type": "array",
+ "items": {
+ "type": "string",
+ "enum": [
+ "text",
+ "markdown",
+ "html"
+ ]
+ }
+ },
+ "style": "form",
+ "explode": false
+ },
+ {
+ "name": "requestTimeoutSecs",
+ "in": "query",
+ "description": "The maximum time (in seconds) allowed for request. If the request exceeds this time, it will be marked as failed and only already finished results will be returned",
+ "required": false,
+ "schema": {
+ "type": "integer",
+ "minimum": 1,
+ "maximum": 600,
+ "default": 45
+ }
+ },
+ {
+ "name": "serpProxyGroup",
+ "in": "query",
+ "description": "Proxy group for loading search results.",
+ "required": false,
+ "schema": {
+ "type": "string",
+ "enum": [
+ "GOOGLE_SERP",
+ "SHADER"
+ ],
+ "default": "GOOGLE_SERP"
+ }
+ },
+ {
+ "name": "serpMaxRetries",
+ "in": "query",
+ "description": "Maximum retries for Google search requests on errors.",
+ "required": false,
+ "schema": {
+ "type": "integer",
+ "minimum": 0,
+ "maximum": 3,
+ "default": 1
+ }
+ },
+ {
+ "name": "initialConcurrency",
+ "in": "query",
+ "description": "Initial number of browsers running in parallel.",
+ "required": false,
+ "schema": {
+ "type": "integer",
+ "minimum": 0,
+ "maximum": 50,
+ "default": 5
+ }
+ },
+ {
+ "name": "minConcurrency",
+ "in": "query",
+ "description": "Minimum number of browsers running in parallel.",
+ "required": false,
+ "schema": {
+ "type": "integer",
+ "minimum": 1,
+ "maximum": 50,
+ "default": 3
+ }
+ },
+ {
+ "name": "maxConcurrency",
+ "in": "query",
+ "description": "Maximum number of browsers running in parallel.",
+ "required": false,
+ "schema": {
+ "type": "integer",
+ "minimum": 1,
+ "maximum": 50,
+ "default": 10
+ }
+ },
+ {
+ "name": "maxRequestRetries",
+ "in": "query",
+ "description": "Maximum retries for Playwright content crawler.",
+ "required": false,
+ "schema": {
+ "type": "integer",
+ "minimum": 0,
+ "maximum": 3,
+ "default": 1
+ }
+ },
+ {
+ "name": "requestTimeoutContentCrawlSecs",
+ "in": "query",
+ "description": "Timeout for content crawling (seconds).",
+ "required": false,
+ "schema": {
+ "type": "integer",
+ "minimum": 1,
+ "maximum": 60,
+ "default": 30
+ }
+ },
+ {
+ "name": "dynamicContentWaitSecs",
+ "in": "query",
+ "description": "Time to wait for dynamic content to load (seconds).",
+ "required": false,
+ "schema": {
+ "type": "integer",
+ "default": 10
+ }
+ },
+ {
+ "name": "removeCookieWarnings",
+ "in": "query",
+ "description": "Removes cookie consent dialogs to improve text extraction.",
+ "required": false,
+ "schema": {
+ "type": "boolean",
+ "default": true
+ }
+ },
+ {
+ "name": "debugMode",
+ "in": "query",
+ "description": "Stores debugging information in dataset if enabled.",
+ "required": false,
+ "schema": {
+ "type": "boolean",
+ "default": false
+ }
+ }
+ ],
+ "responses": {
+ "200": {
+ "description": "OK"
+ }
+ }
+ }
+ }
+ }
+}
diff --git a/src/const.ts b/src/const.ts
index fd1eb5e..594da24 100644
--- a/src/const.ts
+++ b/src/const.ts
@@ -3,3 +3,28 @@ export enum ContentCrawlerStatus {
HANDLED = 'handled',
FAILED = 'failed',
}
+
+export const PLAYWRIGHT_REQUEST_TIMEOUT_NORMAL_MODE_SECS = 60;
+
+export const defaults = {
+ debugMode: false,
+ dynamicContentWaitSecs: 10,
+ initialConcurrency: 5,
+ keepAlive: true,
+ maxConcurrency: 10,
+ maxRequestRetries: 1,
+ maxRequestRetriesMax: 3,
+ maxResults: 3,
+ maxResultsMax: 100,
+ minConcurrency: 3,
+ outputFormats: ['markdown'],
+ proxyConfiguration: { useApifyProxy: true },
+ query: 'apify llm',
+ readableTextCharThreshold: 100,
+ removeCookieWarnings: true,
+ requestTimeoutSecs: 40,
+ requestTimeoutSecsMax: 300,
+ serpMaxRetries: 2,
+ serpMaxRetriesMax: 5,
+ serpProxyGroup: 'GOOGLE_SERP',
+};
diff --git a/src/crawlers.ts b/src/crawlers.ts
index a7481e3..d8c8163 100644
--- a/src/crawlers.ts
+++ b/src/crawlers.ts
@@ -42,8 +42,15 @@ export async function createAndStartCrawlers(
playwrightScraperSettings: PlaywrightScraperSettings,
startCrawlers: boolean = true,
) {
- const crawler1 = await createAndStartSearchCrawler(cheerioCrawlerOptions, startCrawlers);
- const crawler2 = await createAndStartCrawlerPlaywright(playwrightCrawlerOptions, playwrightScraperSettings);
+ const crawler1 = await createAndStartSearchCrawler(
+ cheerioCrawlerOptions,
+ startCrawlers,
+ );
+ const crawler2 = await createAndStartCrawlerPlaywright(
+ playwrightCrawlerOptions,
+ playwrightScraperSettings,
+ startCrawlers,
+ );
return [crawler1, crawler2];
}
diff --git a/src/defaults.json b/src/defaults.json
deleted file mode 100644
index f7cae11..0000000
--- a/src/defaults.json
+++ /dev/null
@@ -1,19 +0,0 @@
-{
- "debugMode": false,
- "dynamicContentWaitSecs": 10,
- "initialConcurrency": 5,
- "keepAlive": true,
- "maxConcurrency": 10,
- "maxRequestRetries": 1,
- "maxRequestRetriesSearch": 3,
- "maxResults": 3,
- "minConcurrency": 3,
- "outputFormats": ["text"],
- "proxyConfiguration": { "useApifyProxy": true },
- "proxyGroupSearch": "GOOGLE_SERP",
- "query": "",
- "readableTextCharThreshold": 100,
- "removeCookieWarnings": true,
- "requestTimeoutSecs": 45,
- "requestTimeoutContentCrawlSecs": 30
-}
diff --git a/src/google-search/google-extractors-urls.ts b/src/google-search/google-extractors-urls.ts
index 76488ee..5bb3cbb 100644
--- a/src/google-search/google-extractors-urls.ts
+++ b/src/google-search/google-extractors-urls.ts
@@ -42,7 +42,7 @@ const extractResultsFromSelectors = ($: CheerioAPI, selectors: string[]) => {
const parseResult = ($: CheerioAPI, el: Element) => {
$(el).find('div.action-menu').remove();
- const descriptionSelector = '.VwiC3b span';
+ const descriptionSelector = '.VwiC3b';
const searchResult: OrganicResult = {
description: ($(el).find(descriptionSelector).text() || '').trim(),
title: $(el).find('h3').first().text() || '',
diff --git a/src/input.ts b/src/input.ts
index 0a9aa09..aa50cf4 100644
--- a/src/input.ts
+++ b/src/input.ts
@@ -2,20 +2,18 @@ import { Actor } from 'apify';
import { BrowserName, CheerioCrawlerOptions, log, PlaywrightCrawlerOptions } from 'crawlee';
import { firefox } from 'playwright';
-import defaults from './defaults.json' with { type: 'json' };
+import { defaults } from './const.js';
import { UserInputError } from './errors.js';
-import type { Input, PlaywrightScraperSettings } from './types.js';
+import type { Input, PlaywrightScraperSettings, OutputFormats } from './types.js';
/**
* Processes the input and returns the settings for the crawler (adapted from: Website Content Crawler).
*/
export async function processInput(originalInput: Partial) {
- const input: Input = { ...(defaults as unknown as Input), ...originalInput };
+ const input = { ...defaults, ...originalInput } as Input;
- if (input.dynamicContentWaitSecs >= input.requestTimeoutSecs) {
- input.dynamicContentWaitSecs = Math.round(input.requestTimeoutSecs / 2);
- }
+ validateAndFillInput(input);
const {
debugMode,
@@ -25,20 +23,20 @@ export async function processInput(originalInput: Partial) {
minConcurrency,
maxConcurrency,
maxRequestRetries,
- maxRequestRetriesSearch,
+ serpMaxRetries,
outputFormats,
proxyConfiguration,
- proxyGroupSearch,
+ serpProxyGroup,
readableTextCharThreshold,
removeCookieWarnings,
} = input;
log.setLevel(debugMode ? log.LEVELS.DEBUG : log.LEVELS.INFO);
- const proxySearch = await Actor.createProxyConfiguration({ groups: [proxyGroupSearch] });
+ const proxySearch = await Actor.createProxyConfiguration({ groups: [serpProxyGroup] });
const cheerioCrawlerOptions: CheerioCrawlerOptions = {
keepAlive,
- maxRequestRetries: maxRequestRetriesSearch,
+ maxRequestRetries: serpMaxRetries,
proxyConfiguration: proxySearch,
autoscaledPoolOptions: { desiredConcurrency: 1 },
};
@@ -48,7 +46,7 @@ export async function processInput(originalInput: Partial) {
keepAlive,
maxRequestRetries,
proxyConfiguration: proxy,
- requestHandlerTimeoutSecs: input.requestTimeoutContentCrawlSecs,
+ requestHandlerTimeoutSecs: input.requestTimeoutSecs,
launchContext: {
launcher: firefox,
},
@@ -79,11 +77,42 @@ export async function processInput(originalInput: Partial) {
return { input, cheerioCrawlerOptions, playwrightCrawlerOptions, playwrightScraperSettings };
}
-export async function checkInputsAreValid(input: Partial) {
+export function validateAndFillInput(input: Input) {
+ const validateRange = (
+ value: number | undefined,
+ min: number,
+ max: number,
+ defaultValue: number,
+ fieldName: string,
+ ) => {
+ if (value === undefined || value < min) {
+ log.warning(`The "${fieldName}" parameter must be at least ${min}. Using default value ${defaultValue}.`);
+ return defaultValue;
+ } if (value > max) {
+ log.warning(`The "${fieldName}" parameter is limited to ${max}. Using default max value ${max}.`);
+ return max;
+ }
+ return value;
+ };
if (!input.query) {
throw new UserInputError('The "query" parameter must be provided and non-empty');
}
- if (input.maxResults !== undefined && input.maxResults <= 0) {
- throw new UserInputError('The "maxResults" parameter must be greater than 0');
+
+ input.maxResults = validateRange(input.maxResults, 1, defaults.maxResultsMax, defaults.maxResults, 'maxResults');
+ input.requestTimeoutSecs = validateRange(input.requestTimeoutSecs, 1, defaults.requestTimeoutSecsMax, defaults.requestTimeoutSecs, 'requestTimeoutSecs');
+ input.serpMaxRetries = validateRange(input.serpMaxRetries, 0, defaults.serpMaxRetriesMax, defaults.serpMaxRetries, 'serpMaxRetries');
+ input.maxRequestRetries = validateRange(input.maxRequestRetries, 0, defaults.maxRequestRetriesMax, defaults.maxRequestRetries, 'maxRequestRetries');
+
+ if (!input.outputFormats || input.outputFormats.length === 0) {
+ input.outputFormats = defaults.outputFormats as OutputFormats[];
+ log.warning(`The "outputFormats" parameter must be a non-empty array. Using default value ${defaults.outputFormats}.`);
+ } else if (input.outputFormats.some((format) => !['text', 'markdown', 'html'].includes(format))) {
+ throw new UserInputError('The "outputFormats" parameter must contain only "text", "markdown" or "html"');
+ }
+ if (input.serpProxyGroup !== 'GOOGLE_SERP' && input.serpProxyGroup !== 'SHADER') {
+ throw new UserInputError('The "serpProxyGroup" parameter must be either "GOOGLE_SERP" or "SHADER"');
+ }
+ if (input.dynamicContentWaitSecs >= input.requestTimeoutSecs) {
+ input.dynamicContentWaitSecs = Math.round(input.requestTimeoutSecs / 2);
}
}
diff --git a/src/main.ts b/src/main.ts
index b1e735b..0578b70 100644
--- a/src/main.ts
+++ b/src/main.ts
@@ -1,13 +1,22 @@
import { Actor } from 'apify';
import { log } from 'crawlee';
import { createServer, IncomingMessage, ServerResponse } from 'http';
+import { v4 as uuidv4 } from 'uuid';
-import { addSearchRequest, createAndStartCrawlers, getPlaywrightCrawlerKey } from './crawlers.js';
+import { PLAYWRIGHT_REQUEST_TIMEOUT_NORMAL_MODE_SECS } from './const.js';
+import { addPlaywrightCrawlRequest, addSearchRequest, createAndStartCrawlers, getPlaywrightCrawlerKey } from './crawlers.js';
import { UserInputError } from './errors.js';
-import { checkInputsAreValid, processInput } from './input.js';
+import { processInput } from './input.js';
import { addTimeoutToAllResponses, sendResponseError } from './responses.js';
import { Input } from './types.js';
-import { parseParameters, checkForExtraParams, createSearchRequest, addTimeMeasureEvent } from './utils.js';
+import {
+ addTimeMeasureEvent,
+ checkForExtraParams,
+ createRequest,
+ createSearchRequest,
+ interpretAsUrl,
+ parseParameters,
+} from './utils.js';
await Actor.init();
@@ -32,20 +41,29 @@ async function getSearch(request: IncomingMessage, response: ServerResponse) {
playwrightScraperSettings,
} = await processInput(params as Partial);
- await checkInputsAreValid(input);
-
// playwrightCrawlerKey is used to identify the crawler that should process the search results
const playwrightCrawlerKey = getPlaywrightCrawlerKey(playwrightCrawlerOptions, playwrightScraperSettings);
await createAndStartCrawlers(cheerioCrawlerOptions, playwrightCrawlerOptions, playwrightScraperSettings);
- const req = createSearchRequest(
- input.query,
- input.maxResults,
- playwrightCrawlerKey,
- cheerioCrawlerOptions.proxyConfiguration,
- );
+ const inputUrl = interpretAsUrl(input.query);
+ input.query = inputUrl ?? input.query;
+ // Create a request depending on whether the input is a URL or search query
+ const req = inputUrl
+ ? createRequest({ url: input.query }, uuidv4(), null)
+ : createSearchRequest(
+ input.query,
+ input.maxResults,
+ playwrightCrawlerKey,
+ cheerioCrawlerOptions.proxyConfiguration,
+ );
addTimeMeasureEvent(req.userData!, 'request-received', requestReceivedTime);
- await addSearchRequest(req, response, cheerioCrawlerOptions);
+ if (inputUrl) {
+ // If the input query is a URL, we don't need to run the search crawler
+ log.info(`Skipping search crawler as ${input.query} is a valid URL`);
+ await addPlaywrightCrawlRequest(req, req.uniqueKey!, playwrightCrawlerKey);
+ } else {
+ await addSearchRequest(req, response, cheerioCrawlerOptions);
+ }
setTimeout(() => {
sendResponseError(req.uniqueKey!, 'Timed out');
}, input.requestTimeoutSecs * 1000);
@@ -93,8 +111,7 @@ log.info(`Loaded input: ${JSON.stringify(input)},
`);
if (Actor.getEnv().metaOrigin === 'STANDBY') {
- log.info('Actor is running in STANDBY mode with default parameters. '
- + 'Changing these parameters on the fly is not supported at the moment.');
+ log.info('Actor is running in STANDBY mode');
const port = Actor.isAtHome() ? process.env.ACTOR_STANDBY_PORT : 3000;
server.listen(port, async () => {
@@ -106,10 +123,9 @@ if (Actor.getEnv().metaOrigin === 'STANDBY') {
log.info('Actor is running in the NORMAL mode');
try {
const startedTime = Date.now();
- await checkInputsAreValid(input);
-
cheerioCrawlerOptions.keepAlive = false;
playwrightCrawlerOptions.keepAlive = false;
+ playwrightCrawlerOptions.requestHandlerTimeoutSecs = PLAYWRIGHT_REQUEST_TIMEOUT_NORMAL_MODE_SECS;
// playwrightCrawlerKey is used to identify the crawler that should process the search results
const playwrightCrawlerKey = getPlaywrightCrawlerKey(playwrightCrawlerOptions, playwrightScraperSettings);
@@ -120,20 +136,31 @@ if (Actor.getEnv().metaOrigin === 'STANDBY') {
false,
);
- const req = createSearchRequest(
- input.query,
- input.maxResults,
- playwrightCrawlerKey,
- cheerioCrawlerOptions.proxyConfiguration,
- );
+ const inputUrl = interpretAsUrl(input.query);
+ input.query = inputUrl ?? input.query;
+ // Create a request depending on whether the input is a URL or search query
+ const req = inputUrl
+ ? createRequest({ url: input.query }, uuidv4(), null)
+ : createSearchRequest(
+ input.query,
+ input.maxResults,
+ playwrightCrawlerKey,
+ cheerioCrawlerOptions.proxyConfiguration,
+ );
addTimeMeasureEvent(req.userData!, 'actor-started', startedTime);
- await addSearchRequest(req, null, cheerioCrawlerOptions);
- log.info(`Running search crawler with request: ${JSON.stringify(req)}`);
- addTimeMeasureEvent(req.userData!, 'before-cheerio-run', startedTime);
- await searchCrawler!.run();
+ if (inputUrl) {
+ // If the input query is a URL, we don't need to run the search crawler
+ log.info(`Skipping Google Search query because "${input.query}" is a valid URL`);
+ await addPlaywrightCrawlRequest(req, req.uniqueKey!, playwrightCrawlerKey);
+ } else {
+ await addSearchRequest(req, null, cheerioCrawlerOptions);
+ addTimeMeasureEvent(req.userData!, 'before-cheerio-run', startedTime);
+ log.info(`Running Google Search crawler with request: ${JSON.stringify(req)}`);
+ await searchCrawler!.run();
+ }
- log.info(`Running content crawler with request: ${JSON.stringify(req)}`);
addTimeMeasureEvent(req.userData!, 'before-playwright-run', startedTime);
+ log.info(`Running target page crawler with request: ${JSON.stringify(req)}`);
await playwrightCrawler!.run();
} catch (e) {
const error = e as Error;
diff --git a/src/playwright-req-handler.ts b/src/playwright-req-handler.ts
index 374729a..03c4fd8 100644
--- a/src/playwright-req-handler.ts
+++ b/src/playwright-req-handler.ts
@@ -9,6 +9,8 @@ import { addTimeMeasureEvent, transformTimeMeasuresToRelative } from './utils.js
import { processHtml } from './website-content-crawler/html-processing.js';
import { htmlToMarkdown } from './website-content-crawler/markdown.js';
+const ACTOR_TIMEOUT_AT = process.env.ACTOR_TIMEOUT_AT ? parseInt(process.env.ACTOR_TIMEOUT_AT, 10) : null;
+
/**
* Waits for the `time` to pass, but breaks early if the page is loaded (source: Website Content Crawler).
*/
@@ -20,12 +22,27 @@ async function waitForPlaywright({ page }: PlaywrightCrawlingContext, time: numb
return Promise.race([page.waitForLoadState('networkidle', { timeout: 0 }), sleep(time - hardDelay)]);
}
+/**
+ * Decide whether to wait based on the remaining time left for the Actor to run.
+ * Always waits if the Actor is in the STANDBY_MODE.
+ */
+export function hasTimeLeftToTimeout(time: number) {
+ if (process.env.STANDBY_MODE) return true;
+ if (!ACTOR_TIMEOUT_AT) return true;
+
+ const timeLeft = ACTOR_TIMEOUT_AT - Date.now();
+ if (timeLeft > time) return true;
+
+ log.debug('Not enough time left to wait for dynamic content. Skipping');
+ return false;
+}
+
/**
* Waits for the `time`, but checks the content length every half second and breaks early if it hasn't changed
* in last 2 seconds (source: Website Content Crawler).
*/
export async function waitForDynamicContent(context: PlaywrightCrawlingContext, time: number) {
- if (context.page) {
+ if (context.page && hasTimeLeftToTimeout(time)) {
await waitForPlaywright(context, time);
}
}
@@ -73,9 +90,9 @@ export async function requestHandlerPlaywright(
requestStatus: ContentCrawlerStatus.FAILED,
},
metadata: { url: request.url },
- googleSearchResult: request.userData.googleSearchResult!,
+ searchResult: request.userData.searchResult!,
query: request.userData.query,
- text: request.userData.googleSearchResult?.description || '',
+ text: '',
};
log.info(`Adding result to the Apify dataset, url: ${request.url}`);
await context.pushData(resultSkipped);
@@ -102,7 +119,7 @@ export async function requestHandlerPlaywright(
uniqueKey: request.uniqueKey,
requestStatus: ContentCrawlerStatus.HANDLED,
},
- googleSearchResult: request.userData.googleSearchResult!,
+ searchResult: request.userData.searchResult!,
metadata: {
author: $('meta[name=author]').first().attr('content') ?? null,
title: $('title').first().text(),
@@ -111,8 +128,8 @@ export async function requestHandlerPlaywright(
languageCode: $html.first().attr('lang') ?? null,
url: request.url,
},
- text,
query: request.userData.query,
+ text: settings.outputFormats.includes('text') ? text : null,
markdown: settings.outputFormats.includes('markdown') ? htmlToMarkdown(processedHtml) : null,
html: settings.outputFormats.includes('html') ? processedHtml : null,
};
@@ -145,12 +162,12 @@ export async function failedRequestHandlerPlaywright(request: Request, err: Erro
uniqueKey: request.uniqueKey,
requestStatus: ContentCrawlerStatus.FAILED,
},
- googleSearchResult: request.userData.googleSearchResult!,
+ searchResult: request.userData.searchResult!,
metadata: {
url: request.url,
- title: request.userData.googleSearchResult?.title,
+ title: '',
},
- text: request.userData.googleSearchResult?.description || '',
+ text: '',
};
log.info(`Adding result to the Apify dataset, url: ${request.url}`);
await Actor.pushData(resultErr);
diff --git a/src/responses.ts b/src/responses.ts
index 08821eb..d8bd604 100644
--- a/src/responses.ts
+++ b/src/responses.ts
@@ -46,7 +46,7 @@ export const addEmptyResultToResponse = (responseId: string, request: RequestOpt
const result: Partial