- ![]() -
-
 +### Current tools supported
+
+| ML framework/HLS backend | (Q)Keras | PyTorch | (Q)ONNX | Vivado HLS | Intel HLS | Vitis HLS |
+|--------------------------|-----------|---------|----------------|------------|-----------|--------------|
+| MLP | supported | limited | in development | supported | supported | experimental |
+| CNN | supported | limited | in development | supported | supported | experimental |
+| RNN (LSTM) | supported | N/A | in development | supported | supported | N/A |
+| GNN (GarNet) | supported | N/A | N/A | N/A | N/A | N/A |
+
+
+### Compile an example model
+
+```python
+import hls4ml
+
+# Fetch a keras model from our example repository
+# This will download our example model to your working directory and return an example configuration file
+config = hls4ml.utils.fetch_example_model('KERAS_3layer.json')
+
+# You can print the configuration to see some default parameters
+print(config)
+
+# Convert it to a hls project
+hls_model = hls4ml.converters.keras_to_hls(config)
+
+# Print full list of example models if you want to explore more
+hls4ml.utils.fetch_example_list()
+
+# Use Vivado HLS to synthesize the model
+# This might take several minutes
+hls_model.build()
+
+# Print out the report if you want
+hls4ml.report.read_vivado_report('my-hls-test')
+
+```
+
+### More resources
+
The main hls4ml tutorial code is kept on [GitHub](https://github.com/fastmachinelearning/hls4ml-tutorial). Users are welcome to walk through the notebooks at their own pace. There is also a set of slides linked to the [README](https://github.com/fastmachinelearning/hls4ml-tutorial/blob/master/README.md).
That said, there have been several cases where the hls4ml developers have given live demonstrations and tutorials. Below is a non-exhaustive list of tutorials given in the last few years (newest on top).
diff --git a/content/inference/qonnx.md b/content/inference/qonnx.md
new file mode 100644
index 0000000..6e80b47
--- /dev/null
+++ b/content/inference/qonnx.md
@@ -0,0 +1,24 @@
+# Direct inference with (Q)ONNX Runtime
+
+[](http://qonnx.readthedocs.io/)
+[](https://badge.fury.io/py/qonnx)
+[](https://arxiv.org/abs/2206.07527)
+
+Text taken and adopted from the QONNX [README.md](https://github.com/fastmachinelearning/qonnx/blob/main/README.md).
+
+
+### Current tools supported
+
+| ML framework/HLS backend | (Q)Keras | PyTorch | (Q)ONNX | Vivado HLS | Intel HLS | Vitis HLS |
+|--------------------------|-----------|---------|----------------|------------|-----------|--------------|
+| MLP | supported | limited | in development | supported | supported | experimental |
+| CNN | supported | limited | in development | supported | supported | experimental |
+| RNN (LSTM) | supported | N/A | in development | supported | supported | N/A |
+| GNN (GarNet) | supported | N/A | N/A | N/A | N/A | N/A |
+
+
+### Compile an example model
+
+```python
+import hls4ml
+
+# Fetch a keras model from our example repository
+# This will download our example model to your working directory and return an example configuration file
+config = hls4ml.utils.fetch_example_model('KERAS_3layer.json')
+
+# You can print the configuration to see some default parameters
+print(config)
+
+# Convert it to a hls project
+hls_model = hls4ml.converters.keras_to_hls(config)
+
+# Print full list of example models if you want to explore more
+hls4ml.utils.fetch_example_list()
+
+# Use Vivado HLS to synthesize the model
+# This might take several minutes
+hls_model.build()
+
+# Print out the report if you want
+hls4ml.report.read_vivado_report('my-hls-test')
+
+```
+
+### More resources
+
The main hls4ml tutorial code is kept on [GitHub](https://github.com/fastmachinelearning/hls4ml-tutorial). Users are welcome to walk through the notebooks at their own pace. There is also a set of slides linked to the [README](https://github.com/fastmachinelearning/hls4ml-tutorial/blob/master/README.md).
That said, there have been several cases where the hls4ml developers have given live demonstrations and tutorials. Below is a non-exhaustive list of tutorials given in the last few years (newest on top).
diff --git a/content/inference/qonnx.md b/content/inference/qonnx.md
new file mode 100644
index 0000000..6e80b47
--- /dev/null
+++ b/content/inference/qonnx.md
@@ -0,0 +1,24 @@
+# Direct inference with (Q)ONNX Runtime
+
+[](http://qonnx.readthedocs.io/)
+[](https://badge.fury.io/py/qonnx)
+[](https://arxiv.org/abs/2206.07527)
+
+Text taken and adopted from the QONNX [README.md](https://github.com/fastmachinelearning/qonnx/blob/main/README.md).
+
+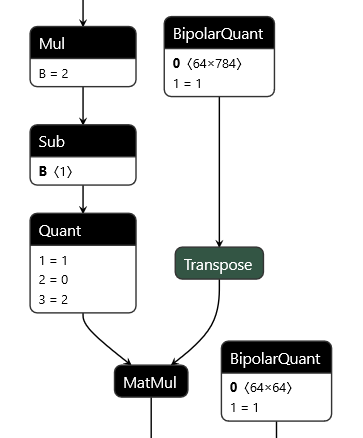 +
+QONNX (Quantized ONNX) introduces three new custom operators -- [`Quant`](docs/qonnx-custom-ops/quant_op.md), [`BipolarQuant`](docs/qonnx-custom-ops/bipolar_quant_op.md), and [`Trunc`](docs/qonnx-custom-ops/trunc_op.md) -- in order to represent arbitrary-precision uniform quantization in [ONNX](onnx.md). This enables:
+
+* Representation of binary, ternary, 3-bit, 4-bit, 6-bit or any other quantization.
+* Quantization is an operator itself, and can be applied to any parameter or layer input.
+* Flexible choices for scaling factor and zero-point granularity.
+* Quantized values are carried using standard `float` datatypes to remain [ONNX](onnx.md) protobuf-compatible.
+
+This repository contains a set of Python utilities to work with QONNX models, including but not limited to:
+
+* executing QONNX models for (slow) functional verification
+* shape inference, constant folding and other basic optimizations
+* summarizing the inference cost of a QONNX model in terms of mixed-precision MACs, parameter and activation volume
+* Python infrastructure for writing transformations and defining executable, shape-inferencable custom ops
+* (experimental) data layout conversion from standard ONNX NCHW to custom QONNX NHWC ops
diff --git a/content/resources/fpga_resources/index.md b/content/resources/fpga_resources/index.md
index 67d86a3..a3e34ce 100644
--- a/content/resources/fpga_resources/index.md
+++ b/content/resources/fpga_resources/index.md
@@ -1,2 +1,13 @@
-Work in progress.
+# CMS-ML FPGA Resource
+## Introduction
+Welcome to FPGA Resource tab! Our tab is designed to provide accurate, up-to-date, and relevant information about tooling used in CMS for ML on FPGAs.
+## FPGA Basics
+
+Field-Programmable Gate Array (FPGA) are reconfigurable hardware for creating custom digital circuits. FPGAs are build out of Configurable Logic Blocks (CLBs), Programmable Interconnects, and I/O Blocks. They are used in areas where high parallel processing and high performance is needed.
+
+To programm an FPGA one has two main options. The first one is to use a Hardware Design Languages (HDL) while the second one is to use High-Level Design Tools (HLS). In the HDL case one has the control about everything but the design flow can be kind of tricky. Mostly two languages are used VHDL, which is verbose and structured, and Verilog, which is more compact and looks more like a c-style language. In CMS most of the FPGAs are programmed using VHDL.
+
+When it comes to vendors there are two big onces: Xilinx (part of AMD) and Altera (part of Intel). Both vendors provide there own tooling to simulate, synthesis and debug the design. Xilinx FPGAs are used for CMS and they have Vivado for design, simulation, synthesis, and debugging tasks and Vitis for software development for Xilinx FPGAs and SoCs. Intel FPGAs are programmed using Quartus Prime. For HLS tools they come with Vivado HLS (Xilinx) and HLS Compiler (Intel).
+
+To simplify the pipeline from a trained model to an implementation on the FPGA CMS is supporting different tools, which are explained in the inference section ([hls4ml](../../inference/hls4ml.md), [conifer](../../inference/conifer.md), [qonnx](../../inference/qonnx.md)). Furthermore, tools for quantize aware training are used (QKeras, [HGQ](../../training/HGQ.md)).
diff --git a/content/training/HGQ.md b/content/training/HGQ.md
new file mode 100644
index 0000000..d2861df
--- /dev/null
+++ b/content/training/HGQ.md
@@ -0,0 +1,48 @@
+High Granularity Quantization (HGQ)
+
+[](https://calad0i.github.io/HGQ/)
+[](https://badge.fury.io/py/hgq)
+[](https://arxiv.org/abs/2405.00645)
+
+Text taken and adopted from the HGQ [README.md](https://github.com/calad0i/HGQ/blob/master/README.md).
+
+[High Granularity Quantization (HGQ)](https://github.com/calad0i/HGQ/) is a library that performs gradient-based automatic bitwidth optimization and quantization-aware training algorithm for neural networks to be deployed on FPGAs. By laveraging gradients, it allows for bitwidth optimization at arbitrary granularity, up to per-weight and per-activation level.
+
+
+
+Conversion of models made with HGQ library is fully supported. The HGQ models are first converted to proxy model format, which can then be parsed by hls4ml bit-accurately. Below is an example of how to create a model with HGQ and convert it to hls4ml model.
+
+```python
+ import keras
+ from HGQ.layers import HDense, HDenseBatchNorm, HQuantize
+ from HGQ import ResetMinMax, FreeBOPs
+
+ model = keras.models.Sequential([
+ HQuantize(beta=1.e-5),
+ HDenseBatchNorm(32, beta=1.e-5, activation='relu'),
+ HDenseBatchNorm(32, beta=1.e-5, activation='relu'),
+ HDense(10, beta=1.e-5),
+ ])
+
+ opt = keras.optimizers.Adam(learning_rate=0.001)
+ loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
+ model.compile(optimizer=opt, loss=loss, metrics=['accuracy'])
+ callbacks = [ResetMinMax(), FreeBOPs()]
+
+ model.fit(..., callbacks=callbacks)
+
+ from HGQ import trace_minmax, to_proxy_model
+ from hls4ml.converters import convert_from_keras_model
+
+ trace_minmax(model, x_train, cover_factor=1.0)
+ proxy = to_proxy_model(model, aggressive=True)
+
+ model_hls = convert_from_keras_model(
+ proxy,
+ backend='vivado',
+ output_dir=...,
+ part=...
+ )
+```
+
+An interactive example of HGQ can be found in the [kaggle notebook](https://www.kaggle.com/code/calad0i/small-jet-tagger-with-hgq-1). Full documentation can be found at [calad0i.github.io/HGQ](https://calad0i.github.io/HGQ/>).
diff --git a/mkdocs.yml b/mkdocs.yml
index 6ee7d00..e94e4ab 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -150,6 +150,7 @@ nav:
- PyTorch: inference/pytorch.md
- PyTorch Geometric: inference/pyg.md
- ONNX: inference/onnx.md
+ - QONNX: inference/qonnx.md
- XGBoost: inference/xgboost.md
- hls4ml: inference/hls4ml.md
- conifer: inference/conifer.md
@@ -168,4 +169,5 @@ nav:
- Training as a Service:
- MLaaS4HEP: training/MLaaS4HEP.md
- Autoencoders: training/autoencoders.md
+ - HGQ: training/HGQ.md
# - Benchmarking:
+
+QONNX (Quantized ONNX) introduces three new custom operators -- [`Quant`](docs/qonnx-custom-ops/quant_op.md), [`BipolarQuant`](docs/qonnx-custom-ops/bipolar_quant_op.md), and [`Trunc`](docs/qonnx-custom-ops/trunc_op.md) -- in order to represent arbitrary-precision uniform quantization in [ONNX](onnx.md). This enables:
+
+* Representation of binary, ternary, 3-bit, 4-bit, 6-bit or any other quantization.
+* Quantization is an operator itself, and can be applied to any parameter or layer input.
+* Flexible choices for scaling factor and zero-point granularity.
+* Quantized values are carried using standard `float` datatypes to remain [ONNX](onnx.md) protobuf-compatible.
+
+This repository contains a set of Python utilities to work with QONNX models, including but not limited to:
+
+* executing QONNX models for (slow) functional verification
+* shape inference, constant folding and other basic optimizations
+* summarizing the inference cost of a QONNX model in terms of mixed-precision MACs, parameter and activation volume
+* Python infrastructure for writing transformations and defining executable, shape-inferencable custom ops
+* (experimental) data layout conversion from standard ONNX NCHW to custom QONNX NHWC ops
diff --git a/content/resources/fpga_resources/index.md b/content/resources/fpga_resources/index.md
index 67d86a3..a3e34ce 100644
--- a/content/resources/fpga_resources/index.md
+++ b/content/resources/fpga_resources/index.md
@@ -1,2 +1,13 @@
-Work in progress.
+# CMS-ML FPGA Resource
+## Introduction
+Welcome to FPGA Resource tab! Our tab is designed to provide accurate, up-to-date, and relevant information about tooling used in CMS for ML on FPGAs.
+## FPGA Basics
+
+Field-Programmable Gate Array (FPGA) are reconfigurable hardware for creating custom digital circuits. FPGAs are build out of Configurable Logic Blocks (CLBs), Programmable Interconnects, and I/O Blocks. They are used in areas where high parallel processing and high performance is needed.
+
+To programm an FPGA one has two main options. The first one is to use a Hardware Design Languages (HDL) while the second one is to use High-Level Design Tools (HLS). In the HDL case one has the control about everything but the design flow can be kind of tricky. Mostly two languages are used VHDL, which is verbose and structured, and Verilog, which is more compact and looks more like a c-style language. In CMS most of the FPGAs are programmed using VHDL.
+
+When it comes to vendors there are two big onces: Xilinx (part of AMD) and Altera (part of Intel). Both vendors provide there own tooling to simulate, synthesis and debug the design. Xilinx FPGAs are used for CMS and they have Vivado for design, simulation, synthesis, and debugging tasks and Vitis for software development for Xilinx FPGAs and SoCs. Intel FPGAs are programmed using Quartus Prime. For HLS tools they come with Vivado HLS (Xilinx) and HLS Compiler (Intel).
+
+To simplify the pipeline from a trained model to an implementation on the FPGA CMS is supporting different tools, which are explained in the inference section ([hls4ml](../../inference/hls4ml.md), [conifer](../../inference/conifer.md), [qonnx](../../inference/qonnx.md)). Furthermore, tools for quantize aware training are used (QKeras, [HGQ](../../training/HGQ.md)).
diff --git a/content/training/HGQ.md b/content/training/HGQ.md
new file mode 100644
index 0000000..d2861df
--- /dev/null
+++ b/content/training/HGQ.md
@@ -0,0 +1,48 @@
+High Granularity Quantization (HGQ)
+
+[](https://calad0i.github.io/HGQ/)
+[](https://badge.fury.io/py/hgq)
+[](https://arxiv.org/abs/2405.00645)
+
+Text taken and adopted from the HGQ [README.md](https://github.com/calad0i/HGQ/blob/master/README.md).
+
+[High Granularity Quantization (HGQ)](https://github.com/calad0i/HGQ/) is a library that performs gradient-based automatic bitwidth optimization and quantization-aware training algorithm for neural networks to be deployed on FPGAs. By laveraging gradients, it allows for bitwidth optimization at arbitrary granularity, up to per-weight and per-activation level.
+
+
+
+Conversion of models made with HGQ library is fully supported. The HGQ models are first converted to proxy model format, which can then be parsed by hls4ml bit-accurately. Below is an example of how to create a model with HGQ and convert it to hls4ml model.
+
+```python
+ import keras
+ from HGQ.layers import HDense, HDenseBatchNorm, HQuantize
+ from HGQ import ResetMinMax, FreeBOPs
+
+ model = keras.models.Sequential([
+ HQuantize(beta=1.e-5),
+ HDenseBatchNorm(32, beta=1.e-5, activation='relu'),
+ HDenseBatchNorm(32, beta=1.e-5, activation='relu'),
+ HDense(10, beta=1.e-5),
+ ])
+
+ opt = keras.optimizers.Adam(learning_rate=0.001)
+ loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
+ model.compile(optimizer=opt, loss=loss, metrics=['accuracy'])
+ callbacks = [ResetMinMax(), FreeBOPs()]
+
+ model.fit(..., callbacks=callbacks)
+
+ from HGQ import trace_minmax, to_proxy_model
+ from hls4ml.converters import convert_from_keras_model
+
+ trace_minmax(model, x_train, cover_factor=1.0)
+ proxy = to_proxy_model(model, aggressive=True)
+
+ model_hls = convert_from_keras_model(
+ proxy,
+ backend='vivado',
+ output_dir=...,
+ part=...
+ )
+```
+
+An interactive example of HGQ can be found in the [kaggle notebook](https://www.kaggle.com/code/calad0i/small-jet-tagger-with-hgq-1). Full documentation can be found at [calad0i.github.io/HGQ](https://calad0i.github.io/HGQ/>).
diff --git a/mkdocs.yml b/mkdocs.yml
index 6ee7d00..e94e4ab 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -150,6 +150,7 @@ nav:
- PyTorch: inference/pytorch.md
- PyTorch Geometric: inference/pyg.md
- ONNX: inference/onnx.md
+ - QONNX: inference/qonnx.md
- XGBoost: inference/xgboost.md
- hls4ml: inference/hls4ml.md
- conifer: inference/conifer.md
@@ -168,4 +169,5 @@ nav:
- Training as a Service:
- MLaaS4HEP: training/MLaaS4HEP.md
- Autoencoders: training/autoencoders.md
+ - HGQ: training/HGQ.md
# - Benchmarking: