diff --git a/docs-website/sidebars.js b/docs-website/sidebars.js
index 986066ee14a729..28a471d57f995e 100644
--- a/docs-website/sidebars.js
+++ b/docs-website/sidebars.js
@@ -96,7 +96,7 @@ module.exports = {
className: "saasOnly",
},
{
- label: "Assertion Notes (Troubleshooting & Documentation)",
+ label: "Adding Notes to Assertions",
type: "doc",
id: "docs/managed-datahub/observe/assertion-notes",
className: "saasOnly",
diff --git a/docs/managed-datahub/observe/assertions.md b/docs/managed-datahub/observe/assertions.md
index 6f1039b9a66979..a8bc9a37d41539 100644
--- a/docs/managed-datahub/observe/assertions.md
+++ b/docs/managed-datahub/observe/assertions.md
@@ -2,8 +2,7 @@
:::note Supported Data Platforms
Currently we support monitoring data on Snowflake, Redshift, BigQuery, and Databricks as part of DataHub Cloud Observe.
-For other data platforms, DataHub Cloud Observe can monitor assertions against dataset metrics (such as volume, or column nullness) and dataset freshenss by using the ingested statistics for each asset.
-Column Value and Custom SQL Assertions are not currently supported for other data platforms.
+DataHub Cloud Observe can still monitor assertions for other data platforms against dataset metrics (such as row count, or column nullness) and dataset freshenss by using the [ingested statistics](/metadata-ingestion/docs/dev_guides/sql_profiles.md).
:::
An assertion is **a data quality test that finds data that violates a specified rule.**
@@ -25,13 +24,11 @@ For DataHub-provided assertion runners, we can deploy an agent in your environme
#### Bulk Creating Assertions
-You can bulk create Freshness and Volume [Smart Assertions](/docs/managed-datahub/observe/smart-assertions.md) (AI Anomaly Monitors) across several tables at once via the [Data Health Dashboard](/docs/managed-datahub/observe/data-health-dashboard.md):
-
-
+You can bulk create Freshness and Volume [Smart Assertions](/docs/managed-datahub/observe/smart-assertions.md) (AI Anomaly Monitors) across several tables at once via the [Data Health Dashboard](/docs/managed-datahub/observe/data-health-dashboard.md).
To bulk create column metric assertions on a given dataset, follow the steps under the **Anomaly Detection** section of [Column Assertion](https://docs.datahub.com/docs/managed-datahub/observe/column-assertions#anomaly-detection-with-smart-assertions-).
-### AI Anomaly Detection (Smart Assertions)
+### Detecting Anomalies Across Massive Data Landscapes
There are many cases where either you do not have the time to figure out what a good rule for an assertion is, or strict rules simply do not suffice for your data validation needs. Traditional rule-based assertions can become inadequate when dealing with complex data patterns or large-scale operations.
@@ -45,7 +42,7 @@ Here are some typical situations where manual assertion rules fall short:
- **Dynamic data environments** - When data patterns evolve over time, manually updating assertion rules becomes a maintenance burden that can lead to false positives or missed anomalies.
-### The Smart Assertion Solution
+### The AI Smart Assertion Solution
In these scenarios, you may want to consider creating a [Smart Assertion](./smart-assertions.md) to let machine learning automatically detect the normal patterns in your data and alert you when anomalies occur. This approach allows for more flexible and adaptive data quality monitoring without the overhead of manual rule maintenance.
diff --git a/docs/managed-datahub/observe/column-assertions.md b/docs/managed-datahub/observe/column-assertions.md
index 0614a38ab89caa..bc9cad4a07f4d5 100644
--- a/docs/managed-datahub/observe/column-assertions.md
+++ b/docs/managed-datahub/observe/column-assertions.md
@@ -126,86 +126,92 @@ Once these are in place, you're ready to create your Column Assertions!
### Steps
-1. Navigate to the Table that you want to monitor
-2. Click the **Quality** tab
+#### 1. Navigate to the Table that you want to monitor
+
+#### 2. Click the **Quality** tab
-3. Click **+ Create Assertion**
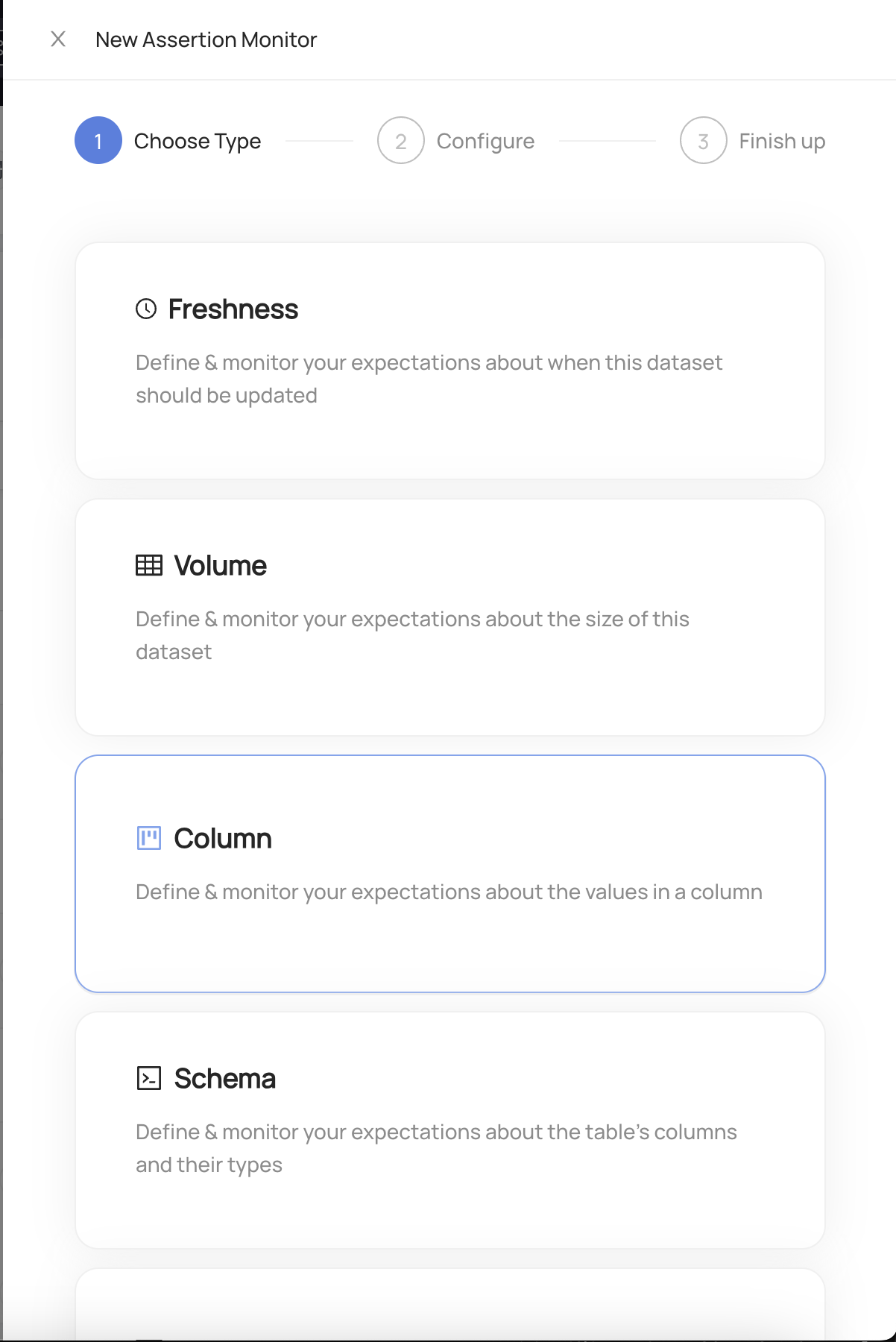
+#### 3. Click **+ Create Assertion**
+
+#### 4. Choose **'Column'**
-4. Choose **Column**
+#### 5. Configure the evaluation **schedule**.
-5. Configure the evaluation **schedule**. This is the frequency at which the assertion will be evaluated to produce a
- pass or fail result, and the times when the column values will be checked.
+This is the frequency at which the assertion will be evaluated to produce a
+pass or fail result, and the times when the column values will be checked.
-6. Configure the **column assertion type**. You can choose from **Column Value** or **Column Metric**.
- **Column Value** assertions are used to monitor the value of a specific column in a table, and ensure that every row
- adheres to a specific condition. **Column Metric** assertions are used to compute a metric for that column, and then compare the value of that metric to your expectations.
+#### 6. Configure the **column assertion type**.
+
+You can choose from **Column Value** or **Column Metric**.
+**Column Value** assertions are used to monitor the value of a specific column in a table, and ensure that every row
+adheres to a specific condition. **Column Metric** assertions are used to compute a metric for that column, and then compare the value of that metric to your expectations.

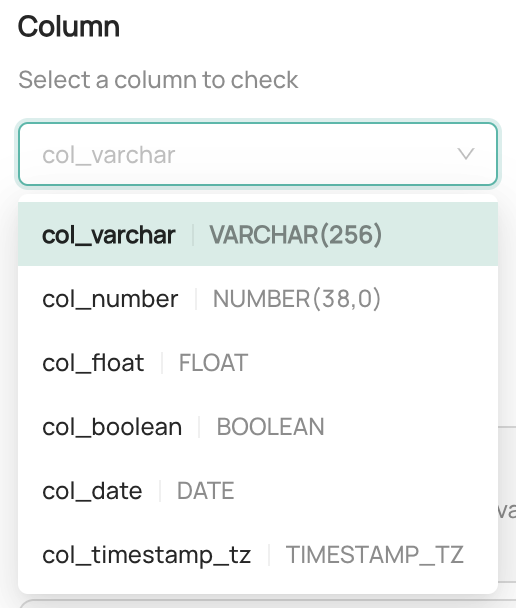
-7. Configure the **column selection**. This defines the column that should be monitored by the Column Assertion.
- You can choose from any of the columns from the table listed in the dropdown.
+#### 7. Configure the **column selection**.
+
+This defines the column that should be monitored by the Column Assertion.
+You can choose from any of the columns from the table listed in the dropdown.
-8. Configure the **evaluation criteria**. This step varies based on the type of assertion you chose in the previous step.
+#### 8. Configure the **evaluation criteria**. This step varies based on the type of assertion you chose in the previous step.
- - **Column Value Assertions**: You will be able to choose from a set of operators that can be applied to the column
- value. The options presented will vary based on the data type of the selected column. For example with numeric types, you
- can check that the column value is greater than a specific value. For string types, you can check that the column value
- matches a particular regex pattern. You will also be able to control the behavior of null values in the column. If the
- **Allow Nulls** option is _disabled_, any null values encountered will be reported as a failure when evaluating the
- assertion.
+- **Column Value Assertions**: You will be able to choose from a set of operators that can be applied to the column
+ value. The options presented will vary based on the data type of the selected column. For example with numeric types, you
+ can check that the column value is greater than a specific value. For string types, you can check that the column value
+ matches a particular regex pattern. You will also be able to control the behavior of null values in the column. If the
+ **Allow Nulls** option is _disabled_, any null values encountered will be reported as a failure when evaluating the
+ assertion. Note, Smart Assertions are not supported for Column Value Assertions today.
- - **Column Metric Assertions**: You will be able to choose from a list of common metrics and then specify the operator
- and value to compare against. The list of metrics will vary based on the data type of the selected column. For example
- with numeric types, you can choose to compute the average value of the column, and then assert that it is greater than a
- specific number. For string types, you can choose to compute the max length of all column values, and then assert that it
- is less than a specific number.
+- **Column Metric Assertions**: You will be able to choose from a list of common metrics and then specify the operator
+ and value to compare against. The list of metrics will vary based on the data type of the selected column. For example
+ with numeric types, you can choose to compute the average value of the column, and then assert that it is greater than a
+ specific number. For string types, you can choose to compute the max length of all column values, and then assert that it
+ is less than a specific number. You can also select the **Detect with AI** option to use Smart Assertions to detect anomalies in the column metric.
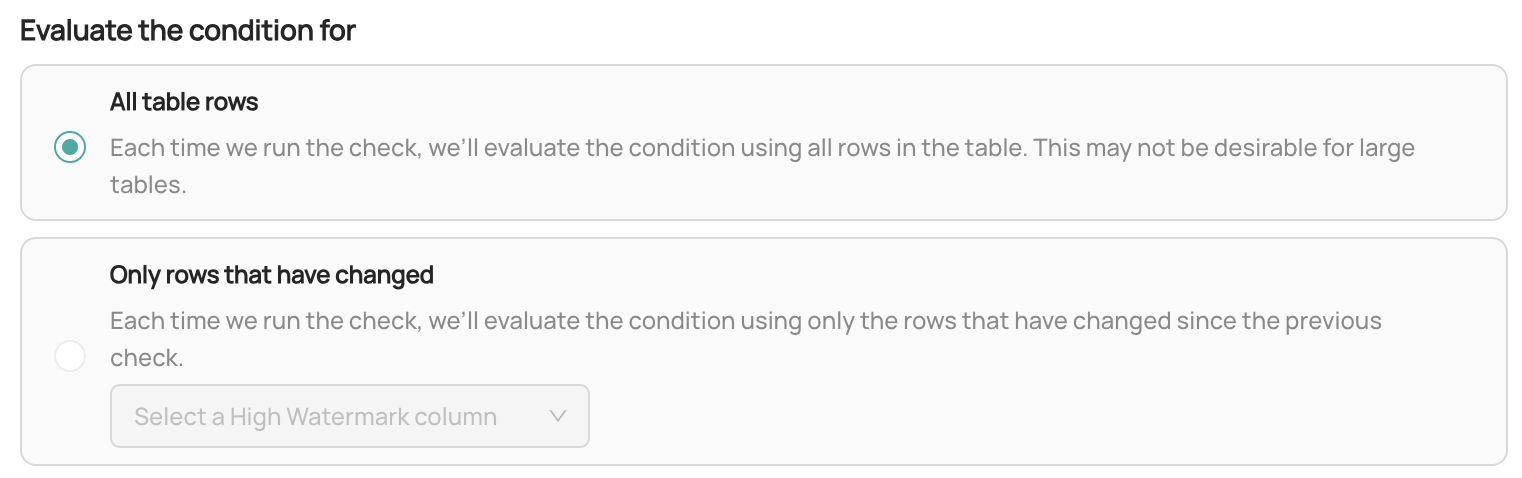
-9. Configure the **row evaluation type**. This defines which rows in the table the Column Assertion should evaluate. You can choose
- from the following options:
+#### 9. Configure the **row evaluation type**. This defines which rows in the table the Column Assertion should evaluate.
- - **All Table Rows**: Evaluate the Column Assertion against all rows in the table. This is the default option. Note that
- this may not be desirable for large tables.
+- **All Table Rows**: Evaluate the Column Assertion against all rows in the table. This is the default option. Note that
+ this may not be desirable for large tables.
- - **Only Rows That Have Changed**: Evaluate the Column Assertion only against rows that have changed since the last
- evaluation. If you choose this option, you will need to specify a **High Watermark Column** to help determine which rows
- have changed. A **High Watermark Column** is a column that contains a constantly-incrementing value - a date, a time, or
- another always-increasing number. When selected, a query will be issued to the table find only the rows which have changed since the last assertion run.
+- **Only Rows That Have Changed**: Evaluate the Column Assertion only against rows that have changed since the last
+ evaluation. If you choose this option, you will need to specify a **High Watermark Column** to help determine which rows
+ have changed. A **High Watermark Column** is a column that contains a constantly-incrementing value - a date, a time, or
+ another always-increasing number. When selected, a query will be issued to the table find only the rows which have changed since the last assertion run.
-10. (Optional) Click **Advanced** to further customize the Column Assertion. The options listed here will vary based on the
- type of assertion you chose in the previous step.
+#### 10. (Optional) Click **Advanced** to further customize the Column Assertion.
+
+The options listed here will vary based on the type of assertion you chose in the previous step.
- - **Invalid Values Threshold**: For **Column Value** assertions, you can configure the number of invalid values
- (i.e. rows) that are allowed to fail before the assertion is marked as failing. This is useful if you want to allow a limited number
- of invalid values in the column. By default this is 0, meaning the assertion will fail if any rows have an invalid column value.
+- **Invalid Values Threshold**: For **Column Value** assertions, you can configure the number of invalid values
+ (i.e. rows) that are allowed to fail before the assertion is marked as failing. This is useful if you want to allow a limited number
+ of invalid values in the column. By default this is 0, meaning the assertion will fail if any rows have an invalid column value.
- - **Source**: For **Column Metric** assertions, you can choose the mechanism that will be used to obtain the column
- metric. **Query** will issue a query to the dataset to compute the metric. **DataHub Dataset Profile** will use the
- DataHub Dataset Profile metadata to compute the metric. Note that this option requires that dataset profiling
- statistics are up-to-date as of the assertion run time.
+- **Source**: For **Column Metric** assertions, you can choose the mechanism that will be used to obtain the column
+ metric. **Query** will issue a query to the dataset to compute the metric. This issues a query to the table, which can be more expensive than Information Schema.
+ **DataHub Dataset Profile** will use the DataHub Dataset Profile metadata to compute the metric. This is the cheapest option, but requires that Dataset Profiles are reported to DataHub. By default, Ingestion will report Dataset Profiles to DataHub, which can be and infrequent. You can report Dataset Profiles via the DataHub APIs for more frequent and reliable data.
- - **Additional Filters**: You can choose to add additional filters to the query that will be used to evaluate the
- assertion. This is useful if you want to limit the assertion to a subset of rows in the table. Note this option will not
- be available if you choose **DataHub Dataset Profile** as the **source**.
+- **Additional Filters**: You can choose to add additional filters to the query that will be used to evaluate the
+ assertion. This is useful if you want to limit the assertion to a subset of rows in the table. Note this option will not
+ be available if you choose **DataHub Dataset Profile** as the **source**.
-11. Configure actions that should be taken when the Column Assertion passes or fails
+#### 11. Configure actions that should be taken when the Column Assertion passes or fails
 @@ -217,7 +223,7 @@ Once these are in place, you're ready to create your Column Assertions!
- **Resolve incident**: Automatically resolved any incidents that were raised due to failures in this Column Assertion. Note that
any other incidents will not be impacted.
-12. Click **Next** and then **Save**.
+#### 12. Click **Next** and then **Save**.
And that's it! DataHub will now begin to monitor your Column Assertion for the table.
@@ -276,7 +282,7 @@ Note that to create or delete Assertions and Monitors for a specific entity on D
In order to create or update a Column Assertion, you can the `upsertDatasetColumnAssertionMonitor` mutation.
-##### Examples
+#### Examples
Creating a Field Values Column Assertion that runs every 8 hours:
diff --git a/docs/managed-datahub/observe/freshness-assertions.md b/docs/managed-datahub/observe/freshness-assertions.md
index f7a37d3fceaf52..dda4d4abb94a17 100644
--- a/docs/managed-datahub/observe/freshness-assertions.md
+++ b/docs/managed-datahub/observe/freshness-assertions.md
@@ -188,14 +188,14 @@ _Check whether the table has changed in a specific window of time_
@@ -217,7 +223,7 @@ Once these are in place, you're ready to create your Column Assertions!
- **Resolve incident**: Automatically resolved any incidents that were raised due to failures in this Column Assertion. Note that
any other incidents will not be impacted.
-12. Click **Next** and then **Save**.
+#### 12. Click **Next** and then **Save**.
And that's it! DataHub will now begin to monitor your Column Assertion for the table.
@@ -276,7 +282,7 @@ Note that to create or delete Assertions and Monitors for a specific entity on D
In order to create or update a Column Assertion, you can the `upsertDatasetColumnAssertionMonitor` mutation.
-##### Examples
+#### Examples
Creating a Field Values Column Assertion that runs every 8 hours:
diff --git a/docs/managed-datahub/observe/freshness-assertions.md b/docs/managed-datahub/observe/freshness-assertions.md
index f7a37d3fceaf52..dda4d4abb94a17 100644
--- a/docs/managed-datahub/observe/freshness-assertions.md
+++ b/docs/managed-datahub/observe/freshness-assertions.md
@@ -188,14 +188,14 @@ _Check whether the table has changed in a specific window of time_
-- **Audit Log**: Check the Data Platform operational audit log to determine whether the table changed within the evaluation period.
-- **Information Schema**: Check the Data Platform system metadata tables to determine whether the table changed within the evaluation period.
+- **Audit Log**: Check the Data Platform operational audit log to determine whether the table changed within the evaluation period. This will filter out No-Ops (e.g. `INSERT 0`). However, the Audit Log can be delayed by several hours depending on the Data Platform. This is also a little more costly on the warehouse than Information Schema.
+- **Information Schema**: Check the Data Platform system metadata tables to determine whether the table changed within the evaluation period. This is the optimal balance between cost and accuracy for most Data Platforms.
- **Last Modified Column**: Check for the presence of rows using a "Last Modified Time" column, which should reflect the time at which a given row was last changed in the table, to
- determine whether the table changed within the evaluation period.
+ determine whether the table changed within the evaluation period. This issues a query to the table, which can be more expensive than Information Schema.
- **High Watermark Column**: Monitor changes to a continuously-increasing "high watermark" column value to determine whether a table
has been changed. This option is particularly useful for tables that grow consistently with time, for example fact or event (e.g. click-stream) tables. It is not available
- when using a fixed lookback period.
-- **DataHub Operation**: Use DataHub Operations to determine whether the table changed within the evaluation period.
+ when using a fixed lookback period. This issues a query to the table, which can be more expensive than Information Schema.
+- **DataHub Operation**: Use DataHub Operations to determine whether the table changed within the evaluation period. This is the cheapest option, but requires that Operations are reported to DataHub. By default, Ingestion will report Operations to DataHub, which can be and infrequent. You can report Operations via the DataHub APIs for more frequent and reliable data.
8. Configure actions that should be taken when the Freshness Assertion passes or fails
diff --git a/docs/managed-datahub/observe/volume-assertions.md b/docs/managed-datahub/observe/volume-assertions.md
index b2ae055543d969..c451e37b8073cd 100644
--- a/docs/managed-datahub/observe/volume-assertions.md
+++ b/docs/managed-datahub/observe/volume-assertions.md
@@ -114,15 +114,15 @@ source types vary by the platform, but generally fall into these categories:
- **Information Schema**: A system Table that is exposed by the Data Warehouse which contains live information about the Databases
and Tables stored inside the Data Warehouse, including their row count. It is usually efficient to check, but can in some cases be slightly delayed to update
- once a change has been made to a table.
+ once a change has been made to a table. This is the optimal balance between cost and accuracy for most Data Platforms.
- **Query**: A `COUNT(*)` query is used to retrieve the latest row count for a table, with optional SQL filters applied (depending on platform).
This can be less efficient to check depending on the size of the table. This approach is more portable, as it does not involve
- system warehouse tables, it is also easily portable across Data Warehouse and Data Lake providers.
+ system warehouse tables, it is also easily portable across Data Warehouse and Data Lake providers. This issues a query to the table, which can be more expensive than Information Schema.
- **DataHub Dataset Profile**: The DataHub Dataset Profile aspect is used to retrieve the latest row count information for a table.
Using this option avoids contacting your data platform, and instead uses the DataHub Dataset Profile metadata to evaluate Volume Assertions.
- Note if you have not configured an ingestion source through DataHub, then this may be the only option available.
+ Note if you have not configured a managed ingestion source through DataHub, then this may be the only option available. This is the cheapest option, but requires that Dataset Profiles are reported to DataHub. By default, Ingestion will report Dataset Profiles to DataHub, which can be and infrequent. You can report Dataset Profiles via the DataHub APIs for more frequent and reliable data.
Volume Assertions also have an off switch: they can be started or stopped at any time with the click of button.