Table of content
- CNN
- Convolution Layer
- Pooling Layer
- Pooling over (through) time
- Max-over-time pooling
- Average-over-time pooling
- Local pooling
- (Local) Max pooling
- (Local) Average pooling
- Pooling over (through) time
- Fully-connected (Dense, Linear) Layer
- RNN
- LSTM
- RNN
- Technique
- Normalization
- Regularization
- Gated Units used Vetrically
- Residual Block
- Highway Block
- Other
- CRF
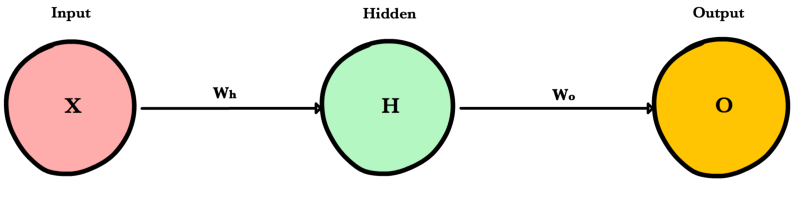
Holds the data your model will train on. Each neuron in the input layer represents a unique attribute in your dataset (e.g. height, hair color, etc.).
The final layer in a network. It receives input from the previous hidden layer, optionally applies an activation function, and returns an output representing your model’s prediction.
Hidden Layer
Sits between the input and output layers and applies an activation function before passing on the results. There are often multiple hidden layers in a network. In traditional networks, hidden layers are typically fully-connected layers — each neuron receives input from all the previous layer’s neurons and sends its output to every neuron in the next layer. This contrasts with how convolutional layers work where the neurons send their output to only some of the neurons in the next layer.
Number of Layers of a NN = number of Hidden Layers + number of Output Layers
Covolution Kernel aka. Filter, Feature Map (i.e. the Weights)
- usually have multiple "channels" - hope filters specialized in different things to gain different latent feature
Convolution without padding will shrink the output length based on the window size
- another way of compressing data
- to see a bigger spread of the sentence without having many parameters
aka. Subsampling Layer
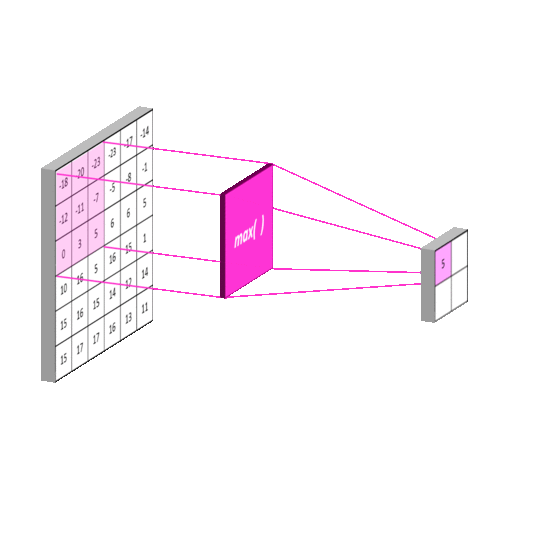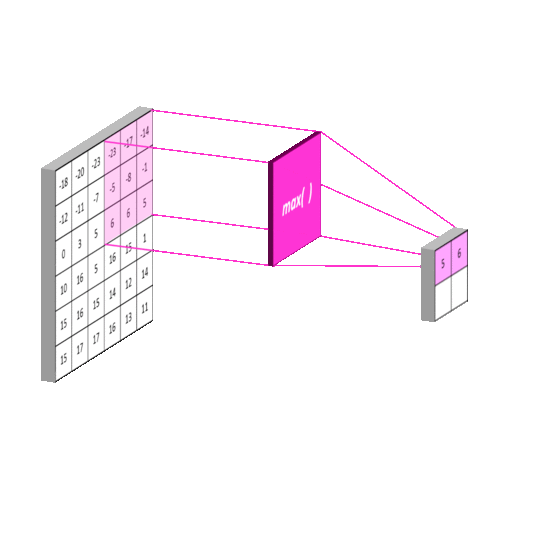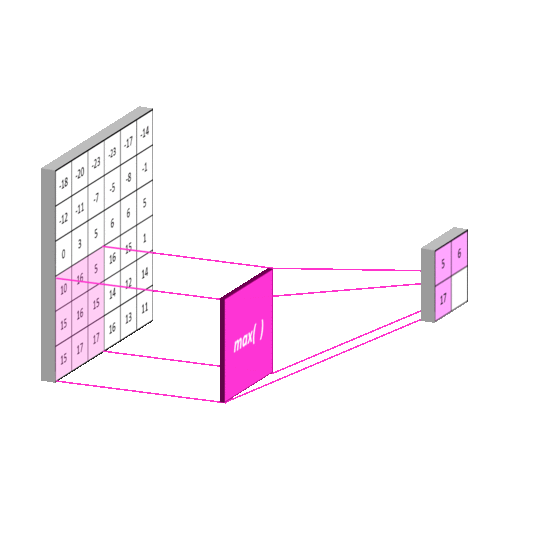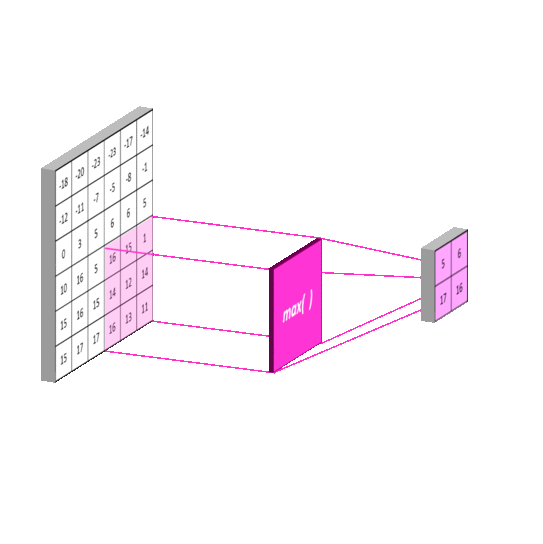
- Reduce numbers of feature
- Prevent overfitting
Back Propagation
- Max Pooling: Pooling using a "max" filter with stride equal to the kernel size
- Average Pooling
- In NLP, max pooling is better, because a lot of signals in NLP are sparse!
- Pooling Over (Through) Time (Over-time Pooling)
- Max-over-time Pooling: capture most important activation (maximum over time)
- Local Pooling
- Local Max Pooling
- K-Max Pooling Over Time
- keep the orders of the "maxes"
- In CV, pooling is normally mean local pooling
- In NLP, pooling is normally mean pooling over time (global pooling)
normalization
- Transform the output of a batch by scaling the activations to have zero mean and unit variance (i.e. standard deviation of one) => Z-transform of statistics
- often used in CNNs
- updated per batch so fluctuation don't affect things much
- Use of BatchNorm makes models much less sensitive to parameter initialization (since outputs are automatically rescaled)
- Use of BatchNorm also tends to make tuning of learning rates simpler
a regularization technique => deal with overfitting
- Create masking vector
$r$ of Bernoulli random variables with probability$p$ (a hyperparameter) of being 1 - Delete features during training
- At test time, no dropout, scale final vector by probability
$p$
Reasoning: Prevents co-adaptation (overfitting to seeing specific feature constellations)
=> Usually Dropout gives 2~4% accuracy improvement!
CS224n 2019 Assignment 3 1-(b) Dropout (Another scaling method (scale during training))
like the gating/skipping in LSTM and GRU
Key idea: summing candidate update with shortcut connection (is needed for very deep networks to work)
- Network:
$F(x) = \operatorname{Conv}(\operatorname{ReLU}(\operatorname{Conv}(x)))$ - Identity
$x$
Residual blocks — Building blocks of ResNet - Towards Data Science
$\circ$ : Hadamard product (element-wise product)
- T-gate:
$T(x)$ - C-gate:
$C(x)$
Review: Highway Networks — Gating Function To Highway (Image Classification)
- threelittlemonkeys/lstm-crf-pytorch: LSTM-CRF in PyTorch
- 如何用簡單易懂的例子解釋條件隨機場(CRF)模型?它和HMM有什麼區別? - 知乎
- 最通俗易懂的BiLSTM-CRF模型中的CRF層介紹 - 知乎
- 如何理解LSTM後接CRF? - 知乎
Dive Into Deep Learning
- Ch3.13 Dropout
- Ch5.4 Pooling Layer
- Ch5.10 BatchNorm