diff --git a/.github/workflows/build_on_pr.yml b/.github/workflows/build_on_pr.yml
index 5bdadca783b3..27ab7c76aab5 100644
--- a/.github/workflows/build_on_pr.yml
+++ b/.github/workflows/build_on_pr.yml
@@ -91,7 +91,7 @@ jobs:
container:
image: hpcaitech/pytorch-cuda:2.1.0-12.1.0
options: --gpus all --rm -v /dev/shm -v /data/scratch/llama-tiny:/data/scratch/llama-tiny
- timeout-minutes: 60
+ timeout-minutes: 75
defaults:
run:
shell: bash
diff --git a/colossalai/inference/README.md b/colossalai/inference/README.md
index 0bdaf347d295..abecd48865b4 100644
--- a/colossalai/inference/README.md
+++ b/colossalai/inference/README.md
@@ -1,229 +1,194 @@
-# 🚀 Colossal-Inference
+# ⚡️ ColossalAI-Inference
+## 📚 Table of Contents
-## Table of Contents
+- [⚡️ ColossalAI-Inference](#️-colossalai-inference)
+ - [📚 Table of Contents](#-table-of-contents)
+ - [📌 Introduction](#-introduction)
+ - [🛠 Design and Implementation](#-design-and-implementation)
+ - [🕹 Usage](#-usage)
+ - [🪅 Support Matrix](#-support-matrix)
+ - [🗺 Roadmap](#-roadmap)
+ - [🌟 Acknowledgement](#-acknowledgement)
-- [💡 Introduction](#introduction)
-- [🔗 Design](#design)
-- [🔨 Usage](#usage)
- - [Quick start](#quick-start)
- - [Example](#example)
-- [📊 Performance](#performance)
-## Introduction
+## 📌 Introduction
+ColossalAI-Inference is a module which offers acceleration to the inference execution of Transformers models, especially LLMs. In ColossalAI-Inference, we leverage high-performance kernels, KV cache, paged attention, continous batching and other techniques to accelerate the inference of LLMs. We also provide simple and unified APIs for the sake of user-friendliness.
-`Colossal Inference` is a module that contains colossal-ai designed inference framework, featuring high performance, steady and easy usability. `Colossal Inference` incorporated the advantages of the latest open-source inference systems, including LightLLM, TGI, vLLM, FasterTransformer and flash attention. while combining the design of Colossal AI, especially Shardformer, to reduce the learning curve for users.
+## 🛠 Design and Implementation
-## Design
+### :book: Overview
-Colossal Inference is composed of three main components:
+ColossalAI-Inference has **4** major components, namely namely `engine`,`request handler`,`cache manager`, and `modeling`.
-1. High performance kernels and ops: which are inspired from existing libraries and modified correspondingly.
-2. Efficient memory management mechanism:which includes the key-value cache manager, allowing for zero memory waste during inference.
- 1. `cache manager`: serves as a memory manager to help manage the key-value cache, it integrates functions such as memory allocation, indexing and release.
- 2. `batch_infer_info`: holds all essential elements of a batch inference, which is updated every batch.
-3. High-level inference engine combined with `Shardformer`: it allows our inference framework to easily invoke and utilize various parallel methods.
- 1. `HybridEngine`: it is a high level interface that integrates with shardformer, especially for multi-card (tensor parallel, pipline parallel) inference:
- 2. `modeling.llama.LlamaInferenceForwards`: contains the `forward` methods for llama inference. (in this case : llama)
- 3. `policies.llama.LlamaModelInferPolicy` : contains the policies for `llama` models, which is used to call `shardformer` and segmentate the model forward in tensor parallelism way.
+- **Engine**: It orchestrates the inference step. During inference, it recives a request, calls `request handler` to schedule a decoding batch, and executes the model forward pass to perform a iteration. It returns the inference results back to the user at the end.
+- **Request Handler**: It manages requests and schedules a proper batch from exisiting requests.
+- **Cache manager** It is bound within the `request handler`, updates cache blocks and logical block tables as scheduled by the `request handler`.
+- **Modelling**: We rewrite the model and layers of LLMs to simplify and optimize the forward pass for inference.
-## Architecture of inference:
+A high-level view of the inter-component interaction is given below. We would also introduce more details in the next few sections.
-In this section we discuss how the colossal inference works and integrates with the `Shardformer` . The details can be found in our codes.
+
+
+
+
-
+### :mailbox_closed: Engine
+Engine is designed as the entry point where the user kickstarts an inference loop. User can easily instantialize an inference engine with the inference configuration and execute requests. The engine object will expose the following APIs for inference:
-## Roadmap of our implementation
+- `generate`: main function which handles inputs, performs inference and returns outputs
+- `add_request`: add request to the waiting list
+- `step`: perform one decoding iteration. The `request handler` first schedules a batch to do prefill/decoding. Then, it invokes a model to generate a batch of token and afterwards does logit processing and sampling, checks and decodes finished requests.
-- [x] Design cache manager and batch infer state
-- [x] Design TpInference engine to integrates with `Shardformer`
-- [x] Register corresponding high-performance `kernel` and `ops`
-- [x] Design policies and forwards (e.g. `Llama` and `Bloom`)
- - [x] policy
- - [x] context forward
- - [x] token forward
- - [x] support flash-decoding
-- [x] Support all models
- - [x] Llama
- - [x] Llama-2
- - [x] Bloom
- - [x] Chatglm2
-- [x] Quantization
- - [x] GPTQ
- - [x] SmoothQuant
-- [ ] Benchmarking for all models
+### :game_die: Request Handler
-## Get started
+Request handler is responsible for managing requests and scheduling a proper batch from exisiting requests. According to the existing work and experiments, we do believe that it is beneficial to increase the length of decoding sequences. In our design, we partition requests into three priorities depending on their lengths, the longer sequences are first considered.
-### Installation
+
+
+
+
-```bash
-pip install -e .
-```
-
-### Requirements
-
-Install dependencies.
-
-```bash
-pip install -r requirements/requirements-infer.txt
-
-# if you want use smoothquant quantization, please install torch-int
-git clone --recurse-submodules https://github.com/Guangxuan-Xiao/torch-int.git
-cd torch-int
-git checkout 65266db1eadba5ca78941b789803929e6e6c6856
-pip install -r requirements.txt
-source environment.sh
-bash build_cutlass.sh
-python setup.py install
-```
+### :radio: KV cache and cache manager
-### Docker
+We design a unified block cache and cache manager to allocate and manage memory. The physical memory is allocated before decoding and represented by a logical block table. During decoding process, cache manager administrates the physical memory through `block table` and other components(i.e. engine) can focus on the lightweight `block table`. More details are given below.
-You can use docker run to use docker container to set-up environment
+- `cache block`: We group physical memory into different memory blocks. A typical cache block is shaped `(num_kv_heads, head_size, block_size)`. We determine the block number beforehand. The memory allocation and computation are executed at the granularity of memory block.
+- `block table`: Block table is the logical representation of cache blocks. Concretely, a block table of a single sequence is a 1D tensor, with each element holding a block ID. Block ID of `-1` means "Not Allocated". In each iteration, we pass through a batch block table to the corresponding model.
-```
-# env: python==3.8, cuda 11.6, pytorch == 1.13.1 triton==2.0.0.dev20221202, vllm kernels support, flash-attention-2 kernels support
-docker pull hpcaitech/colossalai-inference:v2
-docker run -it --gpus all --name ANY_NAME -v $PWD:/workspace -w /workspace hpcaitech/colossalai-inference:v2 /bin/bash
-
-# enter into docker container
-cd /path/to/ColossalAI
-pip install -e .
-
-```
+
+
+
+
+ Example of Batch Block Table
+
+
-## Usage
-### Quick start
-example files are in
+### :railway_car: Modeling
-```bash
-cd ColossalAI/examples
-python hybrid_llama.py --path /path/to/model --tp_size 2 --pp_size 2 --batch_size 4 --max_input_size 32 --max_out_len 16 --micro_batch_size 2
-```
+Modeling contains models and layers, which are hand-crafted for better performance easier usage. Deeply integrated with `shardformer`, we also construct policy for our models. In order to minimize users' learning costs, our models are aligned with [Transformers](https://github.com/huggingface/transformers)
+## 🕹 Usage
+### :arrow_right: Quick Start
-### Example
```python
-# import module
-from colossalai.inference import CaiInferEngine
+import torch
+import transformers
import colossalai
-from transformers import LlamaForCausalLM, LlamaTokenizer
+from colossalai.inference import InferenceEngine, InferenceConfig
+from pprint import pprint
-#launch distributed environment
colossalai.launch_from_torch()
-# load original model and tokenizer
-model = LlamaForCausalLM.from_pretrained("/path/to/model")
-tokenizer = LlamaTokenizer.from_pretrained("/path/to/model")
-
-# generate token ids
-input = ["Introduce a landmark in London","Introduce a landmark in Singapore"]
-data = tokenizer(input, return_tensors='pt')
-
-# set parallel parameters
-tp_size=2
-pp_size=2
-max_output_len=32
-micro_batch_size=1
-
-# initial inference engine
-engine = CaiInferEngine(
- tp_size=tp_size,
- pp_size=pp_size,
- model=model,
- max_output_len=max_output_len,
- micro_batch_size=micro_batch_size,
-)
-
-# inference
-output = engine.generate(data)
-
-# get results
-if dist.get_rank() == 0:
- assert len(output[0]) == max_output_len, f"{len(output)}, {max_output_len}"
-
+# Step 1: create a model in "transformers" way
+model_path = "lmsys/vicuna-7b-v1.3"
+model = transformers.LlamaForCausalLM.from_pretrained(model_path).cuda()
+tokenizer = transformers.AutoTokenizer.from_pretrained(model_path)
+
+# Step 2: create an inference_config
+inference_config = InferenceConfig(
+ dtype=torch.float16,
+ max_batch_size=4,
+ max_input_len=1024,
+ max_output_len=512,
+ use_cuda_kernel=True,
+ use_cuda_graph=False, # Turn on if you want to use CUDA Graph to accelerate inference
+ )
+
+# Step 3: create an engine with model and config
+engine = InferenceEngine(model, tokenizer, inference_config, verbose=True)
+
+# Step 4: try inference
+prompts = ['Who is the best player in the history of NBA?']
+response = engine.generate(prompts)
+pprint(response)
```
-## Performance
-
-### environment:
-
-We conducted multiple benchmark tests to evaluate the performance. We compared the inference `latency` and `throughputs` between `colossal-inference` and original `hugging-face torch fp16`.
-
-For various models, experiments were conducted using multiple batch sizes under the consistent model configuration of `7 billion(7b)` parameters, `1024` input length, and 128 output length. The obtained results are as follows (due to time constraints, the evaluation has currently been performed solely on the `A100` single GPU performance; multi-GPU performance will be addressed in the future):
-
-### Single GPU Performance:
-
-Currently the stats below are calculated based on A100 (single GPU), and we calculate token latency based on average values of context-forward and decoding forward process, which means we combine both of processes to calculate token generation times. We are actively developing new features and methods to further optimize the performance of LLM models. Please stay tuned.
-
-### Tensor Parallelism Inference
-
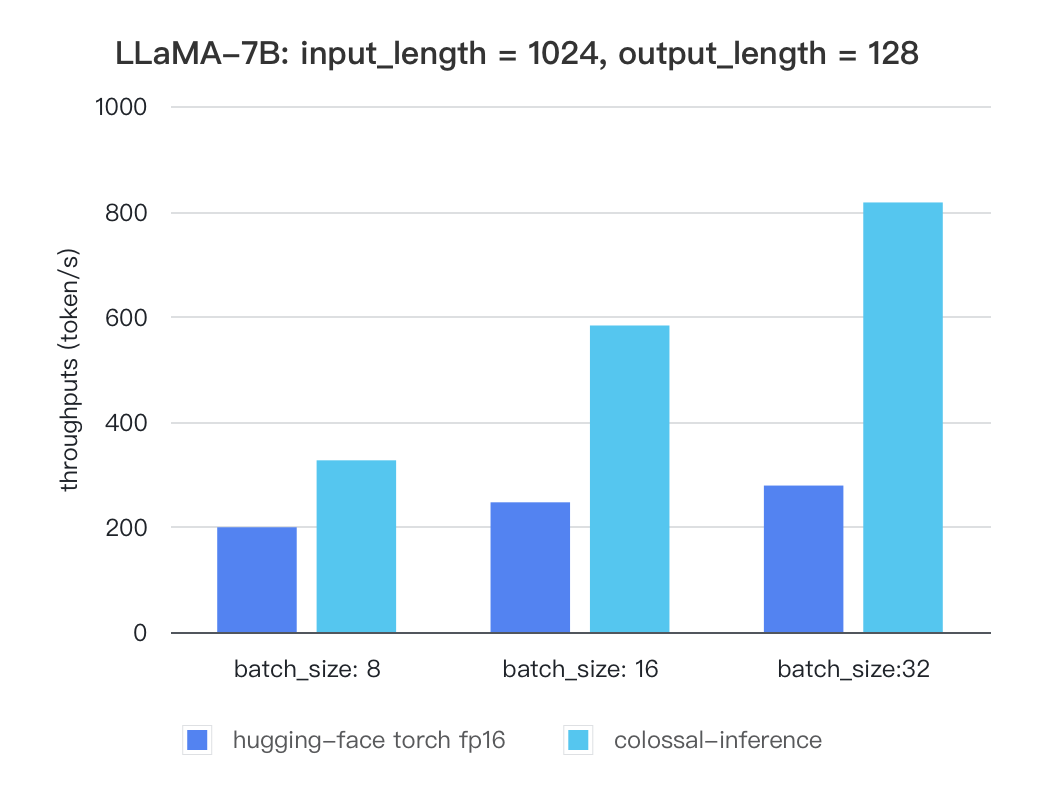
-##### Llama
+### :bookmark: Customize your inference engine
+Besides the basic quick-start inference, you can also customize your inference engine via modifying config or upload your own model or decoding components (logit processors or sampling strategies).
-| batch_size | 8 | 16 | 32 |
-|:-----------------------:|:------:|:------:|:------:|
-| hugging-face torch fp16 | 199.12 | 246.56 | 278.4 |
-| colossal-inference | 326.4 | 582.72 | 816.64 |
+#### Inference Config
+Inference Config is a unified api for generation process. You can define the value of args to control the generation, like `max_batch_size`,`max_output_len`,`dtype` to decide the how many sequences can be handled at a time, and how many tokens to output. Refer to the source code for more detail.
-
-
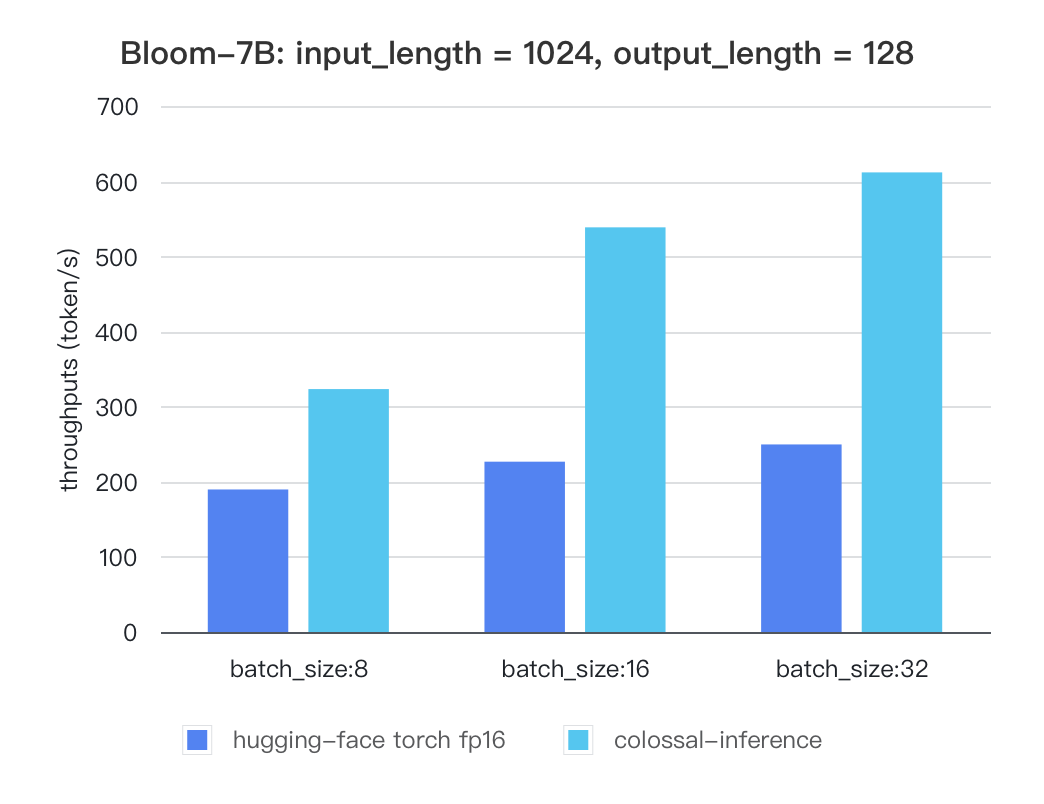
-#### Bloom
-
-| batch_size | 8 | 16 | 32 |
-|:-----------------------:|:------:|:------:|:------:|
-| hugging-face torch fp16 | 189.68 | 226.66 | 249.61 |
-| colossal-inference | 323.28 | 538.52 | 611.64 |
-
-
-
-
-### Pipline Parallelism Inference
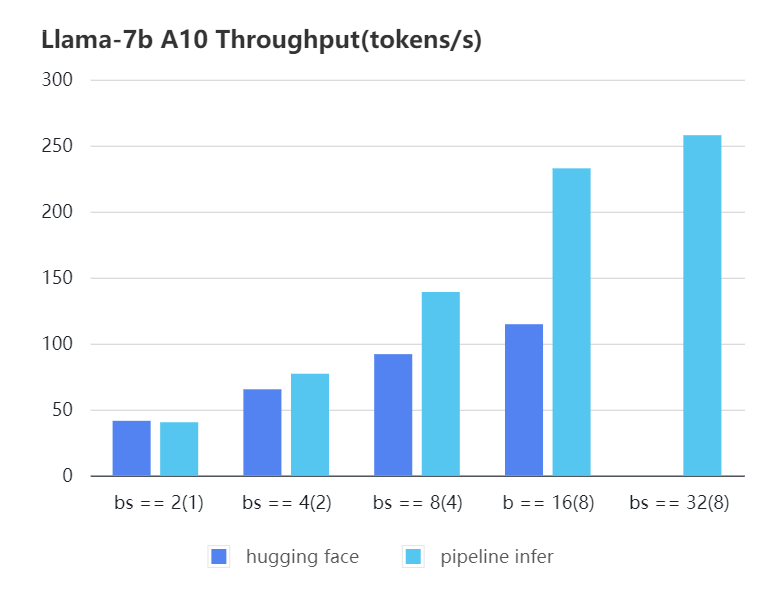
-We conducted multiple benchmark tests to evaluate the performance. We compared the inference `latency` and `throughputs` between `Pipeline Inference` and `hugging face` pipeline. The test environment is 2 * A10, 20G / 2 * A800, 80G. We set input length=1024, output length=128.
-
-
-#### A10 7b, fp16
-
-| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16) |
-|:----------------------------:|:-----:|:-----:|:------:|:------:|:------:|:------:|
-| Pipeline Inference | 40.35 | 77.10 | 139.03 | 232.70 | 257.81 | OOM |
-| Hugging Face | 41.43 | 65.30 | 91.93 | 114.62 | OOM | OOM |
-
-
-
-
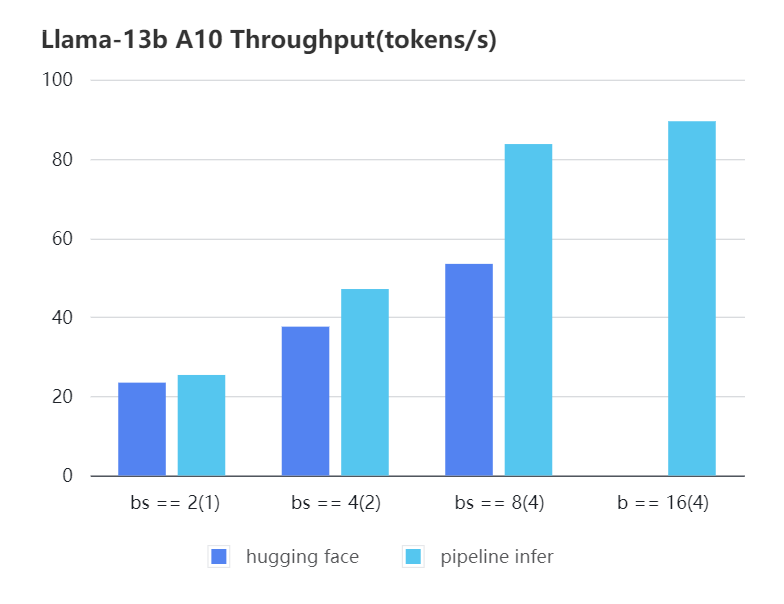
-#### A10 13b, fp16
-
-| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(4) |
-|:----------------------------:|:-----:|:-----:|:-----:|:-----:|
-| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
-| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
-
-
-
-
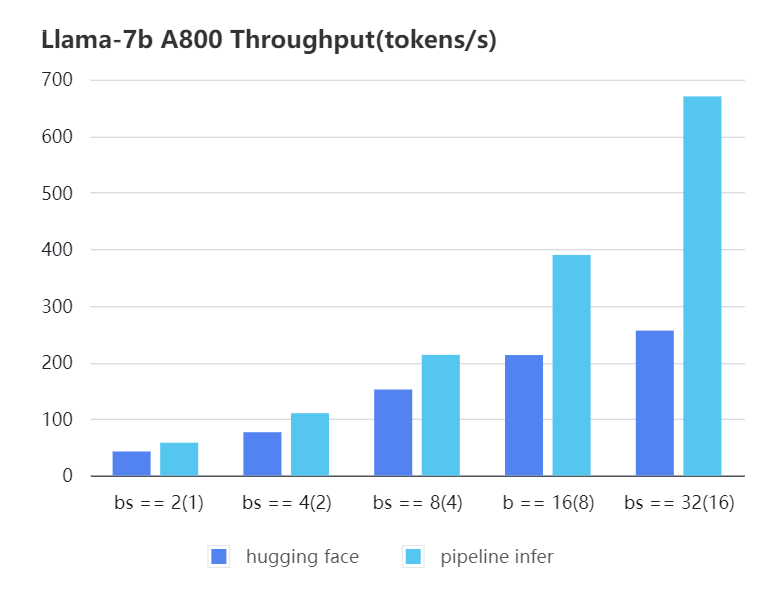
-#### A800 7b, fp16
-
-| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
-|:----------------------------:|:-----:|:------:|:------:|:------:|:------:|
-| Pipeline Inference | 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
-| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
-
-
-
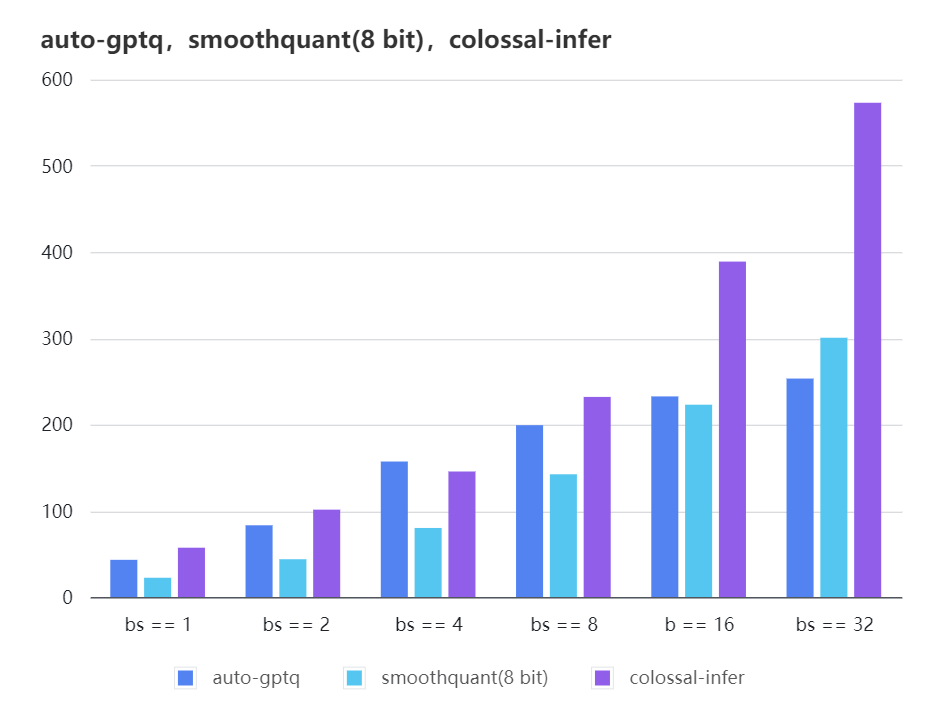
-### Quantization LLama
-
-| batch_size | 8 | 16 | 32 |
-|:-------------:|:------:|:------:|:------:|
-| auto-gptq | 199.20 | 232.56 | 253.26 |
-| smooth-quant | 142.28 | 222.96 | 300.59 |
-| colossal-gptq | 231.98 | 388.87 | 573.03 |
-
-
+#### Generation Config
+In colossal-inference, Generation config api is inherited from [Transformers](https://github.com/huggingface/transformers). Usage is aligned. By default, it is automatically generated by our system and you don't bother to construct one. If you have such demand, you can also create your own and send it to your engine.
+#### Logit Processors
+The `Logit Processosr` receives logits and return processed results. You can take the following step to make your own.
+```python
+@register_logit_processor("name")
+def xx_logit_processor(logits, args):
+ logits = do_some_process(logits)
+ return logits
+```
-The results of more models are coming soon!
+#### Sampling Strategies
+We offer 3 main sampling strategies now (i.e. `greedy sample`, `multinomial sample`, `beam_search sample`), you can refer to [sampler](/ColossalAI/colossalai/inference/sampler.py) for more details. We would strongly appreciate if you can contribute your varities.
+
+## 🪅 Support Matrix
+
+| Model | KV Cache | Paged Attention | Kernels | Tensor Parallelism | Speculative Decoding |
+| - | - | - | - | - | - |
+| Llama | ✅ | ✅ | ✅ | 🔜 | ✅ |
+
+
+Notations:
+- ✅: supported
+- ❌: not supported
+- 🔜: still developing, will support soon
+
+## 🗺 Roadmap
+
+- [x] KV Cache
+- [x] Paged Attention
+- [x] High-Performance Kernels
+- [x] Llama Modelling
+- [x] User Documentation
+- [x] Speculative Decoding
+- [ ] Tensor Parallelism
+- [ ] Beam Search
+- [ ] Early stopping
+- [ ] Logger system
+- [ ] SplitFuse
+- [ ] Continuous Batching
+- [ ] Online Inference
+- [ ] Benchmarking
+
+## 🌟 Acknowledgement
+
+This project was written from scratch but we learned a lot from several other great open-source projects during development. Therefore, we wish to fully acknowledge their contribution to the open-source community. These projects include
+
+- [vLLM](https://github.com/vllm-project/vllm)
+- [LightLLM](https://github.com/ModelTC/lightllm)
+- [flash-attention](https://github.com/Dao-AILab/flash-attention)
+
+If you wish to cite relevant research papars, you can find the reference below.
+
+```bibtex
+# vllm
+@inproceedings{kwon2023efficient,
+ title={Efficient Memory Management for Large Language Model Serving with PagedAttention},
+ author={Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph E. Gonzalez and Hao Zhang and Ion Stoica},
+ booktitle={Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles},
+ year={2023}
+}
+
+# flash attention v1 & v2
+@inproceedings{dao2022flashattention,
+ title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
+ author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{\'e}, Christopher},
+ booktitle={Advances in Neural Information Processing Systems},
+ year={2022}
+}
+@article{dao2023flashattention2,
+ title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
+ author={Dao, Tri},
+ year={2023}
+}
+
+# we do not find any research work related to lightllm
+```
diff --git a/colossalai/inference/__init__.py b/colossalai/inference/__init__.py
index a95205efaa78..5f2effca65a0 100644
--- a/colossalai/inference/__init__.py
+++ b/colossalai/inference/__init__.py
@@ -1,4 +1,4 @@
-from .engine import InferenceEngine
-from .engine.policies import BloomModelInferPolicy, ChatGLM2InferPolicy, LlamaModelInferPolicy
+from .config import InferenceConfig
+from .core import InferenceEngine
-__all__ = ["InferenceEngine", "LlamaModelInferPolicy", "BloomModelInferPolicy", "ChatGLM2InferPolicy"]
+__all__ = ["InferenceConfig", "InferenceEngine"]
diff --git a/colossalai/inference/batch_bucket.py b/colossalai/inference/batch_bucket.py
new file mode 100644
index 000000000000..f8571c0ca030
--- /dev/null
+++ b/colossalai/inference/batch_bucket.py
@@ -0,0 +1,523 @@
+from typing import Callable, List, Optional, Tuple, Union
+
+import torch
+
+from colossalai.inference.struct import Sequence
+from colossalai.utils import get_current_device
+
+
+class BatchBucket:
+ """Container for a batch of Sequences, which is used to manage the batch of sequences.
+
+ Attrs:
+ _sequences_dict (Dict[int, Sequence]): Map sequence uid to sequence struct
+ seq_uid -> Sequence
+ _sequences_indexes (Dict[int, int]): Map sequence uid to index in the batch
+ seq_uid -> index in the batch (indexing used in sequence_lengths and block_tables)
+ _sequence_lengths (torch.Tensor): Length of each sequence in the batch.
+ The size of the tensor is (max_batch_size,)
+ _block_tables (torch.Tensor): Block table of each sequence in the batch
+ The size of the tensor is (max_batch_size, max_blocks_per_seq)
+ """
+
+ def __init__(
+ self,
+ num_heads,
+ head_dim,
+ max_batch_size,
+ max_length,
+ block_size,
+ kv_max_split_num,
+ fd_interm_tensor=None,
+ device=None,
+ dtype=torch.float16,
+ ):
+ self.num_heads = num_heads
+ self.head_dim = head_dim
+ self.max_batch_size = max_batch_size
+ self.max_length = max_length # in + out len
+ self.block_size = block_size
+ self.kv_max_split_num = kv_max_split_num # Hint used for flash decoding
+ self.fd_interm_tensor = fd_interm_tensor
+ self.device = device or get_current_device()
+ self.dtype = dtype
+
+ self._use_spec_dec = False
+ self._num_tokens_to_verify = None
+
+ self._current_batch_size = 0
+ self._sequences_dict = dict()
+ self._sequences_indexes = dict() # deque(maxlen=self.max_batch_size)
+ self._sequence_lengths = torch.zeros((self.max_batch_size,), dtype=torch.int32)
+ self._sequence_lengths_helper = torch.zeros_like(self._sequence_lengths)
+ max_blocks_per_seq = (self.max_length + block_size - 1) // block_size
+ self._block_tables = torch.full((self.max_batch_size, max_blocks_per_seq), -1, dtype=torch.int32)
+ self._block_tables_helper = torch.full_like(self._block_tables, -1)
+
+ @property
+ def is_empty(self):
+ return self._current_batch_size == 0
+
+ @property
+ def current_batch_size(self):
+ return self._current_batch_size
+
+ def __len__(self):
+ return self._current_batch_size
+
+ @property
+ def available_batch_size(self):
+ return self.max_batch_size - self._current_batch_size
+
+ @property
+ def block_tables(self):
+ return self._block_tables
+
+ @property
+ def seq_lengths(self):
+ return self._sequence_lengths
+
+ @property
+ def seqs_ids(self):
+ return list(self._sequences_dict.keys())
+
+ @property
+ def seqs_li(self):
+ return list(self._sequences_dict.values())
+
+ @property
+ def is_compact(self):
+ assert len(self._sequences_dict) == len(self._sequences_indexes), "BatchBucket indexing is not consistent"
+ return (
+ len(self._sequences_dict)
+ == torch.nonzero(self._sequence_lengths).view(-1).numel()
+ == torch.nonzero(self._block_tables[:, 0] >= 0).numel()
+ )
+
+ @property
+ def use_spec_dec(self) -> bool:
+ return self._use_spec_dec
+
+ @property
+ def num_tokens_to_verify(self) -> int:
+ return self._num_tokens_to_verify
+
+ @property
+ def batch_token_ids(self) -> List[List[int]]:
+ out = []
+ for seq in self.seqs_li:
+ out.append(seq.input_token_id + seq.output_token_id)
+ return out
+
+ def set_use_spec_dec(self, num_tokens_to_verify: int = 5) -> None:
+ """Set batch bucket to use speculatvie decoding.
+ This will notify the adjust the lengths of inputs during modeling,
+ and let the main model verifies tokens in parallel.
+ """
+ self._use_spec_dec = True
+ self._num_tokens_to_verify = num_tokens_to_verify
+
+ def reset_use_spec_dec(self) -> None:
+ """Reset the usage of speculative decoding for the batch bucket"""
+ self._use_spec_dec = False
+ self._num_tokens_to_verify = None
+
+ def _make_compact(self) -> None:
+ # Clean and Compress the batch based on its sequences dict.
+ # Namely,compress sequences to the front and clean the seq lengths and block tables tensors.
+ # NOTE Prevent calling this method multiple times in a single step
+ if self.is_compact:
+ return
+ valid_seq_ids = self._sequences_dict.keys()
+ valid_num = len(valid_seq_ids)
+ valid_indexes = [self._sequences_indexes[seq_id] for seq_id in valid_seq_ids]
+ assert valid_num == len(self._sequences_indexes), "BatchBucket indexing is not consistent"
+ self._sequence_lengths_helper[:valid_num] = self._sequence_lengths[valid_indexes]
+ self._sequence_lengths[:] = self._sequence_lengths_helper[:]
+ self._block_tables_helper[:valid_num, :] = self.block_tables[valid_indexes]
+ self.block_tables[:] = self._block_tables_helper[:]
+ new_idx = 0
+ for seq_id in valid_seq_ids:
+ self._sequences_indexes[seq_id] = new_idx
+ new_idx += 1
+ self._sequence_lengths_helper.fill_(0)
+ self._block_tables_helper.fill_(-1)
+ self._current_batch_size = valid_num
+
+ def add_seq(
+ self,
+ seq: Sequence,
+ alloc_block_table: torch.Tensor = None,
+ alloc_block_table_fn: Callable[[torch.Tensor, int], None] = None,
+ ) -> Union[torch.Tensor, None]:
+ """Add a single sequence to the batch.
+ User could opt to provide either a block table or a function to allocate block tables.
+
+ Args:
+ seq (Sequence): The sequence to be added to the batch
+ alloc_block_table (torch.Tensor): The block tables to be copied and used for the sequence
+ alloc_block_table_fn (Callable[[torch.Tensor, int], None]): The function to allocate blocks for the sequence,
+ which is expected to reserve blocks and update status of kv-cache manager.
+
+ Returns:
+ block_table (torch.Tensor): The block table of the added sequence, used for block allocation in kv-cache manager.
+ None if the sequence cannot be added.
+ """
+ block_table = None
+ # TODO might consider sorting by length
+ if self._current_batch_size < self.max_batch_size:
+ self._sequences_dict[seq.request_id] = seq
+ self._sequences_indexes[seq.request_id] = self._current_batch_size
+ self._sequence_lengths[self._current_batch_size] = seq.sentence_len
+ # NOTE the added seq still require block table allocation by kvcache manager
+ block_table = self._block_tables[self._current_batch_size - 1]
+ if alloc_block_table is not None:
+ # copy block ids from provided block tables
+ self._block_tables[self._current_batch_size - 1] = alloc_block_table
+ elif alloc_block_table_fn:
+ alloc_block_table_fn(block_table, self._sequence_lengths[self._current_batch_size - 1].item())
+ self._current_batch_size += 1
+ return block_table
+
+ def add_seqs(
+ self,
+ seqs: List[Sequence],
+ alloc_block_tables: torch.Tensor = None,
+ alloc_block_tables_fn: Callable[[torch.Tensor, torch.Tensor], None] = None,
+ ) -> Union[torch.Tensor, None]:
+ """Add a list of sequences to the batch.
+ User could opt to provide either block tables or a function to allocate block tables.
+
+ Args:
+ seqs (List[Sequence]): The sequences to be added to the batch
+ alloc_block_tables (torch.Tensor): The block tables to be copied and used for the sequence
+ alloc_block_table_fn (Callable[[torch.Tensor, torch.Tensor], None]): The function to allocate blocks for multiple sequences,
+ which is expected to reserve blocks and update status of kv-cache manager.
+
+ Returns:
+ block_tables (torch.Tensor): The block tables of the added sequences, used for block allocation in kv-cache manager.
+ None if the sequences cannot be added.
+ """
+
+ assert (
+ alloc_block_tables is None or alloc_block_tables_fn is None
+ ), "`alloc_block_tables` and `alloc_block_tables_fn` cannot be provided at the same time"
+
+ num_seqs_to_add = min(self.max_batch_size - self._current_batch_size, len(seqs))
+ block_tables = None
+ if num_seqs_to_add > 0:
+ for i, seq in enumerate(seqs[:num_seqs_to_add]):
+ self._sequences_dict[seq.request_id] = seq
+ self._sequences_indexes[seq.request_id] = self._current_batch_size + i
+ # TODO external (rename): modify Sequence.sentence_len to seq_len
+ self._sequence_lengths[
+ self._current_batch_size : self._current_batch_size + num_seqs_to_add
+ ] = torch.tensor([seq.sentence_len for seq in seqs[:num_seqs_to_add]], dtype=torch.int32)
+ # NOTE block tables to be updated by kvcache manager
+ block_tables = self._block_tables[self._current_batch_size : self._current_batch_size + num_seqs_to_add]
+ if alloc_block_tables is not None:
+ # copy block ids from provided block tables
+ self._block_tables[
+ self._current_batch_size : self._current_batch_size + num_seqs_to_add
+ ] = alloc_block_tables
+ elif alloc_block_tables_fn:
+ alloc_block_tables_fn(
+ block_tables,
+ self._sequence_lengths[self._current_batch_size : self._current_batch_size + num_seqs_to_add],
+ )
+
+ self._current_batch_size += num_seqs_to_add
+ seqs[:] = seqs[num_seqs_to_add:]
+
+ return block_tables
+
+ def pop_seq_update_batch(
+ self, request_id: int, free_block_table_fn: Callable[[torch.Tensor], None] = None
+ ) -> Tuple[Sequence, Union[torch.Tensor, None]]:
+ """Pop a single sequence by id from the batch, and update the batch bucket status.
+
+ Args:
+ request_id (int): The uid of the sequence
+ free_block_table_fn (Callable): The function to free the block table of a sequence,
+ if not provided, then we have to release the block table manually after calling this method
+
+ Returns:
+ A tuple of: seq (Sequence): The target sequence
+ and block_table (torch.Tensor): block table of the target sequence indicating corresponding blocks,
+ none if the sequence is not found or free_block_table_fn is provided.
+ """
+ seq: Sequence = self._sequences_dict.get(request_id)
+ block_table = None
+ if seq is not None:
+ assert request_id in self._sequences_indexes, "Inconsistency in BatchBucket indexing"
+ self._sequences_dict.pop(request_id)
+ seq_b_idx = self._sequences_indexes.get(request_id)
+
+ if self.current_batch_size > 1:
+ # replace seq length of the target seq with that of the last seq in the batch
+ last_seq_b_idx = self.current_batch_size - 1
+ last_seq_id = next(
+ (uid for uid, index in self._sequences_indexes.items() if index == last_seq_b_idx),
+ None,
+ )
+ assert last_seq_id is not None
+ self._sequences_indexes[last_seq_id] = seq_b_idx
+ self._sequence_lengths[seq_b_idx] = self._sequence_lengths[last_seq_b_idx]
+ self._sequence_lengths[last_seq_b_idx].fill_(0)
+ # free the block table of the seq, or return a copy of the block table (to be processed outside)
+ if free_block_table_fn:
+ free_block_table_fn(self._block_tables[seq_b_idx])
+ else:
+ block_table = self._block_tables[seq_b_idx].detach().clone()
+ # replace block table of the target seq with that of the last seq in the batch
+ self._block_tables[seq_b_idx] = self._block_tables[last_seq_b_idx]
+ self._block_tables[last_seq_b_idx].fill_(-1)
+ else:
+ if free_block_table_fn:
+ free_block_table_fn(self._block_tables[0])
+ else:
+ block_table = self._block_tables[0].detach().clone()
+ self._sequence_lengths[0].fill_(0)
+ self._block_tables[0].fill_(-1)
+ self._sequences_indexes.pop(request_id)
+ self._current_batch_size -= 1
+
+ return seq, block_table
+
+ def pop_seqs(
+ self, request_ids: List[int], free_block_table_fn: Callable[[torch.Tensor], None] = None
+ ) -> Tuple[List[Sequence], List[torch.Tensor]]:
+ """Iteratively pop a list of sequences by uid.
+
+ Args:
+ request_ids (List[int]): The uids of the sequences
+ free_block_table_fn (Callable): The function to free the block table of a sequence,
+ if not provided, then we have to release the block table manually after calling this method
+ Returns:
+ A tuple of: seqs (List[Sequence]): The target sequences
+ and block_tables (List[torch.Tensor]): block tables of the target sequences indicating corresponding blocks
+ """
+ seqs = []
+ block_tables = []
+ for request_id in request_ids:
+ seq, block_table = self.pop_seq_update_batch(request_id, free_block_table_fn)
+ if seq is not None:
+ seqs.append(seq)
+ if block_table is not None:
+ block_tables.append(block_table)
+ return seqs, block_tables
+
+ def pop_n_seqs(
+ self, n: int, free_block_table_fn: Callable[[torch.Tensor], None] = None
+ ) -> Tuple[List[Sequence], List[torch.Tensor]]:
+ """Pop the first n sequences in the batch (FIFO).
+ If n is greater than the current batch szie, pop all the sequences in the batch.
+
+ Args:
+ n (int): The number of sequences to pop out
+ free_block_table_fn (Callable): The function to free the block table of a single sequence
+ Returns:
+ A tuple of: seqs (List[Sequence]): The target sequences,
+ and block_tables (List[torch.Tensor]): block tables of the target sequences indicating corresponding blocks
+ """
+ # NOTE Prevent calling this method multiple times in a single step
+ seqs = []
+ block_tables = []
+ n = min(n, self.current_batch_size)
+ seq_ids = list(self._sequences_dict.keys())[:n]
+ for seq_id in seq_ids:
+ seq = self._sequences_dict.pop(seq_id)
+ seq_b_idx = self._sequences_indexes.pop(seq_id)
+ if free_block_table_fn:
+ free_block_table_fn(self.block_tables[seq_b_idx])
+ else:
+ block_tables.append(self.block_tables[seq_b_idx].detach().clone())
+ seqs.append(seq)
+ if not self.is_compact:
+ self._make_compact()
+
+ return seqs, block_tables
+
+ def pop_finished(
+ self, free_block_table_fn: Callable[[torch.Tensor], None] = None
+ ) -> Tuple[List[Sequence], List[torch.Tensor]]:
+ """Pop finished sequences in the batch and a list of block tables of the finished sequences,
+ if free_block_table_fn is not provided.
+
+ Args:
+ free_block_table_fn (Callable): The function to free the block table of a single sequence
+ Returns:
+ A tuple of: finished_seqs (List[Sequence]): The finished sequences,
+ and finished_block_tables (List[torch.Tensor]): block tables of the finished sequences.
+ """
+ finished_seqs = []
+ finished_block_tables = []
+ for seq in self._sequences_dict.values():
+ if seq.check_finish():
+ finished_seqs.append(seq)
+ # Use `pop_seq_update_batch`` to update the batch status for just a few of finished seqs,
+ # otherwise, pop seqs directly and then call `_make_compact` to compress the batch.
+ # For now, the performance difference is not significant, so we use the frist method to pop seqs.
+ # Precise evaluations to be done.
+ for seq in finished_seqs:
+ _, block_table = self.pop_seq_update_batch(seq.request_id, free_block_table_fn)
+ if block_table is not None:
+ finished_block_tables.append(block_table)
+
+ return finished_seqs, finished_block_tables
+
+ # TODO arg type not support beam search sampling yet
+ def append_batch_tokens(self, tokens: torch.Tensor) -> None:
+ """Append a batch of tokens to the sequences in the batch"""
+ assert self.current_batch_size == tokens.size(0), "Batch size mismatch"
+
+ if self.current_batch_size > 0:
+ tokens = tokens.tolist()
+ for seq_id, seq in self._sequences_dict.items():
+ index_in_b = self._sequences_indexes[seq_id]
+ curr_tokens = tokens[index_in_b]
+ if not isinstance(curr_tokens, list):
+ curr_tokens = [curr_tokens]
+ seq.output_token_id += curr_tokens
+ seq.check_finish()
+ self._sequence_lengths[: self.current_batch_size] += 1
+
+ def revoke_batch_tokens(self, n_tokens: int, n_seqs: int = 1) -> None:
+ """Revoke the last n output tokens of the sequences in the batch
+
+ Args:
+ n_tokens (int): The number of output tokens to revoke from each sequence.
+ It does not count in the context tokens (input tokens).
+ n_seqs (int): The first n sequences to revoke tokens from. Defaults to 1.
+ For now, speculative decoding only supports batch size 1.
+ """
+ if n_tokens >= 1:
+ seqs_iter = iter(self._sequences_dict.items())
+ for _ in range(n_seqs):
+ seq_id, seq = next(seqs_iter)
+ assert seq.output_len >= n_tokens, "Revoking len exceeds the current output len of the sequence"
+ seq.output_token_id = seq.output_token_id[:-n_tokens]
+ seq.revoke_finished_status()
+ self._sequence_lengths[self._sequences_indexes[seq_id]] -= n_tokens
+
+ def clear(self, free_block_tables_fn: Optional[Callable[[torch.Tensor], None]]) -> List[int]:
+ """Clear all the sequences in the batch.
+
+ free_block_tables_fn (Optional[Callable]): The function to free the block tables of all the sequences in a batch
+ """
+ seqs = list(self._sequences_dict.values())
+ self._sequences_dict.clear()
+ self._sequences_indexes.clear()
+ if free_block_tables_fn:
+ free_block_tables_fn(self.block_tables, self._current_batch_size)
+ self._block_tables.fill_(-1)
+ self._sequence_lengths.fill_(0)
+ self._current_batch_size = 0
+ return seqs
+
+ def merge(self, other: "BatchBucket") -> List[int]:
+ """Merge the sequences in the other batch into the current batch.
+ Merge as possible as the current batch can, if it does not have available spaces
+ holding all the sequences in the other batch
+
+ Usage:
+ > New incoming sequence added to prefil batch
+ prefill bb curr batch size < prefil_ratio * prefill bb max batch size
+ > New incoming sequence added to prefil batch
+ prefill bb curr batch size == prefil_ratio * prefill bb max batch size
+ > Pause Decoding
+ > Prefill
+ > Move sequences in prefill bb => decoding bb
+ > Put back the out-of-volume sequences into the running pool
+
+ Returns:
+ unmerged_ids (List[int]): a list of sequence uids that are not merged into the current batch
+ """
+ unmerged_ids = []
+ num_seqs_to_merge = min(self.available_batch_size, other.current_batch_size)
+ if num_seqs_to_merge > 0:
+ seqs, block_tables_li = other.pop_n_seqs(num_seqs_to_merge)
+ block_tables = torch.stack(block_tables_li)
+ self.add_seqs(seqs, alloc_block_tables=block_tables)
+ unmerged_ids = other.seqs_ids
+
+ return unmerged_ids
+
+ ########## The following methods are expected to be used in modeling ###########
+
+ # For compatibility.
+ # NOTE: This is an assumption way to determine the stage of the batch.
+ @property
+ def is_prompts(self) -> bool:
+ assert len(self._sequences_dict) > 0, "No sequence in the batch"
+ first_seq = next(iter(self._sequences_dict.values()))
+ if first_seq.output_len == 0:
+ return True
+ return False
+
+ def get_1D_inputs_spec_dec(self, n: int) -> torch.Tensor:
+ # Used for main model verification in **Decoding Stage**
+ # `n` is the number of tokens to be verified,
+ # and so that prepare the last `n` tokens of each sequence as the inputs
+ assert len(self._sequences_dict) > 0, "No sequence in the batch"
+ assert all(
+ seq.output_len >= n for seq in self._sequences_dict.values()
+ ), "Sequence output tokens must be greater than or equal to the number of tokens to be verified."
+ out_li = []
+ seq_ids = sorted(self._sequences_indexes.keys(), key=lambda x: self._sequences_indexes[x])
+ for seq_id in seq_ids:
+ seq: Sequence = self._sequences_dict[seq_id]
+ out_li.extend(seq.output_token_id[-n:])
+ return torch.tensor(out_li, dtype=torch.long, device=self.device)
+
+ # For compatibility
+ def get_1D_inputs(self) -> torch.Tensor:
+ assert len(self._sequences_dict) > 0, "No sequence in the batch"
+ first_seq = next(iter(self._sequences_dict.values())) # not exactly the first sequence
+ if first_seq.output_len == 0:
+ # Assume prefill stage
+ assert all(
+ seq.output_len == 0 for seq in self._sequences_dict.values()
+ ), "Sequence stage (Prefill/Decoding) must be the same in the batch"
+ out_li = []
+ seq_ids = sorted(self._sequences_indexes.keys(), key=lambda x: self._sequences_indexes[x])
+ for seq_id in seq_ids:
+ seq: Sequence = self._sequences_dict[seq_id]
+ out_li.extend(seq.input_token_id)
+ return torch.tensor(out_li, dtype=torch.long, device=self.device)
+ else:
+ # Assume decoding stage
+ if self.use_spec_dec:
+ # For Speculative Decoding
+ # the number of tokens to be verified in parallel plus the correct token in the last step
+ return self.get_1D_inputs_spec_dec(self.num_tokens_to_verify + 1)
+ assert all(
+ seq.output_len > 0 for seq in self._sequences_dict.values()
+ ), "Sequence stage (Prefill/Decoding) must be the same in the batch"
+ assert self.is_compact, "BatchBucket is not compact"
+ out = torch.empty([self.current_batch_size], dtype=torch.long)
+ for seq_id, index_in_b in self._sequences_indexes.items():
+ seq: Sequence = self._sequences_dict[seq_id]
+ out[index_in_b] = seq.output_token_id[-1]
+ return out.to(device=self.device)
+
+ # For compatibility
+ def get_block_table_tensor(self) -> torch.Tensor:
+ assert self.is_compact # Debug usage
+ block_table = self.block_tables[: self.current_batch_size]
+ return block_table.to(device=self.device)
+
+ # For compatibility
+ def get_sequence_lengths(self) -> torch.Tensor:
+ assert self.is_compact # Debug usage
+ sequence_lengths = self.seq_lengths[: self.current_batch_size]
+ return sequence_lengths.to(device=self.device)
+
+ # For compatibility
+ @property
+ def fd_inter_tensor(self) -> None:
+ assert self.fd_interm_tensor is not None, "fd_interm_tensor is not provided"
+ return self.fd_interm_tensor
+
+ def __repr__(self) -> str:
+ return f"(sequences_dict={self._sequences_dict}, is_prompts={self.is_prompts})"
diff --git a/colossalai/inference/config.py b/colossalai/inference/config.py
new file mode 100644
index 000000000000..70faf34e36a4
--- /dev/null
+++ b/colossalai/inference/config.py
@@ -0,0 +1,341 @@
+"""
+Our config contains various options for inference optimization, it is a unified API that wraps all the configurations for inference.
+"""
+import logging
+from abc import ABC, abstractmethod
+from dataclasses import dataclass, fields
+from typing import Any, Dict, List, Optional, Union
+
+import torch
+from transformers.generation import GenerationConfig
+
+from colossalai.inference.flash_decoding_utils import FDIntermTensors
+
+GibiByte = 1024**3
+
+logger = logging.Logger(__name__)
+
+_DTYPE_MAPPING = {
+ "fp16": torch.float16,
+ "bf16": torch.bfloat16,
+ "fp32": torch.float32,
+}
+
+_ALLOWED_DTYPES = [torch.float16, torch.bfloat16, torch.float32]
+
+_DEFAULT_PROMPT_TEMPLATES = {
+ "llama": "[INST] <>\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n<>\n{input_text}[/INST]",
+ "baichuan": " {input_text} ",
+ "vicuna": "A chat between a curious user and an assistant. The assistant gives helpful, detailed, accurate, uncensored responses to the user input. USER: {input_text}\nASSISTANT: ",
+}
+
+
+class RPC_PARAM(ABC):
+ """
+ NOTE(lry89757) We use rpyc to transport param between client and server.
+ Rpyc only support the type of `POD` in python as the param, so we should take some smart ways to transport the data like tensor or some sophisticated classes.
+ Drawing on the logic of `__setstate__`, `__getstate__`, we will let some classes(will be rpc param later) inherit this base class, and rewrite the to_rpc_param and from_rpc_param. We will invoke `to_rpc_param` in client to pass the params and recover the param in server side by `from_rpc_param`.
+ """
+
+ @abstractmethod
+ def to_rpc_param(self):
+ return NotImplementedError
+
+ @staticmethod
+ @abstractmethod
+ def from_rpc_param():
+ return NotImplementedError
+
+
+@dataclass
+class InputMetaData(RPC_PARAM):
+ """The input info for a single step
+
+ Args:
+ block_tables (torch.Tensor, optional): Sequences' BlockTables Defaults to None.
+ sequence_lengths (torch.Tensor): A tensor containing sequence lengths.
+ fd_inter_tensor (torch.Tensor, optional): A tensor representing intermediate data for flash decoding. Defaults to None.
+ batch_size (int, optional): The current batch size. Defaults to 64.
+ is_prompts (bool, optional): Indicates whether prefill or decoding. Defaults to False(decoding).
+ use_cuda_kernel(bool): Whether to use cuda kernel, faster but lose some precision occasionally
+ use_cuda_graph (bool, optional): Indicates whether to use the CUDA graph. Defaults to False.
+ kv_seq_len (int, optional): Key-value sequence length. Defaults to 512.
+ head_dim (int, optional): Head dimension. Defaults to 32.
+ high_precision(bool, optional): Whether to use float32 for underlying calculations of float16 data to achieve higher precision, Defaults to False.
+ dtype (torch.dtype, optional): The computation type of tensor, Defaults to torch.float32.
+ use_spec_dec (bool): Indicate whether to use speculative decoding.
+ num_tokens_to_verify (int): The number of tokens to verify in speculative decoding. Only valid when `use_spec_dec` is set to True.
+ batch_token_ids (List[List[int]], optional): input_token_ids + output_token_ids of current batch. Only used for `repetition_penalty`, `no_repeat_ngram_size` in sampler process.
+ """
+
+ block_tables: torch.Tensor = None
+ sequence_lengths: torch.Tensor = None
+ fd_inter_tensor: FDIntermTensors = None
+ batch_size: int = 64 # current_batch_size
+ is_prompts: bool = False
+ use_cuda_kernel: bool = False
+ use_cuda_graph: bool = False
+ kv_seq_len: int = 512
+ head_dim: int = 32
+ high_precision: bool = False
+ dtype: torch.dtype = torch.float32
+ use_spec_dec: bool = False
+ num_tokens_to_verify: int = 0
+ batch_token_ids: Optional[
+ List[List[int]]
+ ] = None # for `repetition_penalty`, `no_repeat_ngram_size` in sampler process
+
+ def to_rpc_param(self) -> Dict[str, any]:
+ return {
+ "block_tables": self.block_tables.tolist(),
+ "sequence_lengths": self.sequence_lengths.tolist(),
+ "batch_size": self.batch_size,
+ "is_prompts": self.is_prompts,
+ "use_cuda_kernel": self.use_cuda_kernel,
+ "use_cuda_graph": self.use_cuda_graph,
+ "kv_seq_len": self.kv_seq_len,
+ "head_dim": self.head_dim,
+ "high_precision": self.high_precision,
+ "dtype": str(self.dtype).split(".")[-1],
+ "use_spec_dec": self.use_spec_dec,
+ "num_tokens_to_verify": self.num_tokens_to_verify,
+ "batch_token_ids": self.batch_token_ids,
+ }
+
+ @staticmethod
+ def from_rpc_param(rpc_dict: Dict[str, any]) -> "InputMetaData":
+ """
+ We intentionally don't use `dict.get` method to ensure we pass the right rpc param, or program will show error message
+ """
+ from colossalai.accelerator import get_accelerator
+
+ dtype = getattr(torch, rpc_dict["dtype"])
+ return InputMetaData(
+ block_tables=torch.tensor(
+ rpc_dict["block_tables"], dtype=torch.int, device=get_accelerator().get_current_device()
+ ),
+ sequence_lengths=torch.tensor(
+ rpc_dict["sequence_lengths"], dtype=torch.int, device=get_accelerator().get_current_device()
+ ),
+ batch_size=rpc_dict["batch_size"],
+ is_prompts=rpc_dict["is_prompts"],
+ use_cuda_kernel=rpc_dict["use_cuda_kernel"],
+ use_cuda_graph=rpc_dict["use_cuda_graph"],
+ kv_seq_len=rpc_dict["kv_seq_len"],
+ head_dim=rpc_dict["head_dim"],
+ high_precision=rpc_dict["high_precision"],
+ dtype=dtype,
+ use_spec_dec=rpc_dict["use_spec_dec"],
+ num_tokens_to_verify=rpc_dict["num_tokens_to_verify"],
+ batch_token_ids=rpc_dict["batch_token_ids"],
+ )
+
+ def __repr__(self) -> str:
+ return (
+ f"InputMetaData(block_tables={self.block_tables}, "
+ f"sequence_lengths={self.sequence_lengths}, "
+ f"fd_inter_tensor={self.fd_inter_tensor}, "
+ f"batch_size={self.batch_size}, "
+ f"is_prompts={self.is_prompts}, "
+ f"use_cuda_kernel={self.use_cuda_kernel}, "
+ f"use_cuda_graph={self.use_cuda_graph}, "
+ f"kv_seq_len={self.kv_seq_len}, "
+ f"use_spec_dec={self.use_spec_dec}, "
+ f"num_tokens_to_verify={self.num_tokens_to_verify})"
+ )
+
+
+@dataclass
+class InferenceConfig(RPC_PARAM):
+ """The inference configuration.
+
+ Args:
+ max_batch_size (int): Maximum batch size, defaults to 8.
+ max_output_len (int): Maximum output length, defaults to 256.
+ max_input_len (int): Maximum input length, defaults to 256.
+ dtype (Union[str, torch.dtype]): The data type for weights and activations.
+ kv_cache_dtype (Optional[str]): The data type of kv_cache, defaults to None.
+ prompt_template (Optional[str]): The prompt template for generation, defaults to None.
+ do_sample (bool): Whether to use sampling for generation, defaults to False.
+ beam_width (int): The maximum beam width used to initialize KV Cache, defaults to 1.
+ During generation, the beam width provided as sampling parameter should be less than or equivalent to this value.
+ prefill_ratio (Optional[float]): A controling ratio for prefill and decoding in running list, defaults to 1.2. We will do a step of prefill
+ when the actual value exceeds this ratio.
+ pad_input: Whether to pad all inputs to the max length.
+ early_stopping (Optional[bool]): Whether to stop the generation when all beam hypotheses have finished or not, defaults to False.
+ top_k (Optional[int]): The number of highest probability vocabulary tokens to keep for top-k-filtering, defaults to None.
+ top_p (Optional[float]): The cumulative probability threshold for retaining tokens with a total probability above it, defaults to None.
+ temperature (Optional[float]): Randomness used to control randomization, defaults to 1.0.
+ repetition_penalty (Optional[float]): The parameter that influences the model's treatment of new tokens in relation to their appearance in the prompt and the generated text. Values greater than 1 incentivize the model to introduce new tokens, whereas values less than 1 incentivize token repetition., defaults to 1.0.
+ no_repeat_ngram_size (Optional[int]): If no_repeat_ngram_size > 0, the consecutive tokens of ngram size can only appear once in inference sentences.
+ n_spec_tokens (int): The maximum number of speculating tokens, defaults to None.
+ glimpse_large_kv (bool): Whether to use large KV in drafter model, defaults to False.
+ block_size (int): The number of blocks in a logical block, defaults to 16.
+ tp_size (int): Tensor parallel size, defaults to 1.
+ pp_size (int): Pipeline parallel size, defaults to 1.
+ micro_batch_size (int): the micro batch size, defaults to 1. Only useful when `pp_size` > 1.
+ micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
+ use_cuda_kernel(bool): Whether to use cuda kernel, faster but lose some precision occasionally
+ use_cuda_graph (bool): Whether to enforce CUDA graph execution. If False, we will disable CUDA graph and always execute the model in eager mode. If True, we will use eager execution in hybrid.
+ max_context_len_to_capture (int): max context len that could be captured by CUDA Graph, per sequence
+ high_precision(Optional[bool]): Whether to use float32 for underlying calculations of float16 data to achieve higher precision, defaults to False.
+ ignore_eos(bool): Whether to ignore the EOS token and continue generating tokens when encountering the EOS token.
+ """
+
+ # NOTE: arrange configs according to their importance and frequency of usage
+
+ # runtime limit
+ max_batch_size: int = 8
+ max_output_len: int = 256
+ max_input_len: int = 256
+
+ # general configs
+ dtype: Union[str, torch.dtype] = torch.float16 # use fp16 by default
+ kv_cache_dtype: Optional[str] = None
+
+ # generation configs
+ prompt_template: Optional[str] = None
+ do_sample: bool = False
+ beam_width: int = 1 # TODO: beam search is not support for now
+ prefill_ratio: Optional[
+ float
+ ] = 1.2 # the ratio of prefill sequences to decoding sequences, we do prefill step once the actual value exceeds ratio
+ pad_input: bool = False
+ early_stopping: Optional[bool] = False
+ top_k: Optional[int] = None
+ top_p: Optional[float] = None
+ temperature: Optional[float] = 1.0
+ no_repeat_ngram_size: Optional[int] = 0
+ repetition_penalty: Optional[float] = 1.0
+
+ # speculative decoding configs
+ max_n_spec_tokens: int = 5
+ glimpse_large_kv: bool = False
+
+ # paged attention configs
+ block_size: int = 16
+
+ # model parallelism configs
+ tp_size: int = 1
+ pp_size: int = 1
+ micro_batch_size: int = 1
+ micro_batch_buffer_size: int = None
+ high_precision: Optional[bool] = False
+
+ # cuda kernel option
+ use_cuda_kernel: bool = False
+
+ # cuda_graph
+ use_cuda_graph: bool = False # NOTE only when we have the graph for specific decoding batch size can we use the cuda graph for inference
+ max_context_len_to_capture: int = 512
+ ignore_eos: bool = False
+
+ def __post_init__(self):
+ self.max_context_len_to_capture = self.max_input_len + self.max_output_len
+ self._verify_config()
+
+ def _verify_config(self) -> None:
+ """
+ Verify the input config
+ """
+ # check dtype
+ if isinstance(self.dtype, str):
+ # convert string dtype to torch dtype
+ assert (
+ self.dtype in _DTYPE_MAPPING
+ ), f"Expected the dtype string argument to be in {list(_DTYPE_MAPPING.keys())} but found an unknown dtype: {self.dtype}"
+ self.dtype = _DTYPE_MAPPING[self.dtype]
+ assert (
+ self.dtype in _ALLOWED_DTYPES
+ ), f"Expected dtype to be in {_ALLOWED_DTYPES} but found an unknown dtype: {self.dtype}"
+
+ if self.kv_cache_dtype:
+ assert (
+ self.use_cuda_kernel and self.kv_cache_dtype == "fp8"
+ ), f"FP8 kv_cache is only supported with use_cuda_kernel open now"
+ self.kv_cache_dtype = torch.uint8
+
+ # skip using casting when the data type is float32
+ if self.dtype == torch.float32:
+ self.high_precision = False
+
+ # check prompt template
+ if self.prompt_template is None:
+ return
+
+ if self.prompt_template in _DEFAULT_PROMPT_TEMPLATES:
+ self.prompt_template = _DEFAULT_PROMPT_TEMPLATES[self.prompt_template]
+ else:
+ # make sure the template can be formatted with input_text
+ assert (
+ "{input_text}" in self.prompt_template
+ ), "The prompt template should contain '{input_text}' for formatting the input text. For example: 'USER: {input_text}\n\nASSISTANT: '"
+
+ def to_generation_config(self, model_config) -> GenerationConfig:
+ meta_config = {
+ "max_length": self.max_input_len + self.max_output_len,
+ "max_new_tokens": self.max_output_len,
+ "early_stopping": self.early_stopping,
+ "do_sample": self.do_sample,
+ "num_beams": self.beam_width,
+ }
+ for type in ["repetition_penalty", "no_repeat_ngram_size", "temperature", "top_k", "top_p"]:
+ if hasattr(self, type):
+ meta_config[type] = getattr(self, type)
+ for type in ["pad_token_id", "bos_token_id", "eos_token_id"]:
+ if hasattr(model_config, type):
+ meta_config[type] = getattr(model_config, type)
+
+ return GenerationConfig.from_dict(meta_config)
+
+ def to_rpc_param(self) -> dict:
+ kwargs = {
+ "dtype": str(self.dtype).split(".")[-1],
+ "max_n_spec_tokens": self.max_n_spec_tokens,
+ "max_batch_size": self.max_batch_size,
+ "max_input_len": self.max_input_len,
+ "max_output_len": self.max_output_len,
+ "tp_size": self.tp_size,
+ "pp_size": self.pp_size,
+ "pad_input": self.pad_input,
+ "early_stopping": self.early_stopping,
+ "do_sample": self.do_sample,
+ "beam_width": self.beam_width,
+ "kv_cache_dtype": str(self.kv_cache_dtype).split(".")[-1],
+ }
+ return kwargs
+
+ @staticmethod
+ def from_rpc_param(rpc_dict: dict) -> "InferenceConfig":
+ """
+ We intentionally don't use `dict.get` method to ensure we pass the right rpc param, or program will show error message
+ """
+ return InferenceConfig(
+ dtype=getattr(torch, rpc_dict["dtype"]),
+ max_n_spec_tokens=rpc_dict["max_n_spec_tokens"],
+ max_batch_size=rpc_dict["max_batch_size"],
+ max_input_len=rpc_dict["max_input_len"],
+ max_output_len=rpc_dict["max_output_len"],
+ tp_size=rpc_dict["tp_size"],
+ pp_size=rpc_dict["pp_size"],
+ pad_input=rpc_dict["pad_input"],
+ early_stopping=rpc_dict["early_stopping"],
+ do_sample=rpc_dict["do_sample"],
+ beam_width=rpc_dict["beam_width"],
+ kv_cache_dtype=getattr(torch, rpc_dict["kv_cache_dtype"], None),
+ )
+
+ @classmethod
+ def from_dict(cls, config_dict: Dict[str, Any]) -> "InferenceConfig":
+ # Get the list of attributes of this dataclass.
+ attrs = [attr.name for attr in fields(cls)]
+ inference_config_args = {}
+ for attr in attrs:
+ if attr in config_dict:
+ inference_config_args[attr] = config_dict[attr]
+ else:
+ inference_config_args[attr] = getattr(cls, attr)
+
+ # Set the attributes from the parsed arguments.
+ inference_config = cls(**inference_config_args)
+ return inference_config
diff --git a/colossalai/inference/core/__init__.py b/colossalai/inference/core/__init__.py
new file mode 100644
index 000000000000..c18c2e59b522
--- /dev/null
+++ b/colossalai/inference/core/__init__.py
@@ -0,0 +1,4 @@
+from .engine import InferenceEngine
+from .request_handler import RequestHandler
+
+__all__ = ["InferenceEngine", "RequestHandler"]
diff --git a/colossalai/inference/core/async_engine.py b/colossalai/inference/core/async_engine.py
new file mode 100644
index 000000000000..6f7ab15d8f58
--- /dev/null
+++ b/colossalai/inference/core/async_engine.py
@@ -0,0 +1,309 @@
+import asyncio
+import logging
+from functools import partial
+from typing import AsyncIterator, Dict, Iterable, List, Optional, Set, Tuple, Type
+
+from colossalai.inference.core.engine import InferenceEngine
+
+# CLI logger
+logging.basicConfig(level=logging.DEBUG, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
+logger = logging.getLogger("colossalai-inference")
+
+
+def _raise_exception_on_finish(task: asyncio.Task, request_tracker: "Tracer") -> None:
+ msg = "Task finished unexpectedly. This should never happen! "
+ try:
+ try:
+ task.result()
+ except asyncio.CancelledError:
+ return
+ except Exception as exc:
+ raise RuntimeError(msg + " See stack trace above for the actual cause.") from exc
+ raise RuntimeError(msg)
+ except Exception as exc:
+ request_tracker.propagate_exception(exc)
+ raise exc
+
+
+class RequstStream:
+ """
+ A stream of Output for a request that can be iterated over asynchronously.
+ Attributes: 1.request_id: The id of the request.
+ 2._future: A future that will be set when the request is finished.
+ Methods: set_result and get_result, results will be set when finished, for once, and
+ the `self.future` will be set to done.
+
+ """
+
+ def __init__(self, request_id: int) -> None:
+ self.request_id = request_id
+ self._future = asyncio.Future()
+
+ def set_result(self, result) -> None:
+ """Set final result and signal taht it's ready"""
+ if not self._future.done():
+ self._future.set_result(result)
+
+ async def get_result(self):
+ """Wait for the result to be set and return it."""
+ return await self._future
+
+ @property
+ def finished(self) -> bool:
+ """Check if the stream has finished by checking if the future is done."""
+ return self._future.done()
+
+
+class Tracer:
+ """
+ Recording new requests and finished requests.
+ Attributes: 1._request_streams: We create one stream for each request to trace the output.
+ 2._finished_requests: A queue to store the finished requests.
+ 3._new_requests: New requests will be stored in this queue first, before sending them to the engine.
+ 4.new_requests_event: An event to notify the engine that there are new requests.
+ """
+
+ def __init__(self) -> None:
+ self._request_streams: Dict[int, RequstStream] = {}
+ self._finished_requests: asyncio.Queue[int] = asyncio.Queue()
+ self._new_requests: asyncio.Queue[Tuple[RequstStream, dict]] = asyncio.Queue()
+ self.new_requests_event = None
+
+ def __contains__(self, item):
+ return item in self._request_streams
+
+ def init_event(self):
+ self.new_requests_event = asyncio.Event()
+
+ def propagate_exception(self, exc: Exception, request_id: Optional[int] = None) -> None:
+ """
+ Propagate an exception to request streams (all if request_id is None).
+ """
+ if request_id is not None:
+ self._request_streams[request_id].set_result(exc)
+ else:
+ for stream in self._request_streams.values():
+ stream.set_result(exc)
+
+ def process_finished_request(self, finished_request) -> None:
+ """Process a finished request from the engine."""
+ request_id = finished_request.request_id
+ try:
+ self._request_streams[request_id].set_result(finished_request)
+ except:
+ raise RuntimeError(f"The request_id {request_id} is not found in our stream, please check")
+ self.abort_request(request_id)
+
+ def add_request(self, request_id: int, **engine_add_request_kwargs) -> RequstStream:
+ """
+ Add a request to be sent to the engine on the next background
+ loop iteration.
+ """
+ if request_id in self._request_streams:
+ raise KeyError(f"Request {request_id} already exists.")
+
+ stream = RequstStream(request_id)
+ logger.info(f"Added request {request_id}.")
+ self._new_requests.put_nowait((stream, {"request_id": request_id, **engine_add_request_kwargs}))
+ self.new_requests_event.set()
+
+ return stream
+
+ def abort_request(self, request_id: int, *, verbose: bool = False) -> None:
+ """Abort a request during next background loop iteration."""
+ if verbose:
+ logger.info(f"Aborted request {request_id}.")
+
+ self._finished_requests.put_nowait(request_id)
+
+ if request_id not in self._request_streams or self._request_streams[request_id].finished:
+ # The request has already finished or been aborted.
+ # The requests in new_requests will be aborted when try to get them(if marked aborted)
+ return
+
+ self._request_streams[request_id].set_result(None)
+
+ def get_new_requests(self):
+ """
+ Get new requests from http server.
+ """
+ new_requests: List[Dict] = []
+ finished_requests: Set[int] = set()
+
+ while not self._finished_requests.empty():
+ request_id = self._finished_requests.get_nowait()
+ finished_requests.add(request_id)
+
+ while not self._new_requests.empty():
+ stream, new_request = self._new_requests.get_nowait()
+ if new_request["request_id"] in finished_requests:
+ # The request has been aborted.
+ stream.set_result(None)
+ continue
+ self._request_streams[stream.request_id] = stream
+ new_requests.append(new_request)
+
+ self.new_requests_event.clear()
+
+ return new_requests
+
+ async def wait_for_new_requests(self):
+ await self.new_requests_event.wait()
+
+
+class _AsyncInferenceEngine(InferenceEngine):
+ """
+ Async methods for Inference Engine. This engine is an extension for InferenceEngine, and the additional methods will only be used for
+ Methods: 1. async_step: The async version of Engine.step()
+ """
+
+ async def async_step(self) -> List[str]:
+ """
+ The async version of Engine.step()
+ Performs one decoding iteration and returns newly generated results.
+
+ It first schedules the sequences to be executed in the next iteration.
+ Then, it executes the model and updates the scheduler with the model
+ outputs. Finally, it decodes the sequences and returns the newly
+ generated results.
+ """
+ batch = self.request_handler.schedule()
+ loop = asyncio.get_running_loop()
+
+ # Use run_in_executor to asyncally run the sync method model.forward().
+ logits = await loop.run_in_executor(
+ None,
+ self.model,
+ batch,
+ self.k_cache,
+ self.v_cache,
+ )
+
+ if self.inference_config.pad_input:
+ logits = logits[:, -1, :]
+ self.request_handler.search_tokens(self.generation_config, logits)
+
+ finished_sequences = self.request_handler.update()
+ for sequence in finished_sequences:
+ sequence.output = self.tokenizer.decode(sequence.output_token_id)
+
+ return finished_sequences, self.request_handler.total_requests_in_batch_bucket() > 0
+
+
+class AsyncInferenceEngine:
+ """An asynchronous wrapper for the InferenceEngine class.
+
+ This class is used to wrap the InferenceEngine class to make it asynchronous.
+ It uses asyncio to create a background loop that keeps processing incoming
+ requests. Note that this class does not hold model directly, when incoming a new
+ request, it first called `add_request` and the Tracer will record the request, putting
+ it to the background `InferenceEngine`(done in background loop) to process. You can
+ consider this engine as an interface.
+ """
+
+ _engine_class: Type[_AsyncInferenceEngine] = _AsyncInferenceEngine
+
+ def __init__(self, start_engine_loop: bool = True, **kwargs):
+ self.engine = self._init_engine(**kwargs)
+ self.background_loop = None
+ # reference to the unshielded loop
+ self._background_loop_unshielded = None
+ self.start_engine_loop = start_engine_loop
+ self._request_tracer = Tracer()
+
+ @property
+ def background_loop_status(self):
+ return self.background_loop is not None and not self.background_loop.done()
+
+ def start_background_loop(self):
+ if self.background_loop_status:
+ raise RuntimeError("Existing loop is running")
+
+ self._request_tracer.init_event()
+
+ self._background_loop_unshielded = asyncio.get_event_loop().create_task(self.run_engine_loop())
+ self._background_loop_unshielded.add_done_callback(
+ partial(_raise_exception_on_finish, request_tracker=self._request_tracer)
+ )
+ self.background_loop = asyncio.shield(self._background_loop_unshielded)
+
+ def _init_engine(self, **kwargs):
+ return self._engine_class(**kwargs)
+
+ async def step(self):
+ """
+ Run engine to process requests
+
+ Returns True if there are in-progress requests.
+ """
+ new_requests = self._request_tracer.get_new_requests()
+ for new_request in new_requests:
+ self.engine.add_single_request(**new_request)
+ newly_finished_seqs, has_running_requests = await self.engine.async_step()
+
+ for seq in newly_finished_seqs:
+ self._request_tracer.process_finished_request(seq)
+
+ return has_running_requests
+
+ async def _engine_abort(self, request_ids: Iterable[int]):
+ self.engine.abort_request(request_ids)
+
+ async def abort(self, request_id: int):
+ """
+ Abort a single request
+ """
+ if not self.background_loop_status:
+ raise RuntimeError("Background loop is not running or launched correctly.")
+ return self._abort(request_id)
+
+ def _abort(self, request_id: int):
+ self._request_tracer.abort_request(request_id)
+
+ async def run_engine_loop(self):
+ processing_requests = False
+ while True:
+ if not processing_requests:
+ await self._request_tracer.wait_for_new_requests()
+ processing_requests = await self.step()
+ await asyncio.sleep(0)
+
+ async def add_request(
+ self,
+ request_id: int,
+ prompt: Optional[str],
+ prompt_token_ids: Optional[List[int]] = None,
+ ) -> RequstStream:
+ """
+ Add a request to the background tracker(waiting queue), start the background loop if needed.
+ """
+ if not self.background_loop_status:
+ if self.start_engine_loop:
+ self.start_background_loop()
+ else:
+ raise RuntimeError("Background loop is not running.")
+ stream = self._request_tracer.add_request(
+ request_id,
+ prompt=prompt,
+ prompt_token_ids=prompt_token_ids,
+ )
+ return stream
+
+ async def generate(
+ self,
+ request_id: int,
+ prompt: Optional[str],
+ prompt_token_ids: Optional[List[int]] = None,
+ ) -> AsyncIterator[str]:
+ """
+ Generate output from a request. It receives the request from http server, adds it into the
+ waitting queue of Async Engine and streams the output sequence.
+ """
+ try:
+ stream = await self.add_request(request_id, prompt, prompt_token_ids=prompt_token_ids)
+ return await stream.get_result()
+
+ except (Exception, asyncio.CancelledError) as e:
+ # If there is an exception or coroutine is cancelled, abort the request.
+ self._abort(request_id)
+ raise e
diff --git a/colossalai/inference/core/engine.py b/colossalai/inference/core/engine.py
new file mode 100644
index 000000000000..7b456b8bea4f
--- /dev/null
+++ b/colossalai/inference/core/engine.py
@@ -0,0 +1,756 @@
+import time
+from itertools import count
+from typing import Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+from torch import distributed as dist
+from transformers import (
+ AutoConfig,
+ AutoModelForCausalLM,
+ GenerationConfig,
+ PreTrainedTokenizer,
+ PreTrainedTokenizerFast,
+)
+from transformers.models.llama.modeling_llama import LlamaForCausalLM
+
+from colossalai.accelerator import get_accelerator
+from colossalai.cluster import ProcessGroupMesh
+from colossalai.inference.batch_bucket import BatchBucket
+from colossalai.inference.config import InferenceConfig, InputMetaData
+from colossalai.inference.graph_runner import CUDAGraphRunner
+from colossalai.inference.modeling.policy import model_policy_map
+from colossalai.inference.sampler import search_tokens
+from colossalai.inference.spec import Drafter, GlideInput
+from colossalai.inference.struct import Sequence
+from colossalai.inference.utils import get_model_size, has_index_file
+from colossalai.interface import ModelWrapper
+from colossalai.logging import get_dist_logger
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer import ShardConfig, ShardFormer
+from colossalai.shardformer.policies.base_policy import Policy
+
+from .request_handler import RequestHandler
+
+__all__ = ["InferenceEngine"]
+
+PP_AXIS, TP_AXIS = 0, 1
+
+_supported_models = {
+ "LlamaForCausalLM": LlamaForCausalLM,
+ "BaichuanForCausalLM": AutoModelForCausalLM,
+}
+
+_BATCH_SIZES_TO_CAPTURE = [1, 2, 4] + [8 * i for i in range(1, 33)]
+
+
+class InferenceEngine:
+
+ """
+ InferenceEngine which manages the inference process..
+
+ Args:
+ model_or_path (nn.Module or str): Path or nn.Module of this model.
+ tokenizer Optional[(Union[PreTrainedTokenizer, PreTrainedTokenizerFast])]: Path of the tokenizer to use.
+ inference_config (Optional[InferenceConfig], optional): Store the configuration information related to inference.
+ verbose (bool): Determine whether or not to log the generation process.
+ model_policy ("Policy"): the policy to shardformer model. It will be determined by the model type if not provided.
+ """
+
+ def __init__(
+ self,
+ model_or_path: Union[nn.Module, str],
+ tokenizer: Union[PreTrainedTokenizer, PreTrainedTokenizerFast],
+ inference_config: InferenceConfig,
+ verbose: bool = False,
+ model_policy: Policy = None,
+ ) -> None:
+ self.inference_config = inference_config
+ self.dtype = inference_config.dtype
+ self.high_precision = inference_config.high_precision
+
+ self.verbose = verbose
+ self.logger = get_dist_logger(__name__)
+
+ self.init_model(model_or_path, model_policy)
+
+ self.generation_config = inference_config.to_generation_config(self.model_config)
+
+ self.tokenizer = tokenizer
+ self.tokenizer.pad_token = self.tokenizer.eos_token
+
+ self.request_handler = RequestHandler(self.inference_config, self.model_config)
+ self.k_cache, self.v_cache = self.request_handler.get_kvcache()
+ # DISCUSS maybe move this into batch info?
+
+ self.counter = count()
+
+ self.use_cuda_graph = self.inference_config.use_cuda_graph
+ if self.use_cuda_graph:
+ self.graph_runners: Dict[int, CUDAGraphRunner] = {}
+ self.graph_memory_pool = None # Set during graph capture.
+ if verbose:
+ self.logger.info("Colossal AI CUDA Graph Capture on")
+
+ self.capture_model(self.k_cache, self.v_cache)
+
+ # Model and relatable attrs of speculative decoding will be set by `enable_spec_dec`
+ self.use_spec_dec = False
+ self.drafter_model = None
+ self.drafter = None
+ self.use_glide = False
+ self.n_spec_tokens = self.inference_config.max_n_spec_tokens
+
+ self._verify_args()
+
+ def init_model(self, model_or_path: Union[nn.Module, str], model_policy: Policy = None):
+ """
+ Shard model or/and Load weight
+
+ Args:
+ model_or_path Union[nn.Module, str]: path to the checkpoint or model of transformer format.
+ model_policy (Policy): the policy to replace the model
+ """
+
+ casuallm = None
+ if isinstance(model_or_path, str):
+ try:
+ hf_config = AutoConfig.from_pretrained(model_or_path, trust_remote_code=True)
+ arch = getattr(hf_config, "architectures")[0]
+ if arch in _supported_models.keys():
+ casuallm = _supported_models[arch](hf_config)
+ if isinstance(casuallm, AutoModelForCausalLM):
+ # NOTE(caidi) It's necessary to add half() here, otherwise baichuan13B will overflow the memory.
+ model = AutoModelForCausalLM.from_pretrained(model_or_path, trust_remote_code=True).half()
+ else:
+ model = _supported_models[arch](hf_config)
+ else:
+ raise ValueError(f"Model {arch} is not supported.")
+
+ except Exception as e:
+ self.logger.error(
+ f"An exception occurred during loading model: {e}, model should be loaded by transformers\n"
+ )
+ else:
+ model = model_or_path
+
+ self.model_config = model.config
+
+ torch.cuda.empty_cache()
+ init_gpu_memory = torch.cuda.mem_get_info()[0]
+
+ self.device = get_accelerator().get_current_device()
+ if self.verbose:
+ self.logger.info(f"the device is {self.device}")
+
+ model = model.to(self.dtype).eval()
+
+ if self.verbose:
+ self.logger.info(
+ f"Before the shard, Rank: [{dist.get_rank()}], model size: {get_model_size(model)} GB, model's device is: {model.device}"
+ )
+
+ if model_policy is None:
+ if self.inference_config.pad_input:
+ model_type = "padding_" + self.model_config.model_type
+ else:
+ model_type = "nopadding_" + self.model_config.model_type
+ model_policy = model_policy_map[model_type]()
+
+ pg_mesh = ProcessGroupMesh(self.inference_config.pp_size, self.inference_config.tp_size)
+ tp_group = pg_mesh.get_group_along_axis(TP_AXIS)
+
+ self.model = self._shardformer(
+ model,
+ model_policy,
+ None,
+ tp_group=tp_group,
+ )
+
+ self.model = ModelWrapper(model).to(self.device)
+
+ if self.verbose:
+ self.logger.info(
+ f"After the shard, Rank: [{dist.get_rank()}], model size: {get_model_size(self.model)} GB, model's device is: {model.device}"
+ )
+
+ if isinstance(model_or_path, str) and not isinstance(casuallm, AutoModelForCausalLM):
+ from colossalai.inference.core.plugin import InferCheckpoint_io
+
+ cpt_io = InferCheckpoint_io()
+ if_has_index_file, model_index_file = has_index_file(model_or_path)
+ assert if_has_index_file, "the model path is invalid"
+ cpt_io.load_model(self.model, model_index_file)
+
+ free_gpu_memory, total_gpu_memory = torch.cuda.mem_get_info()
+ peak_memory = init_gpu_memory - free_gpu_memory
+ if self.verbose:
+ self.logger.info(
+ f"Rank [{dist.get_rank()}], Model Weight Max Occupy {peak_memory / (1024 ** 3)} GB, Model size: {get_model_size(self.model)} GB"
+ )
+
+ @torch.inference_mode()
+ def capture_model(self, k_cache: List[torch.Tensor], v_cache: List[torch.Tensor]):
+ assert self.use_cuda_graph, "please turn on the cuda graph"
+
+ if self.verbose:
+ self.logger.info("Colossal AI CUDA Graph Capture begin")
+
+ t_capture_begin = time.perf_counter()
+
+ block_size = self.inference_config.block_size
+ head_dim = self.model_config.hidden_size // self.model_config.num_attention_heads
+
+ # Prepare dummy inputs. These will be reused for all batch sizes.
+ max_batch_size = max(_BATCH_SIZES_TO_CAPTURE)
+ max_context_len_to_capture = self.inference_config.max_context_len_to_capture
+ max_num_blocks = (max_context_len_to_capture + block_size - 1) // block_size
+ input_tokens_ids = torch.zeros(max_batch_size, dtype=torch.long).cuda()
+ # self.graph_block_tables = np.zeros((max(_BATCH_SIZES_TO_CAPTURE), max_num_blocks), dtype=np.int32)
+ self.graph_block_tables = np.full((max(_BATCH_SIZES_TO_CAPTURE), max_num_blocks), -1, dtype=np.int32)
+ self.graph_block_tables[:, 0] = np.arange(max_num_blocks, max_num_blocks + max(_BATCH_SIZES_TO_CAPTURE))
+ self.graph_block_tables[0, :] = np.arange(
+ 0, max_num_blocks
+ ) # NOTE this is a hack to insure cuda grpah could capture the fixed cuda kernel grid in flash decoding, to make the first seqlen as the max_seq_len
+ block_tables = torch.from_numpy(self.graph_block_tables).cuda()
+ output_tensor = torch.zeros(
+ (max_batch_size, self.model_config.num_attention_heads * head_dim), dtype=self.dtype, device=self.device
+ )
+ fd_inter_tensor = self.request_handler.running_bb.fd_inter_tensor
+
+ max_num_seqs = self.inference_config.max_batch_size
+ batch_size_capture_list = [bs for bs in _BATCH_SIZES_TO_CAPTURE if bs <= max_num_seqs]
+ sequence_lengths = torch.ones(max_batch_size, dtype=torch.int).cuda()
+ # NOTE this is a hack to insure cuda grpah could capture the fixed cuda kernel grid in flash decoding, to make the first seqlen as the max_seq_len
+ sequence_lengths[0] = torch.tensor(
+ self.inference_config.max_context_len_to_capture - 1, dtype=torch.int32
+ ).cuda()
+
+ # NOTE: Capturing the largest batch size first may help reduce the
+ # memory usage of CUDA graph.
+ for batch_size in reversed(batch_size_capture_list):
+ if self.verbose:
+ self.logger.info(f"batch size {batch_size} graph capturing")
+
+ input_meta_data = InputMetaData(
+ block_tables=block_tables[:batch_size],
+ sequence_lengths=sequence_lengths[:batch_size],
+ fd_inter_tensor=fd_inter_tensor,
+ batch_size=batch_size,
+ is_prompts=False,
+ use_cuda_graph=True,
+ high_precision=False,
+ kv_seq_len=sequence_lengths[:batch_size].max().item(),
+ head_dim=head_dim,
+ dtype=self.dtype,
+ )
+
+ graph_runner = CUDAGraphRunner(self.model)
+ graph_runner.capture(
+ input_tokens_ids[:batch_size],
+ output_tensor[:batch_size],
+ input_meta_data,
+ k_caches=k_cache,
+ v_caches=v_cache,
+ memory_pool=self.graph_memory_pool,
+ )
+ self.graph_memory_pool = graph_runner.graph.pool()
+ self.graph_runners[batch_size] = graph_runner
+
+ t_capture_end = time.perf_counter()
+
+ if self.verbose:
+ self.logger.info(f"CUDA Graph capture time: {t_capture_end - t_capture_begin} s")
+
+ def _verify_args(self) -> None:
+ """Verify the input args"""
+ if not isinstance(self.inference_config, InferenceConfig):
+ raise TypeError("Invalid type of inference config provided.")
+ if not isinstance(self.model, nn.Module):
+ raise TypeError(f"the model type must be nn.Module, but got {type(self.model)}")
+ if not isinstance(self.tokenizer, (PreTrainedTokenizerFast, PreTrainedTokenizer)):
+ raise TypeError(
+ f"the tokenizer type must be PreTrainedTokenizer or PreTrainedTokenizerFast, but got {type(self.tokenizer)}"
+ )
+ if isinstance(self.model, ModelWrapper):
+ model = self.model.module
+ assert (
+ model.__class__.__name__ in _supported_models.keys()
+ ), f"Model {self.model.__class__.__name__} is not supported."
+
+ def _shardformer(
+ self,
+ model: nn.Module,
+ model_policy: Policy,
+ stage_manager: PipelineStageManager = None,
+ tp_group: ProcessGroupMesh = None,
+ ) -> nn.Module:
+ """
+ Initialize ShardConfig and replace the model with shardformer.
+
+ Args:
+ model (nn.Module): Path or nn.Module of this model.
+ model_policy (Policy): The policy to shardformer model which is determined by the model type.
+ stage_manager (PipelineStageManager, optional): Used to manage pipeline stages. Defaults to None.
+ tp_group (ProcessGroupMesh, optional): Used to manage the process TP group mesh. Defaults to None.
+
+ Returns:
+ nn.Module: The model optimized by Shardformer.
+ """
+
+ shardconfig = ShardConfig(
+ tensor_parallel_process_group=tp_group,
+ pipeline_stage_manager=stage_manager,
+ enable_tensor_parallelism=(self.inference_config.tp_size > 1),
+ enable_fused_normalization=False,
+ enable_all_optimization=False,
+ enable_flash_attention=False,
+ enable_jit_fused=False,
+ enable_sequence_parallelism=False,
+ )
+ shardformer = ShardFormer(shard_config=shardconfig)
+ shard_model, _ = shardformer.optimize(model, model_policy)
+ return shard_model
+
+ def enable_spec_dec(
+ self,
+ drafter_model: nn.Module = None,
+ n_spec_tokens: int = None,
+ use_glide_drafter: bool = False,
+ ) -> None:
+ """Initialize drafter (if it has not yet), and enable Speculative Decoding for subsequent generations.
+
+ Args:
+ drafter_model (nn.Module): The drafter model (small model) used to speculate tokens.
+ If provided, the previous drafter and drafter model, if exist, will be overwritten.
+ n_spec_tokens (Optional[int]): The number of tokens to speculate in each round of speculating-verifying.
+ If not provided, `max_n_spec_tokens` in InferenceConfig will be used.
+ use_glide_drafter (bool): Whether to use glide model for speculative decoding. Defaults to False.
+ If True, the drafter model will be replaced by a glide model.
+
+ ```python
+ ...
+ engine = InferenceEngine(model, tokenizer, inference_config)
+
+ engine.enable_spec_dec(drafter_model, n_spec_tokens=5)
+ engine.generate(...) # Speculative Decoding
+
+ engine.disable_spec_dec()
+ engine.generate(...) # Normal generation
+
+ engine.enable_spec_dec()
+ engine.generate(...) # Speculative-Decoding using previously set drafter model and number of spec tokens
+ engine.clear_spec_dec()
+ ```
+ """
+ if drafter_model is None and self.drafter is None:
+ raise ValueError("Drafter not initialized. Please provide a Drafter Model")
+ if n_spec_tokens is not None:
+ assert 1 < n_spec_tokens <= self.inference_config.max_n_spec_tokens
+ self.n_spec_tokens = n_spec_tokens
+ if drafter_model is not None:
+ assert isinstance(drafter_model, nn.Module)
+ # overwrite the drafter, if exists
+ self.clear_spec_dec()
+ self.drafter_model = drafter_model
+ self.drafter = Drafter(
+ self.drafter_model,
+ self.tokenizer,
+ device=self.device,
+ dtype=self.dtype,
+ )
+
+ # check if the provided drafter model is compatible with GLIDE structure
+ # when `use_glide_drafter` is set to True
+ if (
+ use_glide_drafter
+ and hasattr(drafter_model, "model")
+ and hasattr(drafter_model.model, "layers")
+ and hasattr(drafter_model.model.layers[0], "cross_attn")
+ ):
+ self.use_glide = use_glide_drafter
+ elif use_glide_drafter:
+ self.logger.warning(
+ f"`use_glide_drafter` is provided as {use_glide_drafter}, "
+ f"but the provided drafter model is not compatible with GLIDE structure."
+ f"Falling back to use the default drafter model (non-GLIDE)."
+ )
+ self.request_handler.set_spec_dec_mode(self.n_spec_tokens)
+ # using speculative decoding for subsequent generations
+ self.use_spec_dec = True
+
+ def disable_spec_dec(self) -> None:
+ """Disable using speculative decoding for subsequent generations."""
+ self.request_handler.unset_spec_dec_mode()
+ # set back to the maximum number of tokens to speculate
+ self.n_spec_tokens = self.inference_config.max_n_spec_tokens
+ self.use_glide = False
+ self.use_spec_dec = False
+
+ def clear_spec_dec(self) -> None:
+ """Clear relatable structures of speculative decoding, if exist."""
+ if self.use_spec_dec:
+ self.disable_spec_dec()
+ if self.drafter_model or self.drafter:
+ self.drafter_model = None
+ self.drafter = None
+ torch.cuda.empty_cache()
+ self.use_glide = False
+ self.use_spec_dec = False
+
+ def steps_spec_dec(self) -> List[Sequence]:
+ """
+ Run Speculative Decoding steps. This is like retrieving a single batch and launch inference
+ with many steps of speculating by a drafter model as well as verifying by a main model.
+
+ Returns:
+ List[Sequence]: finished sequences generated by one step.
+ """
+ batch = self.request_handler.schedule() # prefill batch
+ assert batch.current_batch_size == 1, "Only support bsz 1 for speculative decoding for now."
+
+ input_token_ids, output_tensor, input_meta_data = self.prepare_input(batch)
+
+ if input_meta_data.use_cuda_graph:
+ model_executable = self.graph_runners[input_meta_data.batch_size]
+ else:
+ model_executable = self.model
+
+ # 1. Prefill small model (Drafter) - fill past kv cache for drafter model
+ # NOTE For glide drafter models, we won't actually apply glide during prefill stage
+ drafter_out = self.drafter.speculate(input_token_ids, 1, None)
+ next_token_ids_spec = drafter_out.next_tokens
+ drafter_past_key_values = drafter_out.past_key_values
+
+ # 2. Prefill main model (Verifier) - fill past kv cache for main model
+ logits = model_executable(input_token_ids, output_tensor, input_meta_data, self.k_cache, self.v_cache)
+ next_tokens = search_tokens(self.generation_config, logits, batch_token_ids=batch.batch_token_ids)
+ # append new inputs to the batch, temporarily
+ batch.append_batch_tokens(next_tokens)
+ self.request_handler.allocate_batch_spec_dec(batch, 1)
+ already_allocated_kv_len = batch.seq_lengths[0].item()
+ input_token_ids = batch.get_1D_inputs_spec_dec(1)
+
+ finished_sequences = self.request_handler.update()
+
+ while True:
+ # HACK Retrieve the running batch
+ # Using RequestHandler.schedule here will re-allocate same kv cache for the batch
+ batch = self.request_handler.running_bb # running batch
+ assert batch.current_batch_size == 1, "Only support bsz 1 for speculative decoding for now."
+
+ # 3. Decoding - Drafter model speculates `n` tokens
+ glide_input = None
+ if self.use_glide:
+ glide_input = GlideInput(
+ batch.get_block_table_tensor(),
+ self.k_cache[-1], # use kv cahces of the last layer
+ self.v_cache[-1],
+ batch.get_sequence_lengths(),
+ )
+
+ drafter_out = self.drafter.speculate(
+ input_token_ids,
+ self.n_spec_tokens,
+ drafter_past_key_values,
+ glide_input=glide_input,
+ )
+ next_token_ids_spec = drafter_out.next_tokens
+ drafter_past_key_values = drafter_out.past_key_values
+ drafter_spec_length = drafter_out.speculated_length
+
+ for next_token_id_spec in next_token_ids_spec:
+ self.request_handler.append_next_tokens(next_token_id_spec.unsqueeze(0))
+ cur_length = batch.seq_lengths[0].item()
+ if already_allocated_kv_len < cur_length:
+ self.request_handler.allocate_batch_spec_dec(batch, n=cur_length - already_allocated_kv_len)
+ already_allocated_kv_len = cur_length
+
+ # 4. Decoding - Main model verifies `n` tokens in parallel
+ if drafter_spec_length < batch.num_tokens_to_verify:
+ batch.set_use_spec_dec(num_tokens_to_verify=drafter_spec_length)
+ input_token_ids, output_tensor, input_meta_data = self.prepare_input(batch)
+ logits = model_executable(input_token_ids, output_tensor, input_meta_data, self.k_cache, self.v_cache)
+
+ next_tokens = search_tokens(self.generation_config, logits, batch_token_ids=batch.batch_token_ids)
+
+ # 5. Compare and process the results
+ diff_indexes = torch.nonzero(~(next_tokens[:-1] == next_token_ids_spec))
+ n_matches = drafter_spec_length if diff_indexes.size(0) == 0 else diff_indexes[0][0].item()
+
+ # revoke appended tokens for each Sequence in the current batch
+ batch.revoke_batch_tokens(drafter_spec_length - n_matches) # revoke drafted tokens
+
+ # append the last correct token generated by the main model
+ self.request_handler.append_next_tokens(next_tokens[n_matches].unsqueeze(0))
+
+ # trim past key values of the drafter model
+ drafter_past_key_values = Drafter.trim_kv_cache(
+ drafter_past_key_values, drafter_spec_length - n_matches - 1
+ )
+
+ # prepare inputs for the next round of speculation
+ n = 1 if n_matches < drafter_spec_length else 2
+ input_token_ids = batch.get_1D_inputs_spec_dec(n)
+
+ self.request_handler.update_batch_finished(batch, generation_config=self.generation_config)
+ finished_sequences = self.request_handler.update()
+ if len(finished_sequences) > 0:
+ break
+
+ # Reset back the number of speculated tokens of the batch,
+ # this is used to handle the last round of speculation, in which case the number of speculated tokens
+ # by the drafter is less than the number of speculated tokens set to the engine.
+ batch.set_use_spec_dec(num_tokens_to_verify=self.n_spec_tokens)
+
+ return finished_sequences
+
+ def generate(
+ self,
+ request_ids: Union[List[int], int] = None,
+ prompts: Union[List[str], str] = None,
+ prompts_token_ids: Union[List[int], torch.Tensor, np.ndarray] = None,
+ return_token_ids: bool = False,
+ generation_config: Optional[GenerationConfig] = None,
+ ) -> List[str]:
+ """
+ Executing the inference step.
+
+ Args:
+ prompts (Union[List[str], optional): Input prompts. Defaults to None.
+ prompts_token_ids (List[List[int]], optional): token ids of input prompts. Defaults to None.
+ request_ids (List[int], optional): The request ID. Defaults to None.
+ return_token_ids (bool): Whether to return output token ids. Defaults to False.
+ generation_config (GenerationConfig, optional): Huggingface GenerationConfig used for inference. Defaults to None.
+
+ Returns:
+ List[str]: Inference result returned by one generation.
+ """
+ with torch.inference_mode():
+ if isinstance(prompts, str) and isinstance(request_ids, int):
+ prompts = [prompts]
+ request_ids = [request_ids]
+ if prompts is not None or prompts_token_ids is not None:
+ gen_config_dict = generation_config.to_dict() if generation_config is not None else {}
+ self.add_request(
+ request_ids=request_ids,
+ prompts=prompts,
+ prompts_token_ids=prompts_token_ids,
+ **gen_config_dict,
+ )
+
+ output_seqs_list = []
+ total_tokens_list = []
+
+ # intuition: If user provide a generation config, we should replace the existing one.
+ if generation_config is not None:
+ self.generation_config = generation_config
+
+ if self.use_spec_dec:
+ assert self.drafter is not None, "Drafter Model is not initialized."
+ while self.request_handler.check_unfinished_seqs():
+ output_seqs_list += self.steps_spec_dec()
+ else:
+ while self.request_handler.check_unfinished_seqs():
+ output_seqs_list += self.step()
+
+ output_seqs_list = sorted(output_seqs_list, key=lambda x: int(x.request_id))
+
+ for seq in output_seqs_list:
+ total_tokens_list.append(seq.input_token_id + seq.output_token_id)
+
+ output_str = self.tokenizer.batch_decode(total_tokens_list, skip_special_tokens=True)
+
+ if return_token_ids:
+ output_tokens_list = [seq.output_token_id for seq in output_seqs_list]
+ return output_str, output_tokens_list
+ else:
+ return output_str
+
+ @property
+ def has_prompt_template(self) -> bool:
+ """ """
+ return self.inference_config.prompt_template is not None
+
+ def format_prompt(self, prompts: Union[List[str], str]) -> Union[List[str], str]:
+ """
+ This method will format the input prompt according to the prompt template given to the InferenceConfig.
+ """
+ assert (
+ self.has_prompt_template
+ ), "Found the prompt_template is None. Please provide a valid prompt_template in InferenceConfig."
+
+ if isinstance(prompts, (list, tuple)):
+ return [self.inference_config.prompt_template.format(input_text=prompt) for prompt in prompts]
+ elif isinstance(prompts, str):
+ return self.inference_config.prompt_template.format(input_text=prompts)
+ else:
+ raise TypeError(f"Expected the input prompt to be one of list, tuple, or str, but got {type(prompts)}.")
+
+ def add_request(
+ self,
+ request_ids: Union[List[int], int] = None,
+ prompts: List[str] = None,
+ prompts_token_ids: Union[List[int], torch.Tensor, np.ndarray] = None,
+ **kwargs,
+ ) -> None:
+ """
+ Add requests.
+
+ Args:
+ request_ids (List[int], optional): The request ID. Defaults to None.
+ prompts (Union[List[str], optional): Input prompts. Defaults to None.
+ prompts_token_ids (List[List[int]], optional): token ids of input prompts. Defaults to None.
+ """
+
+ # apply the prompt template to the input prompts
+
+ if self.has_prompt_template and prompts is not None:
+ prompts = self.format_prompt(prompts)
+
+ block_size = self.inference_config.block_size
+
+ if request_ids is not None and not isinstance(request_ids, list):
+ request_ids = [request_ids]
+
+ if prompts is not None and not isinstance(prompts, list):
+ prompts = [prompts]
+
+ if prompts_token_ids is None:
+ assert prompts, "When the prompts_token_ids is none, the input prompt list must be provided."
+ prompts_token_ids = self.tokenizer.batch_encode_plus(prompts, padding=self.inference_config.pad_input)[
+ "input_ids"
+ ]
+
+ # list of torch Tensor
+ if isinstance(prompts_token_ids, list):
+ if isinstance(prompts_token_ids[0], torch.Tensor):
+ prompts_token_ids = [prompt_token_id.tolist() for prompt_token_id in prompts_token_ids]
+ elif isinstance(prompts_token_ids, torch.Tensor) or isinstance(prompts_token_ids, np.ndarray):
+ prompts_token_ids = prompts_token_ids.tolist()
+ else:
+ raise TypeError(
+ f"The dtype of prompts_token_ids must be one of list, torch.Tensor, np.ndarray, but got {type(prompts_token_ids)}."
+ )
+
+ assert (
+ len(prompts_token_ids[0]) <= self.inference_config.max_input_len
+ ), f"The length of input prompts {len(prompts_token_ids[0])} must be less than max_input_len {self.inference_config.max_input_len}."
+
+ prompts_num = len(prompts_token_ids)
+
+ for i in range(prompts_num):
+ if request_ids:
+ assert isinstance(
+ request_ids[0], int
+ ), f"The request_id type must be int, but got {type(request_ids[0])}"
+ assert len(request_ids) == prompts_num
+ request_id = request_ids[i]
+ else:
+ request_id = next(self.counter)
+ if prompts == None:
+ prompt = None
+ else:
+ prompt = prompts[i]
+
+ max_length = kwargs.get("max_length", None)
+ max_new_tokens = kwargs.get("max_new_tokens", None)
+ if max_length is None and max_new_tokens is None:
+ max_new_tokens = self.generation_config.max_new_tokens or self.inference_config.max_output_len
+ elif max_length is not None:
+ max_new_tokens = max_length - len(prompts_token_ids[i])
+
+ sequence = Sequence(
+ request_id,
+ prompt,
+ prompts_token_ids[i],
+ block_size,
+ None,
+ self.tokenizer.eos_token_id,
+ self.tokenizer.pad_token_id,
+ max_output_len=max_new_tokens,
+ ignore_eos=self.inference_config.ignore_eos,
+ )
+ self.request_handler.add_sequence(sequence)
+
+ def prepare_input(self, batch: BatchBucket) -> Tuple[torch.Tensor, torch.Tensor, InputMetaData]:
+ input_ids = batch.get_1D_inputs()
+ sequence_lengths = batch.get_sequence_lengths()
+
+ if batch.is_prompts:
+ n_tokens = sequence_lengths.sum().item()
+ else:
+ n_tokens = batch.current_batch_size
+ if batch.use_spec_dec:
+ n_tokens = batch.num_tokens_to_verify + 1
+ assert n_tokens == input_ids.size(0)
+ n_tokens = n_tokens * batch.current_batch_size
+ output_tensor = torch.zeros(
+ (n_tokens, batch.num_heads * batch.head_dim), dtype=batch.dtype, device=batch.device
+ )
+
+ batch_token_ids = None
+ config_dict = self.generation_config.to_dict()
+ # process repetition_penalty, no_repeat_ngram_size
+ for type in ["repetition_penalty", "no_repeat_ngram_size"]:
+ if type in config_dict and config_dict[type] is not None:
+ batch_token_ids = batch.batch_token_ids
+
+ # only when we have the graph for specific decoding batch size can we use the cuda graph for inference
+ use_cuda_graph = False
+ if self.use_cuda_graph and not batch.is_prompts and batch.current_batch_size in self.graph_runners.keys():
+ use_cuda_graph = True
+
+ input_meta_data = InputMetaData(
+ block_tables=batch.get_block_table_tensor(),
+ sequence_lengths=sequence_lengths,
+ fd_inter_tensor=batch.fd_inter_tensor,
+ batch_size=batch.current_batch_size,
+ is_prompts=batch.is_prompts,
+ use_cuda_kernel=self.inference_config.use_cuda_kernel,
+ use_cuda_graph=use_cuda_graph,
+ high_precision=self.high_precision,
+ kv_seq_len=sequence_lengths.max().item(),
+ head_dim=batch.head_dim,
+ dtype=batch.dtype,
+ use_spec_dec=batch.use_spec_dec,
+ num_tokens_to_verify=batch.num_tokens_to_verify,
+ batch_token_ids=batch_token_ids,
+ )
+
+ return input_ids, output_tensor, input_meta_data
+
+ def step(self) -> List[str]:
+ """
+ In each step, do the follows:
+ 1. Run RequestHandler.schedule() and get the batch used for inference.
+ 2. Get the input, inputinfo and output placeholder from the batchbucket
+ 3. Run model to generate the next token
+ 4. Update waiting list and running list in RequestHandler and get finished sequences.
+ 5. Decode and return finished sequences.
+
+ Returns:
+ List[str]: Decoded finished sequences generated by one step.
+ """
+
+ batch = self.request_handler.schedule()
+
+ input_token_ids, output_tensor, input_meta_data = self.prepare_input(batch)
+
+ if input_meta_data.use_cuda_graph:
+ model_executable = self.graph_runners[input_meta_data.batch_size]
+ else:
+ model_executable = self.model
+
+ # TODO: padding_id is used for generating attn_mask and will be removed if nopad version is supported.
+ logits = model_executable(input_token_ids, output_tensor, input_meta_data, self.k_cache, self.v_cache)
+ if self.inference_config.pad_input:
+ logits = logits[:, -1, :]
+ next_tokens = search_tokens(
+ self.generation_config, logits, input_meta_data.is_prompts, batch_token_ids=input_meta_data.batch_token_ids
+ )
+ self.request_handler.append_next_tokens(next_tokens)
+ finished_sequences = self.request_handler.update()
+
+ return finished_sequences
diff --git a/colossalai/inference/core/plugin.py b/colossalai/inference/core/plugin.py
new file mode 100644
index 000000000000..d6a2b8b16550
--- /dev/null
+++ b/colossalai/inference/core/plugin.py
@@ -0,0 +1,140 @@
+import logging
+import os
+from functools import reduce
+from pathlib import Path
+from typing import Optional
+
+import torch
+
+from colossalai.checkpoint_io.general_checkpoint_io import GeneralCheckpointIO
+from colossalai.checkpoint_io.index_file import CheckpointIndexFile
+from colossalai.checkpoint_io.utils import is_safetensors_available, load_shard_state_dict, load_state_dict_into_model
+from colossalai.cluster import DistCoordinator
+from colossalai.interface import ModelWrapper
+
+try:
+ from torch.nn.modules.module import _EXTRA_STATE_KEY_SUFFIX
+except ImportError:
+ _EXTRA_STATE_KEY_SUFFIX = "_extra_state"
+
+
+class InferCheckpoint_io(GeneralCheckpointIO):
+ """
+ This class is for inference model loading, most codes are copied from colossalai.checkpoint_io.hybrid_parallel_checkpoint_io.HybridParallelCheckpointIO.
+ Origin HybridParallelCheckpointIO contains some codes about MixPrecision-Training, so we remove them and build a relatively clean class specifically for Inference.
+ """
+
+ def __init__(
+ self,
+ verbose: bool = True,
+ ) -> None:
+ super().__init__()
+ self.verbose = verbose
+ self.coordinator = DistCoordinator()
+
+ def load_sharded_model(self, model: ModelWrapper, checkpoint_index_file: Path, strict: bool = False):
+ """
+ Load sharded model with the given path to index file of checkpoint folder.
+
+ Args:
+ model (nn.Module): The model to be loaded.
+ checkpoint_index_file (str): Path to the index file of checkpointing folder.
+ strict (bool, optional): For name matching during loading state_dict. Defaults to False.
+ This argument should be manually set to False since params on same device might be stored in different files.
+ """
+ assert isinstance(model, ModelWrapper), "Please boost the model before loading!"
+ model = model.unwrap()
+
+ # Check whether the checkpoint uses safetensors.
+ use_safetensors = False
+ if "safetensors" in checkpoint_index_file.name:
+ use_safetensors = True
+
+ if use_safetensors and not is_safetensors_available():
+ raise ImportError("`safe_serialization` requires the `safetensors` library: `pip install safetensors`.")
+
+ # Read checkpoint index file.
+ ckpt_index_file = CheckpointIndexFile.from_file(checkpoint_index_file)
+ ckpt_root_path = ckpt_index_file.root_path
+ weight_map = ckpt_index_file.weight_map
+ strict = False
+
+ # Load params & buffers to model.
+ # Keep a record of loaded files so that file will not be repeatedly loaded.
+ loaded_file = set()
+
+ missing_keys = []
+ missing_file_keys = []
+
+ def _load(name: str):
+ if name not in weight_map:
+ missing_file_keys.append(name)
+ return
+ filename = weight_map[name]
+
+ # If this param/buffer has been loaded before, directly return.
+ if filename in loaded_file:
+ return
+
+ file_path = os.path.join(ckpt_root_path, filename)
+ state_dict = load_shard_state_dict(Path(file_path), use_safetensors)
+
+ load_state_dict_into_model(
+ model, state_dict, missing_keys=missing_keys, strict=strict, load_sub_module=True
+ )
+ loaded_file.add(filename)
+
+ # Load parameters.
+ for name, _ in model.named_parameters():
+ _load(name)
+
+ # Load buffers.
+ non_persistent_buffers = set()
+ for n, m in model.named_modules():
+ non_persistent_buffers |= set(".".join((n, b)) for b in m._non_persistent_buffers_set)
+ for name, buf in model.named_buffers():
+ if buf is not None and name not in non_persistent_buffers:
+ _load(name)
+
+ # Load extra states.
+ extra_state_key = _EXTRA_STATE_KEY_SUFFIX
+ if (
+ getattr(model.__class__, "get_extra_state", torch.nn.Module.get_extra_state)
+ is not torch.nn.Module.get_extra_state
+ ):
+ _load(extra_state_key)
+
+ if self.verbose and self.coordinator.is_master():
+ logging.info(f"The model has been successfully loaded from sharded checkpoint: {ckpt_root_path}.")
+
+ if len(missing_keys) == 0:
+ raise RuntimeError(
+ "No weigth is loaded into the model. Please check the checkpoint files and the model structure."
+ )
+
+ remain_keys = reduce(lambda a, b: a & b, map(set, missing_keys))
+ remain_keys = remain_keys.union(set(missing_file_keys))
+ if len(remain_keys) > 0:
+ if strict:
+ error_msgs = "Missing key(s) in state_dict: {}. ".format(
+ ", ".join('"{}"'.format(k) for k in missing_keys)
+ )
+ raise RuntimeError(
+ "Error(s) in loading state_dict for {}:\n\t{}".format(
+ self.__class__.__name__, "\n\t".join(error_msgs)
+ )
+ )
+ else:
+ if self.coordinator.is_master():
+ logging.info(f"The following keys are not loaded from checkpoint: {remain_keys}")
+
+ def save_sharded_model(
+ self,
+ model: ModelWrapper,
+ checkpoint: str,
+ gather_dtensor: bool = True,
+ prefix: Optional[str] = None,
+ size_per_shard: int = 1024,
+ use_safetensors: bool = False,
+ ) -> None:
+ return NotImplementedError
diff --git a/colossalai/inference/core/request_handler.py b/colossalai/inference/core/request_handler.py
new file mode 100644
index 000000000000..5085c55558b4
--- /dev/null
+++ b/colossalai/inference/core/request_handler.py
@@ -0,0 +1,401 @@
+from typing import Dict, List, Union
+
+import torch
+from transformers.configuration_utils import PretrainedConfig
+from transformers.generation import GenerationConfig
+
+from colossalai.inference.batch_bucket import BatchBucket
+from colossalai.inference.config import InferenceConfig
+from colossalai.inference.flash_decoding_utils import FDIntermTensors
+from colossalai.inference.kv_cache import KVCacheManager, RPCKVCacheManager
+from colossalai.inference.struct import RequestStatus, Sequence
+from colossalai.logging import get_dist_logger
+
+logger = get_dist_logger(__name__)
+
+__all__ = ["RunningList", "RequestHandler"]
+
+
+class RunningList:
+ """
+ RunningList is an structure for recording the running sequences, contains prefill and decoding list.
+ Prefilling samples will be hold until the actual ratio of prefill samples versus decoding samples exceeds ratio.
+
+ Args:
+ prefill_ratio: (float) A ratio for determing whether to perform prefill or not.
+ _prefill (OrderedDict[Sequence]): Mapping of sequence uid -> Sequence.
+ _decoding (OrderedDict[Sequence]): Mapping of sequence uid -> Sequence.
+ """
+
+ def __init__(self, prefill_ratio: int, prefill: List[Sequence] = None) -> None:
+ self.prefill_ratio = prefill_ratio
+ self._decoding: Dict[int, Sequence] = dict()
+ self._prefill: Dict[int, Sequence] = (
+ dict({seq.request_id: seq for seq in self._prefill}) if prefill is not None else dict()
+ )
+
+ @property
+ def decoding(self):
+ return list(self._decoding.values())
+
+ @property
+ def prefill(self):
+ return list(self._prefill.values())
+
+ @property
+ def prefill_seq_num(self):
+ return len(self._prefill)
+
+ @property
+ def decoding_seq_num(self):
+ return len(self._decoding)
+
+ @property
+ def total_seq_num(self):
+ return self.prefill_seq_num + self.decoding_seq_num
+
+ def append(self, seq: Sequence):
+ assert (seq.request_id not in self._prefill) and (
+ seq.request_id not in self._decoding
+ ), f"Sequence uid {seq.request_id} already exists."
+ self._prefill[seq.request_id] = seq
+
+ def extend(self, seqs: List[Sequence]):
+ for seq in seqs:
+ self._prefill[seq.request_id] = seq
+
+ def find_seq(self, request_id) -> Union[Sequence, None]:
+ seq = None
+ if request_id in self._decoding:
+ seq = self._decoding[request_id]
+ elif request_id in self._prefill:
+ seq = self._prefill[request_id]
+ return seq
+
+ def remove(self, seq: Sequence) -> None:
+ if seq.request_id in self._decoding:
+ self._decoding.pop(seq.request_id)
+ elif seq.request_id in self._prefill:
+ self._prefill.pop(seq.request_id)
+ else:
+ raise ValueError(f"Sequence {seq.request_id} is not in running list")
+
+ def ready_for_prefill(self):
+ if not self._decoding:
+ return len(self._prefill) > 0
+ return len(self._prefill) / len(self._decoding) >= self.prefill_ratio
+
+ def is_empty(self):
+ return not self._decoding and not self._prefill
+
+ def mark_prefill_running(self) -> None:
+ for seq_id in self._prefill:
+ self._prefill[seq_id].mark_running()
+
+ def move_prefill_to_decoding(self, seq_ids: List[int]) -> None:
+ for seq_id in seq_ids:
+ assert seq_id in self._prefill, f"Sequence {seq_id} is not in prefill list"
+ self._decoding[seq_id] = self._prefill.pop(seq_id)
+
+
+class RequestHandler:
+ """
+ RequestHandler is the core for handling existing requests and updating current batch.
+ During generation process, we call schedule function each iteration to update current batch.
+
+ Args:
+ inference_config: Configuration for initialize and manage kv cache.
+ model_config: Configuration for model
+ dtype (torch.dtype): The data type for weights and activations.
+ """
+
+ def __init__(self, inference_config: InferenceConfig, model_config: PretrainedConfig) -> None:
+ self.inference_config = inference_config
+ self.running_list: RunningList = RunningList(inference_config.prefill_ratio)
+ self.waiting_list: List[List] = [[], [], []]
+ self.done_list: List[Sequence] = []
+ self.dtype = inference_config.dtype
+ self.max_batch_size = inference_config.max_batch_size
+
+ # initialize cache
+ self._init_cache(model_config)
+
+ # initialize batch
+ device = torch.cuda.current_device()
+ kv_max_split_num = (
+ inference_config.max_input_len + inference_config.max_output_len + inference_config.block_size - 1
+ ) // inference_config.block_size
+ head_dim = model_config.hidden_size // model_config.num_attention_heads
+
+ fd_inter_tensor = FDIntermTensors()
+
+ if fd_inter_tensor._tensors_initialized:
+ fd_inter_tensor._reset()
+
+ # For Spec-Dec, process the speculated tokens plus the token in the last step for each seq
+ max_n_tokens = self.max_batch_size
+ max_n_tokens *= self.inference_config.max_n_spec_tokens + 1
+
+ fd_inter_tensor.initialize(
+ max_batch_size=max_n_tokens,
+ num_attn_heads=model_config.num_attention_heads // inference_config.tp_size,
+ kv_max_split_num=kv_max_split_num,
+ head_dim=head_dim,
+ dtype=self.dtype,
+ device=device,
+ )
+
+ # TODO In the continuous batching scenario, the batch size may be greater than max_batch_size,
+ # which may cause bugs and this issue should be fixed later.
+ self.running_bb = BatchBucket(
+ num_heads=model_config.num_attention_heads // inference_config.tp_size,
+ head_dim=head_dim,
+ max_batch_size=self.max_batch_size,
+ max_length=inference_config.max_input_len + inference_config.max_output_len,
+ block_size=inference_config.block_size,
+ kv_max_split_num=kv_max_split_num,
+ fd_interm_tensor=fd_inter_tensor,
+ dtype=self.dtype,
+ device=device,
+ )
+ self.prefill_bb = BatchBucket(
+ num_heads=model_config.num_attention_heads // inference_config.tp_size,
+ head_dim=head_dim,
+ max_batch_size=self.max_batch_size,
+ max_length=inference_config.max_input_len + inference_config.max_output_len,
+ block_size=inference_config.block_size,
+ kv_max_split_num=kv_max_split_num,
+ fd_interm_tensor=fd_inter_tensor,
+ dtype=self.dtype,
+ device=device,
+ )
+
+ def _init_cache(self, model_config):
+ self.cache_manager = KVCacheManager(self.inference_config, model_config)
+
+ def _has_waiting(self) -> bool:
+ return any(lst for lst in self.waiting_list)
+
+ def get_kvcache(self):
+ return self.cache_manager.get_kv_cache()
+
+ def set_spec_dec_mode(self, n_spec_tokens: int):
+ self.prefill_bb.set_use_spec_dec(n_spec_tokens)
+ self.running_bb.set_use_spec_dec(n_spec_tokens)
+
+ def unset_spec_dec_mode(self):
+ self.prefill_bb.reset_use_spec_dec()
+ self.running_bb.reset_use_spec_dec()
+
+ def schedule(self):
+ """
+ The main logic of request handler.
+ """
+ if self._has_waiting():
+ # Try to allocate cache blocks for the sequence using a priority of prompt length.
+ for lst in reversed(self.waiting_list):
+ if lst:
+ remove_list = []
+ for seq in lst:
+ if seq.input_len > self.inference_config.max_input_len:
+ # If the prompt length is longer than max_input_len, abort the sequence.
+ logger.warning(
+ f"the prompt(Request id = {seq.request_id}) length is longer than max_input_len, abort this sequence."
+ )
+ self.abort_sequence(seq.request_id)
+ remove_list.append(seq)
+ break
+
+ num_seqs_to_add = min(len(lst), self.max_batch_size - self.running_list.total_seq_num)
+ # for now the recycle logic is not working
+ remove_list.extend(lst[:num_seqs_to_add])
+ self.running_list.extend(lst[:num_seqs_to_add])
+
+ for seq in remove_list:
+ lst.remove(seq)
+
+ if self.running_list.ready_for_prefill():
+ num_seqs_to_add = min(self.running_list.prefill_seq_num, self.prefill_bb.available_batch_size)
+ # overwrite the number of sequences to add to 1 if use_spec_dec is enabled
+ # TODO (zhaoyuanheng): support speculative decoding for batch size > 1
+ if self.prefill_bb.use_spec_dec:
+ num_seqs_to_add = 1
+
+ for seq in self.running_list.prefill[:num_seqs_to_add]:
+ seq.mark_running()
+ # allocate blocks for the prefill batch
+ self.prefill_bb.add_seqs(
+ self.running_list.prefill[:num_seqs_to_add],
+ alloc_block_tables_fn=self.cache_manager.allocate_context_from_block_tables,
+ )
+
+ return self.prefill_bb
+
+ if not self.running_bb.is_empty:
+ seqs_ids_to_recycle = self.cache_manager.allocate_tokens_from_block_tables(
+ self.running_bb.block_tables, self.running_bb.seq_lengths, self.running_bb.current_batch_size
+ )
+ if seqs_ids_to_recycle:
+ seqs_to_recycle = self.running_bb.pop_seqs(seqs_ids_to_recycle)
+ for seq in seqs_to_recycle:
+ seq.recycle()
+ self.running_list.remove(seq)
+ self.waiting_list[-1].append(seq)
+ # the recycled sequences are handled with highest priority.
+
+ return self.running_bb
+
+ def allocate_batch_spec_dec(self, batch: BatchBucket, n: int):
+ assert batch.use_spec_dec
+ if n > 0:
+ self.cache_manager.allocate_n_tokens_from_block_tables(
+ batch.block_tables, batch.seq_lengths, batch.current_batch_size, n=n
+ )
+
+ def add_sequence(self, req: Sequence):
+ """
+ Add the request to waiting list.
+ """
+ assert not self._find_sequence(req.request_id), f"Sequence {req.request_id} already exists."
+ assert (
+ req.input_len <= self.inference_config.max_input_len
+ ), f"Sequence {req.request_id} exceeds input length limit"
+ self.waiting_list[req.input_len * 3 // (self.inference_config.max_input_len + 1)].append(req)
+
+ def abort_sequence(self, request_id: int):
+ """
+ Abort the request.
+ """
+ result = self._find_sequence(request_id)
+ if result is not None:
+ seq, priority = result
+ if seq.status == RequestStatus.WAITING:
+ seq.mark_aborted()
+ self.waiting_list[priority].remove(seq)
+ elif seq.status.is_running():
+ self.running_bb.pop_seq_update_batch(seq.request_id, self.cache_manager.free_block_table)
+ self.running_list.remove(seq)
+ else:
+ try:
+ self.done_list.remove(seq)
+ except:
+ return
+ return
+
+ def _find_sequence(self, request_id: int) -> Sequence:
+ """
+ Find the request by request_id.
+ """
+ for priority, lst in enumerate(self.waiting_list):
+ for seq in lst:
+ if seq.request_id == request_id:
+ return seq, priority
+
+ if self.running_list.find_seq(request_id):
+ return seq, None
+
+ return None
+
+ def update_seq_finished(self, sequence: Sequence, generation_config: GenerationConfig):
+ if (
+ sequence.output_token_id[-1] == generation_config.eos_token_id
+ or sequence.output_len >= generation_config.max_length
+ ):
+ sequence.mark_finished()
+
+ def update_batch_finished(self, batch: BatchBucket, generation_config: GenerationConfig):
+ for seq in batch.seqs_li:
+ max_length = generation_config.max_length
+ max_new_tokens = generation_config.max_new_tokens
+ if max_length is not None:
+ max_new_tokens = max_length - seq.input_len
+ if seq.output_token_id[-1] == generation_config.eos_token_id or seq.output_len >= max_new_tokens:
+ seq.mark_finished()
+
+ def check_unfinished_seqs(self) -> bool:
+ return self._has_waiting() or not self.running_list.is_empty()
+
+ def total_requests_in_batch_bucket(self) -> int:
+ return self.prefill_bb.current_batch_size + self.running_bb.current_batch_size
+
+ def append_next_tokens(self, sample_tokens: torch.Tensor):
+ assert sample_tokens.dim() == 1
+ n_elements = sample_tokens.size(0)
+ if not self.prefill_bb.is_empty:
+ assert (
+ self.prefill_bb.current_batch_size == n_elements
+ ), f"Incompatible size: {n_elements} tokens to append while prefill batch size {self.prefill_bb.current_batch_size}"
+ self.prefill_bb.append_batch_tokens(sample_tokens)
+ else:
+ assert (
+ self.running_bb.current_batch_size == n_elements
+ ), f"Incompatible size: {n_elements} tokens to append while running batch size {self.running_bb.current_batch_size}"
+ self.running_bb.append_batch_tokens(sample_tokens)
+
+ def update(self):
+ """
+ Update current running list and done list
+ """
+ if not self.prefill_bb.is_empty:
+ self.running_list.move_prefill_to_decoding(self.prefill_bb.seqs_ids)
+ self.running_bb.merge(self.prefill_bb)
+ # clear the prefill batch without assigning a free_block_tables_fn
+ # since we want to reuse the memory recorded on the block tables
+ self.prefill_bb.clear(free_block_tables_fn=None)
+
+ finished_seqs, _ = self.running_bb.pop_finished(self.cache_manager.free_block_table)
+ for seq in finished_seqs:
+ self.running_list.remove(seq)
+ self.done_list.extend(finished_seqs)
+
+ return finished_seqs
+
+
+class RPCRequestHandler(RequestHandler):
+ """
+ RPC Version of request handler
+ """
+
+ def __init__(self, inference_config: InferenceConfig, model_config: PretrainedConfig) -> None:
+ self.inference_config = inference_config
+ self.running_list: RunningList = RunningList(inference_config.prefill_ratio)
+ self.waiting_list: List[List] = [[], [], []]
+ self.done_list: List[Sequence] = []
+ self.dtype = inference_config.dtype
+ self.max_batch_size = inference_config.max_batch_size
+
+ # initialize cache
+ self._init_cache(model_config)
+
+ # initialize batch
+ torch.cuda.current_device()
+ kv_max_split_num = (
+ inference_config.max_input_len + inference_config.max_output_len + inference_config.block_size - 1
+ ) // inference_config.block_size
+ head_dim = model_config.hidden_size // model_config.num_attention_heads
+
+ # TODO In the continuous batching scenario, the batch size may be greater than max_batch_size,
+ # which may cause bugs and this issue should be fixed later.
+ self.running_bb = BatchBucket(
+ num_heads=model_config.num_attention_heads // inference_config.tp_size,
+ head_dim=head_dim,
+ max_batch_size=self.max_batch_size,
+ max_length=inference_config.max_input_len + inference_config.max_output_len,
+ block_size=inference_config.block_size,
+ kv_max_split_num=kv_max_split_num,
+ fd_interm_tensor=None,
+ dtype=self.dtype,
+ )
+ self.prefill_bb = BatchBucket(
+ num_heads=model_config.num_attention_heads // inference_config.tp_size,
+ head_dim=head_dim,
+ max_batch_size=self.max_batch_size,
+ max_length=inference_config.max_input_len + inference_config.max_output_len,
+ block_size=inference_config.block_size,
+ kv_max_split_num=kv_max_split_num,
+ fd_interm_tensor=None,
+ dtype=self.dtype,
+ )
+
+ def _init_cache(self, model_config):
+ self.cache_manager = RPCKVCacheManager(self.inference_config, model_config)
diff --git a/colossalai/inference/core/rpc_engine.py b/colossalai/inference/core/rpc_engine.py
new file mode 100644
index 000000000000..9602147f55e5
--- /dev/null
+++ b/colossalai/inference/core/rpc_engine.py
@@ -0,0 +1,291 @@
+import asyncio
+from itertools import count
+from time import sleep
+from typing import List, Tuple, Union
+
+import rpyc
+import torch
+import torch.nn as nn
+from rpyc.utils.server import ThreadedServer
+from torch import multiprocessing as mp
+from transformers import AutoConfig, PreTrainedTokenizer, PreTrainedTokenizerFast
+from transformers.configuration_utils import PretrainedConfig
+
+from colossalai.inference.batch_bucket import BatchBucket
+from colossalai.inference.config import InferenceConfig, InputMetaData
+from colossalai.inference.executor.rpc_worker import rpcWorkerService
+from colossalai.inference.utils import find_available_ports
+from colossalai.logging import get_dist_logger
+from colossalai.shardformer.policies.base_policy import Policy
+
+from .engine import InferenceEngine
+from .request_handler import RPCRequestHandler
+
+__all__ = ["RPCInferenceEngine"]
+
+
+def run_server(host, port, event: mp.Event = None):
+ server = ThreadedServer(
+ rpcWorkerService, port=port, protocol_config={"allow_public_attrs": True, "allow_all_attrs": True}
+ )
+ if event:
+ event.set()
+ server.start()
+
+
+class RPCInferenceEngine(InferenceEngine):
+
+ """
+ InferenceEngine which manages the inference process..
+
+ NOTE This `RPCInferenceEngine` is designed for multiple-card/online serving.
+ Original `InferenceEngine` is designed for single card and offline service, though it supports multi-card offline inference.
+
+ Args:
+ model_or_path (nn.Module or str): Path or nn.Module of this model, Currently we don't support `nn.Module` Format
+ tokenizer Optional[(Union[PreTrainedTokenizer, PreTrainedTokenizerFast])]: Path of the tokenizer to use.
+ inference_config (Optional[InferenceConfig], optional): Store the configuration information related to inference.
+ verbose (bool): Determine whether or not to log the generation process.
+ model_policy ("Policy"): the policy to shardformer model. It will be determined by the model type if not provided.
+ """
+
+ def __init__(
+ self,
+ model_or_path: Union[nn.Module, str],
+ tokenizer: Union[PreTrainedTokenizer, PreTrainedTokenizerFast],
+ inference_config: InferenceConfig,
+ verbose: bool = False,
+ model_policy: Policy = None,
+ ) -> None:
+ """
+ If you input a real model loaded by transformers, the init will take quite a long time
+ Currently we don't support model(nn.Module) format as the param.
+ """
+
+ torch.multiprocessing.set_start_method("spawn", force=True)
+
+ self.inference_config = inference_config
+ self.tokenizer = tokenizer
+ self.tokenizer.pad_token = self.tokenizer.eos_token
+
+ self.verbose = verbose
+ self.logger = get_dist_logger(__name__)
+
+ try:
+ if isinstance(model_or_path, str):
+ self.model_config = AutoConfig.from_pretrained(model_or_path, trust_remote_code=True)
+ elif isinstance(model_or_path, nn.Module):
+ self.logger.error(
+ f"An exception occurred during loading model Config: For {__class__.__name__}, we don't support param like nn.Module currently\n"
+ )
+ # self.model_config = model_or_path.config
+ else:
+ self.logger.error(
+ f"An exception occurred during loading model Config: Please pass right param for {__class__.__name__}\n"
+ )
+ except Exception as e:
+ self.logger.error(
+ f"An exception occurred during loading model Config: {e}, The path should be transformers-like\n"
+ )
+ self.generation_config = inference_config.to_generation_config(self.model_config)
+
+ self.tp_size = inference_config.tp_size
+ self.events = [mp.Event() for _ in range(self.tp_size)]
+
+ # This operation will init the dist env and models
+ self.workers: List[rpcWorkerService] = []
+ self.init_workers()
+
+ asyncio.run(self.init_model(model_or_path, model_policy))
+
+ # init the scheduler and logic block manager
+ self.request_handler = self.init_scheduler(self.inference_config, self.model_config)
+
+ # init the physical cache
+ alloc_shape = self.request_handler.cache_manager.get_physical_cache_shape()
+ self.init_device_cache(alloc_shape)
+
+ self.use_cuda_graph = self.inference_config.use_cuda_graph
+ self.high_precision = inference_config.high_precision
+ self.dtype = inference_config.dtype
+
+ # Model and relatable attrs of speculative decoding will be set by `enable_spec_dec`
+ self.use_spec_dec = False
+ self.drafter_model = None
+ self.drafter = None
+ self.use_glide = False
+ self.n_spec_tokens = self.inference_config.max_n_spec_tokens
+
+ self.counter = count()
+ self._verify_args()
+
+ self.logger.info("engine init over ")
+
+ def _verify_args(self) -> None:
+ """Verify the input args"""
+ if not isinstance(self.inference_config, InferenceConfig):
+ raise TypeError("Invalid type of inference config provided.")
+ if not isinstance(self.tokenizer, (PreTrainedTokenizerFast, PreTrainedTokenizer)):
+ raise TypeError(
+ f"the tokenizer type must be PreTrainedTokenizer or PreTrainedTokenizerFast, but got {type(self.tokenizer)}"
+ )
+
+ def init_workers(self):
+ rpc_ports = find_available_ports(self.tp_size)
+ self.worker_processes = []
+ # mp.set_start_method('spawn')
+ for event, rpc_port in zip(self.events, rpc_ports):
+ p = mp.Process(target=run_server, args=("localhost", rpc_port, event))
+ p.start()
+ self.worker_processes.append(p)
+ self.logger.info(f"Starting RPC Worker on localhost:{rpc_port}...")
+
+ # Wait for all servers to start
+ for event in self.events:
+ event.wait()
+ event.clear()
+
+ sleep(0.05)
+
+ self.logger.info(f"init rpc server done.")
+
+ for rpc_port in rpc_ports:
+ try:
+ conn = rpyc.connect(
+ "localhost",
+ rpc_port,
+ config={"allow_pickle": True, "allow_public_attrs": True, "allow_all_attrs": True},
+ )
+ self.workers.append(conn.root)
+ except:
+ raise Exception("conn error!")
+ self.logger.info(f"Build RPC Connection Success! Begin to load model...")
+ asyncio.run(self.init_worker_env())
+ self.logger.info(f"init dist env over")
+
+ async def async_parallel_wrapper(self, f, *args, **kwargs):
+ async_res = rpyc.async_(f)(*args, **kwargs)
+ await asyncio.to_thread(async_res.wait)
+ assert async_res.ready
+ return async_res.value
+
+ async def init_worker_env(self):
+ assert len(self.workers) == self.tp_size, "init workers first"
+
+ dist_group_port = find_available_ports(1)[0]
+ init_tasks = [
+ self.async_parallel_wrapper(
+ worker.init_dist_env, rank, self.inference_config.tp_size, "127.0.0.1", dist_group_port
+ )
+ for rank, worker in enumerate(self.workers)
+ ]
+
+ await asyncio.gather(*init_tasks)
+
+ async def init_model(self, model_or_path: Union[nn.Module, str], model_policy: Policy = None):
+ assert len(self.workers) == self.tp_size, "init workers first"
+
+ inference_config_param = self.inference_config.to_rpc_param()
+ model_path = model_or_path
+ model_policy_param = model_policy.to_rpc_param() if model_policy else None
+
+ init_tasks = [
+ self.async_parallel_wrapper(worker.init_model, inference_config_param, model_path, model_policy_param)
+ for rank, worker in enumerate(self.workers)
+ ]
+
+ await asyncio.gather(*init_tasks)
+
+ def init_scheduler(self, inference_config: InferenceConfig, model_config: PretrainedConfig) -> RPCRequestHandler:
+ return RPCRequestHandler(inference_config, model_config)
+
+ async def _init_device_cache(self, alloc_shape: Tuple[int, int, int, int]):
+ assert len(self.workers) == self.tp_size, "init workers first"
+
+ init_tasks = [self.async_parallel_wrapper(worker.init_cache, alloc_shape) for worker in self.workers]
+
+ await asyncio.gather(*init_tasks)
+
+ def init_device_cache(self, alloc_shape: Tuple[Tuple[int, ...], Tuple[int, ...]]):
+ asyncio.run(self._init_device_cache(alloc_shape))
+
+ def prepare_input(self, batch: BatchBucket) -> Tuple[List[int], InputMetaData]:
+ input_ids = batch.get_1D_inputs()
+ sequence_lengths = batch.get_sequence_lengths()
+
+ if batch.is_prompts:
+ n_tokens = sequence_lengths.sum().item()
+ else:
+ n_tokens = batch.current_batch_size
+ if batch.use_spec_dec:
+ n_tokens = batch.num_tokens_to_verify + 1
+ assert n_tokens == input_ids.size(0)
+ n_tokens = n_tokens * batch.current_batch_size
+
+ batch_token_ids = None
+ config_dict = self.generation_config.to_dict()
+ # process repetition_penalty, no_repeat_ngram_size
+ for type in ["repetition_penalty", "no_repeat_ngram_size"]:
+ if type in config_dict and config_dict[type] is not None:
+ batch_token_ids = batch.batch_token_ids
+
+ # only when we have the graph for specific decoding batch size can we use the cuda graph for inference
+ use_cuda_graph = False
+ if self.use_cuda_graph and not batch.is_prompts and batch.current_batch_size in self.graph_runners.keys():
+ use_cuda_graph = True
+
+ input_meta_data = InputMetaData(
+ block_tables=batch.get_block_table_tensor(),
+ sequence_lengths=sequence_lengths,
+ fd_inter_tensor=None,
+ batch_size=batch.current_batch_size,
+ is_prompts=batch.is_prompts,
+ use_cuda_kernel=self.inference_config.use_cuda_kernel,
+ use_cuda_graph=use_cuda_graph,
+ high_precision=self.high_precision,
+ kv_seq_len=sequence_lengths.max().item(),
+ head_dim=batch.head_dim,
+ dtype=batch.dtype,
+ use_spec_dec=batch.use_spec_dec,
+ num_tokens_to_verify=batch.num_tokens_to_verify,
+ batch_token_ids=batch_token_ids,
+ )
+
+ return input_ids.tolist(), input_meta_data
+
+ async def step_(self, input_token_ids, input_meta_data: InputMetaData):
+ assert len(self.workers) == self.tp_size, "init workers first"
+
+ init_tasks = [
+ self.async_parallel_wrapper(worker.execute_model_forward, input_token_ids, input_meta_data.to_rpc_param())
+ for worker in self.workers
+ ]
+ ret = await asyncio.gather(*init_tasks)
+
+ return ret[0]
+
+ def step(self) -> List[str]:
+ batch = self.request_handler.schedule()
+
+ input_token_ids, input_meta_data = self.prepare_input(batch)
+ # TODO: padding_id is used for generating attn_mask and will be removed if nopad version is supported.
+ next_tokens = asyncio.run(self.step_(input_token_ids, input_meta_data))
+
+ # update the request_handler
+ next_tokens = torch.tensor(next_tokens, dtype=torch.int)
+ self.request_handler.append_next_tokens(next_tokens)
+ finished_sequences = self.request_handler.update()
+ return finished_sequences
+
+ def kill_workers(self):
+ """
+ I don't find a good way to implicit invoke self.kill_workers
+ """
+ assert len(self.workers) != 0
+ for proc in self.worker_processes:
+ proc.kill()
+ proc.join()
+ self.logger.info(f"worker killed, serving end")
+
+ def __del__(self):
+ self.kill_workers()
diff --git a/colossalai/inference/engine/__init__.py b/colossalai/inference/engine/__init__.py
deleted file mode 100644
index 6e60da695a22..000000000000
--- a/colossalai/inference/engine/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .engine import InferenceEngine
-
-__all__ = ["InferenceEngine"]
diff --git a/colossalai/inference/engine/engine.py b/colossalai/inference/engine/engine.py
deleted file mode 100644
index 61da5858aa86..000000000000
--- a/colossalai/inference/engine/engine.py
+++ /dev/null
@@ -1,195 +0,0 @@
-from typing import Union
-
-import torch
-import torch.distributed as dist
-import torch.nn as nn
-from transformers.utils import logging
-
-from colossalai.cluster import ProcessGroupMesh
-from colossalai.pipeline.schedule.generate import GenerateSchedule
-from colossalai.pipeline.stage_manager import PipelineStageManager
-from colossalai.shardformer import ShardConfig, ShardFormer
-from colossalai.shardformer.policies.base_policy import Policy
-
-from ..kv_cache import MemoryManager
-from .microbatch_manager import MicroBatchManager
-from .policies import model_policy_map
-
-PP_AXIS, TP_AXIS = 0, 1
-
-_supported_models = [
- "LlamaForCausalLM",
- "BloomForCausalLM",
- "LlamaGPTQForCausalLM",
- "SmoothLlamaForCausalLM",
- "ChatGLMForConditionalGeneration",
-]
-
-
-class InferenceEngine:
- """
- InferenceEngine is a class that handles the pipeline parallel inference.
-
- Args:
- tp_size (int): the size of tensor parallelism.
- pp_size (int): the size of pipeline parallelism.
- dtype (str): the data type of the model, should be one of 'fp16', 'fp32', 'bf16'.
- model (`nn.Module`): the model not in pipeline style, and will be modified with `ShardFormer`.
- model_policy (`colossalai.shardformer.policies.base_policy.Policy`): the policy to shardformer model. It will be determined by the model type if not provided.
- micro_batch_size (int): the micro batch size. Only useful when `pp_size` > 1.
- micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
- max_batch_size (int): the maximum batch size.
- max_input_len (int): the maximum input length.
- max_output_len (int): the maximum output length.
- quant (str): the quantization method, should be one of 'smoothquant', 'gptq', None.
- verbose (bool): whether to return the time cost of each step.
-
- """
-
- def __init__(
- self,
- tp_size: int = 1,
- pp_size: int = 1,
- dtype: str = "fp16",
- model: nn.Module = None,
- model_policy: Policy = None,
- micro_batch_size: int = 1,
- micro_batch_buffer_size: int = None,
- max_batch_size: int = 4,
- max_input_len: int = 32,
- max_output_len: int = 32,
- quant: str = None,
- verbose: bool = False,
- # TODO: implement early_stopping, and various gerneration options
- early_stopping: bool = False,
- do_sample: bool = False,
- num_beams: int = 1,
- ) -> None:
- if quant == "gptq":
- from ..quant.gptq import GPTQManager
-
- self.gptq_manager = GPTQManager(model.quantize_config, max_input_len=max_input_len)
- model = model.model
- elif quant == "smoothquant":
- model = model.model
-
- assert model.__class__.__name__ in _supported_models, f"Model {model.__class__.__name__} is not supported."
- assert (
- tp_size * pp_size == dist.get_world_size()
- ), f"TP size({tp_size}) * PP size({pp_size}) should be equal to the global world size ({dist.get_world_size()})"
- assert model, "Model should be provided."
- assert dtype in ["fp16", "fp32", "bf16"], "dtype should be one of 'fp16', 'fp32', 'bf16'"
-
- assert max_batch_size <= 64, "Max batch size exceeds the constraint"
- assert max_input_len + max_output_len <= 4096, "Max length exceeds the constraint"
- assert quant in ["smoothquant", "gptq", None], "quant should be one of 'smoothquant', 'gptq'"
- self.pp_size = pp_size
- self.tp_size = tp_size
- self.quant = quant
-
- logger = logging.get_logger(__name__)
- if quant == "smoothquant" and dtype != "fp32":
- dtype = "fp32"
- logger.warning_once("Warning: smoothquant only support fp32 and int8 mix precision. set dtype to fp32")
-
- if dtype == "fp16":
- self.dtype = torch.float16
- model.half()
- elif dtype == "bf16":
- self.dtype = torch.bfloat16
- model.to(torch.bfloat16)
- else:
- self.dtype = torch.float32
-
- if model_policy is None:
- model_policy = model_policy_map[model.config.model_type]()
-
- # Init pg mesh
- pg_mesh = ProcessGroupMesh(pp_size, tp_size)
-
- stage_manager = PipelineStageManager(pg_mesh, PP_AXIS, True if pp_size * tp_size > 1 else False)
- self.cache_manager_list = [
- self._init_manager(model, max_batch_size, max_input_len, max_output_len)
- for _ in range(micro_batch_buffer_size or pp_size)
- ]
- self.mb_manager = MicroBatchManager(
- stage_manager.stage,
- micro_batch_size,
- micro_batch_buffer_size or pp_size,
- max_input_len,
- max_output_len,
- self.cache_manager_list,
- )
- self.verbose = verbose
- self.schedule = GenerateSchedule(stage_manager, self.mb_manager, verbose)
-
- self.model = self._shardformer(
- model, model_policy, stage_manager, pg_mesh.get_group_along_axis(TP_AXIS) if pp_size * tp_size > 1 else None
- )
- if quant == "gptq":
- self.gptq_manager.post_init_gptq_buffer(self.model)
-
- def generate(self, input_list: Union[list, dict]):
- """
- Args:
- input_list (list): a list of input data, each element is a `BatchEncoding` or `dict`.
-
- Returns:
- out (list): a list of output data, each element is a list of token.
- timestamp (float): the time cost of the inference, only return when verbose is `True`.
- """
-
- out, timestamp = self.schedule.generate_step(self.model, iter([input_list]))
- if self.verbose:
- return out, timestamp
- else:
- return out
-
- def _shardformer(self, model, model_policy, stage_manager, tp_group):
- shardconfig = ShardConfig(
- tensor_parallel_process_group=tp_group,
- pipeline_stage_manager=stage_manager,
- enable_tensor_parallelism=(self.tp_size > 1),
- enable_fused_normalization=False,
- enable_all_optimization=False,
- enable_flash_attention=False,
- enable_jit_fused=False,
- enable_sequence_parallelism=False,
- extra_kwargs={"quant": self.quant},
- )
- shardformer = ShardFormer(shard_config=shardconfig)
- shard_model, _ = shardformer.optimize(model, model_policy)
- return shard_model.cuda()
-
- def _init_manager(self, model, max_batch_size: int, max_input_len: int, max_output_len: int) -> None:
- max_total_token_num = max_batch_size * (max_input_len + max_output_len)
- if model.config.model_type == "llama":
- head_dim = model.config.hidden_size // model.config.num_attention_heads
- head_num = model.config.num_key_value_heads // self.tp_size
- num_hidden_layers = (
- model.config.num_hidden_layers
- if hasattr(model.config, "num_hidden_layers")
- else model.config.num_layers
- )
- layer_num = num_hidden_layers // self.pp_size
- elif model.config.model_type == "bloom":
- head_dim = model.config.hidden_size // model.config.n_head
- head_num = model.config.n_head // self.tp_size
- num_hidden_layers = model.config.n_layer
- layer_num = num_hidden_layers // self.pp_size
- elif model.config.model_type == "chatglm":
- head_dim = model.config.hidden_size // model.config.num_attention_heads
- if model.config.multi_query_attention:
- head_num = model.config.multi_query_group_num // self.tp_size
- else:
- head_num = model.config.num_attention_heads // self.tp_size
- num_hidden_layers = model.config.num_layers
- layer_num = num_hidden_layers // self.pp_size
- else:
- raise NotImplementedError("Only support llama, bloom and chatglm model.")
-
- if self.quant == "smoothquant":
- cache_manager = MemoryManager(max_total_token_num, torch.int8, head_num, head_dim, layer_num)
- else:
- cache_manager = MemoryManager(max_total_token_num, self.dtype, head_num, head_dim, layer_num)
- return cache_manager
diff --git a/colossalai/inference/engine/microbatch_manager.py b/colossalai/inference/engine/microbatch_manager.py
deleted file mode 100644
index 7264b81e06a0..000000000000
--- a/colossalai/inference/engine/microbatch_manager.py
+++ /dev/null
@@ -1,248 +0,0 @@
-from enum import Enum
-from typing import Dict
-
-import torch
-
-from ..kv_cache import BatchInferState, MemoryManager
-
-__all__ = "MicroBatchManager"
-
-
-class Status(Enum):
- PREFILL = 1
- GENERATE = 2
- DONE = 3
- COOLDOWN = 4
-
-
-class MicroBatchDescription:
- """
- This is the class to record the information of each microbatch, and also do some update operation.
- This class is the base class of `HeadMicroBatchDescription` and `BodyMicroBatchDescription`, for more
- details, please refer to the doc of these two classes blow.
-
- Args:
- inputs_dict (Dict[str, torch.Tensor]): the inputs of current stage. The key should have `input_ids` and `attention_mask`.
- output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
- """
-
- def __init__(
- self,
- inputs_dict: Dict[str, torch.Tensor],
- max_input_len: int,
- max_output_len: int,
- cache_manager: MemoryManager,
- ) -> None:
- self.mb_length = inputs_dict["input_ids"].shape[-1]
- self.target_length = self.mb_length + max_output_len
- self.infer_state = BatchInferState.init_from_batch(
- batch=inputs_dict, max_input_len=max_input_len, max_output_len=max_output_len, cache_manager=cache_manager
- )
- # print(f"[init] {inputs_dict}, {max_input_len}, {max_output_len}, {cache_manager}, {self.infer_state}")
-
- def update(self, *args, **kwargs):
- pass
-
- @property
- def state(self):
- """
- Return the state of current micro batch, when current length is equal to target length,
- the state is DONE, otherwise GENERATE
-
- """
- # TODO: add the condition for early stopping
- if self.cur_length == self.target_length:
- return Status.DONE
- elif self.cur_length == self.target_length - 1:
- return Status.COOLDOWN
- else:
- return Status.GENERATE
-
- @property
- def cur_length(self):
- """
- Return the current sequence length of micro batch
-
- """
-
-
-class HeadMicroBatchDescription(MicroBatchDescription):
- """
- This class is used to record the information of the first stage of pipeline, the first stage should have attributes `input_ids` and `attention_mask`
- and `new_tokens`, and the `new_tokens` is the tokens generated by the first stage. Also due to the schedule of pipeline, the operation to update the
- information and the condition to determine the state is different from other stages.
-
- Args:
- inputs_dict (Dict[str, torch.Tensor]): the inputs of current stage. The key should have `input_ids` and `attention_mask`.
- output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
-
- """
-
- def __init__(
- self,
- inputs_dict: Dict[str, torch.Tensor],
- max_input_len: int,
- max_output_len: int,
- cache_manager: MemoryManager,
- ) -> None:
- super().__init__(inputs_dict, max_input_len, max_output_len, cache_manager)
- assert inputs_dict is not None
- assert inputs_dict.get("input_ids") is not None and inputs_dict.get("attention_mask") is not None
- self.input_ids = inputs_dict["input_ids"]
- self.attn_mask = inputs_dict["attention_mask"]
- self.new_tokens = None
-
- def update(self, new_token: torch.Tensor = None):
- if new_token is not None:
- self._update_newtokens(new_token)
- if self.state is not Status.DONE and new_token is not None:
- self._update_attnmask()
-
- def _update_newtokens(self, new_token: torch.Tensor):
- if self.new_tokens is None:
- self.new_tokens = new_token
- else:
- self.new_tokens = torch.cat([self.new_tokens, new_token], dim=-1)
-
- def _update_attnmask(self):
- self.attn_mask = torch.cat(
- (self.attn_mask, torch.ones((self.attn_mask.shape[0], 1), dtype=torch.int64, device="cuda")), dim=-1
- )
-
- @property
- def cur_length(self):
- """
- When there is no new_token, the length is mb_length, otherwise the sequence length is `mb_length` plus the length of new_token
-
- """
- if self.new_tokens is None:
- return self.mb_length
- else:
- return self.mb_length + len(self.new_tokens[0])
-
-
-class BodyMicroBatchDescription(MicroBatchDescription):
- """
- This class is used to record the information of the stages except the first stage of pipeline, the stages should have attributes `hidden_states` and `past_key_values`,
-
- Args:
- inputs_dict (Dict[str, torch.Tensor]): will always be `None`. Other stages only receive hiddenstates from previous stage.
- """
-
- def __init__(
- self,
- inputs_dict: Dict[str, torch.Tensor],
- max_input_len: int,
- max_output_len: int,
- cache_manager: MemoryManager,
- ) -> None:
- super().__init__(inputs_dict, max_input_len, max_output_len, cache_manager)
-
- @property
- def cur_length(self):
- """
- When there is no kv_cache, the length is mb_length, otherwise the sequence length is `kv_cache[0][0].shape[-2]` plus 1
-
- """
- return self.infer_state.seq_len.max().item()
-
-
-class MicroBatchManager:
- """
- MicroBatchManager is a class that manages the micro batch.
-
- Args:
- stage (int): stage id of current stage.
- micro_batch_size (int): the micro batch size.
- micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
-
- """
-
- def __init__(
- self,
- stage: int,
- micro_batch_size: int,
- micro_batch_buffer_size: int,
- max_input_len: int,
- max_output_len: int,
- cache_manager_list: MemoryManager,
- ):
- self.stage = stage
- self.micro_batch_size = micro_batch_size
- self.buffer_size = micro_batch_buffer_size
- self.max_input_len = max_input_len
- self.max_output_len = max_output_len
- self.cache_manager_list = cache_manager_list
- self.mb_description_buffer = {}
- self.new_tokens_buffer = {}
- self.idx = 0
-
- def add_description(self, inputs_dict: Dict[str, torch.Tensor]):
- if self.stage == 0:
- self.mb_description_buffer[self.idx] = HeadMicroBatchDescription(
- inputs_dict, self.max_input_len, self.max_output_len, self.cache_manager_list[self.idx]
- )
- else:
- self.mb_description_buffer[self.idx] = BodyMicroBatchDescription(
- inputs_dict, self.max_input_len, self.max_output_len, self.cache_manager_list[self.idx]
- )
-
- def step(self, new_token: torch.Tensor = None):
- """
- Update the state if microbatch manager, 2 conditions.
- 1. For first stage in PREFILL, receive inputs and outputs, `_add_description` will save its inputs.
- 2. For other condition, only receive the output of previous stage, and update the description.
-
- Args:
- inputs_dict (Dict[str, torch.Tensor]): the inputs of current stage. The key should have `input_ids` and `attention_mask`.
- output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
- new_token (torch.Tensor): the new token generated by current stage.
- """
- # Add description first if the description is None
- self.cur_description.update(new_token)
- return self.cur_state
-
- def export_new_tokens(self):
- new_tokens_list = []
- for i in self.mb_description_buffer.values():
- new_tokens_list.extend(i.new_tokens.tolist())
- return new_tokens_list
-
- def is_micro_batch_done(self):
- if len(self.mb_description_buffer) == 0:
- return False
- for mb in self.mb_description_buffer.values():
- if mb.state != Status.DONE:
- return False
- return True
-
- def clear(self):
- self.mb_description_buffer.clear()
- for cache in self.cache_manager_list:
- cache.free_all()
-
- def next(self):
- self.idx = (self.idx + 1) % self.buffer_size
-
- def _remove_description(self):
- self.mb_description_buffer.pop(self.idx)
-
- @property
- def cur_description(self) -> MicroBatchDescription:
- return self.mb_description_buffer.get(self.idx)
-
- @property
- def cur_infer_state(self):
- if self.cur_description is None:
- return None
- return self.cur_description.infer_state
-
- @property
- def cur_state(self):
- """
- Return the state of current micro batch, when current description is None, the state is PREFILL
-
- """
- if self.cur_description is None:
- return Status.PREFILL
- return self.cur_description.state
diff --git a/colossalai/inference/engine/modeling/__init__.py b/colossalai/inference/engine/modeling/__init__.py
deleted file mode 100644
index 8a9e9999d3c5..000000000000
--- a/colossalai/inference/engine/modeling/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-from .bloom import BloomInferenceForwards
-from .chatglm2 import ChatGLM2InferenceForwards
-from .llama import LlamaInferenceForwards
-
-__all__ = ["LlamaInferenceForwards", "BloomInferenceForwards", "ChatGLM2InferenceForwards"]
diff --git a/colossalai/inference/engine/modeling/_utils.py b/colossalai/inference/engine/modeling/_utils.py
deleted file mode 100644
index 068b64b4f829..000000000000
--- a/colossalai/inference/engine/modeling/_utils.py
+++ /dev/null
@@ -1,67 +0,0 @@
-"""
-Utils for model inference
-"""
-import os
-
-import torch
-
-from colossalai.kernel.triton.copy_kv_cache_dest import copy_kv_cache_to_dest
-
-
-def copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index, mem_manager):
- """
- This function copies the key and value cache to the memory cache
- Args:
- layer_id : id of current layer
- key_buffer : key cache
- value_buffer : value cache
- context_mem_index : index of memory cache in kv cache manager
- mem_manager : cache manager
- """
- copy_kv_cache_to_dest(key_buffer, context_mem_index, mem_manager.key_buffer[layer_id])
- copy_kv_cache_to_dest(value_buffer, context_mem_index, mem_manager.value_buffer[layer_id])
-
-
-def init_to_get_rotary(self, base=10000, use_elem=False):
- """
- This function initializes the rotary positional embedding, it is compatible for all models and is called in ShardFormer
- Args:
- self : Model that holds the rotary positional embedding
- base : calculation arg
- use_elem : activated when using chatglm-based models
- """
- self.config.head_dim_ = self.config.hidden_size // self.config.num_attention_heads
- if not hasattr(self.config, "rope_scaling"):
- rope_scaling_factor = 1.0
- else:
- rope_scaling_factor = self.config.rope_scaling.factor if self.config.rope_scaling is not None else 1.0
-
- if hasattr(self.config, "max_sequence_length"):
- max_seq_len = self.config.max_sequence_length
- elif hasattr(self.config, "max_position_embeddings"):
- max_seq_len = self.config.max_position_embeddings * rope_scaling_factor
- else:
- max_seq_len = 2048 * rope_scaling_factor
- base = float(base)
-
- # NTK ref: https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/
- ntk_alpha = os.environ.get("INFER_NTK_ALPHA", None)
-
- if ntk_alpha is not None:
- ntk_alpha = float(ntk_alpha)
- assert ntk_alpha >= 1, "NTK alpha must be greater than or equal to 1"
- if ntk_alpha > 1:
- print(f"Note: NTK enabled, alpha set to {ntk_alpha}")
- max_seq_len *= ntk_alpha
- base = base * (ntk_alpha ** (self.head_dim_ / (self.head_dim_ - 2))) # Base change formula
-
- n_elem = self.config.head_dim_
- if use_elem:
- n_elem //= 2
-
- inv_freq = 1.0 / (base ** (torch.arange(0, n_elem, 2, device="cpu", dtype=torch.float32) / n_elem))
- t = torch.arange(max_seq_len + 1024 * 64, device="cpu", dtype=torch.float32) / rope_scaling_factor
- freqs = torch.outer(t, inv_freq)
-
- self._cos_cached = torch.cos(freqs).to(torch.float16).cuda()
- self._sin_cached = torch.sin(freqs).to(torch.float16).cuda()
diff --git a/colossalai/inference/engine/modeling/bloom.py b/colossalai/inference/engine/modeling/bloom.py
deleted file mode 100644
index 4c098d3e4c80..000000000000
--- a/colossalai/inference/engine/modeling/bloom.py
+++ /dev/null
@@ -1,452 +0,0 @@
-import math
-import warnings
-from typing import List, Optional, Tuple, Union
-
-import torch
-import torch.distributed as dist
-from torch.nn import functional as F
-from transformers.models.bloom.modeling_bloom import (
- BaseModelOutputWithPastAndCrossAttentions,
- BloomAttention,
- BloomBlock,
- BloomForCausalLM,
- BloomModel,
-)
-from transformers.utils import logging
-
-from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
-from colossalai.kernel.triton import bloom_context_attn_fwd, copy_kv_cache_to_dest, token_attention_fwd
-from colossalai.pipeline.stage_manager import PipelineStageManager
-
-try:
- from lightllm.models.bloom.triton_kernel.context_flashattention_nopad import (
- context_attention_fwd as lightllm_bloom_context_attention_fwd,
- )
-
- HAS_LIGHTLLM_KERNEL = True
-except:
- HAS_LIGHTLLM_KERNEL = False
-
-
-def generate_alibi(n_head, dtype=torch.float16):
- """
- This method is adapted from `_generate_alibi` function
- in `lightllm/models/bloom/layer_weights/transformer_layer_weight.py`
- of the ModelTC/lightllm GitHub repository.
- This method is originally the `build_alibi_tensor` function
- in `transformers/models/bloom/modeling_bloom.py`
- of the huggingface/transformers GitHub repository.
- """
-
- def get_slopes_power_of_2(n):
- start = 2 ** (-(2 ** -(math.log2(n) - 3)))
- return [start * start**i for i in range(n)]
-
- def get_slopes(n):
- if math.log2(n).is_integer():
- return get_slopes_power_of_2(n)
- else:
- closest_power_of_2 = 2 ** math.floor(math.log2(n))
- slopes_power_of_2 = get_slopes_power_of_2(closest_power_of_2)
- slopes_double = get_slopes(2 * closest_power_of_2)
- slopes_combined = slopes_power_of_2 + slopes_double[0::2][: n - closest_power_of_2]
- return slopes_combined
-
- slopes = get_slopes(n_head)
- return torch.tensor(slopes, dtype=dtype)
-
-
-class BloomInferenceForwards:
- """
- This class serves a micro library for bloom inference forwards.
- We intend to replace the forward methods for BloomForCausalLM, BloomModel, BloomBlock, and BloomAttention,
- as well as prepare_inputs_for_generation method for BloomForCausalLM.
- For future improvement, we might want to skip replacing methods for BloomForCausalLM,
- and call BloomModel.forward iteratively in TpInferEngine
- """
-
- @staticmethod
- def bloom_for_causal_lm_forward(
- self: BloomForCausalLM,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
- attention_mask: Optional[torch.Tensor] = None,
- head_mask: Optional[torch.Tensor] = None,
- inputs_embeds: Optional[torch.Tensor] = None,
- labels: Optional[torch.Tensor] = None,
- use_cache: Optional[bool] = False,
- output_attentions: Optional[bool] = False,
- output_hidden_states: Optional[bool] = False,
- return_dict: Optional[bool] = False,
- infer_state: BatchInferState = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- tp_group: Optional[dist.ProcessGroup] = None,
- **deprecated_arguments,
- ):
- r"""
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
- `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
- are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
- """
- logger = logging.get_logger(__name__)
-
- if deprecated_arguments.pop("position_ids", False) is not False:
- # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
- warnings.warn(
- "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
- " passing `position_ids`.",
- FutureWarning,
- )
-
- # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- # If is first stage and hidden_states is not None, go throught lm_head first
- if stage_manager.is_first_stage() and hidden_states is not None:
- lm_logits = self.lm_head(hidden_states)
- return {"logits": lm_logits}
-
- outputs = BloomInferenceForwards.bloom_model_forward(
- self.transformer,
- input_ids,
- past_key_values=past_key_values,
- attention_mask=attention_mask,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- infer_state=infer_state,
- stage_manager=stage_manager,
- hidden_states=hidden_states,
- stage_index=stage_index,
- tp_group=tp_group,
- )
-
- return outputs
-
- @staticmethod
- def bloom_model_forward(
- self: BloomModel,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
- attention_mask: Optional[torch.Tensor] = None,
- head_mask: Optional[torch.LongTensor] = None,
- inputs_embeds: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = False,
- return_dict: Optional[bool] = None,
- infer_state: BatchInferState = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- tp_group: Optional[dist.ProcessGroup] = None,
- **deprecated_arguments,
- ) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPastAndCrossAttentions]:
- logger = logging.get_logger(__name__)
-
- # add warnings here
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
- if use_cache:
- logger.warning_once("use_cache=True is not supported for pipeline models at the moment.")
- use_cache = False
-
- if deprecated_arguments.pop("position_ids", False) is not False:
- # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
- warnings.warn(
- "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
- " passing `position_ids`.",
- FutureWarning,
- )
- if len(deprecated_arguments) > 0:
- raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
-
- # Prepare head mask if needed
- # 1.0 in head_mask indicate we keep the head
- # attention_probs has shape batch_size x num_heads x N x N
- # head_mask has shape n_layer x batch x num_heads x N x N
- head_mask = self.get_head_mask(head_mask, self.config.n_layer)
-
- # first stage
- if stage_manager.is_first_stage():
- # check inputs and inputs embeds
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- batch_size, seq_length = input_ids.shape
- elif inputs_embeds is not None:
- batch_size, seq_length, _ = inputs_embeds.shape
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
-
- if inputs_embeds is None:
- inputs_embeds = self.word_embeddings(input_ids)
-
- hidden_states = self.word_embeddings_layernorm(inputs_embeds)
- # other stage
- else:
- input_shape = hidden_states.shape[:-1]
- batch_size, seq_length = input_shape
-
- if infer_state.is_context_stage:
- past_key_values_length = 0
- else:
- past_key_values_length = infer_state.max_len_in_batch - 1
-
- if seq_length != 1:
- # prefill stage
- infer_state.is_context_stage = True # set prefill stage, notify attention layer
- infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
- BatchInferState.init_block_loc(
- infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
- )
- else:
- infer_state.is_context_stage = False
- alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
- if alloc_mem is not None:
- infer_state.decode_is_contiguous = True
- infer_state.decode_mem_index = alloc_mem[0]
- infer_state.decode_mem_start = alloc_mem[1]
- infer_state.decode_mem_end = alloc_mem[2]
- infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
- else:
- print(f" *** Encountered allocation non-contiguous")
- print(f" infer_state.max_len_in_batch : {infer_state.max_len_in_batch}")
- infer_state.decode_is_contiguous = False
- alloc_mem = infer_state.cache_manager.alloc(batch_size)
- infer_state.decode_mem_index = alloc_mem
- infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
-
- if attention_mask is None:
- attention_mask = torch.ones((batch_size, infer_state.max_len_in_batch), device=hidden_states.device)
- else:
- attention_mask = attention_mask.to(hidden_states.device)
-
- # NOTE revise: we might want to store a single 1D alibi(length is #heads) in model,
- # or store to BatchInferState to prevent re-calculating
- # When we have multiple process group (e.g. dp together with tp), we need to pass the pg to here
- tp_size = dist.get_world_size(tp_group) if tp_group is not None else 1
- curr_tp_rank = dist.get_rank(tp_group) if tp_group is not None else 0
- alibi = (
- generate_alibi(self.num_heads * tp_size)
- .contiguous()[curr_tp_rank * self.num_heads : (curr_tp_rank + 1) * self.num_heads]
- .cuda()
- )
- causal_mask = self._prepare_attn_mask(
- attention_mask,
- input_shape=(batch_size, seq_length),
- past_key_values_length=past_key_values_length,
- )
-
- infer_state.decode_layer_id = 0
-
- start_idx, end_idx = stage_index[0], stage_index[1]
- if past_key_values is None:
- past_key_values = tuple([None] * (end_idx - start_idx + 1))
-
- for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
- block = self.h[idx]
- outputs = block(
- hidden_states,
- layer_past=past_key_value,
- attention_mask=causal_mask,
- head_mask=head_mask[idx],
- use_cache=use_cache,
- output_attentions=output_attentions,
- alibi=alibi,
- infer_state=infer_state,
- )
-
- infer_state.decode_layer_id += 1
- hidden_states = outputs[0]
-
- if stage_manager.is_last_stage() or stage_manager.num_stages == 1:
- hidden_states = self.ln_f(hidden_states)
-
- # update indices
- infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
- infer_state.seq_len += 1
- infer_state.max_len_in_batch += 1
-
- # always return dict for imediate stage
- return {"hidden_states": hidden_states}
-
- @staticmethod
- def bloom_block_forward(
- self: BloomBlock,
- hidden_states: torch.Tensor,
- alibi: torch.Tensor,
- attention_mask: torch.Tensor,
- layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
- head_mask: Optional[torch.Tensor] = None,
- use_cache: bool = False,
- output_attentions: bool = False,
- infer_state: Optional[BatchInferState] = None,
- ):
- # hidden_states: [batch_size, seq_length, hidden_size]
-
- # Layer norm at the beginning of the transformer layer.
- layernorm_output = self.input_layernorm(hidden_states)
-
- # Layer norm post the self attention.
- if self.apply_residual_connection_post_layernorm:
- residual = layernorm_output
- else:
- residual = hidden_states
-
- # Self attention.
- attn_outputs = self.self_attention(
- layernorm_output,
- residual,
- layer_past=layer_past,
- attention_mask=attention_mask,
- alibi=alibi,
- head_mask=head_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- infer_state=infer_state,
- )
-
- attention_output = attn_outputs[0]
-
- outputs = attn_outputs[1:]
-
- layernorm_output = self.post_attention_layernorm(attention_output)
-
- # Get residual
- if self.apply_residual_connection_post_layernorm:
- residual = layernorm_output
- else:
- residual = attention_output
-
- # MLP.
- output = self.mlp(layernorm_output, residual)
-
- if use_cache:
- outputs = (output,) + outputs
- else:
- outputs = (output,) + outputs[1:]
-
- return outputs # hidden_states, present, attentions
-
- @staticmethod
- def bloom_attention_forward(
- self: BloomAttention,
- hidden_states: torch.Tensor,
- residual: torch.Tensor,
- alibi: torch.Tensor,
- attention_mask: torch.Tensor,
- layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
- head_mask: Optional[torch.Tensor] = None,
- use_cache: bool = False,
- output_attentions: bool = False,
- infer_state: Optional[BatchInferState] = None,
- ):
- fused_qkv = self.query_key_value(hidden_states) # [batch_size, seq_length, 3 x hidden_size]
-
- # 3 x [batch_size, seq_length, num_heads, head_dim]
- (query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
- batch_size, q_length, H, D_HEAD = query_layer.shape
- k = key_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
- v = value_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
-
- mem_manager = infer_state.cache_manager
- layer_id = infer_state.decode_layer_id
-
- if infer_state.is_context_stage:
- # context process
- max_input_len = q_length
- b_start_loc = infer_state.start_loc
- b_seq_len = infer_state.seq_len[:batch_size]
- q = query_layer.reshape(-1, H, D_HEAD)
-
- copy_kv_cache_to_dest(k, infer_state.context_mem_index, mem_manager.key_buffer[layer_id])
- copy_kv_cache_to_dest(v, infer_state.context_mem_index, mem_manager.value_buffer[layer_id])
-
- # output = self.output[:batch_size*q_length, :, :]
- output = torch.empty_like(q)
-
- if HAS_LIGHTLLM_KERNEL:
- lightllm_bloom_context_attention_fwd(q, k, v, output, alibi, b_start_loc, b_seq_len, max_input_len)
- else:
- bloom_context_attn_fwd(q, k, v, output, b_start_loc, b_seq_len, max_input_len, alibi)
-
- context_layer = output.view(batch_size, q_length, H * D_HEAD)
- else:
- # query_layer = query_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
- # need shape: batch_size, H, D_HEAD (q_length == 1), input q shape : (batch_size, q_length(1), H, D_HEAD)
- assert q_length == 1, "for non-context process, we only support q_length == 1"
- q = query_layer.reshape(-1, H, D_HEAD)
-
- if infer_state.decode_is_contiguous:
- # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
- cache_k = infer_state.cache_manager.key_buffer[layer_id][
- infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
- ]
- cache_v = infer_state.cache_manager.value_buffer[layer_id][
- infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
- ]
- cache_k.copy_(k)
- cache_v.copy_(v)
- else:
- # if decode is not contiguous, use triton kernel to copy key and value cache
- # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head]
- copy_kv_cache_to_dest(k, infer_state.decode_mem_index, mem_manager.key_buffer[layer_id])
- copy_kv_cache_to_dest(v, infer_state.decode_mem_index, mem_manager.value_buffer[layer_id])
-
- b_start_loc = infer_state.start_loc
- b_loc = infer_state.block_loc
- b_seq_len = infer_state.seq_len
- output = torch.empty_like(q)
- token_attention_fwd(
- q,
- mem_manager.key_buffer[layer_id],
- mem_manager.value_buffer[layer_id],
- output,
- b_loc,
- b_start_loc,
- b_seq_len,
- infer_state.max_len_in_batch,
- alibi,
- )
-
- context_layer = output.view(batch_size, q_length, H * D_HEAD)
-
- # NOTE: always set present as none for now, instead of returning past key value to the next decoding,
- # we create the past key value pair from the cache manager
- present = None
-
- # aggregate results across tp ranks. See here: https://github.com/pytorch/pytorch/issues/76232
- if self.pretraining_tp > 1 and self.slow_but_exact:
- slices = self.hidden_size / self.pretraining_tp
- output_tensor = torch.zeros_like(context_layer)
- for i in range(self.pretraining_tp):
- output_tensor = output_tensor + F.linear(
- context_layer[:, :, int(i * slices) : int((i + 1) * slices)],
- self.dense.weight[:, int(i * slices) : int((i + 1) * slices)],
- )
- else:
- output_tensor = self.dense(context_layer)
-
- # dropout is not required here during inference
- output_tensor = residual + output_tensor
-
- outputs = (output_tensor, present)
- assert output_attentions is False, "we do not support output_attentions at this time"
-
- return outputs
diff --git a/colossalai/inference/engine/modeling/chatglm2.py b/colossalai/inference/engine/modeling/chatglm2.py
deleted file mode 100644
index 56e777bb2b87..000000000000
--- a/colossalai/inference/engine/modeling/chatglm2.py
+++ /dev/null
@@ -1,492 +0,0 @@
-from typing import List, Optional, Tuple
-
-import torch
-from transformers.utils import logging
-
-from colossalai.inference.kv_cache import BatchInferState
-from colossalai.kernel.triton.token_attention_kernel import Llama2TokenAttentionForwards
-from colossalai.pipeline.stage_manager import PipelineStageManager
-from colossalai.shardformer import ShardConfig
-from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
- ChatGLMForConditionalGeneration,
- ChatGLMModel,
- GLMBlock,
- GLMTransformer,
- SelfAttention,
- split_tensor_along_last_dim,
-)
-
-from ._utils import copy_kv_to_mem_cache
-
-try:
- from lightllm.models.chatglm2.triton_kernel.rotary_emb import rotary_emb_fwd as chatglm2_rotary_emb_fwd
- from lightllm.models.llama2.triton_kernel.context_flashattention_nopad import (
- context_attention_fwd as lightllm_llama2_context_attention_fwd,
- )
-
- HAS_LIGHTLLM_KERNEL = True
-except:
- print("please install lightllm from source to run inference: https://github.com/ModelTC/lightllm")
- HAS_LIGHTLLM_KERNEL = False
-
-
-def get_masks(self, input_ids, past_length, padding_mask=None):
- batch_size, seq_length = input_ids.shape
- full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
- full_attention_mask.tril_()
- if past_length:
- full_attention_mask = torch.cat(
- (
- torch.ones(batch_size, seq_length, past_length, device=input_ids.device),
- full_attention_mask,
- ),
- dim=-1,
- )
-
- if padding_mask is not None:
- full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
- if not past_length and padding_mask is not None:
- full_attention_mask -= padding_mask.unsqueeze(-1) - 1
- full_attention_mask = (full_attention_mask < 0.5).bool()
- full_attention_mask.unsqueeze_(1)
- return full_attention_mask
-
-
-def get_position_ids(batch_size, seq_length, device):
- position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
- return position_ids
-
-
-class ChatGLM2InferenceForwards:
- """
- This class holds forwards for Chatglm2 inference.
- We intend to replace the forward methods for ChatGLMModel, ChatGLMEecoderLayer, and ChatGLMAttention.
- """
-
- @staticmethod
- def chatglm_for_conditional_generation_forward(
- self: ChatGLMForConditionalGeneration,
- input_ids: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.Tensor] = None,
- attention_mask: Optional[torch.Tensor] = None,
- past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.Tensor] = None,
- labels: Optional[torch.Tensor] = None,
- use_cache: Optional[bool] = True,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- return_last_logit: Optional[bool] = False,
- infer_state: Optional[BatchInferState] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- shard_config: ShardConfig = None,
- ):
- logger = logging.get_logger(__name__)
-
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- # If is first stage and hidden_states is not None, go throught lm_head first
- if stage_manager.is_first_stage() and hidden_states is not None:
- if return_last_logit:
- hidden_states = hidden_states[-1:]
- lm_logits = self.transformer.output_layer(hidden_states)
- lm_logits = lm_logits.transpose(0, 1).contiguous()
- return {"logits": lm_logits}
-
- outputs = self.transformer(
- input_ids=input_ids,
- position_ids=position_ids,
- attention_mask=attention_mask,
- past_key_values=past_key_values,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- infer_state=infer_state,
- stage_manager=stage_manager,
- hidden_states=hidden_states,
- stage_index=stage_index,
- shard_config=shard_config,
- )
-
- return outputs
-
- @staticmethod
- def chatglm_model_forward(
- self: ChatGLMModel,
- input_ids: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.Tensor] = None,
- attention_mask: Optional[torch.BoolTensor] = None,
- full_attention_mask: Optional[torch.BoolTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
- inputs_embeds: Optional[torch.Tensor] = None,
- use_cache: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- infer_state: BatchInferState = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- shard_config: ShardConfig = None,
- ):
- output_hidden_states = (
- output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
- )
-
- if stage_manager.is_first_stage():
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- batch_size, seq_length = input_ids.shape
- elif inputs_embeds is not None:
- batch_size, seq_length, _ = inputs_embeds.shape
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
- if inputs_embeds is None:
- inputs_embeds = self.embedding(input_ids)
- if position_ids is None:
- position_ids = get_position_ids(batch_size, seq_length, input_ids.device)
- hidden_states = inputs_embeds
- else:
- assert hidden_states is not None, "hidden_states should not be None in non-first stage"
- seq_length, batch_size, _ = hidden_states.shape
- if position_ids is None:
- position_ids = get_position_ids(batch_size, seq_length, hidden_states.device)
-
- if infer_state.is_context_stage:
- past_key_values_length = 0
- else:
- past_key_values_length = infer_state.max_len_in_batch - 1
-
- seq_length_with_past = seq_length + past_key_values_length
-
- # prefill stage at first
- if seq_length != 1:
- infer_state.is_context_stage = True
- infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
- infer_state.init_block_loc(
- infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
- )
- else:
- infer_state.is_context_stage = False
- alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
- if alloc_mem is not None:
- infer_state.decode_is_contiguous = True
- infer_state.decode_mem_index = alloc_mem[0]
- infer_state.decode_mem_start = alloc_mem[1]
- infer_state.decode_mem_end = alloc_mem[2]
- infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
- else:
- print(f" *** Encountered allocation non-contiguous")
- print(
- f" infer_state.cache_manager.past_key_values_length: {infer_state.cache_manager.past_key_values_length}"
- )
- infer_state.decode_is_contiguous = False
- alloc_mem = infer_state.cache_manager.alloc(batch_size)
- infer_state.decode_mem_index = alloc_mem
- infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
-
- # related to rotary embedding
- if infer_state.is_context_stage:
- infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
- position_ids.view(-1).shape[0], -1
- )
- infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
- position_ids.view(-1).shape[0], -1
- )
- else:
- seq_len = infer_state.seq_len
- infer_state.position_cos = torch.index_select(self._cos_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
- infer_state.position_sin = torch.index_select(self._sin_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
- infer_state.other_kv_index = infer_state.block_loc[0, infer_state.max_len_in_batch - 1].item()
-
- if self.pre_seq_len is not None:
- if past_key_values is None:
- past_key_values = self.get_prompt(
- batch_size=batch_size,
- device=input_ids.device,
- dtype=inputs_embeds.dtype,
- )
- if attention_mask is not None:
- attention_mask = torch.cat(
- [
- attention_mask.new_ones((batch_size, self.pre_seq_len)),
- attention_mask,
- ],
- dim=-1,
- )
- if full_attention_mask is None:
- if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
- full_attention_mask = get_masks(
- self, input_ids, infer_state.cache_manager.past_key_values_length, padding_mask=attention_mask
- )
-
- # Run encoder.
- hidden_states = self.encoder(
- hidden_states,
- full_attention_mask,
- kv_caches=past_key_values,
- use_cache=use_cache,
- output_hidden_states=output_hidden_states,
- infer_state=infer_state,
- stage_manager=stage_manager,
- stage_index=stage_index,
- shard_config=shard_config,
- )
-
- # update indices
- infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
- infer_state.seq_len += 1
- infer_state.max_len_in_batch += 1
-
- return {"hidden_states": hidden_states}
-
- @staticmethod
- def chatglm_encoder_forward(
- self: GLMTransformer,
- hidden_states,
- attention_mask,
- kv_caches=None,
- use_cache: Optional[bool] = True,
- output_hidden_states: Optional[bool] = False,
- infer_state: Optional[BatchInferState] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- stage_index: Optional[List[int]] = None,
- shard_config: ShardConfig = None,
- ):
- hidden_states = hidden_states.transpose(0, 1).contiguous()
-
- infer_state.decode_layer_id = 0
- start_idx, end_idx = stage_index[0], stage_index[1]
- if kv_caches is None:
- kv_caches = tuple([None] * (end_idx - start_idx + 1))
-
- for idx, kv_cache in zip(range(start_idx, end_idx), kv_caches):
- layer = self.layers[idx]
- layer_ret = layer(
- hidden_states,
- attention_mask,
- kv_cache=kv_cache,
- use_cache=use_cache,
- infer_state=infer_state,
- )
- infer_state.decode_layer_id += 1
-
- hidden_states, _ = layer_ret
-
- hidden_states = hidden_states.transpose(0, 1).contiguous()
-
- if self.post_layer_norm and (stage_manager.is_last_stage() or stage_manager.num_stages == 1):
- # Final layer norm.
- hidden_states = self.final_layernorm(hidden_states)
-
- return hidden_states
-
- @staticmethod
- def chatglm_glmblock_forward(
- self: GLMBlock,
- hidden_states,
- attention_mask,
- kv_cache=None,
- use_cache=True,
- infer_state: Optional[BatchInferState] = None,
- ):
- # hidden_states: [s, b, h]
-
- # Layer norm at the beginning of the transformer layer.
- layernorm_output = self.input_layernorm(hidden_states)
- # Self attention.
- attention_output, kv_cache = self.self_attention(
- layernorm_output,
- attention_mask,
- kv_cache=kv_cache,
- use_cache=use_cache,
- infer_state=infer_state,
- )
- # Residual connection.
- if self.apply_residual_connection_post_layernorm:
- residual = layernorm_output
- else:
- residual = hidden_states
- layernorm_input = torch.nn.functional.dropout(attention_output, p=self.hidden_dropout, training=self.training)
- layernorm_input = residual + layernorm_input
- # Layer norm post the self attention.
- layernorm_output = self.post_attention_layernorm(layernorm_input)
- # MLP.
- mlp_output = self.mlp(layernorm_output)
-
- # Second residual connection.
- if self.apply_residual_connection_post_layernorm:
- residual = layernorm_output
- else:
- residual = layernorm_input
-
- output = torch.nn.functional.dropout(mlp_output, p=self.hidden_dropout, training=self.training)
- output = residual + output
- return output, kv_cache
-
- @staticmethod
- def chatglm_flash_attn_kvcache_forward(
- self: SelfAttention,
- hidden_states,
- attention_mask,
- kv_cache=None,
- use_cache=True,
- infer_state: Optional[BatchInferState] = None,
- ):
- assert use_cache is True, "use_cache should be set to True using this chatglm attention"
- # hidden_states: original :[sq, b, h] --> this [b, sq, h]
- batch_size = hidden_states.shape[0]
- hidden_size = hidden_states.shape[-1]
- # Attention heads [sq, b, h] --> [sq, b, (np * 3 * hn)]
- mixed_x_layer = self.query_key_value(hidden_states)
- if self.multi_query_attention:
- (query_layer, key_layer, value_layer) = mixed_x_layer.split(
- [
- self.num_attention_heads_per_partition * self.hidden_size_per_attention_head,
- self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
- self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
- ],
- dim=-1,
- )
- query_layer = query_layer.view(
- query_layer.size()[:-1]
- + (
- self.num_attention_heads_per_partition,
- self.hidden_size_per_attention_head,
- )
- )
- key_layer = key_layer.view(
- key_layer.size()[:-1]
- + (
- self.num_multi_query_groups_per_partition,
- self.hidden_size_per_attention_head,
- )
- )
- value_layer = value_layer.view(
- value_layer.size()[:-1]
- + (
- self.num_multi_query_groups_per_partition,
- self.hidden_size_per_attention_head,
- )
- )
-
- else:
- new_tensor_shape = mixed_x_layer.size()[:-1] + (
- self.num_attention_heads_per_partition,
- 3 * self.hidden_size_per_attention_head,
- )
- mixed_x_layer = mixed_x_layer.view(*new_tensor_shape)
- # [sq, b, np, 3 * hn] --> 3 [sq, b, np, hn]
- (query_layer, key_layer, value_layer) = split_tensor_along_last_dim(mixed_x_layer, 3)
- cos, sin = infer_state.position_cos, infer_state.position_sin
-
- chatglm2_rotary_emb_fwd(
- query_layer.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head), cos, sin
- )
- if self.multi_query_attention:
- chatglm2_rotary_emb_fwd(
- key_layer.view(-1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head),
- cos,
- sin,
- )
- else:
- chatglm2_rotary_emb_fwd(
- key_layer.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head),
- cos,
- sin,
- )
-
- # reshape q k v to [bsz*sql, num_heads, head_dim] 2*1 ,32/2 ,128
- query_layer = query_layer.reshape(
- -1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head
- )
- key_layer = key_layer.reshape(
- -1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head
- )
- value_layer = value_layer.reshape(
- -1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head
- )
-
- if infer_state.is_context_stage:
- # first token generation:
- # copy key and value calculated in current step to memory manager
- copy_kv_to_mem_cache(
- infer_state.decode_layer_id,
- key_layer,
- value_layer,
- infer_state.context_mem_index,
- infer_state.cache_manager,
- )
- attn_output = torch.empty_like(query_layer.contiguous().view(-1, self.projection_size))
-
- # NOTE: no bug in context attn fwd (del it )
- lightllm_llama2_context_attention_fwd(
- query_layer,
- key_layer,
- value_layer,
- attn_output.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head),
- infer_state.start_loc,
- infer_state.seq_len,
- infer_state.max_len_in_batch,
- )
-
- else:
- if infer_state.decode_is_contiguous:
- # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
- cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
- infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
- ]
- cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
- infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
- ]
- cache_k.copy_(key_layer)
- cache_v.copy_(value_layer)
- else:
- # if decode is not contiguous, use triton kernel to copy key and value cache
- # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
- copy_kv_to_mem_cache(
- infer_state.decode_layer_id,
- key_layer,
- value_layer,
- infer_state.decode_mem_index,
- infer_state.cache_manager,
- )
-
- # second token and follows
- attn_output = torch.empty_like(query_layer.contiguous().view(-1, self.projection_size))
- cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
- : infer_state.decode_mem_end, :, :
- ]
- cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
- : infer_state.decode_mem_end, :, :
- ]
-
- # ==================================
- # core attention computation is replaced by triton kernel
- # ==================================
- Llama2TokenAttentionForwards.token_attn(
- query_layer,
- cache_k,
- cache_v,
- attn_output,
- infer_state.block_loc,
- infer_state.start_loc,
- infer_state.seq_len,
- infer_state.max_len_in_batch,
- infer_state.other_kv_index,
- )
-
- # =================
- # Output:[b,sq, h]
- # =================
- output = self.dense(attn_output).reshape(batch_size, -1, hidden_size)
-
- return output, kv_cache
diff --git a/colossalai/inference/engine/modeling/llama.py b/colossalai/inference/engine/modeling/llama.py
deleted file mode 100644
index a7efb4026be0..000000000000
--- a/colossalai/inference/engine/modeling/llama.py
+++ /dev/null
@@ -1,503 +0,0 @@
-# This code is adapted from huggingface transformers: https://github.com/huggingface/transformers/blob/v4.34.1/src/transformers/models/llama/modeling_llama.py
-import math
-from typing import List, Optional, Tuple
-
-import torch
-from transformers.models.llama.modeling_llama import LlamaAttention, LlamaDecoderLayer, LlamaForCausalLM, LlamaModel
-from transformers.utils import logging
-
-from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
-from colossalai.kernel.triton import llama_context_attn_fwd, token_attention_fwd
-from colossalai.kernel.triton.token_attention_kernel import Llama2TokenAttentionForwards
-from colossalai.pipeline.stage_manager import PipelineStageManager
-
-from ._utils import copy_kv_to_mem_cache
-
-try:
- from lightllm.models.llama2.triton_kernel.context_flashattention_nopad import (
- context_attention_fwd as lightllm_llama2_context_attention_fwd,
- )
- from lightllm.models.llama.triton_kernel.context_flashattention_nopad import (
- context_attention_fwd as lightllm_context_attention_fwd,
- )
- from lightllm.models.llama.triton_kernel.rotary_emb import rotary_emb_fwd as llama_rotary_embedding_fwd
-
- HAS_LIGHTLLM_KERNEL = True
-except:
- print("please install lightllm from source to run inference: https://github.com/ModelTC/lightllm")
- HAS_LIGHTLLM_KERNEL = False
-
-try:
- from colossalai.kernel.triton.flash_decoding import token_flash_decoding
-
- HAS_TRITON_FLASH_DECODING_KERNEL = True
-except:
- print(
- "no triton flash decoding support, please install lightllm from https://github.com/ModelTC/lightllm/blob/ece7b43f8a6dfa74027adc77c2c176cff28c76c8"
- )
- HAS_TRITON_FLASH_DECODING_KERNEL = False
-
-try:
- from flash_attn import flash_attn_with_kvcache
-
- HAS_FLASH_KERNEL = True
-except:
- HAS_FLASH_KERNEL = False
- print("please install flash attentiom from https://github.com/Dao-AILab/flash-attention")
-
-
-def rotate_half(x):
- """Rotates half the hidden dims of the input."""
- x1 = x[..., : x.shape[-1] // 2]
- x2 = x[..., x.shape[-1] // 2 :]
- return torch.cat((-x2, x1), dim=-1)
-
-
-def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
- # The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
- cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
- sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
- cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
- sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
-
- q_embed = (q * cos) + (rotate_half(q) * sin)
- k_embed = (k * cos) + (rotate_half(k) * sin)
- return q_embed, k_embed
-
-
-def llama_triton_context_attention(
- query_states, key_states, value_states, attn_output, infer_state, num_key_value_groups=1
-):
- if num_key_value_groups == 1:
- if HAS_LIGHTLLM_KERNEL is False:
- llama_context_attn_fwd(
- query_states,
- key_states,
- value_states,
- attn_output,
- infer_state.start_loc,
- infer_state.seq_len,
- infer_state.max_len_in_batch,
- )
- else:
- lightllm_context_attention_fwd(
- query_states,
- key_states,
- value_states,
- attn_output,
- infer_state.start_loc,
- infer_state.seq_len,
- infer_state.max_len_in_batch,
- )
- else:
- assert HAS_LIGHTLLM_KERNEL is True, "You have to install lightllm kernels to run llama2 model"
- lightllm_llama2_context_attention_fwd(
- query_states,
- key_states,
- value_states,
- attn_output,
- infer_state.start_loc,
- infer_state.seq_len,
- infer_state.max_len_in_batch,
- )
-
-
-def llama_triton_token_attention(
- query_states, attn_output, infer_state, num_key_value_groups=1, q_head_num=-1, head_dim=-1
-):
- if HAS_TRITON_FLASH_DECODING_KERNEL and q_head_num != -1 and head_dim != -1:
- token_flash_decoding(
- q=query_states,
- o_tensor=attn_output,
- infer_state=infer_state,
- q_head_num=q_head_num,
- head_dim=head_dim,
- cache_k=infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
- cache_v=infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
- )
- return
-
- if num_key_value_groups == 1:
- token_attention_fwd(
- query_states,
- infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
- infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
- attn_output,
- infer_state.block_loc,
- infer_state.start_loc,
- infer_state.seq_len,
- infer_state.max_len_in_batch,
- )
- else:
- Llama2TokenAttentionForwards.token_attn(
- query_states,
- infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
- infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
- attn_output,
- infer_state.block_loc,
- infer_state.start_loc,
- infer_state.seq_len,
- infer_state.max_len_in_batch,
- infer_state.other_kv_index,
- )
-
-
-class LlamaInferenceForwards:
- """
- This class holds forwards for llama inference.
- We intend to replace the forward methods for LlamaModel, LlamaDecoderLayer, and LlamaAttention for LlamaForCausalLM.
- """
-
- @staticmethod
- def llama_causal_lm_forward(
- self: LlamaForCausalLM,
- input_ids: torch.LongTensor = None,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[List[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- infer_state: BatchInferState = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ):
- r"""
- Args:
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
- config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
- (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
-
- """
- logger = logging.get_logger(__name__)
-
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- # If is first stage and hidden_states is None, go throught lm_head first
- if stage_manager.is_first_stage() and hidden_states is not None:
- lm_logits = self.lm_head(hidden_states)
- return {"logits": lm_logits}
-
- # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
- outputs = LlamaInferenceForwards.llama_model_forward(
- self.model,
- input_ids=input_ids,
- attention_mask=attention_mask,
- position_ids=position_ids,
- past_key_values=past_key_values,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- infer_state=infer_state,
- stage_manager=stage_manager,
- hidden_states=hidden_states,
- stage_index=stage_index,
- )
-
- return outputs
-
- @staticmethod
- def llama_model_forward(
- self: LlamaModel,
- input_ids: torch.LongTensor = None,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[List[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- infer_state: BatchInferState = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ):
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- # retrieve input_ids and inputs_embeds
- if stage_manager is None or stage_manager.is_first_stage():
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
- elif input_ids is not None:
- batch_size, seq_length = input_ids.shape
- elif inputs_embeds is not None:
- batch_size, seq_length, _ = inputs_embeds.shape
- else:
- raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
- device = input_ids.device if input_ids is not None else inputs_embeds.device
- if inputs_embeds is None:
- inputs_embeds = self.embed_tokens(input_ids)
- hidden_states = inputs_embeds
- else:
- assert stage_manager is not None
- assert hidden_states is not None, f"hidden_state should not be none in stage {stage_manager.stage}"
- input_shape = hidden_states.shape[:-1]
- batch_size, seq_length = input_shape
- device = hidden_states.device
-
- if infer_state.is_context_stage:
- past_key_values_length = 0
- else:
- past_key_values_length = infer_state.max_len_in_batch - 1
-
- # NOTE: differentiate with prefill stage
- # block_loc require different value-assigning method for two different stage
- if use_cache and seq_length != 1:
- # NOTE assume prefill stage
- # allocate memory block
- infer_state.is_context_stage = True # set prefill stage, notify attention layer
- infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
- infer_state.init_block_loc(
- infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
- )
- else:
- infer_state.is_context_stage = False
- alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
- if alloc_mem is not None:
- infer_state.decode_is_contiguous = True
- infer_state.decode_mem_index = alloc_mem[0]
- infer_state.decode_mem_start = alloc_mem[1]
- infer_state.decode_mem_end = alloc_mem[2]
- infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
- else:
- infer_state.decode_is_contiguous = False
- alloc_mem = infer_state.cache_manager.alloc(batch_size)
- infer_state.decode_mem_index = alloc_mem
- infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
-
- if position_ids is None:
- position_ids = torch.arange(
- past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
- )
- position_ids = position_ids.repeat(batch_size, 1)
- position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
- else:
- position_ids = position_ids.view(-1, seq_length).long()
-
- if infer_state.is_context_stage:
- infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
- position_ids.view(-1).shape[0], -1
- )
- infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
- position_ids.view(-1).shape[0], -1
- )
-
- else:
- seq_len = infer_state.seq_len
- infer_state.position_cos = torch.index_select(self._cos_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
- infer_state.position_sin = torch.index_select(self._sin_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
- infer_state.other_kv_index = infer_state.block_loc[0, infer_state.max_len_in_batch - 1].item()
-
- # embed positions
- if attention_mask is None:
- attention_mask = torch.ones(
- (batch_size, infer_state.max_len_in_batch), dtype=torch.bool, device=hidden_states.device
- )
-
- attention_mask = self._prepare_decoder_attention_mask(
- attention_mask, (batch_size, seq_length), hidden_states, past_key_values_length
- )
-
- # decoder layers
- infer_state.decode_layer_id = 0
-
- start_idx, end_idx = stage_index[0], stage_index[1]
- if past_key_values is None:
- past_key_values = tuple([None] * (end_idx - start_idx + 1))
-
- for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
- decoder_layer = self.layers[idx]
- # NOTE: modify here for passing args to decoder layer
- layer_outputs = decoder_layer(
- hidden_states,
- attention_mask=attention_mask,
- position_ids=position_ids,
- past_key_value=past_key_value,
- output_attentions=output_attentions,
- use_cache=use_cache,
- infer_state=infer_state,
- )
- infer_state.decode_layer_id += 1
- hidden_states = layer_outputs[0]
-
- if stage_manager.is_last_stage() or stage_manager.num_stages == 1:
- hidden_states = self.norm(hidden_states)
-
- # update indices
- # infer_state.block_loc[:, infer_state.max_len_in_batch-1] = infer_state.total_token_num + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
- infer_state.start_loc += torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
- infer_state.seq_len += 1
- infer_state.max_len_in_batch += 1
-
- return {"hidden_states": hidden_states}
-
- @staticmethod
- def llama_decoder_layer_forward(
- self: LlamaDecoderLayer,
- hidden_states: torch.Tensor,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_value: Optional[Tuple[torch.Tensor]] = None,
- output_attentions: Optional[bool] = False,
- use_cache: Optional[bool] = False,
- infer_state: Optional[BatchInferState] = None,
- ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
- residual = hidden_states
-
- hidden_states = self.input_layernorm(hidden_states)
- # Self Attention
- hidden_states, self_attn_weights, present_key_value = self.self_attn(
- hidden_states=hidden_states,
- attention_mask=attention_mask,
- position_ids=position_ids,
- past_key_value=past_key_value,
- output_attentions=output_attentions,
- use_cache=use_cache,
- infer_state=infer_state,
- )
-
- hidden_states = residual + hidden_states
-
- # Fully Connected
- residual = hidden_states
- hidden_states = self.post_attention_layernorm(hidden_states)
- hidden_states = self.mlp(hidden_states)
- hidden_states = residual + hidden_states
-
- outputs = (hidden_states,)
-
- if output_attentions:
- outputs += (self_attn_weights,)
-
- if use_cache:
- outputs += (present_key_value,)
-
- return outputs
-
- @staticmethod
- def llama_flash_attn_kvcache_forward(
- self: LlamaAttention,
- hidden_states: torch.Tensor,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_value: Optional[Tuple[torch.Tensor]] = None,
- output_attentions: bool = False,
- use_cache: bool = False,
- infer_state: Optional[BatchInferState] = None,
- ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
- assert use_cache is True, "use_cache should be set to True using this llama attention"
-
- bsz, q_len, _ = hidden_states.size()
-
- # NOTE might think about better way to handle transposed k and v
- # key_states [bs, seq_len, num_heads, head_dim/embed_size_per_head]
- # key_states_transposed [bs, num_heads, seq_len, head_dim/embed_size_per_head]
-
- query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim)
- key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim)
- value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim)
-
- # NOTE might want to revise
- # need some way to record the length of past key values cache
- # since we won't return past_key_value_cache right now
-
- cos, sin = infer_state.position_cos, infer_state.position_sin
-
- llama_rotary_embedding_fwd(query_states.view(-1, self.num_heads, self.head_dim), cos, sin)
- llama_rotary_embedding_fwd(key_states.view(-1, self.num_key_value_heads, self.head_dim), cos, sin)
-
- query_states = query_states.reshape(-1, self.num_heads, self.head_dim)
- key_states = key_states.reshape(-1, self.num_key_value_heads, self.head_dim)
- value_states = value_states.reshape(-1, self.num_key_value_heads, self.head_dim)
-
- if infer_state.is_context_stage:
- # first token generation
- # copy key and value calculated in current step to memory manager
- copy_kv_to_mem_cache(
- infer_state.decode_layer_id,
- key_states,
- value_states,
- infer_state.context_mem_index,
- infer_state.cache_manager,
- )
- attn_output = torch.empty_like(query_states)
-
- llama_triton_context_attention(
- query_states,
- key_states,
- value_states,
- attn_output,
- infer_state,
- num_key_value_groups=self.num_key_value_groups,
- )
- else:
- if infer_state.decode_is_contiguous:
- # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
- cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
- infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
- ]
- cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
- infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
- ]
- cache_k.copy_(key_states)
- cache_v.copy_(value_states)
- else:
- # if decode is not contiguous, use triton kernel to copy key and value cache
- # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
- copy_kv_to_mem_cache(
- infer_state.decode_layer_id,
- key_states,
- value_states,
- infer_state.decode_mem_index,
- infer_state.cache_manager,
- )
-
- if HAS_LIGHTLLM_KERNEL:
- attn_output = torch.empty_like(query_states)
- llama_triton_token_attention(
- query_states=query_states,
- attn_output=attn_output,
- infer_state=infer_state,
- num_key_value_groups=self.num_key_value_groups,
- q_head_num=q_len * self.num_heads,
- head_dim=self.head_dim,
- )
- else:
- self.num_heads // self.num_key_value_heads
- cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id]
- cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id]
-
- query_states = query_states.view(bsz, -1, self.num_heads, self.head_dim)
- copy_cache_k = cache_k.view(bsz, -1, self.num_key_value_heads, self.head_dim)
- copy_cache_v = cache_v.view(bsz, -1, self.num_key_value_heads, self.head_dim)
-
- attn_output = flash_attn_with_kvcache(
- q=query_states,
- k_cache=copy_cache_k,
- v_cache=copy_cache_v,
- softmax_scale=1 / math.sqrt(self.head_dim),
- causal=True,
- )
-
- attn_output = attn_output.view(bsz, q_len, self.hidden_size)
-
- attn_output = self.o_proj(attn_output)
-
- # return past_key_value as None
- return attn_output, None, None
diff --git a/colossalai/inference/engine/policies/__init__.py b/colossalai/inference/engine/policies/__init__.py
deleted file mode 100644
index 269d1c57b276..000000000000
--- a/colossalai/inference/engine/policies/__init__.py
+++ /dev/null
@@ -1,11 +0,0 @@
-from .bloom import BloomModelInferPolicy
-from .chatglm2 import ChatGLM2InferPolicy
-from .llama import LlamaModelInferPolicy
-
-model_policy_map = {
- "llama": LlamaModelInferPolicy,
- "bloom": BloomModelInferPolicy,
- "chatglm": ChatGLM2InferPolicy,
-}
-
-__all__ = ["LlamaModelInferPolicy", "BloomModelInferPolicy", "ChatGLM2InferPolicy", "model_polic_map"]
diff --git a/colossalai/inference/engine/policies/bloom.py b/colossalai/inference/engine/policies/bloom.py
deleted file mode 100644
index 5bc47c3c1a49..000000000000
--- a/colossalai/inference/engine/policies/bloom.py
+++ /dev/null
@@ -1,127 +0,0 @@
-from functools import partial
-from typing import List
-
-import torch
-from torch.nn import LayerNorm, Module
-
-import colossalai.shardformer.layer as col_nn
-from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
-from colossalai.shardformer.policies.bloom import BloomForCausalLMPolicy
-
-from ..modeling.bloom import BloomInferenceForwards
-
-try:
- from colossalai.kernel.triton import layer_norm
-
- HAS_TRITON_NORM = True
-except:
- print("Some of our kernels require triton. You might want to install triton from https://github.com/openai/triton")
- HAS_TRITON_NORM = False
-
-
-def get_triton_layernorm_forward():
- if HAS_TRITON_NORM:
-
- def _triton_layernorm_forward(self: LayerNorm, hidden_states: torch.Tensor):
- return layer_norm(hidden_states, self.weight.data, self.bias, self.eps)
-
- return _triton_layernorm_forward
- else:
- return None
-
-
-class BloomModelInferPolicy(BloomForCausalLMPolicy):
- def __init__(self) -> None:
- super().__init__()
-
- def module_policy(self):
- from transformers.models.bloom.modeling_bloom import BloomAttention, BloomBlock, BloomForCausalLM, BloomModel
-
- policy = super().module_policy()
- if self.shard_config.extra_kwargs.get("quant", None) == "gptq":
- from colossalai.inference.quant.gptq.cai_gptq import ColCaiQuantLinear, RowCaiQuantLinear
-
- policy[BloomBlock] = ModulePolicyDescription(
- attribute_replacement={
- "self_attention.hidden_size": self.model.config.hidden_size
- // self.shard_config.tensor_parallel_size,
- "self_attention.split_size": self.model.config.hidden_size
- // self.shard_config.tensor_parallel_size,
- "self_attention.num_heads": self.model.config.n_head // self.shard_config.tensor_parallel_size,
- },
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="self_attention.query_key_value",
- target_module=ColCaiQuantLinear,
- kwargs={"split_num": 3},
- ),
- SubModuleReplacementDescription(
- suffix="self_attention.dense", target_module=RowCaiQuantLinear, kwargs={"split_num": 1}
- ),
- SubModuleReplacementDescription(
- suffix="self_attention.attention_dropout",
- target_module=col_nn.DropoutForParallelInput,
- ),
- SubModuleReplacementDescription(
- suffix="mlp.dense_h_to_4h", target_module=ColCaiQuantLinear, kwargs={"split_num": 1}
- ),
- SubModuleReplacementDescription(
- suffix="mlp.dense_4h_to_h", target_module=RowCaiQuantLinear, kwargs={"split_num": 1}
- ),
- ],
- )
- # NOTE set inference mode to shard config
- self.shard_config._infer()
-
- # set as default, in inference we also use pipeline style forward, just setting stage as 1
- self.set_pipeline_forward(
- model_cls=BloomForCausalLM,
- new_forward=partial(
- BloomInferenceForwards.bloom_for_causal_lm_forward,
- tp_group=self.shard_config.tensor_parallel_process_group,
- ),
- policy=policy,
- )
-
- method_replacement = {"forward": BloomInferenceForwards.bloom_model_forward}
- self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomModel)
-
- method_replacement = {"forward": BloomInferenceForwards.bloom_block_forward}
- self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomBlock)
-
- method_replacement = {"forward": BloomInferenceForwards.bloom_attention_forward}
- self.append_or_create_method_replacement(
- description=method_replacement, policy=policy, target_key=BloomAttention
- )
-
- if HAS_TRITON_NORM:
- infer_method = get_triton_layernorm_forward()
- method_replacement = {"forward": partial(infer_method)}
- self.append_or_create_method_replacement(
- description=method_replacement, policy=policy, target_key=LayerNorm
- )
-
- return policy
-
- def get_held_layers(self) -> List[Module]:
- """Get pipeline layers for current stage."""
- assert self.pipeline_stage_manager is not None
-
- if self.model.__class__.__name__ == "BloomModel":
- module = self.model
- else:
- module = self.model.transformer
- stage_manager = self.pipeline_stage_manager
-
- held_layers = []
- layers_per_stage = stage_manager.distribute_layers(len(module.h))
- if stage_manager.is_first_stage():
- held_layers.append(module.word_embeddings)
- held_layers.append(module.word_embeddings_layernorm)
- held_layers.append(self.model.lm_head)
- start_idx, end_idx = stage_manager.get_stage_index(layers_per_stage)
- held_layers.extend(module.h[start_idx:end_idx])
- if stage_manager.is_last_stage():
- held_layers.append(module.ln_f)
-
- return held_layers
diff --git a/colossalai/inference/engine/policies/chatglm2.py b/colossalai/inference/engine/policies/chatglm2.py
deleted file mode 100644
index c7c6f3b927e1..000000000000
--- a/colossalai/inference/engine/policies/chatglm2.py
+++ /dev/null
@@ -1,89 +0,0 @@
-from typing import List
-
-import torch.nn as nn
-
-from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
- ChatGLMForConditionalGeneration,
- ChatGLMModel,
- GLMBlock,
- GLMTransformer,
- SelfAttention,
-)
-
-# import colossalai
-from colossalai.shardformer.policies.chatglm2 import ChatGLMModelPolicy
-
-from ..modeling._utils import init_to_get_rotary
-from ..modeling.chatglm2 import ChatGLM2InferenceForwards
-
-try:
- HAS_TRITON_RMSNORM = True
-except:
- print("you should install triton from https://github.com/openai/triton")
- HAS_TRITON_RMSNORM = False
-
-
-class ChatGLM2InferPolicy(ChatGLMModelPolicy):
- def __init__(self) -> None:
- super().__init__()
-
- def module_policy(self):
- policy = super().module_policy()
- self.shard_config._infer()
-
- model_infer_forward = ChatGLM2InferenceForwards.chatglm_model_forward
- method_replacement = {"forward": model_infer_forward}
- self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=ChatGLMModel)
-
- encoder_infer_forward = ChatGLM2InferenceForwards.chatglm_encoder_forward
- method_replacement = {"forward": encoder_infer_forward}
- self.append_or_create_method_replacement(
- description=method_replacement, policy=policy, target_key=GLMTransformer
- )
-
- encoder_layer_infer_forward = ChatGLM2InferenceForwards.chatglm_glmblock_forward
- method_replacement = {"forward": encoder_layer_infer_forward}
- self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=GLMBlock)
-
- attn_infer_forward = ChatGLM2InferenceForwards.chatglm_flash_attn_kvcache_forward
- method_replacement = {"forward": attn_infer_forward}
- self.append_or_create_method_replacement(
- description=method_replacement, policy=policy, target_key=SelfAttention
- )
- if self.shard_config.enable_tensor_parallelism:
- policy[GLMBlock].attribute_replacement["self_attention.num_multi_query_groups_per_partition"] = (
- self.model.config.multi_query_group_num // self.shard_config.tensor_parallel_size
- )
- # for rmsnorm and others, we need to check the shape
-
- self.set_pipeline_forward(
- model_cls=ChatGLMForConditionalGeneration,
- new_forward=ChatGLM2InferenceForwards.chatglm_for_conditional_generation_forward,
- policy=policy,
- )
-
- return policy
-
- def get_held_layers(self) -> List[nn.Module]:
- module = self.model.transformer
- stage_manager = self.pipeline_stage_manager
-
- held_layers = []
- layers_per_stage = stage_manager.distribute_layers(module.num_layers)
- if stage_manager.is_first_stage():
- held_layers.append(module.embedding)
- held_layers.append(module.output_layer)
- start_idx, end_idx = stage_manager.get_stage_index(layers_per_stage)
- held_layers.extend(module.encoder.layers[start_idx:end_idx])
- if stage_manager.is_last_stage():
- if module.encoder.post_layer_norm:
- held_layers.append(module.encoder.final_layernorm)
-
- # rotary_pos_emb is needed for all stages
- held_layers.append(module.rotary_pos_emb)
-
- return held_layers
-
- def postprocess(self):
- init_to_get_rotary(self.model.transformer)
- return self.model
diff --git a/colossalai/inference/engine/policies/llama.py b/colossalai/inference/engine/policies/llama.py
deleted file mode 100644
index a57a4e50cdb9..000000000000
--- a/colossalai/inference/engine/policies/llama.py
+++ /dev/null
@@ -1,206 +0,0 @@
-from functools import partial
-from typing import List
-
-import torch
-from torch.nn import Module
-from transformers.models.llama.modeling_llama import (
- LlamaAttention,
- LlamaDecoderLayer,
- LlamaForCausalLM,
- LlamaModel,
- LlamaRMSNorm,
-)
-
-from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
-
-# import colossalai
-from colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy
-
-from ..modeling._utils import init_to_get_rotary
-from ..modeling.llama import LlamaInferenceForwards
-
-try:
- from colossalai.kernel.triton import rmsnorm_forward
-
- HAS_TRITON_RMSNORM = True
-except:
- print("you should install triton from https://github.com/openai/triton")
- HAS_TRITON_RMSNORM = False
-
-
-def get_triton_rmsnorm_forward():
- if HAS_TRITON_RMSNORM:
-
- def _triton_rmsnorm_forward(self: LlamaRMSNorm, hidden_states: torch.Tensor):
- return rmsnorm_forward(hidden_states, self.weight.data, self.variance_epsilon)
-
- return _triton_rmsnorm_forward
- else:
- return None
-
-
-class LlamaModelInferPolicy(LlamaForCausalLMPolicy):
- def __init__(self) -> None:
- super().__init__()
-
- def module_policy(self):
- policy = super().module_policy()
- decoder_attribute_replacement = {
- "self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
- "self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
- "self_attn.num_key_value_heads": self.model.config.num_key_value_heads
- // self.shard_config.tensor_parallel_size,
- }
- if self.shard_config.extra_kwargs.get("quant", None) == "gptq":
- from colossalai.inference.quant.gptq.cai_gptq import ColCaiQuantLinear, RowCaiQuantLinear
-
- policy[LlamaDecoderLayer] = ModulePolicyDescription(
- attribute_replacement=decoder_attribute_replacement,
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="self_attn.q_proj",
- target_module=ColCaiQuantLinear,
- kwargs={"split_num": 1},
- ),
- SubModuleReplacementDescription(
- suffix="self_attn.k_proj",
- target_module=ColCaiQuantLinear,
- kwargs={"split_num": 1},
- ),
- SubModuleReplacementDescription(
- suffix="self_attn.v_proj",
- target_module=ColCaiQuantLinear,
- kwargs={"split_num": 1},
- ),
- SubModuleReplacementDescription(
- suffix="self_attn.o_proj",
- target_module=RowCaiQuantLinear,
- kwargs={"split_num": 1},
- ),
- SubModuleReplacementDescription(
- suffix="mlp.gate_proj",
- target_module=ColCaiQuantLinear,
- kwargs={"split_num": 1},
- ),
- SubModuleReplacementDescription(
- suffix="mlp.up_proj",
- target_module=ColCaiQuantLinear,
- kwargs={"split_num": 1},
- ),
- SubModuleReplacementDescription(
- suffix="mlp.down_proj",
- target_module=RowCaiQuantLinear,
- kwargs={"split_num": 1},
- ),
- ],
- )
-
- elif self.shard_config.extra_kwargs.get("quant", None) == "smoothquant":
- from colossalai.inference.quant.smoothquant.models.llama import LlamaSmoothquantDecoderLayer
- from colossalai.inference.quant.smoothquant.models.parallel_linear import (
- ColW8A8BFP32OFP32Linear,
- RowW8A8B8O8Linear,
- RowW8A8BFP32O32LinearSiLU,
- RowW8A8BFP32OFP32Linear,
- )
-
- policy[LlamaSmoothquantDecoderLayer] = ModulePolicyDescription(
- attribute_replacement=decoder_attribute_replacement,
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="self_attn.q_proj",
- target_module=RowW8A8B8O8Linear,
- kwargs={"split_num": 1},
- ),
- SubModuleReplacementDescription(
- suffix="self_attn.k_proj",
- target_module=RowW8A8B8O8Linear,
- kwargs={"split_num": 1},
- ),
- SubModuleReplacementDescription(
- suffix="self_attn.v_proj",
- target_module=RowW8A8B8O8Linear,
- kwargs={"split_num": 1},
- ),
- SubModuleReplacementDescription(
- suffix="self_attn.o_proj",
- target_module=ColW8A8BFP32OFP32Linear,
- kwargs={"split_num": 1},
- ),
- SubModuleReplacementDescription(
- suffix="mlp.gate_proj",
- target_module=RowW8A8BFP32O32LinearSiLU,
- kwargs={"split_num": 1},
- ),
- SubModuleReplacementDescription(
- suffix="mlp.up_proj",
- target_module=RowW8A8BFP32OFP32Linear,
- kwargs={"split_num": 1},
- ),
- SubModuleReplacementDescription(
- suffix="mlp.down_proj",
- target_module=ColW8A8BFP32OFP32Linear,
- kwargs={"split_num": 1},
- ),
- ],
- )
- self.shard_config._infer()
-
- infer_forward = LlamaInferenceForwards.llama_model_forward
- method_replacement = {"forward": partial(infer_forward)}
- self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaModel)
-
- infer_forward = LlamaInferenceForwards.llama_decoder_layer_forward
- method_replacement = {"forward": partial(infer_forward)}
- self.append_or_create_method_replacement(
- description=method_replacement, policy=policy, target_key=LlamaDecoderLayer
- )
-
- infer_forward = LlamaInferenceForwards.llama_flash_attn_kvcache_forward
- method_replacement = {"forward": partial(infer_forward)}
- self.append_or_create_method_replacement(
- description=method_replacement, policy=policy, target_key=LlamaAttention
- )
-
- # set as default, in inference we also use pipeline style forward, just setting stage as 1
- self.set_pipeline_forward(
- model_cls=LlamaForCausalLM, new_forward=LlamaInferenceForwards.llama_causal_lm_forward, policy=policy
- )
-
- infer_forward = None
- if HAS_TRITON_RMSNORM:
- infer_forward = get_triton_rmsnorm_forward()
-
- if infer_forward is not None:
- method_replacement = {"forward": partial(infer_forward)}
- self.append_or_create_method_replacement(
- description=method_replacement, policy=policy, target_key=LlamaRMSNorm
- )
-
- return policy
-
- def postprocess(self):
- init_to_get_rotary(self.model.model)
- return self.model
-
- def get_held_layers(self) -> List[Module]:
- """Get pipeline layers for current stage."""
- assert self.pipeline_stage_manager is not None
-
- if self.model.__class__.__name__ == "LlamaModel":
- module = self.model
- else:
- module = self.model.model
- stage_manager = self.pipeline_stage_manager
-
- held_layers = []
- layers_per_stage = stage_manager.distribute_layers(len(module.layers))
- if stage_manager.is_first_stage():
- held_layers.append(module.embed_tokens)
- held_layers.append(self.model.lm_head)
- start_idx, end_idx = stage_manager.get_stage_index(layers_per_stage)
- held_layers.extend(module.layers[start_idx:end_idx])
- if stage_manager.is_last_stage():
- held_layers.append(module.norm)
-
- return held_layers
diff --git a/colossalai/inference/executor/rpc_worker.py b/colossalai/inference/executor/rpc_worker.py
new file mode 100644
index 000000000000..4b84dcc858af
--- /dev/null
+++ b/colossalai/inference/executor/rpc_worker.py
@@ -0,0 +1,300 @@
+import os
+from typing import List, Tuple, Union
+
+import rpyc
+import torch
+import torch.distributed as dist
+from torch import nn
+from transformers import AutoConfig, AutoModelForCausalLM
+from transformers.models.llama.modeling_llama import LlamaForCausalLM
+
+import colossalai
+from colossalai.accelerator import get_accelerator
+from colossalai.cluster import ProcessGroupMesh
+from colossalai.inference.config import InferenceConfig, InputMetaData
+from colossalai.inference.flash_decoding_utils import FDIntermTensors
+from colossalai.inference.modeling.policy import (
+ NoPaddingBaichuanModelInferPolicy,
+ NoPaddingLlamaModelInferPolicy,
+ model_policy_map,
+)
+from colossalai.inference.sampler import search_tokens
+from colossalai.inference.utils import get_model_size, has_index_file
+from colossalai.interface import ModelWrapper
+from colossalai.logging import get_dist_logger
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer import ShardConfig, ShardFormer
+from colossalai.shardformer.policies.base_policy import Policy
+
+PP_AXIS, TP_AXIS = 0, 1
+
+_SUPPORTED_MODELS = {
+ "LlamaForCausalLM": LlamaForCausalLM,
+ "BaichuanForCausalLM": AutoModelForCausalLM,
+}
+
+_SUPPORTED_MODEL_POLICIES = {
+ "NoPaddingLlamaModelInferPolicy": NoPaddingLlamaModelInferPolicy,
+ "NoPaddingBaichuanModelInferPolicy": NoPaddingBaichuanModelInferPolicy,
+}
+
+logger = get_dist_logger(__name__)
+
+
+class rpcWorkerService(rpyc.Service):
+
+ """
+ Execute the computation tasks and manage its own kv cache
+
+ Func with prefix `exposed_` will be invoked by client.
+ """
+
+ def exposed_init_dist_env(self, rank, world_size, master_address, master_port):
+ logger.info(f"init process group for rank {rank}")
+ colossalai.launch(rank=rank, world_size=world_size, port=master_port, host=master_address)
+ logger.info(f"init process group done for rank {rank}")
+
+ def exposed_init_model(
+ self, inference_config_param: dict, model_or_path: Union[nn.Module, str], model_policy_param: str = None
+ ):
+ assert dist.is_initialized(), "invoke init_dist_env first please!"
+
+ self.inference_config = InferenceConfig.from_rpc_param(inference_config_param)
+ model_policy = _SUPPORTED_MODEL_POLICIES[model_policy_param]() if model_policy_param else None
+
+ self.dtype = self.inference_config.dtype
+ self.verbose = True
+
+ self._init_model(model_or_path, model_policy)
+ self._init_fd_tensor()
+ self._init_output_tensor()
+ logger.info(f"init model done for rank {dist.get_rank()}")
+
+ def exposed_init_cache(self, alloc_shape: Tuple[Tuple[int, ...], Tuple[int, ...]]):
+ """Initialize the physical cache on the device.
+
+ For each layer of the model, we allocate two tensors for key and value respectively,
+ with shape of [num_blocks, num_kv_heads, block_size, head_size]
+ """
+ kalloc_shape, valloc_shape = alloc_shape
+ num_layers = self.model_config.num_hidden_layers
+
+ self.k_cache: List[torch.Tensor] = []
+ self.v_cache: List[torch.Tensor] = []
+ for _ in range(num_layers):
+ self.k_cache.append(
+ torch.zeros(
+ kalloc_shape,
+ dtype=self.inference_config.kv_cache_dtype,
+ device=get_accelerator().get_current_device(),
+ )
+ )
+ self.v_cache.append(
+ torch.zeros(
+ valloc_shape,
+ dtype=self.inference_config.kv_cache_dtype,
+ device=get_accelerator().get_current_device(),
+ )
+ )
+ logger.info("physical cache init over")
+
+ def exposed_execute_model_forward(self, input_token_ids_param: List[int], input_meta_data_param: dict):
+ # prepare the data for model forward
+ input_meta_data = InputMetaData.from_rpc_param(input_meta_data_param)
+ input_meta_data.fd_inter_tensor = self.fd_inter_tensor
+ if input_meta_data.is_prompts:
+ n_tokens = input_meta_data.sequence_lengths.sum().item()
+ else:
+ n_tokens = input_meta_data.batch_size
+ input_token_ids = torch.tensor(input_token_ids_param, dtype=torch.int, device=self.device)
+
+ # execute the model
+ logits = self.model(
+ input_token_ids,
+ self.output_tensor[:n_tokens],
+ input_meta_data,
+ self.k_cache,
+ self.v_cache,
+ )
+
+ # sampler
+ if self.inference_config.pad_input:
+ logits = logits[:, -1, :]
+ next_tokens = search_tokens(
+ self.inference_config.to_generation_config(self.model_config),
+ logits,
+ input_meta_data.is_prompts,
+ input_meta_data.batch_token_ids,
+ )
+
+ # return the tokens generated to scheduler
+ return next_tokens.tolist()
+
+ def _init_output_tensor(self):
+ alloc_shape = (
+ self.inference_config.max_batch_size
+ * (self.inference_config.max_input_len + self.inference_config.max_output_len),
+ self.model_config.hidden_size // self.inference_config.tp_size,
+ )
+ self.output_tensor = torch.zeros(alloc_shape, dtype=self.dtype, device=self.device)
+
+ def _init_fd_tensor(self):
+ fd_inter_tensor = FDIntermTensors()
+
+ if fd_inter_tensor._tensors_initialized:
+ fd_inter_tensor._reset()
+
+ # For Spec-Dec, process the speculated tokens plus the token in the last step for each seq
+ max_n_tokens = self.inference_config.max_batch_size
+ max_n_tokens *= self.inference_config.max_n_spec_tokens + 1
+
+ inference_config = self.inference_config
+ kv_max_split_num = (
+ inference_config.max_input_len + inference_config.max_output_len + inference_config.block_size - 1
+ ) // inference_config.block_size
+ head_dim = self.model_config.hidden_size // self.model_config.num_attention_heads
+
+ fd_inter_tensor.initialize(
+ max_batch_size=max_n_tokens,
+ num_attn_heads=self.model_config.num_attention_heads // self.inference_config.tp_size,
+ kv_max_split_num=kv_max_split_num,
+ head_dim=head_dim,
+ dtype=self.dtype,
+ device=get_accelerator().get_current_device(),
+ )
+
+ self.fd_inter_tensor = fd_inter_tensor
+
+ def _init_model(self, model_or_path: Union[nn.Module, str], model_policy: Policy = None):
+ """
+ Shard model or/and Load weight
+
+ Shard model: When we set tp_size > 1, we will shard the model by given model_policy.
+ Load Weight: If we pass a local model path, we will load the model weight by checkpoint_io. If it is a remote-transformer url, we will use `AutoModel.from_pretrained` api of transformers lib
+
+ Args:
+ model_or_path Union[nn.Module, str]: path to the checkpoint or model of transformer format.
+ model_policy (Policy): the policy to replace the model
+ """
+
+ if isinstance(model_or_path, str):
+ is_local = os.path.isdir(model_or_path)
+ try:
+ hf_config = AutoConfig.from_pretrained(model_or_path, trust_remote_code=True)
+ arch = getattr(hf_config, "architectures")[0]
+ if is_local:
+ model = _SUPPORTED_MODELS[arch](hf_config)
+ else:
+ # load the real checkpoint
+ model = _SUPPORTED_MODELS[arch].from_pretrained(model_or_path, trust_remote_code=True)
+ except Exception as e:
+ logger.error(
+ f"An exception occurred during loading model: {e}, model should be loaded by transformers\n"
+ )
+ else:
+ model = model_or_path
+
+ self.model_config = model.config
+
+ torch.cuda.empty_cache()
+ init_gpu_memory = torch.cuda.mem_get_info()[0]
+
+ self.device = get_accelerator().get_current_device()
+ torch.cuda.set_device(self.device)
+ if self.verbose:
+ logger.info(f"the device is {self.device}")
+
+ model = model.to(dtype=self.dtype, non_blocking=False).eval()
+
+ if self.verbose:
+ logger.info(
+ f"Before the shard, Rank: [{dist.get_rank()}], model size: {get_model_size(model)} GB, model's device is: {model.device}"
+ )
+
+ if model_policy is None:
+ if self.inference_config.pad_input:
+ model_type = "padding_" + self.model_config.model_type
+ else:
+ model_type = "nopadding_" + self.model_config.model_type
+ model_policy = model_policy_map[model_type]()
+
+ pg_mesh = ProcessGroupMesh(self.inference_config.pp_size, self.inference_config.tp_size)
+ tp_group = pg_mesh.get_group_along_axis(TP_AXIS)
+
+ self.model = self._shardformer(
+ model,
+ model_policy,
+ None,
+ tp_group=tp_group,
+ )
+
+ self.model = ModelWrapper(model).to(device=get_accelerator().get_current_device())
+
+ if self.verbose:
+ logger.info(
+ f"After the shard, Rank: [{dist.get_rank()}], model size: {get_model_size(self.model)} GB, model's device is: {model.device}"
+ )
+
+ if isinstance(model_or_path, str) and is_local:
+ from colossalai.inference.core.plugin import InferCheckpoint_io
+
+ cpt_io = InferCheckpoint_io()
+ if_has_index_file, model_index_file = has_index_file(model_or_path)
+ assert if_has_index_file, "the model path is invalid"
+ cpt_io.load_model(self.model, model_index_file)
+
+ free_gpu_memory, total_gpu_memory = torch.cuda.mem_get_info()
+ peak_memory = init_gpu_memory - free_gpu_memory
+ if self.verbose:
+ logger.info(
+ f"Rank [{dist.get_rank()}], Model Weight Max Occupy {peak_memory / (1024 ** 3)} GB, Model size: {get_model_size(self.model)} GB"
+ )
+
+ def _shardformer(
+ self,
+ model: nn.Module,
+ model_policy: Policy,
+ stage_manager: PipelineStageManager = None,
+ tp_group: ProcessGroupMesh = None,
+ ) -> nn.Module:
+ """
+ Initialize ShardConfig and replace the model with shardformer.
+
+ Args:
+ model (nn.Module): Path or nn.Module of this model.
+ model_policy (Policy): The policy to shardformer model which is determined by the model type.
+ stage_manager (PipelineStageManager, optional): Used to manage pipeline stages. Defaults to None.
+ tp_group (ProcessGroupMesh, optional): Used to manage the process TP group mesh. Defaults to None.
+
+ Returns:
+ nn.Module: The model optimized by Shardformer.
+ """
+
+ shardconfig = ShardConfig(
+ tensor_parallel_process_group=tp_group,
+ pipeline_stage_manager=stage_manager,
+ enable_tensor_parallelism=(self.inference_config.tp_size > 1),
+ enable_fused_normalization=False,
+ enable_all_optimization=False,
+ enable_flash_attention=False,
+ enable_jit_fused=False,
+ enable_sequence_parallelism=False,
+ )
+ shardformer = ShardFormer(shard_config=shardconfig)
+ shard_model, _ = shardformer.optimize(model, model_policy)
+ return shard_model
+
+ def exposed_compute_only_for_test(self):
+ dist_rank = dist.get_rank()
+
+ # Dummy data for each worker
+ data = torch.tensor([dist_rank], dtype=torch.float).cuda(dist_rank)
+ dist.barrier()
+
+ # Perform distributed all_reduce
+ dist.all_reduce(data, op=dist.ReduceOp.SUM)
+
+ dist.barrier()
+ logger.info(f"Worker rank {dist_rank}: Sum after all_reduce: {data.item()}")
+
+ return data.item()
diff --git a/colossalai/inference/flash_decoding_utils.py b/colossalai/inference/flash_decoding_utils.py
new file mode 100644
index 000000000000..8f9534d6adf4
--- /dev/null
+++ b/colossalai/inference/flash_decoding_utils.py
@@ -0,0 +1,64 @@
+import torch
+
+from colossalai.context.singleton_meta import SingletonMeta
+from colossalai.utils import get_current_device
+
+
+class FDIntermTensors(metaclass=SingletonMeta):
+ """Singleton class to hold tensors used for storing intermediate values in flash-decoding.
+ For now, it holds intermediate output and logsumexp (which will be used in reduction step along kv)
+ """
+
+ def __init__(self):
+ self._tensors_initialized = False
+
+ def _reset(self):
+ self._tensors_initialized = False
+ del self._mid_output
+ del self._mid_output_lse
+
+ @property
+ def is_initialized(self):
+ return self._tensors_initialized
+
+ @property
+ def mid_output(self):
+ assert self.is_initialized, "Intermediate tensors not initialized yet"
+ return self._mid_output
+
+ @property
+ def mid_output_lse(self):
+ assert self.is_initialized, "Intermediate tensors not initialized yet"
+ return self._mid_output_lse
+
+ def initialize(
+ self,
+ max_batch_size: int,
+ num_attn_heads: int,
+ kv_max_split_num: int,
+ head_dim: int,
+ dtype: torch.dtype = torch.float32,
+ device: torch.device = get_current_device(),
+ ) -> None:
+ """Initialize tensors.
+
+ Args:
+ max_batch_size (int): The maximum batch size over all the model forward.
+ This could be greater than the batch size in attention forward func when using dynamic batch size.
+ num_attn_heads (int)): Number of attention heads.
+ kv_max_split_num (int): The maximum number of blocks splitted on kv in flash-decoding algorithm.
+ **The maximum length/size of blocks splitted on kv should be the kv cache block size.**
+ head_dim (int): Head dimension.
+ dtype (torch.dtype, optional): Data type to be assigned to intermediate tensors.
+ device (torch.device, optional): Device used to initialize intermediate tensors.
+ """
+ assert not self.is_initialized, "Intermediate tensors used for Flash-Decoding have been initialized."
+
+ self._mid_output = torch.empty(
+ size=(max_batch_size, num_attn_heads, kv_max_split_num, head_dim), dtype=dtype, device=device
+ )
+ self._mid_output_lse = torch.empty(
+ size=(max_batch_size, num_attn_heads, kv_max_split_num), dtype=dtype, device=device
+ )
+
+ self._tensors_initialized = True
diff --git a/colossalai/inference/graph_runner.py b/colossalai/inference/graph_runner.py
new file mode 100644
index 000000000000..e8b805574e43
--- /dev/null
+++ b/colossalai/inference/graph_runner.py
@@ -0,0 +1,100 @@
+from typing import Dict, List
+
+import torch
+from torch import nn
+
+from colossalai.inference.config import InputMetaData
+from colossalai.logging import get_dist_logger
+
+
+class CUDAGraphRunner:
+ def __init__(self, model: nn.Module):
+ self.model = model
+ self.graph = None
+ self.input_buffers: Dict[str, torch.Tensor] = {}
+ self.output_buffers: Dict[str, torch.Tensor] = {}
+ self.logger = get_dist_logger(__name__)
+
+ def capture(
+ self,
+ input_tokens_ids: torch.Tensor,
+ output_tensor: torch.Tensor,
+ inputmetadata: InputMetaData,
+ k_caches: List[torch.Tensor] = None,
+ v_caches: List[torch.Tensor] = None,
+ memory_pool=None,
+ ) -> None:
+ assert self.graph is None
+
+ # run kernel once to cache the kernel, avoid stream capture error
+ hidden_states_origin_model = self.model(
+ input_tokens_ids,
+ output_tensor,
+ inputmetadata,
+ k_caches,
+ v_caches,
+ )
+ torch.cuda.synchronize()
+
+ # Capture the graph.
+ # self.logger.info(f"begin capture model...")
+ self.graph = torch.cuda.CUDAGraph()
+ with torch.cuda.graph(self.graph, pool=memory_pool):
+ hidden_states_cuda_graph = self.model(
+ input_tokens_ids,
+ output_tensor,
+ inputmetadata,
+ k_caches,
+ v_caches,
+ )
+ torch.cuda.synchronize()
+
+ # Save the input and output buffers, because replay always uses the same virtual memory space
+ self.input_buffers = {
+ "input_tokens_ids": input_tokens_ids,
+ "output_tensor": output_tensor,
+ "block_tables": inputmetadata.block_tables,
+ "sequence_lengths": inputmetadata.sequence_lengths,
+ # "fd_inter_tensor_mid_output": inputmetadata.fd_inter_tensor._mid_output,
+ # "fd_inter_tensor_mid_output_lse": inputmetadata.fd_inter_tensor._mid_output_lse,
+ "k_caches": k_caches,
+ "v_caches": v_caches,
+ }
+ self.output_buffers = {"logits": hidden_states_cuda_graph}
+ return
+
+ def forward(
+ self,
+ input_tokens_ids: torch.Tensor,
+ output_tensor: torch.Tensor,
+ inputmetadata: InputMetaData,
+ k_caches: List[torch.Tensor] = None,
+ v_caches: List[torch.Tensor] = None,
+ ) -> torch.Tensor:
+ # Copy the input tensors to the input buffers.
+ self.input_buffers["input_tokens_ids"].copy_(input_tokens_ids, non_blocking=True)
+ self.input_buffers["output_tensor"].copy_(output_tensor, non_blocking=True)
+
+ # for flexible block_table
+ self.input_buffers["block_tables"].fill_(-1)
+ M, N = inputmetadata.block_tables.shape
+ self.input_buffers["block_tables"][:M, :N].copy_(inputmetadata.block_tables, non_blocking=True)
+
+ self.input_buffers["sequence_lengths"].copy_(inputmetadata.sequence_lengths, non_blocking=True)
+
+ # we only have a global fd_inter_tensor so we don't need to copy them
+ # self.input_buffers["fd_inter_tensor_mid_output"].copy_(inputmetadata.fd_inter_tensor.mid_output, non_blocking=True)
+ # self.input_buffers["fd_inter_tensor_mid_output_lse"].copy_(inputmetadata.fd_inter_tensor.mid_output_lse, non_blocking=True)
+
+ # KV caches are fixed tensors, so we don't need to copy them.
+ # self.input_buffers["k_caches"].copy_(k_caches, non_blocking=True)
+ # self.input_buffers["v_caches"].copy_(v_caches, non_blocking=True)
+
+ # Run the graph.
+ self.graph.replay()
+
+ # Return the output tensor.
+ return self.output_buffers["logits"]
+
+ def __call__(self, *args, **kwargs):
+ return self.forward(*args, **kwargs)
diff --git a/colossalai/inference/kv_cache/__init__.py b/colossalai/inference/kv_cache/__init__.py
index 5b6ca182efae..b232db936774 100644
--- a/colossalai/inference/kv_cache/__init__.py
+++ b/colossalai/inference/kv_cache/__init__.py
@@ -1,2 +1,4 @@
-from .batch_infer_state import BatchInferState
-from .kvcache_manager import MemoryManager
+from .block_cache import CacheBlock
+from .kvcache_manager import KVCacheManager, RPCKVCacheManager
+
+__all__ = ["CacheBlock", "KVCacheManager", "RPCKVCacheManager"]
diff --git a/colossalai/inference/kv_cache/batch_infer_state.py b/colossalai/inference/kv_cache/batch_infer_state.py
deleted file mode 100644
index f707a86df37e..000000000000
--- a/colossalai/inference/kv_cache/batch_infer_state.py
+++ /dev/null
@@ -1,118 +0,0 @@
-# might want to consider combine with InferenceConfig in colossalai/ppinference/inference_config.py later
-from dataclasses import dataclass
-
-import torch
-from transformers.tokenization_utils_base import BatchEncoding
-
-from .kvcache_manager import MemoryManager
-
-
-# adapted from: lightllm/server/router/model_infer/infer_batch.py
-@dataclass
-class BatchInferState:
- r"""
- Information to be passed and used for a batch of inputs during
- a single model forward
- """
- batch_size: int
- max_len_in_batch: int
-
- cache_manager: MemoryManager = None
-
- block_loc: torch.Tensor = None
- start_loc: torch.Tensor = None
- seq_len: torch.Tensor = None
- past_key_values_len: int = None
-
- is_context_stage: bool = False
- context_mem_index: torch.Tensor = None
- decode_is_contiguous: bool = None
- decode_mem_start: int = None
- decode_mem_end: int = None
- decode_mem_index: torch.Tensor = None
- decode_layer_id: int = None
-
- device: torch.device = torch.device("cuda")
-
- @property
- def total_token_num(self):
- # return self.batch_size * self.max_len_in_batch
- assert self.seq_len is not None and self.seq_len.size(0) > 0
- return int(torch.sum(self.seq_len))
-
- def set_cache_manager(self, manager: MemoryManager):
- self.cache_manager = manager
-
- # adapted from: https://github.com/ModelTC/lightllm/blob/28c1267cfca536b7b4f28e921e03de735b003039/lightllm/common/infer_utils.py#L1
- @staticmethod
- def init_block_loc(
- b_loc: torch.Tensor, seq_len: torch.Tensor, max_len_in_batch: int, alloc_mem_index: torch.Tensor
- ):
- """in-place update block loc mapping based on the sequence length of the inputs in current bath"""
- start_index = 0
- seq_len_numpy = seq_len.cpu().numpy()
- for i, cur_seq_len in enumerate(seq_len_numpy):
- b_loc[i, max_len_in_batch - cur_seq_len : max_len_in_batch] = alloc_mem_index[
- start_index : start_index + cur_seq_len
- ]
- start_index += cur_seq_len
- return
-
- @classmethod
- def init_from_batch(
- cls,
- batch: torch.Tensor,
- max_input_len: int,
- max_output_len: int,
- cache_manager: MemoryManager,
- ):
- if not isinstance(batch, (BatchEncoding, dict, list, torch.Tensor)):
- raise TypeError(f"batch type {type(batch)} is not supported in prepare_batch_state")
-
- input_ids_list = None
- attention_mask = None
-
- if isinstance(batch, (BatchEncoding, dict)):
- input_ids_list = batch["input_ids"]
- attention_mask = batch["attention_mask"]
- else:
- input_ids_list = batch
- if isinstance(input_ids_list[0], int): # for a single input
- input_ids_list = [input_ids_list]
- attention_mask = [attention_mask] if attention_mask is not None else attention_mask
-
- batch_size = len(input_ids_list)
-
- seq_start_indexes = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
- seq_lengths = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
- start_index = 0
-
- max_len_in_batch = -1
- if isinstance(batch, (BatchEncoding, dict)):
- for i, attn_mask in enumerate(attention_mask):
- curr_seq_len = len(attn_mask)
- seq_lengths[i] = curr_seq_len
- seq_start_indexes[i] = start_index
- start_index += curr_seq_len
- max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
- else:
- length = max(len(input_id) for input_id in input_ids_list)
- for i, input_ids in enumerate(input_ids_list):
- curr_seq_len = length
- seq_lengths[i] = curr_seq_len
- seq_start_indexes[i] = start_index
- start_index += curr_seq_len
- max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
- block_loc = torch.zeros((batch_size, max_input_len + max_output_len), dtype=torch.long, device="cuda")
-
- return cls(
- batch_size=batch_size,
- max_len_in_batch=max_len_in_batch,
- seq_len=seq_lengths.to("cuda"),
- start_loc=seq_start_indexes.to("cuda"),
- block_loc=block_loc,
- decode_layer_id=0,
- past_key_values_len=0,
- is_context_stage=True,
- cache_manager=cache_manager,
- )
diff --git a/colossalai/inference/kv_cache/block_cache.py b/colossalai/inference/kv_cache/block_cache.py
new file mode 100644
index 000000000000..755c9581e224
--- /dev/null
+++ b/colossalai/inference/kv_cache/block_cache.py
@@ -0,0 +1,58 @@
+from typing import Any
+
+__all__ = ["CacheBlock"]
+
+
+class CacheBlock:
+ """A simplified version of logical cache block used for Paged Attention."""
+
+ def __init__(self, block_id: int, block_size: int, elem_size: int, k_ptrs: Any = None, v_ptrs: Any = None):
+ # Unique id of a cache block
+ self.block_id = block_id
+
+ # size/capacity of the block in terms of the number of tokens it can hold
+ self.block_size = block_size
+
+ # element size in bytes
+ self.elem_size = elem_size
+
+ # For common cases, we track the relationships between logical and physical caches in KV Cache Manager,
+ # Additionally, k, v pointers can be optionally used for tracking the physical cache by CacheBlock itself.
+ self.k_ptrs = k_ptrs
+ self.v_ptrs = v_ptrs
+
+ self.ref_count = 0
+ # the number of slots that have been allocated (i.e. the number of tokens occupying the block)
+ self.allocated_size = 0
+ # the token ids whose KV Cache would be written to corresponding physical caches
+ # TODO add logics to update token_ids
+ self.token_ids = [None] * self.block_size
+
+ @property
+ def available_space(self) -> int:
+ # `allocated_size` is ensured to be less than or equal to `block_size`
+ return self.block_size - self.allocated_size
+
+ def add_ref(self) -> None:
+ self.ref_count += 1
+
+ def remove_ref(self) -> None:
+ assert self.ref_count > 0, f"Block#{self.block_id} has no reference to remove."
+ self.ref_count -= 1
+
+ def has_ref(self) -> bool:
+ return self.ref_count > 0
+
+ def allocate(self, size: int) -> None:
+ assert size <= self.available_space, f"Block#{self.block_id} has no available space to allocate."
+ self.allocated_size += size
+
+ def is_empty(self):
+ return self.allocated_size < 1
+
+ def clear(self) -> None:
+ self.ref_count = 0
+ self.allocated_size = 0
+
+ def __repr__(self):
+ return f"CacheBlock#{self.block_id}(ref#{self.ref_count}, allocated#{self.allocated_size})"
diff --git a/colossalai/inference/kv_cache/kvcache_manager.py b/colossalai/inference/kv_cache/kvcache_manager.py
index dda46a756cc3..a20bd8ee79ea 100644
--- a/colossalai/inference/kv_cache/kvcache_manager.py
+++ b/colossalai/inference/kv_cache/kvcache_manager.py
@@ -1,106 +1,576 @@
-"""
-Refered/Modified from lightllm/common/mem_manager.py
-of the ModelTC/lightllm GitHub repository
-https://github.com/ModelTC/lightllm/blob/050af3ce65edca617e2f30ec2479397d5bb248c9/lightllm/common/mem_manager.py
-we slightly changed it to make it suitable for our colossal-ai shardformer TP-engine design.
-"""
+from typing import List, Tuple
+
import torch
-from transformers.utils import logging
+from transformers.configuration_utils import PretrainedConfig
+
+from colossalai.inference.config import InferenceConfig
+from colossalai.inference.struct import Sequence
+from colossalai.logging import get_dist_logger
+from colossalai.utils import get_current_device
+
+from .block_cache import CacheBlock
+
+__all__ = ["KVCacheManager"]
+
+GIGABYTE = 1024**3
-class MemoryManager:
- r"""
- Manage token block indexes and allocate physical memory for key and value cache
+class KVCacheManager:
+ """KVCacheManager manages both the logical cache blocks and physical KV cache (tensors).
- Args:
- size: maximum token number used as the size of key and value buffer
- dtype: data type of cached key and value
- head_num: number of heads the memory manager is responsible for
- head_dim: embedded size per head
- layer_num: the number of layers in the model
- device: device used to store the key and value cache
+ NOTE: The KVCacheManager is designed to be interacted with indices of logical blocks.
+ That is, it won't allocate and return a physical cache to the engine or scheduler;
+ instead, it will mark the logical block as allocated and update the block id representing
+ the physical cache to the caller. The physical cache is actually used and updated in kernels.
+
+ Example
+ A block table of a single sequence before block allocation might be:
+ | -1 | -1 | -1 | -1 | -1 | -1 |
+ where the maximum blocks per sequence is 6
+ The block table after block allocation might be:
+ | 0 | 1 | 2 | -1 | -1 | -1 |
+ Then the logical blocks with id 0, 1, and 2, are allocated for this sequence,
+ and the physical caches, each with size of `block_size * kv_head_num * head_size * elem_size` for a single layer,
+ corresponding to these blocks will be used to read/write KV Caches in kernels.
+
+ For a batch of sequences, the block tables after allocation might be:
+ | 0 | 1 | 2 | -1 | -1 | -1 |
+ | 3 | 4 | 5 | 6 | 7 | -1 |
+ | 8 | 9 | 10 | 11 | -1 | -1 |
+ | 12 | 13 | 14 | 15 | -1 | -1 |
+ where 16 logical cache blocks are allocated and the same number of physical cache blocks will be used in kernels.
+
+ Currently, allocations and updates are done at granularity of a single sequence.
+ That is, the block table should be a 1D tensor of shape [max_blocks_per_sequence].
+ And it's possible to have a batch of sequences with different lengths of block tables.
"""
- def __init__(
+ def __init__(self, config: InferenceConfig, model_config: PretrainedConfig) -> None:
+ self.logger = get_dist_logger(__name__)
+ self.device = get_current_device()
+
+ # Parallel settings
+ self.tp_size = config.tp_size
+ # Model settings
+ self.dtype = config.dtype
+
+ if config.kv_cache_dtype is None:
+ self.kv_cache_dtype = config.dtype
+ else:
+ self.kv_cache_dtype = config.kv_cache_dtype
+
+ self.elem_size_in_bytes = torch.tensor([], dtype=self.dtype).element_size()
+ self.num_layers = model_config.num_hidden_layers
+ self.head_num = model_config.num_attention_heads
+ self.head_size = model_config.hidden_size // self.head_num
+ if hasattr(model_config, "num_key_value_heads"):
+ self.kv_head_num = model_config.num_key_value_heads
+ else:
+ self.kv_head_num = self.head_num
+
+ assert (
+ self.kv_head_num % self.tp_size == 0
+ ), f"Cannot shard {self.kv_head_num} heads with tp size {self.tp_size}"
+ self.kv_head_num //= self.tp_size
+ self.beam_width = config.beam_width
+ self.max_batch_size = config.max_batch_size
+ self.max_input_length = config.max_input_len
+ self.max_output_length = config.max_output_len
+ # Cache block settings
+ self.block_size = config.block_size
+ # NOTE: `num_blocks` is not prompted, but evaluated from the maximum input/output length, and the maximum batch size
+ self.max_blocks_per_sequence = (
+ self.max_input_length + self.max_output_length + self.block_size - 1
+ ) // self.block_size
+ self.num_blocks = self.max_blocks_per_sequence * self.max_batch_size * self.beam_width
+
+ # Physical cache allocation
+ if config.use_cuda_kernel:
+ x = 16 // torch.tensor([], dtype=config.dtype).element_size()
+ kalloc_shape = (self.num_blocks, self.kv_head_num, self.head_size // x, self.block_size, x)
+ valloc_shape = (self.num_blocks, self.kv_head_num, self.block_size, self.head_size)
+ self.logger.info(
+ f"Allocating K cache with shape: {kalloc_shape}, V cache with shape: {valloc_shape} consisting of {self.num_blocks} blocks."
+ )
+ self._kv_caches = self._init_device_caches(kalloc_shape, valloc_shape)
+ else:
+ alloc_shape = (self.num_blocks, self.kv_head_num, self.block_size, self.head_size)
+ self.logger.info(f"Allocating KV cache with shape: {alloc_shape} consisting of {self.num_blocks} blocks.")
+ self._kv_caches = self._init_device_caches(alloc_shape, alloc_shape)
+ self.total_physical_cache_size_in_bytes = (
+ self.elem_size_in_bytes
+ * self.num_layers
+ * 2
+ * self.num_blocks
+ * self.block_size
+ * self.kv_head_num
+ * self.head_size
+ )
+ self.logger.info(
+ f"Allocated {self.total_physical_cache_size_in_bytes / GIGABYTE:.2f} GB of KV cache on device {self.device}."
+ )
+ # Logical cache blocks allocation
+ self._available_blocks = self.num_blocks
+ self._cache_blocks = tuple(self._init_logical_caches())
+ # block availablity state 0->allocated, 1->free
+ self._block_states = torch.ones((self.num_blocks,), dtype=torch.bool)
+ self._block_states_cum = torch.zeros(size=(self.num_blocks + 1,), dtype=torch.int64)
+ self._block_finder = torch.zeros((self.num_blocks,), dtype=torch.int64)
+
+ @property
+ def total_num_blocks(self) -> int:
+ """Get the total number of logical cache blocks."""
+ return self.num_blocks
+
+ @property
+ def num_available_blocks(self) -> int:
+ """Get the number of available cache blocks."""
+ return self._available_blocks
+
+ def get_head_size(self):
+ return self.head_size
+
+ def get_kv_cache(self):
+ """Get k_cache and v_cache"""
+ return self._kv_caches
+
+ def get_max_blocks_per_sequence(self) -> int:
+ """Get the maximum number of blocks that can be allocated for a single sequence."""
+ # TODO Consider removing this function as we plan to implement "half-dynamic" batching in schduler/request handler,
+ # which will make the max_blocks_per_sequence dynamic based on the prompt lengths of sequences
+ # in the current batch.
+ return self.max_blocks_per_sequence
+
+ def check_allocation(self, seq: Sequence) -> bool:
+ num_blocks_needed = (seq.input_len + self.max_output_length + self.block_size - 1) // self.block_size
+ return num_blocks_needed <= self.num_available_blocks
+
+ def get_block_kv_ptrs(self, block_id: int, layer_id: int) -> Tuple[List[int], List[int]]:
+ """Get the key and value pointers of physical caches (of specific layer) corresponding to a logical cache block."""
+ block: CacheBlock = self._cache_blocks[block_id]
+ return block.k_ptrs[layer_id], block.v_ptrs[layer_id]
+
+ def get_block_table_kv_ptrs(self, block_table: torch.Tensor, layer_id: int) -> Tuple[int, int]:
+ """Get the key and value pointers of physical caches (of specific layer) corresponding to logical cache blocks indicated by the block table."""
+ k_ptrs = []
+ v_ptrs = []
+ for block_id in block_table:
+ if block_id >= 0:
+ block: CacheBlock = self._cache_blocks[block_id]
+ k_ptrs.append(block.k_ptrs[layer_id])
+ v_ptrs.append(block.v_ptrs[layer_id])
+ return k_ptrs, v_ptrs
+
+ def allocate_context_from_block_table(self, block_table: torch.Tensor, context_len: int) -> None:
+ """Allocate the logical cache blocks for a single sequence during prefill stage,
+ and updates the provided block table with the allocated block ids.
+
+ Args:
+ block_table: A 1D tensor of shape [max_blocks_per_sequence], mapping of token_position_id -> block_id.
+ context_len: The length of the processing sequnece.
+ """
+ assert block_table.dim() == 1
+ if not torch.all(block_table < 0):
+ self.logger.error("Some slots on provided block table have been allocated.")
+ blocks_required = (context_len + self.block_size - 1) // self.block_size
+ if blocks_required > self._available_blocks:
+ self.logger.warning(
+ f"No enough blocks to allocate. Available blocks {self._available_blocks}; context length {context_len}."
+ )
+ return
+
+ # Try contiguous allocation
+ torch.cumsum(self._block_states, dim=-1, out=self._block_states_cum[1:])
+ torch.subtract(
+ self._block_states_cum[blocks_required:],
+ self._block_states_cum[:-blocks_required],
+ out=self._block_finder[blocks_required - 1 :],
+ )
+ end_indexes = torch.nonzero(self._block_finder == blocks_required, as_tuple=False).view(-1)
+ if end_indexes.numel() > 0:
+ # contiguous cache exists
+ end_idx = end_indexes[0].item() + 1 # open interval
+ start_idx = end_idx - blocks_required # closed interval
+ block_indexes = torch.arange(start_idx, end_idx, device=block_table.device)
+ else:
+ # non-contiguous cache
+ available_block_indexes = torch.nonzero(self._block_states == 0).view(-1)
+ block_indexes = available_block_indexes[:blocks_required]
+ # Update block table
+ block_table[:blocks_required] = block_indexes
+ # Update cache blocks
+ self._block_states[block_indexes] = 0
+ self._available_blocks -= blocks_required
+ for block_id in block_indexes.tolist():
+ block: CacheBlock = self._cache_blocks[block_id]
+ block.add_ref()
+ if block_id == block_indexes[-1].item():
+ self._allocate_on_block(
+ block, block.block_size if context_len % block.block_size == 0 else context_len % block.block_size
+ )
+ else:
+ self._allocate_on_block(block, block.block_size)
+
+ def allocate_context_from_block_tables(self, block_tables: torch.Tensor, context_lengths: torch.Tensor) -> None:
+ """Allocate logical cache blocks for a batch of sequences during prefill stage.
+
+ Args:
+ block_tables (torch.Tensor): [bsz, max_blocks_per_sequence]
+ context_lengths (torch.Tensor): [bsz]]
+ """
+ assert block_tables.dim() == 2
+ assert block_tables.size(0) == context_lengths.size(0)
+ if not torch.all(block_tables < 0):
+ self.logger.error("Some slots on provided block table have been allocated.")
+ blocks_required = (context_lengths + self.block_size - 1) // self.block_size
+ num_blocks_required = torch.sum(blocks_required).item()
+ assert isinstance(num_blocks_required, int)
+ if num_blocks_required > self._available_blocks:
+ self.logger.warning(
+ f"Lacking blocks to allocate. Available blocks {self._available_blocks}; blocks asked {num_blocks_required}."
+ )
+ return
+
+ bsz = block_tables.size(0)
+ # Try contiguous allocation
+ torch.cumsum(self._block_states, dim=-1, out=self._block_states_cum[1:])
+ torch.subtract(
+ self._block_states_cum[num_blocks_required:],
+ self._block_states_cum[:-num_blocks_required],
+ out=self._block_finder[num_blocks_required - 1 :],
+ )
+ end_indexes = torch.nonzero(self._block_finder == num_blocks_required, as_tuple=False).view(-1)
+ if end_indexes.numel() > 0:
+ # contiguous cache exists
+ end_idx = end_indexes[0].item() + 1 # open interval
+ start_idx = end_idx - num_blocks_required # closed interval
+ alloc_block_ids = torch.arange(start_idx, end_idx)
+ for i in range(bsz):
+ curr_required = blocks_required[i]
+ block_tables[i, :curr_required] = torch.arange(
+ start_idx, start_idx + curr_required, device=block_tables.device
+ )
+ start_idx += curr_required
+ else:
+ # non-contiguous cache
+ available_block_ids = torch.nonzero(self._block_states > 0).view(-1)
+ alloc_block_ids = available_block_ids[:num_blocks_required]
+ alloc_block_ids = alloc_block_ids.to(dtype=block_tables.dtype, device=block_tables.device)
+ start_idx = 0
+ for i in range(bsz):
+ curr_required = blocks_required[i]
+ block_tables[i, :curr_required] = alloc_block_ids[start_idx, start_idx + curr_required]
+ start_idx += curr_required
+
+ # Update cache blocks
+ self._block_states[alloc_block_ids] = 0
+ self._available_blocks -= num_blocks_required
+ last_block_locs = torch.cumsum(blocks_required, dim=0) - 1
+ last_block_locs = last_block_locs.to(device=alloc_block_ids.device)
+
+ for i, block_id in enumerate(alloc_block_ids[last_block_locs]):
+ block: CacheBlock = self._cache_blocks[block_id]
+ block.add_ref()
+ self._allocate_on_block(
+ block,
+ block.block_size
+ if context_lengths[i] % block.block_size == 0
+ else context_lengths[i].item() % block.block_size,
+ )
+ for block_id in alloc_block_ids:
+ if block_id in alloc_block_ids[last_block_locs]:
+ continue
+ block: CacheBlock = self._cache_blocks[block_id]
+ block.add_ref()
+ self._allocate_on_block(block, block.block_size)
+
+ def allocate_token_from_block_table(self, block_table: torch.Tensor, context_len: int) -> None:
+ """Allocate the logical cache block for a single sequence during decoding stage,
+ and updates the provided block table if a new cache block is needed.
+
+ Args:
+ block_table: A 1D tensor of shape [max_blocks_per_sequence], mapping of token_position_id -> block_id.
+ context_len: The length of the processing sequnece (already-allocated length).
+ """
+ assert block_table.dim() == 1
+ # The last allocated block may be either partially or fully occupied.
+ # `alloc_local_block_idx` is the index of block to be allocated on provided block table.
+ alloc_local_block_idx = context_len // self.block_size
+ return self.allocate_single_block(block_table, alloc_local_block_idx)
+
+ def allocate_tokens_from_block_tables(
+ self, block_tables: torch.Tensor, context_lens: torch.Tensor, bsz: int = None
+ ) -> List[int]:
+ """Allocate logical cache blocks for a batch of sequences during decoding stage.
+
+ Usage:
+ allocate_context_from_block_tables
+ model forward (block tables & context lengths passed)
+ update context lengths
+ allocate_tokens_from_block_tables
+ model forward
+ update context lengths
+ allocate_tokens_from_block_tables
+ model forward
+ update context lengths
+ ...
+
+ Args:
+ block_tables (torch.Tensor): [bsz, max_blocks_per_sequence]
+ context_lengths (torch.Tensor): [bsz]
+
+ Returns:
+ List[int]: list of sequence uid to be recycled
+ """
+ assert block_tables.dim() == 2
+ assert context_lens.dim() == 1
+
+ bsz = block_tables.size(0) if bsz is None else bsz
+
+ alloc_local_block_indexes = (context_lens[:bsz]) // self.block_size
+ block_global_ids = block_tables[torch.arange(0, bsz), alloc_local_block_indexes]
+ seqs_to_recycle = []
+ new_blocks_required = torch.sum(block_global_ids < 0).item()
+ seqs_req_new_blocks = torch.nonzero(block_global_ids < 0).squeeze()
+
+ if new_blocks_required > 0:
+ if new_blocks_required > self._available_blocks:
+ # TODO might want to revise the logic here
+ # Process the first (_available_blocks) sequences that require new blocks
+ # Put the rest of the sequences back to recycled
+ seqs_req_new_blocks, seqs_to_recycle = (
+ seqs_req_new_blocks[: self._available_blocks],
+ seqs_req_new_blocks[self._available_blocks :],
+ )
+ for seq_id in seqs_to_recycle:
+ self.free_block_table(block_tables[seq_id])
+ new_blocks_required = self._available_blocks
+
+ # NOTE might want to alloc contiguous logic
+ free_block_ids = torch.nonzero(self._block_states > 0).view(-1)
+ alloc_block_ids = free_block_ids[:new_blocks_required].to(
+ dtype=block_tables.dtype, device=block_tables.device
+ )
+
+ for block_id in alloc_block_ids:
+ block: CacheBlock = self._cache_blocks[block_id]
+ block.add_ref()
+ self._block_states[block_id] = 0
+ self._available_blocks -= 1
+ block_tables[seqs_req_new_blocks, alloc_local_block_indexes[seqs_req_new_blocks]] = alloc_block_ids
+ block_global_ids = block_tables[torch.arange(0, bsz), alloc_local_block_indexes]
+
+ for block_id in block_global_ids:
+ self._allocate_on_block(self._cache_blocks[block_id], 1)
+
+ return seqs_to_recycle
+
+ def allocate_n_tokens_from_block_tables(
self,
- size: int,
- dtype: torch.dtype,
- head_num: int,
- head_dim: int,
- layer_num: int,
- device: torch.device = torch.device("cuda"),
- ):
- self.logger = logging.get_logger(__name__)
- self.available_size = size
- self.max_len_in_batch = 0
- self._init_mem_states(size, device)
- self._init_kv_buffers(size, device, dtype, head_num, head_dim, layer_num)
-
- def _init_mem_states(self, size, device):
- """Initialize tensors used to manage memory states"""
- self.mem_state = torch.ones((size,), dtype=torch.bool, device=device)
- self.mem_cum_sum = torch.empty((size,), dtype=torch.int32, device=device)
- self.indexes = torch.arange(0, size, dtype=torch.long, device=device)
-
- def _init_kv_buffers(self, size, device, dtype, head_num, head_dim, layer_num):
- """Initialize key buffer and value buffer on specified device"""
- self.key_buffer = [
- torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
+ block_tables: torch.Tensor,
+ context_lens: torch.Tensor,
+ bsz: int,
+ n: int,
+ ) -> List[int]:
+ """Allocate logical cache blocks for `n` new tokens for a batch of sequences during decoding stage."""
+ assert block_tables.dim() == 2
+ assert context_lens.dim() == 1
+
+ bsz = block_tables.size(0) if bsz is None else bsz
+ assert bsz == 1, "Support bsz 1 for now" # TODO support bsz > 1
+
+ seqs_to_recycle = []
+ for i in range(n):
+ seqs_to_recycle += self.allocate_tokens_from_block_tables(block_tables, context_lens - n + i + 1, bsz)
+
+ return seqs_to_recycle
+
+ def allocate_single_block(self, block_table: torch.Tensor, block_local_idx: int) -> int:
+ """Allocate space asked on a single block in the block table, specified by the provided position id,
+ and updates the provided block table with the allocated block.
+
+ Args:
+ block_table: A 1D tensor of shape [max_blocks_per_sequence], mapping of token_position_id -> block_id.
+ block_local_idx: The index of the block in the block table.
+ space_asked: i.e. The number of tokens to be assigned space for.
+ Returns:
+ The remaining space required to be allocated (in other blocks).
+ """
+ space_asked = 1
+ block_global_id = block_table[block_local_idx].item()
+ if block_global_id < 0:
+ # Allocate a new block if the current position is not assigned a block yet
+ if self._available_blocks <= 0:
+ # No available blocks to allocate, we free current sequence and return it to
+ self.free_block_table(block_table)
+ return True
+ free_block_id = torch.nonzero(self._block_states == 1).view(-1)[0]
+ block: CacheBlock = self._cache_blocks[free_block_id]
+ block.add_ref()
+ block_global_id = block.block_id
+ self._available_blocks -= 1
+ self._block_states[block_global_id] = 0
+ block_table[block_local_idx] = block_global_id
+ block: CacheBlock = self._cache_blocks[block_global_id]
+ return self._allocate_on_block(block, space_asked)
+ # only when space asked if fully satisfied, the return value will be zero.
+
+ def free_block_table(self, block_table: torch.Tensor) -> None:
+ """Free the logical cache blocks for **a single sequence**."""
+ assert block_table.dim() == 1
+ for i, global_block_id in enumerate(block_table.tolist()):
+ if global_block_id < 0:
+ return
+ block: CacheBlock = self._cache_blocks[global_block_id]
+ block.remove_ref()
+ if not block.has_ref():
+ block.allocated_size = 0
+ self._available_blocks += 1
+ self._block_states[global_block_id] = 1
+ # reset the block id in the block table (if we maintain a 2D tensors as block tables in Engine)
+ block_table[i] = -1
+
+ def free_block_tables(self, block_tables: torch.Tensor, first_n: int = None) -> None:
+ """Release the logical cache blocks for a batch of sequences.
+ If `first_n` is provided, only the blocks for the first several sequences will be released.
+ """
+ assert block_tables.dim() == 2
+ first_n = block_tables.size(0) if first_n is None else first_n
+ for block_table in block_tables[:first_n]:
+ self.free_block_table(block_table)
+
+ def clear_all(self) -> None:
+ """Clear all the references and allocations on all the cache blocks."""
+ for block in self._cache_blocks:
+ block.clear()
+ self._available_blocks = self.num_blocks
+ self._block_states[:] = 1
+
+ def get_physical_cache(self, layer_id: int, block_idx: int) -> Tuple[torch.Tensor, torch.Tensor]:
+ """Get the tensor corresponding to the cache block with the prompted id for a specific layer."""
+ return self._kv_caches[0][layer_id][block_idx], self._kv_caches[1][layer_id][block_idx]
+
+ def _allocate_on_block(self, block: CacheBlock, space_asked: int) -> int:
+ """Allocate a specific size of space on a provided cache block.
+
+ Returns:
+ The remaining space required to be allocated (in other blocks).
+ """
+ assert block.available_space > 0, f"Found no available space left in the chosen block {block}."
+ space_to_allocate = min(block.available_space, space_asked)
+ block.allocate(space_to_allocate)
+ return space_asked - space_to_allocate
+
+ def _init_logical_caches(self):
+ """Initialize the logical cache blocks.
+
+ NOTE This function should be called only after the physical caches have been allocated.
+ The data pointers of physical caches will be binded to each logical cache block.
+ """
+ assert self._kv_caches is not None and len(self._kv_caches[0]) > 0
+ blocks = []
+ physical_block_size = self.elem_size_in_bytes * self.block_size * self.kv_head_num * self.head_size
+ k_ptrs = [
+ self._kv_caches[0][layer_idx].data_ptr() - physical_block_size for layer_idx in range(self.num_layers)
]
- self.value_buffer = [
- torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
+ v_ptrs = [
+ self._kv_caches[1][layer_idx].data_ptr() - physical_block_size for layer_idx in range(self.num_layers)
]
+ for i in range(self.num_blocks):
+ k_ptrs = [first_block_ptr + physical_block_size for first_block_ptr in k_ptrs]
+ v_ptrs = [first_block_ptr + physical_block_size for first_block_ptr in v_ptrs]
+ cache_block = CacheBlock(i, self.block_size, self.elem_size_in_bytes, k_ptrs, v_ptrs)
+ blocks.append(cache_block)
+ return blocks
- @torch.no_grad()
- def alloc(self, required_size):
- """allocate space of required_size by providing indexes representing available physical spaces"""
- if required_size > self.available_size:
- self.logger.warning(f"No enough cache: required_size {required_size} " f"left_size {self.available_size}")
- return None
- torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
- select_index = torch.logical_and(self.mem_cum_sum <= required_size, self.mem_state == 1)
- select_index = self.indexes[select_index]
- self.mem_state[select_index] = 0
- self.available_size -= len(select_index)
- return select_index
-
- @torch.no_grad()
- def alloc_contiguous(self, required_size):
- """allocate contiguous space of required_size"""
- if required_size > self.available_size:
- self.logger.warning(f"No enough cache: required_size {required_size} " f"left_size {self.available_size}")
- return None
- torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
- sum_size = len(self.mem_cum_sum)
- loc_sums = (
- self.mem_cum_sum[required_size - 1 :]
- - self.mem_cum_sum[0 : sum_size - required_size + 1]
- + self.mem_state[0 : sum_size - required_size + 1]
- )
- can_used_loc = self.indexes[0 : sum_size - required_size + 1][loc_sums == required_size]
- if can_used_loc.shape[0] == 0:
+ def _init_device_caches(
+ self, kalloc_shape: Tuple[int, ...], valloc_shape: Tuple[int, ...]
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """Initialize the physical cache on the device.
+
+ For each layer of the model, we allocate two tensors for key and value respectively,
+ with shape of [num_blocks, num_kv_heads, block_size, head_size]
+ """
+ k_cache: List[torch.Tensor] = []
+ v_cache: List[torch.Tensor] = []
+ for _ in range(self.num_layers):
+ k_cache.append(torch.zeros(kalloc_shape, dtype=self.kv_cache_dtype, device=self.device))
+ v_cache.append(torch.zeros(valloc_shape, dtype=self.kv_cache_dtype, device=self.device))
+ return k_cache, v_cache
+
+
+class RPCKVCacheManager(KVCacheManager):
+ def __init__(self, config: InferenceConfig, model_config: PretrainedConfig, verbose: bool = False) -> None:
+ self.logger = get_dist_logger(__name__)
+ self.device = get_current_device()
+ self.config = config
+
+ # Parallel settings
+ self.tp_size = config.tp_size
+ # Model settings
+ self.dtype = config.dtype
+ self.elem_size_in_bytes = torch.tensor([], dtype=self.dtype).element_size()
+ self.num_layers = model_config.num_hidden_layers
+ self.head_num = model_config.num_attention_heads
+ self.head_size = model_config.hidden_size // self.head_num
+ if hasattr(model_config, "num_key_value_heads"):
+ self.kv_head_num = model_config.num_key_value_heads
+ else:
+ self.kv_head_num = self.head_num
+
+ if config.kv_cache_dtype is None:
+ self.kv_cache_dtype = config.dtype
+ else:
+ self.kv_cache_dtype = config.kv_cache_dtype
+
+ assert (
+ self.kv_head_num % self.tp_size == 0
+ ), f"Cannot shard {self.kv_head_num} heads with tp size {self.tp_size}"
+ self.kv_head_num //= self.tp_size
+ self.beam_width = config.beam_width
+ self.max_batch_size = config.max_batch_size
+ self.max_input_length = config.max_input_len
+ self.max_output_length = config.max_output_len
+ # Cache block settings
+ self.block_size = config.block_size
+ # NOTE: `num_blocks` is not prompted, but evaluated from the maximum input/output length, and the maximum batch size
+ self.max_blocks_per_sequence = (
+ self.max_input_length + self.max_output_length + self.block_size - 1
+ ) // self.block_size
+ self.num_blocks = self.max_blocks_per_sequence * self.max_batch_size * self.beam_width
+
+ # Logical cache blocks allocation
+ self._available_blocks = self.num_blocks
+ self._cache_blocks = tuple(self._init_logical_caches())
+ # block availablity state 0->allocated, 1->free
+ self._block_states = torch.ones((self.num_blocks,), dtype=torch.bool)
+ self._block_states_cum = torch.zeros(size=(self.num_blocks + 1,), dtype=torch.int64)
+ self._block_finder = torch.zeros((self.num_blocks,), dtype=torch.int64)
+
+ def get_physical_cache_shape(self) -> Tuple[Tuple[int, ...], Tuple[int, ...]]:
+ # Physical cache allocation
+ if self.config.use_cuda_kernel:
+ x = 16 // torch.tensor([], dtype=self.config.dtype).element_size()
+ kalloc_shape = (self.num_blocks, self.kv_head_num, self.head_size // x, self.block_size, x)
+ valloc_shape = (self.num_blocks, self.kv_head_num, self.block_size, self.head_size)
self.logger.info(
- f"No enough contiguous cache: required_size {required_size} " f"left_size {self.available_size}"
+ f"Allocating K cache with shape: {kalloc_shape}, V cache with shape: {valloc_shape} consisting of {self.num_blocks} blocks."
)
- return None
- start_loc = can_used_loc[0]
- select_index = self.indexes[start_loc : start_loc + required_size]
- self.mem_state[select_index] = 0
- self.available_size -= len(select_index)
- start = start_loc.item()
- end = start + required_size
- return select_index, start, end
-
- @torch.no_grad()
- def free(self, free_index):
- """free memory by updating memory states based on given indexes"""
- self.available_size += free_index.shape[0]
- self.mem_state[free_index] = 1
-
- @torch.no_grad()
- def free_all(self):
- """free all memory by updating memory states"""
- self.available_size = len(self.mem_state)
- self.mem_state[:] = 1
- self.max_len_in_batch = 0
- # self.logger.info("freed all space of memory manager")
+ else:
+ alloc_shape = (self.num_blocks, self.kv_head_num, self.block_size, self.head_size)
+ kalloc_shape = alloc_shape
+ valloc_shape = alloc_shape
+ self.logger.info(f"Allocating KV cache with shape: {alloc_shape} consisting of {self.num_blocks} blocks.")
+ return kalloc_shape, valloc_shape
+
+ def get_kv_cache(self):
+ """Get k_cache and v_cache"""
+ return NotImplementedError
+
+ def _init_logical_caches(self):
+ """Initialize the logical cache blocks."""
+ blocks = []
+ for i in range(self.num_blocks):
+ cache_block = CacheBlock(i, self.block_size, self.elem_size_in_bytes, k_ptrs=None, v_ptrs=None)
+ blocks.append(cache_block)
+ return blocks
diff --git a/colossalai/inference/logit_processors.py b/colossalai/inference/logit_processors.py
new file mode 100644
index 000000000000..8e4b29ae6f75
--- /dev/null
+++ b/colossalai/inference/logit_processors.py
@@ -0,0 +1,148 @@
+# This code is adapted from huggingface transformers: https://github.com/huggingface/transformers/blob/v4.36.2/src/transformers/generation/logits_process.py
+from typing import List
+
+import torch
+import torch.nn.functional as F
+
+_LOGIT_PROCESSOR_MAP = {}
+
+
+def register_logit_processor(process_type):
+ """
+ register flops computation function for operation.
+ """
+
+ def register(func):
+ global _LOGIT_PROCESSOR_MAP
+ _LOGIT_PROCESSOR_MAP[process_type] = func
+ return func
+
+ return register
+
+
+@register_logit_processor("no_repeat_ngram_size")
+def no_repeat_ngram_size_logit_process(logits, ngram_size: int, batch_token_ids: List[List[int]]):
+ """
+ enforces no repetition of n-grams to avoid repetitions of word sequences.
+ """
+
+ if not isinstance(ngram_size, int) or ngram_size < 0:
+ raise ValueError(f"'temperature={ngram_size}' should be a strictly positive integer.")
+
+ if ngram_size != 0:
+ batch_size = len(batch_token_ids)
+
+ for batch_id in range(batch_size):
+ current_token_ids = batch_token_ids[batch_id]
+ current_len = len(current_token_ids)
+ if current_len + 1 < ngram_size:
+ continue
+
+ ngrams_dict = {}
+
+ for ngram in zip(*[current_token_ids[i:] for i in range(ngram_size)]):
+ prev_ngram_tuple = tuple(ngram[:-1])
+ ngrams_dict[prev_ngram_tuple] = ngrams_dict.get(prev_ngram_tuple, []) + [ngram[-1]]
+
+ prev_ngrams = tuple(current_token_ids[current_len + 1 - ngram_size : current_len])
+ banned_token = ngrams_dict.get(prev_ngrams, [])
+
+ logits[batch_id, banned_token] = -float("inf")
+
+ return logits
+
+
+@register_logit_processor("repetition_penalty")
+def repetition_penalty_logit_process(logits, penalty: float, batch_token_ids: List[List[int]]):
+ """
+ apply the penalty to the tokens present in the prompt.
+ """
+
+ if not isinstance(penalty, float) or not (penalty > 0):
+ raise ValueError(f"'penalty={penalty}' has to be a strictly positive float and greater than 0.")
+
+ logit_list = []
+
+ # TODO(yuehuayingxueluo) This is only a temporary implementation. Later, we will implement presence_penalties, frequency_penalties, and repetition_penalties using CUDA kernels.
+ if penalty != 1.0:
+ for batch_id in range(len(batch_token_ids)):
+ current_logit = logits[batch_id]
+ current_token = torch.tensor(batch_token_ids[batch_id], dtype=torch.long, device=logits.device)
+
+ curretn_socre = torch.gather(current_logit, 0, current_token)
+ curretn_socre = torch.where(curretn_socre < 0, curretn_socre * penalty, curretn_socre / penalty)
+ logit_list.append(current_logit.scatter(0, current_token, curretn_socre))
+
+ logits = torch.stack(logit_list)
+
+ return logits
+
+
+@register_logit_processor("temperature")
+def temperature_logit_process(logits, temperature: float):
+ """
+ apply temperature scaling.
+ """
+
+ if not isinstance(temperature, float) or not (0.0 < temperature <= 1.0):
+ except_msg = f"'temperature={temperature}' should be a strictly positive float, less than or equal to 1.0 and greater than 0."
+ if temperature == 0.0:
+ except_msg += "if you want to use greedy decoding strategies, set `do_sample=False`."
+ raise ValueError(except_msg)
+
+ return logits if temperature == 1.0 else logits / temperature
+
+
+@register_logit_processor("top_k")
+def top_k_logit_processor(logits, top_k: int):
+ """
+ top_k logit processor
+ """
+
+ if not isinstance(top_k, int) or top_k <= 0:
+ raise ValueError(f"`top_k` should be a strictly positive integer, but got {top_k}.")
+
+ indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
+ logits[indices_to_remove] = -float("inf")
+ return logits
+
+
+@register_logit_processor("top_p")
+def top_p_logit_processor(logits, top_p: float):
+ """
+ top_p logit processor
+ """
+
+ if top_p < 0 or top_p > 1.0:
+ raise ValueError(f"`top_p` should be a float > 0 and < 1, but got {top_p}.")
+
+ sorted_logits, sorted_indices = torch.sort(logits, descending=True)
+ cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
+
+ sorted_indices_to_remove = cumulative_probs > top_p
+
+ sorted_indices_to_remove = torch.roll(sorted_indices_to_remove, 1, -1)
+ sorted_indices_to_remove[..., 0] = 0
+
+ indices_to_remove = sorted_indices_to_remove.scatter(dim=1, index=sorted_indices, src=sorted_indices_to_remove)
+ logits[indices_to_remove] = -float("inf")
+ return logits
+
+
+def logit_processor(processor: str, logits, *args, **kwargs):
+ """
+ do logit process for given logits.
+
+ Args:
+ processor(str): the type of logit processor
+ logits(torch.Tensor): input logits
+
+ Returns:
+ logits after process
+ """
+ if processor not in _LOGIT_PROCESSOR_MAP:
+ return logits
+ else:
+ func = _LOGIT_PROCESSOR_MAP[processor]
+ logits = func(logits, *args, **kwargs)
+ return logits
diff --git a/colossalai/inference/quant/smoothquant/__init__.py b/colossalai/inference/modeling/__init__.py
similarity index 100%
rename from colossalai/inference/quant/smoothquant/__init__.py
rename to colossalai/inference/modeling/__init__.py
diff --git a/colossalai/inference/modeling/layers/__init__.py b/colossalai/inference/modeling/layers/__init__.py
new file mode 100644
index 000000000000..e69de29bb2d1
diff --git a/colossalai/inference/modeling/layers/attention.py b/colossalai/inference/modeling/layers/attention.py
new file mode 100644
index 000000000000..43ccdc430ef1
--- /dev/null
+++ b/colossalai/inference/modeling/layers/attention.py
@@ -0,0 +1,313 @@
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from transformers.modeling_attn_mask_utils import AttentionMaskConverter
+
+
+def copy_to_cache(source, cache, lengths, block_tables, type: str = "prefill"):
+ """
+ Func: copy key/value into key/value cache.
+
+ Args: key/value(source): shape [bsz,seq_len,num_heads,head_size]
+ cache: shape [num_blocks, num_kv_heads, head_size, block_size]
+ lengths: key/value lengths
+ block_tables
+ """
+ num_blocks, num_heads, block_size, head_size = cache.shape
+ bsz, max_blocks_per_seq = block_tables.shape
+ needed_blocks = (lengths + block_size - 1) // block_size
+
+ if type == "prefill":
+ for i in range(bsz):
+ seq_len = lengths[i]
+ block_num = needed_blocks[i]
+ token_id = 0
+ for block_idx in range(block_num - 1):
+ cache[block_tables[i][block_idx]] = source[i][token_id : token_id + block_size].permute(1, 0, 2)
+ token_id += block_size
+ cache[block_tables[i][block_num - 1], :, : seq_len - token_id, :] = source[i][token_id:seq_len].permute(
+ 1, 0, 2
+ )
+ elif type == "decoding":
+ assert source.size(1) == 1, "seq_len should be equal to 1 when decoding."
+ source = source.squeeze(1)
+ slot_idx = (lengths + block_size - 1) % block_size
+ for i in range(bsz):
+ cache[block_tables[i, needed_blocks[i] - 1], :, slot_idx[i], :] = source[i]
+
+ return cache
+
+
+def convert_kvcache(cache, lengths, block_tables, pad_id=0):
+ """
+ Func: convert key/value cache for calculation
+
+ Args: cache: shape [num_blocks, num_heads, block_size, head_size]
+ lengths: key/value length
+ block_tables
+ pad_id: padded_id
+ """
+ num_blocks, num_heads, block_size, head_size = cache.shape
+
+ needed_blocks = (lengths + block_size - 1) // block_size
+ num_remaing_tokens = lengths % block_size
+ num_remaing_tokens[num_remaing_tokens == 0] += block_size
+ bsz = block_tables.shape[0]
+ seq_len = max(lengths)
+ padded_cache = []
+ for i in range(bsz):
+ _cache = torch.cat(
+ (
+ cache[block_tables[i][: needed_blocks[i] - 1]].permute((0, 2, 1, 3)).reshape(-1, num_heads, head_size),
+ cache[block_tables[i][needed_blocks[i] - 1], :, : num_remaing_tokens[i], :].permute(1, 0, 2),
+ ),
+ dim=0,
+ )
+ padding = seq_len - _cache.size(0)
+ if padding > 0:
+ _cache = F.pad(_cache, (0, 0, 0, 0, 0, padding), value=pad_id)
+ padded_cache.append(_cache)
+ return torch.stack(padded_cache, dim=0)
+
+
+class PagedAttention:
+ """
+ Pure Torch implementation version of paged_attention.
+ Holds different types of forward function and useful components.
+ """
+
+ @staticmethod
+ def pad_and_reshape(tensor, seq_lengths, max_seq_len, num_heads, head_size):
+ """
+ Transform 1D no_pad tensor into 2D padded tensor with shape [bsz,seq_len,num_heads,head_size]
+ """
+ bsz = len(seq_lengths)
+ padded_tensor = torch.zeros(bsz, max_seq_len, num_heads, head_size, dtype=tensor.dtype)
+
+ token_idx = 0
+ for i, seq_len in enumerate(seq_lengths):
+ seq_tensor = tensor[token_idx : token_idx + seq_len]
+ padded_tensor[i, :seq_len, :, :] = seq_tensor
+ token_idx += seq_len
+ return padded_tensor
+
+ @staticmethod
+ def generate_padding_mask(lengths, max_seq_len):
+ range_tensor = torch.arange(max_seq_len).expand(len(lengths), max_seq_len)
+ padding_mask = range_tensor < lengths.unsqueeze(1)
+ return padding_mask
+
+ @staticmethod
+ def repeat_kv(hidden_states: torch.Tensor, n_rep: int = 1) -> torch.Tensor:
+ """
+ Essential component for MQA. Equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep).
+ Args: hidden_states(batch, num_key_value_heads, seqlen, head_dim)
+ n_rep: times of repeatition.
+ Output: hidden_states (batch, num_attention_heads, seqlen, head_dim)
+ """
+ if n_rep == 1:
+ return hidden_states
+
+ batch, num_key_value_heads, seq_len, head_dim = hidden_states.shape
+ num_attention_heads = n_rep * num_key_value_heads
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, seq_len, head_dim)
+
+ return hidden_states.reshape(batch, num_attention_heads, seq_len, head_dim)
+
+ @staticmethod
+ def nopad_context_forward(
+ q: torch.Tensor, # [num_tokens, num_heads, head_size]
+ k: torch.Tensor, # [num_tokens, num_kv_heads, head_size]
+ v: torch.Tensor,
+ k_cache: torch.Tensor, # [num_blocks, num_heads, block_size, head_size]
+ v_cache: torch.Tensor,
+ context_lengths: torch.Tensor, # [num_seqs]
+ block_tables: torch.Tensor, # [num_seqs,max_blocks_per_sequence]
+ ):
+ """
+ NOTE: q,k,v are projected and applied rotary embedding, all aligned with triton version.
+ """
+ # Fisrt, do shape verification
+ num_tokens, num_heads, head_size = q.shape
+ num_kv_heads = k.shape[-2]
+
+ assert num_heads % num_kv_heads == 0, "num_kv_heads should be divisible by num_heads"
+ num_kv_groups = num_heads // num_kv_heads
+
+ block_size = k_cache.size(-2)
+ bsz, max_blocks_per_sequence = block_tables.shape
+ max_seq_len = max_blocks_per_sequence * block_size
+ assert q.shape[-1] == k.shape[-1] == v.shape[-1]
+ assert q.shape[0] == k.shape[0] == v.shape[0]
+ assert context_lengths.shape[0] == block_tables.shape[0]
+ shape = (bsz, max_seq_len, num_heads, head_size)
+ input_shape = shape[:2]
+
+ q = PagedAttention.pad_and_reshape(
+ q, context_lengths, max_seq_len, num_heads, head_size
+ ) # bsz,seqlen,num_heads,head_size
+ k = PagedAttention.pad_and_reshape(k, context_lengths, max_seq_len, num_heads, head_size)
+ v = PagedAttention.pad_and_reshape(v, context_lengths, max_seq_len, num_heads, head_size)
+
+ copy_to_cache(k, k_cache, lengths=context_lengths, block_tables=block_tables)
+ copy_to_cache(v, v_cache, lengths=context_lengths, block_tables=block_tables)
+
+ attn_mask = AttentionMaskConverter._make_causal_mask(input_shape, q.dtype, q.device, past_key_values_length=0)
+ attn_mask = attn_mask + PagedAttention.generate_padding_mask(context_lengths, max_seq_len)
+
+ q = q.transpose(1, 2)
+ k = PagedAttention.repeat_kv(k.transpose(1, 2), num_kv_groups)
+ v = PagedAttention.repeat_kv(v.transpose(1, 2), num_kv_groups)
+
+ # position_ids = torch.arange(0, max_seq_len, dtype=torch.long, device=query.device)
+ # position_ids = position_ids.unsqueeze(0)
+ # cos, sin = self.rotary_emb(value, max_seq_len)
+ # query, key = apply_rotary_pos_emb(query, key, cos, sin, position_ids)
+
+ attn_weights = torch.matmul(q, k.transpose(2, 3)) / math.sqrt(head_size)
+ if attn_weights.size() != (bsz, num_heads, max_seq_len, max_seq_len):
+ raise ValueError(f"Got wrong attn_weights, should be in shape {(bsz,num_heads,max_seq_len,max_seq_len)}.")
+
+ if attn_mask is not None:
+ attn_weights += attn_mask
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(q.dtype)
+ attn_output = torch.matmul(attn_weights, v)
+
+ if attn_output.size() != (bsz, num_heads, max_seq_len, head_size):
+ raise ValueError(f"Got wrong attn_output, should be in shape {(bsz,num_heads,max_seq_len,head_size)}.")
+ attn_output = attn_output.transpose(1, 2).contiguous().reshape(bsz, max_seq_len, -1)
+
+ del attn_weights
+
+ return attn_output
+
+ @staticmethod
+ def pad_context_forward(
+ q: torch.Tensor, # [batch_size, seq_len, num_heads, head_size]
+ k: torch.Tensor, # [batch_size, seq_len, num_kv_heads, head_size]
+ v: torch.Tensor,
+ k_cache: torch.Tensor, # [num_blocks, num_heads, block_size, head_size]
+ v_cache: torch.Tensor,
+ context_lengths: torch.Tensor, # [num_seqs]
+ block_tables: torch.Tensor, # [num_seqs,max_blocks_per_sequence]
+ attn_mask: torch.Tensor = None, # [bsz, input_lengths + output_lengths]
+ ):
+ # Firt, do shape verification
+ bsz, seq_len, num_heads, head_size = q.shape
+ num_kv_heads = k.shape[-2]
+ assert num_heads % num_kv_heads == 0, "num_kv_heads should be divisible by num_heads"
+ num_kv_groups = num_heads // num_kv_heads
+ block_size = k_cache.size(-2)
+ assert q.shape[0] == k.shape[0] == v.shape[0] == block_tables.shape[0]
+ block_tables.shape[-1] * block_size
+
+ # Copy kv to memory(rotary embedded)
+ copy_to_cache(k, k_cache, lengths=context_lengths, block_tables=block_tables)
+ copy_to_cache(v, v_cache, lengths=context_lengths, block_tables=block_tables)
+
+ q = q.transpose(1, 2)
+ k = PagedAttention.repeat_kv(k.transpose(1, 2), num_kv_groups)
+ v = PagedAttention.repeat_kv(v.transpose(1, 2), num_kv_groups)
+
+ attn_weights = torch.matmul(q, k.transpose(2, 3)) / math.sqrt(head_size)
+
+ padding_mask = None
+
+ if attn_mask is not None:
+ padding_mask = AttentionMaskConverter._expand_mask(attn_mask, q.dtype, seq_len)
+
+ attn_mask = AttentionMaskConverter._make_causal_mask(
+ (bsz, seq_len), q.dtype, q.device, past_key_values_length=seq_len - seq_len
+ )
+
+ if padding_mask is not None:
+ attn_mask = attn_mask.masked_fill(padding_mask.bool(), torch.finfo(q.dtype).min)
+
+ if attn_weights.size() != (bsz, num_heads, seq_len, seq_len):
+ raise ValueError(f"Got wrong attn_weights, should be in shape {(bsz,num_heads,seq_len,seq_len)}.")
+ if attn_mask is not None:
+ attn_weights += attn_mask
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(q.dtype)
+ attn_output = torch.matmul(attn_weights, v)
+
+ if attn_output.size() != (bsz, num_heads, seq_len, head_size):
+ raise ValueError(f"Got wrong attn_output, should be in shape {(bsz,num_heads,seq_len,head_size)}.")
+
+ attn_output = attn_output.transpose(1, 2).contiguous().reshape(bsz, seq_len, -1)
+
+ return attn_output
+
+ @staticmethod
+ def pad_decoding_forward(
+ q: torch.Tensor, # [bsz, 1, num_heads, head_size]
+ k: torch.Tensor, # [bsz, 1, num_kv_heads, head_size]
+ v: torch.Tensor,
+ k_cache: torch.Tensor, # [num_blocks, num_heads, block_size, head_size]
+ v_cache: torch.Tensor,
+ lengths: torch.Tensor, # [num_seqs]: input_lengths + output_lengths
+ block_tables: torch.Tensor, # [num_seqs,max_blocks_per_sequence]
+ attn_mask: torch.Tensor = None, # [bsz, input_lengths + output_lengths]
+ ):
+ # Firt, do shape verification.
+ bsz, q_length, num_heads, head_size = q.shape
+
+ num_kv_heads = k.shape[-2]
+ assert num_heads % num_kv_heads == 0, "num_kv_heads should be divisible by num_heads"
+ num_kv_groups = num_heads // num_kv_heads
+ seq_len = max(lengths)
+
+ assert q.shape[0] == k.shape[0] == v.shape[0] == block_tables.shape[0]
+
+ copy_to_cache(k, k_cache, lengths=lengths, block_tables=block_tables, type="decoding")
+ copy_to_cache(v, v_cache, lengths=lengths, block_tables=block_tables, type="decoding")
+
+ k = convert_kvcache(k_cache, lengths, block_tables) # bsz, seqlen,
+ v = convert_kvcache(v_cache, lengths, block_tables)
+
+ q = q.transpose(1, 2)
+ k = PagedAttention.repeat_kv(k.transpose(1, 2), num_kv_groups)
+ v = PagedAttention.repeat_kv(v.transpose(1, 2), num_kv_groups)
+
+ attn_weights = torch.matmul(q, k.transpose(2, 3)) / math.sqrt(head_size)
+ if attn_weights.size() != (bsz, num_heads, 1, seq_len):
+ raise ValueError(f"Got wrong attn_weights, should be in shape {(bsz,num_heads,1,seq_len)}.")
+
+ padding_mask = None
+ if attn_mask is not None:
+ padding_mask = AttentionMaskConverter._expand_mask(attn_mask, q.dtype, q_length)
+
+ attn_mask = AttentionMaskConverter._make_causal_mask(
+ (bsz, q_length), q.dtype, q.device, past_key_values_length=seq_len - q_length
+ )
+
+ if padding_mask is not None:
+ attn_mask = attn_mask.masked_fill(padding_mask.bool(), torch.finfo(q.dtype).min)
+
+ attn_weights += attn_mask
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(q.dtype)
+ attn_output = torch.matmul(attn_weights, v)
+
+ if attn_output.size() != (bsz, num_heads, 1, head_size):
+ raise ValueError(f"Got wrong attn_output, should be in shape {(bsz,num_heads,1,head_size)}.")
+ attn_output = attn_output.transpose(1, 2).contiguous().reshape(bsz, 1, -1)
+
+ return attn_output
+
+ @staticmethod
+ def no_pad_decoding_forward(
+ self,
+ q: torch.Tensor, # [num_tokens, num_heads, head_size]
+ k: torch.Tensor,
+ v: torch.Tensor,
+ k_cache: torch.Tensor, # [num_blocks, num_heads, head_size, block_size]
+ v_cache: torch.Tensor,
+ lengths: torch.Tensor, # [num_seqs]: input_lengths + output_lengths
+ block_tables: torch.Tensor, # [num_seqs,max_blocks_per_sequence]
+ ):
+ return self.pad_decoding_forward(
+ q.unsqueeze(1), k.unsqueeze(1), v.unsqueeze(1), k_cache, v_cache, lengths, block_tables
+ )
diff --git a/colossalai/inference/modeling/layers/baichuan_tp_linear.py b/colossalai/inference/modeling/layers/baichuan_tp_linear.py
new file mode 100644
index 000000000000..e050dd71c8b2
--- /dev/null
+++ b/colossalai/inference/modeling/layers/baichuan_tp_linear.py
@@ -0,0 +1,43 @@
+from typing import List, Union
+
+import torch.nn as nn
+from torch.distributed import ProcessGroup
+
+from colossalai.shardformer.layer import Linear1D_Col
+from colossalai.shardformer.layer.parallel_module import ParallelModule
+
+
+class BaichuanLMHeadLinear1D_Col(Linear1D_Col):
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ module.in_features = module.weight.size(1)
+ module.out_features = module.weight.size(0)
+ module.bias = None
+ module.weight.data = nn.functional.normalize(module.weight)
+
+ return Linear1D_Col.from_native_module(
+ module,
+ process_group,
+ *args,
+ **kwargs,
+ )
+
+
+class BaichuanWpackLinear1D_Col(Linear1D_Col):
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ in_features = module.in_features * 3
+ out_features = module.out_features // 3
+ module.weight.data = module.weight.view(3, out_features, -1).transpose(0, 1).reshape(out_features, in_features)
+ module.bias = None
+
+ return Linear1D_Col.from_native_module(
+ module,
+ process_group,
+ *args,
+ **kwargs,
+ )
diff --git a/colossalai/inference/modeling/models/__init__.py b/colossalai/inference/modeling/models/__init__.py
new file mode 100644
index 000000000000..e69de29bb2d1
diff --git a/colossalai/inference/modeling/models/glide_llama.py b/colossalai/inference/modeling/models/glide_llama.py
new file mode 100644
index 000000000000..7b25f3e7489d
--- /dev/null
+++ b/colossalai/inference/modeling/models/glide_llama.py
@@ -0,0 +1,475 @@
+# This is modified from huggingface transformers
+# https://github.com/huggingface/transformers/blob/v4.36.2/src/transformers/models/llama/modeling_llama.py
+import warnings
+from types import MethodType
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+from transformers.cache_utils import Cache, DynamicCache
+from transformers.modeling_attn_mask_utils import (
+ _prepare_4d_causal_attention_mask,
+ _prepare_4d_causal_attention_mask_for_sdpa,
+)
+from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
+from transformers.models.llama.modeling_llama import (
+ LlamaAttention,
+ LlamaConfig,
+ LlamaDecoderLayer,
+ LlamaDynamicNTKScalingRotaryEmbedding,
+ LlamaForCausalLM,
+ LlamaLinearScalingRotaryEmbedding,
+ LlamaMLP,
+ LlamaModel,
+ LlamaRMSNorm,
+ LlamaRotaryEmbedding,
+)
+
+from colossalai.inference.spec import GlideInput
+from colossalai.kernel.triton import flash_decoding_attention
+from colossalai.logging import get_dist_logger
+
+logger = get_dist_logger(__name__)
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_single_rotary_pos_emb(q, cos, sin, position_ids):
+ # The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
+ cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
+ sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
+ cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ return q_embed
+
+
+def glide_llama_causal_lm_forward(
+ self: LlamaForCausalLM,
+ input_ids: torch.LongTensor = None,
+ glide_input: Optional[GlideInput] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+) -> Union[Tuple, CausalLMOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, LlamaForCausalLM
+
+ >>> model = LlamaForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
+ >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ glide_input=glide_input,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ logits = self.lm_head(hidden_states)
+ logits = logits.float()
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return output
+
+ return CausalLMOutputWithPast(
+ loss=None,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+def glide_llama_model_forward(
+ self: LlamaModel,
+ input_ids: torch.LongTensor = None,
+ glide_input: GlideInput = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape[:2]
+ elif inputs_embeds is not None:
+ batch_size, seq_length = inputs_embeds.shape[:2]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ past_key_values_length = 0
+ if use_cache:
+ use_legacy_cache = not isinstance(past_key_values, Cache)
+ if use_legacy_cache:
+ past_key_values = DynamicCache.from_legacy_cache(past_key_values)
+ past_key_values_length = past_key_values.get_usable_length(seq_length)
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.unsqueeze(0)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if self._use_flash_attention_2:
+ # 2d mask is passed through the layers
+ attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
+ elif self._use_sdpa and not output_attentions:
+ # output_attentions=True can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ )
+ else:
+ # 4d mask is passed through the layers
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
+ )
+
+ # embed positions
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = () if use_cache else None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ # GlideLlamaDecoderLayer
+ layer_outputs = decoder_layer(
+ hidden_states,
+ glide_input=glide_input,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache = layer_outputs[2 if output_attentions else 1]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = None
+ if use_cache:
+ next_cache = next_decoder_cache.to_legacy_cache() if use_legacy_cache else next_decoder_cache
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+class GlideLlamaConfig(LlamaConfig):
+ """Configuration class with specific arguments used by GLIDE llama model as a drafter"""
+
+ def __init__(
+ self,
+ large_hidden_size=4096,
+ large_num_attention_heads=32,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+ self.large_hidden_size = large_hidden_size
+ self.large_num_attention_heads = large_num_attention_heads
+
+
+class LlamaCrossAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: GlideLlamaConfig):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.hidden_size // self.num_heads
+ self.num_key_value_heads = config.num_key_value_heads
+ self.num_key_value_groups = self.num_heads // self.num_key_value_heads
+ self.max_position_embeddings = config.max_position_embeddings
+
+ if (self.head_dim * self.num_heads) != self.hidden_size:
+ raise ValueError(
+ f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
+ f" and `num_heads`: {self.num_heads})."
+ )
+
+ # large model (verifier) configs
+ self.large_hidden_size = config.large_hidden_size
+ self.large_num_heads = config.large_num_attention_heads
+ self.large_head_dim = self.large_hidden_size // self.large_num_heads
+
+ self.q_proj = nn.Linear(self.hidden_size, self.large_num_heads * self.large_head_dim, bias=False)
+ self.o_proj = nn.Linear(self.large_num_heads * self.large_head_dim, self.hidden_size, bias=False)
+ self._init_rope()
+
+ def _init_rope(self):
+ if self.config.rope_scaling is None:
+ self.rotary_emb = LlamaRotaryEmbedding(
+ self.large_head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ )
+ else:
+ scaling_type = self.config.rope_scaling["type"]
+ scaling_factor = self.config.rope_scaling["factor"]
+ if scaling_type == "linear":
+ self.rotary_emb = LlamaLinearScalingRotaryEmbedding(
+ self.large_head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ scaling_factor=scaling_factor,
+ )
+ elif scaling_type == "dynamic":
+ self.rotary_emb = LlamaDynamicNTKScalingRotaryEmbedding(
+ self.large_head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ scaling_factor=scaling_factor,
+ )
+ else:
+ raise ValueError(f"Unknown RoPE scaling type {scaling_type}")
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ glide_input: GlideInput = None, # Used for glimpsing main model's KV caches
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Optional[torch.Tensor]:
+ bsz, q_len, _ = hidden_states.size()
+
+ block_tables = glide_input.block_tables
+ large_k_cache = glide_input.large_k_cache
+ large_v_cache = glide_input.large_v_cache
+ sequence_lengths = glide_input.sequence_lengths
+ cache_block_size = large_k_cache.size(-2)
+
+ query_states = self.q_proj(hidden_states)
+ kv_seq_len = sequence_lengths.max().item()
+
+ query_states = query_states.view(bsz, -1, self.large_num_heads, self.large_head_dim).transpose(1, 2)
+
+ # for RoPE
+ cos, sin = self.rotary_emb(query_states, seq_len=kv_seq_len + 32)
+ query_states = apply_single_rotary_pos_emb(query_states, cos, sin, position_ids)
+ query_states = query_states.transpose(1, 2)
+ query_states = query_states.reshape(-1, self.large_num_heads, self.large_head_dim)
+
+ attn_output = flash_decoding_attention(
+ q=query_states,
+ k_cache=large_k_cache,
+ v_cache=large_v_cache,
+ kv_seq_len=sequence_lengths,
+ block_tables=block_tables,
+ block_size=cache_block_size,
+ max_seq_len_in_batch=kv_seq_len,
+ ) # attn_output: [bsz * q_len, num_heads * head_dim]
+
+ attn_output = attn_output.reshape(bsz, q_len, self.large_hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output
+
+
+# A class to be used to replace LlamaDecoderLayer in a Llama Model as Drafter in speculative decoding.
+# Refer to GLIDE with a CAPE https://arxiv.org/pdf/2402.02082.pdf
+class GlideLlamaDecoderLayer(nn.Module):
+ def __init__(self, config: GlideLlamaConfig, layer_idx: Optional[int] = None):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+ self.self_attn = LlamaAttention(config=config, layer_idx=layer_idx)
+ self.cross_attn = LlamaCrossAttention(config=config)
+ self.mlp = LlamaMLP(config)
+ self.input_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ @staticmethod
+ def from_native_module(module: LlamaDecoderLayer, *args, **kwargs) -> "GlideLlamaDecoderLayer":
+ """Build a GlideLlamaDecoderLayer from a native LlamaDecoderLayer"""
+ config: LlamaConfig = module.mlp.config # XXX
+ layer_idx = module.self_attn.layer_idx
+ glide_config = GlideLlamaConfig(**config.to_dict())
+ glide_decoder_layer = GlideLlamaDecoderLayer(glide_config, layer_idx=layer_idx)
+
+ return glide_decoder_layer
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ glide_input: GlideInput = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ **kwargs,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*):
+ attention mask of size `(batch_size, sequence_length)` if flash attention is used or `(batch_size, 1,
+ query_sequence_length, key_sequence_length)` if default attention is used.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
+ )
+
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ **kwargs,
+ )
+ hidden_states = residual + hidden_states
+
+ curr_q_len = hidden_states.size(1)
+ # Cross attention
+ if glide_input is None or not glide_input.glimpse_ready:
+ warnings.warn(
+ "Data used for glimpsing the past KV caches of the main model (verifier) is not complete. "
+ "Fall back to normal decoder layer modeling (drafter). "
+ "This might lead to incorrect results when using the Glide Models for speculative decoding."
+ )
+ elif curr_q_len == 1:
+ # Notice that we skip prefill stage
+ # always use the output of the main model as the inputs for the next round of speculation
+ residual = hidden_states
+
+ hidden_states = self.cross_attn(
+ hidden_states=hidden_states,
+ glide_input=glide_input,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ use_cache=True,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+
+class GlideLlamaForCausalLM(LlamaForCausalLM):
+ def __init__(self, config: GlideLlamaConfig):
+ super().__init__(config)
+ self.config = config
+ bound_method = MethodType(glide_llama_causal_lm_forward, self)
+ setattr(self, "forward", bound_method)
+ bound_method = MethodType(glide_llama_model_forward, self.model)
+ model = getattr(self, "model")
+ setattr(model, "forward", bound_method)
+ replaced_layers = nn.ModuleList(
+ [GlideLlamaDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
+ )
+ setattr(model, "layers", replaced_layers)
diff --git a/colossalai/inference/modeling/models/nopadding_baichuan.py b/colossalai/inference/modeling/models/nopadding_baichuan.py
new file mode 100644
index 000000000000..e6b39ccfa20d
--- /dev/null
+++ b/colossalai/inference/modeling/models/nopadding_baichuan.py
@@ -0,0 +1,420 @@
+# This code is adapted from huggingface baichuan model: hhttps://huggingface.co/baichuan-inc/Baichuan2-13B-Base/blob/main/modeling_baichuan.py
+import itertools
+import math
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+from torch.distributed import ProcessGroup
+
+from colossalai.inference.flash_decoding_utils import FDIntermTensors
+from colossalai.inference.modeling.models.nopadding_llama import NopadLlamaMLP
+from colossalai.kernel.kernel_loader import InferenceOpsLoader
+from colossalai.kernel.triton import (
+ context_attention_unpadded,
+ copy_k_to_blocked_cache,
+ decoding_fused_rotary_embedding,
+ flash_decoding_attention,
+ rms_layernorm,
+ rotary_embedding,
+)
+from colossalai.logging import get_dist_logger
+from colossalai.shardformer.layer.parallel_module import ParallelModule
+from colossalai.tensor.d_tensor import Layout, distribute_tensor, is_distributed_tensor
+
+logger = get_dist_logger(__name__)
+
+try:
+ from flash_attn import flash_attn_varlen_func
+
+ use_flash_attn2 = True
+except ImportError:
+ use_flash_attn2 = False
+ logger.warning(f"flash_attn2 has not been installed yet, we will use triton flash attn instead.")
+
+logger = get_dist_logger(__name__)
+
+try:
+ from flash_attn import flash_attn_varlen_func
+
+ use_flash_attn2 = True
+except ImportError:
+ use_flash_attn2 = False
+ logger.warning(f"flash_attn2 has not been installed yet, we will use triton flash attn instead.")
+
+inference_ops = InferenceOpsLoader().load()
+
+logger = get_dist_logger(__name__)
+
+
+# alibi slopes calculation adapted from https://github.com/huggingface/transformers/blob/v4.36.0/src/transformers/models/bloom/modeling_bloom.py#L57
+def get_alibi_slopes(num_heads: int, device: torch.device) -> torch.Tensor:
+ closest_power_of_2 = 2 ** math.floor(math.log2(num_heads))
+ base = torch.tensor(2 ** (-(2 ** -(math.log2(closest_power_of_2) - 3))), dtype=torch.float32, device=device)
+ powers = torch.arange(1, 1 + closest_power_of_2, dtype=torch.int32, device=device)
+ slopes = torch.pow(base, powers)
+ if closest_power_of_2 != num_heads:
+ extra_base = torch.tensor(
+ 2 ** (-(2 ** -(math.log2(2 * closest_power_of_2) - 3))), dtype=torch.float32, device=device
+ )
+ num_remaining_heads = min(closest_power_of_2, num_heads - closest_power_of_2)
+ extra_powers = torch.arange(1, 1 + 2 * num_remaining_heads, 2, dtype=torch.int32, device=device)
+ slopes = torch.cat([slopes, torch.pow(extra_base, extra_powers)], dim=0)
+ return slopes
+
+
+def baichuan_rmsnorm_forward(
+ self,
+ hidden_states: torch.Tensor,
+ norm_output: torch.Tensor,
+ residual: torch.Tensor = None,
+ use_cuda_kernel: bool = True,
+):
+ # Used to address the issue of inconsistent epsilon variable names in baichuan2 7b and 13b.
+ if hasattr(self, "variance_epsilon"):
+ eps = self.variance_epsilon
+ elif hasattr(self, "epsilon"):
+ eps = self.epsilon
+ else:
+ TypeError(
+ "Currently, the variable name for the epsilon of baichuan7B/13B should be 'variance_epsilon' or 'epsilon'."
+ )
+ if use_cuda_kernel:
+ if residual is not None:
+ inference_ops.fused_add_rms_layernorm(hidden_states, residual, self.weight.data, eps)
+ return hidden_states, residual
+
+ if norm_output is None:
+ norm_output = torch.empty_like(hidden_states)
+ inference_ops.rms_layernorm(norm_output, hidden_states, self.weight.data, eps)
+ return norm_output, hidden_states
+ else:
+ return rms_layernorm(hidden_states, self.weight.data, eps, norm_output, residual)
+
+
+class NopadBaichuanAttention(ParallelModule):
+ def __init__(
+ self,
+ config,
+ attn_qproj_w: torch.Tensor = None,
+ attn_kproj_w: torch.Tensor = None,
+ attn_vproj_w: torch.Tensor = None,
+ attn_oproj: ParallelModule = None,
+ num_heads: int = None,
+ hidden_size: int = None,
+ process_group: ProcessGroup = None,
+ helper_layout: Layout = None,
+ ):
+ """This layer will replace the BaichuanAttention.
+
+ Args:
+ config (BaichuanConfig): Holding the Baichuan model config.
+ attn_qproj_w (torch.Tensor, optional): The transposed q_proj weight. Defaults to None.
+ attn_kproj_w (torch.Tensor, optional): The transposed k_proj weight. Defaults to None.
+ attn_vproj_w (torch.Tensor, optional): The transposed v_proj weight. Defaults to None.
+ attn_oproj (Linear1D_Row, optional): The Linear1D_Row o_proj weight. Defaults to None.
+ """
+ ParallelModule.__init__(self)
+ self.o_proj = attn_oproj
+
+ self.config = config
+ self.num_heads = num_heads
+ self.hidden_size = hidden_size
+ self.head_dim = self.hidden_size // self.num_heads
+ self.process_group = process_group
+ qkv_weight_list = [attn_qproj_w.transpose(0, 1), attn_kproj_w.transpose(0, 1), attn_vproj_w.transpose(0, 1)]
+ self.qkv_weight = nn.Parameter(torch.stack(qkv_weight_list, dim=0))
+
+ self.helper_layout = helper_layout
+
+ self.alibi_slopes = None
+ self.use_alibi_attn = False
+ # Used for Baichuan13B
+ if config.hidden_size == 5120:
+ slopes_start = self.process_group.rank() * num_heads
+ self.use_alibi_attn = True
+ self.alibi_slopes = get_alibi_slopes(config.num_attention_heads, device=attn_qproj_w.device)[
+ slopes_start : slopes_start + num_heads
+ ].contiguous()
+ self.alibi_slopes = nn.Parameter(self.alibi_slopes)
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> "NopadBaichuanAttention":
+ """Used for initialize the weight of NopadBaichuanAttention by origin BaichuanAttention.
+
+ Args:
+ module (nn.Module): The origin BaichuanAttention layer.
+ """
+
+ config = module.config
+ q_proj_w, k_proj_w, v_proj_w = module.W_pack.weight.view((module.hidden_size, 3, -1)).transpose(0, 1)
+
+ attn_qproj_w = q_proj_w
+ attn_kproj_w = k_proj_w
+ attn_vproj_w = v_proj_w
+ attn_oproj = module.o_proj
+
+ helper_layout = (
+ module.W_pack.weight.dist_layout
+ ) # NOTE this is a hack for the right load/shard of qkv_weight(used in _load_from_state_dict)
+
+ attn_layer = NopadBaichuanAttention(
+ config=config,
+ attn_qproj_w=attn_qproj_w,
+ attn_kproj_w=attn_kproj_w,
+ attn_vproj_w=attn_vproj_w,
+ attn_oproj=attn_oproj,
+ num_heads=module.num_heads,
+ hidden_size=module.hidden_size,
+ process_group=process_group,
+ helper_layout=helper_layout,
+ )
+
+ return attn_layer
+
+ def _load_from_state_dict(
+ self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
+ ):
+ for hook in self._load_state_dict_pre_hooks.values():
+ hook(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs)
+
+ persistent_buffers = {k: v for k, v in self._buffers.items() if k not in self._non_persistent_buffers_set}
+ local_name_params = itertools.chain(self._parameters.items(), persistent_buffers.items())
+ local_state = {k: v for k, v in local_name_params if v is not None}
+
+ key = "qkv_weight"
+ qkv_w = state_dict[prefix + "W_pack.weight"]
+
+ in_features = qkv_w.size(1)
+ out_features = qkv_w.size(0) // 3
+
+ qkv_w.data = qkv_w.view((3, out_features, -1)).transpose(0, 1).reshape(out_features, in_features * 3)
+
+ device_mesh = self.helper_layout.device_mesh
+ sharding_spec = self.helper_layout.sharding_spec
+ qkv_w = distribute_tensor(qkv_w, device_mesh, sharding_spec)
+
+ qkv_w = qkv_w.transpose(0, 1).reshape(3, in_features, -1)
+ input_param = nn.Parameter(
+ qkv_w
+ ) # NOTE qkv_weight doesn't have to be a distensor, Like input_param = sharded_tensor_to_param(input_param)
+
+ param = local_state[key]
+
+ try:
+ with torch.no_grad():
+ param.copy_(input_param)
+ except Exception as ex:
+ error_msgs.append(
+ 'While copying the parameter named "{}", '
+ "whose dimensions in the model are {} and "
+ "whose dimensions in the checkpoint are {}, "
+ "an exception occurred : {}.".format(key, param.size(), input_param.size(), ex.args)
+ )
+
+ strict = False # to avoid unexpected_keys
+ super()._load_from_state_dict(
+ state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ block_tables: torch.Tensor,
+ k_cache: torch.Tensor,
+ v_cache: torch.Tensor,
+ sequence_lengths: torch.Tensor,
+ cos_sin: Tuple[torch.Tensor],
+ fd_inter_tensor: FDIntermTensors,
+ is_prompts: bool = True,
+ is_verifier: bool = False,
+ tokens_to_verify: int = None,
+ kv_seq_len: int = 0,
+ output_tensor: torch.Tensor = None,
+ sm_scale: int = None,
+ use_cuda_kernel: bool = True,
+ cu_seqlens: torch.Tensor = None,
+ high_precision: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """
+ Args:
+ hidden_states (torch.Tensor): input to the layer of shape [token_num, embed_dim].
+ block_tables (torch.Tensor): A 2D tensor of shape [batch_size, max_blocks_per_sequence],
+ storing mapping of token_position_id -> block_id.
+ k_cache (torch.Tensor): It holds the GPU memory for the key cache.
+ v_cache (torch.Tensor): It holds the GPU memory for the key cache.
+ sequence_lengths (torch.Tensor, optional): Holding the sequence length of each sequence.
+ cos_sin (Tuple[torch.Tensor], optional): Holding cos and sin.
+ fd_inter_tensor (FDIntermTensors, optional): Holding tensors used for
+ storing intermediate values in flash-decoding.
+ is_prompts (bool, optional): Whether the current inference process is in the context input phase. Defaults to True.
+ kv_seq_len (int, optional): The max sequence length of input sequences. Defaults to 0.
+ output_tensor (torch.Tensor, optional): The mid tensor holds the output of attention. Defaults to None.
+ sm_scale (int, optional): Used for flash attention. Defaults to None.
+ use_cuda_kernel: (bool, optional): Whether to use cuda kernel. Defaults to True.
+ cu_seqlens(torch.Tensor, optional): Holding the cumulative sum of sequence length.
+ high_precision(Optional[bool]): Whether to use float32 for underlying calculations of float16 data to achieve higher precision, defaults to False.
+ """
+
+ token_nums = hidden_states.size(0)
+ # fused qkv
+ hidden_states = hidden_states.expand(3, -1, -1)
+ query_states, key_states, value_states = (
+ torch.bmm(hidden_states, self.qkv_weight).view(3, token_nums, self.num_heads, self.head_dim).unbind(0)
+ )
+
+ block_size = k_cache.size(-2)
+
+ if is_prompts:
+ if not is_verifier and use_cuda_kernel and query_states.dtype != torch.float32 and use_flash_attn2:
+ # flash attn 2 currently only supports FP16/BF16.
+ if not self.use_alibi_attn:
+ inference_ops.rotary_embedding(query_states, key_states, cos_sin[0], cos_sin[1], high_precision)
+ inference_ops.context_kv_cache_memcpy(
+ key_states, value_states, k_cache, v_cache, sequence_lengths, cu_seqlens, block_tables, kv_seq_len
+ )
+ attn_output = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens,
+ cu_seqlens_k=cu_seqlens,
+ max_seqlen_q=kv_seq_len,
+ max_seqlen_k=kv_seq_len,
+ dropout_p=0.0,
+ softmax_scale=sm_scale,
+ causal=True,
+ alibi_slopes=self.alibi_slopes,
+ )
+ attn_output = attn_output.view(token_nums, -1)
+ else:
+ if not self.use_alibi_attn:
+ rotary_embedding(query_states, key_states, cos_sin[0], cos_sin[1])
+ attn_output = context_attention_unpadded(
+ q=query_states,
+ k=key_states,
+ v=value_states,
+ k_cache=k_cache,
+ v_cache=v_cache,
+ context_lengths=sequence_lengths,
+ block_tables=block_tables,
+ block_size=block_size,
+ output=output_tensor,
+ alibi_slopes=self.alibi_slopes,
+ max_seq_len=kv_seq_len,
+ sm_scale=sm_scale,
+ use_new_kcache_layout=use_cuda_kernel,
+ )
+ else:
+ q_len = tokens_to_verify + 1 if is_verifier else 1
+
+ if use_cuda_kernel:
+ if not self.use_alibi_attn:
+ inference_ops.rotary_embedding_and_cache_copy(
+ query_states,
+ key_states,
+ value_states,
+ cos_sin[0],
+ cos_sin[1],
+ k_cache,
+ v_cache,
+ sequence_lengths,
+ block_tables,
+ high_precision,
+ )
+ else:
+ inference_ops.decode_kv_cache_memcpy(
+ key_states, value_states, k_cache, v_cache, sequence_lengths, block_tables
+ )
+ inference_ops.flash_decoding_attention(
+ output_tensor,
+ query_states,
+ k_cache,
+ v_cache,
+ sequence_lengths,
+ block_tables,
+ block_size,
+ kv_seq_len,
+ fd_inter_tensor.mid_output,
+ fd_inter_tensor.mid_output_lse,
+ self.alibi_slopes,
+ sm_scale,
+ )
+ attn_output = output_tensor
+ else:
+ if not is_verifier and not self.use_alibi_attn:
+ decoding_fused_rotary_embedding(
+ query_states,
+ key_states,
+ value_states,
+ cos_sin[0],
+ cos_sin[1],
+ k_cache,
+ v_cache,
+ block_tables,
+ sequence_lengths,
+ )
+ else:
+ if not self.use_alibi_attn:
+ rotary_embedding(query_states, key_states, cos_sin[0], cos_sin[1])
+ copy_k_to_blocked_cache(
+ key_states, k_cache, kv_lengths=sequence_lengths, block_tables=block_tables, n=q_len
+ )
+ copy_k_to_blocked_cache(
+ value_states, v_cache, kv_lengths=sequence_lengths, block_tables=block_tables, n=q_len
+ )
+
+ attn_output = flash_decoding_attention(
+ q=query_states,
+ k_cache=k_cache,
+ v_cache=v_cache,
+ kv_seq_len=sequence_lengths,
+ block_tables=block_tables,
+ block_size=block_size,
+ max_seq_len_in_batch=kv_seq_len,
+ output=output_tensor,
+ mid_output=fd_inter_tensor.mid_output,
+ mid_output_lse=fd_inter_tensor.mid_output_lse,
+ alibi_slopes=self.alibi_slopes,
+ sm_scale=sm_scale,
+ q_len=q_len,
+ )
+
+ attn_output = attn_output.view(-1, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output
+
+ def extra_repr(self) -> str:
+ return f"qkv_weight_proj MergedLinear1D_Col: in_features={self.qkv_weight.shape[1]}x3, out_features={self.qkv_weight.shape[2]}, bias=False"
+
+
+# NOTE This will cause difference as out length increases.
+class NopadBaichuanMLP(NopadLlamaMLP):
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ """Used for initialize the weight of NopadBaichuanMLP by origin MLP(Baichuan).
+
+ Args:
+ module (nn.Module): The origin MLP(Baichuan) layer.
+ """
+ mlp_gproj_w = module.gate_proj.weight
+ assert is_distributed_tensor(
+ module.gate_proj.weight
+ ), "gate_proj.weight must be dtensor so we could get the layout of the weight"
+ mlp_uproj_w = module.up_proj.weight
+ mlp_dproj = module.down_proj
+
+ mlp_layer = NopadBaichuanMLP(
+ config=None,
+ mlp_gproj_w=mlp_gproj_w,
+ mlp_uproj_w=mlp_uproj_w,
+ mlp_dproj=mlp_dproj,
+ process_group=process_group,
+ )
+
+ return mlp_layer
diff --git a/colossalai/inference/modeling/models/nopadding_llama.py b/colossalai/inference/modeling/models/nopadding_llama.py
new file mode 100644
index 000000000000..5b8b43d4e651
--- /dev/null
+++ b/colossalai/inference/modeling/models/nopadding_llama.py
@@ -0,0 +1,695 @@
+# This code is adapted from huggingface transformers: https://github.com/huggingface/transformers/blob/v4.34.1/src/transformers/models/llama/modeling_llama.py
+import itertools
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+from torch import nn
+from torch.distributed import ProcessGroup
+from transformers.models.llama.modeling_llama import (
+ LlamaAttention,
+ LlamaConfig,
+ LlamaDecoderLayer,
+ LlamaForCausalLM,
+ LlamaMLP,
+ LlamaModel,
+ LlamaRMSNorm,
+)
+
+from colossalai.inference.config import InputMetaData
+from colossalai.inference.flash_decoding_utils import FDIntermTensors
+from colossalai.kernel.kernel_loader import InferenceOpsLoader
+from colossalai.kernel.triton import (
+ context_attention_unpadded,
+ copy_k_to_blocked_cache,
+ decoding_fused_rotary_embedding,
+ flash_decoding_attention,
+ get_xine_cache,
+ rms_layernorm,
+ rotary_embedding,
+)
+from colossalai.logging import get_dist_logger
+from colossalai.shardformer.layer.parallel_module import ParallelModule
+from colossalai.tensor.d_tensor import distribute_tensor, is_distributed_tensor
+
+inference_ops = InferenceOpsLoader().load()
+
+logger = get_dist_logger(__name__)
+
+try:
+ from flash_attn import flash_attn_varlen_func
+
+ use_flash_attn2 = True
+except ImportError:
+ use_flash_attn2 = False
+ logger.warning(f"flash_attn2 has not been installed yet, we will use triton flash attn instead.")
+
+
+def llama_causal_lm_forward(
+ self: LlamaForCausalLM,
+ input_tokens_ids: torch.Tensor,
+ output_tensor: torch.Tensor,
+ inputmetadata: InputMetaData,
+ k_caches: List[torch.Tensor] = None,
+ v_caches: List[torch.Tensor] = None,
+) -> torch.Tensor:
+ """This function will replace the forward function of LlamaForCausalLM.
+
+ Args:
+ batch (BatchInfo): It stores the necessary input information for this inference.
+ k_caches (List[torch.Tensor]): It holds the GPU memory for the key cache.
+ v_caches (List[torch.Tensor]): It holds the GPU memory for the value cache.
+ high_precision(Optional[bool]): Whether to use float32 for underlying calculations of float16 data to achieve higher precision, defaults to False.
+ """
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ hidden_states = llama_model_forward(
+ self.model,
+ input_tokens_ids=input_tokens_ids,
+ output_tensor=output_tensor,
+ inputmetadata=inputmetadata,
+ k_caches=k_caches,
+ v_caches=v_caches,
+ use_cuda_kernel=inputmetadata.use_cuda_kernel, # Note currently the cuda kernel of layernorm, rotary_embedding_and_cache_copy couldn't pass the unitest but triton kernel could
+ high_precision=inputmetadata.high_precision,
+ )
+
+ logits = self.lm_head(hidden_states)
+ return logits
+
+
+def llama_model_forward(
+ self: LlamaModel,
+ input_tokens_ids: torch.Tensor,
+ output_tensor: torch.Tensor,
+ inputmetadata: InputMetaData,
+ k_caches: List[torch.Tensor] = None,
+ v_caches: List[torch.Tensor] = None,
+ use_cuda_kernel: Optional[bool] = True,
+ high_precision: bool = False,
+) -> torch.Tensor:
+ """This function will replace the forward function of LlamaModel.
+
+ Args:
+ batch (BatchInfo, optional): It stores the necessary input information for this inference.. Defaults to None.
+ k_caches (List[torch.Tensor], optional): It holds the GPU memory for the key cache. Defaults to None.
+ v_caches (List[torch.Tensor], optional): It holds the GPU memory for the value cache. Defaults to None.
+ high_precision(Optional[bool]): Whether to use float32 for underlying calculations of float16 data to achieve higher precision, defaults to False.
+ """
+ block_tables = inputmetadata.block_tables
+ sequence_lengths = inputmetadata.sequence_lengths
+ kv_seq_len = inputmetadata.kv_seq_len
+
+ # NOTE (yuanheng-zhao): fow now, only triton kernels support verification process
+ # during speculative-decoding (`q_len > 1`)
+ # We will expicitly disable `use_cuda_kernel` here when speculative-decoding is enabled
+ if inputmetadata.use_spec_dec and use_cuda_kernel:
+ use_cuda_kernel = False
+ logger.warning("CUDA kernel is disabled for speculative-decoding.")
+
+ hidden_states = self.embed_tokens(input_tokens_ids)
+
+ cu_seqlens = None
+
+ # NOTE (yuanheng-zhao): we do not use cuda kernels for speculative-decoding for now
+ if inputmetadata.use_spec_dec:
+ # For speculative-decoding Prefill and Verifying Stage
+ if inputmetadata.is_prompts:
+ # output tensor shape is the same as normal Prefill Stage
+ rotary_indexes = [torch.arange(0, length) for length in sequence_lengths]
+ else:
+ # the number of tokens to be verified in parallel plus the correct token in the last step
+ n_tokens = inputmetadata.num_tokens_to_verify + 1
+ assert n_tokens == hidden_states.size(0)
+ rotary_indexes = [(length - n_tokens + i).view(-1) for i in range(n_tokens) for length in sequence_lengths]
+ rotary_indexes = torch.cat(rotary_indexes, dim=-1)
+ cos_sin = (self._cos_cached[rotary_indexes], self._sin_cached[rotary_indexes])
+
+ elif use_cuda_kernel:
+ if inputmetadata.dtype != torch.float32 and use_flash_attn2:
+ cu_seqlens = F.pad(torch.cumsum(sequence_lengths, dim=0, dtype=torch.torch.int32), (1, 0))
+
+ hidden_dim = self._cos_cached.size(-1)
+ total_length = hidden_states.size(0)
+ cos = torch.empty((total_length, hidden_dim), dtype=self._cos_cached.dtype, device=self._cos_cached.device)
+ sin = torch.empty((total_length, hidden_dim), dtype=self._sin_cached.dtype, device=self._sin_cached.device)
+ inference_ops.get_cos_and_sin(
+ self._cos_cached, self._sin_cached, cos, sin, sequence_lengths, kv_seq_len, inputmetadata.is_prompts
+ )
+ cos_sin = (cos, sin)
+ else:
+ cos_sin = get_xine_cache(sequence_lengths, self._cos_cached, self._sin_cached, inputmetadata.is_prompts)
+
+ sm_scale = 1.0 / (inputmetadata.head_dim**0.5)
+
+ norm_output = torch.empty_like(hidden_states)
+ tokens_to_verify = inputmetadata.num_tokens_to_verify if inputmetadata.use_spec_dec else None
+ residual = None
+
+ for layer_id, decoder_layer in enumerate(self.layers):
+ hidden_states, residual = decoder_layer(
+ hidden_states,
+ residual=residual,
+ block_tables=block_tables,
+ k_cache=k_caches[layer_id],
+ v_cache=v_caches[layer_id],
+ is_prompts=inputmetadata.is_prompts,
+ is_verifier=inputmetadata.use_spec_dec,
+ tokens_to_verify=tokens_to_verify,
+ sequence_lengths=sequence_lengths,
+ cos_sin=cos_sin,
+ fd_inter_tensor=inputmetadata.fd_inter_tensor,
+ kv_seq_len=kv_seq_len,
+ output_tensor=output_tensor,
+ norm_output=norm_output,
+ sm_scale=sm_scale,
+ use_cuda_kernel=use_cuda_kernel,
+ cu_seqlens=cu_seqlens,
+ high_precision=high_precision,
+ )
+
+ if inputmetadata.is_prompts:
+ seq_len_cumsum = sequence_lengths.cumsum(dim=0)
+ hidden_states = hidden_states[seq_len_cumsum - 1].contiguous()
+ residual = residual[seq_len_cumsum - 1].contiguous()
+ norm_output = torch.empty_like(hidden_states)
+ hidden_states, _ = self.norm(hidden_states, norm_output, residual, use_cuda_kernel)
+
+ return hidden_states
+
+
+def llama_decoder_layer_forward(
+ self: LlamaDecoderLayer,
+ hidden_states: torch.Tensor,
+ residual: torch.Tensor,
+ block_tables: torch.Tensor,
+ k_cache: torch.Tensor,
+ v_cache: torch.Tensor,
+ sequence_lengths: torch.Tensor,
+ cos_sin: Tuple[torch.Tensor],
+ fd_inter_tensor: FDIntermTensors,
+ is_prompts: bool = True,
+ is_verifier: bool = False,
+ tokens_to_verify: int = None,
+ kv_seq_len: int = 0,
+ output_tensor: torch.Tensor = None,
+ norm_output: torch.Tensor = None,
+ sm_scale: int = None,
+ use_cuda_kernel: bool = True,
+ cu_seqlens: torch.Tensor = None,
+ high_precision: bool = False,
+) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """This function will replace the forward function of LlamaDecoderLayer.
+
+ Args:
+ hidden_states (torch.Tensor): input to the layer of shape [token_num, embed_dim].
+ residual (torch.Tensor): shape [token_num, embed_dim], used to be added to hidden_states in out_proj.
+ block_tables (torch.Tensor): A 2D tensor of shape [batch_size, max_blocks_per_sequence],
+ storing mapping of token_position_id -> block_id.
+ k_cache (torch.Tensor): It holds the GPU memory for the key cache.
+ v_cache (torch.Tensor): It holds the GPU memory for the key cache.
+ sequence_lengths (torch.Tensor): Holding the sequence length of each sequence.
+ cos_sin (Tuple[torch.Tensor]): Holding cos and sin.
+ fd_inter_tensor (FDIntermTensors): Holding tensors used for
+ storing intermediate values in flash-decoding.
+ is_prompts (bool, optional): Whether the current inference process is in the context input phase. Defaults to True.
+ kv_seq_len (int, optional): The max sequence length of input sequences. Defaults to 0.
+ output_tensor (torch.Tensor, optional): The mid tensor holds the output of attention. Defaults to None.
+ norm_output (torch.Tensor, optional): The mid tensor holds the output of layernorm. Defaults to None.
+ sm_scale (int, optional): Used for flash attention. Defaults to None.
+ use_cuda_kernel: (bool, optional): Whether to use cuda kernel. Defaults to True.
+ cu_seqlens(torch.Tensor, optional): Holding the cumulative sum of sequence length.
+ high_precision(Optional[bool]): Whether to use float32 for underlying calculations of float16 data to achieve higher precision, defaults to False.
+ """
+
+ hidden_states, residual = self.input_layernorm(hidden_states, norm_output, residual, use_cuda_kernel)
+ # Self Attention
+ hidden_states = self.self_attn(
+ hidden_states=hidden_states,
+ block_tables=block_tables,
+ k_cache=k_cache,
+ v_cache=v_cache,
+ is_prompts=is_prompts,
+ is_verifier=is_verifier,
+ tokens_to_verify=tokens_to_verify,
+ sequence_lengths=sequence_lengths,
+ cos_sin=cos_sin,
+ fd_inter_tensor=fd_inter_tensor,
+ kv_seq_len=kv_seq_len,
+ output_tensor=output_tensor,
+ sm_scale=sm_scale,
+ use_cuda_kernel=use_cuda_kernel,
+ cu_seqlens=cu_seqlens,
+ high_precision=high_precision,
+ )
+
+ # Fully Connected
+ hidden_states, residual = self.post_attention_layernorm(hidden_states, norm_output, residual, use_cuda_kernel)
+ hidden_states = self.mlp(hidden_states)
+
+ return hidden_states, residual
+
+
+def llama_rmsnorm_forward(
+ self: LlamaRMSNorm,
+ hidden_states: torch.Tensor,
+ norm_output: torch.Tensor,
+ residual: torch.Tensor = None,
+ use_cuda_kernel: bool = True,
+):
+ if use_cuda_kernel:
+ if residual is not None:
+ inference_ops.fused_add_rms_layernorm(hidden_states, residual, self.weight.data, self.variance_epsilon)
+ return hidden_states, residual
+
+ if norm_output is None:
+ norm_output = torch.empty_like(hidden_states)
+ inference_ops.rms_layernorm(norm_output, hidden_states, self.weight.data, self.variance_epsilon)
+ return norm_output, hidden_states
+ else:
+ return rms_layernorm(hidden_states, self.weight.data, self.variance_epsilon, norm_output, residual)
+
+
+class NopadLlamaMLP(LlamaMLP, ParallelModule):
+ def __init__(
+ self,
+ config: LlamaConfig,
+ mlp_gproj_w: torch.Tensor = None,
+ mlp_uproj_w: torch.Tensor = None,
+ mlp_dproj: ParallelModule = None,
+ process_group: ProcessGroup = None,
+ ):
+ """A Unified Layer for
+
+ Args:
+ config (LlamaConfig): Holding the Llama model config.
+ mlp_gproj_w (torch.Tensor, optional): The transposed gate_proj weight. Defaults to None.
+ mlp_uproj_w (torch.Tensor, optional): The transposed up_proj weight. Defaults to None.
+ mlp_dproj (Linear1D_Row, optional): The Linear1D_Row mlp_dproj weight. Defaults to None.
+ """
+ ParallelModule.__init__(self)
+ self.config = config
+ assert is_distributed_tensor(
+ mlp_gproj_w
+ ), "mlp_gproj_w must be dtensor so we could get the layout of the weight"
+ self.helper_layout = (
+ mlp_gproj_w.dist_layout
+ ) # NOTE this is a hack for the right load/shard of gate_up_weight(used in _load_from_state_dict)
+ self.gate_up_weight = nn.Parameter(
+ torch.stack([mlp_gproj_w.transpose(0, 1), mlp_uproj_w.transpose(0, 1)], dim=0)
+ )
+ self.down_proj = mlp_dproj
+ self.process_group = process_group
+
+ @staticmethod
+ def from_native_module(
+ module: LlamaMLP, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ """Used for initialize the weight of NopadLlamaMLP by origin LlamaMLP.
+
+ Args:
+ module (LlamaMLP): The origin LlamaMLP layer.
+ """
+
+ config = module.config
+
+ mlp_gproj_w = module.gate_proj.weight
+ assert is_distributed_tensor(
+ module.gate_proj.weight
+ ), "gate_proj.weight must be dtensor so we could get the layout of the weight"
+ mlp_uproj_w = module.up_proj.weight
+ mlp_dproj = module.down_proj
+
+ mlp_layer = NopadLlamaMLP(
+ config=config,
+ mlp_gproj_w=mlp_gproj_w,
+ mlp_uproj_w=mlp_uproj_w,
+ mlp_dproj=mlp_dproj,
+ process_group=process_group,
+ )
+
+ return mlp_layer
+
+ def _load_from_state_dict(
+ self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
+ ):
+ # NOTE This is a hack to ensure we could load the right weight from LlamaMLP checkpoint due to the use of torch.stack(gate_weight, up_weight)
+
+ for hook in self._load_state_dict_pre_hooks.values():
+ hook(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs)
+
+ persistent_buffers = {k: v for k, v in self._buffers.items() if k not in self._non_persistent_buffers_set}
+ local_name_params = itertools.chain(self._parameters.items(), persistent_buffers.items())
+ local_state = {k: v for k, v in local_name_params if v is not None}
+
+ key = "gate_up_weight"
+ k1 = "gate_proj.weight"
+ k2 = "up_proj.weight"
+
+ gate_w = state_dict[prefix + k1]
+ up_w = state_dict[prefix + k2]
+
+ device_mesh = self.helper_layout.device_mesh
+ sharding_spec = self.helper_layout.sharding_spec
+ gate_w = distribute_tensor(gate_w, device_mesh, sharding_spec)
+ up_w = distribute_tensor(up_w, device_mesh, sharding_spec)
+
+ gate_up_w = torch.stack([gate_w.T, up_w.T], dim=0)
+
+ input_param = nn.Parameter(
+ gate_up_w
+ ) # NOTE gate_up_weight doesn't have to be a distensor, Like input_param = sharded_tensor_to_param(input_param)
+ param = local_state[key]
+
+ try:
+ with torch.no_grad():
+ param.copy_(input_param)
+ except Exception as ex:
+ error_msgs.append(
+ 'While copying the parameter named "{}", '
+ "whose dimensions in the model are {} and "
+ "whose dimensions in the checkpoint are {}, "
+ "an exception occurred : {}.".format(key, param.size(), input_param.size(), ex.args)
+ )
+
+ strict = False # to avoid unexpected_keys
+ super()._load_from_state_dict(
+ state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
+ )
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ """
+ Args:
+ hidden_states (torch.Tensor): input to the layer of shape [token_num, embed_dim].
+ """
+ hidden_states = hidden_states.expand(2, -1, -1)
+ gate_up_proj_out = torch.bmm(hidden_states, self.gate_up_weight)
+ act_out = inference_ops.silu_and_mul(gate_up_proj_out)
+
+ return self.down_proj(act_out)
+
+ def extra_repr(self) -> str:
+ return f"gate_up_proj MergedLinear1D_Col: in_features={self.gate_up_weight.shape[1]}x2, out_features={self.gate_up_weight.shape[2]}, bias=False"
+
+
+class NopadLlamaAttention(LlamaAttention, ParallelModule):
+ def __init__(
+ self,
+ config: LlamaConfig,
+ layer_idx: Optional[int] = None,
+ attn_qproj_w: torch.Tensor = None,
+ attn_kproj_w: torch.Tensor = None,
+ attn_vproj_w: torch.Tensor = None,
+ attn_oproj: ParallelModule = None,
+ process_group: ProcessGroup = None,
+ num_heads: int = None,
+ hidden_size: int = None,
+ num_key_value_heads: int = None,
+ ):
+ """This layer will replace the LlamaAttention.
+
+ Args:
+ config (LlamaConfig): Holding the Llama model config.
+ layer_idx (Optional[int], optional): The decode layer id of this attention layer. Defaults to None.
+ attn_qproj_w (torch.Tensor, optional): The transposed q_proj weight. Defaults to None.
+ attn_kproj_w (torch.Tensor, optional): The transposed k_proj weight. Defaults to None.
+ attn_vproj_w (torch.Tensor, optional): The transposed v_proj weight. Defaults to None.
+ attn_oproj (Linear1D_Row, optional): The Linear1D_Row o_proj weight. Defaults to None.
+ """
+ ParallelModule.__init__(self)
+ self.config = config
+ self.layer_idx = layer_idx
+
+ self.o_proj = attn_oproj
+ self.process_group = process_group
+
+ self.attention_dropout = config.attention_dropout
+ self.hidden_size = hidden_size
+ self.num_heads = num_heads
+ self.head_dim = self.hidden_size // self.num_heads
+ self.num_key_value_heads = num_key_value_heads
+ self.num_key_value_groups = self.num_heads // self.num_key_value_heads
+ self.max_position_embeddings = config.max_position_embeddings
+ self.rope_theta = config.rope_theta
+ self.is_causal = True
+
+ if self.num_heads == self.num_key_value_heads:
+ qkv_weight_list = [attn_qproj_w.transpose(0, 1), attn_kproj_w.transpose(0, 1), attn_vproj_w.transpose(0, 1)]
+ self.qkv_weight = nn.Parameter(torch.stack(qkv_weight_list, dim=0))
+ self.helper_layout = (
+ attn_qproj_w.dist_layout
+ ) # NOTE this is a hack for the right load/shard of qkv_weight(used in _load_from_state_dict)
+ else:
+ self.q_proj_weight = nn.Parameter(attn_qproj_w.transpose(0, 1).contiguous())
+ self.k_proj_weight = nn.Parameter(attn_kproj_w.transpose(0, 1).contiguous())
+ self.v_proj_weight = nn.Parameter(attn_vproj_w.transpose(0, 1).contiguous())
+
+ @staticmethod
+ def from_native_module(
+ module: LlamaAttention, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ """Used for initialize the weight of NopadLlamaAttention by origin LlamaAttention.
+
+ Args:
+ module (LlamaAttention): The origin LlamaAttention layer.
+ """
+
+ config = module.config
+ layer_idx = module.layer_idx
+
+ attn_qproj_w = module.q_proj.weight
+ attn_kproj_w = module.k_proj.weight
+ attn_vproj_w = module.v_proj.weight
+ assert is_distributed_tensor(attn_qproj_w), "attn_qproj_w must be dist tensor"
+ attn_oproj = module.o_proj
+
+ attn_layer = NopadLlamaAttention(
+ config=config,
+ layer_idx=layer_idx,
+ attn_qproj_w=attn_qproj_w,
+ attn_kproj_w=attn_kproj_w,
+ attn_vproj_w=attn_vproj_w,
+ attn_oproj=attn_oproj,
+ process_group=process_group,
+ num_heads=module.num_heads,
+ hidden_size=module.hidden_size,
+ num_key_value_heads=module.num_key_value_heads,
+ )
+
+ return attn_layer
+
+ # Replace transformers.models.llama.modeling_llama.LlamaAttention.forward
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ block_tables: torch.Tensor,
+ k_cache: torch.Tensor,
+ v_cache: torch.Tensor,
+ sequence_lengths: torch.Tensor,
+ cos_sin: Tuple[torch.Tensor],
+ fd_inter_tensor: FDIntermTensors,
+ is_prompts: bool = True,
+ is_verifier: bool = False,
+ tokens_to_verify: int = None,
+ kv_seq_len: int = 0,
+ output_tensor: torch.Tensor = None,
+ sm_scale: int = None,
+ use_cuda_kernel: bool = True,
+ cu_seqlens: torch.Tensor = None,
+ high_precision: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """
+ Args:
+ hidden_states (torch.Tensor): input to the layer of shape [token_num, embed_dim].
+ block_tables (torch.Tensor): A 2D tensor of shape [batch_size, max_blocks_per_sequence],
+ storing mapping of token_position_id -> block_id.
+ k_cache (torch.Tensor): It holds the GPU memory for the key cache.
+ v_cache (torch.Tensor): It holds the GPU memory for the key cache.
+ sequence_lengths (torch.Tensor, optional): Holding the sequence length of each sequence.
+ cos_sin (Tuple[torch.Tensor], optional): Holding cos and sin.
+ fd_inter_tensor (FDIntermTensors, optional): Holding tensors used for
+ storing intermediate values in flash-decoding.
+ is_prompts (bool, optional): Whether the current inference process is in the context input phase. Defaults to True.
+ kv_seq_len (int, optional): The max sequence length of input sequences. Defaults to 0.
+ output_tensor (torch.Tensor, optional): The mid tensor holds the output of attention. Defaults to None.
+ sm_scale (int, optional): Used for flash attention. Defaults to None.
+ use_cuda_kernel: (bool, optional): Whether to use cuda kernel. Defaults to True.
+ cu_seqlens(torch.Tensor, optional): Holding the cumulative sum of sequence length.
+ high_precision(Optional[bool]): Whether to use float32 for underlying calculations of float16 data to achieve higher precision, defaults to False.
+ """
+
+ token_nums = hidden_states.size(0)
+
+ if self.num_heads != self.num_key_value_heads:
+ query_states = torch.mm(hidden_states, self.q_proj_weight).view(-1, self.num_heads, self.head_dim)
+ key_states = torch.mm(hidden_states, self.k_proj_weight).view(-1, self.num_key_value_heads, self.head_dim)
+ value_states = torch.mm(hidden_states, self.v_proj_weight).view(-1, self.num_key_value_heads, self.head_dim)
+ else:
+ # fused qkv
+ hidden_states = hidden_states.expand(3, -1, -1)
+ query_states, key_states, value_states = (
+ torch.bmm(hidden_states, self.qkv_weight).view(3, token_nums, self.num_heads, self.head_dim).unbind(0)
+ )
+
+ block_size = k_cache.size(-2)
+
+ if is_prompts:
+ if not is_verifier and use_cuda_kernel and query_states.dtype != torch.float32 and use_flash_attn2:
+ # flash attn 2 currently only supports FP16/BF16.
+ inference_ops.rotary_embedding(query_states, key_states, cos_sin[0], cos_sin[1], high_precision)
+ inference_ops.context_kv_cache_memcpy(
+ key_states, value_states, k_cache, v_cache, sequence_lengths, cu_seqlens, block_tables, kv_seq_len
+ )
+
+ attn_output = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens,
+ cu_seqlens_k=cu_seqlens,
+ max_seqlen_q=kv_seq_len,
+ max_seqlen_k=kv_seq_len,
+ dropout_p=0.0,
+ softmax_scale=sm_scale,
+ causal=True,
+ )
+ attn_output = attn_output.view(token_nums, -1)
+ else:
+ rotary_embedding(query_states, key_states, cos_sin[0], cos_sin[1])
+ attn_output = context_attention_unpadded(
+ q=query_states,
+ k=key_states,
+ v=value_states,
+ k_cache=k_cache,
+ v_cache=v_cache,
+ context_lengths=sequence_lengths,
+ block_tables=block_tables,
+ block_size=block_size,
+ output=output_tensor,
+ max_seq_len=kv_seq_len,
+ sm_scale=sm_scale,
+ use_new_kcache_layout=use_cuda_kernel,
+ )
+ else:
+ q_len = tokens_to_verify + 1 if is_verifier else 1
+
+ if use_cuda_kernel:
+ inference_ops.rotary_embedding_and_cache_copy(
+ query_states,
+ key_states,
+ value_states,
+ cos_sin[0],
+ cos_sin[1],
+ k_cache,
+ v_cache,
+ sequence_lengths,
+ block_tables,
+ high_precision,
+ )
+ inference_ops.flash_decoding_attention(
+ output_tensor,
+ query_states,
+ k_cache,
+ v_cache,
+ sequence_lengths,
+ block_tables,
+ block_size,
+ kv_seq_len,
+ fd_inter_tensor.mid_output,
+ fd_inter_tensor.mid_output_lse,
+ None,
+ sm_scale,
+ )
+ attn_output = output_tensor
+ else:
+ if is_verifier:
+ rotary_embedding(query_states, key_states, cos_sin[0], cos_sin[1])
+ copy_k_to_blocked_cache(
+ key_states, k_cache, kv_lengths=sequence_lengths, block_tables=block_tables, n=q_len
+ )
+ copy_k_to_blocked_cache(
+ value_states, v_cache, kv_lengths=sequence_lengths, block_tables=block_tables, n=q_len
+ )
+ else:
+ decoding_fused_rotary_embedding(
+ query_states,
+ key_states,
+ value_states,
+ cos_sin[0],
+ cos_sin[1],
+ k_cache,
+ v_cache,
+ block_tables,
+ sequence_lengths,
+ )
+ attn_output = flash_decoding_attention(
+ q=query_states,
+ k_cache=k_cache,
+ v_cache=v_cache,
+ kv_seq_len=sequence_lengths,
+ block_tables=block_tables,
+ block_size=block_size,
+ max_seq_len_in_batch=kv_seq_len,
+ output=output_tensor,
+ mid_output=fd_inter_tensor.mid_output,
+ mid_output_lse=fd_inter_tensor.mid_output_lse,
+ sm_scale=sm_scale,
+ kv_group_num=self.num_key_value_groups,
+ q_len=q_len,
+ )
+
+ attn_output = attn_output.view(-1, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+ return attn_output
+
+ def _load_from_state_dict(
+ self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
+ ):
+ # NOTE This is a hack to ensure we could load the right weight from LlamaAttention checkpoint due to the use of torch.stack(q_weight, k_weight, v_weight)
+ for hook in self._load_state_dict_pre_hooks.values():
+ hook(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs)
+
+ persistent_buffers = {k: v for k, v in self._buffers.items() if k not in self._non_persistent_buffers_set}
+ local_name_params = itertools.chain(self._parameters.items(), persistent_buffers.items())
+ local_state = {k: v for k, v in local_name_params if v is not None}
+
+ key = "qkv_weight"
+ k1 = "q_proj.weight"
+ k2 = "k_proj.weight"
+ k3 = "v_proj.weight"
+ q_w = state_dict[prefix + k1]
+ k_w = state_dict[prefix + k2]
+ v_w = state_dict[prefix + k3]
+
+ device_mesh = self.helper_layout.device_mesh
+ sharding_spec = self.helper_layout.sharding_spec
+ q_w = distribute_tensor(q_w, device_mesh, sharding_spec)
+ k_w = distribute_tensor(k_w, device_mesh, sharding_spec)
+ v_w = distribute_tensor(v_w, device_mesh, sharding_spec)
+
+ qkv_w = torch.stack([q_w.T, k_w.T, v_w.T], dim=0)
+
+ input_param = nn.Parameter(
+ qkv_w
+ ) # NOTE qkv_weight doesn't have to be a distensor, Like input_param = sharded_tensor_to_param(input_param)
+
+ param = local_state[key]
+
+ try:
+ with torch.no_grad():
+ param.copy_(input_param)
+ except Exception as ex:
+ error_msgs.append(
+ 'While copying the parameter named "{}", '
+ "whose dimensions in the model are {} and "
+ "whose dimensions in the checkpoint are {}, "
+ "an exception occurred : {}.".format(key, param.size(), input_param.size(), ex.args)
+ )
+
+ strict = False # to avoid unexpected_keys
+ super()._load_from_state_dict(
+ state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
+ )
+
+ def extra_repr(self) -> str:
+ return f"qkv_weight_proj MergedLinear1D_Col: in_features={self.qkv_weight.shape[1]}x3, out_features={self.qkv_weight.shape[2]}, bias=False"
diff --git a/colossalai/inference/modeling/policy/__init__.py b/colossalai/inference/modeling/policy/__init__.py
new file mode 100644
index 000000000000..fa03955907fe
--- /dev/null
+++ b/colossalai/inference/modeling/policy/__init__.py
@@ -0,0 +1,16 @@
+from .glide_llama import GlideLlamaModelPolicy
+from .nopadding_baichuan import NoPaddingBaichuanModelInferPolicy
+from .nopadding_llama import NoPaddingLlamaModelInferPolicy
+
+model_policy_map = {
+ "nopadding_llama": NoPaddingLlamaModelInferPolicy,
+ "nopadding_baichuan": NoPaddingBaichuanModelInferPolicy,
+ "glide_llama": GlideLlamaModelPolicy,
+}
+
+__all__ = [
+ "NoPaddingLlamaModelInferPolicy",
+ "NoPaddingBaichuanModelInferPolicy",
+ "GlideLlamaModelPolicy",
+ "model_polic_map",
+]
diff --git a/colossalai/inference/modeling/policy/glide_llama.py b/colossalai/inference/modeling/policy/glide_llama.py
new file mode 100644
index 000000000000..817b3324ed7d
--- /dev/null
+++ b/colossalai/inference/modeling/policy/glide_llama.py
@@ -0,0 +1,45 @@
+from transformers.models.llama.modeling_llama import LlamaForCausalLM, LlamaModel
+
+from colossalai.inference.modeling.models.glide_llama import (
+ GlideLlamaDecoderLayer,
+ glide_llama_causal_lm_forward,
+ glide_llama_model_forward,
+)
+from colossalai.inference.utils import init_to_get_rotary
+from colossalai.shardformer.policies.base_policy import SubModuleReplacementDescription
+from colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy
+
+
+class GlideLlamaModelPolicy(LlamaForCausalLMPolicy):
+ def module_policy(self):
+ policy = super().module_policy()
+
+ num_layers = self.model.config.num_hidden_layers
+ self.append_or_create_submodule_replacement(
+ description=[
+ SubModuleReplacementDescription(
+ suffix=f"layers[{i}]",
+ target_module=GlideLlamaDecoderLayer,
+ )
+ for i in range(num_layers)
+ ],
+ policy=policy,
+ target_key=LlamaModel,
+ )
+ self.append_or_create_method_replacement(
+ description={"forward": glide_llama_model_forward},
+ policy=policy,
+ target_key=LlamaModel,
+ )
+ self.append_or_create_method_replacement(
+ description={"forward": glide_llama_causal_lm_forward},
+ policy=policy,
+ target_key=LlamaForCausalLM,
+ )
+
+ return policy
+
+ def postprocess(self):
+ for layer in self.model.model.layers:
+ init_to_get_rotary(layer.cross_attn)
+ return self.model
diff --git a/colossalai/inference/modeling/policy/nopadding_baichuan.py b/colossalai/inference/modeling/policy/nopadding_baichuan.py
new file mode 100644
index 000000000000..78268d6e7e85
--- /dev/null
+++ b/colossalai/inference/modeling/policy/nopadding_baichuan.py
@@ -0,0 +1,110 @@
+from colossalai.inference.config import RPC_PARAM
+from colossalai.inference.modeling.layers.baichuan_tp_linear import (
+ BaichuanLMHeadLinear1D_Col,
+ BaichuanWpackLinear1D_Col,
+)
+from colossalai.inference.modeling.models.nopadding_baichuan import (
+ NopadBaichuanAttention,
+ NopadBaichuanMLP,
+ baichuan_rmsnorm_forward,
+)
+from colossalai.inference.modeling.models.nopadding_llama import (
+ llama_causal_lm_forward,
+ llama_decoder_layer_forward,
+ llama_model_forward,
+)
+from colossalai.inference.utils import init_to_get_rotary
+from colossalai.shardformer.layer import Linear1D_Col, Linear1D_Row
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
+from colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy
+
+
+class NoPaddingBaichuanModelInferPolicy(LlamaForCausalLMPolicy, RPC_PARAM):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ policy = super().module_policy()
+
+ if self.shard_config.enable_tensor_parallelism:
+ decoder_attribute_replacement = {
+ "self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
+ "self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ }
+ if getattr(self.model.config, "num_key_value_heads", False):
+ decoder_attribute_replacement["self_attn.num_key_value_heads"] = (
+ self.model.config.num_key_value_heads // self.shard_config.tensor_parallel_size
+ )
+ else:
+ decoder_attribute_replacement = None
+
+ # used for Baichuan 7B and 13B for baichuan DecoderLayer
+ for DecoderLayer in ["DecoderLayer", "BaichuanLayer"]:
+ policy[DecoderLayer] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="mlp.gate_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.up_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.down_proj",
+ target_module=Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp",
+ target_module=NopadBaichuanMLP,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.W_pack",
+ target_module=BaichuanWpackLinear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn",
+ target_module=NopadBaichuanAttention,
+ ),
+ ],
+ )
+
+ self.append_or_create_method_replacement(
+ description={"forward": llama_decoder_layer_forward}, policy=policy, target_key=DecoderLayer
+ )
+
+ policy["BaichuanForCausalLM"] = ModulePolicyDescription(
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="lm_head", target_module=BaichuanLMHeadLinear1D_Col, kwargs={"gather_output": True}
+ )
+ ],
+ )
+
+ self.append_or_create_method_replacement(
+ description={"forward": llama_causal_lm_forward}, policy=policy, target_key="BaichuanForCausalLM"
+ )
+ self.append_or_create_method_replacement(
+ description={"forward": llama_model_forward}, policy=policy, target_key="BaichuanModel"
+ )
+ self.append_or_create_method_replacement(
+ description={"forward": baichuan_rmsnorm_forward}, policy=policy, target_key="RMSNorm"
+ )
+
+ return policy
+
+ def postprocess(self):
+ init_to_get_rotary(self.model.model)
+ return self.model
+
+ def to_rpc_param(self) -> str:
+ return __class__.__name__
+
+ @staticmethod
+ def from_rpc_param() -> "NoPaddingBaichuanModelInferPolicy":
+ return NoPaddingBaichuanModelInferPolicy()
diff --git a/colossalai/inference/modeling/policy/nopadding_llama.py b/colossalai/inference/modeling/policy/nopadding_llama.py
new file mode 100644
index 000000000000..24cf7c740b10
--- /dev/null
+++ b/colossalai/inference/modeling/policy/nopadding_llama.py
@@ -0,0 +1,112 @@
+from transformers.models.llama.modeling_llama import LlamaDecoderLayer, LlamaForCausalLM, LlamaModel, LlamaRMSNorm
+
+from colossalai.inference.config import RPC_PARAM
+from colossalai.inference.modeling.models.nopadding_llama import (
+ NopadLlamaAttention,
+ NopadLlamaMLP,
+ llama_causal_lm_forward,
+ llama_decoder_layer_forward,
+ llama_model_forward,
+ llama_rmsnorm_forward,
+)
+from colossalai.inference.utils import init_to_get_rotary
+from colossalai.shardformer.layer import Linear1D_Col, Linear1D_Row
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
+from colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy
+
+
+class NoPaddingLlamaModelInferPolicy(LlamaForCausalLMPolicy, RPC_PARAM):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ policy = super().module_policy()
+
+ if self.shard_config.enable_tensor_parallelism:
+ decoder_attribute_replacement = {
+ "self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
+ "self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ }
+ if getattr(self.model.config, "num_key_value_heads", False):
+ decoder_attribute_replacement["self_attn.num_key_value_heads"] = (
+ self.model.config.num_key_value_heads // self.shard_config.tensor_parallel_size
+ )
+ else:
+ decoder_attribute_replacement = None
+
+ policy[LlamaDecoderLayer] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="mlp.gate_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.up_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.down_proj",
+ target_module=Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp",
+ target_module=NopadLlamaMLP,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn",
+ target_module=NopadLlamaAttention,
+ ),
+ ],
+ )
+
+ policy[LlamaForCausalLM] = ModulePolicyDescription(
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="lm_head", target_module=Linear1D_Col, kwargs={"gather_output": True}
+ )
+ ],
+ )
+
+ # self.shard_config._infer()
+ self.append_or_create_method_replacement(
+ description={"forward": llama_causal_lm_forward}, policy=policy, target_key=LlamaForCausalLM
+ )
+ self.append_or_create_method_replacement(
+ description={"forward": llama_model_forward}, policy=policy, target_key=LlamaModel
+ )
+ self.append_or_create_method_replacement(
+ description={"forward": llama_decoder_layer_forward}, policy=policy, target_key=LlamaDecoderLayer
+ )
+ self.append_or_create_method_replacement(
+ description={"forward": llama_rmsnorm_forward}, policy=policy, target_key=LlamaRMSNorm
+ )
+
+ return policy
+
+ def postprocess(self):
+ init_to_get_rotary(self.model.model, self.model.config.rope_theta)
+ return self.model
+
+ def to_rpc_param(self) -> str:
+ return __class__.__name__
+
+ @staticmethod
+ def from_rpc_param() -> "NoPaddingLlamaModelInferPolicy":
+ return NoPaddingLlamaModelInferPolicy()
diff --git a/colossalai/inference/quant/__init__.py b/colossalai/inference/quant/__init__.py
deleted file mode 100644
index 18e0de9cc9fc..000000000000
--- a/colossalai/inference/quant/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-from .smoothquant.models.llama import SmoothLlamaForCausalLM
diff --git a/colossalai/inference/quant/gptq/__init__.py b/colossalai/inference/quant/gptq/__init__.py
deleted file mode 100644
index 4cf1fd658a41..000000000000
--- a/colossalai/inference/quant/gptq/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-from .cai_gptq import HAS_AUTO_GPTQ
-
-if HAS_AUTO_GPTQ:
- from .cai_gptq import CaiGPTQLinearOp, CaiQuantLinear
- from .gptq_manager import GPTQManager
diff --git a/colossalai/inference/quant/gptq/cai_gptq/__init__.py b/colossalai/inference/quant/gptq/cai_gptq/__init__.py
deleted file mode 100644
index 4ed76293bd81..000000000000
--- a/colossalai/inference/quant/gptq/cai_gptq/__init__.py
+++ /dev/null
@@ -1,14 +0,0 @@
-import warnings
-
-HAS_AUTO_GPTQ = False
-try:
- import auto_gptq
-
- HAS_AUTO_GPTQ = True
-except ImportError:
- warnings.warn("please install auto-gptq from https://github.com/PanQiWei/AutoGPTQ")
- HAS_AUTO_GPTQ = False
-
-if HAS_AUTO_GPTQ:
- from .cai_quant_linear import CaiQuantLinear, ColCaiQuantLinear, RowCaiQuantLinear
- from .gptq_op import CaiGPTQLinearOp
diff --git a/colossalai/inference/quant/gptq/cai_gptq/cai_quant_linear.py b/colossalai/inference/quant/gptq/cai_gptq/cai_quant_linear.py
deleted file mode 100644
index 36339ac88486..000000000000
--- a/colossalai/inference/quant/gptq/cai_gptq/cai_quant_linear.py
+++ /dev/null
@@ -1,354 +0,0 @@
-# Adapted from AutoGPTQ auto_gptq: https://github.com/PanQiWei/AutoGPTQ
-
-import math
-import warnings
-from typing import List, Union
-
-import numpy as np
-import torch
-import torch.distributed as dist
-import torch.nn as nn
-from torch.distributed import ProcessGroup
-
-from colossalai.lazy import LazyInitContext
-from colossalai.shardformer.layer import ParallelModule
-
-from .gptq_op import CaiGPTQLinearOp
-
-HAS_GPTQ_CUDA = False
-try:
- from colossalai.kernel.op_builder.gptq import GPTQBuilder
-
- gptq_cuda = GPTQBuilder().load()
- HAS_GPTQ_CUDA = True
-except ImportError:
- warnings.warn("CUDA gptq is not installed")
- HAS_GPTQ_CUDA = False
-
-
-class CaiQuantLinear(nn.Module):
- def __init__(self, bits, groupsize, infeatures, outfeatures, bias, tp_size=1, tp_rank=0, row_split=False):
- super().__init__()
- if bits not in [2, 4, 8]:
- raise NotImplementedError("Only 2,4,8 bits are supported.")
- self.infeatures = infeatures
- self.outfeatures = outfeatures
- self.bits = bits
- self.maxq = 2**self.bits - 1
- self.groupsize = groupsize if groupsize != -1 else infeatures
-
- self.register_buffer("qweight", torch.zeros((infeatures // 32 * self.bits, outfeatures), dtype=torch.int32))
- self.register_buffer(
- "qzeros",
- torch.zeros((math.ceil(infeatures / self.groupsize), outfeatures // 32 * self.bits), dtype=torch.int32),
- )
- self.register_buffer(
- "scales", torch.zeros((math.ceil(infeatures / self.groupsize), outfeatures), dtype=torch.float16)
- )
- if row_split:
- self.register_buffer(
- "g_idx",
- torch.tensor(
- [(i + (tp_rank * self.infeatures)) // self.groupsize for i in range(infeatures)], dtype=torch.int32
- ),
- )
- else:
- self.register_buffer(
- "g_idx", torch.tensor([i // self.groupsize for i in range(infeatures)], dtype=torch.int32)
- )
-
- if bias:
- self.register_buffer("bias", torch.zeros((outfeatures), dtype=torch.float16))
- else:
- self.bias = None
-
- self.gptq_linear = CaiGPTQLinearOp(groupsize, bits)
-
- self.q4 = None
- self.empty_tensor = torch.empty((1, 1), device="meta")
- self.tp_size = tp_size
- self.tp_rank = tp_rank
- self.row_split = row_split
-
- def pack(self, linear, scales, zeros, g_idx=None):
- g_idx = (
- g_idx.clone()
- if g_idx is not None
- else torch.tensor([i // self.groupsize for i in range(self.infeatures)], dtype=torch.int32)
- )
-
- scales = scales.t().contiguous()
- zeros = zeros.t().contiguous()
- scale_zeros = zeros * scales
- half_scales = scales.clone().half()
- # print("scale shape ", scales.shape, scale_zeros.shape, linear.weight.shape)
- self.scales = scales.clone().half()
- if linear.bias is not None:
- self.bias = linear.bias.clone().half()
-
- pbits = 32
- ptype = torch.int32
- unsign_type = np.uint32
- sign_type = np.int32
-
- intweight = []
- for idx in range(self.infeatures):
- intweight.append(
- torch.round((linear.weight.data[:, idx] + scale_zeros[g_idx[idx]]) / half_scales[g_idx[idx]]).to(ptype)[
- :, None
- ]
- )
- intweight = torch.cat(intweight, dim=1)
- intweight = intweight.t().contiguous()
- intweight = intweight.numpy().astype(unsign_type)
- qweight = np.zeros((intweight.shape[0] // pbits * self.bits, intweight.shape[1]), dtype=unsign_type)
-
- i = 0
- row = 0
-
- while row < qweight.shape[0]:
- if self.bits in [2, 4, 8]:
- for j in range(i, i + (pbits // self.bits)):
- qweight[row] |= intweight[j] << (self.bits * (j - i))
- i += pbits // self.bits
- row += 1
- else:
- raise NotImplementedError("Only 2,4,8 bits are supported.")
- qweight = qweight.astype(sign_type)
- qweight1 = torch.from_numpy(qweight)
- qweight1 = qweight1.contiguous() # .to("cuda")
- self.qweight.data.copy_(qweight1)
-
- qzeros = np.zeros((zeros.shape[0], zeros.shape[1] // pbits * self.bits), dtype=unsign_type)
- zeros -= 1
- zeros = zeros.numpy().astype(unsign_type)
- i = 0
- col = 0
- while col < qzeros.shape[1]:
- if self.bits in [2, 4, 8]:
- for j in range(i, i + (pbits // self.bits)):
- qzeros[:, col] |= zeros[:, j] << (self.bits * (j - i))
- i += pbits // self.bits
- col += 1
- else:
- raise NotImplementedError("Only 2,4,8 bits are supported.")
- qzeros = qzeros.astype(sign_type)
- qzeros = torch.from_numpy(qzeros)
- qzeros = qzeros
- self.qzeros.data.copy_(qzeros)
-
- if torch.equal(self.g_idx.to(g_idx.device), g_idx):
- self.g_idx = None
- else:
- self.g_idx = g_idx
-
- def init_q4(self):
- assert self.qweight.device.type == "cuda"
- self.q4_width = self.qweight.shape[1]
- if self.g_idx is not None:
- if self.row_split and torch.equal(
- self.g_idx,
- torch.tensor(
- [(i + (self.tp_rank * self.infeatures)) // self.groupsize for i in range(self.infeatures)],
- dtype=torch.int32,
- device=self.g_idx.device,
- ),
- ):
- self.g_idx = None
- elif torch.equal(
- self.g_idx,
- torch.tensor(
- [i // self.groupsize for i in range(self.infeatures)], dtype=torch.int32, device=self.g_idx.device
- ),
- ):
- self.g_idx = None
-
- if self.g_idx is not None:
- g_idx = self.g_idx.to("cpu")
- else:
- g_idx = self.empty_tensor
-
- self.q4 = gptq_cuda.make_q4(self.qweight, self.qzeros, self.scales, g_idx, torch.cuda.current_device())
- torch.cuda.synchronize()
-
- def forward(self, x):
- outshape = x.shape[:-1] + (self.outfeatures,)
-
- if HAS_GPTQ_CUDA and self.bits == 4:
- if self.q4 is None:
- self.init_q4()
-
- x = x.view(-1, x.shape[-1])
- output = torch.empty((x.shape[0], self.outfeatures), dtype=torch.float16, device=x.device)
- gptq_cuda.q4_matmul(x.half(), self.q4, output)
- if self.bias is not None and (not self.row_split or self.tp_size == 1):
- output.add_(self.bias)
- else:
- if self.bias is not None and (not self.row_split or self.tp_size == 1):
- bias = self.bias
- else:
- bias = None
- output = self.gptq_linear(
- x,
- self.qweight,
- self.scales,
- self.qzeros,
- g_idx=self.g_idx,
- bias=bias,
- )
- return output.view(outshape)
-
-
-def split_column_copy(gptq_linear, cai_linear, tp_size=1, tp_rank=0, split_num=1):
- qweights = gptq_linear.qweight.split(gptq_linear.out_features // split_num, dim=-1)
- qzeros = gptq_linear.qzeros.split(gptq_linear.out_features // (32 // cai_linear.bits) // split_num, dim=-1)
- scales = gptq_linear.scales.split(gptq_linear.out_features // split_num, dim=-1)
- g_idx = gptq_linear.g_idx
- if gptq_linear.bias is not None:
- bias = gptq_linear.bias.split(gptq_linear.out_features // split_num, dim=-1)
-
- cai_split_out_features = cai_linear.outfeatures // split_num
- zero_split_block = cai_linear.outfeatures // (32 // cai_linear.bits) // split_num
-
- for i in range(split_num):
- cai_linear.qweight[:, i * cai_split_out_features : (i + 1) * cai_split_out_features] = qweights[i][
- :, tp_rank * cai_split_out_features : (tp_rank + 1) * cai_split_out_features
- ]
- cai_linear.qzeros[:, i * zero_split_block : (i + 1) * zero_split_block] = qzeros[i][
- :, tp_rank * zero_split_block : (tp_rank + 1) * zero_split_block
- ]
- cai_linear.scales[:, i * cai_split_out_features : (i + 1) * cai_split_out_features] = scales[i][
- :, tp_rank * cai_split_out_features : (tp_rank + 1) * cai_split_out_features
- ]
- if cai_linear.bias is not None:
- cai_linear.bias[i * cai_split_out_features : (i + 1) * cai_split_out_features] = bias[i][
- tp_rank * cai_split_out_features : (tp_rank + 1) * cai_split_out_features
- ]
-
- cai_linear.g_idx.copy_(g_idx)
-
-
-def split_row_copy(gptq_linear, cai_linear, tp_rank=0, split_num=1):
- qweights = gptq_linear.qweight.split(gptq_linear.in_features // split_num, dim=0)
- qzeros = gptq_linear.qzeros.split(gptq_linear.in_features // split_num, dim=0)
- scales = gptq_linear.scales.split(gptq_linear.in_features // split_num, dim=0)
- g_idxs = gptq_linear.g_idx.split(gptq_linear.in_features // split_num, dim=0)
-
- cai_split_in_features = cai_linear.infeatures // (32 // cai_linear.bits) // split_num
- zero_split_block = cai_linear.infeatures // cai_linear.groupsize // split_num
- idx_split_features = cai_linear.infeatures // split_num
-
- for i in range(split_num):
- cai_linear.qweight[i * cai_split_in_features : (i + 1) * cai_split_in_features, :] = qweights[i][
- tp_rank * cai_split_in_features : (tp_rank + 1) * cai_split_in_features, :
- ]
- cai_linear.qzeros[i * zero_split_block : (i + 1) * zero_split_block, :] = qzeros[i][
- tp_rank * zero_split_block : (tp_rank + 1) * zero_split_block, :
- ]
- cai_linear.scales[i * zero_split_block : (i + 1) * zero_split_block, :] = scales[i][
- tp_rank * zero_split_block : (tp_rank + 1) * zero_split_block, :
- ]
- cai_linear.g_idx[i * idx_split_features : (i + 1) * idx_split_features] = g_idxs[i][
- tp_rank * idx_split_features : (tp_rank + 1) * idx_split_features
- ]
- if cai_linear.bias is not None:
- cai_linear.bias.copy_(gptq_linear.bias)
-
-
-class RowCaiQuantLinear(CaiQuantLinear, ParallelModule):
- def __init__(self, bits, groupsize, infeatures, outfeatures, bias, tp_size=1, tp_rank=0, row_split=False):
- super().__init__(
- bits, groupsize, infeatures, outfeatures, bias, tp_size=tp_size, tp_rank=tp_rank, row_split=row_split
- )
- self.process_group = None
-
- @staticmethod
- def from_native_module(
- module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
- ) -> ParallelModule:
- LazyInitContext.materialize(module)
- # get the attributes
- in_features = module.in_features
-
- # ensure only one process group is passed
- if isinstance(process_group, (list, tuple)):
- assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
- process_group = process_group[0]
-
- tp_size = dist.get_world_size(process_group)
- tp_rank = dist.get_rank(process_group)
-
- if in_features < tp_size:
- return module
-
- if in_features % tp_size != 0:
- raise ValueError(
- f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
- )
- linear_1d = RowCaiQuantLinear(
- module.bits,
- module.group_size,
- module.in_features // tp_size,
- module.out_features,
- module.bias is not None,
- tp_size=tp_size,
- tp_rank=tp_rank,
- row_split=True,
- )
- linear_1d.process_group = process_group
-
- split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
- return linear_1d
-
- def forward(self, x):
- output = super().forward(x)
- if self.tp_size > 1:
- dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
- if self.bias is not None:
- output.add_(self.bias)
- return output
-
-
-class ColCaiQuantLinear(CaiQuantLinear, ParallelModule):
- def __init__(self, bits, groupsize, infeatures, outfeatures, bias, tp_size=1, tp_rank=0, row_split=False):
- super().__init__(
- bits, groupsize, infeatures, outfeatures, bias, tp_size=tp_size, tp_rank=tp_rank, row_split=row_split
- )
- self.process_group = None
-
- @staticmethod
- def from_native_module(
- module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
- ) -> ParallelModule:
- LazyInitContext.materialize(module)
- # get the attributes
- in_features = module.in_features
-
- # ensure only one process group is passed
- if isinstance(process_group, (list, tuple)):
- assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
- process_group = process_group[0]
-
- tp_size = dist.get_world_size(process_group)
- tp_rank = dist.get_rank(process_group)
-
- if in_features < tp_size:
- return module
-
- if in_features % tp_size != 0:
- raise ValueError(
- f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
- )
- linear_1d = ColCaiQuantLinear(
- module.bits,
- module.group_size,
- module.in_features,
- module.out_features // tp_size,
- module.bias is not None,
- tp_size=tp_size,
- tp_rank=tp_rank,
- )
- linear_1d.process_group = process_group
-
- split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
- return linear_1d
diff --git a/colossalai/inference/quant/gptq/cai_gptq/gptq_op.py b/colossalai/inference/quant/gptq/cai_gptq/gptq_op.py
deleted file mode 100644
index a8902eb35cd0..000000000000
--- a/colossalai/inference/quant/gptq/cai_gptq/gptq_op.py
+++ /dev/null
@@ -1,58 +0,0 @@
-import torch
-
-from colossalai.kernel.triton import gptq_fused_linear_triton
-
-
-class CaiGPTQLinearOp(torch.nn.Module):
- def __init__(self, gptq_group_size, gptq_quant_bits):
- super(CaiGPTQLinearOp, self).__init__()
- self.group_size = gptq_group_size
- self.bits = gptq_quant_bits
- self.maxq = 2**self.bits - 1
- self.empty_tensor = torch.zeros(4, device=torch.cuda.current_device())
-
- def forward(
- self,
- input: torch.Tensor,
- weight: torch.Tensor,
- weight_scales: torch.Tensor,
- weight_zeros: torch.Tensor,
- g_idx: torch.Tensor = None,
- act_type=0,
- bias: torch.Tensor = None,
- residual: torch.Tensor = None,
- qkv_fused=False,
- ):
- add_bias = True
- if bias is None:
- bias = self.empty_tensor
- add_bias = False
-
- add_residual = True
- if residual is None:
- residual = self.empty_tensor
- add_residual = False
- x = input.view(-1, input.shape[-1])
-
- out = gptq_fused_linear_triton(
- x,
- weight,
- weight_scales,
- weight_zeros,
- bias,
- residual,
- self.bits,
- self.maxq,
- self.group_size,
- qkv_fused,
- add_bias,
- add_residual,
- act_type=act_type,
- g_idx=g_idx,
- )
- if qkv_fused:
- out = out.view(3, input.shape[0], input.shape[1], weight.shape[-1])
- else:
- out = out.view(input.shape[0], input.shape[1], weight.shape[-1])
-
- return out
diff --git a/colossalai/inference/quant/gptq/gptq_manager.py b/colossalai/inference/quant/gptq/gptq_manager.py
deleted file mode 100644
index 2d352fbef2b9..000000000000
--- a/colossalai/inference/quant/gptq/gptq_manager.py
+++ /dev/null
@@ -1,61 +0,0 @@
-import torch
-
-
-class GPTQManager:
- def __init__(self, quant_config, max_input_len: int = 1):
- self.max_dq_buffer_size = 1
- self.max_inner_outer_dim = 1
- self.bits = quant_config.bits
- self.use_act_order = quant_config.desc_act
- self.max_input_len = 1
- self.gptq_temp_state_buffer = None
- self.gptq_temp_dq_buffer = None
- self.quant_config = quant_config
-
- def post_init_gptq_buffer(self, model: torch.nn.Module) -> None:
- from .cai_gptq import CaiQuantLinear
-
- HAS_GPTQ_CUDA = False
- try:
- from colossalai.kernel.op_builder.gptq import GPTQBuilder
-
- gptq_cuda = GPTQBuilder().load()
- HAS_GPTQ_CUDA = True
- except ImportError:
- warnings.warn("CUDA gptq is not installed")
- HAS_GPTQ_CUDA = False
-
- for name, submodule in model.named_modules():
- if isinstance(submodule, CaiQuantLinear):
- self.max_dq_buffer_size = max(self.max_dq_buffer_size, submodule.qweight.numel() * 8)
-
- if self.use_act_order:
- self.max_inner_outer_dim = max(
- self.max_inner_outer_dim, submodule.infeatures, submodule.outfeatures
- )
- self.bits = submodule.bits
- if not (HAS_GPTQ_CUDA and self.bits == 4):
- return
-
- max_input_len = 1
- if self.use_act_order:
- max_input_len = self.max_input_len
- # The temp_state buffer is required to reorder X in the act-order case.
- # The temp_dq buffer is required to dequantize weights when using cuBLAS, typically for the prefill.
- self.gptq_temp_state_buffer = torch.zeros(
- (max_input_len, self.max_inner_outer_dim), dtype=torch.float16, device=torch.cuda.current_device()
- )
- self.gptq_temp_dq_buffer = torch.zeros(
- (1, self.max_dq_buffer_size), dtype=torch.float16, device=torch.cuda.current_device()
- )
-
- gptq_cuda.prepare_buffers(
- torch.device(torch.cuda.current_device()), self.gptq_temp_state_buffer, self.gptq_temp_dq_buffer
- )
- # Using the default from exllama repo here.
- matmul_recons_thd = 8
- matmul_fused_remap = False
- matmul_no_half2 = False
- gptq_cuda.set_tuning_params(matmul_recons_thd, matmul_fused_remap, matmul_no_half2)
-
- torch.cuda.empty_cache()
diff --git a/colossalai/inference/quant/smoothquant/models/__init__.py b/colossalai/inference/quant/smoothquant/models/__init__.py
deleted file mode 100644
index 1663028da138..000000000000
--- a/colossalai/inference/quant/smoothquant/models/__init__.py
+++ /dev/null
@@ -1,10 +0,0 @@
-try:
- import torch_int
-
- HAS_TORCH_INT = True
-except ImportError:
- HAS_TORCH_INT = False
- print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
-
-if HAS_TORCH_INT:
- from .llama import LLamaSmoothquantAttention, LlamaSmoothquantMLP
diff --git a/colossalai/inference/quant/smoothquant/models/base_model.py b/colossalai/inference/quant/smoothquant/models/base_model.py
deleted file mode 100644
index f3afe5d83bb0..000000000000
--- a/colossalai/inference/quant/smoothquant/models/base_model.py
+++ /dev/null
@@ -1,494 +0,0 @@
-# Adapted from AutoGPTQ: https://github.com/PanQiWei/AutoGPTQ
-# Adapted from smoothquant: https://github.com/mit-han-lab/smoothquant/blob/main/smoothquant/calibration.py
-# Adapted from smoothquant: https://github.com/mit-han-lab/smoothquant/blob/main/smoothquant/smooth.py
-
-import os
-import warnings
-from abc import abstractmethod
-from functools import partial
-from os.path import isdir, isfile, join
-from typing import Dict, List, Optional, Union
-
-import numpy as np
-import torch
-import torch.nn as nn
-import transformers
-from safetensors.torch import save_file as safe_save
-from tqdm import tqdm
-from transformers import AutoConfig, AutoModelForCausalLM, PreTrainedModel
-from transformers.modeling_utils import no_init_weights
-from transformers.utils.generic import ContextManagers
-from transformers.utils.hub import PushToHubMixin, cached_file
-
-from colossalai.inference.kv_cache.batch_infer_state import BatchInferState, MemoryManager
-
-try:
- import accelerate
-
- HAS_ACCELERATE = True
-except ImportError:
- HAS_ACCELERATE = False
- print("accelerate is not installed.")
-
-
-SUPPORTED_MODELS = ["llama"]
-
-
-class BaseSmoothForCausalLM(nn.Module, PushToHubMixin):
- layer_type: str = None
-
- def __init__(self, model: PreTrainedModel, quantized: bool = False):
- super().__init__()
-
- self.model = model
- self.model_type = self.model.config.model_type
- self._quantized = quantized
- self.config = self.model.config
- self.cache_manager = None
- self.max_total_token_num = 0
-
- @property
- def quantized(self):
- return self._quantized
-
- def init_cache_manager(self, max_total_token_num=2048):
- if self.config.model_type == "llama":
- head_num = self.config.num_key_value_heads
- layer_num = self.config.num_hidden_layers
- head_dim = self.config.hidden_size // head_num
-
- self.cache_manager = MemoryManager(max_total_token_num, torch.int8, head_num, head_dim, layer_num)
- self.max_total_token_num = max_total_token_num
-
- def init_batch_state(self, max_output_len=256, **kwargs):
- input_ids = kwargs["input_ids"]
- batch_size = len(input_ids)
-
- seq_start_indexes = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
- seq_lengths = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
- start_index = 0
- max_len_in_batch = -1
-
- for i in range(batch_size):
- seq_len = len(input_ids[i])
- seq_lengths[i] = seq_len
- seq_start_indexes[i] = start_index
- start_index += seq_len
- max_len_in_batch = seq_len if seq_len > max_len_in_batch else max_len_in_batch
-
- if "max_total_token_num" in kwargs.keys():
- max_total_token_num = kwargs["max_total_token_num"]
- self.init_cache_manager(max_total_token_num)
-
- if "max_new_tokens" in kwargs.keys():
- max_output_len = kwargs["max_new_tokens"]
-
- if batch_size * (max_len_in_batch + max_output_len) > self.max_total_token_num:
- max_total_token_num = batch_size * (max_len_in_batch + max_output_len)
- warnings.warn(f"reset max tokens to {max_total_token_num}")
- self.init_cache_manager(max_total_token_num)
-
- block_loc = torch.empty((batch_size, max_len_in_batch + max_output_len), dtype=torch.long, device="cuda")
- batch_infer_state = BatchInferState(batch_size, max_len_in_batch)
- batch_infer_state.seq_len = seq_lengths.to("cuda")
- batch_infer_state.start_loc = seq_start_indexes.to("cuda")
- batch_infer_state.block_loc = block_loc
- batch_infer_state.decode_layer_id = 0
- batch_infer_state.is_context_stage = True
- batch_infer_state.set_cache_manager(self.cache_manager)
- batch_infer_state.cache_manager.free_all()
- return batch_infer_state
-
- @abstractmethod
- @torch.inference_mode()
- def quantize(
- self,
- examples: List[Dict[str, Union[List[int], torch.LongTensor]]],
- ):
- if self.quantized:
- raise EnvironmentError("can't execute quantize because the model is quantized.")
-
- def forward(self, *args, **kwargs):
- return self.model(*args, **kwargs)
-
- def generate(self, **kwargs):
- """shortcut for model.generate"""
-
- batch_infer_state = self.init_batch_state(**kwargs)
- if self.config.model_type == "llama":
- setattr(self.model.model, "infer_state", batch_infer_state)
-
- with torch.inference_mode():
- return self.model.generate(**kwargs)
-
- def prepare_inputs_for_generation(self, *args, **kwargs):
- """shortcut for model.prepare_inputs_for_generation"""
- return self.model.prepare_inputs_for_generation(*args, **kwargs)
-
- def collect_act_scales(self, model, tokenizer, dataset, device, num_samples=512, seq_len=512):
- for text in tqdm(dataset):
- input_ids = tokenizer(text, return_tensors="pt", max_length=seq_len, truncation=True).input_ids.to(device)
- model(input_ids)
-
- def collect_act_dict(self, model, tokenizer, dataset, act_dict, device, num_samples=512, seq_len=512):
- pbar = tqdm(dataset)
- for text in pbar:
- input_ids = tokenizer(text, return_tensors="pt", max_length=seq_len, truncation=True).input_ids.to(device)
- model(input_ids)
- mean_scale = np.mean([v["input"] for v in act_dict.values()])
- pbar.set_description(f"Mean input scale: {mean_scale:.2f}")
-
- # Adatped from https://github.com/mit-han-lab/smoothquant/blob/main/smoothquant/calibration.py
- def get_act_scales(self, model, tokenizer, dataset, num_samples=512, seq_len=512):
- model.eval()
- device = next(model.parameters()).device
- act_scales = {}
-
- def stat_tensor(name, tensor):
- hidden_dim = tensor.shape[-1]
- tensor = tensor.view(-1, hidden_dim).abs().detach()
- comming_max = torch.max(tensor, dim=0)[0].float().cpu()
- if name in act_scales:
- act_scales[name] = torch.max(act_scales[name], comming_max)
- else:
- act_scales[name] = comming_max
-
- def stat_input_hook(m, x, y, name):
- if isinstance(x, tuple):
- x = x[0]
- stat_tensor(name, x)
-
- hooks = []
- for name, m in model.named_modules():
- if isinstance(m, nn.Linear):
- hooks.append(m.register_forward_hook(partial(stat_input_hook, name=name)))
-
- self.collect_act_scales(model, tokenizer, dataset, device, num_samples, seq_len)
-
- for h in hooks:
- h.remove()
-
- return act_scales
-
- # Adapted from https://github.com/mit-han-lab/smoothquant/blob/main/smoothquant/smooth.py
- @torch.no_grad()
- def smooth_ln_fcs(self, ln, fcs, act_scales, alpha=0.5):
- if not isinstance(fcs, list):
- fcs = [fcs]
- for fc in fcs:
- assert isinstance(fc, nn.Linear)
- assert ln.weight.numel() == fc.in_features == act_scales.numel()
-
- device, dtype = fcs[0].weight.device, fcs[0].weight.dtype
- act_scales = act_scales.to(device=device, dtype=dtype)
- weight_scales = torch.cat([fc.weight.abs().max(dim=0, keepdim=True)[0] for fc in fcs], dim=0)
- weight_scales = weight_scales.max(dim=0)[0].clamp(min=1e-5)
-
- scales = (act_scales.pow(alpha) / weight_scales.pow(1 - alpha)).clamp(min=1e-5).to(device).to(dtype)
-
- ln.weight.div_(scales)
- if hasattr(ln, "bias"):
- ln.bias.div_(scales)
-
- for fc in fcs:
- fc.weight.mul_(scales.view(1, -1))
-
- @classmethod
- def create_quantized_model(model):
- raise NotImplementedError("Not implement create_quantized_model method")
-
- # Adapted from AutoGPTQ: https://github.com/PanQiWei/AutoGPTQ/blob/main/auto_gptq/modeling/_base.py
- def save_quantized(
- self,
- save_dir: str,
- model_basename: str,
- use_safetensors: bool = False,
- safetensors_metadata: Optional[Dict[str, str]] = None,
- ):
- """save quantized model and configs to local disk"""
- os.makedirs(save_dir, exist_ok=True)
-
- if not self.quantized:
- raise EnvironmentError("can only save quantized model, please execute .quantize first.")
-
- self.model.to("cpu")
-
- model_base_name = model_basename # or f"smooth-"
- if use_safetensors:
- model_save_name = model_base_name + ".safetensors"
- state_dict = self.model.state_dict()
- state_dict = {k: v.clone().contiguous() for k, v in state_dict.items()}
- if safetensors_metadata is None:
- safetensors_metadata = {}
- elif not isinstance(safetensors_metadata, dict):
- raise TypeError("safetensors_metadata must be a dictionary.")
- else:
- print(f"Received safetensors_metadata: {safetensors_metadata}")
- new_safetensors_metadata = {}
- converted_keys = False
- for key, value in safetensors_metadata.items():
- if not isinstance(key, str) or not isinstance(value, str):
- converted_keys = True
- try:
- new_key = str(key)
- new_value = str(value)
- except Exception as e:
- raise TypeError(
- f"safetensors_metadata: both keys and values must be strings and an error occured when trying to convert them: {e}"
- )
- if new_key in new_safetensors_metadata:
- print(
- f"After converting safetensors_metadata keys to strings, the key '{new_key}' is duplicated. Ensure that all your metadata keys are strings to avoid overwriting."
- )
- new_safetensors_metadata[new_key] = new_value
- safetensors_metadata = new_safetensors_metadata
- if converted_keys:
- print(
- f"One or more safetensors_metadata keys or values had to be converted to str(). Final safetensors_metadata: {safetensors_metadata}"
- )
-
- # Format is required to enable Accelerate to load the metadata
- # otherwise it raises an OSError
- safetensors_metadata["format"] = "pt"
-
- safe_save(state_dict, join(save_dir, model_save_name), safetensors_metadata)
- else:
- model_save_name = model_base_name + ".bin"
- torch.save(self.model.state_dict(), join(save_dir, model_save_name))
-
- self.model.config.save_pretrained(save_dir)
-
- # Adapted from AutoGPTQ: https://github.com/PanQiWei/AutoGPTQ/blob/main/auto_gptq/modeling/_base.py
- def save_pretrained(
- self,
- save_dir: str,
- use_safetensors: bool = False,
- safetensors_metadata: Optional[Dict[str, str]] = None,
- **kwargs,
- ):
- """alias of save_quantized"""
- warnings.warn("you are using save_pretrained, which will re-direct to save_quantized.")
- self.save_quantized(save_dir, use_safetensors, safetensors_metadata)
-
- # Adapted from AutoGPTQ: https://github.com/PanQiWei/AutoGPTQ/blob/main/auto_gptq/modeling/_base.py
- @classmethod
- def from_pretrained(
- cls,
- pretrained_model_name_or_path: str,
- max_memory: Optional[dict] = None,
- trust_remote_code: bool = False,
- torch_dtype: torch.dtype = torch.float16,
- **model_init_kwargs,
- ):
- if not torch.cuda.is_available():
- raise EnvironmentError("Load pretrained model to do quantization requires CUDA available.")
-
- def skip(*args, **kwargs):
- pass
-
- torch.nn.init.kaiming_uniform_ = skip
- torch.nn.init.uniform_ = skip
- torch.nn.init.normal_ = skip
-
- # Parameters related to loading from Hugging Face Hub
- cache_dir = model_init_kwargs.pop("cache_dir", None)
- force_download = model_init_kwargs.pop("force_download", False)
- resume_download = model_init_kwargs.pop("resume_download", False)
- proxies = model_init_kwargs.pop("proxies", None)
- local_files_only = model_init_kwargs.pop("local_files_only", False)
- use_auth_token = model_init_kwargs.pop("use_auth_token", None)
- revision = model_init_kwargs.pop("revision", None)
- subfolder = model_init_kwargs.pop("subfolder", "")
- model_init_kwargs.pop("_commit_hash", None)
-
- cached_file_kwargs = {
- "cache_dir": cache_dir,
- "force_download": force_download,
- "proxies": proxies,
- "resume_download": resume_download,
- "local_files_only": local_files_only,
- "use_auth_token": use_auth_token,
- "revision": revision,
- "subfolder": subfolder,
- }
-
- config = AutoConfig.from_pretrained(pretrained_model_name_or_path, trust_remote_code=True, **cached_file_kwargs)
- if config.model_type not in SUPPORTED_MODELS:
- raise TypeError(f"{config.model_type} isn't supported yet.")
-
- # enforce some values despite user specified
- model_init_kwargs["torch_dtype"] = torch_dtype
- model_init_kwargs["trust_remote_code"] = trust_remote_code
- if max_memory:
- if "disk" in max_memory:
- raise NotImplementedError("disk offload not support yet.")
- with accelerate.init_empty_weights():
- model = AutoModelForCausalLM.from_config(config, trust_remote_code=True)
- model.tie_weights()
-
- max_memory = accelerate.utils.get_balanced_memory(
- model,
- max_memory=max_memory,
- no_split_module_classes=[cls.layer_type],
- dtype=model_init_kwargs["torch_dtype"],
- low_zero=False,
- )
- model_init_kwargs["device_map"] = accelerate.infer_auto_device_map(
- model,
- max_memory=max_memory,
- no_split_module_classes=[cls.layer_type],
- dtype=model_init_kwargs["torch_dtype"],
- )
- model_init_kwargs["low_cpu_mem_usage"] = True
-
- del model
- else:
- model_init_kwargs["device_map"] = None
- model_init_kwargs["low_cpu_mem_usage"] = False
-
- torch.cuda.empty_cache()
-
- merged_kwargs = {**model_init_kwargs, **cached_file_kwargs}
- model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path, **merged_kwargs)
-
- model_config = model.config.to_dict()
- seq_len_keys = ["max_position_embeddings", "seq_length", "n_positions"]
- if any([k in model_config for k in seq_len_keys]):
- for key in seq_len_keys:
- if key in model_config:
- model.seqlen = model_config[key]
- break
- else:
- warnings.warn("can't get model's sequence length from model config, will set to 4096.")
- model.seqlen = 4096
- model.eval()
-
- return cls(model, False)
-
- # Adapted from AutoGPTQ: https://github.com/PanQiWei/AutoGPTQ/blob/main/auto_gptq/modeling/_base.py
- @classmethod
- def from_quantized(
- cls,
- model_name_or_path: Optional[str],
- model_basename: Optional[str] = None,
- device_map: Optional[Union[str, Dict[str, Union[int, str]]]] = None,
- max_memory: Optional[dict] = None,
- device: Optional[Union[str, int]] = None,
- low_cpu_mem_usage: bool = False,
- torch_dtype: Optional[torch.dtype] = None,
- use_safetensors: bool = False,
- trust_remote_code: bool = False,
- **kwargs,
- ):
- """load quantized model from local disk"""
-
- # Parameters related to loading from Hugging Face Hub
- cache_dir = kwargs.pop("cache_dir", None)
- force_download = kwargs.pop("force_download", False)
- resume_download = kwargs.pop("resume_download", False)
- proxies = kwargs.pop("proxies", None)
- local_files_only = kwargs.pop("local_files_only", False)
- use_auth_token = kwargs.pop("use_auth_token", None)
- revision = kwargs.pop("revision", None)
- subfolder = kwargs.pop("subfolder", "")
- commit_hash = kwargs.pop("_commit_hash", None)
-
- cached_file_kwargs = {
- "cache_dir": cache_dir,
- "force_download": force_download,
- "proxies": proxies,
- "resume_download": resume_download,
- "local_files_only": local_files_only,
- "use_auth_token": use_auth_token,
- "revision": revision,
- "subfolder": subfolder,
- "_raise_exceptions_for_missing_entries": False,
- "_commit_hash": commit_hash,
- }
-
- # == step1: prepare configs and file names == #
- config = AutoConfig.from_pretrained(
- model_name_or_path, trust_remote_code=trust_remote_code, **cached_file_kwargs
- )
-
- if config.model_type not in SUPPORTED_MODELS:
- raise TypeError(f"{config.model_type} isn't supported yet.")
-
- extensions = []
- if use_safetensors:
- extensions.append(".safetensors")
- else:
- extensions += [".bin", ".pt"]
-
- model_name_or_path = str(model_name_or_path)
- is_local = isdir(model_name_or_path)
-
- resolved_archive_file = None
- if is_local:
- model_save_name = join(model_name_or_path, model_basename)
- for ext in extensions:
- if isfile(model_save_name + ext):
- resolved_archive_file = model_save_name + ext
- break
- else: # remote
- for ext in extensions:
- resolved_archive_file = cached_file(model_name_or_path, model_basename + ext, **cached_file_kwargs)
- if resolved_archive_file is not None:
- break
-
- if resolved_archive_file is None: # Could not find a model file to use
- raise FileNotFoundError(f"Could not find model in {model_name_or_path}")
-
- model_save_name = resolved_archive_file
-
- # == step2: convert model to quantized-model (replace Linear) == #
- def skip(*args, **kwargs):
- pass
-
- torch.nn.init.kaiming_uniform_ = skip
- torch.nn.init.uniform_ = skip
- torch.nn.init.normal_ = skip
-
- transformers.modeling_utils._init_weights = False
-
- init_contexts = [no_init_weights()]
- if low_cpu_mem_usage:
- init_contexts.append(accelerate.init_empty_weights(include_buffers=True))
-
- with ContextManagers(init_contexts):
- model = AutoModelForCausalLM.from_config(
- config, trust_remote_code=trust_remote_code, torch_dtype=torch_dtype
- )
- cls.create_quantized_model(model)
- model.tie_weights()
-
- # == step3: load checkpoint to quantized-model == #
- accelerate.utils.modeling.load_checkpoint_in_model(
- model, checkpoint=model_save_name, offload_state_dict=True, offload_buffers=True
- )
-
- # == step4: set seqlen == #
- model_config = model.config.to_dict()
- seq_len_keys = ["max_position_embeddings", "seq_length", "n_positions"]
- if any([k in model_config for k in seq_len_keys]):
- for key in seq_len_keys:
- if key in model_config:
- model.seqlen = model_config[key]
- break
- else:
- warnings.warn("can't get model's sequence length from model config, will set to 4096.")
- model.seqlen = 4096
-
- return cls(
- model,
- True,
- )
-
- def __getattr__(self, item):
- try:
- return super().__getattr__(item)
- except:
- return getattr(self.model, item)
-
-
-__all__ = ["BaseSmoothForCausalLM"]
diff --git a/colossalai/inference/quant/smoothquant/models/linear.py b/colossalai/inference/quant/smoothquant/models/linear.py
deleted file mode 100644
index 03d994b32489..000000000000
--- a/colossalai/inference/quant/smoothquant/models/linear.py
+++ /dev/null
@@ -1,189 +0,0 @@
-# modified from torch-int: https://github.com/Guangxuan-Xiao/torch-int/blob/main/torch_int/nn/linear.py
-
-import torch
-
-try:
- from torch_int._CUDA import linear_a8_w8_b8_o8, linear_a8_w8_bfp32_ofp32
- from torch_int.functional.quantization import quantize_per_tensor_absmax
-
- HAS_TORCH_INT = True
-except ImportError:
- HAS_TORCH_INT = False
- print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
-
-
-try:
- from colossalai.kernel.op_builder.smoothquant import SmoothquantBuilder
-
- smoothquant_cuda = SmoothquantBuilder().load()
- HAS_SMOOTHQUANT_CUDA = True
-except:
- HAS_SMOOTHQUANT_CUDA = False
- print("CUDA smoothquant linear is not installed")
-
-
-class W8A8BFP32O32LinearSiLU(torch.nn.Module):
- def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
- super().__init__()
- self.in_features = in_features
- self.out_features = out_features
-
- self.register_buffer(
- "weight",
- torch.randint(
- -127,
- 127,
- (self.out_features, self.in_features),
- dtype=torch.int8,
- requires_grad=False,
- ),
- )
- self.register_buffer(
- "bias",
- torch.zeros((1, self.out_features), dtype=torch.float, requires_grad=False),
- )
- self.register_buffer("a", torch.tensor(alpha))
-
- def to(self, *args, **kwargs):
- super().to(*args, **kwargs)
- self.weight = self.weight.to(*args, **kwargs)
- self.bias = self.bias.to(*args, **kwargs)
- return self
-
- @torch.no_grad()
- def forward(self, x):
- x_shape = x.shape
- x = x.view(-1, x_shape[-1])
- y = smoothquant_cuda.linear_silu_a8_w8_bfp32_ofp32(x, self.weight, self.bias, self.a.item(), 1.0)
- y = y.view(*x_shape[:-1], -1)
- return y
-
- @staticmethod
- def from_float(module: torch.nn.Linear, input_scale):
- int8_module = W8A8BFP32O32LinearSiLU(module.in_features, module.out_features)
- int8_weight, weight_scale = quantize_per_tensor_absmax(module.weight)
- alpha = input_scale * weight_scale
- int8_module.weight = int8_weight
- if module.bias is not None:
- int8_module.bias.data.copy_(module.bias.to(torch.float))
- int8_module.a = alpha
- return int8_module
-
-
-# modified from torch-int: https://github.com/Guangxuan-Xiao/torch-int/blob/main/torch_int/nn/linear.py
-class W8A8B8O8Linear(torch.nn.Module):
- # For qkv_proj
- def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
- super().__init__()
- self.in_features = in_features
- self.out_features = out_features
-
- self.register_buffer(
- "weight",
- torch.randint(
- -127,
- 127,
- (self.out_features, self.in_features),
- dtype=torch.int8,
- requires_grad=False,
- ),
- )
- self.register_buffer(
- "bias",
- torch.zeros((1, self.out_features), dtype=torch.int8, requires_grad=False),
- )
- self.register_buffer("a", torch.tensor(alpha))
- self.register_buffer("b", torch.tensor(beta))
-
- def to(self, *args, **kwargs):
- super().to(*args, **kwargs)
- self.weight = self.weight.to(*args, **kwargs)
- self.bias = self.bias.to(*args, **kwargs)
- return self
-
- @torch.no_grad()
- def forward(self, x):
- x_shape = x.shape
- x = x.view(-1, x_shape[-1])
- y = linear_a8_w8_b8_o8(x, self.weight, self.bias, self.a.item(), self.b.item())
- y = y.view(*x_shape[:-1], -1)
- return y
-
- @staticmethod
- def from_float(module: torch.nn.Linear, input_scale, output_scale):
- int8_module = W8A8B8O8Linear(module.in_features, module.out_features)
- int8_weight, weight_scale = quantize_per_tensor_absmax(module.weight)
- alpha = input_scale * weight_scale / output_scale
- int8_module.weight = int8_weight
- int8_module.a = alpha
-
- if module.bias is not None:
- int8_bias, bias_scale = quantize_per_tensor_absmax(module.bias)
- int8_module.bias = int8_bias
- beta = bias_scale / output_scale
- int8_module.b = beta
-
- return int8_module
-
-
-# modified from torch-int: https://github.com/Guangxuan-Xiao/torch-int/blob/main/torch_int/nn/linear.py
-class W8A8BFP32OFP32Linear(torch.nn.Module):
- # For fc2 and out_proj
- def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
- super().__init__()
- self.in_features = in_features
- self.out_features = out_features
-
- self.register_buffer(
- "weight",
- torch.randint(
- -127,
- 127,
- (self.out_features, self.in_features),
- dtype=torch.int8,
- requires_grad=False,
- ),
- )
- self.register_buffer(
- "bias",
- torch.zeros((1, self.out_features), dtype=torch.float32, requires_grad=False),
- )
- self.register_buffer("a", torch.tensor(alpha))
-
- def _apply(self, fn):
- # prevent the bias from being converted to half
- super()._apply(fn)
- if self.bias is not None:
- self.bias = self.bias.to(torch.float32)
- return self
-
- def to(self, *args, **kwargs):
- super().to(*args, **kwargs)
- self.weight = self.weight.to(*args, **kwargs)
- if self.bias is not None:
- self.bias = self.bias.to(*args, **kwargs)
- self.bias = self.bias.to(torch.float32)
- return self
-
- @torch.no_grad()
- def forward(self, x):
- x_shape = x.shape
- x = x.view(-1, x_shape[-1])
- y = linear_a8_w8_bfp32_ofp32(x, self.weight, self.bias, self.a.item(), 1)
- y = y.view(*x_shape[:-1], -1)
- return y
-
- @staticmethod
- def from_float(module: torch.nn.Linear, input_scale):
- int8_module = W8A8BFP32OFP32Linear(module.in_features, module.out_features)
- int8_weight, weight_scale = quantize_per_tensor_absmax(module.weight)
- alpha = input_scale * weight_scale
- int8_module.weight = int8_weight
- int8_module.a = alpha
- int8_module.input_scale = input_scale
- int8_module.weight_scale = weight_scale
-
- if module.bias is not None:
- int8_module.bias = module.bias.to(torch.float32)
-
- return int8_module
diff --git a/colossalai/inference/quant/smoothquant/models/llama.py b/colossalai/inference/quant/smoothquant/models/llama.py
deleted file mode 100644
index bb74dc49d7af..000000000000
--- a/colossalai/inference/quant/smoothquant/models/llama.py
+++ /dev/null
@@ -1,852 +0,0 @@
-import math
-import os
-import types
-from collections import defaultdict
-from functools import partial
-from typing import List, Optional, Tuple, Union
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from transformers import PreTrainedModel
-from transformers.modeling_outputs import BaseModelOutputWithPast
-from transformers.models.llama.configuration_llama import LlamaConfig
-from transformers.models.llama.modeling_llama import (
- LLAMA_INPUTS_DOCSTRING,
- LlamaAttention,
- LlamaDecoderLayer,
- LlamaMLP,
- LlamaRotaryEmbedding,
- rotate_half,
-)
-from transformers.utils import add_start_docstrings_to_model_forward
-
-from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
-from colossalai.kernel.triton import (
- copy_kv_cache_to_dest,
- int8_rotary_embedding_fwd,
- smooth_llama_context_attn_fwd,
- smooth_token_attention_fwd,
-)
-
-try:
- from torch_int.nn.bmm import BMM_S8T_S8N_F32T, BMM_S8T_S8N_S8T
-
- HAS_TORCH_INT = True
-except ImportError:
- HAS_TORCH_INT = False
- print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
-
-
-from .base_model import BaseSmoothForCausalLM
-from .linear import W8A8B8O8Linear, W8A8BFP32O32LinearSiLU, W8A8BFP32OFP32Linear
-
-
-def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
- """
- This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
- num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
- """
- batch, num_key_value_heads, slen, head_dim = hidden_states.shape
- if n_rep == 1:
- return hidden_states
- hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
- return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
-
-
-class LLamaSmoothquantAttention(nn.Module):
- def __init__(
- self,
- hidden_size: int,
- num_heads: int,
- ):
- super().__init__()
- self.hidden_size = hidden_size
- self.num_heads = num_heads
- self.head_dim = hidden_size // num_heads
-
- if (self.head_dim * num_heads) != self.hidden_size:
- raise ValueError(
- f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
- f" and `num_heads`: {num_heads})."
- )
-
- self.qk_bmm = BMM_S8T_S8N_F32T(1.0)
- self.pv_bmm = BMM_S8T_S8N_S8T(1.0)
-
- self.k_proj = W8A8B8O8Linear(hidden_size, hidden_size)
- self.v_proj = W8A8B8O8Linear(hidden_size, hidden_size)
- self.q_proj = W8A8B8O8Linear(hidden_size, hidden_size)
- self.o_proj = W8A8BFP32OFP32Linear(hidden_size, hidden_size)
-
- self.register_buffer("q_output_scale", torch.tensor([1.0]))
- self.register_buffer("k_output_scale", torch.tensor([1.0]))
- self.register_buffer("v_output_scale", torch.tensor([1.0]))
- self.register_buffer("q_rotary_output_scale", torch.tensor([1.0]))
- self.register_buffer("k_rotary_output_scale", torch.tensor([1.0]))
- self.register_buffer("out_input_scale", torch.tensor([1.0]))
- self.register_buffer("attn_input_scale", torch.tensor([1.0]))
-
- self._init_rope()
- self.num_key_value_heads = num_heads
-
- def _init_rope(self):
- self.rotary_emb = LlamaRotaryEmbedding(
- self.head_dim,
- max_position_embeddings=2048,
- base=10000.0,
- )
-
- @staticmethod
- def pack(
- module: LlamaAttention,
- attn_input_scale: float,
- q_output_scale: float,
- k_output_scale: float,
- v_output_scale: float,
- q_rotary_output_scale: float,
- k_rotary_output_scale: float,
- out_input_scale: float,
- ):
- int8_module = LLamaSmoothquantAttention(module.hidden_size, module.num_heads)
-
- int8_module.attn_input_scale = torch.tensor([attn_input_scale])
-
- int8_module.q_output_scale = torch.tensor([q_output_scale])
- int8_module.k_output_scale = torch.tensor([k_output_scale])
- int8_module.v_output_scale = torch.tensor([v_output_scale])
-
- int8_module.q_rotary_output_scale = torch.tensor([q_rotary_output_scale])
- int8_module.k_rotary_output_scale = torch.tensor([k_rotary_output_scale])
-
- int8_module.q_proj = W8A8B8O8Linear.from_float(module.q_proj, attn_input_scale, q_output_scale)
- int8_module.k_proj = W8A8B8O8Linear.from_float(module.k_proj, attn_input_scale, k_output_scale)
- int8_module.v_proj = W8A8B8O8Linear.from_float(module.v_proj, attn_input_scale, v_output_scale)
- int8_module.o_proj = W8A8BFP32OFP32Linear.from_float(module.o_proj, out_input_scale)
-
- int8_module.out_input_scale = torch.tensor([out_input_scale])
-
- return int8_module
-
- def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
- return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
-
- @torch.no_grad()
- def forward(
- self,
- hidden_states: torch.Tensor,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_value: Optional[Tuple[torch.Tensor]] = None,
- output_attentions: bool = False,
- use_cache: bool = False,
- padding_mask: Optional[torch.LongTensor] = None,
- infer_state: Optional[BatchInferState] = None,
- ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
- bsz, q_len, _ = hidden_states.size()
-
- query_states = self.q_proj(hidden_states)
- key_states = self.k_proj(hidden_states)
- value_states = self.v_proj(hidden_states)
-
- cos, sin = infer_state.position_cos, infer_state.position_sin
-
- int8_rotary_embedding_fwd(
- query_states.view(-1, self.num_heads, self.head_dim),
- cos,
- sin,
- self.q_output_scale.item(),
- self.q_rotary_output_scale.item(),
- )
- int8_rotary_embedding_fwd(
- key_states.view(-1, self.num_heads, self.head_dim),
- cos,
- sin,
- self.k_output_scale.item(),
- self.k_rotary_output_scale.item(),
- )
-
- def _copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index, mem_manager):
- copy_kv_cache_to_dest(key_buffer, context_mem_index, mem_manager.key_buffer[layer_id])
- copy_kv_cache_to_dest(value_buffer, context_mem_index, mem_manager.value_buffer[layer_id])
- return
-
- query_states = query_states.view(-1, self.num_heads, self.head_dim)
- key_states = key_states.view(-1, self.num_heads, self.head_dim)
- value_states = value_states.view(-1, self.num_heads, self.head_dim)
-
- if infer_state.is_context_stage:
- # first token generation
-
- # copy key and value calculated in current step to memory manager
- _copy_kv_to_mem_cache(
- infer_state.decode_layer_id,
- key_states,
- value_states,
- infer_state.context_mem_index,
- infer_state.cache_manager,
- )
-
- attn_output = torch.empty_like(query_states)
-
- smooth_llama_context_attn_fwd(
- query_states,
- key_states,
- value_states,
- attn_output,
- self.q_rotary_output_scale.item(),
- self.k_rotary_output_scale.item(),
- self.v_output_scale.item(),
- self.out_input_scale.item(),
- infer_state.start_loc,
- infer_state.seq_len,
- q_len,
- )
-
- else:
- if infer_state.decode_is_contiguous:
- # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
- cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
- infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
- ]
- cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
- infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
- ]
- cache_k.copy_(key_states)
- cache_v.copy_(value_states)
- else:
- # if decode is not contiguous, use triton kernel to copy key and value cache
- # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
- _copy_kv_to_mem_cache(
- infer_state.decode_layer_id,
- key_states,
- value_states,
- infer_state.decode_mem_index,
- infer_state.cache_manager,
- )
-
- # (batch_size, seqlen, nheads, headdim)
- attn_output = torch.empty_like(query_states)
-
- smooth_token_attention_fwd(
- query_states,
- infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
- infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
- attn_output,
- self.q_rotary_output_scale.item(),
- self.k_rotary_output_scale.item(),
- self.v_output_scale.item(),
- self.out_input_scale.item(),
- infer_state.block_loc,
- infer_state.start_loc,
- infer_state.seq_len,
- infer_state.max_len_in_batch,
- )
-
- attn_output = attn_output.view(bsz, q_len, self.num_heads * self.head_dim)
- attn_output = self.o_proj(attn_output)
-
- return attn_output, None, None
-
-
-class LlamaLayerNormQ(torch.nn.Module):
- def __init__(self, dim, eps=1e-5):
- super().__init__()
- self.input_scale = 1.0
- self.variance_epsilon = eps
- self.register_buffer("weight", torch.ones(dim, dtype=torch.float32))
-
- def forward(self, x):
- ln_output_fp = torch.nn.functional.layer_norm(x, x.shape[-1:], self.weight, None, self.variance_epsilon)
- ln_output_int8 = ln_output_fp.round().clamp(-128, 127).to(torch.int8)
- return ln_output_int8
-
- @staticmethod
- def from_float(module: torch.nn.LayerNorm, output_scale: float):
- assert module.weight.shape[0] == module.weight.numel()
- q_module = LlamaLayerNormQ(module.weight.shape[0], module.variance_epsilon)
- q_module.weight = module.weight / output_scale
- return q_module
-
-
-class LlamaSmoothquantMLP(nn.Module):
- def __init__(self, intermediate_size, hidden_size):
- super().__init__()
- self.gate_proj = W8A8BFP32O32LinearSiLU(hidden_size, intermediate_size)
- self.up_proj = W8A8BFP32OFP32Linear(hidden_size, intermediate_size)
- self.down_proj = W8A8BFP32OFP32Linear(intermediate_size, hidden_size)
- self.register_buffer("down_proj_input_scale", torch.tensor([1.0]))
-
- @staticmethod
- def pack(
- mlp_module: LlamaMLP,
- gate_proj_input_scale: float,
- up_proj_input_scale: float,
- down_proj_input_scale: float,
- ):
- int8_module = LlamaSmoothquantMLP(
- mlp_module.intermediate_size,
- mlp_module.hidden_size,
- )
-
- int8_module.gate_proj = W8A8BFP32O32LinearSiLU.from_float(mlp_module.gate_proj, gate_proj_input_scale)
- int8_module.up_proj = W8A8BFP32OFP32Linear.from_float(mlp_module.up_proj, up_proj_input_scale)
- int8_module.down_proj = W8A8BFP32OFP32Linear.from_float(mlp_module.down_proj, down_proj_input_scale)
- int8_module.down_proj_input_scale = torch.tensor([down_proj_input_scale])
- return int8_module
-
- def forward(
- self,
- hidden_states: torch.Tensor,
- ):
- x_shape = hidden_states.shape
- gate_out = self.gate_proj(hidden_states)
- up_out = self.up_proj(hidden_states)
- inter_out = gate_out * up_out
- inter_out = inter_out.div_(self.down_proj_input_scale.item()).round().clamp(-128, 127).to(torch.int8)
- down_out = self.down_proj(inter_out)
- down_out = down_out.view(*x_shape[:-1], -1)
- return down_out
-
-
-class LlamaSmoothquantDecoderLayer(nn.Module):
- def __init__(self, config: LlamaConfig):
- super().__init__()
- self.hidden_size = config.hidden_size
- self.self_attn = LLamaSmoothquantAttention(config.hidden_size, config.num_attention_heads)
-
- self.mlp = LlamaSmoothquantMLP(config.intermediate_size, config.hidden_size)
- self.input_layernorm = LlamaLayerNormQ(config.hidden_size, eps=config.rms_norm_eps)
-
- self.post_attention_layernorm = LlamaLayerNormQ(config.hidden_size, eps=config.rms_norm_eps)
-
- @staticmethod
- def pack(
- module: LlamaDecoderLayer,
- attn_input_scale: float,
- q_output_scale: float,
- k_output_scale: float,
- v_output_scale: float,
- q_rotary_output_scale: float,
- k_rotary_output_scale: float,
- out_input_scale: float,
- gate_input_scale: float,
- up_input_scale: float,
- down_input_scale: float,
- ):
- config = module.self_attn.config
- int8_decoder_layer = LlamaSmoothquantDecoderLayer(config)
-
- int8_decoder_layer.input_layernorm = LlamaLayerNormQ.from_float(module.input_layernorm, attn_input_scale)
- int8_decoder_layer.self_attn = LLamaSmoothquantAttention.pack(
- module.self_attn,
- attn_input_scale,
- q_output_scale,
- k_output_scale,
- v_output_scale,
- q_rotary_output_scale,
- k_rotary_output_scale,
- out_input_scale,
- )
-
- int8_decoder_layer.post_attention_layernorm = LlamaLayerNormQ.from_float(
- module.post_attention_layernorm, gate_input_scale
- )
-
- int8_decoder_layer.mlp = LlamaSmoothquantMLP.pack(
- module.mlp,
- gate_input_scale,
- up_input_scale,
- down_input_scale,
- )
-
- return int8_decoder_layer
-
- def forward(
- self,
- hidden_states: torch.Tensor,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_value: Optional[Tuple[torch.Tensor]] = None,
- output_attentions: Optional[bool] = False,
- use_cache: Optional[bool] = False,
- padding_mask: Optional[torch.LongTensor] = None,
- infer_state: Optional[BatchInferState] = None,
- ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
- """
- Args:
- hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
- attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
- `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
- output_attentions (`bool`, *optional*):
- Whether or not to return the attentions tensors of all attention layers. See `attentions` under
- returned tensors for more detail.
- use_cache (`bool`, *optional*):
- If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
- (see `past_key_values`).
- past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
- """
-
- residual = hidden_states
-
- hidden_states = self.input_layernorm(hidden_states)
-
- # Self Attention
- hidden_states, self_attn_weights, present_key_value = self.self_attn(
- hidden_states=hidden_states,
- attention_mask=attention_mask,
- position_ids=position_ids,
- past_key_value=past_key_value,
- output_attentions=output_attentions,
- use_cache=use_cache,
- padding_mask=padding_mask,
- infer_state=infer_state,
- )
- hidden_states = residual + hidden_states
-
- # Fully Connected
- residual = hidden_states
- hidden_states = self.post_attention_layernorm(hidden_states)
- hidden_states = self.mlp(hidden_states)
- hidden_states = residual + hidden_states
-
- return hidden_states, None, None
-
-
-class LlamaApplyRotary(nn.Module):
- def __init__(self):
- super().__init__()
-
- def forward(self, x, cos, sin, position_ids):
- # The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
- cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
- sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
- cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
- sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
- x_embed = (x * cos) + (rotate_half(x) * sin)
-
- return x_embed
-
-
-# Adapted from https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py
-def llama_decoder_layer_forward(
- self,
- hidden_states: torch.Tensor,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_value: Optional[Tuple[torch.Tensor]] = None,
- output_attentions: bool = False,
- use_cache: bool = False,
- padding_mask: Optional[torch.LongTensor] = None,
-) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
- bsz, q_len, _ = hidden_states.size()
-
- if self.config.pretraining_tp > 1:
- key_value_slicing = (self.num_key_value_heads * self.head_dim) // self.config.pretraining_tp
- query_slices = self.q_proj.weight.split((self.num_heads * self.head_dim) // self.config.pretraining_tp, dim=0)
- key_slices = self.k_proj.weight.split(key_value_slicing, dim=0)
- value_slices = self.v_proj.weight.split(key_value_slicing, dim=0)
-
- query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.config.pretraining_tp)]
- query_states = torch.cat(query_states, dim=-1)
-
- key_states = [F.linear(hidden_states, key_slices[i]) for i in range(self.config.pretraining_tp)]
- key_states = torch.cat(key_states, dim=-1)
-
- value_states = [F.linear(hidden_states, value_slices[i]) for i in range(self.config.pretraining_tp)]
- value_states = torch.cat(value_states, dim=-1)
-
- else:
- query_states = self.q_proj(hidden_states)
- key_states = self.k_proj(hidden_states)
- value_states = self.v_proj(hidden_states)
-
- query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
- key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
- value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
-
- kv_seq_len = key_states.shape[-2]
- if past_key_value is not None:
- kv_seq_len += past_key_value[0].shape[-2]
- cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
- query_states = self.q_apply_rotary(query_states, cos, sin, position_ids)
- key_states = self.k_apply_rotary(key_states, cos, sin, position_ids)
-
- if past_key_value is not None:
- # reuse k, v, self_attention
- key_states = torch.cat([past_key_value[0], key_states], dim=2)
- value_states = torch.cat([past_key_value[1], value_states], dim=2)
-
- past_key_value = (key_states, value_states) if use_cache else None
-
- key_states = repeat_kv(key_states, self.num_key_value_groups)
- value_states = repeat_kv(value_states, self.num_key_value_groups)
-
- attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
-
- if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
- raise ValueError(
- f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
- f" {attn_weights.size()}"
- )
-
- if attention_mask is not None:
- if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
- raise ValueError(
- f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
- )
- attn_weights = attn_weights + attention_mask
-
- # upcast attention to fp32
- attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
- attn_output = torch.matmul(attn_weights, value_states)
-
- if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
- raise ValueError(
- f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
- f" {attn_output.size()}"
- )
-
- attn_output = attn_output.transpose(1, 2).contiguous()
-
- attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
-
- if self.config.pretraining_tp > 1:
- attn_output = attn_output.split(self.hidden_size // self.config.pretraining_tp, dim=2)
- o_proj_slices = self.o_proj.weight.split(self.hidden_size // self.config.pretraining_tp, dim=1)
- attn_output = sum([F.linear(attn_output[i], o_proj_slices[i]) for i in range(self.config.pretraining_tp)])
- else:
- attn_output = self.o_proj(attn_output)
-
- if not output_attentions:
- attn_weights = None
-
- return attn_output, attn_weights, past_key_value
-
-
-def init_to_get_rotary(config, base=10000, use_elem=False):
- """
- This function initializes the rotary positional embedding, it is compatible for all models and is called in ShardFormer
- Args:
- base : calculation arg
- use_elem : activated when using chatglm-based models
- """
- config.head_dim_ = config.hidden_size // config.num_attention_heads
- if not hasattr(config, "rope_scaling"):
- rope_scaling_factor = 1.0
- else:
- rope_scaling_factor = config.rope_scaling.factor if config.rope_scaling is not None else 1.0
-
- if hasattr(config, "max_sequence_length"):
- max_seq_len = config.max_sequence_length
- elif hasattr(config, "max_position_embeddings"):
- max_seq_len = config.max_position_embeddings * rope_scaling_factor
- else:
- max_seq_len = 2048 * rope_scaling_factor
- base = float(base)
-
- # NTK ref: https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/
- try:
- ntk_alpha = float(os.environ.get("INFER_NTK_ALPHA", 1))
- assert ntk_alpha >= 1
- if ntk_alpha > 1:
- print(f"Note: NTK enabled, alpha set to {ntk_alpha}")
- max_seq_len *= ntk_alpha
- base = base * (ntk_alpha ** (config.head_dim_ / (config.head_dim_ - 2))) # Base change formula
- except:
- pass
-
- n_elem = config.head_dim_
- if use_elem:
- n_elem //= 2
-
- inv_freq = 1.0 / (base ** (torch.arange(0, n_elem, 2, device="cpu", dtype=torch.float32) / n_elem))
- t = torch.arange(max_seq_len + 1024 * 64, device="cpu", dtype=torch.float32) / rope_scaling_factor
- freqs = torch.outer(t, inv_freq)
-
- _cos_cached = torch.cos(freqs).to(torch.float)
- _sin_cached = torch.sin(freqs).to(torch.float)
- return _cos_cached, _sin_cached
-
-
-# Adapted from https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py
-@add_start_docstrings_to_model_forward(LLAMA_INPUTS_DOCSTRING)
-def llama_model_forward(
- self,
- input_ids: torch.LongTensor = None,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[List[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
-) -> Union[Tuple, BaseModelOutputWithPast]:
- output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
- output_hidden_states = (
- output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
- )
- use_cache = use_cache if use_cache is not None else self.config.use_cache
-
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- # retrieve input_ids and inputs_embeds
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- batch_size, seq_length = input_ids.shape
- elif inputs_embeds is not None:
- batch_size, seq_length, _ = inputs_embeds.shape
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
-
- infer_state = self.infer_state
- if infer_state.is_context_stage:
- past_key_values_length = 0
- else:
- past_key_values_length = infer_state.max_len_in_batch - 1
-
- seq_length_with_past = seq_length + past_key_values_length
-
- # NOTE: differentiate with prefill stage
- # block_loc require different value-assigning method for two different stage
- # NOTE: differentiate with prefill stage
- # block_loc require different value-assigning method for two different stage
- if infer_state.is_context_stage:
- infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
- infer_state.init_block_loc(
- infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
- )
- else:
- alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
- if alloc_mem is not None:
- infer_state.decode_is_contiguous = True
- infer_state.decode_mem_index = alloc_mem[0]
- infer_state.decode_mem_start = alloc_mem[1]
- infer_state.decode_mem_end = alloc_mem[2]
- infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
- else:
- print(f" *** Encountered allocation non-contiguous")
- print(f" infer_state.cache_manager.max_len_in_batch: {infer_state.max_len_in_batch}")
- infer_state.decode_is_contiguous = False
- alloc_mem = infer_state.cache_manager.alloc(batch_size)
- infer_state.decode_mem_index = alloc_mem
- infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
-
- if position_ids is None:
- device = input_ids.device if input_ids is not None else inputs_embeds.device
- position_ids = torch.arange(
- past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
- )
- position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
- else:
- position_ids = position_ids.view(-1, seq_length).long()
-
- if inputs_embeds is None:
- inputs_embeds = self.embed_tokens(input_ids)
- # embed positions
- if attention_mask is None:
- attention_mask = torch.ones((batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device)
- padding_mask = None
- else:
- if 0 in attention_mask:
- padding_mask = attention_mask
- else:
- padding_mask = None
-
- attention_mask = self._prepare_decoder_attention_mask(
- attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
- )
-
- hidden_states = inputs_embeds
-
- if self.gradient_checkpointing and self.training:
- raise NotImplementedError("not implement gradient_checkpointing and training options ")
-
- if past_key_values_length == 0:
- infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
- position_ids.view(-1).shape[0], -1
- )
- infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
- position_ids.view(-1).shape[0], -1
- )
- else:
- infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(batch_size, -1)
- infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(batch_size, -1)
-
- # decoder layers
- all_hidden_states = () if output_hidden_states else None
- all_self_attns = () if output_attentions else None
- next_decoder_cache = () if use_cache else None
- infer_state.decode_layer_id = 0
- for idx, decoder_layer in enumerate(self.layers):
- if output_hidden_states:
- all_hidden_states += (hidden_states,)
-
- past_key_value = past_key_values[idx] if past_key_values is not None else None
-
- layer_outputs = decoder_layer(
- hidden_states,
- attention_mask=attention_mask,
- position_ids=position_ids,
- past_key_value=past_key_value,
- output_attentions=output_attentions,
- use_cache=use_cache,
- padding_mask=padding_mask,
- infer_state=infer_state,
- )
-
- hidden_states = layer_outputs[0]
- infer_state.decode_layer_id += 1
-
- if use_cache:
- next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
-
- if output_attentions:
- all_self_attns += (layer_outputs[1],)
-
- hidden_states = self.norm(hidden_states)
-
- # add hidden states from the last decoder layer
- if output_hidden_states:
- all_hidden_states += (hidden_states,)
-
- infer_state.is_context_stage = False
- infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
- infer_state.seq_len += 1
- infer_state.max_len_in_batch += 1
-
- next_cache = next_decoder_cache if use_cache else None
- if not return_dict:
- return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
- return BaseModelOutputWithPast(
- last_hidden_state=hidden_states,
- past_key_values=next_cache,
- hidden_states=all_hidden_states,
- attentions=all_self_attns,
- )
-
-
-class SmoothLlamaForCausalLM(BaseSmoothForCausalLM):
- layer_type = "LlamaDecoderLayer"
-
- def __init__(self, model: PreTrainedModel, quantized: bool = False):
- super().__init__(model, quantized)
-
- # Adatped from https://github.com/mit-han-lab/smoothquant/blob/main/smoothquant/calibration.py
- def get_act_dict(
- self,
- tokenizer,
- dataset,
- num_samples=512,
- seq_len=512,
- ):
- llama_model = self.model
-
- llama_model.eval()
- device = next(llama_model.parameters()).device
- # print("model:", llama_model)
- act_dict = defaultdict(dict)
-
- def stat_io_hook(m, x, y, name):
- if isinstance(x, tuple):
- x = x[0]
- if name not in act_dict or "input" not in act_dict[name]:
- act_dict[name]["input"] = x.detach().abs().max().item()
- else:
- act_dict[name]["input"] = max(act_dict[name]["input"], x.detach().abs().max().item())
- if isinstance(y, tuple):
- y = y[0]
- if name not in act_dict or "output" not in act_dict[name]:
- act_dict[name]["output"] = y.detach().abs().max().item()
- else:
- act_dict[name]["output"] = max(act_dict[name]["output"], y.detach().abs().max().item())
-
- for name, m in llama_model.named_modules():
- if isinstance(m, LlamaAttention):
- setattr(m, "q_apply_rotary", LlamaApplyRotary())
- setattr(m, "k_apply_rotary", LlamaApplyRotary())
- m.forward = types.MethodType(llama_decoder_layer_forward, m)
-
- hooks = []
- for name, m in llama_model.named_modules():
- if isinstance(m, LlamaApplyRotary):
- hooks.append(m.register_forward_hook(partial(stat_io_hook, name=name)))
- if isinstance(m, torch.nn.Linear):
- hooks.append(m.register_forward_hook(partial(stat_io_hook, name=name)))
-
- self.collect_act_dict(llama_model, tokenizer, dataset, act_dict, device, num_samples, seq_len)
-
- for hook in hooks:
- hook.remove()
- return act_dict
-
- def smooth_fn(self, scales, alpha=0.5):
- model = self.model
- for name, module in model.named_modules():
- if isinstance(module, LlamaDecoderLayer):
- attn_ln = module.input_layernorm
- qkv = [module.self_attn.q_proj, module.self_attn.k_proj, module.self_attn.v_proj]
- qkv_input_scales = scales[name + ".self_attn.q_proj"]
- self.smooth_ln_fcs(attn_ln, qkv, qkv_input_scales, alpha)
-
- def create_quantized_model(model):
- llama_config = model.config
- for i, layer in enumerate(model.model.layers):
- model.model.layers[i] = LlamaSmoothquantDecoderLayer(llama_config)
-
- model.model.forward = types.MethodType(llama_model_forward, model.model)
- cos, sin = init_to_get_rotary(llama_config)
- model.model.register_buffer("_cos_cached", cos)
- model.model.register_buffer("_sin_cached", sin)
-
- def quantized(
- self,
- tokenizer,
- dataset,
- num_samples=512,
- seq_len=512,
- alpha=0.5,
- ):
- llama_model = self.model
- llama_config = llama_model.config
-
- act_scales = self.get_act_scales(llama_model, tokenizer, dataset, num_samples, seq_len)
-
- self.smooth_fn(act_scales, alpha)
-
- act_dict = self.get_act_dict(tokenizer, dataset, num_samples, seq_len)
- decoder_layer_scales = []
-
- for idx in range(llama_config.num_hidden_layers):
- scale_dict = {}
- scale_dict["attn_input_scale"] = act_dict[f"model.layers.{idx}.self_attn.q_proj"]["input"] / 127
- scale_dict["q_output_scale"] = act_dict[f"model.layers.{idx}.self_attn.q_proj"]["output"] / 127
- scale_dict["k_output_scale"] = act_dict[f"model.layers.{idx}.self_attn.k_proj"]["output"] / 127
- scale_dict["v_output_scale"] = act_dict[f"model.layers.{idx}.self_attn.v_proj"]["output"] / 127
-
- scale_dict["q_rotary_output_scale"] = (
- act_dict[f"model.layers.{idx}.self_attn.q_apply_rotary"]["output"] / 127
- )
- scale_dict["k_rotary_output_scale"] = (
- act_dict[f"model.layers.{idx}.self_attn.k_apply_rotary"]["output"] / 127
- )
-
- scale_dict["out_input_scale"] = act_dict[f"model.layers.{idx}.self_attn.o_proj"]["input"] / 127
-
- scale_dict["gate_input_scale"] = act_dict[f"model.layers.{idx}.mlp.gate_proj"]["input"] / 127
- scale_dict["up_input_scale"] = act_dict[f"model.layers.{idx}.mlp.up_proj"]["input"] / 127
- scale_dict["down_input_scale"] = act_dict[f"model.layers.{idx}.mlp.down_proj"]["input"] / 127
-
- decoder_layer_scales.append(scale_dict)
-
- for i, layer in enumerate(llama_model.model.layers):
- orig_layer = layer
- llama_model.model.layers[i] = LlamaSmoothquantDecoderLayer.pack(orig_layer, **decoder_layer_scales[i])
-
- llama_model.model.forward = types.MethodType(llama_model_forward, llama_model.model)
-
- cos, sin = init_to_get_rotary(llama_config)
- llama_model.model.register_buffer("_cos_cached", cos.to(self.model.device))
- llama_model.model.register_buffer("_sin_cached", sin.to(self.model.device))
diff --git a/colossalai/inference/quant/smoothquant/models/parallel_linear.py b/colossalai/inference/quant/smoothquant/models/parallel_linear.py
deleted file mode 100644
index 962b687a1d05..000000000000
--- a/colossalai/inference/quant/smoothquant/models/parallel_linear.py
+++ /dev/null
@@ -1,264 +0,0 @@
-from typing import List, Union
-
-import torch
-import torch.distributed as dist
-import torch.nn as nn
-from torch.distributed import ProcessGroup
-
-from colossalai.lazy import LazyInitContext
-from colossalai.shardformer.layer import ParallelModule
-
-from .linear import W8A8B8O8Linear, W8A8BFP32O32LinearSiLU, W8A8BFP32OFP32Linear
-
-
-def split_row_copy(smooth_linear, para_linear, tp_size=1, tp_rank=0, split_num=1):
- qweights = smooth_linear.weight.split(smooth_linear.out_features // split_num, dim=0)
- if smooth_linear.bias is not None:
- bias = smooth_linear.bias.split(smooth_linear.out_features // split_num, dim=0)
-
- smooth_split_out_features = para_linear.out_features // split_num
-
- for i in range(split_num):
- para_linear.weight[i * smooth_split_out_features : (i + 1) * smooth_split_out_features, :] = qweights[i][
- tp_rank * smooth_split_out_features : (tp_rank + 1) * smooth_split_out_features, :
- ]
-
- if para_linear.bias is not None:
- para_linear.bias[:, i * smooth_split_out_features : (i + 1) * smooth_split_out_features] = bias[i][
- :, tp_rank * smooth_split_out_features : (tp_rank + 1) * smooth_split_out_features
- ]
-
-
-def split_column_copy(smooth_linear, para_linear, tp_rank=0, split_num=1):
- qweights = smooth_linear.weight.split(smooth_linear.in_features // split_num, dim=-1)
-
- smooth_split_in_features = para_linear.in_features // split_num
-
- for i in range(split_num):
- para_linear.weight[:, i * smooth_split_in_features : (i + 1) * smooth_split_in_features] = qweights[i][
- :, tp_rank * smooth_split_in_features : (tp_rank + 1) * smooth_split_in_features
- ]
-
- if smooth_linear.bias is not None:
- para_linear.bias.copy_(smooth_linear.bias)
-
-
-class RowW8A8B8O8Linear(W8A8B8O8Linear, ParallelModule):
- def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
- super().__init__(in_features, out_features, alpha, beta)
- self.process_group = None
- self.tp_size = 1
- self.tp_rank = 0
-
- @staticmethod
- def from_native_module(
- module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
- ) -> ParallelModule:
- LazyInitContext.materialize(module)
- # get the attributes
- out_features = module.out_features
-
- # ensure only one process group is passed
- if isinstance(process_group, (list, tuple)):
- assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
- process_group = process_group[0]
-
- tp_size = dist.get_world_size(process_group)
- tp_rank = dist.get_rank(process_group)
-
- if out_features < tp_size:
- return module
-
- if out_features % tp_size != 0:
- raise ValueError(
- f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
- )
- linear_1d = RowW8A8B8O8Linear(module.in_features, module.out_features // tp_size)
- linear_1d.tp_size = tp_size
- linear_1d.tp_rank = tp_rank
- linear_1d.process_group = process_group
- linear_1d.a = module.a.clone().detach()
- linear_1d.b = module.b.clone().detach()
- split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
- return linear_1d
-
-
-class ColW8A8B8O8Linear(W8A8B8O8Linear, ParallelModule):
- def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
- super().__init__(in_features, out_features, alpha, beta)
- self.process_group = None
- self.tp_size = 1
- self.tp_rank = 0
-
- @staticmethod
- def from_native_module(
- module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
- ) -> ParallelModule:
- LazyInitContext.materialize(module)
- # get the attributes
- in_features = module.in_features
-
- # ensure only one process group is passed
- if isinstance(process_group, (list, tuple)):
- assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
- process_group = process_group[0]
-
- tp_size = dist.get_world_size(process_group)
- tp_rank = dist.get_rank(process_group)
-
- if in_features < tp_size:
- return module
-
- if in_features % tp_size != 0:
- raise ValueError(
- f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
- )
- linear_1d = ColW8A8B8O8Linear(module.in_features // tp_size, module.out_features)
- linear_1d.tp_size = tp_size
- linear_1d.tp_rank = tp_rank
- linear_1d.process_group = process_group
- linear_1d.a = torch.tensor(module.a)
- linear_1d.b = torch.tensor(module.b)
-
- split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
- if linear_1d.bias is not None:
- linear_1d.bias = linear_1d.bias // tp_size
-
- return linear_1d
-
- @torch.no_grad()
- def forward(self, x):
- output = super().forward(x)
- if self.tp_size > 1:
- dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
- return output
-
-
-class RowW8A8BFP32O32LinearSiLU(W8A8BFP32O32LinearSiLU, ParallelModule):
- def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
- super().__init__(in_features, out_features, alpha, beta)
- self.process_group = None
- self.tp_size = 1
- self.tp_rank = 0
-
- @staticmethod
- def from_native_module(
- module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
- ) -> ParallelModule:
- LazyInitContext.materialize(module)
- # get the attributes
- out_features = module.out_features
-
- # ensure only one process group is passed
- if isinstance(process_group, (list, tuple)):
- assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
- process_group = process_group[0]
-
- tp_size = dist.get_world_size(process_group)
- tp_rank = dist.get_rank(process_group)
-
- if out_features < tp_size:
- return module
-
- if out_features % tp_size != 0:
- raise ValueError(
- f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
- )
- linear_1d = RowW8A8BFP32O32LinearSiLU(module.in_features, module.out_features // tp_size)
- linear_1d.tp_size = tp_size
- linear_1d.tp_rank = tp_rank
- linear_1d.process_group = process_group
- linear_1d.a = module.a.clone().detach()
-
- split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
- return linear_1d
-
-
-class RowW8A8BFP32OFP32Linear(W8A8BFP32OFP32Linear, ParallelModule):
- def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
- super().__init__(in_features, out_features, alpha, beta)
- self.process_group = None
- self.tp_size = 1
- self.tp_rank = 0
-
- @staticmethod
- def from_native_module(
- module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
- ) -> ParallelModule:
- LazyInitContext.materialize(module)
- # get the attributes
- out_features = module.out_features
-
- # ensure only one process group is passed
- if isinstance(process_group, (list, tuple)):
- assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
- process_group = process_group[0]
-
- tp_size = dist.get_world_size(process_group)
- tp_rank = dist.get_rank(process_group)
-
- if out_features < tp_size:
- return module
-
- if out_features % tp_size != 0:
- raise ValueError(
- f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
- )
- linear_1d = RowW8A8BFP32OFP32Linear(module.in_features, module.out_features // tp_size)
- linear_1d.tp_size = tp_size
- linear_1d.tp_rank = tp_rank
- linear_1d.process_group = process_group
- linear_1d.a = module.a.clone().detach()
-
- split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
- return linear_1d
-
-
-class ColW8A8BFP32OFP32Linear(W8A8BFP32OFP32Linear, ParallelModule):
- def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
- super().__init__(in_features, out_features, alpha, beta)
- self.process_group = None
- self.tp_size = 1
- self.tp_rank = 0
-
- @staticmethod
- def from_native_module(
- module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
- ) -> ParallelModule:
- LazyInitContext.materialize(module)
- # get the attributes
- in_features = module.in_features
-
- # ensure only one process group is passed
- if isinstance(process_group, (list, tuple)):
- assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
- process_group = process_group[0]
-
- tp_size = dist.get_world_size(process_group)
- tp_rank = dist.get_rank(process_group)
-
- if in_features < tp_size:
- return module
-
- if in_features % tp_size != 0:
- raise ValueError(
- f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
- )
- linear_1d = ColW8A8BFP32OFP32Linear(module.in_features // tp_size, module.out_features)
- linear_1d.tp_size = tp_size
- linear_1d.tp_rank = tp_rank
- linear_1d.process_group = process_group
- linear_1d.a = module.a.clone().detach()
-
- split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
- if linear_1d.bias is not None:
- linear_1d.bias = linear_1d.bias / tp_size
-
- return linear_1d
-
- @torch.no_grad()
- def forward(self, x):
- output = super().forward(x)
- if self.tp_size > 1:
- dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
- return output
diff --git a/colossalai/inference/sampler.py b/colossalai/inference/sampler.py
new file mode 100644
index 000000000000..d3857a3bda70
--- /dev/null
+++ b/colossalai/inference/sampler.py
@@ -0,0 +1,108 @@
+from typing import List, Optional, Tuple
+
+import torch
+from transformers.generation import GenerationConfig
+
+from colossalai.inference.logit_processors import logit_processor
+
+
+def greedy_sample(
+ generation_config,
+ logprobs: torch.Tensor,
+) -> torch.Tensor:
+ """
+ Sample tokens greedyly.
+ """
+ results = torch.argmax(logprobs, dim=-1)
+ return results
+
+
+def multinomial_sample(
+ generation_config,
+ probs: torch.Tensor,
+) -> torch.Tensor:
+ """
+ Sample tokens in a random phase.
+ """
+ random_results = torch.multinomial(probs, num_samples=1).squeeze(1)
+ return random_results
+
+
+def beam_search_sample(
+ generation_config,
+ logprobs: torch.Tensor,
+ is_prompt: bool = False,
+) -> List[Tuple[List[int], List[int]]]:
+ """
+ Sample tokens with beam search.
+ We sample 2 * beam_width candidates to make sure that with high probability we can get `beam_width` candidates in addition to
+ the finished sequences for the next iteration.
+
+ ref:
+ https://github.com/tensorflow/tensor2tensor/blob/bafdc1b67730430d38d6ab802cbd51f9d053ba2e/tensor2tensor/utils/beam_search.py#L557-L563
+ for details. See also HF reference:
+ https://github.com/huggingface/transformers/blob/a4dd53d88e4852f023332d284ff07a01afcd5681/src/transformers/generation/utils.py#L3063-L3065
+
+ # NOTE: this beam search sample function is wrong now.
+ """
+
+ beam_width = generation_config.num_beams
+ results = []
+ if is_prompt:
+ # Prompt phase.
+ parent_ids = [0] * (2 * beam_width)
+ _, next_token_ids = torch.topk(logprobs[0], 2 * beam_width)
+ next_token_ids = next_token_ids.tolist()
+ else:
+ # Generation phase.
+ # cumulative_logprobs = [seq_data[seq_id].cumulative_logprob for seq_id in seq_ids]
+ cumulative_logprobs = torch.tensor(logprobs, dtype=torch.float, device=seq_group_logprobs.device)
+ seq_group_logprobs = seq_group_logprobs + cumulative_logprobs.unsqueeze(dim=1)
+ _, topk_ids = torch.topk(logprobs.flatten(), 2 * beam_width)
+
+ results.append((next_token_ids, parent_ids))
+ return results
+
+
+def _sample(probs: torch.Tensor, logprobs: torch.Tensor, generation_config: GenerationConfig, is_prompt: bool = False):
+ if generation_config.num_beams == 1:
+ if generation_config.do_sample:
+ sample_tokens = multinomial_sample(generation_config, probs)
+ else:
+ sample_tokens = greedy_sample(generation_config, logprobs)
+ else:
+ sample_tokens = beam_search_sample(generation_config, logprobs, is_prompt=is_prompt)
+
+ return sample_tokens
+
+
+def search_tokens(
+ generation_config: GenerationConfig,
+ logits,
+ is_prompt: bool = False,
+ batch_token_ids: Optional[List[List[int]]] = None,
+):
+ """
+ Sample tokens for finished requests.
+ """
+ # NOTE: need to decide the granularity to process logits (sequence or batch)
+ config_dict = generation_config.to_dict()
+ # process repetition_penalty, no_repeat_ngram_size
+ for type in ["repetition_penalty", "no_repeat_ngram_size"]:
+ if type in config_dict and config_dict[type] is not None:
+ logits = logit_processor(type, logits, config_dict[type], batch_token_ids)
+
+ # do logit processor
+ if generation_config.do_sample:
+ # process temperature, top_k, top_p
+ for type in ["temperature", "top_k", "top_p"]:
+ if type in config_dict and config_dict[type] is not None:
+ logits = logit_processor(type, logits, config_dict[type])
+
+ # calculate probs
+ probs = torch.softmax(logits, dim=-1, dtype=torch.float)
+ logprobs = torch.log_softmax(logits, dim=-1, dtype=torch.float)
+
+ # sample the next tokens
+ sample_tokens = _sample(probs, logprobs, generation_config, is_prompt)
+ return sample_tokens
diff --git a/colossalai/inference/server/README.md b/colossalai/inference/server/README.md
new file mode 100644
index 000000000000..8b5f29fc097d
--- /dev/null
+++ b/colossalai/inference/server/README.md
@@ -0,0 +1,27 @@
+# Online Service
+Colossal-Inference supports fast-api based online service. Simple completion and chat are both supported. Follow the commands below and
+you can simply construct a server with both completion and chat functionalities. For now we only support `Llama` model, we will fullfill
+the blank quickly.
+
+# Usage
+```bash
+# First, Lauch an API locally.
+python3 -m colossalai.inference.server.api_server --model path of your llama2 model --chat_template "{% for message in messages %}
+{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}"
+
+
+# Second, you can turn to the page `http://127.0.0.1:8000/docs` to check the api
+
+# For completion service, you can invoke it
+curl -X POST http://127.0.0.1:8000/completion -H 'Content-Type: application/json' -d '{"prompt":"hello, who are you? ","stream":"False"}'
+
+# For chat service, you can invoke it
+curl -X POST http://127.0.0.1:8000/completion -H 'Content-Type: application/json' -d '{"converation":
+ [{"role": "system", "content": "you are a helpful assistant"},
+ {"role": "user", "content": "what is 1+1?"},],
+ "stream": "False",}'
+# If you just want to test a simple generation, turn to generate api
+curl -X POST http://127.0.0.1:8000/generate -H 'Content-Type: application/json' -d '{"prompt":"hello, who are you? ","stream":"False"}'
+
+```
+We also support streaming output, simply change the `stream` to `True` in the request body.
diff --git a/colossalai/inference/server/__init__.py b/colossalai/inference/server/__init__.py
new file mode 100644
index 000000000000..e69de29bb2d1
diff --git a/colossalai/inference/server/api_server.py b/colossalai/inference/server/api_server.py
new file mode 100644
index 000000000000..dfbd2c9061ae
--- /dev/null
+++ b/colossalai/inference/server/api_server.py
@@ -0,0 +1,210 @@
+"""
+Doc:
+ Feature:
+ - FastAPI based http server for Colossal-Inference
+ - Completion Service Supported
+ Usage: (for local user)
+ - First, Lauch an API locally. `python3 -m colossalai.inference.server.api_server --model path of your llama2 model`
+ - Second, you can turn to the page `http://127.0.0.1:8000/docs` to check the api
+ - For completion service, you can invoke it by using `curl -X POST http://127.0.0.1:8000/completion \
+ -H 'Content-Type: application/json' \
+ -d '{"prompt":"hello, who are you? ","stream":"False"}'`
+ Version: V1.0
+"""
+
+import argparse
+import json
+
+import uvicorn
+from fastapi import FastAPI, Request
+from fastapi.responses import JSONResponse, Response, StreamingResponse
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+from colossalai.inference.config import InferenceConfig
+from colossalai.inference.server.chat_service import ChatServing
+from colossalai.inference.server.completion_service import CompletionServing
+from colossalai.inference.server.utils import id_generator
+
+from colossalai.inference.core.async_engine import AsyncInferenceEngine, InferenceEngine # noqa
+
+TIMEOUT_KEEP_ALIVE = 5 # seconds.
+supported_models_dict = {"Llama_Models": ("llama2-7b",)}
+prompt_template_choices = ["llama", "vicuna"]
+async_engine = None
+chat_serving = None
+completion_serving = None
+
+app = FastAPI()
+
+
+# NOTE: (CjhHa1) models are still under development, need to be updated
+@app.get("/models")
+def get_available_models() -> Response:
+ return JSONResponse(supported_models_dict)
+
+
+@app.post("/generate")
+async def generate(request: Request) -> Response:
+ """Generate completion for the request.
+
+ A request should be a JSON object with the following fields:
+ - prompts: the prompts to use for the generation.
+ - stream: whether to stream the results or not.
+ - other fields:
+ """
+ request_dict = await request.json()
+ prompt = request_dict.pop("prompt")
+ stream = request_dict.pop("stream", "false").lower()
+
+ request_id = id_generator()
+ generation_config = get_generation_config(request_dict)
+ results = engine.generate(request_id, prompt, generation_config=generation_config)
+
+ # Streaming case
+ def stream_results():
+ for request_output in results:
+ ret = {"text": request_output[len(prompt) :]}
+ yield (json.dumps(ret) + "\0").encode("utf-8")
+
+ if stream == "true":
+ return StreamingResponse(stream_results())
+
+ # Non-streaming case
+ final_output = None
+ for request_output in results:
+ if request.is_disconnected():
+ # Abort the request if the client disconnects.
+ engine.abort(request_id)
+ return Response(status_code=499)
+ final_output = request_output[len(prompt) :]
+
+ assert final_output is not None
+ ret = {"text": final_output}
+ return JSONResponse(ret)
+
+
+@app.post("/completion")
+async def create_completion(request: Request):
+ request_dict = await request.json()
+ stream = request_dict.pop("stream", "false").lower()
+ generation_config = get_generation_config(request_dict)
+ result = await completion_serving.create_completion(request, generation_config)
+
+ ret = {"request_id": result.request_id, "text": result.output}
+ if stream == "true":
+ return StreamingResponse(content=json.dumps(ret) + "\0", media_type="text/event-stream")
+ else:
+ return JSONResponse(content=ret)
+
+
+@app.post("/chat")
+async def create_chat(request: Request):
+ request_dict = await request.json()
+
+ stream = request_dict.get("stream", "false").lower()
+ generation_config = get_generation_config(request_dict)
+ message = await chat_serving.create_chat(request, generation_config)
+ if stream == "true":
+ return StreamingResponse(content=message, media_type="text/event-stream")
+ else:
+ ret = {"role": message.role, "text": message.content}
+ return ret
+
+
+def get_generation_config(request):
+ generation_config = async_engine.engine.generation_config
+ for arg in request:
+ if hasattr(generation_config, arg):
+ generation_config[arg] = request[arg]
+ return generation_config
+
+
+def add_engine_config(parser):
+ parser.add_argument("--model", type=str, default="llama2-7b", help="name or path of the huggingface model to use")
+
+ parser.add_argument(
+ "--max-model-len",
+ type=int,
+ default=None,
+ help="model context length. If unspecified, " "will be automatically derived from the model.",
+ )
+ # Parallel arguments
+ parser.add_argument("--tensor-parallel-size", "-tp", type=int, default=1, help="number of tensor parallel replicas")
+
+ # KV cache arguments
+ parser.add_argument("--block-size", type=int, default=16, choices=[8, 16, 32], help="token block size")
+
+ parser.add_argument("--max_batch_size", type=int, default=8, help="maximum number of batch size")
+
+ # generation arguments
+ parser.add_argument(
+ "--prompt_template",
+ choices=prompt_template_choices,
+ default=None,
+ help=f"Allowed choices are {','.join(prompt_template_choices)}. Default to None.",
+ )
+ return parser
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Colossal-Inference API server.")
+
+ parser.add_argument("--host", type=str, default="127.0.0.1")
+ parser.add_argument("--port", type=int, default=8000)
+ parser.add_argument("--ssl-keyfile", type=str, default=None)
+ parser.add_argument("--ssl-certfile", type=str, default=None)
+ parser.add_argument(
+ "--root-path", type=str, default=None, help="FastAPI root_path when app is behind a path based routing proxy"
+ )
+ parser.add_argument(
+ "--model-name",
+ type=str,
+ default=None,
+ help="The model name used in the API. If not "
+ "specified, the model name will be the same as "
+ "the huggingface name.",
+ )
+ parser.add_argument(
+ "--chat-template",
+ type=str,
+ default=None,
+ help="The file path to the chat template, " "or the template in single-line form " "for the specified model",
+ )
+ parser.add_argument(
+ "--response-role",
+ type=str,
+ default="assistant",
+ help="The role name to return if " "`request.add_generation_prompt=true`.",
+ )
+ parser = add_engine_config(parser)
+
+ return parser.parse_args()
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ inference_config = InferenceConfig.from_dict(vars(args))
+ model = AutoModelForCausalLM.from_pretrained(args.model)
+ tokenizer = AutoTokenizer.from_pretrained(args.model)
+ async_engine = AsyncInferenceEngine(
+ start_engine_loop=True, model=model, tokenizer=tokenizer, inference_config=inference_config
+ )
+ engine = async_engine.engine
+ completion_serving = CompletionServing(async_engine, served_model=model.__class__.__name__)
+ chat_serving = ChatServing(
+ async_engine,
+ served_model=model.__class__.__name__,
+ tokenizer=tokenizer,
+ response_role=args.response_role,
+ chat_template=args.chat_template,
+ )
+ app.root_path = args.root_path
+ uvicorn.run(
+ app=app,
+ host=args.host,
+ port=args.port,
+ log_level="debug",
+ timeout_keep_alive=TIMEOUT_KEEP_ALIVE,
+ ssl_keyfile=args.ssl_keyfile,
+ ssl_certfile=args.ssl_certfile,
+ )
diff --git a/colossalai/inference/server/chat_service.py b/colossalai/inference/server/chat_service.py
new file mode 100644
index 000000000000..d84e82d2989a
--- /dev/null
+++ b/colossalai/inference/server/chat_service.py
@@ -0,0 +1,142 @@
+import asyncio
+import codecs
+import logging
+
+from fastapi import Request
+
+from colossalai.inference.core.async_engine import AsyncInferenceEngine
+
+from .utils import ChatCompletionResponseStreamChoice, ChatMessage, DeltaMessage, id_generator
+
+logger = logging.getLogger("colossalai-inference")
+
+
+class ChatServing:
+ def __init__(
+ self, engine: AsyncInferenceEngine, served_model: str, tokenizer, response_role: str, chat_template=None
+ ):
+ self.engine = engine
+ self.served_model = served_model
+ self.tokenizer = tokenizer
+ self.response_role = response_role
+ self._load_chat_template(chat_template)
+ try:
+ asyncio.get_running_loop()
+ except RuntimeError:
+ pass
+
+ async def create_chat(self, request: Request, generation_config):
+ request_dict = await request.json()
+ messages = request_dict["messages"]
+ stream = request_dict.pop("stream", "false").lower()
+ add_generation_prompt = request_dict.pop("add_generation_prompt", False)
+ request_id = id_generator()
+ try:
+ prompt = self.tokenizer.apply_chat_template(
+ conversation=messages,
+ tokenize=False,
+ add_generation_prompt=add_generation_prompt,
+ )
+ except Exception as e:
+ raise RuntimeError(f"Error in applying chat template from request: {str(e)}")
+
+ # it is not a intuitive way
+ self.engine.engine.generation_config = generation_config
+ result_generator = self.engine.generate(request_id, prompt=prompt)
+
+ if stream == "true":
+ return self.chat_completion_stream_generator(request, request_dict, result_generator, request_id)
+ else:
+ return await self.chat_completion_full_generator(request, request_dict, result_generator, request_id)
+
+ async def chat_completion_stream_generator(self, request, request_dict, result_generator, request_id: int):
+ # Send first response for each request.n (index) with the role
+ role = self.get_chat_request_role(request, request_dict)
+ n = request_dict.get("n", 1)
+ echo = request_dict.get("echo", "false").lower()
+ for i in range(n):
+ choice_data = ChatCompletionResponseStreamChoice(index=i, message=DeltaMessage(role=role))
+ data = choice_data.model_dump_json(exclude_unset=True)
+ yield f"data: {data}\n\n"
+
+ # Send response to echo the input portion of the last message
+ if echo == "true":
+ last_msg_content = ""
+ if (
+ request_dict["messages"]
+ and isinstance(request_dict["messages"], list)
+ and request_dict["messages"][-1].get("content")
+ and request_dict["messages"][-1].get("role") == role
+ ):
+ last_msg_content = request_dict["messages"][-1]["content"]
+ if last_msg_content:
+ for i in range(n):
+ choice_data = ChatCompletionResponseStreamChoice(
+ index=i, message=DeltaMessage(content=last_msg_content)
+ )
+ data = choice_data.model_dump_json(exclude_unset=True)
+ yield f"data: {data}\n\n"
+
+ result = await result_generator
+ choice_data = DeltaMessage(content=result.output)
+ data = choice_data.model_dump_json(exclude_unset=True, exclude_none=True)
+ yield f"data: {data}\n\n"
+
+ # Send the final done message after all response.n are finished
+ yield "data: [DONE]\n\n"
+
+ async def chat_completion_full_generator(
+ self,
+ request: Request,
+ request_dict: dict,
+ result_generator,
+ request_id,
+ ):
+ if await request.is_disconnected():
+ # Abort the request if the client disconnects.
+ await self.engine.abort(request_id)
+ return {"error_msg": "Client disconnected"}
+
+ result = await result_generator
+ assert result is not None
+ role = self.get_chat_request_role(request, request_dict)
+ choice_data = ChatMessage(role=role, content=result.output)
+ echo = request_dict.get("echo", "false").lower()
+
+ if echo == "true":
+ last_msg_content = ""
+ if (
+ request.messages
+ and isinstance(request.messages, list)
+ and request.messages[-1].get("content")
+ and request.messages[-1].get("role") == role
+ ):
+ last_msg_content = request.messages[-1]["content"]
+
+ full_message = last_msg_content + choice_data.content
+ choice_data.content = full_message
+
+ return choice_data
+
+ def get_chat_request_role(self, request: Request, request_dict: dict) -> str:
+ add_generation_prompt = request_dict.get("add_generation_prompt", False)
+ if add_generation_prompt:
+ return self.response_role
+ else:
+ return request_dict["messages"][-1]["role"]
+
+ def _load_chat_template(self, chat_template):
+ if chat_template is not None:
+ try:
+ with open(chat_template, "r") as f:
+ self.tokenizer.chat_template = f.read()
+ except OSError:
+ # If opening a file fails, set chat template to be args to
+ # ensure we decode so our escape are interpreted correctly
+ self.tokenizer.chat_template = codecs.decode(chat_template, "unicode_escape")
+
+ logger.info(f"Using supplied chat template:\n{self.tokenizer.chat_template}")
+ elif self.tokenizer.chat_template is not None:
+ logger.info(f"Using default chat template:\n{self.tokenizer.chat_template}")
+ else:
+ logger.warning("No chat template provided. Chat API will not work.")
diff --git a/colossalai/inference/server/completion_service.py b/colossalai/inference/server/completion_service.py
new file mode 100644
index 000000000000..61833b031fb7
--- /dev/null
+++ b/colossalai/inference/server/completion_service.py
@@ -0,0 +1,34 @@
+import asyncio
+
+from colossalai.inference.core.async_engine import AsyncInferenceEngine
+
+from .utils import id_generator
+
+
+class CompletionServing:
+ def __init__(self, engine: AsyncInferenceEngine, served_model: str):
+ self.engine = engine
+ self.served_model = served_model
+
+ try:
+ asyncio.get_running_loop()
+ except RuntimeError:
+ pass
+
+ async def create_completion(self, request, generation_config):
+ request_dict = await request.json()
+ request_id = id_generator()
+
+ prompt = request_dict.pop("prompt")
+
+ # it is not a intuitive way
+ self.engine.engine.generation_config = generation_config
+ result_generator = self.engine.generate(request_id, prompt=prompt)
+
+ if await request.is_disconnected():
+ # Abort the request if the client disconnects.
+ await self.engine.abort(request_id)
+ raise RuntimeError("Client disconnected")
+
+ final_res = await result_generator
+ return final_res
diff --git a/colossalai/inference/server/utils.py b/colossalai/inference/server/utils.py
new file mode 100644
index 000000000000..9eac26576c6c
--- /dev/null
+++ b/colossalai/inference/server/utils.py
@@ -0,0 +1,36 @@
+from typing import Any, Optional
+
+from pydantic import BaseModel
+
+
+# make it singleton
+class NumericIDGenerator:
+ _instance = None
+
+ def __new__(cls):
+ if cls._instance is None:
+ cls._instance = super(NumericIDGenerator, cls).__new__(cls)
+ cls._instance.current_id = 0
+ return cls._instance
+
+ def __call__(self):
+ self.current_id += 1
+ return self.current_id
+
+
+id_generator = NumericIDGenerator()
+
+
+class ChatMessage(BaseModel):
+ role: str
+ content: Any
+
+
+class DeltaMessage(BaseModel):
+ role: Optional[str] = None
+ content: Optional[Any] = None
+
+
+class ChatCompletionResponseStreamChoice(BaseModel):
+ index: int
+ message: DeltaMessage
diff --git a/colossalai/inference/spec/README.md b/colossalai/inference/spec/README.md
new file mode 100644
index 000000000000..d6faaea2efd7
--- /dev/null
+++ b/colossalai/inference/spec/README.md
@@ -0,0 +1,96 @@
+# Speculative Decoding
+
+Colossal-Inference supports speculative decoding using the inference engine, with optimized kernels and cache management for the main model.
+
+Both a drafter model (small model) and a main model (large model) will be used during speculative decoding process. The drafter model will generate a few tokens sequentially, and then the main model will validate those candidate tokens in parallel and accept validated ones. The decoding process will be speeded up, for the latency of speculating multiple tokens by the drafter model is lower than that by the main model.
+
+Moreover, Colossal-Inference also supports GLIDE, a modified draft model architecture that reuses key and value caches from the main model, which improves the acceptance rate and increment the speed-up ratio. Details can be found in research paper GLIDE with a CAPE - A Low-Hassle Method to Accelerate Speculative Decoding on [arXiv](https://arxiv.org/pdf/2402.02082.pdf).
+
+Right now, Colossal-Inference offers a GLIDE model compatible with vicuna7B. You can find the fine-tuned GLIDE drafter model `cxdu/glide47m-vicuna7b` on the HuggingFace Hub: https://huggingface.co/cxdu/glide47m-vicuna7b.
+
+## Usage
+
+For main model, you might want to use model card `lmsys/vicuna-7b-v1.5` at [HuggingFace Hub](https://huggingface.co/lmsys/vicuna-7b-v1.5).
+For regular drafter model, you might want to use model card `JackFram/llama-68m` at [HuggingFace Hub](https://huggingface.co/JackFram/llama-68m).
+For the GLIDE drafter model, you could use model card `cxdu/glide47m-vicuna7b` at [HuggingFace Hub](https://huggingface.co/cxdu/glide47m-vicuna7b).
+
+```python
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+import colossalai
+from colossalai.inference.config import InferenceConfig
+from colossalai.inference.core.engine import InferenceEngine, GenerationConfig
+from colossalai.inference.modeling.models.glide_llama import GlideLlamaForCausalLM, GlideLlamaConfig
+
+# launch colossalai, setup distributed environment
+colossalai.launch_from_torch()
+
+# main model
+model_path_or_name = "REPLACE_TO_VICUNA_7B_PATH_OR_MODEL_CARD"
+model = AutoModelForCausalLM.from_pretrained(model_path_or_name)
+
+# use the same tokenizer for both the main model and the drafter model
+tokenizer = AutoTokenizer.from_pretrained(model_path_or_name)
+tokenizer.pad_token = tokenizer.eos_token
+
+# drafter model
+drafter_model_path_or_name = "REPLACE_TO_LLAMA_68M_PATH_OR_MODEL_CARD"
+drafter_model = AutoModelForCausalLM.from_pretrained(drafter_model_path_or_name)
+
+# Initialize the inference engine
+inference_config = InferenceConfig(
+ dtype="fp16",
+ max_batch_size=1,
+ max_input_len=256,
+ max_output_len=256,
+ prefill_ratio=1.2,
+ block_size=16,
+ max_n_spec_tokens=5,
+ prompt_template="vicuna",
+)
+engine = InferenceEngine(model, tokenizer, inference_config, verbose=True)
+
+# turn on speculative decoding with the drafter model
+engine.enable_spec_dec(drafter_model)
+
+prompt = "Compose an engaging travel blog post about a recent trip to Hawaii, highlighting cultural experiences and must-see attractions. "
+generation_config = GenerationConfig(
+ pad_token_id=tokenizer.eos_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ max_length=128,
+ num_beams=1,
+ do_sample=False,
+)
+out = engine.generate(prompts=[prompt], generation_config=generation_config)
+print(out)
+
+# use GLIDE Llama model as drafter model
+drafter_model_path_or_name = "cxdu/glide47m-vicuna7b"
+glide_config = GlideLlamaConfig(
+ intermediate_size=8192,
+ large_hidden_size=4096,
+ large_num_attention_heads=32,
+ num_hidden_layers=1,
+)
+drafter_model = GlideLlamaForCausalLM.from_pretrained(drafter_model_path_or_name, config=glide_config)
+
+# turn on speculative decoding with the GLIDE model
+engine.enable_spec_dec(drafter_model, use_glide_drafter=True)
+out = engine.generate(prompts=[prompt], generation_config=generation_config)
+print(out)
+```
+
+You could run the above code by
+```bash
+colossalai run --nproc_per_node 1 script_name.py
+```
+
+## Benchmark
+
+With batch size 1, testing with gsm8k and MT-Bench dataset on NVIDIA H800 80G:
+
+| Method | Tokens/Sec |
+| :--------------------------- | :--------- |
+| Non-Spec-Dec | ~90 |
+| Spec-Dec | ~115 |
+| Spec-Dec with GLIDE Model | ~135 |
diff --git a/colossalai/inference/spec/__init__.py b/colossalai/inference/spec/__init__.py
new file mode 100644
index 000000000000..b1a05f6a407e
--- /dev/null
+++ b/colossalai/inference/spec/__init__.py
@@ -0,0 +1,4 @@
+from .drafter import Drafter
+from .struct import DrafterOutput, GlideInput
+
+__all__ = ["Drafter", "DrafterOutput", "GlideInput"]
diff --git a/colossalai/inference/spec/drafter.py b/colossalai/inference/spec/drafter.py
new file mode 100644
index 000000000000..3144b2c90c95
--- /dev/null
+++ b/colossalai/inference/spec/drafter.py
@@ -0,0 +1,121 @@
+from typing import Optional, Tuple
+
+import torch
+import torch.nn as nn
+from transformers import PreTrainedTokenizer
+
+from colossalai.utils import get_current_device
+
+from .struct import DrafterOutput, GlideInput
+
+
+class Drafter:
+ """Container for the Drafter Model (Assistant Model) used in Speculative Decoding.
+
+ Args:
+ model (nn.Module): The drafter model.
+ tokenizer (transformers.PreTrainedTokenizer): The tokenizer for the drafter model.
+ device (torch.device): The device for the drafter model.
+ """
+
+ def __init__(
+ self,
+ model: nn.Module,
+ tokenizer: PreTrainedTokenizer,
+ device: torch.device = None,
+ dtype: torch.dtype = torch.float16,
+ ):
+ self._tokenizer = tokenizer
+ self._device = device or get_current_device()
+ self._dtype = dtype
+ self._drafter_model = model.to(self._device)
+ self._drafter_model = model.to(self._dtype)
+ self._drafter_model.eval()
+
+ def get_model(self) -> nn.Module:
+ return self._drafter_model
+
+ @staticmethod
+ def trim_kv_cache(
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]], invalid_token_num: int
+ ) -> Tuple[Tuple[torch.FloatTensor]]:
+ """Trim the last `invalid_token_num` kv caches.
+
+ past_key_values (Tuple[Tuple[torch.FloatTensor]]): The past key values with shape
+ num_layers x 2 x (bsz x num_heads x seq_len x head_dim)
+ invalid_token_num (int): The number of invalid tokens to trim.
+ """
+ if past_key_values is None or invalid_token_num < 1:
+ return past_key_values
+
+ trimmed_past_key_values = []
+ for layer_idx in range(len(past_key_values)):
+ past_key_value = past_key_values[layer_idx]
+ trimmed_past_key_values.append(
+ (
+ past_key_value[0][:, :, :-invalid_token_num, :],
+ past_key_value[1][:, :, :-invalid_token_num, :],
+ )
+ )
+ past_key_values = tuple(trimmed_past_key_values)
+ return past_key_values
+
+ @torch.inference_mode()
+ def speculate(
+ self,
+ input_ids: torch.Tensor,
+ n_spec_tokens: int,
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ glide_input: Optional[GlideInput] = None,
+ ) -> DrafterOutput:
+ """Generate n_spec_tokens tokens using the drafter model.
+
+ Args:
+ input_ids (torch.Tensor): Input token ids.
+ n_spec_tokens (int): Number of tokens to speculate.
+ past_key_values (Tuple[Tuple[torch.FloatTensor]]): The past key values of the input sequence.
+ glide_input (Optional[GlideInput]): The packed input for glimpsing kv caches of the main model,
+ when using the glide model as a drafter.
+ """
+ assert n_spec_tokens >= 1, f"Invalid number {n_spec_tokens} to speculate"
+
+ # For compatibility with transformers of versions before 4.38.0
+ if input_ids.dim() == 1:
+ input_ids = input_ids.unsqueeze(0)
+
+ logits = []
+ token_ids = []
+
+ kwargs = {"return_dict": True, "use_cache": True}
+ if glide_input:
+ # required only when using glide model
+ kwargs["glide_input"] = glide_input
+
+ for _ in range(n_spec_tokens):
+ # update past key values
+ kwargs["past_key_values"] = past_key_values
+
+ outputs = self._drafter_model(input_ids, **kwargs)
+ next_token_logits = outputs.logits[:, -1, :]
+
+ # NOTE Only use greedy search for speculating.
+ # As the drafter model usually has only a few layers with few parameters,
+ # introducing sampling will make the speculation unstable and lead to worse performance.
+ next_token_ids = torch.argmax(next_token_logits, dim=-1)
+
+ logits.append(next_token_logits)
+ token_ids.append(next_token_ids)
+ if next_token_ids.item() == self._tokenizer.eos_token_id:
+ # TODO(yuanheng-zhao) support bsz > 1
+ break
+ input_ids = next_token_ids[:, None]
+ past_key_values = outputs.past_key_values
+
+ speculated_length = len(token_ids) # For now, only support bsz 1
+ logits = torch.concat(logits, dim=0)
+ token_ids = torch.concat(token_ids, dim=-1)
+
+ out = DrafterOutput(
+ speculated_length=speculated_length, logits=logits, next_tokens=token_ids, past_key_values=past_key_values
+ )
+ return out
diff --git a/colossalai/inference/spec/struct.py b/colossalai/inference/spec/struct.py
new file mode 100644
index 000000000000..143f26d09a59
--- /dev/null
+++ b/colossalai/inference/spec/struct.py
@@ -0,0 +1,55 @@
+from dataclasses import dataclass
+from typing import Optional, Tuple
+
+import torch
+
+
+@dataclass
+class DrafterOutput:
+ """
+ Dataclass for drafter model outputs.
+
+ Args:
+ speculated_length (int): Speculated length of the output sequence
+ It is always less than or equal to spec_num during drafter's speculation process
+ logits (torch.FloatTensor): Logits of the output sequence
+ next_tokens (torch.Tensor): Next token ids
+ past_key_values (Optional[Tuple[Tuple[torch.FloatTensor]]]): Past key values of the output sequence
+ """
+
+ speculated_length: int = None
+ logits: torch.FloatTensor = None
+ next_tokens: torch.Tensor = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+ def __post_init__(self):
+ assert self.speculated_length is not None and self.speculated_length >= 0
+ if self.past_key_values is not None:
+ assert isinstance(self.past_key_values, tuple), "Past key values should be a tuple"
+ assert all([isinstance(past_key_value, tuple) for past_key_value in self.past_key_values])
+
+
+@dataclass
+class GlideInput:
+ """Dataclass for Glide Models (e.g. `colossalai/inference/modeling/models/glide_llama.py`).
+ Used for pack data that will be used during glimpsing KV Caches of the main model.
+
+ Args:
+ block_tables (torch.Tensor): [num_seqs, max_blocks_per_seq] The block table of KV Caches.
+ large_k_cache (torch.Tensor): [num_blocks, num_kv_heads, block_size, head_size]
+ Blocked key cache of the main model
+ large_v_cache (torch.Tensor): Blocked value cache of the main model. It has the same shape as k cache.
+ sequence_lengths (torch.Tensor): [num_seqs] Sequence lengths of the current batch.
+ """
+
+ block_tables: torch.Tensor = None
+ large_k_cache: torch.Tensor = None
+ large_v_cache: torch.Tensor = None
+ sequence_lengths: torch.Tensor = None
+
+ @property
+ def glimpse_ready(self):
+ return all(
+ attr is not None
+ for attr in [self.block_tables, self.large_k_cache, self.large_v_cache, self.sequence_lengths]
+ )
diff --git a/colossalai/inference/struct.py b/colossalai/inference/struct.py
new file mode 100644
index 000000000000..1a3094a27e2d
--- /dev/null
+++ b/colossalai/inference/struct.py
@@ -0,0 +1,180 @@
+import enum
+from dataclasses import dataclass
+from typing import Any, List
+
+from colossalai.logging import get_dist_logger
+
+logger = get_dist_logger(__name__)
+
+"""
+The abstraction of request and sequence are defined here.
+"""
+
+
+class RequestStatus(enum.Enum):
+ """
+ The status of Sentences
+ """
+
+ # running status
+ WAITING = enum.auto()
+ RUNNING = enum.auto()
+ ABORTED = enum.auto()
+
+ # completion status
+ OVERLENGTH = enum.auto()
+ COMPLETED = enum.auto()
+ LENGTH_CAPPED = enum.auto()
+
+ # recycle status
+ RECYCLED = enum.auto()
+
+ @staticmethod
+ def is_finished(status: "RequestStatus") -> bool:
+ return status in [
+ RequestStatus.OVERLENGTH,
+ RequestStatus.COMPLETED,
+ RequestStatus.LENGTH_CAPPED,
+ ]
+
+ @staticmethod
+ def is_running(status: "RequestStatus") -> bool:
+ return status == RequestStatus.RUNNING
+
+ @staticmethod
+ def is_waiting(status: "RequestStatus") -> bool:
+ return status == RequestStatus.WAITING
+
+
+@dataclass
+class Sequence:
+ """Store information of input sequence.
+
+ Args:
+ request_id (int): The ID of input sequence.
+ prompt (str): The prompt of input sequence.
+ input_token_id (List[int]): The tokens ID of input sequence.
+ block_size (int): The block size of input sequence.
+ sample_params (SampleParams): The sample_params of input sequence.
+ block_table (torch.Tensor): The index of input sequence in block_table.
+ eos_token_id (int): The eos token id for this inference process.
+ pad_token_id (int): The pad token id for this inference process.
+ max_output_len (int): Maximum output length.
+ ignore_eos(bool): Whether to ignore the EOS token and continue generating tokens when encountering the EOS token.
+ output(str): The output of sequence
+ """
+
+ request_id: int
+ prompt: str
+ input_token_id: List[int]
+ block_size: int
+ sample_params: Any # SampleParams needs to be imported later.
+ eos_token_id: int
+ pad_token_id: int
+ max_output_len: int = 256
+ # NOTE(caidi) This is a temporary solution. It's better to move the logic to turn on or off the flag in sampling module in future.
+ ignore_eos: bool = False
+ output: str = None
+
+ def __post_init__(self):
+ self.output_token_id = []
+ self.status = RequestStatus.WAITING
+
+ @property
+ def sentence_len(self) -> int:
+ """
+ Get length of current sentence.
+ """
+ return len(self.input_token_id) + len(self.output_token_id)
+
+ @property
+ def input_len(self) -> int:
+ """
+ Get length of input sentence.
+ """
+ return len(self.input_token_id)
+
+ @property
+ def output_len(self) -> int:
+ """
+ Get length of output sentence.
+ """
+ return len(self.output_token_id)
+
+ def check_finish(self) -> bool:
+ """
+ Check whether the inference is finished.
+
+ Returns:
+ bool: Whether the inference is finished.
+ """
+ if RequestStatus.is_finished(self.status):
+ return True
+
+ if self.output_token_id:
+ if (
+ self.output_token_id[-1] == self.eos_token_id and not self.ignore_eos
+ ) or self.output_len >= self.max_output_len:
+ self.status = RequestStatus.COMPLETED
+ return True
+
+ return False
+
+ def revoke_finished_status(self) -> None:
+ """
+ Revoke the finished status of the sequence.
+ This is only used by speculative decoding for now.
+ """
+ if RequestStatus.is_finished(self.status):
+ self.status = RequestStatus.RUNNING
+
+ def __hash__(self):
+ return hash(self.request_id)
+
+ def mark_running(self) -> None:
+ """
+ Set status for prefill reqs.
+ """
+ assert (
+ self.status == RequestStatus.WAITING or RequestStatus.RECYCLED
+ ), "Sequence is not in WAITTING/RECYCLED STATUS"
+ self.status = RequestStatus.RUNNING
+
+ def mark_finished(self) -> None:
+ """
+ Set status for finished reqs.
+ """
+ self.status = RequestStatus.COMPLETED
+
+ def mark_aborted(self) -> None:
+ """
+ Set status for aborted reqs.
+ """
+ self.status = RequestStatus.ABORTED
+
+ def recycle(self) -> None:
+ """
+ Recycle a running sequnce to waiitting list
+ """
+ assert (
+ not self.check_finish() and not self.status == RequestStatus.ABORTED
+ ), "The running sequence \
+ is already done but it still in running list"
+ self.status = RequestStatus.RECYCLED
+
+ def __repr__(self) -> str:
+ return (
+ f"(request_id={self.request_id}, "
+ f"prompt={self.prompt},\n"
+ f"output_token_id={self.output_token_id},\n"
+ f"output={self.output},\n"
+ f"status={self.status.name},\n"
+ f"sample_params={self.sample_params},\n"
+ f"input_len={self.input_len},\n"
+ f"output_len={self.output_len})\n"
+ )
+
+
+def _pad_to_max(x: List[int], max_len: int, pad: int) -> List[int]:
+ assert len(x) <= max_len
+ return [pad] * (max_len - len(x)) + x
diff --git a/colossalai/inference/utils.py b/colossalai/inference/utils.py
new file mode 100644
index 000000000000..072bedec3587
--- /dev/null
+++ b/colossalai/inference/utils.py
@@ -0,0 +1,115 @@
+"""
+Utils for model inference
+"""
+import os
+import re
+from pathlib import Path
+from typing import Optional, Tuple
+
+import torch
+from torch import nn
+
+from colossalai.testing import free_port
+
+
+def init_to_get_rotary(self, base=10000, use_elem=False):
+ """
+ This function initializes the rotary positional embedding, it is compatible for all models and is called in ShardFormer
+ Args:
+ self : Model that holds the rotary positional embedding
+ base : calculation arg
+ use_elem : activated when using chatglm-based models
+ """
+ self.config.head_dim_ = self.config.hidden_size // self.config.num_attention_heads
+ if not hasattr(self.config, "rope_scaling"):
+ rope_scaling_factor = 1.0
+ else:
+ rope_scaling_factor = self.config.rope_scaling.factor if self.config.rope_scaling is not None else 1.0
+
+ if hasattr(self.config, "max_sequence_length"):
+ max_seq_len = self.config.max_sequence_length
+ elif hasattr(self.config, "max_position_embeddings"):
+ max_seq_len = self.config.max_position_embeddings * rope_scaling_factor
+ else:
+ max_seq_len = 2048 * rope_scaling_factor
+ base = float(base)
+
+ # NTK ref: https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/
+ ntk_alpha = os.environ.get("INFER_NTK_ALPHA", None)
+
+ if ntk_alpha is not None:
+ ntk_alpha = float(ntk_alpha)
+ assert ntk_alpha >= 1, "NTK alpha must be greater than or equal to 1"
+ if ntk_alpha > 1:
+ print(f"Note: NTK enabled, alpha set to {ntk_alpha}")
+ max_seq_len *= ntk_alpha
+ base = base * (ntk_alpha ** (self.head_dim_ / (self.head_dim_ - 2))) # Base change formula
+
+ n_elem = self.config.head_dim_
+ if use_elem:
+ n_elem //= 2
+
+ inv_freq = 1.0 / (base ** (torch.arange(0, n_elem, 2, device="cpu", dtype=torch.float32) / n_elem))
+ t = torch.arange(max_seq_len + 1024 * 64, device="cpu", dtype=torch.float32) / rope_scaling_factor
+ freqs = torch.outer(t, inv_freq)
+
+ self._cos_cached = torch.cos(freqs).to(self.dtype).cuda()
+ self._sin_cached = torch.sin(freqs).to(self.dtype).cuda()
+
+
+def has_index_file(checkpoint_path: str) -> Tuple[bool, Optional[Path]]:
+ """
+ Check whether the checkpoint has an index file.
+
+ Args:
+ checkpoint_path (str): path to the checkpoint.
+
+ Returns:
+ Tuple[bool, Optional[Path]]: a tuple of (has_index_file, index_file_path)
+ """
+ checkpoint_path = Path(checkpoint_path)
+ if checkpoint_path.is_file():
+ # check if it is .index.json
+ reg = re.compile("(.*?).index((\..*)?).json")
+ if reg.fullmatch(checkpoint_path.name) is not None:
+ return True, checkpoint_path
+ else:
+ return False, None
+ elif checkpoint_path.is_dir():
+ index_files = list(checkpoint_path.glob("*.index.*json"))
+
+ for index_file in index_files:
+ if "safetensors" in index_file.__str__():
+ return True, index_file.__str__() # return the safetensors file first
+
+ if len(index_files) == 1:
+ return True, index_files[0]
+ else:
+ assert (
+ len(index_files) == 1
+ ), f"Expected to find one .index.json file in {checkpoint_path}, but found {len(index_files)}"
+ return False, None
+ else:
+ raise RuntimeError(f"Invalid checkpoint path {checkpoint_path}. Expected a file or a directory.")
+
+
+def get_model_size(model: nn.Module):
+ """Calculates the total size of the model weights (including biases) in bytes.
+ Args:
+ model: The PyTorch model to analyze.
+ Returns:
+ The total size of the model weights in bytes.
+ """
+ total_size = 0
+ for key, param in model.named_parameters():
+ total_size += param.element_size() * param.numel()
+ return total_size / (1024**3)
+
+
+def find_available_ports(num: int):
+ try:
+ free_ports = [free_port() for i in range(num)]
+ except OSError as e:
+ print(f"An OS error occurred: {e}")
+ raise RuntimeError("Error finding available ports")
+ return free_ports
diff --git a/colossalai/kernel/kernel_loader.py b/colossalai/kernel/kernel_loader.py
index 2dff3bcbcc5e..2411b6482ac1 100644
--- a/colossalai/kernel/kernel_loader.py
+++ b/colossalai/kernel/kernel_loader.py
@@ -8,6 +8,7 @@
FlashAttentionNpuExtension,
FlashAttentionSdpaCudaExtension,
FusedOptimizerCudaExtension,
+ InferenceOpsCudaExtension,
LayerNormCudaExtension,
MoeCudaExtension,
ScaledMaskedSoftmaxCudaExtension,
@@ -21,6 +22,7 @@
"LayerNormLoader",
"MoeLoader",
"FusedOptimizerLoader",
+ "InferenceOpsLoader",
"ScaledMaskedSoftmaxLoader",
"ScaledUpperTriangleMaskedSoftmaxLoader",
]
@@ -97,6 +99,10 @@ class FusedOptimizerLoader(KernelLoader):
REGISTRY = [FusedOptimizerCudaExtension]
+class InferenceOpsLoader(KernelLoader):
+ REGISTRY = [InferenceOpsCudaExtension]
+
+
class ScaledMaskedSoftmaxLoader(KernelLoader):
REGISTRY = [ScaledMaskedSoftmaxCudaExtension]
diff --git a/colossalai/kernel/triton/__init__.py b/colossalai/kernel/triton/__init__.py
index 20da71d394bd..4d2c17db1824 100644
--- a/colossalai/kernel/triton/__init__.py
+++ b/colossalai/kernel/triton/__init__.py
@@ -8,24 +8,24 @@
# There may exist import error even if we have triton installed.
if HAS_TRITON:
- from .context_attention import bloom_context_attn_fwd, llama_context_attn_fwd
- from .copy_kv_cache_dest import copy_kv_cache_to_dest
- from .fused_layernorm import layer_norm
- from .gptq_triton import gptq_fused_linear_triton
- from .int8_rotary_embedding_kernel import int8_rotary_embedding_fwd
- from .smooth_attention import smooth_llama_context_attn_fwd, smooth_token_attention_fwd
+ from .context_attn_unpad import context_attention_unpadded
+ from .flash_decoding import flash_decoding_attention
+ from .fused_rotary_embedding import fused_rotary_embedding
+ from .kvcache_copy import copy_k_to_blocked_cache, copy_kv_to_blocked_cache
+ from .no_pad_rotary_embedding import decoding_fused_rotary_embedding, rotary_embedding
+ from .rms_layernorm import rms_layernorm
+ from .rotary_cache_copy import get_xine_cache
from .softmax import softmax
- from .token_attention_kernel import token_attention_fwd
__all__ = [
- "llama_context_attn_fwd",
- "bloom_context_attn_fwd",
+ "context_attention_unpadded",
+ "flash_decoding_attention",
+ "copy_k_to_blocked_cache",
+ "copy_kv_to_blocked_cache",
"softmax",
- "layer_norm",
- "copy_kv_cache_to_dest",
- "token_attention_fwd",
- "gptq_fused_linear_triton",
- "int8_rotary_embedding_fwd",
- "smooth_llama_context_attn_fwd",
- "smooth_token_attention_fwd",
+ "rms_layernorm",
+ "rotary_embedding",
+ "fused_rotary_embedding",
+ "get_xine_cache",
+ "decoding_fused_rotary_embedding",
]
diff --git a/colossalai/kernel/triton/context_attention.py b/colossalai/kernel/triton/context_attention.py
deleted file mode 100644
index 1725581d637c..000000000000
--- a/colossalai/kernel/triton/context_attention.py
+++ /dev/null
@@ -1,434 +0,0 @@
-import math
-
-import torch
-
-try:
- import triton
- import triton.language as tl
-
- HAS_TRITON = True
-except ImportError:
- HAS_TRITON = False
- print("please install triton from https://github.com/openai/triton")
-
-if HAS_TRITON:
- """
- this function is modified from
- https://github.com/ModelTC/lightllm/blob/f093edc20683ac3ea1bca3fb5d8320a0dd36cf7b/lightllm/models/llama/triton_kernel/context_flashattention_nopad.py#L10
- """
- if triton.__version__ < "2.1.0":
-
- @triton.jit
- def _context_flash_attention_kernel(
- Q,
- K,
- V,
- sm_scale,
- B_Start_Loc,
- B_Seqlen,
- TMP,
- alibi_ptr,
- Out,
- stride_qbs,
- stride_qh,
- stride_qd,
- stride_kbs,
- stride_kh,
- stride_kd,
- stride_vbs,
- stride_vh,
- stride_vd,
- stride_obs,
- stride_oh,
- stride_od,
- stride_tmp_b,
- stride_tmp_h,
- stride_tmp_s,
- # suggtest set-up 64, 128, 256, 512
- BLOCK_M: tl.constexpr,
- BLOCK_DMODEL: tl.constexpr,
- BLOCK_N: tl.constexpr,
- ):
- batch_id = tl.program_id(0)
- cur_head = tl.program_id(1)
- start_m = tl.program_id(2)
-
- # initialize offsets
- offs_n = tl.arange(0, BLOCK_N)
- offs_d = tl.arange(0, BLOCK_DMODEL)
- offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
-
- # get batch info
- cur_batch_seq_len = tl.load(B_Seqlen + batch_id)
- cur_batch_start_index = tl.load(B_Start_Loc + batch_id)
- block_start_loc = BLOCK_M * start_m
-
- load_p_ptrs = (
- Q
- + (cur_batch_start_index + offs_m[:, None]) * stride_qbs
- + cur_head * stride_qh
- + offs_d[None, :] * stride_qd
- )
- q = tl.load(load_p_ptrs, mask=offs_m[:, None] < cur_batch_seq_len, other=0.0)
-
- k_ptrs = K + offs_n[None, :] * stride_kbs + cur_head * stride_kh + offs_d[:, None] * stride_kd
- v_ptrs = V + offs_n[:, None] * stride_vbs + cur_head * stride_vh + offs_d[None, :] * stride_vd
- t_ptrs = TMP + batch_id * stride_tmp_b + cur_head * stride_tmp_h + offs_m * stride_tmp_s
-
- m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
- l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
- acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
-
- if alibi_ptr is not None:
- alibi_m = tl.load(alibi_ptr + cur_head)
-
- block_mask = tl.where(block_start_loc < cur_batch_seq_len, 1, 0)
-
- for start_n in range(0, block_mask * (start_m + 1) * BLOCK_M, BLOCK_N):
- start_n = tl.multiple_of(start_n, BLOCK_N)
- k = tl.load(
- k_ptrs + (cur_batch_start_index + start_n) * stride_kbs,
- mask=(start_n + offs_n[None, :]) < cur_batch_seq_len,
- other=0.0,
- )
-
- qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
- qk += tl.dot(q, k)
- qk *= sm_scale
-
- if alibi_ptr is not None:
- alibi_loc = offs_m[:, None] - (start_n + offs_n[None, :])
- qk -= alibi_loc * alibi_m
-
- qk = tl.where(offs_m[:, None] >= (start_n + offs_n[None, :]), qk, float("-inf"))
-
- m_ij = tl.max(qk, 1)
- p = tl.exp(qk - m_ij[:, None])
- l_ij = tl.sum(p, 1)
- # -- update m_i and l_i
- m_i_new = tl.maximum(m_i, m_ij)
- alpha = tl.exp(m_i - m_i_new)
- beta = tl.exp(m_ij - m_i_new)
- l_i_new = alpha * l_i + beta * l_ij
- # -- update output accumulator --
- # scale p
- p_scale = beta / l_i_new
- p = p * p_scale[:, None]
- # scale acc
- acc_scale = l_i / l_i_new * alpha
- tl.store(t_ptrs, acc_scale)
- acc_scale = tl.load(t_ptrs)
- acc = acc * acc_scale[:, None]
- # update acc
- v = tl.load(
- v_ptrs + (cur_batch_start_index + start_n) * stride_vbs,
- mask=(start_n + offs_n[:, None]) < cur_batch_seq_len,
- other=0.0,
- )
-
- p = p.to(v.dtype)
- acc += tl.dot(p, v)
- # update m_i and l_i
- l_i = l_i_new
- m_i = m_i_new
-
- off_o = (
- (cur_batch_start_index + offs_m[:, None]) * stride_obs
- + cur_head * stride_oh
- + offs_d[None, :] * stride_od
- )
- out_ptrs = Out + off_o
- tl.store(out_ptrs, acc, mask=offs_m[:, None] < cur_batch_seq_len)
- return
-
- else:
- # this function is modified from https://github.com/ModelTC/lightllm/blob/main/lightllm/models/llama/triton_kernel/context_flashattention_nopad.py#L11
- @triton.jit
- def _context_flash_attention_kernel_2(
- Q,
- K,
- V,
- sm_scale,
- Alibi,
- B_Start_Loc,
- B_Seqlen,
- Out,
- kv_group_num,
- stride_qbs,
- stride_qh,
- stride_qd,
- stride_kbs,
- stride_kh,
- stride_kd,
- stride_vbs,
- stride_vh,
- stride_vd,
- stride_obs,
- stride_oh,
- stride_od,
- BLOCK_M: tl.constexpr,
- BLOCK_DMODEL: tl.constexpr,
- BLOCK_N: tl.constexpr,
- ):
- cur_batch = tl.program_id(0)
- cur_head = tl.program_id(1)
- start_m = tl.program_id(2)
-
- if kv_group_num is not None:
- cur_kv_head = cur_head // kv_group_num
-
- cur_batch_seq_len = tl.load(B_Seqlen + cur_batch)
- cur_batch_in_all_start_index = tl.load(B_Start_Loc + cur_batch)
-
- block_start_loc = BLOCK_M * start_m
-
- # initialize offsets
- offs_n = tl.arange(0, BLOCK_N)
- offs_d = tl.arange(0, BLOCK_DMODEL)
- offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
- off_q = (
- (cur_batch_in_all_start_index + offs_m[:, None]) * stride_qbs
- + cur_head * stride_qh
- + offs_d[None, :] * stride_qd
- )
- if kv_group_num is None or kv_group_num == 1:
- off_k = offs_n[None, :] * stride_kbs + cur_head * stride_kh + offs_d[:, None] * stride_kd
- off_v = offs_n[:, None] * stride_vbs + cur_head * stride_vh + offs_d[None, :] * stride_vd
- else:
- off_k = offs_n[None, :] * stride_kbs + cur_kv_head * stride_kh + offs_d[:, None] * stride_kd
- off_v = offs_n[:, None] * stride_vbs + cur_kv_head * stride_vh + offs_d[None, :] * stride_vd
-
- q = tl.load(Q + off_q, mask=offs_m[:, None] < cur_batch_seq_len, other=0.0)
-
- k_ptrs = K + off_k
- v_ptrs = V + off_v
-
- m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
- l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
- acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
-
- if Alibi is not None:
- alibi_m = tl.load(Alibi + cur_head)
-
- block_mask = tl.where(block_start_loc < cur_batch_seq_len, 1, 0)
-
- for start_n in range(0, block_mask * (start_m + 1) * BLOCK_M, BLOCK_N):
- start_n = tl.multiple_of(start_n, BLOCK_N)
- # -- compute qk ----
- k = tl.load(
- k_ptrs + (cur_batch_in_all_start_index + start_n) * stride_kbs,
- mask=(start_n + offs_n[None, :]) < cur_batch_seq_len,
- other=0.0,
- )
-
- qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
- qk += tl.dot(q, k)
- qk *= sm_scale
-
- if Alibi is not None:
- alibi_loc = offs_m[:, None] - (start_n + offs_n[None, :])
- qk -= alibi_loc * alibi_m
-
- qk = tl.where(offs_m[:, None] >= (start_n + offs_n[None, :]), qk, float("-inf"))
-
- m_ij = tl.max(qk, 1)
- p = tl.exp(qk - m_ij[:, None])
- l_ij = tl.sum(p, 1)
- # -- update m_i and l_i
- m_i_new = tl.maximum(m_i, m_ij)
- alpha = tl.exp(m_i - m_i_new)
- beta = tl.exp(m_ij - m_i_new)
- l_i_new = alpha * l_i + beta * l_ij
- # -- update output accumulator --
- # scale p
- p_scale = beta / l_i_new
- p = p * p_scale[:, None]
- # scale acc
- acc_scale = l_i / l_i_new * alpha
- acc = acc * acc_scale[:, None]
- # update acc
- v = tl.load(
- v_ptrs + (cur_batch_in_all_start_index + start_n) * stride_vbs,
- mask=(start_n + offs_n[:, None]) < cur_batch_seq_len,
- other=0.0,
- )
-
- p = p.to(v.dtype)
- acc += tl.dot(p, v)
- # update m_i and l_i
- l_i = l_i_new
- m_i = m_i_new
- # initialize pointers to output
- off_o = (
- (cur_batch_in_all_start_index + offs_m[:, None]) * stride_obs
- + cur_head * stride_oh
- + offs_d[None, :] * stride_od
- )
- out_ptrs = Out + off_o
- tl.store(out_ptrs, acc, mask=offs_m[:, None] < cur_batch_seq_len)
- return
-
- @torch.no_grad()
- def bloom_context_attn_fwd(q, k, v, o, b_start_loc, b_seq_len, max_input_len, alibi=None):
- BLOCK = 128
- # shape constraints
- Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
- assert Lq == Lk, "context process only supports equal query, key, value length"
- assert Lk == Lv, "context process only supports equal query, key, value length"
- assert Lk in {16, 32, 64, 128}
-
- sm_scale = 1.0 / math.sqrt(Lk)
- batch, head = b_seq_len.shape[0], q.shape[1]
-
- grid = (batch, head, triton.cdiv(max_input_len, BLOCK))
-
- num_warps = 4 if Lk <= 64 else 8
-
- if triton.__version__ < "2.1.0":
- tmp = torch.empty((batch, head, max_input_len + 256), device=q.device, dtype=torch.float32)
- _context_flash_attention_kernel[grid](
- q,
- k,
- v,
- sm_scale,
- b_start_loc,
- b_seq_len,
- tmp,
- alibi,
- o,
- q.stride(0),
- q.stride(1),
- q.stride(2),
- k.stride(0),
- k.stride(1),
- k.stride(2),
- v.stride(0),
- v.stride(1),
- v.stride(2),
- o.stride(0),
- o.stride(1),
- o.stride(2),
- tmp.stride(0),
- tmp.stride(1),
- tmp.stride(2),
- # manually setting this blcok num, we can use tuning config to futher speed-up
- BLOCK_M=BLOCK,
- BLOCK_DMODEL=Lk,
- BLOCK_N=BLOCK,
- num_warps=num_warps,
- num_stages=1,
- )
- else:
- _context_flash_attention_kernel_2[grid](
- q,
- k,
- v,
- sm_scale,
- alibi,
- b_start_loc,
- b_seq_len,
- o,
- None,
- q.stride(0),
- q.stride(1),
- q.stride(2),
- k.stride(0),
- k.stride(1),
- k.stride(2),
- v.stride(0),
- v.stride(1),
- v.stride(2),
- o.stride(0),
- o.stride(1),
- o.stride(2),
- BLOCK_M=BLOCK,
- BLOCK_DMODEL=Lk,
- BLOCK_N=BLOCK,
- num_warps=num_warps,
- num_stages=1,
- )
-
- return
-
- @torch.no_grad()
- def llama_context_attn_fwd(q, k, v, o, b_start_loc, b_seq_len, max_input_len):
- BLOCK = 128
- # shape constraints
- Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
- assert Lq == Lk, "context process only supports equal query, key, value length"
- assert Lk == Lv, "context process only supports equal query, key, value length"
- assert Lk in {16, 32, 64, 128}
-
- sm_scale = 1.0 / math.sqrt(Lk)
- batch, head = b_seq_len.shape[0], q.shape[1]
-
- grid = (batch, head, triton.cdiv(max_input_len, BLOCK))
-
- tmp = torch.empty((batch, head, max_input_len + 256), device=q.device, dtype=torch.float32)
- num_warps = 4 if Lk <= 64 else 8
- # num_warps = 4
-
- if triton.__version__ < "2.1.0":
- _context_flash_attention_kernel[grid](
- q,
- k,
- v,
- sm_scale,
- b_start_loc,
- b_seq_len,
- tmp,
- None,
- o,
- q.stride(0),
- q.stride(1),
- q.stride(2),
- k.stride(0),
- k.stride(1),
- k.stride(2),
- v.stride(0),
- v.stride(1),
- v.stride(2),
- o.stride(0),
- o.stride(1),
- o.stride(2),
- tmp.stride(0),
- tmp.stride(1),
- tmp.stride(2),
- BLOCK_M=BLOCK,
- BLOCK_DMODEL=Lk,
- BLOCK_N=BLOCK,
- num_warps=num_warps,
- num_stages=1,
- )
- else:
- kv_group_num = q.shape[1] // k.shape[1]
- _context_flash_attention_kernel_2[grid](
- q,
- k,
- v,
- sm_scale,
- None,
- b_start_loc,
- b_seq_len,
- o,
- kv_group_num,
- q.stride(0),
- q.stride(1),
- q.stride(2),
- k.stride(0),
- k.stride(1),
- k.stride(2),
- v.stride(0),
- v.stride(1),
- v.stride(2),
- o.stride(0),
- o.stride(1),
- o.stride(2),
- BLOCK_M=BLOCK,
- BLOCK_DMODEL=Lk,
- BLOCK_N=BLOCK,
- num_warps=num_warps,
- num_stages=1,
- )
-
- return
diff --git a/colossalai/kernel/triton/context_attn_unpad.py b/colossalai/kernel/triton/context_attn_unpad.py
new file mode 100644
index 000000000000..9c69c4125d62
--- /dev/null
+++ b/colossalai/kernel/triton/context_attn_unpad.py
@@ -0,0 +1,727 @@
+# Applying the FlashAttention V2 as described in:
+# "FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning"
+# by Tri Dao, 2023
+# https://github.com/Dao-AILab/flash-attention
+#
+# Inspired and modified from Triton Tutorial - Fused Attention
+# https://triton-lang.org/main/getting-started/tutorials/06-fused-attention.html
+
+import torch
+import triton
+import triton.language as tl
+
+
+# Triton 2.1.0
+@triton.jit
+def _fwd_context_paged_attention_kernel(
+ Q,
+ K,
+ V,
+ O,
+ KCache,
+ VCache,
+ BLOCK_TABLES, # [num_seqs, max_blocks_per_sequence]
+ batch_size,
+ stride_qt,
+ stride_qh,
+ stride_qd,
+ stride_kt,
+ stride_kh,
+ stride_kd,
+ stride_vt,
+ stride_vh,
+ stride_vd,
+ stride_ot,
+ stride_oh,
+ stride_od,
+ stride_cacheb,
+ stride_cacheh,
+ stride_cachebs,
+ stride_cached,
+ stride_bts,
+ stride_btb,
+ context_lengths,
+ sm_scale,
+ KV_GROUPS: tl.constexpr,
+ BLOCK_SIZE: tl.constexpr,
+ HEAD_DIM: tl.constexpr,
+ BLOCK_M: tl.constexpr,
+ BLOCK_N: tl.constexpr,
+):
+ cur_seq_idx = tl.program_id(0)
+ if cur_seq_idx >= batch_size:
+ return
+ cur_head_idx = tl.program_id(1)
+ block_start_m = tl.program_id(2) # Br, max_input_len // Block_M
+ cur_kv_head_idx = cur_head_idx // KV_GROUPS
+
+ # NOTE It requires BLOCK_M, BLOCK_N, and BLOCK_SIZE to be the same
+ tl.static_assert(BLOCK_M == BLOCK_N)
+ tl.static_assert(BLOCK_N == BLOCK_SIZE)
+
+ # get the current sequence length from provided context lengths tensor
+ cur_seq_len = tl.load(context_lengths + cur_seq_idx)
+ # NOTE when talking to fused QKV and a nopadding context attention,
+ # we assume that the input Q/K/V is contiguous, and thus here `prev_seq_len_sum`
+ # could be considered as the start index of the current sequence.
+ # FIXME might want to explore better way to get the summation of prev seq lengths.
+ # `tl.sum(tensor[:end])` is invalid as tensor slice is not supported in triton.
+ prev_seq_len_sum = 0
+ for i in range(0, cur_seq_idx):
+ prev_seq_len_sum += tl.load(context_lengths + i)
+
+ offset_q = prev_seq_len_sum * stride_qt + cur_head_idx * stride_qh
+ offset_kv = prev_seq_len_sum * stride_kt + cur_kv_head_idx * stride_kh
+ Q_block_ptr = tl.make_block_ptr(
+ base=Q + offset_q,
+ shape=(cur_seq_len, HEAD_DIM),
+ strides=(stride_qt, stride_qd),
+ offsets=(block_start_m * BLOCK_M, 0),
+ block_shape=(BLOCK_M, HEAD_DIM),
+ order=(1, 0),
+ )
+ K_block_ptr = tl.make_block_ptr(
+ base=K + offset_kv,
+ shape=(HEAD_DIM, cur_seq_len),
+ strides=(stride_kd, stride_kt),
+ offsets=(0, 0),
+ block_shape=(HEAD_DIM, BLOCK_N),
+ order=(0, 1),
+ )
+ V_block_ptr = tl.make_block_ptr(
+ base=V + offset_kv,
+ shape=(cur_seq_len, HEAD_DIM),
+ strides=(stride_vt, stride_vd),
+ offsets=(0, 0),
+ block_shape=(BLOCK_N, HEAD_DIM),
+ order=(1, 0),
+ )
+ O_block_ptr = tl.make_block_ptr(
+ base=O + offset_q,
+ shape=(cur_seq_len, HEAD_DIM),
+ strides=(stride_ot, stride_od),
+ offsets=(block_start_m * BLOCK_M, 0),
+ block_shape=(BLOCK_M, HEAD_DIM),
+ order=(1, 0),
+ )
+
+ # block table for the current sequence
+ block_table_ptr = BLOCK_TABLES + cur_seq_idx * stride_bts
+ # block indexes on block table (i.e. 0, 1, 2, ..., max_blocks_per_seq)
+ # Consider `block_start_m` as the logical block idx in the current block table,
+ # as we have BLOCK_M the same size as the block size.
+ cur_block_table_idx = block_start_m
+ cur_block_id = tl.load(block_table_ptr + cur_block_table_idx * stride_btb)
+ offset_kvcache = cur_block_id * stride_cacheb + cur_kv_head_idx * stride_cacheh
+
+ offsets_m = block_start_m * BLOCK_M + tl.arange(0, BLOCK_M)
+ offsets_n = tl.arange(0, BLOCK_N)
+ m_i = tl.full([BLOCK_M], float("-inf"), dtype=tl.float32)
+ l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
+ acc = tl.zeros([BLOCK_M, HEAD_DIM], dtype=tl.float32)
+
+ if block_start_m * BLOCK_M >= cur_seq_len:
+ return
+
+ Q_i = tl.load(Q_block_ptr, boundary_check=(1, 0))
+
+ for block_start_n in range(0, (block_start_m + 1) * BLOCK_M, BLOCK_N):
+ block_start_n = tl.multiple_of(block_start_n, BLOCK_N)
+
+ k = tl.load(K_block_ptr, boundary_check=(0, 1))
+ S_ij = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
+ S_ij += tl.dot(Q_i, k)
+ S_ij *= sm_scale
+ S_ij += tl.where(offsets_m[:, None] >= (block_start_n + offsets_n[None, :]), 0, float("-inf"))
+
+ m_ij = tl.max(S_ij, 1) # rowmax(Sij)
+ m_ij = tl.maximum(m_i, m_ij) # m_ij
+ S_ij -= m_ij[:, None]
+ p_ij_hat = tl.exp(S_ij)
+ scale = tl.exp(m_i - m_ij)
+ l_ij = scale * l_i + tl.sum(p_ij_hat, 1)
+ acc = acc * scale[:, None]
+
+ v = tl.load(V_block_ptr, boundary_check=(1, 0))
+ p_ij_hat = p_ij_hat.to(v.type.element_ty)
+
+ acc += tl.dot(p_ij_hat, v)
+ l_i = l_ij
+ m_i = m_ij
+ K_block_ptr = tl.advance(K_block_ptr, (0, BLOCK_N))
+ V_block_ptr = tl.advance(V_block_ptr, (BLOCK_N, 0))
+
+ acc = acc / l_i[:, None]
+ tl.store(O_block_ptr, acc.to(O.type.element_ty), boundary_check=(1, 0))
+
+ if cur_head_idx % KV_GROUPS == 0:
+ # Copy k to corresponding cache block
+ offsets_dmodel = tl.arange(0, HEAD_DIM)
+ offsets_kt = block_start_m * BLOCK_M + tl.arange(0, BLOCK_M)
+ offsets_k = K + offset_kv + offsets_dmodel[None, :] * stride_kd + offsets_kt[:, None] * stride_kt
+ k = tl.load(offsets_k, mask=offsets_kt[:, None] < cur_seq_len, other=0.0)
+ offsets_kcachebs = tl.arange(0, BLOCK_SIZE)
+ offsets_kcache = (
+ KCache
+ + offset_kvcache
+ + offsets_dmodel[None, :] * stride_cached
+ + offsets_kcachebs[:, None] * stride_cachebs
+ )
+ tl.store(offsets_kcache, k, mask=offsets_kcachebs[:, None] < cur_seq_len - block_start_m * BLOCK_SIZE)
+ # Copy v to corresponding cache block
+ offsets_vd = offsets_dmodel
+ offsets_vt = block_start_m * BLOCK_N + tl.arange(0, BLOCK_N)
+ offsets_v = V + offset_kv + offsets_vt[None, :] * stride_vt + offsets_vd[:, None] * stride_vd
+ v = tl.load(offsets_v, mask=offsets_vt[None, :] < cur_seq_len, other=0.0)
+ offsets_vcachebs = offsets_kcachebs # same block size range, just to notify here
+ offsets_vcache = (
+ VCache
+ + offset_kvcache
+ + offsets_vcachebs[None, :] * stride_cachebs
+ + offsets_dmodel[:, None] * stride_cached
+ )
+ tl.store(offsets_vcache, v, mask=offsets_vcachebs[None, :] < cur_seq_len - block_start_m * BLOCK_SIZE)
+
+ return
+
+
+# Triton 2.1.0
+# TODO(yuanheng-zhao): This is a temporary dispatch to use the new layout for kcache
+# merge `_fwd_context_paged_attention_kernel_v2` with `_fwd_context_paged_attention_kernel` later
+# as the kcache layout has been supported in the whole triton flow.
+@triton.jit
+def _fwd_context_paged_attention_kernel_v2(
+ Q,
+ K,
+ V,
+ O,
+ KCache, # [num_blocks, num_kv_heads, head_dim // x, block_size, x]
+ VCache, # [num_blocks, num_kv_heads, block_size, head_dim]
+ BLOCK_TABLES, # [num_seqs, max_blocks_per_sequence]
+ batch_size,
+ stride_qt,
+ stride_qh,
+ stride_qd,
+ stride_kt,
+ stride_kh,
+ stride_kd,
+ stride_vt,
+ stride_vh,
+ stride_vd,
+ stride_ot,
+ stride_oh,
+ stride_od,
+ stride_cacheb, # v cache stride(0) - num_blocks
+ stride_cacheh, # v cache stride(1) - num_kv_heads
+ stride_cachebs, # v cache stride(2) - block_size
+ stride_cached, # v cache stride(3) - head_dim
+ stride_bts,
+ stride_btb,
+ context_lengths,
+ sm_scale,
+ KV_GROUPS: tl.constexpr,
+ BLOCK_SIZE: tl.constexpr,
+ HEAD_DIM: tl.constexpr,
+ KCACHE_X: tl.constexpr, # k stride on the second last dimension
+ BLOCK_M: tl.constexpr,
+ BLOCK_N: tl.constexpr,
+):
+ cur_seq_idx = tl.program_id(0)
+ if cur_seq_idx >= batch_size:
+ return
+ cur_head_idx = tl.program_id(1)
+ block_start_m = tl.program_id(2) # Br, max_input_len // Block_M
+ cur_kv_head_idx = cur_head_idx // KV_GROUPS
+
+ # NOTE It requires BLOCK_M, BLOCK_N, and BLOCK_SIZE to be the same
+ tl.static_assert(BLOCK_M == BLOCK_N)
+ tl.static_assert(BLOCK_N == BLOCK_SIZE)
+
+ # get the current sequence length from provided context lengths tensor
+ cur_seq_len = tl.load(context_lengths + cur_seq_idx)
+ # NOTE when talking to fused QKV and a nopadding context attention,
+ # we assume that the input Q/K/V is contiguous, and thus here `prev_seq_len_sum`
+ # could be considered as the start index of the current sequence.
+ # FIXME might want to explore better way to get the summation of prev seq lengths.
+ # `tl.sum(tensor[:end])` is invalid as tensor slice is not supported in triton.
+ prev_seq_len_sum = 0
+ for i in range(0, cur_seq_idx):
+ prev_seq_len_sum += tl.load(context_lengths + i)
+
+ offset_q = prev_seq_len_sum * stride_qt + cur_head_idx * stride_qh
+ offset_kv = prev_seq_len_sum * stride_kt + cur_kv_head_idx * stride_kh
+ Q_block_ptr = tl.make_block_ptr(
+ base=Q + offset_q,
+ shape=(cur_seq_len, HEAD_DIM),
+ strides=(stride_qt, stride_qd),
+ offsets=(block_start_m * BLOCK_M, 0),
+ block_shape=(BLOCK_M, HEAD_DIM),
+ order=(1, 0),
+ )
+ K_block_ptr = tl.make_block_ptr(
+ base=K + offset_kv,
+ shape=(HEAD_DIM, cur_seq_len),
+ strides=(stride_kd, stride_kt),
+ offsets=(0, 0),
+ block_shape=(HEAD_DIM, BLOCK_N),
+ order=(0, 1),
+ )
+ V_block_ptr = tl.make_block_ptr(
+ base=V + offset_kv,
+ shape=(cur_seq_len, HEAD_DIM),
+ strides=(stride_vt, stride_vd),
+ offsets=(0, 0),
+ block_shape=(BLOCK_N, HEAD_DIM),
+ order=(1, 0),
+ )
+ O_block_ptr = tl.make_block_ptr(
+ base=O + offset_q,
+ shape=(cur_seq_len, HEAD_DIM),
+ strides=(stride_ot, stride_od),
+ offsets=(block_start_m * BLOCK_M, 0),
+ block_shape=(BLOCK_M, HEAD_DIM),
+ order=(1, 0),
+ )
+
+ # block table for the current sequence
+ block_table_ptr = BLOCK_TABLES + cur_seq_idx * stride_bts
+ # block indexes on block table (i.e. 0, 1, 2, ..., max_blocks_per_seq)
+ # Consider `block_start_m` as the logical block idx in the current block table,
+ # as we have BLOCK_M the same size as the block size.
+ cur_block_table_idx = block_start_m
+ cur_block_id = tl.load(block_table_ptr + cur_block_table_idx * stride_btb)
+ offset_kvcache = cur_block_id * stride_cacheb + cur_kv_head_idx * stride_cacheh
+
+ offsets_m = block_start_m * BLOCK_M + tl.arange(0, BLOCK_M)
+ offsets_n = tl.arange(0, BLOCK_N)
+ m_i = tl.full([BLOCK_M], float("-inf"), dtype=tl.float32)
+ l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
+ acc = tl.zeros([BLOCK_M, HEAD_DIM], dtype=tl.float32)
+
+ if block_start_m * BLOCK_M >= cur_seq_len:
+ return
+
+ Q_i = tl.load(Q_block_ptr, boundary_check=(1, 0))
+
+ for block_start_n in range(0, (block_start_m + 1) * BLOCK_M, BLOCK_N):
+ block_start_n = tl.multiple_of(block_start_n, BLOCK_N)
+
+ k = tl.load(K_block_ptr, boundary_check=(0, 1))
+ S_ij = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
+ S_ij += tl.dot(Q_i, k)
+ S_ij *= sm_scale
+ S_ij += tl.where(offsets_m[:, None] >= (block_start_n + offsets_n[None, :]), 0, float("-inf"))
+
+ m_ij = tl.max(S_ij, 1) # rowmax(Sij)
+ m_ij = tl.maximum(m_i, m_ij) # m_ij
+ S_ij -= m_ij[:, None]
+ p_ij_hat = tl.exp(S_ij)
+ scale = tl.exp(m_i - m_ij)
+ l_ij = scale * l_i + tl.sum(p_ij_hat, 1)
+ acc = acc * scale[:, None]
+
+ v = tl.load(V_block_ptr, boundary_check=(1, 0))
+ p_ij_hat = p_ij_hat.to(v.type.element_ty)
+
+ acc += tl.dot(p_ij_hat, v)
+ l_i = l_ij
+ m_i = m_ij
+ K_block_ptr = tl.advance(K_block_ptr, (0, BLOCK_N))
+ V_block_ptr = tl.advance(V_block_ptr, (BLOCK_N, 0))
+
+ acc = acc / l_i[:, None]
+ tl.store(O_block_ptr, acc.to(O.type.element_ty), boundary_check=(1, 0))
+
+ if cur_head_idx % KV_GROUPS == 0:
+ # Copy k to corresponding cache block
+ block_range = tl.arange(0, BLOCK_SIZE)
+ X_range = tl.arange(0, KCACHE_X)
+ # unroll the loop aggressively
+ for split_x in tl.static_range(HEAD_DIM // KCACHE_X):
+ offsets_dmodel_x_partition = tl.arange(split_x * KCACHE_X, (split_x + 1) * KCACHE_X)
+ offsets_k = K + offset_kv + offsets_dmodel_x_partition[None, :] * stride_kd + offsets_m[:, None] * stride_kt
+ k = tl.load(offsets_k, mask=offsets_m[:, None] < cur_seq_len, other=0.0)
+ # HACK: KCache must be contiguous in order to apply the following offsets calculation
+ offsets_kcache = (
+ KCache
+ + offset_kvcache
+ + split_x * BLOCK_SIZE * KCACHE_X
+ + block_range[:, None] * KCACHE_X
+ + X_range[None, :]
+ )
+ tl.store(offsets_kcache, k, mask=block_range[:, None] < cur_seq_len - block_start_m * BLOCK_SIZE)
+ # Copy v to corresponding cache block
+ offsets_vd = tl.arange(0, HEAD_DIM) # offsets_dmodel
+ offsets_vt = block_start_m * BLOCK_N + offsets_n
+ offsets_v = V + offset_kv + offsets_vt[None, :] * stride_vt + offsets_vd[:, None] * stride_vd
+ v = tl.load(offsets_v, mask=offsets_vt[None, :] < cur_seq_len, other=0.0)
+ offsets_vcache = (
+ VCache + offset_kvcache + block_range[None, :] * stride_cachebs + offsets_vd[:, None] * stride_cached
+ )
+ tl.store(offsets_vcache, v, mask=block_range[None, :] < cur_seq_len - block_start_m * BLOCK_SIZE)
+
+ return
+
+
+# Triton 2.1.0
+@triton.jit
+def _alibi_fwd_context_paged_attention_kernel(
+ Q,
+ K,
+ V,
+ O,
+ KCache,
+ VCache,
+ BLOCK_TABLES, # [num_seqs, max_blocks_per_sequence]
+ batch_size,
+ alibi_slopes,
+ stride_qt,
+ stride_qh,
+ stride_qd,
+ stride_kt,
+ stride_kh,
+ stride_kd,
+ stride_vt,
+ stride_vh,
+ stride_vd,
+ stride_ot,
+ stride_oh,
+ stride_od,
+ stride_cacheb,
+ stride_cacheh,
+ stride_cachebs,
+ stride_cached,
+ stride_bts,
+ stride_btb,
+ context_lengths,
+ sm_scale,
+ KV_GROUPS: tl.constexpr,
+ BLOCK_SIZE: tl.constexpr,
+ HEAD_DIM: tl.constexpr,
+ BLOCK_M: tl.constexpr,
+ BLOCK_N: tl.constexpr,
+):
+ cur_seq_idx = tl.program_id(0)
+ if cur_seq_idx >= batch_size:
+ return
+ cur_head_idx = tl.program_id(1)
+ block_start_m = tl.program_id(2) # Br, max_input_len // Block_M
+ cur_kv_head_idx = cur_head_idx // KV_GROUPS
+
+ global_block_start_offest = block_start_m * BLOCK_M
+
+ # NOTE It requires BLOCK_M, BLOCK_N, and BLOCK_SIZE to be the same
+ tl.static_assert(BLOCK_M == BLOCK_N)
+ tl.static_assert(BLOCK_N == BLOCK_SIZE)
+
+ # get the current sequence length from provided context lengths tensor
+ cur_seq_len = tl.load(context_lengths + cur_seq_idx)
+ # NOTE when talking to fused QKV and a nopadding context attention,
+ # we assume that the input Q/K/V is contiguous, and thus here `prev_seq_len_sum`
+ # could be considered as the start index of the current sequence.
+ # FIXME might want to explore better way to get the summation of prev seq lengths.
+ # `tl.sum(tensor[:end])` is invalid as tensor slice is not supported in triton.
+ prev_seq_len_sum = 0
+ for i in range(0, cur_seq_idx):
+ prev_seq_len_sum += tl.load(context_lengths + i)
+
+ offset_q = prev_seq_len_sum * stride_qt + cur_head_idx * stride_qh
+ offset_kv = prev_seq_len_sum * stride_kt + cur_kv_head_idx * stride_kh
+ Q_block_ptr = tl.make_block_ptr(
+ base=Q + offset_q,
+ shape=(cur_seq_len, HEAD_DIM),
+ strides=(stride_qt, stride_qd),
+ offsets=(global_block_start_offest, 0),
+ block_shape=(BLOCK_M, HEAD_DIM),
+ order=(1, 0),
+ )
+ K_block_ptr = tl.make_block_ptr(
+ base=K + offset_kv,
+ shape=(HEAD_DIM, cur_seq_len),
+ strides=(stride_kd, stride_kt),
+ offsets=(0, 0),
+ block_shape=(HEAD_DIM, BLOCK_N),
+ order=(0, 1),
+ )
+ V_block_ptr = tl.make_block_ptr(
+ base=V + offset_kv,
+ shape=(cur_seq_len, HEAD_DIM),
+ strides=(stride_vt, stride_vd),
+ offsets=(0, 0),
+ block_shape=(BLOCK_N, HEAD_DIM),
+ order=(1, 0),
+ )
+ O_block_ptr = tl.make_block_ptr(
+ base=O + offset_q,
+ shape=(cur_seq_len, HEAD_DIM),
+ strides=(stride_ot, stride_od),
+ offsets=(global_block_start_offest, 0),
+ block_shape=(BLOCK_M, HEAD_DIM),
+ order=(1, 0),
+ )
+
+ # block table for the current sequence
+ block_table_ptr = BLOCK_TABLES + cur_seq_idx * stride_bts
+ # block indexes on block table (i.e. 0, 1, 2, ..., max_blocks_per_seq)
+ # Consider `block_start_m` as the logical block idx in the current block table,
+ # as we have BLOCK_M the same size as the block size.
+ cur_block_table_idx = block_start_m
+ cur_block_id = tl.load(block_table_ptr + cur_block_table_idx * stride_btb)
+ offset_kvcache = cur_block_id * stride_cacheb + cur_kv_head_idx * stride_cacheh
+
+ offsets_m = global_block_start_offest + tl.arange(0, BLOCK_M)
+ offsets_n = tl.arange(0, BLOCK_N)
+ m_i = tl.full([BLOCK_M], float("-inf"), dtype=tl.float32)
+ l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
+ acc = tl.zeros([BLOCK_M, HEAD_DIM], dtype=tl.float32)
+
+ # load alibi_slope
+ alibi_slope = tl.load(alibi_slopes + cur_head_idx)
+ m_alibi_offset = tl.arange(0, BLOCK_M)[:, None] + global_block_start_offest
+ n_alibi_offset = tl.arange(0, BLOCK_N)[None, :]
+
+ if global_block_start_offest >= cur_seq_len:
+ return
+
+ Q_i = tl.load(Q_block_ptr, boundary_check=(1, 0))
+
+ for block_start_n in range(0, (block_start_m + 1) * BLOCK_M, BLOCK_N):
+ block_start_n = tl.multiple_of(block_start_n, BLOCK_N)
+
+ k = tl.load(K_block_ptr, boundary_check=(0, 1))
+ S_ij = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
+ S_ij += tl.dot(Q_i, k)
+ S_ij *= sm_scale
+ S_ij += tl.where(offsets_m[:, None] >= (block_start_n + offsets_n[None, :]), 0, float("-inf"))
+
+ alibi = (n_alibi_offset + block_start_n - m_alibi_offset) * alibi_slope
+ alibi = tl.where((alibi <= 0) & (m_alibi_offset < cur_seq_len), alibi, float("-inf"))
+ S_ij += alibi
+
+ m_ij = tl.max(S_ij, 1) # rowmax(Sij)
+ m_ij = tl.maximum(m_i, m_ij) # m_ij
+ S_ij -= m_ij[:, None]
+ p_ij_hat = tl.exp(S_ij)
+ scale = tl.exp(m_i - m_ij)
+ l_ij = scale * l_i + tl.sum(p_ij_hat, 1)
+ acc = acc * scale[:, None]
+
+ v = tl.load(V_block_ptr, boundary_check=(1, 0))
+ p_ij_hat = p_ij_hat.to(v.type.element_ty)
+
+ acc += tl.dot(p_ij_hat, v)
+ l_i = l_ij
+ m_i = m_ij
+ K_block_ptr = tl.advance(K_block_ptr, (0, BLOCK_N))
+ V_block_ptr = tl.advance(V_block_ptr, (BLOCK_N, 0))
+
+ acc = acc / l_i[:, None]
+ tl.store(O_block_ptr, acc.to(O.type.element_ty), boundary_check=(1, 0))
+
+ if cur_head_idx % KV_GROUPS == 0:
+ # Copy k to corresponding cache block
+ offsets_dmodel = tl.arange(0, HEAD_DIM)
+ offsets_kt = global_block_start_offest + tl.arange(0, BLOCK_M)
+ offsets_k = K + offset_kv + offsets_dmodel[None, :] * stride_kd + offsets_kt[:, None] * stride_kt
+ k = tl.load(offsets_k, mask=offsets_kt[:, None] < cur_seq_len, other=0.0)
+ offsets_kcachebs = tl.arange(0, BLOCK_SIZE)
+ offsets_kcache = (
+ KCache
+ + offset_kvcache
+ + offsets_dmodel[None, :] * stride_cached
+ + offsets_kcachebs[:, None] * stride_cachebs
+ )
+ tl.store(offsets_kcache, k, mask=offsets_kcachebs[:, None] < cur_seq_len - block_start_m * BLOCK_SIZE)
+ # Copy v to corresponding cache block
+ offsets_vd = offsets_dmodel
+ offsets_vt = block_start_m * BLOCK_N + tl.arange(0, BLOCK_N)
+ offsets_v = V + offset_kv + offsets_vt[None, :] * stride_vt + offsets_vd[:, None] * stride_vd
+ v = tl.load(offsets_v, mask=offsets_vt[None, :] < cur_seq_len, other=0.0)
+ offsets_vcachebs = offsets_kcachebs # same block size range, just to notify here
+ offsets_vcache = (
+ VCache
+ + offset_kvcache
+ + offsets_vcachebs[None, :] * stride_cachebs
+ + offsets_dmodel[:, None] * stride_cached
+ )
+ tl.store(offsets_vcache, v, mask=offsets_vcachebs[None, :] < cur_seq_len - block_start_m * BLOCK_SIZE)
+
+ return
+
+
+def context_attention_unpadded(
+ q: torch.Tensor, # [num_tokens, num_heads, head_dim]
+ k: torch.Tensor, # [num_tokens, num_kv_heads, head_dim]
+ v: torch.Tensor, # [num_tokens, num_kv_heads, head_dim]
+ k_cache: torch.Tensor, # [num_blocks, num_kv_heads, block_size, head_dim]
+ v_cache: torch.Tensor, # [num_blocks, num_kv_heads, block_size, head_dim]
+ context_lengths: torch.Tensor, # [num_seqs]
+ block_tables: torch.Tensor, # [num_seqs, max_blocks_per_sequence],
+ block_size: int,
+ output: torch.Tensor = None, # [num_tokens, num_heads, head_dim]
+ alibi_slopes: torch.Tensor = None, # [num_heads]
+ max_seq_len: int = None,
+ sm_scale: int = None,
+ # NOTE(yuanheng-zhao): the following flag is used to determine whether to use the new layout for kcache
+ # [num_blocks, num_kv_heads, head_dim // x, block_size, x] - must be contiguous
+ use_new_kcache_layout: bool = False,
+):
+ Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
+ assert Lq == Lk == Lv
+ assert Lk in {32, 64, 128, 256}
+ assert q.shape[0] == k.shape[0] == v.shape[0]
+ k_cache_shape = k_cache.shape
+ v_cache_shape = v_cache.shape
+ if use_new_kcache_layout:
+ assert (
+ len(k_cache_shape) == 5
+ and k_cache_shape[1] == v_cache_shape[1]
+ and k_cache_shape[2] * k_cache_shape[4] == v_cache_shape[3]
+ ), f"Invalid KCache shape {k_cache_shape} and VCache shape {v_cache_shape}"
+ else:
+ assert k_cache_shape == v_cache_shape, f"Invalid KCache shape {k_cache_shape} and VCache shape {v_cache_shape}"
+ assert context_lengths.shape[0] == block_tables.shape[0]
+
+ num_tokens, num_heads, head_dim = q.shape
+ num_kv_heads = k.shape[-2]
+ assert num_kv_heads > 0 and num_heads % num_kv_heads == 0
+ num_kv_group = num_heads // num_kv_heads
+
+ num_seqs, max_blocks_per_seq = block_tables.shape
+ max_seq_len = context_lengths.max().item() if max_seq_len is None else max_seq_len
+ sm_scale = 1.0 / (Lq**0.5) if sm_scale is None else sm_scale
+ output = (
+ torch.empty((num_tokens, num_heads * head_dim), dtype=q.dtype, device=q.device) if output is None else output
+ )
+
+ # NOTE For now, BLOCK_M and BLOCK_N are supposed to be equivalent with
+ # the size of physical cache block (i.e. `block_size`)
+ assert block_size in {16, 32, 64, 128}
+ BLOCK_M = BLOCK_N = block_size
+
+ # NOTE use `triton.next_power_of_2` here to utilize the cache mechanism of triton
+ # To optimize, revise batching/scheduling to batch 2^n sequences in a batch (preferred)
+ grid = (triton.next_power_of_2(num_seqs), num_heads, triton.cdiv(max_seq_len, BLOCK_M))
+
+ if use_new_kcache_layout:
+ # TODO(yuanheng-zhao): Since the alibi kernel is pretty similar to the original one,
+ # the code (alibi kernel) will be refactored later to avoid code duplication, when
+ # the whole triton flow with new k cache layout has been supported and tested.
+ assert (
+ alibi_slopes is None
+ ), "Alibi Slopes will be supported with new kcache layout later when the whole triton flow is ready"
+ x = k_cache_shape[4] # Intuition: 16 // dtype_size
+
+ _fwd_context_paged_attention_kernel_v2[grid](
+ q,
+ k,
+ v,
+ output,
+ k_cache,
+ v_cache,
+ block_tables,
+ num_seqs,
+ q.stride(0),
+ q.stride(1),
+ q.stride(2),
+ k.stride(0),
+ k.stride(1),
+ k.stride(2),
+ v.stride(0),
+ v.stride(1),
+ v.stride(2),
+ output.stride(0),
+ head_dim,
+ 1,
+ v_cache.stride(0),
+ v_cache.stride(1),
+ v_cache.stride(2),
+ v_cache.stride(3),
+ block_tables.stride(0),
+ block_tables.stride(1),
+ context_lengths,
+ sm_scale,
+ KV_GROUPS=num_kv_group,
+ BLOCK_SIZE=block_size,
+ HEAD_DIM=Lk,
+ KCACHE_X=x,
+ BLOCK_M=BLOCK_M,
+ BLOCK_N=BLOCK_N,
+ )
+ return output
+
+ if alibi_slopes is not None:
+ _alibi_fwd_context_paged_attention_kernel[grid](
+ q,
+ k,
+ v,
+ output,
+ k_cache,
+ v_cache,
+ block_tables,
+ num_seqs,
+ alibi_slopes,
+ q.stride(0),
+ q.stride(1),
+ q.stride(2),
+ k.stride(0),
+ k.stride(1),
+ k.stride(2),
+ v.stride(0),
+ v.stride(1),
+ v.stride(2),
+ output.stride(0),
+ head_dim,
+ 1,
+ k_cache.stride(0),
+ k_cache.stride(1),
+ k_cache.stride(2),
+ k_cache.stride(3),
+ block_tables.stride(0),
+ block_tables.stride(1),
+ context_lengths,
+ sm_scale,
+ num_kv_group,
+ block_size,
+ HEAD_DIM=Lk,
+ BLOCK_M=BLOCK_M,
+ BLOCK_N=BLOCK_N,
+ )
+ else:
+ _fwd_context_paged_attention_kernel[grid](
+ q,
+ k,
+ v,
+ output,
+ k_cache,
+ v_cache,
+ block_tables,
+ num_seqs,
+ q.stride(0),
+ q.stride(1),
+ q.stride(2),
+ k.stride(0),
+ k.stride(1),
+ k.stride(2),
+ v.stride(0),
+ v.stride(1),
+ v.stride(2),
+ output.stride(0),
+ head_dim,
+ 1,
+ k_cache.stride(0),
+ k_cache.stride(1),
+ k_cache.stride(2),
+ k_cache.stride(3),
+ block_tables.stride(0),
+ block_tables.stride(1),
+ context_lengths,
+ sm_scale,
+ num_kv_group,
+ block_size,
+ HEAD_DIM=Lk,
+ BLOCK_M=BLOCK_M,
+ BLOCK_N=BLOCK_N,
+ )
+
+ return output
diff --git a/colossalai/kernel/triton/copy_kv_cache_dest.py b/colossalai/kernel/triton/copy_kv_cache_dest.py
deleted file mode 100644
index b8e6ab1d05ad..000000000000
--- a/colossalai/kernel/triton/copy_kv_cache_dest.py
+++ /dev/null
@@ -1,71 +0,0 @@
-import torch
-
-try:
- import triton
- import triton.language as tl
-
- HAS_TRITON = True
-except ImportError:
- HAS_TRITON = False
- print("please install triton from https://github.com/openai/triton")
-
-if HAS_TRITON:
- # adapted from https://github.com/ModelTC/lightllm/blob/5c559dd7981ed67679a08a1e09a88fb4c1550b3a/lightllm/common/triton_kernel/destindex_copy_kv.py
- @triton.jit
- def _fwd_copy_kv_cache_dest(
- kv_cache_ptr,
- dest_index_ptr,
- out,
- stride_k_bs,
- stride_k_h,
- stride_k_d,
- stride_o_bs,
- stride_o_h,
- stride_o_d,
- head_num,
- BLOCK_DMODEL: tl.constexpr,
- BLOCK_HEAD: tl.constexpr,
- ):
- cur_index = tl.program_id(0)
- offs_h = tl.arange(0, BLOCK_HEAD)
- offs_d = tl.arange(0, BLOCK_DMODEL)
-
- dest_index = tl.load(dest_index_ptr + cur_index)
-
- cache_offsets = stride_k_h * offs_h[:, None] + stride_k_d * offs_d[None, :]
- k_ptrs = kv_cache_ptr + cur_index * stride_k_bs + cache_offsets
-
- o_offsets = stride_o_h * offs_h[:, None] + stride_o_d * offs_d[None, :]
- o_ptrs = out + dest_index * stride_o_bs + o_offsets
-
- k = tl.load(k_ptrs, mask=offs_h[:, None] < head_num, other=0.0)
- tl.store(o_ptrs, k, mask=offs_h[:, None] < head_num)
- return
-
- # adepted from https://github.com/ModelTC/lightllm/blob/5c559dd7981ed67679a08a1e09a88fb4c1550b3a/lightllm/common/triton_kernel/destindex_copy_kv.py
- @torch.no_grad()
- def copy_kv_cache_to_dest(k_ptr, dest_index_ptr, out):
- seq_len = dest_index_ptr.shape[0]
- head_num = k_ptr.shape[1]
- head_dim = k_ptr.shape[2]
- assert head_num == out.shape[1], "head_num should be the same for k_ptr and out"
- assert head_dim == out.shape[2], "head_dim should be the same for k_ptr and out"
-
- num_warps = 2
- _fwd_copy_kv_cache_dest[(seq_len,)](
- k_ptr,
- dest_index_ptr,
- out,
- k_ptr.stride(0),
- k_ptr.stride(1),
- k_ptr.stride(2),
- out.stride(0),
- out.stride(1),
- out.stride(2),
- head_num,
- BLOCK_DMODEL=head_dim,
- BLOCK_HEAD=triton.next_power_of_2(head_num),
- num_warps=num_warps,
- num_stages=2,
- )
- return
diff --git a/colossalai/kernel/triton/custom_autotune.py b/colossalai/kernel/triton/custom_autotune.py
deleted file mode 100644
index 17bb1cf0070c..000000000000
--- a/colossalai/kernel/triton/custom_autotune.py
+++ /dev/null
@@ -1,176 +0,0 @@
-# code from AutoGPTQ auto_gptq: https://github.com/PanQiWei/AutoGPTQ/blob/main/auto_gptq/nn_modules/triton_utils/custom_autotune.py
-
-import builtins
-import math
-import time
-from typing import Dict
-
-import triton
-
-
-class CustomizedTritonAutoTuner(triton.KernelInterface):
- def __init__(
- self,
- fn,
- arg_names,
- configs,
- key,
- reset_to_zero,
- prune_configs_by: Dict = None,
- nearest_power_of_two: bool = False,
- ):
- if not configs:
- self.configs = [triton.Config({}, num_warps=4, num_stages=2)]
- else:
- self.configs = configs
- self.key_idx = [arg_names.index(k) for k in key]
- self.nearest_power_of_two = nearest_power_of_two
- self.cache = {}
- # hook to reset all required tensor to zeros before relaunching a kernel
- self.hook = lambda args: 0
- if reset_to_zero is not None:
- self.reset_idx = [arg_names.index(k) for k in reset_to_zero]
-
- def _hook(args):
- for i in self.reset_idx:
- args[i].zero_()
-
- self.hook = _hook
- self.arg_names = arg_names
- # prune configs
- if prune_configs_by:
- perf_model, top_k = prune_configs_by["perf_model"], prune_configs_by["top_k"]
- if "early_config_prune" in prune_configs_by:
- early_config_prune = prune_configs_by["early_config_prune"]
- else:
- perf_model, top_k, early_config_prune = None, None, None
- self.perf_model, self.configs_top_k = perf_model, top_k
- self.early_config_prune = early_config_prune
- self.fn = fn
-
- def _bench(self, *args, config, **meta):
- # check for conflicts, i.e. meta-parameters both provided
- # as kwargs and by the autotuner
- conflicts = meta.keys() & config.kwargs.keys()
- if conflicts:
- raise ValueError(
- f"Conflicting meta-parameters: {', '.join(conflicts)}."
- " Make sure that you don't re-define auto-tuned symbols."
- )
- # augment meta-parameters with tunable ones
- current = dict(meta, **config.kwargs)
-
- def kernel_call():
- if config.pre_hook:
- config.pre_hook(self.nargs)
- self.hook(args)
- self.fn.run(*args, num_warps=config.num_warps, num_stages=config.num_stages, **current)
-
- try:
- # In testings using only 40 reps seems to be close enough and it appears to be what PyTorch uses
- # PyTorch also sets fast_flush to True, but I didn't see any speedup so I'll leave the default
- return triton.testing.do_bench(kernel_call, percentiles=(0.5, 0.2, 0.8), rep=40)
- except triton.compiler.OutOfResources:
- return (float("inf"), float("inf"), float("inf"))
-
- def run(self, *args, **kwargs):
- self.nargs = dict(zip(self.arg_names, args))
- if len(self.configs) > 1:
- key = tuple(args[i] for i in self.key_idx)
-
- # This reduces the amount of autotuning by rounding the keys to the nearest power of two
- # In my testing this gives decent results, and greatly reduces the amount of tuning required
- if self.nearest_power_of_two:
- key = tuple([2 ** int(math.log2(x) + 0.5) for x in key])
-
- if key not in self.cache:
- # prune configs
- pruned_configs = self.prune_configs(kwargs)
- bench_start = time.time()
- timings = {config: self._bench(*args, config=config, **kwargs) for config in pruned_configs}
- bench_end = time.time()
- self.bench_time = bench_end - bench_start
- self.cache[key] = builtins.min(timings, key=timings.get)
- self.hook(args)
- self.configs_timings = timings
- config = self.cache[key]
- else:
- config = self.configs[0]
- self.best_config = config
- if config.pre_hook is not None:
- config.pre_hook(self.nargs)
- return self.fn.run(*args, num_warps=config.num_warps, num_stages=config.num_stages, **kwargs, **config.kwargs)
-
- def prune_configs(self, kwargs):
- pruned_configs = self.configs
- if self.early_config_prune:
- pruned_configs = self.early_config_prune(self.configs, self.nargs)
- if self.perf_model:
- top_k = self.configs_top_k
- if isinstance(top_k, float) and top_k <= 1.0:
- top_k = int(len(self.configs) * top_k)
- if len(pruned_configs) > top_k:
- est_timing = {
- config: self.perf_model(
- **self.nargs,
- **kwargs,
- **config.kwargs,
- num_stages=config.num_stages,
- num_warps=config.num_warps,
- )
- for config in pruned_configs
- }
- pruned_configs = sorted(est_timing.keys(), key=lambda x: est_timing[x])[:top_k]
- return pruned_configs
-
- def warmup(self, *args, **kwargs):
- self.nargs = dict(zip(self.arg_names, args))
- for config in self.prune_configs(kwargs):
- self.fn.warmup(
- *args,
- num_warps=config.num_warps,
- num_stages=config.num_stages,
- **kwargs,
- **config.kwargs,
- )
- self.nargs = None
-
-
-def autotune(configs, key, prune_configs_by=None, reset_to_zero=None, nearest_power_of_two=False):
- def decorator(fn):
- return CustomizedTritonAutoTuner(
- fn, fn.arg_names, configs, key, reset_to_zero, prune_configs_by, nearest_power_of_two
- )
-
- return decorator
-
-
-def matmul248_kernel_config_pruner(configs, nargs):
- """
- The main purpose of this function is to shrink BLOCK_SIZE_* when the corresponding dimension is smaller.
- """
- m = max(2 ** int(math.ceil(math.log2(nargs["M"]))), 16)
- n = max(2 ** int(math.ceil(math.log2(nargs["N"]))), 16)
- k = max(2 ** int(math.ceil(math.log2(nargs["K"]))), 16)
-
- used = set()
- for config in configs:
- block_size_m = min(m, config.kwargs["BLOCK_SIZE_M"])
- block_size_n = min(n, config.kwargs["BLOCK_SIZE_N"])
- block_size_k = min(k, config.kwargs["BLOCK_SIZE_K"])
- group_size_m = config.kwargs["GROUP_SIZE_M"]
-
- if (block_size_m, block_size_n, block_size_k, group_size_m, config.num_stages, config.num_warps) in used:
- continue
-
- used.add((block_size_m, block_size_n, block_size_k, group_size_m, config.num_stages, config.num_warps))
- yield triton.Config(
- {
- "BLOCK_SIZE_M": block_size_m,
- "BLOCK_SIZE_N": block_size_n,
- "BLOCK_SIZE_K": block_size_k,
- "GROUP_SIZE_M": group_size_m,
- },
- num_stages=config.num_stages,
- num_warps=config.num_warps,
- )
diff --git a/colossalai/kernel/triton/flash_decoding.py b/colossalai/kernel/triton/flash_decoding.py
index ac733dede3b7..2fb8231cc977 100644
--- a/colossalai/kernel/triton/flash_decoding.py
+++ b/colossalai/kernel/triton/flash_decoding.py
@@ -1,47 +1,533 @@
-# adepted from https://github.com/ModelTC/lightllm/blob/ece7b43f8a6dfa74027adc77c2c176cff28c76c8/lightllm/models/llama/triton_kernel/flash_decoding.py
+# Applying Flash-Decoding as descibed in
+# https://pytorch.org/blog/flash-decoding/
+# by Tri Dao, 2023
import torch
+import triton
+import triton.language as tl
-try:
- from lightllm.models.llama.triton_kernel.flash_decoding_stage1 import flash_decode_stage1
- from lightllm.models.llama.triton_kernel.flash_decoding_stage2 import flash_decode_stage2
-
- HAS_LIGHTLLM_KERNEL = True
-except:
- print("install lightllm from https://github.com/ModelTC/lightllm/blob/ece7b43f8a6dfa74027adc77c2c176cff28c76c8")
- HAS_LIGHTLLM_KERNEL = False
-
-
-if HAS_LIGHTLLM_KERNEL:
-
- def token_flash_decoding(q, o_tensor, infer_state, q_head_num, head_dim, cache_k, cache_v):
- BLOCK_SEQ = 256
- batch_size = infer_state.batch_size
- max_len_in_batch = infer_state.max_len_in_batch
-
- calcu_shape1 = (batch_size, q_head_num, head_dim)
-
- if getattr(infer_state, "mid_o", None) is None:
- infer_state.mid_o = torch.empty(
- [batch_size, q_head_num, max_len_in_batch // BLOCK_SEQ + 1, head_dim],
- dtype=torch.float32,
- device="cuda",
- )
- infer_state.mid_o_logexpsum = torch.empty(
- [batch_size, q_head_num, max_len_in_batch // BLOCK_SEQ + 1], dtype=torch.float32, device="cuda"
- )
-
- mid_o = infer_state.mid_o
- mid_o_logexpsum = infer_state.mid_o_logexpsum
-
- flash_decode_stage1(
- q.view(calcu_shape1),
- cache_k,
- cache_v,
- infer_state.block_loc,
- infer_state.seq_len,
- infer_state.max_len_in_batch,
- mid_o,
- mid_o_logexpsum,
- BLOCK_SEQ,
+
+# Triton 2.1.0
+@triton.jit
+def _flash_decoding_fwd_kernel(
+ Q, # [batch_size * q_len, head_num, head_dim]
+ KCache, # [num_blocks, num_kv_heads, block_size, head_dim]
+ VCache, # [num_blocks, num_kv_heads, block_size, head_dim],
+ # or [num_blocks, num_kv_heads, head_dim//x, block_size, x], depends on strides provided
+ block_tables, # [batch_size, max_blocks_per_sequence]
+ mid_o, # [batch_size * q_len, head_num, kv_split_num, head_dim]
+ mid_o_lse, # [batch_size * q_len, head_num, kv_split_num]
+ kv_seq_len, # [batch_size]
+ q_len,
+ batch_size,
+ kv_group_num,
+ x,
+ sm_scale,
+ stride_qt,
+ stride_qh,
+ stride_qd,
+ stride_kcb,
+ stride_kch,
+ stride_kcsplit_x,
+ stride_kcs,
+ stride_kcd,
+ stride_vcb,
+ stride_vch,
+ stride_vcs,
+ stride_vcd,
+ stride_bts,
+ stride_btb,
+ stride_mid_ot,
+ stride_mid_oh,
+ stride_mid_ob,
+ stride_mid_od,
+ stride_mid_o_lset,
+ stride_mid_o_lseh,
+ stride_mid_o_lseb,
+ BLOCK_KV: tl.constexpr,
+ BLOCK_SIZE: tl.constexpr,
+ HEAD_DIM: tl.constexpr,
+):
+ cur_token_idx = tl.program_id(0)
+ cur_seq_idx = cur_token_idx // q_len
+ if cur_seq_idx >= batch_size:
+ return
+ cur_token_off = (cur_token_idx % q_len) - q_len + 1
+ cur_head_idx = tl.program_id(1)
+ block_start_kv = tl.program_id(2) # for splitting k/v
+
+ # NOTE It requires BLOCK_KV and BLOCK_SIZE to be the same
+ # TODO might want to replace with BLOCK_KV % BLOCK_SIZE == 0 (optimize BLOCK_KV as multiple of BLOCK_SIZE)
+ # and then support calculating multiple kv cache blocks on an instance
+ tl.static_assert(BLOCK_KV == BLOCK_SIZE)
+ # get the current (kv) sequence length
+ # cur_token_off is used as a "mask" here for spec-dec during verification process
+ cur_kv_seq_len = tl.load(kv_seq_len + cur_seq_idx) + cur_token_off
+ if block_start_kv * BLOCK_KV >= cur_kv_seq_len:
+ return
+ offsets_dmodel = tl.arange(0, HEAD_DIM)
+ offsets_block = tl.arange(0, BLOCK_SIZE)
+
+ # block table for the current sequence
+ block_table_ptr = block_tables + cur_seq_idx * stride_bts
+ # cur_bt_start_idx = block_start_kv * (BLOCK_KV // BLOCK_SIZE)
+ # cur_block_id = tl.load(block_table_ptr + cur_bt_start_idx * stride_btb)
+ cur_block_id = tl.load(block_table_ptr + block_start_kv * stride_btb)
+ cur_occupied_size = tl.where(
+ (block_start_kv + 1) * BLOCK_SIZE <= cur_kv_seq_len, BLOCK_SIZE, cur_kv_seq_len - block_start_kv * BLOCK_SIZE
+ )
+ tl.device_assert(cur_occupied_size >= 0)
+
+ offsets_q = cur_token_idx * stride_qt + cur_head_idx * stride_qh + offsets_dmodel * stride_qd
+ q = tl.load(Q + offsets_q)
+ cur_kv_head_idx = cur_head_idx // kv_group_num
+ offset_kvcache = cur_block_id * stride_kcb + cur_kv_head_idx * stride_kch
+ offsets_k = (
+ offset_kvcache
+ + (offsets_dmodel[None, :] // x) * stride_kcsplit_x
+ + (offsets_dmodel[None, :] % x) * stride_kcd
+ + offsets_block[:, None] * stride_kcs
+ )
+ k_cur_block = tl.load(KCache + offsets_k)
+ V_block_ptr = tl.make_block_ptr(
+ base=VCache + offset_kvcache,
+ shape=(cur_occupied_size, HEAD_DIM),
+ strides=(stride_vcs, stride_vcd),
+ offsets=(0, 0),
+ block_shape=(BLOCK_SIZE, HEAD_DIM),
+ order=(0, 1),
+ )
+ v_cur_block = tl.load(V_block_ptr)
+ acc = tl.zeros([HEAD_DIM], dtype=tl.float32)
+ # use block size of the paged/blocked kv cache
+ S_ij = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
+
+ # NOTE a trick to come across triton's requirement that values in both first and second input shapes must be >= 16,
+ # Multiplying two tensors with shapes [1, d] * [d, block_size] will fail.
+ # Refer to https://github.com/openai/triton/discussions/895
+ S_ij += tl.sum(q[None, :] * k_cur_block, 1)
+ S_ij *= sm_scale
+ S_ij += tl.where(block_start_kv * BLOCK_KV + offsets_block < cur_kv_seq_len, 0, float("-inf"))
+
+ m = tl.max(S_ij, 0)
+ S_ij -= m
+ p_ij_hat = tl.exp(S_ij)
+ l = tl.sum(p_ij_hat, 0)
+ p_ij_hat = p_ij_hat.to(v_cur_block.type.element_ty)
+ acc += tl.sum(v_cur_block * p_ij_hat[:, None], 0)
+ acc = acc / l
+
+ offsets_mid_o = (
+ cur_token_idx * stride_mid_ot
+ + cur_head_idx * stride_mid_oh
+ + block_start_kv * stride_mid_ob
+ + offsets_dmodel * stride_mid_od
+ )
+ tl.store(mid_o + offsets_mid_o, acc)
+ offsets_mid_o_lse = (
+ cur_token_idx * stride_mid_o_lset + cur_head_idx * stride_mid_o_lseh + block_start_kv * stride_mid_o_lseb
+ )
+ # logsumexp L^(j) = m^(j) + log(l^(j))
+ tl.store(mid_o_lse + offsets_mid_o_lse, m + tl.log(l))
+
+
+# Triton 2.1.0
+@triton.jit
+def _alibi_flash_decoding_fwd_kernel(
+ Q, # [batch_size * q_len, head_num, head_dim]
+ KCache, # [num_blocks, num_kv_heads, block_size, head_dim]
+ VCache, # [num_blocks, num_kv_heads, block_size, head_dim]
+ block_tables, # [batch_size, max_blocks_per_sequence]
+ mid_o, # [batch_size * q_len, head_num, kv_split_num, head_dim]
+ mid_o_lse, # [batch_size * q_len, head_num, kv_split_num]
+ kv_seq_len, # [batch_size]
+ q_len,
+ batch_size,
+ alibi_slopes,
+ stride_qt,
+ stride_qh,
+ stride_qd,
+ stride_cacheb,
+ stride_cacheh,
+ stride_cachebs,
+ stride_cached,
+ stride_bts,
+ stride_btb,
+ stride_mid_ot,
+ stride_mid_oh,
+ stride_mid_ob,
+ stride_mid_od,
+ stride_mid_o_lset,
+ stride_mid_o_lseh,
+ stride_mid_o_lseb,
+ sm_scale,
+ KV_GROUPS: tl.constexpr,
+ BLOCK_KV: tl.constexpr,
+ BLOCK_SIZE: tl.constexpr,
+ HEAD_DIM: tl.constexpr,
+):
+ cur_token_idx = tl.program_id(0)
+ cur_seq_idx = cur_token_idx // q_len
+ if cur_seq_idx >= batch_size:
+ return
+ cur_token_off = (cur_token_idx % q_len) - q_len + 1
+ cur_head_idx = tl.program_id(1)
+ block_start_kv = tl.program_id(2) # for splitting k/v
+
+ # NOTE It requires BLOCK_KV and BLOCK_SIZE to be the same
+ # TODO might want to replace with BLOCK_KV % BLOCK_SIZE == 0 (optimize BLOCK_KV as multiple of BLOCK_SIZE)
+ # and then support calculating multiple kv cache blocks on an instance
+ tl.static_assert(BLOCK_KV == BLOCK_SIZE)
+ # get the current (kv) sequence length
+ # cur_token_off is used as a "mask" here for spec-dec during verification process
+ cur_kv_seq_len = tl.load(kv_seq_len + cur_seq_idx) + cur_token_off
+ if block_start_kv * BLOCK_KV >= cur_kv_seq_len:
+ return
+
+ offsets_dmodel = tl.arange(0, HEAD_DIM)
+ offsets_q = cur_token_idx * stride_qt + cur_head_idx * stride_qh + offsets_dmodel * stride_qd
+ q = tl.load(Q + offsets_q)
+ # block table for the current sequence
+ block_table_ptr = block_tables + cur_seq_idx * stride_bts
+ # cur_bt_start_idx = block_start_kv * (BLOCK_KV // BLOCK_SIZE)
+ # cur_block_id = tl.load(block_table_ptr + cur_bt_start_idx * stride_btb)
+ cur_block_id = tl.load(block_table_ptr + block_start_kv * stride_btb)
+ cur_occupied_size = tl.where(
+ (block_start_kv + 1) * BLOCK_SIZE <= cur_kv_seq_len, BLOCK_SIZE, cur_kv_seq_len - block_start_kv * BLOCK_SIZE
+ )
+ tl.device_assert(cur_occupied_size >= 0)
+
+ cur_kv_head_idx = cur_head_idx // KV_GROUPS
+ offset_kvcache = cur_block_id * stride_cacheb + cur_kv_head_idx * stride_cacheh
+ K_block_ptr = tl.make_block_ptr(
+ base=KCache + offset_kvcache,
+ shape=(cur_occupied_size, HEAD_DIM),
+ strides=(stride_cachebs, stride_cached),
+ offsets=(0, 0),
+ block_shape=(BLOCK_SIZE, HEAD_DIM),
+ order=(0, 1),
+ )
+ V_block_ptr = tl.make_block_ptr(
+ base=VCache + offset_kvcache,
+ shape=(cur_occupied_size, HEAD_DIM),
+ strides=(stride_cachebs, stride_cached),
+ offsets=(0, 0),
+ block_shape=(BLOCK_SIZE, HEAD_DIM),
+ order=(0, 1),
+ )
+ k_cur_block = tl.load(K_block_ptr)
+ v_cur_block = tl.load(V_block_ptr)
+ acc = tl.zeros([HEAD_DIM], dtype=tl.float32)
+ # use block size of the paged/blocked kv cache
+ S_ij = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
+
+ alibi_slope = tl.load(alibi_slopes + cur_head_idx)
+ position_k_offset = block_start_kv * BLOCK_KV + tl.arange(0, BLOCK_SIZE)
+
+ # NOTE a trick to come across triton's requirement that values in both first and second input shapes must be >= 16,
+ # Multiplying two tensors with shapes [1, d] * [d, block_size] will fail.
+ # Refer to https://github.com/openai/triton/discussions/895
+ S_ij += tl.sum(q[None, :] * k_cur_block, 1)
+ S_ij *= sm_scale
+ S_ij -= alibi_slope * (cur_kv_seq_len - 1 - position_k_offset)
+ S_ij = tl.where(cur_kv_seq_len > position_k_offset, S_ij, float("-inf"))
+
+ m = tl.max(S_ij, 0)
+ S_ij -= m
+ p_ij_hat = tl.exp(S_ij)
+ l = tl.sum(p_ij_hat, 0)
+ p_ij_hat = p_ij_hat.to(v_cur_block.type.element_ty)
+ acc += tl.sum(v_cur_block * p_ij_hat[:, None], 0)
+ acc = acc / l
+
+ offsets_mid_o = (
+ cur_token_idx * stride_mid_ot
+ + cur_head_idx * stride_mid_oh
+ + block_start_kv * stride_mid_ob
+ + offsets_dmodel * stride_mid_od
+ )
+ tl.store(mid_o + offsets_mid_o, acc)
+ offsets_mid_o_lse = (
+ cur_token_idx * stride_mid_o_lset + cur_head_idx * stride_mid_o_lseh + block_start_kv * stride_mid_o_lseb
+ )
+ # logsumexp L^(j) = m^(j) + log(l^(j))
+ tl.store(mid_o_lse + offsets_mid_o_lse, m + tl.log(l))
+
+
+# Triton 2.1.0
+@triton.jit
+def _flash_decoding_fwd_reduce_kernel(
+ mid_o, # [batch_size, head_num, kv_split_num, head_dim]
+ mid_o_lse, # [batch_size, head_num, kv_split_num]
+ O, # [batch_size, num_heads, head_dim] or [batch_size, 1, num_heads, head_dim]
+ kv_seq_len,
+ q_len,
+ batch_size,
+ stride_mid_ot,
+ stride_mid_oh,
+ stride_mid_ob,
+ stride_mid_od,
+ stride_o_lset,
+ stride_o_lseh,
+ stride_o_lseb,
+ stride_ot,
+ stride_oh,
+ stride_od,
+ BLOCK_KV: tl.constexpr,
+ HEAD_DIM: tl.constexpr,
+):
+ cur_token_idx = tl.program_id(0)
+ cur_seq_idx = cur_token_idx // q_len
+ if cur_seq_idx >= batch_size:
+ return
+ cur_head_idx = tl.program_id(1)
+
+ # cur_token_off is used as a "mask" here for spec-dec during verification process
+ cur_token_off = (cur_token_idx % q_len) - q_len + 1
+ cur_kv_seq_len = tl.load(kv_seq_len + cur_seq_idx) + cur_token_off
+ offsets_dmodel = tl.arange(0, HEAD_DIM)
+
+ # NOTE currently the block size BLOCK_KV splitting kv is relatively small as we have
+ # BLOCK_KV == BLOCK_SIZE for now. We might want to decrease the number of blocks of kv splitted.
+ kv_split_num = (cur_kv_seq_len + BLOCK_KV - 1) // BLOCK_KV
+ m_i = float("-inf") # max logic
+ l = 0.0 # sum exp
+ acc = tl.zeros([HEAD_DIM], dtype=tl.float32)
+
+ offsets_mid_o = cur_token_idx * stride_mid_ot + cur_head_idx * stride_mid_oh + offsets_dmodel
+ offset_mid_lse = cur_token_idx * stride_o_lset + cur_head_idx * stride_o_lseh
+ for block_i in range(0, kv_split_num, 1):
+ mid_o_block = tl.load(mid_o + offsets_mid_o + block_i * stride_mid_ob)
+ lse = tl.load(mid_o_lse + offset_mid_lse + block_i * stride_o_lseb)
+ m_ij = tl.maximum(m_i, lse)
+ scale = tl.exp(m_i - m_ij)
+ acc = acc * scale
+ lse -= m_ij
+ exp_logic = tl.exp(lse)
+ acc += exp_logic * mid_o_block
+ l = scale * l + exp_logic
+ m_i = m_ij
+
+ acc = acc / l
+ offsets_O = cur_token_idx * stride_ot + cur_head_idx * stride_oh + offsets_dmodel
+ tl.store(O + offsets_O, acc.to(O.type.element_ty))
+ return
+
+
+# Decoding Stage
+# Used with blocked KV Cache (PagedAttention)
+def flash_decoding_attention(
+ q: torch.Tensor,
+ k_cache: torch.Tensor,
+ v_cache: torch.Tensor,
+ kv_seq_len: torch.Tensor,
+ block_tables: torch.Tensor,
+ block_size: int,
+ max_seq_len_in_batch: int = None,
+ output: torch.Tensor = None,
+ mid_output: torch.Tensor = None,
+ mid_output_lse: torch.Tensor = None,
+ alibi_slopes: torch.Tensor = None,
+ sm_scale: int = None,
+ kv_group_num: int = 1,
+ q_len: int = 1, # NOTE alibi flash decoding does not support q_len > 1 at this moment.
+ use_new_kcache_layout: bool = False,
+):
+ """
+ Flash decoding implemented with a blocked KV Cache (PagedAttention) during decoding stage.
+
+ Args:
+ q (torch.Tensor): [bsz * q_len, num_heads, head_dim]
+ q_len > 1 only for verification process in speculative-decoding.
+ k_cache (torch.Tensor): [num_blocks, num_kv_heads, block_size, head_dim]
+ v_cache (torch.Tensor): [num_blocks, num_kv_heads, block_size, head_dim]
+ kv_seq_len (torch.Tensor): [batch_size]
+ records the (kv) sequence lengths incorporating past kv sequence lengths.
+ block_tables (torch.Tensor): [batch_size, max_blocks_per_sequence]
+ max_seq_len_in_batch (int): Maximum sequence length in the batch.
+ output (torch.Tensor): [bsz, num_heads * head_dim]
+ mid_output (torch.Tensor): [max_bsz * q_len, num_heads, kv_max_split_num, head_dim]
+ Intermediate output tensor. `max_bsz` should be greater than or equal to `bsz`.
+ q_len > 1 only for verification process in speculative-decoding.
+ mid_output_lse (torch.Tensor): [max_bsz * q_len, num_heads, kv_max_split_num]
+ Log-sum-exp of intermediate output. `max_bsz` should be greater than or equal to `bsz`.
+ q_len > 1 only for verification process in speculative-decoding.
+ alibi_slopes (torch.Tensor): [num_heads] alibi slopes used for alibi flash decoding.
+ block_size (int): Size of each block in the blocked key/value cache.
+ num_kv_group (int, optional): Number of key/value groups. Defaults to 1.
+ q_length (int): Query length. Use for speculative decoding when `q_length` > 1 (i.e. the last n tokens).
+ Defaults to 1.
+ use_new_kcache_layout (bool): Whether to use the new kcache layout. Defaults to False.
+
+ Returns:
+ Output tensor with shape [bsz * q_len, num_heads * head_dim]
+ """
+ q = q.squeeze() if q.dim() == 4 else q
+ assert q.dim() == 3, f"Incompatible q dim: {q.dim()}"
+ n_tokens, num_heads, head_dim = q.shape
+ assert n_tokens % q_len == 0, "Invalid q_len"
+ bsz = n_tokens // q_len
+
+ assert head_dim in {32, 64, 128, 256}
+ assert kv_seq_len.shape[0] == block_tables.shape[0] == bsz, (
+ f"Got incompatible batch size (number of seqs):\n"
+ f" KV seq lengths bsz {kv_seq_len.size(0)}, Block tables bsz {block_tables.size(0)}, "
+ f"batch size {bsz}"
+ )
+ assert k_cache.size(-2) == v_cache.size(-2) == block_size, (
+ f"Got incompatible block size on kv caches:\n"
+ f" assigned block_size {block_size}, k_cache block_size {k_cache.size(-2)}, "
+ f"v_cache block_size {v_cache.size(-2)}"
+ )
+
+ # NOTE BLOCK_KV could be considered as block splitting the sequence on k/v
+ # For now, BLOCK_KV is supposed to be equivalent with the size of physical cache block (i.e.`block_size`)
+ assert block_size in {16, 32, 64, 128}
+ BLOCK_KV = block_size
+
+ sm_scale = 1.0 / (head_dim**0.5) if sm_scale is None else sm_scale
+ max_seq_len_in_batch = kv_seq_len.max().item() if max_seq_len_in_batch is None else max_seq_len_in_batch
+ # For compatibility (TODO revise modeling in future)
+ kv_max_split_num = (max_seq_len_in_batch + BLOCK_KV - 1) // BLOCK_KV
+
+ if mid_output is None:
+ mid_output = torch.empty(
+ (bsz * q_len, num_heads, kv_max_split_num, head_dim), dtype=torch.float32, device=q.device
)
- flash_decode_stage2(mid_o, mid_o_logexpsum, infer_state.seq_len, o_tensor.view(calcu_shape1), BLOCK_SEQ)
+ if mid_output_lse is None:
+ mid_output_lse = torch.empty((bsz * q_len, num_heads, kv_max_split_num), dtype=torch.float32, device=q.device)
+ if output is None:
+ # A hack to prevent `view` operation in modeling
+ output = torch.empty((bsz * q_len, num_heads * head_dim), dtype=q.dtype, device=q.device)
+
+ assert (
+ mid_output.size(2) == mid_output_lse.size(2) >= kv_max_split_num
+ ), "Incompatible kv split number of intermediate output tensors"
+ assert (
+ mid_output.size(0) == mid_output_lse.size(0) >= output.size(0) == n_tokens
+ ), f"Incompatible first dimension of output tensors"
+
+ # NOTE use `triton.next_power_of_2` here to utilize the cache mechanism of triton
+ # To optimize, revise batching/scheduling to batch 2^n sequences in a batch (preferred)
+ grid = lambda META: (
+ triton.next_power_of_2(bsz * q_len),
+ num_heads,
+ triton.cdiv(triton.next_power_of_2(max_seq_len_in_batch), META["BLOCK_KV"]),
+ )
+
+ if alibi_slopes is not None:
+ # TODO(yuanheng-zhao): Since the alibi kernel is pretty similar to the original one,
+ # the code (alibi kernel) will be refactored later to avoid code duplication, when
+ # the whole triton flow with new k cache layout has been supported and tested.
+ assert (
+ not use_new_kcache_layout
+ ), "Alibi Slopes will be supported with new kcache layout later when the whole triton flow is ready"
+
+ _alibi_flash_decoding_fwd_kernel[grid](
+ q,
+ k_cache,
+ v_cache,
+ block_tables,
+ mid_output,
+ mid_output_lse,
+ kv_seq_len,
+ q_len,
+ bsz,
+ alibi_slopes,
+ q.stride(0),
+ q.stride(1),
+ q.stride(2),
+ k_cache.stride(0),
+ k_cache.stride(1),
+ k_cache.stride(2),
+ k_cache.stride(3),
+ block_tables.stride(0),
+ block_tables.stride(1),
+ mid_output.stride(0),
+ mid_output.stride(1),
+ mid_output.stride(2),
+ mid_output.stride(3),
+ mid_output_lse.stride(0),
+ mid_output_lse.stride(1),
+ mid_output_lse.stride(2),
+ sm_scale,
+ KV_GROUPS=kv_group_num,
+ BLOCK_KV=block_size,
+ BLOCK_SIZE=block_size,
+ HEAD_DIM=head_dim,
+ )
+ else:
+ # For KCache and VCache with the same layout
+ x = head_dim
+ kcsplit_x_stride, kcs_stride, kcd_stride = 0, k_cache.stride(2), k_cache.stride(3)
+ # For KCache layout [num_blocks, num_kv_heads, head_dim//x, block_size, x]
+ if use_new_kcache_layout:
+ assert (
+ k_cache.dim() == 5
+ and k_cache.shape[1] == v_cache.shape[1]
+ and k_cache.shape[2] * k_cache.shape[4] == v_cache.shape[3]
+ ), f"Invalid KCache shape {k_cache.shape} and VCache shape {v_cache.shape}"
+ x = k_cache.size(-1)
+ kcsplit_x_stride, kcs_stride, kcd_stride = k_cache.stride()[-3:]
+
+ _flash_decoding_fwd_kernel[grid](
+ q,
+ k_cache,
+ v_cache,
+ block_tables,
+ mid_output,
+ mid_output_lse,
+ kv_seq_len,
+ q_len,
+ bsz,
+ kv_group_num,
+ x,
+ sm_scale,
+ q.stride(0),
+ q.stride(1),
+ q.stride(2),
+ k_cache.stride(0),
+ k_cache.stride(1),
+ kcsplit_x_stride,
+ kcs_stride,
+ kcd_stride,
+ v_cache.stride(0),
+ v_cache.stride(1),
+ v_cache.stride(2),
+ v_cache.stride(3),
+ block_tables.stride(0),
+ block_tables.stride(1),
+ mid_output.stride(0),
+ mid_output.stride(1),
+ mid_output.stride(2),
+ mid_output.stride(3),
+ mid_output_lse.stride(0),
+ mid_output_lse.stride(1),
+ mid_output_lse.stride(2),
+ BLOCK_KV=block_size,
+ BLOCK_SIZE=block_size,
+ HEAD_DIM=head_dim,
+ )
+
+ grid = (triton.next_power_of_2(bsz * q_len), num_heads)
+ _flash_decoding_fwd_reduce_kernel[grid](
+ mid_output,
+ mid_output_lse,
+ output,
+ kv_seq_len,
+ q_len,
+ bsz,
+ mid_output.stride(0),
+ mid_output.stride(1),
+ mid_output.stride(2),
+ mid_output.stride(3),
+ mid_output_lse.stride(0),
+ mid_output_lse.stride(1),
+ mid_output_lse.stride(2),
+ output.stride(0),
+ head_dim,
+ 1,
+ BLOCK_KV=block_size,
+ HEAD_DIM=head_dim,
+ )
+
+ return output
diff --git a/colossalai/kernel/triton/fused_layernorm.py b/colossalai/kernel/triton/fused_layernorm.py
deleted file mode 100644
index 24083b050808..000000000000
--- a/colossalai/kernel/triton/fused_layernorm.py
+++ /dev/null
@@ -1,78 +0,0 @@
-import torch
-
-try:
- import triton
- import triton.language as tl
-
- HAS_TRITON = True
-except ImportError:
- HAS_TRITON = False
- print("please install triton from https://github.com/openai/triton")
-
-if HAS_TRITON:
- # CREDITS: These functions are adapted from the Triton tutorial
- # https://triton-lang.org/main/getting-started/tutorials/05-layer-norm.html
-
- @triton.jit
- def _layer_norm_fwd_fused(
- X, # pointer to the input
- Y, # pointer to the output
- W, # pointer to the weights
- B, # pointer to the biases
- stride, # how much to increase the pointer when moving by 1 row
- N, # number of columns in X
- eps, # epsilon to avoid division by zero
- BLOCK_SIZE: tl.constexpr,
- ):
- # Map the program id to the row of X and Y it should compute.
- row = tl.program_id(0)
- Y += row * stride
- X += row * stride
- # Compute mean
- mean = 0
- _mean = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
- for off in range(0, N, BLOCK_SIZE):
- cols = off + tl.arange(0, BLOCK_SIZE)
- a = tl.load(X + cols, mask=cols < N, other=0.0).to(tl.float32)
- _mean += a
- mean = tl.sum(_mean, axis=0) / N
- # Compute variance
- _var = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
- for off in range(0, N, BLOCK_SIZE):
- cols = off + tl.arange(0, BLOCK_SIZE)
- x = tl.load(X + cols, mask=cols < N, other=0.0).to(tl.float32)
- x = tl.where(cols < N, x - mean, 0.0)
- _var += x * x
- var = tl.sum(_var, axis=0) / N
- rstd = 1 / tl.sqrt(var + eps)
- # Normalize and apply linear transformation
- for off in range(0, N, BLOCK_SIZE):
- cols = off + tl.arange(0, BLOCK_SIZE)
- mask = cols < N
- w = tl.load(W + cols, mask=mask)
- b = tl.load(B + cols, mask=mask)
- x = tl.load(X + cols, mask=mask, other=0.0).to(tl.float32)
- x_hat = (x - mean) * rstd
- y = x_hat * w + b
- # Write output
- tl.store(Y + cols, y.to(tl.float16), mask=mask)
-
- @torch.no_grad()
- def layer_norm(x, weight, bias, eps):
- # allocate output
- y = torch.empty_like(x)
- # reshape input data into 2D tensor
- x_arg = x.reshape(-1, x.shape[-1])
- M, N = x_arg.shape
- # Less than 64KB per feature: enqueue fused kernel
- MAX_FUSED_SIZE = 65536 // x.element_size()
- BLOCK_SIZE = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
- if N > BLOCK_SIZE:
- raise RuntimeError("This layer norm doesn't support feature dim >= 64KB.")
- # heuristics for number of warps
- num_warps = min(max(BLOCK_SIZE // 256, 1), 8)
- # enqueue kernel
- _layer_norm_fwd_fused[(M,)](
- x_arg, y, weight, bias, x_arg.stride(0), N, eps, BLOCK_SIZE=BLOCK_SIZE, num_warps=num_warps
- )
- return y
diff --git a/colossalai/kernel/triton/fused_rotary_embedding.py b/colossalai/kernel/triton/fused_rotary_embedding.py
new file mode 100644
index 000000000000..cf2a70f7b64e
--- /dev/null
+++ b/colossalai/kernel/triton/fused_rotary_embedding.py
@@ -0,0 +1,181 @@
+import torch
+import triton
+import triton.language as tl
+
+
+@triton.jit
+def fused_rotary_emb(
+ q,
+ k,
+ cos_cache,
+ sin_cache,
+ cumsum_lengths,
+ q_token_stride,
+ q_head_stride,
+ k_token_stride,
+ k_head_stride,
+ head_dim_stride,
+ cos_token_stride,
+ cos_dim_stride,
+ q_total_tokens,
+ Q_HEAD_NUM: tl.constexpr,
+ K_HEAD_NUM: tl.constexpr,
+ HEAD_DIM: tl.constexpr,
+ BLOCK_HEAD: tl.constexpr,
+ BLOCK_SIZE: tl.constexpr,
+ N_ELEMENTS: tl.constexpr,
+):
+ block_head_index = tl.program_id(0)
+ block_group_index = tl.program_id(1)
+ group_token_index = tl.program_id(2)
+ idx = block_group_index * BLOCK_SIZE + group_token_index
+
+ # original seq_idx and pos
+ cumsum_lens = tl.load(cumsum_lengths + tl.arange(0, N_ELEMENTS))
+ ori_seq_idx = idx - tl.max(tl.where(cumsum_lens <= idx, cumsum_lens, 0))
+ cos = tl.load(
+ cos_cache + ori_seq_idx * cos_token_stride + tl.arange(0, HEAD_DIM // 2) * cos_dim_stride
+ ) # [1,HEAD_DIM//2]
+ sin = tl.load(sin_cache + ori_seq_idx * cos_token_stride + tl.arange(0, HEAD_DIM // 2) * cos_dim_stride)
+
+ cur_head_range = block_head_index * BLOCK_HEAD + tl.arange(0, BLOCK_HEAD)
+ dim_range0 = tl.arange(0, HEAD_DIM // 2)
+ dim_range1 = tl.arange(HEAD_DIM // 2, HEAD_DIM)
+
+ off_q0 = (
+ idx * q_token_stride
+ + cur_head_range[None, :, None] * q_head_stride
+ + dim_range0[None, None, :] * head_dim_stride
+ )
+ off_q1 = (
+ idx * q_token_stride
+ + cur_head_range[None, :, None] * q_head_stride
+ + dim_range1[None, None, :] * head_dim_stride
+ )
+
+ off_k0 = (
+ idx * k_token_stride
+ + cur_head_range[None, :, None] * k_head_stride
+ + dim_range0[None, None, :] * head_dim_stride
+ )
+ off_k1 = (
+ idx * q_token_stride
+ + cur_head_range[None, :, None] * k_head_stride
+ + dim_range1[None, None, :] * head_dim_stride
+ )
+
+ q_0 = tl.load(
+ q + off_q0,
+ mask=((cur_head_range[None, :, None] < Q_HEAD_NUM) & (idx < q_total_tokens)),
+ other=0.0,
+ )
+
+ q_1 = tl.load(
+ q + off_q1,
+ mask=((cur_head_range[None, :, None] < Q_HEAD_NUM) & (idx < q_total_tokens)),
+ other=0.0,
+ )
+
+ k_0 = tl.load(
+ k + off_k0,
+ mask=((cur_head_range[None, :, None] < K_HEAD_NUM) & (idx < q_total_tokens)),
+ other=0.0,
+ )
+
+ k_1 = tl.load(
+ k + off_k1,
+ mask=((cur_head_range[None, :, None] < K_HEAD_NUM) & (idx < q_total_tokens)),
+ other=0.0,
+ )
+
+ out_q0 = q_0 * cos - q_1 * sin
+ out_q1 = k_0 * sin + k_1 * cos
+
+ out_k0 = q_0 * cos - q_1 * sin
+ out_k1 = k_0 * sin + k_1 * cos
+ # concat
+ tl.store(
+ q + off_q0,
+ out_q0,
+ mask=((cur_head_range[None, :, None] < Q_HEAD_NUM) & (idx < q_total_tokens)),
+ )
+ tl.store(
+ q + off_q1,
+ out_q1,
+ mask=((cur_head_range[None, :, None] < Q_HEAD_NUM) & (idx < q_total_tokens)),
+ )
+
+ tl.store(
+ k + off_k0,
+ out_k0,
+ mask=((cur_head_range[None, :, None] < K_HEAD_NUM) & (idx < q_total_tokens)),
+ )
+ tl.store(
+ k + off_k1,
+ out_k1,
+ mask=((cur_head_range[None, :, None] < K_HEAD_NUM) & (idx < q_total_tokens)),
+ )
+
+
+def fused_rotary_embedding(
+ q: torch.Tensor,
+ k: torch.Tensor,
+ cos: torch.Tensor,
+ sin: torch.Tensor,
+ lengths,
+):
+ """
+ Args:
+ q: query tensor, [total_tokens, head_num, head_dim]
+ k: key tensor, [total_tokens, head_num, head_dim]
+ cos: cosine for rotary embedding, [max_position_len, head_dim]
+ sin: sine for rotary embedding, [max_position_len, head_dim]
+ lengths [num_seqs]
+ """
+ q_total_tokens, q_head_num, head_dim = q.shape
+ assert q.size(0) == k.size(0)
+ BLOCK_HEAD = 4
+ BLOCK_SIZE = 8
+ cumsum_lens = torch.cumsum(lengths, dim=0)
+
+ grid = (triton.cdiv(q_head_num, BLOCK_HEAD), triton.cdiv(q_total_tokens, BLOCK_SIZE), BLOCK_SIZE)
+
+ if head_dim >= 128:
+ num_warps = 8
+ else:
+ num_warps = 4
+
+ q_token_stride = q.stride(0)
+ q_head_stride = q.stride(1)
+ head_dim_stride = q.stride(2)
+
+ k_token_stride = k.stride(0)
+ k_head_stride = k.stride(1)
+
+ k_head_num = q.shape[1]
+
+ cos_token_stride = cos.stride(0)
+ cos_dim_stride = cos.stride(1)
+
+ fused_rotary_emb[grid](
+ q,
+ k,
+ cos,
+ sin,
+ cumsum_lens,
+ q_token_stride,
+ q_head_stride,
+ k_token_stride,
+ k_head_stride,
+ head_dim_stride,
+ cos_token_stride,
+ cos_dim_stride,
+ q_total_tokens,
+ Q_HEAD_NUM=q_head_num,
+ K_HEAD_NUM=k_head_num,
+ HEAD_DIM=head_dim,
+ BLOCK_HEAD=BLOCK_HEAD,
+ BLOCK_SIZE=BLOCK_SIZE,
+ N_ELEMENTS=triton.next_power_of_2(q_total_tokens),
+ num_warps=num_warps,
+ )
diff --git a/colossalai/kernel/triton/gptq_triton.py b/colossalai/kernel/triton/gptq_triton.py
deleted file mode 100644
index 2dc1fe04438a..000000000000
--- a/colossalai/kernel/triton/gptq_triton.py
+++ /dev/null
@@ -1,543 +0,0 @@
-# Adapted from AutoGPTQ auto_gptq: https://github.com/PanQiWei/AutoGPTQ
-
-import torch
-import triton
-import triton.language as tl
-
-from .custom_autotune import autotune, matmul248_kernel_config_pruner
-
-
-@triton.jit
-def tanh(x):
- # Tanh is just a scaled sigmoid
- return 2 * tl.sigmoid(2 * x) - 1
-
-
-@triton.jit
-def cosh(x):
- exp_x = tl.exp(x)
- return (exp_x + 1.0 / exp_x) * 0.5
-
-
-# a Triton implementation of the most used activations
-# See for instance http://arxiv.org/abs/1606.08415 for an overview
-
-
-# ReLU
-@triton.jit
-def relu(x):
- """
- ReLU_ activation function
-
- .. _ReLU: https://pytorch.org/docs/stable/generated/torch.nn.ReLU.html
- """
- return tl.where(x >= 0, x, 0.0)
-
-
-@triton.jit
-def squared_relu(x):
- """
- Squared ReLU activation, as proposed in the Primer_ paper.
-
- .. _Primer: https://arxiv.org/abs/2109.08668
- """
- x_sq = x * x
- return tl.where(x > 0.0, x_sq, 0.0)
-
-
-@triton.jit
-def star_relu(x):
- """
- Star ReLU activation, as proposed in the "MetaFormer Baselines for Vision"_ paper.
-
- .. _ "MetaFormer Baselines for Vision": https://arxiv.org/pdf/2210.13452.pdf
- """
- x_sq = x * x
- return 0.8944 * tl.where(x > 0.0, x_sq, 0.0) - 0.4472
-
-
-# Leaky ReLU
-@triton.jit
-def leaky_relu(x):
- """
- LeakyReLU_ activation
-
- .. _LeakyReLU: https://pytorch.org/docs/stable/generated/torch.nn.LeakyReLU.html
- """
- return tl.where(x >= 0.0, x, 0.01 * x)
-
-
-@triton.jit
-def gelu(x):
- """
- GeLU_ activation - Gaussian error linear unit
-
- .. _GeLU: https://arxiv.org/pdf/1606.08415.pdf
- """
- return 0.5 * x * (1 + tanh(_kAlpha * (x + 0.044715 * x * x * x)))
-
-
-@triton.jit
-def smelu(x):
- """
- SmeLU_ activation - Smooth ReLU with beta=2.0
-
- .. _SmeLU: https://arxiv.org/pdf/2202.06499.pdf
- """
- beta = 2.0
-
- relu = tl.where(x >= beta, x, 0.0)
- return tl.where(tl.abs(x) <= beta, (x + beta) * (x + beta) / (4.0 * beta), relu)
-
-
-@triton.jit
-def silu(x):
- return x * tl.sigmoid(x)
-
-
-@autotune(
- configs=[
- triton.Config(
- {"BLOCK_SIZE_M": 64, "BLOCK_SIZE_N": 256, "BLOCK_SIZE_K": 32, "GROUP_SIZE_M": 8}, num_stages=4, num_warps=4
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 128, "BLOCK_SIZE_N": 128, "BLOCK_SIZE_K": 32, "GROUP_SIZE_M": 8}, num_stages=4, num_warps=4
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 64, "BLOCK_SIZE_N": 128, "BLOCK_SIZE_K": 32, "GROUP_SIZE_M": 8}, num_stages=4, num_warps=4
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 128, "BLOCK_SIZE_N": 32, "BLOCK_SIZE_K": 32, "GROUP_SIZE_M": 8}, num_stages=4, num_warps=4
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 64, "BLOCK_SIZE_N": 64, "BLOCK_SIZE_K": 32, "GROUP_SIZE_M": 8}, num_stages=4, num_warps=4
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 64, "BLOCK_SIZE_N": 128, "BLOCK_SIZE_K": 32, "GROUP_SIZE_M": 8}, num_stages=2, num_warps=8
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 64, "BLOCK_SIZE_N": 64, "BLOCK_SIZE_K": 64, "GROUP_SIZE_M": 8}, num_stages=3, num_warps=8
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 32, "BLOCK_SIZE_N": 32, "BLOCK_SIZE_K": 128, "GROUP_SIZE_M": 8}, num_stages=2, num_warps=4
- ),
- ],
- key=["M", "N", "K"],
- nearest_power_of_two=True,
- prune_configs_by={
- "early_config_prune": matmul248_kernel_config_pruner,
- "perf_model": None,
- "top_k": None,
- },
-)
-@triton.jit
-def cai_gptq_matmul_248_kernel(
- a_ptr,
- b_ptr,
- c_ptr,
- scales_ptr,
- zeros_ptr,
- bias_ptr,
- residual_ptr,
- M,
- N,
- K,
- bits,
- maxq,
- gptq_group_size,
- stride_am,
- stride_ak,
- stride_bk,
- stride_bn,
- stride_cm,
- stride_cn,
- stride_scales,
- stride_zeros,
- QKV_FUSED: tl.constexpr,
- ADD_BIAS: tl.constexpr,
- ADD_RESIDUAL: tl.constexpr,
- ACT_TYPE: tl.constexpr,
- BLOCK_SIZE_M: tl.constexpr,
- BLOCK_SIZE_N: tl.constexpr,
- BLOCK_SIZE_K: tl.constexpr,
- GROUP_SIZE_M: tl.constexpr,
-):
- """
- Compute the matrix multiplication C = A x B.
- A is of shape (M, K) float16
- B is of shape (K//8, N) int32
- C is of shape (M, N) float16
- scales is of shape (G, N) float16
- zeros is of shape (G, N) float16
- """
- infearure_per_bits = 32 // bits
-
- pid = tl.program_id(axis=0)
- NK = K
-
- num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
- num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
- num_pid_k = tl.cdiv(NK, BLOCK_SIZE_K)
- qkv_offset = pid // (num_pid_m * num_pid_n)
- pid = pid % (num_pid_m * num_pid_n)
- num_pid_in_group = GROUP_SIZE_M * num_pid_n
- group_id = pid // num_pid_in_group
- first_pid_m = group_id * GROUP_SIZE_M
- group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
- pid_m = first_pid_m + (pid % group_size_m)
- pid_n = (pid % num_pid_in_group) // group_size_m
-
- offs_am = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
- offs_bn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
- offs_k = tl.arange(0, BLOCK_SIZE_K)
- # offs_bk = offs_k + qkv_offset * NK
- a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak) # (BLOCK_SIZE_M, BLOCK_SIZE_K)
-
- a_mask = offs_am[:, None] < M
- # b_ptrs is set up such that it repeats elements along the K axis 8 times
- b_ptrs = (
- b_ptr
- + qkv_offset * N * NK // infearure_per_bits
- + ((offs_k[:, None] // infearure_per_bits) * stride_bk + offs_bn[None, :] * stride_bn)
- ) # (BLOCK_SIZE_K, BLOCK_SIZE_N)
- # g_ptrs = g_ptr + offs_k
- # shifter is used to extract the N bits of each element in the 32-bit word from B
- scales_ptrs = scales_ptr + qkv_offset * NK * N // gptq_group_size + offs_bn[None, :]
- zeros_ptrs = (
- zeros_ptr
- + qkv_offset * NK * N // gptq_group_size // infearure_per_bits
- + (offs_bn[None, :] // infearure_per_bits)
- )
-
- shifter = (offs_k % infearure_per_bits) * bits
- zeros_shifter = (offs_bn % infearure_per_bits) * bits
- accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
- g_idx_base = tl.arange(0, BLOCK_SIZE_K)
- g_idx_base = g_idx_base // gptq_group_size
- g_idx = g_idx_base
- # tl.device_print("gidx, ", g_idx)
-
- scales = tl.load(scales_ptrs + g_idx[:, None] * stride_scales) # (BLOCK_SIZE_K, BLOCK_SIZE_N,)
- zeros = tl.load(zeros_ptrs + g_idx[:, None] * stride_zeros) # (BLOCK_SIZE_K, BLOCK_SIZE_N,)
- zeros = (zeros >> zeros_shifter[None, :]) & maxq
- zeros = zeros + 1
-
- for k in range(0, num_pid_k):
- # g_idx = tl.load(g_ptrs)
- # if (k + 1) * BLOCK_SIZE_K > currend_group_end:
- scales = tl.load(scales_ptrs + g_idx[:, None] * stride_scales) # (BLOCK_SIZE_K, BLOCK_SIZE_N,)
- zeros = tl.load(zeros_ptrs + g_idx[:, None] * stride_zeros) # (BLOCK_SIZE_K, BLOCK_SIZE_N,)
- zeros = (zeros >> zeros_shifter[None, :]) & maxq
- zeros = zeros + 1
- # Fetch scales and zeros; these are per-outfeature and thus reused in the inner loop
- a = tl.load(a_ptrs, mask=a_mask, other=0.0) # (BLOCK_SIZE_M, BLOCK_SIZE_K)
- b = tl.load(b_ptrs) # (BLOCK_SIZE_K, BLOCK_SIZE_N), but repeated
- # Now we need to unpack b (which is N-bit values) into 32-bit values
- b = (b >> shifter[:, None]) & maxq # Extract the N-bit values
- b = (b - zeros).to(tl.float16) * scales # Scale and shift
- accumulator += tl.dot(a, b)
-
- a_ptrs += BLOCK_SIZE_K
- b_ptrs += (BLOCK_SIZE_K // infearure_per_bits) * stride_bk
- g_idx = g_idx_base + ((k + 1) * BLOCK_SIZE_K) // gptq_group_size
- # if (k + 2) * BLOCK_SIZE_K > currend_group_end:
-
- c_ptrs = c_ptr + qkv_offset * M * N + stride_cm * offs_am[:, None] + stride_cn * offs_bn[None, :]
- c_mask = (offs_am[:, None] < M) & (offs_bn[None, :] < N)
-
- if ADD_BIAS:
- bias_mask = offs_bn < N
- offs_bn += qkv_offset * N
- bias_ptrs = bias_ptr + stride_cn * offs_bn
- bias = tl.load(bias_ptrs, mask=bias_mask, other=0.0) # (BLOCK_SIZE_M, BLOCK_SIZE_K)
- accumulator += bias[None, :]
-
- if ACT_TYPE == 1:
- accumulator = relu(accumulator)
- elif ACT_TYPE == 2:
- accumulator = gelu(accumulator)
- elif ACT_TYPE == 3:
- accumulator = silu(accumulator)
-
- if ADD_RESIDUAL:
- residual_ptrs = residual_ptr + stride_cm * offs_am[:, None] + stride_cn * offs_bn[None, :]
- res = tl.load(residual_ptrs, mask=c_mask, other=0.0)
- accumulator += res
-
- tl.store(c_ptrs, accumulator, mask=c_mask)
-
-
-# Adapted from AutoGPTQ auto_gptq: https://github.com/PanQiWei/AutoGPTQ
-@autotune(
- configs=[
- triton.Config(
- {"BLOCK_SIZE_M": 64, "BLOCK_SIZE_N": 256, "BLOCK_SIZE_K": 32, "GROUP_SIZE_M": 8}, num_stages=4, num_warps=4
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 128, "BLOCK_SIZE_N": 128, "BLOCK_SIZE_K": 32, "GROUP_SIZE_M": 8}, num_stages=4, num_warps=4
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 64, "BLOCK_SIZE_N": 128, "BLOCK_SIZE_K": 32, "GROUP_SIZE_M": 8}, num_stages=4, num_warps=4
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 128, "BLOCK_SIZE_N": 32, "BLOCK_SIZE_K": 32, "GROUP_SIZE_M": 8}, num_stages=4, num_warps=4
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 64, "BLOCK_SIZE_N": 64, "BLOCK_SIZE_K": 32, "GROUP_SIZE_M": 8}, num_stages=4, num_warps=4
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 64, "BLOCK_SIZE_N": 128, "BLOCK_SIZE_K": 32, "GROUP_SIZE_M": 8}, num_stages=2, num_warps=8
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 64, "BLOCK_SIZE_N": 64, "BLOCK_SIZE_K": 64, "GROUP_SIZE_M": 8}, num_stages=3, num_warps=8
- ),
- triton.Config(
- {"BLOCK_SIZE_M": 32, "BLOCK_SIZE_N": 32, "BLOCK_SIZE_K": 128, "GROUP_SIZE_M": 8}, num_stages=2, num_warps=4
- ),
- ],
- key=["M", "N", "K"],
- nearest_power_of_two=True,
- prune_configs_by={
- "early_config_prune": matmul248_kernel_config_pruner,
- "perf_model": None,
- "top_k": None,
- },
-)
-@triton.jit
-def cai_gptq_idx_matmul_248_kernel(
- a_ptr,
- b_ptr,
- c_ptr,
- scales_ptr,
- zeros_ptr,
- idx_ptr,
- bias_ptr,
- residual_ptr,
- M,
- N,
- K,
- bits,
- maxq,
- gptq_group_size,
- stride_am,
- stride_ak,
- stride_bk,
- stride_bn,
- stride_cm,
- stride_cn,
- stride_scales,
- stride_zeros,
- QKV_FUSED: tl.constexpr,
- ADD_BIAS: tl.constexpr,
- ADD_RESIDUAL: tl.constexpr,
- ACT_TYPE: tl.constexpr,
- BLOCK_SIZE_M: tl.constexpr,
- BLOCK_SIZE_N: tl.constexpr,
- BLOCK_SIZE_K: tl.constexpr,
- GROUP_SIZE_M: tl.constexpr,
-):
- """
- Compute the matrix multiplication C = A x B.
- A is of shape (M, K) float16
- B is of shape (K//8, N) int32
- C is of shape (M, N) float16
- scales is of shape (G, N) float16
- zeros is of shape (G, N) float16
- """
- infearure_per_bits = 32 // bits
-
- pid = tl.program_id(axis=0)
- NK = K
-
- # if QKV_FUSED:
- # NK = K//3
- # else:
- # NK = K
- # NK = K
-
- num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
- num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
- num_pid_k = tl.cdiv(NK, BLOCK_SIZE_K)
- qkv_offset = pid // (num_pid_m * num_pid_n)
- pid = pid % (num_pid_m * num_pid_n)
- num_pid_in_group = GROUP_SIZE_M * num_pid_n
- group_id = pid // num_pid_in_group
- first_pid_m = group_id * GROUP_SIZE_M
- group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
- pid_m = first_pid_m + (pid % group_size_m)
- pid_n = (pid % num_pid_in_group) // group_size_m
-
- offs_am = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
- offs_bn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
- offs_k = tl.arange(0, BLOCK_SIZE_K)
- # offs_bk = offs_k + qkv_offset * NK
- a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak) # (BLOCK_SIZE_M, BLOCK_SIZE_K)
-
- a_mask = offs_am[:, None] < M
- # b_ptrs is set up such that it repeats elements along the K axis 8 times
- b_ptrs = (
- b_ptr
- + qkv_offset * N * NK // infearure_per_bits
- + ((offs_k[:, None] // infearure_per_bits) * stride_bk + offs_bn[None, :] * stride_bn)
- ) # (BLOCK_SIZE_K, BLOCK_SIZE_N)
- # g_ptrs = g_ptr + offs_k
- # shifter is used to extract the N bits of each element in the 32-bit word from B
- scales_ptrs = scales_ptr + qkv_offset * NK * N // gptq_group_size + offs_bn[None, :]
- zeros_ptrs = (
- zeros_ptr
- + qkv_offset * NK * N // gptq_group_size // infearure_per_bits
- + (offs_bn[None, :] // infearure_per_bits)
- )
-
- shifter = (offs_k % infearure_per_bits) * bits
- zeros_shifter = (offs_bn % infearure_per_bits) * bits
- accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
- g_ptrs = idx_ptr + offs_k
- g_idx = tl.load(g_ptrs)
- # tl.device_print("gidx, ", g_idx)
- zeros_ptrs = zeros_ptr + (offs_bn[None, :] // infearure_per_bits)
-
- scales = tl.load(scales_ptrs + g_idx[:, None] * stride_scales) # (BLOCK_SIZE_K, BLOCK_SIZE_N,)
-
- for k in range(0, num_pid_k):
- g_idx = tl.load(g_ptrs)
- scales = tl.load(scales_ptrs + g_idx[:, None] * stride_scales) # (BLOCK_SIZE_K, BLOCK_SIZE_N,)
- zeros = tl.load(zeros_ptrs + g_idx[:, None] * stride_zeros) # (BLOCK_SIZE_K, BLOCK_SIZE_N,)
-
- zeros = (zeros >> zeros_shifter[None, :]) & maxq
- zeros = zeros + 1
-
- # Fetch scales and zeros; these are per-outfeature and thus reused in the inner loop
- a = tl.load(a_ptrs, mask=a_mask, other=0.0) # (BLOCK_SIZE_M, BLOCK_SIZE_K)
- b = tl.load(b_ptrs) # (BLOCK_SIZE_K, BLOCK_SIZE_N), but repeated
- # Now we need to unpack b (which is N-bit values) into 32-bit values
- b = (b >> shifter[:, None]) & maxq # Extract the N-bit values
- b = (b - zeros).to(tl.float16) * scales # Scale and shift
- accumulator += tl.dot(a, b)
-
- a_ptrs += BLOCK_SIZE_K
- b_ptrs += (BLOCK_SIZE_K // infearure_per_bits) * stride_bk
- g_ptrs += BLOCK_SIZE_K
-
- c_ptrs = c_ptr + qkv_offset * M * N + stride_cm * offs_am[:, None] + stride_cn * offs_bn[None, :]
- c_mask = (offs_am[:, None] < M) & (offs_bn[None, :] < N)
-
- if ADD_BIAS:
- bias_mask = offs_bn < N
- offs_bn += qkv_offset * N
- bias_ptrs = bias_ptr + stride_cn * offs_bn
- bias = tl.load(bias_ptrs, mask=bias_mask, other=0.0) # (BLOCK_SIZE_M, BLOCK_SIZE_K)
- accumulator += bias[None, :]
-
- if ACT_TYPE == 1:
- accumulator = relu(accumulator)
- elif ACT_TYPE == 2:
- accumulator = gelu(accumulator)
- elif ACT_TYPE == 3:
- accumulator = silu(accumulator)
-
- if ADD_RESIDUAL:
- residual_ptrs = residual_ptr + stride_cm * offs_am[:, None] + stride_cn * offs_bn[None, :]
- res = tl.load(residual_ptrs, mask=c_mask, other=0.0)
- accumulator += res
-
- tl.store(c_ptrs, accumulator, mask=c_mask)
-
-
-def gptq_fused_linear_triton(
- input,
- qweight,
- scales,
- qzeros,
- bias,
- residual,
- bits,
- maxq,
- gptq_group_size,
- qkv_fused,
- add_bias,
- add_residual,
- g_idx=None,
- act_type=0,
-):
- # print("gptq fused ", qkv_fused, add_bias, add_residual)
- assert input.is_cuda, "input is not in cuda"
- assert qweight.is_cuda, "qweight is not in cuda"
- assert scales.is_cuda, "scales is not in cuda"
- assert qzeros.is_cuda, "qzeros is not in cuda"
-
- with torch.cuda.device(input.device):
- if qkv_fused:
- grid = lambda META: (
- triton.cdiv(input.shape[0], META["BLOCK_SIZE_M"])
- * triton.cdiv(qweight.shape[1], META["BLOCK_SIZE_N"])
- * 3,
- )
- output = torch.empty((input.shape[0] * 3, qweight.shape[1]), device=input.device, dtype=torch.float16)
- else:
- grid = lambda META: (
- triton.cdiv(input.shape[0], META["BLOCK_SIZE_M"]) * triton.cdiv(qweight.shape[1], META["BLOCK_SIZE_N"]),
- )
- output = torch.empty((input.shape[0], qweight.shape[1]), device=input.device, dtype=torch.float16)
- # print("dtype, ", qweight.dtype, output.dtype, scales.dtype, qzeros.dtype, bias.dtype, residual.dtype)
- if g_idx is None:
- cai_gptq_matmul_248_kernel[grid](
- input,
- qweight,
- output,
- scales,
- qzeros,
- bias,
- residual,
- input.shape[0],
- qweight.shape[1],
- input.shape[1],
- bits,
- maxq,
- gptq_group_size,
- input.stride(0),
- input.stride(1),
- qweight.stride(0),
- qweight.stride(1),
- output.stride(0),
- output.stride(1),
- scales.stride(0),
- qzeros.stride(0),
- QKV_FUSED=qkv_fused,
- ADD_BIAS=add_bias,
- ADD_RESIDUAL=add_residual,
- ACT_TYPE=act_type,
- )
- else:
- cai_gptq_idx_matmul_248_kernel[grid](
- input,
- qweight,
- output,
- scales,
- qzeros,
- g_idx,
- bias,
- residual,
- input.shape[0],
- qweight.shape[1],
- input.shape[1],
- bits,
- maxq,
- gptq_group_size,
- input.stride(0),
- input.stride(1),
- qweight.stride(0),
- qweight.stride(1),
- output.stride(0),
- output.stride(1),
- scales.stride(0),
- qzeros.stride(0),
- QKV_FUSED=qkv_fused,
- ADD_BIAS=add_bias,
- ADD_RESIDUAL=add_residual,
- ACT_TYPE=act_type,
- )
- if qkv_fused:
- return output.view(3, input.shape[0], qweight.shape[1])
- else:
- return output
diff --git a/colossalai/kernel/triton/int8_rotary_embedding_kernel.py b/colossalai/kernel/triton/int8_rotary_embedding_kernel.py
deleted file mode 100644
index 537dd164d1ab..000000000000
--- a/colossalai/kernel/triton/int8_rotary_embedding_kernel.py
+++ /dev/null
@@ -1,117 +0,0 @@
-# Adapted from ModelTC https://github.com/ModelTC/lightllm
-import torch
-import triton
-import triton.language as tl
-
-
-@triton.jit
-def _rotary_kernel(
- q,
- input_scale,
- output_scale,
- Cos,
- Sin,
- q_bs_stride,
- q_h_stride,
- q_d_stride,
- cos_bs_stride,
- cos_d_stride,
- total_len,
- HEAD_NUM: tl.constexpr,
- BLOCK_HEAD: tl.constexpr,
- BLOCK_SEQ: tl.constexpr,
- HEAD_DIM: tl.constexpr,
-):
- current_head_index = tl.program_id(0)
- current_seq_index = tl.program_id(1)
-
- dim_range0 = tl.arange(0, HEAD_DIM // 2)
- dim_range1 = tl.arange(HEAD_DIM // 2, HEAD_DIM)
-
- current_head_range = current_head_index * BLOCK_HEAD + tl.arange(0, BLOCK_HEAD)
- current_seq_range = current_seq_index * BLOCK_SEQ + tl.arange(0, BLOCK_SEQ)
-
- off_q0 = (
- current_seq_range[:, None, None] * q_bs_stride
- + current_head_range[None, :, None] * q_h_stride
- + dim_range0[None, None, :] * q_d_stride
- )
- off_q1 = (
- current_seq_range[:, None, None] * q_bs_stride
- + current_head_range[None, :, None] * q_h_stride
- + dim_range1[None, None, :] * q_d_stride
- )
-
- off_dimcos_sin = current_seq_range[:, None, None] * cos_bs_stride + dim_range0[None, None, :] * cos_d_stride
-
- q0 = tl.load(
- q + off_q0,
- mask=(current_seq_range[:, None, None] < total_len) & (current_head_range[None, :, None] < HEAD_NUM),
- other=0.0,
- )
- q1 = tl.load(
- q + off_q1,
- mask=(current_seq_range[:, None, None] < total_len) & (current_head_range[None, :, None] < HEAD_NUM),
- other=0.0,
- )
-
- cos = tl.load(Cos + off_dimcos_sin, mask=current_seq_range[:, None, None] < total_len, other=0.0)
- sin = tl.load(Sin + off_dimcos_sin, mask=current_seq_range[:, None, None] < total_len, other=0.0)
-
- q0 = q0.to(tl.float32) * input_scale
- q1 = q1.to(tl.float32) * input_scale
-
- out0 = (q0 * cos - q1 * sin) / output_scale
- out1 = (q0 * sin + q1 * cos) / output_scale
-
- out0 = out0.to(tl.int8)
- out1 = out1.to(tl.int8)
-
- tl.store(
- q + off_q0,
- out0,
- mask=(current_seq_range[:, None, None] < total_len) & (current_head_range[None, :, None] < HEAD_NUM),
- )
- tl.store(
- q + off_q1,
- out1,
- mask=(current_seq_range[:, None, None] < total_len) & (current_head_range[None, :, None] < HEAD_NUM),
- )
-
- return
-
-
-@torch.no_grad()
-def int8_rotary_embedding_fwd(q, cos, sin, input_scale, output_scale):
- total_len = q.shape[0]
- head_num = q.shape[1]
- head_dim = q.shape[2]
- assert q.shape[0] == cos.shape[0] and q.shape[0] == sin.shape[0], f"q shape {q.shape} cos shape {cos.shape}"
- BLOCK_HEAD = 4
- BLOCK_SEQ = 32
- grid = (triton.cdiv(head_num, BLOCK_HEAD), triton.cdiv(total_len, BLOCK_SEQ))
- if head_dim >= 128:
- num_warps = 8
- else:
- num_warps = 4
-
- _rotary_kernel[grid](
- q,
- input_scale,
- output_scale,
- cos,
- sin,
- q.stride(0),
- q.stride(1),
- q.stride(2),
- cos.stride(0),
- cos.stride(1),
- total_len,
- HEAD_NUM=head_num,
- BLOCK_HEAD=BLOCK_HEAD,
- BLOCK_SEQ=BLOCK_SEQ,
- HEAD_DIM=head_dim,
- num_warps=num_warps,
- num_stages=1,
- )
- return
diff --git a/colossalai/kernel/triton/kvcache_copy.py b/colossalai/kernel/triton/kvcache_copy.py
new file mode 100644
index 000000000000..77397b5cb6cf
--- /dev/null
+++ b/colossalai/kernel/triton/kvcache_copy.py
@@ -0,0 +1,296 @@
+import torch
+import triton
+import triton.language as tl
+
+
+# Triton 2.1.0
+# supports two types of cache layouts
+# 1. [num_blocks, num_kv_heads, block_size, head_dim]
+# 2. [num_blocks, num_kv_heads, head_dim // x, block_size, x]
+@triton.jit
+def _copy_to_kcache_seqlen_n_kernel(
+ K, # K or V
+ KCache, # [num_blocks, num_kv_heads, head_dim // x, block_size, x]
+ BLOCK_TABLES,
+ seq_lengths,
+ stride_kt,
+ stride_kh,
+ stride_kd,
+ stride_kcb,
+ stride_kch,
+ stride_kcsplit_x,
+ stride_kcs,
+ stride_kcx,
+ stride_bts,
+ stride_btb,
+ block_size,
+ n_tokens,
+ HEAD_DIM: tl.constexpr,
+ KCACHE_X: tl.constexpr,
+):
+ # `n_tokens` is used to specify the number of tokens to copy for each sequence
+ # When n_tokens > 1, tokens from different sequences are packed into the first dimension of the grid,
+ # `seq_lengths` must be the lengths of sequences counting the number of tokens to copy
+ # E.g. if n_tokens = 5, seq_lengths = [12, 15], then the already-copied position ids are [0-6, 0-9]
+ # for the two sequences, respectively. And the position ids to be copied are [7-11, 9-14].
+ # When n_tokens = 1, consider token idx as the sequence idx, since it's only used during regular decoding stage
+ cur_token_idx = tl.program_id(0)
+ cur_seq_idx = cur_token_idx // n_tokens
+ # `cur_token_shift` is only valid and functional when `n_tokens` > 1
+ cur_token_shift = cur_token_idx - (n_tokens * (cur_seq_idx + 1))
+ cur_kv_head_idx = tl.program_id(1)
+ split_x_idx = tl.program_id(2)
+
+ past_kv_seq_len = tl.load(seq_lengths + cur_seq_idx) + cur_token_shift
+ last_bt_block_idx = past_kv_seq_len // block_size
+ block_table_ptr = BLOCK_TABLES + cur_seq_idx * stride_bts
+ block_id = tl.load(block_table_ptr + last_bt_block_idx * stride_btb)
+ offset_last_block = past_kv_seq_len % block_size
+ offsets_dmodel = split_x_idx * KCACHE_X + tl.arange(0, KCACHE_X)
+ offsets_k = cur_token_idx * stride_kt + cur_kv_head_idx * stride_kh + offsets_dmodel * stride_kd
+ k = tl.load(K + offsets_k)
+ offsets_kcache = (
+ block_id * stride_kcb
+ + cur_kv_head_idx * stride_kch
+ + split_x_idx * stride_kcsplit_x
+ + offset_last_block * stride_kcs
+ + tl.arange(0, KCACHE_X)
+ )
+ tl.store(KCache + offsets_kcache, k)
+ return
+
+
+# Triton 2.1.0
+@triton.jit
+def _copy_to_kvcache_seqlen1_kernel(
+ K,
+ V,
+ KCache,
+ VCache,
+ BLOCK_TABLES,
+ context_lengths,
+ stride_kt,
+ stride_kh,
+ stride_kd,
+ stride_vt,
+ stride_vh,
+ stride_vd,
+ stride_kcb,
+ stride_kch,
+ stride_kcsplit_x,
+ stride_kcs,
+ stride_kcd,
+ stride_vcb,
+ stride_vch,
+ stride_vcs,
+ stride_vcd,
+ stride_bts,
+ stride_btb,
+ block_size,
+ HEAD_DIM: tl.constexpr,
+ KCACHE_X: tl.constexpr,
+):
+ cur_seq_idx = tl.program_id(0)
+ cur_kv_head_idx = tl.program_id(1)
+
+ past_kv_seq_len = tl.load(context_lengths + cur_seq_idx) - 1
+ last_bt_block_idx = past_kv_seq_len // block_size
+ block_table_ptr = BLOCK_TABLES + cur_seq_idx * stride_bts
+ block_id = tl.load(block_table_ptr + last_bt_block_idx * stride_btb)
+ offsets_in_last_block = past_kv_seq_len % block_size
+
+ range_x = tl.arange(0, KCACHE_X)
+ offsets_dmodel_x_partition = tl.arange(0, KCACHE_X)
+
+ for split_x in tl.static_range(HEAD_DIM // KCACHE_X):
+ offsets_dmodel_x_partition = tl.arange(split_x * KCACHE_X, (split_x + 1) * KCACHE_X)
+ offsets_k = cur_seq_idx * stride_kt + cur_kv_head_idx * stride_kh + offsets_dmodel_x_partition * stride_kd
+ k = tl.load(K + offsets_k)
+ offsets_v = cur_seq_idx * stride_vt + cur_kv_head_idx * stride_vh + offsets_dmodel_x_partition * stride_vd
+ v = tl.load(V + offsets_v)
+
+ offsets_kcache = (
+ block_id * stride_kcb
+ + cur_kv_head_idx * stride_kch
+ + split_x * stride_kcsplit_x
+ + offsets_in_last_block * stride_kcs
+ + range_x
+ )
+ tl.store(KCache + offsets_kcache, k)
+ offsets_vcache = (
+ block_id * stride_vcb
+ + cur_kv_head_idx * stride_vch
+ + offsets_in_last_block * stride_vcs
+ + offsets_dmodel_x_partition * stride_vcd
+ )
+ tl.store(VCache + offsets_vcache, v)
+ return
+
+
+def copy_k_to_blocked_cache(
+ k: torch.Tensor,
+ k_cache: torch.Tensor,
+ kv_lengths: torch.Tensor,
+ block_tables: torch.Tensor,
+ n: int = 1,
+ use_new_kcache_layout: bool = False,
+):
+ """
+ Copy keys or values to the blocked key/value cache during decoding stage.
+
+ Args:
+ k (torch.Tensor): [bsz, 1, num_kv_heads, head_dim]/[bsz, num_kv_heads, head_dim] - Keys or values during decoding with seq len 1.
+ [bsz * n, num_kv_heads, head_dim] - Keys or values with seq len n
+ k_cache (torch.Tensor): [num_blocks, num_kv_heads, block_size, head_dim] - Blocked key or value cache.
+ new KCache Layout [num_blocks, num_kv_heads, head_dim // x, block_size, x]
+ kv_lengths (torch.Tensor): [bsz] - Past key/value sequence lengths plus current sequence length for each sequence.
+ block_tables (torch.Tensor): [bsz, max_blocks_per_sequence] - Block tables for each sequence.
+ n (int): Number of tokens to copy for each sequence. Default to 1.
+ use_new_kcache_layout (bool): Whether to use the new layout for kcache. Default to False.
+ """
+ assert k.dtype == k_cache.dtype, "Expected consistent dtype for tensor and cache."
+ if k.dim() == 4:
+ k = k.reshape(-1, k.size(-2), k.size(-1))
+ k_shape = k.shape
+ bsz, num_kv_heads, head_dim = k_shape
+ # NOTE when n > 1, the shape of k is [bsz * n, num_kv_heads, head_dim]
+ if n > 1:
+ assert bsz % n == 0, "Each sequence should have the same number of tokens to be copied"
+ bsz = bsz // n
+
+ assert kv_lengths.shape[0] == block_tables.shape[0] == bsz, (
+ f"Got incompatible batch size (number of seqs):\n"
+ f" Past kv sequence lengths bsz {kv_lengths.shape[0]}; "
+ f" block tables bsz {block_tables.shape[0]}, input k batch size {bsz}"
+ )
+
+ k_cache_shape = k_cache.shape
+ # Modify if the shape of kv cahce is changed.
+ block_size = k_cache_shape[-2]
+
+ x = head_dim
+ stride_kcsplit_x, stride_kcs, stride_kcd = 0, k_cache.stride(2), k_cache.stride(3)
+ if use_new_kcache_layout:
+ # when using kcache layout [num_blocks, num_kv_heads, head_dim // x, block_size, x]
+ assert (
+ len(k_cache_shape) == 5
+ and k_cache_shape[1] == k_shape[1]
+ and k_cache_shape[2] * k_cache_shape[4] == k_shape[2]
+ ), f"Incompatible k_cache shape {k_cache_shape} with k shape {k_shape}"
+ x = k_cache.size(-1)
+ stride_kcsplit_x, stride_kcs, stride_kcd = k_cache.stride()[2:]
+
+ num_warps = 8 if head_dim > 128 else 4
+ grid = (bsz * n, num_kv_heads, head_dim // x)
+ _copy_to_kcache_seqlen_n_kernel[grid](
+ k,
+ k_cache,
+ block_tables,
+ kv_lengths,
+ k.stride(0),
+ k.stride(1),
+ k.stride(2),
+ k_cache.stride(0),
+ k_cache.stride(1),
+ stride_kcsplit_x,
+ stride_kcs,
+ stride_kcd,
+ block_tables.stride(0),
+ block_tables.stride(1),
+ block_size,
+ n_tokens=n,
+ HEAD_DIM=head_dim,
+ KCACHE_X=x,
+ num_warps=num_warps,
+ )
+
+
+def copy_kv_to_blocked_cache(
+ k: torch.Tensor,
+ v: torch.Tensor,
+ k_cache: torch.Tensor,
+ v_cache: torch.Tensor,
+ kv_lengths: torch.Tensor,
+ block_tables: torch.Tensor,
+ use_new_kcache_layout: bool = False,
+):
+ """
+ Copy keys or values to the blocked key/value cache during decoding stage.
+
+ Args:
+ k (torch.Tensor): [bsz, 1, num_kv_heads, head_dim]/[bsz, num_kv_heads, head_dim] - Keys during decoding with seq len 1.
+ v (torch.Tensor): [bsz, 1, num_kv_heads, head_dim]/[bsz, num_kv_heads, head_dim] - Values during decoding with seq len 1.
+ k_cache (torch.Tensor): [num_blocks, num_kv_heads, block_size, head_dim] - Blocked key cache.
+ v_cache (torch.Tensor): [num_blocks, num_kv_heads, block_size, head_dim] - Blocked value cache.
+ kv_lengths (torch.Tensor): [bsz] - Past key/value sequence lengths plus current sequence length for each sequence.
+ block_tables (torch.Tensor): [bsz, max_blocks_per_sequence] - Block tables for each sequence.
+ use_new_kcache_layout (bool): Whether to use the new layout for kcache. Default to False.
+ """
+ k_cache_shape = k_cache.shape
+ v_cache_shape = v_cache.shape
+
+ if use_new_kcache_layout:
+ assert (
+ len(k_cache_shape) == 5
+ and k_cache_shape[1] == v_cache_shape[1]
+ and k_cache_shape[2] * k_cache_shape[4] == v_cache_shape[3]
+ ), f"Invalid KCache shape {k_cache_shape} and VCache shape {v_cache_shape}"
+ else:
+ assert k.size(-1) == k_cache_shape[-1], "Incompatible head dim"
+ assert (
+ k_cache_shape == v_cache_shape
+ ), f"Incompatible KCache shape {k_cache_shape} and VCache shape {v_cache_shape}"
+ assert v.size(-1) == v_cache_shape[-1], "Incompatible head dim"
+
+ k = k.squeeze(1) if k.dim() == 4 else k
+ assert k.dim() == 3, f"Incompatible k dim {k.dim()}"
+ v = v.squeeze(1) if v.dim() == 4 else v
+ assert v.dim() == 3, f"Incompatible v dim {v.dim()}"
+
+ bsz, num_kv_heads, head_dim = k.shape
+ assert kv_lengths.shape[0] == block_tables.shape[0] == bsz, (
+ f"Got incompatible batch size (number of seqs):\n"
+ f" Past kv sequence lengths bsz {kv_lengths.shape[0]}; "
+ f" block tables bsz {block_tables.shape[0]}, input k batch size {bsz}"
+ )
+
+ # Modify if the shape of kv cahce is changed.
+ block_size = k_cache.size(-2)
+
+ x = head_dim
+ stride_kcsplit_x, stride_kcs, stride_kcd = 0, k_cache.stride(2), k_cache.stride(3)
+ if use_new_kcache_layout:
+ x = k_cache.size(-1)
+ stride_kcsplit_x, stride_kcs, stride_kcd = k_cache.stride()[2:]
+
+ num_warps = 8 if head_dim > 128 else 4
+ grid = (bsz, num_kv_heads)
+ _copy_to_kvcache_seqlen1_kernel[grid](
+ k,
+ v,
+ k_cache,
+ v_cache,
+ block_tables,
+ kv_lengths,
+ k.stride(0),
+ k.stride(1),
+ k.stride(2),
+ v.stride(0),
+ v.stride(1),
+ v.stride(2),
+ k_cache.stride(0),
+ k_cache.stride(1),
+ stride_kcsplit_x,
+ stride_kcs,
+ stride_kcd,
+ v_cache.stride(0),
+ v_cache.stride(1),
+ v_cache.stride(2),
+ v_cache.stride(3),
+ block_tables.stride(0),
+ block_tables.stride(1),
+ block_size,
+ HEAD_DIM=head_dim,
+ KCACHE_X=x,
+ num_warps=num_warps,
+ )
diff --git a/colossalai/kernel/triton/no_pad_rotary_embedding.py b/colossalai/kernel/triton/no_pad_rotary_embedding.py
new file mode 100644
index 000000000000..e0da816bdc90
--- /dev/null
+++ b/colossalai/kernel/triton/no_pad_rotary_embedding.py
@@ -0,0 +1,659 @@
+import warnings
+from typing import Optional
+
+import torch
+import triton
+import triton.language as tl
+
+"""
+# Base autotune if needed
+@triton.autotune(
+ configs=[
+ triton.Config({'BLOCK_HEAD':4,"BLOCK_TOKENS":4,},num_warps=4),
+ triton.Config({'BLOCK_HEAD':4,"BLOCK_TOKENS":8,},num_warps=8),
+ triton.Config({'BLOCK_HEAD':8,"BLOCK_TOKENS":8,},num_warps=8),
+ triton.Config({'BLOCK_HEAD':4,"BLOCK_TOKENS":4,},num_warps=16),
+ triton.Config({'BLOCK_HEAD':4,"BLOCK_TOKENS":4,},num_warps=32),
+ triton.Config({'BLOCK_HEAD':16,"BLOCK_TOKENS":16,},num_warps=4),
+ triton.Config({'BLOCK_HEAD':8,"BLOCK_TOKENS":16,},num_warps=8),
+ ],
+ key=['HEAD_DIM','q_total_tokens','Q_HEAD_NUM']
+)
+"""
+
+
+@triton.jit
+def rotary_embedding_kernel(
+ q,
+ k,
+ cos,
+ sin,
+ q_token_stride,
+ q_head_stride,
+ k_token_stride,
+ k_head_stride,
+ head_dim_stride,
+ cos_token_stride,
+ cos_stride,
+ q_total_tokens,
+ Q_HEAD_NUM: tl.constexpr,
+ KV_GROUP_NUM: tl.constexpr,
+ HEAD_DIM: tl.constexpr,
+ BLOCK_TOKENS: tl.constexpr, # token range length
+):
+ cur_head_idx = tl.program_id(0)
+ cur_token_block_idx = tl.program_id(1)
+
+ tokens_range = cur_token_block_idx * BLOCK_TOKENS + tl.arange(0, BLOCK_TOKENS)
+ dim_range0 = tl.arange(0, HEAD_DIM // 2)
+ dim_range1 = tl.arange(HEAD_DIM // 2, HEAD_DIM)
+
+ off_cos_sin = tokens_range[:, None] * cos_token_stride + dim_range0[None, :] * cos_stride
+ loaded_cos = tl.load(cos + off_cos_sin, mask=(tokens_range[:, None] < q_total_tokens), other=0.0)
+ loaded_sin = tl.load(sin + off_cos_sin, mask=(tokens_range[:, None] < q_total_tokens), other=0.0)
+
+ off_q0 = (
+ tokens_range[:, None, None] * q_token_stride
+ + cur_head_idx * q_head_stride
+ + dim_range0[None, None, :] * head_dim_stride
+ )
+ off_q1 = (
+ tokens_range[:, None, None] * q_token_stride
+ + cur_head_idx * q_head_stride
+ + dim_range1[None, None, :] * head_dim_stride
+ )
+ loaded_q0 = tl.load(
+ q + off_q0,
+ mask=((cur_head_idx < Q_HEAD_NUM) & (tokens_range[:, None, None] < q_total_tokens)),
+ other=0.0,
+ )
+ loaded_q1 = tl.load(
+ q + off_q1,
+ mask=((cur_head_idx < Q_HEAD_NUM) & (tokens_range[:, None, None] < q_total_tokens)),
+ other=0.0,
+ )
+ out_q0 = loaded_q0 * loaded_cos[:, None, :] - loaded_q1 * loaded_sin[:, None, :]
+ out_q1 = loaded_q0 * loaded_sin[:, None, :] + loaded_q1 * loaded_cos[:, None, :]
+
+ tl.store(
+ q + off_q0,
+ out_q0,
+ mask=((cur_head_idx < Q_HEAD_NUM) & (tokens_range[:, None, None] < q_total_tokens)),
+ )
+ tl.store(
+ q + off_q1,
+ out_q1,
+ mask=((cur_head_idx < Q_HEAD_NUM) & (tokens_range[:, None, None] < q_total_tokens)),
+ )
+
+ handle_kv = cur_head_idx % KV_GROUP_NUM == 0
+ if handle_kv:
+ k_head_idx = cur_head_idx // KV_GROUP_NUM
+ off_k0 = (
+ tokens_range[:, None, None] * k_token_stride
+ + k_head_idx * k_head_stride
+ + dim_range0[None, None, :] * head_dim_stride
+ )
+ off_k1 = (
+ tokens_range[:, None, None] * k_token_stride
+ + k_head_idx * k_head_stride
+ + dim_range1[None, None, :] * head_dim_stride
+ )
+ loaded_k0 = tl.load(
+ k + off_k0,
+ mask=(tokens_range[:, None, None] < q_total_tokens),
+ other=0.0,
+ )
+ loaded_k1 = tl.load(
+ k + off_k1,
+ mask=(tokens_range[:, None, None] < q_total_tokens),
+ other=0.0,
+ )
+ out_k0 = loaded_k0 * loaded_cos[:, None, :] - loaded_k1 * loaded_sin[:, None, :]
+ out_k1 = loaded_k0 * loaded_sin[:, None, :] + loaded_k1 * loaded_cos[:, None, :]
+ tl.store(
+ k + off_k0,
+ out_k0,
+ mask=(tokens_range[:, None, None] < q_total_tokens),
+ )
+ tl.store(
+ k + off_k1,
+ out_k1,
+ mask=(tokens_range[:, None, None] < q_total_tokens),
+ )
+
+
+@triton.jit
+def fused_rotary_embedding_kernel(
+ q,
+ k,
+ cos,
+ sin,
+ kv_cache,
+ BLOCK_TABLES,
+ context_lengths,
+ q_token_stride,
+ q_head_stride,
+ k_token_stride,
+ k_head_stride,
+ head_dim_stride,
+ cos_token_stride,
+ cos_stride,
+ cacheb_stride,
+ cacheh_stride,
+ cachebs_stride,
+ cached_stride,
+ bts_stride,
+ btb_stride,
+ block_size,
+ q_total_tokens,
+ Q_HEAD_NUM: tl.constexpr,
+ K_HEAD_NUM: tl.constexpr,
+ HEAD_DIM: tl.constexpr,
+ BLOCK_HEAD: tl.constexpr,
+ BLOCK_TOKENS: tl.constexpr,
+):
+ block_head_index = tl.program_id(0)
+ block_token_index = tl.program_id(1)
+
+ tokens_range = block_token_index * BLOCK_TOKENS + tl.arange(0, BLOCK_TOKENS)
+ head_range = block_head_index * BLOCK_HEAD + tl.arange(0, BLOCK_HEAD)
+
+ dim_range0 = tl.arange(0, HEAD_DIM // 2)
+ dim_range1 = tl.arange(HEAD_DIM // 2, HEAD_DIM)
+
+ off_q0 = (
+ tokens_range[:, None, None] * q_token_stride
+ + head_range[None, :, None] * q_head_stride
+ + dim_range0[None, None, :] * head_dim_stride
+ )
+ off_q1 = (
+ tokens_range[:, None, None] * q_token_stride
+ + head_range[None, :, None] * q_head_stride
+ + dim_range1[None, None, :] * head_dim_stride
+ )
+ off_k0 = (
+ tokens_range[:, None, None] * k_token_stride
+ + head_range[None, :, None] * k_head_stride
+ + dim_range0[None, None, :] * head_dim_stride
+ )
+ off_k1 = (
+ tokens_range[:, None, None] * k_token_stride
+ + head_range[None, :, None] * k_head_stride
+ + dim_range1[None, None, :] * head_dim_stride
+ )
+
+ loaded_q0 = tl.load(
+ q + off_q0,
+ mask=((head_range[None, :, None] < Q_HEAD_NUM) & (tokens_range[:, None, None] < q_total_tokens)),
+ other=0.0,
+ )
+ loaded_q1 = tl.load(
+ q + off_q1,
+ mask=((head_range[None, :, None] < Q_HEAD_NUM) & (tokens_range[:, None, None] < q_total_tokens)),
+ other=0.0,
+ )
+
+ loaded_k0 = tl.load(
+ k + off_k0,
+ mask=((head_range[None, :, None] < K_HEAD_NUM) & (tokens_range[:, None, None] < q_total_tokens)),
+ other=0.0,
+ )
+
+ loaded_k1 = tl.load(
+ k + off_k1,
+ mask=((head_range[None, :, None] < K_HEAD_NUM) & (tokens_range[:, None, None] < q_total_tokens)),
+ other=0.0,
+ )
+
+ off_cos_sin = tokens_range[:, None] * cos_token_stride + dim_range0[None, :] * cos_stride
+
+ loaded_cos = tl.load(cos + off_cos_sin, mask=(tokens_range[:, None] < q_total_tokens), other=0.0)
+ loaded_sin = tl.load(sin + off_cos_sin, mask=(tokens_range[:, None] < q_total_tokens), other=0.0)
+
+ out_q0 = loaded_q0 * loaded_cos[:, None, :] - loaded_q1 * loaded_sin[:, None, :]
+ out_q1 = loaded_q0 * loaded_sin[:, None, :] + loaded_q1 * loaded_cos[:, None, :]
+
+ out_k0 = loaded_k0 * loaded_cos[:, None, :] - loaded_k1 * loaded_sin[:, None, :]
+ out_k1 = loaded_k0 * loaded_sin[:, None, :] + loaded_k1 * loaded_cos[:, None, :] # total_tokens, head_num, head_dim
+
+ past_kv_seq_len = tl.load(context_lengths + tokens_range, mask=(tokens_range < q_total_tokens)) - 1
+
+ last_block_idx = past_kv_seq_len // block_size
+ block_table_ptr = BLOCK_TABLES + tokens_range * bts_stride
+ block_ids = tl.load(block_table_ptr + last_block_idx * btb_stride, mask=(tokens_range < q_total_tokens))
+ offsets_in_last_block = (past_kv_seq_len % block_size) * cachebs_stride
+
+ kv_range0 = (
+ block_ids[:, None, None, None] * cacheb_stride
+ + head_range[None, :, None, None] * cacheh_stride
+ + offsets_in_last_block[:, None, None, None]
+ + dim_range0[None, None, None, :] * cached_stride
+ )
+ kv_range1 = (
+ block_ids[:, None, None, None] * cacheb_stride
+ + head_range[None, :, None, None] * cacheh_stride
+ + offsets_in_last_block[:, None, None, None]
+ + dim_range1[None, None, None, :] * cached_stride
+ )
+
+ tl.store(
+ kv_cache + kv_range0,
+ out_k0[:, :, None, :],
+ )
+ tl.store(
+ kv_cache + kv_range1,
+ out_k1[:, :, None, :],
+ )
+
+ # concat
+ tl.store(
+ q + off_q0,
+ out_q0,
+ mask=((head_range[None, :, None] < Q_HEAD_NUM) & (tokens_range[:, None, None] < q_total_tokens)),
+ )
+ tl.store(
+ q + off_q1,
+ out_q1,
+ mask=((head_range[None, :, None] < Q_HEAD_NUM) & (tokens_range[:, None, None] < q_total_tokens)),
+ )
+ tl.store(
+ k + off_k0,
+ out_k0,
+ mask=((head_range[None, :, None] < K_HEAD_NUM) & (tokens_range[:, None, None] < q_total_tokens)),
+ )
+ tl.store(
+ k + off_k1,
+ out_k1,
+ mask=((head_range[None, :, None] < K_HEAD_NUM) & (tokens_range[:, None, None] < q_total_tokens)),
+ )
+
+
+@triton.jit
+def fused_rotary_embedding_kernel_v2(
+ q,
+ k,
+ cos,
+ sin,
+ kv_cache,
+ BLOCK_TABLES,
+ context_lengths,
+ q_token_stride,
+ q_head_stride,
+ k_token_stride,
+ k_head_stride,
+ head_dim_stride,
+ cos_token_stride,
+ cos_stride,
+ cacheb_stride,
+ cacheh_stride,
+ cachebs_stride,
+ cached_stride,
+ bts_stride,
+ btb_stride,
+ block_size,
+ q_total_tokens,
+ Q_HEAD_NUM: tl.constexpr,
+ HEAD_DIM: tl.constexpr,
+):
+ block_head_index = tl.program_id(0)
+ if block_head_index >= Q_HEAD_NUM:
+ return
+ block_token_index = tl.program_id(1)
+
+ dim_range0 = tl.arange(0, HEAD_DIM // 2)
+ dim_range1 = tl.arange(HEAD_DIM // 2, HEAD_DIM)
+
+ off_q0 = block_token_index * q_token_stride + block_head_index * q_head_stride + dim_range0 * head_dim_stride
+ off_q1 = block_token_index * q_token_stride + block_head_index * q_head_stride + dim_range1 * head_dim_stride
+ off_k0 = block_token_index * k_token_stride + block_head_index * k_head_stride + dim_range0 * head_dim_stride
+ off_k1 = block_token_index * k_token_stride + block_head_index * k_head_stride + dim_range1 * head_dim_stride
+
+ loaded_q0 = tl.load(
+ q + off_q0,
+ )
+ loaded_q1 = tl.load(
+ q + off_q1,
+ )
+
+ loaded_k0 = tl.load(
+ k + off_k0,
+ )
+
+ loaded_k1 = tl.load(
+ k + off_k1,
+ )
+
+ off_cos_sin = block_token_index * cos_token_stride + dim_range0 * cos_stride
+
+ loaded_cos = tl.load(cos + off_cos_sin, mask=(block_token_index < q_total_tokens), other=0.0)
+ loaded_sin = tl.load(sin + off_cos_sin, mask=(block_token_index < q_total_tokens), other=0.0)
+
+ out_q0 = loaded_q0 * loaded_cos - loaded_q1 * loaded_sin
+ out_q1 = loaded_q0 * loaded_sin + loaded_q1 * loaded_cos
+
+ out_k0 = loaded_k0 * loaded_cos - loaded_k1 * loaded_sin
+ out_k1 = loaded_k0 * loaded_sin + loaded_k1 * loaded_cos # total_tokens, head_num, head_dim
+
+ past_kv_seq_len = tl.load(context_lengths + block_token_index) - 1
+
+ last_block_idx = past_kv_seq_len // block_size
+ block_table_ptr = BLOCK_TABLES + block_token_index * bts_stride
+ block_ids = tl.load(block_table_ptr + last_block_idx * btb_stride, mask=(block_token_index < q_total_tokens))
+ offsets_in_last_block = (past_kv_seq_len % block_size) * cachebs_stride
+
+ kv_range0 = (
+ block_ids * cacheb_stride
+ + block_head_index * cacheh_stride
+ + offsets_in_last_block
+ + dim_range0 * cached_stride
+ )
+ kv_range1 = (
+ block_ids * cacheb_stride
+ + block_head_index * cacheh_stride
+ + offsets_in_last_block
+ + dim_range1 * cached_stride
+ )
+
+ tl.store(
+ kv_cache + kv_range0,
+ out_k0,
+ )
+ tl.store(
+ kv_cache + kv_range1,
+ out_k1,
+ )
+
+ # concat
+ tl.store(
+ q + off_q0,
+ out_q0,
+ )
+ tl.store(
+ q + off_q1,
+ out_q1,
+ )
+
+
+@triton.jit
+def decoding_fused_rotary_embedding_kernel(
+ q,
+ k,
+ v,
+ cos,
+ sin,
+ k_cache,
+ v_cache,
+ BLOCK_TABLES,
+ context_lengths,
+ x,
+ q_token_stride,
+ q_head_stride,
+ k_token_stride,
+ k_head_stride,
+ head_dim_stride,
+ cos_token_stride,
+ cos_stride,
+ kcb_stride,
+ kch_stride,
+ kcsplit_x_stride,
+ kcs_stride,
+ kcd_stride,
+ vcb_stride,
+ vch_stride,
+ vcs_stride,
+ vcd_stride,
+ bts_stride,
+ btb_stride,
+ block_size,
+ KV_GROUP_NUM: tl.constexpr,
+ HEAD_DIM: tl.constexpr,
+):
+ cur_head_idx = tl.program_id(0)
+ cur_token_idx = tl.program_id(1)
+
+ dim_range = tl.arange(0, HEAD_DIM)
+ dim_range0 = tl.arange(0, HEAD_DIM // 2)
+ dim_range1 = tl.arange(HEAD_DIM // 2, HEAD_DIM)
+
+ off_q = cur_token_idx * q_token_stride + cur_head_idx * q_head_stride
+ off_q0 = off_q + dim_range0 * head_dim_stride
+ off_q1 = off_q + dim_range1 * head_dim_stride
+
+ loaded_q0 = tl.load(q + off_q0)
+ loaded_q1 = tl.load(q + off_q1)
+ off_cos_sin = cur_token_idx * cos_token_stride + dim_range0 * cos_stride
+ loaded_cos = tl.load(cos + off_cos_sin)
+ loaded_sin = tl.load(sin + off_cos_sin)
+
+ out_q0 = loaded_q0 * loaded_cos - loaded_q1 * loaded_sin
+ out_q1 = loaded_q0 * loaded_sin + loaded_q1 * loaded_cos
+ tl.store(q + off_q0, out_q0)
+ tl.store(q + off_q1, out_q1)
+
+ handle_kv = cur_head_idx % KV_GROUP_NUM == 0
+ if handle_kv:
+ cur_k_head_idx = cur_head_idx // KV_GROUP_NUM
+ off_kv = cur_token_idx * k_token_stride + cur_k_head_idx * k_head_stride
+ off_k0 = off_kv + dim_range0 * head_dim_stride
+ off_k1 = off_kv + dim_range1 * head_dim_stride
+ loaded_k0 = tl.load(k + off_k0)
+ loaded_k1 = tl.load(k + off_k1)
+
+ out_k0 = loaded_k0 * loaded_cos - loaded_k1 * loaded_sin
+ out_k1 = loaded_k0 * loaded_sin + loaded_k1 * loaded_cos
+
+ # NOTE The precondition here is that it's only for unpadded inputs during decoding stage,
+ # and so that we could directly use the token index as the sequence index
+ past_kv_seq_len = tl.load(context_lengths + cur_token_idx) - 1
+
+ last_block_idx = past_kv_seq_len // block_size
+ block_ids = tl.load(BLOCK_TABLES + cur_token_idx * bts_stride + last_block_idx * btb_stride)
+ offsets_in_last_block = past_kv_seq_len % block_size
+ offsets_cache_base = block_ids * kcb_stride + cur_k_head_idx * kch_stride
+ k_range0 = (
+ offsets_cache_base
+ + offsets_in_last_block * kcs_stride
+ + (dim_range0 // x) * kcsplit_x_stride
+ + (dim_range0 % x) * kcd_stride
+ )
+ k_range1 = (
+ offsets_cache_base
+ + offsets_in_last_block * kcs_stride
+ + (dim_range1 // x) * kcsplit_x_stride
+ + (dim_range1 % x) * kcd_stride
+ )
+ tl.store(k_cache + k_range0, out_k0)
+ tl.store(k_cache + k_range1, out_k1)
+
+ off_v = off_kv + dim_range * head_dim_stride
+ loaded_v = tl.load(v + off_v)
+ v_range = (
+ block_ids * vcb_stride
+ + cur_k_head_idx * vch_stride
+ + offsets_in_last_block * vcs_stride
+ + dim_range * vcd_stride
+ )
+ tl.store(v_cache + v_range, loaded_v)
+
+
+def rotary_embedding(
+ q: torch.Tensor,
+ k: torch.Tensor,
+ cos: torch.Tensor,
+ sin: torch.Tensor,
+ k_cache: Optional[torch.Tensor] = None,
+ block_tables: Optional[torch.Tensor] = None,
+ kv_lengths: Optional[torch.Tensor] = None,
+):
+ """
+ Args:
+ q: query tensor, [total_tokens, head_num, head_dim]
+ k: key tensor, [total_tokens, kv_head_num, head_dim]
+ cos: cosine for rotary embedding, [max_position_len, head_dim]
+ sin: sine for rotary embedding, [max_position_len, head_dim]
+ k_cache (torch.Tensor): Blocked key cache. [num_blocks, num_kv_heads, block_size, head_dim]
+ kv_lengths, Past key/value sequence lengths plus current sequence length for each sequence. [bsz]
+ block_tables: Block tables for each sequence. [bsz, max_blocks_per_sequence]
+ """
+ q_total_tokens, q_head_num, head_dim = q.shape
+ assert q.size(0) == k.size(0)
+ BLOCK_TOKENS = 4
+
+ if head_dim >= 512:
+ num_warps = 16
+ elif head_dim >= 256:
+ num_warps = 8
+ else:
+ num_warps = 4
+
+ k_head_num = k.size(1)
+ q_token_stride, q_head_stride, head_dim_stride = q.stride()
+ k_token_stride, k_head_stride, _ = k.stride()
+ cos_token_stride, cos_stride = cos.stride()
+
+ assert q_head_num % k_head_num == 0
+ kv_group_num = q_head_num // k_head_num
+
+ if k_cache == None:
+ grid = lambda META: (
+ q_head_num,
+ triton.cdiv(q_total_tokens, META["BLOCK_TOKENS"]),
+ )
+ rotary_embedding_kernel[grid](
+ q,
+ k,
+ cos,
+ sin,
+ q_token_stride,
+ q_head_stride,
+ k_token_stride,
+ k_head_stride,
+ head_dim_stride,
+ cos_token_stride,
+ cos_stride,
+ q_total_tokens,
+ Q_HEAD_NUM=q_head_num,
+ KV_GROUP_NUM=kv_group_num,
+ HEAD_DIM=head_dim,
+ BLOCK_TOKENS=BLOCK_TOKENS,
+ num_warps=num_warps,
+ )
+ else:
+ warnings.warn("Fused rotary embedding Triton kernel will be deprecated as the new kcache layout is supported")
+ grid = (triton.next_power_of_2(q_head_num), q_total_tokens)
+ fused_rotary_embedding_kernel_v2[grid](
+ q,
+ k,
+ cos,
+ sin,
+ k_cache,
+ block_tables,
+ kv_lengths,
+ q_token_stride,
+ q_head_stride,
+ k_token_stride,
+ k_head_stride,
+ head_dim_stride,
+ cos_token_stride,
+ cos_stride,
+ k_cache.stride(0),
+ k_cache.stride(1),
+ k_cache.stride(2),
+ k_cache.stride(3),
+ block_tables.stride(0),
+ block_tables.stride(1),
+ k_cache.size(-2),
+ q_total_tokens,
+ Q_HEAD_NUM=q_head_num,
+ HEAD_DIM=head_dim,
+ num_warps=num_warps,
+ )
+ return
+
+
+def decoding_fused_rotary_embedding(
+ q: torch.Tensor,
+ k: torch.Tensor,
+ v: torch.Tensor,
+ cos: torch.Tensor,
+ sin: torch.Tensor,
+ k_cache: Optional[torch.Tensor] = None,
+ v_cache: Optional[torch.Tensor] = None,
+ block_tables: Optional[torch.Tensor] = None,
+ kv_lengths: Optional[torch.Tensor] = None,
+ use_new_kcache_layout: bool = False,
+):
+ """
+ Args:
+ q: query tensor, [total_tokens, head_num, head_dim]
+ k: key tensor, [total_tokens, kv_head_num, head_dim]
+ v: value tensor, [total tokens, kv_head_num, head_dim]
+ cos: cosine for rotary embedding, [max_position_len, head_dim]
+ sin: sine for rotary embedding, [max_position_len, head_dim]
+ k_cache (torch.Tensor): Blocked key cache. [num_blocks, kv_head_num, block_size, head_dim]
+ v_cache (torch.Tensor): Blocked value cache. [num_blocks, kv_head_num, block_size, head_dim]
+ kv_lengths, Past key/value sequence lengths plus current sequence length for each sequence. [bsz]
+ block_tables: Block tables for each sequence. [bsz, max_blocks_per_sequence]
+ """
+ q_total_tokens, q_head_num, head_dim = q.shape
+ assert q.size(0) == k.size(0) == v.size(0)
+
+ if head_dim >= 512:
+ num_warps = 16
+ elif head_dim >= 256:
+ num_warps = 8
+ else:
+ num_warps = 4
+ k_head_num = k.size(1)
+ kv_group_num = q_head_num // k_head_num
+
+ # For KCache and VCache with the same layout
+ x = head_dim
+ kcsplit_x_stride, kcs_stride, kcd_stride = 0, k_cache.stride(2), k_cache.stride(3)
+ # For KCache layout [num_blocks, num_kv_heads, head_dim//x, block_size, x]
+ if use_new_kcache_layout:
+ assert (
+ k_cache.dim() == 5
+ and k_cache.shape[1] == v_cache.shape[1]
+ and k_cache.shape[2] * k_cache.shape[4] == v_cache.shape[3]
+ ), f"Invalid KCache shape {k_cache.shape} and VCache shape {v_cache.shape}"
+ x = k_cache.size(-1)
+ kcsplit_x_stride, kcs_stride, kcd_stride = k_cache.stride()[-3:]
+
+ grid = (q_head_num, q_total_tokens)
+ decoding_fused_rotary_embedding_kernel[grid](
+ q,
+ k,
+ v,
+ cos,
+ sin,
+ k_cache,
+ v_cache,
+ block_tables,
+ kv_lengths,
+ x,
+ q.stride(0),
+ q.stride(1),
+ k.stride(0),
+ k.stride(1),
+ q.stride(2),
+ cos.stride(0),
+ cos.stride(1),
+ k_cache.stride(0),
+ k_cache.stride(1),
+ kcsplit_x_stride,
+ kcs_stride,
+ kcd_stride,
+ v_cache.stride(0),
+ v_cache.stride(1),
+ v_cache.stride(2),
+ v_cache.stride(3),
+ block_tables.stride(0),
+ block_tables.stride(1),
+ k_cache.size(-2),
+ KV_GROUP_NUM=kv_group_num,
+ HEAD_DIM=head_dim,
+ num_warps=num_warps,
+ )
+ return
diff --git a/colossalai/kernel/triton/rms_layernorm.py b/colossalai/kernel/triton/rms_layernorm.py
new file mode 100644
index 000000000000..fb320750340f
--- /dev/null
+++ b/colossalai/kernel/triton/rms_layernorm.py
@@ -0,0 +1,116 @@
+try:
+ import triton
+ import triton.language as tl
+
+ HAS_TRITON = True
+except ImportError:
+ HAS_TRITON = False
+ print("please install triton from https://github.com/openai/triton")
+
+if HAS_TRITON:
+ # CREDITS: These functions are adapted from the Triton tutorial
+ # https://triton-lang.org/main/getting-started/tutorials/05-layer-norm.html
+
+ @triton.jit
+ def _rmsnorm_kernel(
+ X, # pointer to the input
+ Y, # pointer to the output
+ W, # pointer to the weights
+ stride, # how much to increase the pointer when moving by 1 row
+ N, # number of columns in X
+ eps, # epsilon to avoid division by zero
+ BLOCK_SIZE: tl.constexpr,
+ ):
+ # This triton kernel implements Root Mean Square Layer Norm (RMSNorm).
+
+ # Map the program id to the row of X and Y it should compute.
+ row = tl.program_id(0)
+ Y += row * stride
+ X += row * stride
+ # Compute variance
+ _var = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
+ for off in range(0, N, BLOCK_SIZE):
+ cols = off + tl.arange(0, BLOCK_SIZE)
+ x = tl.load(X + cols, mask=cols < N, other=0.0).to(tl.float32)
+ x = tl.where(cols < N, x, 0.0)
+ _var += x * x
+ var = tl.sum(_var, axis=0) / N
+ rstd = 1 / tl.sqrt(var + eps)
+ # Normalize and apply linear transformation
+ for off in range(0, N, BLOCK_SIZE):
+ cols = off + tl.arange(0, BLOCK_SIZE)
+ mask = cols < N
+ w = tl.load(W + cols, mask=mask)
+ x = tl.load(X + cols, mask=mask, other=0.0).to(tl.float32)
+ x_hat = x * rstd
+ y = x_hat * w
+ # Write output
+ tl.store(Y + cols, y.to(tl.float16), mask=mask)
+
+ @triton.jit
+ def _rmsnorm_with_residual_kernel(
+ X, # pointer to the input
+ Y, # pointer to the output
+ R, # pointer to the residual
+ W, # pointer to the weights
+ stride, # how much to increase the pointer when moving by 1 row
+ N, # number of columns in X
+ eps, # epsilon to avoid division by zero
+ BLOCK_SIZE: tl.constexpr,
+ ):
+ # This triton kernel implements Root Mean Square Layer Norm (RMSNorm).
+
+ # Map the program id to the row of X and Y it should compute.
+ row = tl.program_id(0)
+ Y += row * stride
+ X += row * stride
+ R += row * stride
+ # Compute variance
+ _var = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
+ for off in range(0, N, BLOCK_SIZE):
+ cols = off + tl.arange(0, BLOCK_SIZE)
+ x = tl.load(X + cols, mask=cols < N, other=0.0).to(tl.float32)
+ x = tl.where(cols < N, x, 0.0)
+ r = tl.load(R + cols, mask=cols < N, other=0.0).to(tl.float32)
+ r = tl.where(cols < N, r, 0.0)
+ x = x + r
+ _var += x * x
+ mask = cols < N
+ tl.store(X + cols, x.to(tl.float16), mask=mask)
+ var = tl.sum(_var, axis=0) / N
+ rstd = 1 / tl.sqrt(var + eps)
+ # Normalize and apply linear transformation
+ for off in range(0, N, BLOCK_SIZE):
+ cols = off + tl.arange(0, BLOCK_SIZE)
+ mask = cols < N
+ w = tl.load(W + cols, mask=mask)
+ x = tl.load(X + cols, mask=mask, other=0.0).to(tl.float32)
+ x_hat = x * rstd
+ y = x_hat * w
+ # Write output
+ tl.store(Y + cols, y.to(tl.float16), mask=mask)
+
+ def rms_layernorm(x, weight, eps, norm_output=None, residual=None):
+ # allocate output
+ y = (
+ x * 0 if norm_output is None else norm_output
+ ) # to make the operation non-functional, store y as the intermediate activation
+ M, N = x.shape
+ # Less than 64KB per feature: enqueue fused kernel
+ MAX_FUSED_SIZE = 65536 // x.element_size()
+
+ BLOCK_SIZE = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
+ if N > MAX_FUSED_SIZE:
+ raise RuntimeError("This layer norm doesn't support feature dim >= 64KB.")
+
+ # heuristics for number of warps
+ num_warps = min(max(triton.next_power_of_2(N) // 256, 8), 32)
+
+ # enqueue kernel
+ if residual is None:
+ _rmsnorm_kernel[(M,)](x, y, weight, x.stride(0), N, eps, BLOCK_SIZE=BLOCK_SIZE, num_warps=num_warps)
+ else:
+ _rmsnorm_with_residual_kernel[(M,)](
+ x, y, residual, weight, x.stride(0), N, eps, BLOCK_SIZE=BLOCK_SIZE, num_warps=num_warps
+ )
+ return y, x
diff --git a/colossalai/kernel/triton/rotary_cache_copy.py b/colossalai/kernel/triton/rotary_cache_copy.py
new file mode 100644
index 000000000000..48dc7de4377e
--- /dev/null
+++ b/colossalai/kernel/triton/rotary_cache_copy.py
@@ -0,0 +1,147 @@
+import torch
+import triton
+import triton.language as tl
+
+
+@triton.jit
+def prefill_cache_kernel(
+ cos_cache,
+ sin_cache,
+ cumsum_lengths,
+ cos_output,
+ sin_output,
+ cache_stride,
+ hidden_stride,
+ total_length,
+ HIDDEN_DIM: tl.constexpr,
+ N_ELEMENTS: tl.constexpr,
+ BLOCK_SIZE: tl.constexpr,
+):
+ idx0 = tl.program_id(axis=0)
+ idx1 = tl.program_id(axis=1)
+ idx = idx0 * BLOCK_SIZE + idx1
+
+ # original seq_idx and pos
+ cumsum_lens = tl.load(cumsum_lengths + tl.arange(0, N_ELEMENTS))
+ ori_seq_idx = idx - tl.max(tl.where(cumsum_lens <= idx, cumsum_lens, 0))
+ cos_cache_part = tl.load(
+ cos_cache + ori_seq_idx * cache_stride + tl.arange(0, HIDDEN_DIM) * hidden_stride, mask=idx < total_length
+ )
+ sin_cache_part = tl.load(
+ sin_cache + ori_seq_idx * cache_stride + tl.arange(0, HIDDEN_DIM) * hidden_stride, mask=idx < total_length
+ )
+ tl.store(
+ cos_output + idx * cache_stride + tl.arange(0, HIDDEN_DIM) * hidden_stride,
+ cos_cache_part,
+ mask=idx < total_length,
+ )
+ tl.store(
+ sin_output + idx * cache_stride + tl.arange(0, HIDDEN_DIM) * hidden_stride,
+ sin_cache_part,
+ mask=idx < total_length,
+ )
+
+
+@triton.jit
+def decoding_cache_kernel(
+ cos_cache,
+ sin_cache,
+ lengths,
+ cos_output,
+ sin_output,
+ cache_stride,
+ hidden_stride,
+ HIDDEN_DIM: tl.constexpr,
+ NUM_SEQS: tl.constexpr,
+ BLOCK_SIZE: tl.constexpr,
+):
+ idx = tl.program_id(0) * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
+ ori_seq_idx = tl.load(lengths + idx, mask=(idx < NUM_SEQS), other=None) # [BLOCK_SIZE,]
+ cos_cache_part = tl.load(
+ cos_cache + ori_seq_idx[:, None] * cache_stride + tl.arange(0, HIDDEN_DIM)[None, :] * hidden_stride,
+ mask=idx[:, None] < NUM_SEQS,
+ )
+ sin_cache_part = tl.load(
+ sin_cache + ori_seq_idx[:, None] * cache_stride + tl.arange(0, HIDDEN_DIM)[None, :] * hidden_stride,
+ mask=idx[:, None] < NUM_SEQS,
+ )
+ tl.store(
+ cos_output + (idx[:, None] * cache_stride + tl.arange(0, HIDDEN_DIM)[None, :] * hidden_stride),
+ cos_cache_part,
+ mask=idx[:, None] < NUM_SEQS,
+ )
+ tl.store(
+ sin_output + (idx[:, None] * cache_stride + tl.arange(0, HIDDEN_DIM)[None, :] * hidden_stride),
+ sin_cache_part,
+ mask=idx[:, None] < NUM_SEQS,
+ )
+
+
+def get_xine_cache(lengths: torch.Tensor, cos_cache: torch.Tensor, sin_cache: torch.Tensor, is_prompts: bool = False):
+ """
+ Transform cos/sin cache into no pad sequence, with two different modes.
+ Args:
+ lengths: shape(num_seqs,), stores lenghth of each sequence.
+ cache: shape(max_rotary_position(e.g.2048), head_dim), cos/sin cache constrcuted in model.
+ is_prompts: bool, mark if in prefill mode.
+ For prefill mode:
+ cos/sin cache for each sequence is equal to its length.
+ For decoding mode:
+ cos/sin cache is only needed for the last token.
+ """
+ assert cos_cache.shape[1] == sin_cache.shape[1]
+ _, hidden_dim = cos_cache.shape
+ num_seqs = lengths.numel()
+
+ if hidden_dim >= 256:
+ num_warps = 16
+ elif hidden_dim >= 128:
+ num_warps = 8
+ else:
+ num_warps = 4
+
+ cache_stride = cos_cache.stride(0)
+ hidden_stride = cos_cache.stride(1)
+
+ if is_prompts:
+ BLOCK_SIZE = 16
+ total_length = lengths.sum().item()
+ cumsum_lens = torch.cumsum(lengths, dim=0)
+ cos_output = torch.empty((total_length, hidden_dim), dtype=cos_cache.dtype, device=cos_cache.device)
+ sin_output = torch.empty((total_length, hidden_dim), dtype=sin_cache.dtype, device=sin_cache.device)
+ grid = (triton.cdiv(total_length, BLOCK_SIZE), BLOCK_SIZE)
+ prefill_cache_kernel[grid](
+ cos_cache,
+ sin_cache,
+ cumsum_lens,
+ cos_output,
+ sin_output,
+ cache_stride,
+ hidden_stride,
+ total_length,
+ HIDDEN_DIM=hidden_dim,
+ N_ELEMENTS=triton.next_power_of_2(num_seqs),
+ BLOCK_SIZE=BLOCK_SIZE,
+ num_warps=num_warps,
+ )
+ else:
+ BLOCK_SIZE = 4
+ nlengths = torch.as_tensor(lengths) - 1
+ cos_output = torch.empty((num_seqs, hidden_dim), dtype=cos_cache.dtype, device=cos_cache.device)
+ sin_output = torch.empty((num_seqs, hidden_dim), dtype=sin_cache.dtype, device=sin_cache.device)
+ grid = (triton.cdiv(num_seqs, BLOCK_SIZE),)
+ decoding_cache_kernel[grid](
+ cos_cache,
+ sin_cache,
+ nlengths,
+ cos_output,
+ sin_output,
+ cache_stride,
+ hidden_stride,
+ HIDDEN_DIM=hidden_dim,
+ NUM_SEQS=num_seqs,
+ BLOCK_SIZE=BLOCK_SIZE,
+ num_warps=num_warps,
+ )
+
+ return cos_output, sin_output
diff --git a/colossalai/kernel/triton/self_attention_nofusion.py b/colossalai/kernel/triton/self_attention_nofusion.py
deleted file mode 100644
index 50d6786bd940..000000000000
--- a/colossalai/kernel/triton/self_attention_nofusion.py
+++ /dev/null
@@ -1,164 +0,0 @@
-import torch
-
-try:
- import triton
-
- HAS_TRITON = True
-except ImportError:
- HAS_TRITON = False
- print("please install triton from https://github.com/openai/triton")
-
-if HAS_TRITON:
- from .qkv_matmul_kernel import qkv_gemm_4d_kernel
- from .softmax import softmax_kernel
-
- # adpeted from https://github.com/microsoft/DeepSpeed/blob/master/deepspeed/ops/transformer/inference/triton/triton_matmul_kernel.py#L312
- def self_attention_forward_without_fusion(
- q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, input_mask: torch.Tensor, scale: float
- ):
- r"""A function to do QKV Attention calculation by calling GEMM and softmax triton kernels
- Args:
- q (torch.Tensor): Q embedding in attention layer, shape should be (batch, seq_len, num_heads, head_size)
- k (torch.Tensor): K embedding in attention layer, shape should be (batch, seq_len, num_heads, head_size)
- v (torch.Tensor): V embedding in attention layer, shape should be (batch, seq_len, num_heads, head_size)
- input_mask (torch.Tensor): mask for softmax layer, shape should be (batch, num_heads, seq_lem, seq_len)
- scale: the float scale value which is used to multiply with Q*K^T before doing softmax
-
- Return:
- output (Torch.Tensor): The output shape is (batch, seq_len, num_heads, head_size)
- """
- assert len(q.shape) == 4, "the shape of q val must be 4"
- batches, M, H, K = q.shape
- assert q.shape == k.shape, "the shape of q and the shape of k must be equal"
- assert q.shape == v.shape, "the shape of q and the shape of v must be equal"
- assert q.shape[-1] == k.shape[-1], "the last dimension of q and k must be equal"
-
- N = k.shape[1]
-
- # head_size * num_of_head
- d_model = q.shape[-1] * q.shape[-2]
-
- score_output = torch.empty((batches, H, M, N), device=q.device, dtype=q.dtype)
-
- grid = lambda meta: (
- batches,
- H,
- triton.cdiv(M, meta["BLOCK_SIZE_M"]) * triton.cdiv(N, meta["BLOCK_SIZE_N"]),
- )
-
- qkv_gemm_4d_kernel[grid](
- q,
- k,
- score_output,
- M,
- N,
- K,
- q.stride(0),
- q.stride(2),
- q.stride(1),
- q.stride(3),
- k.stride(0),
- k.stride(2),
- k.stride(3),
- k.stride(1),
- score_output.stride(0),
- score_output.stride(1),
- score_output.stride(2),
- score_output.stride(3),
- scale=scale,
- # currently manually setting, later on we can use auto-tune config to match best setting
- BLOCK_SIZE_M=64,
- BLOCK_SIZE_N=32,
- BLOCK_SIZE_K=32,
- GROUP_SIZE_M=8,
- )
-
- softmax_output = torch.empty(score_output.shape, device=score_output.device, dtype=score_output.dtype)
- score_output_shape = score_output.shape
-
- score_output = score_output.view(-1, score_output.shape[-1])
- n_rows, n_cols = score_output.shape
-
- if n_rows <= 350000:
- block_size = max(triton.next_power_of_2(n_cols), 2)
- num_warps = 4
- if block_size >= 4096:
- num_warps = 16
- elif block_size >= 2048:
- num_warps = 8
- else:
- num_warps = 4
-
- softmax_kernel[(n_rows,)](
- softmax_output,
- score_output,
- score_output.stride(0),
- n_cols,
- mask_ptr=input_mask,
- num_warps=num_warps,
- BLOCK_SIZE=block_size,
- )
-
- else:
- # NOTE: change softmax kernel functions to make it suitable for large size dimension
- softmax_output = torch.nn.functional.softmax(score_output, dim=-1)
- softmax_output = softmax_output.view(*score_output_shape)
-
- batches, H, M, K = softmax_output.shape
- N = v.shape[-1]
-
- output = torch.empty((batches, M, H, N), device=softmax_output.device, dtype=softmax_output.dtype)
-
- grid = lambda meta: (
- batches,
- H,
- triton.cdiv(M, meta["BLOCK_SIZE_M"]) * triton.cdiv(N, meta["BLOCK_SIZE_N"]),
- )
-
- qkv_gemm_4d_kernel[grid](
- softmax_output,
- v,
- output,
- M,
- N,
- K,
- softmax_output.stride(0),
- softmax_output.stride(1),
- softmax_output.stride(2),
- softmax_output.stride(3),
- v.stride(0),
- v.stride(2),
- v.stride(1),
- v.stride(3),
- output.stride(0),
- output.stride(2),
- output.stride(1),
- output.stride(3),
- BLOCK_SIZE_M=128,
- BLOCK_SIZE_N=64,
- BLOCK_SIZE_K=64,
- GROUP_SIZE_M=8,
- scale=-1,
- )
- return output.view(batches, -1, d_model)
-
- # modified from https://github.com/microsoft/DeepSpeed/blob/master/deepspeed/ops/transformer/inference/triton/attention.py#L212
- def self_attention_compute_using_triton(
- qkv, input_mask, layer_past, alibi, scale, head_size, triangular=False, use_flash=False
- ):
- assert qkv.is_contiguous()
- assert alibi is None, "current triton self-attention does not support alibi"
- batches = qkv.shape[0]
- d_model = qkv.shape[-1] // 3
- num_of_heads = d_model // head_size
-
- q = qkv[:, :, :d_model]
- k = qkv[:, :, d_model : d_model * 2]
- v = qkv[:, :, d_model * 2 :]
- q = q.view(batches, -1, num_of_heads, head_size)
- k = k.view(batches, -1, num_of_heads, head_size)
- v = v.view(batches, -1, num_of_heads, head_size)
-
- data_output_triton = self_attention_forward_without_fusion(q, k, v, input_mask, scale)
-
- return data_output_triton
diff --git a/colossalai/kernel/triton/smooth_attention.py b/colossalai/kernel/triton/smooth_attention.py
deleted file mode 100644
index 071de58e20c0..000000000000
--- a/colossalai/kernel/triton/smooth_attention.py
+++ /dev/null
@@ -1,652 +0,0 @@
-import math
-
-import torch
-
-try:
- import triton
- import triton.language as tl
-
- HAS_TRITON = True
-except ImportError:
- HAS_TRITON = False
- print("please install triton from https://github.com/openai/triton")
-
-if HAS_TRITON:
- """
- this functions are modified from https://github.com/ModelTC/lightllm
- """
-
- # Adapted from https://github.com/ModelTC/lightllm/blob/main/lightllm/models/llama/triton_kernel/context_flashattention_nopad.py
- @triton.jit
- def _context_flash_attention_kernel(
- Q,
- K,
- V,
- q_input_scale,
- k_input_scale,
- v_input_scale,
- pv_output_scale,
- sm_scale,
- B_Start_Loc,
- B_Seqlen,
- TMP,
- alibi_ptr,
- Out,
- stride_qbs,
- stride_qh,
- stride_qd,
- stride_kbs,
- stride_kh,
- stride_kd,
- stride_vbs,
- stride_vh,
- stride_vd,
- stride_obs,
- stride_oh,
- stride_od,
- stride_tmp_b,
- stride_tmp_h,
- stride_tmp_s,
- # suggtest set-up 64, 128, 256, 512
- BLOCK_M: tl.constexpr,
- BLOCK_DMODEL: tl.constexpr,
- BLOCK_N: tl.constexpr,
- ):
- batch_id = tl.program_id(0)
- cur_head = tl.program_id(1)
- start_m = tl.program_id(2)
-
- # initialize offsets
- offs_n = tl.arange(0, BLOCK_N)
- offs_d = tl.arange(0, BLOCK_DMODEL)
- offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
-
- # get batch info
- cur_batch_seq_len = tl.load(B_Seqlen + batch_id)
- cur_batch_start_index = tl.load(B_Start_Loc + batch_id)
- block_start_loc = BLOCK_M * start_m
-
- load_p_ptrs = (
- Q
- + (cur_batch_start_index + offs_m[:, None]) * stride_qbs
- + cur_head * stride_qh
- + offs_d[None, :] * stride_qd
- )
- q = tl.load(load_p_ptrs, mask=offs_m[:, None] < cur_batch_seq_len, other=0.0)
- q = q.to(tl.float16) * q_input_scale.to(tl.float16)
-
- k_ptrs = K + offs_n[None, :] * stride_kbs + cur_head * stride_kh + offs_d[:, None] * stride_kd
- v_ptrs = V + offs_n[:, None] * stride_vbs + cur_head * stride_vh + offs_d[None, :] * stride_vd
- t_ptrs = TMP + batch_id * stride_tmp_b + cur_head * stride_tmp_h + offs_m * stride_tmp_s
-
- m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
- l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
- acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
-
- if alibi_ptr is not None:
- alibi_m = tl.load(alibi_ptr + cur_head)
-
- block_mask = tl.where(block_start_loc < cur_batch_seq_len, 1, 0)
-
- for start_n in range(0, block_mask * (start_m + 1) * BLOCK_M, BLOCK_N):
- start_n = tl.multiple_of(start_n, BLOCK_N)
- k = tl.load(
- k_ptrs + (cur_batch_start_index + start_n) * stride_kbs,
- mask=(start_n + offs_n[None, :]) < cur_batch_seq_len,
- other=0.0,
- )
- k = k.to(tl.float16) * k_input_scale.to(tl.float16)
-
- qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
- qk += tl.dot(q, k)
- qk *= sm_scale
-
- if alibi_ptr is not None:
- alibi_loc = offs_m[:, None] - (start_n + offs_n[None, :])
- qk -= alibi_loc * alibi_m
-
- qk = tl.where(offs_m[:, None] >= (start_n + offs_n[None, :]), qk, float("-inf"))
-
- m_ij = tl.max(qk, 1)
- p = tl.exp(qk - m_ij[:, None])
- l_ij = tl.sum(p, 1)
- # -- update m_i and l_i
- m_i_new = tl.maximum(m_i, m_ij)
- alpha = tl.exp(m_i - m_i_new)
- beta = tl.exp(m_ij - m_i_new)
- l_i_new = alpha * l_i + beta * l_ij
- # -- update output accumulator --
- # scale p
- p_scale = beta / l_i_new
- p = p * p_scale[:, None]
- # scale acc
- acc_scale = l_i / l_i_new * alpha
- tl.store(t_ptrs, acc_scale)
- acc_scale = tl.load(t_ptrs)
- acc = acc * acc_scale[:, None]
- # update acc
- v = tl.load(
- v_ptrs + (cur_batch_start_index + start_n) * stride_vbs,
- mask=(start_n + offs_n[:, None]) < cur_batch_seq_len,
- other=0.0,
- )
-
- v = v.to(tl.float16) * v_input_scale.to(tl.float16)
- p = p.to(v.dtype)
- acc += tl.dot(p, v)
- # update m_i and l_i
- l_i = l_i_new
- m_i = m_i_new
- acc = (acc / pv_output_scale.to(tl.float16)).to(tl.int8)
- off_o = (
- (cur_batch_start_index + offs_m[:, None]) * stride_obs + cur_head * stride_oh + offs_d[None, :] * stride_od
- )
- out_ptrs = Out + off_o
- tl.store(out_ptrs, acc, mask=offs_m[:, None] < cur_batch_seq_len)
- return
-
- @torch.no_grad()
- def smooth_llama_context_attn_fwd(
- q, k, v, o, q_input_scale, k_input_scale, v_input_scale, pv_output_scale, b_start_loc, b_seq_len, max_input_len
- ):
- BLOCK = 128
- # shape constraints
- Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
- assert Lq == Lk, "context process only supports equal query, key, value length"
- assert Lk == Lv, "context process only supports equal query, key, value length"
- assert Lk in {16, 32, 64, 128}
- sm_scale = 1.0 / math.sqrt(Lk)
- batch, head = b_seq_len.shape[0], q.shape[1]
- grid = (batch, head, triton.cdiv(max_input_len, BLOCK))
-
- tmp = torch.empty((batch, head, max_input_len + 256), device=q.device, dtype=torch.float32)
- num_warps = 4 if Lk <= 64 else 8
-
- _context_flash_attention_kernel[grid](
- q,
- k,
- v,
- q_input_scale,
- k_input_scale,
- v_input_scale,
- pv_output_scale,
- sm_scale,
- b_start_loc,
- b_seq_len,
- tmp,
- None,
- o,
- q.stride(0),
- q.stride(1),
- q.stride(2),
- k.stride(0),
- k.stride(1),
- k.stride(2),
- v.stride(0),
- v.stride(1),
- v.stride(2),
- o.stride(0),
- o.stride(1),
- o.stride(2),
- tmp.stride(0),
- tmp.stride(1),
- tmp.stride(2),
- BLOCK_M=BLOCK,
- BLOCK_DMODEL=Lk,
- BLOCK_N=BLOCK,
- num_warps=num_warps,
- num_stages=1,
- )
- return
-
- # Adapted from https://github.com/ModelTC/lightllm/blob/main/lightllm/models/llama/triton_kernel/token_attention_nopad_att1.py
- @triton.jit
- def _token_attn_1_kernel(
- Q,
- K,
- q_input_scale,
- k_input_scale,
- sm_scale,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seqlen,
- max_kv_cache_len,
- attn_out,
- kv_cache_loc_b_stride,
- kv_cache_loc_s_stride,
- q_batch_stride,
- q_head_stride,
- q_head_dim_stride,
- k_batch_stride,
- k_head_stride,
- k_head_dim_stride,
- attn_head_stride,
- attn_batch_stride,
- HEAD_DIM: tl.constexpr,
- BLOCK_N: tl.constexpr,
- ):
- current_batch = tl.program_id(0)
- current_head = tl.program_id(1)
- start_n = tl.program_id(2)
-
- offs_d = tl.arange(0, HEAD_DIM)
- current_batch_seq_len = tl.load(kv_cache_seqlen + current_batch)
- current_batch_in_all_start_index = tl.load(kv_cache_start_loc + current_batch)
-
- current_batch_start_index = max_kv_cache_len - current_batch_seq_len
- current_batch_end_index = max_kv_cache_len
-
- off_q = current_batch * q_batch_stride + current_head * q_head_stride + offs_d * q_head_dim_stride
-
- offs_n = start_n * BLOCK_N + tl.arange(0, BLOCK_N)
-
- block_stard_index = start_n * BLOCK_N
- block_mask = tl.where(block_stard_index < current_batch_seq_len, 1, 0)
-
- for start_mark in range(0, block_mask, 1):
- q = tl.load(Q + off_q + start_mark)
- q = q.to(tl.float16) * q_input_scale.to(tl.float16)
- offs_n_new = current_batch_start_index + offs_n
- k_loc = tl.load(
- kv_cache_loc + kv_cache_loc_b_stride * current_batch + kv_cache_loc_s_stride * offs_n_new,
- mask=offs_n_new < current_batch_end_index,
- other=0,
- )
- off_k = k_loc[:, None] * k_batch_stride + current_head * k_head_stride + offs_d[None, :] * k_head_dim_stride
- k = tl.load(K + off_k, mask=offs_n_new[:, None] < current_batch_end_index, other=0.0)
- k = k.to(tl.float16) * k_input_scale.to(tl.float16)
- att_value = tl.sum(q[None, :] * k, 1)
- att_value *= sm_scale
- off_o = current_head * attn_head_stride + (current_batch_in_all_start_index + offs_n) * attn_batch_stride
- tl.store(attn_out + off_o, att_value, mask=offs_n_new < current_batch_end_index)
- return
-
- # Adapted from https://github.com/ModelTC/lightllm/blob/main/lightllm/models/llama/triton_kernel/token_attention_nopad_att1.py
- @triton.jit
- def _token_attn_1_alibi_kernel(
- Q,
- K,
- q_input_scale,
- k_input_scale,
- sm_scale,
- alibi,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seqlen,
- max_kv_cache_len,
- attn_out,
- kv_cache_loc_b_stride,
- kv_cache_loc_s_stride,
- q_batch_stride,
- q_head_stride,
- q_head_dim_stride,
- k_batch_stride,
- k_head_stride,
- k_head_dim_stride,
- attn_head_stride,
- attn_batch_stride,
- HEAD_DIM: tl.constexpr,
- BLOCK_N: tl.constexpr,
- ):
- current_batch = tl.program_id(0)
- current_head = tl.program_id(1)
- start_n = tl.program_id(2)
-
- offs_d = tl.arange(0, HEAD_DIM)
- current_batch_seq_len = tl.load(kv_cache_seqlen + current_batch)
- current_batch_in_all_start_index = tl.load(kv_cache_start_loc + current_batch)
-
- current_batch_start_index = max_kv_cache_len - current_batch_seq_len
- current_batch_end_index = max_kv_cache_len
-
- off_q = current_batch * q_batch_stride + current_head * q_head_stride + offs_d * q_head_dim_stride
-
- offs_n = start_n * BLOCK_N + tl.arange(0, BLOCK_N)
-
- block_stard_index = start_n * BLOCK_N
- block_mask = tl.where(block_stard_index < current_batch_seq_len, 1, 0)
-
- for start_mark in range(0, block_mask, 1):
- alibi_m = tl.load(alibi + current_head)
- q = tl.load(Q + off_q + start_mark)
- q = q.to(tl.float16) * q_input_scale.to(tl.float16)
-
- offs_n_new = current_batch_start_index + offs_n
- k_loc = tl.load(
- kv_cache_loc + kv_cache_loc_b_stride * current_batch + kv_cache_loc_s_stride * offs_n_new,
- mask=offs_n_new < current_batch_end_index,
- other=0,
- )
- off_k = k_loc[:, None] * k_batch_stride + current_head * k_head_stride + offs_d[None, :] * k_head_dim_stride
- k = tl.load(K + off_k, mask=offs_n_new[:, None] < current_batch_end_index, other=0.0)
- k = k.to(tl.float16) * k_input_scale.to(tl.float16)
- att_value = tl.sum(q[None, :] * k, 1)
- att_value *= sm_scale
- att_value -= alibi_m * (current_batch_seq_len - 1 - offs_n)
- off_o = current_head * attn_head_stride + (current_batch_in_all_start_index + offs_n) * attn_batch_stride
- tl.store(attn_out + off_o, att_value, mask=offs_n_new < current_batch_end_index)
- return
-
- @torch.no_grad()
- def token_attn_fwd_1(
- q,
- k,
- attn_out,
- q_input_scale,
- k_input_scale,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seqlen,
- max_kv_cache_len,
- alibi=None,
- ):
- BLOCK = 32
- # shape constraints
- q_head_dim, k_head_dim = q.shape[-1], k.shape[-1]
- assert q_head_dim == k_head_dim
- assert k_head_dim in {16, 32, 64, 128}
- sm_scale = 1.0 / (k_head_dim**0.5)
-
- batch, head_num = kv_cache_loc.shape[0], q.shape[1]
-
- grid = (batch, head_num, triton.cdiv(max_kv_cache_len, BLOCK))
-
- num_warps = 4 if k_head_dim <= 64 else 8
- num_warps = 2
-
- if alibi is not None:
- _token_attn_1_alibi_kernel[grid](
- q,
- k,
- q_input_scale,
- k_input_scale,
- sm_scale,
- alibi,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seqlen,
- max_kv_cache_len,
- attn_out,
- kv_cache_loc.stride(0),
- kv_cache_loc.stride(1),
- q.stride(0),
- q.stride(1),
- q.stride(2),
- k.stride(0),
- k.stride(1),
- k.stride(2),
- attn_out.stride(0),
- attn_out.stride(1),
- HEAD_DIM=k_head_dim,
- BLOCK_N=BLOCK,
- num_warps=num_warps,
- num_stages=1,
- )
- else:
- _token_attn_1_kernel[grid](
- q,
- k,
- q_input_scale,
- k_input_scale,
- sm_scale,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seqlen,
- max_kv_cache_len,
- attn_out,
- kv_cache_loc.stride(0),
- kv_cache_loc.stride(1),
- q.stride(0),
- q.stride(1),
- q.stride(2),
- k.stride(0),
- k.stride(1),
- k.stride(2),
- attn_out.stride(0),
- attn_out.stride(1),
- HEAD_DIM=k_head_dim,
- BLOCK_N=BLOCK,
- num_warps=num_warps,
- num_stages=1,
- )
- return
-
- # Adapted from https://github.com/ModelTC/lightllm/blob/main/lightllm/models/llama/triton_kernel/token_attention_softmax_and_reducev.py
- @triton.jit
- def _token_attn_softmax_fwd(
- softmax_logics,
- kv_cache_start_loc,
- kv_cache_seqlen,
- softmax_prob_out,
- logics_head_dim_stride,
- logics_batch_stride,
- prob_head_dim_stride,
- prob_batch_stride,
- BLOCK_SIZE: tl.constexpr,
- ):
- current_batch = tl.program_id(0)
- current_head = tl.program_id(1)
-
- col_offsets = tl.arange(0, BLOCK_SIZE)
- current_batch_seq_len = tl.load(kv_cache_seqlen + current_batch)
- current_batch_in_all_start_index = tl.load(kv_cache_start_loc + current_batch)
-
- row = tl.load(
- softmax_logics
- + current_head * logics_head_dim_stride
- + (current_batch_in_all_start_index + col_offsets) * logics_batch_stride,
- mask=col_offsets < current_batch_seq_len,
- other=-float("inf"),
- ).to(tl.float32)
-
- row_minus_max = row - tl.max(row, axis=0)
- numerator = tl.exp(row_minus_max)
- denominator = tl.sum(numerator, axis=0)
- softmax_output = numerator / denominator
-
- tl.store(
- softmax_prob_out
- + current_head * prob_head_dim_stride
- + (current_batch_in_all_start_index + col_offsets) * prob_batch_stride,
- softmax_output,
- mask=col_offsets < current_batch_seq_len,
- )
- return
-
- @torch.no_grad()
- def token_attn_softmax_fwd(softmax_logics, kv_cache_start_loc, kv_cache_seqlen, softmax_prob_out, max_kv_cache_len):
- BLOCK_SIZE = triton.next_power_of_2(max_kv_cache_len)
- batch, head_num = kv_cache_start_loc.shape[0], softmax_logics.shape[0]
-
- num_warps = 4
- if BLOCK_SIZE >= 2048:
- num_warps = 8
- if BLOCK_SIZE >= 4096:
- num_warps = 16
-
- _token_attn_softmax_fwd[(batch, head_num)](
- softmax_logics,
- kv_cache_start_loc,
- kv_cache_seqlen,
- softmax_prob_out,
- softmax_logics.stride(0),
- softmax_logics.stride(1),
- softmax_prob_out.stride(0),
- softmax_prob_out.stride(1),
- num_warps=num_warps,
- BLOCK_SIZE=BLOCK_SIZE,
- )
- return
-
- # Adapted from https://github.com/ModelTC/lightllm/blob/main/lightllm/models/llama/triton_kernel/token_attention_nopad_att1.py
- @triton.jit
- def _token_attn_2_kernel(
- Prob,
- V,
- attn_out,
- v_input_scale,
- pv_output_scale,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seqlen,
- max_kv_cache_len,
- kv_cache_loc_b_stride,
- kv_cache_loc_s_stride,
- prob_head_dim_stride,
- prob_batch_stride,
- v_batch_stride,
- v_head_stride,
- v_head_dim_stride,
- attn_out_batch_stride,
- attn_out_head_stride,
- attn_out_head_dim_stride,
- HEAD_DIM: tl.constexpr,
- BLOCK_N: tl.constexpr,
- ):
- current_batch = tl.program_id(0)
- current_head = tl.program_id(1)
-
- offs_n = tl.arange(0, BLOCK_N)
- offs_d = tl.arange(0, HEAD_DIM)
- current_batch_seq_len = tl.load(kv_cache_seqlen + current_batch)
- current_batch_start_index = max_kv_cache_len - current_batch_seq_len
- current_batch_in_all_start_index = tl.load(kv_cache_start_loc + current_batch)
-
- v_loc_off = current_batch * kv_cache_loc_b_stride + (current_batch_start_index + offs_n) * kv_cache_loc_s_stride
- p_offs = current_head * prob_head_dim_stride + (current_batch_in_all_start_index + offs_n) * prob_batch_stride
- v_offs = current_head * v_head_stride + offs_d[None, :] * v_head_dim_stride
-
- acc = tl.zeros([HEAD_DIM], dtype=tl.float32)
- for start_n in range(0, current_batch_seq_len, BLOCK_N):
- start_n = tl.multiple_of(start_n, BLOCK_N)
- p_value = tl.load(
- Prob + p_offs + start_n * kv_cache_loc_s_stride,
- mask=(start_n + offs_n) < current_batch_seq_len,
- other=0.0,
- )
- v_loc = tl.load(
- kv_cache_loc + v_loc_off + start_n * kv_cache_loc_s_stride,
- mask=(start_n + offs_n) < current_batch_seq_len,
- other=0.0,
- )
- v_value = tl.load(
- V + v_offs + v_loc[:, None] * v_batch_stride,
- mask=(start_n + offs_n[:, None]) < current_batch_seq_len,
- other=0.0,
- )
- v_value = v_value.to(tl.float16) * v_input_scale.to(tl.float16)
- acc += tl.sum(p_value[:, None] * v_value, 0)
-
- acc = (acc / pv_output_scale.to(tl.float16)).to(tl.int8)
- off_o = (
- current_batch * attn_out_batch_stride
- + current_head * attn_out_head_stride
- + offs_d * attn_out_head_dim_stride
- )
- out_ptrs = attn_out + off_o
- tl.store(out_ptrs, acc)
- return
-
- @torch.no_grad()
- def token_attn_fwd_2(
- prob,
- v,
- attn_out,
- v_input_scale,
- pv_output_scale,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seqlen,
- max_kv_cache_len,
- ):
- if triton.__version__ >= "2.1.0":
- BLOCK = 128
- else:
- BLOCK = 64
- batch, head = kv_cache_loc.shape[0], v.shape[1]
- grid = (batch, head)
- num_warps = 4
- dim = v.shape[-1]
-
- _token_attn_2_kernel[grid](
- prob,
- v,
- attn_out,
- v_input_scale,
- pv_output_scale,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seqlen,
- max_kv_cache_len,
- kv_cache_loc.stride(0),
- kv_cache_loc.stride(1),
- prob.stride(0),
- prob.stride(1),
- v.stride(0),
- v.stride(1),
- v.stride(2),
- attn_out.stride(0),
- attn_out.stride(1),
- attn_out.stride(2),
- HEAD_DIM=dim,
- BLOCK_N=BLOCK,
- num_warps=num_warps,
- num_stages=1,
- )
- return
-
- @torch.no_grad()
- def smooth_token_attention_fwd(
- q,
- k,
- v,
- attn_out,
- q_input_scale,
- k_input_scale,
- v_input_scale,
- pv_output_scale,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seq_len,
- max_len_in_batch,
- alibi=None,
- ):
- head_num = k.shape[1]
- batch_size = kv_cache_seq_len.shape[0]
- calcu_shape1 = (batch_size, head_num, k.shape[2])
- total_token_num = k.shape[0]
-
- att_m_tensor = torch.empty((head_num, total_token_num), dtype=torch.float32, device="cuda")
-
- token_attn_fwd_1(
- q.view(calcu_shape1),
- k,
- att_m_tensor,
- q_input_scale,
- k_input_scale,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seq_len,
- max_len_in_batch,
- alibi=alibi,
- )
-
- prob = torch.empty_like(att_m_tensor)
-
- token_attn_softmax_fwd(att_m_tensor, kv_cache_start_loc, kv_cache_seq_len, prob, max_len_in_batch)
- att_m_tensor = None
- token_attn_fwd_2(
- prob,
- v,
- attn_out.view(calcu_shape1),
- v_input_scale,
- pv_output_scale,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seq_len,
- max_len_in_batch,
- )
-
- prob = None
-
- return
diff --git a/colossalai/kernel/triton/token_attention_kernel.py b/colossalai/kernel/triton/token_attention_kernel.py
deleted file mode 100644
index d8ac278c77dd..000000000000
--- a/colossalai/kernel/triton/token_attention_kernel.py
+++ /dev/null
@@ -1,244 +0,0 @@
-# Adapted from ModelTC https://github.com/ModelTC/lightllm
-
-
-import torch
-
-try:
- import triton
- import triton.language as tl
-
- HAS_TRITON = True
-except ImportError:
- HAS_TRITON = False
- print("please install triton from https://github.com/openai/triton")
-
-try:
- from lightllm.models.bloom.triton_kernel.token_attention_nopad_att1 import (
- token_att_fwd as lightllm_bloom_token_att_fwd,
- )
- from lightllm.models.llama.triton_kernel.token_attention_nopad_att1 import (
- token_att_fwd as lightllm_llama_token_att_fwd,
- )
- from lightllm.models.llama.triton_kernel.token_attention_nopad_reduceV import (
- token_att_fwd2 as lightllm_llama_token_att_fwd2,
- )
- from lightllm.models.llama.triton_kernel.token_attention_nopad_softmax import (
- token_softmax_fwd as lightllm_llama_token_softmax_fwd,
- )
-
- HAS_TRITON_TOKEN_ATTENTION = True
-except ImportError:
- print("unable to import lightllm kernels")
- HAS_TRITON_TOKEN_ATTENTION = False
-
-if HAS_TRITON:
-
- @torch.no_grad()
- def token_attention_fwd(
- q, k, v, attn_out, kv_cache_loc, kv_cache_start_loc, kv_cache_seq_len, max_len_in_batch, alibi=None
- ):
- head_num = k.shape[1]
- batch_size = kv_cache_seq_len.shape[0]
- calcu_shape1 = (batch_size, head_num, k.shape[2])
- total_token_num = k.shape[0]
-
- att_m_tensor = torch.empty((head_num, total_token_num), dtype=q.dtype, device="cuda")
-
- if alibi is None:
- lightllm_llama_token_att_fwd(
- q.view(calcu_shape1),
- k,
- att_m_tensor,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seq_len,
- max_len_in_batch,
- )
- else:
- lightllm_bloom_token_att_fwd(
- q.view(calcu_shape1),
- k,
- att_m_tensor,
- alibi,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seq_len,
- max_len_in_batch,
- )
-
- prob = torch.empty_like(att_m_tensor)
-
- lightllm_llama_token_softmax_fwd(att_m_tensor, kv_cache_start_loc, kv_cache_seq_len, prob, max_len_in_batch)
- att_m_tensor = None
- lightllm_llama_token_att_fwd2(
- prob, v, attn_out.view(calcu_shape1), kv_cache_loc, kv_cache_start_loc, kv_cache_seq_len, max_len_in_batch
- )
- prob = None
- return
-
-
-class Llama2TokenAttentionForwards:
- @staticmethod
- @triton.jit
-
- # this function is adapted from https://github.com/ModelTC/lightllm/blob/5c559dd7981ed67679a08a1e09a88fb4c1550b3a/lightllm/models/llama2/triton_kernel/token_attention_nopad_softmax.py#L8
- def _fwd_kernel(
- Logics,
- V,
- Out,
- B_Loc,
- B_Start_Loc,
- B_Seqlen,
- max_input_len,
- stride_logic_h,
- stride_logic_bs,
- stride_vbs,
- stride_vh,
- stride_vd,
- stride_obs,
- stride_oh,
- stride_od,
- stride_b_loc_b,
- stride_b_loc_s,
- other_kv_index, # avoid nan information
- kv_group_num,
- BLOCK_DMODEL: tl.constexpr,
- BLOCK_N: tl.constexpr,
- ):
- cur_batch = tl.program_id(0)
- cur_head = tl.program_id(1)
-
- cur_kv_head = cur_head // kv_group_num
-
- cur_batch_seq_len = tl.load(B_Seqlen + cur_batch)
- cur_batch_start_loc = tl.load(B_Start_Loc + cur_batch)
-
- offs_n = tl.arange(0, BLOCK_N)
- offs_d = tl.arange(0, BLOCK_DMODEL)
-
- off_v = cur_kv_head * stride_vh + offs_d[None, :] * stride_vd
- off_b_loc = cur_batch * stride_b_loc_b + (max_input_len - cur_batch_seq_len) * stride_b_loc_s
-
- v_ptrs = V + off_v
-
- e_max = float("-inf")
- e_sum = 0.0
- acc = tl.zeros([BLOCK_DMODEL], dtype=tl.float32)
-
- for start_n in range(0, cur_batch_seq_len, BLOCK_N):
- start_n = tl.multiple_of(start_n, BLOCK_N)
- v_index = tl.load(
- B_Loc + off_b_loc + (start_n + offs_n) * stride_b_loc_s,
- mask=(start_n + offs_n) < cur_batch_seq_len,
- other=other_kv_index,
- )
-
- qk = tl.load(
- Logics + cur_head * stride_logic_h + (cur_batch_start_loc + start_n + offs_n) * stride_logic_bs,
- mask=start_n + offs_n < cur_batch_seq_len,
- other=float("-inf"),
- )
-
- n_e_max = tl.maximum(tl.max(qk, 0), e_max)
- old_scale = tl.exp(e_max - n_e_max)
- p = tl.exp(qk - n_e_max)
- e_sum = e_sum * old_scale + tl.sum(p, 0)
- v = tl.load(v_ptrs + v_index[:, None] * stride_vbs)
- acc = acc * old_scale + tl.sum(p[:, None] * v, 0)
- e_max = n_e_max
-
- acc = acc / e_sum
- off_o = cur_batch * stride_obs + cur_head * stride_oh + offs_d * stride_od
- out_ptrs = Out + off_o
- tl.store(out_ptrs, acc)
- return
-
- # this function is adapted from https://github.com/ModelTC/lightllm/blob/5c559dd7981ed67679a08a1e09a88fb4c1550b3a/lightllm/models/llama2/triton_kernel/token_attention_nopad_softmax.py#L36
- @staticmethod
- @torch.no_grad()
- def token_softmax_reducev_fwd(logics, v, o, b_loc, b_start_loc, b_seq_len, max_input_len, other_kv_index):
- BLOCK = 64
- batch, head = b_seq_len.shape[0], logics.shape[0]
- grid = (batch, head)
- kv_group_num = logics.shape[0] // v.shape[1]
-
- num_warps = 1
- Llama2TokenAttentionForwards._fwd_kernel[grid](
- logics,
- v,
- o,
- b_loc,
- b_start_loc,
- b_seq_len,
- max_input_len,
- logics.stride(0),
- logics.stride(1),
- v.stride(0),
- v.stride(1),
- v.stride(2),
- o.stride(0),
- o.stride(1),
- o.stride(2),
- b_loc.stride(0),
- b_loc.stride(1),
- other_kv_index,
- kv_group_num,
- BLOCK_DMODEL=v.shape[-1],
- BLOCK_N=BLOCK,
- num_warps=num_warps,
- num_stages=3,
- )
- return
-
- # this is the interface of llama2 attn forward
- @staticmethod
- @torch.no_grad()
- def token_attn(
- q, k, v, attn_out, kv_cache_loc, kv_cache_start_loc, kv_cache_seq_len, max_len_in_batch, other_kv_index
- ):
- total_token_num = k.shape[0]
- batch_size, head_num, head_dim = q.shape
- calcu_shape1 = (batch_size, head_num, head_dim)
- att_m_tensor = torch.empty((head_num, total_token_num), dtype=q.dtype, device="cuda")
-
- lightllm_llama_token_att_fwd(
- q,
- k,
- att_m_tensor,
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seq_len,
- max_len_in_batch,
- )
-
- if triton.__version__ == "2.0.0":
- prob = torch.empty_like(att_m_tensor)
- lightllm_llama_token_softmax_fwd(att_m_tensor, kv_cache_start_loc, kv_cache_seq_len, prob, max_len_in_batch)
- att_m_tensor = None
-
- lightllm_llama_token_att_fwd2(
- prob,
- v,
- attn_out.view(calcu_shape1),
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seq_len,
- max_len_in_batch,
- )
-
- prob = None
- return
-
- elif triton.__version__ >= "2.1.0":
- Llama2TokenAttentionForwards.token_softmax_reducev_fwd(
- att_m_tensor,
- v,
- attn_out.view(calcu_shape1),
- kv_cache_loc,
- kv_cache_start_loc,
- kv_cache_seq_len,
- max_len_in_batch,
- other_kv_index,
- )
- else:
- raise Exception("not support triton version")
diff --git a/colossalai/legacy/inference/hybridengine/engine.py b/colossalai/legacy/inference/hybridengine/engine.py
index 019a678ceb02..10239071fe1b 100644
--- a/colossalai/legacy/inference/hybridengine/engine.py
+++ b/colossalai/legacy/inference/hybridengine/engine.py
@@ -133,7 +133,7 @@ def inference(self, input_list):
"""
assert isinstance(
input_list, (BatchEncoding, dict)
- ), f"Only accept BatchEncoding or dict as input, but get {input_list.__class__.__name__}."
+ ), f"Only accept BatchEncoding or dict as input, but got {input_list.__class__.__name__}."
if isinstance(input_list, BatchEncoding):
input_list = input_list.data
out, timestamp = self.schedule.generate_step(self.model, iter([input_list]))
diff --git a/colossalai/shardformer/layer/embedding.py b/colossalai/shardformer/layer/embedding.py
index cb7eceae4d25..9b77774aaeaa 100644
--- a/colossalai/shardformer/layer/embedding.py
+++ b/colossalai/shardformer/layer/embedding.py
@@ -249,7 +249,6 @@ class VocabParallelEmbedding1D(PaddingParallelModule):
The ``args`` and ``kwargs`` used in :class:``torch.nn.functional.embedding`` should contain:
::
-
max_norm (float, optional): If given, each embedding vector with norm larger than max_norm is
renormalized to have norm max_norm. Note: this will modify weight in-place.
norm_type (float, optional): The p of the p-norm to compute for the max_norm option. Default 2.
diff --git a/colossalai/shardformer/policies/llama.py b/colossalai/shardformer/policies/llama.py
index 6e541f792248..713175c6cc13 100644
--- a/colossalai/shardformer/policies/llama.py
+++ b/colossalai/shardformer/policies/llama.py
@@ -141,9 +141,11 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
assert (
self.model.config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
), f"The number of attention heads must be divisible by tensor parallel size."
- assert (
- self.model.config.num_key_value_heads % self.shard_config.tensor_parallel_size == 0
- ), f"The number of key_value heads must be divisible by tensor parallel size."
+ if hasattr(self.model.config, "num_key_value_heads"):
+ assert (
+ self.model.config.num_key_value_heads >= self.shard_config.tensor_parallel_size
+ and self.model.config.num_key_value_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of key_value heads must be divisible by, and must not be less than tensor parallel size."
decoder_attribute_replacement = {
"self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
"self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
diff --git a/colossalai/shardformer/shard/shard_config.py b/colossalai/shardformer/shard/shard_config.py
index 98e72d8b346a..453e8d23ebdb 100644
--- a/colossalai/shardformer/shard/shard_config.py
+++ b/colossalai/shardformer/shard/shard_config.py
@@ -125,9 +125,3 @@ def _turn_on_all_optimization(self):
# It may also slow down training when seq len is small. Plz enable manually.
# self.enable_sequence_parallelism = True
# self.enable_sequence_overlap = True
-
- def _infer(self):
- """
- Set default params for inference.
- """
- # assert self.pipeline_stage_manager is None, "pipeline parallelism is not supported in inference for now"
diff --git a/colossalai/shardformer/shard/shardformer.py b/colossalai/shardformer/shard/shardformer.py
index b3991c4f0d9b..b54c5827316e 100644
--- a/colossalai/shardformer/shard/shardformer.py
+++ b/colossalai/shardformer/shard/shardformer.py
@@ -1,6 +1,7 @@
import os
from typing import Dict, List, Tuple
+import torch.distributed as dist
import torch.nn as nn
from torch import Tensor
@@ -36,7 +37,11 @@ class ShardFormer:
"""
def __init__(self, shard_config: ShardConfig):
- self.coordinator = DistCoordinator()
+ self.is_distributed = dist.is_initialized()
+ if self.is_distributed:
+ self.coordinator = DistCoordinator()
+ else:
+ self.coordinator = None
self.shard_config = shard_config
def optimize(self, model: nn.Module, policy: Policy = None) -> Tuple[nn.Module, List[Dict[int, Tensor]]]:
diff --git a/examples/inference/benchmark_llama.py b/examples/inference/benchmark_llama.py
deleted file mode 100644
index a23ab500a6c2..000000000000
--- a/examples/inference/benchmark_llama.py
+++ /dev/null
@@ -1,167 +0,0 @@
-import argparse
-import time
-
-import torch
-import torch.distributed as dist
-import transformers
-
-import colossalai
-from colossalai.accelerator import get_accelerator
-from colossalai.inference import InferenceEngine
-from colossalai.testing import clear_cache_before_run, rerun_if_address_is_in_use, spawn
-
-GIGABYTE = 1024**3
-MEGABYTE = 1024 * 1024
-
-CONFIG_MAP = {
- "toy": transformers.LlamaConfig(num_hidden_layers=4),
- "llama-7b": transformers.LlamaConfig(
- hidden_size=4096,
- intermediate_size=11008,
- num_attention_heads=32,
- num_hidden_layers=32,
- num_key_value_heads=32,
- max_position_embeddings=2048,
- ),
- "llama-13b": transformers.LlamaConfig(
- hidden_size=5120,
- intermediate_size=13824,
- num_attention_heads=40,
- num_hidden_layers=40,
- num_key_value_heads=40,
- max_position_embeddings=2048,
- ),
- "llama2-7b": transformers.LlamaConfig(
- hidden_size=4096,
- intermediate_size=11008,
- num_attention_heads=32,
- num_hidden_layers=32,
- num_key_value_heads=32,
- max_position_embeddings=4096,
- ),
- "llama2-13b": transformers.LlamaConfig(
- hidden_size=5120,
- intermediate_size=13824,
- num_attention_heads=40,
- num_hidden_layers=40,
- num_key_value_heads=40,
- max_position_embeddings=4096,
- ),
-}
-
-
-def data_gen(batch_size: int = 4, seq_len: int = 512):
- input_ids = torch.randint(10, 30000, (batch_size, seq_len), device=get_accelerator().get_current_device())
- attention_mask = torch.ones_like(input_ids)
- data = dict(input_ids=input_ids, attention_mask=attention_mask)
- return data
-
-
-def print_details_info(outputs, model_config, args, whole_end2end):
- msg: str = ""
-
- if dist.get_rank() == 0:
- msg += "-------Perf Summary-------\n"
- if args.verbose:
- timestamps = outputs[1]
- prefill = []
- encoder = []
- end2end = []
- for timestamp in timestamps:
- prefill.append(timestamp[1] - timestamp[0])
- encoder.append(
- sum(timestamp[i + 1] - timestamp[i] for i in range(1, len(timestamp) - 1)) / (len(timestamp) - 2)
- )
- end2end.append(timestamp[-1] - timestamp[0])
-
- mb_avg_end2end = sum(end2end) / len(end2end)
- mb_avg_latency = mb_avg_end2end / (args.output_len * args.mb_size)
-
- msg += f"Average prefill time: {sum(prefill) / len(prefill) * 1000:.2f} ms\n"
- msg += f"Average encode time: {sum(encoder) / len(encoder) * 1000:.2f} ms\n"
- msg += f"Average micro batch end2end time: {mb_avg_end2end * 1000:.2f} ms\n"
- msg += f"Average micro batch per token latency: {mb_avg_latency * 1000:.2f} ms\n"
-
- whole_avg_latency = whole_end2end / (args.output_len * args.batch_size)
- num_layers = getattr(model_config, "num_layers", model_config.num_hidden_layers)
- num_parameters = num_layers * model_config.hidden_size * model_config.hidden_size * 12 / args.pp_size
- if args.dtype in ["fp16", "bf16"]:
- num_bytes = 2
- else:
- num_bytes = 4
-
- msg += f"Whole batch end2end time: {whole_end2end * 1000:.2f} ms\n"
- msg += f"Whole batch per token latency: {whole_avg_latency * 1000:.2f} ms\n"
- msg += f"Throughput: {args.output_len * args.batch_size / whole_end2end:.2f} tokens/s\n"
- msg += f"Flops: {num_parameters * num_bytes / whole_avg_latency / 1e12:.2f} TFLOPS\n"
-
- if torch.cuda.is_available():
- msg += f"-------Memory Summary Device:{get_accelerator().current_device()}-------\n"
- msg += f"Max memory allocated: {get_accelerator().max_memory_allocated() / GIGABYTE:.2f} GB\n"
- msg += f"Max memory reserved: {get_accelerator().max_memory_reserved() / GIGABYTE:.2f} GB\n"
-
- print(msg)
-
-
-def benchmark_inference(args):
- config = CONFIG_MAP[args.model]
- model = transformers.LlamaForCausalLM(config)
- if dist.get_rank() == 0:
- print("Model loaded")
- engine = InferenceEngine(
- pp_size=args.pp_size,
- tp_size=args.tp_size,
- dtype=args.dtype,
- micro_batch_size=args.mb_size,
- model=model,
- verbose=args.verbose,
- max_batch_size=args.batch_size,
- max_input_len=args.seq_len,
- max_output_len=args.output_len,
- )
- data = data_gen(args.batch_size, args.seq_len)
-
- N_WARMUP_STEPS = 2
-
- for _ in range(N_WARMUP_STEPS):
- engine.generate(data)
-
- torch.cuda.synchronize()
- whole_end2end = time.time()
- outputs = engine.generate(data)
- torch.cuda.synchronize()
- whole_end2end = time.time() - whole_end2end
-
- print_details_info(outputs, model.config, args, whole_end2end)
-
-
-def hybrid_inference(rank, world_size, port, args):
- colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
- benchmark_inference(args)
-
-
-@rerun_if_address_is_in_use()
-@clear_cache_before_run()
-def benchmark(args):
- spawn(hybrid_inference, nprocs=args.tp_size * args.pp_size, args=args)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "-m",
- "--model",
- default="toy",
- help="the size of model",
- choices=["toy", "llama-7b", "llama-13b", "llama2-7b", "llama2-13b"],
- )
- parser.add_argument("-b", "--batch_size", type=int, default=8, help="batch size")
- parser.add_argument("-s", "--seq_len", type=int, default=8, help="sequence length")
- parser.add_argument("--mb_size", type=int, default=1, help="micro_batch_size")
- parser.add_argument("--pp_size", type=int, default=1, help="pipeline size")
- parser.add_argument("--tp_size", type=int, default=1, help="pipeline size")
- parser.add_argument("--output_len", type=int, default=128, help="Output length")
- parser.add_argument("--dtype", type=str, default="fp16", help="data type")
- parser.add_argument("-v", "--verbose", default=False, action="store_true")
- args = parser.parse_args()
- benchmark(args)
diff --git a/examples/inference/benchmark_ops/benchmark_context_attn_unpad.py b/examples/inference/benchmark_ops/benchmark_context_attn_unpad.py
new file mode 100644
index 000000000000..18fe76cf0688
--- /dev/null
+++ b/examples/inference/benchmark_ops/benchmark_context_attn_unpad.py
@@ -0,0 +1,133 @@
+import torch
+from transformers.modeling_attn_mask_utils import AttentionMaskConverter
+
+from colossalai.inference.modeling.layers.attention import PagedAttention
+from colossalai.kernel.triton import context_attention_unpadded
+from colossalai.utils import get_current_device
+from tests.test_infer.test_kernels.triton.kernel_utils import generate_caches_and_block_tables_v2, torch_attn_ref
+
+try:
+ import triton # noqa
+
+except ImportError:
+ print("please install triton from https://github.com/openai/triton")
+
+HEAD_DIM = 32
+BATCH = 16
+BLOCK_SIZE = 32
+SAME_LEN = True
+WARM_UPS = 10
+REPS = 100
+configs = [
+ triton.testing.Benchmark(
+ x_names=["KV_LEN"],
+ x_vals=[2**i for i in range(8, 13)],
+ # x_vals=[x for x in range(256, 8192, 256)],
+ line_arg="provider",
+ line_vals=["torch", "triton", "triton_new_klayout"],
+ line_names=["Torch", "Triton", "Triton_new_klayout"],
+ styles=[("red", "-"), ("blue", "-"), ("green", "-")],
+ ylabel="ms",
+ plot_name=f"context_attn-block_size-{BLOCK_SIZE}-batch{BATCH}",
+ args={"bsz": BATCH, "block_size": BLOCK_SIZE, "same_context_len": SAME_LEN, "kv_group_num": 1},
+ )
+]
+
+
+@triton.testing.perf_report(configs)
+def bench_kernel(
+ bsz,
+ KV_LEN,
+ provider,
+ block_size: int,
+ kv_group_num: int,
+ same_context_len: bool,
+):
+ num_attn_heads = 16
+ max_num_blocks_per_seq = triton.cdiv(KV_LEN, block_size)
+ max_seq_len = block_size * max_num_blocks_per_seq
+
+ num_kv_heads = num_attn_heads // kv_group_num
+ assert isinstance(num_kv_heads, int) and num_kv_heads > 0, "Invalid number of kv heads."
+ dtype = torch.float16
+ device = get_current_device()
+
+ if same_context_len:
+ context_lengths = torch.tensor([max_seq_len for _ in range(bsz)], dtype=torch.int32, device=device)
+ else:
+ context_lengths = torch.randint(low=1, high=max_seq_len, size=(bsz,), dtype=torch.int32, device=device)
+ num_tokens = torch.sum(context_lengths).item()
+
+ qkv_size = (num_tokens, num_attn_heads + 2 * num_kv_heads, HEAD_DIM)
+ qkv_unpad = torch.empty(size=qkv_size, dtype=dtype, device=device).normal_(mean=0.0, std=0.5)
+ q_unpad, k_unpad, v_unpad = torch.split(qkv_unpad, [num_attn_heads, num_kv_heads, num_kv_heads], dim=-2)
+ q_unpad = q_unpad.contiguous()
+ k_cache_ref, v_cache_ref, block_tables = generate_caches_and_block_tables_v2(
+ k_unpad, v_unpad, context_lengths, bsz, max_num_blocks_per_seq, block_size, dtype, device
+ )
+ block_tables = block_tables.to(device=device)
+
+ quantiles = [0.5, 0.2, 0.8]
+ if provider == "torch":
+ q_padded = PagedAttention.pad_and_reshape(q_unpad, context_lengths, max_seq_len, num_attn_heads, HEAD_DIM)
+ k_padded = PagedAttention.pad_and_reshape(k_unpad, context_lengths, max_seq_len, num_kv_heads, HEAD_DIM)
+ v_padded = PagedAttention.pad_and_reshape(v_unpad, context_lengths, max_seq_len, num_kv_heads, HEAD_DIM)
+ q_padded, k_padded, v_padded = (
+ q_padded.to(device=device),
+ k_padded.to(device=device),
+ v_padded.to(device=device),
+ )
+ q_padded = q_padded.transpose(1, 2)
+ k_padded = PagedAttention.repeat_kv(k_padded.transpose(1, 2), kv_group_num)
+ v_padded = PagedAttention.repeat_kv(v_padded.transpose(1, 2), kv_group_num)
+ # This benchmark ignores the padding mask. *Only* use the-same-length inputs for benchmarkings
+ attn_mask = AttentionMaskConverter._make_causal_mask(
+ (bsz, max_seq_len), q_padded.dtype, q_padded.device, past_key_values_length=0
+ )
+ attn_mask = attn_mask.to(device=q_padded.device)
+ fn = lambda: torch_attn_ref(
+ q_padded,
+ k_padded,
+ v_padded,
+ attn_mask,
+ bsz,
+ max_seq_len,
+ max_seq_len,
+ num_attn_heads,
+ num_kv_heads,
+ HEAD_DIM,
+ )
+ ms, min_ms, max_ms = triton.testing.do_bench(fn, warmup=WARM_UPS, rep=REPS, quantiles=quantiles)
+ elif provider == "triton":
+ k_cache_triton = torch.zeros_like(k_cache_ref)
+ v_cache_triton = torch.zeros_like(v_cache_ref)
+ fn = lambda: context_attention_unpadded(
+ q_unpad, k_unpad, v_unpad, k_cache_triton, v_cache_triton, context_lengths, block_tables, block_size
+ )
+ ms, min_ms, max_ms = triton.testing.do_bench(fn, warmup=WARM_UPS, rep=REPS, quantiles=quantiles)
+ elif provider == "triton_new_klayout":
+ # NOTE New kcache layout (num_blocks, num_kv_heads, head_dim // x, block_size, x)
+ # to be applied around the cuda and triton kernels.
+ # Here we want to make sure it does not cause downgrade in performance.
+ x = 16 // torch.tensor([], dtype=dtype).element_size()
+ k_cache_shape = (bsz * max_num_blocks_per_seq, num_kv_heads, HEAD_DIM // x, block_size, x)
+ k_cache_triton = torch.zeros(size=k_cache_shape, dtype=dtype, device=device)
+ v_cache_triton = torch.zeros_like(v_cache_ref)
+ fn = lambda: context_attention_unpadded(
+ q_unpad,
+ k_unpad,
+ v_unpad,
+ k_cache_triton,
+ v_cache_triton,
+ context_lengths,
+ block_tables,
+ block_size,
+ use_new_kcache_layout=True,
+ )
+ ms, min_ms, max_ms = triton.testing.do_bench(fn, warmup=WARM_UPS, rep=REPS, quantiles=quantiles)
+
+ return ms, min_ms, max_ms
+
+
+if __name__ == "__main__":
+ bench_kernel.run(save_path=".", print_data=True)
diff --git a/examples/inference/benchmark_ops/benchmark_decoding_attn.py b/examples/inference/benchmark_ops/benchmark_decoding_attn.py
new file mode 100644
index 000000000000..4471ddadab9c
--- /dev/null
+++ b/examples/inference/benchmark_ops/benchmark_decoding_attn.py
@@ -0,0 +1,143 @@
+import torch
+
+from colossalai.kernel.triton import flash_decoding_attention
+from colossalai.utils import get_current_device
+from tests.test_infer.test_kernels.triton.kernel_utils import (
+ convert_kv_unpad_to_padded,
+ create_attention_mask,
+ generate_caches_and_block_tables_v2,
+ generate_caches_and_block_tables_v3,
+ torch_attn_ref,
+)
+from tests.test_infer.test_kernels.triton.test_decoding_attn import prepare_data
+
+try:
+ import triton # noqa
+
+except ImportError:
+ print("please install triton from https://github.com/openai/triton")
+
+Q_LEN = 1
+HEAD_DIM = 128
+BATCH = 16
+BLOCK_SIZE = 32
+SAME_LEN = True
+WARM_UPS = 10
+REPS = 100
+configs = [
+ triton.testing.Benchmark(
+ x_names=["KV_LEN"],
+ x_vals=[2**i for i in range(8, 14)],
+ # x_vals=[x for x in range(256, 8192, 256)],
+ line_arg="provider",
+ line_vals=["torch", "triton", "triton_new_kcache_layout"],
+ line_names=["Torch", "Triton", "Triton New KCache Layout"],
+ styles=[("red", "-"), ("blue", "-"), ("yellow", "-")],
+ ylabel="ms",
+ plot_name=f"decoding-block_size-{BLOCK_SIZE}-batch{BATCH}",
+ args={"bsz": BATCH, "block_size": BLOCK_SIZE, "same_context_len": SAME_LEN, "kv_group_num": 1},
+ )
+]
+
+
+@triton.testing.perf_report(configs)
+def bench_kernel(
+ bsz,
+ KV_LEN,
+ provider,
+ block_size: int,
+ kv_group_num: int,
+ same_context_len: bool,
+):
+ num_attn_heads = 16
+ max_num_blocks_per_seq = triton.cdiv(KV_LEN, block_size)
+ max_seq_len = block_size * max_num_blocks_per_seq
+
+ num_kv_heads = num_attn_heads // kv_group_num
+ assert isinstance(num_kv_heads, int) and num_kv_heads > 0, "Invalid number of kv heads."
+ block_size * max_num_blocks_per_seq
+ dtype = torch.float16
+ device = get_current_device()
+
+ q, k_unpad, v_unpad, kv_lengths = prepare_data(
+ bsz, num_attn_heads, num_kv_heads, HEAD_DIM, same_context_len, Q_LEN, max_seq_len, dtype, device
+ )
+ max_seq_len_in_b = kv_lengths.max().item() # for random lengths
+ # the maximum block length splitted on kv should be the kv cache block size
+ kv_max_split_num = (max_seq_len_in_b + block_size - 1) // block_size
+ sm_scale = 1.0 / (HEAD_DIM**0.5)
+ output = torch.empty((bsz, num_attn_heads, HEAD_DIM), dtype=dtype, device=device)
+ mid_output = torch.empty(
+ size=(bsz, num_attn_heads, kv_max_split_num, HEAD_DIM), dtype=torch.float32, device=q.device
+ )
+ mid_output_lse = torch.empty(size=(bsz, num_attn_heads, kv_max_split_num), dtype=torch.float32, device=q.device)
+
+ quantiles = [0.5, 0.2, 0.8]
+ if provider == "torch":
+ k_torch = convert_kv_unpad_to_padded(k_unpad, kv_lengths, bsz, max_seq_len_in_b)
+ v_torch = convert_kv_unpad_to_padded(v_unpad, kv_lengths, bsz, max_seq_len_in_b)
+ torch_padding_mask = create_attention_mask(kv_lengths, bsz, Q_LEN, max_seq_len_in_b, q.device)
+ fn = lambda: torch_attn_ref(
+ q,
+ k_torch,
+ v_torch,
+ torch_padding_mask,
+ bsz,
+ Q_LEN,
+ max_seq_len_in_b,
+ num_attn_heads,
+ num_kv_heads,
+ HEAD_DIM,
+ )
+ ms, min_ms, max_ms = triton.testing.do_bench(fn, warmup=WARM_UPS, rep=REPS, quantiles=quantiles)
+ elif provider == "triton":
+ k_cache, v_cache, block_tables = generate_caches_and_block_tables_v2(
+ k_unpad, v_unpad, kv_lengths, bsz, max_num_blocks_per_seq, block_size, dtype, device
+ )
+ block_tables = block_tables.to(device=device)
+ fn = lambda: flash_decoding_attention(
+ # Here we use q.squeeze(2) because we hide the q_len dimension (which is equivalent to 1),
+ # refer to attention forward in modeling.
+ q.squeeze(2),
+ k_cache,
+ v_cache,
+ kv_lengths,
+ block_tables,
+ block_size,
+ max_seq_len_in_b,
+ output,
+ mid_output,
+ mid_output_lse,
+ sm_scale=sm_scale,
+ kv_group_num=kv_group_num,
+ ) # [bsz, 1, num_heads, head_dim]
+ ms, min_ms, max_ms = triton.testing.do_bench(fn, warmup=WARM_UPS, rep=REPS, quantiles=quantiles)
+ elif provider == "triton_new_kcache_layout":
+ k_cache, v_cache, block_tables = generate_caches_and_block_tables_v3(
+ k_unpad, v_unpad, kv_lengths, bsz, max_num_blocks_per_seq, block_size, dtype, device
+ )
+ block_tables = block_tables.to(device=device)
+ fn = lambda: flash_decoding_attention(
+ # Here we use q.squeeze(2) because we hide the q_len dimension (which is equivalent to 1),
+ # refer to attention forward in modeling.
+ q.squeeze(2),
+ k_cache,
+ v_cache,
+ kv_lengths,
+ block_tables,
+ block_size,
+ max_seq_len_in_b,
+ output,
+ mid_output,
+ mid_output_lse,
+ sm_scale=sm_scale,
+ kv_group_num=kv_group_num,
+ use_new_kcache_layout=True,
+ )
+ ms, min_ms, max_ms = triton.testing.do_bench(fn, warmup=WARM_UPS, rep=REPS, quantiles=quantiles)
+
+ return ms, min_ms, max_ms
+
+
+if __name__ == "__main__":
+ bench_kernel.run(save_path=".", print_data=True)
diff --git a/examples/inference/benchmark_ops/benchmark_flash_decoding_attention.py b/examples/inference/benchmark_ops/benchmark_flash_decoding_attention.py
new file mode 100644
index 000000000000..d90de6664ed6
--- /dev/null
+++ b/examples/inference/benchmark_ops/benchmark_flash_decoding_attention.py
@@ -0,0 +1,182 @@
+import torch
+
+from colossalai.kernel.kernel_loader import InferenceOpsLoader
+from colossalai.kernel.triton import flash_decoding_attention
+from colossalai.utils import get_current_device
+from tests.test_infer.test_kernels.triton.kernel_utils import (
+ generate_caches_and_block_tables_v2,
+ generate_caches_and_block_tables_v3,
+ generate_caches_and_block_tables_vllm,
+)
+
+try:
+ import triton # noqa
+except ImportError:
+ print("please install triton from https://github.com/openai/triton")
+
+inference_ops = InferenceOpsLoader().load()
+
+# Triton benchmark plot attributions
+configs = [
+ triton.testing.Benchmark(
+ x_names=["MAX_NUM_BLOCKS_PER_SEQ"],
+ x_vals=[2**i for i in range(2, 8)],
+ line_arg="provider",
+ line_vals=[
+ "vllm_paged_decoding_attention",
+ "triton_flash_decoding_attention",
+ "cuda_flash_decoding_attention",
+ ],
+ line_names=[
+ "vllm_paged_decoding_attention",
+ "triton_flash_decoding_attention",
+ "cuda_flash_decoding_attention",
+ ],
+ styles=[("red", "-"), ("blue", "-"), ("yellow", "-")],
+ ylabel="ms",
+ plot_name=f"FlashDecodingAttention benchmarking results",
+ args={"BATCH_SIZE": 16, "BLOCK_SIZE": 32, "HEAD_SIZE": 128, "KV_GROUP_NUM": 2},
+ )
+]
+
+
+def prepare_data(
+ BATCH_SIZE: int,
+ HEAD_SIZE: int,
+ NUM_ATTN_HEADS: int,
+ NUM_KV_HEADS: int,
+ MAX_SEQ_LEN: int,
+ dtype=torch.float16,
+ device="cuda",
+):
+ # Use the provided maximum sequence length for each sequence when testing with teh same context length,
+ # otherwise generate random context lengths.
+ # returns
+ # q [BATCH_SIZE, NUM_ATTN_HEADS, HEAD_SIZE]
+ # k_unpad/v_unpad [num_tokens, NUM_KV_HEADS, HEAD_SIZE]
+ kv_lengths = torch.randint(low=1, high=MAX_SEQ_LEN, size=(BATCH_SIZE,), dtype=torch.int32, device=device)
+ num_tokens = torch.sum(kv_lengths).item()
+
+ q_size = (BATCH_SIZE, 1, NUM_ATTN_HEADS, HEAD_SIZE)
+ q = torch.empty(size=q_size, dtype=dtype, device=device).normal_(mean=0.0, std=0.5).transpose(1, 2)
+ kv_size = (num_tokens, 2 * NUM_KV_HEADS, HEAD_SIZE)
+ kv_unpad = torch.empty(size=kv_size, dtype=dtype, device=device).normal_(mean=0.0, std=0.5)
+ k_unpad, v_unpad = torch.split(kv_unpad, [NUM_KV_HEADS, NUM_KV_HEADS], dim=-2)
+
+ return q, k_unpad, v_unpad, kv_lengths
+
+
+@triton.testing.perf_report(configs)
+def benchmark_flash_decoding_attention(
+ provider: str,
+ BATCH_SIZE: int,
+ BLOCK_SIZE: int,
+ MAX_NUM_BLOCKS_PER_SEQ: int,
+ HEAD_SIZE: int,
+ KV_GROUP_NUM: int,
+):
+ try:
+ from vllm._C import ops as vllm_ops
+ except ImportError:
+ raise ImportError("Please install vllm from https://github.com/vllm-project/vllm")
+
+ warmup = 10
+ rep = 1000
+
+ dtype = torch.float16
+
+ NUM_ATTN_HEADS = 16
+
+ NUM_KV_HEADS = NUM_ATTN_HEADS // KV_GROUP_NUM
+ assert isinstance(NUM_KV_HEADS, int) and NUM_KV_HEADS > 0, "Invalid number of kv heads."
+ MAX_SEQ_LEN = BLOCK_SIZE * MAX_NUM_BLOCKS_PER_SEQ
+ device = get_current_device()
+
+ q, k_unpad, v_unpad, kv_seq_lengths = prepare_data(
+ BATCH_SIZE, HEAD_SIZE, NUM_ATTN_HEADS, NUM_KV_HEADS, MAX_SEQ_LEN, dtype, device
+ )
+
+ triton_k_cache, triton_v_cache, _ = generate_caches_and_block_tables_v2(
+ k_unpad, v_unpad, kv_seq_lengths, BATCH_SIZE, MAX_NUM_BLOCKS_PER_SEQ, BLOCK_SIZE, dtype, device
+ )
+
+ k_cache, v_cache, block_tables = generate_caches_and_block_tables_v3(
+ k_unpad, v_unpad, kv_seq_lengths, BATCH_SIZE, MAX_NUM_BLOCKS_PER_SEQ, BLOCK_SIZE, dtype, device
+ )
+
+ vllm_k_cache, vllm_v_cache, _ = generate_caches_and_block_tables_vllm(
+ k_unpad, v_unpad, kv_seq_lengths, BATCH_SIZE, MAX_NUM_BLOCKS_PER_SEQ, BLOCK_SIZE, dtype, device
+ )
+
+ block_tables = block_tables.to(device=device)
+ max_seq_len_across_batch = kv_seq_lengths.max().item()
+ kv_max_split_num = (max_seq_len_across_batch + BLOCK_SIZE - 1) // BLOCK_SIZE
+ output = torch.empty((BATCH_SIZE, NUM_ATTN_HEADS, HEAD_SIZE), dtype=dtype, device=device)
+ sm_scale = 1.0 / (HEAD_SIZE**0.5)
+ alibi_slopes = None
+ kv_scale = 1.0
+
+ mid_output = torch.empty(
+ size=(BATCH_SIZE, NUM_ATTN_HEADS, kv_max_split_num, HEAD_SIZE), dtype=torch.float32, device=device
+ )
+ mid_output_lse = torch.empty(
+ size=(BATCH_SIZE, NUM_ATTN_HEADS, kv_max_split_num), dtype=torch.float32, device=device
+ )
+
+ if provider == "vllm_paged_decoding_attention":
+ alibi_slopes = None
+ fn = lambda: vllm_ops.paged_attention_v1(
+ output,
+ q.squeeze(2),
+ vllm_k_cache,
+ vllm_v_cache,
+ NUM_KV_HEADS,
+ sm_scale,
+ block_tables,
+ kv_seq_lengths,
+ BLOCK_SIZE,
+ max_seq_len_across_batch,
+ alibi_slopes,
+ "auto",
+ kv_scale,
+ )
+ elif provider == "triton_flash_decoding_attention":
+ fn = lambda: flash_decoding_attention(
+ q.squeeze(2),
+ triton_k_cache,
+ triton_v_cache,
+ kv_seq_lengths,
+ block_tables,
+ BLOCK_SIZE,
+ max_seq_len_across_batch,
+ output,
+ mid_output,
+ mid_output_lse,
+ sm_scale=sm_scale,
+ kv_group_num=KV_GROUP_NUM,
+ ) # [bsz, 1, num_heads, head_dim]
+ elif provider == "cuda_flash_decoding_attention":
+ fn = lambda: inference_ops.flash_decoding_attention(
+ output,
+ q.squeeze(2),
+ k_cache,
+ v_cache,
+ kv_seq_lengths,
+ block_tables,
+ BLOCK_SIZE,
+ max_seq_len_across_batch,
+ mid_output,
+ mid_output_lse,
+ alibi_slopes,
+ sm_scale,
+ )
+ else:
+ raise ValueError("Undefined provider.")
+
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+
+ return ms
+
+
+if __name__ == "__main__":
+ benchmark_flash_decoding_attention.run(save_path=".", print_data=True)
diff --git a/examples/inference/benchmark_ops/benchmark_fused_rotary_embdding_unpad.py b/examples/inference/benchmark_ops/benchmark_fused_rotary_embdding_unpad.py
new file mode 100644
index 000000000000..80939f5a1e50
--- /dev/null
+++ b/examples/inference/benchmark_ops/benchmark_fused_rotary_embdding_unpad.py
@@ -0,0 +1,137 @@
+import torch
+
+from colossalai.kernel.kernel_loader import InferenceOpsLoader
+from colossalai.kernel.triton import copy_kv_to_blocked_cache, decoding_fused_rotary_embedding, rotary_embedding
+from tests.test_infer.test_kernels.triton.kernel_utils import (
+ mock_alloc_block_table_and_kvcache_v2,
+ mock_alloc_block_table_and_kvcache_v3,
+ mock_alloc_single_token,
+)
+
+inference_ops = InferenceOpsLoader().load()
+
+try:
+ import triton # noqa
+
+except ImportError:
+ print("please install triton from https://github.com/openai/triton")
+
+
+BATCH = 16
+configs = [
+ triton.testing.Benchmark(
+ x_names=["num_tokens"],
+ x_vals=[2**i for i in range(4, 11)],
+ line_arg="provider",
+ line_vals=[
+ "triton_rotary_emb_func",
+ "triton_fused_rotary_emb_func",
+ "triton_fused_rotary_emb_func_new_kcache_layout",
+ "cuda_rotary_emb_func",
+ "cuda_fused_rotary_emb_func",
+ ],
+ line_names=[
+ "triton_rotary_emb_func",
+ "triton_fused_rotary_emb_func",
+ "triton_fused_rotary_emb_func(new layout)",
+ "cuda_rotary_emb_func",
+ "cuda_fused_rotary_emb_func",
+ ],
+ styles=[("red", "-"), ("blue", "-"), ("purple", "-"), ("green", "-"), ("yellow", "-")],
+ ylabel="ms",
+ plot_name=f"rotary_emb-batch-{BATCH}",
+ args={"num_kv_heads": 16},
+ )
+]
+
+
+@triton.testing.perf_report(configs)
+def benchmark_rotary_emb(
+ provider: str,
+ num_tokens: int,
+ num_kv_heads: int,
+):
+ BATCH_SIZE = 16
+ SEQ_LEN = num_tokens // BATCH_SIZE
+ max_num_blocks_per_seq = 8
+ block_size = 64
+ warmup = 10
+ rep = 100
+
+ head_dim = 4096
+ dtype = torch.float16
+
+ q_shape = (num_tokens, num_kv_heads, head_dim)
+ q = -2.3 + 0.5 * torch.randn(q_shape, dtype=dtype, device="cuda")
+ k_shape = (num_tokens, num_kv_heads, head_dim)
+ k = -2.3 + 0.5 * torch.randn(k_shape, dtype=dtype, device="cuda")
+ v = -2.3 + 0.5 * torch.randn(k_shape, dtype=dtype, device="cuda")
+
+ cos_shape = (num_tokens, head_dim // 2)
+
+ cos = -1.2 + 0.5 * torch.randn(cos_shape, dtype=dtype, device="cuda")
+ sin = -2.0 + 0.5 * torch.randn(cos_shape, dtype=dtype, device="cuda")
+ cache_shape = (BATCH_SIZE * max_num_blocks_per_seq, num_kv_heads, block_size, head_dim)
+ k_cache = torch.zeros(size=cache_shape, dtype=dtype, device="cuda")
+ v_cache = torch.zeros(size=cache_shape, dtype=dtype, device="cuda")
+ x = 16 // torch.tensor([], dtype=dtype).element_size()
+ new_cache_shape = (BATCH_SIZE * max_num_blocks_per_seq, num_kv_heads, head_dim // x, block_size, x)
+ new_k_cache = torch.zeros(size=new_cache_shape, dtype=dtype, device="cuda")
+
+ past_kv_seq_lengths = torch.tensor([SEQ_LEN - 1 for _ in range(BATCH_SIZE)], dtype=torch.int32, device="cuda")
+ block_tables = mock_alloc_block_table_and_kvcache_v2(
+ k, v, k_cache, v_cache, past_kv_seq_lengths, BATCH_SIZE, max_num_blocks_per_seq, block_size
+ )
+ _ = mock_alloc_block_table_and_kvcache_v3(
+ k, v, new_k_cache, v_cache, past_kv_seq_lengths, BATCH_SIZE, max_num_blocks_per_seq, block_size
+ )
+ new_k = torch.randn((BATCH_SIZE, num_kv_heads, head_dim), dtype=dtype, device="cuda")
+ new_q = torch.randn_like(new_k)
+ new_v = torch.randn_like(new_k)
+
+ mock_alloc_single_token(block_tables, past_kv_seq_lengths, block_size)
+ kv_seq_lengths = past_kv_seq_lengths + 1
+ block_tables = block_tables.to(device="cuda")
+
+ quantiles = [0.5, 0.2, 0.8]
+ if provider == "triton_rotary_emb_func":
+ fn = lambda: [
+ rotary_embedding(new_q, new_k, cos, sin),
+ copy_kv_to_blocked_cache(
+ new_k, new_v, k_cache, v_cache, kv_lengths=kv_seq_lengths, block_tables=block_tables
+ ),
+ ]
+ elif provider == "triton_fused_rotary_emb_func":
+ fn = lambda: decoding_fused_rotary_embedding(
+ new_q, new_k, new_v, cos, sin, k_cache, v_cache, block_tables, kv_seq_lengths
+ )
+ elif provider == "triton_fused_rotary_emb_func_new_kcache_layout":
+ x = 16 // torch.tensor([], dtype=dtype).element_size()
+ kcache_shape = (BATCH_SIZE * max_num_blocks_per_seq, num_kv_heads, head_dim // x, block_size, x)
+ k_cache = torch.zeros(size=kcache_shape, dtype=dtype, device="cuda")
+ block_tables = mock_alloc_block_table_and_kvcache_v3(
+ k, v, k_cache, v_cache, past_kv_seq_lengths, BATCH_SIZE, max_num_blocks_per_seq, block_size
+ )
+ mock_alloc_single_token(block_tables, past_kv_seq_lengths, block_size)
+ block_tables = block_tables.to(device="cuda")
+ fn = lambda: decoding_fused_rotary_embedding(
+ new_q, new_k, new_v, cos, sin, k_cache, v_cache, block_tables, kv_seq_lengths, use_new_kcache_layout=True
+ )
+ elif provider == "cuda_rotary_emb_func":
+ fn = lambda: [
+ inference_ops.rotary_embedding(new_q, new_k, cos, sin, True),
+ inference_ops.decode_kv_cache_memcpy(new_k, new_v, new_k_cache, v_cache, kv_seq_lengths, block_tables),
+ ]
+ elif provider == "cuda_fused_rotary_emb_func":
+ fn = lambda: inference_ops.rotary_embedding_and_cache_copy(
+ new_q, new_k, new_v, cos, sin, new_k_cache, v_cache, kv_seq_lengths, block_tables, True
+ )
+ else:
+ raise ValueError("Undefined provider")
+
+ ms, min_ms, max_ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep, quantiles=quantiles)
+ return ms, min_ms, max_ms
+
+
+if __name__ == "__main__":
+ benchmark_rotary_emb.run(save_path=".", print_data=True)
diff --git a/examples/inference/benchmark_ops/benchmark_kv_cache_memcopy.py b/examples/inference/benchmark_ops/benchmark_kv_cache_memcopy.py
new file mode 100644
index 000000000000..0232cb90e677
--- /dev/null
+++ b/examples/inference/benchmark_ops/benchmark_kv_cache_memcopy.py
@@ -0,0 +1,91 @@
+import torch
+
+from colossalai.inference.modeling.layers.attention import copy_to_cache
+from colossalai.kernel.kernel_loader import InferenceOpsLoader
+from colossalai.kernel.triton import copy_kv_to_blocked_cache
+from colossalai.utils import get_current_device
+from tests.test_infer.test_kernels.cuda.test_kv_cache_memcpy import prepare_data as prepare_data_new_kcache_layout
+from tests.test_infer.test_kernels.triton.test_kvcache_copy import prepare_data
+
+try:
+ import triton # noqa
+except ImportError:
+ print("please install triton from https://github.com/openai/triton")
+
+inference_ops = InferenceOpsLoader().load()
+
+HEAD_DIM = 128
+BATCH = 16
+BLOCK_SIZE = 32
+SAME_LEN = True
+WARM_UPS = 10
+REPS = 100
+configs = [
+ triton.testing.Benchmark(
+ x_names=["KV_SEQ_LEN"],
+ x_vals=[2**i for i in range(8, 13)],
+ line_arg="provider",
+ line_vals=["torch_copy_func", "triton_copy_func", "triton_new_kcache_layout", "cuda_copy_func"],
+ line_names=["torch_copy_func", "triton_copy_func", "triton_new_kcache_layout", "cuda_copy_func"],
+ styles=[("red", "-"), ("blue", "-"), ("yellow", "-"), ("green", "-")],
+ ylabel="ms",
+ plot_name=f"kvcache_copy_decoding_stage-batch-{BATCH}",
+ args={"bsz": BATCH, "block_size": 16, "max_seq_len": 8192, "num_kv_heads": 16, "same_context_len": True},
+ )
+]
+
+
+@triton.testing.perf_report(configs)
+def benchmark_kvcache_copy(
+ provider: str,
+ bsz: int,
+ block_size: int,
+ max_seq_len: int,
+ KV_SEQ_LEN: int, # maximum past kv length (unequal context lens in batch) or past kv len (equal context lens)
+ num_kv_heads: int,
+ same_context_len: bool,
+):
+ dtype = torch.float16
+ device = get_current_device()
+
+ assert KV_SEQ_LEN <= max_seq_len, "Assigned maximum kv length must be smaller or equal to maximum seq len"
+
+ new_k, new_v, k_cache, v_cache, context_lengths, block_tables = prepare_data(
+ bsz,
+ num_kv_heads,
+ HEAD_DIM,
+ block_size,
+ max_seq_len // block_size,
+ same_context_len,
+ KV_SEQ_LEN,
+ device=device,
+ dtype=dtype,
+ )
+
+ quantiles = [0.5, 0.2, 0.8]
+ if provider == "torch_copy_func":
+ fn = lambda: copy_to_cache(new_k, k_cache, lengths=context_lengths, block_tables=block_tables, type="decoding")
+ elif provider == "triton_copy_func":
+ fn = lambda: copy_kv_to_blocked_cache(new_k, new_v, k_cache, v_cache, context_lengths, block_tables)
+ elif provider == "triton_new_kcache_layout":
+ # NOTE New kcache layout (num_blocks, num_kv_heads, head_dim // x, block_size, x) to be applied
+ x = 16 // torch.tensor([], dtype=dtype).element_size()
+ k_cache_shape = (bsz * max_seq_len // block_size, num_kv_heads, HEAD_DIM // x, block_size, x)
+ k_cache = torch.zeros(size=k_cache_shape, dtype=dtype, device=device) # update k_cache layout
+ fn = lambda: copy_kv_to_blocked_cache(
+ new_k, new_v, k_cache, v_cache, context_lengths, block_tables, use_new_kcache_layout=True
+ )
+ elif provider == "cuda_copy_func":
+ _, _, k_cache, _, _, _, _, _, _ = prepare_data_new_kcache_layout(
+ bsz, num_kv_heads, block_size, max_seq_len // block_size, context_lengths - 1, device, dtype
+ )
+ new_k = new_k.squeeze(1) if new_k.dim() == 4 else new_k
+ new_v = new_v.squeeze(1) if new_v.dim() == 4 else new_v
+ fn = lambda: inference_ops.decode_kv_cache_memcpy(new_k, new_v, k_cache, v_cache, context_lengths, block_tables)
+
+ ms, min_ms, max_ms = triton.testing.do_bench(fn, warmup=WARM_UPS, rep=REPS, quantiles=quantiles)
+ return ms, min_ms, max_ms
+
+
+if __name__ == "__main__":
+ benchmark_kvcache_copy.run(save_path=".", print_data=True)
diff --git a/examples/inference/benchmark_ops/benchmark_rmsnorm.py b/examples/inference/benchmark_ops/benchmark_rmsnorm.py
new file mode 100644
index 000000000000..deddac8b127a
--- /dev/null
+++ b/examples/inference/benchmark_ops/benchmark_rmsnorm.py
@@ -0,0 +1,87 @@
+import torch
+
+from colossalai.kernel.kernel_loader import InferenceOpsLoader
+from colossalai.kernel.triton import rms_layernorm
+
+try:
+ import triton # noqa
+except ImportError:
+ print("please install triton from https://github.com/openai/triton")
+
+inference_ops = InferenceOpsLoader().load()
+
+# Triton benchmark plot attributions
+configs = [
+ triton.testing.Benchmark(
+ x_names=["SEQUENCE_TOTAL"],
+ x_vals=[i for i in range(128, 1025, 128)],
+ line_arg="provider",
+ line_vals=[
+ "vllm_rms_layernorm",
+ "triton_rms_layernorm",
+ "cuda_rms_layernorm",
+ "vllm_rms_layernorm_with_residual",
+ "triton_rms_layernorm_with_residual",
+ "cuda_rms_layernorm_with_residual",
+ ],
+ line_names=[
+ "vllm_rms_layernorm",
+ "triton_rms_layernorm",
+ "cuda_rms_layernorm",
+ "vllm_rms_layernorm_with_residual",
+ "triton_rms_layernorm_with_residual",
+ "cuda_rms_layernorm_with_residual",
+ ],
+ styles=[("red", "-"), ("blue", "-"), ("yellow", "-"), ("red", "--"), ("blue", "--"), ("yellow", "--")],
+ ylabel="ms",
+ plot_name=f"RMSNorm benchmarking results",
+ args={"HIDDEN_SIZE": 5120},
+ )
+]
+
+
+@triton.testing.perf_report(configs)
+def benchmark_rms_layernorm(
+ provider: str,
+ SEQUENCE_TOTAL: int,
+ HIDDEN_SIZE: int,
+):
+ try:
+ from vllm.model_executor.layers.layernorm import RMSNorm
+ except ImportError:
+ raise ImportError("Please install vllm from https://github.com/vllm-project/vllm")
+
+ warmup = 10
+ rep = 1000
+
+ dtype = torch.float16
+ eps = 1e-5
+ x_shape = (SEQUENCE_TOTAL, HIDDEN_SIZE)
+ w_shape = (x_shape[-1],)
+ residual = torch.rand(x_shape, dtype=dtype, device="cuda")
+ weight = torch.ones(w_shape, dtype=dtype, device="cuda")
+ vllm_norm = RMSNorm(hidden_size=HIDDEN_SIZE, eps=eps).to(dtype=dtype, device="cuda")
+ x = -2.3 + 0.5 * torch.randn(x_shape, dtype=dtype, device="cuda")
+ if provider == "vllm_rms_layernorm":
+ fn = lambda: vllm_norm(x)
+ elif provider == "triton_rms_layernorm":
+ fn = lambda: rms_layernorm(x, weight, eps=eps)
+ elif provider == "cuda_rms_layernorm":
+ out = torch.empty_like(x)
+ fn = lambda: inference_ops.rms_layernorm(out, x, weight, eps)
+ elif provider == "vllm_rms_layernorm_with_residual":
+ fn = lambda: vllm_norm(x, residual=residual)
+ elif provider == "triton_rms_layernorm_with_residual":
+ fn = lambda: rms_layernorm(x, weight, eps=eps, residual=residual)
+ elif provider == "cuda_rms_layernorm_with_residual":
+ fn = lambda: inference_ops.fused_add_rms_layernorm(x, residual, weight, eps)
+ else:
+ raise ValueError("Undefined provider.")
+
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+
+ return ms
+
+
+if __name__ == "__main__":
+ benchmark_rms_layernorm.run(save_path=".", print_data=True)
diff --git a/examples/inference/benchmark_ops/benchmark_rotary_embedding.py b/examples/inference/benchmark_ops/benchmark_rotary_embedding.py
new file mode 100644
index 000000000000..97cf2e0b2451
--- /dev/null
+++ b/examples/inference/benchmark_ops/benchmark_rotary_embedding.py
@@ -0,0 +1,76 @@
+import torch
+import triton
+from vllm._C import ops
+
+from colossalai.kernel.kernel_loader import InferenceOpsLoader
+from colossalai.kernel.triton import rotary_embedding
+
+inference_ops = InferenceOpsLoader().load()
+
+BATCH = 16
+configs = [
+ triton.testing.Benchmark(
+ x_names=["num_tokens"],
+ x_vals=[2**i for i in range(4, 12)],
+ line_arg="provider",
+ line_vals=["triton_func", "colossal_cuda_func", "vllm_cuda_func"],
+ line_names=["triton_func", "colossal_cuda_func", "vllm_cuda_func"],
+ styles=[("red", "-"), ("blue", "-"), ("yellow", "-")],
+ ylabel="ms",
+ plot_name=f"rotary_emb-batch-{BATCH}",
+ args={"num_kv_heads": 16},
+ )
+]
+
+
+def torch_rotary_emb(x, cos, sin):
+ seq_len, h, dim = x.shape
+ x0 = x[:, :, 0 : dim // 2]
+ x1 = x[:, :, dim // 2 : dim]
+ cos = cos.view((seq_len, 1, dim // 2))
+ sin = sin.view((seq_len, 1, dim // 2))
+ o0 = x0 * cos - x1 * sin
+ o1 = x0 * sin + x1 * cos
+ return torch.cat((o0, o1), dim=-1)
+
+
+@triton.testing.perf_report(configs)
+def benchmark_rotary_emb(
+ provider: str,
+ num_tokens: int,
+ num_kv_heads: int,
+):
+ warmup = 10
+ rep = 100
+
+ head_dim = 128
+ dtype = torch.float16
+ q_shape = (num_tokens, num_kv_heads, head_dim)
+ q = -2.3 + 0.5 * torch.randn(q_shape, dtype=dtype, device="cuda")
+ k_shape = (num_tokens, num_kv_heads, head_dim)
+ k = -2.3 + 0.5 * torch.randn(k_shape, dtype=dtype, device="cuda")
+ cos_shape = (4096, head_dim // 2)
+ cos = -1.2 + 0.5 * torch.randn(cos_shape, dtype=dtype, device="cuda")
+ sin = -2.0 + 0.5 * torch.randn(cos_shape, dtype=dtype, device="cuda")
+
+ cos_sin = torch.stack((cos, sin), dim=1).contiguous()
+
+ positions = torch.arange(num_tokens).cuda()
+
+ if provider == "triton_func":
+ fn = lambda: rotary_embedding(q, k, cos, sin)
+ elif provider == "colossal_cuda_func":
+ fn = lambda: inference_ops.rotary_embedding(q, k, cos, sin)
+ elif provider == "vllm_cuda_func":
+ q = q.view(num_tokens, -1)
+ k = k.view(num_tokens, -1)
+ fn = lambda: ops.rotary_embedding(positions, q, k, head_dim, cos_sin, True)
+ else:
+ raise ValueError("Undefined provider")
+
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+ return ms
+
+
+if __name__ == "__main__":
+ benchmark_rotary_emb.run(save_path=".", print_data=True)
diff --git a/examples/inference/benchmark_ops/benchmark_xine_copy.py b/examples/inference/benchmark_ops/benchmark_xine_copy.py
new file mode 100644
index 000000000000..633ceb6f1651
--- /dev/null
+++ b/examples/inference/benchmark_ops/benchmark_xine_copy.py
@@ -0,0 +1,54 @@
+import torch
+
+from colossalai.kernel.triton import get_xine_cache
+from tests.test_infer.test_kernels.triton.test_xine_copy import get_cos_sin
+
+try:
+ import triton # noqa
+
+except ImportError:
+ print("please install triton from https://github.com/openai/triton")
+
+
+configs = [
+ triton.testing.Benchmark(
+ x_names=["max_num_tokens"],
+ x_vals=[2**i for i in range(6, 12)],
+ line_arg="provider",
+ line_vals=["torch_get_cos_sin", "triton_get_cos_sin"],
+ line_names=["torch_get_cos_sin", "triton_get_cos_sin"],
+ styles=[("red", "-"), ("blue", "-")],
+ ylabel="ms",
+ plot_name="Get_cos-sin_func",
+ args={"batch_size": 16, "head_dim": 256},
+ )
+]
+
+
+@triton.testing.perf_report(configs)
+def benchmark_get_xine_cache(
+ provider: str,
+ max_num_tokens: int,
+ batch_size: int,
+ head_dim: int,
+):
+ warmup = 10
+ rep = 1000
+ dtype = torch.float16
+ cos_cache = torch.randn((8912, head_dim), dtype=dtype, device="cuda")
+ sin_cache = torch.randn((8912, head_dim), dtype=dtype, device="cuda")
+ lengths = torch.randint(2, max_num_tokens, (batch_size,), device="cuda")
+
+ if provider == "torch_get_cos_sin":
+ fn = lambda: get_cos_sin(lengths, cos_cache, sin_cache, is_prompts=True, dtype=dtype)
+ elif provider == "triton_get_cos_sin":
+ fn = lambda: get_xine_cache(lengths, cos_cache, sin_cache, is_prompts=True)
+ else:
+ raise ValueError("Undefined provider")
+
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+ return ms
+
+
+if __name__ == "__main__":
+ benchmark_get_xine_cache.run(save_path=".", print_data=True)
diff --git a/examples/inference/benchmark_ops/test_ci.sh b/examples/inference/benchmark_ops/test_ci.sh
new file mode 100644
index 000000000000..e69de29bb2d1
diff --git a/examples/inference/build_smoothquant_weight.py b/examples/inference/build_smoothquant_weight.py
deleted file mode 100644
index d60ce1c1d618..000000000000
--- a/examples/inference/build_smoothquant_weight.py
+++ /dev/null
@@ -1,59 +0,0 @@
-import argparse
-import os
-
-import torch
-from datasets import load_dataset
-from transformers import LlamaTokenizer
-
-from colossalai.inference.quant.smoothquant.models.llama import SmoothLlamaForCausalLM
-
-
-def build_model_and_tokenizer(model_name):
- tokenizer = LlamaTokenizer.from_pretrained(model_name, model_max_length=512)
- kwargs = {"torch_dtype": torch.float16, "device_map": "sequential"}
- model = SmoothLlamaForCausalLM.from_pretrained(model_name, **kwargs)
- model = model.to(torch.float32)
- return model, tokenizer
-
-
-def parse_args():
- parser = argparse.ArgumentParser()
- parser.add_argument("--model-name", type=str, help="model name")
- parser.add_argument(
- "--output-path",
- type=str,
- help="where to save the checkpoint",
- )
- parser.add_argument(
- "--dataset-path",
- type=str,
- help="location of the calibration dataset",
- )
- parser.add_argument("--num-samples", type=int, default=10)
- parser.add_argument("--seq-len", type=int, default=512)
- args = parser.parse_args()
- return args
-
-
-@torch.no_grad()
-def main():
- args = parse_args()
- model_path = args.model_name
- dataset_path = args.dataset_path
- output_path = args.output_path
- num_samples = args.num_samples
- seq_len = args.seq_len
-
- model, tokenizer = build_model_and_tokenizer(model_path)
- if not os.path.exists(dataset_path):
- raise FileNotFoundError(f"Cannot find the dataset at {args.dataset_path}")
- dataset = load_dataset("json", data_files=dataset_path, split="train")
-
- model.quantized(tokenizer, dataset, num_samples=num_samples, seq_len=seq_len)
- model = model.cuda()
-
- model.save_quantized(output_path, model_basename="llama-7b")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/inference/client/locustfile.py b/examples/inference/client/locustfile.py
new file mode 100644
index 000000000000..a65c8b667263
--- /dev/null
+++ b/examples/inference/client/locustfile.py
@@ -0,0 +1,58 @@
+from locust import HttpUser, between, tag, task
+
+
+class QuickstartUser(HttpUser):
+ wait_time = between(1, 5)
+
+ @tag("online-generation")
+ @task(5)
+ def completion(self):
+ self.client.post("/completion", json={"prompt": "hello, who are you? ", "stream": "False"})
+
+ @tag("online-generation")
+ @task(5)
+ def completion_streaming(self):
+ self.client.post("/completion", json={"prompt": "hello, who are you? ", "stream": "True"})
+
+ @tag("online-chat")
+ @task(5)
+ def chat(self):
+ self.client.post(
+ "/chat",
+ json={
+ "converation": [
+ {"role": "system", "content": "you are a helpful assistant"},
+ {"role": "user", "content": "what is 1+1?"},
+ ],
+ "stream": "False",
+ },
+ )
+
+ @tag("online-chat")
+ @task(5)
+ def chat_streaming(self):
+ self.client.post(
+ "/chat",
+ json={
+ "converation": [
+ {"role": "system", "content": "you are a helpful assistant"},
+ {"role": "user", "content": "what is 1+1?"},
+ ],
+ "stream": "True",
+ },
+ )
+
+ @tag("offline-generation")
+ @task(5)
+ def generate_streaming(self):
+ self.client.post("/generate", json={"prompt": "Can you help me? ", "stream": "True"})
+
+ @tag("offline-generation")
+ @task(5)
+ def generate(self):
+ self.client.post("/generate", json={"prompt": "Can you help me? ", "stream": "False"})
+
+ @tag("online-generation", "offline-generation")
+ @task
+ def get_models(self):
+ self.client.get("/models")
diff --git a/examples/inference/client/run_locust.sh b/examples/inference/client/run_locust.sh
new file mode 100644
index 000000000000..fe742fda98be
--- /dev/null
+++ b/examples/inference/client/run_locust.sh
@@ -0,0 +1,27 @@
+#!/bin/bash
+
+#argument1: model_path
+
+# launch server
+model_path=${1:-"lmsys/vicuna-7b-v1.3"}
+chat_template="{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}"
+echo "Model Path: $model_path"
+echo "Starting server..."
+python -m colossalai.inference.server.api_server --model $model_path --chat-template $chat_template &
+SERVER_PID=$!
+
+# waiting time
+sleep 60
+
+# Run Locust
+echo "Starting Locust..."
+echo "The test will automatically begin, you can turn to http://0.0.0.0:8089 for more information."
+echo "Test completion api first"
+locust -f locustfile.py -t 300 --tags online-generation --host http://127.0.0.1:8000 --autostart --users 100 --stop-timeout 10
+echo "Test chat api"
+locust -f locustfile.py -t 300 --tags online-chat --host http://127.0.0.1:8000 --autostart --users 100 --stop-timeout 10
+# kill Server
+echo "Stopping server..."
+kill $SERVER_PID
+
+echo "Test and server shutdown completely"
diff --git a/examples/inference/client/test_ci.sh b/examples/inference/client/test_ci.sh
new file mode 100644
index 000000000000..b130fc486bfe
--- /dev/null
+++ b/examples/inference/client/test_ci.sh
@@ -0,0 +1,4 @@
+#!/bin/bash
+echo "Skip the test (this test is slow)"
+
+# bash ./run_benchmark.sh
diff --git a/examples/inference/llama/benchmark_llama.py b/examples/inference/llama/benchmark_llama.py
new file mode 100644
index 000000000000..2d24d87adfd1
--- /dev/null
+++ b/examples/inference/llama/benchmark_llama.py
@@ -0,0 +1,275 @@
+import argparse
+import time
+from contextlib import nullcontext
+
+import torch
+import torch.distributed as dist
+import transformers
+from transformers import AutoTokenizer, GenerationConfig
+from vllm import LLM, SamplingParams
+
+import colossalai
+from colossalai.accelerator import get_accelerator
+from colossalai.inference.config import InferenceConfig
+from colossalai.inference.core.engine import InferenceEngine
+from colossalai.testing import clear_cache_before_run, rerun_if_address_is_in_use, spawn
+
+GIGABYTE = 1024**3
+MEGABYTE = 1024 * 1024
+
+CONFIG_MAP = {
+ "toy": transformers.LlamaConfig(num_hidden_layers=4),
+ "llama-7b": transformers.LlamaConfig(
+ hidden_size=4096,
+ intermediate_size=11008,
+ num_attention_heads=32,
+ num_hidden_layers=32,
+ num_key_value_heads=32,
+ max_position_embeddings=2048,
+ ),
+ "llama-13b": transformers.LlamaConfig(
+ hidden_size=5120,
+ intermediate_size=13824,
+ num_attention_heads=40,
+ num_hidden_layers=40,
+ num_key_value_heads=40,
+ max_position_embeddings=2048,
+ ),
+ "llama2-7b": transformers.LlamaConfig(
+ hidden_size=4096,
+ intermediate_size=11008,
+ num_attention_heads=32,
+ num_hidden_layers=32,
+ num_key_value_heads=32,
+ max_position_embeddings=4096,
+ ),
+ "llama2-13b": transformers.LlamaConfig(
+ hidden_size=5120,
+ intermediate_size=13824,
+ num_attention_heads=40,
+ num_hidden_layers=40,
+ num_key_value_heads=40,
+ max_position_embeddings=4096,
+ ),
+ "llama3-8b": transformers.LlamaConfig(
+ hidden_size=4096,
+ intermediate_size=14336,
+ num_attention_heads=32,
+ num_hidden_layers=32,
+ num_key_value_heads=8,
+ max_position_embeddings=8192,
+ ),
+ "llama3-70b": transformers.LlamaConfig(
+ hidden_size=8192,
+ intermediate_size=28672,
+ num_attention_heads=64,
+ num_hidden_layers=80,
+ num_key_value_heads=8,
+ max_position_embeddings=8192,
+ ),
+}
+
+
+def data_gen(batch_size: int = 4, seq_len: int = 512):
+ input_ids = torch.randint(10, 30000, (batch_size, seq_len), device=get_accelerator().get_current_device())
+ return input_ids
+
+
+def print_details_info(model_config, args, whole_end2end, total_token_num):
+ msg: str = ""
+
+ if dist.get_rank() == 0:
+ msg += "-------Perf Summary-------\n"
+ whole_avg_latency = whole_end2end / (total_token_num)
+ num_layers = getattr(model_config, "num_layers", model_config.num_hidden_layers)
+ num_parameters = num_layers * model_config.hidden_size * model_config.hidden_size * 12
+ if args.dtype in ["fp16", "bf16"]:
+ num_bytes = 2
+ else:
+ num_bytes = 4
+
+ msg += f"Whole batch end2end time: {whole_end2end * 1000:.2f} ms\n"
+ msg += f"Whole batch per token latency: {whole_avg_latency * 1000:.2f} ms\n"
+ msg += f"Throughput: {total_token_num / whole_end2end:.2f} tokens/s\n"
+ msg += f"Flops: {num_parameters * num_bytes / whole_avg_latency / 1e12:.2f} TFLOPS\n"
+
+ if torch.cuda.is_available():
+ msg += f"-------Memory Summary Device:{get_accelerator().current_device()}-------\n"
+ msg += f"Max memory allocated: {get_accelerator().max_memory_allocated() / GIGABYTE:.2f} GB\n"
+ msg += f"Max memory reserved: {get_accelerator().max_memory_reserved() / GIGABYTE:.2f} GB\n"
+
+ print(msg)
+
+
+def benchmark_inference(args):
+ with torch.no_grad():
+ config = CONFIG_MAP[args.model]
+ config.pad_token_id = config.eos_token_id
+
+ if args.mode != "vllm":
+ if args.test_random_weight:
+ model = transformers.LlamaForCausalLM(config).cuda()
+ tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/llama-tokenizer")
+ else:
+ assert args.model_path, "When testing pretrained weights, the model path must be provided.'"
+ model = transformers.LlamaForCausalLM.from_pretrained(args.model_path).cuda()
+ tokenizer = AutoTokenizer.from_pretrained(args.model_path)
+
+ model = model.eval()
+
+ if args.dtype == "fp16":
+ model = model.half()
+ elif args.dtype == "bf16":
+ model = model.to(torch.bfloat16)
+
+ generation_config = GenerationConfig(
+ pad_token_id=tokenizer.pad_token_id,
+ max_length=args.seq_len + args.output_len,
+ # max_new_tokens=args.max_output_len,
+ )
+
+ if args.continous_batching:
+ mbsz = args.mbsz
+ else:
+ mbsz = args.batch_size
+ if args.mode == "colossalai":
+ inference_config = InferenceConfig(
+ dtype=args.dtype,
+ max_batch_size=mbsz,
+ max_input_len=args.seq_len,
+ max_output_len=args.output_len,
+ prefill_ratio=1.2,
+ block_size=32,
+ tp_size=args.tp_size,
+ use_cuda_kernel=True,
+ )
+ engine = InferenceEngine(model, tokenizer, inference_config, verbose=True)
+ elif args.mode == "vllm":
+ engine = LLM(
+ model=args.model_path,
+ tokenizer="hf-internal-testing/llama-tokenizer",
+ max_num_seqs=mbsz,
+ dtype="float16",
+ enforce_eager=True,
+ )
+
+ sampling_params = SamplingParams(
+ max_tokens=args.output_len,
+ )
+ else:
+ engine = model
+
+ data = data_gen(mbsz, args.seq_len)
+
+ if args.mode == "colossalai" or args.mode == "vllm":
+ data = data.tolist()
+
+ N_WARMUP_STEPS = 2
+
+ ctx = (
+ torch.profiler.profile(
+ record_shapes=True,
+ with_stack=True,
+ with_modules=True,
+ activities=[
+ torch.profiler.ProfilerActivity.CPU,
+ torch.profiler.ProfilerActivity.CUDA,
+ ],
+ schedule=torch.profiler.schedule(wait=0, warmup=N_WARMUP_STEPS, active=1),
+ on_trace_ready=torch.profiler.tensorboard_trace_handler(f"./tb_log_{args.batch_size}_" + args.mode),
+ )
+ if args.profile
+ else nullcontext()
+ )
+
+ with ctx:
+ for _ in range(N_WARMUP_STEPS):
+ if args.mode == "colossalai":
+ engine.generate(prompts_token_ids=data, generation_config=generation_config)
+ elif args.mode == "vllm":
+ engine.generate(prompt_token_ids=data, sampling_params=sampling_params)
+ else:
+ engine.generate(data, generation_config=generation_config)
+ if args.profile:
+ ctx.step()
+
+ if args.nsys:
+ torch.cuda.cudart().cudaProfilerStart()
+
+ torch.cuda.synchronize()
+
+ whole_end2end = time.perf_counter()
+
+ if args.mode == "colossalai":
+ for _ in range(args.batch_size // mbsz):
+ output, output_tokens_list = engine.generate(
+ prompts_token_ids=data, generation_config=generation_config, return_token_ids=True
+ )
+ elif args.mode == "vllm":
+ for _ in range(args.batch_size // mbsz):
+ output = engine.generate(prompt_token_ids=data, sampling_params=sampling_params)
+ else:
+ for _ in range(args.batch_size // mbsz):
+ output = engine.generate(data, generation_config=generation_config)
+
+ whole_end2end = time.perf_counter() - whole_end2end
+
+ if args.mode == "colossalai":
+ total_token_num = sum([len(output_tokens) for output_tokens in output_tokens_list])
+ elif args.mode == "vllm":
+ total_token_num = sum([len(out.outputs[0].token_ids) for out in output])
+ else:
+ total_token_num = sum([len(out) for out in output])
+
+ print("total_token_num: ", total_token_num)
+ if args.nsys:
+ torch.cuda.cudart().cudaProfilerStop()
+ if args.profile:
+ ctx.step()
+ print(f"config:batch_size {args.batch_size}, input_len{ args.seq_len}, output_len {args.output_len}")
+ print_details_info(config, args, whole_end2end, total_token_num)
+
+
+def hybrid_inference(rank, world_size, port, args):
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ benchmark_inference(args)
+
+
+@rerun_if_address_is_in_use()
+@clear_cache_before_run()
+def benchmark(args):
+ spawn(hybrid_inference, nprocs=args.tp_size, args=args)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "-m",
+ "--model",
+ default="toy",
+ help="the size of model",
+ choices=["toy", "llama-7b", "llama-13b", "llama2-7b", "llama2-13b", "llama3-8b", "llama3-70b"],
+ )
+ parser.add_argument("--model_path", type=str, default=None, help="The pretrained weights path")
+ parser.add_argument("-b", "--batch_size", type=int, default=8, help="batch size")
+ parser.add_argument("--mbsz", type=int, default=8, help="batch size for one step")
+ parser.add_argument("-s", "--seq_len", type=int, default=8, help="input sequence length")
+ parser.add_argument("--tp_size", type=int, default=1, help="Tensor Parallelism size")
+ parser.add_argument("--output_len", type=int, default=128, help="Output length")
+ parser.add_argument("--dtype", type=str, default="fp16", help="data type", choices=["fp16", "fp32", "bf16"])
+ parser.add_argument(
+ "--test_random_weight", default=False, action="store_true", help="whether to test random weight"
+ )
+ parser.add_argument("--profile", default=False, action="store_true", help="enable torch profiler")
+ parser.add_argument("--nsys", default=False, action="store_true", help="enable nsys profiler")
+ parser.add_argument(
+ "--mode",
+ default="colossalai",
+ choices=["colossalai", "transformers", "vllm"],
+ help="decide which inference framework to run",
+ )
+ parser.add_argument(
+ "-cb", "--continous_batching", default=False, action="store_true", help="enable continous batching"
+ )
+ args = parser.parse_args()
+ benchmark(args)
diff --git a/examples/inference/llama/benchmark_llama3.py b/examples/inference/llama/benchmark_llama3.py
new file mode 100644
index 000000000000..07ebdb2b1bfb
--- /dev/null
+++ b/examples/inference/llama/benchmark_llama3.py
@@ -0,0 +1,216 @@
+import argparse
+import time
+from contextlib import nullcontext
+
+import torch
+import transformers
+from transformers import AutoTokenizer, GenerationConfig
+
+import colossalai
+from colossalai.accelerator import get_accelerator
+from colossalai.cluster import DistCoordinator
+from colossalai.inference.config import InferenceConfig
+from colossalai.inference.core.engine import InferenceEngine
+from colossalai.testing import clear_cache_before_run, rerun_if_address_is_in_use, spawn
+
+GIGABYTE = 1024**3
+MEGABYTE = 1024**2
+N_WARMUP_STEPS = 2
+
+CONFIG_MAP = {
+ "toy": transformers.LlamaConfig(num_hidden_layers=4),
+ "llama-7b": transformers.LlamaConfig(
+ hidden_size=4096,
+ intermediate_size=11008,
+ num_attention_heads=32,
+ num_hidden_layers=32,
+ num_key_value_heads=32,
+ max_position_embeddings=2048,
+ ),
+ "llama-13b": transformers.LlamaConfig(
+ hidden_size=5120,
+ intermediate_size=13824,
+ num_attention_heads=40,
+ num_hidden_layers=40,
+ num_key_value_heads=40,
+ max_position_embeddings=2048,
+ ),
+ "llama2-7b": transformers.LlamaConfig(
+ hidden_size=4096,
+ intermediate_size=11008,
+ num_attention_heads=32,
+ num_hidden_layers=32,
+ num_key_value_heads=32,
+ max_position_embeddings=4096,
+ ),
+ "llama2-13b": transformers.LlamaConfig(
+ hidden_size=5120,
+ intermediate_size=13824,
+ num_attention_heads=40,
+ num_hidden_layers=40,
+ num_key_value_heads=40,
+ max_position_embeddings=4096,
+ ),
+ "llama3-8b": transformers.LlamaConfig(
+ hidden_size=4096,
+ intermediate_size=14336,
+ num_attention_heads=32,
+ num_hidden_layers=32,
+ num_key_value_heads=8,
+ max_position_embeddings=8192,
+ ),
+ "llama3-70b": transformers.LlamaConfig(
+ hidden_size=8192,
+ intermediate_size=28672,
+ num_attention_heads=64,
+ num_hidden_layers=80,
+ num_key_value_heads=8,
+ max_position_embeddings=8192,
+ ),
+}
+
+
+def data_gen(batch_size: int = 4, seq_len: int = 512):
+ input_ids = torch.randint(10, 30000, (batch_size, seq_len), device=get_accelerator().get_current_device())
+ return input_ids.tolist()
+
+
+def print_details_info(model_config, whole_end2end, total_token_num, dtype, coordinator=None):
+ if coordinator is None:
+ coordinator = DistCoordinator()
+ msg = "-------Perf Summary-------\n"
+ whole_avg_latency = whole_end2end / (total_token_num)
+ num_layers = getattr(model_config, "num_layers", model_config.num_hidden_layers)
+ num_parameters = num_layers * model_config.hidden_size * model_config.hidden_size * 12
+ if dtype in ["fp16", "bf16"]:
+ num_bytes = 2
+ elif dtype == "fp32":
+ num_bytes = 4
+ else:
+ raise ValueError(f"Unsupported dtype {dtype}")
+
+ msg += f"Whole batch end2end time: {whole_end2end * 1000:.2f} ms\n"
+ msg += f"Whole batch per token latency: {whole_avg_latency * 1000:.2f} ms\n"
+ msg += f"Throughput: {total_token_num / whole_end2end:.2f} tokens/s\n"
+ msg += f"Flops: {num_parameters * num_bytes / whole_avg_latency / 1e12:.2f} TFLOPS\n"
+ if torch.cuda.is_available():
+ msg += f"-------Memory Summary Device:{get_accelerator().current_device()}-------\n"
+ msg += f"Max memory allocated: {get_accelerator().max_memory_allocated() / GIGABYTE:.2f} GB\n"
+ msg += f"Max memory reserved: {get_accelerator().max_memory_reserved() / GIGABYTE:.2f} GB\n"
+
+ coordinator.print_on_master(msg)
+
+
+def benchmark_inference(args):
+ coordinator = DistCoordinator()
+
+ config = CONFIG_MAP[args.model]
+ config.pad_token_id = config.eos_token_id
+ if args.model_path is not None:
+ model = transformers.LlamaForCausalLM.from_pretrained(args.model_path)
+ tokenizer = AutoTokenizer.from_pretrained(args.model_path)
+ else:
+ # Random weights
+ model = transformers.LlamaForCausalLM(config)
+ tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/llama-tokenizer")
+ if args.dtype == "fp16":
+ model = model.half()
+ elif args.dtype == "bf16":
+ model = model.to(torch.bfloat16)
+
+ inference_config = InferenceConfig(
+ dtype=args.dtype,
+ max_batch_size=args.batch_size,
+ max_input_len=args.max_seq_len,
+ max_output_len=args.max_output_len,
+ prefill_ratio=1.2,
+ block_size=32,
+ tp_size=args.tp_size,
+ use_cuda_kernel=True,
+ )
+ engine = InferenceEngine(model, tokenizer, inference_config, verbose=True)
+
+ data = data_gen(args.batch_size, args.max_seq_len)
+ generation_config = GenerationConfig(
+ pad_token_id=tokenizer.pad_token_id,
+ max_length=args.max_seq_len + args.max_output_len,
+ # max_new_tokens=args.max_output_len,
+ )
+ coordinator.print_on_master(f"Generation Config: \n{generation_config.to_dict()}")
+
+ ctx = (
+ torch.profiler.profile(
+ record_shapes=True,
+ with_stack=True,
+ with_modules=True,
+ activities=[
+ torch.profiler.ProfilerActivity.CPU,
+ torch.profiler.ProfilerActivity.CUDA,
+ ],
+ schedule=torch.profiler.schedule(wait=0, warmup=N_WARMUP_STEPS, active=1),
+ on_trace_ready=torch.profiler.tensorboard_trace_handler(
+ f"./tb_log_{args.batch_size}_{args.max_seq_len}_{args.max_output_len}"
+ ),
+ )
+ if args.profile
+ else nullcontext()
+ )
+ with ctx:
+ for _ in range(N_WARMUP_STEPS):
+ engine.generate(prompts_token_ids=data, generation_config=generation_config)
+ if args.profile:
+ ctx.step()
+ if args.nsys:
+ torch.cuda.cudart().cudaProfilerStart()
+
+ torch.cuda.synchronize()
+ whole_end2end = time.perf_counter()
+ output, output_tokens_list = engine.generate(
+ prompts_token_ids=data, generation_config=generation_config, return_token_ids=True
+ )
+ torch.cuda.synchronize()
+ whole_end2end = time.perf_counter() - whole_end2end
+
+ total_token_num = sum([len(output_tokens) for output_tokens in output_tokens_list])
+ coordinator.print_on_master(f"total_token_num: {total_token_num}")
+ if args.nsys:
+ torch.cuda.cudart().cudaProfilerStop()
+ if args.profile:
+ ctx.step()
+
+ print_details_info(model.config, whole_end2end, total_token_num, args.dtype, coordinator=coordinator)
+
+
+def inference(rank, world_size, port, args):
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ benchmark_inference(args)
+
+
+@rerun_if_address_is_in_use()
+@clear_cache_before_run()
+def benchmark(args):
+ spawn(inference, nprocs=args.tp_size, args=args)
+
+
+# python benchmark_llama3.py -m llama3-8b -b 16 -s 256 -o 256
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "-m",
+ "--model",
+ default="llama3-8b",
+ help="The version of Llama model",
+ choices=["toy", "llama-7b", "llama-13b", "llama2-7b", "llama2-13b", "llama3-8b", "llama3-70b"],
+ )
+ parser.add_argument("-p", "--model_path", type=str, default=None, help="The pretrained weights path")
+ parser.add_argument("-b", "--batch_size", type=int, default=8, help="batch size")
+ parser.add_argument("-s", "--max_seq_len", type=int, default=8, help="input sequence length")
+ parser.add_argument("-o", "--max_output_len", type=int, default=128, help="Output length")
+ parser.add_argument("-t", "--tp_size", type=int, default=1, help="Tensor Parallelism size")
+ parser.add_argument("-d", "--dtype", type=str, default="fp16", help="Data type", choices=["fp16", "fp32", "bf16"])
+ parser.add_argument("--profile", default=False, action="store_true", help="enable torch profiler")
+ parser.add_argument("--nsys", default=False, action="store_true", help="enable nsys profiler")
+
+ args = parser.parse_args()
+
+ benchmark(args)
diff --git a/examples/inference/llama/llama_generation.py b/examples/inference/llama/llama_generation.py
new file mode 100644
index 000000000000..5a373dccdbd0
--- /dev/null
+++ b/examples/inference/llama/llama_generation.py
@@ -0,0 +1,81 @@
+import argparse
+
+from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
+
+import colossalai
+from colossalai.cluster import DistCoordinator
+from colossalai.inference.config import InferenceConfig
+from colossalai.inference.core.engine import InferenceEngine
+from colossalai.inference.modeling.policy.nopadding_llama import NoPaddingLlamaModelInferPolicy
+
+# For Llama 3, we'll use the following configuration
+MODEL_CLS = AutoModelForCausalLM
+POLICY_CLS = NoPaddingLlamaModelInferPolicy
+
+
+def infer(args):
+ # ==============================
+ # Launch colossalai, setup distributed environment
+ # ==============================
+ colossalai.launch_from_torch()
+ coordinator = DistCoordinator()
+
+ # ==============================
+ # Load model and tokenizer
+ # ==============================
+ model_path_or_name = args.model
+ model = MODEL_CLS.from_pretrained(model_path_or_name)
+ tokenizer = AutoTokenizer.from_pretrained(model_path_or_name)
+ tokenizer.pad_token = tokenizer.eos_token
+ coordinator.print_on_master(f"Model Config:\n{model.config}")
+
+ # ==============================
+ # Initialize InferenceEngine
+ # ==============================
+ inference_config = InferenceConfig(
+ dtype=args.dtype,
+ max_batch_size=args.max_batch_size,
+ max_input_len=args.max_input_len,
+ max_output_len=args.max_output_len,
+ prefill_ratio=1.2,
+ block_size=16,
+ tp_size=args.tp_size,
+ use_cuda_kernel=args.use_cuda_kernel,
+ )
+ coordinator.print_on_master(f"Initializing Inference Engine...")
+ engine = InferenceEngine(model, tokenizer, inference_config, model_policy=POLICY_CLS(), verbose=True)
+
+ # ==============================
+ # Generation
+ # ==============================
+ generation_config = GenerationConfig(
+ pad_token_id=tokenizer.eos_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ max_length=args.max_length,
+ do_sample=True,
+ )
+ coordinator.print_on_master(f"Generating...")
+ out = engine.generate(prompts=[args.prompt], generation_config=generation_config)
+ coordinator.print_on_master(out[0])
+
+
+# colossalai run --nproc_per_node 1 llama_generation.py -m MODEL_PATH
+if __name__ == "__main__":
+ # ==============================
+ # Parse Arguments
+ # ==============================
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-m", "--model", type=str, help="Path to the model or model name")
+ parser.add_argument(
+ "-p", "--prompt", type=str, default="Introduce some landmarks in the United Kingdom, such as", help="Prompt"
+ )
+ parser.add_argument("-b", "--max_batch_size", type=int, default=1, help="Max batch size")
+ parser.add_argument("-i", "--max_input_len", type=int, default=128, help="Max input length")
+ parser.add_argument("-o", "--max_output_len", type=int, default=128, help="Max output length")
+ parser.add_argument("-t", "--tp_size", type=int, default=1, help="Tensor Parallelism size")
+ parser.add_argument("-d", "--dtype", type=str, default="fp16", help="Data type", choices=["fp16", "fp32", "bf16"])
+ parser.add_argument("--use_cuda_kernel", action="store_true", help="Use CUDA kernel, use Triton by default")
+ parser.add_argument("--max_length", type=int, default=32, help="Max length for generation")
+ args = parser.parse_args()
+
+ infer(args)
diff --git a/examples/inference/llama/run_benchmark.sh b/examples/inference/llama/run_benchmark.sh
new file mode 100755
index 000000000000..1927159765ba
--- /dev/null
+++ b/examples/inference/llama/run_benchmark.sh
@@ -0,0 +1,33 @@
+ROOT=$(realpath $(dirname $0))
+echo $ROOT
+PY_SCRIPT=${ROOT}/benchmark_llama.py
+GPU=$(nvidia-smi -L | head -1 | cut -d' ' -f4 | cut -d'-' -f1)
+mode=$1
+
+mkdir -p logs
+
+CUDA_VISIBLE_DEVICES_set_n_least_memory_usage() {
+ local n=${1:-"9999"}
+ echo "GPU Memory Usage:"
+ local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
+ | tail -n +2 \
+ | nl -v 0 \
+ | tee /dev/tty \
+ | sort -g -k 2 \
+ | awk '{print $1}' \
+ | head -n $n)
+ export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
+ echo "Now CUDA_VISIBLE_DEVICES is set to:"
+ echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
+}
+
+CUDA_VISIBLE_DEVICES_set_n_least_memory_usage 1
+
+# benchmark llama2-7b one single GPU
+for input_len in 128 512 1024; do
+ for output_len in 128 256; do
+ for bsz in 16 32 64; do
+ python3 ${PY_SCRIPT} -m llama2-7b --tp_size 1 -b ${bsz} -s ${input_len} --output_len ${output_len} --mode ${mode} --test_random_weight | tee logs/${bsz}_${input_len}_${output_len}_${mode}_${GPU}.txt
+ done
+ done
+done
diff --git a/examples/inference/llama/test_ci.sh b/examples/inference/llama/test_ci.sh
new file mode 100644
index 000000000000..b130fc486bfe
--- /dev/null
+++ b/examples/inference/llama/test_ci.sh
@@ -0,0 +1,4 @@
+#!/bin/bash
+echo "Skip the test (this test is slow)"
+
+# bash ./run_benchmark.sh
diff --git a/examples/inference/run_benchmark.sh b/examples/inference/run_benchmark.sh
deleted file mode 100755
index 394222ea62b8..000000000000
--- a/examples/inference/run_benchmark.sh
+++ /dev/null
@@ -1,15 +0,0 @@
-ROOT=$(realpath $(dirname $0))
-PY_SCRIPT=${ROOT}/benchmark_llama.py
-GPU=$(nvidia-smi -L | head -1 | cut -d' ' -f4 | cut -d'-' -f1)
-
-mkdir -p logs
-
-# benchmark llama2-7b one single GPU
-for bsz in 16 32 64; do
- python3 ${PY_SCRIPT} -m llama2-7b --tp_size 1 --pp_size 1 -b $bsz -s 256 --output_len 128 | tee logs/${GPU}_${bsz}_256.txt
-done
-
-
-for bsz in 4 8 16 32 64; do
- python3 ${PY_SCRIPT} -m llama2-7b --tp_size 1 --pp_size 1 -b $bsz -s 1024 --output_len 128 | tee logs/${GPU}_${bsz}_1024.txt
-done
diff --git a/examples/inference/run_llama_inference.py b/examples/inference/run_llama_inference.py
deleted file mode 100644
index a4e6fd0a143d..000000000000
--- a/examples/inference/run_llama_inference.py
+++ /dev/null
@@ -1,98 +0,0 @@
-import argparse
-
-import torch
-import torch.distributed as dist
-from transformers import LlamaForCausalLM, LlamaTokenizer
-
-import colossalai
-from colossalai.accelerator import get_accelerator
-from colossalai.inference import InferenceEngine
-from colossalai.testing import spawn
-
-INPUT_TEXTS = [
- "What is the longest river in the world?",
- "Explain the difference between process and thread in compouter science.",
-]
-
-
-def run_inference(args):
- llama_model_path = args.model_path
- llama_tokenize_path = args.tokenizer_path or args.model_path
-
- max_input_len = args.max_input_len
- max_output_len = args.max_output_len
- max_batch_size = args.batch_size
- micro_batch_size = args.micro_batch_size
- tp_size = args.tp_size
- pp_size = args.pp_size
- rank = dist.get_rank()
-
- tokenizer = LlamaTokenizer.from_pretrained(llama_tokenize_path, padding_side="left")
- tokenizer.pad_token_id = tokenizer.eos_token_id
-
- if args.quant is None:
- model = LlamaForCausalLM.from_pretrained(llama_model_path, pad_token_id=tokenizer.pad_token_id)
- elif args.quant == "gptq":
- from auto_gptq import AutoGPTQForCausalLM
-
- model = AutoGPTQForCausalLM.from_quantized(
- llama_model_path, inject_fused_attention=False, device=torch.cuda.current_device()
- )
- elif args.quant == "smoothquant":
- from colossalai.inference.quant.smoothquant.models.llama import SmoothLlamaForCausalLM
-
- model = SmoothLlamaForCausalLM.from_quantized(llama_model_path, model_basename=args.smoothquant_base_name)
- model = model.cuda()
-
- engine = InferenceEngine(
- tp_size=tp_size,
- pp_size=pp_size,
- model=model,
- max_input_len=max_input_len,
- max_output_len=max_output_len,
- max_batch_size=max_batch_size,
- micro_batch_size=micro_batch_size,
- quant=args.quant,
- dtype=args.dtype,
- )
-
- inputs = tokenizer(INPUT_TEXTS, return_tensors="pt", padding="longest", max_length=max_input_len, truncation=True)
- inputs = {k: v.to(get_accelerator().get_current_device()) for k, v in inputs.items()}
- outputs = engine.generate(inputs)
-
- if rank == 0:
- output_texts = tokenizer.batch_decode(outputs, skip_special_tokens=True)
- for input_text, output_text in zip(INPUT_TEXTS, output_texts):
- print(f"Input: {input_text}")
- print(f"Output: {output_text}")
-
-
-def run_tp_pipeline_inference(rank, world_size, port, args):
- colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
- run_inference(args)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("-p", "--model_path", type=str, help="Model path", required=True)
- parser.add_argument("-i", "--input", default="What is the longest river in the world?")
- parser.add_argument("-t", "--tokenizer_path", type=str, help="Tokenizer path", default=None)
- parser.add_argument(
- "-q",
- "--quant",
- type=str,
- choices=["gptq", "smoothquant"],
- default=None,
- help="quantization type: 'gptq' or 'smoothquant'",
- )
- parser.add_argument("--smoothquant_base_name", type=str, default=None, help="soothquant base name")
- parser.add_argument("--tp_size", type=int, default=1, help="Tensor parallel size")
- parser.add_argument("--pp_size", type=int, default=1, help="Pipeline parallel size")
- parser.add_argument("-b", "--batch_size", type=int, default=4, help="Maximum batch size")
- parser.add_argument("--max_input_len", type=int, default=2048, help="Maximum input length")
- parser.add_argument("--max_output_len", type=int, default=64, help="Maximum output length")
- parser.add_argument("--micro_batch_size", type=int, default=1, help="Micro batch size")
- parser.add_argument("--dtype", default="fp16", type=str)
-
- args = parser.parse_args()
- spawn(run_tp_pipeline_inference, nprocs=args.tp_size * args.pp_size, args=args)
diff --git a/examples/language/openmoe/model/modeling_openmoe.py b/examples/language/openmoe/model/modeling_openmoe.py
index fdd8442f506b..5a9e30dd4542 100644
--- a/examples/language/openmoe/model/modeling_openmoe.py
+++ b/examples/language/openmoe/model/modeling_openmoe.py
@@ -35,7 +35,20 @@
replace_return_docstrings,
)
-from colossalai.kernel.extensions.flash_attention import HAS_FLASH_ATTN
+try:
+ # TODO: remove this after updating openmoe example
+ # NOTE(yuanheng-zhao): This is a temporary fix for the issue that
+ # the flash_attention module is not imported correctly for different CI tests.
+ # We replace the import path `colossalai.kernel.extensions.flash_attention`
+ # because in the current example test, colossalai version <= 0.3.6 is installed,
+ # where `colossalai.kernel.extensions.flash_attention` is still valid;
+ # however in unit test `test_moe_checkpoint`, the lastest version of colossalai is installed,
+ # where extension has been refactored and the path is not valid.
+ import flash_attention # noqa
+
+ HAS_FLASH_ATTN = True
+except:
+ HAS_FLASH_ATTN = False
from colossalai.kernel.triton.llama_act_combine_kernel import HAS_TRITON
from colossalai.moe.layers import SparseMLP
from colossalai.moe.manager import MOE_MANAGER
diff --git a/extensions/__init__.py b/extensions/__init__.py
index 0dbadba81905..c392a16b5a61 100644
--- a/extensions/__init__.py
+++ b/extensions/__init__.py
@@ -1,9 +1,14 @@
-from .cpu_adam import CpuAdamArmExtension, CpuAdamX86Extension
-from .flash_attention import FlashAttentionDaoCudaExtension, FlashAttentionNpuExtension, FlashAttentionSdpaCudaExtension
-from .layernorm import LayerNormCudaExtension
-from .moe import MoeCudaExtension
-from .optimizer import FusedOptimizerCudaExtension
-from .softmax import ScaledMaskedSoftmaxCudaExtension, ScaledUpperTriangleMaskedSoftmaxCudaExtension
+from .pybind.cpu_adam import CpuAdamArmExtension, CpuAdamX86Extension
+from .pybind.flash_attention import (
+ FlashAttentionDaoCudaExtension,
+ FlashAttentionNpuExtension,
+ FlashAttentionSdpaCudaExtension,
+)
+from .pybind.inference import InferenceOpsCudaExtension
+from .pybind.layernorm import LayerNormCudaExtension
+from .pybind.moe import MoeCudaExtension
+from .pybind.optimizer import FusedOptimizerCudaExtension
+from .pybind.softmax import ScaledMaskedSoftmaxCudaExtension, ScaledUpperTriangleMaskedSoftmaxCudaExtension
ALL_EXTENSIONS = [
CpuAdamArmExtension,
@@ -11,6 +16,7 @@
LayerNormCudaExtension,
MoeCudaExtension,
FusedOptimizerCudaExtension,
+ InferenceOpsCudaExtension,
ScaledMaskedSoftmaxCudaExtension,
ScaledUpperTriangleMaskedSoftmaxCudaExtension,
FlashAttentionDaoCudaExtension,
@@ -24,6 +30,7 @@
"LayerNormCudaExtension",
"MoeCudaExtension",
"FusedOptimizerCudaExtension",
+ "InferenceOpsCudaExtension",
"ScaledMaskedSoftmaxCudaExtension",
"ScaledUpperTriangleMaskedSoftmaxCudaExtension",
"FlashAttentionDaoCudaExtension",
diff --git a/extensions/cpp_extension.py b/extensions/cpp_extension.py
index 3adb65fb8f4e..aaa43f964c25 100644
--- a/extensions/cpp_extension.py
+++ b/extensions/cpp_extension.py
@@ -25,6 +25,9 @@ def __init__(self, name: str, priority: int = 1):
def csrc_abs_path(self, path):
return os.path.join(self.relative_to_abs_path("csrc"), path)
+ def pybind_abs_path(self, path):
+ return os.path.join(self.relative_to_abs_path("pybind"), path)
+
def relative_to_abs_path(self, code_path: str) -> str:
"""
This function takes in a path relative to the colossalai root directory and return the absolute path.
@@ -116,6 +119,7 @@ def include_dirs(self) -> List[str]:
"""
This function should return a list of include files for extensions.
"""
+ return [self.csrc_abs_path("")]
@abstractmethod
def cxx_flags(self) -> List[str]:
diff --git a/extensions/csrc/__init__.py b/extensions/csrc/__init__.py
index 0eac28d23e24..e69de29bb2d1 100644
--- a/extensions/csrc/__init__.py
+++ b/extensions/csrc/__init__.py
@@ -1,11 +0,0 @@
-from .layer_norm import MixedFusedLayerNorm as LayerNorm
-from .multihead_attention import MultiHeadAttention
-from .scaled_softmax import AttnMaskType, FusedScaleMaskSoftmax, ScaledUpperTriangMaskedSoftmax
-
-__all__ = [
- "LayerNorm",
- "MultiHeadAttention",
- "FusedScaleMaskSoftmax",
- "ScaledUpperTriangMaskedSoftmax",
- "AttnMaskType",
-]
diff --git a/extensions/csrc/common/data_type.h b/extensions/csrc/common/data_type.h
new file mode 100644
index 000000000000..7cc7cfabbdaf
--- /dev/null
+++ b/extensions/csrc/common/data_type.h
@@ -0,0 +1,53 @@
+#pragma once
+
+#if defined(COLOSSAL_WITH_CUDA)
+#include
+#include
+#endif
+
+namespace colossalAI {
+namespace dtype {
+
+struct bfloat164 {
+#ifdef COLOSSAL_WITH_CUDA
+ __nv_bfloat162 x;
+ __nv_bfloat162 y;
+#endif
+};
+
+struct bfloat168 {
+#ifdef COLOSSAL_WITH_CUDA
+ __nv_bfloat162 x;
+ __nv_bfloat162 y;
+ __nv_bfloat162 z;
+ __nv_bfloat162 w;
+#endif
+};
+
+struct half4 {
+#ifdef COLOSSAL_WITH_CUDA
+ half2 x;
+ half2 y;
+#endif
+};
+
+struct half8 {
+#ifdef COLOSSAL_WITH_CUDA
+ half2 x;
+ half2 y;
+ half2 z;
+ half2 w;
+#endif
+};
+
+struct float8 {
+#ifdef COLOSSAL_WITH_CUDA
+ float2 x;
+ float2 y;
+ float2 z;
+ float2 w;
+#endif
+};
+
+} // namespace dtype
+} // namespace colossalAI
diff --git a/extensions/csrc/cuda/type_shim.h b/extensions/csrc/common/micros.h
similarity index 85%
rename from extensions/csrc/cuda/type_shim.h
rename to extensions/csrc/common/micros.h
index 03ccc02635fa..cf7d0ce35c1f 100644
--- a/extensions/csrc/cuda/type_shim.h
+++ b/extensions/csrc/common/micros.h
@@ -4,9 +4,10 @@
This file is adapted from fused adam in NVIDIA/apex, commit a109f85
Licensed under the MIT License.
*/
-#include
-#include "compat.h"
+#pragma once
+
+#include
#define DISPATCH_HALF_AND_BFLOAT(TYPE, NAME, ...) \
switch (TYPE) { \
@@ -24,6 +25,37 @@
AT_ERROR(#NAME, " not implemented for '", toString(TYPE), "'"); \
}
+#define DISPATCH_FLOAT_HALF_AND_BFLOAT(TYPE, NAME, ...) \
+ switch (TYPE) { \
+ case at::ScalarType::Float: { \
+ using scalar_t = float; \
+ __VA_ARGS__; \
+ break; \
+ } \
+ case at::ScalarType::Half: { \
+ using scalar_t = at::Half; \
+ __VA_ARGS__; \
+ break; \
+ } \
+ case at::ScalarType::BFloat16: { \
+ using scalar_t = at::BFloat16; \
+ __VA_ARGS__; \
+ break; \
+ } \
+ default: \
+ AT_ERROR(#NAME, " not implemented for '", toString(TYPE), "'"); \
+ }
+
+#define DISPATCH_FLOAT_HALF_AND_BFLOAT_WITH_HIGH_PRECISION(HIGH_PRECISION, \
+ TYPE, NAME, ...) \
+ if (HIGH_PRECISION) { \
+ const bool high_precision = true; \
+ DISPATCH_FLOAT_HALF_AND_BFLOAT(TYPE, NAME, __VA_ARGS__); \
+ } else { \
+ const bool high_precision = false; \
+ DISPATCH_FLOAT_HALF_AND_BFLOAT(TYPE, NAME, __VA_ARGS__); \
+ }
+
#define DISPATCH_FLOAT_HALF_AND_BFLOAT_INOUT_TYPES(TYPEIN, TYPEOUT, NAME, ...) \
switch (TYPEIN) { \
case at::ScalarType::Float: { \
@@ -191,89 +223,12 @@
"'"); \
}
-template
-__device__ __forceinline__ T reduce_block_into_lanes(
- T *x, T val, int lanes = 1,
- bool share_result = false) // lanes is intended to be <= 32.
-{
- int tid = threadIdx.x + threadIdx.y * blockDim.x;
- int blockSize =
- blockDim.x * blockDim.y; // blockSize is intended to be a multiple of 32.
-
- if (blockSize >= 64) {
- x[tid] = val;
- __syncthreads();
- }
-
-#pragma unroll
- for (int i = (blockSize >> 1); i >= 64; i >>= 1) {
- if (tid < i) x[tid] = x[tid] + x[tid + i];
- __syncthreads();
- }
-
- T final;
-
- if (tid < 32) {
- if (blockSize >= 64)
- final = x[tid] + x[tid + 32];
- else
- final = val;
- // __SYNCWARP();
-
-#pragma unroll
- for (int i = 16; i >= lanes; i >>= 1)
- final = final + __shfl_down_sync(0xffffffff, final, i);
- }
-
- if (share_result) {
- if (tid < lanes) x[tid] = final; // EpilogueOp
- // Make sure the smem result is visible to all warps.
- __syncthreads();
- }
-
- return final;
-}
-
-template
-__device__ __forceinline__ T reduce_block_into_lanes_max_op(
- T *x, T val, int lanes = 1,
- bool share_result = false) // lanes is intended to be <= 32.
-{
- int tid = threadIdx.x + threadIdx.y * blockDim.x;
- int blockSize =
- blockDim.x * blockDim.y; // blockSize is intended to be a multiple of 32.
-
- if (blockSize >= 64) {
- x[tid] = val;
- __syncthreads();
- }
-
-#pragma unroll
- for (int i = (blockSize >> 1); i >= 64; i >>= 1) {
- if (tid < i) x[tid] = fmaxf(fabsf(x[tid]), fabsf(x[tid + i]));
- __syncthreads();
- }
-
- T final;
-
- if (tid < 32) {
- if (blockSize >= 64)
- final = fmaxf(fabsf(x[tid]), fabsf(x[tid + 32]));
- else
- final = val;
- // __SYNCWARP();
-
-#pragma unroll
- for (int i = 16; i >= lanes; i >>= 1)
- final =
- fmaxf(fabsf(final), fabsf(__shfl_down_sync(0xffffffff, final, i)));
- }
-
- if (share_result) {
- if (tid < lanes) x[tid] = final; // EpilogueOp
- // Make sure the smem result is visible to all warps.
- __syncthreads();
- }
-
- return final;
-}
+#if defined(COLOSSAL_WITH_CUDA)
+#define HOST __host__
+#define DEVICE __device__
+#define HOSTDEVICE __host__ __device__
+#else
+#define HOST
+#define DEVICE
+#define HOSTDEVICE
+#endif
diff --git a/extensions/csrc/common/mp_type_traits.h b/extensions/csrc/common/mp_type_traits.h
new file mode 100644
index 000000000000..7a27f26507a5
--- /dev/null
+++ b/extensions/csrc/common/mp_type_traits.h
@@ -0,0 +1,55 @@
+#pragma once
+
+#include
+
+#include "micros.h"
+
+#if defined(COLOSSAL_WITH_CUDA)
+#include
+#include
+#endif
+
+namespace colossalAI {
+namespace common {
+
+template
+struct MPTypeTrait {
+ using Type = float;
+};
+
+template <>
+struct MPTypeTrait {
+ using Type = float;
+};
+
+template <>
+struct MPTypeTrait {
+ using Type = float;
+};
+
+template <>
+struct MPTypeTrait {
+ using Type = float;
+};
+
+#if defined(COLOSSAL_WITH_CUDA)
+template <>
+struct MPTypeTrait {
+ using Type = float;
+};
+
+template <>
+struct MPTypeTrait<__nv_bfloat16> {
+ using Type = float;
+};
+#endif
+
+template
+struct ScalarTypeTrait {
+ using Type =
+ typename std::conditional::Type,
+ T>::type;
+};
+
+} // namespace common
+} // namespace colossalAI
diff --git a/extensions/csrc/common/target.h b/extensions/csrc/common/target.h
new file mode 100644
index 000000000000..ee3072f62d71
--- /dev/null
+++ b/extensions/csrc/common/target.h
@@ -0,0 +1,134 @@
+#pragma once
+
+#include
+#include
+#include
+
+namespace colossalAI {
+namespace common {
+
+class Target {
+ public:
+ enum class OS : int {
+ Unk = -1,
+ Linux,
+ Windows,
+ };
+ enum class Arch : int {
+ Unk = -1,
+ X86,
+ Arm,
+ NVGPU,
+ AMDGPU,
+ Ascend,
+ };
+ enum class BitLen : int {
+ Unk = -1,
+ k32,
+ k64,
+ };
+
+ explicit Target(OS os, Arch arch, BitLen bitlen)
+ : os_(os), arch_(arch), bitlen_(bitlen) {}
+
+ bool defined() const {
+ return (os_ != OS::Unk) && (arch_ != Arch::Unk) && (bitlen_ != BitLen::Unk);
+ }
+
+ std::string str() const {
+ std::string s{"OS: "};
+ switch (os_) {
+ case OS::Unk:
+ s += "Unk";
+ break;
+ case OS::Linux:
+ s += "Linux";
+ break;
+ case OS::Windows:
+ s += "Windows";
+ break;
+ default:
+ throw std::invalid_argument("Invalid OS type!");
+ }
+ s += "\t";
+ s += "Arch: ";
+
+ switch (arch_) {
+ case Arch::Unk:
+ s += "Unk";
+ break;
+ case Arch::X86:
+ s += "X86";
+ break;
+ case Arch::Arm:
+ s += "Arm";
+ break;
+ case Arch::NVGPU:
+ s += "NVGPU";
+ break;
+ case Arch::AMDGPU:
+ s += "AMDGPU";
+ break;
+ case Arch::Ascend:
+ s += "Ascend";
+ break;
+ default:
+ throw std::invalid_argument("Invalid Arch type!");
+ }
+ s += "\t";
+ s += "BitLen: ";
+
+ switch (bitlen_) {
+ case BitLen::Unk:
+ s += "Unk";
+ break;
+ case BitLen::k32:
+ s += "k32";
+ break;
+ case BitLen::k64:
+ s += "k64";
+ break;
+ default:
+ throw std::invalid_argument("Invalid target bit length!");
+ }
+
+ return s;
+ }
+
+ OS os() const { return os_; }
+ Arch arch() const { return arch_; }
+ BitLen bitlen() const { return bitlen_; }
+
+ static Target DefaultX86Target();
+ static Target DefaultArmTarget();
+ static Target DefaultRocmTarget();
+ static Target DefaultAscendTarget();
+
+ static Target DefaultCUDATarget() {
+ return Target(OS::Linux, Arch::NVGPU, BitLen::k64);
+ }
+
+ friend std::ostream& operator<<(std::ostream& os, const Target& target);
+ friend bool operator==(const Target& lhs, const Target& rhs);
+ friend bool operator!=(const Target& lhs, const Target& rhs);
+
+ private:
+ OS os_{OS::Unk};
+ Arch arch_{Arch::Unk};
+ BitLen bitlen_{BitLen::Unk};
+};
+
+std::ostream& operator<<(std::ostream& os, const Target& target) {
+ std::cout << target.str() << std::endl;
+}
+bool operator==(const Target& lhs, const Target& rhs) {
+ return (lhs.os_ == rhs.os_) && (lhs.arch_ == rhs.arch_) &&
+ (lhs.bitlen_ == rhs.bitlen_);
+}
+bool operator!=(const Target& lhs, const Target& rhs) {
+ return (lhs.os_ != rhs.os_) && (lhs.arch_ != rhs.arch_) &&
+ (lhs.bitlen_ != rhs.bitlen_);
+}
+
+} // namespace common
+} // namespace colossalAI
diff --git a/extensions/csrc/common/vec_type_traits.h b/extensions/csrc/common/vec_type_traits.h
new file mode 100644
index 000000000000..9e12ab71b86c
--- /dev/null
+++ b/extensions/csrc/common/vec_type_traits.h
@@ -0,0 +1,76 @@
+#pragma once
+
+#if defined(COLOSSAL_WITH_CUDA)
+#include
+#include
+#endif
+
+#include
+#include
+
+#include "common/data_type.h"
+
+namespace colossalAI {
+namespace common {
+
+template
+struct VecTypeTrait {};
+
+template
+struct FloatVecTypeTrait {};
+
+#define VEC_TYPE_TRAITS_SPECIALIZATION(T, VEC_SIZE, VECT, ARGS...) \
+ template \
+ struct VecTypeTrait { \
+ using Type = VECT; \
+ };
+
+VEC_TYPE_TRAITS_SPECIALIZATION(T, 1, T, typename T)
+
+#if defined(COLOSSAL_WITH_CUDA)
+
+VEC_TYPE_TRAITS_SPECIALIZATION(at::BFloat16, 1, __nv_bfloat16)
+VEC_TYPE_TRAITS_SPECIALIZATION(at::BFloat16, 2, __nv_bfloat162)
+VEC_TYPE_TRAITS_SPECIALIZATION(at::BFloat16, 4, float2)
+VEC_TYPE_TRAITS_SPECIALIZATION(at::BFloat16, 8, float4)
+VEC_TYPE_TRAITS_SPECIALIZATION(at::Half, 1, half)
+VEC_TYPE_TRAITS_SPECIALIZATION(at::Half, 2, half2)
+VEC_TYPE_TRAITS_SPECIALIZATION(at::Half, 4, float2)
+VEC_TYPE_TRAITS_SPECIALIZATION(at::Half, 8, float4)
+
+VEC_TYPE_TRAITS_SPECIALIZATION(uint8_t, 2, uint16_t)
+VEC_TYPE_TRAITS_SPECIALIZATION(uint8_t, 4, uint32_t)
+VEC_TYPE_TRAITS_SPECIALIZATION(uint8_t, 8, uint2)
+VEC_TYPE_TRAITS_SPECIALIZATION(__nv_bfloat16, 2, __nv_bfloat162);
+VEC_TYPE_TRAITS_SPECIALIZATION(__nv_bfloat16, 4, dtype::bfloat164);
+VEC_TYPE_TRAITS_SPECIALIZATION(__nv_bfloat16, 8, dtype::bfloat168);
+VEC_TYPE_TRAITS_SPECIALIZATION(half, 2, half2);
+VEC_TYPE_TRAITS_SPECIALIZATION(half, 4, dtype::half4);
+VEC_TYPE_TRAITS_SPECIALIZATION(half, 8, dtype::half8);
+VEC_TYPE_TRAITS_SPECIALIZATION(float, 2, float2)
+VEC_TYPE_TRAITS_SPECIALIZATION(float, 4, float4)
+VEC_TYPE_TRAITS_SPECIALIZATION(float, 8, dtype::float8)
+#endif /* defined(COLOSSAL_WITH_CUDA) */
+
+#undef VEC_TYPE_TRAITS_SPECIALIZATION
+
+#define FLOATVEC_TYPE_TRAITS_SPECIALIZATION(T, FLOATT, ARGS...) \
+ template \
+ struct FloatVecTypeTrait { \
+ using Type = FLOATT; \
+ };
+
+#if defined(COLOSSAL_WITH_CUDA)
+FLOATVEC_TYPE_TRAITS_SPECIALIZATION(float2, float2)
+FLOATVEC_TYPE_TRAITS_SPECIALIZATION(float4, float4)
+FLOATVEC_TYPE_TRAITS_SPECIALIZATION(__nv_bfloat162, float2);
+FLOATVEC_TYPE_TRAITS_SPECIALIZATION(dtype::bfloat164, float4);
+FLOATVEC_TYPE_TRAITS_SPECIALIZATION(dtype::bfloat168, dtype::float8);
+FLOATVEC_TYPE_TRAITS_SPECIALIZATION(half2, float2);
+FLOATVEC_TYPE_TRAITS_SPECIALIZATION(dtype::half4, float4);
+FLOATVEC_TYPE_TRAITS_SPECIALIZATION(dtype::half8, dtype::float8);
+#endif /* COLOSSAL_WITH_CUDA */
+
+#undef FLOATVEC_TYPE_TRAITS_SPECIALIZATION
+} // namespace common
+} // namespace colossalAI
diff --git a/extensions/csrc/cuda/compat.h b/extensions/csrc/cuda/compat.h
deleted file mode 100644
index a62beef91a8a..000000000000
--- a/extensions/csrc/cuda/compat.h
+++ /dev/null
@@ -1,10 +0,0 @@
-// modified from https://github.com/NVIDIA/apex/blob/master/csrc/compat.h
-#ifndef TORCH_CHECK
-#define TORCH_CHECK AT_CHECK
-#endif
-
-#ifdef VERSION_GE_1_3
-#define DATA_PTR data_ptr
-#else
-#define DATA_PTR data
-#endif
diff --git a/extensions/csrc/cuda/include/block_reduce.h b/extensions/csrc/cuda/include/block_reduce.h
deleted file mode 100644
index 38103c1734c8..000000000000
--- a/extensions/csrc/cuda/include/block_reduce.h
+++ /dev/null
@@ -1,312 +0,0 @@
-/* Copyright 2021 The LightSeq Team
- Copyright Tencent/TurboTransformers
- This block_reduce_n is adapted from Tencent/TurboTransformers
-*/
-#pragma once
-#include
-#include
-#include
-
-enum class ReduceType { kMax = 0, kSum };
-const unsigned int WARP_REDUCE_MASK = 0xffffffff;
-const float REDUCE_FLOAT_INF_NEG = -100000000.f;
-const float REDUCE_FLOAT_INF_POS = 100000000.f;
-const unsigned int WARP_REDUCE_SIZE = 32;
-
-template
-__forceinline__ __device__ T warpReduceSum(T val) {
- for (int mask = (WARP_REDUCE_SIZE >> 1); mask > 0; mask >>= 1)
- val += __shfl_xor_sync(WARP_REDUCE_MASK, val, mask, WARP_REDUCE_SIZE);
- return val;
-}
-
-/* Calculate the sum of all elements in a block */
-template
-__forceinline__ __device__ T blockReduceSum(T val) {
- static __shared__ T shared[32];
- int lane = threadIdx.x & 0x1f;
- int wid = threadIdx.x >> 5;
-
- val = warpReduceSum(val);
-
- if (lane == 0) shared[wid] = val;
- __syncthreads();
-
- val = (threadIdx.x < (blockDim.x >> 5)) ? shared[lane] : (T)0.0f;
- val = warpReduceSum(val);
- return val;
-}
-
-template
-__inline__ __device__ void blockReduce(float *pval);
-
-// use template to make code more concise
-template
-__inline__ __device__ void warpReduce(float *pval);
-
-// static
-template <>
-__inline__ __device__ void warpReduce(float *pval) {
- *pval = max(*pval, __shfl_xor_sync(WARP_REDUCE_MASK, *pval, 16, 32));
- *pval = max(*pval, __shfl_xor_sync(WARP_REDUCE_MASK, *pval, 8, 32));
- *pval = max(*pval, __shfl_xor_sync(WARP_REDUCE_MASK, *pval, 4, 32));
- *pval = max(*pval, __shfl_xor_sync(WARP_REDUCE_MASK, *pval, 2, 32));
- *pval = max(*pval, __shfl_xor_sync(WARP_REDUCE_MASK, *pval, 1, 32));
-}
-
-template <>
-__inline__ __device__ void warpReduce(float *pval) {
- float val0_tmp, val1_tmp;
-#define WarpReduceMaxOneStep(a, b) \
- val0_tmp = __shfl_xor_sync(WARP_REDUCE_MASK, *(pval), a, b); \
- val1_tmp = __shfl_xor_sync(WARP_REDUCE_MASK, *(pval + 1), a, b); \
- *(pval) = max(val0_tmp, *(pval)); \
- *(pval + 1) = max(val1_tmp, *(pval + 1));
-
- WarpReduceMaxOneStep(16, 32);
- WarpReduceMaxOneStep(8, 32);
- WarpReduceMaxOneStep(4, 32);
- WarpReduceMaxOneStep(2, 32);
- WarpReduceMaxOneStep(1, 32);
-#undef WarpReduceMaxOneStep
-}
-
-template <>
-__inline__ __device__ void warpReduce(float *pval) {
- *pval += __shfl_xor_sync(WARP_REDUCE_MASK, *pval, 16, 32);
- *pval += __shfl_xor_sync(WARP_REDUCE_MASK, *pval, 8, 32);
- *pval += __shfl_xor_sync(WARP_REDUCE_MASK, *pval, 4, 32);
- *pval += __shfl_xor_sync(WARP_REDUCE_MASK, *pval, 2, 32);
- *pval += __shfl_xor_sync(WARP_REDUCE_MASK, *pval, 1, 32);
-}
-
-/*
- * Unorll for loop for warpreduce to
- * imporve instruction issue efficiency
- * ElemX means there are X numbers to be summed
- */
-
-template <>
-__inline__ __device__ void warpReduce(float *pval) {
- float val0_tmp, val1_tmp;
-#define WarpReduceSumOneStep(a, b) \
- val0_tmp = __shfl_xor_sync(WARP_REDUCE_MASK, *(pval + 0), a, b); \
- val1_tmp = __shfl_xor_sync(WARP_REDUCE_MASK, *(pval + 1), a, b); \
- *(pval + 0) += val0_tmp; \
- *(pval + 1) += val1_tmp
-
- WarpReduceSumOneStep(16, 32);
- WarpReduceSumOneStep(8, 32);
- WarpReduceSumOneStep(4, 32);
- WarpReduceSumOneStep(2, 32);
- WarpReduceSumOneStep(1, 32);
-
-#undef WarpReduceSumOneStep
-}
-
-template <>
-__inline__ __device__ void warpReduce(float *pval) {
- float val0_tmp, val1_tmp, val2_tmp, val3_tmp;
-#define WarpReduceSumOneStep(a, b) \
- val0_tmp = __shfl_xor_sync(WARP_REDUCE_MASK, *(pval + 0), a, b); \
- val1_tmp = __shfl_xor_sync(WARP_REDUCE_MASK, *(pval + 1), a, b); \
- val2_tmp = __shfl_xor_sync(WARP_REDUCE_MASK, *(pval + 2), a, b); \
- val3_tmp = __shfl_xor_sync(WARP_REDUCE_MASK, *(pval + 3), a, b); \
- *(pval + 0) += val0_tmp; \
- *(pval + 1) += val1_tmp; \
- *(pval + 2) += val2_tmp; \
- *(pval + 3) += val3_tmp
-
- WarpReduceSumOneStep(16, 32);
- WarpReduceSumOneStep(8, 32);
- WarpReduceSumOneStep(4, 32);
- WarpReduceSumOneStep(2, 32);
- WarpReduceSumOneStep(1, 32);
-#undef WarpReduceSumOneStep
-}
-
-template <>
-__inline__ __device__ void blockReduce(float *pval) {
- const int num = 1;
- static __shared__ float shared[num][32];
- int lane_id = threadIdx.x & 0x1f;
- int wid = threadIdx.x >> 5;
-
- warpReduce(pval);
-
- if (lane_id == 0) {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- shared[i][wid] = *(pval + i);
- }
- }
- __syncthreads();
-
- if (threadIdx.x < (blockDim.x >> 5)) {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- *(pval + i) = shared[i][lane_id];
- }
- } else {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- *(pval + i) = 0.f;
- }
- }
- warpReduce(pval);
-}
-
-template <>
-__inline__ __device__ void blockReduce(float *pval) {
- const int num = 2;
- static __shared__ float shared[num][32];
- int lane_id = threadIdx.x & 0x1f;
- int wid = threadIdx.x >> 5;
-
- warpReduce(pval);
-
- if (lane_id == 0) {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- shared[i][wid] = *(pval + i);
- }
- }
- __syncthreads();
-
- if (threadIdx.x < (blockDim.x >> 5)) {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- *(pval + i) = shared[i][lane_id];
- }
- } else {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- *(pval + i) = 0.f;
- }
- }
- warpReduce(pval);
-}
-
-template <>
-__inline__ __device__ void blockReduce(float *pval) {
- const int num = 4;
- static __shared__ float shared[num][32];
- int lane_id = threadIdx.x & 0x1f;
- int wid = threadIdx.x >> 5;
-
- warpReduce(pval);
-
- if (lane_id == 0) {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- shared[i][wid] = *(pval + i);
- }
- }
- __syncthreads();
-
- if (threadIdx.x < (blockDim.x >> 5)) {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- *(pval + i) = shared[i][lane_id];
- }
- } else {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- *(pval + i) = 0.f;
- }
- }
- warpReduce(pval);
-}
-
-template <>
-__inline__ __device__ void blockReduce(float *pval) {
- const int num = 1;
- static __shared__ float shared[num][32];
- int lane_id = threadIdx.x & 0x1f;
- int wid = threadIdx.x >> 5;
-
- warpReduce(pval);
-
- if (lane_id == 0) {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- shared[i][wid] = *(pval + i);
- }
- }
- __syncthreads();
-
- if (threadIdx.x < (blockDim.x >> 5)) {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- *(pval + i) = shared[i][lane_id];
- }
- } else {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- *(pval + i) = REDUCE_FLOAT_INF_NEG;
- }
- }
- warpReduce(pval);
-}
-
-template <>
-__inline__ __device__ void blockReduce(float *pval) {
- const int num = 1;
- static __shared__ float shared[num][32];
- int lane_id = threadIdx.x & 0x1f;
- int wid = threadIdx.x >> 5;
-
- warpReduce(pval);
-
- if (lane_id == 0) {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- shared[i][wid] = *(pval + i);
- }
- }
- __syncthreads();
-
- if (threadIdx.x < (blockDim.x >> 5)) {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- *(pval + i) = shared[i][lane_id];
- }
- } else {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- *(pval + i) = REDUCE_FLOAT_INF_NEG;
- }
- }
- warpReduce(pval);
-}
-
-template <>
-__inline__ __device__ void blockReduce(float *pval) {
- const int num = 1;
- static __shared__ float shared[num][32];
- int lane_id = threadIdx.x & 0x1f;
- int wid = threadIdx.x >> 5;
-
- warpReduce(pval);
-
- if (lane_id == 0) {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- shared[i][wid] = *(pval + i);
- }
- }
- __syncthreads();
-
- if (threadIdx.x < (blockDim.x >> 5)) {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- *(pval + i) = shared[i][lane_id];
- }
- } else {
-#pragma unroll
- for (int i = 0; i < num; ++i) {
- *(pval + i) = REDUCE_FLOAT_INF_NEG;
- }
- }
- warpReduce(pval);
-}
diff --git a/extensions/csrc/cuda/scaled_masked_softmax_cuda.cu b/extensions/csrc/cuda/scaled_masked_softmax_cuda.cu
deleted file mode 100644
index 41781ebc7fe0..000000000000
--- a/extensions/csrc/cuda/scaled_masked_softmax_cuda.cu
+++ /dev/null
@@ -1,89 +0,0 @@
-/*This code from NVIDIA Megatron:
- * with minor changes. */
-
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-
-#include "scaled_masked_softmax.h"
-#include "type_shim.h"
-
-namespace multihead_attn {
-namespace fused_softmax {
-namespace scaled_masked_softmax {
-
-int get_batch_per_block_cuda(int query_seq_len, int key_seq_len, int batches,
- int attn_heads) {
- return get_batch_per_block(query_seq_len, key_seq_len, batches, attn_heads);
-}
-
-torch::Tensor fwd_cuda(torch::Tensor const& input, torch::Tensor const& mask,
- float scale_factor) {
- // input is a 4d tensor with dimensions [batches, attn_heads, seq_len,
- // seq_len]
- const int batches = input.size(0);
- const int pad_batches = mask.size(0);
- const int attn_heads = input.size(1);
- const int query_seq_len = input.size(2);
- const int key_seq_len = input.size(3);
- TORCH_INTERNAL_ASSERT(key_seq_len <= 2048);
- TORCH_INTERNAL_ASSERT(query_seq_len > 1);
- TORCH_INTERNAL_ASSERT(pad_batches == 1 || pad_batches == batches);
- TORCH_INTERNAL_ASSERT(mask.size(1) == 1);
- TORCH_INTERNAL_ASSERT(mask.size(2) == query_seq_len);
- TORCH_INTERNAL_ASSERT(mask.size(3) == key_seq_len);
-
- // Output
- auto act_options = input.options().requires_grad(false);
- torch::Tensor softmax_results = torch::empty(
- {batches, attn_heads, query_seq_len, key_seq_len}, act_options);
-
- // Softmax Intermediate Result Ptr
- void* input_ptr = static_cast(input.data_ptr());
- void* mask_ptr = static_cast(mask.data_ptr());
- void* softmax_results_ptr = static_cast(softmax_results.data_ptr());
-
- DISPATCH_HALF_AND_BFLOAT(
- input.scalar_type(), "dispatch_scaled_masked_softmax_forward",
- dispatch_scaled_masked_softmax_forward(
- reinterpret_cast(softmax_results_ptr),
- reinterpret_cast(input_ptr),
- reinterpret_cast(mask_ptr), scale_factor,
- query_seq_len, key_seq_len, batches, attn_heads, pad_batches););
- return softmax_results;
-}
-
-torch::Tensor bwd_cuda(torch::Tensor const& output_grads_,
- torch::Tensor const& softmax_results_,
- float scale_factor) {
- auto output_grads = output_grads_.contiguous();
- auto softmax_results = softmax_results_.contiguous();
-
- // output grads is a 4d tensor with dimensions [batches, attn_heads, seq_len,
- // seq_len]
- const int batches = output_grads.size(0);
- const int attn_heads = output_grads.size(1);
- const int query_seq_len = output_grads.size(2);
- const int key_seq_len = output_grads.size(3);
-
- void* output_grads_ptr = static_cast(output_grads.data_ptr());
-
- // Softmax Grad
- DISPATCH_HALF_AND_BFLOAT(
- output_grads_.scalar_type(), "dispatch_scaled_masked_softmax_backward",
- dispatch_scaled_masked_softmax_backward(
- reinterpret_cast(output_grads_ptr),
- reinterpret_cast(output_grads_ptr),
- reinterpret_cast(softmax_results.data_ptr()),
- scale_factor, query_seq_len, key_seq_len, batches, attn_heads););
-
- // backward pass is completely in-place
- return output_grads;
-}
-} // namespace scaled_masked_softmax
-} // namespace fused_softmax
-} // namespace multihead_attn
diff --git a/extensions/csrc/cuda/scaled_upper_triang_masked_softmax_cuda.cu b/extensions/csrc/cuda/scaled_upper_triang_masked_softmax_cuda.cu
deleted file mode 100644
index 62c56e6f7870..000000000000
--- a/extensions/csrc/cuda/scaled_upper_triang_masked_softmax_cuda.cu
+++ /dev/null
@@ -1,75 +0,0 @@
-/*This code from NVIDIA Megatron:
- * with minor changes. */
-
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-
-#include "scaled_upper_triang_masked_softmax.h"
-#include "type_shim.h"
-
-namespace multihead_attn {
-namespace fused_softmax {
-namespace scaled_upper_triang_masked_softmax {
-
-torch::Tensor fwd_cuda(torch::Tensor const& input, float scale_factor) {
- // input is a 3d tensor with dimensions [attn_batches, seq_len, seq_len]
- const int attn_batches = input.size(0);
- const int seq_len = input.size(1);
- TORCH_INTERNAL_ASSERT(seq_len <= 2048);
-
- // Output
- auto act_options = input.options().requires_grad(false);
- torch::Tensor softmax_results =
- torch::empty({attn_batches, seq_len, seq_len}, act_options);
-
- // Softmax Intermediate Result Ptr
- void* input_ptr = static_cast(input.data_ptr());
- void* softmax_results_ptr = static_cast(softmax_results.data_ptr());
-
- DISPATCH_HALF_AND_BFLOAT(
- input.scalar_type(),
- "dispatch_scaled_upper_triang_masked_softmax_forward",
- dispatch_scaled_upper_triang_masked_softmax_forward(
- reinterpret_cast(softmax_results_ptr),
- reinterpret_cast(input_ptr), scale_factor, seq_len,
- seq_len, attn_batches););
- return softmax_results;
-}
-
-torch::Tensor bwd_cuda(torch::Tensor const& output_grads_,
- torch::Tensor const& softmax_results_,
- float scale_factor) {
- auto output_grads = output_grads_.contiguous();
- auto softmax_results = softmax_results_.contiguous();
-
- // output grads is a 3d tensor with dimensions [attn_batches, seq_len,
- // seq_len]
- const int attn_batches = output_grads.size(0);
- const int seq_len = output_grads.size(1);
- TORCH_INTERNAL_ASSERT(output_grads.size(1) == output_grads.size(2));
-
- void* output_grads_ptr = static_cast(output_grads.data_ptr());
-
- // Softmax Grad
- DISPATCH_HALF_AND_BFLOAT(
- output_grads_.scalar_type(),
- "dispatch_scaled_upper_triang_masked_softmax_backward",
- dispatch_scaled_upper_triang_masked_softmax_backward(
- reinterpret_cast(output_grads_ptr),
- reinterpret_cast(output_grads_ptr),
- reinterpret_cast(softmax_results.data_ptr()),
- scale_factor, seq_len, seq_len, attn_batches););
-
- // backward pass is completely in-place
- return output_grads;
-}
-} // namespace scaled_upper_triang_masked_softmax
-} // namespace fused_softmax
-} // namespace multihead_attn
diff --git a/extensions/csrc/funcs/binary_functor.h b/extensions/csrc/funcs/binary_functor.h
new file mode 100644
index 000000000000..90726a02fcb1
--- /dev/null
+++ b/extensions/csrc/funcs/binary_functor.h
@@ -0,0 +1,231 @@
+#pragma once
+
+#if defined(COLOSSAL_WITH_CUDA)
+#include
+#include
+#include
+#include
+#endif
+
+#include
+
+#include "cast_functor.h"
+#include "common/data_type.h"
+#include "common/micros.h"
+
+namespace colossalAI {
+namespace funcs {
+
+enum class BinaryOpType { kAdd = 0, kMinus, kMul, kDiv, kMax, kMin };
+
+// Note(LiuYang): This file provides base math operation for data type
+// include POD and cuda built-in type such as half and __nv_bfloat16.
+// Implementation of common and simple binary operators should be placed here,
+// otherwise, they should be placed in a new file under functors dir.
+template
+struct BinaryOpFunctor;
+
+#define STMTS_WRAPPER(...) __VA_ARGS__
+
+#define COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION( \
+ LT, RT, RET, BINARY_OP_TYPE, FUNCTION_MODIFIER, STMTS, ARGS...) \
+ template \
+ struct BinaryOpFunctor \
+ : public std::binary_function { \
+ FUNCTION_MODIFIER RET operator()(LT lhs, RT rhs) STMTS \
+ };
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(T, T, T, BinaryOpType::kAdd, HOSTDEVICE,
+ STMTS_WRAPPER({ return lhs + rhs; }),
+ typename T)
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(T, T, T, BinaryOpType::kMinus,
+ HOSTDEVICE,
+ STMTS_WRAPPER({ return lhs - rhs; }),
+ typename T)
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(T, T, T, BinaryOpType::kMul, HOSTDEVICE,
+ STMTS_WRAPPER({ return lhs * rhs; }),
+ typename T)
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(T, T, T, BinaryOpType::kDiv, HOSTDEVICE,
+ STMTS_WRAPPER({ return lhs / rhs; }),
+ typename T)
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(T, T, T, BinaryOpType::kMax, HOSTDEVICE,
+ STMTS_WRAPPER({ return max(lhs, rhs); }),
+ typename T)
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(T, T, T, BinaryOpType::kMin, HOSTDEVICE,
+ STMTS_WRAPPER({ return min(lhs, rhs); }),
+ typename T)
+
+#if defined(COLOSSAL_WITH_CUDA)
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(half, half, half, BinaryOpType::kMinus,
+ DEVICE, STMTS_WRAPPER({
+ return __hsub(lhs, rhs);
+ }))
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(half, half, half, BinaryOpType::kAdd,
+ DEVICE, STMTS_WRAPPER({
+ return __hadd(lhs, rhs);
+ }))
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(half2, half2, half2, BinaryOpType::kAdd,
+ DEVICE, STMTS_WRAPPER({
+ return __hadd2(lhs, rhs);
+ }))
+
+#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 800
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(__nv_bfloat16, __nv_bfloat16,
+ __nv_bfloat16, BinaryOpType::kAdd,
+ DEVICE, STMTS_WRAPPER({
+ return __hadd(lhs, rhs);
+ }))
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(__nv_bfloat16, __nv_bfloat16,
+ __nv_bfloat16, BinaryOpType::kMinus,
+ DEVICE, STMTS_WRAPPER({
+ return __hsub(lhs, rhs);
+ }))
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(__nv_bfloat162, __nv_bfloat162,
+ __nv_bfloat162, BinaryOpType::kAdd,
+ DEVICE, STMTS_WRAPPER({
+ return __hadd2(lhs, rhs);
+ }))
+#else
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(
+ __nv_bfloat16, __nv_bfloat16, __nv_bfloat16, BinaryOpType::kAdd, DEVICE,
+ STMTS_WRAPPER({
+ return __float2bfloat16(__bfloat162float(lhs) + __bfloat162float(rhs));
+ }))
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(
+ __nv_bfloat16, __nv_bfloat16, __nv_bfloat16, BinaryOpType::kMinus, DEVICE,
+ STMTS_WRAPPER({
+ return __float2bfloat16(__bfloat162float(lhs) - __bfloat162float(rhs));
+ }))
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(
+ __nv_bfloat162, __nv_bfloat162, __nv_bfloat162, BinaryOpType::kAdd, DEVICE,
+ STMTS_WRAPPER({
+ return __floats2bfloat162_rn(__low2float(lhs) + __low2float(rhs),
+ __high2float(lhs) + __high2float(rhs));
+ }))
+#endif /* defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 800 */
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(half, half, half, BinaryOpType::kMul,
+ DEVICE, STMTS_WRAPPER({
+ return __hmul(lhs, rhs);
+ }))
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(half2, half2, half2, BinaryOpType::kMul,
+ DEVICE, STMTS_WRAPPER({
+ return __hmul2(lhs, rhs);
+ }))
+
+#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 800
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(__nv_bfloat16, __nv_bfloat16,
+ __nv_bfloat16, BinaryOpType::kMul,
+ DEVICE, STMTS_WRAPPER({
+ return __hmul(lhs, rhs);
+ }))
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(__nv_bfloat162, __nv_bfloat162,
+ __nv_bfloat162, BinaryOpType::kMul,
+ DEVICE, STMTS_WRAPPER({
+ return __hmul2(lhs, rhs);
+ }))
+#else
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(
+ __nv_bfloat16, __nv_bfloat16, __nv_bfloat16, BinaryOpType::kMul, DEVICE,
+ STMTS_WRAPPER({
+ return __float2bfloat16(__bfloat162float(lhs) * __bfloat162float(rhs));
+ }))
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(
+ __nv_bfloat162, __nv_bfloat162, __nv_bfloat162, BinaryOpType::kMul, DEVICE,
+ STMTS_WRAPPER({
+ return __floats2bfloat162_rn(__low2float(lhs) * __low2float(rhs),
+ __high2float(lhs) * __high2float(rhs));
+ }))
+#endif /* defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 800 */
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(
+ float2, float2, float2, BinaryOpType::kMul, DEVICE,
+ STMTS_WRAPPER({ return make_float2(lhs.x * rhs.x, lhs.y * rhs.y); }))
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(float4, float4, float4,
+ BinaryOpType::kMul, DEVICE,
+ STMTS_WRAPPER({
+ return make_float4(
+ lhs.x * rhs.x, lhs.y * rhs.y,
+ lhs.z * rhs.z, lhs.w * rhs.w);
+ }))
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(
+ __nv_bfloat162, __nv_bfloat162, float2, BinaryOpType::kMul, DEVICE,
+ STMTS_WRAPPER({
+ CastFunctor<__nv_bfloat162, float2> cast;
+ BinaryOpFunctor mul;
+ float2 fa = cast(lhs);
+ float2 fb = cast(rhs);
+ return mul(fa, fb);
+ }))
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(dtype::bfloat164, dtype::bfloat164,
+ float4, BinaryOpType::kMul, DEVICE,
+ STMTS_WRAPPER({
+ float4 fc;
+ CastFunctor<__nv_bfloat16, float> cast;
+ fc.x = cast(lhs.x.x) * cast(rhs.x.x);
+ fc.y = cast(lhs.x.y) * cast(rhs.x.y);
+ fc.z = cast(lhs.y.x) * cast(rhs.y.x);
+ fc.w = cast(lhs.y.y) * cast(rhs.y.y);
+ return fc;
+ }))
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(
+ dtype::bfloat168, dtype::bfloat168, dtype::float8, BinaryOpType::kMul,
+ DEVICE, STMTS_WRAPPER({
+ dtype::float8 fc;
+ BinaryOpFunctor<__nv_bfloat162, __nv_bfloat162, float2,
+ BinaryOpType::kMul>
+ mul;
+ fc.x = mul(lhs.x, rhs.x);
+ fc.y = mul(lhs.y, rhs.y);
+ fc.z = mul(lhs.z, rhs.z);
+ fc.w = mul(lhs.w, rhs.w);
+ return fc;
+ }))
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(
+ half2, half2, float2, BinaryOpType::kMul, DEVICE, STMTS_WRAPPER({
+ CastFunctor cast;
+ BinaryOpFunctor mul;
+ float2 fa = cast(lhs);
+ float2 fb = cast(rhs);
+ return mul(fa, fb);
+ }))
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(dtype::half4, dtype::half4, float4,
+ BinaryOpType::kMul, DEVICE,
+ STMTS_WRAPPER({
+ float4 fc;
+ CastFunctor cast;
+ fc.x = cast(lhs.x.x) * cast(rhs.x.x);
+ fc.y = cast(lhs.x.y) * cast(rhs.x.y);
+ fc.z = cast(lhs.y.x) * cast(rhs.y.x);
+ fc.w = cast(lhs.y.y) * cast(rhs.y.y);
+ return fc;
+ }))
+
+COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION(
+ dtype::half8, dtype::half8, dtype::float8, BinaryOpType::kMul, DEVICE,
+ STMTS_WRAPPER({
+ dtype::float8 fc;
+ BinaryOpFunctor mul;
+ fc.x = mul(lhs.x, rhs.x);
+ fc.y = mul(lhs.y, rhs.y);
+ fc.z = mul(lhs.z, rhs.z);
+ fc.w = mul(lhs.w, rhs.w);
+ return fc;
+ }))
+
+#endif /* defined(COLOSSAL_WITH_CUDA) */
+
+#undef COLOSSAL_BINARY_FUNCTOR_SPECIALIZATION
+#undef STMTS_WRAPPER
+} // namespace funcs
+} // namespace colossalAI
diff --git a/extensions/csrc/funcs/cast_functor.h b/extensions/csrc/funcs/cast_functor.h
new file mode 100644
index 000000000000..588357d6b4bf
--- /dev/null
+++ b/extensions/csrc/funcs/cast_functor.h
@@ -0,0 +1,503 @@
+#pragma once
+
+#if defined(COLOSSAL_WITH_CUDA)
+#include
+#include
+#include
+#include
+#include
+#endif
+
+#include
+#include
+
+#include
+
+#include "common/data_type.h"
+#include "common/micros.h"
+
+// Note(LiuYang): This file provides base math operation for data type
+// include POD and cuda built-in type such as half and __nv_bfloat16
+
+namespace colossalAI {
+namespace funcs {
+
+template
+struct CastFunctor : public std::unary_function {
+ HOSTDEVICE To operator()(From val) { return static_cast(val); }
+};
+
+#define STMTS_WRAPPER(...) __VA_ARGS__
+
+#define COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(FROM, TO, FUNCTION_MODIFIER, \
+ STMTS) \
+ template <> \
+ struct CastFunctor : public std::unary_function { \
+ FUNCTION_MODIFIER TO operator()(FROM val) STMTS \
+ };
+
+#if defined(COLOSSAL_WITH_CUDA)
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(int2, float2, DEVICE, STMTS_WRAPPER({
+ return make_float2(val.x, val.y);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float, float2, DEVICE, STMTS_WRAPPER({
+ return make_float2(val, val);
+ }))
+
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(half2, float2, DEVICE, STMTS_WRAPPER({
+ return __half22float2(val);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float2, half2, DEVICE, STMTS_WRAPPER({
+ return __float22half2_rn(val);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float, half, DEVICE, STMTS_WRAPPER({
+ return __float2half_rn(val);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float, half2, DEVICE, STMTS_WRAPPER({
+ return __float2half2_rn(val);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(half, half2, DEVICE, STMTS_WRAPPER({
+ return __half2half2(val);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(half, float, DEVICE, STMTS_WRAPPER({
+ return __half2float(val);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float4, dtype::half4, DEVICE,
+ STMTS_WRAPPER({
+ dtype::half4 dst;
+ dst.x = __floats2half2_rn(val.x, val.y);
+ dst.y = __floats2half2_rn(val.z, val.w);
+ return dst;
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(dtype::half4, float4, DEVICE,
+ STMTS_WRAPPER({
+ float4 dst;
+ dst.x = __half2float(val.x.x);
+ dst.y = __half2float(val.x.y);
+ dst.z = __half2float(val.y.x);
+ dst.w = __half2float(val.y.y);
+ return dst;
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(dtype::float8, dtype::half8, DEVICE,
+ STMTS_WRAPPER({
+ dtype::half8 dst;
+ dst.x = __float22half2_rn(val.x);
+ dst.y = __float22half2_rn(val.y);
+ dst.z = __float22half2_rn(val.z);
+ dst.w = __float22half2_rn(val.w);
+ return dst;
+ }))
+
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float, __nv_bfloat162, DEVICE,
+ STMTS_WRAPPER({
+ return __float2bfloat162_rn(val);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float, __nv_bfloat16, DEVICE,
+ STMTS_WRAPPER({
+ return __float2bfloat16_rn(val);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(__nv_bfloat16, float, DEVICE,
+ STMTS_WRAPPER({
+ return __bfloat162float(val);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float4, dtype::bfloat164, DEVICE,
+ STMTS_WRAPPER({
+ dtype::bfloat164 dst;
+ dst.x =
+ __floats2bfloat162_rn(val.x, val.y);
+ dst.y =
+ __floats2bfloat162_rn(val.z, val.w);
+ return dst;
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(dtype::bfloat164, float4, DEVICE,
+ STMTS_WRAPPER({
+ float4 dst;
+ dst.x = __bfloat162float(val.x.x);
+ dst.y = __bfloat162float(val.x.y);
+ dst.z = __bfloat162float(val.y.x);
+ dst.w = __bfloat162float(val.y.y);
+ return dst;
+ }))
+#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 800
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(__nv_bfloat16, __nv_bfloat162, DEVICE,
+ STMTS_WRAPPER({
+ return __bfloat162bfloat162(val);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(__nv_bfloat162, float2, DEVICE,
+ STMTS_WRAPPER({
+ return __bfloat1622float2(val);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float2, __nv_bfloat162, DEVICE,
+ STMTS_WRAPPER({
+ return __float22bfloat162_rn(val);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(dtype::float8, dtype::bfloat168, DEVICE,
+ STMTS_WRAPPER({
+ dtype::bfloat168 dst;
+ dst.x = __float22bfloat162_rn(val.x);
+ dst.y = __float22bfloat162_rn(val.y);
+ dst.z = __float22bfloat162_rn(val.z);
+ dst.w = __float22bfloat162_rn(val.w);
+ return dst;
+ }))
+#else
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(__nv_bfloat16, __nv_bfloat162, DEVICE,
+ STMTS_WRAPPER({
+ __nv_bfloat162 dst;
+ dst.x = val;
+ dst.y = val;
+ return dst;
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(__nv_bfloat162, float2, DEVICE,
+ STMTS_WRAPPER({
+ return make_float2(__low2float(val),
+ __high2float(val));
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float2, __nv_bfloat162, DEVICE,
+ STMTS_WRAPPER({
+ return __floats2bfloat162_rn(val.x,
+ val.y);
+ }))
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ dtype::float8, dtype::bfloat168, DEVICE, STMTS_WRAPPER({
+ dtype::bfloat168 dst;
+ dst.x = __floats2bfloat162_rn(val.x.x, val.x.y);
+ dst.y = __floats2bfloat162_rn(val.y.x, val.y.y);
+ dst.z = __floats2bfloat162_rn(val.z.x, val.z.y);
+ dst.w = __floats2bfloat162_rn(val.w.x, val.w.y);
+ return dst;
+ }))
+#endif /* defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 800 */
+
+// quant utils
+// fp8 -> half raw
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(uint8_t, uint16_t, DEVICE, STMTS_WRAPPER({
+ __half_raw res = __nv_cvt_fp8_to_halfraw(
+ val, __NV_E5M2);
+ return res.x;
+ }))
+
+// half raw -> fp8
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(uint16_t, uint8_t, DEVICE, STMTS_WRAPPER({
+ __half_raw tmp;
+ tmp.x = val;
+ __nv_fp8_storage_t res =
+ __nv_cvt_halfraw_to_fp8(
+ tmp, __NV_SATFINITE, __NV_E5M2);
+ return static_cast(res);
+ }))
+
+// fp8x2 -> half2 raw
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(uint16_t, uint32_t, DEVICE, STMTS_WRAPPER({
+ union {
+ uint16_t u16[2];
+ uint32_t u32;
+ } tmp;
+ __half2_raw res =
+ __nv_cvt_fp8x2_to_halfraw2(
+ val, __NV_E5M2);
+ tmp.u16[0] = res.x;
+ tmp.u16[1] = res.y;
+ return tmp.u32;
+ }))
+
+// fp8x4 -> half2x2 raw
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ uint32_t, uint2, DEVICE, STMTS_WRAPPER({
+ union {
+ uint2 u32x2;
+ uint32_t u32[2];
+ } tmp;
+ tmp.u32[0] =
+ CastFunctor()(static_cast(val));
+ tmp.u32[1] =
+ CastFunctor()(static_cast(val >> 16U));
+ return tmp.u32x2;
+ }))
+
+// fp8x8 -> half2x4 raw
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ uint2, uint4, DEVICE, STMTS_WRAPPER({
+ union {
+ uint4 u64x2;
+ uint2 u64[2];
+ } tmp;
+ tmp.u64[0] = CastFunctor()(val.x);
+ tmp.u64[1] = CastFunctor()(val.y);
+ return tmp.u64x2;
+ }))
+
+// fp8 -> half
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(uint8_t, half, DEVICE, STMTS_WRAPPER({
+ __half_raw res = __nv_cvt_fp8_to_halfraw(
+ val, __NV_E5M2);
+ return half(res);
+ }))
+
+// half -> fp8
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(half, uint8_t, DEVICE, STMTS_WRAPPER({
+ __half_raw tmp(val);
+ __nv_fp8_storage_t res =
+ __nv_cvt_halfraw_to_fp8(
+ tmp, __NV_SATFINITE, __NV_E5M2);
+ return static_cast(res);
+ }))
+
+// fp8x2 -> half2
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(uint16_t, half2, DEVICE, STMTS_WRAPPER({
+ __half2_raw res =
+ __nv_cvt_fp8x2_to_halfraw2(
+ val, __NV_E5M2);
+ return half2(res);
+ }))
+
+// half2 -> fp8x2
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(half2, uint16_t, DEVICE, STMTS_WRAPPER({
+ __half2_raw tmp(val);
+ __nv_fp8x2_storage_t res =
+ __nv_cvt_halfraw2_to_fp8x2(
+ tmp, __NV_SATFINITE, __NV_E5M2);
+ return static_cast(res);
+ }))
+
+// fp8x4 -> half4
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ uint32_t, dtype::half4, DEVICE, STMTS_WRAPPER({
+ half2 tmp1, tmp2;
+ tmp1 = CastFunctor()(static_cast(val));
+ tmp2 = CastFunctor()(static_cast(val >> 16U));
+ dtype::half4 res;
+ res.x = tmp1;
+ res.y = tmp2;
+ return res;
+ }))
+
+// half4 -> fp8x4
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ dtype::half4, uint32_t, DEVICE, STMTS_WRAPPER({
+ half2 x, y;
+ x = val.x;
+ y = val.y;
+ uint16_t lo, hi;
+ lo = CastFunctor()(x);
+ hi = CastFunctor()(y);
+ uint32_t res;
+ asm volatile("mov.b32 %0, {%1, %2};\n" : "=r"(res) : "h"(lo), "h"(hi));
+ return res;
+ }))
+
+// fp8x8 -> half8
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ uint2, dtype::half8, DEVICE, STMTS_WRAPPER({
+ dtype::half4 tmp1, tmp2;
+ tmp1 = CastFunctor()(val.x);
+ tmp2 = CastFunctor()(val.y);
+ dtype::half8 res;
+ res.x = tmp1.x;
+ res.y = tmp1.y;
+ res.z = tmp2.x;
+ res.w = tmp2.y;
+ return res;
+ }))
+
+// fp8 -> __nv_bfloat16
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ uint8_t, __nv_bfloat16, DEVICE, STMTS_WRAPPER({
+ // Note there is no direct convert function from fp8 to bf16.
+ // fp8 -> half
+ __half_raw res = __nv_cvt_fp8_to_halfraw(val, __NV_E5M2);
+ // half -> float -> bf16
+ float tmp;
+ asm volatile("cvt.f32.f16 %0, %1;\n" : "=f"(tmp) : "h"(res.x));
+ return __float2bfloat16(tmp);
+ }))
+
+// fp8x2 -> __nv_bfloat162
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ uint16_t, __nv_bfloat162, DEVICE, STMTS_WRAPPER({
+ __nv_bfloat162 res;
+ res.x = CastFunctor()(static_cast(val));
+ res.y = CastFunctor()(
+ static_cast(val >> 8U));
+ return res;
+ }))
+
+// fp8x4 -> bfloat164
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ uint32_t, dtype::bfloat164, DEVICE, STMTS_WRAPPER({
+ dtype::bfloat164 res;
+ res.x =
+ CastFunctor()(static_cast(val));
+ res.y = CastFunctor()(
+ static_cast(val >> 16U));
+ return res;
+ }))
+
+// fp8x8 -> bfloat168
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ uint2, dtype::bfloat168, DEVICE, STMTS_WRAPPER({
+ dtype::bfloat164 tmp1, tmp2;
+ tmp1 = CastFunctor()(val.x);
+ tmp2 = CastFunctor()(val.y);
+ dtype::bfloat168 res;
+ res.x = tmp1.x;
+ res.y = tmp1.y;
+ res.z = tmp2.x;
+ res.w = tmp2.y;
+ return res;
+ }))
+
+// fp8 -> float
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ uint8_t, float, DEVICE, STMTS_WRAPPER({
+ // fp8 -> half
+ uint16_t tmp = CastFunctor()(val);
+ // half -> float
+ float res;
+ asm volatile("cvt.f32.f16 %0, %1;\n" : "=f"(res) : "h"(tmp));
+ return res;
+ }))
+
+// float -> fp8
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float, uint8_t, DEVICE, STMTS_WRAPPER({
+ __nv_fp8_storage_t res =
+ __nv_cvt_float_to_fp8(
+ val, __NV_SATFINITE, __NV_E5M2);
+ return static_cast(res);
+ }))
+
+// fp8x2 -> float2
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ uint16_t, float2, DEVICE, STMTS_WRAPPER({
+ // fp8x2 -> half2
+ uint32_t tmp = CastFunctor()(val);
+ // half2 -> float2
+ uint16_t lo, hi;
+ asm volatile("mov.b32 {%0, %1}, %2;\n" : "=h"(lo), "=h"(hi) : "r"(tmp));
+ float lof, hif;
+ asm volatile("cvt.f32.f16 %0, %1;\n" : "=f"(lof) : "h"(lo));
+ asm volatile("cvt.f32.f16 %0, %1;\n" : "=f"(hif) : "h"(hi));
+ return make_float2(lof, hif);
+ }))
+
+// float2 -> fp8x2
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ float2, uint16_t, DEVICE, STMTS_WRAPPER({
+ uint16_t tmp1 =
+ static_cast(CastFunctor()(val.x));
+ uint16_t tmp2 =
+ static_cast(CastFunctor()(val.y));
+ uint16_t res = (tmp2 << 8U) | tmp1;
+ return res;
+ }))
+
+// float4 -> fp8x4
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float4, uint32_t, DEVICE, STMTS_WRAPPER({
+ uint32_t a, b, c, d;
+ a = CastFunctor()(val.x);
+ b = CastFunctor()(val.y);
+ c = CastFunctor()(val.z);
+ d = CastFunctor()(val.w);
+ return (d << 24U) | (c << 16U) |
+ (b << 8U) | a;
+ }))
+
+// fp8x4 -> float4
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ uint32_t, float4, DEVICE, STMTS_WRAPPER({
+ float4 res;
+ res.x = CastFunctor()(static_cast(val));
+ res.y = CastFunctor()(static_cast(val >> 8U));
+ res.z = CastFunctor()(static_cast(val >> 16U));
+ res.w = CastFunctor()(static_cast(val >> 24U));
+ return res;
+ }))
+
+// fp8x8 -> float8
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ uint2, dtype::float8, DEVICE, STMTS_WRAPPER({
+ dtype::float8 res;
+ res.x = CastFunctor()(static_cast(val.x));
+ res.y =
+ CastFunctor()(static_cast(val.x >> 16U));
+ res.z = CastFunctor()(static_cast(val.y));
+ res.w =
+ CastFunctor()(static_cast(val.y >> 16U));
+ return res;
+ }))
+
+// bf16 -> fp8
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(__nv_bfloat16, uint8_t, DEVICE,
+ STMTS_WRAPPER({
+#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ < 800
+ assert(false);
+#else
+ __nv_fp8_storage_t res =
+ __nv_cvt_bfloat16raw_to_fp8(
+ __nv_bfloat16_raw(val),
+ __NV_SATFINITE, __NV_E5M2);
+ return static_cast(res);
+#endif
+ }))
+
+// bf162 -> fp8x2
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ __nv_bfloat162, uint16_t, DEVICE, STMTS_WRAPPER({
+ uint16_t a =
+ static_cast(CastFunctor<__nv_bfloat16, uint8_t>()(val.x));
+ uint16_t b =
+ static_cast(CastFunctor<__nv_bfloat16, uint8_t>()(val.y));
+ return (b << 8U) | a;
+ }))
+
+// bf164 -> fp8x4
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ dtype::bfloat164, uint32_t, DEVICE, STMTS_WRAPPER({
+ uint32_t res;
+ uint16_t a, b;
+ a = CastFunctor<__nv_bfloat162, uint16_t>()(val.x);
+ b = CastFunctor<__nv_bfloat162, uint16_t>()(val.y);
+ asm volatile("mov.b32 %0, {%1, %2};\n" : "=r"(res) : "h"(a), "h"(b));
+ return res;
+ }))
+
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float2, uint32_t, DEVICE, STMTS_WRAPPER({
+ union {
+ half2 float16;
+ uint32_t uint32;
+ };
+
+ float16 = __float22half2_rn(val);
+ return uint32;
+ }))
+
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(float4, uint2, DEVICE, STMTS_WRAPPER({
+ uint2 b;
+ float2 c;
+ c.x = val.x;
+ c.y = val.y;
+ b.x = CastFunctor()(c);
+
+ c.x = val.z;
+ c.y = val.w;
+ b.y = CastFunctor()(c);
+
+ return b;
+ }))
+
+COLOSSAL_CAST_FUNCTOR_SPECIALIZATION(
+ dtype::float8, uint4, DEVICE, STMTS_WRAPPER({
+ uint4 b;
+ b.x = CastFunctor()(val.x);
+ b.y = CastFunctor()(val.y);
+ b.z = CastFunctor()(val.z);
+ b.w = CastFunctor()(val.w);
+ return b;
+ }))
+
+#endif /* defined(COLOSSAL_WITH_CUDA) */
+
+#undef STMTS_WRAPPER
+#undef COLOSSAL_CAST_FUNCTOR_SPECIALIZATION
+} // namespace funcs
+} // namespace colossalAI
diff --git a/extensions/csrc/funcs/reduce_function.h b/extensions/csrc/funcs/reduce_function.h
new file mode 100644
index 000000000000..58ff1e5bc0cc
--- /dev/null
+++ b/extensions/csrc/funcs/reduce_function.h
@@ -0,0 +1,94 @@
+#pragma once
+
+#if defined(COLOSSAL_WITH_CUDA)
+#include
+#include
+#include
+
+#include "binary_functor.h"
+
+namespace colossalAI {
+namespace funcs {
+
+const float kReduceFloatInfNeg = -100000000.f;
+const float kReduceFloatInfPos = 100000000.f;
+const unsigned int kWarpReduceMask = 0xffffffff;
+
+enum class ReduceType { kMax = 0, kSum };
+
+template
+struct GetOpForReduceType;
+
+template
+struct GetOpForReduceType {
+ using Op = funcs::BinaryOpFunctor;
+};
+
+template
+struct GetOpForReduceType {
+ using Op = funcs::BinaryOpFunctor;
+};
+
+#define COLOSSAL_SHFL_FUNCTION(MASK, VAL_PTR, DELTA, WIDTH, OP, LANES) \
+ _Pragma("unroll") for (int offset = 0; offset < LANES; ++offset) { \
+ *(VAL_PTR + offset) = \
+ OP(*(VAL_PTR + offset), \
+ __shfl_xor_sync(MASK, *(VAL_PTR + offset), DELTA, WIDTH)); \
+ }
+
+#define COLOSSAL_WARP_REDUCE_IMPL(MASK, VAL_PTR, WIDTH, OP, LANES) \
+ _Pragma("unroll") for (int DELTA = (WIDTH >> 1); DELTA > 0; DELTA >>= 1) { \
+ COLOSSAL_SHFL_FUNCTION(MASK, VAL_PTR, DELTA, WIDTH, OP, LANES) \
+ }
+
+#define COLOSSAL_BLOCK_REDUCE_IMPL(DTYPE, VAL_PTR, OP, LANES, DEFAULT_VALUE, \
+ REDUCE_TYPE) \
+ __shared__ T shm[LANES][32]; \
+ int lane_id = threadIdx.x & 0x1f; \
+ int warp_id = threadIdx.x >> 5; \
+ \
+ warp_reduce(VAL_PTR); \
+ if (lane_id == 0) { \
+ for (int offset = 0; offset < LANES; ++offset) { \
+ shm[offset][warp_id] = *(VAL_PTR + offset); \
+ } \
+ } \
+ __syncthreads(); \
+ \
+ _Pragma("unroll") for (int offset = 0; offset < LANES; ++offset) { \
+ *(VAL_PTR + offset) = (threadIdx.x < (blockDim.x >> 5)) \
+ ? shm[offset][lane_id] \
+ : static_cast(DEFAULT_VALUE); \
+ } \
+ warp_reduce(VAL_PTR);
+
+template
+__forceinline__ __device__ void warp_reduce(T* pval) {
+ typename GetOpForReduceType::Op op;
+ COLOSSAL_WARP_REDUCE_IMPL(kWarpReduceMask, pval, width, op, lanes);
+}
+
+template
+__forceinline__ __device__ constexpr T GetDefaultValueForBlockReduce() {
+ if constexpr (rtype == ReduceType::kSum) {
+ return static_cast(0.0f);
+ } else if constexpr (rtype == ReduceType::kMax) {
+ return static_cast(kReduceFloatInfNeg);
+ }
+}
+
+template
+__forceinline__ __device__ void block_reduce(T* pval) {
+ constexpr T kDefaultValue = GetDefaultValueForBlockReduce();
+ typename GetOpForReduceType::Op op;
+ COLOSSAL_BLOCK_REDUCE_IMPL(T, pval, op, lanes, kDefaultValue, rtype);
+}
+
+#undef COLOSSAL_SHFL_FUNCTION
+#undef COLOSSAL_WARP_REDUCE_IMPL
+#undef COLOSSAL_BLOCK_REDUCE_IMPL
+
+} // namespace funcs
+} // namespace colossalAI
+
+#endif /* defined(COLOSSAL_WITH_CUDA) */
diff --git a/extensions/csrc/funcs/ternary_functor.h b/extensions/csrc/funcs/ternary_functor.h
new file mode 100644
index 000000000000..8d0c95f10d63
--- /dev/null
+++ b/extensions/csrc/funcs/ternary_functor.h
@@ -0,0 +1,214 @@
+#pragma once
+
+#if defined(COLOSSAL_WITH_CUDA)
+#include
+#include
+#include
+#include
+#endif
+
+#include
+
+#include
+
+#include "cast_functor.h"
+#include "common/micros.h"
+
+namespace colossalAI {
+namespace funcs {
+
+enum class TernaryOpType { kFma = 0 };
+
+template
+struct TernaryOpFunctor;
+
+#define STMTS_WRAPPER(...) __VA_ARGS__
+
+#define COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION( \
+ LT, RT, RET, TERNARY_OP_TYPE, FUNCTION_MODIFIER, STMTS, ARGS...) \
+ template \
+ struct TernaryOpFunctor { \
+ FUNCTION_MODIFIER RET operator()(LT a, RT b, RET c) STMTS \
+ };
+
+#if defined(COLOSSAL_WITH_CUDA)
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(float, float, float,
+ TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({
+ float d;
+ d = fma(a, b, c);
+ return d;
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(float2, float2, float2,
+ TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({
+ float2 d;
+ d.x = fma(a.x, b.x, c.x);
+ d.y = fma(a.y, b.y, c.y);
+ return d;
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(float, float2, float2,
+ TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({
+ float2 d;
+ d.x = fma(a, b.x, c.x);
+ d.y = fma(a, b.y, c.y);
+ return d;
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(float4, float4, float4,
+ TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({
+ float4 d;
+ d.x = fma(a.x, b.x, c.x);
+ d.y = fma(a.y, b.y, c.y);
+ d.z = fma(a.z, b.z, c.z);
+ d.w = fma(a.w, b.w, c.w);
+ return d;
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(float, float4, float4,
+ TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({
+ float4 d;
+ d.x = fma(a, b.x, c.x);
+ d.y = fma(a, b.y, c.y);
+ d.z = fma(a, b.z, c.z);
+ d.w = fma(a, b.w, c.w);
+ return d;
+ }))
+
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ half, half, float, TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({ return __half2float(a) * __half2float(b) + c; }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ half2, half2, float2, TernaryOpType::kFma, DEVICE, STMTS_WRAPPER({
+ CastFunctor cast;
+ TernaryOpFunctor fma;
+ float2 fa = cast(a);
+ float2 fb = cast(b);
+ return fma(fa, fb, c);
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ half, half2, float2, TernaryOpType::kFma, DEVICE, STMTS_WRAPPER({
+ CastFunctor cast;
+ TernaryOpFunctor fma;
+ return fma(cast(a), b, c);
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ dtype::half4, dtype::half4, float4, TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({
+ float4 fd;
+ CastFunctor cast;
+ TernaryOpFunctor fma;
+ fd = fma(cast(a), cast(b), c);
+ return fd;
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ half, dtype::half4, float4, TernaryOpType::kFma, DEVICE, STMTS_WRAPPER({
+ float4 fd;
+ CastFunctor cast0;
+ CastFunctor cast1;
+ TernaryOpFunctor fma;
+ fd = fma(cast0(a), cast1(b), c);
+ return fd;
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ dtype::half8, dtype::half8, dtype::float8, TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({
+ dtype::float8 fd;
+ TernaryOpFunctor fma;
+ fd.x = fma(a.x, b.x, c.x);
+ fd.y = fma(a.y, b.y, c.y);
+ fd.z = fma(a.z, b.z, c.z);
+ fd.w = fma(a.w, b.w, c.w);
+ return fd;
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ half, dtype::half8, dtype::float8, TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({
+ dtype::float8 fd;
+ CastFunctor cast;
+ TernaryOpFunctor fma;
+ half2 s = cast(a);
+ fd.x = fma(s, b.x, c.x);
+ fd.y = fma(s, b.y, c.y);
+ fd.z = fma(s, b.z, c.z);
+ fd.w = fma(s, b.w, c.w);
+ return fd;
+ }))
+
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ __nv_bfloat16, __nv_bfloat16, float, TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({ return __bfloat162float(a) * __bfloat162float(b) + c; }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ __nv_bfloat162, __nv_bfloat162, float2, TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({
+ CastFunctor<__nv_bfloat162, float2> cast;
+ TernaryOpFunctor fma;
+ float2 fa = cast(a);
+ float2 fb = cast(b);
+ return fma(fa, fb, c);
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ __nv_bfloat16, __nv_bfloat162, float2, TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({
+ CastFunctor<__nv_bfloat16, __nv_bfloat162> cast;
+ TernaryOpFunctor<__nv_bfloat162, __nv_bfloat162, float2,
+ TernaryOpType::kFma>
+ fma;
+ return fma(cast(a), b, c);
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ dtype::bfloat164, dtype::bfloat164, float4, TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({
+ float4 fd;
+ CastFunctor cast;
+ TernaryOpFunctor fma;
+ fd = fma(cast(a), cast(b), c);
+ return fd;
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ __nv_bfloat16, dtype::bfloat164, float4, TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({
+ float4 fd;
+ CastFunctor<__nv_bfloat16, float> cast0;
+ CastFunctor cast1;
+ TernaryOpFunctor fma;
+ fd = fma(cast0(a), cast1(b), c);
+ return fd;
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ dtype::bfloat168, dtype::bfloat168, dtype::float8, TernaryOpType::kFma,
+ DEVICE, STMTS_WRAPPER({
+ dtype::float8 fd;
+ TernaryOpFunctor<__nv_bfloat162, __nv_bfloat162, float2,
+ TernaryOpType::kFma>
+ fma;
+ fd.x = fma(a.x, b.x, c.x);
+ fd.y = fma(a.y, b.y, c.y);
+ fd.z = fma(a.z, b.z, c.z);
+ fd.w = fma(a.w, b.w, c.w);
+ return fd;
+ }))
+COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION(
+ __nv_bfloat16, dtype::bfloat168, dtype::float8, TernaryOpType::kFma, DEVICE,
+ STMTS_WRAPPER({
+ dtype::float8 fd;
+ CastFunctor<__nv_bfloat16, __nv_bfloat162> cast;
+ TernaryOpFunctor<__nv_bfloat162, __nv_bfloat162, float2,
+ TernaryOpType::kFma>
+ fma;
+ __nv_bfloat162 s = cast(a);
+ fd.x = fma(s, b.x, c.x);
+ fd.y = fma(s, b.y, c.y);
+ fd.z = fma(s, b.z, c.z);
+ fd.w = fma(s, b.w, c.w);
+ return fd;
+ }))
+
+#endif /* defined(COLOSSAL_WITH_CUDA) */
+
+#undef COLOSSAL_TERNARY_FUNCTOR_SPECIALIZATION
+#undef STMTS_WRAPPER
+
+} // namespace funcs
+} // namespace colossalAI
diff --git a/extensions/csrc/funcs/unary_functor.h b/extensions/csrc/funcs/unary_functor.h
new file mode 100644
index 000000000000..207a0ff972d4
--- /dev/null
+++ b/extensions/csrc/funcs/unary_functor.h
@@ -0,0 +1,67 @@
+#pragma once
+
+#if defined(COLOSSAL_WITH_CUDA)
+#include
+#include
+#include
+#include
+#endif
+
+#include
+
+#include "common/data_type.h"
+#include "common/micros.h"
+
+namespace colossalAI {
+namespace funcs {
+
+// Note(LiuYang): As a retrieved table to check which operation is supported
+// already
+enum class UnaryOpType { kLog2Ceil = 0, kAbs, kSum };
+
+// Note(LiuYang): Implementation of common and simple unary operators should be
+// placed here, otherwise, they should be placed in a new file under functors
+// dir.
+template
+struct UnaryOpFunctor;
+
+#define COLOSSAL_UNARY_FUNCTOR_SPECIALIZATION( \
+ FROM, TO, UNARY_OP_TYPE, FUNCTION_MODIFIER, STMTS, ARGS...) \
+ template \
+ struct UnaryOpFunctor \
+ : public std::unary_function { \
+ FUNCTION_MODIFIER TO operator()(FROM val) STMTS \
+ };
+
+COLOSSAL_UNARY_FUNCTOR_SPECIALIZATION(
+ T, T, UnaryOpType::kAbs, HOSTDEVICE, { return std::abs(val); }, typename T)
+
+COLOSSAL_UNARY_FUNCTOR_SPECIALIZATION(int, int, UnaryOpType::kLog2Ceil,
+ HOSTDEVICE, {
+ int log2_value = 0;
+ while ((1 << log2_value) < val)
+ ++log2_value;
+ return log2_value;
+ })
+
+#if defined(COLOSSAL_WITH_CUDA)
+
+COLOSSAL_UNARY_FUNCTOR_SPECIALIZATION(float2, float, UnaryOpType::kSum, DEVICE,
+ { return val.x + val.y; })
+
+COLOSSAL_UNARY_FUNCTOR_SPECIALIZATION(float4, float, UnaryOpType::kSum, DEVICE,
+ { return val.x + val.y + val.z + val.w; })
+
+COLOSSAL_UNARY_FUNCTOR_SPECIALIZATION(dtype::float8, float, UnaryOpType::kSum,
+ DEVICE, {
+ return val.x.x + val.x.y + val.y.x +
+ val.y.y + val.z.x + val.z.y +
+ val.w.x + val.w.y;
+ })
+
+#endif /* defined(COLOSSAL_WITH_CUDA) */
+
+#undef COLOSSAL_UARY_FUNCTOR_SPECIALIZATION
+
+} // namespace funcs
+} // namespace colossalAI
diff --git a/extensions/csrc/arm/cpu_adam_arm.cpp b/extensions/csrc/kernel/arm/cpu_adam_arm.cpp
similarity index 100%
rename from extensions/csrc/arm/cpu_adam_arm.cpp
rename to extensions/csrc/kernel/arm/cpu_adam_arm.cpp
diff --git a/extensions/csrc/arm/cpu_adam_arm.h b/extensions/csrc/kernel/arm/cpu_adam_arm.h
similarity index 100%
rename from extensions/csrc/arm/cpu_adam_arm.h
rename to extensions/csrc/kernel/arm/cpu_adam_arm.h
diff --git a/extensions/csrc/kernel/cuda/activation_kernel.cu b/extensions/csrc/kernel/cuda/activation_kernel.cu
new file mode 100644
index 000000000000..c69003d84ac9
--- /dev/null
+++ b/extensions/csrc/kernel/cuda/activation_kernel.cu
@@ -0,0 +1,77 @@
+#include
+#include
+#include
+
+#include "common/micros.h"
+#include "common/mp_type_traits.h"
+
+using colossalAI::common::MPTypeTrait;
+
+template
+__device__ __forceinline__ T silu_kernel(const T& x) {
+ // x * sigmoid(x)
+ using MT = typename MPTypeTrait::Type;
+ return static_cast((static_cast(x)) / (static_cast(1.0f) + expf(static_cast(-x))));
+}
+
+template
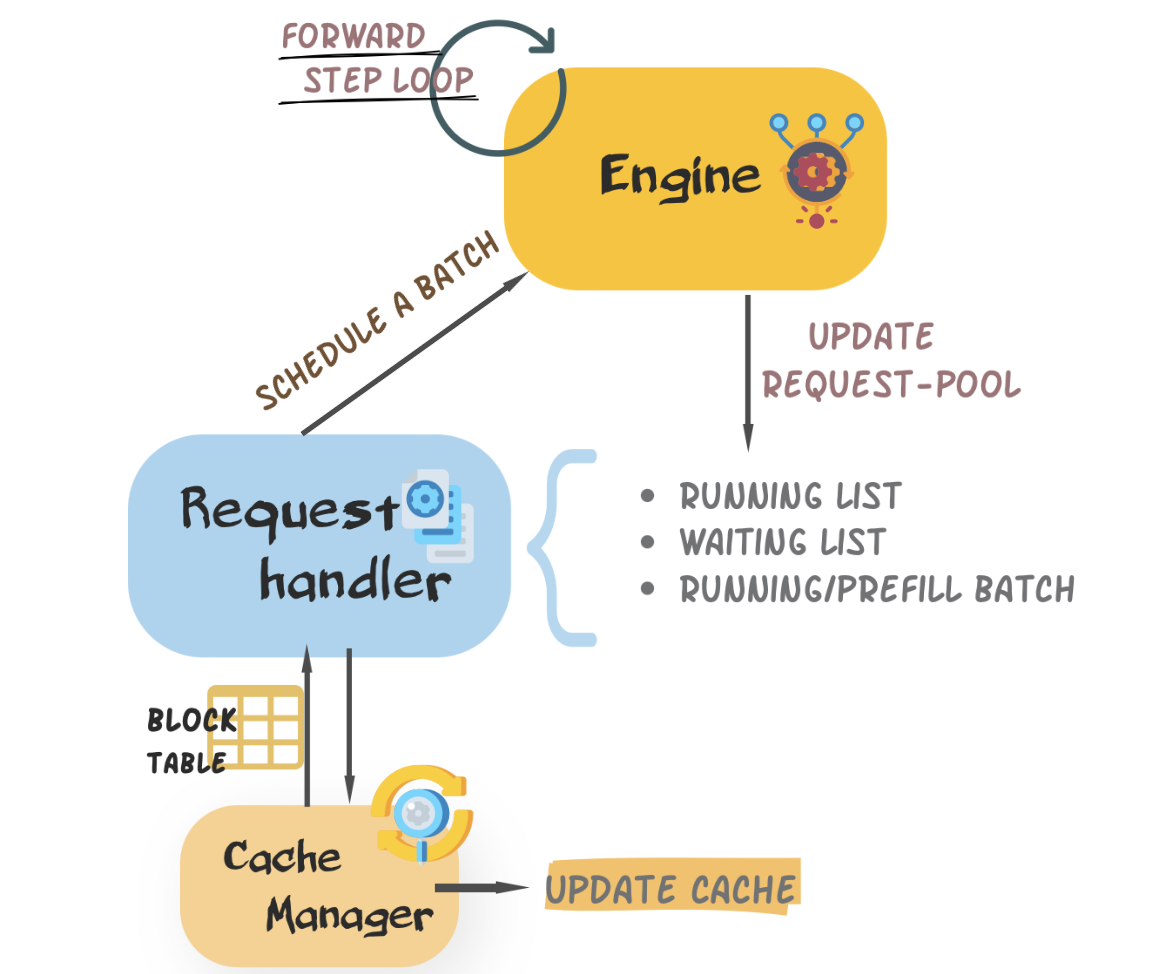 +
+ 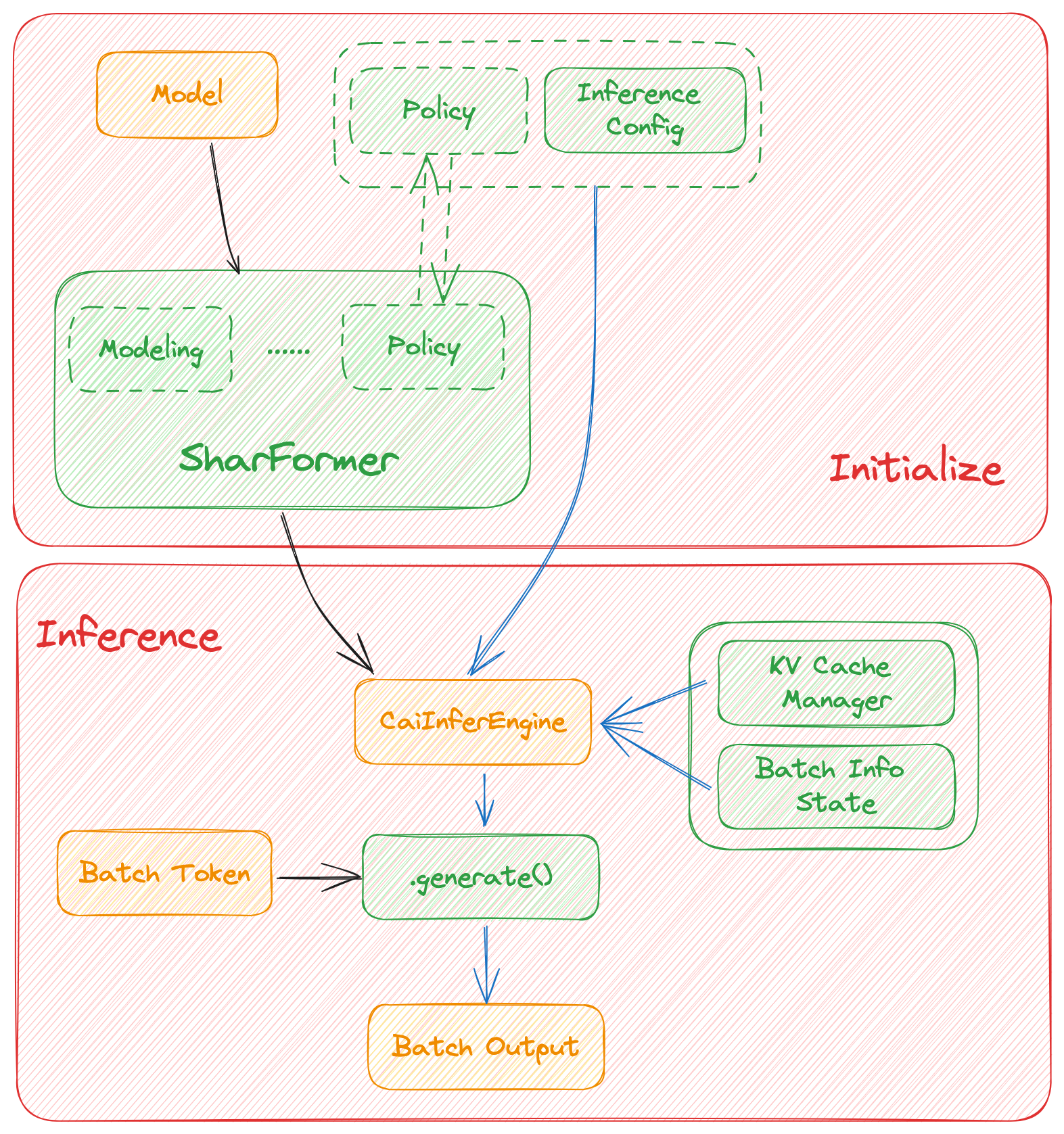 +### :mailbox_closed: Engine
+Engine is designed as the entry point where the user kickstarts an inference loop. User can easily instantialize an inference engine with the inference configuration and execute requests. The engine object will expose the following APIs for inference:
-## Roadmap of our implementation
+- `generate`: main function which handles inputs, performs inference and returns outputs
+- `add_request`: add request to the waiting list
+- `step`: perform one decoding iteration. The `request handler` first schedules a batch to do prefill/decoding. Then, it invokes a model to generate a batch of token and afterwards does logit processing and sampling, checks and decodes finished requests.
-- [x] Design cache manager and batch infer state
-- [x] Design TpInference engine to integrates with `Shardformer`
-- [x] Register corresponding high-performance `kernel` and `ops`
-- [x] Design policies and forwards (e.g. `Llama` and `Bloom`)
- - [x] policy
- - [x] context forward
- - [x] token forward
- - [x] support flash-decoding
-- [x] Support all models
- - [x] Llama
- - [x] Llama-2
- - [x] Bloom
- - [x] Chatglm2
-- [x] Quantization
- - [x] GPTQ
- - [x] SmoothQuant
-- [ ] Benchmarking for all models
+### :game_die: Request Handler
-## Get started
+Request handler is responsible for managing requests and scheduling a proper batch from exisiting requests. According to the existing work and experiments, we do believe that it is beneficial to increase the length of decoding sequences. In our design, we partition requests into three priorities depending on their lengths, the longer sequences are first considered.
-### Installation
+
+### :mailbox_closed: Engine
+Engine is designed as the entry point where the user kickstarts an inference loop. User can easily instantialize an inference engine with the inference configuration and execute requests. The engine object will expose the following APIs for inference:
-## Roadmap of our implementation
+- `generate`: main function which handles inputs, performs inference and returns outputs
+- `add_request`: add request to the waiting list
+- `step`: perform one decoding iteration. The `request handler` first schedules a batch to do prefill/decoding. Then, it invokes a model to generate a batch of token and afterwards does logit processing and sampling, checks and decodes finished requests.
-- [x] Design cache manager and batch infer state
-- [x] Design TpInference engine to integrates with `Shardformer`
-- [x] Register corresponding high-performance `kernel` and `ops`
-- [x] Design policies and forwards (e.g. `Llama` and `Bloom`)
- - [x] policy
- - [x] context forward
- - [x] token forward
- - [x] support flash-decoding
-- [x] Support all models
- - [x] Llama
- - [x] Llama-2
- - [x] Bloom
- - [x] Chatglm2
-- [x] Quantization
- - [x] GPTQ
- - [x] SmoothQuant
-- [ ] Benchmarking for all models
+### :game_die: Request Handler
-## Get started
+Request handler is responsible for managing requests and scheduling a proper batch from exisiting requests. According to the existing work and experiments, we do believe that it is beneficial to increase the length of decoding sequences. In our design, we partition requests into three priorities depending on their lengths, the longer sequences are first considered.
-### Installation
+ +
+  +
+