From d696d99f3a48f004163b459429c51e0e27400a3c Mon Sep 17 00:00:00 2001
From: AmadeusGB <1069830494@qq.com>
Date: Tue, 11 Mar 2025 16:48:15 -0700
Subject: [PATCH 1/2] update cn version
---
units/cn/_toctree.yml | 260 ++++
units/cn/communication/certification.mdx | 29 +
units/cn/communication/conclusion.mdx | 24 +
units/cn/live1/live1.mdx | 9 +
units/cn/unit0/discord101.mdx | 37 +
units/cn/unit0/introduction.mdx | 136 ++
units/cn/unit0/setup.mdx | 31 +
units/cn/unit1/additional-readings.mdx | 14 +
units/cn/unit1/conclusion.mdx | 21 +
units/cn/unit1/deep-rl.mdx | 20 +
units/cn/unit1/exp-exp-tradeoff.mdx | 36 +
units/cn/unit1/glossary.mdx | 70 +
units/cn/unit1/hands-on.mdx | 702 ++++++++++
units/cn/unit1/introduction.mdx | 27 +
units/cn/unit1/quiz.mdx | 168 +++
units/cn/unit1/rl-framework.mdx | 141 ++
units/cn/unit1/summary.mdx | 19 +
units/cn/unit1/tasks.mdx | 26 +
units/cn/unit1/two-methods.mdx | 90 ++
units/cn/unit1/what-is-rl.mdx | 40 +
units/cn/unit2/additional-readings.mdx | 15 +
units/cn/unit2/bellman-equation.mdx | 63 +
units/cn/unit2/conclusion.mdx | 20 +
units/cn/unit2/glossary.mdx | 47 +
units/cn/unit2/hands-on.mdx | 1148 +++++++++++++++++
units/cn/unit2/introduction.mdx | 26 +
units/cn/unit2/mc-vs-td.mdx | 135 ++
units/cn/unit2/mid-way-quiz.mdx | 106 ++
units/cn/unit2/mid-way-recap.mdx | 17 +
units/cn/unit2/q-learning-example.mdx | 83 ++
units/cn/unit2/q-learning-recap.mdx | 24 +
units/cn/unit2/q-learning.mdx | 160 +++
units/cn/unit2/quiz2.mdx | 96 ++
.../unit2/two-types-value-based-methods.mdx | 85 ++
units/cn/unit2/what-is-rl.mdx | 25 +
units/cn/unit3/additional-readings.mdx | 9 +
units/cn/unit3/conclusion.mdx | 17 +
units/cn/unit3/deep-q-algorithm.mdx | 105 ++
units/cn/unit3/deep-q-network.mdx | 41 +
units/cn/unit3/from-q-to-dqn.mdx | 34 +
units/cn/unit3/glossary.mdx | 37 +
units/cn/unit3/hands-on.mdx | 341 +++++
units/cn/unit3/introduction.mdx | 19 +
units/cn/unit3/quiz.mdx | 104 ++
units/cn/unit4/additional-readings.mdx | 20 +
units/cn/unit4/advantages-disadvantages.mdx | 74 ++
units/cn/unit4/conclusion.mdx | 15 +
units/cn/unit4/glossary.mdx | 25 +
units/cn/unit4/hands-on.mdx | 1019 +++++++++++++++
units/cn/unit4/introduction.mdx | 24 +
units/cn/unit4/pg-theorem.mdx | 86 ++
units/cn/unit4/policy-gradient.mdx | 122 ++
units/cn/unit4/quiz.mdx | 82 ++
.../unit4/what-are-policy-based-methods.mdx | 42 +
units/cn/unit5/bonus.mdx | 19 +
units/cn/unit5/conclusion.mdx | 22 +
units/cn/unit5/curiosity.mdx | 50 +
units/cn/unit5/hands-on.mdx | 416 ++++++
units/cn/unit5/how-mlagents-works.mdx | 68 +
units/cn/unit5/introduction.mdx | 31 +
units/cn/unit5/pyramids.mdx | 39 +
units/cn/unit5/quiz.mdx | 132 ++
units/cn/unit5/snowball-target.mdx | 57 +
units/cn/unit6/additional-readings.mdx | 17 +
units/cn/unit6/advantage-actor-critic.mdx | 70 +
units/cn/unit6/conclusion.mdx | 11 +
units/cn/unit6/hands-on.mdx | 396 ++++++
units/cn/unit6/introduction.mdx | 22 +
units/cn/unit6/quiz.mdx | 123 ++
units/cn/unit6/variance-problem.mdx | 31 +
units/cn/unit7/additional-readings.mdx | 17 +
units/cn/unit7/conclusion.mdx | 11 +
units/cn/unit7/hands-on.mdx | 322 +++++
units/cn/unit7/introduction-to-marl.mdx | 55 +
units/cn/unit7/introduction.mdx | 36 +
units/cn/unit7/multi-agent-setting.mdx | 57 +
units/cn/unit7/quiz.mdx | 139 ++
units/cn/unit7/self-play.mdx | 134 ++
units/cn/unit8/additional-readings.mdx | 21 +
.../cn/unit8/clipped-surrogate-objective.mdx | 69 +
units/cn/unit8/conclusion-sf.mdx | 13 +
units/cn/unit8/conclusion.mdx | 9 +
units/cn/unit8/hands-on-cleanrl.mdx | 1078 ++++++++++++++++
units/cn/unit8/hands-on-sf.mdx | 430 ++++++
units/cn/unit8/introduction-sf.mdx | 13 +
units/cn/unit8/introduction.mdx | 23 +
units/cn/unit8/intuition-behind-ppo.mdx | 16 +
units/cn/unit8/visualize.mdx | 68 +
units/cn/unitbonus1/conclusion.mdx | 12 +
units/cn/unitbonus1/how-huggy-works.mdx | 66 +
units/cn/unitbonus1/introduction.mdx | 7 +
units/cn/unitbonus1/play.mdx | 18 +
units/cn/unitbonus1/train.mdx | 348 +++++
units/cn/unitbonus2/hands-on.mdx | 16 +
units/cn/unitbonus2/introduction.mdx | 7 +
units/cn/unitbonus2/optuna.mdx | 15 +
units/cn/unitbonus3/curriculum-learning.mdx | 53 +
units/cn/unitbonus3/decision-transformers.mdx | 31 +
units/cn/unitbonus3/envs-to-try.mdx | 88 ++
units/cn/unitbonus3/generalisation.mdx | 12 +
units/cn/unitbonus3/godotrl.mdx | 257 ++++
units/cn/unitbonus3/introduction.mdx | 11 +
units/cn/unitbonus3/language-models.mdx | 45 +
units/cn/unitbonus3/learning-agents.mdx | 37 +
units/cn/unitbonus3/model-based.mdx | 32 +
units/cn/unitbonus3/offline-online.mdx | 37 +
units/cn/unitbonus3/rl-documentation.mdx | 51 +
units/cn/unitbonus3/rlhf.mdx | 50 +
units/cn/unitbonus3/student-works.mdx | 68 +
units/cn/unitbonus5/conclusion.mdx | 5 +
.../unitbonus5/customize-the-environment.mdx | 27 +
units/cn/unitbonus5/getting-started.mdx | 266 ++++
units/cn/unitbonus5/introduction.mdx | 23 +
units/cn/unitbonus5/the-environment.mdx | 9 +
units/cn/unitbonus5/train-our-robot.mdx | 53 +
115 files changed, 11825 insertions(+)
create mode 100644 units/cn/_toctree.yml
create mode 100644 units/cn/communication/certification.mdx
create mode 100644 units/cn/communication/conclusion.mdx
create mode 100644 units/cn/live1/live1.mdx
create mode 100644 units/cn/unit0/discord101.mdx
create mode 100644 units/cn/unit0/introduction.mdx
create mode 100644 units/cn/unit0/setup.mdx
create mode 100644 units/cn/unit1/additional-readings.mdx
create mode 100644 units/cn/unit1/conclusion.mdx
create mode 100644 units/cn/unit1/deep-rl.mdx
create mode 100644 units/cn/unit1/exp-exp-tradeoff.mdx
create mode 100644 units/cn/unit1/glossary.mdx
create mode 100644 units/cn/unit1/hands-on.mdx
create mode 100644 units/cn/unit1/introduction.mdx
create mode 100644 units/cn/unit1/quiz.mdx
create mode 100644 units/cn/unit1/rl-framework.mdx
create mode 100644 units/cn/unit1/summary.mdx
create mode 100644 units/cn/unit1/tasks.mdx
create mode 100644 units/cn/unit1/two-methods.mdx
create mode 100644 units/cn/unit1/what-is-rl.mdx
create mode 100644 units/cn/unit2/additional-readings.mdx
create mode 100644 units/cn/unit2/bellman-equation.mdx
create mode 100644 units/cn/unit2/conclusion.mdx
create mode 100644 units/cn/unit2/glossary.mdx
create mode 100644 units/cn/unit2/hands-on.mdx
create mode 100644 units/cn/unit2/introduction.mdx
create mode 100644 units/cn/unit2/mc-vs-td.mdx
create mode 100644 units/cn/unit2/mid-way-quiz.mdx
create mode 100644 units/cn/unit2/mid-way-recap.mdx
create mode 100644 units/cn/unit2/q-learning-example.mdx
create mode 100644 units/cn/unit2/q-learning-recap.mdx
create mode 100644 units/cn/unit2/q-learning.mdx
create mode 100644 units/cn/unit2/quiz2.mdx
create mode 100644 units/cn/unit2/two-types-value-based-methods.mdx
create mode 100644 units/cn/unit2/what-is-rl.mdx
create mode 100644 units/cn/unit3/additional-readings.mdx
create mode 100644 units/cn/unit3/conclusion.mdx
create mode 100644 units/cn/unit3/deep-q-algorithm.mdx
create mode 100644 units/cn/unit3/deep-q-network.mdx
create mode 100644 units/cn/unit3/from-q-to-dqn.mdx
create mode 100644 units/cn/unit3/glossary.mdx
create mode 100644 units/cn/unit3/hands-on.mdx
create mode 100644 units/cn/unit3/introduction.mdx
create mode 100644 units/cn/unit3/quiz.mdx
create mode 100644 units/cn/unit4/additional-readings.mdx
create mode 100644 units/cn/unit4/advantages-disadvantages.mdx
create mode 100644 units/cn/unit4/conclusion.mdx
create mode 100644 units/cn/unit4/glossary.mdx
create mode 100644 units/cn/unit4/hands-on.mdx
create mode 100644 units/cn/unit4/introduction.mdx
create mode 100644 units/cn/unit4/pg-theorem.mdx
create mode 100644 units/cn/unit4/policy-gradient.mdx
create mode 100644 units/cn/unit4/quiz.mdx
create mode 100644 units/cn/unit4/what-are-policy-based-methods.mdx
create mode 100644 units/cn/unit5/bonus.mdx
create mode 100644 units/cn/unit5/conclusion.mdx
create mode 100644 units/cn/unit5/curiosity.mdx
create mode 100644 units/cn/unit5/hands-on.mdx
create mode 100644 units/cn/unit5/how-mlagents-works.mdx
create mode 100644 units/cn/unit5/introduction.mdx
create mode 100644 units/cn/unit5/pyramids.mdx
create mode 100644 units/cn/unit5/quiz.mdx
create mode 100644 units/cn/unit5/snowball-target.mdx
create mode 100644 units/cn/unit6/additional-readings.mdx
create mode 100644 units/cn/unit6/advantage-actor-critic.mdx
create mode 100644 units/cn/unit6/conclusion.mdx
create mode 100644 units/cn/unit6/hands-on.mdx
create mode 100644 units/cn/unit6/introduction.mdx
create mode 100644 units/cn/unit6/quiz.mdx
create mode 100644 units/cn/unit6/variance-problem.mdx
create mode 100644 units/cn/unit7/additional-readings.mdx
create mode 100644 units/cn/unit7/conclusion.mdx
create mode 100644 units/cn/unit7/hands-on.mdx
create mode 100644 units/cn/unit7/introduction-to-marl.mdx
create mode 100644 units/cn/unit7/introduction.mdx
create mode 100644 units/cn/unit7/multi-agent-setting.mdx
create mode 100644 units/cn/unit7/quiz.mdx
create mode 100644 units/cn/unit7/self-play.mdx
create mode 100644 units/cn/unit8/additional-readings.mdx
create mode 100644 units/cn/unit8/clipped-surrogate-objective.mdx
create mode 100644 units/cn/unit8/conclusion-sf.mdx
create mode 100644 units/cn/unit8/conclusion.mdx
create mode 100644 units/cn/unit8/hands-on-cleanrl.mdx
create mode 100644 units/cn/unit8/hands-on-sf.mdx
create mode 100644 units/cn/unit8/introduction-sf.mdx
create mode 100644 units/cn/unit8/introduction.mdx
create mode 100644 units/cn/unit8/intuition-behind-ppo.mdx
create mode 100644 units/cn/unit8/visualize.mdx
create mode 100644 units/cn/unitbonus1/conclusion.mdx
create mode 100644 units/cn/unitbonus1/how-huggy-works.mdx
create mode 100644 units/cn/unitbonus1/introduction.mdx
create mode 100644 units/cn/unitbonus1/play.mdx
create mode 100644 units/cn/unitbonus1/train.mdx
create mode 100644 units/cn/unitbonus2/hands-on.mdx
create mode 100644 units/cn/unitbonus2/introduction.mdx
create mode 100644 units/cn/unitbonus2/optuna.mdx
create mode 100644 units/cn/unitbonus3/curriculum-learning.mdx
create mode 100644 units/cn/unitbonus3/decision-transformers.mdx
create mode 100644 units/cn/unitbonus3/envs-to-try.mdx
create mode 100644 units/cn/unitbonus3/generalisation.mdx
create mode 100644 units/cn/unitbonus3/godotrl.mdx
create mode 100644 units/cn/unitbonus3/introduction.mdx
create mode 100644 units/cn/unitbonus3/language-models.mdx
create mode 100644 units/cn/unitbonus3/learning-agents.mdx
create mode 100644 units/cn/unitbonus3/model-based.mdx
create mode 100644 units/cn/unitbonus3/offline-online.mdx
create mode 100644 units/cn/unitbonus3/rl-documentation.mdx
create mode 100644 units/cn/unitbonus3/rlhf.mdx
create mode 100644 units/cn/unitbonus3/student-works.mdx
create mode 100644 units/cn/unitbonus5/conclusion.mdx
create mode 100644 units/cn/unitbonus5/customize-the-environment.mdx
create mode 100644 units/cn/unitbonus5/getting-started.mdx
create mode 100644 units/cn/unitbonus5/introduction.mdx
create mode 100644 units/cn/unitbonus5/the-environment.mdx
create mode 100644 units/cn/unitbonus5/train-our-robot.mdx
diff --git a/units/cn/_toctree.yml b/units/cn/_toctree.yml
new file mode 100644
index 00000000..f96d14cd
--- /dev/null
+++ b/units/cn/_toctree.yml
@@ -0,0 +1,260 @@
+- title: Unit 0. Welcome to the course
+ sections:
+ - local: unit0/introduction
+ title: Welcome to the course 🤗
+ - local: unit0/setup
+ title: Setup
+ - local: unit0/discord101
+ title: Discord 101
+- title: Unit 1. Introduction to Deep Reinforcement Learning
+ sections:
+ - local: unit1/introduction
+ title: Introduction
+ - local: unit1/what-is-rl
+ title: What is Reinforcement Learning?
+ - local: unit1/rl-framework
+ title: The Reinforcement Learning Framework
+ - local: unit1/tasks
+ title: The type of tasks
+ - local: unit1/exp-exp-tradeoff
+ title: The Exploration/ Exploitation tradeoff
+ - local: unit1/two-methods
+ title: The two main approaches for solving RL problems
+ - local: unit1/deep-rl
+ title: The “Deep” in Deep Reinforcement Learning
+ - local: unit1/summary
+ title: Summary
+ - local: unit1/glossary
+ title: Glossary
+ - local: unit1/hands-on
+ title: Hands-on
+ - local: unit1/quiz
+ title: Quiz
+ - local: unit1/conclusion
+ title: Conclusion
+ - local: unit1/additional-readings
+ title: Additional Readings
+- title: Bonus Unit 1. Introduction to Deep Reinforcement Learning with Huggy
+ sections:
+ - local: unitbonus1/introduction
+ title: Introduction
+ - local: unitbonus1/how-huggy-works
+ title: How Huggy works?
+ - local: unitbonus1/train
+ title: Train Huggy
+ - local: unitbonus1/play
+ title: Play with Huggy
+ - local: unitbonus1/conclusion
+ title: Conclusion
+- title: Live 1. How the course work, Q&A, and playing with Huggy
+ sections:
+ - local: live1/live1
+ title: Live 1. How the course work, Q&A, and playing with Huggy 🐶
+- title: Unit 2. Introduction to Q-Learning
+ sections:
+ - local: unit2/introduction
+ title: Introduction
+ - local: unit2/what-is-rl
+ title: What is RL? A short recap
+ - local: unit2/two-types-value-based-methods
+ title: The two types of value-based methods
+ - local: unit2/bellman-equation
+ title: The Bellman Equation, simplify our value estimation
+ - local: unit2/mc-vs-td
+ title: Monte Carlo vs Temporal Difference Learning
+ - local: unit2/mid-way-recap
+ title: Mid-way Recap
+ - local: unit2/mid-way-quiz
+ title: Mid-way Quiz
+ - local: unit2/q-learning
+ title: Introducing Q-Learning
+ - local: unit2/q-learning-example
+ title: A Q-Learning example
+ - local: unit2/q-learning-recap
+ title: Q-Learning Recap
+ - local: unit2/glossary
+ title: Glossary
+ - local: unit2/hands-on
+ title: Hands-on
+ - local: unit2/quiz2
+ title: Q-Learning Quiz
+ - local: unit2/conclusion
+ title: Conclusion
+ - local: unit2/additional-readings
+ title: Additional Readings
+- title: Unit 3. Deep Q-Learning with Atari Games
+ sections:
+ - local: unit3/introduction
+ title: Introduction
+ - local: unit3/from-q-to-dqn
+ title: From Q-Learning to Deep Q-Learning
+ - local: unit3/deep-q-network
+ title: The Deep Q-Network (DQN)
+ - local: unit3/deep-q-algorithm
+ title: The Deep Q Algorithm
+ - local: unit3/glossary
+ title: Glossary
+ - local: unit3/hands-on
+ title: Hands-on
+ - local: unit3/quiz
+ title: Quiz
+ - local: unit3/conclusion
+ title: Conclusion
+ - local: unit3/additional-readings
+ title: Additional Readings
+- title: Bonus Unit 2. Automatic Hyperparameter Tuning with Optuna
+ sections:
+ - local: unitbonus2/introduction
+ title: Introduction
+ - local: unitbonus2/optuna
+ title: Optuna
+ - local: unitbonus2/hands-on
+ title: Hands-on
+- title: Unit 4. Policy Gradient with PyTorch
+ sections:
+ - local: unit4/introduction
+ title: Introduction
+ - local: unit4/what-are-policy-based-methods
+ title: What are the policy-based methods?
+ - local: unit4/advantages-disadvantages
+ title: The advantages and disadvantages of policy-gradient methods
+ - local: unit4/policy-gradient
+ title: Diving deeper into policy-gradient
+ - local: unit4/pg-theorem
+ title: (Optional) the Policy Gradient Theorem
+ - local: unit4/glossary
+ title: Glossary
+ - local: unit4/hands-on
+ title: Hands-on
+ - local: unit4/quiz
+ title: Quiz
+ - local: unit4/conclusion
+ title: Conclusion
+ - local: unit4/additional-readings
+ title: Additional Readings
+- title: Unit 5. Introduction to Unity ML-Agents
+ sections:
+ - local: unit5/introduction
+ title: Introduction
+ - local: unit5/how-mlagents-works
+ title: How ML-Agents works?
+ - local: unit5/snowball-target
+ title: The SnowballTarget environment
+ - local: unit5/pyramids
+ title: The Pyramids environment
+ - local: unit5/curiosity
+ title: (Optional) What is curiosity in Deep Reinforcement Learning?
+ - local: unit5/hands-on
+ title: Hands-on
+ - local: unit5/bonus
+ title: Bonus. Learn to create your own environments with Unity and MLAgents
+ - local: unit5/quiz
+ title: Quiz
+ - local: unit5/conclusion
+ title: Conclusion
+- title: Unit 6. Actor Critic methods with Robotics environments
+ sections:
+ - local: unit6/introduction
+ title: Introduction
+ - local: unit6/variance-problem
+ title: The Problem of Variance in Reinforce
+ - local: unit6/advantage-actor-critic
+ title: Advantage Actor Critic (A2C)
+ - local: unit6/hands-on
+ title: Advantage Actor Critic (A2C) using Robotics Simulations with Panda-Gym 🤖
+ - local: unit6/quiz
+ title: Quiz
+ - local: unit6/conclusion
+ title: Conclusion
+ - local: unit6/additional-readings
+ title: Additional Readings
+- title: Unit 7. Introduction to Multi-Agents and AI vs AI
+ sections:
+ - local: unit7/introduction
+ title: Introduction
+ - local: unit7/introduction-to-marl
+ title: An introduction to Multi-Agents Reinforcement Learning (MARL)
+ - local: unit7/multi-agent-setting
+ title: Designing Multi-Agents systems
+ - local: unit7/self-play
+ title: Self-Play
+ - local: unit7/hands-on
+ title: Let's train our soccer team to beat your classmates' teams (AI vs. AI)
+ - local: unit7/quiz
+ title: Quiz
+ - local: unit7/conclusion
+ title: Conclusion
+ - local: unit7/additional-readings
+ title: Additional Readings
+- title: Unit 8. Part 1 Proximal Policy Optimization (PPO)
+ sections:
+ - local: unit8/introduction
+ title: Introduction
+ - local: unit8/intuition-behind-ppo
+ title: The intuition behind PPO
+ - local: unit8/clipped-surrogate-objective
+ title: Introducing the Clipped Surrogate Objective Function
+ - local: unit8/visualize
+ title: Visualize the Clipped Surrogate Objective Function
+ - local: unit8/hands-on-cleanrl
+ title: PPO with CleanRL
+ - local: unit8/conclusion
+ title: Conclusion
+ - local: unit8/additional-readings
+ title: Additional Readings
+- title: Unit 8. Part 2 Proximal Policy Optimization (PPO) with Doom
+ sections:
+ - local: unit8/introduction-sf
+ title: Introduction
+ - local: unit8/hands-on-sf
+ title: PPO with Sample Factory and Doom
+ - local: unit8/conclusion-sf
+ title: Conclusion
+- title: Bonus Unit 3. Advanced Topics in Reinforcement Learning
+ sections:
+ - local: unitbonus3/introduction
+ title: Introduction
+ - local: unitbonus3/model-based
+ title: Model-Based Reinforcement Learning
+ - local: unitbonus3/offline-online
+ title: Offline vs. Online Reinforcement Learning
+ - local: unitbonus3/generalisation
+ title: Generalisation Reinforcement Learning
+ - local: unitbonus3/rlhf
+ title: Reinforcement Learning from Human Feedback
+ - local: unitbonus3/decision-transformers
+ title: Decision Transformers and Offline RL
+ - local: unitbonus3/language-models
+ title: Language models in RL
+ - local: unitbonus3/curriculum-learning
+ title: (Automatic) Curriculum Learning for RL
+ - local: unitbonus3/envs-to-try
+ title: Interesting environments to try
+ - local: unitbonus3/learning-agents
+ title: An introduction to Unreal Learning Agents
+ - local: unitbonus3/godotrl
+ title: An Introduction to Godot RL
+ - local: unitbonus3/student-works
+ title: Students projects
+ - local: unitbonus3/rl-documentation
+ title: Brief introduction to RL documentation
+- title: Bonus Unit 5. Imitation Learning with Godot RL Agents
+ sections:
+ - local: unitbonus5/introduction
+ title: Introduction
+ - local: unitbonus5/the-environment
+ title: The environment
+ - local: unitbonus5/getting-started
+ title: Getting started
+ - local: unitbonus5/train-our-robot
+ title: Train our robot
+ - local: unitbonus5/customize-the-environment
+ title: (Optional) Customize the environment
+ - local: unitbonus5/conclusion
+ title: Conclusion
+- title: Certification and congratulations
+ sections:
+ - local: communication/conclusion
+ title: Congratulations
+ - local: communication/certification
+ title: Get your certificate of completion
diff --git a/units/cn/communication/certification.mdx b/units/cn/communication/certification.mdx
new file mode 100644
index 00000000..0326b224
--- /dev/null
+++ b/units/cn/communication/certification.mdx
@@ -0,0 +1,29 @@
+# 认证流程
+
+认证流程**完全免费**:
+
+- 获取*完成证书*:你需要**通过80%的作业**。
+- 获取*优秀证书*:你需要**通过100%的作业**。
+
+**没有截止日期,课程是自定进度的**。
+
+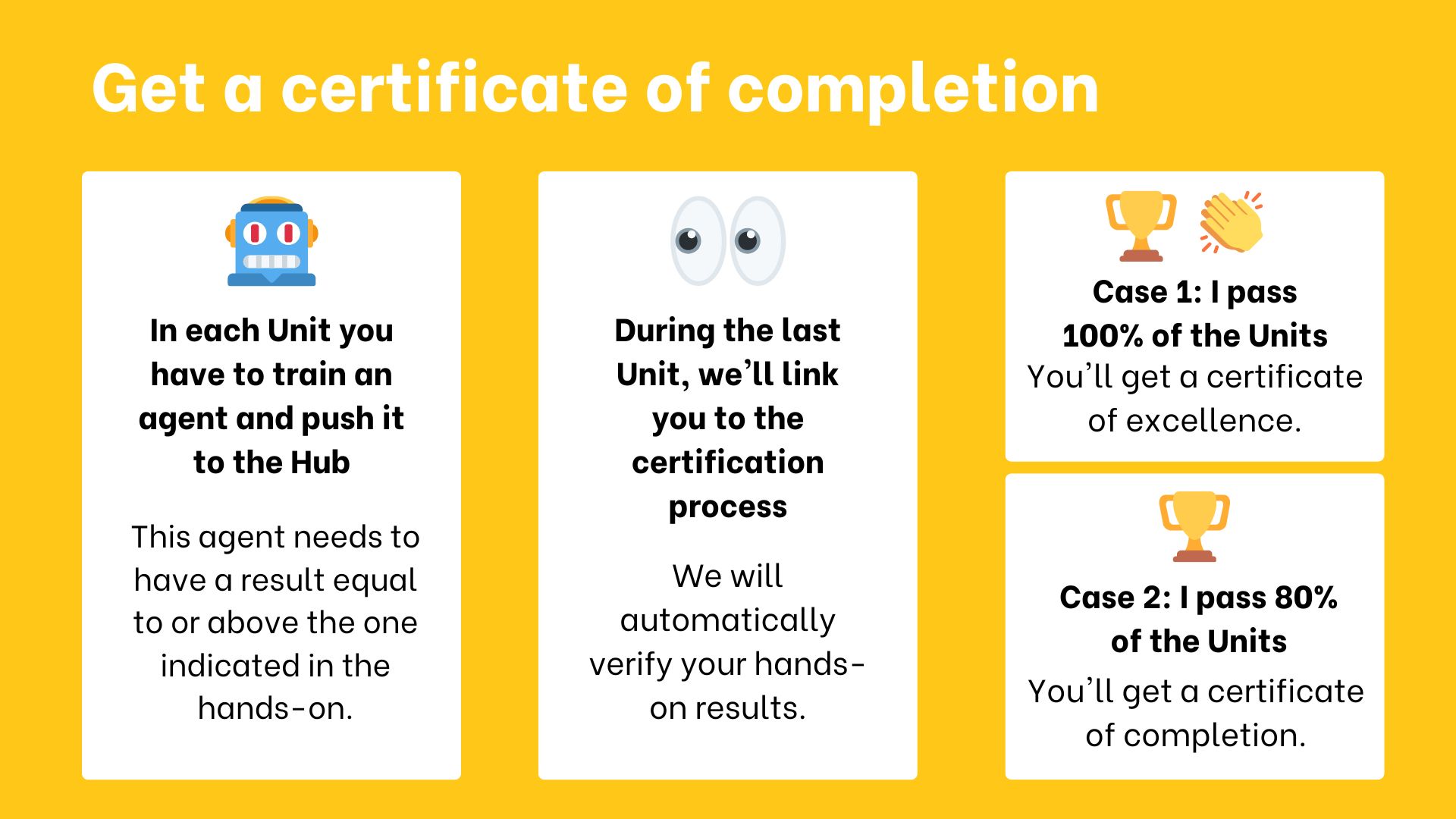 +
+当我们说通过时,**我们的意思是你的模型必须被推送到Hub并获得等于或高于最低要求的结果**。
+
+要检查你的进度以及哪些单元你已通过/未通过:https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+
+现在你已准备好进行认证流程,你需要:
+
+1. 前往:https://huggingface.co/spaces/huggingface-projects/Deep-RL-Course-Certification/
+2. 输入你的*hugging face用户名*、*名字*、*姓氏*
+
+3. 点击"生成我的证书"。
+ - 如果你通过了80%的作业,**恭喜**你获得了完成证书。
+ - 如果你通过了100%的作业,**恭喜**你获得了优秀证书。
+ - 如果你低于80%,不要气馁!检查哪些单元你需要重做以获取证书。
+
+4. 你可以下载PDF格式和PNG格式的证书。
+
+欢迎在Twitter上分享你的证书(标记@ThomasSimonini和@huggingface)以及在LinkedIn上分享。
+
diff --git a/units/cn/communication/conclusion.mdx b/units/cn/communication/conclusion.mdx
new file mode 100644
index 00000000..bc4e73e3
--- /dev/null
+++ b/units/cn/communication/conclusion.mdx
@@ -0,0 +1,24 @@
+# 恭喜
+
+
+
+当我们说通过时,**我们的意思是你的模型必须被推送到Hub并获得等于或高于最低要求的结果**。
+
+要检查你的进度以及哪些单元你已通过/未通过:https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+
+现在你已准备好进行认证流程,你需要:
+
+1. 前往:https://huggingface.co/spaces/huggingface-projects/Deep-RL-Course-Certification/
+2. 输入你的*hugging face用户名*、*名字*、*姓氏*
+
+3. 点击"生成我的证书"。
+ - 如果你通过了80%的作业,**恭喜**你获得了完成证书。
+ - 如果你通过了100%的作业,**恭喜**你获得了优秀证书。
+ - 如果你低于80%,不要气馁!检查哪些单元你需要重做以获取证书。
+
+4. 你可以下载PDF格式和PNG格式的证书。
+
+欢迎在Twitter上分享你的证书(标记@ThomasSimonini和@huggingface)以及在LinkedIn上分享。
+
diff --git a/units/cn/communication/conclusion.mdx b/units/cn/communication/conclusion.mdx
new file mode 100644
index 00000000..bc4e73e3
--- /dev/null
+++ b/units/cn/communication/conclusion.mdx
@@ -0,0 +1,24 @@
+# 恭喜
+
+ +
+
+**恭喜你完成本课程!** 通过坚持不懈、努力工作和决心,**你已经获得了深度强化学习的坚实基础**。
+
+但完成本课程**并不是你旅程的终点**。这只是开始:不要犹豫,去探索奖励单元3,那里我们展示了你可能感兴趣的主题。也不要犹豫**分享你正在做的事情,并在discord服务器中提问**
+
+**感谢**你参与本课程。**我希望你喜欢这门课程,就像我喜欢编写它一样**。
+
+欢迎**使用[此表单](https://forms.gle/BzKXWzLAGZESGNaE9)给我们反馈如何改进课程**
+
+别忘了**在下一部分查看如何获取(如果你通过了)你的完成证书🎓。**
+
+最后一件事,要与强化学习团队和我保持联系:
+
+- [在Twitter上关注我](https://twitter.com/thomassimonini)
+- [关注Hugging Face的Twitter账号](https://twitter.com/huggingface)
+- [加入Hugging Face Discord](https://www.hf.co/join/discord)
+
+## 持续学习,保持精彩 🤗
+
+Thomas Simonini,
diff --git a/units/cn/live1/live1.mdx b/units/cn/live1/live1.mdx
new file mode 100644
index 00000000..cf53a356
--- /dev/null
+++ b/units/cn/live1/live1.mdx
@@ -0,0 +1,9 @@
+# 直播1:课程如何运作,问答,以及与Huggy互动
+
+在这第一次直播中,我们解释了课程如何运作(范围、单元、挑战等)并回答了你们的问题。
+
+最后,我们看了一些你们训练的月球着陆器代理,并与你们的Huggies🐶互动
+
+
+
+要了解下一次直播的安排,**请查看discord服务器**。我们也会**给你发送电子邮件**。如果你不能参加,别担心,我们会录制直播内容。
\ No newline at end of file
diff --git a/units/cn/unit0/discord101.mdx b/units/cn/unit0/discord101.mdx
new file mode 100644
index 00000000..ea68592b
--- /dev/null
+++ b/units/cn/unit0/discord101.mdx
@@ -0,0 +1,37 @@
+# Discord 101 [[discord-101]]
+
+嘿!我是Huggy,一只狗狗🐕,我期待在这个强化学习课程中与你一起训练!
+虽然我对捡拾木棍知之甚少(目前如此),但我对Discord略知一二。所以我写了这份指南来帮助你了解它!
+
+
+
+
+**恭喜你完成本课程!** 通过坚持不懈、努力工作和决心,**你已经获得了深度强化学习的坚实基础**。
+
+但完成本课程**并不是你旅程的终点**。这只是开始:不要犹豫,去探索奖励单元3,那里我们展示了你可能感兴趣的主题。也不要犹豫**分享你正在做的事情,并在discord服务器中提问**
+
+**感谢**你参与本课程。**我希望你喜欢这门课程,就像我喜欢编写它一样**。
+
+欢迎**使用[此表单](https://forms.gle/BzKXWzLAGZESGNaE9)给我们反馈如何改进课程**
+
+别忘了**在下一部分查看如何获取(如果你通过了)你的完成证书🎓。**
+
+最后一件事,要与强化学习团队和我保持联系:
+
+- [在Twitter上关注我](https://twitter.com/thomassimonini)
+- [关注Hugging Face的Twitter账号](https://twitter.com/huggingface)
+- [加入Hugging Face Discord](https://www.hf.co/join/discord)
+
+## 持续学习,保持精彩 🤗
+
+Thomas Simonini,
diff --git a/units/cn/live1/live1.mdx b/units/cn/live1/live1.mdx
new file mode 100644
index 00000000..cf53a356
--- /dev/null
+++ b/units/cn/live1/live1.mdx
@@ -0,0 +1,9 @@
+# 直播1:课程如何运作,问答,以及与Huggy互动
+
+在这第一次直播中,我们解释了课程如何运作(范围、单元、挑战等)并回答了你们的问题。
+
+最后,我们看了一些你们训练的月球着陆器代理,并与你们的Huggies🐶互动
+
+
+
+要了解下一次直播的安排,**请查看discord服务器**。我们也会**给你发送电子邮件**。如果你不能参加,别担心,我们会录制直播内容。
\ No newline at end of file
diff --git a/units/cn/unit0/discord101.mdx b/units/cn/unit0/discord101.mdx
new file mode 100644
index 00000000..ea68592b
--- /dev/null
+++ b/units/cn/unit0/discord101.mdx
@@ -0,0 +1,37 @@
+# Discord 101 [[discord-101]]
+
+嘿!我是Huggy,一只狗狗🐕,我期待在这个强化学习课程中与你一起训练!
+虽然我对捡拾木棍知之甚少(目前如此),但我对Discord略知一二。所以我写了这份指南来帮助你了解它!
+
+ +
+Discord是一个免费的聊天平台。如果你用过Slack,**它非常相似**。有一个拥有50000名成员的Hugging Face社区Discord服务器,你可以点击这里一键加入。这么多人类可以一起玩耍!
+
+刚开始使用Discord可能有点令人生畏,所以让我带你了解一下。
+
+当你[注册我们的Discord服务器](http://hf.co/join/discord)时,你将选择你的兴趣。确保**点击"强化学习"**,你将获得访问包含所有课程相关频道的强化学习类别的权限。如果你想加入更多频道,尽管去做吧!🚀
+
+然后点击下一步,你将在`#introduce-yourself`频道**介绍自己**。
+
+
+
+
+Discord是一个免费的聊天平台。如果你用过Slack,**它非常相似**。有一个拥有50000名成员的Hugging Face社区Discord服务器,你可以点击这里一键加入。这么多人类可以一起玩耍!
+
+刚开始使用Discord可能有点令人生畏,所以让我带你了解一下。
+
+当你[注册我们的Discord服务器](http://hf.co/join/discord)时,你将选择你的兴趣。确保**点击"强化学习"**,你将获得访问包含所有课程相关频道的强化学习类别的权限。如果你想加入更多频道,尽管去做吧!🚀
+
+然后点击下一步,你将在`#introduce-yourself`频道**介绍自己**。
+
+
+ +
+它们位于强化学习类别中。**不要忘记通过在`role-assigment`中点击🤖强化学习来注册这些频道**。
+- `rl-announcements`:我们在这里提供**关于课程的最新信息**。
+- `rl-discussions`:你可以在这里**讨论强化学习并分享信息**。
+- `rl-study-group`:你可以在这里**提问并与同学交流**。
+- `rl-i-made-this`:你可以在这里**分享你的项目和模型**。
+
+HF社区服务器有一个蓬勃发展的人类社区,他们对许多领域感兴趣,所以你也可以从中学习。有论文讨论、活动和许多其他内容。
+
+这有用吗?我可以分享一些技巧:
+
+- 还有**语音频道**你也可以使用,尽管大多数人更喜欢文字聊天。
+- 你可以**使用markdown风格**进行文字聊天。所以如果你正在编写代码,你可以使用这种风格。可惜这对链接不太适用。
+- 你也可以开启线程!当**是一个长对话**时,这是个好主意。
+
+希望这对你有用!如果你有问题,尽管问!
+
+回头见!
+
+Huggy 🐶
diff --git a/units/cn/unit0/introduction.mdx b/units/cn/unit0/introduction.mdx
new file mode 100644
index 00000000..58e4e89b
--- /dev/null
+++ b/units/cn/unit0/introduction.mdx
@@ -0,0 +1,136 @@
+# 欢迎来到 🤗 深度强化学习课程 [[introduction]]
+
+
+
+它们位于强化学习类别中。**不要忘记通过在`role-assigment`中点击🤖强化学习来注册这些频道**。
+- `rl-announcements`:我们在这里提供**关于课程的最新信息**。
+- `rl-discussions`:你可以在这里**讨论强化学习并分享信息**。
+- `rl-study-group`:你可以在这里**提问并与同学交流**。
+- `rl-i-made-this`:你可以在这里**分享你的项目和模型**。
+
+HF社区服务器有一个蓬勃发展的人类社区,他们对许多领域感兴趣,所以你也可以从中学习。有论文讨论、活动和许多其他内容。
+
+这有用吗?我可以分享一些技巧:
+
+- 还有**语音频道**你也可以使用,尽管大多数人更喜欢文字聊天。
+- 你可以**使用markdown风格**进行文字聊天。所以如果你正在编写代码,你可以使用这种风格。可惜这对链接不太适用。
+- 你也可以开启线程!当**是一个长对话**时,这是个好主意。
+
+希望这对你有用!如果你有问题,尽管问!
+
+回头见!
+
+Huggy 🐶
diff --git a/units/cn/unit0/introduction.mdx b/units/cn/unit0/introduction.mdx
new file mode 100644
index 00000000..58e4e89b
--- /dev/null
+++ b/units/cn/unit0/introduction.mdx
@@ -0,0 +1,136 @@
+# 欢迎来到 🤗 深度强化学习课程 [[introduction]]
+
+ +
+欢迎来到人工智能中最引人入胜的主题:**深度强化学习**。
+
+本课程将**从入门到专家级别教授你深度强化学习**。它完全免费且开源!
+
+在这个介绍单元中,你将:
+
+- 了解更多关于**课程内容**。
+- **确定你要走的路径**(自学或认证流程)。
+- 了解更多关于你将参与的**AI对战AI挑战**。
+- 了解更多**关于我们**。
+- **创建你的Hugging Face账户**(免费)。
+- **注册我们的Discord服务器**,这是你可以与同学和我们(Hugging Face团队)交流的地方。
+
+让我们开始吧!
+
+## 你能期待什么? [[expect]]
+
+在本课程中,你将:
+
+- 📖 在**理论和实践**中学习深度强化学习。
+- 🧑💻 学习**使用著名的深度强化学习库**,如[Stable Baselines3](https://stable-baselines3.readthedocs.io/en/master/)、[RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)、[Sample Factory](https://samplefactory.dev/)和[CleanRL](https://github.com/vwxyzjn/cleanrl)。
+- 🤖 **在独特的环境中训练智能体**,如[SnowballFight](https://huggingface.co/spaces/ThomasSimonini/SnowballFight)、[Huggy the Doggo 🐶](https://huggingface.co/spaces/ThomasSimonini/Huggy)、[VizDoom (Doom)](https://vizdoom.cs.put.edu.pl/)以及经典环境如[Space Invaders](https://gymnasium.farama.org/environments/atari/space_invaders/)、[PyBullet](https://pybullet.org/wordpress/)等。
+- 💾 通过一行代码**将你训练的智能体分享到Hub**,并从社区下载强大的智能体。
+- 🏆 参与挑战,你将**评估你的智能体与其他团队相比的表现。你还将有机会与你训练的智能体对战**。
+- 🎓 通过完成80%的作业**获得完成证书**。
+
+还有更多!
+
+在本课程结束时,**你将从基础到SOTA(最先进的)方法获得坚实的基础**。
+
+不要忘记**注册课程**(我们收集你的电子邮件是为了能够**在每个单元发布时向你发送链接,并提供有关挑战和更新的信息**。)
+
+在这里注册 👉 这里
+
+
+## 课程是什么样的? [[course-look-like]]
+
+本课程由以下部分组成:
+
+- *理论部分*:你在理论上学习**概念**。
+- *实践部分*:你将学习**使用著名的深度强化学习库**来在独特的环境中训练你的智能体。这些实践将是**Google Colab笔记本,配有教程视频**,如果你更喜欢通过视频格式学习!
+
+- *挑战*:你将让你的智能体在不同的挑战中与其他智能体竞争。还将有[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)供你比较智能体的表现。
+
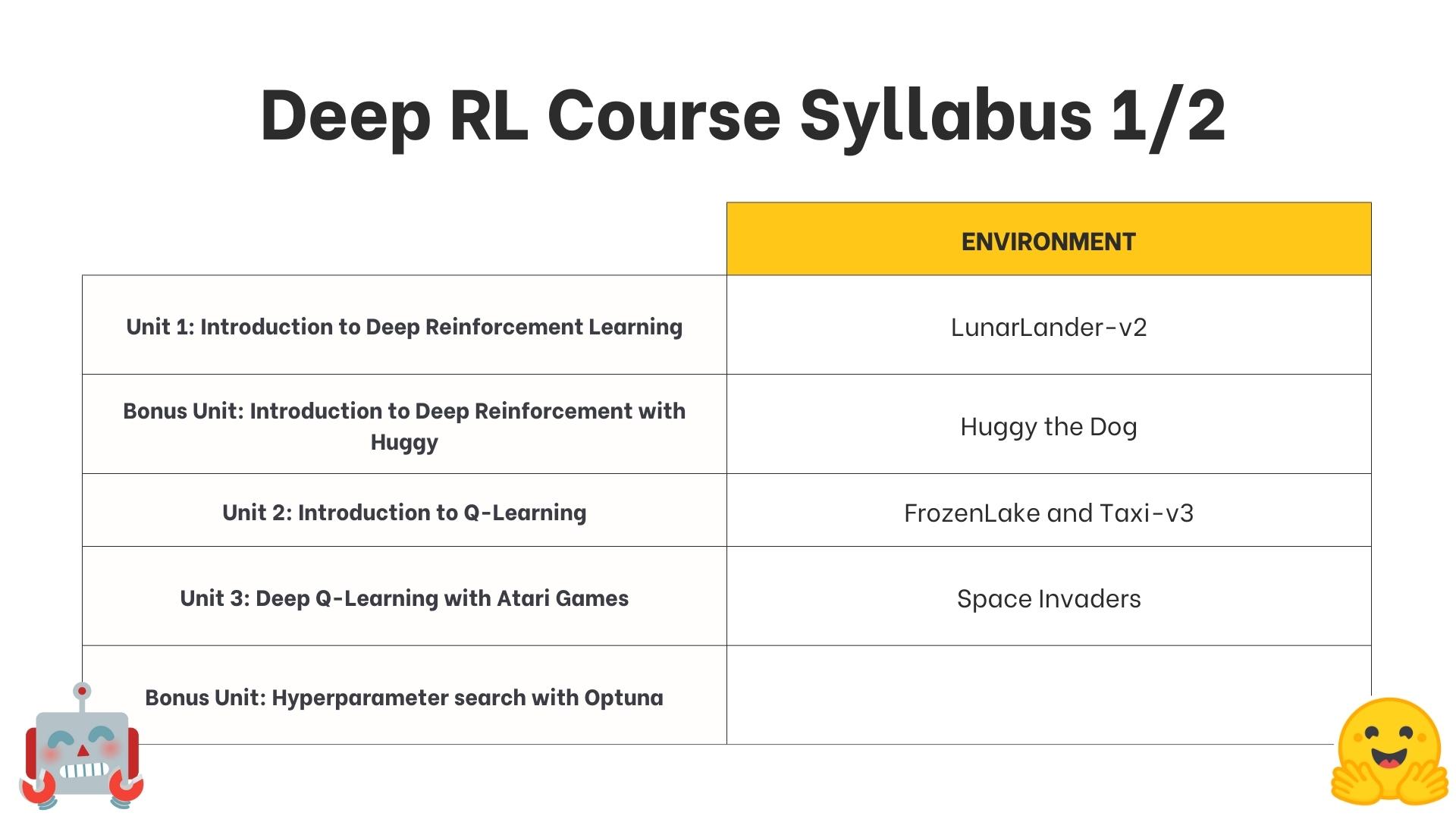
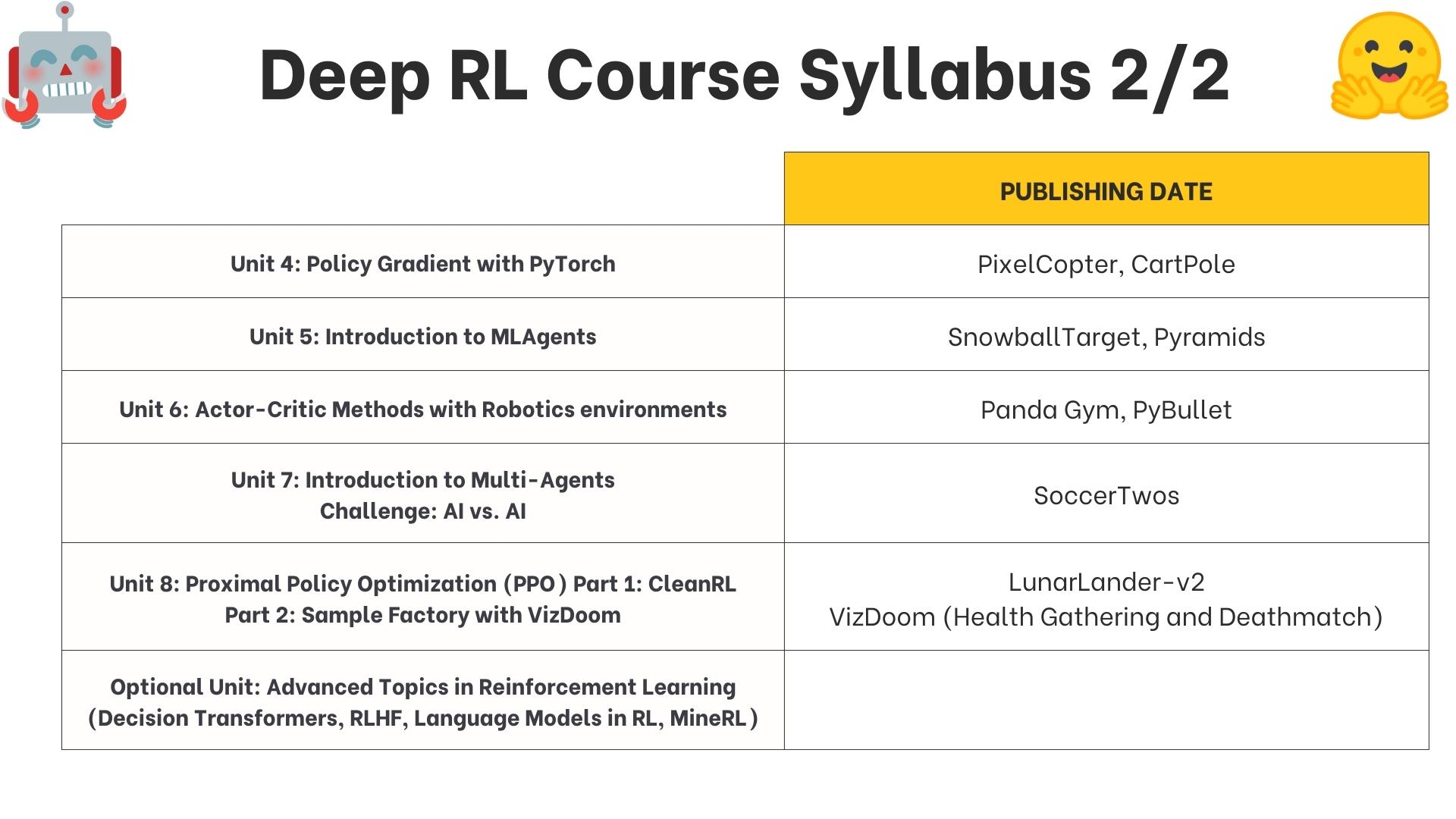
+## 课程大纲是什么? [[syllabus]]
+
+这是课程的大纲:
+
+
+
+欢迎来到人工智能中最引人入胜的主题:**深度强化学习**。
+
+本课程将**从入门到专家级别教授你深度强化学习**。它完全免费且开源!
+
+在这个介绍单元中,你将:
+
+- 了解更多关于**课程内容**。
+- **确定你要走的路径**(自学或认证流程)。
+- 了解更多关于你将参与的**AI对战AI挑战**。
+- 了解更多**关于我们**。
+- **创建你的Hugging Face账户**(免费)。
+- **注册我们的Discord服务器**,这是你可以与同学和我们(Hugging Face团队)交流的地方。
+
+让我们开始吧!
+
+## 你能期待什么? [[expect]]
+
+在本课程中,你将:
+
+- 📖 在**理论和实践**中学习深度强化学习。
+- 🧑💻 学习**使用著名的深度强化学习库**,如[Stable Baselines3](https://stable-baselines3.readthedocs.io/en/master/)、[RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)、[Sample Factory](https://samplefactory.dev/)和[CleanRL](https://github.com/vwxyzjn/cleanrl)。
+- 🤖 **在独特的环境中训练智能体**,如[SnowballFight](https://huggingface.co/spaces/ThomasSimonini/SnowballFight)、[Huggy the Doggo 🐶](https://huggingface.co/spaces/ThomasSimonini/Huggy)、[VizDoom (Doom)](https://vizdoom.cs.put.edu.pl/)以及经典环境如[Space Invaders](https://gymnasium.farama.org/environments/atari/space_invaders/)、[PyBullet](https://pybullet.org/wordpress/)等。
+- 💾 通过一行代码**将你训练的智能体分享到Hub**,并从社区下载强大的智能体。
+- 🏆 参与挑战,你将**评估你的智能体与其他团队相比的表现。你还将有机会与你训练的智能体对战**。
+- 🎓 通过完成80%的作业**获得完成证书**。
+
+还有更多!
+
+在本课程结束时,**你将从基础到SOTA(最先进的)方法获得坚实的基础**。
+
+不要忘记**注册课程**(我们收集你的电子邮件是为了能够**在每个单元发布时向你发送链接,并提供有关挑战和更新的信息**。)
+
+在这里注册 👉 这里
+
+
+## 课程是什么样的? [[course-look-like]]
+
+本课程由以下部分组成:
+
+- *理论部分*:你在理论上学习**概念**。
+- *实践部分*:你将学习**使用著名的深度强化学习库**来在独特的环境中训练你的智能体。这些实践将是**Google Colab笔记本,配有教程视频**,如果你更喜欢通过视频格式学习!
+
+- *挑战*:你将让你的智能体在不同的挑战中与其他智能体竞争。还将有[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)供你比较智能体的表现。
+
+## 课程大纲是什么? [[syllabus]]
+
+这是课程的大纲:
+
+ +
+ +
+## 两条路径:选择你自己的冒险 [[two-paths]]
+
+
+
+## 两条路径:选择你自己的冒险 [[two-paths]]
+
+ +
+你可以选择以下方式学习本课程:
+
+- *获取完成证书*:你需要完成80%的作业。
+- *获取优秀证书*:你需要完成100%的作业。
+- *作为简单的旁听*:你可以参与所有挑战,如果你想的话也可以做作业。
+
+**没有截止日期,课程是自定进度的**。
+两条路径**都是完全免费的**。
+无论你选择哪条路径,我们建议你**遵循推荐的学习节奏,与同学一起享受课程和挑战**。
+
+你不需要告诉我们你选择了哪条路径。**如果你完成了超过80%的作业,你将获得证书**。
+
+## 认证流程 [[certification-process]]
+
+认证流程**完全免费**:
+
+- *获取完成证书*:你需要完成80%的作业。
+- *获取优秀证书*:你需要完成100%的作业。
+
+再次强调,**没有截止日期**,因为课程是自定进度的。但我们的建议**是遵循推荐的学习节奏部分**。
+
+
+
+## 如何充分利用课程? [[advice]]
+
+为了充分利用课程,我们有一些建议:
+
+1. 在Discord中加入学习小组:小组学习总是更容易。为此,你需要加入我们的discord服务器。如果你是Discord新手,别担心!我们有一些工具可以帮助你了解它。
+2. **做测验和作业**:学习的最佳方式是实践和自我测试。
+3. **制定计划保持同步**:你可以使用下面我们推荐的学习节奏或创建自己的计划。
+
+
+
+你可以选择以下方式学习本课程:
+
+- *获取完成证书*:你需要完成80%的作业。
+- *获取优秀证书*:你需要完成100%的作业。
+- *作为简单的旁听*:你可以参与所有挑战,如果你想的话也可以做作业。
+
+**没有截止日期,课程是自定进度的**。
+两条路径**都是完全免费的**。
+无论你选择哪条路径,我们建议你**遵循推荐的学习节奏,与同学一起享受课程和挑战**。
+
+你不需要告诉我们你选择了哪条路径。**如果你完成了超过80%的作业,你将获得证书**。
+
+## 认证流程 [[certification-process]]
+
+认证流程**完全免费**:
+
+- *获取完成证书*:你需要完成80%的作业。
+- *获取优秀证书*:你需要完成100%的作业。
+
+再次强调,**没有截止日期**,因为课程是自定进度的。但我们的建议**是遵循推荐的学习节奏部分**。
+
+
+
+## 如何充分利用课程? [[advice]]
+
+为了充分利用课程,我们有一些建议:
+
+1. 在Discord中加入学习小组:小组学习总是更容易。为此,你需要加入我们的discord服务器。如果你是Discord新手,别担心!我们有一些工具可以帮助你了解它。
+2. **做测验和作业**:学习的最佳方式是实践和自我测试。
+3. **制定计划保持同步**:你可以使用下面我们推荐的学习节奏或创建自己的计划。
+
+ +
+## 我需要哪些工具? [[tools]]
+
+你只需要3样东西:
+
+- *一台电脑*,有互联网连接。
+- *Google Colab(免费版)*:我们大多数实践将使用Google Colab,**免费版就足够了**。
+- 一个*Hugging Face账户*:用于推送和加载模型。如果你还没有账户,可以在**[这里](https://hf.co/join)**创建一个(免费)。
+
+
+
+## 我需要哪些工具? [[tools]]
+
+你只需要3样东西:
+
+- *一台电脑*,有互联网连接。
+- *Google Colab(免费版)*:我们大多数实践将使用Google Colab,**免费版就足够了**。
+- 一个*Hugging Face账户*:用于推送和加载模型。如果你还没有账户,可以在**[这里](https://hf.co/join)**创建一个(免费)。
+
+ +
+
+## 推荐的学习节奏是什么? [[recommended-pace]]
+
+本课程的每一章都设计为**在1周内完成,每周大约需要3-4小时的工作**。但是,你可以根据需要花费尽可能多的时间来完成课程。如果你想更深入地研究某个主题,我们将提供额外的资源来帮助你实现这一目标。
+
+## 我们是谁 [[who-are-we]]
+关于作者:
+
+- Thomas Simonini是Hugging Face 🤗的开发者倡导者,专注于深度强化学习。他于2018年创立了深度强化学习课程,该课程成为深度强化学习领域中使用最广泛的课程之一。
+
+关于团队:
+
+- Omar Sanseviero是Hugging Face的机器学习工程师,他在机器学习、社区和开源的交叉领域工作。此前,Omar在Google的Assistant和TensorFlow Graphics团队担任软件工程师。他来自秘鲁,喜欢羊驼🦙。
+- Sayak Paul是Hugging Face的开发者倡导工程师。他对表示学习领域(自监督、半监督、模型鲁棒性)感兴趣。他喜欢观看犯罪和动作惊悚片🔪。
+
+
+## 本课程中有哪些挑战? [[challenges]]
+
+在课程的这个新版本中,你有两种类型的挑战:
+- [排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard),用于比较你的智能体与其他同学的智能体的表现。
+- [AI对战AI挑战](https://huggingface.co/learn/deep-rl-course/unit7/introduction?fw=pt),你可以训练你的智能体并与其他同学的智能体竞争。
+
+
+
+
+## 推荐的学习节奏是什么? [[recommended-pace]]
+
+本课程的每一章都设计为**在1周内完成,每周大约需要3-4小时的工作**。但是,你可以根据需要花费尽可能多的时间来完成课程。如果你想更深入地研究某个主题,我们将提供额外的资源来帮助你实现这一目标。
+
+## 我们是谁 [[who-are-we]]
+关于作者:
+
+- Thomas Simonini是Hugging Face 🤗的开发者倡导者,专注于深度强化学习。他于2018年创立了深度强化学习课程,该课程成为深度强化学习领域中使用最广泛的课程之一。
+
+关于团队:
+
+- Omar Sanseviero是Hugging Face的机器学习工程师,他在机器学习、社区和开源的交叉领域工作。此前,Omar在Google的Assistant和TensorFlow Graphics团队担任软件工程师。他来自秘鲁,喜欢羊驼🦙。
+- Sayak Paul是Hugging Face的开发者倡导工程师。他对表示学习领域(自监督、半监督、模型鲁棒性)感兴趣。他喜欢观看犯罪和动作惊悚片🔪。
+
+
+## 本课程中有哪些挑战? [[challenges]]
+
+在课程的这个新版本中,你有两种类型的挑战:
+- [排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard),用于比较你的智能体与其他同学的智能体的表现。
+- [AI对战AI挑战](https://huggingface.co/learn/deep-rl-course/unit7/introduction?fw=pt),你可以训练你的智能体并与其他同学的智能体竞争。
+
+ +
+## 我发现了一个bug,或者我想改进课程 [[contribute]]
+
+欢迎贡献 🤗
+
+- 如果你*在笔记本中发现了一个bug 🐛*,请提出一个issue并**描述问题**。
+- 如果你*想改进课程*,你可以提交一个Pull Request。
+
+## 我还有问题 [[questions]]
+
+请在我们的discord服务器 #rl-discussions中提问。
diff --git a/units/cn/unit0/setup.mdx b/units/cn/unit0/setup.mdx
new file mode 100644
index 00000000..57bbea42
--- /dev/null
+++ b/units/cn/unit0/setup.mdx
@@ -0,0 +1,31 @@
+# 设置 [[setup]]
+
+在了解了所有这些信息后,是时候开始了。我们将做两件事:
+
+1. **创建你的Hugging Face账户**(如果还没有的话)
+2. **注册Discord并介绍自己**(不要害羞🤗)
+
+### 让我们创建我的Hugging Face账户
+
+(如果还没有的话)在这里创建一个HF账户
+
+### 让我们加入我们的Discord服务器
+
+你现在可以注册我们的Discord服务器。这是你**可以与社区和我们聊天,创建和加入学习小组一起成长等**的地方
+
+👉🏻 在这里加入我们的discord服务器。
+
+当你加入时,记得在#introduce-yourself中介绍自己,并在#channels-and-roles中注册强化学习频道。
+
+我们有多个与强化学习相关的频道:
+- `rl-announcements`:我们在这里提供关于课程的最新信息。
+- `rl-discussions`:你可以在这里讨论强化学习并分享信息。
+- `rl-study-group`:你可以在这里创建和加入学习小组。
+- `rl-i-made-this`:你可以在这里分享你的项目和模型。
+
+如果这是你第一次使用Discord,我们写了一个Discord 101来获取最佳实践。查看下一部分。
+
+恭喜!**你刚刚完成了入门**。你现在已准备好开始学习深度强化学习。祝你玩得开心!
+
+
+### 持续学习,保持精彩 🤗
diff --git a/units/cn/unit1/additional-readings.mdx b/units/cn/unit1/additional-readings.mdx
new file mode 100644
index 00000000..cfeb4a39
--- /dev/null
+++ b/units/cn/unit1/additional-readings.mdx
@@ -0,0 +1,14 @@
+# 额外阅读材料 [[additional-readings]]
+
+这些是**可选阅读材料**,如果你想深入学习。
+
+## 深度强化学习 [[deep-rl]]
+
+- [强化学习导论,Richard Sutton和Andrew G. Barto著,第1、2和3章](http://incompleteideas.net/book/RLbook2020.pdf)
+- [深度强化学习基础系列,L1 MDPs,精确解法,最大熵强化学习,Pieter Abbeel主讲](https://youtu.be/2GwBez0D20A)
+- [OpenAI的Spinning Up RL,第1部分:强化学习的关键概念](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html)
+
+## Gym [[gym]]
+
+- [OpenAI Gym入门:基本构建模块](https://blog.paperspace.com/getting-started-with-openai-gym/)
+- [创建你自己的Gym自定义环境](https://www.gymlibrary.dev/content/environment_creation/)
diff --git a/units/cn/unit1/conclusion.mdx b/units/cn/unit1/conclusion.mdx
new file mode 100644
index 00000000..8903b2e1
--- /dev/null
+++ b/units/cn/unit1/conclusion.mdx
@@ -0,0 +1,21 @@
+# 结论 [[conclusion]]
+
+恭喜你完成本单元!**这是最大的一个单元**,包含了大量信息。同时恭喜你完成教程。你刚刚训练了你的第一个深度强化学习智能体并与社区分享了它们!🥳
+
+如果你对其中的一些元素**仍然感到困惑是很正常的**。我和所有学习强化学习的人都曾有过同样的感受。
+
+在继续之前**花时间真正理解这些材料**。在进入有趣的部分之前,掌握这些元素并建立坚实的基础很重要。
+
+当然,在课程中,我们将再次使用和解释这些术语,但在深入学习下一个单元之前最好先理解它们。
+
+在下一个(奖励)单元中,我们将通过**训练Huggy狗狗去捡拾木棍**来强化我们刚刚学到的知识。
+
+然后你将能够与它一起玩耍🤗。
+
+
+
+## 我发现了一个bug,或者我想改进课程 [[contribute]]
+
+欢迎贡献 🤗
+
+- 如果你*在笔记本中发现了一个bug 🐛*,请提出一个issue并**描述问题**。
+- 如果你*想改进课程*,你可以提交一个Pull Request。
+
+## 我还有问题 [[questions]]
+
+请在我们的discord服务器 #rl-discussions中提问。
diff --git a/units/cn/unit0/setup.mdx b/units/cn/unit0/setup.mdx
new file mode 100644
index 00000000..57bbea42
--- /dev/null
+++ b/units/cn/unit0/setup.mdx
@@ -0,0 +1,31 @@
+# 设置 [[setup]]
+
+在了解了所有这些信息后,是时候开始了。我们将做两件事:
+
+1. **创建你的Hugging Face账户**(如果还没有的话)
+2. **注册Discord并介绍自己**(不要害羞🤗)
+
+### 让我们创建我的Hugging Face账户
+
+(如果还没有的话)在这里创建一个HF账户
+
+### 让我们加入我们的Discord服务器
+
+你现在可以注册我们的Discord服务器。这是你**可以与社区和我们聊天,创建和加入学习小组一起成长等**的地方
+
+👉🏻 在这里加入我们的discord服务器。
+
+当你加入时,记得在#introduce-yourself中介绍自己,并在#channels-and-roles中注册强化学习频道。
+
+我们有多个与强化学习相关的频道:
+- `rl-announcements`:我们在这里提供关于课程的最新信息。
+- `rl-discussions`:你可以在这里讨论强化学习并分享信息。
+- `rl-study-group`:你可以在这里创建和加入学习小组。
+- `rl-i-made-this`:你可以在这里分享你的项目和模型。
+
+如果这是你第一次使用Discord,我们写了一个Discord 101来获取最佳实践。查看下一部分。
+
+恭喜!**你刚刚完成了入门**。你现在已准备好开始学习深度强化学习。祝你玩得开心!
+
+
+### 持续学习,保持精彩 🤗
diff --git a/units/cn/unit1/additional-readings.mdx b/units/cn/unit1/additional-readings.mdx
new file mode 100644
index 00000000..cfeb4a39
--- /dev/null
+++ b/units/cn/unit1/additional-readings.mdx
@@ -0,0 +1,14 @@
+# 额外阅读材料 [[additional-readings]]
+
+这些是**可选阅读材料**,如果你想深入学习。
+
+## 深度强化学习 [[deep-rl]]
+
+- [强化学习导论,Richard Sutton和Andrew G. Barto著,第1、2和3章](http://incompleteideas.net/book/RLbook2020.pdf)
+- [深度强化学习基础系列,L1 MDPs,精确解法,最大熵强化学习,Pieter Abbeel主讲](https://youtu.be/2GwBez0D20A)
+- [OpenAI的Spinning Up RL,第1部分:强化学习的关键概念](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html)
+
+## Gym [[gym]]
+
+- [OpenAI Gym入门:基本构建模块](https://blog.paperspace.com/getting-started-with-openai-gym/)
+- [创建你自己的Gym自定义环境](https://www.gymlibrary.dev/content/environment_creation/)
diff --git a/units/cn/unit1/conclusion.mdx b/units/cn/unit1/conclusion.mdx
new file mode 100644
index 00000000..8903b2e1
--- /dev/null
+++ b/units/cn/unit1/conclusion.mdx
@@ -0,0 +1,21 @@
+# 结论 [[conclusion]]
+
+恭喜你完成本单元!**这是最大的一个单元**,包含了大量信息。同时恭喜你完成教程。你刚刚训练了你的第一个深度强化学习智能体并与社区分享了它们!🥳
+
+如果你对其中的一些元素**仍然感到困惑是很正常的**。我和所有学习强化学习的人都曾有过同样的感受。
+
+在继续之前**花时间真正理解这些材料**。在进入有趣的部分之前,掌握这些元素并建立坚实的基础很重要。
+
+当然,在课程中,我们将再次使用和解释这些术语,但在深入学习下一个单元之前最好先理解它们。
+
+在下一个(奖励)单元中,我们将通过**训练Huggy狗狗去捡拾木棍**来强化我们刚刚学到的知识。
+
+然后你将能够与它一起玩耍🤗。
+
+ +
+最后,我们非常希望**听到你对课程的看法以及我们如何改进它**。如果你有一些反馈,请👉 [填写此表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 持续学习,保持精彩 🤗
+
+
diff --git a/units/cn/unit1/deep-rl.mdx b/units/cn/unit1/deep-rl.mdx
new file mode 100644
index 00000000..b17e61d5
--- /dev/null
+++ b/units/cn/unit1/deep-rl.mdx
@@ -0,0 +1,20 @@
+# 强化学习中的"深度" [[deep-rl]]
+
+
+到目前为止我们讨论的是强化学习。但"深度"在哪里发挥作用呢?
+
+
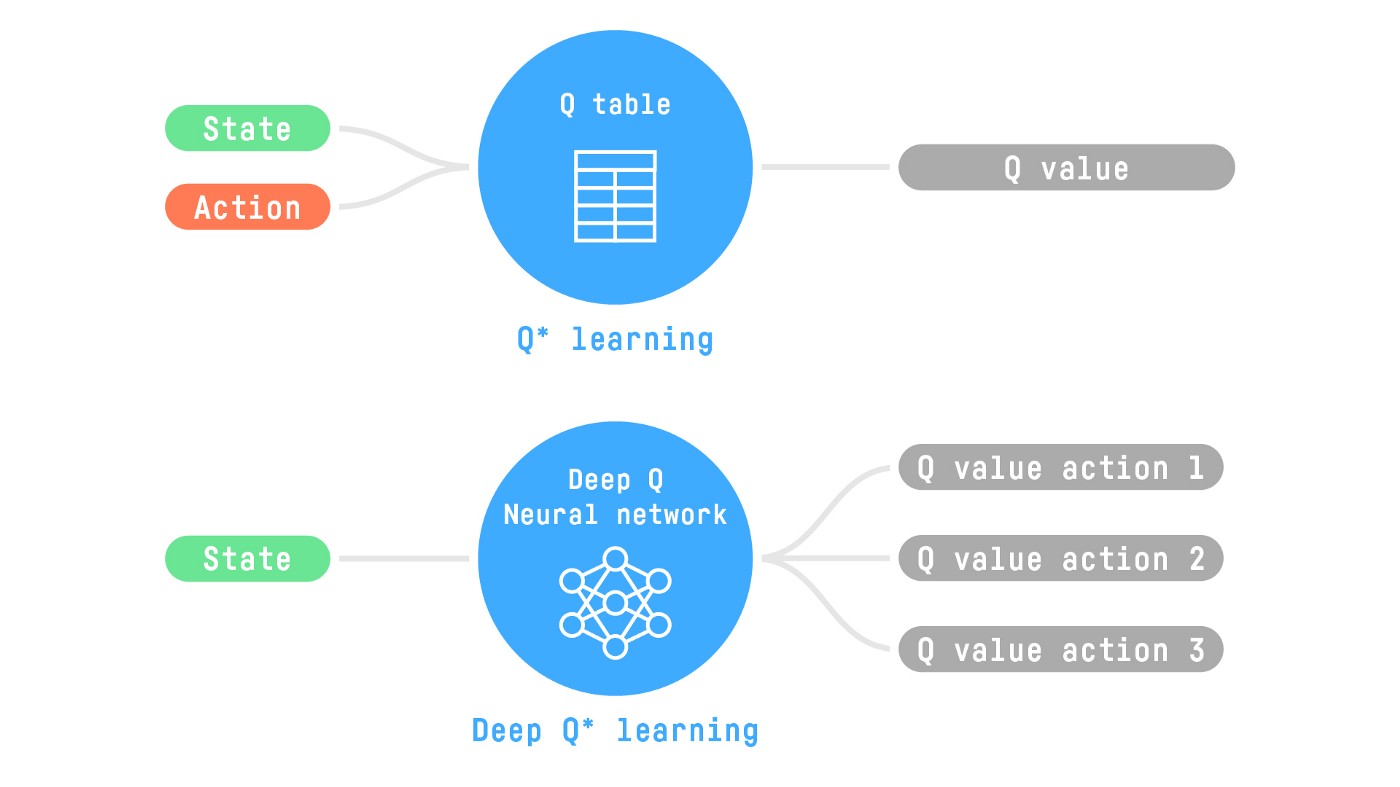
+深度强化学习引入**深度神经网络来解决强化学习问题**——因此得名"深度"。
+
+例如,在下一个单元中,我们将学习两种基于价值的算法:Q-Learning(经典强化学习)和Deep Q-Learning。
+
+你会看到两者的区别在于,在第一种方法中,**我们使用传统算法**创建一个Q表,帮助我们找出在每个状态下应该采取什么行动。
+
+在第二种方法中,**我们将使用神经网络**(来近似Q值)。
+
+
+
+
+最后,我们非常希望**听到你对课程的看法以及我们如何改进它**。如果你有一些反馈,请👉 [填写此表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 持续学习,保持精彩 🤗
+
+
diff --git a/units/cn/unit1/deep-rl.mdx b/units/cn/unit1/deep-rl.mdx
new file mode 100644
index 00000000..b17e61d5
--- /dev/null
+++ b/units/cn/unit1/deep-rl.mdx
@@ -0,0 +1,20 @@
+# 强化学习中的"深度" [[deep-rl]]
+
+
+到目前为止我们讨论的是强化学习。但"深度"在哪里发挥作用呢?
+
+
+深度强化学习引入**深度神经网络来解决强化学习问题**——因此得名"深度"。
+
+例如,在下一个单元中,我们将学习两种基于价值的算法:Q-Learning(经典强化学习)和Deep Q-Learning。
+
+你会看到两者的区别在于,在第一种方法中,**我们使用传统算法**创建一个Q表,帮助我们找出在每个状态下应该采取什么行动。
+
+在第二种方法中,**我们将使用神经网络**(来近似Q值)。
+
+
+ +图表灵感来自Udacity的Q学习笔记本
+
+
+如果你对深度学习不熟悉,你绝对应该观看[FastAI的实用深度学习课程](https://course.fast.ai)(免费)。
diff --git a/units/cn/unit1/exp-exp-tradeoff.mdx b/units/cn/unit1/exp-exp-tradeoff.mdx
new file mode 100644
index 00000000..0fc29708
--- /dev/null
+++ b/units/cn/unit1/exp-exp-tradeoff.mdx
@@ -0,0 +1,36 @@
+# 探索/利用权衡 [[exp-exp-tradeoff]]
+
+最后,在研究解决强化学习问题的不同方法之前,我们必须涵盖另一个非常重要的主题:*探索/利用权衡。*
+
+- *探索*是通过尝试随机动作来探索环境,以**找到关于环境的更多信息。**
+- *利用*是**利用已知信息来最大化奖励。**
+
+记住,我们的强化学习智能体的目标是最大化预期的累积奖励。然而,**我们可能会陷入一个常见的陷阱**。
+
+让我们举个例子:
+
+
+图表灵感来自Udacity的Q学习笔记本
+
+
+如果你对深度学习不熟悉,你绝对应该观看[FastAI的实用深度学习课程](https://course.fast.ai)(免费)。
diff --git a/units/cn/unit1/exp-exp-tradeoff.mdx b/units/cn/unit1/exp-exp-tradeoff.mdx
new file mode 100644
index 00000000..0fc29708
--- /dev/null
+++ b/units/cn/unit1/exp-exp-tradeoff.mdx
@@ -0,0 +1,36 @@
+# 探索/利用权衡 [[exp-exp-tradeoff]]
+
+最后,在研究解决强化学习问题的不同方法之前,我们必须涵盖另一个非常重要的主题:*探索/利用权衡。*
+
+- *探索*是通过尝试随机动作来探索环境,以**找到关于环境的更多信息。**
+- *利用*是**利用已知信息来最大化奖励。**
+
+记住,我们的强化学习智能体的目标是最大化预期的累积奖励。然而,**我们可能会陷入一个常见的陷阱**。
+
+让我们举个例子:
+
+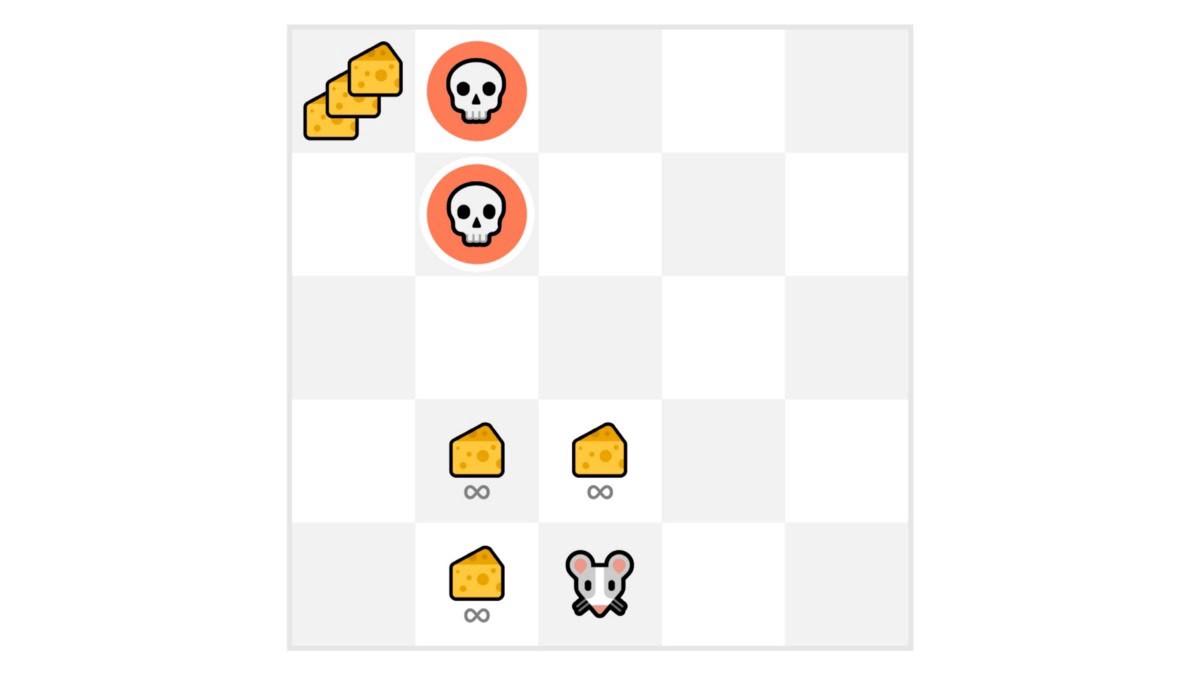 +
+在这个游戏中,我们的老鼠可以获得**无限量的小奶酪**(每个+1)。但在迷宫的顶部,有一大堆奶酪(+1000)。
+
+然而,如果我们只专注于利用,我们的智能体将永远无法到达那一大堆奶酪。相反,它只会利用**最近的奖励来源**,即使这个来源很小(利用)。
+
+但如果我们的智能体进行一点探索,它可以**发现大奖励**(一堆大奶酪)。
+
+这就是我们所说的探索/利用权衡。我们需要平衡**探索环境**和**利用我们对环境已知的信息**之间的比例。
+
+因此,我们必须**定义一个规则来帮助处理这种权衡**。我们将在未来的单元中看到处理它的不同方法。
+
+如果这仍然令人困惑,**想想一个现实问题:选择餐厅的问题:**
+
+
+
+
+
+在这个游戏中,我们的老鼠可以获得**无限量的小奶酪**(每个+1)。但在迷宫的顶部,有一大堆奶酪(+1000)。
+
+然而,如果我们只专注于利用,我们的智能体将永远无法到达那一大堆奶酪。相反,它只会利用**最近的奖励来源**,即使这个来源很小(利用)。
+
+但如果我们的智能体进行一点探索,它可以**发现大奖励**(一堆大奶酪)。
+
+这就是我们所说的探索/利用权衡。我们需要平衡**探索环境**和**利用我们对环境已知的信息**之间的比例。
+
+因此,我们必须**定义一个规则来帮助处理这种权衡**。我们将在未来的单元中看到处理它的不同方法。
+
+如果这仍然令人困惑,**想想一个现实问题:选择餐厅的问题:**
+
+
+
+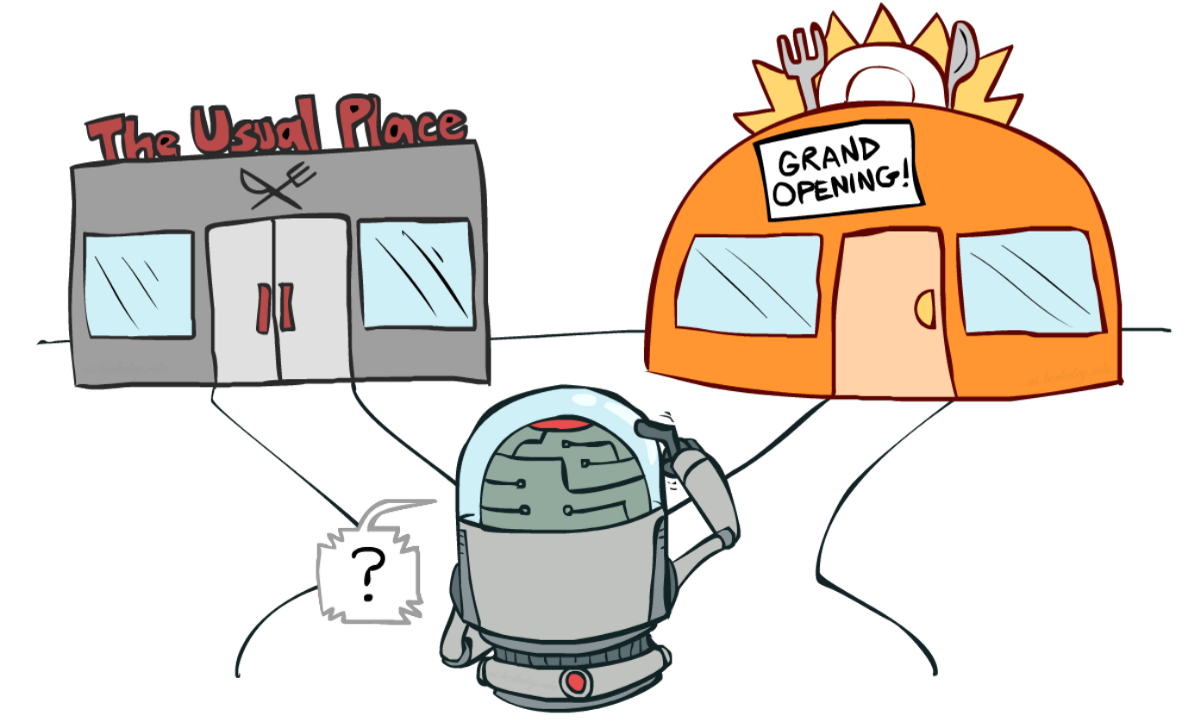 +来源:伯克利AI课程
+
+
+- *利用*:你每天都去同一家你知道很好的餐厅,**冒着错过另一家更好餐厅的风险。**
+- *探索*:尝试你从未去过的餐厅,冒着体验不好的风险,**但也有可能获得一次奇妙的体验。**
+
+总结一下:
+
+来源:伯克利AI课程
+
+
+- *利用*:你每天都去同一家你知道很好的餐厅,**冒着错过另一家更好餐厅的风险。**
+- *探索*:尝试你从未去过的餐厅,冒着体验不好的风险,**但也有可能获得一次奇妙的体验。**
+
+总结一下:
+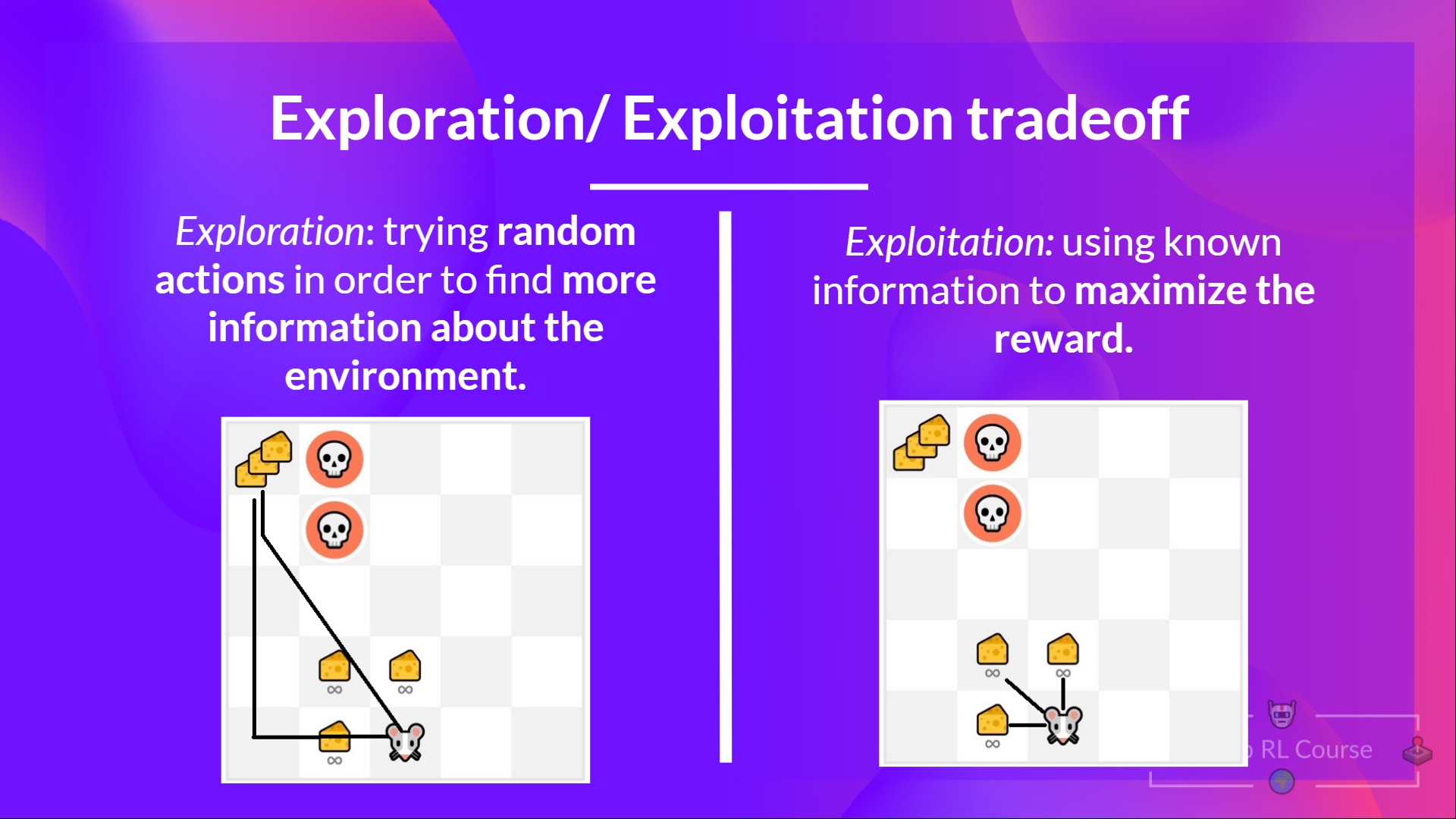 diff --git a/units/cn/unit1/glossary.mdx b/units/cn/unit1/glossary.mdx
new file mode 100644
index 00000000..ebec9c19
--- /dev/null
+++ b/units/cn/unit1/glossary.mdx
@@ -0,0 +1,70 @@
+# 术语表 [[glossary]]
+
+这是一个社区创建的术语表。欢迎贡献!
+
+### 智能体
+
+智能体通过**试错学习做决策,从环境中获得奖励和惩罚**。
+
+### 环境
+
+环境是一个模拟世界,**智能体可以通过与之交互来学习**。
+
+### 马尔可夫性质
+
+它意味着我们的智能体采取的行动**仅取决于当前状态,而与过去的状态和行动无关**。
+
+### 观察/状态
+
+- **状态**:对世界状态的完整描述。
+- **观察**:对环境/世界状态的部分描述。
+
+### 动作
+
+- **离散动作**:有限数量的动作,如左、右、上和下。
+- **连续动作**:无限可能的动作;例如,在自动驾驶汽车的情况下,驾驶场景有无限可能发生的动作。
+
+### 奖励和折扣
+
+- **奖励**:强化学习中的基本因素。告诉智能体所采取的行动是好还是坏。
+- 强化学习算法专注于最大化**累积奖励**。
+- **奖励假设**:强化学习问题可以被表述为(累积)回报的最大化。
+- 进行**折扣**是因为在开始时获得的奖励比长期奖励更可能发生,因为它们比长期奖励更可预测。
+
+### 任务
+
+- **情节性**:有起点和终点。
+- **连续性**:有起点但没有终点。
+
+### 探索与利用权衡
+
+- **探索**:通过尝试随机动作来探索环境,从环境中获取反馈/回报/奖励。
+- **利用**:利用我们对环境的了解来获得最大奖励。
+- **探索-利用权衡**:它平衡了我们想要**探索**环境的程度和我们想要**利用**我们对环境所知道的信息的程度。
+
+### 策略
+
+- **策略**:被称为智能体的大脑。它告诉我们在给定状态下应该采取什么行动。
+- **最优策略**:当智能体按照它行动时,**最大化**预期回报的策略。它是通过*训练*学习的。
+
+### 基于策略的方法:
+
+- 解决强化学习问题的一种方法。
+- 在这种方法中,直接学习策略。
+- 将每个状态映射到该状态下的最佳相应动作。或者映射到该状态下可能动作集合的概率分布。
+
+### 基于价值的方法:
+
+- 解决强化学习问题的另一种方法。
+- 在这里,我们不是训练策略,而是训练一个**价值函数**,将每个状态映射到处于该状态的预期价值。
+
+欢迎贡献 🤗
+
+如果你想改进课程,你可以[提交一个Pull Request。](https://github.com/huggingface/deep-rl-class/pulls)
+
+这个术语表的实现要感谢:
+
+- [@lucifermorningstar1305](https://github.com/lucifermorningstar1305)
+- [@daspartho](https://github.com/daspartho)
+- [@misza222](https://github.com/misza222)
+
diff --git a/units/cn/unit1/hands-on.mdx b/units/cn/unit1/hands-on.mdx
new file mode 100644
index 00000000..5cb86cfd
--- /dev/null
+++ b/units/cn/unit1/hands-on.mdx
@@ -0,0 +1,702 @@
+# 训练你的第一个深度强化学习智能体 🤖 [[hands-on]]
+
+
+
+
+
+
+现在你已经学习了强化学习的基础知识,你已经准备好训练你的第一个智能体并通过Hub与社区分享它了🔥:
+一个月球着陆器智能体,它将学习如何正确地在月球上着陆 🌕
+
+
diff --git a/units/cn/unit1/glossary.mdx b/units/cn/unit1/glossary.mdx
new file mode 100644
index 00000000..ebec9c19
--- /dev/null
+++ b/units/cn/unit1/glossary.mdx
@@ -0,0 +1,70 @@
+# 术语表 [[glossary]]
+
+这是一个社区创建的术语表。欢迎贡献!
+
+### 智能体
+
+智能体通过**试错学习做决策,从环境中获得奖励和惩罚**。
+
+### 环境
+
+环境是一个模拟世界,**智能体可以通过与之交互来学习**。
+
+### 马尔可夫性质
+
+它意味着我们的智能体采取的行动**仅取决于当前状态,而与过去的状态和行动无关**。
+
+### 观察/状态
+
+- **状态**:对世界状态的完整描述。
+- **观察**:对环境/世界状态的部分描述。
+
+### 动作
+
+- **离散动作**:有限数量的动作,如左、右、上和下。
+- **连续动作**:无限可能的动作;例如,在自动驾驶汽车的情况下,驾驶场景有无限可能发生的动作。
+
+### 奖励和折扣
+
+- **奖励**:强化学习中的基本因素。告诉智能体所采取的行动是好还是坏。
+- 强化学习算法专注于最大化**累积奖励**。
+- **奖励假设**:强化学习问题可以被表述为(累积)回报的最大化。
+- 进行**折扣**是因为在开始时获得的奖励比长期奖励更可能发生,因为它们比长期奖励更可预测。
+
+### 任务
+
+- **情节性**:有起点和终点。
+- **连续性**:有起点但没有终点。
+
+### 探索与利用权衡
+
+- **探索**:通过尝试随机动作来探索环境,从环境中获取反馈/回报/奖励。
+- **利用**:利用我们对环境的了解来获得最大奖励。
+- **探索-利用权衡**:它平衡了我们想要**探索**环境的程度和我们想要**利用**我们对环境所知道的信息的程度。
+
+### 策略
+
+- **策略**:被称为智能体的大脑。它告诉我们在给定状态下应该采取什么行动。
+- **最优策略**:当智能体按照它行动时,**最大化**预期回报的策略。它是通过*训练*学习的。
+
+### 基于策略的方法:
+
+- 解决强化学习问题的一种方法。
+- 在这种方法中,直接学习策略。
+- 将每个状态映射到该状态下的最佳相应动作。或者映射到该状态下可能动作集合的概率分布。
+
+### 基于价值的方法:
+
+- 解决强化学习问题的另一种方法。
+- 在这里,我们不是训练策略,而是训练一个**价值函数**,将每个状态映射到处于该状态的预期价值。
+
+欢迎贡献 🤗
+
+如果你想改进课程,你可以[提交一个Pull Request。](https://github.com/huggingface/deep-rl-class/pulls)
+
+这个术语表的实现要感谢:
+
+- [@lucifermorningstar1305](https://github.com/lucifermorningstar1305)
+- [@daspartho](https://github.com/daspartho)
+- [@misza222](https://github.com/misza222)
+
diff --git a/units/cn/unit1/hands-on.mdx b/units/cn/unit1/hands-on.mdx
new file mode 100644
index 00000000..5cb86cfd
--- /dev/null
+++ b/units/cn/unit1/hands-on.mdx
@@ -0,0 +1,702 @@
+# 训练你的第一个深度强化学习智能体 🤖 [[hands-on]]
+
+
+
+
+
+
+现在你已经学习了强化学习的基础知识,你已经准备好训练你的第一个智能体并通过Hub与社区分享它了🔥:
+一个月球着陆器智能体,它将学习如何正确地在月球上着陆 🌕
+
+ +
+最后,你将**把这个训练好的智能体上传到Hugging Face Hub 🤗,这是一个免费、开放的平台,人们可以在这里分享ML模型、数据集和演示。**
+
+感谢我们的排行榜,你将能够比较你的结果与其他同学的结果,并交流最佳实践来提高你的智能体的分数。谁将赢得第1单元的挑战🏆?
+
+为了验证这个实践环节的[认证过程](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process),你需要将你训练好的模型推送到Hub并**获得 >= 200的结果**。
+
+要找到你的结果,请前往[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+**如果你找不到你的模型,请前往页面底部并点击刷新按钮。**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+你可以在这里查看你的进度 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+
+让我们开始吧!🚀
+
+**要开始实践,请点击Open In Colab按钮** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit1/unit1.ipynb)
+
+我们强烈**建议学生使用Google Colab进行实践练习**,而不是在个人电脑上运行它们。
+
+通过使用Google Colab,**你可以专注于学习和实验,而不必担心设置环境的技术方面**。
+
+# 第1单元:训练你的第一个深度强化学习智能体 🤖
+
+
+
+最后,你将**把这个训练好的智能体上传到Hugging Face Hub 🤗,这是一个免费、开放的平台,人们可以在这里分享ML模型、数据集和演示。**
+
+感谢我们的排行榜,你将能够比较你的结果与其他同学的结果,并交流最佳实践来提高你的智能体的分数。谁将赢得第1单元的挑战🏆?
+
+为了验证这个实践环节的[认证过程](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process),你需要将你训练好的模型推送到Hub并**获得 >= 200的结果**。
+
+要找到你的结果,请前往[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+**如果你找不到你的模型,请前往页面底部并点击刷新按钮。**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+你可以在这里查看你的进度 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+
+让我们开始吧!🚀
+
+**要开始实践,请点击Open In Colab按钮** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit1/unit1.ipynb)
+
+我们强烈**建议学生使用Google Colab进行实践练习**,而不是在个人电脑上运行它们。
+
+通过使用Google Colab,**你可以专注于学习和实验,而不必担心设置环境的技术方面**。
+
+# 第1单元:训练你的第一个深度强化学习智能体 🤖
+
+ +
+在这个笔记本中,你将训练你的**第一个深度强化学习智能体**,一个月球着陆器智能体,它将学习如何**正确地在月球上着陆 🌕**。使用[Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/),一个深度强化学习库,与社区分享它们,并尝试不同的配置
+
+
+### 环境 🎮
+
+- [LunarLander-v2](https://gymnasium.farama.org/environments/box2d/lunar_lander/)
+
+### 使用的库 📚
+
+- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/)
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在Github仓库上提出一个issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在笔记本结束时,你将:
+
+- 能够使用**Gymnasium**,环境库。
+- 能够使用**Stable-Baselines3**,深度强化学习库。
+- 能够**将你训练好的智能体推送到Hub**,并附带一个漂亮的视频回放和评估分数 🔥。
+
+
+## 本笔记本来自深度强化学习课程
+
+
+
+在这个笔记本中,你将训练你的**第一个深度强化学习智能体**,一个月球着陆器智能体,它将学习如何**正确地在月球上着陆 🌕**。使用[Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/),一个深度强化学习库,与社区分享它们,并尝试不同的配置
+
+
+### 环境 🎮
+
+- [LunarLander-v2](https://gymnasium.farama.org/environments/box2d/lunar_lander/)
+
+### 使用的库 📚
+
+- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/)
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在Github仓库上提出一个issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在笔记本结束时,你将:
+
+- 能够使用**Gymnasium**,环境库。
+- 能够使用**Stable-Baselines3**,深度强化学习库。
+- 能够**将你训练好的智能体推送到Hub**,并附带一个漂亮的视频回放和评估分数 🔥。
+
+
+## 本笔记本来自深度强化学习课程
+
+ +
+在这个免费课程中,你将:
+
+- 📖 在**理论和实践**中学习深度强化学习。
+- 🧑💻 学习**使用著名的深度强化学习库**,如Stable Baselines3、RL Baselines3 Zoo、CleanRL和Sample Factory 2.0。
+- 🤖 在**独特的环境中训练智能体**
+- 🎓 通过完成80%的作业**获得完成证书**。
+
+还有更多!
+
+查看 📚 课程大纲 👉 https://simoninithomas.github.io/deep-rl-course
+
+不要忘记**注册课程**(我们收集你的电子邮件是为了能够**在每个单元发布时向你发送链接,并提供有关挑战和更新的信息**。)
+
+与我们保持联系和提问的最佳方式是**加入我们的discord服务器**,与社区和我们交流 👉🏻 https://discord.gg/ydHrjt3WP5
+
+## 先决条件 🏗️
+
+在深入笔记本之前,你需要:
+
+🔲 📝 **[阅读第0单元](https://huggingface.co/deep-rl-course/unit0/introduction)**,它为你提供了关于课程的所有**信息,并帮助你入门** 🤗
+
+🔲 📚 **通过[阅读第1单元](https://huggingface.co/deep-rl-course/unit1/introduction)来了解强化学习的基础知识**(MC、TD、奖励假设...)。
+
+## 深度强化学习的简要回顾 📚
+
+
+
+在这个免费课程中,你将:
+
+- 📖 在**理论和实践**中学习深度强化学习。
+- 🧑💻 学习**使用著名的深度强化学习库**,如Stable Baselines3、RL Baselines3 Zoo、CleanRL和Sample Factory 2.0。
+- 🤖 在**独特的环境中训练智能体**
+- 🎓 通过完成80%的作业**获得完成证书**。
+
+还有更多!
+
+查看 📚 课程大纲 👉 https://simoninithomas.github.io/deep-rl-course
+
+不要忘记**注册课程**(我们收集你的电子邮件是为了能够**在每个单元发布时向你发送链接,并提供有关挑战和更新的信息**。)
+
+与我们保持联系和提问的最佳方式是**加入我们的discord服务器**,与社区和我们交流 👉🏻 https://discord.gg/ydHrjt3WP5
+
+## 先决条件 🏗️
+
+在深入笔记本之前,你需要:
+
+🔲 📝 **[阅读第0单元](https://huggingface.co/deep-rl-course/unit0/introduction)**,它为你提供了关于课程的所有**信息,并帮助你入门** 🤗
+
+🔲 📚 **通过[阅读第1单元](https://huggingface.co/deep-rl-course/unit1/introduction)来了解强化学习的基础知识**(MC、TD、奖励假设...)。
+
+## 深度强化学习的简要回顾 📚
+
+ +
+让我们对第一单元中学到的内容做一个简要回顾:
+
+- 强化学习是一种**从行动中学习的计算方法**。我们构建一个智能体,通过**与环境进行试错交互**并接收奖励(负面或正面)作为反馈来从环境中学习。
+
+- 任何强化学习智能体的目标都是**最大化其预期累积奖励**(也称为预期回报),因为强化学习基于*奖励假设*,即所有目标都可以描述为预期累积奖励的最大化。
+
+- 强化学习过程是一个**循环,输出状态、动作、奖励和下一个状态的序列**。
+
+- 为了计算预期累积奖励(预期回报),**我们对奖励进行折扣**:较早(在游戏开始时)获得的奖励更有可能发生,因为它们比长期未来奖励更可预测。
+
+- 为了解决RL问题,你需要找到一个**最优策略**;策略是你的AI的"大脑",它会告诉你给定状态时要采取的动作。最优策略是最大化预期回报的策略。
+
+有两种找到最优策略的方法:
+
+- 通过**直接训练策略**:策略学习方法。
+- 通过**训练价值函数**来告诉我们每个状态的预期回报,并使用这个函数来定义我们的策略:价值学习方法。
+
+- 最后,我们谈到了深度强化学习,因为**我们引入了深度神经网络来估计要采取的动作(策略学习)或估计状态的价值(价值学习),因此得名"深度"。**
+
+# 让我们训练我们的第一个深度强化学习智能体并将其上传到Hub 🚀
+
+## 获取证书 🎓
+
+为了验证这个实践环节的[认证过程](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process),你需要将你训练好的模型推送到Hub并**获得 >= 200的结果**。
+
+要找到你的结果,请前往[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。为此,请转到`Runtime > Change Runtime type`
+
+
+
+让我们对第一单元中学到的内容做一个简要回顾:
+
+- 强化学习是一种**从行动中学习的计算方法**。我们构建一个智能体,通过**与环境进行试错交互**并接收奖励(负面或正面)作为反馈来从环境中学习。
+
+- 任何强化学习智能体的目标都是**最大化其预期累积奖励**(也称为预期回报),因为强化学习基于*奖励假设*,即所有目标都可以描述为预期累积奖励的最大化。
+
+- 强化学习过程是一个**循环,输出状态、动作、奖励和下一个状态的序列**。
+
+- 为了计算预期累积奖励(预期回报),**我们对奖励进行折扣**:较早(在游戏开始时)获得的奖励更有可能发生,因为它们比长期未来奖励更可预测。
+
+- 为了解决RL问题,你需要找到一个**最优策略**;策略是你的AI的"大脑",它会告诉你给定状态时要采取的动作。最优策略是最大化预期回报的策略。
+
+有两种找到最优策略的方法:
+
+- 通过**直接训练策略**:策略学习方法。
+- 通过**训练价值函数**来告诉我们每个状态的预期回报,并使用这个函数来定义我们的策略:价值学习方法。
+
+- 最后,我们谈到了深度强化学习,因为**我们引入了深度神经网络来估计要采取的动作(策略学习)或估计状态的价值(价值学习),因此得名"深度"。**
+
+# 让我们训练我们的第一个深度强化学习智能体并将其上传到Hub 🚀
+
+## 获取证书 🎓
+
+为了验证这个实践环节的[认证过程](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process),你需要将你训练好的模型推送到Hub并**获得 >= 200的结果**。
+
+要找到你的结果,请前往[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。为此,请转到`Runtime > Change Runtime type`
+
+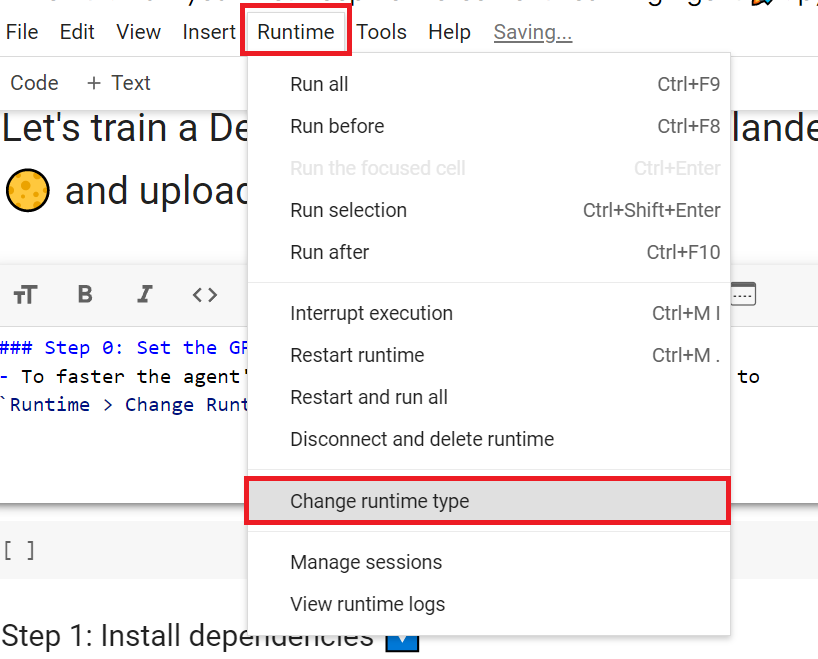 +
+- `Hardware Accelerator > GPU`
+
+
+
+- `Hardware Accelerator > GPU`
+
+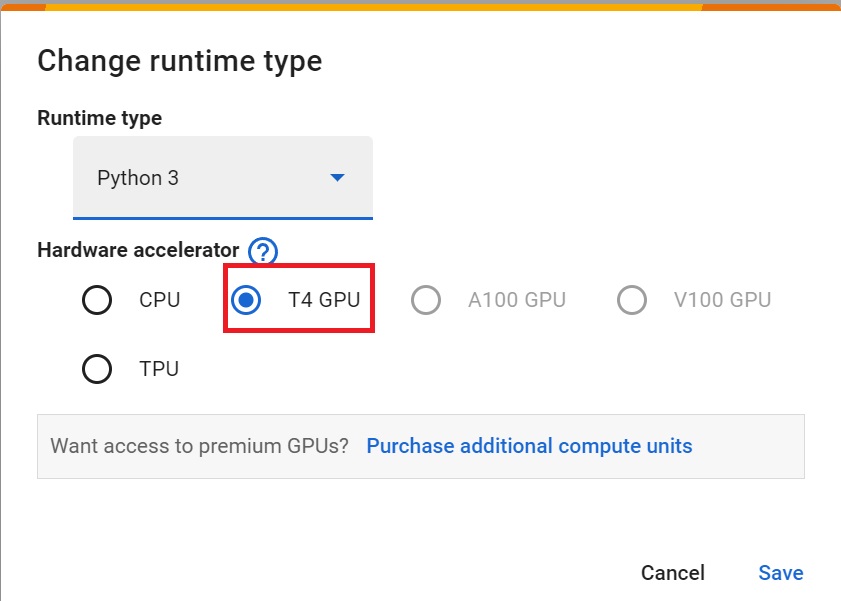 +
+## 安装依赖项并创建虚拟屏幕 🔽
+
+第一步是安装依赖项,我们将安装多个依赖项。
+
+- `gymnasium[box2d]`:包含LunarLander-v2环境🌛
+- `stable-baselines3[extra]`:深度强化学习库。
+- `huggingface_sb3`:Stable-baselines3的附加代码,用于从Hugging Face🤗Hub加载和上传模型。
+
+为了更轻松,我们创建了一个脚本来安装所有这些依赖项。
+
+```bash
+apt install swig cmake
+```
+
+```bash
+pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit1/requirements-unit1.txt
+```
+
+在笔记本中,我们需要生成一个回放视频。为此,使用colab,**我们需要有一个虚拟屏幕来渲染环境**(从而记录帧)。
+
+因此,以下单元格将安装虚拟屏幕库并创建和运行虚拟屏幕🖥
+
+```bash
+sudo apt-get update
+apt install python3-opengl
+apt install ffmpeg
+apt install xvfb
+pip3 install pyvirtualdisplay
+```
+
+为了确保新安装的库被使用,**有时需要重新启动笔记本运行时**。下一个单元格将强制**运行时崩溃,因此你需要重新连接并从这里开始运行代码**。感谢这个技巧,**我们将能够运行我们的虚拟屏幕**。
+
+```python
+import os
+
+os.kill(os.getpid(), 9)
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## 导入包 📦
+
+一个附加库我们导入是huggingface_hub**以便能够从hub上传和下载训练好的模型**。
+
+
+Hugging Face Hub 🤗 作为一个中心平台,任何人都可以在这里分享和探索模型和数据集。它具有版本控制、指标、可视化和其他功能,这些功能将使你能够轻松地与他人协作。
+
+你可以在这里查看所有可用的深度强化学习模型👉 https://huggingface.co/models?pipeline_tag=reinforcement-learning&sort=downloads
+
+🏋 包含我们环境的库叫做Gymnasium。
+**你将在深度强化学习中大量使用Gymnasium。**
+
+Gymnasium是**Gym库的新版本**,[由Farama基金会维护](https://farama.org/)。
+
+```python
+import gymnasium
+
+from huggingface_sb3 import load_from_hub, package_to_hub
+from huggingface_hub import (
+ notebook_login,
+) # To log to our Hugging Face account to be able to upload models to the Hub.
+
+from stable_baselines3 import PPO
+from stable_baselines3.common.env_util import make_vec_env
+from stable_baselines3.common.evaluation import evaluate_policy
+from stable_baselines3.common.monitor import Monitor
+```
+
+## 了解Gymnasium及其工作原理 🤖
+
+🏋 包含我们环境的库叫做Gymnasium。
+**你将在深度强化学习中大量使用Gymnasium。**
+
+Gymnasium是**Gym库的新版本**,[由Farama基金会维护](https://farama.org/)。
+
+Gymnasium库提供两件事:
+
+- 一个允许你**创建强化学习环境**的接口。
+- 一个**环境集合**(gym-control、atari、box2D等)。
+
+让我们看一个例子,但首先让我们回顾一下强化学习循环。
+
+
+
+在每一步:
+- 我们的智能体从**环境**接收一个**状态(S0)**——我们接收游戏的第一帧(环境)。
+- 基于该**状态(S0)**,智能体采取一个**动作(A0)**——我们的智能体将向右移动。
+- 环境转换到一个**新状态(S1)**——新的帧。
+- 环境给智能体一些**奖励(R1)**——我们没有死亡*(正奖励+1)*。
+
+
+使用Gymnasium:
+
+1️⃣ 我们使用`gymnasium.make()`创建我们的环境
+
+2️⃣ 我们使用`observation = env.reset()`将环境重置为其初始状态
+
+在每一步:
+
+3️⃣ 使用我们的模型获取一个动作(在我们的例子中,我们采取一个随机动作)
+
+4️⃣ 使用`env.step(action)`,我们在环境中执行这个动作并获得
+- `observation`:新的状态(st+1)
+- `reward`:执行动作后获得的奖励
+- `terminated`:表示剧集是否终止(智能体达到终止状态)
+- `truncated`:在这个新版本中引入,表示时间限制或者智能体是否超出环境边界等情况。
+- `info`:提供额外信息的字典(取决于环境)。
+
+更多解释请查看这里 👉 https://gymnasium.farama.org/api/env/#gymnasium.Env.step
+
+如果剧集终止:
+- 我们使用`observation = env.reset()`将环境重置为其初始状态
+
+**让我们看一个例子!** 确保阅读代码
+
+
+```python
+import gymnasium as gym
+
+# First, we create our environment called LunarLander-v2
+env = gym.make("LunarLander-v2")
+
+# Then we reset this environment
+observation, info = env.reset()
+
+for _ in range(20):
+ # Take a random action
+ action = env.action_space.sample()
+ print("Action taken:", action)
+
+ # Do this action in the environment and get
+ # next_state, reward, terminated, truncated and info
+ observation, reward, terminated, truncated, info = env.step(action)
+
+ # If the game is terminated (in our case we land, crashed) or truncated (timeout)
+ if terminated or truncated:
+ # Reset the environment
+ print("Environment is reset")
+ observation, info = env.reset()
+
+env.close()
+```
+
+## 创建月球着陆器环境 🌛 并了解它如何工作
+
+### 环境 🎮
+
+在这第一个教程中,我们将训练我们的智能体,一个[月球着陆器](https://gymnasium.farama.org/environments/box2d/lunar_lander/),**在月球上正确着陆**。为此,智能体需要学习**调整其速度和位置(水平、垂直和角度)以正确着陆。**
+
+---
+
+
+💡 当你开始使用一个环境时,一个好习惯是查看其文档
+
+👉 https://gymnasium.farama.org/environments/box2d/lunar_lander/
+
+---
+
+
+让我们看看环境是什么样子:
+
+
+```python
+# We create our environment with gym.make("")
+env = gym.make("LunarLander-v2")
+env.reset()
+print("_____OBSERVATION SPACE_____ \n")
+print("Observation Space Shape", env.observation_space.shape)
+print("Sample observation", env.observation_space.sample()) # Get a random observation
+```
+
+我们发现`Observation Space Shape (8,)`,观察是一个大小为8的向量,其中每个值包含不同的信息:
+- 水平板坐标(x)
+- 垂直板坐标(y)
+- 水平速度(x)
+- 垂直速度(y)
+- 角度
+- 角速度
+- 如果左腿接触点接触地面(布尔值)
+- 如果右腿接触点接触地面(布尔值)
+
+
+```python
+print("\n _____ACTION SPACE_____ \n")
+print("Action Space Shape", env.action_space.n)
+print("Action Space Sample", env.action_space.sample()) # Take a random action
+```
+
+动作空间(智能体可以采取的可能动作集)是离散的,有4个可用动作🎮:
+
+- 动作0:什么都不做,
+- 动作1:开左方向引擎,
+- 动作2:开主引擎,
+- 动作3:开右方向引擎。
+
+奖励函数(在每个时间步给予奖励的函数):
+
+每一步都会授予奖励。一个剧集的总奖励是**该剧集中所有步骤的奖励之和**。
+
+对于每一步,奖励:
+
+- 如果着陆器与着陆板更接近/更远,则增加/减少。
+- 如果着陆器移动得更慢/更快,则增加/减少。
+- 如果着陆器倾斜(角度不是水平),则减少。
+- 如果每条腿都接触地面,则每条腿增加10分。
+- 如果每帧侧引擎点火,则每帧减少0.03分。
+- 如果每帧主引擎点火,则每帧减少0.3分。
+
+该剧集将收到**额外奖励-100或+100分,以分别因坠毁或安全着陆而结束**。
+
+一个剧集被**认为是一个解决方案,如果它得分至少200分**。
+
+#### Vectorized Environment
+
+- 我们创建一个向量化环境(一种将多个独立环境堆叠到一个环境中的方法),这样**我们将在训练期间拥有更多多样化的体验**。
+
+```python
+# Create the environment
+env = make_vec_env("LunarLander-v2", n_envs=16)
+```
+
+## Create the Model 🤖
+
+- 我们已经研究了我们的环境,并且理解了问题:能够通过控制左、右和主方向引擎正确地将月球着陆器降落到着陆板上。现在让我们构建我们将用来解决这个问题的算法 🚀.
+
+- 我们已经研究了我们的环境并理解了问题:**能够通过控制左、右和主方向引擎来正确地在月球上着陆**。现在让我们构建我们将使用的算法来解决这个问题🚀。
+
+- 为此,我们将使用我们的第一个深度强化学习库,[Stable Baselines3 (SB3)](https://stable-baselines3.readthedocs.io/en/master/)。
+
+- SB3是一组**可靠的PyTorch强化学习算法实现**。
+
+💡 当你使用新库时,首先查看文档是一个好习惯:https://stable-baselines3.readthedocs.io/en/master/ and then try some tutorials.
+
+----
+
+
+
+## 安装依赖项并创建虚拟屏幕 🔽
+
+第一步是安装依赖项,我们将安装多个依赖项。
+
+- `gymnasium[box2d]`:包含LunarLander-v2环境🌛
+- `stable-baselines3[extra]`:深度强化学习库。
+- `huggingface_sb3`:Stable-baselines3的附加代码,用于从Hugging Face🤗Hub加载和上传模型。
+
+为了更轻松,我们创建了一个脚本来安装所有这些依赖项。
+
+```bash
+apt install swig cmake
+```
+
+```bash
+pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit1/requirements-unit1.txt
+```
+
+在笔记本中,我们需要生成一个回放视频。为此,使用colab,**我们需要有一个虚拟屏幕来渲染环境**(从而记录帧)。
+
+因此,以下单元格将安装虚拟屏幕库并创建和运行虚拟屏幕🖥
+
+```bash
+sudo apt-get update
+apt install python3-opengl
+apt install ffmpeg
+apt install xvfb
+pip3 install pyvirtualdisplay
+```
+
+为了确保新安装的库被使用,**有时需要重新启动笔记本运行时**。下一个单元格将强制**运行时崩溃,因此你需要重新连接并从这里开始运行代码**。感谢这个技巧,**我们将能够运行我们的虚拟屏幕**。
+
+```python
+import os
+
+os.kill(os.getpid(), 9)
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## 导入包 📦
+
+一个附加库我们导入是huggingface_hub**以便能够从hub上传和下载训练好的模型**。
+
+
+Hugging Face Hub 🤗 作为一个中心平台,任何人都可以在这里分享和探索模型和数据集。它具有版本控制、指标、可视化和其他功能,这些功能将使你能够轻松地与他人协作。
+
+你可以在这里查看所有可用的深度强化学习模型👉 https://huggingface.co/models?pipeline_tag=reinforcement-learning&sort=downloads
+
+🏋 包含我们环境的库叫做Gymnasium。
+**你将在深度强化学习中大量使用Gymnasium。**
+
+Gymnasium是**Gym库的新版本**,[由Farama基金会维护](https://farama.org/)。
+
+```python
+import gymnasium
+
+from huggingface_sb3 import load_from_hub, package_to_hub
+from huggingface_hub import (
+ notebook_login,
+) # To log to our Hugging Face account to be able to upload models to the Hub.
+
+from stable_baselines3 import PPO
+from stable_baselines3.common.env_util import make_vec_env
+from stable_baselines3.common.evaluation import evaluate_policy
+from stable_baselines3.common.monitor import Monitor
+```
+
+## 了解Gymnasium及其工作原理 🤖
+
+🏋 包含我们环境的库叫做Gymnasium。
+**你将在深度强化学习中大量使用Gymnasium。**
+
+Gymnasium是**Gym库的新版本**,[由Farama基金会维护](https://farama.org/)。
+
+Gymnasium库提供两件事:
+
+- 一个允许你**创建强化学习环境**的接口。
+- 一个**环境集合**(gym-control、atari、box2D等)。
+
+让我们看一个例子,但首先让我们回顾一下强化学习循环。
+
+
+
+在每一步:
+- 我们的智能体从**环境**接收一个**状态(S0)**——我们接收游戏的第一帧(环境)。
+- 基于该**状态(S0)**,智能体采取一个**动作(A0)**——我们的智能体将向右移动。
+- 环境转换到一个**新状态(S1)**——新的帧。
+- 环境给智能体一些**奖励(R1)**——我们没有死亡*(正奖励+1)*。
+
+
+使用Gymnasium:
+
+1️⃣ 我们使用`gymnasium.make()`创建我们的环境
+
+2️⃣ 我们使用`observation = env.reset()`将环境重置为其初始状态
+
+在每一步:
+
+3️⃣ 使用我们的模型获取一个动作(在我们的例子中,我们采取一个随机动作)
+
+4️⃣ 使用`env.step(action)`,我们在环境中执行这个动作并获得
+- `observation`:新的状态(st+1)
+- `reward`:执行动作后获得的奖励
+- `terminated`:表示剧集是否终止(智能体达到终止状态)
+- `truncated`:在这个新版本中引入,表示时间限制或者智能体是否超出环境边界等情况。
+- `info`:提供额外信息的字典(取决于环境)。
+
+更多解释请查看这里 👉 https://gymnasium.farama.org/api/env/#gymnasium.Env.step
+
+如果剧集终止:
+- 我们使用`observation = env.reset()`将环境重置为其初始状态
+
+**让我们看一个例子!** 确保阅读代码
+
+
+```python
+import gymnasium as gym
+
+# First, we create our environment called LunarLander-v2
+env = gym.make("LunarLander-v2")
+
+# Then we reset this environment
+observation, info = env.reset()
+
+for _ in range(20):
+ # Take a random action
+ action = env.action_space.sample()
+ print("Action taken:", action)
+
+ # Do this action in the environment and get
+ # next_state, reward, terminated, truncated and info
+ observation, reward, terminated, truncated, info = env.step(action)
+
+ # If the game is terminated (in our case we land, crashed) or truncated (timeout)
+ if terminated or truncated:
+ # Reset the environment
+ print("Environment is reset")
+ observation, info = env.reset()
+
+env.close()
+```
+
+## 创建月球着陆器环境 🌛 并了解它如何工作
+
+### 环境 🎮
+
+在这第一个教程中,我们将训练我们的智能体,一个[月球着陆器](https://gymnasium.farama.org/environments/box2d/lunar_lander/),**在月球上正确着陆**。为此,智能体需要学习**调整其速度和位置(水平、垂直和角度)以正确着陆。**
+
+---
+
+
+💡 当你开始使用一个环境时,一个好习惯是查看其文档
+
+👉 https://gymnasium.farama.org/environments/box2d/lunar_lander/
+
+---
+
+
+让我们看看环境是什么样子:
+
+
+```python
+# We create our environment with gym.make("")
+env = gym.make("LunarLander-v2")
+env.reset()
+print("_____OBSERVATION SPACE_____ \n")
+print("Observation Space Shape", env.observation_space.shape)
+print("Sample observation", env.observation_space.sample()) # Get a random observation
+```
+
+我们发现`Observation Space Shape (8,)`,观察是一个大小为8的向量,其中每个值包含不同的信息:
+- 水平板坐标(x)
+- 垂直板坐标(y)
+- 水平速度(x)
+- 垂直速度(y)
+- 角度
+- 角速度
+- 如果左腿接触点接触地面(布尔值)
+- 如果右腿接触点接触地面(布尔值)
+
+
+```python
+print("\n _____ACTION SPACE_____ \n")
+print("Action Space Shape", env.action_space.n)
+print("Action Space Sample", env.action_space.sample()) # Take a random action
+```
+
+动作空间(智能体可以采取的可能动作集)是离散的,有4个可用动作🎮:
+
+- 动作0:什么都不做,
+- 动作1:开左方向引擎,
+- 动作2:开主引擎,
+- 动作3:开右方向引擎。
+
+奖励函数(在每个时间步给予奖励的函数):
+
+每一步都会授予奖励。一个剧集的总奖励是**该剧集中所有步骤的奖励之和**。
+
+对于每一步,奖励:
+
+- 如果着陆器与着陆板更接近/更远,则增加/减少。
+- 如果着陆器移动得更慢/更快,则增加/减少。
+- 如果着陆器倾斜(角度不是水平),则减少。
+- 如果每条腿都接触地面,则每条腿增加10分。
+- 如果每帧侧引擎点火,则每帧减少0.03分。
+- 如果每帧主引擎点火,则每帧减少0.3分。
+
+该剧集将收到**额外奖励-100或+100分,以分别因坠毁或安全着陆而结束**。
+
+一个剧集被**认为是一个解决方案,如果它得分至少200分**。
+
+#### Vectorized Environment
+
+- 我们创建一个向量化环境(一种将多个独立环境堆叠到一个环境中的方法),这样**我们将在训练期间拥有更多多样化的体验**。
+
+```python
+# Create the environment
+env = make_vec_env("LunarLander-v2", n_envs=16)
+```
+
+## Create the Model 🤖
+
+- 我们已经研究了我们的环境,并且理解了问题:能够通过控制左、右和主方向引擎正确地将月球着陆器降落到着陆板上。现在让我们构建我们将用来解决这个问题的算法 🚀.
+
+- 我们已经研究了我们的环境并理解了问题:**能够通过控制左、右和主方向引擎来正确地在月球上着陆**。现在让我们构建我们将使用的算法来解决这个问题🚀。
+
+- 为此,我们将使用我们的第一个深度强化学习库,[Stable Baselines3 (SB3)](https://stable-baselines3.readthedocs.io/en/master/)。
+
+- SB3是一组**可靠的PyTorch强化学习算法实现**。
+
+💡 当你使用新库时,首先查看文档是一个好习惯:https://stable-baselines3.readthedocs.io/en/master/ and then try some tutorials.
+
+----
+
+ +
+为了解决这个问题,我们将使用SB3 **PPO**。[PPO (aka Proximal Policy Optimization) is one of the SOTA (state of the art) Deep Reinforcement Learning algorithms that you'll study during this course](https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#example%5D).
+
+PPO是一种组合:
+- *基于价值的强化学习方法*:学习一个动作-价值函数,告诉我们**在给定状态和动作下最有价值的动作**。
+- *基于策略的强化学习方法*:学习一个策略,**给我们一个动作的概率分布**。
+
+Stable-Baselines3设置起来很简单:
+
+1️⃣ 你**创建你的环境**(在我们的例子中,这已经在上面完成了)
+
+2️⃣ 你定义**你想要使用的模型并实例化这个模型** `model = PPO("MlpPolicy")`
+
+3️⃣ 你用`model.learn`**训练智能体**并定义训练时间步数
+
+```
+# Create environment
+env = gym.make('LunarLander-v2')
+
+# Instantiate the agent
+model = PPO('MlpPolicy', env, verbose=1)
+# Train the agent
+model.learn(total_timesteps=int(2e5))
+```
+
+
+
+```python
+# TODO: Define a PPO MlpPolicy architecture
+# We use MultiLayerPerceptron (MLPPolicy) because the input is a vector,
+# if we had frames as input we would use CnnPolicy
+model =
+```
+
+#### Solution
+
+```python
+# SOLUTION
+# We added some parameters to accelerate the training
+model = PPO(
+ policy="MlpPolicy",
+ env=env,
+ n_steps=1024,
+ batch_size=64,
+ n_epochs=4,
+ gamma=0.999,
+ gae_lambda=0.98,
+ ent_coef=0.01,
+ verbose=1,
+)
+```
+
+## 训练PPO智能体 🏃
+- 让我们训练我们的智能体1,000,000个时间步,不要忘记在Colab上使用GPU。这将花费大约~20分钟,但如果你只是想尝试一下,你可以使用更少的时间步。
+- 在训练期间,休息一下,喝杯☕,你应得的 🤗
+
+```python
+# TODO: Train it for 1,000,000 timesteps
+
+# TODO: Specify file name for model and save the model to file
+model_name = "ppo-LunarLander-v2"
+```
+
+#### Solution
+
+```python
+# SOLUTION
+# Train it for 1,000,000 timesteps
+model.learn(total_timesteps=1000000)
+# Save the model
+model_name = "ppo-LunarLander-v2"
+model.save(model_name)
+```
+
+## 评估智能体 📈
+
+- 记得用[Monitor](https://stable-baselines3.readthedocs.io/en/master/common/monitor.html)包装环境。
+- 现在我们的月球着陆器智能体已经训练好了 🚀,我们需要**检查它的性能**。
+- Stable-Baselines3提供了一个方法来做这个:`evaluate_policy`。
+- 要填写这部分,你需要[查看文档](https://stable-baselines3.readthedocs.io/en/master/guide/examples.html#basic-usage-training-saving-loading)
+- 在下一步,我们将看到**如何自动评估并分享你的智能体以在排行榜上竞争,但现在让我们自己来做**
+
+
+💡 当你评估你的智能体时,你不应该使用你的训练环境,而是创建一个评估环境。
+
+```python
+# TODO: Evaluate the agent
+# Create a new environment for evaluation
+eval_env =
+
+# Evaluate the model with 10 evaluation episodes and deterministic=True
+mean_reward, std_reward =
+
+# Print the results
+```
+
+#### Solution
+
+```python
+# @title
+eval_env = Monitor(gym.make("LunarLander-v2"))
+mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, deterministic=True)
+print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
+```
+
+- 在我的例子中,我在训练100万步后得到了`200.20 +/- 20.80`的平均奖励,这意味着我们的月球着陆器智能体已经准备好登陆月球了 🌛🥳。
+
+## 在Hub上发布我们训练好的模型 🔥
+现在我们看到训练后得到了好的结果,我们可以用一行代码将我们训练好的模型发布到hub 🤗 上。
+
+📚 库文档 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
+
+这里是一个模型卡片的例子(使用太空入侵者):
+
+通过使用`package_to_hub`,**你可以评估、记录回放、生成你的智能体的模型卡片并将其推送到hub**。
+
+这样:
+- 你可以**展示我们的工作** 🔥
+- 你可以**可视化你的智能体的游戏过程** 👀
+- 你可以**与社区分享一个其他人可以使用的智能体** 💾
+- 你可以**访问一个排行榜 🏆 来看看你的智能体与你的同学相比表现如何** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+
+要能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果还没有完成)在Hugging Face上创建一个账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录,然后,你需要从Hugging Face网站存储你的认证令牌。
+- 创建一个新的令牌(https://huggingface.co/settings/tokens)**具有写入角色**
+
+
+
+为了解决这个问题,我们将使用SB3 **PPO**。[PPO (aka Proximal Policy Optimization) is one of the SOTA (state of the art) Deep Reinforcement Learning algorithms that you'll study during this course](https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#example%5D).
+
+PPO是一种组合:
+- *基于价值的强化学习方法*:学习一个动作-价值函数,告诉我们**在给定状态和动作下最有价值的动作**。
+- *基于策略的强化学习方法*:学习一个策略,**给我们一个动作的概率分布**。
+
+Stable-Baselines3设置起来很简单:
+
+1️⃣ 你**创建你的环境**(在我们的例子中,这已经在上面完成了)
+
+2️⃣ 你定义**你想要使用的模型并实例化这个模型** `model = PPO("MlpPolicy")`
+
+3️⃣ 你用`model.learn`**训练智能体**并定义训练时间步数
+
+```
+# Create environment
+env = gym.make('LunarLander-v2')
+
+# Instantiate the agent
+model = PPO('MlpPolicy', env, verbose=1)
+# Train the agent
+model.learn(total_timesteps=int(2e5))
+```
+
+
+
+```python
+# TODO: Define a PPO MlpPolicy architecture
+# We use MultiLayerPerceptron (MLPPolicy) because the input is a vector,
+# if we had frames as input we would use CnnPolicy
+model =
+```
+
+#### Solution
+
+```python
+# SOLUTION
+# We added some parameters to accelerate the training
+model = PPO(
+ policy="MlpPolicy",
+ env=env,
+ n_steps=1024,
+ batch_size=64,
+ n_epochs=4,
+ gamma=0.999,
+ gae_lambda=0.98,
+ ent_coef=0.01,
+ verbose=1,
+)
+```
+
+## 训练PPO智能体 🏃
+- 让我们训练我们的智能体1,000,000个时间步,不要忘记在Colab上使用GPU。这将花费大约~20分钟,但如果你只是想尝试一下,你可以使用更少的时间步。
+- 在训练期间,休息一下,喝杯☕,你应得的 🤗
+
+```python
+# TODO: Train it for 1,000,000 timesteps
+
+# TODO: Specify file name for model and save the model to file
+model_name = "ppo-LunarLander-v2"
+```
+
+#### Solution
+
+```python
+# SOLUTION
+# Train it for 1,000,000 timesteps
+model.learn(total_timesteps=1000000)
+# Save the model
+model_name = "ppo-LunarLander-v2"
+model.save(model_name)
+```
+
+## 评估智能体 📈
+
+- 记得用[Monitor](https://stable-baselines3.readthedocs.io/en/master/common/monitor.html)包装环境。
+- 现在我们的月球着陆器智能体已经训练好了 🚀,我们需要**检查它的性能**。
+- Stable-Baselines3提供了一个方法来做这个:`evaluate_policy`。
+- 要填写这部分,你需要[查看文档](https://stable-baselines3.readthedocs.io/en/master/guide/examples.html#basic-usage-training-saving-loading)
+- 在下一步,我们将看到**如何自动评估并分享你的智能体以在排行榜上竞争,但现在让我们自己来做**
+
+
+💡 当你评估你的智能体时,你不应该使用你的训练环境,而是创建一个评估环境。
+
+```python
+# TODO: Evaluate the agent
+# Create a new environment for evaluation
+eval_env =
+
+# Evaluate the model with 10 evaluation episodes and deterministic=True
+mean_reward, std_reward =
+
+# Print the results
+```
+
+#### Solution
+
+```python
+# @title
+eval_env = Monitor(gym.make("LunarLander-v2"))
+mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, deterministic=True)
+print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
+```
+
+- 在我的例子中,我在训练100万步后得到了`200.20 +/- 20.80`的平均奖励,这意味着我们的月球着陆器智能体已经准备好登陆月球了 🌛🥳。
+
+## 在Hub上发布我们训练好的模型 🔥
+现在我们看到训练后得到了好的结果,我们可以用一行代码将我们训练好的模型发布到hub 🤗 上。
+
+📚 库文档 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
+
+这里是一个模型卡片的例子(使用太空入侵者):
+
+通过使用`package_to_hub`,**你可以评估、记录回放、生成你的智能体的模型卡片并将其推送到hub**。
+
+这样:
+- 你可以**展示我们的工作** 🔥
+- 你可以**可视化你的智能体的游戏过程** 👀
+- 你可以**与社区分享一个其他人可以使用的智能体** 💾
+- 你可以**访问一个排行榜 🏆 来看看你的智能体与你的同学相比表现如何** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+
+要能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果还没有完成)在Hugging Face上创建一个账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录,然后,你需要从Hugging Face网站存储你的认证令牌。
+- 创建一个新的令牌(https://huggingface.co/settings/tokens)**具有写入角色**
+
+ +
+- 复制令牌
+- 运行下面的单元格并粘贴令牌
+
+```python
+notebook_login()
+!git config --global credential.helper store
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令:`huggingface-cli login`
+
+3️⃣ 我们现在准备使用`package_to_hub()`函数将我们训练好的智能体推送到🤗 Hub 🔥
+
+让我们填写`package_to_hub`函数:
+- `model`:我们训练好的模型。
+- `model_name`:我们在`model_save`中定义的训练模型的名称
+- `model_architecture`:我们使用的模型架构,在我们的例子中是PPO
+- `env_id`:环境的名称,在我们的例子中是`LunarLander-v2`
+- `eval_env`:在eval_env中定义的评估环境
+- `repo_id`:将要创建/更新的Hugging Face Hub仓库的名称`(repo_id = {username}/{repo_name})`
+
+💡 **一个好的名称是`{username}/{model_architecture}-{env_id}`**
+
+- `commit_message`:提交的消息
+
+```python
+import gymnasium as gym
+from stable_baselines3.common.vec_env import DummyVecEnv
+from stable_baselines3.common.env_util import make_vec_env
+
+from huggingface_sb3 import package_to_hub
+
+## TODO: 定义一个repo_id
+## repo_id是Hugging Face Hub上模型仓库的ID(repo_id = {组织}/{仓库名称},例如ThomasSimonini/ppo-LunarLander-v2
+repo_id =
+
+# TODO: 定义环境的名称
+env_id =
+
+# 创建评估环境并设置render_mode="rgb_array"
+eval_env = DummyVecEnv([lambda: gym.make(env_id, render_mode="rgb_array")])
+
+
+# TODO: 定义我们使用的模型架构
+model_architecture = ""
+
+## TODO: 定义提交消息
+commit_message = ""
+
+# 方法保存、评估、生成模型卡片并在将仓库推送到hub之前记录智能体的回放视频
+package_to_hub(model=model, # 我们训练好的模型
+ model_name=model_name, # 我们训练好的模型的名称
+ model_architecture=model_architecture, # 我们使用的模型架构:在我们的例子中是PPO
+ env_id=env_id, # 环境的名称
+ eval_env=eval_env, # 评估环境
+ repo_id=repo_id, # Hugging Face Hub上模型仓库的ID(repo_id = {组织}/{仓库名称},例如ThomasSimonini/ppo-LunarLander-v2
+ commit_message=commit_message)
+```
+
+#### 解决方案
+
+
+```python
+import gymnasium as gym
+
+from stable_baselines3 import PPO
+from stable_baselines3.common.vec_env import DummyVecEnv
+from stable_baselines3.common.env_util import make_vec_env
+
+from huggingface_sb3 import package_to_hub
+
+# 放置你刚刚在上面两个单元格中定义的变量
+# 定义环境的名称
+env_id = "LunarLander-v2"
+
+# TODO: 定义我们使用的模型架构
+model_architecture = "PPO"
+
+## 定义一个repo_id
+## repo_id是Hugging Face Hub上模型仓库的ID(repo_id = {组织}/{仓库名称},例如ThomasSimonini/ppo-LunarLander-v2
+## 更改为你的REPO ID
+repo_id = "ThomasSimonini/ppo-LunarLander-v2" # 更改为你的repo id,你不能用我的推送 😄
+
+## 定义提交消息
+commit_message = "上传PPO LunarLander-v2训练好的智能体"
+
+# 创建评估环境并设置render_mode="rgb_array"
+eval_env = DummyVecEnv([lambda: Monitor(gym.make(env_id, render_mode="rgb_array"))])
+
+# 在这里放置你刚刚填写的package_to_hub函数
+package_to_hub(
+ model=model, # 我们训练好的模型
+ model_name=model_name, # 我们训练好的模型的名称
+ model_architecture=model_architecture, # 我们使用的模型架构:在我们的例子中是PPO
+ env_id=env_id, # 环境的名称
+ eval_env=eval_env, # 评估环境
+ repo_id=repo_id, # Hugging Face Hub上模型仓库的ID(repo_id = {组织}/{仓库名称},例如ThomasSimonini/ppo-LunarLander-v2
+ commit_message=commit_message,
+)
+```
+
+恭喜 🥳 你刚刚训练并上传了你的第一个深度强化学习智能体。上面的脚本应该已经显示了一个模型仓库的链接,如https://huggingface.co/osanseviero/test_sb3。当你访问这个链接时,你可以:
+* 在右侧看到你的智能体的视频预览。
+* 点击"Files and versions"查看仓库中的所有文件。
+* 点击"Use in stable-baselines3"获取显示如何加载模型的代码片段。
+* 一个模型卡片(`README.md`文件),提供模型的描述
+
+在底层,Hub使用基于git的仓库(如果你不知道git是什么,不用担心),这意味着你可以在实验和改进你的智能体时用新版本更新模型。
+
+使用排行榜比较你的LunarLander-v2与你的同学的结果 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+## 从Hub加载保存的LunarLander模型 🤗
+感谢[ironbar](https://github.com/ironbar)的贡献。
+
+从Hub加载保存的模型非常简单。
+
+你可以前往https://huggingface.co/models?library=stable-baselines3 查看所有保存的Stable-baselines3模型的列表。
+1. 你选择一个并复制其repo_id
+
+
+
+- 复制令牌
+- 运行下面的单元格并粘贴令牌
+
+```python
+notebook_login()
+!git config --global credential.helper store
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令:`huggingface-cli login`
+
+3️⃣ 我们现在准备使用`package_to_hub()`函数将我们训练好的智能体推送到🤗 Hub 🔥
+
+让我们填写`package_to_hub`函数:
+- `model`:我们训练好的模型。
+- `model_name`:我们在`model_save`中定义的训练模型的名称
+- `model_architecture`:我们使用的模型架构,在我们的例子中是PPO
+- `env_id`:环境的名称,在我们的例子中是`LunarLander-v2`
+- `eval_env`:在eval_env中定义的评估环境
+- `repo_id`:将要创建/更新的Hugging Face Hub仓库的名称`(repo_id = {username}/{repo_name})`
+
+💡 **一个好的名称是`{username}/{model_architecture}-{env_id}`**
+
+- `commit_message`:提交的消息
+
+```python
+import gymnasium as gym
+from stable_baselines3.common.vec_env import DummyVecEnv
+from stable_baselines3.common.env_util import make_vec_env
+
+from huggingface_sb3 import package_to_hub
+
+## TODO: 定义一个repo_id
+## repo_id是Hugging Face Hub上模型仓库的ID(repo_id = {组织}/{仓库名称},例如ThomasSimonini/ppo-LunarLander-v2
+repo_id =
+
+# TODO: 定义环境的名称
+env_id =
+
+# 创建评估环境并设置render_mode="rgb_array"
+eval_env = DummyVecEnv([lambda: gym.make(env_id, render_mode="rgb_array")])
+
+
+# TODO: 定义我们使用的模型架构
+model_architecture = ""
+
+## TODO: 定义提交消息
+commit_message = ""
+
+# 方法保存、评估、生成模型卡片并在将仓库推送到hub之前记录智能体的回放视频
+package_to_hub(model=model, # 我们训练好的模型
+ model_name=model_name, # 我们训练好的模型的名称
+ model_architecture=model_architecture, # 我们使用的模型架构:在我们的例子中是PPO
+ env_id=env_id, # 环境的名称
+ eval_env=eval_env, # 评估环境
+ repo_id=repo_id, # Hugging Face Hub上模型仓库的ID(repo_id = {组织}/{仓库名称},例如ThomasSimonini/ppo-LunarLander-v2
+ commit_message=commit_message)
+```
+
+#### 解决方案
+
+
+```python
+import gymnasium as gym
+
+from stable_baselines3 import PPO
+from stable_baselines3.common.vec_env import DummyVecEnv
+from stable_baselines3.common.env_util import make_vec_env
+
+from huggingface_sb3 import package_to_hub
+
+# 放置你刚刚在上面两个单元格中定义的变量
+# 定义环境的名称
+env_id = "LunarLander-v2"
+
+# TODO: 定义我们使用的模型架构
+model_architecture = "PPO"
+
+## 定义一个repo_id
+## repo_id是Hugging Face Hub上模型仓库的ID(repo_id = {组织}/{仓库名称},例如ThomasSimonini/ppo-LunarLander-v2
+## 更改为你的REPO ID
+repo_id = "ThomasSimonini/ppo-LunarLander-v2" # 更改为你的repo id,你不能用我的推送 😄
+
+## 定义提交消息
+commit_message = "上传PPO LunarLander-v2训练好的智能体"
+
+# 创建评估环境并设置render_mode="rgb_array"
+eval_env = DummyVecEnv([lambda: Monitor(gym.make(env_id, render_mode="rgb_array"))])
+
+# 在这里放置你刚刚填写的package_to_hub函数
+package_to_hub(
+ model=model, # 我们训练好的模型
+ model_name=model_name, # 我们训练好的模型的名称
+ model_architecture=model_architecture, # 我们使用的模型架构:在我们的例子中是PPO
+ env_id=env_id, # 环境的名称
+ eval_env=eval_env, # 评估环境
+ repo_id=repo_id, # Hugging Face Hub上模型仓库的ID(repo_id = {组织}/{仓库名称},例如ThomasSimonini/ppo-LunarLander-v2
+ commit_message=commit_message,
+)
+```
+
+恭喜 🥳 你刚刚训练并上传了你的第一个深度强化学习智能体。上面的脚本应该已经显示了一个模型仓库的链接,如https://huggingface.co/osanseviero/test_sb3。当你访问这个链接时,你可以:
+* 在右侧看到你的智能体的视频预览。
+* 点击"Files and versions"查看仓库中的所有文件。
+* 点击"Use in stable-baselines3"获取显示如何加载模型的代码片段。
+* 一个模型卡片(`README.md`文件),提供模型的描述
+
+在底层,Hub使用基于git的仓库(如果你不知道git是什么,不用担心),这意味着你可以在实验和改进你的智能体时用新版本更新模型。
+
+使用排行榜比较你的LunarLander-v2与你的同学的结果 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+## 从Hub加载保存的LunarLander模型 🤗
+感谢[ironbar](https://github.com/ironbar)的贡献。
+
+从Hub加载保存的模型非常简单。
+
+你可以前往https://huggingface.co/models?library=stable-baselines3 查看所有保存的Stable-baselines3模型的列表。
+1. 你选择一个并复制其repo_id
+
+ +
+2. 然后我们只需要使用load_from_hub,包含:
+- repo_id
+- filename:仓库内保存的模型及其扩展名(*.zip)
+
+因为我从Hub下载的模型是用Gym(Gymnasium的前一个版本)训练的,我们需要安装shimmy,这是一个API转换工具,它将帮助我们正确运行环境。
+
+Shimmy文档:https://github.com/Farama-Foundation/Shimmy
+
+```python
+!pip install shimmy
+```
+
+```python
+from huggingface_sb3 import load_from_hub
+
+repo_id = "Classroom-workshop/assignment2-omar" # repo_id
+filename = "ppo-LunarLander-v2.zip" # 模型文件名.zip
+
+# 当模型在Python 3.8上训练时,pickle协议是5
+# 但Python 3.6, 3.7使用协议4
+# 为了获得兼容性,我们需要:
+# 1. 安装pickle5(我们在colab开始时已经完成)
+# 2. 创建一个自定义的空对象,我们将其作为参数传递给PPO.load()
+custom_objects = {
+ "learning_rate": 0.0,
+ "lr_schedule": lambda _: 0.0,
+ "clip_range": lambda _: 0.0,
+}
+
+checkpoint = load_from_hub(repo_id, filename)
+model = PPO.load(checkpoint, custom_objects=custom_objects, print_system_info=True)
+```
+
+让我们评估这个智能体:
+
+```python
+# @title
+eval_env = Monitor(gym.make("LunarLander-v2"))
+mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, deterministic=True)
+print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
+```
+
+## 一些额外的挑战 🏆
+学习的最好方法**是自己尝试**!正如你所看到的,当前的智能体表现不是很好。作为第一个建议,你可以训练更多步骤。使用1,000,000步,我们看到了一些很好的结果!
+
+在[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)中,你会找到你的智能体。你能登上榜首吗?
+
+以下是一些实现这一目标的想法:
+* 训练更多步骤
+* 尝试`PPO`的不同超参数。你可以在https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#parameters 查看它们。
+* 查看[Stable-Baselines3文档](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html)并尝试另一个模型,如DQN。
+* **将你新训练的模型**推送到Hub 🔥
+
+**使用[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)比较你的LunarLander-v2与你的同学的结果** 🏆
+
+月球着陆对你来说太无聊了吗?尝试**改变环境**,为什么不使用MountainCar-v0、CartPole-v1或CarRacing-v0?查看它们如何工作[使用gym文档](https://www.gymlibrary.dev/)并享受乐趣 🎉。
+
+________________________________________________________________________
+恭喜你完成本章!这是最大的一章,**包含了大量信息。**
+
+如果你仍然对所有这些元素感到困惑...这完全正常!**这对我和所有学习强化学习的人来说都是一样的。**
+
+花时间真正**理解材料,然后再继续并尝试额外的挑战**。掌握这些元素并建立坚实的基础很重要。
+
+当然,在课程中,我们将深入探讨这些概念,但**在深入下一章之前,最好对它们有一个良好的理解。**
+
+
+下次,在奖励单元1中,你将训练Huggy狗去捡拾木棍。
+
+
+
+2. 然后我们只需要使用load_from_hub,包含:
+- repo_id
+- filename:仓库内保存的模型及其扩展名(*.zip)
+
+因为我从Hub下载的模型是用Gym(Gymnasium的前一个版本)训练的,我们需要安装shimmy,这是一个API转换工具,它将帮助我们正确运行环境。
+
+Shimmy文档:https://github.com/Farama-Foundation/Shimmy
+
+```python
+!pip install shimmy
+```
+
+```python
+from huggingface_sb3 import load_from_hub
+
+repo_id = "Classroom-workshop/assignment2-omar" # repo_id
+filename = "ppo-LunarLander-v2.zip" # 模型文件名.zip
+
+# 当模型在Python 3.8上训练时,pickle协议是5
+# 但Python 3.6, 3.7使用协议4
+# 为了获得兼容性,我们需要:
+# 1. 安装pickle5(我们在colab开始时已经完成)
+# 2. 创建一个自定义的空对象,我们将其作为参数传递给PPO.load()
+custom_objects = {
+ "learning_rate": 0.0,
+ "lr_schedule": lambda _: 0.0,
+ "clip_range": lambda _: 0.0,
+}
+
+checkpoint = load_from_hub(repo_id, filename)
+model = PPO.load(checkpoint, custom_objects=custom_objects, print_system_info=True)
+```
+
+让我们评估这个智能体:
+
+```python
+# @title
+eval_env = Monitor(gym.make("LunarLander-v2"))
+mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, deterministic=True)
+print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
+```
+
+## 一些额外的挑战 🏆
+学习的最好方法**是自己尝试**!正如你所看到的,当前的智能体表现不是很好。作为第一个建议,你可以训练更多步骤。使用1,000,000步,我们看到了一些很好的结果!
+
+在[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)中,你会找到你的智能体。你能登上榜首吗?
+
+以下是一些实现这一目标的想法:
+* 训练更多步骤
+* 尝试`PPO`的不同超参数。你可以在https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#parameters 查看它们。
+* 查看[Stable-Baselines3文档](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html)并尝试另一个模型,如DQN。
+* **将你新训练的模型**推送到Hub 🔥
+
+**使用[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)比较你的LunarLander-v2与你的同学的结果** 🏆
+
+月球着陆对你来说太无聊了吗?尝试**改变环境**,为什么不使用MountainCar-v0、CartPole-v1或CarRacing-v0?查看它们如何工作[使用gym文档](https://www.gymlibrary.dev/)并享受乐趣 🎉。
+
+________________________________________________________________________
+恭喜你完成本章!这是最大的一章,**包含了大量信息。**
+
+如果你仍然对所有这些元素感到困惑...这完全正常!**这对我和所有学习强化学习的人来说都是一样的。**
+
+花时间真正**理解材料,然后再继续并尝试额外的挑战**。掌握这些元素并建立坚实的基础很重要。
+
+当然,在课程中,我们将深入探讨这些概念,但**在深入下一章之前,最好对它们有一个良好的理解。**
+
+
+下次,在奖励单元1中,你将训练Huggy狗去捡拾木棍。
+
+ +
+## 继续学习,保持精彩 🤗
diff --git a/units/cn/unit1/introduction.mdx b/units/cn/unit1/introduction.mdx
new file mode 100644
index 00000000..50068700
--- /dev/null
+++ b/units/cn/unit1/introduction.mdx
@@ -0,0 +1,27 @@
+# 深度强化学习简介 [[introduction-to-deep-reinforcement-learning]]
+
+
+
+
+欢迎来到人工智能中最引人入胜的主题:**深度强化学习**。
+
+深度强化学习是一种机器学习类型,其中智能体通过**执行动作**并**观察结果**来学习**如何在环境中行动**。
+
+在这第一单元中,**你将学习深度强化学习的基础知识。**
+
+
+然后,你将**训练你的深度强化学习智能体,一个月球着陆器,使用Stable-Baselines3(一个深度强化学习库)正确地降落在月球上**。
+
+
+
+
+最后,你将**把这个训练好的智能体上传到Hugging Face Hub 🤗,这是一个免费、开放的平台,人们可以在这里分享机器学习模型、数据集和演示。**
+
+在深入实现深度强化学习智能体之前,**掌握这些元素至关重要**。本章的目标是给你坚实的基础。
+
+
+完成本单元后,在一个奖励单元中,你将**能够训练Huggy狗🐶去捡拾木棍并与它一起玩耍🤗**。
+
+
+
+让我们开始吧!🚀
diff --git a/units/cn/unit1/quiz.mdx b/units/cn/unit1/quiz.mdx
new file mode 100644
index 00000000..9e6ae6a1
--- /dev/null
+++ b/units/cn/unit1/quiz.mdx
@@ -0,0 +1,168 @@
+# 测验 [[quiz]]
+
+学习的最佳方式和[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法**是测试自己**。这将帮助你找出**需要加强知识的地方**。
+
+### 问题1:什么是强化学习?
+
+
+
+## 继续学习,保持精彩 🤗
diff --git a/units/cn/unit1/introduction.mdx b/units/cn/unit1/introduction.mdx
new file mode 100644
index 00000000..50068700
--- /dev/null
+++ b/units/cn/unit1/introduction.mdx
@@ -0,0 +1,27 @@
+# 深度强化学习简介 [[introduction-to-deep-reinforcement-learning]]
+
+
+
+
+欢迎来到人工智能中最引人入胜的主题:**深度强化学习**。
+
+深度强化学习是一种机器学习类型,其中智能体通过**执行动作**并**观察结果**来学习**如何在环境中行动**。
+
+在这第一单元中,**你将学习深度强化学习的基础知识。**
+
+
+然后,你将**训练你的深度强化学习智能体,一个月球着陆器,使用Stable-Baselines3(一个深度强化学习库)正确地降落在月球上**。
+
+
+
+
+最后,你将**把这个训练好的智能体上传到Hugging Face Hub 🤗,这是一个免费、开放的平台,人们可以在这里分享机器学习模型、数据集和演示。**
+
+在深入实现深度强化学习智能体之前,**掌握这些元素至关重要**。本章的目标是给你坚实的基础。
+
+
+完成本单元后,在一个奖励单元中,你将**能够训练Huggy狗🐶去捡拾木棍并与它一起玩耍🤗**。
+
+
+
+让我们开始吧!🚀
diff --git a/units/cn/unit1/quiz.mdx b/units/cn/unit1/quiz.mdx
new file mode 100644
index 00000000..9e6ae6a1
--- /dev/null
+++ b/units/cn/unit1/quiz.mdx
@@ -0,0 +1,168 @@
+# 测验 [[quiz]]
+
+学习的最佳方式和[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法**是测试自己**。这将帮助你找出**需要加强知识的地方**。
+
+### 问题1:什么是强化学习?
+
+
+解答
+
+强化学习是一个**解决控制任务(也称为决策问题)的框架**,通过构建智能体,让它们通过与环境的试错交互学习,并**接收奖励(正面或负面)作为唯一的反馈**。
+
+
+
+
+
+### 问题2:定义强化学习循环
+
+ +
+在每一步:
+- 我们的智能体从环境接收______
+- 基于该______,智能体采取一个______
+- 我们的智能体将向右移动
+- 环境转换到一个______
+- 环境给智能体一个______
+
+
+
+
+### 问题3:状态和观察之间有什么区别?
+
+
+
+### 问题4:任务是强化学习问题的一个实例。有哪两种类型的任务?
+
+
+
+### 问题5:什么是探索/利用权衡?
+
+
+
+在每一步:
+- 我们的智能体从环境接收______
+- 基于该______,智能体采取一个______
+- 我们的智能体将向右移动
+- 环境转换到一个______
+- 环境给智能体一个______
+
+
+
+
+### 问题3:状态和观察之间有什么区别?
+
+
+
+### 问题4:任务是强化学习问题的一个实例。有哪两种类型的任务?
+
+
+
+### 问题5:什么是探索/利用权衡?
+
+
+解答
+
+在强化学习中,我们需要**平衡我们对环境的探索程度和对我们已知环境信息的利用程度**。
+
+- *探索*是通过**尝试随机动作来探索环境,以便找到关于环境的更多信息**。
+
+- *利用*是**利用已知信息来最大化奖励**。
+
+
+
+
+
+
+### 问题6:什么是策略?
+
+
+解答
+
+- 策略π**是我们智能体的大脑**。它是一个函数,告诉我们在给定状态下应该采取什么动作。因此,它定义了智能体在给定时间的行为。
+
+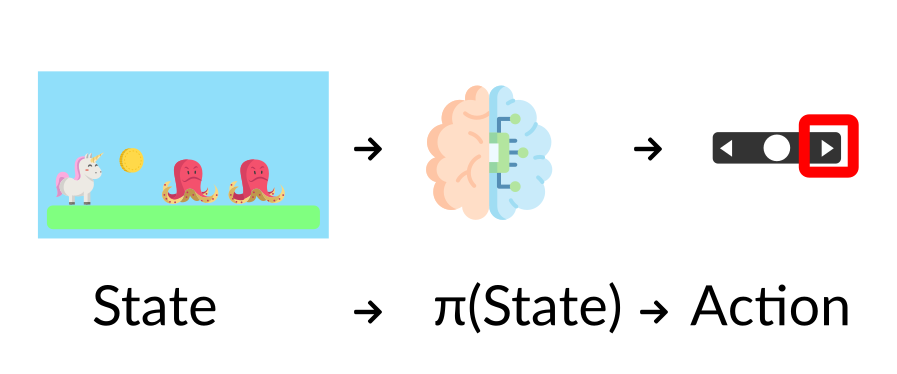 +
+
+
+
+
+
+### 问题7:什么是基于价值的方法?
+
+
+解答
+
+- 基于价值的方法是解决强化学习问题的主要方法之一。
+- 在基于价值的方法中,我们不是训练一个策略函数,而是**训练一个价值函数,将状态映射到处于该状态的预期价值**。
+
+
+
+
+
+### 问题8:什么是基于策略的方法?
+
+
+解答
+
+- 在*基于策略的方法*中,我们**直接学习一个策略函数**。
+- 这个策略函数将**从每个状态映射到该状态下最佳的相应动作**。或者是**在该状态下可能动作集合上的概率分布**。
+
+
+
+
+
+
+
+恭喜你完成这个测验 🥳,如果你错过了一些元素,花时间再次阅读本章以加强(😏)你的知识,但**不要担心**:在课程中我们会再次回顾这些概念,你将**通过实践来加强你的理论知识**。
diff --git a/units/cn/unit1/rl-framework.mdx b/units/cn/unit1/rl-framework.mdx
new file mode 100644
index 00000000..59da1305
--- /dev/null
+++ b/units/cn/unit1/rl-framework.mdx
@@ -0,0 +1,141 @@
+# 强化学习框架 [[the-reinforcement-learning-framework]]
+
+## 强化学习过程 [[the-rl-process]]
+
+
+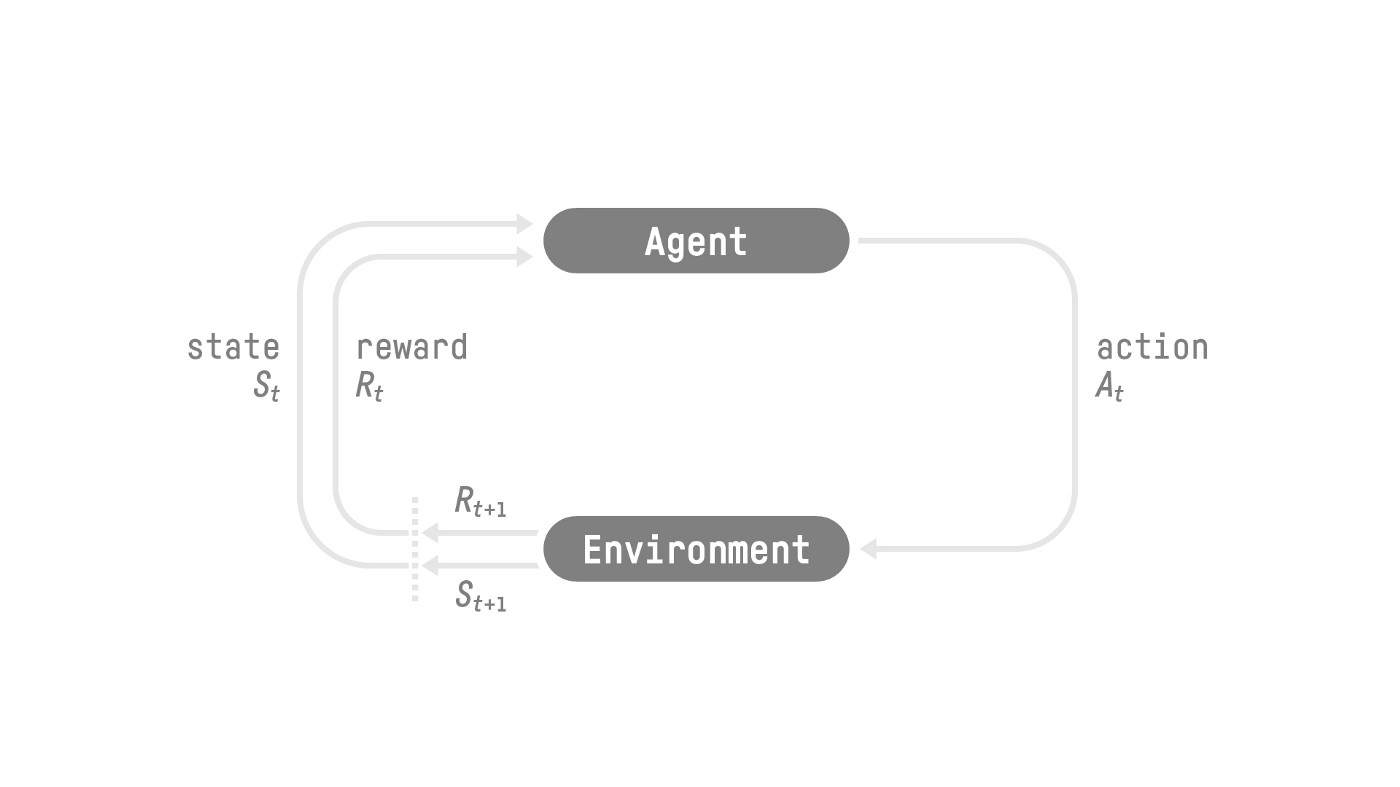 +强化学习过程:状态、动作、奖励和下一状态的循环
+来源:强化学习:简介,Richard Sutton和Andrew G. Barto
+
+
+为了理解强化学习过程,让我们想象一个智能体学习玩平台游戏:
+
+
+
+- 我们的智能体从**环境**接收**状态 \\(S_0\\)**——我们接收游戏的第一帧(环境)。
+- 基于该**状态 \\(S_0\\)**,智能体采取**动作 \\(A_0\\)**——我们的智能体将向右移动。
+- 环境转换到一个**新状态 \\(S_1\\)**——新的帧。
+- 环境给智能体一些**奖励 \\(R_1\\)**——我们没有死亡*(正奖励+1)*。
+
+这个强化学习循环输出一个**状态、动作、奖励和下一状态**的序列。
+
+
+强化学习过程:状态、动作、奖励和下一状态的循环
+来源:强化学习:简介,Richard Sutton和Andrew G. Barto
+
+
+为了理解强化学习过程,让我们想象一个智能体学习玩平台游戏:
+
+
+
+- 我们的智能体从**环境**接收**状态 \\(S_0\\)**——我们接收游戏的第一帧(环境)。
+- 基于该**状态 \\(S_0\\)**,智能体采取**动作 \\(A_0\\)**——我们的智能体将向右移动。
+- 环境转换到一个**新状态 \\(S_1\\)**——新的帧。
+- 环境给智能体一些**奖励 \\(R_1\\)**——我们没有死亡*(正奖励+1)*。
+
+这个强化学习循环输出一个**状态、动作、奖励和下一状态**的序列。
+
+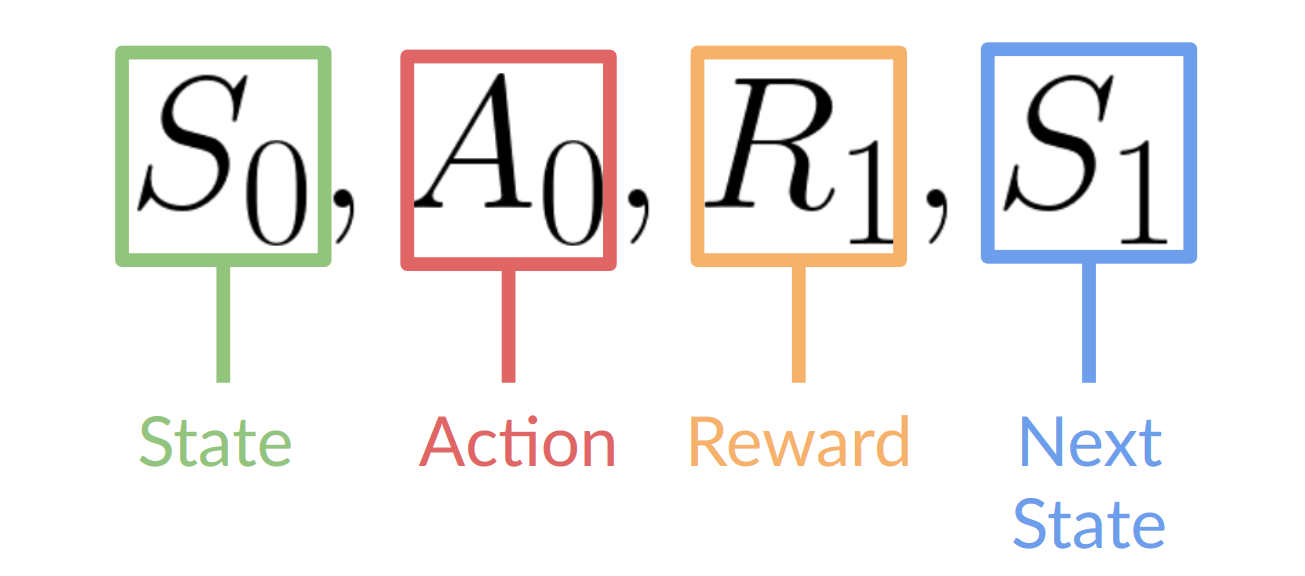 +
+智能体的目标是_最大化_其累积奖励,**称为期望回报。**
+
+## 奖励假设:强化学习的核心思想 [[reward-hypothesis]]
+
+⇒ 为什么智能体的目标是最大化期望回报?
+
+因为强化学习基于**奖励假设**,即所有目标都可以描述为**期望回报(期望累积奖励)的最大化**。
+
+这就是为什么在强化学习中,**为了获得最佳行为,**我们的目标是学习采取**最大化期望累积奖励的动作。**
+
+
+## 马尔可夫性质 [[markov-property]]
+
+在论文中,你会看到强化学习过程被称为**马尔可夫决策过程**(MDP)。
+
+我们将在接下来的单元中再次讨论马尔可夫性质。但如果你今天需要记住关于它的一点,那就是:马尔可夫性质意味着我们的智能体**只需要当前状态就能决定**采取什么动作,而**不需要之前所有状态和动作的历史**。
+
+## 观察/状态空间 [[obs-space]]
+
+观察/状态是**我们的智能体从环境中获得的信息。**在视频游戏的情况下,它可以是一帧(屏幕截图)。在交易智能体的情况下,它可以是某只股票的价值等。
+
+我们需要区分*观察*和*状态*:
+
+- *状态s*:是**世界状态的完整描述**(没有隐藏信息)。在完全观察的环境中。
+
+
+
+
+
+智能体的目标是_最大化_其累积奖励,**称为期望回报。**
+
+## 奖励假设:强化学习的核心思想 [[reward-hypothesis]]
+
+⇒ 为什么智能体的目标是最大化期望回报?
+
+因为强化学习基于**奖励假设**,即所有目标都可以描述为**期望回报(期望累积奖励)的最大化**。
+
+这就是为什么在强化学习中,**为了获得最佳行为,**我们的目标是学习采取**最大化期望累积奖励的动作。**
+
+
+## 马尔可夫性质 [[markov-property]]
+
+在论文中,你会看到强化学习过程被称为**马尔可夫决策过程**(MDP)。
+
+我们将在接下来的单元中再次讨论马尔可夫性质。但如果你今天需要记住关于它的一点,那就是:马尔可夫性质意味着我们的智能体**只需要当前状态就能决定**采取什么动作,而**不需要之前所有状态和动作的历史**。
+
+## 观察/状态空间 [[obs-space]]
+
+观察/状态是**我们的智能体从环境中获得的信息。**在视频游戏的情况下,它可以是一帧(屏幕截图)。在交易智能体的情况下,它可以是某只股票的价值等。
+
+我们需要区分*观察*和*状态*:
+
+- *状态s*:是**世界状态的完整描述**(没有隐藏信息)。在完全观察的环境中。
+
+
+
+ +在国际象棋游戏中,我们从环境接收一个状态,因为我们可以访问整个棋盘信息。
+
+
+在国际象棋游戏中,我们可以访问整个棋盘信息,所以我们从环境接收一个状态。换句话说,环境是完全观察的。
+
+- *观察o*:是**状态的部分描述。**在部分观察的环境中。
+
+
+
+在国际象棋游戏中,我们从环境接收一个状态,因为我们可以访问整个棋盘信息。
+
+
+在国际象棋游戏中,我们可以访问整个棋盘信息,所以我们从环境接收一个状态。换句话说,环境是完全观察的。
+
+- *观察o*:是**状态的部分描述。**在部分观察的环境中。
+
+
+ +在超级马里奥兄弟中,我们只能看到靠近玩家的部分关卡,所以我们接收一个观察。
+
+
+在超级马里奥兄弟中,我们只能看到靠近玩家的部分关卡,所以我们接收一个观察。
+
+在超级马里奥兄弟中,我们处于部分观察的环境中。我们接收一个观察**因为我们只能看到关卡的一部分。**
+
+
+在本课程中,我们使用术语"状态"来表示状态和观察,但我们将在实现中做出区分。
+
+
+总结:
+
+在超级马里奥兄弟中,我们只能看到靠近玩家的部分关卡,所以我们接收一个观察。
+
+
+在超级马里奥兄弟中,我们只能看到靠近玩家的部分关卡,所以我们接收一个观察。
+
+在超级马里奥兄弟中,我们处于部分观察的环境中。我们接收一个观察**因为我们只能看到关卡的一部分。**
+
+
+在本课程中,我们使用术语"状态"来表示状态和观察,但我们将在实现中做出区分。
+
+
+总结:
+ +
+
+## 动作空间 [[action-space]]
+
+动作空间是环境中**所有可能动作的集合。**
+
+动作可以来自*离散*或*连续*空间:
+
+- *离散空间*:可能动作的数量是**有限的**。
+
+
+
+在超级马里奥兄弟中,我们只有4种可能的动作:左、右、上(跳跃)和下(蹲下)。
+
+
+
+同样,在超级马里奥兄弟中,我们有一个有限的动作集,因为我们只有4个方向。
+
+- *连续空间*:可能动作的数量是**无限的**。
+
+
+
+
+
+## 动作空间 [[action-space]]
+
+动作空间是环境中**所有可能动作的集合。**
+
+动作可以来自*离散*或*连续*空间:
+
+- *离散空间*:可能动作的数量是**有限的**。
+
+
+
+在超级马里奥兄弟中,我们只有4种可能的动作:左、右、上(跳跃)和下(蹲下)。
+
+
+
+同样,在超级马里奥兄弟中,我们有一个有限的动作集,因为我们只有4个方向。
+
+- *连续空间*:可能动作的数量是**无限的**。
+
+
+ +自动驾驶汽车智能体有无限多种可能的动作,因为它可以向左转20°、21.1°、21.2°、鸣喇叭、向右转20°……
+
+
+总结:
+
+自动驾驶汽车智能体有无限多种可能的动作,因为它可以向左转20°、21.1°、21.2°、鸣喇叭、向右转20°……
+
+
+总结:
+ +
+考虑这些信息至关重要,因为它在未来选择强化学习算法时**将具有重要性**。
+
+## 奖励和折扣 [[rewards]]
+
+奖励在强化学习中是基础的,因为它是智能体的**唯一反馈**。多亏了它,我们的智能体知道**所采取的动作是好是坏。**
+
+每个时间步**t**的累积奖励可以写为:
+
+
+
+
+考虑这些信息至关重要,因为它在未来选择强化学习算法时**将具有重要性**。
+
+## 奖励和折扣 [[rewards]]
+
+奖励在强化学习中是基础的,因为它是智能体的**唯一反馈**。多亏了它,我们的智能体知道**所采取的动作是好是坏。**
+
+每个时间步**t**的累积奖励可以写为:
+
+
+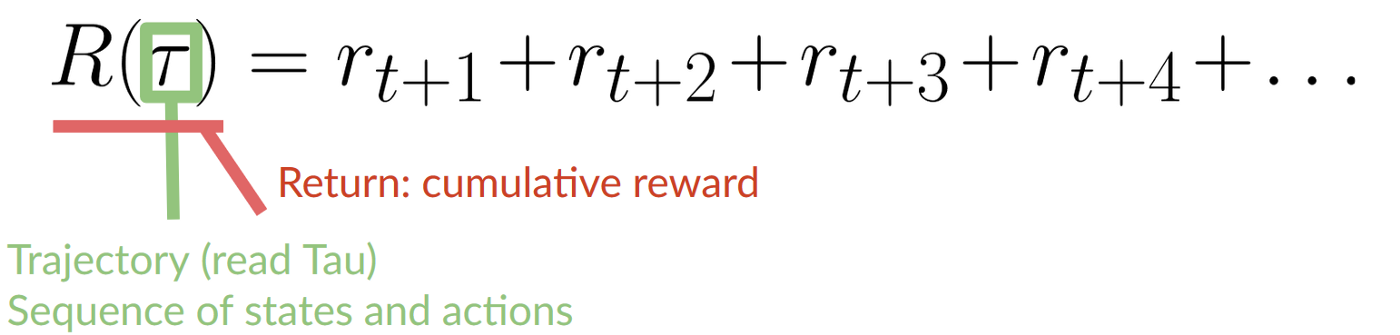 +累积奖励等于序列中所有奖励的总和。
+
+
+这等同于:
+
+
+
+累积奖励等于序列中所有奖励的总和。
+
+
+这等同于:
+
+
+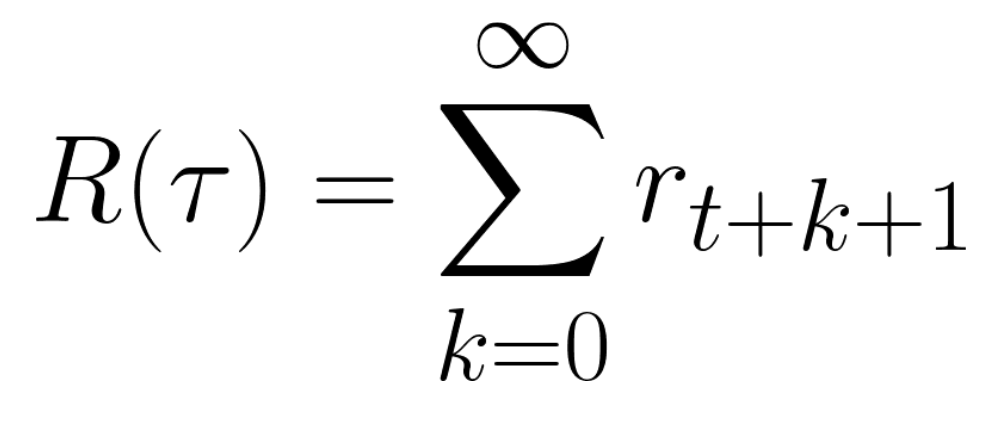 +累积奖励 = rt+1 (rt+k+1 = rt+1+1 = rt+2)+ rt+2 (rt+k+1 = rt+2+1 = rt+3) + ...
+
+
+然而,在现实中,**我们不能就这样简单地把它们加起来。**更早到来的奖励(在游戏开始时)**更有可能发生**,因为它们比长期未来奖励更可预测。
+
+假设你的智能体是这只小老鼠,每个时间步可以移动一个格子,而你的对手是猫(也可以移动)。老鼠的目标是**在被猫吃掉之前吃掉最多的奶酪。**
+
+
+累积奖励 = rt+1 (rt+k+1 = rt+1+1 = rt+2)+ rt+2 (rt+k+1 = rt+2+1 = rt+3) + ...
+
+
+然而,在现实中,**我们不能就这样简单地把它们加起来。**更早到来的奖励(在游戏开始时)**更有可能发生**,因为它们比长期未来奖励更可预测。
+
+假设你的智能体是这只小老鼠,每个时间步可以移动一个格子,而你的对手是猫(也可以移动)。老鼠的目标是**在被猫吃掉之前吃掉最多的奶酪。**
+
+ +
+正如我们在图中所看到的,**吃掉靠近我们的奶酪比吃掉靠近猫的奶酪更有可能**(我们越靠近猫,就越危险)。
+
+因此,**靠近猫的奖励,即使它更大(更多奶酪),也会被更多地折扣**,因为我们不确定我们能否吃到它。
+
+为了折扣奖励,我们这样做:
+
+1. 我们定义一个称为gamma的折扣率。**它必须在0和1之间。**大多数时候在**0.95和0.99之间**。
+- gamma越大,折扣越小。这意味着我们的智能体**更关心长期奖励。**
+- 另一方面,gamma越小,折扣越大。这意味着我们的**智能体更关心短期奖励(最近的奶酪)。**
+
+2. 然后,每个奖励将被gamma的时间步幂次折扣。随着时间步的增加,猫越来越靠近我们,**所以未来的奖励越来越不可能发生。**
+
+我们的折扣期望累积奖励是:
+
+
+正如我们在图中所看到的,**吃掉靠近我们的奶酪比吃掉靠近猫的奶酪更有可能**(我们越靠近猫,就越危险)。
+
+因此,**靠近猫的奖励,即使它更大(更多奶酪),也会被更多地折扣**,因为我们不确定我们能否吃到它。
+
+为了折扣奖励,我们这样做:
+
+1. 我们定义一个称为gamma的折扣率。**它必须在0和1之间。**大多数时候在**0.95和0.99之间**。
+- gamma越大,折扣越小。这意味着我们的智能体**更关心长期奖励。**
+- 另一方面,gamma越小,折扣越大。这意味着我们的**智能体更关心短期奖励(最近的奶酪)。**
+
+2. 然后,每个奖励将被gamma的时间步幂次折扣。随着时间步的增加,猫越来越靠近我们,**所以未来的奖励越来越不可能发生。**
+
+我们的折扣期望累积奖励是:
+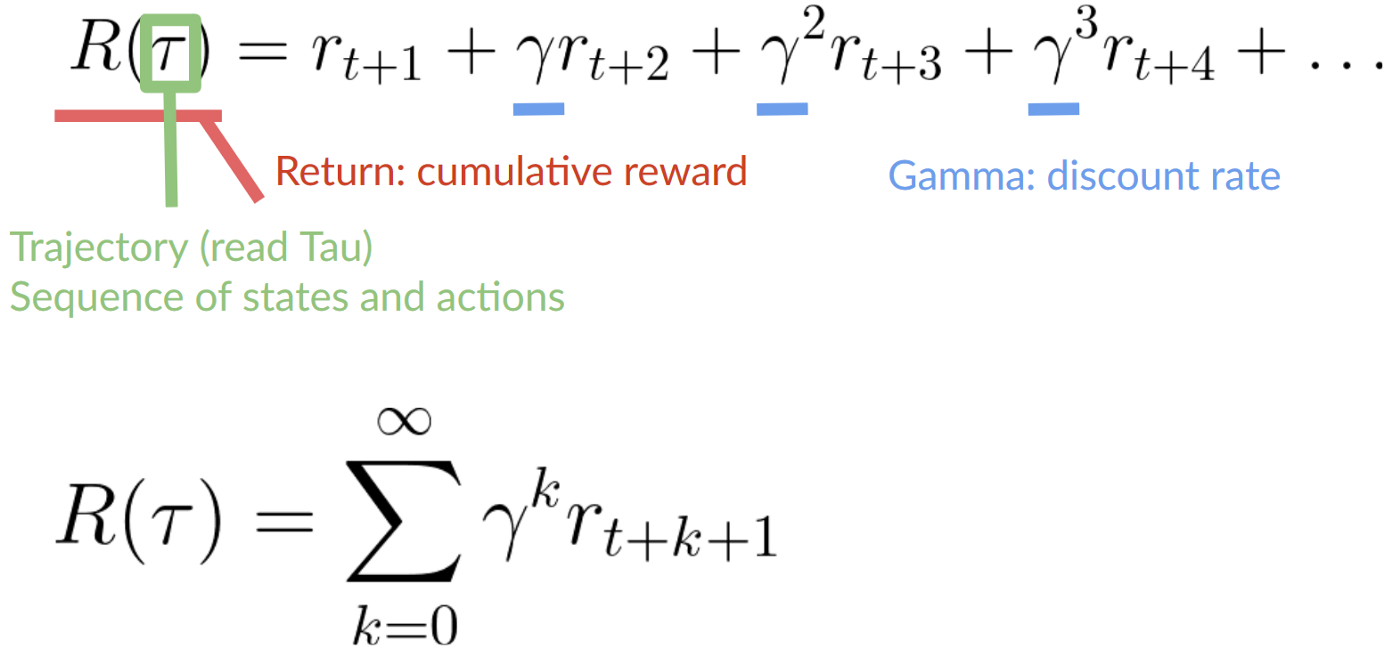 diff --git a/units/cn/unit1/summary.mdx b/units/cn/unit1/summary.mdx
new file mode 100644
index 00000000..9b33b52c
--- /dev/null
+++ b/units/cn/unit1/summary.mdx
@@ -0,0 +1,19 @@
+# 总结 [[summary]]
+
+这里有很多信息!让我们总结一下:
+
+- 强化学习是一种从行动中学习的计算方法。我们构建一个智能体,它通过**与环境的试错交互**学习,并接收奖励(负面或正面)作为反馈。
+
+- 任何强化学习智能体的目标都是最大化其期望累积奖励(也称为期望回报),因为强化学习基于**奖励假设**,即**所有目标都可以描述为期望累积奖励的最大化。**
+
+- 强化学习过程是一个输出**状态、动作、奖励和下一状态**序列的循环。
+
+- 为了计算期望累积奖励(期望回报),我们对奖励进行折扣:更早到来的奖励(在游戏开始时)**更有可能发生,因为它们比长期未来奖励更可预测。**
+
+- 要解决强化学习问题,你需要**找到一个最优策略**。策略是你的智能体的"大脑",它告诉我们**在给定状态下采取什么动作。**最优策略是**给你带来最大化期望回报的动作的策略。**
+
+- 有两种方法可以找到你的最优策略:
+ 1. 通过直接训练你的策略:**基于策略的方法。**
+ 2. 通过训练一个价值函数,告诉我们智能体在每个状态下将获得的期望回报,并使用这个函数来定义我们的策略:**基于价值的方法。**
+
+- 最后,我们谈论深度强化学习是因为我们引入了**深度神经网络来估计要采取的动作(基于策略)或估计状态的价值(基于价值)**,因此得名"深度"。
diff --git a/units/cn/unit1/tasks.mdx b/units/cn/unit1/tasks.mdx
new file mode 100644
index 00000000..561ad71c
--- /dev/null
+++ b/units/cn/unit1/tasks.mdx
@@ -0,0 +1,26 @@
+# 任务类型 [[tasks]]
+
+任务是强化学习问题的**一个实例**。我们可以有两种类型的任务:**情节性**和**持续性**。
+
+## 情节性任务 [[episodic-task]]
+
+在这种情况下,我们有一个起点和一个终点**(一个终止状态)。这创建了一个情节**:状态、动作、奖励和新状态的列表。
+
+例如,想想超级马里奥兄弟:一个情节从启动新的马里奥关卡开始,**当你被杀死或到达关卡末尾时结束。**
+
+
+
+新情节的开始。
+
+
+
+## 持续性任务 [[continuing-tasks]]
+
+这些是永远持续的任务(**没有终止状态**)。在这种情况下,智能体必须**学习如何选择最佳动作并同时与环境交互。**
+
+例如,一个进行自动股票交易的智能体。对于这个任务,没有起点和终止状态。**智能体会一直运行,直到我们决定停止它。**
+
+
diff --git a/units/cn/unit1/summary.mdx b/units/cn/unit1/summary.mdx
new file mode 100644
index 00000000..9b33b52c
--- /dev/null
+++ b/units/cn/unit1/summary.mdx
@@ -0,0 +1,19 @@
+# 总结 [[summary]]
+
+这里有很多信息!让我们总结一下:
+
+- 强化学习是一种从行动中学习的计算方法。我们构建一个智能体,它通过**与环境的试错交互**学习,并接收奖励(负面或正面)作为反馈。
+
+- 任何强化学习智能体的目标都是最大化其期望累积奖励(也称为期望回报),因为强化学习基于**奖励假设**,即**所有目标都可以描述为期望累积奖励的最大化。**
+
+- 强化学习过程是一个输出**状态、动作、奖励和下一状态**序列的循环。
+
+- 为了计算期望累积奖励(期望回报),我们对奖励进行折扣:更早到来的奖励(在游戏开始时)**更有可能发生,因为它们比长期未来奖励更可预测。**
+
+- 要解决强化学习问题,你需要**找到一个最优策略**。策略是你的智能体的"大脑",它告诉我们**在给定状态下采取什么动作。**最优策略是**给你带来最大化期望回报的动作的策略。**
+
+- 有两种方法可以找到你的最优策略:
+ 1. 通过直接训练你的策略:**基于策略的方法。**
+ 2. 通过训练一个价值函数,告诉我们智能体在每个状态下将获得的期望回报,并使用这个函数来定义我们的策略:**基于价值的方法。**
+
+- 最后,我们谈论深度强化学习是因为我们引入了**深度神经网络来估计要采取的动作(基于策略)或估计状态的价值(基于价值)**,因此得名"深度"。
diff --git a/units/cn/unit1/tasks.mdx b/units/cn/unit1/tasks.mdx
new file mode 100644
index 00000000..561ad71c
--- /dev/null
+++ b/units/cn/unit1/tasks.mdx
@@ -0,0 +1,26 @@
+# 任务类型 [[tasks]]
+
+任务是强化学习问题的**一个实例**。我们可以有两种类型的任务:**情节性**和**持续性**。
+
+## 情节性任务 [[episodic-task]]
+
+在这种情况下,我们有一个起点和一个终点**(一个终止状态)。这创建了一个情节**:状态、动作、奖励和新状态的列表。
+
+例如,想想超级马里奥兄弟:一个情节从启动新的马里奥关卡开始,**当你被杀死或到达关卡末尾时结束。**
+
+
+
+新情节的开始。
+
+
+
+## 持续性任务 [[continuing-tasks]]
+
+这些是永远持续的任务(**没有终止状态**)。在这种情况下,智能体必须**学习如何选择最佳动作并同时与环境交互。**
+
+例如,一个进行自动股票交易的智能体。对于这个任务,没有起点和终止状态。**智能体会一直运行,直到我们决定停止它。**
+
+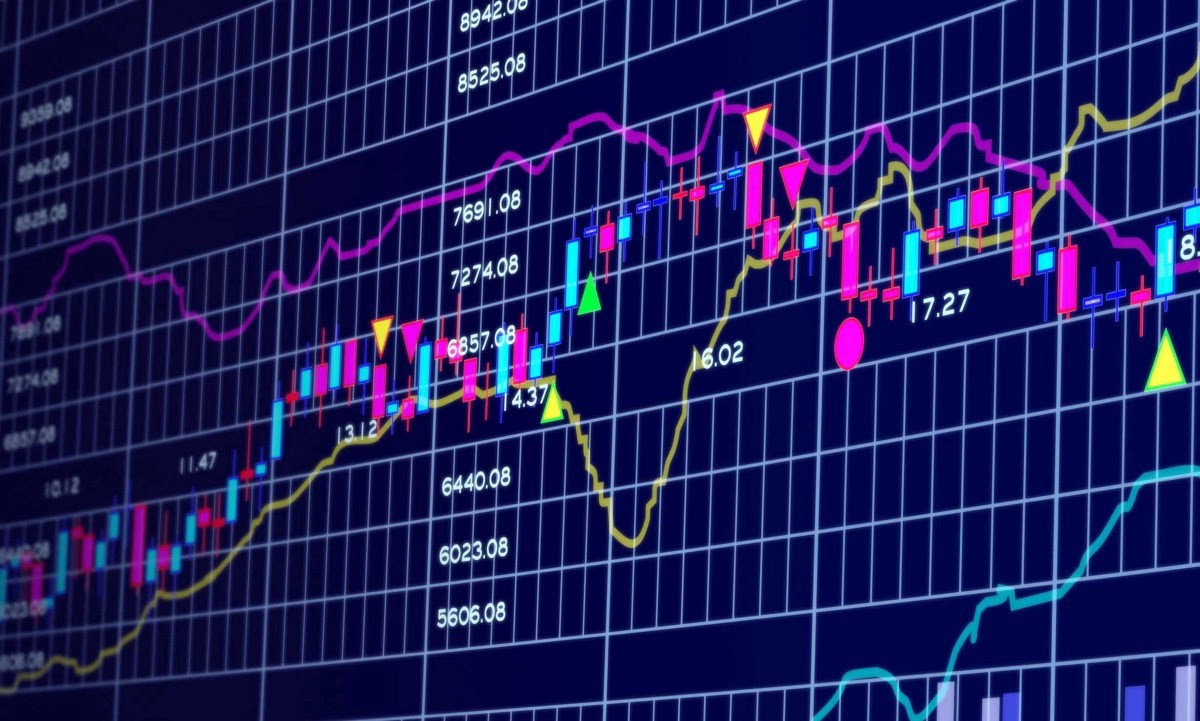 +
+总结:
+
+
+总结:
+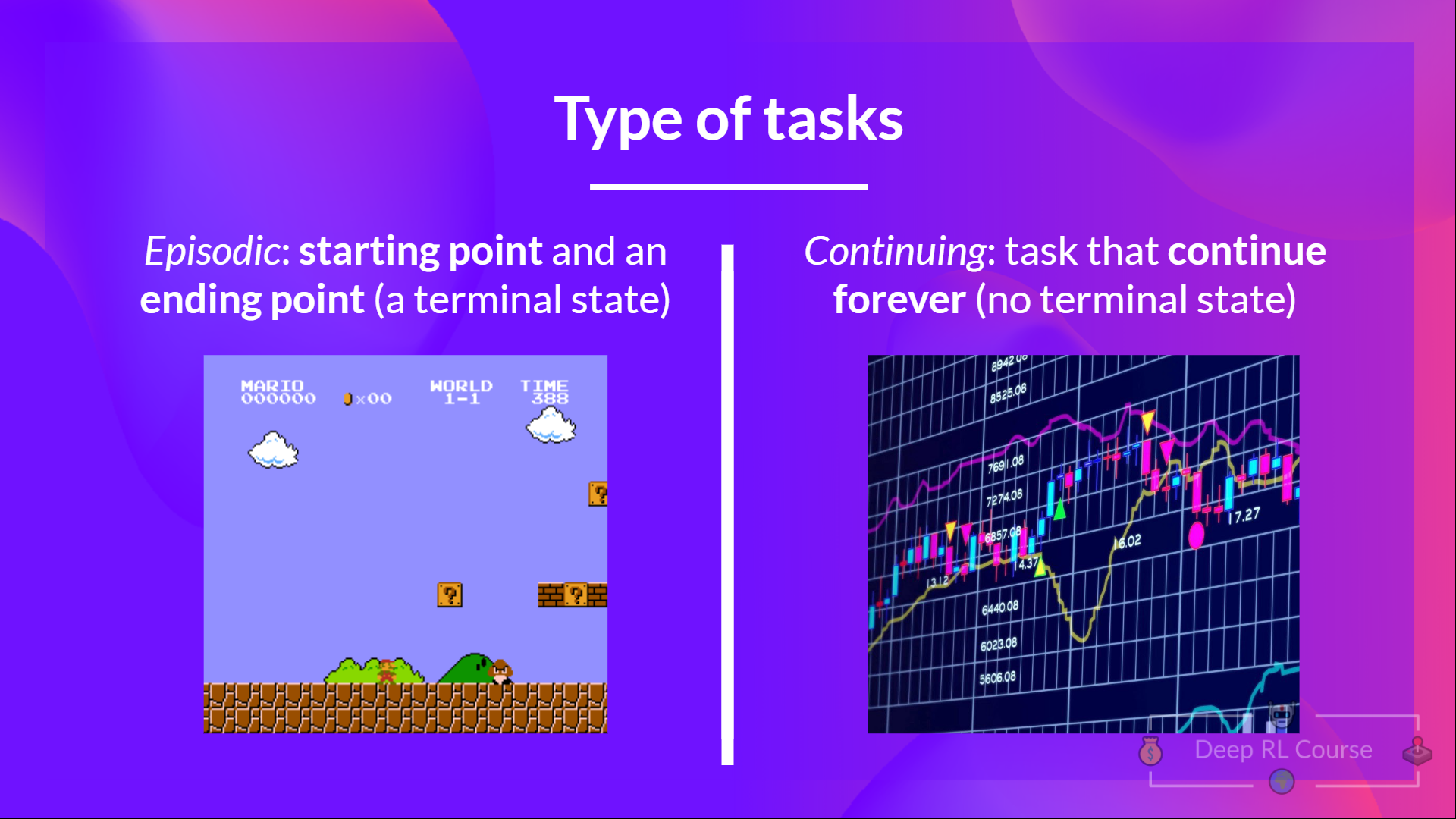 diff --git a/units/cn/unit1/two-methods.mdx b/units/cn/unit1/two-methods.mdx
new file mode 100644
index 00000000..48ee6c94
--- /dev/null
+++ b/units/cn/unit1/two-methods.mdx
@@ -0,0 +1,90 @@
+# 解决强化学习问题的两种主要方法 [[two-methods]]
+
+
+现在我们已经学习了强化学习框架,如何解决强化学习问题呢?
+
+
+换句话说,我们如何构建一个强化学习智能体,使其能够**选择最大化其期望累积奖励的动作?**
+
+## 策略π:智能体的大脑 [[policy]]
+
+策略**π**是**我们智能体的大脑**,它是一个函数,告诉我们在给定状态下**采取什么动作。**因此,它**定义了智能体在给定时间的行为**。
+
+
+
+将策略视为我们智能体的大脑,这个函数会告诉我们在给定状态下采取什么动作
+
+
+这个策略**是我们想要学习的函数**,我们的目标是找到最优策略π\*,即当智能体按照它行动时**最大化期望回报**的策略。我们通过**训练**找到这个π\*。
+
+有两种方法来训练我们的智能体以找到这个最优策略π\*:
+
+- **直接地**,通过教导智能体学习在给定当前状态下**采取什么动作**:**基于策略的方法。**
+- 间接地,**教导智能体学习哪个状态更有价值**,然后采取**导向更有价值状态的动作**:基于价值的方法。
+
+## 基于策略的方法 [[policy-based]]
+
+在基于策略的方法中,**我们直接学习一个策略函数。**
+
+这个函数将定义从每个状态到最佳相应动作的映射。或者,它可以定义**在该状态下可能动作集合上的概率分布。**
+
+
+
diff --git a/units/cn/unit1/two-methods.mdx b/units/cn/unit1/two-methods.mdx
new file mode 100644
index 00000000..48ee6c94
--- /dev/null
+++ b/units/cn/unit1/two-methods.mdx
@@ -0,0 +1,90 @@
+# 解决强化学习问题的两种主要方法 [[two-methods]]
+
+
+现在我们已经学习了强化学习框架,如何解决强化学习问题呢?
+
+
+换句话说,我们如何构建一个强化学习智能体,使其能够**选择最大化其期望累积奖励的动作?**
+
+## 策略π:智能体的大脑 [[policy]]
+
+策略**π**是**我们智能体的大脑**,它是一个函数,告诉我们在给定状态下**采取什么动作。**因此,它**定义了智能体在给定时间的行为**。
+
+
+
+将策略视为我们智能体的大脑,这个函数会告诉我们在给定状态下采取什么动作
+
+
+这个策略**是我们想要学习的函数**,我们的目标是找到最优策略π\*,即当智能体按照它行动时**最大化期望回报**的策略。我们通过**训练**找到这个π\*。
+
+有两种方法来训练我们的智能体以找到这个最优策略π\*:
+
+- **直接地**,通过教导智能体学习在给定当前状态下**采取什么动作**:**基于策略的方法。**
+- 间接地,**教导智能体学习哪个状态更有价值**,然后采取**导向更有价值状态的动作**:基于价值的方法。
+
+## 基于策略的方法 [[policy-based]]
+
+在基于策略的方法中,**我们直接学习一个策略函数。**
+
+这个函数将定义从每个状态到最佳相应动作的映射。或者,它可以定义**在该状态下可能动作集合上的概率分布。**
+
+
+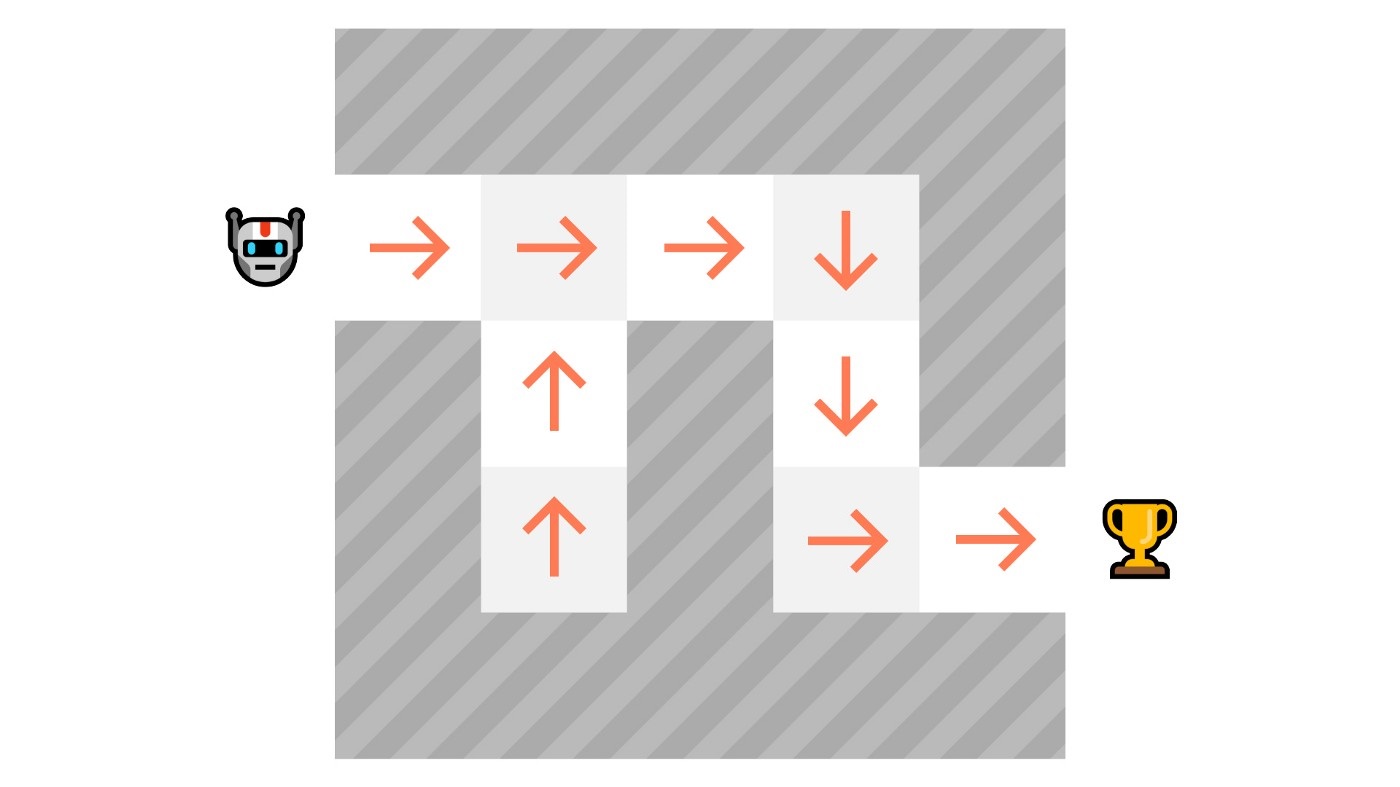 +正如我们在这里看到的,策略(确定性)直接指示每一步要采取的动作。
+
+
+
+我们有两种类型的策略:
+
+
+- *确定性*:在给定状态下的策略**将始终返回相同的动作。**
+
+
+
+正如我们在这里看到的,策略(确定性)直接指示每一步要采取的动作。
+
+
+
+我们有两种类型的策略:
+
+
+- *确定性*:在给定状态下的策略**将始终返回相同的动作。**
+
+
+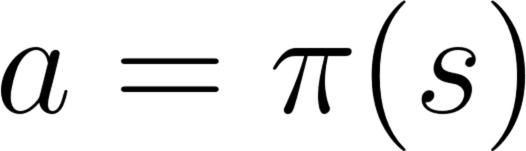 +action = policy(state)
+
+
+
+action = policy(state)
+
+
+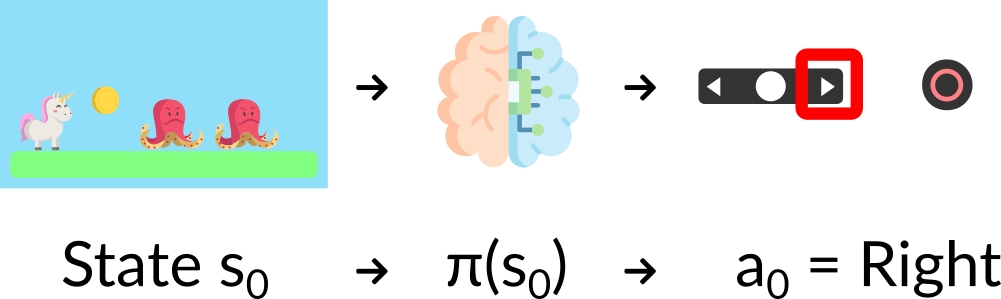 +
+- *随机性*:输出**动作的概率分布。**
+
+
+
+
+- *随机性*:输出**动作的概率分布。**
+
+
+ +policy(actions | state) = 在给定当前状态下,对可能动作集合的概率分布
+
+
+
+
+policy(actions | state) = 在给定当前状态下,对可能动作集合的概率分布
+
+
+
+ +给定一个初始状态,我们的随机策略将输出该状态下可能动作的概率分布。
+
+
+
+如果我们总结一下:
+
+
+给定一个初始状态,我们的随机策略将输出该状态下可能动作的概率分布。
+
+
+
+如果我们总结一下:
+
+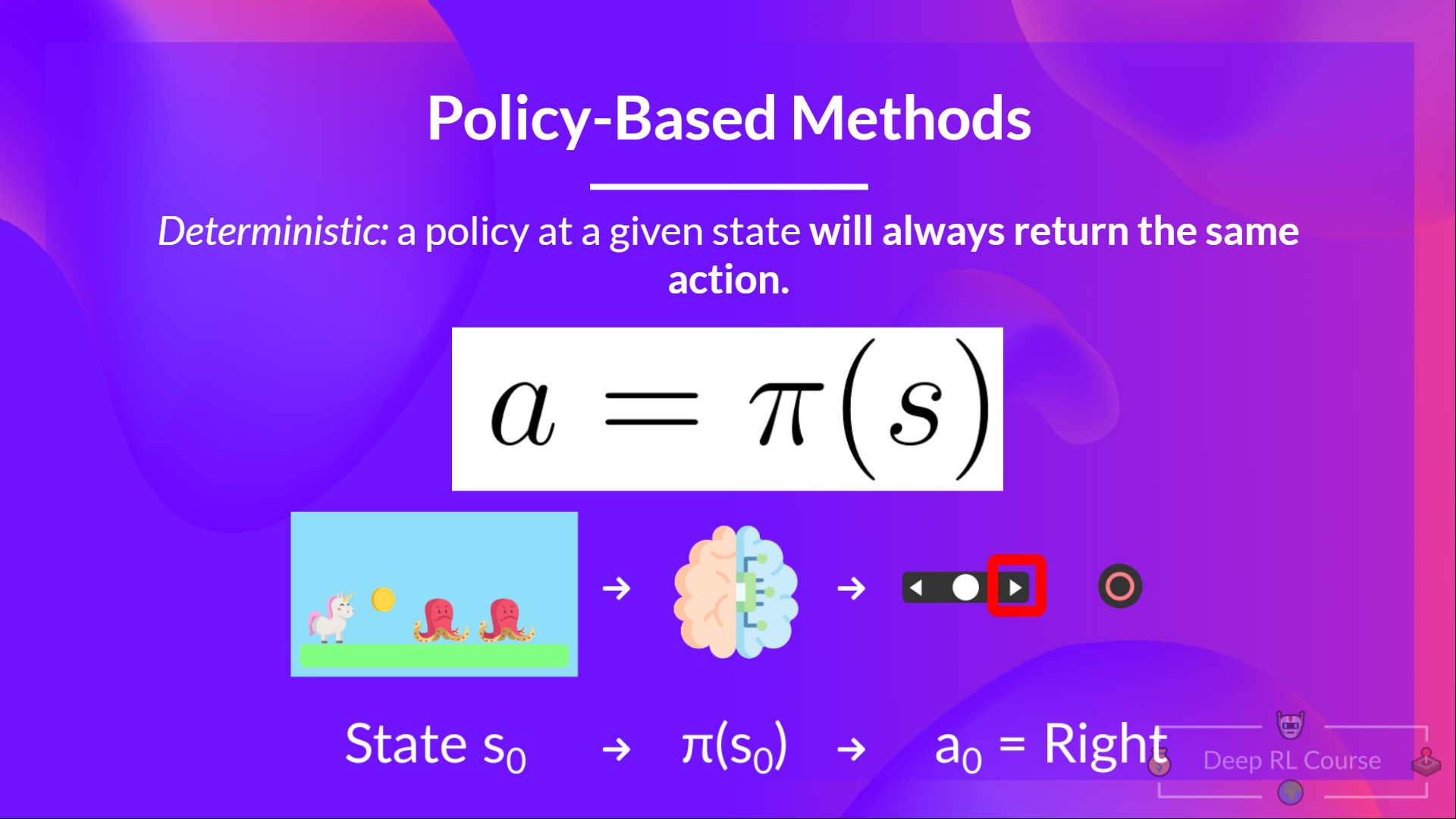 +
+ +
+
+## 基于价值的方法 [[value-based]]
+
+在基于价值的方法中,我们不是学习一个策略函数,而是**学习一个价值函数**,它将状态映射到**处于该状态的期望价值。**
+
+状态的价值是智能体如果**从该状态开始,然后按照我们的策略行动**所能获得的**期望折扣回报**。
+
+"按照我们的策略行动"只是意味着我们的策略是**"前往价值最高的状态"。**
+
+
+
+
+## 基于价值的方法 [[value-based]]
+
+在基于价值的方法中,我们不是学习一个策略函数,而是**学习一个价值函数**,它将状态映射到**处于该状态的期望价值。**
+
+状态的价值是智能体如果**从该状态开始,然后按照我们的策略行动**所能获得的**期望折扣回报**。
+
+"按照我们的策略行动"只是意味着我们的策略是**"前往价值最高的状态"。**
+
+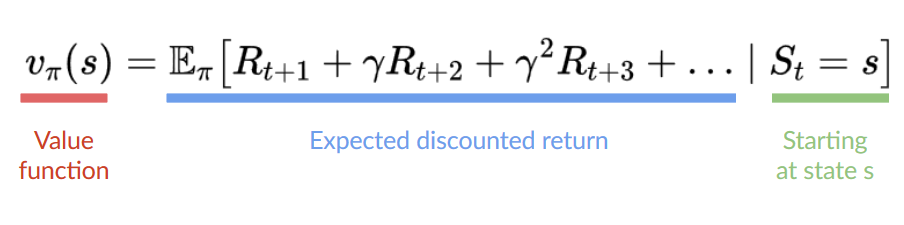 +
+这里我们看到我们的价值函数**为每个可能的状态定义了价值。**
+
+
+
+
+这里我们看到我们的价值函数**为每个可能的状态定义了价值。**
+
+
+ +多亏了我们的价值函数,在每一步我们的策略将选择价值函数定义的价值最大的状态:-7,然后-6,然后-5(依此类推)以达到目标。
+
+
+多亏了我们的价值函数,在每一步我们的策略将选择价值函数定义的价值最大的状态:-7,然后-6,然后-5(依此类推)以达到目标。
+
+如果我们总结一下:
+
+
+多亏了我们的价值函数,在每一步我们的策略将选择价值函数定义的价值最大的状态:-7,然后-6,然后-5(依此类推)以达到目标。
+
+
+多亏了我们的价值函数,在每一步我们的策略将选择价值函数定义的价值最大的状态:-7,然后-6,然后-5(依此类推)以达到目标。
+
+如果我们总结一下:
+
+ +
+ diff --git a/units/cn/unit1/what-is-rl.mdx b/units/cn/unit1/what-is-rl.mdx
new file mode 100644
index 00000000..adf352d3
--- /dev/null
+++ b/units/cn/unit1/what-is-rl.mdx
@@ -0,0 +1,40 @@
+# 什么是强化学习? [[what-is-reinforcement-learning]]
+
+要理解强化学习,让我们从大局观开始。
+
+## 大局观 [[the-big-picture]]
+
+强化学习背后的理念是,一个智能体(人工智能)将通过**与环境交互**(通过试错)并**接收奖励**(负面或正面)作为执行动作的反馈来从环境中学习。
+
+从与环境的交互中学习**来源于我们的自然经验。**
+
+例如,想象把你的小弟弟放在一个他从未玩过的视频游戏前,给他一个控制器,然后让他独自一人。
+
+
+
diff --git a/units/cn/unit1/what-is-rl.mdx b/units/cn/unit1/what-is-rl.mdx
new file mode 100644
index 00000000..adf352d3
--- /dev/null
+++ b/units/cn/unit1/what-is-rl.mdx
@@ -0,0 +1,40 @@
+# 什么是强化学习? [[what-is-reinforcement-learning]]
+
+要理解强化学习,让我们从大局观开始。
+
+## 大局观 [[the-big-picture]]
+
+强化学习背后的理念是,一个智能体(人工智能)将通过**与环境交互**(通过试错)并**接收奖励**(负面或正面)作为执行动作的反馈来从环境中学习。
+
+从与环境的交互中学习**来源于我们的自然经验。**
+
+例如,想象把你的小弟弟放在一个他从未玩过的视频游戏前,给他一个控制器,然后让他独自一人。
+
+
+ +
+你的弟弟将通过按下正确的按钮(动作)与环境(视频游戏)交互。他得到了一枚硬币,那是+1奖励。这是正面的,他刚刚明白在这个游戏中**他必须获取硬币。**
+
+
+
+你的弟弟将通过按下正确的按钮(动作)与环境(视频游戏)交互。他得到了一枚硬币,那是+1奖励。这是正面的,他刚刚明白在这个游戏中**他必须获取硬币。**
+
+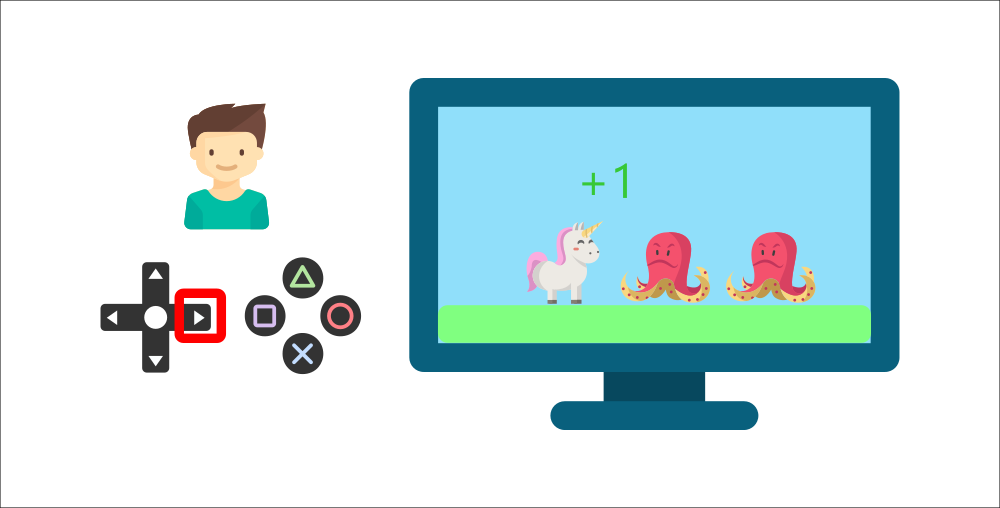 +
+但是,**他再次按下右键**,碰到了一个敌人。他刚刚死了,所以那是-1奖励。
+
+
+
+
+但是,**他再次按下右键**,碰到了一个敌人。他刚刚死了,所以那是-1奖励。
+
+
+ +
+通过与环境的试错交互,你的小弟弟明白了**他需要在这个环境中获取硬币但要避开敌人。**
+
+**没有任何监督**,孩子将在玩游戏方面变得越来越好。
+
+这就是人类和动物如何学习,**通过交互。**强化学习只是**从行动中学习的计算方法。**
+
+
+### 正式定义 [[a-formal-definition]]
+
+我们现在可以给出一个正式定义:
+
+
+强化学习是一个解决控制任务(也称为决策问题)的框架,通过构建智能体,让它们通过与环境的试错交互学习,并接收奖励(正面或负面)作为唯一的反馈。
+
+
+但强化学习是如何工作的呢?
diff --git a/units/cn/unit2/additional-readings.mdx b/units/cn/unit2/additional-readings.mdx
new file mode 100644
index 00000000..77ab5c30
--- /dev/null
+++ b/units/cn/unit2/additional-readings.mdx
@@ -0,0 +1,15 @@
+# 额外阅读材料 [[additional-readings]]
+
+这些是**可选阅读材料**,如果你想深入了解更多内容。
+
+## 蒙特卡洛和时序差分学习 [[mc-td]]
+
+要深入了解蒙特卡洛和时序差分学习:
+
+- 为什么时序差分(TD)方法比蒙特卡洛方法具有更低的方差?
+- 什么时候蒙特卡洛方法优于时序差分方法?
+
+## Q-学习 [[q-learning]]
+
+- 强化学习导论,Richard Sutton和Andrew G. Barto著,第5、6和7章
+- 深度强化学习基础系列,L2深度Q学习,Pieter Abbeel讲授
diff --git a/units/cn/unit2/bellman-equation.mdx b/units/cn/unit2/bellman-equation.mdx
new file mode 100644
index 00000000..199a9f8c
--- /dev/null
+++ b/units/cn/unit2/bellman-equation.mdx
@@ -0,0 +1,63 @@
+# 贝尔曼方程:简化我们的价值估计 [[bellman-equation]]
+
+贝尔曼方程**简化了我们对状态价值或状态-动作价值的计算。**
+
+
+
+
+通过与环境的试错交互,你的小弟弟明白了**他需要在这个环境中获取硬币但要避开敌人。**
+
+**没有任何监督**,孩子将在玩游戏方面变得越来越好。
+
+这就是人类和动物如何学习,**通过交互。**强化学习只是**从行动中学习的计算方法。**
+
+
+### 正式定义 [[a-formal-definition]]
+
+我们现在可以给出一个正式定义:
+
+
+强化学习是一个解决控制任务(也称为决策问题)的框架,通过构建智能体,让它们通过与环境的试错交互学习,并接收奖励(正面或负面)作为唯一的反馈。
+
+
+但强化学习是如何工作的呢?
diff --git a/units/cn/unit2/additional-readings.mdx b/units/cn/unit2/additional-readings.mdx
new file mode 100644
index 00000000..77ab5c30
--- /dev/null
+++ b/units/cn/unit2/additional-readings.mdx
@@ -0,0 +1,15 @@
+# 额外阅读材料 [[additional-readings]]
+
+这些是**可选阅读材料**,如果你想深入了解更多内容。
+
+## 蒙特卡洛和时序差分学习 [[mc-td]]
+
+要深入了解蒙特卡洛和时序差分学习:
+
+- 为什么时序差分(TD)方法比蒙特卡洛方法具有更低的方差?
+- 什么时候蒙特卡洛方法优于时序差分方法?
+
+## Q-学习 [[q-learning]]
+
+- 强化学习导论,Richard Sutton和Andrew G. Barto著,第5、6和7章
+- 深度强化学习基础系列,L2深度Q学习,Pieter Abbeel讲授
diff --git a/units/cn/unit2/bellman-equation.mdx b/units/cn/unit2/bellman-equation.mdx
new file mode 100644
index 00000000..199a9f8c
--- /dev/null
+++ b/units/cn/unit2/bellman-equation.mdx
@@ -0,0 +1,63 @@
+# 贝尔曼方程:简化我们的价值估计 [[bellman-equation]]
+
+贝尔曼方程**简化了我们对状态价值或状态-动作价值的计算。**
+
+
+ +
+根据我们目前所学,我们知道如果要计算\\(V(S_t)\\)(状态的价值),我们需要计算从该状态开始的回报,然后永远遵循策略。**(在以下示例中定义的策略是贪婪策略;为简化起见,我们不对奖励进行折扣)。**
+
+因此,要计算\\(V(S_t)\\),我们需要计算预期奖励的总和。因此:
+
+
+
+
+根据我们目前所学,我们知道如果要计算\\(V(S_t)\\)(状态的价值),我们需要计算从该状态开始的回报,然后永远遵循策略。**(在以下示例中定义的策略是贪婪策略;为简化起见,我们不对奖励进行折扣)。**
+
+因此,要计算\\(V(S_t)\\),我们需要计算预期奖励的总和。因此:
+
+
+ 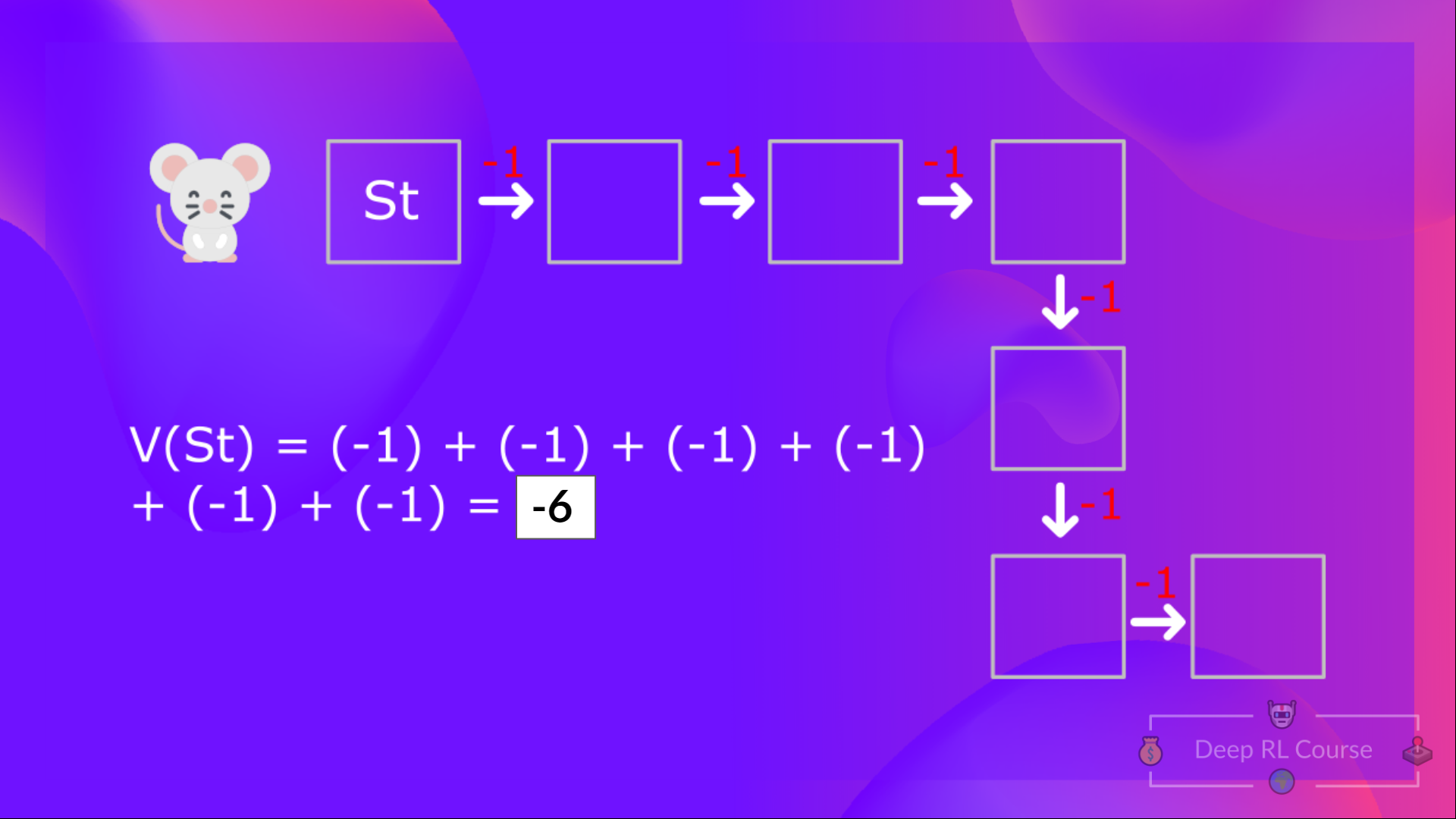 + 计算状态1的价值:如果智能体从该状态开始,然后在所有时间步骤中遵循贪婪策略(采取导向最佳状态价值的动作)所获得的奖励总和。
+
+
+然后,要计算\\(V(S_{t+1})\\),我们需要计算从状态\\(S_{t+1}\\)开始的回报。
+
+
+
+ 计算状态1的价值:如果智能体从该状态开始,然后在所有时间步骤中遵循贪婪策略(采取导向最佳状态价值的动作)所获得的奖励总和。
+
+
+然后,要计算\\(V(S_{t+1})\\),我们需要计算从状态\\(S_{t+1}\\)开始的回报。
+
+
+ 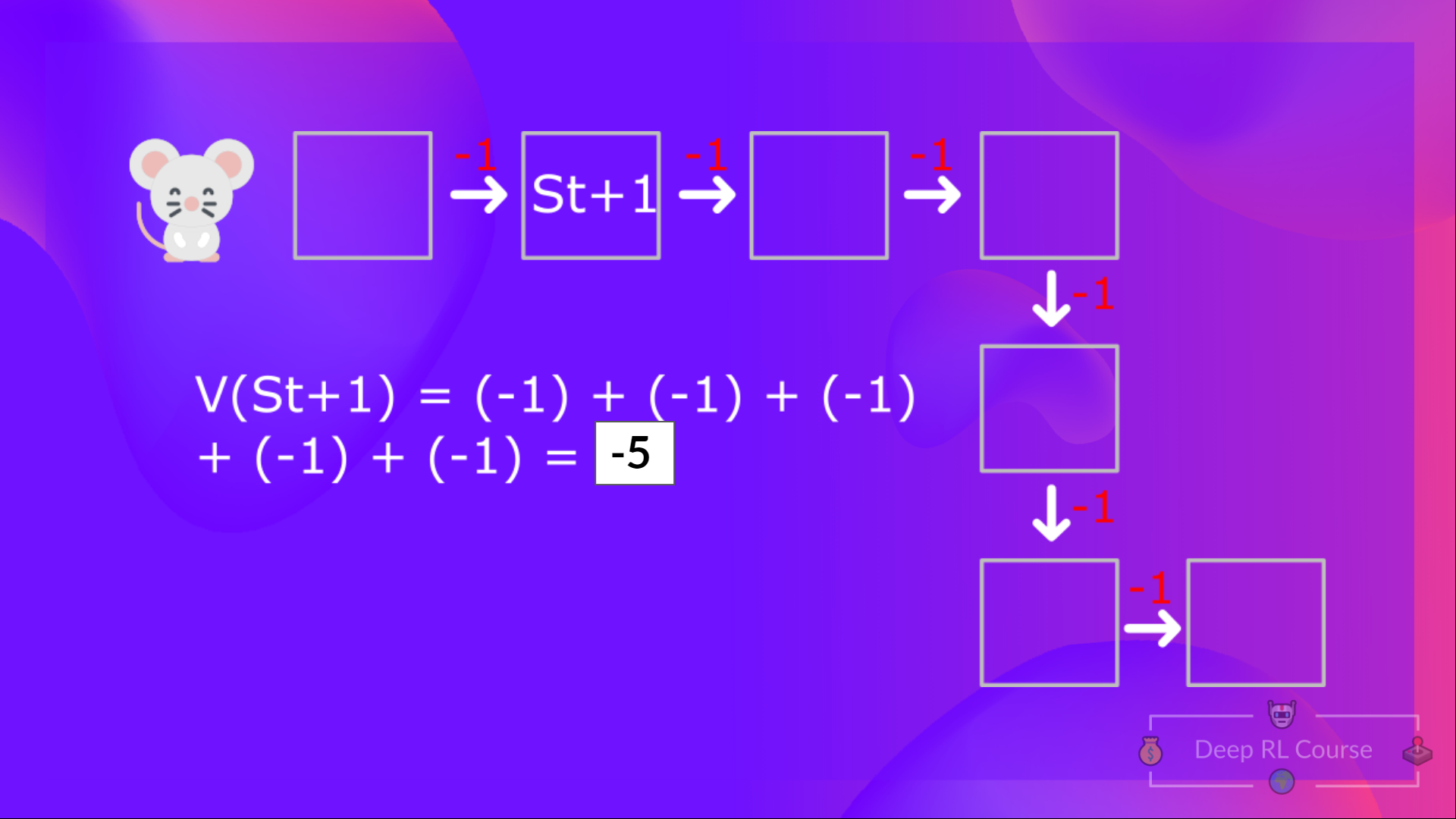 + 计算状态2的价值:如果智能体从该状态开始,然后在所有时间步骤中遵循策略所获得的奖励总和。
+
+
+所以你可能已经注意到,我们在重复计算不同状态的价值,如果你需要为每个状态价值或状态-动作价值都这样做,这可能会很繁琐。
+
+与其为每个状态或每个状态-动作对计算预期回报,**我们可以使用贝尔曼方程。**(提示:如果你知道什么是动态规划,这非常相似!如果你不知道,不用担心!)
+
+贝尔曼方程是一个递归方程,其工作原理如下:我们不必从头开始为每个状态计算回报,而是可以将任何状态的价值视为:
+
+**即时奖励\\(R_{t+1}\\) + 后续状态的折扣价值(\\(\gamma * V(S_{t+1})\\))。**
+
+
+
+ 计算状态2的价值:如果智能体从该状态开始,然后在所有时间步骤中遵循策略所获得的奖励总和。
+
+
+所以你可能已经注意到,我们在重复计算不同状态的价值,如果你需要为每个状态价值或状态-动作价值都这样做,这可能会很繁琐。
+
+与其为每个状态或每个状态-动作对计算预期回报,**我们可以使用贝尔曼方程。**(提示:如果你知道什么是动态规划,这非常相似!如果你不知道,不用担心!)
+
+贝尔曼方程是一个递归方程,其工作原理如下:我们不必从头开始为每个状态计算回报,而是可以将任何状态的价值视为:
+
+**即时奖励\\(R_{t+1}\\) + 后续状态的折扣价值(\\(\gamma * V(S_{t+1})\\))。**
+
+
+  +
+
+
+如果回到我们的例子,我们可以说状态1的价值等于如果我们从该状态开始的预期累积回报。
+
+
+
+
+计算状态1的价值:**如果智能体从状态1开始**,然后**在所有时间步骤中遵循策略**所获得的奖励总和。
+
+这等同于\\(V(S_{t})\\) = 即时奖励\\(R_{t+1}\\) + 下一个状态的折扣价值\\(\gamma * V(S_{t+1})\\)
+
+
+
+
+
+
+如果回到我们的例子,我们可以说状态1的价值等于如果我们从该状态开始的预期累积回报。
+
+
+
+
+计算状态1的价值:**如果智能体从状态1开始**,然后**在所有时间步骤中遵循策略**所获得的奖励总和。
+
+这等同于\\(V(S_{t})\\) = 即时奖励\\(R_{t+1}\\) + 下一个状态的折扣价值\\(\gamma * V(S_{t+1})\\)
+
+
+ 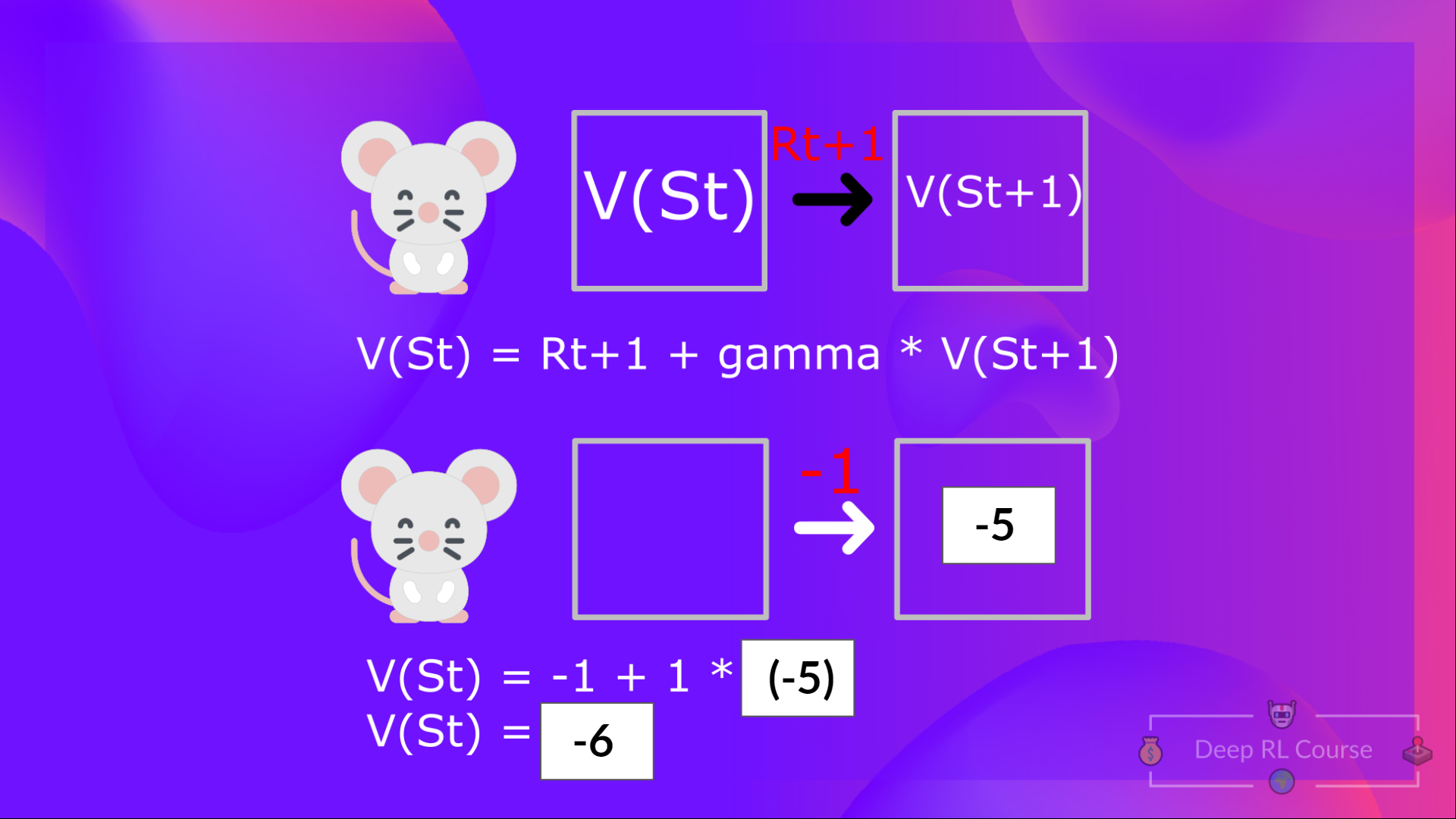 + 为简化起见,这里我们不进行折扣,所以gamma = 1。
+
+
+为了简单起见,这里我们不进行折扣,所以gamma = 1。
+但在本单元的Q-学习部分,你将学习一个gamma = 0.99的例子。
+
+- \\(V(S_{t+1})\\)的价值 = 即时奖励\\(R_{t+2}\\) + 下一个状态的折扣价值(\\(gamma * V(S_{t+2})\\))。
+- 依此类推。
+
+
+
+
+
+总结一下,贝尔曼方程的思想是,我们不必将每个价值计算为预期回报的总和,**这是一个漫长的过程**,而是将价值计算为**即时奖励 + 后续状态的折扣价值的总和。**
+
+在进入下一部分之前,思考一下gamma在贝尔曼方程中的作用。如果gamma的值非常低(例如0.1甚至0)会发生什么?如果值为1会发生什么?如果值非常高,比如一百万,会发生什么?
diff --git a/units/cn/unit2/conclusion.mdx b/units/cn/unit2/conclusion.mdx
new file mode 100644
index 00000000..593d5713
--- /dev/null
+++ b/units/cn/unit2/conclusion.mdx
@@ -0,0 +1,20 @@
+# 结论 [[conclusion]]
+
+恭喜你完成本章!这里有很多信息。也恭喜你完成教程。你刚刚从头实现了你的第一个强化学习智能体并在Hub上分享了它🥳。
+
+当你学习一个新架构时,从头实现**对于理解它如何工作很重要。**
+
+如果你仍然对所有这些元素感到困惑,这是**正常的**。**我和所有学习强化学习的人都曾有过同样的感受。**
+
+在继续之前,花时间真正理解这些材料。
+
+
+在下一章中,我们将通过学习基于Q-学习的第一个深度强化学习算法:深度Q-学习,来深入研究。你将使用RL-Baselines3 Zoo训练一个**DQN智能体来玩Atari游戏**。
+
+
+
+ 为简化起见,这里我们不进行折扣,所以gamma = 1。
+
+
+为了简单起见,这里我们不进行折扣,所以gamma = 1。
+但在本单元的Q-学习部分,你将学习一个gamma = 0.99的例子。
+
+- \\(V(S_{t+1})\\)的价值 = 即时奖励\\(R_{t+2}\\) + 下一个状态的折扣价值(\\(gamma * V(S_{t+2})\\))。
+- 依此类推。
+
+
+
+
+
+总结一下,贝尔曼方程的思想是,我们不必将每个价值计算为预期回报的总和,**这是一个漫长的过程**,而是将价值计算为**即时奖励 + 后续状态的折扣价值的总和。**
+
+在进入下一部分之前,思考一下gamma在贝尔曼方程中的作用。如果gamma的值非常低(例如0.1甚至0)会发生什么?如果值为1会发生什么?如果值非常高,比如一百万,会发生什么?
diff --git a/units/cn/unit2/conclusion.mdx b/units/cn/unit2/conclusion.mdx
new file mode 100644
index 00000000..593d5713
--- /dev/null
+++ b/units/cn/unit2/conclusion.mdx
@@ -0,0 +1,20 @@
+# 结论 [[conclusion]]
+
+恭喜你完成本章!这里有很多信息。也恭喜你完成教程。你刚刚从头实现了你的第一个强化学习智能体并在Hub上分享了它🥳。
+
+当你学习一个新架构时,从头实现**对于理解它如何工作很重要。**
+
+如果你仍然对所有这些元素感到困惑,这是**正常的**。**我和所有学习强化学习的人都曾有过同样的感受。**
+
+在继续之前,花时间真正理解这些材料。
+
+
+在下一章中,我们将通过学习基于Q-学习的第一个深度强化学习算法:深度Q-学习,来深入研究。你将使用RL-Baselines3 Zoo训练一个**DQN智能体来玩Atari游戏**。
+
+
+ +
+
+最后,我们很想**听听你对课程的看法以及我们如何改进它**。如果你有一些反馈,请👉 [填写此表格](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 继续学习,保持优秀 🤗
\ No newline at end of file
diff --git a/units/cn/unit2/glossary.mdx b/units/cn/unit2/glossary.mdx
new file mode 100644
index 00000000..12d5465f
--- /dev/null
+++ b/units/cn/unit2/glossary.mdx
@@ -0,0 +1,47 @@
+# 术语表 [[glossary]]
+
+这是一个社区创建的术语表。欢迎贡献!
+
+
+### 寻找最优策略的策略
+
+- **基于策略的方法。** 策略通常使用神经网络进行训练,以根据状态选择要采取的动作。在这种情况下,是神经网络输出智能体应该采取的动作,而不是使用价值函数。根据从环境接收到的经验,神经网络将被重新调整并提供更好的动作。
+- **基于价值的方法。** 在这种情况下,训练一个价值函数来输出状态或状态-动作对的价值,这将代表我们的策略。然而,这个价值并不定义智能体应该采取什么动作。相反,我们需要根据价值函数的输出指定智能体的行为。例如,我们可以决定采用一种策略,始终采取导致最大奖励的动作(贪婪策略)。总之,策略是一个贪婪策略(或用户做出的任何决定),它使用价值函数的值来决定要采取的动作。
+
+### 在基于价值的方法中,我们可以找到两种主要策略
+
+- **状态价值函数。** 对于每个状态,状态价值函数是如果智能体从该状态开始并遵循策略直到结束所获得的预期回报。
+- **动作价值函数。** 与状态价值函数相比,动作价值函数计算的是对于每个状态和动作对,如果智能体从该状态开始,采取该动作,然后永远遵循策略所获得的预期回报。
+
+### Epsilon-贪婪策略:
+
+- 强化学习中常用的策略,涉及平衡探索和利用。
+- 以1-epsilon的概率选择具有最高预期奖励的动作。
+- 以epsilon的概率选择随机动作。
+- Epsilon通常随时间减少,以将重点转向利用。
+
+### 贪婪策略:
+
+- 总是选择基于当前对环境的了解,预期会导致最高奖励的动作。(仅利用)
+- 始终选择具有最高预期奖励的动作。
+- 不包含任何探索。
+- 在具有不确定性或未知最优动作的环境中可能不利。
+
+### 离策略与在策略算法
+
+- **离策略算法:** 在训练时和推理时使用不同的策略
+- **在策略算法:** 在训练和推理期间使用相同的策略
+
+### 蒙特卡洛和时序差分学习策略
+
+- **蒙特卡洛(MC):** 在情节结束时学习。使用蒙特卡洛,我们等到情节结束,然后根据完整的情节更新价值函数(或策略函数)。
+
+- **时序差分(TD):** 在每一步学习。使用时序差分学习,我们在每一步更新价值函数(或策略函数),而不需要完整的情节。
+
+如果你想改进课程,你可以[提交Pull Request。](https://github.com/huggingface/deep-rl-class/pulls)
+
+这个术语表的实现得益于:
+
+- [Ramón Rueda](https://github.com/ramon-rd)
+- [Hasarindu Perera](https://github.com/hasarinduperera/)
+- [Arkady Arkhangorodsky](https://github.com/arkadyark/)
diff --git a/units/cn/unit2/hands-on.mdx b/units/cn/unit2/hands-on.mdx
new file mode 100644
index 00000000..1218d3eb
--- /dev/null
+++ b/units/cn/unit2/hands-on.mdx
@@ -0,0 +1,1148 @@
+# 实践练习 [[hands-on]]
+
+
+
+
+
+现在我们已经学习了Q-Learning算法,让我们从头开始实现它,并在两个环境中训练我们的Q-Learning智能体:
+1. [Frozen-Lake-v1(非滑动和滑动版本)](https://gymnasium.farama.org/environments/toy_text/frozen_lake/) ☃️:我们的智能体需要**从起始状态(S)到达目标状态(G)**,只能在冰冻的瓦片(F)上行走,并避开洞(H)。
+2. [自动驾驶出租车](https://gymnasium.farama.org/environments/toy_text/taxi/) 🚖 需要**学习如何在城市中导航**,以**将乘客从A点运送到B点**。
+
+
+
+
+最后,我们很想**听听你对课程的看法以及我们如何改进它**。如果你有一些反馈,请👉 [填写此表格](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 继续学习,保持优秀 🤗
\ No newline at end of file
diff --git a/units/cn/unit2/glossary.mdx b/units/cn/unit2/glossary.mdx
new file mode 100644
index 00000000..12d5465f
--- /dev/null
+++ b/units/cn/unit2/glossary.mdx
@@ -0,0 +1,47 @@
+# 术语表 [[glossary]]
+
+这是一个社区创建的术语表。欢迎贡献!
+
+
+### 寻找最优策略的策略
+
+- **基于策略的方法。** 策略通常使用神经网络进行训练,以根据状态选择要采取的动作。在这种情况下,是神经网络输出智能体应该采取的动作,而不是使用价值函数。根据从环境接收到的经验,神经网络将被重新调整并提供更好的动作。
+- **基于价值的方法。** 在这种情况下,训练一个价值函数来输出状态或状态-动作对的价值,这将代表我们的策略。然而,这个价值并不定义智能体应该采取什么动作。相反,我们需要根据价值函数的输出指定智能体的行为。例如,我们可以决定采用一种策略,始终采取导致最大奖励的动作(贪婪策略)。总之,策略是一个贪婪策略(或用户做出的任何决定),它使用价值函数的值来决定要采取的动作。
+
+### 在基于价值的方法中,我们可以找到两种主要策略
+
+- **状态价值函数。** 对于每个状态,状态价值函数是如果智能体从该状态开始并遵循策略直到结束所获得的预期回报。
+- **动作价值函数。** 与状态价值函数相比,动作价值函数计算的是对于每个状态和动作对,如果智能体从该状态开始,采取该动作,然后永远遵循策略所获得的预期回报。
+
+### Epsilon-贪婪策略:
+
+- 强化学习中常用的策略,涉及平衡探索和利用。
+- 以1-epsilon的概率选择具有最高预期奖励的动作。
+- 以epsilon的概率选择随机动作。
+- Epsilon通常随时间减少,以将重点转向利用。
+
+### 贪婪策略:
+
+- 总是选择基于当前对环境的了解,预期会导致最高奖励的动作。(仅利用)
+- 始终选择具有最高预期奖励的动作。
+- 不包含任何探索。
+- 在具有不确定性或未知最优动作的环境中可能不利。
+
+### 离策略与在策略算法
+
+- **离策略算法:** 在训练时和推理时使用不同的策略
+- **在策略算法:** 在训练和推理期间使用相同的策略
+
+### 蒙特卡洛和时序差分学习策略
+
+- **蒙特卡洛(MC):** 在情节结束时学习。使用蒙特卡洛,我们等到情节结束,然后根据完整的情节更新价值函数(或策略函数)。
+
+- **时序差分(TD):** 在每一步学习。使用时序差分学习,我们在每一步更新价值函数(或策略函数),而不需要完整的情节。
+
+如果你想改进课程,你可以[提交Pull Request。](https://github.com/huggingface/deep-rl-class/pulls)
+
+这个术语表的实现得益于:
+
+- [Ramón Rueda](https://github.com/ramon-rd)
+- [Hasarindu Perera](https://github.com/hasarinduperera/)
+- [Arkady Arkhangorodsky](https://github.com/arkadyark/)
diff --git a/units/cn/unit2/hands-on.mdx b/units/cn/unit2/hands-on.mdx
new file mode 100644
index 00000000..1218d3eb
--- /dev/null
+++ b/units/cn/unit2/hands-on.mdx
@@ -0,0 +1,1148 @@
+# 实践练习 [[hands-on]]
+
+
+
+
+
+现在我们已经学习了Q-Learning算法,让我们从头开始实现它,并在两个环境中训练我们的Q-Learning智能体:
+1. [Frozen-Lake-v1(非滑动和滑动版本)](https://gymnasium.farama.org/environments/toy_text/frozen_lake/) ☃️:我们的智能体需要**从起始状态(S)到达目标状态(G)**,只能在冰冻的瓦片(F)上行走,并避开洞(H)。
+2. [自动驾驶出租车](https://gymnasium.farama.org/environments/toy_text/taxi/) 🚖 需要**学习如何在城市中导航**,以**将乘客从A点运送到B点**。
+
+ +
+通过[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard),你将能够与其他同学比较你的结果,并交流最佳实践以提高你的智能体得分。谁将赢得第2单元的挑战?
+
+为了在[认证流程](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process)中验证这个实践练习,你需要将训练好的出租车模型推送到Hub,并**获得 >= 4.5的结果**。
+
+要查找你的结果,请前往[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+有关认证流程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+你可以在这里查看你的进度 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+
+
+**要开始实践练习,请点击"在Colab中打开"按钮** 👇:
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit2/unit2.ipynb)
+
+
+我们强烈**建议学生使用Google Colab进行实践练习**,而不是在个人电脑上运行。
+
+通过使用Google Colab,**你可以专注于学习和实验,而不必担心设置环境的技术方面**。
+
+
+# 第2单元:使用FrozenLake-v1 ⛄ 和Taxi-v3 🚕 的Q-Learning
+
+
+
+通过[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard),你将能够与其他同学比较你的结果,并交流最佳实践以提高你的智能体得分。谁将赢得第2单元的挑战?
+
+为了在[认证流程](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process)中验证这个实践练习,你需要将训练好的出租车模型推送到Hub,并**获得 >= 4.5的结果**。
+
+要查找你的结果,请前往[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+有关认证流程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+你可以在这里查看你的进度 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+
+
+**要开始实践练习,请点击"在Colab中打开"按钮** 👇:
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit2/unit2.ipynb)
+
+
+我们强烈**建议学生使用Google Colab进行实践练习**,而不是在个人电脑上运行。
+
+通过使用Google Colab,**你可以专注于学习和实验,而不必担心设置环境的技术方面**。
+
+
+# 第2单元:使用FrozenLake-v1 ⛄ 和Taxi-v3 🚕 的Q-Learning
+
+ +
+在这个笔记本中,**你将从头开始编写你的第一个强化学习智能体**,使用Q-Learning来玩FrozenLake ❄️,与社区分享它,并尝试不同的配置。
+
+⬇️ 这里是**你在短短几分钟内将要实现的内容**的示例。 ⬇️
+
+
+
+
+### 🎮 环境:
+
+- [FrozenLake-v1](https://gymnasium.farama.org/environments/toy_text/frozen_lake/)
+- [Taxi-v3](https://gymnasium.farama.org/environments/toy_text/taxi/)
+
+### 📚 RL库:
+
+- Python和NumPy
+- [Gymnasium](https://gymnasium.farama.org/)
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现任何问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在完成本笔记本后,你将能够:
+
+- 使用**Gymnasium**,这个环境库。
+- 从头开始编写Q-Learning智能体。
+- **将你训练好的智能体和代码推送到Hub**,附带精美的视频回放和评估分数 🔥。
+
+## 本笔记本来自深度强化学习课程
+
+
+
+在这个免费课程中,你将:
+
+- 📖 **理论和实践**相结合学习深度强化学习。
+- 🧑💻 学习**使用著名的深度强化学习库**,如Stable Baselines3、RL Baselines3 Zoo、CleanRL和Sample Factory 2.0。
+- 🤖 在**独特的环境中训练智能体**
+
+更多内容请查看 📚 课程大纲 👉 https://simoninithomas.github.io/deep-rl-course
+
+不要忘记**注册课程**(我们收集你的电子邮件是为了能够**在每个单元发布时向你发送链接,并提供有关挑战和更新的信息**)。
+
+
+与我们保持联系的最佳方式是加入我们的discord服务器,与社区和我们交流 👉🏻 https://discord.gg/ydHrjt3WP5
+
+## 先决条件 🏗️
+
+在深入学习本笔记本之前,你需要:
+
+🔲 📚 **通过[阅读第2单元](https://huggingface.co/deep-rl-course/unit2/introduction)学习Q-Learning** 🤗
+
+## Q-Learning的简要回顾
+
+*Q-Learning* **是一种强化学习算法,它**:
+
+- 训练*Q-函数*,这是一个**动作-价值函数**,在内部存储中由*Q表*编码,**该表包含所有状态-动作对的值**。
+
+- 给定一个状态和动作,我们的Q-函数**将在Q表中搜索相应的值**。
+
+
+
+在这个笔记本中,**你将从头开始编写你的第一个强化学习智能体**,使用Q-Learning来玩FrozenLake ❄️,与社区分享它,并尝试不同的配置。
+
+⬇️ 这里是**你在短短几分钟内将要实现的内容**的示例。 ⬇️
+
+
+
+
+### 🎮 环境:
+
+- [FrozenLake-v1](https://gymnasium.farama.org/environments/toy_text/frozen_lake/)
+- [Taxi-v3](https://gymnasium.farama.org/environments/toy_text/taxi/)
+
+### 📚 RL库:
+
+- Python和NumPy
+- [Gymnasium](https://gymnasium.farama.org/)
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现任何问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在完成本笔记本后,你将能够:
+
+- 使用**Gymnasium**,这个环境库。
+- 从头开始编写Q-Learning智能体。
+- **将你训练好的智能体和代码推送到Hub**,附带精美的视频回放和评估分数 🔥。
+
+## 本笔记本来自深度强化学习课程
+
+
+
+在这个免费课程中,你将:
+
+- 📖 **理论和实践**相结合学习深度强化学习。
+- 🧑💻 学习**使用著名的深度强化学习库**,如Stable Baselines3、RL Baselines3 Zoo、CleanRL和Sample Factory 2.0。
+- 🤖 在**独特的环境中训练智能体**
+
+更多内容请查看 📚 课程大纲 👉 https://simoninithomas.github.io/deep-rl-course
+
+不要忘记**注册课程**(我们收集你的电子邮件是为了能够**在每个单元发布时向你发送链接,并提供有关挑战和更新的信息**)。
+
+
+与我们保持联系的最佳方式是加入我们的discord服务器,与社区和我们交流 👉🏻 https://discord.gg/ydHrjt3WP5
+
+## 先决条件 🏗️
+
+在深入学习本笔记本之前,你需要:
+
+🔲 📚 **通过[阅读第2单元](https://huggingface.co/deep-rl-course/unit2/introduction)学习Q-Learning** 🤗
+
+## Q-Learning的简要回顾
+
+*Q-Learning* **是一种强化学习算法,它**:
+
+- 训练*Q-函数*,这是一个**动作-价值函数**,在内部存储中由*Q表*编码,**该表包含所有状态-动作对的值**。
+
+- 给定一个状态和动作,我们的Q-函数**将在Q表中搜索相应的值**。
+
+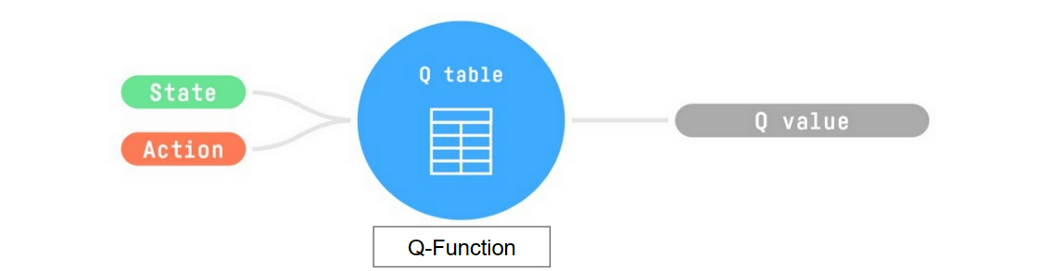 +
+- 当训练完成后,**我们有一个最优的Q-函数,因此有一个最优的Q表**。
+
+- 如果我们**有一个最优的Q-函数**,我们就有一个最优的策略,因为我们**知道对于每个状态,最佳的动作是什么**。
+
+
+
+- 当训练完成后,**我们有一个最优的Q-函数,因此有一个最优的Q表**。
+
+- 如果我们**有一个最优的Q-函数**,我们就有一个最优的策略,因为我们**知道对于每个状态,最佳的动作是什么**。
+
+ +
+
+但是,在开始时,我们的**Q表是没用的,因为它为每个状态-动作对提供了任意值(大多数情况下,我们将Q表初始化为0值)**。但是,随着我们探索环境并更新我们的Q表,它将给我们越来越好的近似值。
+
+
+
+
+但是,在开始时,我们的**Q表是没用的,因为它为每个状态-动作对提供了任意值(大多数情况下,我们将Q表初始化为0值)**。但是,随着我们探索环境并更新我们的Q表,它将给我们越来越好的近似值。
+
+ +
+这是Q-Learning的伪代码:
+
+
+
+这是Q-Learning的伪代码:
+
+ +
+
+# 让我们编写我们的第一个强化学习算法 🚀
+
+为了在[认证流程](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process)中验证这个实践练习,你需要将训练好的出租车模型推送到Hub,并**获得 >= 4.5的结果**。
+
+要查找你的结果,请前往[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+有关认证流程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## 安装依赖项并创建虚拟显示器 🔽
+
+在笔记本中,我们需要生成回放视频。为此,在Colab中,**我们需要有一个虚拟屏幕来渲染环境**(并因此记录帧)。
+
+因此,以下单元将安装库并创建并运行虚拟屏幕 🖥
+
+我们将安装多个库:
+
+- `gymnasium`:包含FrozenLake-v1 ⛄ 和Taxi-v3 🚕 环境。
+- `pygame`:用于FrozenLake-v1和Taxi-v3的UI。
+- `numpy`:用于处理我们的Q表。
+
+Hugging Face Hub 🤗 作为一个中心位置,任何人都可以在这里分享和探索模型和数据集。它具有版本控制、指标、可视化和其他功能,这些功能将使你能够轻松地与他人协作。
+
+你可以在这里查看所有可用的深度强化学习模型(如果它们使用Q Learning)👉 https://huggingface.co/models?other=q-learning
+
+```bash
+pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit2/requirements-unit2.txt
+```
+
+```bash
+sudo apt-get update
+sudo apt-get install -y python3-opengl
+apt install ffmpeg xvfb
+pip3 install pyvirtualdisplay
+```
+
+为了确保使用新安装的库,**有时需要重启笔记本运行时**。下一个单元将强制**运行时崩溃,所以你需要重新连接并从这里开始运行代码**。多亏了这个技巧,**我们将能够运行我们的虚拟屏幕**。
+
+```python
+import os
+
+os.kill(os.getpid(), 9)
+```
+
+```python
+# 虚拟显示器
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## 导入包 📦
+
+除了安装的库外,我们还使用:
+
+- `random`:生成随机数(对于epsilon-greedy策略很有用)。
+- `imageio`:生成回放视频。
+
+```python
+import numpy as np
+import gymnasium as gym
+import random
+import imageio
+import os
+import tqdm
+
+import pickle5 as pickle
+from tqdm.notebook import tqdm
+```
+
+我们现在准备好编写我们的Q-Learning算法了 🔥
+
+# 第1部分:冰湖 ⛄(非滑动版本)
+
+## 创建并理解[FrozenLake环境 ⛄]((https://gymnasium.farama.org/environments/toy_text/frozen_lake/)
+---
+
+💡 当你开始使用一个环境时,一个好习惯是查看它的文档
+
+👉 https://gymnasium.farama.org/environments/toy_text/frozen_lake/
+
+---
+
+我们将训练我们的Q-Learning智能体**从起始状态(S)导航到目标状态(G),只在冰冻的瓦片(F)上行走,并避开洞(H)**。
+
+我们可以有两种大小的环境:
+
+- `map_name="4x4"`:4x4网格版本
+- `map_name="8x8"`:8x8网格版本
+
+
+环境有两种模式:
+
+- `is_slippery=False`:由于冰湖的非滑动性质,智能体总是**朝着预期方向移动**(确定性)。
+- `is_slippery=True`:由于冰湖的滑动性质,智能体**可能不总是朝着预期方向移动**(随机性)。
+
+现在让我们保持简单,使用4x4地图和非滑动版本。
+我们添加一个名为`render_mode`的参数,指定环境应如何可视化。在我们的例子中,因为我们**想在最后记录环境的视频,我们需要将render_mode设置为rgb_array**。
+
+正如[文档中解释的](https://gymnasium.farama.org/api/env/#gymnasium.Env.render) "rgb_array":返回表示环境当前状态的单个帧。帧是一个形状为(x, y, 3)的np.ndarray,表示x乘y像素图像的RGB值。
+
+```python
+# 使用4x4地图和非滑动版本创建FrozenLake-v1环境,并设置render_mode="rgb_array"
+env = gym.make() # TODO 使用正确的参数
+```
+
+### 解决方案
+
+```python
+env = gym.make("FrozenLake-v1", map_name="4x4", is_slippery=False, render_mode="rgb_array")
+```
+
+你可以像这样创建自己的自定义网格:
+
+```python
+desc=["SFFF", "FHFH", "FFFH", "HFFG"]
+gym.make('FrozenLake-v1', desc=desc, is_slippery=True)
+```
+
+但我们现在将使用默认环境。
+
+### 让我们看看环境是什么样子的:
+
+
+```python
+# 我们使用gym.make("<环境名称>")创建环境- `is_slippery=False`:由于冰湖的非滑动性质,智能体总是朝着预期方向移动(确定性)。
+print("_____观察空间_____ \n")
+print("观察空间", env.observation_space)
+print("样本观察", env.observation_space.sample()) # 获取随机观察
+```
+
+我们通过`观察空间形状 Discrete(16)`看到,观察是一个整数,表示**智能体当前位置为current_row * ncols + current_col(其中行和列都从0开始)**。
+
+例如,4x4地图中的目标位置可以计算如下:3 * 4 + 3 = 15。可能的观察数量取决于地图的大小。**例如,4x4地图有16个可能的观察**。
+
+
+例如,这是状态 = 0的样子:
+
+
+
+
+# 让我们编写我们的第一个强化学习算法 🚀
+
+为了在[认证流程](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process)中验证这个实践练习,你需要将训练好的出租车模型推送到Hub,并**获得 >= 4.5的结果**。
+
+要查找你的结果,请前往[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+有关认证流程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## 安装依赖项并创建虚拟显示器 🔽
+
+在笔记本中,我们需要生成回放视频。为此,在Colab中,**我们需要有一个虚拟屏幕来渲染环境**(并因此记录帧)。
+
+因此,以下单元将安装库并创建并运行虚拟屏幕 🖥
+
+我们将安装多个库:
+
+- `gymnasium`:包含FrozenLake-v1 ⛄ 和Taxi-v3 🚕 环境。
+- `pygame`:用于FrozenLake-v1和Taxi-v3的UI。
+- `numpy`:用于处理我们的Q表。
+
+Hugging Face Hub 🤗 作为一个中心位置,任何人都可以在这里分享和探索模型和数据集。它具有版本控制、指标、可视化和其他功能,这些功能将使你能够轻松地与他人协作。
+
+你可以在这里查看所有可用的深度强化学习模型(如果它们使用Q Learning)👉 https://huggingface.co/models?other=q-learning
+
+```bash
+pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit2/requirements-unit2.txt
+```
+
+```bash
+sudo apt-get update
+sudo apt-get install -y python3-opengl
+apt install ffmpeg xvfb
+pip3 install pyvirtualdisplay
+```
+
+为了确保使用新安装的库,**有时需要重启笔记本运行时**。下一个单元将强制**运行时崩溃,所以你需要重新连接并从这里开始运行代码**。多亏了这个技巧,**我们将能够运行我们的虚拟屏幕**。
+
+```python
+import os
+
+os.kill(os.getpid(), 9)
+```
+
+```python
+# 虚拟显示器
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## 导入包 📦
+
+除了安装的库外,我们还使用:
+
+- `random`:生成随机数(对于epsilon-greedy策略很有用)。
+- `imageio`:生成回放视频。
+
+```python
+import numpy as np
+import gymnasium as gym
+import random
+import imageio
+import os
+import tqdm
+
+import pickle5 as pickle
+from tqdm.notebook import tqdm
+```
+
+我们现在准备好编写我们的Q-Learning算法了 🔥
+
+# 第1部分:冰湖 ⛄(非滑动版本)
+
+## 创建并理解[FrozenLake环境 ⛄]((https://gymnasium.farama.org/environments/toy_text/frozen_lake/)
+---
+
+💡 当你开始使用一个环境时,一个好习惯是查看它的文档
+
+👉 https://gymnasium.farama.org/environments/toy_text/frozen_lake/
+
+---
+
+我们将训练我们的Q-Learning智能体**从起始状态(S)导航到目标状态(G),只在冰冻的瓦片(F)上行走,并避开洞(H)**。
+
+我们可以有两种大小的环境:
+
+- `map_name="4x4"`:4x4网格版本
+- `map_name="8x8"`:8x8网格版本
+
+
+环境有两种模式:
+
+- `is_slippery=False`:由于冰湖的非滑动性质,智能体总是**朝着预期方向移动**(确定性)。
+- `is_slippery=True`:由于冰湖的滑动性质,智能体**可能不总是朝着预期方向移动**(随机性)。
+
+现在让我们保持简单,使用4x4地图和非滑动版本。
+我们添加一个名为`render_mode`的参数,指定环境应如何可视化。在我们的例子中,因为我们**想在最后记录环境的视频,我们需要将render_mode设置为rgb_array**。
+
+正如[文档中解释的](https://gymnasium.farama.org/api/env/#gymnasium.Env.render) "rgb_array":返回表示环境当前状态的单个帧。帧是一个形状为(x, y, 3)的np.ndarray,表示x乘y像素图像的RGB值。
+
+```python
+# 使用4x4地图和非滑动版本创建FrozenLake-v1环境,并设置render_mode="rgb_array"
+env = gym.make() # TODO 使用正确的参数
+```
+
+### 解决方案
+
+```python
+env = gym.make("FrozenLake-v1", map_name="4x4", is_slippery=False, render_mode="rgb_array")
+```
+
+你可以像这样创建自己的自定义网格:
+
+```python
+desc=["SFFF", "FHFH", "FFFH", "HFFG"]
+gym.make('FrozenLake-v1', desc=desc, is_slippery=True)
+```
+
+但我们现在将使用默认环境。
+
+### 让我们看看环境是什么样子的:
+
+
+```python
+# 我们使用gym.make("<环境名称>")创建环境- `is_slippery=False`:由于冰湖的非滑动性质,智能体总是朝着预期方向移动(确定性)。
+print("_____观察空间_____ \n")
+print("观察空间", env.observation_space)
+print("样本观察", env.observation_space.sample()) # 获取随机观察
+```
+
+我们通过`观察空间形状 Discrete(16)`看到,观察是一个整数,表示**智能体当前位置为current_row * ncols + current_col(其中行和列都从0开始)**。
+
+例如,4x4地图中的目标位置可以计算如下:3 * 4 + 3 = 15。可能的观察数量取决于地图的大小。**例如,4x4地图有16个可能的观察**。
+
+
+例如,这是状态 = 0的样子:
+
+ +
+```python
+print("\n _____动作空间_____ \n")
+print("动作空间形状", env.action_space.n)
+print("动作空间样本", env.action_space.sample()) # 采取随机动作
+```
+
+动作空间(智能体可以采取的可能动作集)是离散的,有4个可用动作 🎮:
+- 0: 向左走
+- 1: 向下走
+- 2: 向右走
+- 3: 向上走
+
+奖励函数 💰:
+- 到达目标:+1
+- 到达洞:0
+- 到达冰面:0
+
+## 创建并初始化Q表 🗄️
+
+(👀 伪代码的第1步)
+
+
+
+
+是时候初始化我们的Q表了!要知道使用多少行(状态)和列(动作),我们需要知道动作和观察空间。我们已经从前面知道了它们的值,但我们希望以编程方式获取它们,以便我们的算法能够适用于不同的环境。Gym为我们提供了一种方法:`env.action_space.n`和`env.observation_space.n`
+
+
+```python
+state_space =
+print("有 ", state_space, " 个可能的状态")
+
+action_space =
+print("有 ", action_space, " 个可能的动作")
+```
+
+```python
+# 让我们创建大小为(state_space, action_space)的Q表,并使用np.zeros将每个值初始化为0。np.zeros需要一个元组(a,b)
+def initialize_q_table(state_space, action_space):
+ Qtable =
+ return Qtable
+```
+
+```python
+Qtable_frozenlake = initialize_q_table(state_space, action_space)
+```
+
+### 解决方案
+
+```python
+state_space = env.observation_space.n
+print("有 ", state_space, " 个可能的状态")
+
+action_space = env.action_space.n
+print("有 ", action_space, " 个可能的动作")
+```
+
+```python
+# 让我们创建大小为(state_space, action_space)的Q表,并使用np.zeros将每个值初始化为0
+def initialize_q_table(state_space, action_space):
+ Qtable = np.zeros((state_space, action_space))
+ return Qtable
+```
+
+```python
+Qtable_frozenlake = initialize_q_table(state_space, action_space)
+```
+
+## 定义贪婪策略 🤖
+
+记住我们有两种策略,因为Q-Learning是一种**离策略(off-policy)**算法。这意味着我们**使用不同的策略来行动和更新价值函数**。
+
+- Epsilon-贪婪策略(行动策略)
+- 贪婪策略(更新策略)
+
+贪婪策略也将是Q-learning智能体完成训练后我们将拥有的最终策略。贪婪策略用于使用Q表选择动作。
+
+
+
+```python
+print("\n _____动作空间_____ \n")
+print("动作空间形状", env.action_space.n)
+print("动作空间样本", env.action_space.sample()) # 采取随机动作
+```
+
+动作空间(智能体可以采取的可能动作集)是离散的,有4个可用动作 🎮:
+- 0: 向左走
+- 1: 向下走
+- 2: 向右走
+- 3: 向上走
+
+奖励函数 💰:
+- 到达目标:+1
+- 到达洞:0
+- 到达冰面:0
+
+## 创建并初始化Q表 🗄️
+
+(👀 伪代码的第1步)
+
+
+
+
+是时候初始化我们的Q表了!要知道使用多少行(状态)和列(动作),我们需要知道动作和观察空间。我们已经从前面知道了它们的值,但我们希望以编程方式获取它们,以便我们的算法能够适用于不同的环境。Gym为我们提供了一种方法:`env.action_space.n`和`env.observation_space.n`
+
+
+```python
+state_space =
+print("有 ", state_space, " 个可能的状态")
+
+action_space =
+print("有 ", action_space, " 个可能的动作")
+```
+
+```python
+# 让我们创建大小为(state_space, action_space)的Q表,并使用np.zeros将每个值初始化为0。np.zeros需要一个元组(a,b)
+def initialize_q_table(state_space, action_space):
+ Qtable =
+ return Qtable
+```
+
+```python
+Qtable_frozenlake = initialize_q_table(state_space, action_space)
+```
+
+### 解决方案
+
+```python
+state_space = env.observation_space.n
+print("有 ", state_space, " 个可能的状态")
+
+action_space = env.action_space.n
+print("有 ", action_space, " 个可能的动作")
+```
+
+```python
+# 让我们创建大小为(state_space, action_space)的Q表,并使用np.zeros将每个值初始化为0
+def initialize_q_table(state_space, action_space):
+ Qtable = np.zeros((state_space, action_space))
+ return Qtable
+```
+
+```python
+Qtable_frozenlake = initialize_q_table(state_space, action_space)
+```
+
+## 定义贪婪策略 🤖
+
+记住我们有两种策略,因为Q-Learning是一种**离策略(off-policy)**算法。这意味着我们**使用不同的策略来行动和更新价值函数**。
+
+- Epsilon-贪婪策略(行动策略)
+- 贪婪策略(更新策略)
+
+贪婪策略也将是Q-learning智能体完成训练后我们将拥有的最终策略。贪婪策略用于使用Q表选择动作。
+
+ +
+
+```python
+def greedy_policy(Qtable, state):
+ # 利用:选择具有最高状态-动作值的动作
+ action =
+
+ return action
+```
+
+#### 解决方案
+
+```python
+def greedy_policy(Qtable, state):
+ # 利用:选择具有最高状态-动作值的动作
+ action = np.argmax(Qtable[state][:])
+
+ return action
+```
+
+## 定义epsilon-贪婪策略 🤖
+
+Epsilon-贪婪是处理探索/利用权衡的训练策略。
+
+Epsilon-贪婪的思想是:
+
+- 以*概率1 - ɛ*:**我们进行利用**(即我们的智能体选择具有最高状态-动作对值的动作)。
+
+- 以*概率ɛ*:我们进行**探索**(尝试随机动作)。
+
+随着训练的继续,我们逐渐**减少epsilon值,因为我们需要越来越少的探索和更多的利用。**
+
+
+
+
+```python
+def greedy_policy(Qtable, state):
+ # 利用:选择具有最高状态-动作值的动作
+ action =
+
+ return action
+```
+
+#### 解决方案
+
+```python
+def greedy_policy(Qtable, state):
+ # 利用:选择具有最高状态-动作值的动作
+ action = np.argmax(Qtable[state][:])
+
+ return action
+```
+
+## 定义epsilon-贪婪策略 🤖
+
+Epsilon-贪婪是处理探索/利用权衡的训练策略。
+
+Epsilon-贪婪的思想是:
+
+- 以*概率1 - ɛ*:**我们进行利用**(即我们的智能体选择具有最高状态-动作对值的动作)。
+
+- 以*概率ɛ*:我们进行**探索**(尝试随机动作)。
+
+随着训练的继续,我们逐渐**减少epsilon值,因为我们需要越来越少的探索和更多的利用。**
+
+ +
+
+```python
+def epsilon_greedy_policy(Qtable, state, epsilon):
+ # 随机生成一个0到1之间的数
+ random_num =
+ # 如果random_num > epsilon --> 利用
+ if random_num > epsilon:
+ # 选择给定状态下值最高的动作
+ # np.argmax在这里很有用
+ action =
+ # 否则 --> 探索
+ else:
+ action = # 随机选择一个动作
+
+ return action
+```
+
+#### 解决方案
+
+```python
+def epsilon_greedy_policy(Qtable, state, epsilon):
+ # 随机生成一个0到1之间的数
+ random_num = random.uniform(0, 1)
+ # 如果random_num > epsilon --> 利用
+ if random_num > epsilon:
+ # 选择给定状态下值最高的动作
+ # np.argmax在这里很有用
+ action = greedy_policy(Qtable, state)
+ # 否则 --> 探索
+ else:
+ action = env.action_space.sample()
+
+ return action
+```
+
+## 定义超参数 ⚙️
+
+与探索相关的超参数是最重要的参数之一。
+
+- 我们需要确保我们的智能体**探索足够多的状态空间**以学习良好的价值近似。为此,我们需要逐渐降低epsilon。
+- 如果你降低epsilon太快(衰减率太高),**你的智能体可能会陷入困境**,因为你的智能体没有探索足够多的状态空间,因此无法解决问题。
+
+```python
+# 训练参数
+n_training_episodes = 10000 # 总训练回合数
+learning_rate = 0.7 # 学习率
+
+# 评估参数
+n_eval_episodes = 100 # 测试回合总数
+
+# 环境参数
+env_id = "FrozenLake-v1" # 环境名称
+max_steps = 99 # 每回合最大步数
+gamma = 0.95 # 折扣率
+eval_seed = [] # 环境的评估种子
+
+# 探索参数
+max_epsilon = 1.0 # 开始时的探索概率
+min_epsilon = 0.05 # 最小探索概率
+decay_rate = 0.0005 # 探索概率的指数衰减率
+```
+
+## 创建训练循环方法
+
+
+
+训练循环如下:
+
+```
+对于总训练回合中的每个回合:
+
+减少epsilon(因为我们需要越来越少的探索)
+重置环境
+
+ 对于最大时间步数中的每一步:
+ 使用epsilon贪婪策略选择动作At
+ 执行动作(a)并观察结果状态(s')和奖励(r)
+ 使用贝尔曼方程更新Q值 Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
+ 如果完成,结束回合
+ 我们的下一个状态是新状态
+```
+
+```python
+def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
+ for episode in tqdm(range(n_training_episodes)):
+ # 减少epsilon(因为我们需要越来越少的探索)
+ epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
+ # 重置环境
+ state, info = env.reset()
+ step = 0
+ terminated = False
+ truncated = False
+
+ # 重复
+ for step in range(max_steps):
+ # 使用epsilon贪婪策略选择动作At
+ action =
+
+ # 执行动作At并观察Rt+1和St+1
+ # 执行动作(a)并观察结果状态(s')和奖励(r)
+ new_state, reward, terminated, truncated, info =
+
+ # 更新Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
+ Qtable[state][action] =
+
+ # 如果终止或截断,结束回合
+ if terminated or truncated:
+ break
+
+ # 我们的下一个状态是新状态
+ state = new_state
+ return Qtable
+```
+
+#### 解决方案
+
+```python
+def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
+ for episode in tqdm(range(n_training_episodes)):
+ # 减少epsilon(因为我们需要越来越少的探索)
+ epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode)
+ # 重置环境
+ state, info = env.reset()
+ step = 0
+ terminated = False
+ truncated = False
+
+ # 重复
+ for step in range(max_steps):
+ # 使用epsilon贪婪策略选择动作At
+ action = epsilon_greedy_policy(Qtable, state, epsilon)
+
+ # 执行动作At并观察Rt+1和St+1
+ # 执行动作(a)并观察结果状态(s')和奖励(r)
+ new_state, reward, terminated, truncated, info = env.step(action)
+
+ # 更新Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
+ Qtable[state][action] = Qtable[state][action] + learning_rate * (
+ reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action]
+ )
+
+ # 如果终止或截断,结束回合
+ if terminated or truncated:
+ break
+
+ # 我们的下一个状态是新状态
+ state = new_state
+ return Qtable
+```
+
+## 训练Q-Learning智能体 🏃
+
+```python
+Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
+```
+
+## 让我们看看我们的Q-Learning表现在是什么样子 👀
+
+```python
+Qtable_frozenlake
+```
+
+## 评估方法 📝
+
+- 我们定义了将用于测试我们的Q-Learning智能体的评估方法。
+
+```python
+def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
+ """
+ 评估智能体``n_eval_episodes``回合并返回平均奖励和奖励的标准差。
+ :param env: 评估环境
+ :param n_eval_episodes: 评估智能体的回合数
+ :param Q: Q表
+ :param seed: 评估种子数组(用于taxi-v3)
+ """
+ episode_rewards = []
+ for episode in tqdm(range(n_eval_episodes)):
+ if seed:
+ state, info = env.reset(seed=seed[episode])
+ else:
+ state, info = env.reset()
+ step = 0
+ truncated = False
+ terminated = False
+ total_rewards_ep = 0
+
+ for step in range(max_steps):
+ # 选择在给定状态下具有最大预期未来奖励的动作(索引)
+ action = greedy_policy(Q, state)
+ new_state, reward, terminated, truncated, info = env.step(action)
+ total_rewards_ep += reward
+
+ if terminated or truncated:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+```
+
+## 评估我们的Q-Learning智能体 📈
+
+- 通常,你应该有1.0的平均奖励
+- **环境相对简单**,因为状态空间非常小(16)。你可以尝试的是[用滑动版本替换它](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/),这引入了随机性,使环境更加复杂。
+
+```python
+# 评估我们的智能体
+mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
+print(f"平均奖励={mean_reward:.2f} +/- {std_reward:.2f}")
+```
+
+## 将我们训练好的模型发布到Hub 🔥
+
+现在我们在训练后看到了良好的结果,**我们可以用一行代码将我们训练好的模型发布到Hub 🤗**。
+
+这是一个模型卡片的例子:
+
+
+
+
+```python
+def epsilon_greedy_policy(Qtable, state, epsilon):
+ # 随机生成一个0到1之间的数
+ random_num =
+ # 如果random_num > epsilon --> 利用
+ if random_num > epsilon:
+ # 选择给定状态下值最高的动作
+ # np.argmax在这里很有用
+ action =
+ # 否则 --> 探索
+ else:
+ action = # 随机选择一个动作
+
+ return action
+```
+
+#### 解决方案
+
+```python
+def epsilon_greedy_policy(Qtable, state, epsilon):
+ # 随机生成一个0到1之间的数
+ random_num = random.uniform(0, 1)
+ # 如果random_num > epsilon --> 利用
+ if random_num > epsilon:
+ # 选择给定状态下值最高的动作
+ # np.argmax在这里很有用
+ action = greedy_policy(Qtable, state)
+ # 否则 --> 探索
+ else:
+ action = env.action_space.sample()
+
+ return action
+```
+
+## 定义超参数 ⚙️
+
+与探索相关的超参数是最重要的参数之一。
+
+- 我们需要确保我们的智能体**探索足够多的状态空间**以学习良好的价值近似。为此,我们需要逐渐降低epsilon。
+- 如果你降低epsilon太快(衰减率太高),**你的智能体可能会陷入困境**,因为你的智能体没有探索足够多的状态空间,因此无法解决问题。
+
+```python
+# 训练参数
+n_training_episodes = 10000 # 总训练回合数
+learning_rate = 0.7 # 学习率
+
+# 评估参数
+n_eval_episodes = 100 # 测试回合总数
+
+# 环境参数
+env_id = "FrozenLake-v1" # 环境名称
+max_steps = 99 # 每回合最大步数
+gamma = 0.95 # 折扣率
+eval_seed = [] # 环境的评估种子
+
+# 探索参数
+max_epsilon = 1.0 # 开始时的探索概率
+min_epsilon = 0.05 # 最小探索概率
+decay_rate = 0.0005 # 探索概率的指数衰减率
+```
+
+## 创建训练循环方法
+
+
+
+训练循环如下:
+
+```
+对于总训练回合中的每个回合:
+
+减少epsilon(因为我们需要越来越少的探索)
+重置环境
+
+ 对于最大时间步数中的每一步:
+ 使用epsilon贪婪策略选择动作At
+ 执行动作(a)并观察结果状态(s')和奖励(r)
+ 使用贝尔曼方程更新Q值 Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
+ 如果完成,结束回合
+ 我们的下一个状态是新状态
+```
+
+```python
+def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
+ for episode in tqdm(range(n_training_episodes)):
+ # 减少epsilon(因为我们需要越来越少的探索)
+ epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
+ # 重置环境
+ state, info = env.reset()
+ step = 0
+ terminated = False
+ truncated = False
+
+ # 重复
+ for step in range(max_steps):
+ # 使用epsilon贪婪策略选择动作At
+ action =
+
+ # 执行动作At并观察Rt+1和St+1
+ # 执行动作(a)并观察结果状态(s')和奖励(r)
+ new_state, reward, terminated, truncated, info =
+
+ # 更新Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
+ Qtable[state][action] =
+
+ # 如果终止或截断,结束回合
+ if terminated or truncated:
+ break
+
+ # 我们的下一个状态是新状态
+ state = new_state
+ return Qtable
+```
+
+#### 解决方案
+
+```python
+def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
+ for episode in tqdm(range(n_training_episodes)):
+ # 减少epsilon(因为我们需要越来越少的探索)
+ epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode)
+ # 重置环境
+ state, info = env.reset()
+ step = 0
+ terminated = False
+ truncated = False
+
+ # 重复
+ for step in range(max_steps):
+ # 使用epsilon贪婪策略选择动作At
+ action = epsilon_greedy_policy(Qtable, state, epsilon)
+
+ # 执行动作At并观察Rt+1和St+1
+ # 执行动作(a)并观察结果状态(s')和奖励(r)
+ new_state, reward, terminated, truncated, info = env.step(action)
+
+ # 更新Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
+ Qtable[state][action] = Qtable[state][action] + learning_rate * (
+ reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action]
+ )
+
+ # 如果终止或截断,结束回合
+ if terminated or truncated:
+ break
+
+ # 我们的下一个状态是新状态
+ state = new_state
+ return Qtable
+```
+
+## 训练Q-Learning智能体 🏃
+
+```python
+Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
+```
+
+## 让我们看看我们的Q-Learning表现在是什么样子 👀
+
+```python
+Qtable_frozenlake
+```
+
+## 评估方法 📝
+
+- 我们定义了将用于测试我们的Q-Learning智能体的评估方法。
+
+```python
+def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
+ """
+ 评估智能体``n_eval_episodes``回合并返回平均奖励和奖励的标准差。
+ :param env: 评估环境
+ :param n_eval_episodes: 评估智能体的回合数
+ :param Q: Q表
+ :param seed: 评估种子数组(用于taxi-v3)
+ """
+ episode_rewards = []
+ for episode in tqdm(range(n_eval_episodes)):
+ if seed:
+ state, info = env.reset(seed=seed[episode])
+ else:
+ state, info = env.reset()
+ step = 0
+ truncated = False
+ terminated = False
+ total_rewards_ep = 0
+
+ for step in range(max_steps):
+ # 选择在给定状态下具有最大预期未来奖励的动作(索引)
+ action = greedy_policy(Q, state)
+ new_state, reward, terminated, truncated, info = env.step(action)
+ total_rewards_ep += reward
+
+ if terminated or truncated:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+```
+
+## 评估我们的Q-Learning智能体 📈
+
+- 通常,你应该有1.0的平均奖励
+- **环境相对简单**,因为状态空间非常小(16)。你可以尝试的是[用滑动版本替换它](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/),这引入了随机性,使环境更加复杂。
+
+```python
+# 评估我们的智能体
+mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
+print(f"平均奖励={mean_reward:.2f} +/- {std_reward:.2f}")
+```
+
+## 将我们训练好的模型发布到Hub 🔥
+
+现在我们在训练后看到了良好的结果,**我们可以用一行代码将我们训练好的模型发布到Hub 🤗**。
+
+这是一个模型卡片的例子:
+
+ +
+
+在底层,Hub使用基于git的仓库(如果你不知道git是什么,不用担心),这意味着你可以在实验和改进你的智能体时用新版本更新模型。
+
+#### 请勿修改此代码
+
+```python
+from huggingface_hub import HfApi, snapshot_download
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import json
+```
+
+```python
+def record_video(env, Qtable, out_directory, fps=1):
+ """
+ 生成智能体的回放视频
+ :param env
+ :param Qtable: 我们智能体的Q表
+ :param out_directory
+ :param fps: 每秒多少帧(对于taxi-v3和frozenlake-v1我们使用1)
+ """
+ images = []
+ terminated = False
+ truncated = False
+ state, info = env.reset(seed=random.randint(0, 500))
+ img = env.render()
+ images.append(img)
+ while not terminated or truncated:
+ # 选择在给定状态下具有最大预期未来奖励的动作(索引)
+ action = np.argmax(Qtable[state][:])
+ state, reward, terminated, truncated, info = env.step(
+ action
+ ) # 为了记录逻辑,我们直接将next_state = state
+ img = env.render()
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+```
+
+```python
+def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
+ """
+ 评估、生成视频并将模型上传到Hugging Face Hub。
+ 此方法完成整个流程:
+ - 评估模型
+ - 生成模型卡片
+ - 生成智能体的回放视频
+ - 将所有内容推送到Hub
+
+ :param repo_id: repo_id: Hugging Face Hub上模型仓库的ID
+ :param env
+ :param video_fps: 记录视频回放的每秒帧数
+ (对于taxi-v3和frozenlake-v1我们使用1)
+ :param local_repo_path: 本地仓库的位置
+ """
+ _, repo_name = repo_id.split("/")
+
+ eval_env = env
+ api = HfApi()
+
+ # 步骤1:创建仓库
+ repo_url = api.create_repo(
+ repo_id=repo_id,
+ exist_ok=True,
+ )
+
+ # 步骤2:下载文件
+ repo_local_path = Path(snapshot_download(repo_id=repo_id))
+
+ # 步骤3:保存模型
+ if env.spec.kwargs.get("map_name"):
+ model["map_name"] = env.spec.kwargs.get("map_name")
+ if env.spec.kwargs.get("is_slippery", "") == False:
+ model["slippery"] = False
+
+ # 序列化模型
+ with open((repo_local_path) / "q-learning.pkl", "wb") as f:
+ pickle.dump(model, f)
+
+ # 步骤4:评估模型并构建包含评估指标的JSON
+ mean_reward, std_reward = evaluate_agent(
+ eval_env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"]
+ )
+
+ evaluate_data = {
+ "env_id": model["env_id"],
+ "mean_reward": mean_reward,
+ "n_eval_episodes": model["n_eval_episodes"],
+ "eval_datetime": datetime.datetime.now().isoformat(),
+ }
+
+ # 写入一个名为"results.json"的JSON文件,其中包含
+ # 评估结果
+ with open(repo_local_path / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # 步骤5:创建模型卡片
+ env_name = model["env_id"]
+ if env.spec.kwargs.get("map_name"):
+ env_name += "-" + env.spec.kwargs.get("map_name")
+
+ if env.spec.kwargs.get("is_slippery", "") == False:
+ env_name += "-" + "no_slippery"
+
+ metadata = {}
+ metadata["tags"] = [env_name, "q-learning", "reinforcement-learning", "custom-implementation"]
+
+ # 添加指标
+ eval = metadata_eval_result(
+ model_pretty_name=repo_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_name,
+ dataset_id=env_name,
+ )
+
+ # 合并两个字典
+ metadata = {**metadata, **eval}
+
+
+ model_card = f"""
+ # **Q-Learning**智能体玩**{env_id}**
+ 这是一个训练好的**Q-Learning**智能体,可以玩**{env_id}**。
+
+ ## 使用方法
+
+ model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
+
+ # 不要忘记检查是否需要添加额外的属性(is_slippery=False等)
+ env = gym.make(model["env_id"])
+ """
+
+ evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
+
+ readme_path = repo_local_path / "README.md"
+ readme = ""
+ print(readme_path.exists())
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # 将我们的指标保存到Readme元数据
+ metadata_save(readme_path, metadata)
+
+ # 步骤6:录制视频
+ video_path = repo_local_path / "replay.mp4"
+ record_video(env, model["qtable"], video_path, video_fps)
+
+ # 步骤7:将所有内容推送到Hub
+ api.upload_folder(
+ repo_id=repo_id,
+ folder_path=repo_local_path,
+ path_in_repo=".",
+ )
+
+ print("你的模型已推送到Hub。你可以在这里查看你的模型:", repo_url)
+```
+
+### .
+
+通过使用`push_to_hub`,**你可以评估、记录回放、生成智能体的模型卡片并将其推送到Hub**。
+
+这样:
+- 你可以**展示我们的工作** 🔥
+- 你可以**可视化你的智能体的游戏过程** 👀
+- 你可以**与社区分享一个其他人可以使用的智能体** 💾
+- 你可以**访问排行榜 🏆 查看你的智能体与同学相比表现如何** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+
+要能够与社区分享你的模型,还需要遵循以下三个步骤:
+
+1️⃣ (如果尚未完成)创建一个HF账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录,然后,你需要从Hugging Face网站存储你的认证令牌。
+- 创建一个新令牌(https://huggingface.co/settings/tokens)**具有写入权限**
+
+
+
+
+
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令代替:`huggingface-cli login`(或`login`)
+
+3️⃣ 我们现在准备使用`push_to_hub()`函数将我们训练好的智能体推送到🤗 Hub 🔥
+
+- 让我们创建**包含超参数和Q表的模型字典**。
+
+```python
+model = {
+ "env_id": env_id,
+ "max_steps": max_steps,
+ "n_training_episodes": n_training_episodes,
+ "n_eval_episodes": n_eval_episodes,
+ "eval_seed": eval_seed,
+ "learning_rate": learning_rate,
+ "gamma": gamma,
+ "max_epsilon": max_epsilon,
+ "min_epsilon": min_epsilon,
+ "decay_rate": decay_rate,
+ "qtable": Qtable_frozenlake,
+}
+```
+
+让我们填写`push_to_hub`函数:
+
+- `repo_id`:将创建/更新的Hugging Face Hub仓库的名称`
+(repo_id = {username}/{repo_name})`
+💡 一个好的`repo_id`是`{username}/q-{env_id}`
+- `model`:包含超参数和Q表的模型字典。
+- `env`:环境。
+- `commit_message`:提交信息
+
+```python
+model
+```
+
+```python
+username = "" # 填写此处
+repo_name = "q-FrozenLake-v1-4x4-noSlippery"
+push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
+```
+
+恭喜 🥳 你刚刚从头实现、训练并上传了你的第一个强化学习智能体。
+FrozenLake-v1 no_slippery是一个非常简单的环境,让我们尝试一个更难的环境 🔥。
+
+# 第2部分:Taxi-v3 🚖
+
+## 创建并理解[Taxi-v3 🚕](https://gymnasium.farama.org/environments/toy_text/taxi/)
+---
+
+💡 当你开始使用一个环境时,一个好习惯是查看其文档
+
+👉 https://gymnasium.farama.org/environments/toy_text/taxi/
+
+---
+
+在`Taxi-v3` 🚕中,网格世界中有四个指定位置,分别用R(ed)、G(reen)、Y(ellow)和B(lue)表示。
+
+当回合开始时,**出租车从一个随机方格开始**,乘客在一个随机位置。出租车驶向乘客的位置,**接上乘客**,驶向乘客的目的地(四个指定位置中的另一个),然后**放下乘客**。一旦乘客被放下,回合结束。
+
+
+
+
+
+在底层,Hub使用基于git的仓库(如果你不知道git是什么,不用担心),这意味着你可以在实验和改进你的智能体时用新版本更新模型。
+
+#### 请勿修改此代码
+
+```python
+from huggingface_hub import HfApi, snapshot_download
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import json
+```
+
+```python
+def record_video(env, Qtable, out_directory, fps=1):
+ """
+ 生成智能体的回放视频
+ :param env
+ :param Qtable: 我们智能体的Q表
+ :param out_directory
+ :param fps: 每秒多少帧(对于taxi-v3和frozenlake-v1我们使用1)
+ """
+ images = []
+ terminated = False
+ truncated = False
+ state, info = env.reset(seed=random.randint(0, 500))
+ img = env.render()
+ images.append(img)
+ while not terminated or truncated:
+ # 选择在给定状态下具有最大预期未来奖励的动作(索引)
+ action = np.argmax(Qtable[state][:])
+ state, reward, terminated, truncated, info = env.step(
+ action
+ ) # 为了记录逻辑,我们直接将next_state = state
+ img = env.render()
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+```
+
+```python
+def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
+ """
+ 评估、生成视频并将模型上传到Hugging Face Hub。
+ 此方法完成整个流程:
+ - 评估模型
+ - 生成模型卡片
+ - 生成智能体的回放视频
+ - 将所有内容推送到Hub
+
+ :param repo_id: repo_id: Hugging Face Hub上模型仓库的ID
+ :param env
+ :param video_fps: 记录视频回放的每秒帧数
+ (对于taxi-v3和frozenlake-v1我们使用1)
+ :param local_repo_path: 本地仓库的位置
+ """
+ _, repo_name = repo_id.split("/")
+
+ eval_env = env
+ api = HfApi()
+
+ # 步骤1:创建仓库
+ repo_url = api.create_repo(
+ repo_id=repo_id,
+ exist_ok=True,
+ )
+
+ # 步骤2:下载文件
+ repo_local_path = Path(snapshot_download(repo_id=repo_id))
+
+ # 步骤3:保存模型
+ if env.spec.kwargs.get("map_name"):
+ model["map_name"] = env.spec.kwargs.get("map_name")
+ if env.spec.kwargs.get("is_slippery", "") == False:
+ model["slippery"] = False
+
+ # 序列化模型
+ with open((repo_local_path) / "q-learning.pkl", "wb") as f:
+ pickle.dump(model, f)
+
+ # 步骤4:评估模型并构建包含评估指标的JSON
+ mean_reward, std_reward = evaluate_agent(
+ eval_env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"]
+ )
+
+ evaluate_data = {
+ "env_id": model["env_id"],
+ "mean_reward": mean_reward,
+ "n_eval_episodes": model["n_eval_episodes"],
+ "eval_datetime": datetime.datetime.now().isoformat(),
+ }
+
+ # 写入一个名为"results.json"的JSON文件,其中包含
+ # 评估结果
+ with open(repo_local_path / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # 步骤5:创建模型卡片
+ env_name = model["env_id"]
+ if env.spec.kwargs.get("map_name"):
+ env_name += "-" + env.spec.kwargs.get("map_name")
+
+ if env.spec.kwargs.get("is_slippery", "") == False:
+ env_name += "-" + "no_slippery"
+
+ metadata = {}
+ metadata["tags"] = [env_name, "q-learning", "reinforcement-learning", "custom-implementation"]
+
+ # 添加指标
+ eval = metadata_eval_result(
+ model_pretty_name=repo_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_name,
+ dataset_id=env_name,
+ )
+
+ # 合并两个字典
+ metadata = {**metadata, **eval}
+
+
+ model_card = f"""
+ # **Q-Learning**智能体玩**{env_id}**
+ 这是一个训练好的**Q-Learning**智能体,可以玩**{env_id}**。
+
+ ## 使用方法
+
+ model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
+
+ # 不要忘记检查是否需要添加额外的属性(is_slippery=False等)
+ env = gym.make(model["env_id"])
+ """
+
+ evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
+
+ readme_path = repo_local_path / "README.md"
+ readme = ""
+ print(readme_path.exists())
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # 将我们的指标保存到Readme元数据
+ metadata_save(readme_path, metadata)
+
+ # 步骤6:录制视频
+ video_path = repo_local_path / "replay.mp4"
+ record_video(env, model["qtable"], video_path, video_fps)
+
+ # 步骤7:将所有内容推送到Hub
+ api.upload_folder(
+ repo_id=repo_id,
+ folder_path=repo_local_path,
+ path_in_repo=".",
+ )
+
+ print("你的模型已推送到Hub。你可以在这里查看你的模型:", repo_url)
+```
+
+### .
+
+通过使用`push_to_hub`,**你可以评估、记录回放、生成智能体的模型卡片并将其推送到Hub**。
+
+这样:
+- 你可以**展示我们的工作** 🔥
+- 你可以**可视化你的智能体的游戏过程** 👀
+- 你可以**与社区分享一个其他人可以使用的智能体** 💾
+- 你可以**访问排行榜 🏆 查看你的智能体与同学相比表现如何** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+
+要能够与社区分享你的模型,还需要遵循以下三个步骤:
+
+1️⃣ (如果尚未完成)创建一个HF账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录,然后,你需要从Hugging Face网站存储你的认证令牌。
+- 创建一个新令牌(https://huggingface.co/settings/tokens)**具有写入权限**
+
+
+
+
+
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令代替:`huggingface-cli login`(或`login`)
+
+3️⃣ 我们现在准备使用`push_to_hub()`函数将我们训练好的智能体推送到🤗 Hub 🔥
+
+- 让我们创建**包含超参数和Q表的模型字典**。
+
+```python
+model = {
+ "env_id": env_id,
+ "max_steps": max_steps,
+ "n_training_episodes": n_training_episodes,
+ "n_eval_episodes": n_eval_episodes,
+ "eval_seed": eval_seed,
+ "learning_rate": learning_rate,
+ "gamma": gamma,
+ "max_epsilon": max_epsilon,
+ "min_epsilon": min_epsilon,
+ "decay_rate": decay_rate,
+ "qtable": Qtable_frozenlake,
+}
+```
+
+让我们填写`push_to_hub`函数:
+
+- `repo_id`:将创建/更新的Hugging Face Hub仓库的名称`
+(repo_id = {username}/{repo_name})`
+💡 一个好的`repo_id`是`{username}/q-{env_id}`
+- `model`:包含超参数和Q表的模型字典。
+- `env`:环境。
+- `commit_message`:提交信息
+
+```python
+model
+```
+
+```python
+username = "" # 填写此处
+repo_name = "q-FrozenLake-v1-4x4-noSlippery"
+push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
+```
+
+恭喜 🥳 你刚刚从头实现、训练并上传了你的第一个强化学习智能体。
+FrozenLake-v1 no_slippery是一个非常简单的环境,让我们尝试一个更难的环境 🔥。
+
+# 第2部分:Taxi-v3 🚖
+
+## 创建并理解[Taxi-v3 🚕](https://gymnasium.farama.org/environments/toy_text/taxi/)
+---
+
+💡 当你开始使用一个环境时,一个好习惯是查看其文档
+
+👉 https://gymnasium.farama.org/environments/toy_text/taxi/
+
+---
+
+在`Taxi-v3` 🚕中,网格世界中有四个指定位置,分别用R(ed)、G(reen)、Y(ellow)和B(lue)表示。
+
+当回合开始时,**出租车从一个随机方格开始**,乘客在一个随机位置。出租车驶向乘客的位置,**接上乘客**,驶向乘客的目的地(四个指定位置中的另一个),然后**放下乘客**。一旦乘客被放下,回合结束。
+
+
+ +
+
+```python
+env = gym.make("Taxi-v3", render_mode="rgb_array")
+```
+
+**由于有25个出租车位置,5个可能的乘客位置**(包括乘客在出租车中的情况),以及**4个目的地位置**,所以有**500个离散状态**。
+
+
+```python
+state_space = env.observation_space.n
+print("有 ", state_space, " 个可能的状态")
+```
+
+```python
+action_space = env.action_space.n
+print("有 ", action_space, " 个可能的动作")
+```
+
+动作空间(智能体可以采取的可能动作集)是离散的,有**6个可用动作 🎮**:
+
+- 0: 向南移动
+- 1: 向北移动
+- 2: 向东移动
+- 3: 向西移动
+- 4: 接乘客
+- 5: 放下乘客
+
+奖励函数 💰:
+
+- 每步-1,除非触发其他奖励。
+- 送达乘客+20。
+- 非法执行"接客"和"放客"动作-10。
+
+```python
+# 创建我们的Q表,有state_size行和action_size列(500x6)
+Qtable_taxi = initialize_q_table(state_space, action_space)
+print(Qtable_taxi)
+print("Q表形状:", Qtable_taxi.shape)
+```
+
+## 定义超参数 ⚙️
+
+⚠ 请勿修改EVAL_SEED:eval_seed数组**允许我们使用与每位同学相同的出租车起始位置来评估你的智能体**
+
+```python
+# 训练参数
+n_training_episodes = 25000 # 总训练回合数
+learning_rate = 0.7 # 学习率
+
+# 评估参数
+n_eval_episodes = 100 # 测试回合总数
+
+# 请勿修改EVAL_SEED
+eval_seed = [
+ 16,
+ 54,
+ 165,
+ 177,
+ 191,
+ 191,
+ 120,
+ 80,
+ 149,
+ 178,
+ 48,
+ 38,
+ 6,
+ 125,
+ 174,
+ 73,
+ 50,
+ 172,
+ 100,
+ 148,
+ 146,
+ 6,
+ 25,
+ 40,
+ 68,
+ 148,
+ 49,
+ 167,
+ 9,
+ 97,
+ 164,
+ 176,
+ 61,
+ 7,
+ 54,
+ 55,
+ 161,
+ 131,
+ 184,
+ 51,
+ 170,
+ 12,
+ 120,
+ 113,
+ 95,
+ 126,
+ 51,
+ 98,
+ 36,
+ 135,
+ 54,
+ 82,
+ 45,
+ 95,
+ 89,
+ 59,
+ 95,
+ 124,
+ 9,
+ 113,
+ 58,
+ 85,
+ 51,
+ 134,
+ 121,
+ 169,
+ 105,
+ 21,
+ 30,
+ 11,
+ 50,
+ 65,
+ 12,
+ 43,
+ 82,
+ 145,
+ 152,
+ 97,
+ 106,
+ 55,
+ 31,
+ 85,
+ 38,
+ 112,
+ 102,
+ 168,
+ 123,
+ 97,
+ 21,
+ 83,
+ 158,
+ 26,
+ 80,
+ 63,
+ 5,
+ 81,
+ 32,
+ 11,
+ 28,
+ 148,
+] # 评估种子,这确保所有同学的智能体都在相同的出租车起始位置上训练
+# 每个种子都有一个特定的起始状态
+
+# 环境参数
+env_id = "Taxi-v3" # 环境名称
+max_steps = 99 # 每回合最大步数
+gamma = 0.95 # 折扣率
+
+# 探索参数
+max_epsilon = 1.0 # 开始时的探索概率
+min_epsilon = 0.05 # 最小探索概率
+decay_rate = 0.005 # 探索概率的指数衰减率
+```
+
+## 训练我们的Q-Learning智能体 🏃
+
+```python
+Qtable_taxi = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_taxi)
+Qtable_taxi
+```
+
+## 创建模型字典 💾 并将我们训练好的模型发布到Hub 🔥
+
+- 我们创建一个模型字典,其中包含所有训练超参数(为了可重现性)和Q表。
+
+
+```python
+model = {
+ "env_id": env_id,
+ "max_steps": max_steps,
+ "n_training_episodes": n_training_episodes,
+ "n_eval_episodes": n_eval_episodes,
+ "eval_seed": eval_seed,
+ "learning_rate": learning_rate,
+ "gamma": gamma,
+ "max_epsilon": max_epsilon,
+ "min_epsilon": min_epsilon,
+ "decay_rate": decay_rate,
+ "qtable": Qtable_taxi,
+}
+```
+
+```python
+username = "" # 填写此处
+repo_name = "" # 填写此处
+push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
+```
+
+现在它已经在Hub上了,你可以使用排行榜 🏆 比较你的Taxi-v3与同学们的结果 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+
+
+
+
+```python
+env = gym.make("Taxi-v3", render_mode="rgb_array")
+```
+
+**由于有25个出租车位置,5个可能的乘客位置**(包括乘客在出租车中的情况),以及**4个目的地位置**,所以有**500个离散状态**。
+
+
+```python
+state_space = env.observation_space.n
+print("有 ", state_space, " 个可能的状态")
+```
+
+```python
+action_space = env.action_space.n
+print("有 ", action_space, " 个可能的动作")
+```
+
+动作空间(智能体可以采取的可能动作集)是离散的,有**6个可用动作 🎮**:
+
+- 0: 向南移动
+- 1: 向北移动
+- 2: 向东移动
+- 3: 向西移动
+- 4: 接乘客
+- 5: 放下乘客
+
+奖励函数 💰:
+
+- 每步-1,除非触发其他奖励。
+- 送达乘客+20。
+- 非法执行"接客"和"放客"动作-10。
+
+```python
+# 创建我们的Q表,有state_size行和action_size列(500x6)
+Qtable_taxi = initialize_q_table(state_space, action_space)
+print(Qtable_taxi)
+print("Q表形状:", Qtable_taxi.shape)
+```
+
+## 定义超参数 ⚙️
+
+⚠ 请勿修改EVAL_SEED:eval_seed数组**允许我们使用与每位同学相同的出租车起始位置来评估你的智能体**
+
+```python
+# 训练参数
+n_training_episodes = 25000 # 总训练回合数
+learning_rate = 0.7 # 学习率
+
+# 评估参数
+n_eval_episodes = 100 # 测试回合总数
+
+# 请勿修改EVAL_SEED
+eval_seed = [
+ 16,
+ 54,
+ 165,
+ 177,
+ 191,
+ 191,
+ 120,
+ 80,
+ 149,
+ 178,
+ 48,
+ 38,
+ 6,
+ 125,
+ 174,
+ 73,
+ 50,
+ 172,
+ 100,
+ 148,
+ 146,
+ 6,
+ 25,
+ 40,
+ 68,
+ 148,
+ 49,
+ 167,
+ 9,
+ 97,
+ 164,
+ 176,
+ 61,
+ 7,
+ 54,
+ 55,
+ 161,
+ 131,
+ 184,
+ 51,
+ 170,
+ 12,
+ 120,
+ 113,
+ 95,
+ 126,
+ 51,
+ 98,
+ 36,
+ 135,
+ 54,
+ 82,
+ 45,
+ 95,
+ 89,
+ 59,
+ 95,
+ 124,
+ 9,
+ 113,
+ 58,
+ 85,
+ 51,
+ 134,
+ 121,
+ 169,
+ 105,
+ 21,
+ 30,
+ 11,
+ 50,
+ 65,
+ 12,
+ 43,
+ 82,
+ 145,
+ 152,
+ 97,
+ 106,
+ 55,
+ 31,
+ 85,
+ 38,
+ 112,
+ 102,
+ 168,
+ 123,
+ 97,
+ 21,
+ 83,
+ 158,
+ 26,
+ 80,
+ 63,
+ 5,
+ 81,
+ 32,
+ 11,
+ 28,
+ 148,
+] # 评估种子,这确保所有同学的智能体都在相同的出租车起始位置上训练
+# 每个种子都有一个特定的起始状态
+
+# 环境参数
+env_id = "Taxi-v3" # 环境名称
+max_steps = 99 # 每回合最大步数
+gamma = 0.95 # 折扣率
+
+# 探索参数
+max_epsilon = 1.0 # 开始时的探索概率
+min_epsilon = 0.05 # 最小探索概率
+decay_rate = 0.005 # 探索概率的指数衰减率
+```
+
+## 训练我们的Q-Learning智能体 🏃
+
+```python
+Qtable_taxi = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_taxi)
+Qtable_taxi
+```
+
+## 创建模型字典 💾 并将我们训练好的模型发布到Hub 🔥
+
+- 我们创建一个模型字典,其中包含所有训练超参数(为了可重现性)和Q表。
+
+
+```python
+model = {
+ "env_id": env_id,
+ "max_steps": max_steps,
+ "n_training_episodes": n_training_episodes,
+ "n_eval_episodes": n_eval_episodes,
+ "eval_seed": eval_seed,
+ "learning_rate": learning_rate,
+ "gamma": gamma,
+ "max_epsilon": max_epsilon,
+ "min_epsilon": min_epsilon,
+ "decay_rate": decay_rate,
+ "qtable": Qtable_taxi,
+}
+```
+
+```python
+username = "" # 填写此处
+repo_name = "" # 填写此处
+push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
+```
+
+现在它已经在Hub上了,你可以使用排行榜 🏆 比较你的Taxi-v3与同学们的结果 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+
+ +
+# 第3部分:从Hub加载 🔽
+
+Hugging Face Hub 🤗 的一个令人惊叹之处是你可以轻松地从社区加载强大的模型。
+
+从Hub加载保存的模型非常简单:
+
+1. 你前往 https://huggingface.co/models?other=q-learning 查看所有保存的q-learning模型列表。
+2. 选择一个并复制其repo_id
+
+
+
+# 第3部分:从Hub加载 🔽
+
+Hugging Face Hub 🤗 的一个令人惊叹之处是你可以轻松地从社区加载强大的模型。
+
+从Hub加载保存的模型非常简单:
+
+1. 你前往 https://huggingface.co/models?other=q-learning 查看所有保存的q-learning模型列表。
+2. 选择一个并复制其repo_id
+
+ +
+3. 然后我们只需要使用`load_from_hub`,提供:
+- repo_id
+- filename:仓库内保存的模型。
+
+#### 请勿修改此代码
+
+```python
+from urllib.error import HTTPError
+
+from huggingface_hub import hf_hub_download
+
+
+def load_from_hub(repo_id: str, filename: str) -> str:
+ """
+ 从Hugging Face Hub下载模型。
+ :param repo_id: Hugging Face Hub上模型仓库的id
+ :param filename: 仓库中模型zip文件的名称
+ """
+ # 从Hub获取模型,下载并缓存模型到本地磁盘
+ pickle_model = hf_hub_download(repo_id=repo_id, filename=filename)
+
+ with open(pickle_model, "rb") as f:
+ downloaded_model_file = pickle.load(f)
+
+ return downloaded_model_file
+```
+
+### .
+
+```python
+model = load_from_hub(repo_id="ThomasSimonini/q-Taxi-v3", filename="q-learning.pkl") # 尝试使用另一个模型
+
+print(model)
+env = gym.make(model["env_id"])
+
+evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
+```
+
+```python
+model = load_from_hub(
+ repo_id="ThomasSimonini/q-FrozenLake-v1-no-slippery", filename="q-learning.pkl"
+) # 尝试使用另一个模型
+
+env = gym.make(model["env_id"], is_slippery=False)
+
+evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
+```
+
+## 一些额外的挑战 🏆
+
+学习的最佳方式**是自己尝试**!正如你所看到的,当前的智能体表现不是很好。作为第一个建议,你可以训练更多步骤。使用1,000,000步,我们看到了一些很好的结果!
+
+在[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)中,你会找到你的智能体。你能登上榜首吗?
+
+以下是一些攀登排行榜的想法:
+
+* 训练更多步骤
+* 通过查看同学们的做法,尝试不同的超参数。
+* **将你新训练的模型**推送到Hub 🔥
+
+在冰面上行走和驾驶出租车对你来说太无聊了吗?尝试**改变环境**,为什么不使用FrozenLake-v1滑动版本?查看它们如何工作[使用gymnasium文档](https://gymnasium.farama.org/)并享受乐趣 🎉。
+
+_____________________________________________________________________
+恭喜 🥳,你刚刚实现、训练并上传了你的第一个强化学习智能体。
+
+理解Q-Learning是**理解基于价值的方法的重要一步。**
+
+在下一个单元的深度Q-Learning中,我们将看到,虽然创建和更新Q表是一个好策略——**但它不具有可扩展性。**
+
+例如,想象你创建了一个学习玩Doom的智能体。
+
+
+
+3. 然后我们只需要使用`load_from_hub`,提供:
+- repo_id
+- filename:仓库内保存的模型。
+
+#### 请勿修改此代码
+
+```python
+from urllib.error import HTTPError
+
+from huggingface_hub import hf_hub_download
+
+
+def load_from_hub(repo_id: str, filename: str) -> str:
+ """
+ 从Hugging Face Hub下载模型。
+ :param repo_id: Hugging Face Hub上模型仓库的id
+ :param filename: 仓库中模型zip文件的名称
+ """
+ # 从Hub获取模型,下载并缓存模型到本地磁盘
+ pickle_model = hf_hub_download(repo_id=repo_id, filename=filename)
+
+ with open(pickle_model, "rb") as f:
+ downloaded_model_file = pickle.load(f)
+
+ return downloaded_model_file
+```
+
+### .
+
+```python
+model = load_from_hub(repo_id="ThomasSimonini/q-Taxi-v3", filename="q-learning.pkl") # 尝试使用另一个模型
+
+print(model)
+env = gym.make(model["env_id"])
+
+evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
+```
+
+```python
+model = load_from_hub(
+ repo_id="ThomasSimonini/q-FrozenLake-v1-no-slippery", filename="q-learning.pkl"
+) # 尝试使用另一个模型
+
+env = gym.make(model["env_id"], is_slippery=False)
+
+evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
+```
+
+## 一些额外的挑战 🏆
+
+学习的最佳方式**是自己尝试**!正如你所看到的,当前的智能体表现不是很好。作为第一个建议,你可以训练更多步骤。使用1,000,000步,我们看到了一些很好的结果!
+
+在[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)中,你会找到你的智能体。你能登上榜首吗?
+
+以下是一些攀登排行榜的想法:
+
+* 训练更多步骤
+* 通过查看同学们的做法,尝试不同的超参数。
+* **将你新训练的模型**推送到Hub 🔥
+
+在冰面上行走和驾驶出租车对你来说太无聊了吗?尝试**改变环境**,为什么不使用FrozenLake-v1滑动版本?查看它们如何工作[使用gymnasium文档](https://gymnasium.farama.org/)并享受乐趣 🎉。
+
+_____________________________________________________________________
+恭喜 🥳,你刚刚实现、训练并上传了你的第一个强化学习智能体。
+
+理解Q-Learning是**理解基于价值的方法的重要一步。**
+
+在下一个单元的深度Q-Learning中,我们将看到,虽然创建和更新Q表是一个好策略——**但它不具有可扩展性。**
+
+例如,想象你创建了一个学习玩Doom的智能体。
+
+ +
+Doom是一个具有巨大状态空间(数百万个不同状态)的大型环境。为该环境创建和更新Q表将不会高效。
+
+这就是为什么我们将在下一个单元中学习深度Q-Learning,这是一种算法,**其中我们使用神经网络来近似,给定一个状态,每个动作的不同Q值。**
+
+
+
+
+我们在第3单元见! 🔥
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit2/introduction.mdx b/units/cn/unit2/introduction.mdx
new file mode 100644
index 00000000..86943025
--- /dev/null
+++ b/units/cn/unit2/introduction.mdx
@@ -0,0 +1,26 @@
+# Q-Learning简介 [[introduction-q-learning]]
+
+
+
+
+在本课程的第一单元中,我们学习了强化学习(RL)、RL过程以及解决RL问题的不同方法。我们还**训练了我们的第一个智能体并将它们上传到了Hugging Face Hub。**
+
+在本单元中,我们将**深入研究强化学习方法之一:基于价值的方法**,并学习我们的第一个RL算法:**Q-Learning。**
+
+我们还将**从头实现我们的第一个RL智能体**,一个Q-Learning智能体,并在两个环境中训练它:
+
+1. Frozen-Lake-v1(非滑动版本):我们的智能体需要**从起始状态(S)到达目标状态(G)**,只能在冰冻的瓦片(F)上行走,并避开洞(H)。
+2. 自动驾驶出租车:我们的智能体需要**学习如何在城市中导航**,以**将乘客从A点运送到B点。**
+
+
+
+
+具体来说,我们将:
+
+- 学习**基于价值的方法**。
+- 了解**蒙特卡洛方法和时序差分学习之间的区别**。
+- 研究并实现**我们的第一个RL算法**:Q-Learning。
+
+如果你想能够研究深度Q-Learning,这个单元是**基础性的**:深度Q-Learning是第一个玩Atari游戏并在其中一些游戏(打砖块、太空入侵者等)中超越人类水平的深度RL算法。
+
+那么让我们开始吧!🚀
diff --git a/units/cn/unit2/mc-vs-td.mdx b/units/cn/unit2/mc-vs-td.mdx
new file mode 100644
index 00000000..cc8d8a07
--- /dev/null
+++ b/units/cn/unit2/mc-vs-td.mdx
@@ -0,0 +1,135 @@
+# 蒙特卡洛与时序差分学习 [[mc-vs-td]]
+
+在深入研究Q-Learning之前,我们需要讨论的最后一件事是两种学习策略。
+
+记住,RL智能体**通过与环境交互来学习。**其理念是**根据经验和收到的奖励,智能体将更新其价值函数或策略。**
+
+蒙特卡洛和时序差分学习是**如何训练我们的价值函数或策略函数的两种不同策略。**它们**都使用经验来解决RL问题。**
+
+一方面,蒙特卡洛使用**整个回合的经验才开始学习。**另一方面,时序差分仅使用**一个步骤(\\(S_t, A_t, R_{t+1}, S_{t+1}\\))来学习。**
+
+我们将**使用基于价值的方法示例**来解释这两种方法。
+
+## 蒙特卡洛:在回合结束时学习 [[monte-carlo]]
+
+蒙特卡洛等待回合结束,计算\\(G_t\\)(回报),并将其用作**更新\\(V(S_t)\\)的目标。**
+
+因此,它需要**完整的交互回合才能更新我们的价值函数。**
+
+
+
+Doom是一个具有巨大状态空间(数百万个不同状态)的大型环境。为该环境创建和更新Q表将不会高效。
+
+这就是为什么我们将在下一个单元中学习深度Q-Learning,这是一种算法,**其中我们使用神经网络来近似,给定一个状态,每个动作的不同Q值。**
+
+
+
+
+我们在第3单元见! 🔥
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit2/introduction.mdx b/units/cn/unit2/introduction.mdx
new file mode 100644
index 00000000..86943025
--- /dev/null
+++ b/units/cn/unit2/introduction.mdx
@@ -0,0 +1,26 @@
+# Q-Learning简介 [[introduction-q-learning]]
+
+
+
+
+在本课程的第一单元中,我们学习了强化学习(RL)、RL过程以及解决RL问题的不同方法。我们还**训练了我们的第一个智能体并将它们上传到了Hugging Face Hub。**
+
+在本单元中,我们将**深入研究强化学习方法之一:基于价值的方法**,并学习我们的第一个RL算法:**Q-Learning。**
+
+我们还将**从头实现我们的第一个RL智能体**,一个Q-Learning智能体,并在两个环境中训练它:
+
+1. Frozen-Lake-v1(非滑动版本):我们的智能体需要**从起始状态(S)到达目标状态(G)**,只能在冰冻的瓦片(F)上行走,并避开洞(H)。
+2. 自动驾驶出租车:我们的智能体需要**学习如何在城市中导航**,以**将乘客从A点运送到B点。**
+
+
+
+
+具体来说,我们将:
+
+- 学习**基于价值的方法**。
+- 了解**蒙特卡洛方法和时序差分学习之间的区别**。
+- 研究并实现**我们的第一个RL算法**:Q-Learning。
+
+如果你想能够研究深度Q-Learning,这个单元是**基础性的**:深度Q-Learning是第一个玩Atari游戏并在其中一些游戏(打砖块、太空入侵者等)中超越人类水平的深度RL算法。
+
+那么让我们开始吧!🚀
diff --git a/units/cn/unit2/mc-vs-td.mdx b/units/cn/unit2/mc-vs-td.mdx
new file mode 100644
index 00000000..cc8d8a07
--- /dev/null
+++ b/units/cn/unit2/mc-vs-td.mdx
@@ -0,0 +1,135 @@
+# 蒙特卡洛与时序差分学习 [[mc-vs-td]]
+
+在深入研究Q-Learning之前,我们需要讨论的最后一件事是两种学习策略。
+
+记住,RL智能体**通过与环境交互来学习。**其理念是**根据经验和收到的奖励,智能体将更新其价值函数或策略。**
+
+蒙特卡洛和时序差分学习是**如何训练我们的价值函数或策略函数的两种不同策略。**它们**都使用经验来解决RL问题。**
+
+一方面,蒙特卡洛使用**整个回合的经验才开始学习。**另一方面,时序差分仅使用**一个步骤(\\(S_t, A_t, R_{t+1}, S_{t+1}\\))来学习。**
+
+我们将**使用基于价值的方法示例**来解释这两种方法。
+
+## 蒙特卡洛:在回合结束时学习 [[monte-carlo]]
+
+蒙特卡洛等待回合结束,计算\\(G_t\\)(回报),并将其用作**更新\\(V(S_t)\\)的目标。**
+
+因此,它需要**完整的交互回合才能更新我们的价值函数。**
+
+  +
+
+如果我们举个例子:
+
+
+
+
+如果我们举个例子:
+
+ 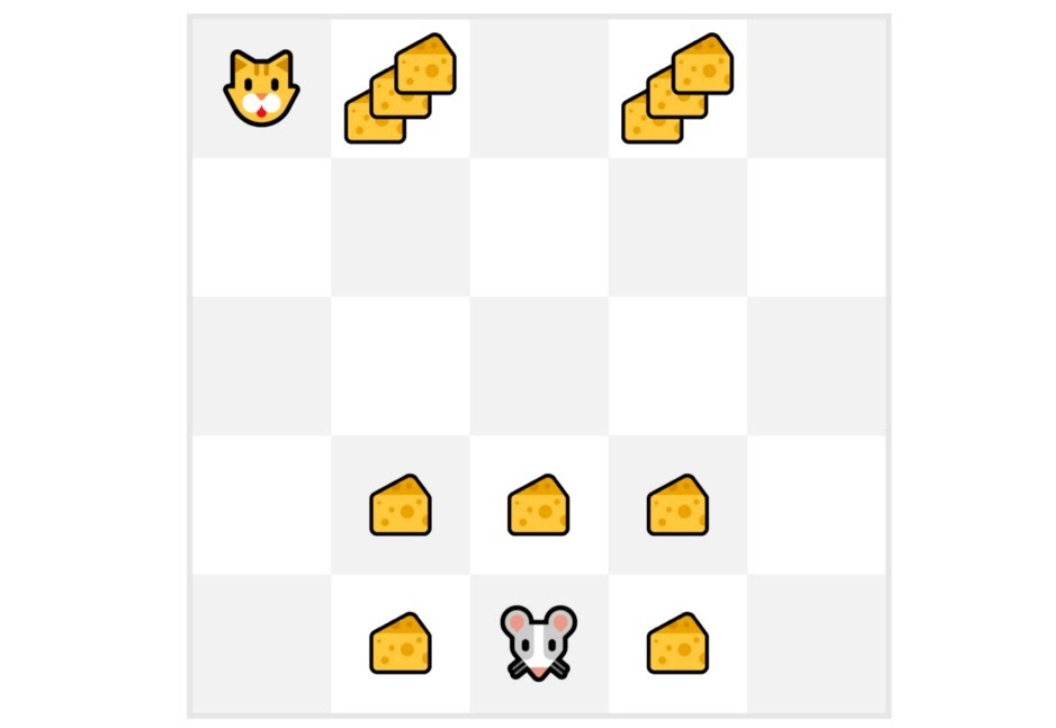 +
+
+- 我们总是**在同一个起点开始回合。**
+- **智能体使用策略采取行动**。例如,使用Epsilon贪婪策略,这是一种在探索(随机行动)和利用之间交替的策略。
+- 我们获得**奖励和下一个状态。**
+- 如果猫吃掉老鼠或老鼠移动>10步,我们终止回合。
+
+- 在回合结束时,**我们有一个状态、动作、奖励和下一个状态元组的列表**
+例如[[底部第3块状态,向左走,+1,底部第2块状态],[底部第2块状态,向左走,+0,底部第1块状态]...]
+
+- **智能体将总结所有奖励\\(G_t\\)**(看看它表现如何)。
+- 然后**根据公式更新\\(V(s_t)\\)**
+
+
+
+
+- 我们总是**在同一个起点开始回合。**
+- **智能体使用策略采取行动**。例如,使用Epsilon贪婪策略,这是一种在探索(随机行动)和利用之间交替的策略。
+- 我们获得**奖励和下一个状态。**
+- 如果猫吃掉老鼠或老鼠移动>10步,我们终止回合。
+
+- 在回合结束时,**我们有一个状态、动作、奖励和下一个状态元组的列表**
+例如[[底部第3块状态,向左走,+1,底部第2块状态],[底部第2块状态,向左走,+0,底部第1块状态]...]
+
+- **智能体将总结所有奖励\\(G_t\\)**(看看它表现如何)。
+- 然后**根据公式更新\\(V(s_t)\\)**
+
+  +
+- 然后**带着这些新知识开始新的游戏**
+
+通过运行越来越多的回合,**智能体将学会越来越好地玩游戏。**
+
+
+
+- 然后**带着这些新知识开始新的游戏**
+
+通过运行越来越多的回合,**智能体将学会越来越好地玩游戏。**
+
+  +
+例如,如果我们使用蒙特卡洛训练状态价值函数:
+
+- 我们初始化我们的价值函数,**使其为每个状态返回0值**
+- 我们的学习率(lr)是0.1,折扣率是1(=无折扣)
+- 我们的老鼠**探索环境并采取随机行动**
+
+
+
+例如,如果我们使用蒙特卡洛训练状态价值函数:
+
+- 我们初始化我们的价值函数,**使其为每个状态返回0值**
+- 我们的学习率(lr)是0.1,折扣率是1(=无折扣)
+- 我们的老鼠**探索环境并采取随机行动**
+
+ 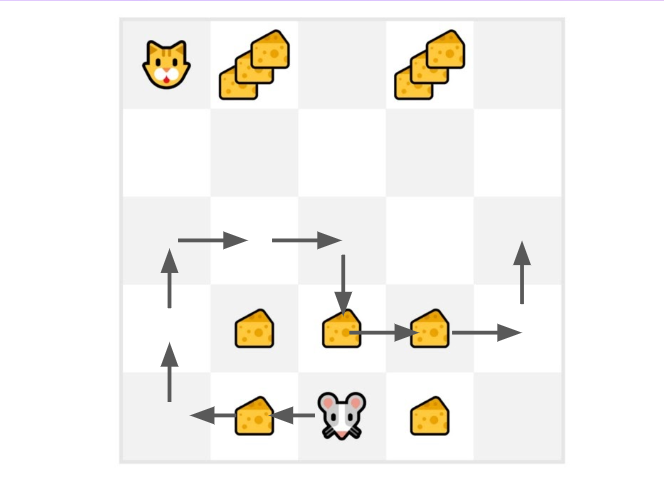 +
+
+- 老鼠走了超过10步,所以回合结束。
+
+
+
+
+- 老鼠走了超过10步,所以回合结束。
+
+  +
+
+
+- 我们有一个状态、动作、奖励、下一个状态的列表,**我们需要计算回报\\(G{t=0}\\)**
+
+\\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\)(为简单起见,我们不折扣奖励)
+
+\\(G_0 = R_{1} + R_{2} + R_{3}…\\)
+
+\\(G_0 = 1 + 0 + 0 + 0 + 0 + 0 + 1 + 1 + 0 + 0\\)
+
+\\(G_0 = 3\\)
+
+- 我们现在可以计算**新的**\\(V(S_0)\\):
+
+
+
+
+
+- 我们有一个状态、动作、奖励、下一个状态的列表,**我们需要计算回报\\(G{t=0}\\)**
+
+\\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\)(为简单起见,我们不折扣奖励)
+
+\\(G_0 = R_{1} + R_{2} + R_{3}…\\)
+
+\\(G_0 = 1 + 0 + 0 + 0 + 0 + 0 + 1 + 1 + 0 + 0\\)
+
+\\(G_0 = 3\\)
+
+- 我们现在可以计算**新的**\\(V(S_0)\\):
+
+  +
+\\(V(S_0) = V(S_0) + lr * [G_0 — V(S_0)]\\)
+
+\\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
+
+\\(V(S_0) = 0.3\\)
+
+
+
+
+\\(V(S_0) = V(S_0) + lr * [G_0 — V(S_0)]\\)
+
+\\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
+
+\\(V(S_0) = 0.3\\)
+
+
+  +
+
+## 时序差分学习:在每一步学习 [[td-learning]]
+
+**另一方面,时序差分只等待一次交互(一步)\\(S_{t+1}\\)**来形成TD目标并使用\\(R_{t+1}\\)和\\(\gamma * V(S_{t+1})\\)更新\\(V(S_t)\\)。
+
+**TD的理念是在每一步更新\\(V(S_t)\\)。**
+
+但因为我们没有经历整个回合,所以我们没有\\(G_t\\)(预期回报)。相反,**我们通过添加\\(R_{t+1}\\)和下一个状态的折扣值来估计\\(G_t\\)。**
+
+这被称为自举。之所以这样称呼,**是因为TD部分基于现有估计\\(V(S_{t+1})\\)而不是完整样本\\(G_t\\)来更新。**
+
+
+
+
+## 时序差分学习:在每一步学习 [[td-learning]]
+
+**另一方面,时序差分只等待一次交互(一步)\\(S_{t+1}\\)**来形成TD目标并使用\\(R_{t+1}\\)和\\(\gamma * V(S_{t+1})\\)更新\\(V(S_t)\\)。
+
+**TD的理念是在每一步更新\\(V(S_t)\\)。**
+
+但因为我们没有经历整个回合,所以我们没有\\(G_t\\)(预期回报)。相反,**我们通过添加\\(R_{t+1}\\)和下一个状态的折扣值来估计\\(G_t\\)。**
+
+这被称为自举。之所以这样称呼,**是因为TD部分基于现有估计\\(V(S_{t+1})\\)而不是完整样本\\(G_t\\)来更新。**
+
+  +
+
+这种方法被称为TD(0)或**单步TD(在任何单个步骤后更新价值函数)。**
+
+
+
+
+这种方法被称为TD(0)或**单步TD(在任何单个步骤后更新价值函数)。**
+
+  +
+如果我们采用相同的例子,
+
+
+
+如果我们采用相同的例子,
+
+  +
+- 我们初始化我们的价值函数,使其为每个状态返回0值。
+- 我们的学习率(lr)是0.1,折扣率是1(无折扣)。
+- 我们的老鼠开始探索环境并采取随机行动:**向左走**
+- 它获得奖励\\(R_{t+1} = 1\\),因为**它吃了一块奶酪**
+
+
+
+- 我们初始化我们的价值函数,使其为每个状态返回0值。
+- 我们的学习率(lr)是0.1,折扣率是1(无折扣)。
+- 我们的老鼠开始探索环境并采取随机行动:**向左走**
+- 它获得奖励\\(R_{t+1} = 1\\),因为**它吃了一块奶酪**
+
+ 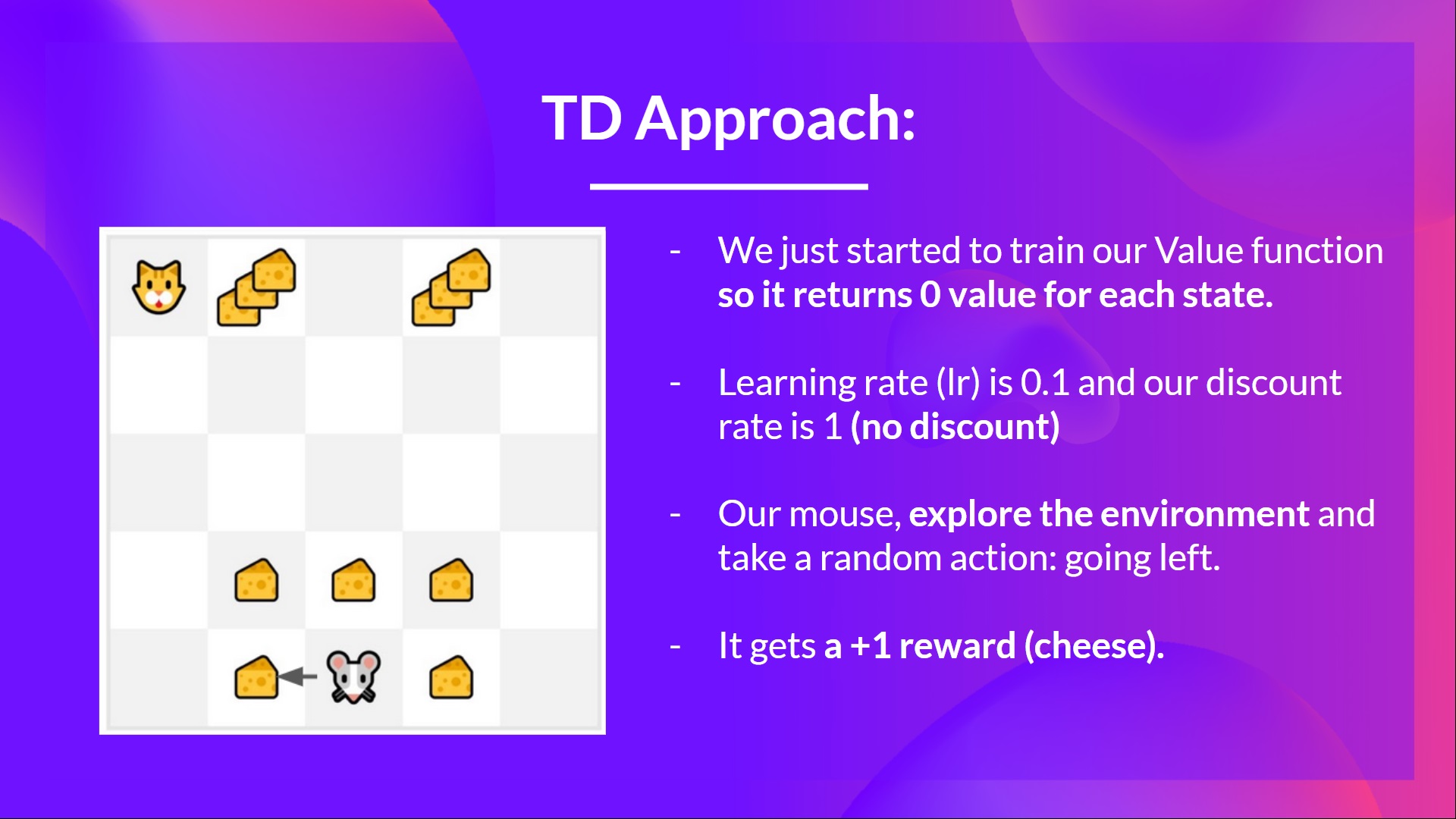 +
+
+
+
+
+ 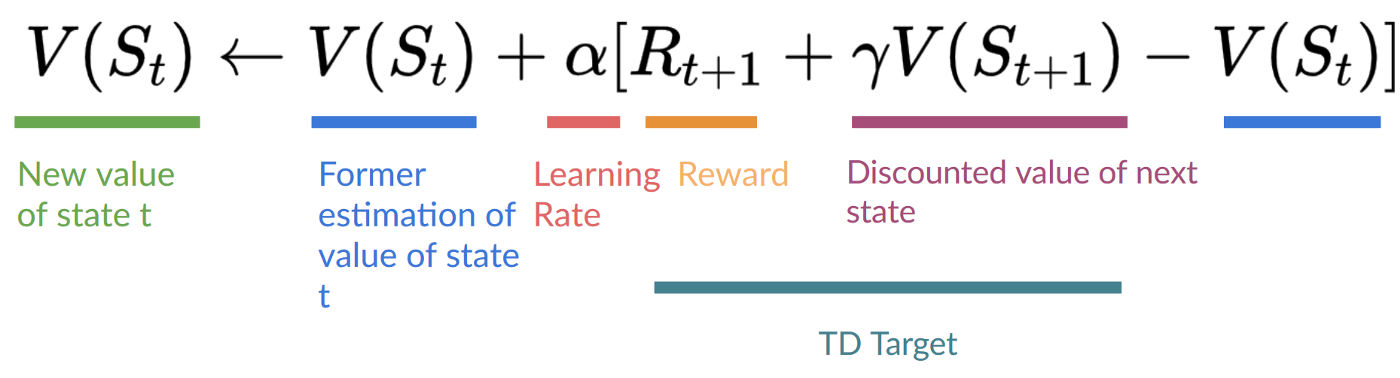 +
+我们现在可以更新\\(V(S_0)\\):
+
+新\\(V(S_0) = V(S_0) + lr * [R_1 + \gamma * V(S_1) - V(S_0)]\\)
+
+新\\(V(S_0) = 0 + 0.1 * [1 + 1 * 0–0]\\)
+
+新\\(V(S_0) = 0.1\\)
+
+所以我们刚刚更新了状态0的价值函数。
+
+现在我们**继续使用我们更新的价值函数与这个环境交互。**
+
+
+
+我们现在可以更新\\(V(S_0)\\):
+
+新\\(V(S_0) = V(S_0) + lr * [R_1 + \gamma * V(S_1) - V(S_0)]\\)
+
+新\\(V(S_0) = 0 + 0.1 * [1 + 1 * 0–0]\\)
+
+新\\(V(S_0) = 0.1\\)
+
+所以我们刚刚更新了状态0的价值函数。
+
+现在我们**继续使用我们更新的价值函数与这个环境交互。**
+
+  +
+ 总结:
+
+ - 使用*蒙特卡洛*,我们从完整的回合更新价值函数,因此**使用这个回合的实际准确折扣回报。**
+ - 使用*TD学习*,我们从一个步骤更新价值函数,并用**称为TD目标的估计回报**替换我们不知道的\\(G_t\\)。
+
+
+
+ 总结:
+
+ - 使用*蒙特卡洛*,我们从完整的回合更新价值函数,因此**使用这个回合的实际准确折扣回报。**
+ - 使用*TD学习*,我们从一个步骤更新价值函数,并用**称为TD目标的估计回报**替换我们不知道的\\(G_t\\)。
+
+ 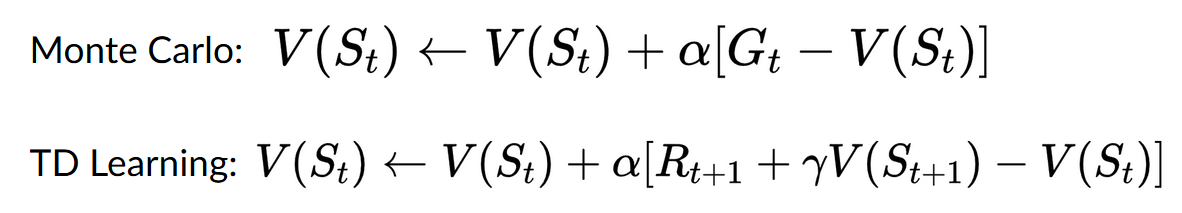 diff --git a/units/cn/unit2/mid-way-quiz.mdx b/units/cn/unit2/mid-way-quiz.mdx
new file mode 100644
index 00000000..33b75906
--- /dev/null
+++ b/units/cn/unit2/mid-way-quiz.mdx
@@ -0,0 +1,106 @@
+# 中途测验 [[mid-way-quiz]]
+
+学习的最佳方式,也是[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法,**就是测试自己。**这将帮助你找出**需要加强知识的地方**。
+
+
+### 问题1:寻找最优策略的两种主要方法是什么?
+
+
+
+
+
+### 问题2:什么是贝尔曼方程?
+
+
diff --git a/units/cn/unit2/mid-way-quiz.mdx b/units/cn/unit2/mid-way-quiz.mdx
new file mode 100644
index 00000000..33b75906
--- /dev/null
+++ b/units/cn/unit2/mid-way-quiz.mdx
@@ -0,0 +1,106 @@
+# 中途测验 [[mid-way-quiz]]
+
+学习的最佳方式,也是[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法,**就是测试自己。**这将帮助你找出**需要加强知识的地方**。
+
+
+### 问题1:寻找最优策略的两种主要方法是什么?
+
+
+
+
+
+### 问题2:什么是贝尔曼方程?
+
+
+解答
+
+**贝尔曼方程是一个递归方程**,其工作原理如下:我们不必为每个状态从头开始计算回报,而是可以将任何状态的价值视为:
+
+Rt+1 + gamma * V(St+1)
+
+即时奖励 + 后续状态的折扣价值
+
+
+
+### 问题3:定义贝尔曼方程的每个部分
+
+ +
+
+
+
+
+
+解答
+
+
+
+
+
+### 问题4:蒙特卡洛和时序差分学习方法之间的区别是什么?
+
+
+
+### 问题5:定义时序差分学习公式的每个部分
+
+ +
+
+
+
+解答
+
+
+
+
+
+
+### 问题6:定义蒙特卡洛学习公式的每个部分
+
+ +
+
+
+
+解答
+
+
+
+
+
+恭喜你完成这个测验 🥳,如果你错过了一些要点,请花时间重新阅读前面的章节,以加强(😏)你的知识。
diff --git a/units/cn/unit2/mid-way-recap.mdx b/units/cn/unit2/mid-way-recap.mdx
new file mode 100644
index 00000000..9d844067
--- /dev/null
+++ b/units/cn/unit2/mid-way-recap.mdx
@@ -0,0 +1,17 @@
+# 中途回顾 [[mid-way-recap]]
+
+在深入研究Q-Learning之前,让我们总结一下我们刚刚学到的内容。
+
+我们有两种类型的基于价值的函数:
+
+- 状态价值函数:输出如果**智能体从给定状态开始,并在此后永远按照策略行动**所能获得的预期回报。
+- 动作价值函数:输出如果**智能体从给定状态开始,在该状态采取给定动作**,然后在此后永远按照策略行动所能获得的预期回报。
+- 在基于价值的方法中,我们不是学习策略,而是**手动定义策略**,然后学习价值函数。如果我们有一个最优价值函数,我们**将拥有一个最优策略。**
+
+更新价值函数有两种方法:
+
+- 使用*蒙特卡洛方法*,我们从完整的回合更新价值函数,因此**使用这个回合的实际折扣回报。**
+- 使用*TD学习方法*,我们从一个步骤更新价值函数,用**称为TD目标的估计回报**替换未知的\\(G_t\\)。
+
+
+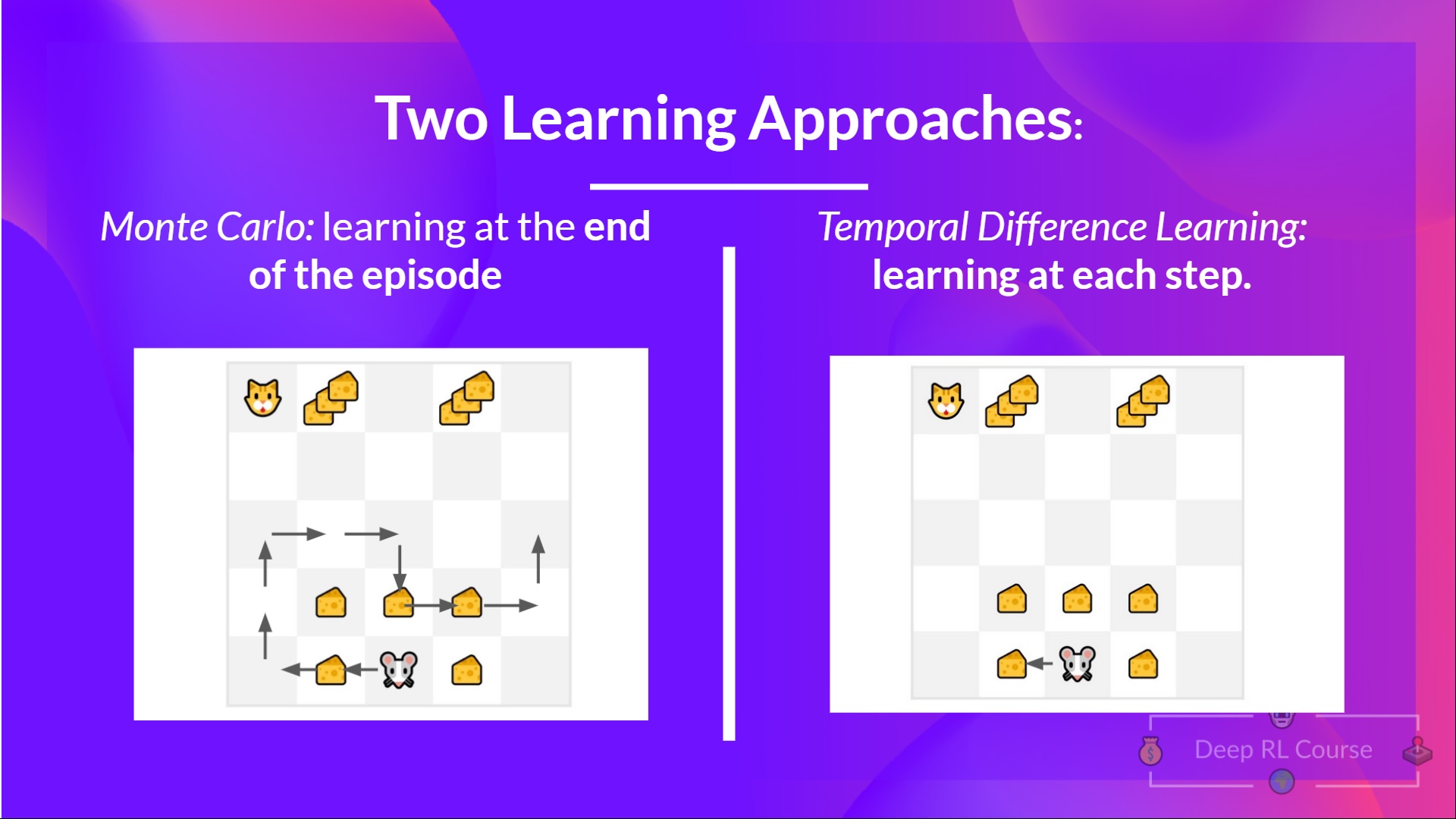 diff --git a/units/cn/unit2/q-learning-example.mdx b/units/cn/unit2/q-learning-example.mdx
new file mode 100644
index 00000000..fef4f18e
--- /dev/null
+++ b/units/cn/unit2/q-learning-example.mdx
@@ -0,0 +1,83 @@
+# Q-Learning示例 [[q-learning-example]]
+
+为了更好地理解Q-Learning,让我们看一个简单的例子:
+
+
diff --git a/units/cn/unit2/q-learning-example.mdx b/units/cn/unit2/q-learning-example.mdx
new file mode 100644
index 00000000..fef4f18e
--- /dev/null
+++ b/units/cn/unit2/q-learning-example.mdx
@@ -0,0 +1,83 @@
+# Q-Learning示例 [[q-learning-example]]
+
+为了更好地理解Q-Learning,让我们看一个简单的例子:
+
+ +
+- 你是这个小迷宫中的一只老鼠。你总是**从同一个起点开始。**
+- 目标是**吃掉右下角的大堆奶酪**并避开毒药。毕竟,谁不喜欢奶酪呢?
+- 如果我们吃了毒药,**吃了大堆奶酪**,或者我们走了超过五步,回合就结束了。
+- 学习率是0.1
+- 折扣率(gamma)是0.99
+
+
+
+- 你是这个小迷宫中的一只老鼠。你总是**从同一个起点开始。**
+- 目标是**吃掉右下角的大堆奶酪**并避开毒药。毕竟,谁不喜欢奶酪呢?
+- 如果我们吃了毒药,**吃了大堆奶酪**,或者我们走了超过五步,回合就结束了。
+- 学习率是0.1
+- 折扣率(gamma)是0.99
+
+ +
+
+奖励函数如下:
+
+- **+0:**进入没有奶酪的状态。
+- **+1:**进入有小奶酪的状态。
+- **+10:**进入有大堆奶酪的状态。
+- **-10:**进入有毒药的状态并因此死亡。
+- **+0** 如果我们走了超过五步。
+
+
+
+
+奖励函数如下:
+
+- **+0:**进入没有奶酪的状态。
+- **+1:**进入有小奶酪的状态。
+- **+10:**进入有大堆奶酪的状态。
+- **-10:**进入有毒药的状态并因此死亡。
+- **+0** 如果我们走了超过五步。
+
+ +
+为了训练我们的智能体获得最优策略(即向右、向右、向下的策略),**我们将使用Q-Learning算法**。
+
+## 步骤1:初始化Q表 [[step1]]
+
+
+
+为了训练我们的智能体获得最优策略(即向右、向右、向下的策略),**我们将使用Q-Learning算法**。
+
+## 步骤1:初始化Q表 [[step1]]
+
+ +
+所以,目前,**我们的Q表是没用的**;我们需要**使用Q-Learning算法训练我们的Q函数。**
+
+让我们进行2个训练时间步:
+
+训练时间步1:
+
+## 步骤2:使用Epsilon贪婪策略选择动作 [[step2]]
+
+因为epsilon很大(= 1.0),我采取随机动作。在这种情况下,我向右走。
+
+
+
+所以,目前,**我们的Q表是没用的**;我们需要**使用Q-Learning算法训练我们的Q函数。**
+
+让我们进行2个训练时间步:
+
+训练时间步1:
+
+## 步骤2:使用Epsilon贪婪策略选择动作 [[step2]]
+
+因为epsilon很大(= 1.0),我采取随机动作。在这种情况下,我向右走。
+
+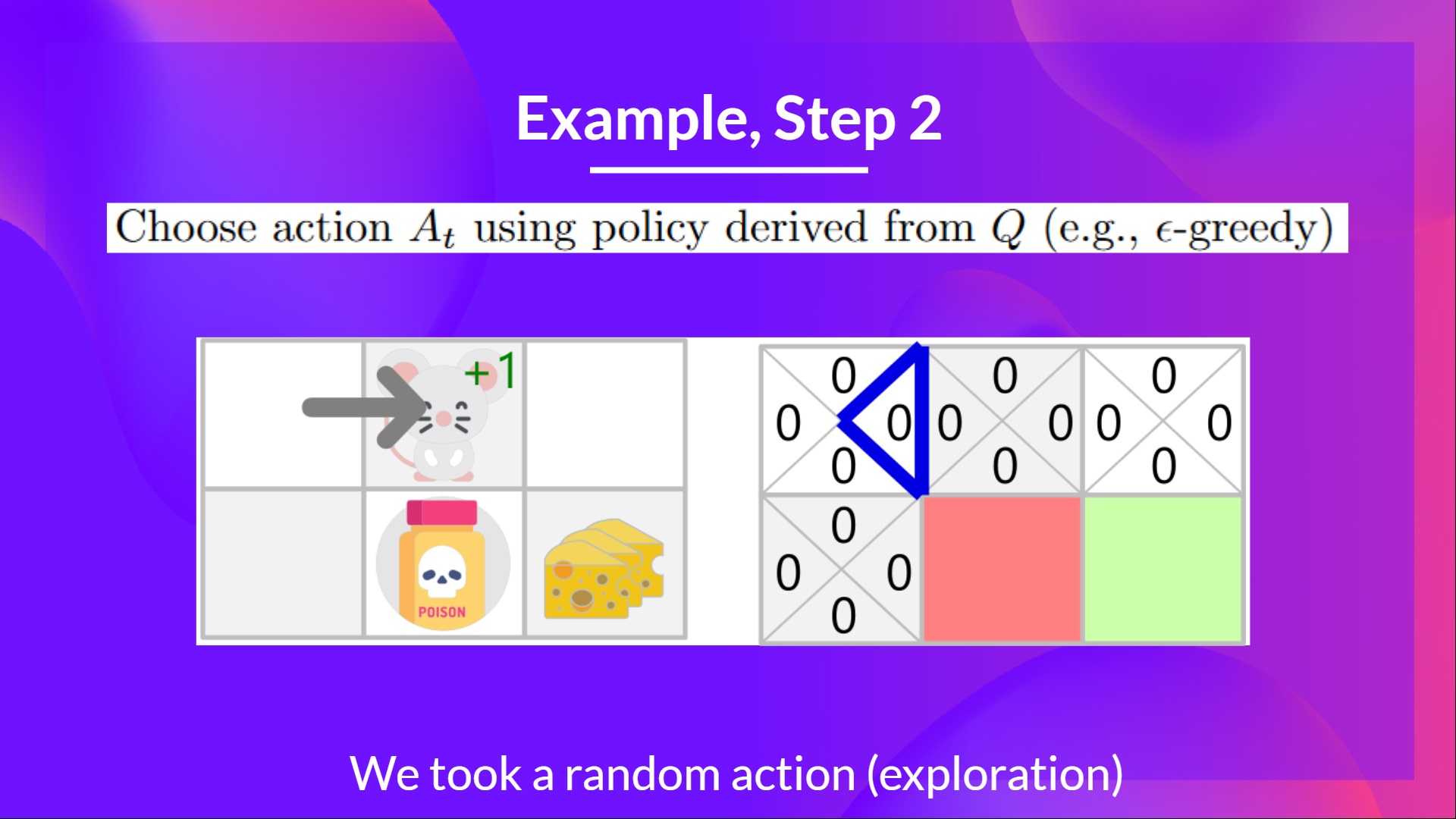 +
+
+## 步骤3:执行动作At,获取Rt+1和St+1 [[step3]]
+
+通过向右走,我得到一小块奶酪,所以\\(R_{t+1} = 1\\),我进入一个新状态。
+
+
+
+
+
+## 步骤3:执行动作At,获取Rt+1和St+1 [[step3]]
+
+通过向右走,我得到一小块奶酪,所以\\(R_{t+1} = 1\\),我进入一个新状态。
+
+
+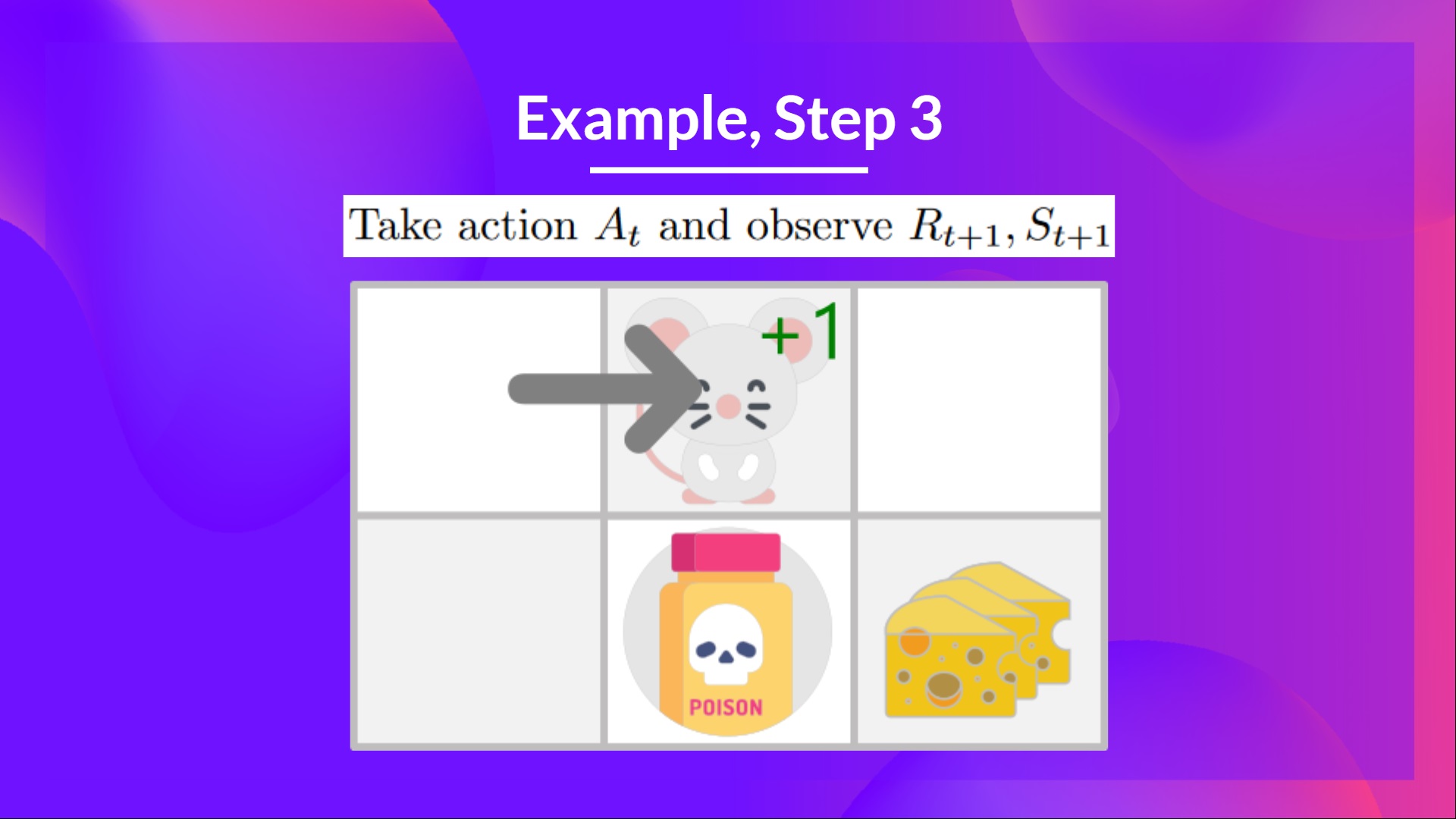 +
+
+## 步骤4:更新Q(St, At) [[step4]]
+
+我们现在可以使用我们的公式更新\\(Q(S_t, A_t)\\)。
+
+
+
+
+## 步骤4:更新Q(St, At) [[step4]]
+
+我们现在可以使用我们的公式更新\\(Q(S_t, A_t)\\)。
+
+ +
+ +
+训练时间步2:
+
+## 步骤2:使用Epsilon贪婪策略选择动作 [[step2-2]]
+
+**我再次采取随机动作,因为epsilon=0.99仍然很大**。(注意我们稍微衰减了epsilon,因为随着训练的进行,我们希望越来越少的探索)。
+
+我采取了"向下"的动作。**这不是一个好动作,因为它会导致我吃到毒药。**
+
+
+
+训练时间步2:
+
+## 步骤2:使用Epsilon贪婪策略选择动作 [[step2-2]]
+
+**我再次采取随机动作,因为epsilon=0.99仍然很大**。(注意我们稍微衰减了epsilon,因为随着训练的进行,我们希望越来越少的探索)。
+
+我采取了"向下"的动作。**这不是一个好动作,因为它会导致我吃到毒药。**
+
+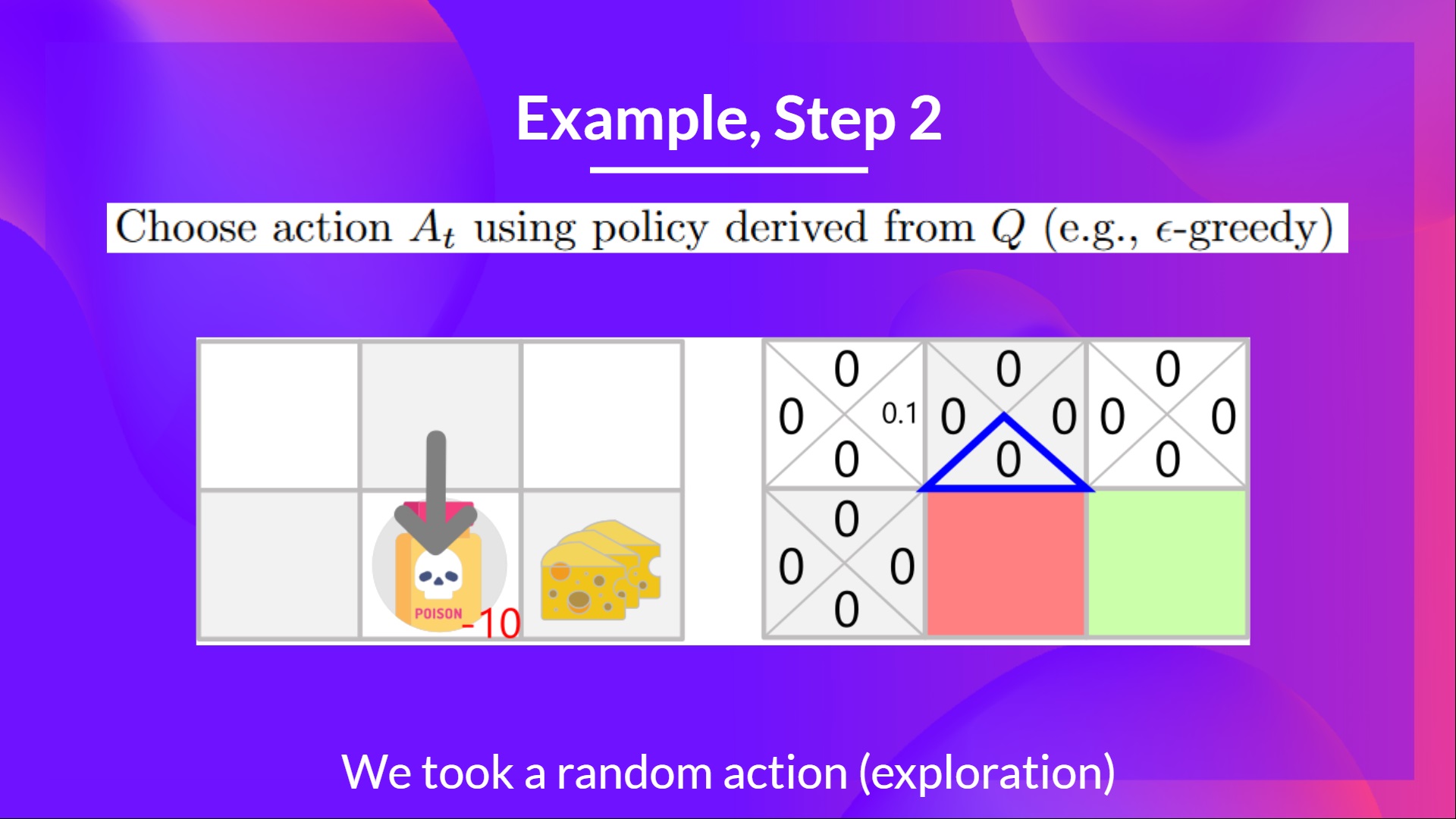 +
+
+## 步骤3:执行动作At,获取Rt+1和St+1 [[step3-3]]
+
+因为我吃了毒药,**我得到\\(R_{t+1} = -10\\),然后我死了。**
+
+
+
+
+## 步骤3:执行动作At,获取Rt+1和St+1 [[step3-3]]
+
+因为我吃了毒药,**我得到\\(R_{t+1} = -10\\),然后我死了。**
+
+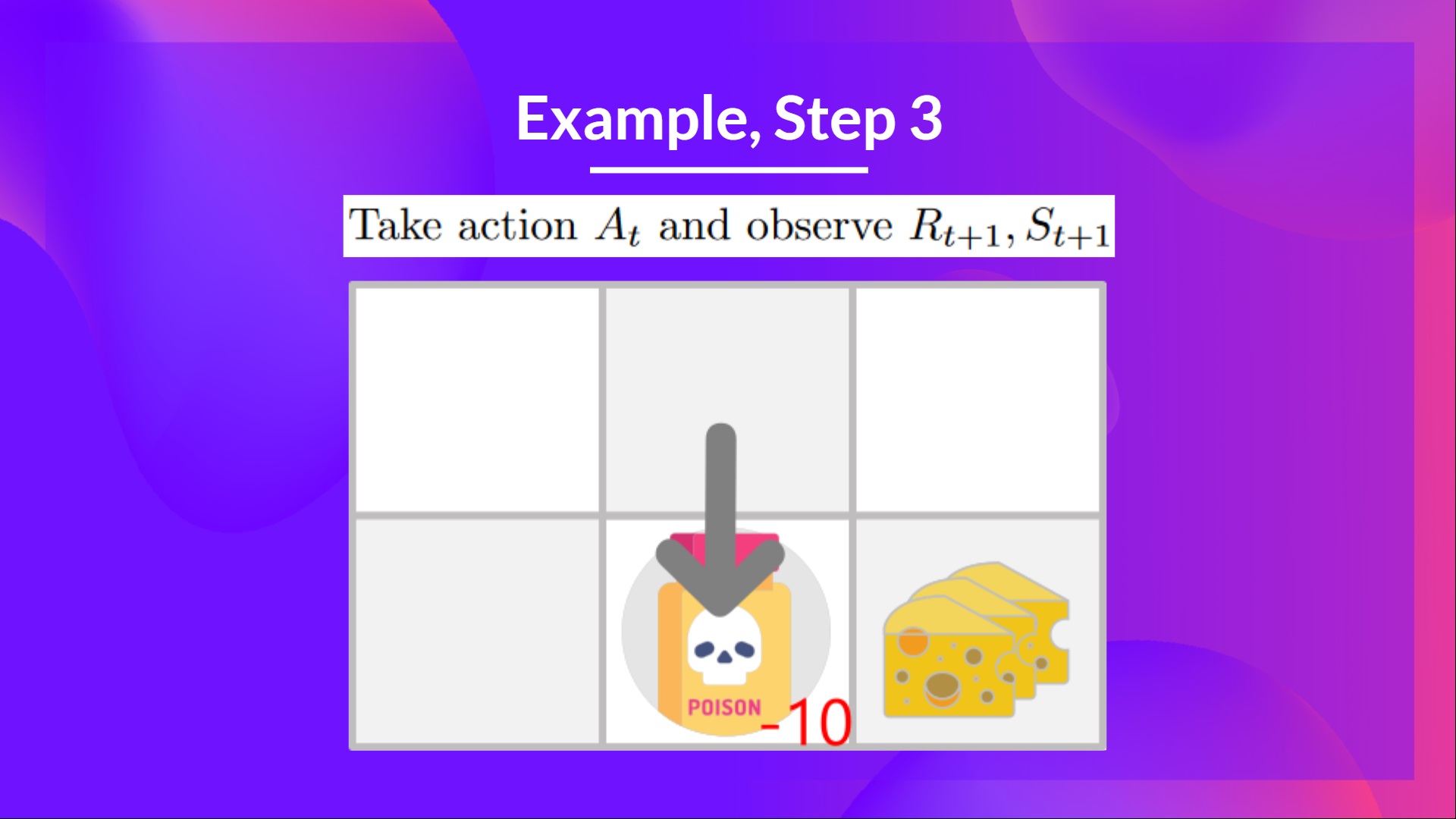 +
+## 步骤4:更新Q(St, At) [[step4-4]]
+
+
+
+## 步骤4:更新Q(St, At) [[step4-4]]
+
+ +
+因为我们死了,所以我们开始一个新的回合。但我们在这里看到的是,**通过两个探索步骤,我的智能体变得更聪明了。**
+
+随着我们继续探索和利用环境并使用TD目标更新Q值,**Q表将给我们越来越好的近似。在训练结束时,我们将获得最优Q函数的估计。**
diff --git a/units/cn/unit2/q-learning-recap.mdx b/units/cn/unit2/q-learning-recap.mdx
new file mode 100644
index 00000000..5ce9de4c
--- /dev/null
+++ b/units/cn/unit2/q-learning-recap.mdx
@@ -0,0 +1,24 @@
+# Q-Learning回顾 [[q-learning-recap]]
+
+
+*Q-Learning* **是一种RL算法,它**:
+
+- 训练一个*Q函数*,一个**动作价值函数**,在内部存储器中由*Q表*编码,**包含所有状态-动作对的值。**
+
+- 给定一个状态和动作,我们的Q函数**将在其Q表中搜索相应的值。**
+
+
+
+- 当训练完成后,**我们拥有一个最优Q函数,或者等效地,一个最优Q表。**
+
+- 如果我们**拥有一个最优Q函数**,我们就拥有一个最优策略,因为我们**知道对于每个状态,最佳的动作是什么。**
+
+
+
+但是,在开始时,我们的**Q表是没用的,因为它为每个状态-动作对给出了任意值(大多数情况下,我们将Q表初始化为0值)**。但是,随着我们探索环境并更新我们的Q表,它将给我们越来越好的近似。
+
+
+
+这是Q-Learning的伪代码:
+
+
diff --git a/units/cn/unit2/q-learning.mdx b/units/cn/unit2/q-learning.mdx
new file mode 100644
index 00000000..b8321dac
--- /dev/null
+++ b/units/cn/unit2/q-learning.mdx
@@ -0,0 +1,160 @@
+# Q-Learning简介 [[q-learning]]
+## 什么是Q-Learning? [[what-is-q-learning]]
+
+Q-Learning是一种**离策略的基于价值的方法,使用TD方法来训练其动作价值函数:**
+
+- *离策略*:我们将在本单元结束时讨论这一点。
+- *基于价值的方法*:通过训练价值函数或动作价值函数间接找到最优策略,这些函数将告诉我们**每个状态或每个状态-动作对的价值。**
+- *TD方法:* **在每一步而不是在回合结束时更新其动作价值函数。**
+
+**Q-Learning是我们用来训练Q函数的算法**,Q函数是一个**动作价值函数**,它确定在特定状态下采取特定动作的价值。
+
+
+
+
+因为我们死了,所以我们开始一个新的回合。但我们在这里看到的是,**通过两个探索步骤,我的智能体变得更聪明了。**
+
+随着我们继续探索和利用环境并使用TD目标更新Q值,**Q表将给我们越来越好的近似。在训练结束时,我们将获得最优Q函数的估计。**
diff --git a/units/cn/unit2/q-learning-recap.mdx b/units/cn/unit2/q-learning-recap.mdx
new file mode 100644
index 00000000..5ce9de4c
--- /dev/null
+++ b/units/cn/unit2/q-learning-recap.mdx
@@ -0,0 +1,24 @@
+# Q-Learning回顾 [[q-learning-recap]]
+
+
+*Q-Learning* **是一种RL算法,它**:
+
+- 训练一个*Q函数*,一个**动作价值函数**,在内部存储器中由*Q表*编码,**包含所有状态-动作对的值。**
+
+- 给定一个状态和动作,我们的Q函数**将在其Q表中搜索相应的值。**
+
+
+
+- 当训练完成后,**我们拥有一个最优Q函数,或者等效地,一个最优Q表。**
+
+- 如果我们**拥有一个最优Q函数**,我们就拥有一个最优策略,因为我们**知道对于每个状态,最佳的动作是什么。**
+
+
+
+但是,在开始时,我们的**Q表是没用的,因为它为每个状态-动作对给出了任意值(大多数情况下,我们将Q表初始化为0值)**。但是,随着我们探索环境并更新我们的Q表,它将给我们越来越好的近似。
+
+
+
+这是Q-Learning的伪代码:
+
+
diff --git a/units/cn/unit2/q-learning.mdx b/units/cn/unit2/q-learning.mdx
new file mode 100644
index 00000000..b8321dac
--- /dev/null
+++ b/units/cn/unit2/q-learning.mdx
@@ -0,0 +1,160 @@
+# Q-Learning简介 [[q-learning]]
+## 什么是Q-Learning? [[what-is-q-learning]]
+
+Q-Learning是一种**离策略的基于价值的方法,使用TD方法来训练其动作价值函数:**
+
+- *离策略*:我们将在本单元结束时讨论这一点。
+- *基于价值的方法*:通过训练价值函数或动作价值函数间接找到最优策略,这些函数将告诉我们**每个状态或每个状态-动作对的价值。**
+- *TD方法:* **在每一步而不是在回合结束时更新其动作价值函数。**
+
+**Q-Learning是我们用来训练Q函数的算法**,Q函数是一个**动作价值函数**,它确定在特定状态下采取特定动作的价值。
+
+
+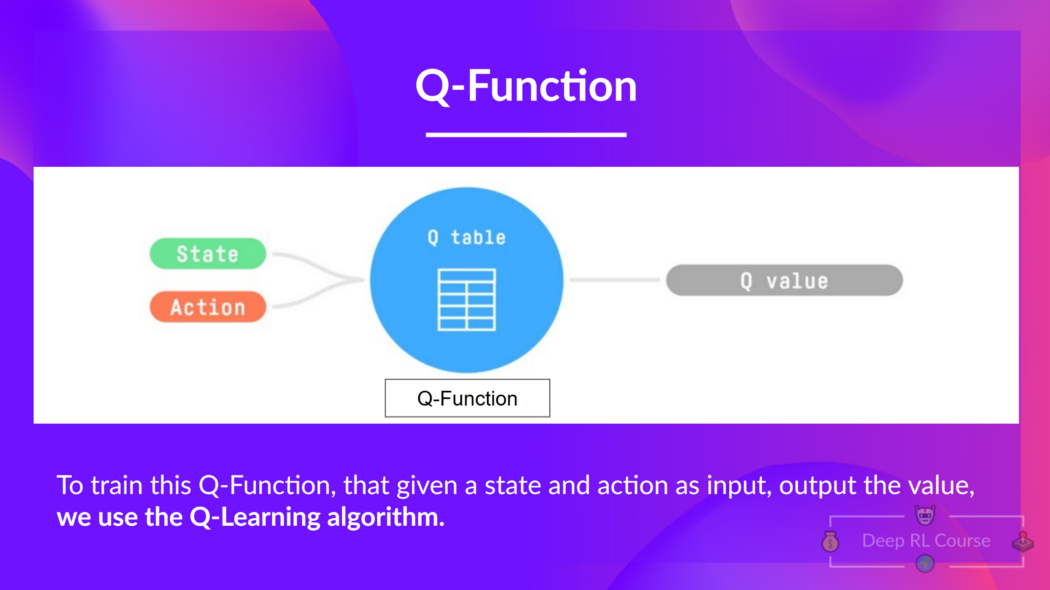 + 给定一个状态和动作,我们的Q函数输出一个状态-动作值(也称为Q值)
+
+
+**Q来源于"质量"(该状态下该动作的价值)。**
+
+让我们回顾一下价值和奖励之间的区别:
+
+- *状态的价值*或*状态-动作对的价值*是我们的智能体如果从这个状态(或状态-动作对)开始,然后按照其策略行动所获得的预期累积奖励。
+- *奖励*是**我在某个状态执行动作后从环境中获得的反馈**。
+
+在内部,我们的Q函数由**Q表编码,这是一个表格,其中每个单元格对应一个状态-动作对的值。**把这个Q表想象为**我们Q函数的记忆或备忘单。**
+
+让我们通过一个迷宫的例子来理解。
+
+
+ 给定一个状态和动作,我们的Q函数输出一个状态-动作值(也称为Q值)
+
+
+**Q来源于"质量"(该状态下该动作的价值)。**
+
+让我们回顾一下价值和奖励之间的区别:
+
+- *状态的价值*或*状态-动作对的价值*是我们的智能体如果从这个状态(或状态-动作对)开始,然后按照其策略行动所获得的预期累积奖励。
+- *奖励*是**我在某个状态执行动作后从环境中获得的反馈**。
+
+在内部,我们的Q函数由**Q表编码,这是一个表格,其中每个单元格对应一个状态-动作对的值。**把这个Q表想象为**我们Q函数的记忆或备忘单。**
+
+让我们通过一个迷宫的例子来理解。
+
+ +
+Q表已初始化。这就是为什么所有值都等于0。这个表**包含了每个状态和动作对应的状态-动作值。**
+对于这个简单的例子,状态仅由老鼠的位置定义。因此,我们的Q表中有2*3行,每行对应老鼠可能的位置。在更复杂的场景中,状态可能包含比角色位置更多的信息。
+
+
+
+Q表已初始化。这就是为什么所有值都等于0。这个表**包含了每个状态和动作对应的状态-动作值。**
+对于这个简单的例子,状态仅由老鼠的位置定义。因此,我们的Q表中有2*3行,每行对应老鼠可能的位置。在更复杂的场景中,状态可能包含比角色位置更多的信息。
+
+ +
+这里我们看到**初始状态并向上移动的状态-动作值为0:**
+
+
+
+这里我们看到**初始状态并向上移动的状态-动作值为0:**
+
+ +
+所以:Q函数使用一个Q表,**该表包含每个状态-动作对的值。**给定一个状态和动作,**我们的Q函数将在其Q表中搜索以输出相应的值。**
+
+
+
+
+
+总结一下,*Q-Learning* **是一种RL算法,它:**
+
+- 训练一个*Q函数*(一个**动作价值函数**),在内部是一个**包含所有状态-动作对值的Q表。**
+- 给定一个状态和动作,我们的Q函数**将在其Q表中搜索相应的值。**
+- 当训练完成后,**我们拥有一个最优Q函数,这意味着我们拥有最优Q表。**
+- 如果我们**拥有一个最优Q函数**,我们**就拥有一个最优策略**,因为我们**知道在每个状态下采取的最佳动作。**
+
+
+
+
+
+在开始时,**我们的Q表是没用的,因为它为每个状态-动作对给出了任意值**(大多数情况下,我们将Q表初始化为0)。随着智能体**探索环境并且我们更新Q表,它将给我们越来越好的近似**,接近最优策略。
+
+
+
+
+所以:Q函数使用一个Q表,**该表包含每个状态-动作对的值。**给定一个状态和动作,**我们的Q函数将在其Q表中搜索以输出相应的值。**
+
+
+
+
+
+总结一下,*Q-Learning* **是一种RL算法,它:**
+
+- 训练一个*Q函数*(一个**动作价值函数**),在内部是一个**包含所有状态-动作对值的Q表。**
+- 给定一个状态和动作,我们的Q函数**将在其Q表中搜索相应的值。**
+- 当训练完成后,**我们拥有一个最优Q函数,这意味着我们拥有最优Q表。**
+- 如果我们**拥有一个最优Q函数**,我们**就拥有一个最优策略**,因为我们**知道在每个状态下采取的最佳动作。**
+
+
+
+
+
+在开始时,**我们的Q表是没用的,因为它为每个状态-动作对给出了任意值**(大多数情况下,我们将Q表初始化为0)。随着智能体**探索环境并且我们更新Q表,它将给我们越来越好的近似**,接近最优策略。
+
+
+ + 我们在这里看到,通过训练,我们的Q表变得更好,因为借助它,我们可以知道每个状态-动作对的值。
+
+
+现在我们了解了什么是Q-Learning、Q函数和Q表,**让我们深入研究Q-Learning算法**。
+
+## Q-Learning算法 [[q-learning-algo]]
+
+这是Q-Learning的伪代码;让我们研究每个部分,**并在实现之前通过一个简单的例子来看看它是如何工作的。**不要被它吓到,它比看起来简单!我们将逐步讲解。
+
+
+
+### 步骤1:初始化Q表 [[step1]]
+
+
+ 我们在这里看到,通过训练,我们的Q表变得更好,因为借助它,我们可以知道每个状态-动作对的值。
+
+
+现在我们了解了什么是Q-Learning、Q函数和Q表,**让我们深入研究Q-Learning算法**。
+
+## Q-Learning算法 [[q-learning-algo]]
+
+这是Q-Learning的伪代码;让我们研究每个部分,**并在实现之前通过一个简单的例子来看看它是如何工作的。**不要被它吓到,它比看起来简单!我们将逐步讲解。
+
+
+
+### 步骤1:初始化Q表 [[step1]]
+
+ +
+
+我们需要为每个状态-动作对初始化Q表。**大多数情况下,我们初始化为0值。**
+
+### 步骤2:使用epsilon贪婪策略选择动作 [[step2]]
+
+
+
+
+epsilon贪婪策略是一种处理探索/利用权衡的策略。
+
+其思想是,初始值ɛ = 1.0:
+
+- *以概率1 — ɛ*:我们进行**利用**(即我们的智能体选择具有最高状态-动作对值的动作)。
+- 以概率ɛ:**我们进行探索**(尝试随机动作)。
+
+在训练开始时,**由于ɛ非常高,进行探索的概率将会很大,所以大多数时候,我们会探索。**但随着训练的进行,我们的**Q表在估计方面变得越来越好,我们逐渐降低epsilon值**,因为我们需要的探索越来越少,而需要更多的利用。
+
+
+
+
+我们需要为每个状态-动作对初始化Q表。**大多数情况下,我们初始化为0值。**
+
+### 步骤2:使用epsilon贪婪策略选择动作 [[step2]]
+
+
+
+
+epsilon贪婪策略是一种处理探索/利用权衡的策略。
+
+其思想是,初始值ɛ = 1.0:
+
+- *以概率1 — ɛ*:我们进行**利用**(即我们的智能体选择具有最高状态-动作对值的动作)。
+- 以概率ɛ:**我们进行探索**(尝试随机动作)。
+
+在训练开始时,**由于ɛ非常高,进行探索的概率将会很大,所以大多数时候,我们会探索。**但随着训练的进行,我们的**Q表在估计方面变得越来越好,我们逐渐降低epsilon值**,因为我们需要的探索越来越少,而需要更多的利用。
+
+ +
+
+### 步骤3:执行动作At,获取奖励Rt+1和下一个状态St+1 [[step3]]
+
+
+
+
+### 步骤3:执行动作At,获取奖励Rt+1和下一个状态St+1 [[step3]]
+
+ +
+### 步骤4:更新Q(St, At) [[step4]]
+
+记住,在TD学习中,我们在交互的**一个步骤之后**更新我们的策略或价值函数(取决于我们选择的RL方法)。
+
+为了产生我们的TD目标,**我们使用即时奖励\\(R_{t+1}\\)加上下一个状态的折扣值**,通过在下一个状态找到使当前Q函数最大化的动作来计算。(我们称之为自举)。
+
+
+
+### 步骤4:更新Q(St, At) [[step4]]
+
+记住,在TD学习中,我们在交互的**一个步骤之后**更新我们的策略或价值函数(取决于我们选择的RL方法)。
+
+为了产生我们的TD目标,**我们使用即时奖励\\(R_{t+1}\\)加上下一个状态的折扣值**,通过在下一个状态找到使当前Q函数最大化的动作来计算。(我们称之为自举)。
+
+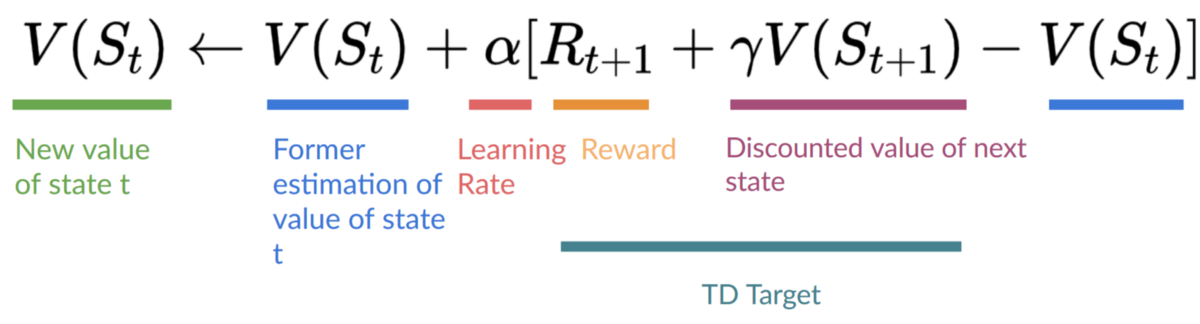 +
+因此,我们的\\(Q(S_t, A_t)\\) **更新公式如下:**
+
+
+
+因此,我们的\\(Q(S_t, A_t)\\) **更新公式如下:**
+
+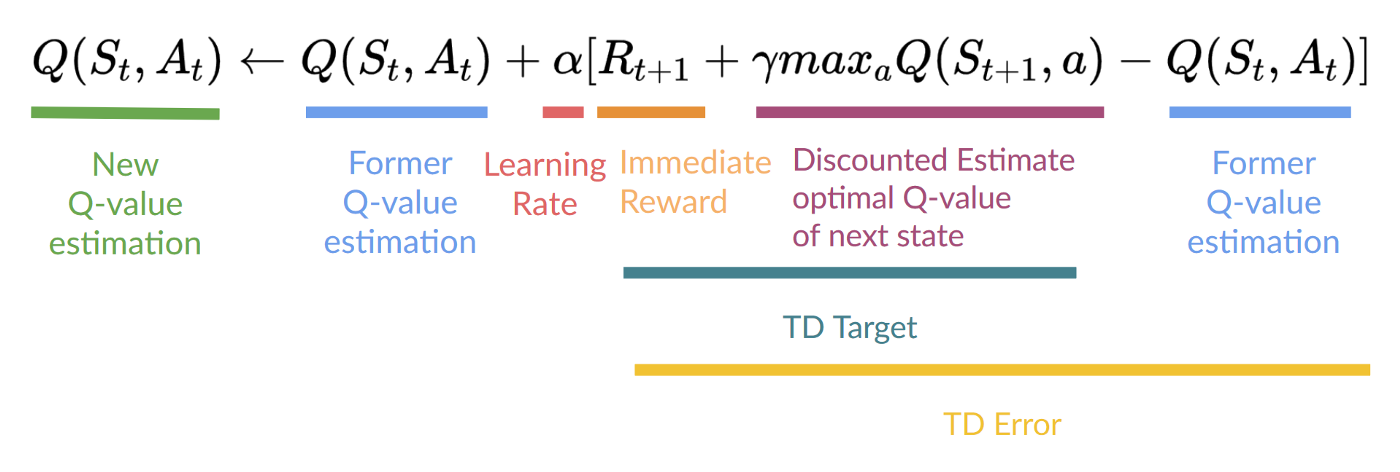 +
+
+
+这意味着要更新我们的\\(Q(S_t, A_t)\\):
+
+- 我们需要\\(S_t, A_t, R_{t+1}, S_{t+1}\\)。
+- 要更新给定状态-动作对的Q值,我们使用TD目标。
+
+我们如何形成TD目标?
+1. 我们在采取动作\\(A_t\\)后获得奖励\\(R_{t+1}\\)。
+2. 为了获得下一个状态的**最佳状态-动作对值**,我们使用贪婪策略选择下一个最佳动作。请注意,这不是epsilon贪婪策略,它将始终选择具有最高状态-动作值的动作。
+
+然后,当这个Q值的更新完成后,我们在新的状态开始,并**再次使用epsilon贪婪策略**选择我们的动作。
+
+**这就是为什么我们说Q Learning是一种离策略算法。**
+
+## 离策略与在策略 [[off-vs-on]]
+
+区别很微妙:
+
+- *离策略*:使用**不同的策略进行行动(推理)和更新(训练)。**
+
+例如,对于Q-Learning,epsilon贪婪策略(行动策略)与用于选择最佳下一状态动作值以更新我们的Q值的贪婪策略(更新策略)不同。
+
+
+
+
+
+
+
+这意味着要更新我们的\\(Q(S_t, A_t)\\):
+
+- 我们需要\\(S_t, A_t, R_{t+1}, S_{t+1}\\)。
+- 要更新给定状态-动作对的Q值,我们使用TD目标。
+
+我们如何形成TD目标?
+1. 我们在采取动作\\(A_t\\)后获得奖励\\(R_{t+1}\\)。
+2. 为了获得下一个状态的**最佳状态-动作对值**,我们使用贪婪策略选择下一个最佳动作。请注意,这不是epsilon贪婪策略,它将始终选择具有最高状态-动作值的动作。
+
+然后,当这个Q值的更新完成后,我们在新的状态开始,并**再次使用epsilon贪婪策略**选择我们的动作。
+
+**这就是为什么我们说Q Learning是一种离策略算法。**
+
+## 离策略与在策略 [[off-vs-on]]
+
+区别很微妙:
+
+- *离策略*:使用**不同的策略进行行动(推理)和更新(训练)。**
+
+例如,对于Q-Learning,epsilon贪婪策略(行动策略)与用于选择最佳下一状态动作值以更新我们的Q值的贪婪策略(更新策略)不同。
+
+
+
+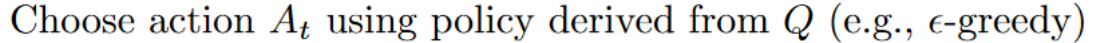 + 行动策略
+
+
+与我们在训练部分使用的策略不同:
+
+
+
+
+ 行动策略
+
+
+与我们在训练部分使用的策略不同:
+
+
+
+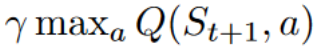 + 更新策略
+
+
+- *在策略:* 使用**相同的策略进行行动和更新。**
+
+例如,对于Sarsa,另一种基于价值的算法,**epsilon贪婪策略选择下一个状态-动作对,而不是贪婪策略。**
+
+
+
+
+ 更新策略
+
+
+- *在策略:* 使用**相同的策略进行行动和更新。**
+
+例如,对于Sarsa,另一种基于价值的算法,**epsilon贪婪策略选择下一个状态-动作对,而不是贪婪策略。**
+
+
+
+ + Sarsa
+
+
+
+
+
diff --git a/units/cn/unit2/quiz2.mdx b/units/cn/unit2/quiz2.mdx
new file mode 100644
index 00000000..02667e52
--- /dev/null
+++ b/units/cn/unit2/quiz2.mdx
@@ -0,0 +1,96 @@
+# 第二次测验 [[quiz2]]
+
+学习的最佳方式,也是[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法,**就是测试自己。**这将帮助你找出**需要加强知识的地方**。
+
+
+### 问题1:什么是Q-Learning?
+
+
+
+
+### 问题2:什么是Q表?
+
+
+
+### 问题3:为什么如果我们有一个最优Q函数Q*,我们就有一个最优策略?
+
+
+ Sarsa
+
+
+
+
+
diff --git a/units/cn/unit2/quiz2.mdx b/units/cn/unit2/quiz2.mdx
new file mode 100644
index 00000000..02667e52
--- /dev/null
+++ b/units/cn/unit2/quiz2.mdx
@@ -0,0 +1,96 @@
+# 第二次测验 [[quiz2]]
+
+学习的最佳方式,也是[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法,**就是测试自己。**这将帮助你找出**需要加强知识的地方**。
+
+
+### 问题1:什么是Q-Learning?
+
+
+
+
+### 问题2:什么是Q表?
+
+
+
+### 问题3:为什么如果我们有一个最优Q函数Q*,我们就有一个最优策略?
+
+
+解答
+
+因为如果我们有一个最优Q函数,我们就有一个最优策略,因为我们知道对于每个状态,最佳的动作是什么。
+
+
+
+
+
+### 问题4:你能解释什么是Epsilon贪婪策略吗?
+
+
+解答
+Epsilon贪婪策略是一种处理探索/利用权衡的策略。
+
+其思想是我们定义epsilon ɛ = 1.0:
+
+- 以*概率1 — ɛ*:我们进行利用(即我们的智能体选择具有最高状态-动作对值的动作)。
+- 以*概率ɛ*:我们进行探索(尝试随机动作)。
+
+
+
+
+
+
+### 问题5:我们如何更新状态-动作对的Q值?
+ +
+
+
+
+解答
+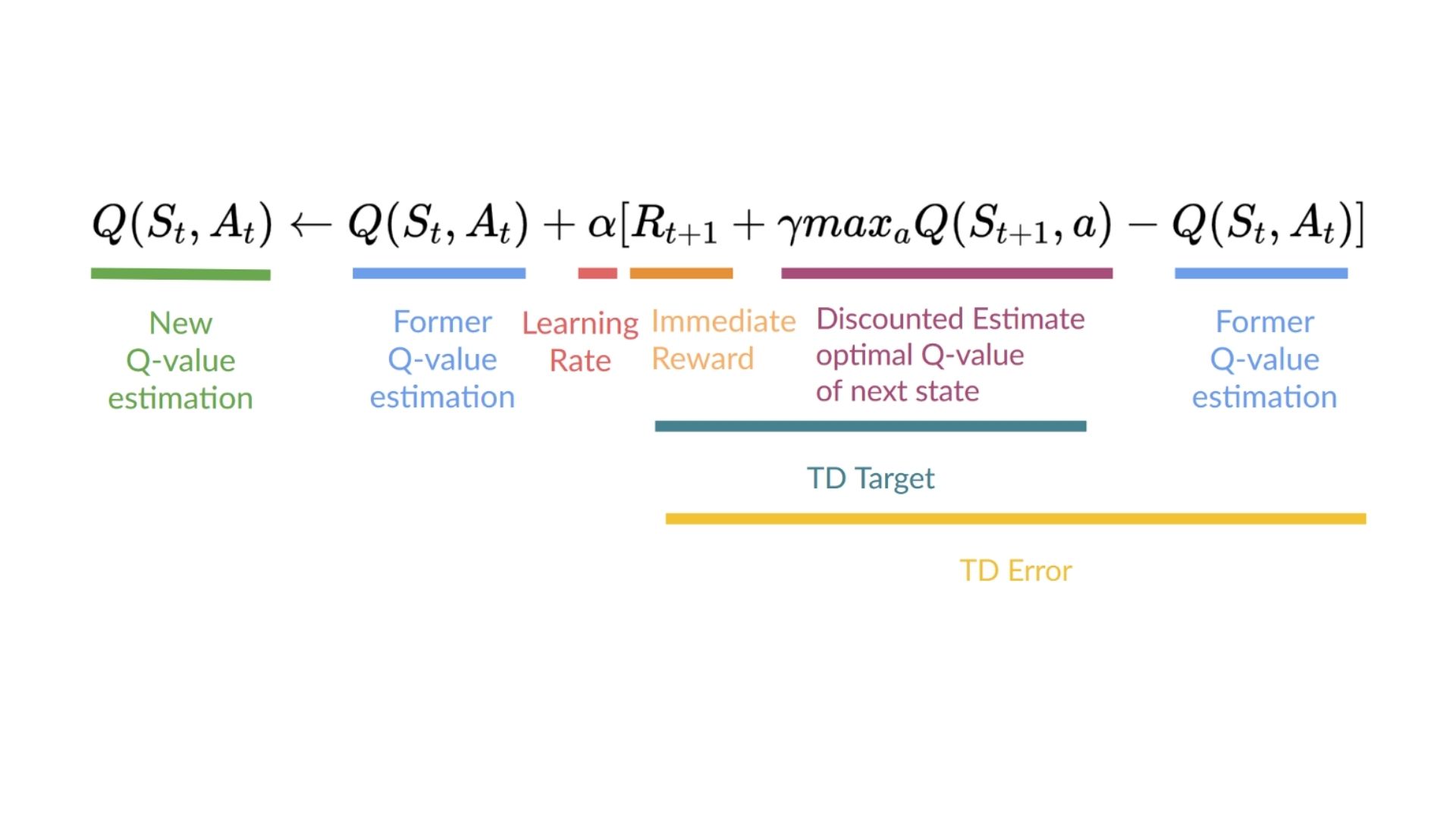 +
+
+
+
+
+
+
+### 问题6:在策略和离策略的区别是什么
+
+
+解答
+
+
+
+恭喜你完成这个测验 🥳,如果你错过了一些要点,请花时间重新阅读前面的章节,以加强(😏)你的知识。
diff --git a/units/cn/unit2/two-types-value-based-methods.mdx b/units/cn/unit2/two-types-value-based-methods.mdx
new file mode 100644
index 00000000..06f5f5fa
--- /dev/null
+++ b/units/cn/unit2/two-types-value-based-methods.mdx
@@ -0,0 +1,85 @@
+# 基于价值的方法的两种类型 [[two-types-value-based-methods]]
+
+在基于价值的方法中,**我们学习一个价值函数**,它**将状态映射到处于该状态的预期价值。**
+
+ +
+状态的价值是**智能体如果从该状态开始,然后按照我们的策略行动所能获得的预期折扣回报。**
+
+
+但是,按照我们的策略行动是什么意思呢?毕竟,在基于价值的方法中,我们没有策略,因为我们训练的是价值函数而不是策略。
+
+
+记住,**RL智能体的目标是找到最优策略π\*。**
+
+为了找到最优策略,我们学习了两种不同的方法:
+
+- *基于策略的方法:* **直接训练策略**,以选择给定状态下应采取的动作(或在该状态下动作的概率分布)。在这种情况下,我们**没有价值函数。**
+
+
+
+状态的价值是**智能体如果从该状态开始,然后按照我们的策略行动所能获得的预期折扣回报。**
+
+
+但是,按照我们的策略行动是什么意思呢?毕竟,在基于价值的方法中,我们没有策略,因为我们训练的是价值函数而不是策略。
+
+
+记住,**RL智能体的目标是找到最优策略π\*。**
+
+为了找到最优策略,我们学习了两种不同的方法:
+
+- *基于策略的方法:* **直接训练策略**,以选择给定状态下应采取的动作(或在该状态下动作的概率分布)。在这种情况下,我们**没有价值函数。**
+
+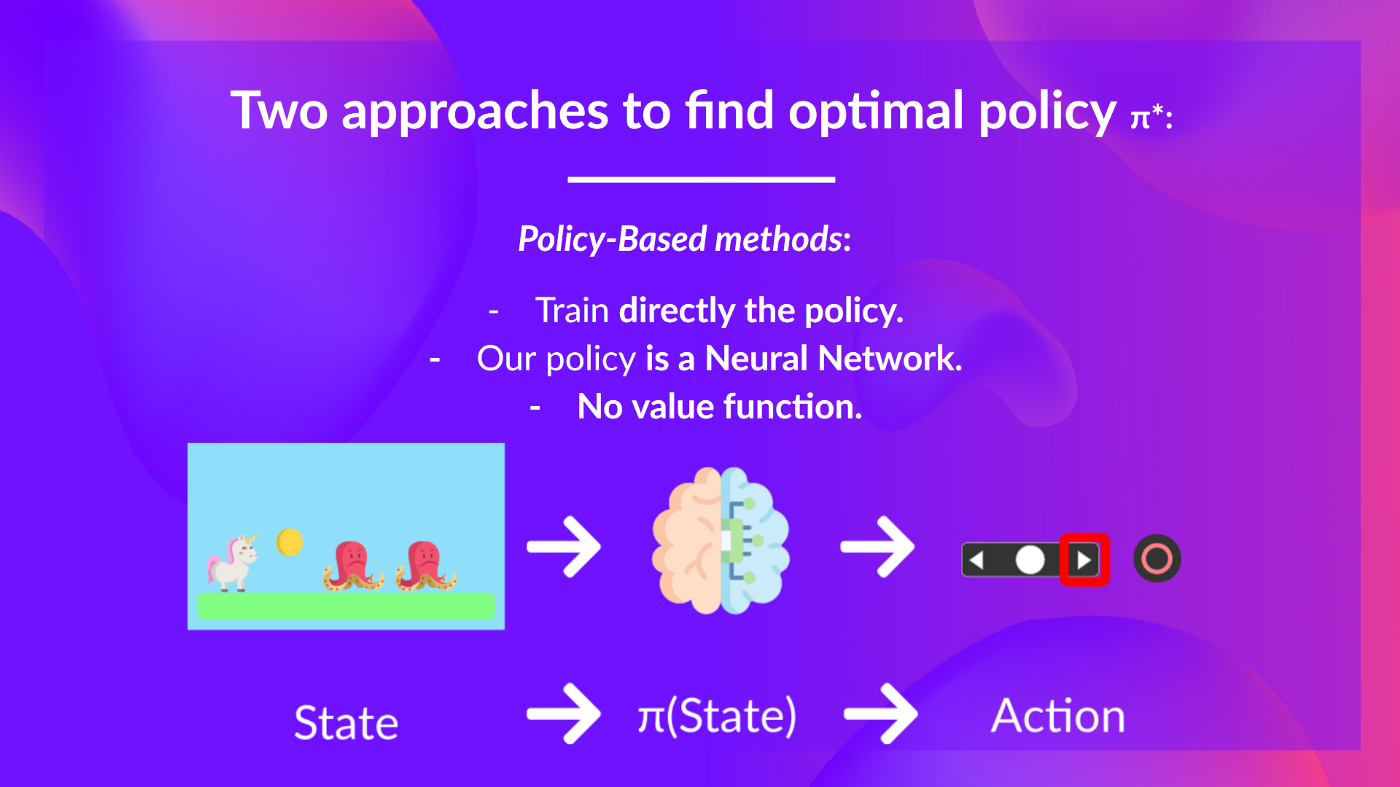 +
+策略以状态作为输入,并输出在该状态下应采取的动作(确定性策略:输出给定状态下的一个动作的策略,与输出动作概率分布的随机策略相反)。
+
+因此,**我们不手动定义策略的行为;是训练过程定义它。**
+
+- *基于价值的方法:* **间接地,通过训练一个价值函数**,输出状态或状态-动作对的价值。给定这个价值函数,我们的策略**将采取行动。**
+
+由于策略没有被训练/学习,**我们需要指定其行为。**例如,如果我们想要一个策略,给定价值函数,总是采取导致最大奖励的动作,**我们将创建一个贪婪策略。**
+
+
+
+
+策略以状态作为输入,并输出在该状态下应采取的动作(确定性策略:输出给定状态下的一个动作的策略,与输出动作概率分布的随机策略相反)。
+
+因此,**我们不手动定义策略的行为;是训练过程定义它。**
+
+- *基于价值的方法:* **间接地,通过训练一个价值函数**,输出状态或状态-动作对的价值。给定这个价值函数,我们的策略**将采取行动。**
+
+由于策略没有被训练/学习,**我们需要指定其行为。**例如,如果我们想要一个策略,给定价值函数,总是采取导致最大奖励的动作,**我们将创建一个贪婪策略。**
+
+
+  + 给定一个状态,我们的动作价值函数(我们训练的)输出该状态下每个动作的价值。然后,我们预定义的贪婪策略选择给定状态或状态-动作对下产生最高价值的动作。
+
+
+因此,无论你使用哪种方法来解决问题,**你都会有一个策略**。在基于价值的方法中,你不训练策略:你的策略**只是一个简单的预先指定的函数**(例如,贪婪策略),它使用价值函数给出的值来选择其动作。
+
+所以区别是:
+
+- 在基于策略的训练中,**通过直接训练策略找到最优策略(表示为π\*)。**
+- 在基于价值的训练中,**找到一个最优价值函数(表示为Q\*或V\*,我们将在下面研究区别)导致拥有一个最优策略。**
+
+
+
+事实上,在基于价值的方法中,大多数时候,你会使用**Epsilon贪婪策略**,它处理探索/利用权衡;我们将在本单元第二部分讨论Q-Learning时谈论这一点。
+
+
+正如我们上面提到的,我们有两种类型的基于价值的函数:
+
+## 状态价值函数 [[state-value-function]]
+
+我们这样写策略π下的状态价值函数:
+
+
+ 给定一个状态,我们的动作价值函数(我们训练的)输出该状态下每个动作的价值。然后,我们预定义的贪婪策略选择给定状态或状态-动作对下产生最高价值的动作。
+
+
+因此,无论你使用哪种方法来解决问题,**你都会有一个策略**。在基于价值的方法中,你不训练策略:你的策略**只是一个简单的预先指定的函数**(例如,贪婪策略),它使用价值函数给出的值来选择其动作。
+
+所以区别是:
+
+- 在基于策略的训练中,**通过直接训练策略找到最优策略(表示为π\*)。**
+- 在基于价值的训练中,**找到一个最优价值函数(表示为Q\*或V\*,我们将在下面研究区别)导致拥有一个最优策略。**
+
+
+
+事实上,在基于价值的方法中,大多数时候,你会使用**Epsilon贪婪策略**,它处理探索/利用权衡;我们将在本单元第二部分讨论Q-Learning时谈论这一点。
+
+
+正如我们上面提到的,我们有两种类型的基于价值的函数:
+
+## 状态价值函数 [[state-value-function]]
+
+我们这样写策略π下的状态价值函数:
+
+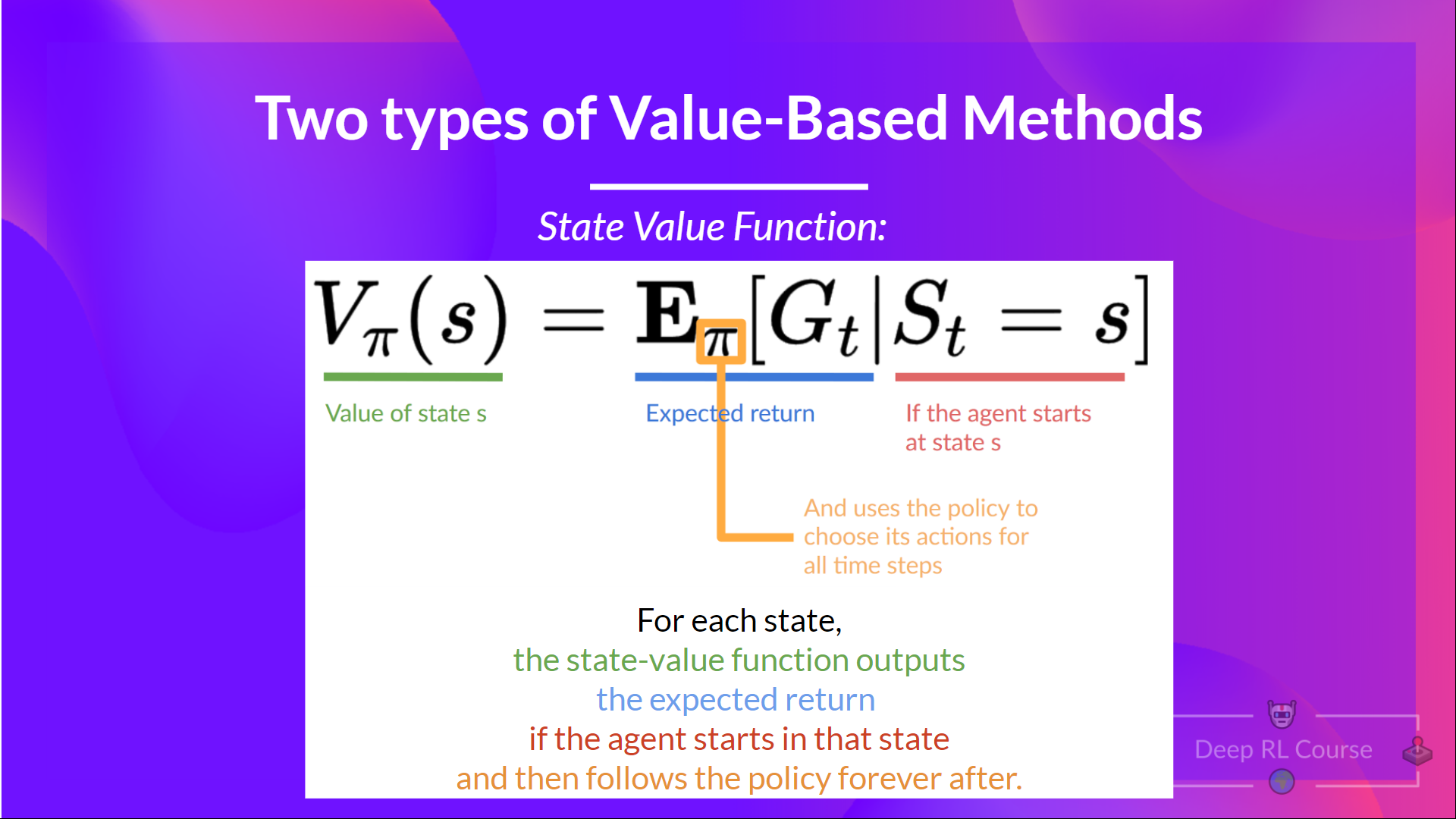 +
+对于每个状态,状态价值函数输出如果智能体**从该状态开始**,然后永远按照策略行动(如果你喜欢,对于所有未来时间步)所能获得的预期回报。
+
+
+
+
+对于每个状态,状态价值函数输出如果智能体**从该状态开始**,然后永远按照策略行动(如果你喜欢,对于所有未来时间步)所能获得的预期回报。
+
+
+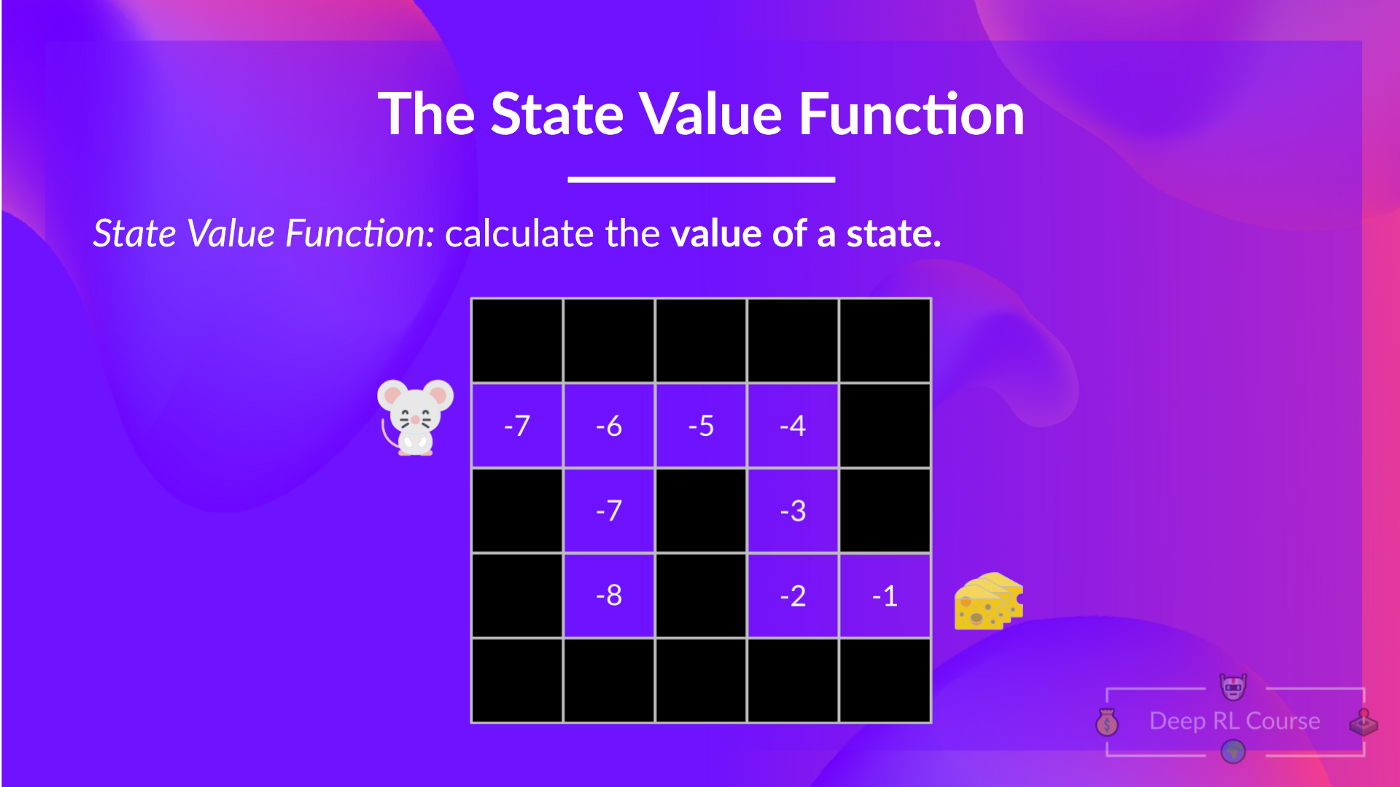 + 如果我们取值为-7的状态:这是从该状态开始并按照我们的策略(贪婪策略)采取行动所能获得的预期回报,即右、右、右、下、下、右、右。
+
+
+## 动作价值函数 [[action-value-function]]
+
+在动作价值函数中,对于每个状态和动作对,动作价值函数**输出预期回报**,如果智能体从该状态开始,采取该动作,然后永远按照策略行动。
+
+在策略\\(π\\)下,在状态\\(s\\)采取动作\\(a\\)的价值是:
+
+
+ 如果我们取值为-7的状态:这是从该状态开始并按照我们的策略(贪婪策略)采取行动所能获得的预期回报,即右、右、右、下、下、右、右。
+
+
+## 动作价值函数 [[action-value-function]]
+
+在动作价值函数中,对于每个状态和动作对,动作价值函数**输出预期回报**,如果智能体从该状态开始,采取该动作,然后永远按照策略行动。
+
+在策略\\(π\\)下,在状态\\(s\\)采取动作\\(a\\)的价值是:
+
+ +
+ +
+
+我们看到区别是:
+
+- 对于状态价值函数,我们计算**状态\\(S_t\\)的价值**
+- 对于动作价值函数,我们计算**状态-动作对(\\(S_t, A_t\\))的价值,因此是在该状态采取该动作的价值。**
+
+
+
+
+
+我们看到区别是:
+
+- 对于状态价值函数,我们计算**状态\\(S_t\\)的价值**
+- 对于动作价值函数,我们计算**状态-动作对(\\(S_t, A_t\\))的价值,因此是在该状态采取该动作的价值。**
+
+
+ 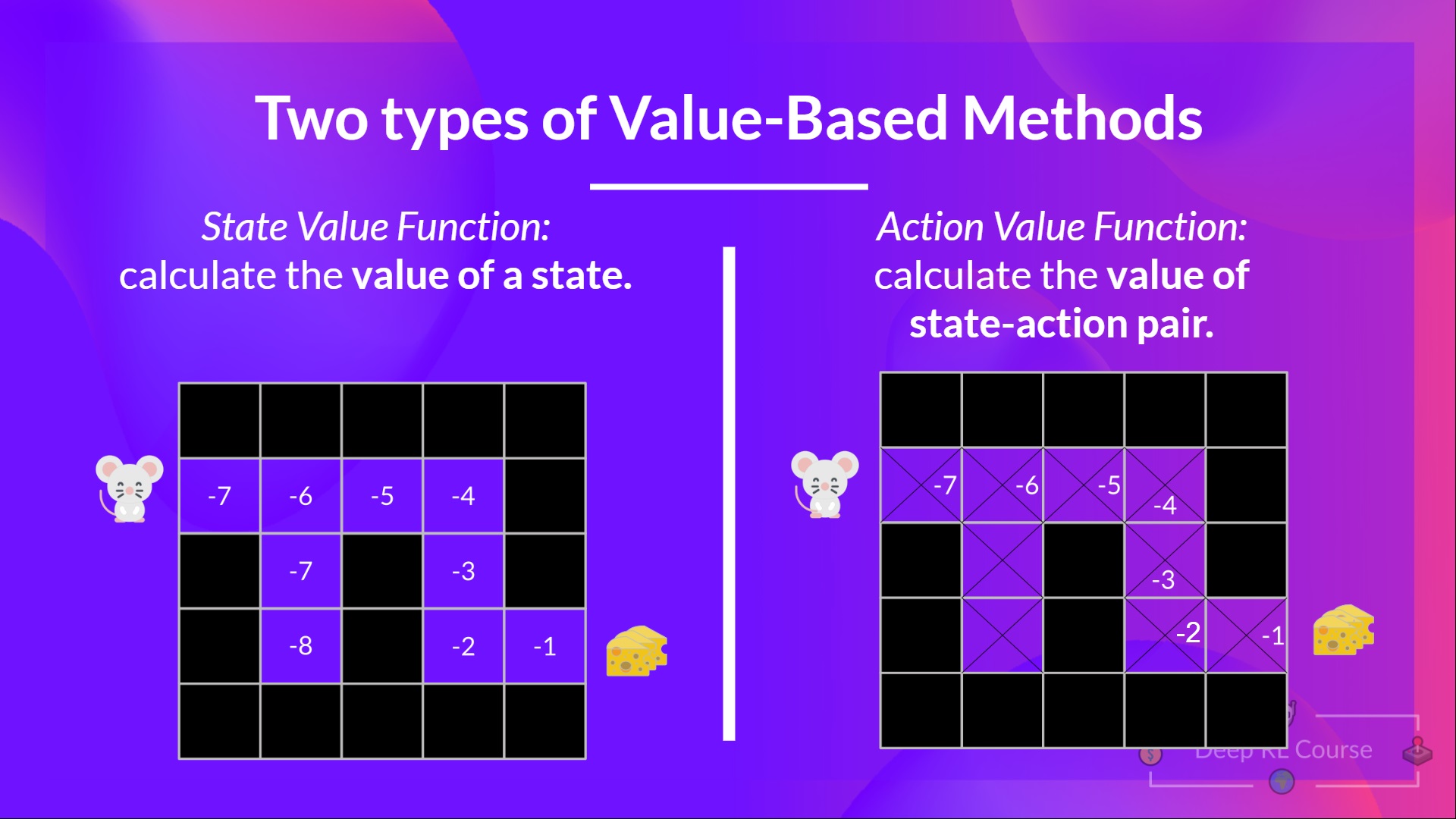 + 注意:我们没有填写动作价值函数示例的所有状态-动作对
+
+
+无论我们选择哪种价值函数(状态价值或动作价值函数),**返回的值都是预期回报。**
+
+然而,问题是**要计算状态或状态-动作对的每个值,我们需要对智能体从该状态开始可能获得的所有奖励进行求和。**
+
+这可能是一个计算成本高昂的过程,**这就是贝尔曼方程的用武之地。**
diff --git a/units/cn/unit2/what-is-rl.mdx b/units/cn/unit2/what-is-rl.mdx
new file mode 100644
index 00000000..ae02b85e
--- /dev/null
+++ b/units/cn/unit2/what-is-rl.mdx
@@ -0,0 +1,25 @@
+# 什么是RL?简短回顾 [[what-is-rl]]
+
+在RL中,我们构建一个能够**做出智能决策**的智能体。例如,一个**学习玩视频游戏的智能体。**或者一个交易智能体,通过决定**购买什么股票以及何时出售**来**学习最大化其收益。**
+
+
+ 注意:我们没有填写动作价值函数示例的所有状态-动作对
+
+
+无论我们选择哪种价值函数(状态价值或动作价值函数),**返回的值都是预期回报。**
+
+然而,问题是**要计算状态或状态-动作对的每个值,我们需要对智能体从该状态开始可能获得的所有奖励进行求和。**
+
+这可能是一个计算成本高昂的过程,**这就是贝尔曼方程的用武之地。**
diff --git a/units/cn/unit2/what-is-rl.mdx b/units/cn/unit2/what-is-rl.mdx
new file mode 100644
index 00000000..ae02b85e
--- /dev/null
+++ b/units/cn/unit2/what-is-rl.mdx
@@ -0,0 +1,25 @@
+# 什么是RL?简短回顾 [[what-is-rl]]
+
+在RL中,我们构建一个能够**做出智能决策**的智能体。例如,一个**学习玩视频游戏的智能体。**或者一个交易智能体,通过决定**购买什么股票以及何时出售**来**学习最大化其收益。**
+
+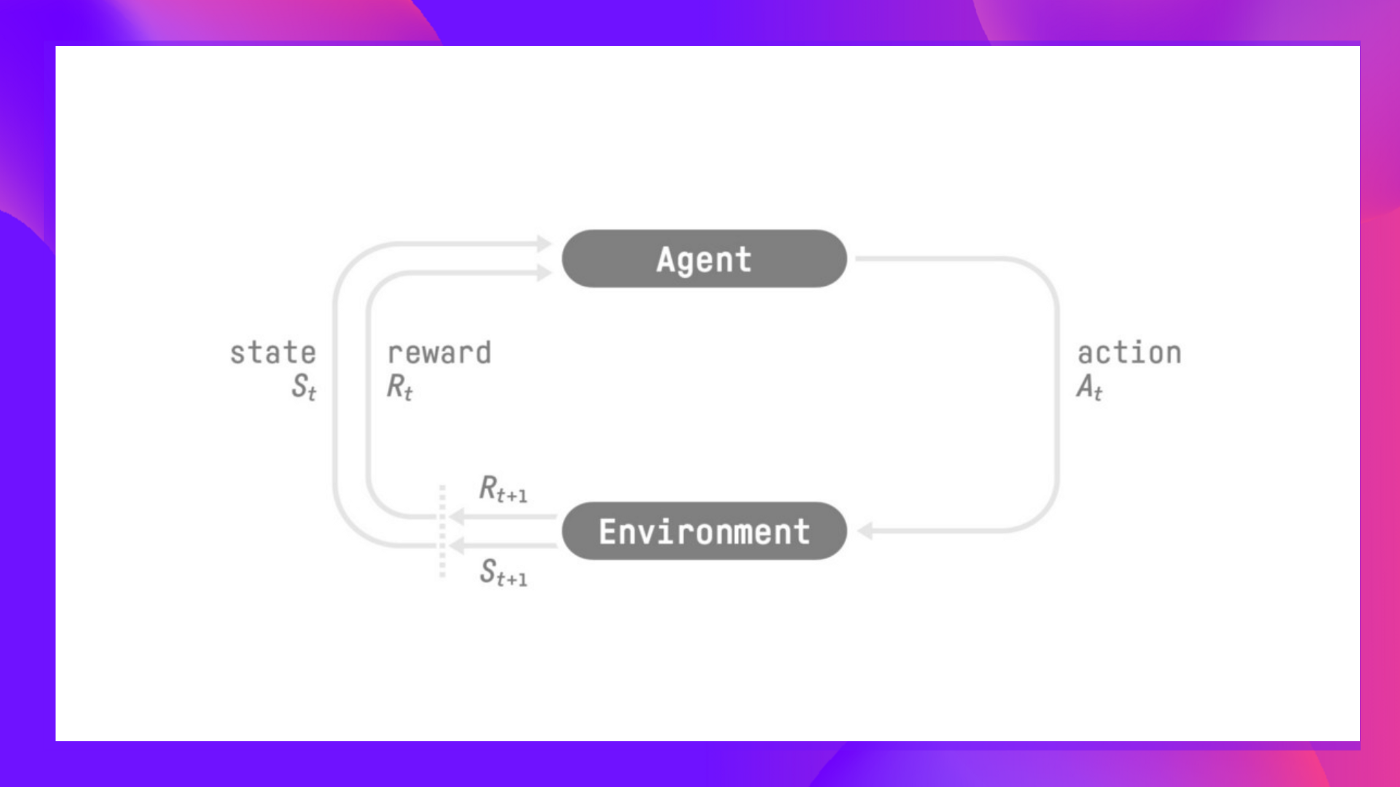 +
+
+为了做出智能决策,我们的智能体将通过**与环境进行试错交互**并接收奖励(正面或负面)**作为唯一反馈**来从环境中学习。
+
+其目标**是最大化其预期累积奖励**(因为奖励假设)。
+
+**智能体的决策过程称为策略π:**给定一个状态,策略将输出一个动作或动作的概率分布。也就是说,给定环境的观察,策略将提供智能体应该采取的动作(或每个动作的多个概率)。
+
+
+
+
+为了做出智能决策,我们的智能体将通过**与环境进行试错交互**并接收奖励(正面或负面)**作为唯一反馈**来从环境中学习。
+
+其目标**是最大化其预期累积奖励**(因为奖励假设)。
+
+**智能体的决策过程称为策略π:**给定一个状态,策略将输出一个动作或动作的概率分布。也就是说,给定环境的观察,策略将提供智能体应该采取的动作(或每个动作的多个概率)。
+
+ +
+**我们的目标是找到一个最优策略π* **,即一个能够带来最佳预期累积奖励的策略。
+
+为了找到这个最优策略(从而解决RL问题),**有两种主要类型的RL方法**:
+
+- *基于策略的方法*:**直接训练策略**,学习给定状态下应采取的动作。
+- *基于价值的方法*:**训练一个价值函数**,学习**哪个状态更有价值**,并使用这个价值函数**采取导向它的动作。**
+
+
+
+**我们的目标是找到一个最优策略π* **,即一个能够带来最佳预期累积奖励的策略。
+
+为了找到这个最优策略(从而解决RL问题),**有两种主要类型的RL方法**:
+
+- *基于策略的方法*:**直接训练策略**,学习给定状态下应采取的动作。
+- *基于价值的方法*:**训练一个价值函数**,学习**哪个状态更有价值**,并使用这个价值函数**采取导向它的动作。**
+
+ +
+在本单元中,**我们将深入研究基于价值的方法。**
diff --git a/units/cn/unit3/additional-readings.mdx b/units/cn/unit3/additional-readings.mdx
new file mode 100644
index 00000000..c09ed8dd
--- /dev/null
+++ b/units/cn/unit3/additional-readings.mdx
@@ -0,0 +1,9 @@
+# 扩展阅读 [[additional-readings]]
+
+以下是**可选阅读材料**,如果你想深入了解更多内容。
+
+- [深度强化学习基础系列,L2 深度Q学习,Pieter Abbeel主讲](https://youtu.be/Psrhxy88zww)
+- [使用深度强化学习玩Atari游戏](https://arxiv.org/abs/1312.5602)
+- [双深度Q学习](https://papers.nips.cc/paper/2010/hash/091d584fced301b442654dd8c23b3fc9-Abstract.html)
+- [优先经验回放](https://arxiv.org/abs/1511.05952)
+- [决斗深度Q学习](https://arxiv.org/abs/1511.06581)
diff --git a/units/cn/unit3/conclusion.mdx b/units/cn/unit3/conclusion.mdx
new file mode 100644
index 00000000..c4142667
--- /dev/null
+++ b/units/cn/unit3/conclusion.mdx
@@ -0,0 +1,17 @@
+# 总结 [[conclusion]]
+
+恭喜你完成本章!这里包含了大量信息。同时恭喜你完成了教程。你刚刚训练了你的第一个深度Q学习智能体并将其分享到Hub上 🥳。
+
+在继续之前,请花时间真正理解这些材料。
+
+不要犹豫,在其他环境中训练你的智能体(Pong、Seaquest、QBert、吃豆人女士)。**学习的最好方式是自己尝试!**
+
+
+
+
+在下一单元中,**我们将学习Optuna**。深度强化学习中最关键的任务之一是找到一组好的训练超参数。Optuna是一个帮助你自动化搜索的库。
+
+最后,我们非常希望**听到你对课程的看法以及我们如何改进它**。如果你有任何反馈,请 👉 [填写此表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 持续学习,保持精彩 🤗
+
diff --git a/units/cn/unit3/deep-q-algorithm.mdx b/units/cn/unit3/deep-q-algorithm.mdx
new file mode 100644
index 00000000..0f9defd4
--- /dev/null
+++ b/units/cn/unit3/deep-q-algorithm.mdx
@@ -0,0 +1,105 @@
+# 深度Q学习算法 [[deep-q-algorithm]]
+
+我们了解到深度Q学习**使用深度神经网络来近似在某个状态下每个可能动作的不同Q值**(价值函数估计)。
+
+与Q学习的区别在于,在训练阶段,我们不是像Q学习那样直接更新状态-动作对的Q值:
+
+
+
+在深度Q学习中,我们创建一个**损失函数,比较我们的Q值预测和Q目标,并使用梯度下降来更新我们的深度Q网络的权重,以更好地近似我们的Q值**。
+
+
+
+在本单元中,**我们将深入研究基于价值的方法。**
diff --git a/units/cn/unit3/additional-readings.mdx b/units/cn/unit3/additional-readings.mdx
new file mode 100644
index 00000000..c09ed8dd
--- /dev/null
+++ b/units/cn/unit3/additional-readings.mdx
@@ -0,0 +1,9 @@
+# 扩展阅读 [[additional-readings]]
+
+以下是**可选阅读材料**,如果你想深入了解更多内容。
+
+- [深度强化学习基础系列,L2 深度Q学习,Pieter Abbeel主讲](https://youtu.be/Psrhxy88zww)
+- [使用深度强化学习玩Atari游戏](https://arxiv.org/abs/1312.5602)
+- [双深度Q学习](https://papers.nips.cc/paper/2010/hash/091d584fced301b442654dd8c23b3fc9-Abstract.html)
+- [优先经验回放](https://arxiv.org/abs/1511.05952)
+- [决斗深度Q学习](https://arxiv.org/abs/1511.06581)
diff --git a/units/cn/unit3/conclusion.mdx b/units/cn/unit3/conclusion.mdx
new file mode 100644
index 00000000..c4142667
--- /dev/null
+++ b/units/cn/unit3/conclusion.mdx
@@ -0,0 +1,17 @@
+# 总结 [[conclusion]]
+
+恭喜你完成本章!这里包含了大量信息。同时恭喜你完成了教程。你刚刚训练了你的第一个深度Q学习智能体并将其分享到Hub上 🥳。
+
+在继续之前,请花时间真正理解这些材料。
+
+不要犹豫,在其他环境中训练你的智能体(Pong、Seaquest、QBert、吃豆人女士)。**学习的最好方式是自己尝试!**
+
+
+
+
+在下一单元中,**我们将学习Optuna**。深度强化学习中最关键的任务之一是找到一组好的训练超参数。Optuna是一个帮助你自动化搜索的库。
+
+最后,我们非常希望**听到你对课程的看法以及我们如何改进它**。如果你有任何反馈,请 👉 [填写此表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 持续学习,保持精彩 🤗
+
diff --git a/units/cn/unit3/deep-q-algorithm.mdx b/units/cn/unit3/deep-q-algorithm.mdx
new file mode 100644
index 00000000..0f9defd4
--- /dev/null
+++ b/units/cn/unit3/deep-q-algorithm.mdx
@@ -0,0 +1,105 @@
+# 深度Q学习算法 [[deep-q-algorithm]]
+
+我们了解到深度Q学习**使用深度神经网络来近似在某个状态下每个可能动作的不同Q值**(价值函数估计)。
+
+与Q学习的区别在于,在训练阶段,我们不是像Q学习那样直接更新状态-动作对的Q值:
+
+
+
+在深度Q学习中,我们创建一个**损失函数,比较我们的Q值预测和Q目标,并使用梯度下降来更新我们的深度Q网络的权重,以更好地近似我们的Q值**。
+
+ +
+深度Q学习训练算法有*两个阶段*:
+
+- **采样**:我们执行动作并**将观察到的经验元组存储在回放记忆中**。
+- **训练**:随机选择一个**小批量的元组,并使用梯度下降更新步骤从这个批次中学习**。
+
+
+
+深度Q学习训练算法有*两个阶段*:
+
+- **采样**:我们执行动作并**将观察到的经验元组存储在回放记忆中**。
+- **训练**:随机选择一个**小批量的元组,并使用梯度下降更新步骤从这个批次中学习**。
+
+ +
+这与Q学习相比并不是唯一的区别。深度Q学习训练**可能会遇到不稳定性**,主要是因为结合了非线性Q值函数(神经网络)和自举(当我们用现有估计而不是实际完整回报更新目标时)。
+
+为了帮助我们稳定训练,我们实现了三种不同的解决方案:
+1. *经验回放*,以**更有效地利用经验**。
+2. *固定Q目标*,**以稳定训练**。
+3. *双深度Q学习*,以**处理Q值过高估计的问题**。
+
+让我们逐一了解它们!
+
+## 经验回放以更有效地利用经验 [[exp-replay]]
+
+为什么我们要创建回放记忆?
+
+深度Q学习中的经验回放有两个功能:
+
+1. **在训练期间更有效地利用经验**。
+通常,在在线强化学习中,智能体与环境交互,获取经验(状态、动作、奖励和下一个状态),从中学习(更新神经网络),然后丢弃它们。这不是很有效。
+
+经验回放通过**更有效地利用训练中的经验**来帮助。我们使用一个回放缓冲区,保存**我们可以在训练期间重复使用的经验样本**。
+
+
+这与Q学习相比并不是唯一的区别。深度Q学习训练**可能会遇到不稳定性**,主要是因为结合了非线性Q值函数(神经网络)和自举(当我们用现有估计而不是实际完整回报更新目标时)。
+
+为了帮助我们稳定训练,我们实现了三种不同的解决方案:
+1. *经验回放*,以**更有效地利用经验**。
+2. *固定Q目标*,**以稳定训练**。
+3. *双深度Q学习*,以**处理Q值过高估计的问题**。
+
+让我们逐一了解它们!
+
+## 经验回放以更有效地利用经验 [[exp-replay]]
+
+为什么我们要创建回放记忆?
+
+深度Q学习中的经验回放有两个功能:
+
+1. **在训练期间更有效地利用经验**。
+通常,在在线强化学习中,智能体与环境交互,获取经验(状态、动作、奖励和下一个状态),从中学习(更新神经网络),然后丢弃它们。这不是很有效。
+
+经验回放通过**更有效地利用训练中的经验**来帮助。我们使用一个回放缓冲区,保存**我们可以在训练期间重复使用的经验样本**。
+ +
+⇒ 这使得智能体能够**多次从相同的经验中学习**。
+
+2. **避免忘记以前的经验(也称为灾难性干扰或灾难性遗忘)并减少经验之间的相关性**。
+- **[灾难性遗忘](https://en.wikipedia.org/wiki/Catastrophic_interference)**:如果我们将连续的经验样本提供给我们的神经网络,我们会遇到的问题是,它倾向于**在获得新经验时忘记以前的经验**。例如,如果智能体在第一关,然后在不同的第二关,它可能会忘记如何在第一关中行为和游戏。
+
+解决方案是创建一个回放缓冲区,在与环境交互时存储经验元组,然后采样一小批元组。这防止了**网络只学习它刚刚做过的事情**。
+
+经验回放还有其他好处。通过随机采样经验,我们消除了观察序列中的相关性,避免了**动作值剧烈振荡或灾难性发散**。
+
+在深度Q学习伪代码中,我们**初始化一个容量为N的回放记忆缓冲区D**(N是你可以定义的超参数)。然后我们将经验存储在记忆中,并在训练阶段采样一批经验来馈送深度Q网络。
+
+
+
+⇒ 这使得智能体能够**多次从相同的经验中学习**。
+
+2. **避免忘记以前的经验(也称为灾难性干扰或灾难性遗忘)并减少经验之间的相关性**。
+- **[灾难性遗忘](https://en.wikipedia.org/wiki/Catastrophic_interference)**:如果我们将连续的经验样本提供给我们的神经网络,我们会遇到的问题是,它倾向于**在获得新经验时忘记以前的经验**。例如,如果智能体在第一关,然后在不同的第二关,它可能会忘记如何在第一关中行为和游戏。
+
+解决方案是创建一个回放缓冲区,在与环境交互时存储经验元组,然后采样一小批元组。这防止了**网络只学习它刚刚做过的事情**。
+
+经验回放还有其他好处。通过随机采样经验,我们消除了观察序列中的相关性,避免了**动作值剧烈振荡或灾难性发散**。
+
+在深度Q学习伪代码中,我们**初始化一个容量为N的回放记忆缓冲区D**(N是你可以定义的超参数)。然后我们将经验存储在记忆中,并在训练阶段采样一批经验来馈送深度Q网络。
+
+ +
+## 固定Q目标以稳定训练 [[fixed-q]]
+
+当我们想要计算TD误差(也称为损失)时,我们计算**TD目标(Q目标)和当前Q值(Q的估计)之间的差异**。
+
+但我们**对真实的TD目标没有任何概念**。我们需要估计它。使用贝尔曼方程,我们看到TD目标只是在该状态下采取该动作的奖励加上下一个状态的最高Q值的折扣。
+
+
+
+然而,问题是我们使用相同的参数(权重)来估计TD目标**和**Q值。因此,TD目标和我们正在改变的参数之间存在显著的相关性。
+
+因此,在训练的每一步,**我们的Q值和目标值都在变化**。我们正在接近我们的目标,但目标也在移动。这就像在追逐一个移动的目标!这可能导致训练中的显著振荡。
+
+这就像你是一个牛仔(Q估计),你想抓住一头牛(Q目标)。你的目标是靠近(减少误差)。
+
+
+
+## 固定Q目标以稳定训练 [[fixed-q]]
+
+当我们想要计算TD误差(也称为损失)时,我们计算**TD目标(Q目标)和当前Q值(Q的估计)之间的差异**。
+
+但我们**对真实的TD目标没有任何概念**。我们需要估计它。使用贝尔曼方程,我们看到TD目标只是在该状态下采取该动作的奖励加上下一个状态的最高Q值的折扣。
+
+
+
+然而,问题是我们使用相同的参数(权重)来估计TD目标**和**Q值。因此,TD目标和我们正在改变的参数之间存在显著的相关性。
+
+因此,在训练的每一步,**我们的Q值和目标值都在变化**。我们正在接近我们的目标,但目标也在移动。这就像在追逐一个移动的目标!这可能导致训练中的显著振荡。
+
+这就像你是一个牛仔(Q估计),你想抓住一头牛(Q目标)。你的目标是靠近(减少误差)。
+
+ +
+在每个时间步,你都试图接近牛,而牛在每个时间步也在移动(因为你使用相同的参数)。
+
+
+
+在每个时间步,你都试图接近牛,而牛在每个时间步也在移动(因为你使用相同的参数)。
+
+ +
+ +这导致了一条奇怪的追逐路径(训练中的显著振荡)。
+
+这导致了一条奇怪的追逐路径(训练中的显著振荡)。
+ +
+相反,我们在伪代码中看到的是:
+- 使用**具有固定参数的单独网络**来估计TD目标
+- **每C步从我们的深度Q网络复制参数**以更新目标网络。
+
+
+
+相反,我们在伪代码中看到的是:
+- 使用**具有固定参数的单独网络**来估计TD目标
+- **每C步从我们的深度Q网络复制参数**以更新目标网络。
+
+ +
+
+
+## 双DQN [[double-dqn]]
+
+双DQN,或双深度Q学习神经网络,是由[Hado van Hasselt](https://papers.nips.cc/paper/3964-double-q-learning)引入的。这种方法**处理Q值过高估计的问题**。
+
+要理解这个问题,请记住我们如何计算TD目标:
+
+
+
+通过计算TD目标,我们面临一个简单的问题:我们如何确定**下一个状态的最佳动作是具有最高Q值的动作?**
+
+我们知道Q值的准确性取决于我们尝试过的动作**和**我们探索过的相邻状态。
+
+因此,在训练开始时,我们没有足够的信息来确定最佳动作。因此,将最大Q值(这是有噪声的)作为最佳动作可能导致假阳性。如果非最优动作经常**被赋予比最优最佳动作更高的Q值,学习将变得复杂**。
+
+解决方案是:当我们计算Q目标时,我们使用两个网络来解耦动作选择和目标Q值生成。我们:
+- 使用我们的**DQN网络**选择下一个状态的最佳动作(具有最高Q值的动作)。
+- 使用我们的**目标网络**计算在下一个状态采取该动作的目标Q值。
+
+因此,双DQN帮助我们减少Q值的过高估计,因此帮助我们更快地训练,并获得更稳定的学习。
+
+自从深度Q学习中引入这三项改进以来,又增加了更多改进,如优先经验回放和决斗深度Q学习。它们超出了本课程的范围,但如果你感兴趣,请查看我们在阅读列表中提供的链接。
diff --git a/units/cn/unit3/deep-q-network.mdx b/units/cn/unit3/deep-q-network.mdx
new file mode 100644
index 00000000..77e41453
--- /dev/null
+++ b/units/cn/unit3/deep-q-network.mdx
@@ -0,0 +1,41 @@
+# 深度Q网络(DQN) [[deep-q-network]]
+这是我们深度Q学习网络的架构:
+
+
+
+
+
+## 双DQN [[double-dqn]]
+
+双DQN,或双深度Q学习神经网络,是由[Hado van Hasselt](https://papers.nips.cc/paper/3964-double-q-learning)引入的。这种方法**处理Q值过高估计的问题**。
+
+要理解这个问题,请记住我们如何计算TD目标:
+
+
+
+通过计算TD目标,我们面临一个简单的问题:我们如何确定**下一个状态的最佳动作是具有最高Q值的动作?**
+
+我们知道Q值的准确性取决于我们尝试过的动作**和**我们探索过的相邻状态。
+
+因此,在训练开始时,我们没有足够的信息来确定最佳动作。因此,将最大Q值(这是有噪声的)作为最佳动作可能导致假阳性。如果非最优动作经常**被赋予比最优最佳动作更高的Q值,学习将变得复杂**。
+
+解决方案是:当我们计算Q目标时,我们使用两个网络来解耦动作选择和目标Q值生成。我们:
+- 使用我们的**DQN网络**选择下一个状态的最佳动作(具有最高Q值的动作)。
+- 使用我们的**目标网络**计算在下一个状态采取该动作的目标Q值。
+
+因此,双DQN帮助我们减少Q值的过高估计,因此帮助我们更快地训练,并获得更稳定的学习。
+
+自从深度Q学习中引入这三项改进以来,又增加了更多改进,如优先经验回放和决斗深度Q学习。它们超出了本课程的范围,但如果你感兴趣,请查看我们在阅读列表中提供的链接。
diff --git a/units/cn/unit3/deep-q-network.mdx b/units/cn/unit3/deep-q-network.mdx
new file mode 100644
index 00000000..77e41453
--- /dev/null
+++ b/units/cn/unit3/deep-q-network.mdx
@@ -0,0 +1,41 @@
+# 深度Q网络(DQN) [[deep-q-network]]
+这是我们深度Q学习网络的架构:
+
+ +
+作为输入,我们将**4帧的堆叠**作为状态通过网络,并输出一个**向量,包含该状态下每个可能动作的Q值**。然后,就像Q学习一样,我们只需使用我们的epsilon-greedy策略来选择要采取的动作。
+
+当神经网络初始化时,**Q值估计非常糟糕**。但在训练过程中,我们的深度Q网络智能体将把情况与适当的动作联系起来,并**学会很好地玩游戏**。
+
+## 输入预处理和时间限制 [[preprocessing]]
+
+我们需要**预处理输入**。这是一个重要步骤,因为我们想**减少状态的复杂性,以减少训练所需的计算时间**。
+
+为了实现这一点,我们**将状态空间减少到84x84并转为灰度**。我们可以这样做,因为Atari环境中的颜色并不增加重要信息。
+这是一个很大的改进,因为我们**将三个颜色通道(RGB)减少到1个**。
+
+在某些游戏中,如果屏幕的某部分不包含重要信息,我们也可以**裁剪屏幕的一部分**。
+然后我们将四帧堆叠在一起。
+
+
+
+作为输入,我们将**4帧的堆叠**作为状态通过网络,并输出一个**向量,包含该状态下每个可能动作的Q值**。然后,就像Q学习一样,我们只需使用我们的epsilon-greedy策略来选择要采取的动作。
+
+当神经网络初始化时,**Q值估计非常糟糕**。但在训练过程中,我们的深度Q网络智能体将把情况与适当的动作联系起来,并**学会很好地玩游戏**。
+
+## 输入预处理和时间限制 [[preprocessing]]
+
+我们需要**预处理输入**。这是一个重要步骤,因为我们想**减少状态的复杂性,以减少训练所需的计算时间**。
+
+为了实现这一点,我们**将状态空间减少到84x84并转为灰度**。我们可以这样做,因为Atari环境中的颜色并不增加重要信息。
+这是一个很大的改进,因为我们**将三个颜色通道(RGB)减少到1个**。
+
+在某些游戏中,如果屏幕的某部分不包含重要信息,我们也可以**裁剪屏幕的一部分**。
+然后我们将四帧堆叠在一起。
+
+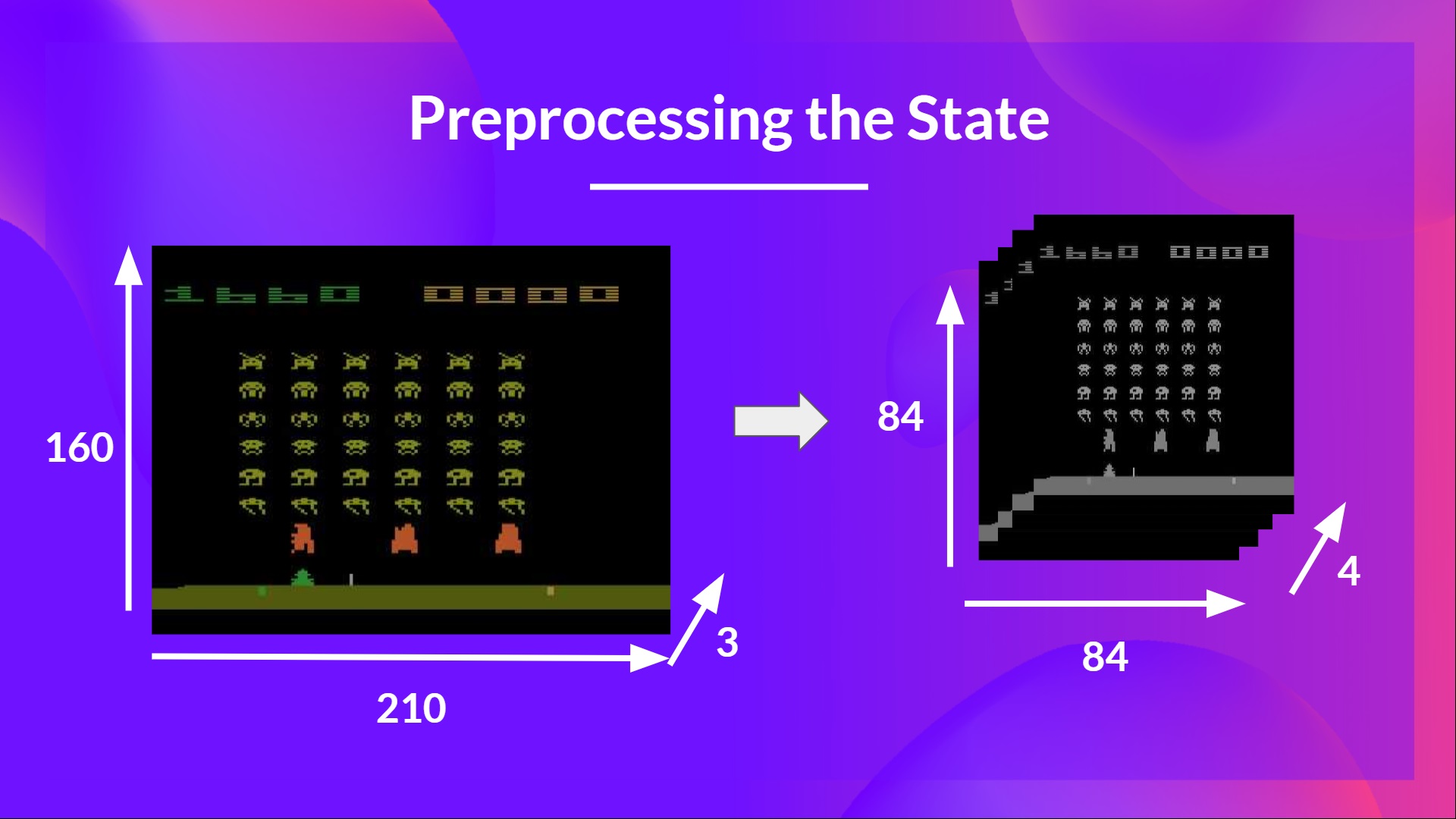 +
+**为什么我们要将四帧堆叠在一起?**
+我们将帧堆叠在一起是因为它帮助我们**处理时间限制问题**。让我们以Pong游戏为例。当你看到这一帧时:
+
+
+
+**为什么我们要将四帧堆叠在一起?**
+我们将帧堆叠在一起是因为它帮助我们**处理时间限制问题**。让我们以Pong游戏为例。当你看到这一帧时:
+
+ +
+你能告诉我球往哪个方向走吗?
+不能,因为一帧不足以感知运动!但如果我再添加三帧呢?**在这里你可以看到球正在向右移动**。
+
+
+
+你能告诉我球往哪个方向走吗?
+不能,因为一帧不足以感知运动!但如果我再添加三帧呢?**在这里你可以看到球正在向右移动**。
+
+ +这就是为什么为了捕捉时间信息,我们将四帧堆叠在一起。
+
+然后堆叠的帧由三个卷积层处理。这些层**允许我们捕捉和利用图像中的空间关系**。而且,由于帧是堆叠在一起的,**我们可以利用这些帧之间的一些时间属性**。
+
+如果你不知道什么是卷积层,不用担心。你可以查看[Udacity免费深度学习课程的第4课](https://www.udacity.com/course/deep-learning-pytorch--ud188)
+
+最后,我们有几个全连接层,输出该状态下每个可能动作的Q值。
+
+
+
+所以,我们看到深度Q学习使用神经网络来近似,给定一个状态,该状态下每个可能动作的不同Q值。现在让我们研究深度Q学习算法。
diff --git a/units/cn/unit3/from-q-to-dqn.mdx b/units/cn/unit3/from-q-to-dqn.mdx
new file mode 100644
index 00000000..d29d4698
--- /dev/null
+++ b/units/cn/unit3/from-q-to-dqn.mdx
@@ -0,0 +1,34 @@
+# 从Q学习到深度Q学习 [[from-q-to-dqn]]
+
+我们了解到**Q学习是一种用来训练Q函数的算法**,Q函数是一个**动作-价值函数**,它确定在特定状态下采取特定动作的价值。
+
+
+
+
+
+**Q来源于"该状态下该动作的质量(Quality)"。**
+
+在内部,我们的Q函数由**Q表编码,这是一个表格,其中每个单元格对应一个状态-动作对的值。** 把这个Q表想象为**我们Q函数的记忆或备忘单**。
+
+问题是Q学习是一种*表格方法*。如果状态和动作空间**不够小,无法通过数组和表格有效表示**,这就成为一个问题。换句话说:它**不具有可扩展性**。
+Q学习在小状态空间环境中表现良好,如:
+
+- FrozenLake,我们有16个状态。
+- Taxi-v3,我们有500个状态。
+
+但想想我们今天要做的事情:我们将训练一个智能体学习玩太空入侵者,这是一个更复杂的游戏,使用帧作为输入。
+
+正如**[Nikita Melkozerov提到的](https://twitter.com/meln1k),Atari环境**的观察空间形状为(210, 160, 3)*,包含从0到255的值,所以这给我们带来了\\(256^{210 \times 160 \times 3} = 256^{100800}\\)个可能的观察(相比之下,我们在可观测宇宙中大约有\\(10^{80}\\)个原子)。
+
+* Atari中的单个帧由210x160像素的图像组成。由于图像是彩色的(RGB),所以有3个通道。这就是为什么形状是(210, 160, 3)。对于每个像素,值可以从0到255。
+
+
+这就是为什么为了捕捉时间信息,我们将四帧堆叠在一起。
+
+然后堆叠的帧由三个卷积层处理。这些层**允许我们捕捉和利用图像中的空间关系**。而且,由于帧是堆叠在一起的,**我们可以利用这些帧之间的一些时间属性**。
+
+如果你不知道什么是卷积层,不用担心。你可以查看[Udacity免费深度学习课程的第4课](https://www.udacity.com/course/deep-learning-pytorch--ud188)
+
+最后,我们有几个全连接层,输出该状态下每个可能动作的Q值。
+
+
+
+所以,我们看到深度Q学习使用神经网络来近似,给定一个状态,该状态下每个可能动作的不同Q值。现在让我们研究深度Q学习算法。
diff --git a/units/cn/unit3/from-q-to-dqn.mdx b/units/cn/unit3/from-q-to-dqn.mdx
new file mode 100644
index 00000000..d29d4698
--- /dev/null
+++ b/units/cn/unit3/from-q-to-dqn.mdx
@@ -0,0 +1,34 @@
+# 从Q学习到深度Q学习 [[from-q-to-dqn]]
+
+我们了解到**Q学习是一种用来训练Q函数的算法**,Q函数是一个**动作-价值函数**,它确定在特定状态下采取特定动作的价值。
+
+
+
+
+
+**Q来源于"该状态下该动作的质量(Quality)"。**
+
+在内部,我们的Q函数由**Q表编码,这是一个表格,其中每个单元格对应一个状态-动作对的值。** 把这个Q表想象为**我们Q函数的记忆或备忘单**。
+
+问题是Q学习是一种*表格方法*。如果状态和动作空间**不够小,无法通过数组和表格有效表示**,这就成为一个问题。换句话说:它**不具有可扩展性**。
+Q学习在小状态空间环境中表现良好,如:
+
+- FrozenLake,我们有16个状态。
+- Taxi-v3,我们有500个状态。
+
+但想想我们今天要做的事情:我们将训练一个智能体学习玩太空入侵者,这是一个更复杂的游戏,使用帧作为输入。
+
+正如**[Nikita Melkozerov提到的](https://twitter.com/meln1k),Atari环境**的观察空间形状为(210, 160, 3)*,包含从0到255的值,所以这给我们带来了\\(256^{210 \times 160 \times 3} = 256^{100800}\\)个可能的观察(相比之下,我们在可观测宇宙中大约有\\(10^{80}\\)个原子)。
+
+* Atari中的单个帧由210x160像素的图像组成。由于图像是彩色的(RGB),所以有3个通道。这就是为什么形状是(210, 160, 3)。对于每个像素,值可以从0到255。
+
+ +
+因此,状态空间是巨大的;由于这一点,为该环境创建和更新Q表将不会是有效的。在这种情况下,最好的想法是使用参数化Q函数\\(Q_{\theta}(s,a)\\)来近似Q值。
+
+这个神经网络将近似,给定一个状态,该状态下每个可能动作的不同Q值。这正是深度Q学习所做的。
+
+
+
+
+现在我们理解了深度Q学习,让我们深入了解深度Q网络。
diff --git a/units/cn/unit3/glossary.mdx b/units/cn/unit3/glossary.mdx
new file mode 100644
index 00000000..ab30fa7d
--- /dev/null
+++ b/units/cn/unit3/glossary.mdx
@@ -0,0 +1,37 @@
+# 术语表
+
+这是一个社区创建的术语表。欢迎贡献!
+
+- **表格方法:** 一种问题类型,其中状态和动作空间小到足以使用数组和表格来表示近似值函数。
+**Q学习**是表格方法的一个例子,因为使用表格来表示不同状态-动作对的值。
+
+- **深度Q学习:** 一种训练神经网络的方法,用于近似给定状态下,该状态的不同可能动作的**Q值**。
+当观察空间太大而无法应用表格Q学习方法时使用。
+
+- **时间限制** 是当环境状态由帧表示时出现的一个困难。单独一帧本身不提供时间信息。
+为了获取时间信息,我们需要将多个帧**堆叠**在一起。
+
+- **深度Q学习的阶段:**
+ - **采样:** 执行动作,并将观察到的经验元组存储在**回放记忆**中。
+ - **训练:** 随机选择元组批次,神经网络使用梯度下降更新其权重。
+
+- **稳定深度Q学习的解决方案:**
+ - **经验回放:** 创建一个回放记忆来保存可以在训练期间重复使用的经验样本。
+ 这允许智能体多次从相同的经验中学习。此外,它帮助智能体在获取新经验时避免忘记以前的经验。
+ - **从回放缓冲区随机采样** 允许消除观察序列中的相关性,防止动作值剧烈振荡或灾难性发散。
+
+ - **固定Q目标:** 为了计算**Q目标**,我们需要使用贝尔曼方程估计下一个状态的折扣最优**Q值**。问题
+ 是相同的网络权重被用来计算**Q目标**和**Q值**。这意味着每次我们修改**Q值**时,**Q目标**也随之移动。
+ 为了避免这个问题,使用一个具有固定参数的单独网络来估计时间差分目标。目标网络通过在特定的**C步**后从
+ 我们的深度Q网络复制参数来更新。
+
+ - **双DQN:** 处理**Q值过高估计**的方法。这个解决方案使用两个网络来解耦动作选择和目标**值生成**:
+ - **DQN网络** 用于选择下一个状态的最佳动作(具有最高**Q值**的动作)
+ - **目标网络** 用于计算在下一个状态采取该动作的目标**Q值**。
+这种方法减少了**Q值**的过高估计,它有助于更快地训练并获得更稳定的学习。
+
+如果你想改进课程,你可以[开启一个拉取请求。](https://github.com/huggingface/deep-rl-class/pulls)
+
+这个术语表的实现要感谢:
+
+- [Dario Paez](https://github.com/dario248)
diff --git a/units/cn/unit3/hands-on.mdx b/units/cn/unit3/hands-on.mdx
new file mode 100644
index 00000000..0154ad6a
--- /dev/null
+++ b/units/cn/unit3/hands-on.mdx
@@ -0,0 +1,341 @@
+# 实践练习 [[hands-on]]
+
+
+
+
+
+
+现在你已经学习了深度Q-Learning的理论,**你已经准备好训练你的深度Q-Learning智能体来玩Atari游戏了**。我们将从太空入侵者开始,但你可以使用任何你想要的Atari游戏 🔥
+
+
+
+
+我们使用的是[RL-Baselines-3 Zoo集成](https://github.com/DLR-RM/rl-baselines3-zoo),这是一个原始版本的深度Q-Learning,没有诸如Double-DQN、Dueling-DQN或优先经验回放等扩展。
+
+另外,**如果你想在这个实践练习之后学习自己实现深度Q-Learning**,你绝对应该看看CleanRL的实现:https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/dqn_atari.py
+
+为了在认证过程中验证这个实践练习,你需要将你训练好的模型推送到Hub并**获得 >= 200的结果**。
+
+要找到你的结果,请前往排行榜并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+**如果你找不到你的模型,请滚动到页面底部并点击刷新按钮。**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+你可以在这里查看你的进度 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+
+
+**要开始实践练习,请点击"在Colab中打开"按钮** 👇:
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit3/unit3.ipynb)
+
+# 第3单元:使用RL Baselines3 Zoo在Atari游戏中实现深度Q-Learning 👾
+
+
+
+因此,状态空间是巨大的;由于这一点,为该环境创建和更新Q表将不会是有效的。在这种情况下,最好的想法是使用参数化Q函数\\(Q_{\theta}(s,a)\\)来近似Q值。
+
+这个神经网络将近似,给定一个状态,该状态下每个可能动作的不同Q值。这正是深度Q学习所做的。
+
+
+
+
+现在我们理解了深度Q学习,让我们深入了解深度Q网络。
diff --git a/units/cn/unit3/glossary.mdx b/units/cn/unit3/glossary.mdx
new file mode 100644
index 00000000..ab30fa7d
--- /dev/null
+++ b/units/cn/unit3/glossary.mdx
@@ -0,0 +1,37 @@
+# 术语表
+
+这是一个社区创建的术语表。欢迎贡献!
+
+- **表格方法:** 一种问题类型,其中状态和动作空间小到足以使用数组和表格来表示近似值函数。
+**Q学习**是表格方法的一个例子,因为使用表格来表示不同状态-动作对的值。
+
+- **深度Q学习:** 一种训练神经网络的方法,用于近似给定状态下,该状态的不同可能动作的**Q值**。
+当观察空间太大而无法应用表格Q学习方法时使用。
+
+- **时间限制** 是当环境状态由帧表示时出现的一个困难。单独一帧本身不提供时间信息。
+为了获取时间信息,我们需要将多个帧**堆叠**在一起。
+
+- **深度Q学习的阶段:**
+ - **采样:** 执行动作,并将观察到的经验元组存储在**回放记忆**中。
+ - **训练:** 随机选择元组批次,神经网络使用梯度下降更新其权重。
+
+- **稳定深度Q学习的解决方案:**
+ - **经验回放:** 创建一个回放记忆来保存可以在训练期间重复使用的经验样本。
+ 这允许智能体多次从相同的经验中学习。此外,它帮助智能体在获取新经验时避免忘记以前的经验。
+ - **从回放缓冲区随机采样** 允许消除观察序列中的相关性,防止动作值剧烈振荡或灾难性发散。
+
+ - **固定Q目标:** 为了计算**Q目标**,我们需要使用贝尔曼方程估计下一个状态的折扣最优**Q值**。问题
+ 是相同的网络权重被用来计算**Q目标**和**Q值**。这意味着每次我们修改**Q值**时,**Q目标**也随之移动。
+ 为了避免这个问题,使用一个具有固定参数的单独网络来估计时间差分目标。目标网络通过在特定的**C步**后从
+ 我们的深度Q网络复制参数来更新。
+
+ - **双DQN:** 处理**Q值过高估计**的方法。这个解决方案使用两个网络来解耦动作选择和目标**值生成**:
+ - **DQN网络** 用于选择下一个状态的最佳动作(具有最高**Q值**的动作)
+ - **目标网络** 用于计算在下一个状态采取该动作的目标**Q值**。
+这种方法减少了**Q值**的过高估计,它有助于更快地训练并获得更稳定的学习。
+
+如果你想改进课程,你可以[开启一个拉取请求。](https://github.com/huggingface/deep-rl-class/pulls)
+
+这个术语表的实现要感谢:
+
+- [Dario Paez](https://github.com/dario248)
diff --git a/units/cn/unit3/hands-on.mdx b/units/cn/unit3/hands-on.mdx
new file mode 100644
index 00000000..0154ad6a
--- /dev/null
+++ b/units/cn/unit3/hands-on.mdx
@@ -0,0 +1,341 @@
+# 实践练习 [[hands-on]]
+
+
+
+
+
+
+现在你已经学习了深度Q-Learning的理论,**你已经准备好训练你的深度Q-Learning智能体来玩Atari游戏了**。我们将从太空入侵者开始,但你可以使用任何你想要的Atari游戏 🔥
+
+
+
+
+我们使用的是[RL-Baselines-3 Zoo集成](https://github.com/DLR-RM/rl-baselines3-zoo),这是一个原始版本的深度Q-Learning,没有诸如Double-DQN、Dueling-DQN或优先经验回放等扩展。
+
+另外,**如果你想在这个实践练习之后学习自己实现深度Q-Learning**,你绝对应该看看CleanRL的实现:https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/dqn_atari.py
+
+为了在认证过程中验证这个实践练习,你需要将你训练好的模型推送到Hub并**获得 >= 200的结果**。
+
+要找到你的结果,请前往排行榜并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+**如果你找不到你的模型,请滚动到页面底部并点击刷新按钮。**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+你可以在这里查看你的进度 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+
+
+**要开始实践练习,请点击"在Colab中打开"按钮** 👇:
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit3/unit3.ipynb)
+
+# 第3单元:使用RL Baselines3 Zoo在Atari游戏中实现深度Q-Learning 👾
+
+ +
+在这个实践练习中,**你将训练一个深度Q-Learning智能体**,使用[RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)玩太空入侵者,这是一个基于[Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/)的训练框架,提供了训练、评估智能体、调整超参数、绘制结果和录制视频的脚本。
+
+我们使用的是[RL-Baselines-3 Zoo集成,这是一个原始版本的深度Q-Learning](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html),没有诸如Double-DQN、Dueling-DQN和优先经验回放等扩展。
+
+### 🎮 环境:
+
+- [SpacesInvadersNoFrameskip-v4](https://gymnasium.farama.org/environments/atari/space_invaders/)
+
+你可以在这里看到太空入侵者版本之间的区别 👉 https://gymnasium.farama.org/environments/atari/space_invaders/#variants
+
+### 📚 RL库:
+
+- [RL-Baselines3-Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)
+
+## 本实践练习的目标 🏆
+
+在完成实践练习后,你将:
+- 能够更深入地**理解RL Baselines3 Zoo的工作原理**。
+- 能够**将你训练好的智能体和代码推送到Hub**,附带精美的视频回放和评估分数 🔥。
+
+## 先决条件 🏗️
+
+在深入学习实践练习之前,你需要:
+
+🔲 📚 **[通过阅读第3单元学习深度Q-Learning](https://huggingface.co/deep-rl-course/unit3/introduction)** 🤗
+
+我们一直在努力改进我们的教程,所以**如果你在这个实践练习中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+# 让我们训练一个玩Atari太空入侵者的深度Q-Learning智能体 👾 并将其上传到Hub。
+
+我们强烈建议学生**使用Google Colab进行实践练习,而不是在个人电脑上运行它们**。
+
+通过使用Google Colab,**你可以专注于学习和实验,而不必担心设置环境的技术方面**。
+
+为了在认证过程中验证这个实践练习,你需要将你训练好的模型推送到Hub并**获得 >= 200的结果**。
+
+要找到你的结果,请前往排行榜并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。为此,请前往`Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+# 安装RL-Baselines3 Zoo及其依赖项 📚
+
+如果你看到`ERROR: pip's dependency resolver does not currently take into account all the packages that are installed.` **这是正常的,不是严重错误**,只是版本冲突。但我们需要的包已经安装。
+
+```python
+# 现在我们安装RL-Baselines3 Zoo的这个更新
+pip install git+https://github.com/DLR-RM/rl-baselines3-zoo
+```
+
+```bash
+apt-get install swig cmake ffmpeg
+```
+
+为了能够在Gymnasium中使用Atari游戏,我们需要安装atari包。并使用accept-rom-license来下载rom文件(游戏文件)。
+
+```python
+!pip install gymnasium[atari]
+!pip install gymnasium[accept-rom-license]
+```
+
+## 创建虚拟显示器 🔽
+
+在实践练习中,我们需要生成回放视频。为此,如果你在无头机器上训练,**我们需要有一个虚拟屏幕来能够渲染环境**(并因此记录帧)。
+
+因此,以下单元将安装库并创建并运行虚拟屏幕 🖥
+
+```bash
+apt install python-opengl
+apt install ffmpeg
+apt install xvfb
+pip3 install pyvirtualdisplay
+```
+
+```python
+# 虚拟显示器
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## 训练我们的深度Q-Learning智能体来玩太空入侵者 👾
+
+要使用RL-Baselines3-Zoo训练智能体,我们只需要做两件事:
+
+1. 创建一个包含我们训练超参数的超参数配置文件,称为`dqn.yml`。
+
+这是一个模板示例:
+
+```
+SpaceInvadersNoFrameskip-v4:
+ env_wrapper:
+ - stable_baselines3.common.atari_wrappers.AtariWrapper
+ frame_stack: 4
+ policy: 'CnnPolicy'
+ n_timesteps: !!float 1e7
+ buffer_size: 100000
+ learning_rate: !!float 1e-4
+ batch_size: 32
+ learning_starts: 100000
+ target_update_interval: 1000
+ train_freq: 4
+ gradient_steps: 1
+ exploration_fraction: 0.1
+ exploration_final_eps: 0.01
+ # 如果为True,你需要在replay_buffer_kwargs中停用handle_timeout_termination
+ optimize_memory_usage: False
+```
+
+在这里我们看到:
+- 我们使用`Atari Wrapper`,它预处理输入(帧减少,灰度,堆叠4帧)
+- 我们使用`CnnPolicy`,因为我们使用卷积层来处理帧
+- 我们训练它1000万个`n_timesteps`
+- 内存(经验回放)大小为100000,即你保存用来再次训练你的智能体的经验步骤数量。
+
+💡 我的建议是**将训练时间步数减少到1M**,这在P100上大约需要90分钟。`!nvidia-smi`将告诉你使用的是什么GPU。在1000万步时,这将需要大约9小时。我建议在你的本地计算机(或其他地方)上运行。只需点击:`File>Download`。
+
+在超参数优化方面,我的建议是专注于这3个超参数:
+- `learning_rate`
+- `buffer_size(经验内存大小)`
+- `batch_size`
+
+作为一个好习惯,你需要**查看文档以了解每个超参数的作用**:https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html#parameters
+
+
+
+2. 我们开始训练并将模型保存在`logs`文件夹中 📁
+
+- 在`--algo`后定义算法,在`-f`后定义保存模型的位置,在`-c`后定义超参数配置的位置。
+
+```bash
+python -m rl_zoo3.train --algo ________ --env SpaceInvadersNoFrameskip-v4 -f _________ -c _________
+```
+
+#### 解决方案
+
+```bash
+python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -c dqn.yml
+```
+
+## 让我们评估我们的智能体 👀
+
+- RL-Baselines3-Zoo提供了`enjoy.py`,一个用于评估我们的智能体的Python脚本。在大多数RL库中,我们称评估脚本为`enjoy.py`。
+- 让我们评估它5000个时间步 🔥
+
+```bash
+python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 --no-render --n-timesteps _________ --folder logs/
+```
+
+#### 解决方案
+
+```bash
+python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 --no-render --n-timesteps 5000 --folder logs/
+```
+
+## 在Hub上发布我们训练好的模型 🚀
+现在我们看到训练后获得了良好的结果,我们可以用一行代码将我们训练好的模型发布到hub 🤗。
+
+
+
+在这个实践练习中,**你将训练一个深度Q-Learning智能体**,使用[RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)玩太空入侵者,这是一个基于[Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/)的训练框架,提供了训练、评估智能体、调整超参数、绘制结果和录制视频的脚本。
+
+我们使用的是[RL-Baselines-3 Zoo集成,这是一个原始版本的深度Q-Learning](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html),没有诸如Double-DQN、Dueling-DQN和优先经验回放等扩展。
+
+### 🎮 环境:
+
+- [SpacesInvadersNoFrameskip-v4](https://gymnasium.farama.org/environments/atari/space_invaders/)
+
+你可以在这里看到太空入侵者版本之间的区别 👉 https://gymnasium.farama.org/environments/atari/space_invaders/#variants
+
+### 📚 RL库:
+
+- [RL-Baselines3-Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)
+
+## 本实践练习的目标 🏆
+
+在完成实践练习后,你将:
+- 能够更深入地**理解RL Baselines3 Zoo的工作原理**。
+- 能够**将你训练好的智能体和代码推送到Hub**,附带精美的视频回放和评估分数 🔥。
+
+## 先决条件 🏗️
+
+在深入学习实践练习之前,你需要:
+
+🔲 📚 **[通过阅读第3单元学习深度Q-Learning](https://huggingface.co/deep-rl-course/unit3/introduction)** 🤗
+
+我们一直在努力改进我们的教程,所以**如果你在这个实践练习中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+# 让我们训练一个玩Atari太空入侵者的深度Q-Learning智能体 👾 并将其上传到Hub。
+
+我们强烈建议学生**使用Google Colab进行实践练习,而不是在个人电脑上运行它们**。
+
+通过使用Google Colab,**你可以专注于学习和实验,而不必担心设置环境的技术方面**。
+
+为了在认证过程中验证这个实践练习,你需要将你训练好的模型推送到Hub并**获得 >= 200的结果**。
+
+要找到你的结果,请前往排行榜并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。为此,请前往`Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+# 安装RL-Baselines3 Zoo及其依赖项 📚
+
+如果你看到`ERROR: pip's dependency resolver does not currently take into account all the packages that are installed.` **这是正常的,不是严重错误**,只是版本冲突。但我们需要的包已经安装。
+
+```python
+# 现在我们安装RL-Baselines3 Zoo的这个更新
+pip install git+https://github.com/DLR-RM/rl-baselines3-zoo
+```
+
+```bash
+apt-get install swig cmake ffmpeg
+```
+
+为了能够在Gymnasium中使用Atari游戏,我们需要安装atari包。并使用accept-rom-license来下载rom文件(游戏文件)。
+
+```python
+!pip install gymnasium[atari]
+!pip install gymnasium[accept-rom-license]
+```
+
+## 创建虚拟显示器 🔽
+
+在实践练习中,我们需要生成回放视频。为此,如果你在无头机器上训练,**我们需要有一个虚拟屏幕来能够渲染环境**(并因此记录帧)。
+
+因此,以下单元将安装库并创建并运行虚拟屏幕 🖥
+
+```bash
+apt install python-opengl
+apt install ffmpeg
+apt install xvfb
+pip3 install pyvirtualdisplay
+```
+
+```python
+# 虚拟显示器
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## 训练我们的深度Q-Learning智能体来玩太空入侵者 👾
+
+要使用RL-Baselines3-Zoo训练智能体,我们只需要做两件事:
+
+1. 创建一个包含我们训练超参数的超参数配置文件,称为`dqn.yml`。
+
+这是一个模板示例:
+
+```
+SpaceInvadersNoFrameskip-v4:
+ env_wrapper:
+ - stable_baselines3.common.atari_wrappers.AtariWrapper
+ frame_stack: 4
+ policy: 'CnnPolicy'
+ n_timesteps: !!float 1e7
+ buffer_size: 100000
+ learning_rate: !!float 1e-4
+ batch_size: 32
+ learning_starts: 100000
+ target_update_interval: 1000
+ train_freq: 4
+ gradient_steps: 1
+ exploration_fraction: 0.1
+ exploration_final_eps: 0.01
+ # 如果为True,你需要在replay_buffer_kwargs中停用handle_timeout_termination
+ optimize_memory_usage: False
+```
+
+在这里我们看到:
+- 我们使用`Atari Wrapper`,它预处理输入(帧减少,灰度,堆叠4帧)
+- 我们使用`CnnPolicy`,因为我们使用卷积层来处理帧
+- 我们训练它1000万个`n_timesteps`
+- 内存(经验回放)大小为100000,即你保存用来再次训练你的智能体的经验步骤数量。
+
+💡 我的建议是**将训练时间步数减少到1M**,这在P100上大约需要90分钟。`!nvidia-smi`将告诉你使用的是什么GPU。在1000万步时,这将需要大约9小时。我建议在你的本地计算机(或其他地方)上运行。只需点击:`File>Download`。
+
+在超参数优化方面,我的建议是专注于这3个超参数:
+- `learning_rate`
+- `buffer_size(经验内存大小)`
+- `batch_size`
+
+作为一个好习惯,你需要**查看文档以了解每个超参数的作用**:https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html#parameters
+
+
+
+2. 我们开始训练并将模型保存在`logs`文件夹中 📁
+
+- 在`--algo`后定义算法,在`-f`后定义保存模型的位置,在`-c`后定义超参数配置的位置。
+
+```bash
+python -m rl_zoo3.train --algo ________ --env SpaceInvadersNoFrameskip-v4 -f _________ -c _________
+```
+
+#### 解决方案
+
+```bash
+python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -c dqn.yml
+```
+
+## 让我们评估我们的智能体 👀
+
+- RL-Baselines3-Zoo提供了`enjoy.py`,一个用于评估我们的智能体的Python脚本。在大多数RL库中,我们称评估脚本为`enjoy.py`。
+- 让我们评估它5000个时间步 🔥
+
+```bash
+python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 --no-render --n-timesteps _________ --folder logs/
+```
+
+#### 解决方案
+
+```bash
+python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 --no-render --n-timesteps 5000 --folder logs/
+```
+
+## 在Hub上发布我们训练好的模型 🚀
+现在我们看到训练后获得了良好的结果,我们可以用一行代码将我们训练好的模型发布到hub 🤗。
+
+ +
+通过使用`rl_zoo3.push_to_hub`,**你可以评估、记录回放、生成智能体的模型卡片并将其推送到hub**。
+
+这样:
+- 你可以**展示我们的工作** 🔥
+- 你可以**可视化你的智能体的游戏过程** 👀
+- 你可以**与社区分享一个其他人可以使用的智能体** 💾
+- 你可以**访问排行榜 🏆 来看看你的智能体与同学相比表现如何** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+要能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果还没有完成)在HF创建一个账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录,然后,你需要从Hugging Face网站存储你的认证令牌。
+- 创建一个新令牌(https://huggingface.co/settings/tokens)**具有写入角色**
+
+
+
+- 复制令牌
+- 运行下面的单元并粘贴令牌
+
+```bash
+from huggingface_hub import notebook_login # 登录我们的Hugging Face账户,以便能够上传模型到Hub。
+notebook_login()
+!git config --global credential.helper store
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令:`huggingface-cli login`
+
+3️⃣ 我们现在准备好将我们训练好的智能体推送到🤗 Hub 🔥
+
+让我们运行push_to_hub.py文件,将我们训练好的智能体上传到Hub。
+
+`--repo-name `:仓库的名称
+
+`-orga`:你的Hugging Face用户名
+
+`-f`:训练好的模型文件夹的位置(在我们的例子中是`logs`)
+
+
+
+通过使用`rl_zoo3.push_to_hub`,**你可以评估、记录回放、生成智能体的模型卡片并将其推送到hub**。
+
+这样:
+- 你可以**展示我们的工作** 🔥
+- 你可以**可视化你的智能体的游戏过程** 👀
+- 你可以**与社区分享一个其他人可以使用的智能体** 💾
+- 你可以**访问排行榜 🏆 来看看你的智能体与同学相比表现如何** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+要能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果还没有完成)在HF创建一个账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录,然后,你需要从Hugging Face网站存储你的认证令牌。
+- 创建一个新令牌(https://huggingface.co/settings/tokens)**具有写入角色**
+
+
+
+- 复制令牌
+- 运行下面的单元并粘贴令牌
+
+```bash
+from huggingface_hub import notebook_login # 登录我们的Hugging Face账户,以便能够上传模型到Hub。
+notebook_login()
+!git config --global credential.helper store
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令:`huggingface-cli login`
+
+3️⃣ 我们现在准备好将我们训练好的智能体推送到🤗 Hub 🔥
+
+让我们运行push_to_hub.py文件,将我们训练好的智能体上传到Hub。
+
+`--repo-name `:仓库的名称
+
+`-orga`:你的Hugging Face用户名
+
+`-f`:训练好的模型文件夹的位置(在我们的例子中是`logs`)
+
+ +
+```bash
+python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 --repo-name _____________________ -orga _____________________ -f logs/
+```
+
+#### 解决方案
+
+```bash
+python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 --repo-name dqn-SpaceInvadersNoFrameskip-v4 -orga ThomasSimonini -f logs/
+```
+
+###.
+
+恭喜 🥳 你刚刚训练并上传了你的第一个使用RL-Baselines-3 Zoo的深度Q-Learning智能体。上面的脚本应该已经显示了一个模型仓库的链接,如https://huggingface.co/ThomasSimonini/dqn-SpaceInvadersNoFrameskip-v4。当你访问这个链接时,你可以:
+
+- 在右侧看到**你的智能体的视频预览**。
+- 点击"Files and versions"查看仓库中的所有文件。
+- 点击"Use in stable-baselines3"获取显示如何加载模型的代码片段。
+- 一个模型卡片(`README.md`文件),它给出了模型的描述和你使用的超参数。
+
+在底层,Hub使用基于git的仓库(如果你不知道git是什么,不用担心),这意味着你可以随着实验和改进你的智能体,用新版本更新模型。
+
+**使用[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)比较你的智能体与同学的结果** 🏆
+
+## 加载一个强大的训练模型 🔥
+
+- Stable-Baselines3团队在Hub上上传了**超过150个训练好的深度强化学习智能体**。
+
+你可以在这里找到它们:👉 https://huggingface.co/sb3
+
+一些例子:
+- 小行星:https://huggingface.co/sb3/dqn-AsteroidsNoFrameskip-v4
+- 光束骑士:https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4
+- 打砖块:https://huggingface.co/sb3/dqn-BreakoutNoFrameskip-v4
+- 公路赛车:https://huggingface.co/sb3/dqn-RoadRunnerNoFrameskip-v4
+
+让我们加载一个玩光束骑士的智能体:https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4
+
+1. 我们使用`rl_zoo3.load_from_hub`下载模型,并将其放在一个新文件夹中,我们可以称之为`rl_trained`
+
+```bash
+# 下载模型并将其保存到logs/文件夹中
+python -m rl_zoo3.load_from_hub --algo dqn --env BeamRiderNoFrameskip-v4 -orga sb3 -f rl_trained/
+```
+
+2. 让我们评估它5000个时间步
+
+```bash
+python -m rl_zoo3.enjoy --algo dqn --env BeamRiderNoFrameskip-v4 -n 5000 -f rl_trained/ --no-render
+```
+
+为什么不尝试训练你自己的**玩BeamRiderNoFrameskip-v4的深度Q-Learning智能体?🏆**
+
+如果你想尝试,请查看https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4#hyperparameters **在模型卡片中,你有训练好的智能体的超参数。**
+
+但是找到超参数可能是一项艰巨的任务。幸运的是,我们将在下一个单元中看到,**如何使用Optuna来优化超参数 🔥。**
+
+
+## 一些额外的挑战 🏆
+
+学习的最好方法**是自己尝试!**
+
+在[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)中,你会找到你的智能体。你能登上榜首吗?
+
+这里有一个你可以尝试训练你的智能体的环境列表:
+- BeamRiderNoFrameskip-v4
+- BreakoutNoFrameskip-v4
+- EnduroNoFrameskip-v4
+- PongNoFrameskip-v4
+
+另外,**如果你想学习自己实现深度Q-Learning**,你绝对应该看看CleanRL的实现:https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/dqn_atari.py
+
+
+
+________________________________________________________________________
+恭喜你完成本章!
+
+如果你仍然对所有这些元素感到困惑...这是完全正常的!**这对我和所有学习RL的人来说都是一样的。**
+
+在继续之前,花时间真正**掌握材料并尝试额外的挑战**。掌握这些元素并建立坚实的基础是很重要的。
+
+在下一个单元中,**我们将学习[Optuna](https://optuna.org/)**。深度强化学习中最关键的任务之一是找到一组好的训练超参数。而Optuna是一个帮助你自动化搜索的库。
+
+
+### 这是与你一起构建的课程 👷🏿♀️
+
+最后,我们希望通过你的反馈迭代地改进和更新课程。如果你有反馈,请填写这个表格 👉 https://forms.gle/3HgA7bEHwAmmLfwh9
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+我们在奖励单元2见!🔥
+
+### 持续学习,保持精彩 🤗
diff --git a/units/cn/unit3/introduction.mdx b/units/cn/unit3/introduction.mdx
new file mode 100644
index 00000000..9500a5eb
--- /dev/null
+++ b/units/cn/unit3/introduction.mdx
@@ -0,0 +1,19 @@
+# 深度Q学习 [[deep-q-learning]]
+
+
+
+
+
+在上一单元中,我们学习了第一个强化学习算法:Q学习,**从头实现了它**,并在两个环境中进行了训练,FrozenLake-v1 ☃️ 和 Taxi-v3 🚕。
+
+我们用这个简单的算法获得了出色的结果,但这些环境相对简单,因为**状态空间是离散且较小的**(FrozenLake-v1有16个不同的状态,Taxi-v3有500个)。相比之下,Atari游戏中的状态空间可能**包含 \\(10^{9}\\) 到 \\(10^{11}\\) 个状态**。
+
+但正如我们将看到的,在大型状态空间环境中,**生成和更新Q表可能变得效率低下。**
+
+因此在本单元中,**我们将学习我们的第一个深度强化学习智能体**:深度Q学习。深度Q学习不使用Q表,而是使用神经网络,该网络接收状态并基于该状态为每个动作近似Q值。
+
+**我们将使用[RL-Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)训练它来玩太空入侵者和其他Atari环境**,RL-Zoo是一个使用Stable-Baselines的强化学习训练框架,提供了训练、评估智能体、调整超参数、绘制结果和录制视频的脚本。
+
+
+
+让我们开始吧!🚀
diff --git a/units/cn/unit3/quiz.mdx b/units/cn/unit3/quiz.mdx
new file mode 100644
index 00000000..42f97920
--- /dev/null
+++ b/units/cn/unit3/quiz.mdx
@@ -0,0 +1,104 @@
+# 测验 [[quiz]]
+
+学习的最佳方式和[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法**是测试自己。**这将帮助你找出**需要加强知识的地方**。
+
+### 问题1:我们提到Q学习是一种表格方法。什么是表格方法?
+
+
+
+```bash
+python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 --repo-name _____________________ -orga _____________________ -f logs/
+```
+
+#### 解决方案
+
+```bash
+python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 --repo-name dqn-SpaceInvadersNoFrameskip-v4 -orga ThomasSimonini -f logs/
+```
+
+###.
+
+恭喜 🥳 你刚刚训练并上传了你的第一个使用RL-Baselines-3 Zoo的深度Q-Learning智能体。上面的脚本应该已经显示了一个模型仓库的链接,如https://huggingface.co/ThomasSimonini/dqn-SpaceInvadersNoFrameskip-v4。当你访问这个链接时,你可以:
+
+- 在右侧看到**你的智能体的视频预览**。
+- 点击"Files and versions"查看仓库中的所有文件。
+- 点击"Use in stable-baselines3"获取显示如何加载模型的代码片段。
+- 一个模型卡片(`README.md`文件),它给出了模型的描述和你使用的超参数。
+
+在底层,Hub使用基于git的仓库(如果你不知道git是什么,不用担心),这意味着你可以随着实验和改进你的智能体,用新版本更新模型。
+
+**使用[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)比较你的智能体与同学的结果** 🏆
+
+## 加载一个强大的训练模型 🔥
+
+- Stable-Baselines3团队在Hub上上传了**超过150个训练好的深度强化学习智能体**。
+
+你可以在这里找到它们:👉 https://huggingface.co/sb3
+
+一些例子:
+- 小行星:https://huggingface.co/sb3/dqn-AsteroidsNoFrameskip-v4
+- 光束骑士:https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4
+- 打砖块:https://huggingface.co/sb3/dqn-BreakoutNoFrameskip-v4
+- 公路赛车:https://huggingface.co/sb3/dqn-RoadRunnerNoFrameskip-v4
+
+让我们加载一个玩光束骑士的智能体:https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4
+
+1. 我们使用`rl_zoo3.load_from_hub`下载模型,并将其放在一个新文件夹中,我们可以称之为`rl_trained`
+
+```bash
+# 下载模型并将其保存到logs/文件夹中
+python -m rl_zoo3.load_from_hub --algo dqn --env BeamRiderNoFrameskip-v4 -orga sb3 -f rl_trained/
+```
+
+2. 让我们评估它5000个时间步
+
+```bash
+python -m rl_zoo3.enjoy --algo dqn --env BeamRiderNoFrameskip-v4 -n 5000 -f rl_trained/ --no-render
+```
+
+为什么不尝试训练你自己的**玩BeamRiderNoFrameskip-v4的深度Q-Learning智能体?🏆**
+
+如果你想尝试,请查看https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4#hyperparameters **在模型卡片中,你有训练好的智能体的超参数。**
+
+但是找到超参数可能是一项艰巨的任务。幸运的是,我们将在下一个单元中看到,**如何使用Optuna来优化超参数 🔥。**
+
+
+## 一些额外的挑战 🏆
+
+学习的最好方法**是自己尝试!**
+
+在[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)中,你会找到你的智能体。你能登上榜首吗?
+
+这里有一个你可以尝试训练你的智能体的环境列表:
+- BeamRiderNoFrameskip-v4
+- BreakoutNoFrameskip-v4
+- EnduroNoFrameskip-v4
+- PongNoFrameskip-v4
+
+另外,**如果你想学习自己实现深度Q-Learning**,你绝对应该看看CleanRL的实现:https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/dqn_atari.py
+
+
+
+________________________________________________________________________
+恭喜你完成本章!
+
+如果你仍然对所有这些元素感到困惑...这是完全正常的!**这对我和所有学习RL的人来说都是一样的。**
+
+在继续之前,花时间真正**掌握材料并尝试额外的挑战**。掌握这些元素并建立坚实的基础是很重要的。
+
+在下一个单元中,**我们将学习[Optuna](https://optuna.org/)**。深度强化学习中最关键的任务之一是找到一组好的训练超参数。而Optuna是一个帮助你自动化搜索的库。
+
+
+### 这是与你一起构建的课程 👷🏿♀️
+
+最后,我们希望通过你的反馈迭代地改进和更新课程。如果你有反馈,请填写这个表格 👉 https://forms.gle/3HgA7bEHwAmmLfwh9
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+我们在奖励单元2见!🔥
+
+### 持续学习,保持精彩 🤗
diff --git a/units/cn/unit3/introduction.mdx b/units/cn/unit3/introduction.mdx
new file mode 100644
index 00000000..9500a5eb
--- /dev/null
+++ b/units/cn/unit3/introduction.mdx
@@ -0,0 +1,19 @@
+# 深度Q学习 [[deep-q-learning]]
+
+
+
+
+
+在上一单元中,我们学习了第一个强化学习算法:Q学习,**从头实现了它**,并在两个环境中进行了训练,FrozenLake-v1 ☃️ 和 Taxi-v3 🚕。
+
+我们用这个简单的算法获得了出色的结果,但这些环境相对简单,因为**状态空间是离散且较小的**(FrozenLake-v1有16个不同的状态,Taxi-v3有500个)。相比之下,Atari游戏中的状态空间可能**包含 \\(10^{9}\\) 到 \\(10^{11}\\) 个状态**。
+
+但正如我们将看到的,在大型状态空间环境中,**生成和更新Q表可能变得效率低下。**
+
+因此在本单元中,**我们将学习我们的第一个深度强化学习智能体**:深度Q学习。深度Q学习不使用Q表,而是使用神经网络,该网络接收状态并基于该状态为每个动作近似Q值。
+
+**我们将使用[RL-Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)训练它来玩太空入侵者和其他Atari环境**,RL-Zoo是一个使用Stable-Baselines的强化学习训练框架,提供了训练、评估智能体、调整超参数、绘制结果和录制视频的脚本。
+
+
+
+让我们开始吧!🚀
diff --git a/units/cn/unit3/quiz.mdx b/units/cn/unit3/quiz.mdx
new file mode 100644
index 00000000..42f97920
--- /dev/null
+++ b/units/cn/unit3/quiz.mdx
@@ -0,0 +1,104 @@
+# 测验 [[quiz]]
+
+学习的最佳方式和[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法**是测试自己。**这将帮助你找出**需要加强知识的地方**。
+
+### 问题1:我们提到Q学习是一种表格方法。什么是表格方法?
+
+
+解答
+
+*表格方法*是一种问题类型,其中状态和动作空间足够小,可以将近似值函数**表示为数组和表格**。例如,**Q学习是一种表格方法**,因为我们使用表格来表示状态和动作值对。
+
+
+
+
+### 问题2:为什么我们不能使用经典的Q学习来解决Atari游戏?
+
+
+
+
+### 问题3:为什么在深度Q学习中使用帧作为输入时,我们要将四个帧堆叠在一起?
+
+
+解答
+
+我们将帧堆叠在一起是因为它帮助我们**处理时间限制问题**:一个帧不足以捕获时间信息。
+例如,在乒乓球游戏中,如果我们的智能体**只获得一个帧,它将无法知道球的方向**。
+
+
+
+
+
+
+
+
+### 问题4:深度Q学习的两个阶段是什么?
+
+
+
+### 问题5:为什么我们在深度Q学习中创建回放记忆?
+
+
+ 解答
+
+**1. 在训练期间更有效地利用经验**
+
+通常,在在线强化学习中,智能体与环境交互,获得经验(状态、动作、奖励和下一个状态),从中学习(更新神经网络),然后丢弃它们。这不是高效的。
+但是,通过经验回放,**我们创建一个回放缓冲区,保存可以在训练期间重复使用的经验样本**。
+
+**2. 避免忘记以前的经验并减少经验之间的相关性**
+
+如果我们向神经网络提供连续的经验样本,我们会遇到的问题是,它**倾向于忘记以前的经验,因为它覆盖了新的经验**。例如,如果我们在第一关,然后是不同的第二关,我们的智能体可能会忘记如何在第一关中行为和游戏。
+
+
+
+
+### 问题6:我们如何使用双深度Q学习?
+
+
+
+ 解答
+
+ 当我们计算Q目标时,我们使用两个网络来解耦动作选择和目标Q值生成。我们:
+
+ - 使用我们的*DQN网络***选择下一个状态的最佳动作**(具有最高Q值的动作)。
+
+ - 使用我们的*目标网络*计算**在下一个状态采取该动作的目标Q值**。
+
+
+
+
+恭喜你完成这个测验 🥳,如果你错过了一些要点,花点时间重新阅读本章以加强(😏)你的知识。
diff --git a/units/cn/unit4/additional-readings.mdx b/units/cn/unit4/additional-readings.mdx
new file mode 100644
index 00000000..b0cd28e8
--- /dev/null
+++ b/units/cn/unit4/additional-readings.mdx
@@ -0,0 +1,20 @@
+# 额外阅读材料
+
+这些是**可选阅读材料**,如果你想深入了解更多内容。
+
+
+## 策略优化简介
+
+- [第3部分:策略优化简介 - Spinning Up文档](https://spinningup.openai.com/en/latest/spinningup/rl_intro3.html)
+
+
+## 策略梯度
+
+- [https://johnwlambert.github.io/policy-gradients/](https://johnwlambert.github.io/policy-gradients/)
+- [强化学习 - 策略梯度解释](https://jonathan-hui.medium.com/rl-policy-gradients-explained-9b13b688b146)
+- [第13章,策略梯度方法;Richard Sutton和Andrew G. Barto著《强化学习导论》](http://incompleteideas.net/book/RLbook2020.pdf)
+
+## 实现
+
+- [PyTorch Reinforce实现](https://github.com/pytorch/examples/blob/main/reinforcement_learning/reinforce.py)
+- [从DDPG到PPO的实现](https://github.com/MrSyee/pg-is-all-you-need)
diff --git a/units/cn/unit4/advantages-disadvantages.mdx b/units/cn/unit4/advantages-disadvantages.mdx
new file mode 100644
index 00000000..1bc58be8
--- /dev/null
+++ b/units/cn/unit4/advantages-disadvantages.mdx
@@ -0,0 +1,74 @@
+# 策略梯度方法的优势和劣势
+
+在这一点上,你可能会问,"但深度Q学习很出色!为什么要使用策略梯度方法?"。为了回答这个问题,让我们研究**策略梯度方法的优势和劣势**。
+
+## 优势
+
+相比于基于价值的方法,策略梯度方法有多种优势。让我们看看其中一些:
+
+### 集成的简单性
+
+我们可以直接估计策略,而无需存储额外的数据(动作值)。
+
+### 策略梯度方法可以学习随机策略
+
+策略梯度方法可以**学习随机策略,而价值函数则不能**。
+
+这有两个后果:
+
+1. 我们**不需要手动实现探索/利用权衡**。由于我们输出的是动作的概率分布,智能体**在探索状态空间时不会总是采取相同的轨迹**。
+
+2. 我们还摆脱了**感知混叠**的问题。感知混叠是指两个状态看起来(或实际上)相同,但需要不同的动作。
+
+让我们举个例子:我们有一个智能吸尘器,其目标是吸尘并避免杀死仓鼠。
+
+
+  +
+
+我们的吸尘器只能感知墙壁的位置。
+
+问题是**两个红色(有颜色的)状态是混叠状态,因为智能体在每个状态都感知到上下墙壁**。
+
+
+
+
+
+我们的吸尘器只能感知墙壁的位置。
+
+问题是**两个红色(有颜色的)状态是混叠状态,因为智能体在每个状态都感知到上下墙壁**。
+
+
+ 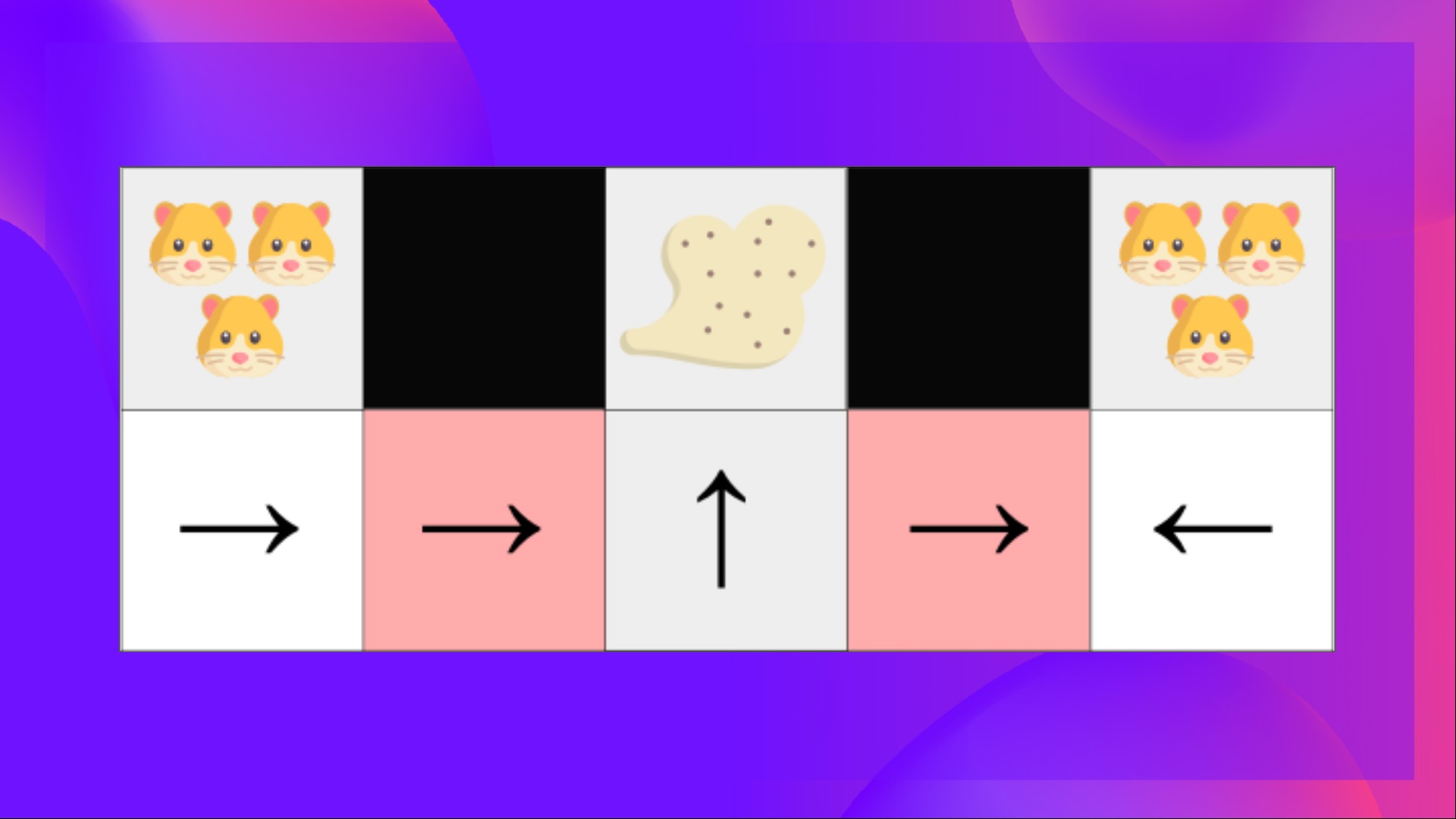 +
+
+在确定性策略下,策略在红色状态下要么总是向右移动,要么总是向左移动。**无论哪种情况都会导致我们的智能体陷入困境,永远无法吸尘**。
+
+在基于价值的强化学习算法下,我们学习一个**准确定性策略**("贪婪epsilon策略")。因此,我们的智能体可能**需要花费大量时间才能找到灰尘**。
+
+另一方面,最优随机策略**将在红色(有颜色的)状态下随机向左或向右移动**。因此,**它不会陷入困境,并且将以高概率达到目标状态**。
+
+
+
+
+
+在确定性策略下,策略在红色状态下要么总是向右移动,要么总是向左移动。**无论哪种情况都会导致我们的智能体陷入困境,永远无法吸尘**。
+
+在基于价值的强化学习算法下,我们学习一个**准确定性策略**("贪婪epsilon策略")。因此,我们的智能体可能**需要花费大量时间才能找到灰尘**。
+
+另一方面,最优随机策略**将在红色(有颜色的)状态下随机向左或向右移动**。因此,**它不会陷入困境,并且将以高概率达到目标状态**。
+
+
+ 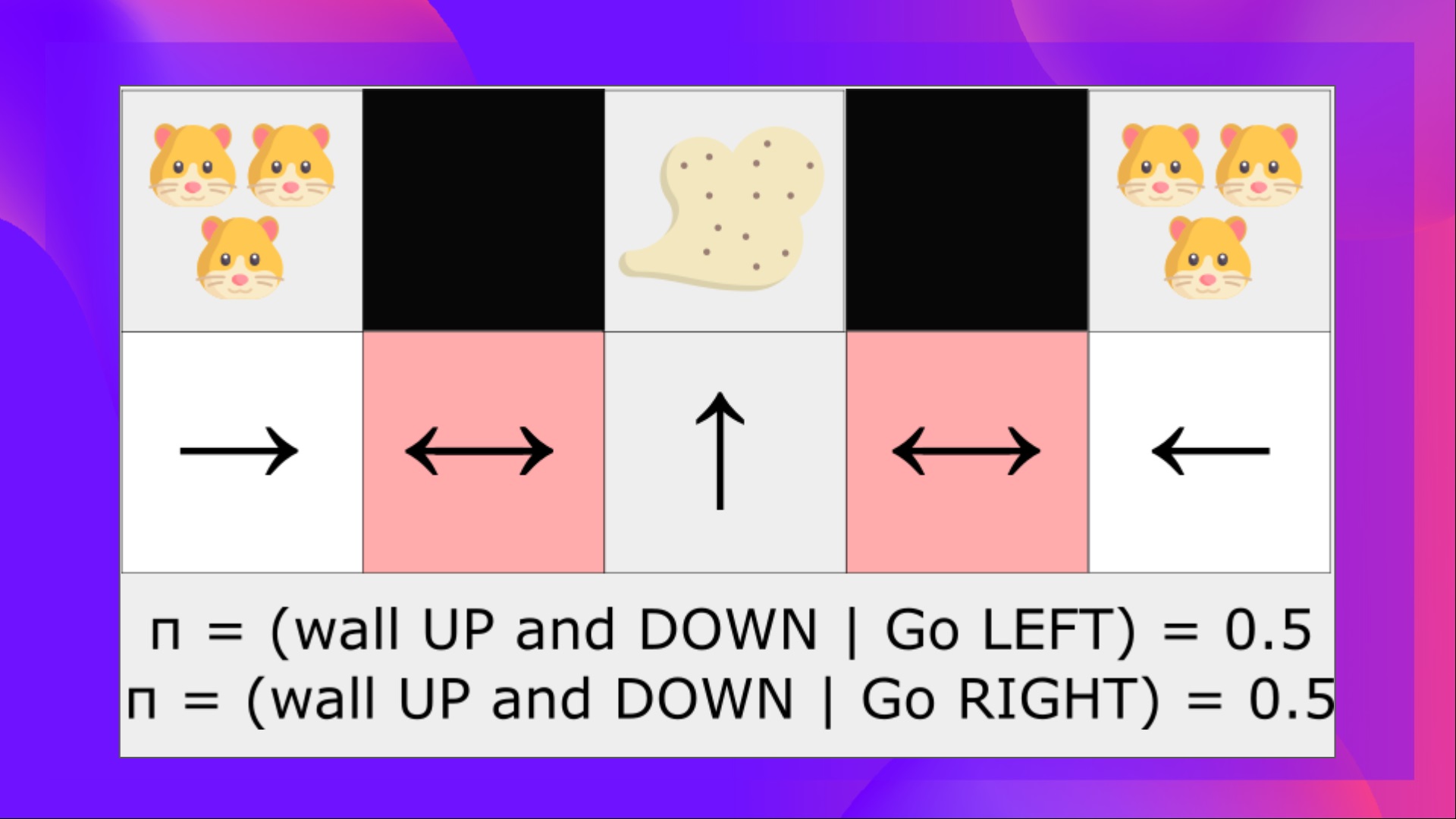 +
+
+### 策略梯度方法在高维动作空间和连续动作空间中更有效
+
+深度Q学习的问题在于,它们的**预测为每个可能的动作分配一个分数(最大期望未来奖励)**,在每个时间步,给定当前状态。
+
+但如果我们有无限可能的动作怎么办?
+
+例如,对于自动驾驶汽车,在每个状态下,你可以有(几乎)无限的动作选择(将方向盘转动15°、17.2°、19.4°、鸣喇叭等)。**我们需要为每个可能的动作输出一个Q值**!而且**取连续输出的最大动作本身就是一个优化问题**!
+
+相反,使用策略梯度方法,我们输出**动作的概率分布**。
+
+### 策略梯度方法具有更好的收敛特性
+
+在基于价值的方法中,我们使用一个激进的运算符来**改变价值函数:我们取Q估计的最大值**。
+因此,如果估计的动作值发生任意小的变化导致不同的动作具有最大值,动作概率可能会发生剧烈变化。
+
+例如,如果在训练过程中,最佳动作是左(Q值为0.22),而在下一个训练步骤中变成了右(因为右的Q值变为0.23),我们就会剧烈地改变策略,因为现在策略大部分时间会选择右而不是左。
+
+另一方面,在策略梯度方法中,随机策略动作偏好(采取动作的概率)**随着时间的推移平滑变化**。
+
+## 劣势
+
+当然,策略梯度方法也有一些劣势:
+
+- **策略梯度方法经常收敛到局部最大值而不是全局最优**。
+- 策略梯度进展较慢,**一步一步:可能需要更长时间来训练(效率低)**。
+- 策略梯度可能具有高方差。我们将在演员-评论家单元中看到为什么会这样,以及如何解决这个问题。
+
+👉 如果你想深入了解策略梯度方法的优势和劣势,[你可以查看这个视频](https://youtu.be/y3oqOjHilio)。
diff --git a/units/cn/unit4/conclusion.mdx b/units/cn/unit4/conclusion.mdx
new file mode 100644
index 00000000..e804f6f8
--- /dev/null
+++ b/units/cn/unit4/conclusion.mdx
@@ -0,0 +1,15 @@
+# 结论
+
+
+**恭喜你完成本单元**!这里有很多信息。
+也恭喜你完成教程。你刚刚使用PyTorch从头编写了第一个深度强化学习智能体,并将其分享到Hub上 🥳。
+
+不要犹豫,**通过改进更复杂环境的实现**来迭代本单元(例如,如何将网络更改为卷积神经网络以处理帧作为观察?)。
+
+在下一个单元中,**我们将通过在Unity环境中训练智能体来学习更多关于Unity MLAgents的知识**。这样,你将准备好参加**AI对抗AI挑战,在那里你将训练你的智能体与其他智能体在雪球大战和足球比赛中竞争**。
+
+听起来很有趣吧?下次见!
+
+最后,我们很想**听听你对课程的看法以及我们如何改进它**。如果你有一些反馈,请 👉 [填写这个表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 持续学习,保持精彩 🤗
diff --git a/units/cn/unit4/glossary.mdx b/units/cn/unit4/glossary.mdx
new file mode 100644
index 00000000..6af0e800
--- /dev/null
+++ b/units/cn/unit4/glossary.mdx
@@ -0,0 +1,25 @@
+# 术语表
+
+这是一个社区创建的术语表。欢迎贡献!
+
+- **深度Q学习:** 一种基于价值的深度强化学习算法,使用深度神经网络来近似给定状态下动作的Q值。深度Q学习的目标是通过学习动作值来找到最大化预期累积奖励的最优策略。
+
+- **基于价值的方法:** 通过估计价值函数作为寻找最优策略的中间步骤的强化学习方法。
+
+- **基于策略的方法:** 不学习价值函数而直接学习近似最优策略的强化学习方法。在实践中,它们输出动作的概率分布。
+
+ 使用策略梯度方法而非基于价值的方法的好处包括:
+ - 集成的简单性:无需存储动作值;
+ - 学习随机策略的能力:智能体在探索状态空间时不会总是采取相同的轨迹,并避免感知混叠问题;
+ - 在高维和连续动作空间中的有效性;以及
+ - 改进的收敛特性。
+
+- **策略梯度:** 基于策略方法的一个子集,其目标是使用梯度上升最大化参数化策略的性能。策略梯度的目标是通过调整策略使好的动作(最大化回报的动作)在未来被更频繁地采样,从而控制动作的概率分布。
+
+- **蒙特卡洛Reinforce:** 一种策略梯度算法,使用整个回合的估计回报来更新策略参数。
+
+如果你想改进课程,你可以[提交Pull Request。](https://github.com/huggingface/deep-rl-class/pulls)
+
+这个术语表的实现要感谢:
+
+- [Diego Carpintero](https://github.com/dcarpintero)
\ No newline at end of file
diff --git a/units/cn/unit4/hands-on.mdx b/units/cn/unit4/hands-on.mdx
new file mode 100644
index 00000000..12169509
--- /dev/null
+++ b/units/cn/unit4/hands-on.mdx
@@ -0,0 +1,1019 @@
+# 实践练习
+
+
+
+
+
+现在我们已经学习了Reinforce的理论,**你已经准备好使用PyTorch编写你的Reinforce智能体**。你将使用CartPole-v1和PixelCopter测试其鲁棒性。
+
+然后你可以迭代并改进这个实现,以适应更高级的环境。
+
+
+
+
+
+### 策略梯度方法在高维动作空间和连续动作空间中更有效
+
+深度Q学习的问题在于,它们的**预测为每个可能的动作分配一个分数(最大期望未来奖励)**,在每个时间步,给定当前状态。
+
+但如果我们有无限可能的动作怎么办?
+
+例如,对于自动驾驶汽车,在每个状态下,你可以有(几乎)无限的动作选择(将方向盘转动15°、17.2°、19.4°、鸣喇叭等)。**我们需要为每个可能的动作输出一个Q值**!而且**取连续输出的最大动作本身就是一个优化问题**!
+
+相反,使用策略梯度方法,我们输出**动作的概率分布**。
+
+### 策略梯度方法具有更好的收敛特性
+
+在基于价值的方法中,我们使用一个激进的运算符来**改变价值函数:我们取Q估计的最大值**。
+因此,如果估计的动作值发生任意小的变化导致不同的动作具有最大值,动作概率可能会发生剧烈变化。
+
+例如,如果在训练过程中,最佳动作是左(Q值为0.22),而在下一个训练步骤中变成了右(因为右的Q值变为0.23),我们就会剧烈地改变策略,因为现在策略大部分时间会选择右而不是左。
+
+另一方面,在策略梯度方法中,随机策略动作偏好(采取动作的概率)**随着时间的推移平滑变化**。
+
+## 劣势
+
+当然,策略梯度方法也有一些劣势:
+
+- **策略梯度方法经常收敛到局部最大值而不是全局最优**。
+- 策略梯度进展较慢,**一步一步:可能需要更长时间来训练(效率低)**。
+- 策略梯度可能具有高方差。我们将在演员-评论家单元中看到为什么会这样,以及如何解决这个问题。
+
+👉 如果你想深入了解策略梯度方法的优势和劣势,[你可以查看这个视频](https://youtu.be/y3oqOjHilio)。
diff --git a/units/cn/unit4/conclusion.mdx b/units/cn/unit4/conclusion.mdx
new file mode 100644
index 00000000..e804f6f8
--- /dev/null
+++ b/units/cn/unit4/conclusion.mdx
@@ -0,0 +1,15 @@
+# 结论
+
+
+**恭喜你完成本单元**!这里有很多信息。
+也恭喜你完成教程。你刚刚使用PyTorch从头编写了第一个深度强化学习智能体,并将其分享到Hub上 🥳。
+
+不要犹豫,**通过改进更复杂环境的实现**来迭代本单元(例如,如何将网络更改为卷积神经网络以处理帧作为观察?)。
+
+在下一个单元中,**我们将通过在Unity环境中训练智能体来学习更多关于Unity MLAgents的知识**。这样,你将准备好参加**AI对抗AI挑战,在那里你将训练你的智能体与其他智能体在雪球大战和足球比赛中竞争**。
+
+听起来很有趣吧?下次见!
+
+最后,我们很想**听听你对课程的看法以及我们如何改进它**。如果你有一些反馈,请 👉 [填写这个表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 持续学习,保持精彩 🤗
diff --git a/units/cn/unit4/glossary.mdx b/units/cn/unit4/glossary.mdx
new file mode 100644
index 00000000..6af0e800
--- /dev/null
+++ b/units/cn/unit4/glossary.mdx
@@ -0,0 +1,25 @@
+# 术语表
+
+这是一个社区创建的术语表。欢迎贡献!
+
+- **深度Q学习:** 一种基于价值的深度强化学习算法,使用深度神经网络来近似给定状态下动作的Q值。深度Q学习的目标是通过学习动作值来找到最大化预期累积奖励的最优策略。
+
+- **基于价值的方法:** 通过估计价值函数作为寻找最优策略的中间步骤的强化学习方法。
+
+- **基于策略的方法:** 不学习价值函数而直接学习近似最优策略的强化学习方法。在实践中,它们输出动作的概率分布。
+
+ 使用策略梯度方法而非基于价值的方法的好处包括:
+ - 集成的简单性:无需存储动作值;
+ - 学习随机策略的能力:智能体在探索状态空间时不会总是采取相同的轨迹,并避免感知混叠问题;
+ - 在高维和连续动作空间中的有效性;以及
+ - 改进的收敛特性。
+
+- **策略梯度:** 基于策略方法的一个子集,其目标是使用梯度上升最大化参数化策略的性能。策略梯度的目标是通过调整策略使好的动作(最大化回报的动作)在未来被更频繁地采样,从而控制动作的概率分布。
+
+- **蒙特卡洛Reinforce:** 一种策略梯度算法,使用整个回合的估计回报来更新策略参数。
+
+如果你想改进课程,你可以[提交Pull Request。](https://github.com/huggingface/deep-rl-class/pulls)
+
+这个术语表的实现要感谢:
+
+- [Diego Carpintero](https://github.com/dcarpintero)
\ No newline at end of file
diff --git a/units/cn/unit4/hands-on.mdx b/units/cn/unit4/hands-on.mdx
new file mode 100644
index 00000000..12169509
--- /dev/null
+++ b/units/cn/unit4/hands-on.mdx
@@ -0,0 +1,1019 @@
+# 实践练习
+
+
+
+
+
+现在我们已经学习了Reinforce的理论,**你已经准备好使用PyTorch编写你的Reinforce智能体**。你将使用CartPole-v1和PixelCopter测试其鲁棒性。
+
+然后你可以迭代并改进这个实现,以适应更高级的环境。
+
+
+  +
+
+
+为了在认证过程中验证这个实践练习,你需要将训练好的模型推送到Hub并:
+
+- 在`Cartpole-v1`中获得 >= 350 的结果
+- 在`PixelCopter`中获得 >= 5 的结果
+
+要查找你的结果,请前往排行榜并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**。**如果你在排行榜上看不到你的模型,请前往排行榜页面底部并点击刷新按钮**。
+
+**如果找不到你的模型,请前往页面底部并点击刷新按钮。**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+你可以在这里查看你的进度 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+
+
+**要开始实践练习,请点击"在Colab中打开"按钮** 👇:
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit4/unit4.ipynb)
+
+我们强烈**建议学生使用Google Colab进行实践练习**,而不是在个人电脑上运行。
+
+通过使用Google Colab,**你可以专注于学习和实验,而不必担心设置环境的技术方面**。
+
+# 第4单元:使用PyTorch编写你的第一个深度强化学习算法:Reinforce。并测试其鲁棒性 💪
+
+
+
+
+
+为了在认证过程中验证这个实践练习,你需要将训练好的模型推送到Hub并:
+
+- 在`Cartpole-v1`中获得 >= 350 的结果
+- 在`PixelCopter`中获得 >= 5 的结果
+
+要查找你的结果,请前往排行榜并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**。**如果你在排行榜上看不到你的模型,请前往排行榜页面底部并点击刷新按钮**。
+
+**如果找不到你的模型,请前往页面底部并点击刷新按钮。**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+你可以在这里查看你的进度 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+
+
+**要开始实践练习,请点击"在Colab中打开"按钮** 👇:
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit4/unit4.ipynb)
+
+我们强烈**建议学生使用Google Colab进行实践练习**,而不是在个人电脑上运行。
+
+通过使用Google Colab,**你可以专注于学习和实验,而不必担心设置环境的技术方面**。
+
+# 第4单元:使用PyTorch编写你的第一个深度强化学习算法:Reinforce。并测试其鲁棒性 💪
+
+ +
+
+在这个笔记本中,你将从头开始编写你的第一个深度强化学习算法:Reinforce(也称为蒙特卡洛策略梯度)。
+
+Reinforce是一种*基于策略的方法*:一种深度强化学习算法,它**尝试直接优化策略,而不使用动作值函数**。
+
+更准确地说,Reinforce是一种*策略梯度方法*,是*基于策略的方法*的一个子类,旨在**通过使用梯度上升估计最优策略的权重来直接优化策略**。
+
+为了测试其鲁棒性,我们将在2个不同的简单环境中训练它:
+- Cartpole-v1
+- PixelcopterEnv
+
+⬇️ 这里是**你在本笔记本结束时将实现的示例**。 ⬇️
+
+
+
+
+### 🎮 环境:
+
+- [CartPole-v1](https://www.gymlibrary.dev/environments/classic_control/cart_pole/)
+- [PixelCopter](https://pygame-learning-environment.readthedocs.io/en/latest/user/games/pixelcopter.html)
+
+### 📚 RL库:
+
+- Python
+- PyTorch
+
+
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在笔记本结束时,你将:
+
+- 能够**使用PyTorch从头开始编写Reinforce算法**。
+- 能够**使用简单环境测试你的智能体的鲁棒性**。
+- 能够**将你训练好的智能体推送到Hub**,附带精美的视频回放和评估分数 🔥。
+
+## 先决条件 🏗️
+
+在深入笔记本之前,你需要:
+
+🔲 📚 [通过阅读第4单元学习策略梯度](https://huggingface.co/deep-rl-course/unit4/introduction)
+
+# 让我们从头开始编写Reinforce算法 🔥
+
+## 一些建议 💡
+
+最好在Google Drive上的副本中运行这个colab,这样**如果它超时**,你仍然在Google Drive上保存了笔记本,不需要从头开始填写所有内容。
+
+要做到这一点,你可以按`Ctrl + S`或`文件 > 在Google Drive中保存副本`。
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。要做到这一点,请前往`运行时 > 更改运行时类型`
+
+
+
+- `硬件加速器 > GPU`
+
+
+
+## 创建虚拟显示器 🖥
+
+在笔记本中,我们需要生成回放视频。为此,使用colab,**我们需要有一个虚拟屏幕来能够渲染环境**(从而记录帧)。
+
+以下单元将安装库并创建并运行虚拟屏幕 🖥
+
+```python
+%%capture
+!apt install python-opengl
+!apt install ffmpeg
+!apt install xvfb
+!pip install pyvirtualdisplay
+!pip install pyglet==1.5.1
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## 安装依赖项 🔽
+
+第一步是安装依赖项。我们将安装多个:
+
+- `gym`
+- `gym-games`:使用PyGame制作的额外gym环境。
+- `huggingface_hub`:Hub作为一个中心位置,任何人都可以分享和探索模型和数据集。它具有版本控制、指标、可视化和其他功能,这些功能将使你能够轻松地与他人协作。
+
+你可能想知道为什么我们安装gym而不是gymnasium(gym的更新版本)?**因为我们使用的gym-games尚未更新为支持gymnasium**。
+
+你在这里会遇到的区别:
+- 在`gym`中,我们没有`terminated`和`truncated`,只有`done`。
+- 在`gym`中,使用`env.step()`返回`state, reward, done, info`
+
+你可以在这里了解更多关于Gym和Gymnasium之间的区别 👉 https://gymnasium.farama.org/content/migration-guide/
+
+你可以在这里查看所有可用的Reinforce模型 👉 https://huggingface.co/models?other=reinforce
+
+你可以在这里找到所有深度强化学习模型 👉 https://huggingface.co/models?pipeline_tag=reinforcement-learning
+
+
+```bash
+!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit4/requirements-unit4.txt
+```
+
+## 导入包 📦
+
+除了导入已安装的库外,我们还导入:
+
+- `imageio`:一个将帮助我们生成回放视频的库
+
+
+
+```python
+import numpy as np
+
+from collections import deque
+
+import matplotlib.pyplot as plt
+%matplotlib inline
+
+# PyTorch
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.optim as optim
+from torch.distributions import Categorical
+
+# Gym
+import gym
+import gym_pygame
+
+# Hugging Face Hub
+from huggingface_hub import notebook_login # To log to our Hugging Face account to be able to upload models to the Hub.
+import imageio
+```
+
+## 检查我们是否有GPU
+
+- 让我们检查我们是否有GPU
+- 如果是这种情况,你应该看到`device:cuda0`
+
+```python
+device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
+```
+
+```python
+print(device)
+```
+
+我们现在准备实现我们的Reinforce算法 🔥
+
+# 第一个智能体:玩CartPole-v1 🤖
+
+## 创建CartPole环境并了解它的工作原理
+
+### [环境 🎮](https://www.gymlibrary.dev/environments/classic_control/cart_pole/)
+
+### 为什么我们使用像CartPole-v1这样的简单环境?
+
+正如[强化学习技巧和窍门](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html)中所解释的,当你从头实现你的智能体时,你需要**确保它正常工作,并在简单环境中找到bug,然后再深入**,因为在简单环境中找到bug会容易得多。
+
+
+> 尝试在玩具问题上有一些"生命迹象"
+
+
+> 通过使其在越来越难的环境中运行来验证实现(你可以将结果与RL zoo进行比较)。对于这一步,你通常需要运行超参数优化。
+
+
+### CartPole-v1环境
+
+> 一个杆通过一个非驱动关节连接到一个推车上,该推车沿着无摩擦的轨道移动。钟摆直立放置在推车上,目标是通过在推车上施加左右方向的力来平衡杆。
+
+
+所以,我们从CartPole-v1开始。目标是向左或向右推动推车,**使杆保持平衡**。
+
+如果出现以下情况,回合结束:
+- 杆角度大于±12°
+- 推车位置大于±2.4
+- 回合长度大于500
+
+每个时间步杆保持平衡,我们都会获得+1的奖励 💰。
+
+```python
+env_id = "CartPole-v1"
+# Create the env
+env = gym.make(env_id)
+
+# Create the evaluation env
+eval_env = gym.make(env_id)
+
+# Get the state space and action space
+s_size = env.observation_space.shape[0]
+a_size = env.action_space.n
+```
+
+```python
+print("_____OBSERVATION SPACE_____ \n")
+print("The State Space is: ", s_size)
+print("Sample observation", env.observation_space.sample()) # Get a random observation
+```
+
+```python
+print("\n _____ACTION SPACE_____ \n")
+print("The Action Space is: ", a_size)
+print("Action Space Sample", env.action_space.sample()) # Take a random action
+```
+
+## 让我们构建Reinforce架构
+
+这个实现基于三个实现:
+- [PyTorch官方强化学习示例](https://github.com/pytorch/examples/blob/main/reinforcement_learning/reinforce.py)
+- [Udacity Reinforce](https://github.com/udacity/deep-reinforcement-learning/blob/master/reinforce/REINFORCE.ipynb)
+- [Chris1nexus对集成的改进](https://github.com/huggingface/deep-rl-class/pull/95)
+
+
+
+
+在这个笔记本中,你将从头开始编写你的第一个深度强化学习算法:Reinforce(也称为蒙特卡洛策略梯度)。
+
+Reinforce是一种*基于策略的方法*:一种深度强化学习算法,它**尝试直接优化策略,而不使用动作值函数**。
+
+更准确地说,Reinforce是一种*策略梯度方法*,是*基于策略的方法*的一个子类,旨在**通过使用梯度上升估计最优策略的权重来直接优化策略**。
+
+为了测试其鲁棒性,我们将在2个不同的简单环境中训练它:
+- Cartpole-v1
+- PixelcopterEnv
+
+⬇️ 这里是**你在本笔记本结束时将实现的示例**。 ⬇️
+
+
+
+
+### 🎮 环境:
+
+- [CartPole-v1](https://www.gymlibrary.dev/environments/classic_control/cart_pole/)
+- [PixelCopter](https://pygame-learning-environment.readthedocs.io/en/latest/user/games/pixelcopter.html)
+
+### 📚 RL库:
+
+- Python
+- PyTorch
+
+
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在笔记本结束时,你将:
+
+- 能够**使用PyTorch从头开始编写Reinforce算法**。
+- 能够**使用简单环境测试你的智能体的鲁棒性**。
+- 能够**将你训练好的智能体推送到Hub**,附带精美的视频回放和评估分数 🔥。
+
+## 先决条件 🏗️
+
+在深入笔记本之前,你需要:
+
+🔲 📚 [通过阅读第4单元学习策略梯度](https://huggingface.co/deep-rl-course/unit4/introduction)
+
+# 让我们从头开始编写Reinforce算法 🔥
+
+## 一些建议 💡
+
+最好在Google Drive上的副本中运行这个colab,这样**如果它超时**,你仍然在Google Drive上保存了笔记本,不需要从头开始填写所有内容。
+
+要做到这一点,你可以按`Ctrl + S`或`文件 > 在Google Drive中保存副本`。
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。要做到这一点,请前往`运行时 > 更改运行时类型`
+
+
+
+- `硬件加速器 > GPU`
+
+
+
+## 创建虚拟显示器 🖥
+
+在笔记本中,我们需要生成回放视频。为此,使用colab,**我们需要有一个虚拟屏幕来能够渲染环境**(从而记录帧)。
+
+以下单元将安装库并创建并运行虚拟屏幕 🖥
+
+```python
+%%capture
+!apt install python-opengl
+!apt install ffmpeg
+!apt install xvfb
+!pip install pyvirtualdisplay
+!pip install pyglet==1.5.1
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## 安装依赖项 🔽
+
+第一步是安装依赖项。我们将安装多个:
+
+- `gym`
+- `gym-games`:使用PyGame制作的额外gym环境。
+- `huggingface_hub`:Hub作为一个中心位置,任何人都可以分享和探索模型和数据集。它具有版本控制、指标、可视化和其他功能,这些功能将使你能够轻松地与他人协作。
+
+你可能想知道为什么我们安装gym而不是gymnasium(gym的更新版本)?**因为我们使用的gym-games尚未更新为支持gymnasium**。
+
+你在这里会遇到的区别:
+- 在`gym`中,我们没有`terminated`和`truncated`,只有`done`。
+- 在`gym`中,使用`env.step()`返回`state, reward, done, info`
+
+你可以在这里了解更多关于Gym和Gymnasium之间的区别 👉 https://gymnasium.farama.org/content/migration-guide/
+
+你可以在这里查看所有可用的Reinforce模型 👉 https://huggingface.co/models?other=reinforce
+
+你可以在这里找到所有深度强化学习模型 👉 https://huggingface.co/models?pipeline_tag=reinforcement-learning
+
+
+```bash
+!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit4/requirements-unit4.txt
+```
+
+## 导入包 📦
+
+除了导入已安装的库外,我们还导入:
+
+- `imageio`:一个将帮助我们生成回放视频的库
+
+
+
+```python
+import numpy as np
+
+from collections import deque
+
+import matplotlib.pyplot as plt
+%matplotlib inline
+
+# PyTorch
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.optim as optim
+from torch.distributions import Categorical
+
+# Gym
+import gym
+import gym_pygame
+
+# Hugging Face Hub
+from huggingface_hub import notebook_login # To log to our Hugging Face account to be able to upload models to the Hub.
+import imageio
+```
+
+## 检查我们是否有GPU
+
+- 让我们检查我们是否有GPU
+- 如果是这种情况,你应该看到`device:cuda0`
+
+```python
+device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
+```
+
+```python
+print(device)
+```
+
+我们现在准备实现我们的Reinforce算法 🔥
+
+# 第一个智能体:玩CartPole-v1 🤖
+
+## 创建CartPole环境并了解它的工作原理
+
+### [环境 🎮](https://www.gymlibrary.dev/environments/classic_control/cart_pole/)
+
+### 为什么我们使用像CartPole-v1这样的简单环境?
+
+正如[强化学习技巧和窍门](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html)中所解释的,当你从头实现你的智能体时,你需要**确保它正常工作,并在简单环境中找到bug,然后再深入**,因为在简单环境中找到bug会容易得多。
+
+
+> 尝试在玩具问题上有一些"生命迹象"
+
+
+> 通过使其在越来越难的环境中运行来验证实现(你可以将结果与RL zoo进行比较)。对于这一步,你通常需要运行超参数优化。
+
+
+### CartPole-v1环境
+
+> 一个杆通过一个非驱动关节连接到一个推车上,该推车沿着无摩擦的轨道移动。钟摆直立放置在推车上,目标是通过在推车上施加左右方向的力来平衡杆。
+
+
+所以,我们从CartPole-v1开始。目标是向左或向右推动推车,**使杆保持平衡**。
+
+如果出现以下情况,回合结束:
+- 杆角度大于±12°
+- 推车位置大于±2.4
+- 回合长度大于500
+
+每个时间步杆保持平衡,我们都会获得+1的奖励 💰。
+
+```python
+env_id = "CartPole-v1"
+# Create the env
+env = gym.make(env_id)
+
+# Create the evaluation env
+eval_env = gym.make(env_id)
+
+# Get the state space and action space
+s_size = env.observation_space.shape[0]
+a_size = env.action_space.n
+```
+
+```python
+print("_____OBSERVATION SPACE_____ \n")
+print("The State Space is: ", s_size)
+print("Sample observation", env.observation_space.sample()) # Get a random observation
+```
+
+```python
+print("\n _____ACTION SPACE_____ \n")
+print("The Action Space is: ", a_size)
+print("Action Space Sample", env.action_space.sample()) # Take a random action
+```
+
+## 让我们构建Reinforce架构
+
+这个实现基于三个实现:
+- [PyTorch官方强化学习示例](https://github.com/pytorch/examples/blob/main/reinforcement_learning/reinforce.py)
+- [Udacity Reinforce](https://github.com/udacity/deep-reinforcement-learning/blob/master/reinforce/REINFORCE.ipynb)
+- [Chris1nexus对集成的改进](https://github.com/huggingface/deep-rl-class/pull/95)
+
+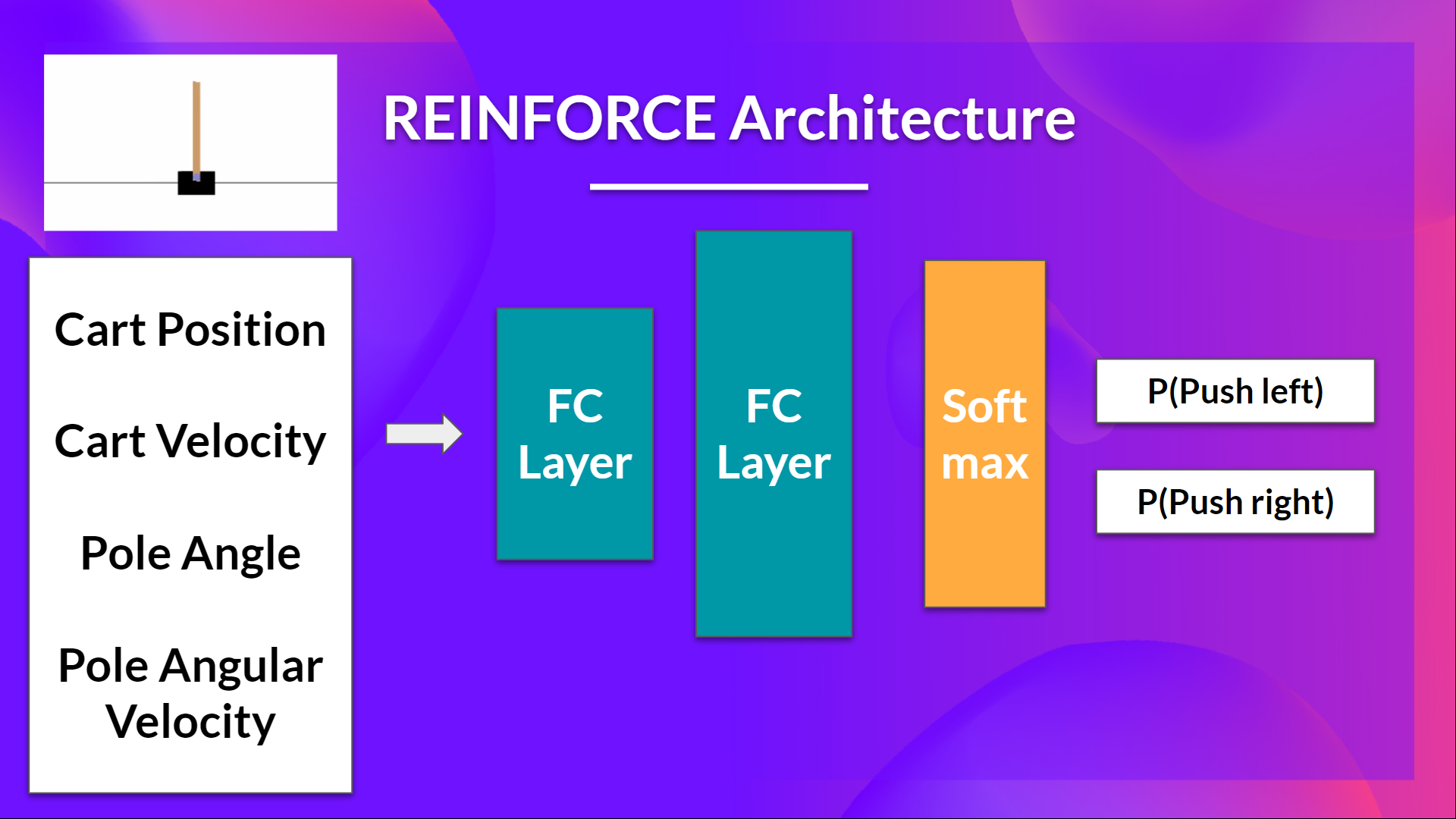 +
+所以我们需要:
+- 两个全连接层(fc1和fc2)。
+- 使用ReLU作为fc1的激活函数
+- 使用Softmax输出动作的概率分布
+
+```python
+class Policy(nn.Module):
+ def __init__(self, s_size, a_size, h_size):
+ super(Policy, self).__init__()
+ # Create two fully connected layers
+
+ ...
+ def forward(self, x):
+
+ ...
+ def act(self, state):
+ """
+ Given a state, take action
+ """
+ state = torch.from_numpy(state).float().unsqueeze(0).to(device)
+ probs = self.forward(state).cpu()
+ m = Categorical(probs)
+ action = np.argmax(m)
+ return action.item(), m.log_prob(action)
+```
+
+### 解决方案
+
+```python
+class Policy(nn.Module):
+ def __init__(self, s_size, a_size, h_size):
+ super(Policy, self).__init__()
+ self.fc1 = nn.Linear(s_size, h_size)
+ self.fc2 = nn.Linear(h_size, a_size)
+
+ def forward(self, x):
+ x = F.relu(self.fc1(x))
+ x = self.fc2(x)
+ return F.softmax(x, dim=1)
+
+ def act(self, state):
+ state = torch.from_numpy(state).float().unsqueeze(0).to(device)
+ probs = self.forward(state).cpu()
+ m = Categorical(probs)
+ action = np.argmax(m)
+ return action.item(), m.log_prob(action)
+```
+
+我犯了一个错误,你能猜出是在哪里吗?
+
+- 让我们进行一次前向传播来找出问题:
+
+```python
+debug_policy = Policy(s_size, a_size, 64).to(device)
+debug_policy.act(env.reset())
+```
+
+- 这里我们看到错误提示`ValueError: The value argument to log_prob must be a Tensor`
+
+- 这意味着`m.log_prob(action)`中的`action`必须是一个张量**但它不是。**
+
+- 你知道为什么吗?检查act函数并尝试找出为什么它不工作。
+
+建议 💡:这个实现中有问题。记住,对于act函数,**我们希望从动作概率分布中采样一个动作**。
+
+
+### (真正的)解决方案
+
+```python
+class Policy(nn.Module):
+ def __init__(self, s_size, a_size, h_size):
+ super(Policy, self).__init__()
+ self.fc1 = nn.Linear(s_size, h_size)
+ self.fc2 = nn.Linear(h_size, a_size)
+
+ def forward(self, x):
+ x = F.relu(self.fc1(x))
+ x = self.fc2(x)
+ return F.softmax(x, dim=1)
+
+ def act(self, state):
+ state = torch.from_numpy(state).float().unsqueeze(0).to(device)
+ probs = self.forward(state).cpu()
+ m = Categorical(probs)
+ action = m.sample()
+ return action.item(), m.log_prob(action)
+```
+
+通过使用CartPole,调试变得更容易,因为**我们知道错误来自我们的集成,而不是来自我们的简单环境**。
+
+- 由于**我们想要从动作概率分布中采样一个动作**,我们不能使用`action = np.argmax(m)`,因为它总是输出具有最高概率的动作。
+
+- 我们需要将其替换为`action = m.sample()`,它将从概率分布P(.|s)中采样一个动作
+
+### 让我们构建Reinforce训练算法
+这是Reinforce算法的伪代码:
+
+
+
+所以我们需要:
+- 两个全连接层(fc1和fc2)。
+- 使用ReLU作为fc1的激活函数
+- 使用Softmax输出动作的概率分布
+
+```python
+class Policy(nn.Module):
+ def __init__(self, s_size, a_size, h_size):
+ super(Policy, self).__init__()
+ # Create two fully connected layers
+
+ ...
+ def forward(self, x):
+
+ ...
+ def act(self, state):
+ """
+ Given a state, take action
+ """
+ state = torch.from_numpy(state).float().unsqueeze(0).to(device)
+ probs = self.forward(state).cpu()
+ m = Categorical(probs)
+ action = np.argmax(m)
+ return action.item(), m.log_prob(action)
+```
+
+### 解决方案
+
+```python
+class Policy(nn.Module):
+ def __init__(self, s_size, a_size, h_size):
+ super(Policy, self).__init__()
+ self.fc1 = nn.Linear(s_size, h_size)
+ self.fc2 = nn.Linear(h_size, a_size)
+
+ def forward(self, x):
+ x = F.relu(self.fc1(x))
+ x = self.fc2(x)
+ return F.softmax(x, dim=1)
+
+ def act(self, state):
+ state = torch.from_numpy(state).float().unsqueeze(0).to(device)
+ probs = self.forward(state).cpu()
+ m = Categorical(probs)
+ action = np.argmax(m)
+ return action.item(), m.log_prob(action)
+```
+
+我犯了一个错误,你能猜出是在哪里吗?
+
+- 让我们进行一次前向传播来找出问题:
+
+```python
+debug_policy = Policy(s_size, a_size, 64).to(device)
+debug_policy.act(env.reset())
+```
+
+- 这里我们看到错误提示`ValueError: The value argument to log_prob must be a Tensor`
+
+- 这意味着`m.log_prob(action)`中的`action`必须是一个张量**但它不是。**
+
+- 你知道为什么吗?检查act函数并尝试找出为什么它不工作。
+
+建议 💡:这个实现中有问题。记住,对于act函数,**我们希望从动作概率分布中采样一个动作**。
+
+
+### (真正的)解决方案
+
+```python
+class Policy(nn.Module):
+ def __init__(self, s_size, a_size, h_size):
+ super(Policy, self).__init__()
+ self.fc1 = nn.Linear(s_size, h_size)
+ self.fc2 = nn.Linear(h_size, a_size)
+
+ def forward(self, x):
+ x = F.relu(self.fc1(x))
+ x = self.fc2(x)
+ return F.softmax(x, dim=1)
+
+ def act(self, state):
+ state = torch.from_numpy(state).float().unsqueeze(0).to(device)
+ probs = self.forward(state).cpu()
+ m = Categorical(probs)
+ action = m.sample()
+ return action.item(), m.log_prob(action)
+```
+
+通过使用CartPole,调试变得更容易,因为**我们知道错误来自我们的集成,而不是来自我们的简单环境**。
+
+- 由于**我们想要从动作概率分布中采样一个动作**,我们不能使用`action = np.argmax(m)`,因为它总是输出具有最高概率的动作。
+
+- 我们需要将其替换为`action = m.sample()`,它将从概率分布P(.|s)中采样一个动作
+
+### 让我们构建Reinforce训练算法
+这是Reinforce算法的伪代码:
+
+ +
+
+
+- 当我们计算回报Gt(第6行)时,我们看到我们计算的是**从时间步t开始**的折扣奖励总和。
+
+- 为什么?因为我们的策略应该只**根据后果来强化动作**:所以在采取动作之前获得的奖励是无用的(因为它们不是由于该动作造成的),**只有在动作之后获得的奖励才重要**。
+
+- 在编写代码之前,你应该阅读[不要让过去分散你的注意力](https://spinningup.openai.com/en/latest/spinningup/rl_intro3.html#don-t-let-the-past-distract-you)这一部分,它解释了为什么我们使用reward-to-go策略梯度。
+
+我们使用[Chris1nexus](https://github.com/Chris1nexus)编写的一种有趣技术来**高效计算每个时间步的回报**。注释解释了这个过程。也不要犹豫[查看PR解释](https://github.com/huggingface/deep-rl-class/pull/95)
+但总体思路是**高效计算每个时间步的回报**。
+
+你可能会问的第二个问题是**为什么我们要最小化损失**?我们之前不是讨论过梯度上升而不是梯度下降吗?
+
+- 我们想要最大化我们的效用函数$J(\theta)$,但在PyTorch和TensorFlow中,**最小化目标函数**更好。
+ - 所以假设我们想在某个时间步强化动作3。在训练之前,这个动作的概率P是0.25。
+ - 所以我们想修改\\(theta\\)使得\\(\pi_\theta(a_3|s; \theta) > 0.25\\)
+ - 因为所有P的总和必须为1,最大化\\(pi_\theta(a_3|s; \theta)\\)将**最小化其他动作的概率**。
+ - 所以我们应该告诉PyTorch**最小化\\(1 - \pi_\theta(a_3|s; \theta)\\)**。
+ - 当\\(\pi_\theta(a_3|s; \theta)\\)接近1时,这个损失函数接近0。
+ - 所以我们鼓励梯度最大化\\(\pi_\theta(a_3|s; \theta)\\)
+
+
+```python
+def reinforce(policy, optimizer, n_training_episodes, max_t, gamma, print_every):
+ # Help us to calculate the score during the training
+ scores_deque = deque(maxlen=100)
+ scores = []
+ # Line 3 of pseudocode
+ for i_episode in range(1, n_training_episodes+1):
+ saved_log_probs = []
+ rewards = []
+ state = # TODO: reset the environment
+ # Line 4 of pseudocode
+ for t in range(max_t):
+ action, log_prob = # TODO get the action
+ saved_log_probs.append(log_prob)
+ state, reward, done, _ = # TODO: take an env step
+ rewards.append(reward)
+ if done:
+ break
+ scores_deque.append(sum(rewards))
+ scores.append(sum(rewards))
+
+ # Line 6 of pseudocode: calculate the return
+ returns = deque(maxlen=max_t)
+ n_steps = len(rewards)
+ # Compute the discounted returns at each timestep,
+ # as the sum of the gamma-discounted return at time t (G_t) + the reward at time t
+
+ # In O(N) time, where N is the number of time steps
+ # (this definition of the discounted return G_t follows the definition of this quantity
+ # shown at page 44 of Sutton&Barto 2017 2nd draft)
+ # G_t = r_(t+1) + r_(t+2) + ...
+
+ # Given this formulation, the returns at each timestep t can be computed
+ # by re-using the computed future returns G_(t+1) to compute the current return G_t
+ # G_t = r_(t+1) + gamma*G_(t+1)
+ # G_(t-1) = r_t + gamma* G_t
+ # (this follows a dynamic programming approach, with which we memorize solutions in order
+ # to avoid computing them multiple times)
+
+ # This is correct since the above is equivalent to (see also page 46 of Sutton&Barto 2017 2nd draft)
+ # G_(t-1) = r_t + gamma*r_(t+1) + gamma*gamma*r_(t+2) + ...
+
+
+ ## Given the above, we calculate the returns at timestep t as:
+ # gamma[t] * return[t] + reward[t]
+ #
+ ## We compute this starting from the last timestep to the first, in order
+ ## to employ the formula presented above and avoid redundant computations that would be needed
+ ## if we were to do it from first to last.
+
+ ## Hence, the queue "returns" will hold the returns in chronological order, from t=0 to t=n_steps
+ ## thanks to the appendleft() function which allows to append to the position 0 in constant time O(1)
+ ## a normal python list would instead require O(N) to do this.
+ for t in range(n_steps)[::-1]:
+ disc_return_t = (returns[0] if len(returns)>0 else 0)
+ returns.appendleft( ) # TODO: complete here
+
+ ## standardization of the returns is employed to make training more stable
+ eps = np.finfo(np.float32).eps.item()
+
+ ## eps is the smallest representable float, which is
+ # added to the standard deviation of the returns to avoid numerical instabilities
+ returns = torch.tensor(returns)
+ returns = (returns - returns.mean()) / (returns.std() + eps)
+
+ # Line 7:
+ policy_loss = []
+ for log_prob, disc_return in zip(saved_log_probs, returns):
+ policy_loss.append(-log_prob * disc_return)
+ policy_loss = torch.cat(policy_loss).sum()
+
+ # Line 8: PyTorch prefers gradient descent
+ optimizer.zero_grad()
+ policy_loss.backward()
+ optimizer.step()
+
+ if i_episode % print_every == 0:
+ print('Episode {}\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_deque)))
+
+ return scores
+```
+
+#### 解决方案
+
+```python
+def reinforce(policy, optimizer, n_training_episodes, max_t, gamma, print_every):
+ # Help us to calculate the score during the training
+ scores_deque = deque(maxlen=100)
+ scores = []
+ # Line 3 of pseudocode
+ for i_episode in range(1, n_training_episodes + 1):
+ saved_log_probs = []
+ rewards = []
+ state = env.reset()
+ # Line 4 of pseudocode
+ for t in range(max_t):
+ action, log_prob = policy.act(state)
+ saved_log_probs.append(log_prob)
+ state, reward, done, _ = env.step(action)
+ rewards.append(reward)
+ if done:
+ break
+ scores_deque.append(sum(rewards))
+ scores.append(sum(rewards))
+
+ # Line 6 of pseudocode: calculate the return
+ returns = deque(maxlen=max_t)
+ n_steps = len(rewards)
+ # Compute the discounted returns at each timestep,
+ # as
+ # the sum of the gamma-discounted return at time t (G_t) + the reward at time t
+ #
+ # In O(N) time, where N is the number of time steps
+ # (this definition of the discounted return G_t follows the definition of this quantity
+ # shown at page 44 of Sutton&Barto 2017 2nd draft)
+ # G_t = r_(t+1) + r_(t+2) + ...
+
+ # Given this formulation, the returns at each timestep t can be computed
+ # by re-using the computed future returns G_(t+1) to compute the current return G_t
+ # G_t = r_(t+1) + gamma*G_(t+1)
+ # G_(t-1) = r_t + gamma* G_t
+ # (this follows a dynamic programming approach, with which we memorize solutions in order
+ # to avoid computing them multiple times)
+
+ # This is correct since the above is equivalent to (see also page 46 of Sutton&Barto 2017 2nd draft)
+ # G_(t-1) = r_t + gamma*r_(t+1) + gamma*gamma*r_(t+2) + ...
+
+ ## Given the above, we calculate the returns at timestep t as:
+ # gamma[t] * return[t] + reward[t]
+ #
+ ## We compute this starting from the last timestep to the first, in order
+ ## to employ the formula presented above and avoid redundant computations that would be needed
+ ## if we were to do it from first to last.
+
+ ## Hence, the queue "returns" will hold the returns in chronological order, from t=0 to t=n_steps
+ ## thanks to the appendleft() function which allows to append to the position 0 in constant time O(1)
+ ## a normal python list would instead require O(N) to do this.
+ for t in range(n_steps)[::-1]:
+ disc_return_t = returns[0] if len(returns) > 0 else 0
+ returns.appendleft(gamma * disc_return_t + rewards[t])
+
+ ## standardization of the returns is employed to make training more stable
+ eps = np.finfo(np.float32).eps.item()
+ ## eps is the smallest representable float, which is
+ # added to the standard deviation of the returns to avoid numerical instabilities
+ returns = torch.tensor(returns)
+ returns = (returns - returns.mean()) / (returns.std() + eps)
+
+ # Line 7:
+ policy_loss = []
+ for log_prob, disc_return in zip(saved_log_probs, returns):
+ policy_loss.append(-log_prob * disc_return)
+ policy_loss = torch.cat(policy_loss).sum()
+
+ # Line 8: PyTorch prefers gradient descent
+ optimizer.zero_grad()
+ policy_loss.backward()
+ optimizer.step()
+
+ if i_episode % print_every == 0:
+ print("Episode {}\tAverage Score: {:.2f}".format(i_episode, np.mean(scores_deque)))
+
+ return scores
+```
+
+## 训练它
+- 我们现在准备训练我们的智能体。
+- 但首先,我们定义一个包含所有训练超参数的变量。
+- 你可以(而且应该😉)更改训练参数
+
+```python
+cartpole_hyperparameters = {
+ "h_size": 16,
+ "n_training_episodes": 1000,
+ "n_evaluation_episodes": 10,
+ "max_t": 1000,
+ "gamma": 1.0,
+ "lr": 1e-2,
+ "env_id": env_id,
+ "state_space": s_size,
+ "action_space": a_size,
+}
+```
+
+```python
+# Create policy and place it to the device
+cartpole_policy = Policy(
+ cartpole_hyperparameters["state_space"],
+ cartpole_hyperparameters["action_space"],
+ cartpole_hyperparameters["h_size"],
+).to(device)
+cartpole_optimizer = optim.Adam(cartpole_policy.parameters(), lr=cartpole_hyperparameters["lr"])
+```
+
+```python
+scores = reinforce(
+ cartpole_policy,
+ cartpole_optimizer,
+ cartpole_hyperparameters["n_training_episodes"],
+ cartpole_hyperparameters["max_t"],
+ cartpole_hyperparameters["gamma"],
+ 100,
+)
+```
+
+## 定义评估方法 📝
+- 这里我们定义评估方法,用于测试我们的Reinforce智能体。
+
+```python
+def evaluate_agent(env, max_steps, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The Reinforce agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ for step in range(max_steps):
+ action, _ = policy.act(state)
+ new_state, reward, done, info = env.step(action)
+ total_rewards_ep += reward
+
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+```
+
+## 评估我们的智能体 📈
+
+```python
+evaluate_agent(
+ eval_env, cartpole_hyperparameters["max_t"], cartpole_hyperparameters["n_evaluation_episodes"], cartpole_policy
+)
+```
+
+### 在Hub上发布我们训练好的模型 🔥
+现在我们看到训练后取得了不错的结果,我们可以用一行代码将训练好的模型发布到Hub 🤗。
+
+这是一个模型卡片的例子:
+
+
+
+
+
+- 当我们计算回报Gt(第6行)时,我们看到我们计算的是**从时间步t开始**的折扣奖励总和。
+
+- 为什么?因为我们的策略应该只**根据后果来强化动作**:所以在采取动作之前获得的奖励是无用的(因为它们不是由于该动作造成的),**只有在动作之后获得的奖励才重要**。
+
+- 在编写代码之前,你应该阅读[不要让过去分散你的注意力](https://spinningup.openai.com/en/latest/spinningup/rl_intro3.html#don-t-let-the-past-distract-you)这一部分,它解释了为什么我们使用reward-to-go策略梯度。
+
+我们使用[Chris1nexus](https://github.com/Chris1nexus)编写的一种有趣技术来**高效计算每个时间步的回报**。注释解释了这个过程。也不要犹豫[查看PR解释](https://github.com/huggingface/deep-rl-class/pull/95)
+但总体思路是**高效计算每个时间步的回报**。
+
+你可能会问的第二个问题是**为什么我们要最小化损失**?我们之前不是讨论过梯度上升而不是梯度下降吗?
+
+- 我们想要最大化我们的效用函数$J(\theta)$,但在PyTorch和TensorFlow中,**最小化目标函数**更好。
+ - 所以假设我们想在某个时间步强化动作3。在训练之前,这个动作的概率P是0.25。
+ - 所以我们想修改\\(theta\\)使得\\(\pi_\theta(a_3|s; \theta) > 0.25\\)
+ - 因为所有P的总和必须为1,最大化\\(pi_\theta(a_3|s; \theta)\\)将**最小化其他动作的概率**。
+ - 所以我们应该告诉PyTorch**最小化\\(1 - \pi_\theta(a_3|s; \theta)\\)**。
+ - 当\\(\pi_\theta(a_3|s; \theta)\\)接近1时,这个损失函数接近0。
+ - 所以我们鼓励梯度最大化\\(\pi_\theta(a_3|s; \theta)\\)
+
+
+```python
+def reinforce(policy, optimizer, n_training_episodes, max_t, gamma, print_every):
+ # Help us to calculate the score during the training
+ scores_deque = deque(maxlen=100)
+ scores = []
+ # Line 3 of pseudocode
+ for i_episode in range(1, n_training_episodes+1):
+ saved_log_probs = []
+ rewards = []
+ state = # TODO: reset the environment
+ # Line 4 of pseudocode
+ for t in range(max_t):
+ action, log_prob = # TODO get the action
+ saved_log_probs.append(log_prob)
+ state, reward, done, _ = # TODO: take an env step
+ rewards.append(reward)
+ if done:
+ break
+ scores_deque.append(sum(rewards))
+ scores.append(sum(rewards))
+
+ # Line 6 of pseudocode: calculate the return
+ returns = deque(maxlen=max_t)
+ n_steps = len(rewards)
+ # Compute the discounted returns at each timestep,
+ # as the sum of the gamma-discounted return at time t (G_t) + the reward at time t
+
+ # In O(N) time, where N is the number of time steps
+ # (this definition of the discounted return G_t follows the definition of this quantity
+ # shown at page 44 of Sutton&Barto 2017 2nd draft)
+ # G_t = r_(t+1) + r_(t+2) + ...
+
+ # Given this formulation, the returns at each timestep t can be computed
+ # by re-using the computed future returns G_(t+1) to compute the current return G_t
+ # G_t = r_(t+1) + gamma*G_(t+1)
+ # G_(t-1) = r_t + gamma* G_t
+ # (this follows a dynamic programming approach, with which we memorize solutions in order
+ # to avoid computing them multiple times)
+
+ # This is correct since the above is equivalent to (see also page 46 of Sutton&Barto 2017 2nd draft)
+ # G_(t-1) = r_t + gamma*r_(t+1) + gamma*gamma*r_(t+2) + ...
+
+
+ ## Given the above, we calculate the returns at timestep t as:
+ # gamma[t] * return[t] + reward[t]
+ #
+ ## We compute this starting from the last timestep to the first, in order
+ ## to employ the formula presented above and avoid redundant computations that would be needed
+ ## if we were to do it from first to last.
+
+ ## Hence, the queue "returns" will hold the returns in chronological order, from t=0 to t=n_steps
+ ## thanks to the appendleft() function which allows to append to the position 0 in constant time O(1)
+ ## a normal python list would instead require O(N) to do this.
+ for t in range(n_steps)[::-1]:
+ disc_return_t = (returns[0] if len(returns)>0 else 0)
+ returns.appendleft( ) # TODO: complete here
+
+ ## standardization of the returns is employed to make training more stable
+ eps = np.finfo(np.float32).eps.item()
+
+ ## eps is the smallest representable float, which is
+ # added to the standard deviation of the returns to avoid numerical instabilities
+ returns = torch.tensor(returns)
+ returns = (returns - returns.mean()) / (returns.std() + eps)
+
+ # Line 7:
+ policy_loss = []
+ for log_prob, disc_return in zip(saved_log_probs, returns):
+ policy_loss.append(-log_prob * disc_return)
+ policy_loss = torch.cat(policy_loss).sum()
+
+ # Line 8: PyTorch prefers gradient descent
+ optimizer.zero_grad()
+ policy_loss.backward()
+ optimizer.step()
+
+ if i_episode % print_every == 0:
+ print('Episode {}\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_deque)))
+
+ return scores
+```
+
+#### 解决方案
+
+```python
+def reinforce(policy, optimizer, n_training_episodes, max_t, gamma, print_every):
+ # Help us to calculate the score during the training
+ scores_deque = deque(maxlen=100)
+ scores = []
+ # Line 3 of pseudocode
+ for i_episode in range(1, n_training_episodes + 1):
+ saved_log_probs = []
+ rewards = []
+ state = env.reset()
+ # Line 4 of pseudocode
+ for t in range(max_t):
+ action, log_prob = policy.act(state)
+ saved_log_probs.append(log_prob)
+ state, reward, done, _ = env.step(action)
+ rewards.append(reward)
+ if done:
+ break
+ scores_deque.append(sum(rewards))
+ scores.append(sum(rewards))
+
+ # Line 6 of pseudocode: calculate the return
+ returns = deque(maxlen=max_t)
+ n_steps = len(rewards)
+ # Compute the discounted returns at each timestep,
+ # as
+ # the sum of the gamma-discounted return at time t (G_t) + the reward at time t
+ #
+ # In O(N) time, where N is the number of time steps
+ # (this definition of the discounted return G_t follows the definition of this quantity
+ # shown at page 44 of Sutton&Barto 2017 2nd draft)
+ # G_t = r_(t+1) + r_(t+2) + ...
+
+ # Given this formulation, the returns at each timestep t can be computed
+ # by re-using the computed future returns G_(t+1) to compute the current return G_t
+ # G_t = r_(t+1) + gamma*G_(t+1)
+ # G_(t-1) = r_t + gamma* G_t
+ # (this follows a dynamic programming approach, with which we memorize solutions in order
+ # to avoid computing them multiple times)
+
+ # This is correct since the above is equivalent to (see also page 46 of Sutton&Barto 2017 2nd draft)
+ # G_(t-1) = r_t + gamma*r_(t+1) + gamma*gamma*r_(t+2) + ...
+
+ ## Given the above, we calculate the returns at timestep t as:
+ # gamma[t] * return[t] + reward[t]
+ #
+ ## We compute this starting from the last timestep to the first, in order
+ ## to employ the formula presented above and avoid redundant computations that would be needed
+ ## if we were to do it from first to last.
+
+ ## Hence, the queue "returns" will hold the returns in chronological order, from t=0 to t=n_steps
+ ## thanks to the appendleft() function which allows to append to the position 0 in constant time O(1)
+ ## a normal python list would instead require O(N) to do this.
+ for t in range(n_steps)[::-1]:
+ disc_return_t = returns[0] if len(returns) > 0 else 0
+ returns.appendleft(gamma * disc_return_t + rewards[t])
+
+ ## standardization of the returns is employed to make training more stable
+ eps = np.finfo(np.float32).eps.item()
+ ## eps is the smallest representable float, which is
+ # added to the standard deviation of the returns to avoid numerical instabilities
+ returns = torch.tensor(returns)
+ returns = (returns - returns.mean()) / (returns.std() + eps)
+
+ # Line 7:
+ policy_loss = []
+ for log_prob, disc_return in zip(saved_log_probs, returns):
+ policy_loss.append(-log_prob * disc_return)
+ policy_loss = torch.cat(policy_loss).sum()
+
+ # Line 8: PyTorch prefers gradient descent
+ optimizer.zero_grad()
+ policy_loss.backward()
+ optimizer.step()
+
+ if i_episode % print_every == 0:
+ print("Episode {}\tAverage Score: {:.2f}".format(i_episode, np.mean(scores_deque)))
+
+ return scores
+```
+
+## 训练它
+- 我们现在准备训练我们的智能体。
+- 但首先,我们定义一个包含所有训练超参数的变量。
+- 你可以(而且应该😉)更改训练参数
+
+```python
+cartpole_hyperparameters = {
+ "h_size": 16,
+ "n_training_episodes": 1000,
+ "n_evaluation_episodes": 10,
+ "max_t": 1000,
+ "gamma": 1.0,
+ "lr": 1e-2,
+ "env_id": env_id,
+ "state_space": s_size,
+ "action_space": a_size,
+}
+```
+
+```python
+# Create policy and place it to the device
+cartpole_policy = Policy(
+ cartpole_hyperparameters["state_space"],
+ cartpole_hyperparameters["action_space"],
+ cartpole_hyperparameters["h_size"],
+).to(device)
+cartpole_optimizer = optim.Adam(cartpole_policy.parameters(), lr=cartpole_hyperparameters["lr"])
+```
+
+```python
+scores = reinforce(
+ cartpole_policy,
+ cartpole_optimizer,
+ cartpole_hyperparameters["n_training_episodes"],
+ cartpole_hyperparameters["max_t"],
+ cartpole_hyperparameters["gamma"],
+ 100,
+)
+```
+
+## 定义评估方法 📝
+- 这里我们定义评估方法,用于测试我们的Reinforce智能体。
+
+```python
+def evaluate_agent(env, max_steps, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The Reinforce agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ for step in range(max_steps):
+ action, _ = policy.act(state)
+ new_state, reward, done, info = env.step(action)
+ total_rewards_ep += reward
+
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+```
+
+## 评估我们的智能体 📈
+
+```python
+evaluate_agent(
+ eval_env, cartpole_hyperparameters["max_t"], cartpole_hyperparameters["n_evaluation_episodes"], cartpole_policy
+)
+```
+
+### 在Hub上发布我们训练好的模型 🔥
+现在我们看到训练后取得了不错的结果,我们可以用一行代码将训练好的模型发布到Hub 🤗。
+
+这是一个模型卡片的例子:
+
+ +
+### 推送到Hub
+#### 请勿修改此代码
+
+```python
+from huggingface_hub import HfApi, snapshot_download
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import json
+import imageio
+
+import tempfile
+
+import os
+```
+
+```python
+def record_video(env, policy, out_directory, fps=30):
+ """
+ Generate a replay video of the agent
+ :param env
+ :param Qtable: Qtable of our agent
+ :param out_directory
+ :param fps: how many frame per seconds (with taxi-v3 and frozenlake-v1 we use 1)
+ """
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _ = policy.act(state)
+ state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+```
+
+```python
+def push_to_hub(repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30
+ ):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the Hub
+
+ :param repo_id: repo_id: id of the model repository from the Hugging Face Hub
+ :param model: the pytorch model we want to save
+ :param hyperparameters: training hyperparameters
+ :param eval_env: evaluation environment
+ :param video_fps: how many frame per seconds to record our video replay
+ """
+
+ _, repo_name = repo_id.split("/")
+ api = HfApi()
+
+ # Step 1: Create the repo
+ repo_url = api.create_repo(
+ repo_id=repo_id,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ local_directory = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model, local_directory / "model.pt")
+
+ # Step 3: Save the hyperparameters to JSON
+ with open(local_directory / "hyperparameters.json", "w") as outfile:
+ json.dump(hyperparameters, outfile)
+
+ # Step 4: Evaluate the model and build JSON
+ mean_reward, std_reward = evaluate_agent(eval_env,
+ hyperparameters["max_t"],
+ hyperparameters["n_evaluation_episodes"],
+ model)
+ # Get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters["env_id"],
+ "mean_reward": mean_reward,
+ "n_evaluation_episodes": hyperparameters["n_evaluation_episodes"],
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(local_directory / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 5: Create the model card
+ env_name = hyperparameters["env_id"]
+
+ metadata = {}
+ metadata["tags"] = [
+ env_name,
+ "reinforce",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-class"
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=repo_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_name,
+ dataset_id=env_name,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ model_card = f"""
+ # **Reinforce** Agent playing **{env_id}**
+ This is a trained model of a **Reinforce** agent playing **{env_id}** .
+ To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
+ """
+
+ readme_path = local_directory / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+ # Step 6: Record a video
+ video_path = local_directory / "replay.mp4"
+ record_video(env, model, video_path, video_fps)
+
+ # Step 7. Push everything to the Hub
+ api.upload_folder(
+ repo_id=repo_id,
+ folder_path=local_directory,
+ path_in_repo=".",
+ )
+
+ print(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+```
+
+通过使用`push_to_hub`,**你可以评估、记录回放、生成智能体的模型卡片,并将其推送到Hub**。
+
+这样:
+- 你可以**展示你的工作** 🔥
+- 你可以**可视化你的智能体的游戏过程** 👀
+- 你可以**与社区分享一个其他人可以使用的智能体** 💾
+- 你可以**访问排行榜 🏆 查看你的智能体与同学相比表现如何** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+
+要能够与社区分享你的模型,还需要遵循三个步骤:
+
+1️⃣ (如果尚未完成)创建一个HF账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录,然后你需要从Hugging Face网站存储你的认证令牌。
+- 创建一个新令牌(https://huggingface.co/settings/tokens)**具有写入权限**
+
+
+
+
+
+
+```python
+notebook_login()
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令:`huggingface-cli login`(或`login`)
+
+3️⃣ 我们现在准备使用`package_to_hub()`函数将训练好的智能体推送到🤗 Hub 🔥
+
+```python
+repo_id = "" # TODO 定义你的仓库ID {username/Reinforce-{model-id}}
+push_to_hub(
+ repo_id,
+ cartpole_policy, # 我们想要保存的模型
+ cartpole_hyperparameters, # 超参数
+ eval_env, # 评估环境
+ video_fps=30
+)
+```
+
+现在我们已经测试了我们实现的鲁棒性,让我们尝试一个更复杂的环境:PixelCopter 🚁
+
+
+
+
+## 第二个智能体:PixelCopter 🚁
+
+### 研究PixelCopter环境 👀
+- [环境文档](https://pygame-learning-environment.readthedocs.io/en/latest/user/games/pixelcopter.html)
+
+
+```python
+env_id = "Pixelcopter-PLE-v0"
+env = gym.make(env_id)
+eval_env = gym.make(env_id)
+s_size = env.observation_space.shape[0]
+a_size = env.action_space.n
+```
+
+```python
+print("_____OBSERVATION SPACE_____ \n")
+print("The State Space is: ", s_size)
+print("Sample observation", env.observation_space.sample()) # Get a random observation
+```
+
+```python
+print("\n _____ACTION SPACE_____ \n")
+print("The Action Space is: ", a_size)
+print("Action Space Sample", env.action_space.sample()) # Take a random action
+```
+
+观察空间(7) 👀:
+- 玩家y位置
+- 玩家速度
+- 玩家到地面的距离
+- 玩家到天花板的距离
+- 下一个障碍物与玩家的x距离
+- 下一个障碍物顶部y位置
+- 下一个障碍物底部y位置
+
+动作空间(2) 🎮:
+- 向上(按加速器)
+- 什么都不做(不按加速器)
+
+奖励函数 💰:
+- 每通过一个垂直障碍物,获得+1的正奖励。每次达到终止状态时,获得-1的负奖励。
+
+### 定义新的策略 🧠
+- 由于环境更复杂,我们需要一个更深的神经网络
+
+```python
+class Policy(nn.Module):
+ def __init__(self, s_size, a_size, h_size):
+ super(Policy, self).__init__()
+ # Define the three layers here
+
+ def forward(self, x):
+ # Define the forward process here
+ return F.softmax(x, dim=1)
+
+ def act(self, state):
+ state = torch.from_numpy(state).float().unsqueeze(0).to(device)
+ probs = self.forward(state).cpu()
+ m = Categorical(probs)
+ action = m.sample()
+ return action.item(), m.log_prob(action)
+```
+
+#### 解决方案
+
+```python
+class Policy(nn.Module):
+ def __init__(self, s_size, a_size, h_size):
+ super(Policy, self).__init__()
+ self.fc1 = nn.Linear(s_size, h_size)
+ self.fc2 = nn.Linear(h_size, h_size * 2)
+ self.fc3 = nn.Linear(h_size * 2, a_size)
+
+ def forward(self, x):
+ x = F.relu(self.fc1(x))
+ x = F.relu(self.fc2(x))
+ x = self.fc3(x)
+ return F.softmax(x, dim=1)
+
+ def act(self, state):
+ state = torch.from_numpy(state).float().unsqueeze(0).to(device)
+ probs = self.forward(state).cpu()
+ m = Categorical(probs)
+ action = m.sample()
+ return action.item(), m.log_prob(action)
+```
+
+### 定义超参数 ⚙️
+- 因为这个环境更复杂。
+- 特别是隐藏层大小,我们需要更多的神经元。
+
+```python
+pixelcopter_hyperparameters = {
+ "h_size": 64,
+ "n_training_episodes": 50000,
+ "n_evaluation_episodes": 10,
+ "max_t": 10000,
+ "gamma": 0.99,
+ "lr": 1e-4,
+ "env_id": env_id,
+ "state_space": s_size,
+ "action_space": a_size,
+}
+```
+
+### 训练它
+- 我们现在准备训练我们的智能体 🔥。
+
+```python
+# Create policy and place it to the device
+# torch.manual_seed(50)
+pixelcopter_policy = Policy(
+ pixelcopter_hyperparameters["state_space"],
+ pixelcopter_hyperparameters["action_space"],
+ pixelcopter_hyperparameters["h_size"],
+).to(device)
+pixelcopter_optimizer = optim.Adam(pixelcopter_policy.parameters(), lr=pixelcopter_hyperparameters["lr"])
+```
+
+```python
+scores = reinforce(
+ pixelcopter_policy,
+ pixelcopter_optimizer,
+ pixelcopter_hyperparameters["n_training_episodes"],
+ pixelcopter_hyperparameters["max_t"],
+ pixelcopter_hyperparameters["gamma"],
+ 1000,
+)
+```
+
+### 在Hub上发布我们训练好的模型 🔥
+
+```python
+repo_id = "" # TODO 定义你的仓库ID {username/Reinforce-{model-id}}
+push_to_hub(
+ repo_id,
+ pixelcopter_policy, # 我们想要保存的模型
+ pixelcopter_hyperparameters, # 超参数
+ eval_env, # 评估环境
+ video_fps=30
+)
+```
+
+## 一些额外的挑战 🏆
+
+学习的最佳方式**是自己尝试**!正如你所看到的,当前的智能体表现不是很好。作为第一个建议,你可以训练更多步骤。但也尝试找到更好的参数。
+
+在[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)中,你会找到你的智能体。你能登上榜首吗?
+
+以下是一些攀登排行榜的想法:
+* 训练更多步骤
+* 通过查看你的同学们所做的工作,尝试不同的超参数 👉 https://huggingface.co/models?other=reinforce
+* **将你新训练的模型**推送到Hub 🔥
+* **改进实现以适应更复杂的环境**(例如,如何将网络更改为卷积神经网络以处理帧作为观察?)
+
+________________________________________________________________________
+
+**恭喜你完成本单元**!这里有很多信息。
+也恭喜你完成教程。你刚刚使用PyTorch从头编写了第一个深度强化学习智能体,并将其分享到Hub上 🥳。
+
+不要犹豫,**通过改进更复杂环境的实现**来迭代本单元(例如,如何将网络更改为卷积神经网络以处理帧作为观察?)。
+
+在下一个单元中,**我们将通过在Unity环境中训练智能体来学习更多关于Unity MLAgents的知识**。这样,你将准备好参加**AI对抗AI挑战,在那里你将训练你的智能体与其他智能体在雪球大战和足球比赛中竞争**。
+
+听起来很有趣吧?下次见!
+
+最后,我们很想**听听你对课程的看法以及我们如何改进它**。如果你有一些反馈,请 👉 [填写这个表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+我们在第5单元见!��
+
+### 持续学习,保持精彩 🤗
diff --git a/units/cn/unit4/introduction.mdx b/units/cn/unit4/introduction.mdx
new file mode 100644
index 00000000..317b93fb
--- /dev/null
+++ b/units/cn/unit4/introduction.mdx
@@ -0,0 +1,24 @@
+# 介绍 [[introduction]]
+
+
+
+在上一单元中,我们学习了深度Q学习。在这种基于价值的深度强化学习算法中,我们**使用深度神经网络来近似状态下每个可能动作的不同Q值。**
+
+自课程开始以来,我们只研究了基于价值的方法,**在这些方法中,我们估计价值函数作为寻找最优策略的中间步骤。**
+
+
+
+在基于价值的方法中,策略 **\\(π\\) 仅仅因为动作价值估计而存在,因为策略只是一个函数**(例如,贪婪策略),它将选择给定状态下具有最高价值的动作。
+
+通过基于策略的方法,我们希望直接优化策略,**而不需要学习价值函数这一中间步骤。**
+
+所以今天,**我们将学习基于策略的方法,并研究这些方法的一个子集,称为策略梯度**。然后,我们将使用PyTorch从头实现我们的第一个策略梯度算法,称为蒙特卡洛 **Reinforce**。
+然后,我们将使用CartPole-v1和PixelCopter环境测试其稳健性。
+
+之后,你将能够迭代并改进这个实现,以适用于更高级的环境。
+
+
+
+
+
+让我们开始吧!
diff --git a/units/cn/unit4/pg-theorem.mdx b/units/cn/unit4/pg-theorem.mdx
new file mode 100644
index 00000000..6bfa0e95
--- /dev/null
+++ b/units/cn/unit4/pg-theorem.mdx
@@ -0,0 +1,86 @@
+# (可选) 策略梯度定理
+
+在这个可选部分中,我们将**研究如何对我们将用来近似策略梯度的目标函数进行微分**。
+
+让我们首先回顾一下我们的不同公式:
+
+1. 目标函数
+
+
+
+### 推送到Hub
+#### 请勿修改此代码
+
+```python
+from huggingface_hub import HfApi, snapshot_download
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import json
+import imageio
+
+import tempfile
+
+import os
+```
+
+```python
+def record_video(env, policy, out_directory, fps=30):
+ """
+ Generate a replay video of the agent
+ :param env
+ :param Qtable: Qtable of our agent
+ :param out_directory
+ :param fps: how many frame per seconds (with taxi-v3 and frozenlake-v1 we use 1)
+ """
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _ = policy.act(state)
+ state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+```
+
+```python
+def push_to_hub(repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30
+ ):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the Hub
+
+ :param repo_id: repo_id: id of the model repository from the Hugging Face Hub
+ :param model: the pytorch model we want to save
+ :param hyperparameters: training hyperparameters
+ :param eval_env: evaluation environment
+ :param video_fps: how many frame per seconds to record our video replay
+ """
+
+ _, repo_name = repo_id.split("/")
+ api = HfApi()
+
+ # Step 1: Create the repo
+ repo_url = api.create_repo(
+ repo_id=repo_id,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ local_directory = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model, local_directory / "model.pt")
+
+ # Step 3: Save the hyperparameters to JSON
+ with open(local_directory / "hyperparameters.json", "w") as outfile:
+ json.dump(hyperparameters, outfile)
+
+ # Step 4: Evaluate the model and build JSON
+ mean_reward, std_reward = evaluate_agent(eval_env,
+ hyperparameters["max_t"],
+ hyperparameters["n_evaluation_episodes"],
+ model)
+ # Get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters["env_id"],
+ "mean_reward": mean_reward,
+ "n_evaluation_episodes": hyperparameters["n_evaluation_episodes"],
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(local_directory / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 5: Create the model card
+ env_name = hyperparameters["env_id"]
+
+ metadata = {}
+ metadata["tags"] = [
+ env_name,
+ "reinforce",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-class"
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=repo_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_name,
+ dataset_id=env_name,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ model_card = f"""
+ # **Reinforce** Agent playing **{env_id}**
+ This is a trained model of a **Reinforce** agent playing **{env_id}** .
+ To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
+ """
+
+ readme_path = local_directory / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+ # Step 6: Record a video
+ video_path = local_directory / "replay.mp4"
+ record_video(env, model, video_path, video_fps)
+
+ # Step 7. Push everything to the Hub
+ api.upload_folder(
+ repo_id=repo_id,
+ folder_path=local_directory,
+ path_in_repo=".",
+ )
+
+ print(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+```
+
+通过使用`push_to_hub`,**你可以评估、记录回放、生成智能体的模型卡片,并将其推送到Hub**。
+
+这样:
+- 你可以**展示你的工作** 🔥
+- 你可以**可视化你的智能体的游戏过程** 👀
+- 你可以**与社区分享一个其他人可以使用的智能体** 💾
+- 你可以**访问排行榜 🏆 查看你的智能体与同学相比表现如何** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+
+要能够与社区分享你的模型,还需要遵循三个步骤:
+
+1️⃣ (如果尚未完成)创建一个HF账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录,然后你需要从Hugging Face网站存储你的认证令牌。
+- 创建一个新令牌(https://huggingface.co/settings/tokens)**具有写入权限**
+
+
+
+
+
+
+```python
+notebook_login()
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令:`huggingface-cli login`(或`login`)
+
+3️⃣ 我们现在准备使用`package_to_hub()`函数将训练好的智能体推送到🤗 Hub 🔥
+
+```python
+repo_id = "" # TODO 定义你的仓库ID {username/Reinforce-{model-id}}
+push_to_hub(
+ repo_id,
+ cartpole_policy, # 我们想要保存的模型
+ cartpole_hyperparameters, # 超参数
+ eval_env, # 评估环境
+ video_fps=30
+)
+```
+
+现在我们已经测试了我们实现的鲁棒性,让我们尝试一个更复杂的环境:PixelCopter 🚁
+
+
+
+
+## 第二个智能体:PixelCopter 🚁
+
+### 研究PixelCopter环境 👀
+- [环境文档](https://pygame-learning-environment.readthedocs.io/en/latest/user/games/pixelcopter.html)
+
+
+```python
+env_id = "Pixelcopter-PLE-v0"
+env = gym.make(env_id)
+eval_env = gym.make(env_id)
+s_size = env.observation_space.shape[0]
+a_size = env.action_space.n
+```
+
+```python
+print("_____OBSERVATION SPACE_____ \n")
+print("The State Space is: ", s_size)
+print("Sample observation", env.observation_space.sample()) # Get a random observation
+```
+
+```python
+print("\n _____ACTION SPACE_____ \n")
+print("The Action Space is: ", a_size)
+print("Action Space Sample", env.action_space.sample()) # Take a random action
+```
+
+观察空间(7) 👀:
+- 玩家y位置
+- 玩家速度
+- 玩家到地面的距离
+- 玩家到天花板的距离
+- 下一个障碍物与玩家的x距离
+- 下一个障碍物顶部y位置
+- 下一个障碍物底部y位置
+
+动作空间(2) 🎮:
+- 向上(按加速器)
+- 什么都不做(不按加速器)
+
+奖励函数 💰:
+- 每通过一个垂直障碍物,获得+1的正奖励。每次达到终止状态时,获得-1的负奖励。
+
+### 定义新的策略 🧠
+- 由于环境更复杂,我们需要一个更深的神经网络
+
+```python
+class Policy(nn.Module):
+ def __init__(self, s_size, a_size, h_size):
+ super(Policy, self).__init__()
+ # Define the three layers here
+
+ def forward(self, x):
+ # Define the forward process here
+ return F.softmax(x, dim=1)
+
+ def act(self, state):
+ state = torch.from_numpy(state).float().unsqueeze(0).to(device)
+ probs = self.forward(state).cpu()
+ m = Categorical(probs)
+ action = m.sample()
+ return action.item(), m.log_prob(action)
+```
+
+#### 解决方案
+
+```python
+class Policy(nn.Module):
+ def __init__(self, s_size, a_size, h_size):
+ super(Policy, self).__init__()
+ self.fc1 = nn.Linear(s_size, h_size)
+ self.fc2 = nn.Linear(h_size, h_size * 2)
+ self.fc3 = nn.Linear(h_size * 2, a_size)
+
+ def forward(self, x):
+ x = F.relu(self.fc1(x))
+ x = F.relu(self.fc2(x))
+ x = self.fc3(x)
+ return F.softmax(x, dim=1)
+
+ def act(self, state):
+ state = torch.from_numpy(state).float().unsqueeze(0).to(device)
+ probs = self.forward(state).cpu()
+ m = Categorical(probs)
+ action = m.sample()
+ return action.item(), m.log_prob(action)
+```
+
+### 定义超参数 ⚙️
+- 因为这个环境更复杂。
+- 特别是隐藏层大小,我们需要更多的神经元。
+
+```python
+pixelcopter_hyperparameters = {
+ "h_size": 64,
+ "n_training_episodes": 50000,
+ "n_evaluation_episodes": 10,
+ "max_t": 10000,
+ "gamma": 0.99,
+ "lr": 1e-4,
+ "env_id": env_id,
+ "state_space": s_size,
+ "action_space": a_size,
+}
+```
+
+### 训练它
+- 我们现在准备训练我们的智能体 🔥。
+
+```python
+# Create policy and place it to the device
+# torch.manual_seed(50)
+pixelcopter_policy = Policy(
+ pixelcopter_hyperparameters["state_space"],
+ pixelcopter_hyperparameters["action_space"],
+ pixelcopter_hyperparameters["h_size"],
+).to(device)
+pixelcopter_optimizer = optim.Adam(pixelcopter_policy.parameters(), lr=pixelcopter_hyperparameters["lr"])
+```
+
+```python
+scores = reinforce(
+ pixelcopter_policy,
+ pixelcopter_optimizer,
+ pixelcopter_hyperparameters["n_training_episodes"],
+ pixelcopter_hyperparameters["max_t"],
+ pixelcopter_hyperparameters["gamma"],
+ 1000,
+)
+```
+
+### 在Hub上发布我们训练好的模型 🔥
+
+```python
+repo_id = "" # TODO 定义你的仓库ID {username/Reinforce-{model-id}}
+push_to_hub(
+ repo_id,
+ pixelcopter_policy, # 我们想要保存的模型
+ pixelcopter_hyperparameters, # 超参数
+ eval_env, # 评估环境
+ video_fps=30
+)
+```
+
+## 一些额外的挑战 🏆
+
+学习的最佳方式**是自己尝试**!正如你所看到的,当前的智能体表现不是很好。作为第一个建议,你可以训练更多步骤。但也尝试找到更好的参数。
+
+在[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)中,你会找到你的智能体。你能登上榜首吗?
+
+以下是一些攀登排行榜的想法:
+* 训练更多步骤
+* 通过查看你的同学们所做的工作,尝试不同的超参数 👉 https://huggingface.co/models?other=reinforce
+* **将你新训练的模型**推送到Hub 🔥
+* **改进实现以适应更复杂的环境**(例如,如何将网络更改为卷积神经网络以处理帧作为观察?)
+
+________________________________________________________________________
+
+**恭喜你完成本单元**!这里有很多信息。
+也恭喜你完成教程。你刚刚使用PyTorch从头编写了第一个深度强化学习智能体,并将其分享到Hub上 🥳。
+
+不要犹豫,**通过改进更复杂环境的实现**来迭代本单元(例如,如何将网络更改为卷积神经网络以处理帧作为观察?)。
+
+在下一个单元中,**我们将通过在Unity环境中训练智能体来学习更多关于Unity MLAgents的知识**。这样,你将准备好参加**AI对抗AI挑战,在那里你将训练你的智能体与其他智能体在雪球大战和足球比赛中竞争**。
+
+听起来很有趣吧?下次见!
+
+最后,我们很想**听听你对课程的看法以及我们如何改进它**。如果你有一些反馈,请 👉 [填写这个表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+我们在第5单元见!��
+
+### 持续学习,保持精彩 🤗
diff --git a/units/cn/unit4/introduction.mdx b/units/cn/unit4/introduction.mdx
new file mode 100644
index 00000000..317b93fb
--- /dev/null
+++ b/units/cn/unit4/introduction.mdx
@@ -0,0 +1,24 @@
+# 介绍 [[introduction]]
+
+
+
+在上一单元中,我们学习了深度Q学习。在这种基于价值的深度强化学习算法中,我们**使用深度神经网络来近似状态下每个可能动作的不同Q值。**
+
+自课程开始以来,我们只研究了基于价值的方法,**在这些方法中,我们估计价值函数作为寻找最优策略的中间步骤。**
+
+
+
+在基于价值的方法中,策略 **\\(π\\) 仅仅因为动作价值估计而存在,因为策略只是一个函数**(例如,贪婪策略),它将选择给定状态下具有最高价值的动作。
+
+通过基于策略的方法,我们希望直接优化策略,**而不需要学习价值函数这一中间步骤。**
+
+所以今天,**我们将学习基于策略的方法,并研究这些方法的一个子集,称为策略梯度**。然后,我们将使用PyTorch从头实现我们的第一个策略梯度算法,称为蒙特卡洛 **Reinforce**。
+然后,我们将使用CartPole-v1和PixelCopter环境测试其稳健性。
+
+之后,你将能够迭代并改进这个实现,以适用于更高级的环境。
+
+
+
+
+
+让我们开始吧!
diff --git a/units/cn/unit4/pg-theorem.mdx b/units/cn/unit4/pg-theorem.mdx
new file mode 100644
index 00000000..6bfa0e95
--- /dev/null
+++ b/units/cn/unit4/pg-theorem.mdx
@@ -0,0 +1,86 @@
+# (可选) 策略梯度定理
+
+在这个可选部分中,我们将**研究如何对我们将用来近似策略梯度的目标函数进行微分**。
+
+让我们首先回顾一下我们的不同公式:
+
+1. 目标函数
+
+ +
+
+2. 轨迹的概率(假设动作来自 \\(\pi_\theta\\)):
+
+
+
+
+2. 轨迹的概率(假设动作来自 \\(\pi_\theta\\)):
+
+ +
+
+所以我们有:
+
+\\(\nabla_\theta J(\theta) = \nabla_\theta \sum_{\tau}P(\tau;\theta)R(\tau)\\)
+
+
+我们可以将和的梯度重写为梯度的和:
+
+\\( = \sum_{\tau} \nabla_\theta (P(\tau;\theta)R(\tau)) = \sum_{\tau} \nabla_\theta P(\tau;\theta)R(\tau) \\) 因为 \\(R(\tau)\\) 不依赖于 \\(\theta\\)
+
+然后我们将和中的每一项乘以 \\(\frac{P(\tau;\theta)}{P(\tau;\theta)}\\)(这是可能的,因为它等于1)
+
+\\( = \sum_{\tau} \frac{P(\tau;\theta)}{P(\tau;\theta)}\nabla_\theta P(\tau;\theta)R(\tau) \\)
+
+
+我们可以进一步简化,因为 \\( \frac{P(\tau;\theta)}{P(\tau;\theta)}\nabla_\theta P(\tau;\theta) = P(\tau;\theta)\frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)} \\)。
+
+因此,我们可以将和重写为
+
+\\( P(\tau;\theta)\frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)}= \sum_{\tau} P(\tau;\theta) \frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)}R(\tau) \\)
+
+然后我们可以使用*对数导数技巧*(也称为*似然比技巧*或*REINFORCE技巧*),这是微积分中的一个简单规则,意味着 \\( \nabla_x log f(x) = \frac{\nabla_x f(x)}{f(x)} \\)
+
+所以鉴于我们有 \\(\frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)} \\),我们将其转换为 \\(\nabla_\theta log P(\tau|\theta) \\)
+
+
+
+所以这是我们的似然策略梯度:
+
+\\( \nabla_\theta J(\theta) = \sum_{\tau} P(\tau;\theta) \nabla_\theta log P(\tau;\theta) R(\tau) \\)
+
+
+
+
+
+感谢这个新公式,我们可以使用轨迹样本来估计梯度(如果你喜欢,我们可以用基于样本的估计来近似似然比策略梯度)。
+
+\\(\nabla_\theta J(\theta) = \frac{1}{m} \sum^{m}_{i=1} \nabla_\theta log P(\tau^{(i)};\theta)R(\tau^{(i)})\\) 其中每个 \\(\tau^{(i)}\\) 是一个采样的轨迹。
+
+
+但我们在这里仍然有一些数学工作要做:我们需要简化 \\( \nabla_\theta log P(\tau|\theta) \\)
+
+我们知道:
+
+\\(\nabla_\theta log P(\tau^{(i)};\theta)= \nabla_\theta log[ \mu(s_0) \prod_{t=0}^{H} P(s_{t+1}^{(i)}|s_{t}^{(i)}, a_{t}^{(i)}) \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)})]\\)
+
+其中 \\(\mu(s_0)\\) 是初始状态分布,\\( P(s_{t+1}^{(i)}|s_{t}^{(i)}, a_{t}^{(i)}) \\) 是MDP的状态转移动态。
+
+我们知道乘积的对数等于对数的和:
+
+\\(\nabla_\theta log P(\tau^{(i)};\theta)= \nabla_\theta \left[log \mu(s_0) + \sum\limits_{t=0}^{H}log P(s_{t+1}^{(i)}|s_{t}^{(i)} a_{t}^{(i)}) + \sum\limits_{t=0}^{H}log \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)})\right] \\)
+
+我们还知道和的梯度等于梯度的和:
+
+\\( \nabla_\theta log P(\tau^{(i)};\theta)=\nabla_\theta log\mu(s_0) + \nabla_\theta \sum\limits_{t=0}^{H} log P(s_{t+1}^{(i)}|s_{t}^{(i)} a_{t}^{(i)}) + \nabla_\theta \sum\limits_{t=0}^{H} log \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)}) \\)
+
+
+由于初始状态分布和MDP的状态转移动态都不依赖于 \\(\theta\\),两项的导数都为0。所以我们可以删除它们:
+
+因为:
+\\(\nabla_\theta \sum_{t=0}^{H} log P(s_{t+1}^{(i)}|s_{t}^{(i)} a_{t}^{(i)}) = 0 \\) 且 \\( \nabla_\theta \mu(s_0) = 0\\)
+
+\\(\nabla_\theta log P(\tau^{(i)};\theta) = \nabla_\theta \sum_{t=0}^{H} log \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)})\\)
+
+我们可以将和的梯度重写为梯度的和:
+
+\\( \nabla_\theta log P(\tau^{(i)};\theta)= \sum_{t=0}^{H} \nabla_\theta log \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)}) \\)
+
+所以,估计策略梯度的最终公式是:
+
+\\( \nabla_{\theta} J(\theta) = \hat{g} = \frac{1}{m} \sum^{m}_{i=1} \sum^{H}_{t=0} \nabla_\theta \log \pi_\theta(a^{(i)}_{t} | s_{t}^{(i)})R(\tau^{(i)}) \\)
diff --git a/units/cn/unit4/policy-gradient.mdx b/units/cn/unit4/policy-gradient.mdx
new file mode 100644
index 00000000..feb81eea
--- /dev/null
+++ b/units/cn/unit4/policy-gradient.mdx
@@ -0,0 +1,122 @@
+# 深入了解策略梯度方法
+
+## 获取全局视角
+
+我们刚刚了解到策略梯度方法旨在找到**最大化期望回报**的参数 \\( \theta \\)。
+
+其思想是我们有一个*参数化的随机策略*。在我们的例子中,神经网络输出动作的概率分布。采取每个动作的概率也被称为*动作偏好*。
+
+如果我们以CartPole-v1为例:
+- 作为输入,我们有一个状态。
+- 作为输出,我们有该状态下动作的概率分布。
+
+
+
+
+所以我们有:
+
+\\(\nabla_\theta J(\theta) = \nabla_\theta \sum_{\tau}P(\tau;\theta)R(\tau)\\)
+
+
+我们可以将和的梯度重写为梯度的和:
+
+\\( = \sum_{\tau} \nabla_\theta (P(\tau;\theta)R(\tau)) = \sum_{\tau} \nabla_\theta P(\tau;\theta)R(\tau) \\) 因为 \\(R(\tau)\\) 不依赖于 \\(\theta\\)
+
+然后我们将和中的每一项乘以 \\(\frac{P(\tau;\theta)}{P(\tau;\theta)}\\)(这是可能的,因为它等于1)
+
+\\( = \sum_{\tau} \frac{P(\tau;\theta)}{P(\tau;\theta)}\nabla_\theta P(\tau;\theta)R(\tau) \\)
+
+
+我们可以进一步简化,因为 \\( \frac{P(\tau;\theta)}{P(\tau;\theta)}\nabla_\theta P(\tau;\theta) = P(\tau;\theta)\frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)} \\)。
+
+因此,我们可以将和重写为
+
+\\( P(\tau;\theta)\frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)}= \sum_{\tau} P(\tau;\theta) \frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)}R(\tau) \\)
+
+然后我们可以使用*对数导数技巧*(也称为*似然比技巧*或*REINFORCE技巧*),这是微积分中的一个简单规则,意味着 \\( \nabla_x log f(x) = \frac{\nabla_x f(x)}{f(x)} \\)
+
+所以鉴于我们有 \\(\frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)} \\),我们将其转换为 \\(\nabla_\theta log P(\tau|\theta) \\)
+
+
+
+所以这是我们的似然策略梯度:
+
+\\( \nabla_\theta J(\theta) = \sum_{\tau} P(\tau;\theta) \nabla_\theta log P(\tau;\theta) R(\tau) \\)
+
+
+
+
+
+感谢这个新公式,我们可以使用轨迹样本来估计梯度(如果你喜欢,我们可以用基于样本的估计来近似似然比策略梯度)。
+
+\\(\nabla_\theta J(\theta) = \frac{1}{m} \sum^{m}_{i=1} \nabla_\theta log P(\tau^{(i)};\theta)R(\tau^{(i)})\\) 其中每个 \\(\tau^{(i)}\\) 是一个采样的轨迹。
+
+
+但我们在这里仍然有一些数学工作要做:我们需要简化 \\( \nabla_\theta log P(\tau|\theta) \\)
+
+我们知道:
+
+\\(\nabla_\theta log P(\tau^{(i)};\theta)= \nabla_\theta log[ \mu(s_0) \prod_{t=0}^{H} P(s_{t+1}^{(i)}|s_{t}^{(i)}, a_{t}^{(i)}) \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)})]\\)
+
+其中 \\(\mu(s_0)\\) 是初始状态分布,\\( P(s_{t+1}^{(i)}|s_{t}^{(i)}, a_{t}^{(i)}) \\) 是MDP的状态转移动态。
+
+我们知道乘积的对数等于对数的和:
+
+\\(\nabla_\theta log P(\tau^{(i)};\theta)= \nabla_\theta \left[log \mu(s_0) + \sum\limits_{t=0}^{H}log P(s_{t+1}^{(i)}|s_{t}^{(i)} a_{t}^{(i)}) + \sum\limits_{t=0}^{H}log \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)})\right] \\)
+
+我们还知道和的梯度等于梯度的和:
+
+\\( \nabla_\theta log P(\tau^{(i)};\theta)=\nabla_\theta log\mu(s_0) + \nabla_\theta \sum\limits_{t=0}^{H} log P(s_{t+1}^{(i)}|s_{t}^{(i)} a_{t}^{(i)}) + \nabla_\theta \sum\limits_{t=0}^{H} log \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)}) \\)
+
+
+由于初始状态分布和MDP的状态转移动态都不依赖于 \\(\theta\\),两项的导数都为0。所以我们可以删除它们:
+
+因为:
+\\(\nabla_\theta \sum_{t=0}^{H} log P(s_{t+1}^{(i)}|s_{t}^{(i)} a_{t}^{(i)}) = 0 \\) 且 \\( \nabla_\theta \mu(s_0) = 0\\)
+
+\\(\nabla_\theta log P(\tau^{(i)};\theta) = \nabla_\theta \sum_{t=0}^{H} log \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)})\\)
+
+我们可以将和的梯度重写为梯度的和:
+
+\\( \nabla_\theta log P(\tau^{(i)};\theta)= \sum_{t=0}^{H} \nabla_\theta log \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)}) \\)
+
+所以,估计策略梯度的最终公式是:
+
+\\( \nabla_{\theta} J(\theta) = \hat{g} = \frac{1}{m} \sum^{m}_{i=1} \sum^{H}_{t=0} \nabla_\theta \log \pi_\theta(a^{(i)}_{t} | s_{t}^{(i)})R(\tau^{(i)}) \\)
diff --git a/units/cn/unit4/policy-gradient.mdx b/units/cn/unit4/policy-gradient.mdx
new file mode 100644
index 00000000..feb81eea
--- /dev/null
+++ b/units/cn/unit4/policy-gradient.mdx
@@ -0,0 +1,122 @@
+# 深入了解策略梯度方法
+
+## 获取全局视角
+
+我们刚刚了解到策略梯度方法旨在找到**最大化期望回报**的参数 \\( \theta \\)。
+
+其思想是我们有一个*参数化的随机策略*。在我们的例子中,神经网络输出动作的概率分布。采取每个动作的概率也被称为*动作偏好*。
+
+如果我们以CartPole-v1为例:
+- 作为输入,我们有一个状态。
+- 作为输出,我们有该状态下动作的概率分布。
+
+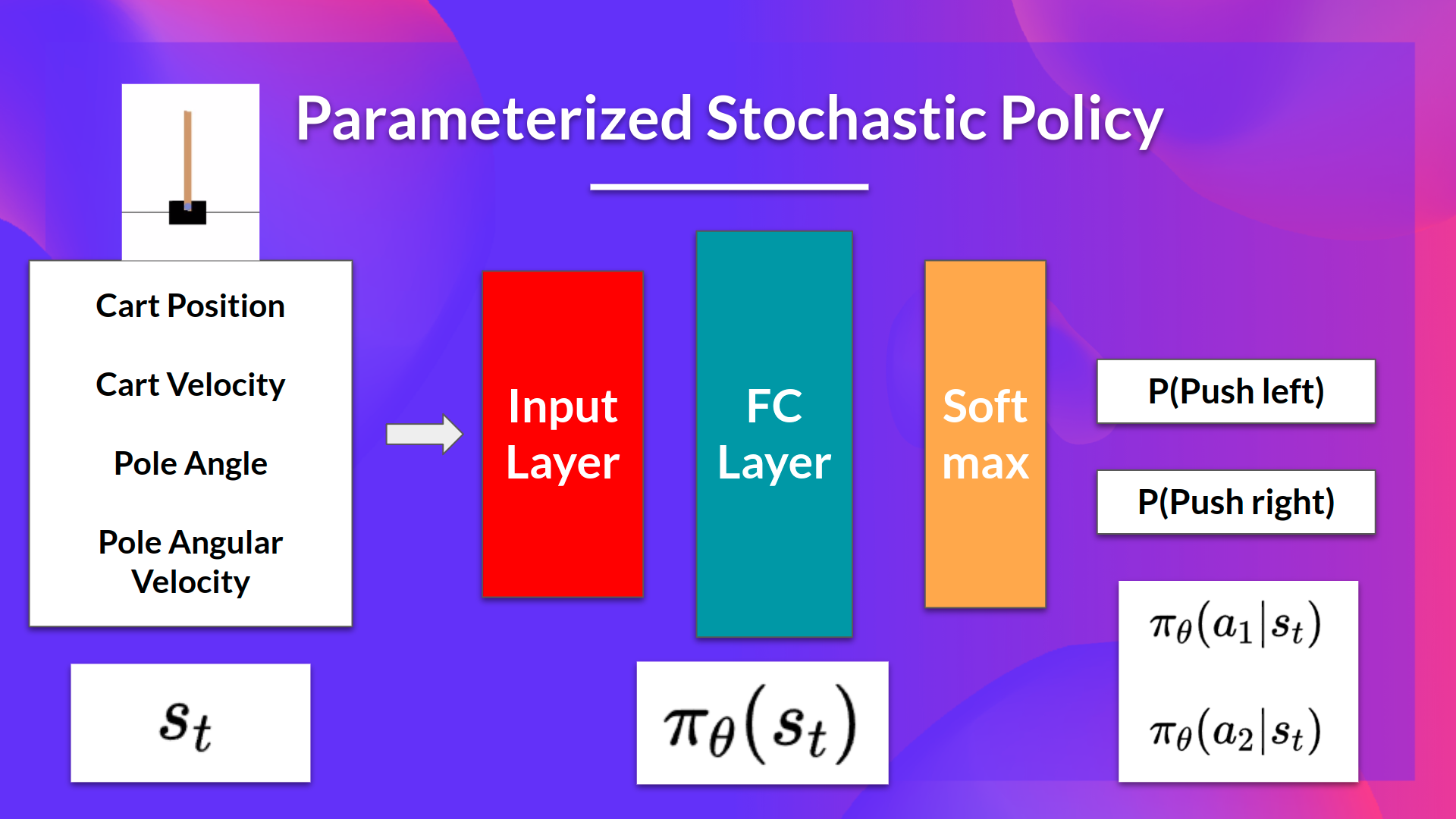 +
+我们使用策略梯度的目标是**控制动作的概率分布**,通过调整策略,使**好的动作(最大化回报的动作)在未来被更频繁地采样。**
+每次智能体与环境交互时,我们调整参数,使好的动作在未来更有可能被采样。
+
+但是**我们如何使用期望回报来优化权重**?
+
+思路是我们要**让智能体在一个回合中交互**。如果我们赢得了这个回合,我们认为采取的每个动作都是好的,必须在未来更多地被采样,因为它们导致了胜利。
+
+所以对于每个状态-动作对,我们想要增加 \\(P(a|s)\\):在该状态下采取该动作的概率。或者如果我们输了,则减少。
+
+策略梯度算法(简化版)看起来像这样:
+
+
+
+我们使用策略梯度的目标是**控制动作的概率分布**,通过调整策略,使**好的动作(最大化回报的动作)在未来被更频繁地采样。**
+每次智能体与环境交互时,我们调整参数,使好的动作在未来更有可能被采样。
+
+但是**我们如何使用期望回报来优化权重**?
+
+思路是我们要**让智能体在一个回合中交互**。如果我们赢得了这个回合,我们认为采取的每个动作都是好的,必须在未来更多地被采样,因为它们导致了胜利。
+
+所以对于每个状态-动作对,我们想要增加 \\(P(a|s)\\):在该状态下采取该动作的概率。或者如果我们输了,则减少。
+
+策略梯度算法(简化版)看起来像这样:
+
+  +
+
+现在我们已经了解了全局视角,让我们深入了解策略梯度方法。
+
+## 深入了解策略梯度方法
+
+我们有一个随机策略 \\(\pi\\),它有一个参数 \\(\theta\\)。这个 \\(\pi\\) 在给定状态的情况下,**输出动作的概率分布**。
+
+
+
+
+
+现在我们已经了解了全局视角,让我们深入了解策略梯度方法。
+
+## 深入了解策略梯度方法
+
+我们有一个随机策略 \\(\pi\\),它有一个参数 \\(\theta\\)。这个 \\(\pi\\) 在给定状态的情况下,**输出动作的概率分布**。
+
+
+  +
+
+其中 \\(\pi_\theta(a_t|s_t)\\) 是智能体在给定我们的策略的情况下,从状态 \\(s_t\\) 选择动作 \\(a_t\\) 的概率。
+
+**但我们如何知道我们的策略是否好?** 我们需要有一种方法来衡量它。为了知道这一点,我们定义了一个分数/目标函数,称为 \\(J(\theta)\\)。
+
+### 目标函数
+
+*目标函数*给出了给定轨迹(不考虑奖励的状态动作序列(与回合相反))的**智能体的性能**,它输出*期望累积奖励*。
+
+
+
+
+其中 \\(\pi_\theta(a_t|s_t)\\) 是智能体在给定我们的策略的情况下,从状态 \\(s_t\\) 选择动作 \\(a_t\\) 的概率。
+
+**但我们如何知道我们的策略是否好?** 我们需要有一种方法来衡量它。为了知道这一点,我们定义了一个分数/目标函数,称为 \\(J(\theta)\\)。
+
+### 目标函数
+
+*目标函数*给出了给定轨迹(不考虑奖励的状态动作序列(与回合相反))的**智能体的性能**,它输出*期望累积奖励*。
+
+ +
+让我们对这个公式给出更多细节:
+- *期望回报*(也称为期望累积奖励),是所有可能的回报 \\(R(\tau)\\) 值的加权平均(权重由 \\(P(\tau;\theta)\\) 给出)。
+
+
+
+
+- \\(R(\tau)\\):任意轨迹的回报。要使用这个量来计算期望回报,我们需要将其乘以每个可能轨迹的概率。
+
+- \\(P(\tau;\theta)\\):每个可能轨迹 \\(\tau\\) 的概率(该概率取决于 \\(\theta\\),因为它定义了用于选择轨迹动作的策略,这会影响访问的状态)。
+
+
+
+- \\(J(\theta)\\):期望回报,我们通过对所有轨迹求和来计算它,给定 \\(\theta\\) 采取该轨迹的概率乘以该轨迹的回报。
+
+我们的目标是通过找到 \\(\theta\\),使其输出最佳动作概率分布,从而最大化期望累积奖励:
+
+
+
+
+让我们对这个公式给出更多细节:
+- *期望回报*(也称为期望累积奖励),是所有可能的回报 \\(R(\tau)\\) 值的加权平均(权重由 \\(P(\tau;\theta)\\) 给出)。
+
+
+
+
+- \\(R(\tau)\\):任意轨迹的回报。要使用这个量来计算期望回报,我们需要将其乘以每个可能轨迹的概率。
+
+- \\(P(\tau;\theta)\\):每个可能轨迹 \\(\tau\\) 的概率(该概率取决于 \\(\theta\\),因为它定义了用于选择轨迹动作的策略,这会影响访问的状态)。
+
+
+
+- \\(J(\theta)\\):期望回报,我们通过对所有轨迹求和来计算它,给定 \\(\theta\\) 采取该轨迹的概率乘以该轨迹的回报。
+
+我们的目标是通过找到 \\(\theta\\),使其输出最佳动作概率分布,从而最大化期望累积奖励:
+
+
+ +
+
+## 梯度上升和策略梯度定理
+
+策略梯度是一个优化问题:我们想要找到 \\(\theta\\) 的值,使我们的目标函数 \\(J(\theta)\\) 最大化,所以我们需要使用**梯度上升**。它是*梯度下降*的反向,因为它给出了 \\(J(\theta)\\) 最陡增加的方向。
+
+(如果你需要复习梯度下降和梯度上升之间的区别,[查看这个](https://www.baeldung.com/cs/gradient-descent-vs-ascent)和[这个](https://stats.stackexchange.com/questions/258721/gradient-ascent-vs-gradient-descent-in-logistic-regression))。
+
+我们的梯度上升更新步骤是:
+
+\\( \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
+
+我们可以反复应用这个更新,希望 \\(\theta\\) 收敛到使 \\(J(\theta)\\) 最大化的值。
+
+然而,计算 \\(J(\theta)\\) 的导数有两个问题:
+1. 我们无法计算目标函数的真实梯度,因为它需要计算每个可能轨迹的概率,这在计算上非常昂贵。
+所以我们想要**用基于样本的估计(收集一些轨迹)来计算梯度估计**。
+
+2. 我们还有另一个问题,我在下一个可选部分中解释。为了对这个目标函数进行微分,我们需要对状态分布进行微分,称为马尔可夫决策过程动态。这与环境相关。它给出了环境在给定当前状态和智能体采取的动作的情况下,进入下一个状态的概率。问题是我们可能不了解它,所以无法对其进行微分。
+
+
+
+幸运的是,我们将使用一个称为策略梯度定理的解决方案,它将帮助我们将目标函数重新表述为一个可微分的函数,不涉及状态分布的微分。
+
+
+
+
+## 梯度上升和策略梯度定理
+
+策略梯度是一个优化问题:我们想要找到 \\(\theta\\) 的值,使我们的目标函数 \\(J(\theta)\\) 最大化,所以我们需要使用**梯度上升**。它是*梯度下降*的反向,因为它给出了 \\(J(\theta)\\) 最陡增加的方向。
+
+(如果你需要复习梯度下降和梯度上升之间的区别,[查看这个](https://www.baeldung.com/cs/gradient-descent-vs-ascent)和[这个](https://stats.stackexchange.com/questions/258721/gradient-ascent-vs-gradient-descent-in-logistic-regression))。
+
+我们的梯度上升更新步骤是:
+
+\\( \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
+
+我们可以反复应用这个更新,希望 \\(\theta\\) 收敛到使 \\(J(\theta)\\) 最大化的值。
+
+然而,计算 \\(J(\theta)\\) 的导数有两个问题:
+1. 我们无法计算目标函数的真实梯度,因为它需要计算每个可能轨迹的概率,这在计算上非常昂贵。
+所以我们想要**用基于样本的估计(收集一些轨迹)来计算梯度估计**。
+
+2. 我们还有另一个问题,我在下一个可选部分中解释。为了对这个目标函数进行微分,我们需要对状态分布进行微分,称为马尔可夫决策过程动态。这与环境相关。它给出了环境在给定当前状态和智能体采取的动作的情况下,进入下一个状态的概率。问题是我们可能不了解它,所以无法对其进行微分。
+
+
+
+幸运的是,我们将使用一个称为策略梯度定理的解决方案,它将帮助我们将目标函数重新表述为一个可微分的函数,不涉及状态分布的微分。
+
+ +
+如果你想了解我们如何推导这个用于近似梯度的公式,请查看下一个(可选)部分。
+
+## Reinforce算法(蒙特卡洛Reinforce)
+
+Reinforce算法,也称为蒙特卡洛策略梯度,是一种策略梯度算法,**使用整个回合的估计回报来更新策略参数** \\(\theta\\):
+
+在循环中:
+- 使用策略 \\(\pi_\theta\\) 收集一个回合 \\(\tau\\)
+- 使用该回合来估计梯度 \\(\hat{g} = \nabla_\theta J(\theta)\\)
+
+
+
+
+如果你想了解我们如何推导这个用于近似梯度的公式,请查看下一个(可选)部分。
+
+## Reinforce算法(蒙特卡洛Reinforce)
+
+Reinforce算法,也称为蒙特卡洛策略梯度,是一种策略梯度算法,**使用整个回合的估计回报来更新策略参数** \\(\theta\\):
+
+在循环中:
+- 使用策略 \\(\pi_\theta\\) 收集一个回合 \\(\tau\\)
+- 使用该回合来估计梯度 \\(\hat{g} = \nabla_\theta J(\theta)\\)
+
+
+ 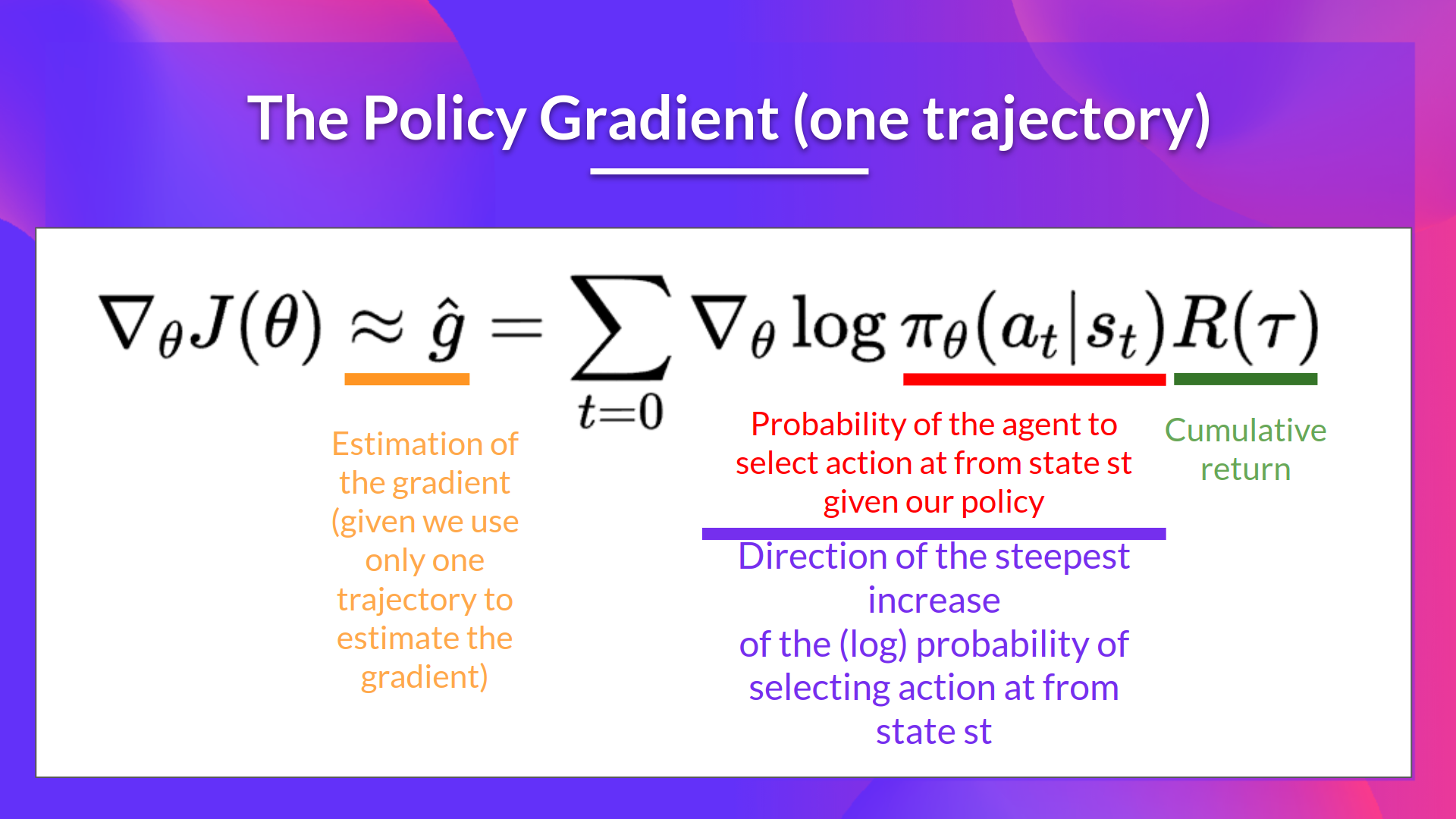 +
+
+- 更新策略的权重:\\(\theta \leftarrow \theta + \alpha \hat{g}\\)
+
+我们可以这样解释这个更新:
+
+- \\(\nabla_\theta log \pi_\theta(a_t|s_t)\\) 是**选择动作 \\(a_t\\) 从状态 \\(s_t\\) 的(对数)概率最陡增加的方向**。
+这告诉我们**如果我们想增加/减少在状态 \\(s_t\\) 选择动作 \\(a_t\\) 的对数概率,我们应该如何改变策略的权重**。
+
+- \\(R(\tau)\\):是评分函数:
+ - 如果回报高,它将**推高**(状态,动作)组合的概率。
+ - 否则,如果回报低,它将**推低**(状态,动作)组合的概率。
+
+
+我们也可以**收集多个回合(轨迹)**来估计梯度:
+
+
+
+
+- 更新策略的权重:\\(\theta \leftarrow \theta + \alpha \hat{g}\\)
+
+我们可以这样解释这个更新:
+
+- \\(\nabla_\theta log \pi_\theta(a_t|s_t)\\) 是**选择动作 \\(a_t\\) 从状态 \\(s_t\\) 的(对数)概率最陡增加的方向**。
+这告诉我们**如果我们想增加/减少在状态 \\(s_t\\) 选择动作 \\(a_t\\) 的对数概率,我们应该如何改变策略的权重**。
+
+- \\(R(\tau)\\):是评分函数:
+ - 如果回报高,它将**推高**(状态,动作)组合的概率。
+ - 否则,如果回报低,它将**推低**(状态,动作)组合的概率。
+
+
+我们也可以**收集多个回合(轨迹)**来估计梯度:
+
+ 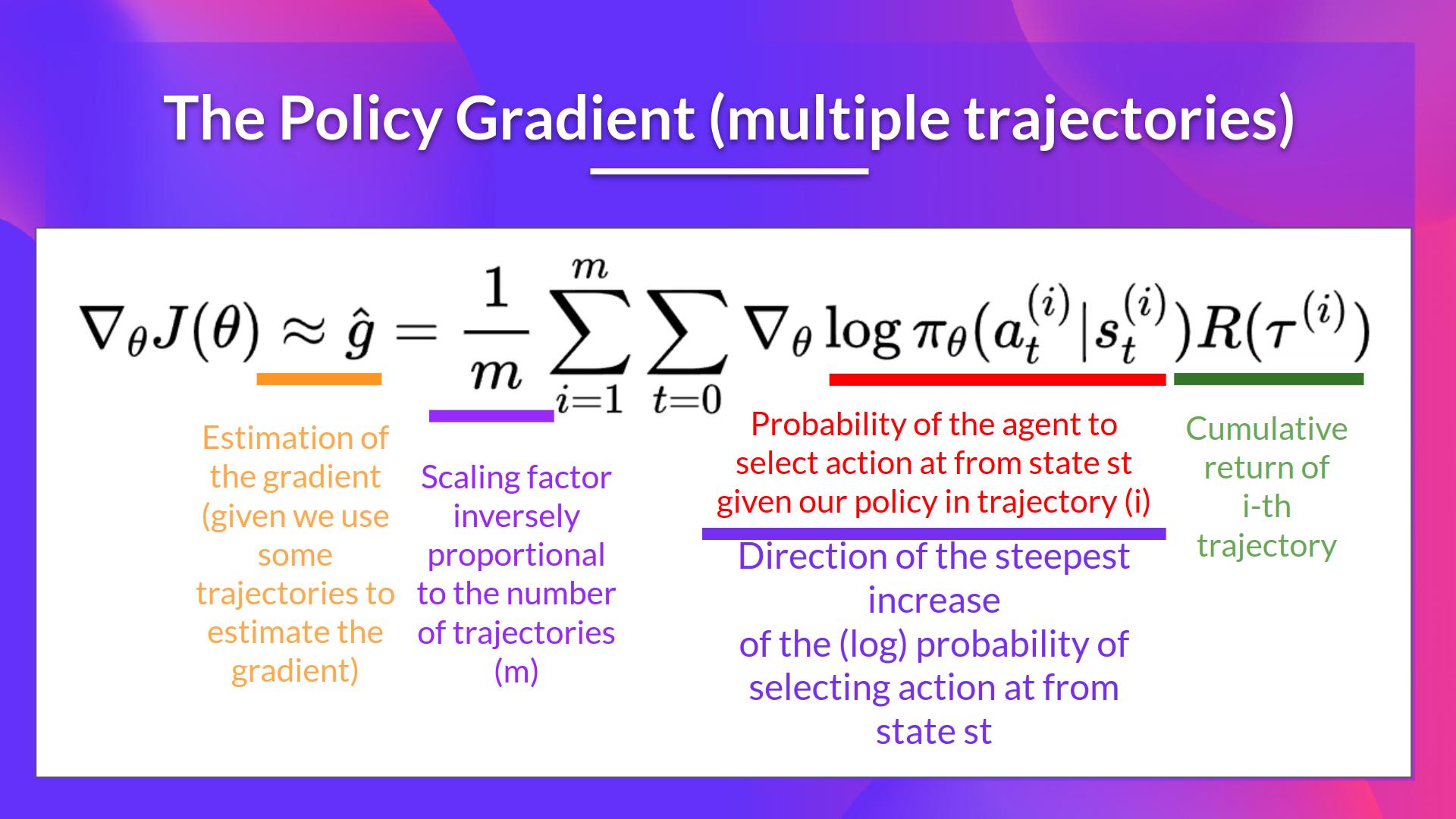 +
diff --git a/units/cn/unit4/quiz.mdx b/units/cn/unit4/quiz.mdx
new file mode 100644
index 00000000..6fbde600
--- /dev/null
+++ b/units/cn/unit4/quiz.mdx
@@ -0,0 +1,82 @@
+# 测验
+
+学习的最佳方式和[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法**是测试自己。**这将帮助你找出**需要加强知识的地方**。
+
+
+### 问题1:相比于基于价值的方法,策略梯度有哪些优势?(选择所有适用的)
+
+
+
+### 问题2:什么是策略梯度定理?
+
+
+
diff --git a/units/cn/unit4/quiz.mdx b/units/cn/unit4/quiz.mdx
new file mode 100644
index 00000000..6fbde600
--- /dev/null
+++ b/units/cn/unit4/quiz.mdx
@@ -0,0 +1,82 @@
+# 测验
+
+学习的最佳方式和[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法**是测试自己。**这将帮助你找出**需要加强知识的地方**。
+
+
+### 问题1:相比于基于价值的方法,策略梯度有哪些优势?(选择所有适用的)
+
+
+
+### 问题2:什么是策略梯度定理?
+
+
+解答
+
+*策略梯度定理*是一个公式,它将帮助我们将目标函数重新表述为一个可微分的函数,不涉及状态分布的微分。
+
+
+
+
+
+
+### 问题3:基于策略的方法和策略梯度方法之间有什么区别?(选择所有适用的)
+
+
+
+
+### 问题4:为什么我们使用梯度上升而不是梯度下降来优化J(θ)?
+
+
+
+恭喜你完成这个测验 🥳,如果你错过了一些要点,花点时间重新阅读本章以加强(😏)你的知识。
diff --git a/units/cn/unit4/what-are-policy-based-methods.mdx b/units/cn/unit4/what-are-policy-based-methods.mdx
new file mode 100644
index 00000000..71d3568e
--- /dev/null
+++ b/units/cn/unit4/what-are-policy-based-methods.mdx
@@ -0,0 +1,42 @@
+# 什么是基于策略的方法?
+
+强化学习的主要目标是**找到最优策略 \\(\pi^{*}\\),使期望累积奖励最大化**。
+因为强化学习基于*奖励假设*:**所有目标都可以描述为期望累积奖励的最大化。**
+
+例如,在足球比赛中(你将在两个单元中训练智能体),目标是赢得比赛。我们可以在强化学习中将这个目标描述为
+**最大化进入对手球门的进球数**(当球越过球门线时)。以及**最小化进入你自己球门的进球数**。
+
+ +
+## 基于价值、基于策略和演员-评论家方法
+
+在第一单元中,我们看到了两种方法来找到(或者,大多数时候,近似)这个最优策略 \\(\pi^{*}\\)。
+
+- 在*基于价值的方法*中,我们学习一个价值函数。
+ - 其思想是最优价值函数导致最优策略 \\(\pi^{*}\\)。
+ - 我们的目标是**最小化预测值和目标值之间的损失**,以近似真实的动作价值函数。
+ - 我们有一个策略,但它是隐式的,因为它**直接从价值函数生成**。例如,在Q学习中,我们使用了(epsilon-)贪婪策略。
+
+- 另一方面,在*基于策略的方法*中,我们直接学习近似 \\(\pi^{*}\\),而不需要学习价值函数。
+ - 其思想是**参数化策略**。例如,使用神经网络 \\(\pi_\theta\\),这个策略将输出动作的概率分布(随机策略)。
+ -
+ - 我们的目标是**使用梯度上升最大化参数化策略的性能**。
+ - 为此,我们控制参数 \\(\theta\\),它将影响状态上动作的分布。
+
+
+
+- 下次,我们将学习*演员-评论家*方法,它是基于价值和基于策略方法的结合。
+
+因此,通过基于策略的方法,我们可以直接优化我们的策略 \\(\pi_\theta\\),使其输出动作的概率分布 \\(\pi_\theta(a|s)\\),从而获得最佳累积回报。
+为此,我们定义一个目标函数 \\(J(\theta)\\),即期望累积奖励,我们**希望找到使这个目标函数最大化的值 \\(\theta\\)**。
+
+## 基于策略和策略梯度方法的区别
+
+策略梯度方法,我们将在本单元中学习,是基于策略方法的一个子类。在基于策略的方法中,优化大多数时候是*在线的*,因为对于每次更新,我们只使用**由我们最新版本的** \\(\pi_\theta\\) **收集的数据(轨迹)**。
+
+这两种方法之间的区别**在于我们如何优化参数** \\(\theta\\):
+
+- 在*基于策略的方法*中,我们直接搜索最优策略。我们可以通过使用诸如爬山、模拟退火或进化策略等技术最大化目标函数的局部近似,**间接**优化参数 \\(\theta\\)。
+- 在*策略梯度方法*中,因为它是基于策略方法的一个子类,我们直接搜索最优策略。但我们通过对目标函数 \\(J(\theta)\\) 的性能执行梯度上升,**直接**优化参数 \\(\theta\\)。
+
+在深入了解策略梯度方法如何工作(目标函数、策略梯度定理、梯度上升等)之前,让我们研究基于策略方法的优势和劣势。
diff --git a/units/cn/unit5/bonus.mdx b/units/cn/unit5/bonus.mdx
new file mode 100644
index 00000000..8eabd883
--- /dev/null
+++ b/units/cn/unit5/bonus.mdx
@@ -0,0 +1,19 @@
+# 附加内容:学习使用Unity和MLAgents创建自己的环境
+
+**你可以使用Unity和MLAgents创建自己的强化学习环境**。使用Unity这样的游戏引擎一开始可能会令人生畏,但以下是你可以平稳学习的步骤。
+
+## 步骤1:学会使用Unity
+
+- 学习Unity的最佳方式是参加["Create with Code"课程](https://learn.unity.com/course/create-with-code):这是一系列为初学者准备的视频,**你将使用Unity创建5个小游戏**。
+
+## 步骤2:使用此教程创建最简单的环境
+
+- 然后,当你知道如何使用Unity后,你可以使用[这个教程创建你的第一个基本RL环境](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Learning-Environment-Create-New.md)。
+
+## 步骤3:迭代并创建优秀的环境
+
+- 现在你已经创建了你的第一个简单环境,你可以迭代到更复杂的环境,使用[MLAgents文档(特别是设计智能体和智能体部分)](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/)
+- 此外,你可以参加由[Adam Kelly](https://twitter.com/aktwelve)提供的免费课程["创建蜂鸟环境"](https://learn.unity.com/course/ml-agents-hummingbirds)
+
+
+玩得开心!如果你创建了自定义环境,不要犹豫,在discord频道`#rl-i-made-this`中分享它们。
diff --git a/units/cn/unit5/conclusion.mdx b/units/cn/unit5/conclusion.mdx
new file mode 100644
index 00000000..e08b06cc
--- /dev/null
+++ b/units/cn/unit5/conclusion.mdx
@@ -0,0 +1,22 @@
+# 结论
+
+恭喜你完成本单元!你刚刚训练了你的第一个ML-Agents并将其分享到Hub上 🥳。
+
+学习的最佳方式是**实践和尝试**。为什么不尝试另一个环境呢?[ML-Agents有18个不同的环境](https://github.com/Unity-Technologies/ml-agents/blob/develop/docs/Learning-Environment-Examples.md)。
+
+例如:
+- [Worm](https://singularite.itch.io/worm),在这里你教一条蠕虫爬行。
+- [Walker](https://singularite.itch.io/walker),在这里你教智能体朝着目标行走。
+
+查看文档了解如何训练它们,并查看Hub上已集成的MLAgents环境列表:https://github.com/huggingface/ml-agents#getting-started
+
+
+
+## 基于价值、基于策略和演员-评论家方法
+
+在第一单元中,我们看到了两种方法来找到(或者,大多数时候,近似)这个最优策略 \\(\pi^{*}\\)。
+
+- 在*基于价值的方法*中,我们学习一个价值函数。
+ - 其思想是最优价值函数导致最优策略 \\(\pi^{*}\\)。
+ - 我们的目标是**最小化预测值和目标值之间的损失**,以近似真实的动作价值函数。
+ - 我们有一个策略,但它是隐式的,因为它**直接从价值函数生成**。例如,在Q学习中,我们使用了(epsilon-)贪婪策略。
+
+- 另一方面,在*基于策略的方法*中,我们直接学习近似 \\(\pi^{*}\\),而不需要学习价值函数。
+ - 其思想是**参数化策略**。例如,使用神经网络 \\(\pi_\theta\\),这个策略将输出动作的概率分布(随机策略)。
+ -
+ - 我们的目标是**使用梯度上升最大化参数化策略的性能**。
+ - 为此,我们控制参数 \\(\theta\\),它将影响状态上动作的分布。
+
+
+
+- 下次,我们将学习*演员-评论家*方法,它是基于价值和基于策略方法的结合。
+
+因此,通过基于策略的方法,我们可以直接优化我们的策略 \\(\pi_\theta\\),使其输出动作的概率分布 \\(\pi_\theta(a|s)\\),从而获得最佳累积回报。
+为此,我们定义一个目标函数 \\(J(\theta)\\),即期望累积奖励,我们**希望找到使这个目标函数最大化的值 \\(\theta\\)**。
+
+## 基于策略和策略梯度方法的区别
+
+策略梯度方法,我们将在本单元中学习,是基于策略方法的一个子类。在基于策略的方法中,优化大多数时候是*在线的*,因为对于每次更新,我们只使用**由我们最新版本的** \\(\pi_\theta\\) **收集的数据(轨迹)**。
+
+这两种方法之间的区别**在于我们如何优化参数** \\(\theta\\):
+
+- 在*基于策略的方法*中,我们直接搜索最优策略。我们可以通过使用诸如爬山、模拟退火或进化策略等技术最大化目标函数的局部近似,**间接**优化参数 \\(\theta\\)。
+- 在*策略梯度方法*中,因为它是基于策略方法的一个子类,我们直接搜索最优策略。但我们通过对目标函数 \\(J(\theta)\\) 的性能执行梯度上升,**直接**优化参数 \\(\theta\\)。
+
+在深入了解策略梯度方法如何工作(目标函数、策略梯度定理、梯度上升等)之前,让我们研究基于策略方法的优势和劣势。
diff --git a/units/cn/unit5/bonus.mdx b/units/cn/unit5/bonus.mdx
new file mode 100644
index 00000000..8eabd883
--- /dev/null
+++ b/units/cn/unit5/bonus.mdx
@@ -0,0 +1,19 @@
+# 附加内容:学习使用Unity和MLAgents创建自己的环境
+
+**你可以使用Unity和MLAgents创建自己的强化学习环境**。使用Unity这样的游戏引擎一开始可能会令人生畏,但以下是你可以平稳学习的步骤。
+
+## 步骤1:学会使用Unity
+
+- 学习Unity的最佳方式是参加["Create with Code"课程](https://learn.unity.com/course/create-with-code):这是一系列为初学者准备的视频,**你将使用Unity创建5个小游戏**。
+
+## 步骤2:使用此教程创建最简单的环境
+
+- 然后,当你知道如何使用Unity后,你可以使用[这个教程创建你的第一个基本RL环境](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Learning-Environment-Create-New.md)。
+
+## 步骤3:迭代并创建优秀的环境
+
+- 现在你已经创建了你的第一个简单环境,你可以迭代到更复杂的环境,使用[MLAgents文档(特别是设计智能体和智能体部分)](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/)
+- 此外,你可以参加由[Adam Kelly](https://twitter.com/aktwelve)提供的免费课程["创建蜂鸟环境"](https://learn.unity.com/course/ml-agents-hummingbirds)
+
+
+玩得开心!如果你创建了自定义环境,不要犹豫,在discord频道`#rl-i-made-this`中分享它们。
diff --git a/units/cn/unit5/conclusion.mdx b/units/cn/unit5/conclusion.mdx
new file mode 100644
index 00000000..e08b06cc
--- /dev/null
+++ b/units/cn/unit5/conclusion.mdx
@@ -0,0 +1,22 @@
+# 结论
+
+恭喜你完成本单元!你刚刚训练了你的第一个ML-Agents并将其分享到Hub上 🥳。
+
+学习的最佳方式是**实践和尝试**。为什么不尝试另一个环境呢?[ML-Agents有18个不同的环境](https://github.com/Unity-Technologies/ml-agents/blob/develop/docs/Learning-Environment-Examples.md)。
+
+例如:
+- [Worm](https://singularite.itch.io/worm),在这里你教一条蠕虫爬行。
+- [Walker](https://singularite.itch.io/walker),在这里你教智能体朝着目标行走。
+
+查看文档了解如何训练它们,并查看Hub上已集成的MLAgents环境列表:https://github.com/huggingface/ml-agents#getting-started
+
+ +
+
+在下一个单元中,我们将学习多智能体。你将训练你的第一个多智能体,在足球和雪球大战中与其他同学的智能体竞争。
+
+
+
+
+在下一个单元中,我们将学习多智能体。你将训练你的第一个多智能体,在足球和雪球大战中与其他同学的智能体竞争。
+
+ +
+最后,我们很想**听听你对课程的看法以及我们如何改进它**。如果你有一些反馈,请 👉 [填写这个表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 持续学习,保持精彩 🤗
diff --git a/units/cn/unit5/curiosity.mdx b/units/cn/unit5/curiosity.mdx
new file mode 100644
index 00000000..5678ab16
--- /dev/null
+++ b/units/cn/unit5/curiosity.mdx
@@ -0,0 +1,50 @@
+# (可选) 什么是深度强化学习中的好奇心?
+
+这是对好奇心的(可选)介绍。如果你想了解更多,可以阅读两篇额外的文章,我们在其中深入探讨了数学细节:
+
+- [通过下一状态预测的好奇心驱动学习](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-next-state-prediction-f7f4e2f592fa)
+- [随机网络蒸馏:好奇心驱动学习的新方法](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938)
+
+## 现代RL中的两个主要问题
+
+要理解什么是好奇心,我们首先需要了解RL中的两个主要问题:
+
+首先是*稀疏奖励问题:*即**大多数奖励不包含信息,因此被设置为零**。
+
+记住,RL基于*奖励假设*,这个想法是每个目标都可以被描述为奖励的最大化。因此,奖励作为RL智能体的反馈;**如果它们没有收到任何反馈,它们对哪些动作适当(或不适当)的知识就无法改变**。
+
+
+
+
+
+最后,我们很想**听听你对课程的看法以及我们如何改进它**。如果你有一些反馈,请 👉 [填写这个表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 持续学习,保持精彩 🤗
diff --git a/units/cn/unit5/curiosity.mdx b/units/cn/unit5/curiosity.mdx
new file mode 100644
index 00000000..5678ab16
--- /dev/null
+++ b/units/cn/unit5/curiosity.mdx
@@ -0,0 +1,50 @@
+# (可选) 什么是深度强化学习中的好奇心?
+
+这是对好奇心的(可选)介绍。如果你想了解更多,可以阅读两篇额外的文章,我们在其中深入探讨了数学细节:
+
+- [通过下一状态预测的好奇心驱动学习](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-next-state-prediction-f7f4e2f592fa)
+- [随机网络蒸馏:好奇心驱动学习的新方法](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938)
+
+## 现代RL中的两个主要问题
+
+要理解什么是好奇心,我们首先需要了解RL中的两个主要问题:
+
+首先是*稀疏奖励问题:*即**大多数奖励不包含信息,因此被设置为零**。
+
+记住,RL基于*奖励假设*,这个想法是每个目标都可以被描述为奖励的最大化。因此,奖励作为RL智能体的反馈;**如果它们没有收到任何反馈,它们对哪些动作适当(或不适当)的知识就无法改变**。
+
+
+
+ +来源:多亏了奖励,我们的智能体知道在那个状态下的这个动作是好的
+
+
+
+例如,在[Vizdoom](https://vizdoom.cs.put.edu.pl/)中,一组基于游戏Doom的"DoomMyWayHome"环境,你的智能体**只有在找到背心时才会得到奖励**。
+然而,背心离你的起点很远,所以你的大多数奖励将是零。因此,如果我们的智能体没有收到有用的反馈(密集奖励),它将需要更长的时间来学习最优策略,并且**它可能会花时间原地打转而不找到目标**。
+
+
+来源:多亏了奖励,我们的智能体知道在那个状态下的这个动作是好的
+
+
+
+例如,在[Vizdoom](https://vizdoom.cs.put.edu.pl/)中,一组基于游戏Doom的"DoomMyWayHome"环境,你的智能体**只有在找到背心时才会得到奖励**。
+然而,背心离你的起点很远,所以你的大多数奖励将是零。因此,如果我们的智能体没有收到有用的反馈(密集奖励),它将需要更长的时间来学习最优策略,并且**它可能会花时间原地打转而不找到目标**。
+
+ +
+第二个大问题是**外部奖励函数是人为制定的;在每个环境中,都需要人类实现一个奖励函数**。但我们如何在大型和复杂的环境中扩展这一点呢?
+
+## 那么什么是好奇心?
+
+解决这些问题的一个方法是**开发一个智能体内在的奖励函数,即由智能体自身生成的**。智能体将作为一个自学习者,因为它将既是学生又是自己的反馈主人。
+
+**这种内在奖励机制被称为好奇心**,因为这种奖励推动智能体探索新颖/不熟悉的状态。为了实现这一点,我们的智能体在探索新轨迹时将获得高奖励。
+
+这种奖励的灵感来自人类的行为方式。**我们自然有一种内在的欲望去探索环境并发现新事物**。
+
+计算这种内在奖励有不同的方法。经典方法(通过下一状态预测的好奇心)是将好奇心**计算为我们的智能体在预测下一个状态时的误差,给定当前状态和采取的动作**。
+
+
+
+第二个大问题是**外部奖励函数是人为制定的;在每个环境中,都需要人类实现一个奖励函数**。但我们如何在大型和复杂的环境中扩展这一点呢?
+
+## 那么什么是好奇心?
+
+解决这些问题的一个方法是**开发一个智能体内在的奖励函数,即由智能体自身生成的**。智能体将作为一个自学习者,因为它将既是学生又是自己的反馈主人。
+
+**这种内在奖励机制被称为好奇心**,因为这种奖励推动智能体探索新颖/不熟悉的状态。为了实现这一点,我们的智能体在探索新轨迹时将获得高奖励。
+
+这种奖励的灵感来自人类的行为方式。**我们自然有一种内在的欲望去探索环境并发现新事物**。
+
+计算这种内在奖励有不同的方法。经典方法(通过下一状态预测的好奇心)是将好奇心**计算为我们的智能体在预测下一个状态时的误差,给定当前状态和采取的动作**。
+
+ +
+因为好奇心的想法是**鼓励我们的智能体执行能够减少智能体预测其行动后果能力的不确定性的动作**(在智能体花费较少时间或具有复杂动态的区域中,不确定性将更高)。
+
+如果智能体在这些状态上花费大量时间,它将善于预测下一个状态(低好奇心)。另一方面,如果它处于一个新的、未探索的状态,预测下一个状态将很困难(高好奇心)。
+
+
+
+因为好奇心的想法是**鼓励我们的智能体执行能够减少智能体预测其行动后果能力的不确定性的动作**(在智能体花费较少时间或具有复杂动态的区域中,不确定性将更高)。
+
+如果智能体在这些状态上花费大量时间,它将善于预测下一个状态(低好奇心)。另一方面,如果它处于一个新的、未探索的状态,预测下一个状态将很困难(高好奇心)。
+
+ +
+使用好奇心将推动我们的智能体偏好具有高预测误差的转换(在智能体花费较少时间或具有复杂动态的区域中,这种误差将更高),**从而更好地探索我们的环境**。
+
+还有**其他好奇心计算方法**。ML-Agents使用一种更高级的方法,称为通过随机网络蒸馏的好奇心。这超出了本教程的范围,但如果你感兴趣,[我写了一篇文章详细解释它](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938)。
diff --git a/units/cn/unit5/hands-on.mdx b/units/cn/unit5/hands-on.mdx
new file mode 100644
index 00000000..54afa235
--- /dev/null
+++ b/units/cn/unit5/hands-on.mdx
@@ -0,0 +1,416 @@
+# 实践练习
+
+
+
+
+我们已经学习了ML-Agents是什么以及它如何工作。我们还研究了将要使用的两个环境。现在我们准备训练我们的智能体了!
+
+
+
+使用好奇心将推动我们的智能体偏好具有高预测误差的转换(在智能体花费较少时间或具有复杂动态的区域中,这种误差将更高),**从而更好地探索我们的环境**。
+
+还有**其他好奇心计算方法**。ML-Agents使用一种更高级的方法,称为通过随机网络蒸馏的好奇心。这超出了本教程的范围,但如果你感兴趣,[我写了一篇文章详细解释它](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938)。
diff --git a/units/cn/unit5/hands-on.mdx b/units/cn/unit5/hands-on.mdx
new file mode 100644
index 00000000..54afa235
--- /dev/null
+++ b/units/cn/unit5/hands-on.mdx
@@ -0,0 +1,416 @@
+# 实践练习
+
+
+
+
+我们已经学习了ML-Agents是什么以及它如何工作。我们还研究了将要使用的两个环境。现在我们准备训练我们的智能体了!
+
+ +
+为了在认证过程中验证这个实践练习,你**只需要将训练好的模型推送到Hub**。
+为了验证这个实践练习,**没有需要达到的最低结果**。但如果你想获得不错的结果,可以尝试达到以下目标:
+
+- 对于[金字塔环境](https://huggingface.co/spaces/unity/ML-Agents-Pyramids):平均奖励 = 1.75
+- 对于[雪球目标环境](https://huggingface.co/spaces/ThomasSimonini/ML-Agents-SnowballTarget):平均奖励 = 15 或在一个回合中击中30个目标。
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+**要开始实践练习,请点击"在Colab中打开"按钮** 👇:
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit5/unit5.ipynb)
+
+我们强烈**建议学生使用Google Colab进行实践练习**,而不是在个人电脑上运行它们。
+
+通过使用Google Colab,**你可以专注于学习和实验,而不必担心**设置环境的技术方面。
+
+# 第5单元:ML-Agents入门
+
+
+
+为了在认证过程中验证这个实践练习,你**只需要将训练好的模型推送到Hub**。
+为了验证这个实践练习,**没有需要达到的最低结果**。但如果你想获得不错的结果,可以尝试达到以下目标:
+
+- 对于[金字塔环境](https://huggingface.co/spaces/unity/ML-Agents-Pyramids):平均奖励 = 1.75
+- 对于[雪球目标环境](https://huggingface.co/spaces/ThomasSimonini/ML-Agents-SnowballTarget):平均奖励 = 15 或在一个回合中击中30个目标。
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+**要开始实践练习,请点击"在Colab中打开"按钮** 👇:
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit5/unit5.ipynb)
+
+我们强烈**建议学生使用Google Colab进行实践练习**,而不是在个人电脑上运行它们。
+
+通过使用Google Colab,**你可以专注于学习和实验,而不必担心**设置环境的技术方面。
+
+# 第5单元:ML-Agents入门
+
+ +
+在这个笔记本中,你将了解ML-Agents并训练两个智能体。
+
+- 第一个智能体将学习**向出现的目标发射雪球**。
+- 第二个智能体需要按下按钮生成一个金字塔,然后导航到金字塔,将其推倒,**并移动到顶部的金砖**。为了做到这一点,它需要探索环境,我们将使用一种称为好奇心的技术。
+
+之后,你将能够**直接在浏览器中观看你的智能体玩游戏**。
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+⬇️ 这里是**你在本单元结束时将实现的内容**的示例。 ⬇️
+
+
+
+在这个笔记本中,你将了解ML-Agents并训练两个智能体。
+
+- 第一个智能体将学习**向出现的目标发射雪球**。
+- 第二个智能体需要按下按钮生成一个金字塔,然后导航到金字塔,将其推倒,**并移动到顶部的金砖**。为了做到这一点,它需要探索环境,我们将使用一种称为好奇心的技术。
+
+之后,你将能够**直接在浏览器中观看你的智能体玩游戏**。
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+⬇️ 这里是**你在本单元结束时将实现的内容**的示例。 ⬇️
+
+ +
+
+
+ +
+### 🎮 环境:
+
+- [金字塔](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Learning-Environment-Examples.md#pyramids)
+- 雪球目标
+
+### 📚 RL库:
+
+- [ML-Agents](https://github.com/Unity-Technologies/ml-agents)
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在完成本笔记本后,你将:
+
+- 理解**ML-Agents**如何工作以及环境库。
+- 能够**在Unity环境中训练智能体**。
+
+## 先决条件 🏗️
+在深入学习本笔记本之前,你需要:
+
+🔲 📚 **通过[阅读第5单元了解ML-Agents是什么以及它如何工作](https://huggingface.co/deep-rl-course/unit5/introduction)** 🤗
+
+# 让我们训练我们的智能体 🚀
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。为此,请转到`Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+## 克隆仓库 🔽
+
+- 我们需要克隆包含**ML-Agents**的仓库。
+
+```bash
+# 克隆仓库(可能需要3分钟)
+git clone --depth 1 https://github.com/Unity-Technologies/ml-agents
+```
+
+## 设置虚拟环境 🔽
+
+- 为了让**ML-Agents**在Colab中成功运行,Colab的Python版本必须满足库的Python要求。
+
+- 我们可以在`setup.py`文件的`python_requires`参数下检查支持的Python版本。这些文件是设置**ML-Agents**库所必需的,可以在以下位置找到:
+ - `/content/ml-agents/ml-agents/setup.py`
+ - `/content/ml-agents/ml-agents-envs/setup.py`
+
+- Colab当前的Python版本(可以使用`!python --version`检查)与库的`python_requires`参数不匹配,因此安装可能会悄无声息地失败,并在稍后执行相同命令时导致如下错误:
+ - `/bin/bash: line 1: mlagents-learn: command not found`
+ - `/bin/bash: line 1: mlagents-push-to-hf: command not found`
+
+- 为了解决这个问题,我们将创建一个与**ML-Agents**库兼容的Python版本的虚拟环境。
+
+`注意:` *为了未来的兼容性,如果Colab的Python版本不兼容,请始终检查安装文件中的`python_requires`参数,并在下面的脚本中将虚拟环境设置为支持的最高Python版本*
+
+```bash
+# Colab当前的Python版本(与ML-Agents不兼容)
+!python --version
+```
+
+```bash
+# 安装virtualenv并创建虚拟环境
+!pip install virtualenv
+!virtualenv myenv
+
+# 下载并安装Miniconda
+!wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
+!chmod +x Miniconda3-latest-Linux-x86_64.sh
+!./Miniconda3-latest-Linux-x86_64.sh -b -f -p /usr/local
+
+# 激活Miniconda并安装Python 3.10.12版本
+!source /usr/local/bin/activate
+!conda install -q -y --prefix /usr/local python=3.10.12 ujson # 在这里指定版本
+
+# 设置Python和conda路径的环境变量
+!export PYTHONPATH=/usr/local/lib/python3.10/site-packages/
+!export CONDA_PREFIX=/usr/local/envs/myenv
+```
+
+```bash
+# 新虚拟环境中的Python版本(与ML-Agents兼容)
+!python --version
+```
+
+## 安装依赖项 🔽
+
+```bash
+# 进入仓库并安装包(可能需要3分钟)
+%cd ml-agents
+pip3 install -e ./ml-agents-envs
+pip3 install -e ./ml-agents
+```
+
+## 雪球目标 ⛄
+
+如果你需要复习这个环境如何工作,请查看此部分 👉
+https://huggingface.co/deep-rl-course/unit5/snowball-target
+
+### 下载并将环境zip文件移动到`./training-envs-executables/linux/`
+
+- 我们的环境可执行文件在一个zip文件中。
+- 我们需要下载它并将其放置到`./training-envs-executables/linux/`
+- 我们使用linux可执行文件,因为我们使用colab,而colab机器的操作系统是Ubuntu(linux)
+
+```bash
+# 在这里,我们创建training-envs-executables和linux目录
+mkdir ./training-envs-executables
+mkdir ./training-envs-executables/linux
+```
+
+我们使用`wget`从https://github.com/huggingface/Snowball-Target下载SnowballTarget.zip文件
+
+```bash
+wget "https://github.com/huggingface/Snowball-Target/raw/main/SnowballTarget.zip" -O ./training-envs-executables/linux/SnowballTarget.zip
+```
+
+我们解压可执行文件.zip文件
+
+```bash
+unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/SnowballTarget.zip
+```
+
+确保你的文件可访问
+
+```bash
+chmod -R 755 ./training-envs-executables/linux/SnowballTarget
+```
+
+### 定义雪球目标配置文件
+- 在ML-Agents中,你在config.yaml文件中**定义训练超参数**。
+
+有多个超参数。要更好地理解它们,你应该阅读[文档](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md)中对每个超参数的解释
+
+
+你需要在./content/ml-agents/config/ppo/中创建一个`SnowballTarget.yaml`配置文件
+
+我们将给你一个初步版本的配置(复制并粘贴到你的`SnowballTarget.yaml文件`中),**但你应该修改它**。
+
+```yaml
+behaviors:
+ SnowballTarget:
+ trainer_type: ppo
+ summary_freq: 10000
+ keep_checkpoints: 10
+ checkpoint_interval: 50000
+ max_steps: 200000
+ time_horizon: 64
+ threaded: true
+ hyperparameters:
+ learning_rate: 0.0003
+ learning_rate_schedule: linear
+ batch_size: 128
+ buffer_size: 2048
+ beta: 0.005
+ epsilon: 0.2
+ lambd: 0.95
+ num_epoch: 3
+ network_settings:
+ normalize: false
+ hidden_units: 256
+ num_layers: 2
+ vis_encode_type: simple
+ reward_signals:
+ extrinsic:
+ gamma: 0.99
+ strength: 1.0
+```
+
+
+
+### 🎮 环境:
+
+- [金字塔](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Learning-Environment-Examples.md#pyramids)
+- 雪球目标
+
+### 📚 RL库:
+
+- [ML-Agents](https://github.com/Unity-Technologies/ml-agents)
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在完成本笔记本后,你将:
+
+- 理解**ML-Agents**如何工作以及环境库。
+- 能够**在Unity环境中训练智能体**。
+
+## 先决条件 🏗️
+在深入学习本笔记本之前,你需要:
+
+🔲 📚 **通过[阅读第5单元了解ML-Agents是什么以及它如何工作](https://huggingface.co/deep-rl-course/unit5/introduction)** 🤗
+
+# 让我们训练我们的智能体 🚀
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。为此,请转到`Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+## 克隆仓库 🔽
+
+- 我们需要克隆包含**ML-Agents**的仓库。
+
+```bash
+# 克隆仓库(可能需要3分钟)
+git clone --depth 1 https://github.com/Unity-Technologies/ml-agents
+```
+
+## 设置虚拟环境 🔽
+
+- 为了让**ML-Agents**在Colab中成功运行,Colab的Python版本必须满足库的Python要求。
+
+- 我们可以在`setup.py`文件的`python_requires`参数下检查支持的Python版本。这些文件是设置**ML-Agents**库所必需的,可以在以下位置找到:
+ - `/content/ml-agents/ml-agents/setup.py`
+ - `/content/ml-agents/ml-agents-envs/setup.py`
+
+- Colab当前的Python版本(可以使用`!python --version`检查)与库的`python_requires`参数不匹配,因此安装可能会悄无声息地失败,并在稍后执行相同命令时导致如下错误:
+ - `/bin/bash: line 1: mlagents-learn: command not found`
+ - `/bin/bash: line 1: mlagents-push-to-hf: command not found`
+
+- 为了解决这个问题,我们将创建一个与**ML-Agents**库兼容的Python版本的虚拟环境。
+
+`注意:` *为了未来的兼容性,如果Colab的Python版本不兼容,请始终检查安装文件中的`python_requires`参数,并在下面的脚本中将虚拟环境设置为支持的最高Python版本*
+
+```bash
+# Colab当前的Python版本(与ML-Agents不兼容)
+!python --version
+```
+
+```bash
+# 安装virtualenv并创建虚拟环境
+!pip install virtualenv
+!virtualenv myenv
+
+# 下载并安装Miniconda
+!wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
+!chmod +x Miniconda3-latest-Linux-x86_64.sh
+!./Miniconda3-latest-Linux-x86_64.sh -b -f -p /usr/local
+
+# 激活Miniconda并安装Python 3.10.12版本
+!source /usr/local/bin/activate
+!conda install -q -y --prefix /usr/local python=3.10.12 ujson # 在这里指定版本
+
+# 设置Python和conda路径的环境变量
+!export PYTHONPATH=/usr/local/lib/python3.10/site-packages/
+!export CONDA_PREFIX=/usr/local/envs/myenv
+```
+
+```bash
+# 新虚拟环境中的Python版本(与ML-Agents兼容)
+!python --version
+```
+
+## 安装依赖项 🔽
+
+```bash
+# 进入仓库并安装包(可能需要3分钟)
+%cd ml-agents
+pip3 install -e ./ml-agents-envs
+pip3 install -e ./ml-agents
+```
+
+## 雪球目标 ⛄
+
+如果你需要复习这个环境如何工作,请查看此部分 👉
+https://huggingface.co/deep-rl-course/unit5/snowball-target
+
+### 下载并将环境zip文件移动到`./training-envs-executables/linux/`
+
+- 我们的环境可执行文件在一个zip文件中。
+- 我们需要下载它并将其放置到`./training-envs-executables/linux/`
+- 我们使用linux可执行文件,因为我们使用colab,而colab机器的操作系统是Ubuntu(linux)
+
+```bash
+# 在这里,我们创建training-envs-executables和linux目录
+mkdir ./training-envs-executables
+mkdir ./training-envs-executables/linux
+```
+
+我们使用`wget`从https://github.com/huggingface/Snowball-Target下载SnowballTarget.zip文件
+
+```bash
+wget "https://github.com/huggingface/Snowball-Target/raw/main/SnowballTarget.zip" -O ./training-envs-executables/linux/SnowballTarget.zip
+```
+
+我们解压可执行文件.zip文件
+
+```bash
+unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/SnowballTarget.zip
+```
+
+确保你的文件可访问
+
+```bash
+chmod -R 755 ./training-envs-executables/linux/SnowballTarget
+```
+
+### 定义雪球目标配置文件
+- 在ML-Agents中,你在config.yaml文件中**定义训练超参数**。
+
+有多个超参数。要更好地理解它们,你应该阅读[文档](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md)中对每个超参数的解释
+
+
+你需要在./content/ml-agents/config/ppo/中创建一个`SnowballTarget.yaml`配置文件
+
+我们将给你一个初步版本的配置(复制并粘贴到你的`SnowballTarget.yaml文件`中),**但你应该修改它**。
+
+```yaml
+behaviors:
+ SnowballTarget:
+ trainer_type: ppo
+ summary_freq: 10000
+ keep_checkpoints: 10
+ checkpoint_interval: 50000
+ max_steps: 200000
+ time_horizon: 64
+ threaded: true
+ hyperparameters:
+ learning_rate: 0.0003
+ learning_rate_schedule: linear
+ batch_size: 128
+ buffer_size: 2048
+ beta: 0.005
+ epsilon: 0.2
+ lambd: 0.95
+ num_epoch: 3
+ network_settings:
+ normalize: false
+ hidden_units: 256
+ num_layers: 2
+ vis_encode_type: simple
+ reward_signals:
+ extrinsic:
+ gamma: 0.99
+ strength: 1.0
+```
+
+ +
+ +
+作为实验,尝试修改一些其他超参数。Unity提供了非常[好的文档,在这里解释每个超参数](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md)。
+
+现在你已经创建了配置文件并理解了大多数超参数的作用,我们准备训练我们的智能体了 🔥。
+
+### 训练智能体
+
+要训练我们的智能体,我们需要**启动mlagents-learn并选择包含环境的可执行文件**。
+
+我们定义四个参数:
+
+1. `mlagents-learn `:超参数配置文件的路径。
+2. `--env`:环境可执行文件的位置。
+3. `--run_id`:你想给训练运行ID起的名称。
+4. `--no-graphics`:在训练期间不启动可视化。
+
+
+
+作为实验,尝试修改一些其他超参数。Unity提供了非常[好的文档,在这里解释每个超参数](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md)。
+
+现在你已经创建了配置文件并理解了大多数超参数的作用,我们准备训练我们的智能体了 🔥。
+
+### 训练智能体
+
+要训练我们的智能体,我们需要**启动mlagents-learn并选择包含环境的可执行文件**。
+
+我们定义四个参数:
+
+1. `mlagents-learn `:超参数配置文件的路径。
+2. `--env`:环境可执行文件的位置。
+3. `--run_id`:你想给训练运行ID起的名称。
+4. `--no-graphics`:在训练期间不启动可视化。
+
+ +
+训练模型并使用`--resume`标志在中断的情况下继续训练。
+
+> 如果你使用`--resume`,第一次可能会失败。尝试重新运行代码块以绕过错误。
+
+训练将根据你的配置需要10到35分钟。去喝杯☕️,你值得拥有 🤗。
+
+```bash
+mlagents-learn ./config/ppo/SnowballTarget.yaml --env=./training-envs-executables/linux/SnowballTarget/SnowballTarget --run-id="SnowballTarget1" --no-graphics
+```
+
+### 将智能体推送到Hugging Face Hub
+
+- 现在我们已经训练了我们的智能体,我们**准备将它推送到Hub并在浏览器上观看它的表现🔥。**
+
+为了能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果你还没有完成)创建一个HF账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录并从Hugging Face网站存储你的认证令牌。
+- 创建一个新令牌(https://huggingface.co/settings/tokens)**具有写入权限**
+
+
+
+- 复制令牌
+- 运行下面的单元格并粘贴令牌
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令:`huggingface-cli login`
+
+然后我们需要运行`mlagents-push-to-hf`。
+
+我们定义四个参数:
+
+1. `--run-id`:训练运行ID的名称。
+2. `--local-dir`:智能体保存的位置,它是results/`run_id名称`,所以在我的例子中是results/First Training。
+3. `--repo-id`:你想创建或更新的Hugging Face仓库的名称。它总是`你的huggingface用户名/仓库名称`
+如果仓库不存在,**它将自动创建**。
+4. `--commit-message`:由于HF仓库是git仓库,你需要提供一个提交消息。
+
+
+
+训练模型并使用`--resume`标志在中断的情况下继续训练。
+
+> 如果你使用`--resume`,第一次可能会失败。尝试重新运行代码块以绕过错误。
+
+训练将根据你的配置需要10到35分钟。去喝杯☕️,你值得拥有 🤗。
+
+```bash
+mlagents-learn ./config/ppo/SnowballTarget.yaml --env=./training-envs-executables/linux/SnowballTarget/SnowballTarget --run-id="SnowballTarget1" --no-graphics
+```
+
+### 将智能体推送到Hugging Face Hub
+
+- 现在我们已经训练了我们的智能体,我们**准备将它推送到Hub并在浏览器上观看它的表现🔥。**
+
+为了能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果你还没有完成)创建一个HF账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录并从Hugging Face网站存储你的认证令牌。
+- 创建一个新令牌(https://huggingface.co/settings/tokens)**具有写入权限**
+
+
+
+- 复制令牌
+- 运行下面的单元格并粘贴令牌
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令:`huggingface-cli login`
+
+然后我们需要运行`mlagents-push-to-hf`。
+
+我们定义四个参数:
+
+1. `--run-id`:训练运行ID的名称。
+2. `--local-dir`:智能体保存的位置,它是results/`run_id名称`,所以在我的例子中是results/First Training。
+3. `--repo-id`:你想创建或更新的Hugging Face仓库的名称。它总是`你的huggingface用户名/仓库名称`
+如果仓库不存在,**它将自动创建**。
+4. `--commit-message`:由于HF仓库是git仓库,你需要提供一个提交消息。
+
+ +
+例如:
+
+`mlagents-push-to-hf --run-id="SnowballTarget1" --local-dir="./results/SnowballTarget1" --repo-id="ThomasSimonini/ppo-SnowballTarget" --commit-message="First Push"`
+
+```python
+mlagents-push-to-hf --run-id= # 添加你的运行ID --local-dir= # 你的本地目录 --repo-id= # 你的仓库ID --commit-message= # 你的提交消息
+```
+
+如果一切正常,你应该在过程结束时看到这个(但URL不同 😆):
+
+
+
+```
+Your model is pushed to the hub. You can view your model here: https://huggingface.co/ThomasSimonini/ppo-SnowballTarget
+```
+
+这是你模型的链接。它包含一个模型卡片,解释如何使用它,你的Tensorboard和你的配置文件。**最棒的是它是一个git仓库,这意味着你可以有不同的提交,通过新的推送更新你的仓库等。**
+
+但现在是最好的部分:**能够在线观看你的智能体 👀。**
+
+### 观看你的智能体玩游戏 👀
+
+这一步很简单:
+
+1. 前往:https://huggingface.co/spaces/ThomasSimonini/ML-Agents-SnowballTarget
+
+2. 启动游戏并通过点击右下角按钮将其全屏显示
+
+
+
+例如:
+
+`mlagents-push-to-hf --run-id="SnowballTarget1" --local-dir="./results/SnowballTarget1" --repo-id="ThomasSimonini/ppo-SnowballTarget" --commit-message="First Push"`
+
+```python
+mlagents-push-to-hf --run-id= # 添加你的运行ID --local-dir= # 你的本地目录 --repo-id= # 你的仓库ID --commit-message= # 你的提交消息
+```
+
+如果一切正常,你应该在过程结束时看到这个(但URL不同 😆):
+
+
+
+```
+Your model is pushed to the hub. You can view your model here: https://huggingface.co/ThomasSimonini/ppo-SnowballTarget
+```
+
+这是你模型的链接。它包含一个模型卡片,解释如何使用它,你的Tensorboard和你的配置文件。**最棒的是它是一个git仓库,这意味着你可以有不同的提交,通过新的推送更新你的仓库等。**
+
+但现在是最好的部分:**能够在线观看你的智能体 👀。**
+
+### 观看你的智能体玩游戏 👀
+
+这一步很简单:
+
+1. 前往:https://huggingface.co/spaces/ThomasSimonini/ML-Agents-SnowballTarget
+
+2. 启动游戏并通过点击右下角按钮将其全屏显示
+
+ +
+1. 在步骤1中,输入你的用户名(你的用户名区分大小写:例如,我的用户名是ThomasSimonini而不是thomassimonini或ThOmasImoNInI)并点击搜索按钮。
+
+2. 在步骤2中,选择你的模型仓库。
+
+3. 在步骤3中,**选择你想要回放的模型**:
+ - 我有多个模型,因为我们每500000个时间步保存一个模型。
+ - 但由于我想要最新的一个,我选择`SnowballTarget.onnx`
+
+👉 **尝试不同的模型步骤来查看智能体的改进情况**是很好的。
+
+
+不要犹豫,在discord的#rl-i-made-this频道分享你的智能体获得的最佳分数 🔥
+
+现在让我们尝试一个更具挑战性的环境,称为金字塔。
+
+## 金字塔 🏆
+
+### 下载并将环境zip文件移动到`./training-envs-executables/linux/`
+- 我们的环境可执行文件在一个zip文件中。
+- 我们需要下载它并将其放置到`./training-envs-executables/linux/`
+- 我们使用linux可执行文件,因为我们使用colab,而colab机器的操作系统是Ubuntu(linux)
+
+我们使用`wget`从https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids.zip下载Pyramids.zip文件
+
+```python
+wget "https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids.zip" -O ./training-envs-executables/linux/Pyramids.zip
+```
+
+解压它
+
+```python
+unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/Pyramids.zip
+```
+
+确保你的文件可访问
+
+```bash
+chmod -R 755 ./training-envs-executables/linux/Pyramids/Pyramids
+```
+
+### 修改PyramidsRND配置文件
+
+- 与第一个环境不同,第一个是自定义的,**金字塔是由Unity团队制作的**。
+- 所以PyramidsRND配置文件已经存在,位于./content/ml-agents/config/ppo/PyramidsRND.yaml
+- 你可能会问为什么PyramidsRND中有"RND"。RND代表*随机网络蒸馏(random network distillation)*,这是一种生成好奇心奖励的方法。如果你想了解更多关于这种技术的信息,我们写了一篇文章解释这种技术:https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938
+
+对于这次训练,我们将修改一件事:
+- 总训练步数超参数太高,因为我们只需要1M训练步数就能达到基准(平均奖励 = 1.75)。
+👉 为此,我们转到config/ppo/PyramidsRND.yaml,**将max_steps更改为1000000。**
+
+
+
+1. 在步骤1中,输入你的用户名(你的用户名区分大小写:例如,我的用户名是ThomasSimonini而不是thomassimonini或ThOmasImoNInI)并点击搜索按钮。
+
+2. 在步骤2中,选择你的模型仓库。
+
+3. 在步骤3中,**选择你想要回放的模型**:
+ - 我有多个模型,因为我们每500000个时间步保存一个模型。
+ - 但由于我想要最新的一个,我选择`SnowballTarget.onnx`
+
+👉 **尝试不同的模型步骤来查看智能体的改进情况**是很好的。
+
+
+不要犹豫,在discord的#rl-i-made-this频道分享你的智能体获得的最佳分数 🔥
+
+现在让我们尝试一个更具挑战性的环境,称为金字塔。
+
+## 金字塔 🏆
+
+### 下载并将环境zip文件移动到`./training-envs-executables/linux/`
+- 我们的环境可执行文件在一个zip文件中。
+- 我们需要下载它并将其放置到`./training-envs-executables/linux/`
+- 我们使用linux可执行文件,因为我们使用colab,而colab机器的操作系统是Ubuntu(linux)
+
+我们使用`wget`从https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids.zip下载Pyramids.zip文件
+
+```python
+wget "https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids.zip" -O ./training-envs-executables/linux/Pyramids.zip
+```
+
+解压它
+
+```python
+unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/Pyramids.zip
+```
+
+确保你的文件可访问
+
+```bash
+chmod -R 755 ./training-envs-executables/linux/Pyramids/Pyramids
+```
+
+### 修改PyramidsRND配置文件
+
+- 与第一个环境不同,第一个是自定义的,**金字塔是由Unity团队制作的**。
+- 所以PyramidsRND配置文件已经存在,位于./content/ml-agents/config/ppo/PyramidsRND.yaml
+- 你可能会问为什么PyramidsRND中有"RND"。RND代表*随机网络蒸馏(random network distillation)*,这是一种生成好奇心奖励的方法。如果你想了解更多关于这种技术的信息,我们写了一篇文章解释这种技术:https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938
+
+对于这次训练,我们将修改一件事:
+- 总训练步数超参数太高,因为我们只需要1M训练步数就能达到基准(平均奖励 = 1.75)。
+👉 为此,我们转到config/ppo/PyramidsRND.yaml,**将max_steps更改为1000000。**
+
+ +
+作为实验,你也应该尝试修改一些其他超参数。Unity提供了非常[好的文档,在这里解释每个超参数](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md)。
+
+我们现在准备训练我们的智能体 🔥。
+
+### 训练智能体
+
+根据你的机器,训练将需要30到45分钟,去喝杯☕️,你值得拥有 🤗。
+
+```python
+mlagents-learn ./config/ppo/PyramidsRND.yaml --env=./training-envs-executables/linux/Pyramids/Pyramids --run-id="Pyramids Training" --no-graphics
+```
+
+### 将智能体推送到Hugging Face Hub
+
+- 现在我们已经训练了我们的智能体,我们**准备将它推送到Hub,以便能够在浏览器上观看它的表现🔥。**
+
+```python
+mlagents-push-to-hf --run-id= # 添加你的运行ID --local-dir= # 你的本地目录 --repo-id= # 你的仓库ID --commit-message= # 你的提交消息
+```
+
+### 观看你的智能体玩游戏 👀
+
+👉 https://huggingface.co/spaces/unity/ML-Agents-Pyramids
+
+### 🎁 奖励:为什么不在另一个环境中训练?
+
+现在你知道如何使用MLAgents训练智能体,**为什么不尝试另一个环境呢?**
+
+MLAgents提供了17个不同的环境,我们正在构建一些自定义环境。学习的最好方式是自己尝试,玩得开心。
+
+
+
+你可以在这里找到目前在Hugging Face上可用环境的完整列表 👉 https://github.com/huggingface/ml-agents#the-environments
+
+用于可视化你的智能体的演示 👉 https://huggingface.co/unity
+
+目前我们已经集成了:
+- [蠕虫](https://huggingface.co/spaces/unity/ML-Agents-Worm)演示,你教一条**蠕虫爬行**。
+- [步行者](https://huggingface.co/spaces/unity/ML-Agents-Walker)演示,你教一个智能体**朝着目标行走**。
+
+今天的内容就到这里。恭喜你完成本教程!
+
+学习的最好方式是实践和尝试。为什么不尝试另一个环境呢?ML-Agents有18个不同的环境,但你也可以创建自己的环境。查看文档并玩得开心!
+
+我们在第6单元见 ,
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit5/how-mlagents-works.mdx b/units/cn/unit5/how-mlagents-works.mdx
new file mode 100644
index 00000000..c49b8ad0
--- /dev/null
+++ b/units/cn/unit5/how-mlagents-works.mdx
@@ -0,0 +1,68 @@
+# Unity ML-Agents是如何工作的? [[how-mlagents-works]]
+
+在训练我们的智能体之前,我们需要了解**什么是ML-Agents以及它是如何工作的**。
+
+## 什么是Unity ML-Agents? [[what-is-mlagents]]
+
+[Unity ML-Agents](https://github.com/Unity-Technologies/ml-agents)是Unity游戏引擎的一个工具包,**允许我们使用Unity创建环境或使用预制环境来训练我们的智能体**。
+
+它由[Unity Technologies](https://unity.com/)开发,Unity Technologies是Unity的开发者,Unity是最著名的游戏引擎之一,被Firewatch、Cuphead和Cities: Skylines等游戏的创作者使用。
+
+
+
+
+作为实验,你也应该尝试修改一些其他超参数。Unity提供了非常[好的文档,在这里解释每个超参数](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md)。
+
+我们现在准备训练我们的智能体 🔥。
+
+### 训练智能体
+
+根据你的机器,训练将需要30到45分钟,去喝杯☕️,你值得拥有 🤗。
+
+```python
+mlagents-learn ./config/ppo/PyramidsRND.yaml --env=./training-envs-executables/linux/Pyramids/Pyramids --run-id="Pyramids Training" --no-graphics
+```
+
+### 将智能体推送到Hugging Face Hub
+
+- 现在我们已经训练了我们的智能体,我们**准备将它推送到Hub,以便能够在浏览器上观看它的表现🔥。**
+
+```python
+mlagents-push-to-hf --run-id= # 添加你的运行ID --local-dir= # 你的本地目录 --repo-id= # 你的仓库ID --commit-message= # 你的提交消息
+```
+
+### 观看你的智能体玩游戏 👀
+
+👉 https://huggingface.co/spaces/unity/ML-Agents-Pyramids
+
+### 🎁 奖励:为什么不在另一个环境中训练?
+
+现在你知道如何使用MLAgents训练智能体,**为什么不尝试另一个环境呢?**
+
+MLAgents提供了17个不同的环境,我们正在构建一些自定义环境。学习的最好方式是自己尝试,玩得开心。
+
+
+
+你可以在这里找到目前在Hugging Face上可用环境的完整列表 👉 https://github.com/huggingface/ml-agents#the-environments
+
+用于可视化你的智能体的演示 👉 https://huggingface.co/unity
+
+目前我们已经集成了:
+- [蠕虫](https://huggingface.co/spaces/unity/ML-Agents-Worm)演示,你教一条**蠕虫爬行**。
+- [步行者](https://huggingface.co/spaces/unity/ML-Agents-Walker)演示,你教一个智能体**朝着目标行走**。
+
+今天的内容就到这里。恭喜你完成本教程!
+
+学习的最好方式是实践和尝试。为什么不尝试另一个环境呢?ML-Agents有18个不同的环境,但你也可以创建自己的环境。查看文档并玩得开心!
+
+我们在第6单元见 ,
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit5/how-mlagents-works.mdx b/units/cn/unit5/how-mlagents-works.mdx
new file mode 100644
index 00000000..c49b8ad0
--- /dev/null
+++ b/units/cn/unit5/how-mlagents-works.mdx
@@ -0,0 +1,68 @@
+# Unity ML-Agents是如何工作的? [[how-mlagents-works]]
+
+在训练我们的智能体之前,我们需要了解**什么是ML-Agents以及它是如何工作的**。
+
+## 什么是Unity ML-Agents? [[what-is-mlagents]]
+
+[Unity ML-Agents](https://github.com/Unity-Technologies/ml-agents)是Unity游戏引擎的一个工具包,**允许我们使用Unity创建环境或使用预制环境来训练我们的智能体**。
+
+它由[Unity Technologies](https://unity.com/)开发,Unity Technologies是Unity的开发者,Unity是最著名的游戏引擎之一,被Firewatch、Cuphead和Cities: Skylines等游戏的创作者使用。
+
+
+ +Firewatch是用Unity制作的
+
+
+## 六个组件 [[six-components]]
+
+使用Unity ML-Agents,你有六个基本组件:
+
+
+
+Firewatch是用Unity制作的
+
+
+## 六个组件 [[six-components]]
+
+使用Unity ML-Agents,你有六个基本组件:
+
+
+ +来源:Unity ML-Agents文档
+
+
+- 第一个是*学习环境*,它包含**Unity场景(环境)和环境元素**(游戏角色)。
+- 第二个是*Python低级API*,它包含**用于与环境交互和操作环境的低级Python接口**。它是我们用来启动训练的API。
+- 然后,我们有*外部通信器*,它**连接学习环境(用C#制作)和低级Python API(Python)**。
+- *Python训练器*:**用PyTorch制作的强化学习算法(PPO、SAC等)**。
+- *Gym包装器*:将RL环境封装在gym包装器中。
+- *PettingZoo包装器*:PettingZoo是gym包装器的多智能体版本。
+
+## 学习组件内部 [[inside-learning-component]]
+
+在学习组件内部,我们有**两个重要元素**:
+
+- 第一个是*智能体组件*,场景的参与者。我们将**通过优化其策略来训练智能体**(这将告诉我们在每个状态下采取什么动作)。该策略被称为*大脑*。
+- 最后,还有*学院*。这个组件**协调智能体及其决策过程**。可以将这个学院视为处理Python API请求的老师。
+
+为了更好地理解其角色,让我们回顾一下RL过程。这可以被建模为一个这样工作的循环:
+
+
+
+RL过程:状态、动作、奖励和下一个状态的循环
+来源:强化学习导论,Richard Sutton和Andrew G. Barto
+
+
+现在,让我们想象一个学习玩平台游戏的智能体。RL过程看起来像这样:
+
+
+
+- 我们的智能体从**环境**接收**状态 \\(S_0\\)** — 我们接收游戏的第一帧(环境)。
+- 基于**状态 \\(S_0\\)**,智能体采取**动作 \\(A_0\\)** — 我们的智能体将向右移动。
+- 环境进入**新状态 \\(S_1\\)** — 新帧。
+- 环境给智能体一些**奖励 \\(R_1\\)** — 我们没有死亡*(正奖励+1)*。
+
+这个RL循环输出一个**状态、动作、奖励和下一个状态**的序列。智能体的目标是**最大化预期累积奖励**。
+
+学院将是**向我们的智能体发送命令并确保智能体同步**的角色:
+
+- 收集观察
+- 使用你的策略选择你的动作
+- 采取动作
+- 如果你达到最大步数或完成任务,则重置。
+
+
+来源:Unity ML-Agents文档
+
+
+- 第一个是*学习环境*,它包含**Unity场景(环境)和环境元素**(游戏角色)。
+- 第二个是*Python低级API*,它包含**用于与环境交互和操作环境的低级Python接口**。它是我们用来启动训练的API。
+- 然后,我们有*外部通信器*,它**连接学习环境(用C#制作)和低级Python API(Python)**。
+- *Python训练器*:**用PyTorch制作的强化学习算法(PPO、SAC等)**。
+- *Gym包装器*:将RL环境封装在gym包装器中。
+- *PettingZoo包装器*:PettingZoo是gym包装器的多智能体版本。
+
+## 学习组件内部 [[inside-learning-component]]
+
+在学习组件内部,我们有**两个重要元素**:
+
+- 第一个是*智能体组件*,场景的参与者。我们将**通过优化其策略来训练智能体**(这将告诉我们在每个状态下采取什么动作)。该策略被称为*大脑*。
+- 最后,还有*学院*。这个组件**协调智能体及其决策过程**。可以将这个学院视为处理Python API请求的老师。
+
+为了更好地理解其角色,让我们回顾一下RL过程。这可以被建模为一个这样工作的循环:
+
+
+
+RL过程:状态、动作、奖励和下一个状态的循环
+来源:强化学习导论,Richard Sutton和Andrew G. Barto
+
+
+现在,让我们想象一个学习玩平台游戏的智能体。RL过程看起来像这样:
+
+
+
+- 我们的智能体从**环境**接收**状态 \\(S_0\\)** — 我们接收游戏的第一帧(环境)。
+- 基于**状态 \\(S_0\\)**,智能体采取**动作 \\(A_0\\)** — 我们的智能体将向右移动。
+- 环境进入**新状态 \\(S_1\\)** — 新帧。
+- 环境给智能体一些**奖励 \\(R_1\\)** — 我们没有死亡*(正奖励+1)*。
+
+这个RL循环输出一个**状态、动作、奖励和下一个状态**的序列。智能体的目标是**最大化预期累积奖励**。
+
+学院将是**向我们的智能体发送命令并确保智能体同步**的角色:
+
+- 收集观察
+- 使用你的策略选择你的动作
+- 采取动作
+- 如果你达到最大步数或完成任务,则重置。
+
+ +
+
+现在我们了解了ML-Agents是如何工作的,**我们准备训练我们的智能体了。**
diff --git a/units/cn/unit5/introduction.mdx b/units/cn/unit5/introduction.mdx
new file mode 100644
index 00000000..32965151
--- /dev/null
+++ b/units/cn/unit5/introduction.mdx
@@ -0,0 +1,31 @@
+# Unity ML-Agents简介 [[introduction-to-ml-agents]]
+
+
+
+强化学习中的一个挑战是**创建环境**。幸运的是,我们可以使用游戏引擎来做到这一点。
+这些引擎,如[Unity](https://unity.com/)、[Godot](https://godotengine.org/)或[Unreal Engine](https://www.unrealengine.com/),是为创建视频游戏而制作的程序。它们非常适合
+创建环境:它们提供物理系统、2D/3D渲染等。
+
+
+其中之一,[Unity](https://unity.com/),创建了[Unity ML-Agents工具包](https://github.com/Unity-Technologies/ml-agents),这是一个基于Unity游戏引擎的插件,允许我们**使用Unity游戏引擎作为环境构建器来训练智能体**。在第一个附加单元中,这就是我们用来训练Huggy抓住棍子的工具!
+
+
+
+
+
+现在我们了解了ML-Agents是如何工作的,**我们准备训练我们的智能体了。**
diff --git a/units/cn/unit5/introduction.mdx b/units/cn/unit5/introduction.mdx
new file mode 100644
index 00000000..32965151
--- /dev/null
+++ b/units/cn/unit5/introduction.mdx
@@ -0,0 +1,31 @@
+# Unity ML-Agents简介 [[introduction-to-ml-agents]]
+
+
+
+强化学习中的一个挑战是**创建环境**。幸运的是,我们可以使用游戏引擎来做到这一点。
+这些引擎,如[Unity](https://unity.com/)、[Godot](https://godotengine.org/)或[Unreal Engine](https://www.unrealengine.com/),是为创建视频游戏而制作的程序。它们非常适合
+创建环境:它们提供物理系统、2D/3D渲染等。
+
+
+其中之一,[Unity](https://unity.com/),创建了[Unity ML-Agents工具包](https://github.com/Unity-Technologies/ml-agents),这是一个基于Unity游戏引擎的插件,允许我们**使用Unity游戏引擎作为环境构建器来训练智能体**。在第一个附加单元中,这就是我们用来训练Huggy抓住棍子的工具!
+
+
+ +来源:ML-Agents文档
+
+
+Unity ML-Agents工具包提供了许多出色的预制环境,从踢足球、学习行走到跳过大墙。
+
+在本单元中,我们将学习使用ML-Agents,但**如果你不知道如何使用Unity游戏引擎,不用担心**:你不需要使用它来训练你的智能体。
+
+所以,今天,我们将训练两个智能体:
+- 第一个将学习**向生成的目标发射雪球**。
+- 第二个需要**按下按钮生成金字塔,然后导航到金字塔,将其推倒,并移动到顶部的金砖**。为了做到这一点,它将需要探索其环境,这将使用一种称为好奇心的技术来完成。
+
+
+
+然后,在训练之后,**你将把训练好的智能体推送到Hugging Face Hub**,你将能够**直接在浏览器上观看它们玩游戏,而无需使用Unity编辑器**。
+
+完成本单元将**为下一个挑战做准备:AI对抗AI,在那里你将在多智能体环境中训练智能体,并与你的同学的智能体竞争**。
+
+听起来很刺激吧?让我们开始吧!
diff --git a/units/cn/unit5/pyramids.mdx b/units/cn/unit5/pyramids.mdx
new file mode 100644
index 00000000..392211b9
--- /dev/null
+++ b/units/cn/unit5/pyramids.mdx
@@ -0,0 +1,39 @@
+# 金字塔环境
+
+这个环境的目标是训练我们的智能体**获取金字塔顶部的金砖。为了做到这一点,它需要按下按钮生成金字塔,导航到金字塔,将其推倒,并移动到顶部的金砖**。
+
+
+来源:ML-Agents文档
+
+
+Unity ML-Agents工具包提供了许多出色的预制环境,从踢足球、学习行走到跳过大墙。
+
+在本单元中,我们将学习使用ML-Agents,但**如果你不知道如何使用Unity游戏引擎,不用担心**:你不需要使用它来训练你的智能体。
+
+所以,今天,我们将训练两个智能体:
+- 第一个将学习**向生成的目标发射雪球**。
+- 第二个需要**按下按钮生成金字塔,然后导航到金字塔,将其推倒,并移动到顶部的金砖**。为了做到这一点,它将需要探索其环境,这将使用一种称为好奇心的技术来完成。
+
+
+
+然后,在训练之后,**你将把训练好的智能体推送到Hugging Face Hub**,你将能够**直接在浏览器上观看它们玩游戏,而无需使用Unity编辑器**。
+
+完成本单元将**为下一个挑战做准备:AI对抗AI,在那里你将在多智能体环境中训练智能体,并与你的同学的智能体竞争**。
+
+听起来很刺激吧?让我们开始吧!
diff --git a/units/cn/unit5/pyramids.mdx b/units/cn/unit5/pyramids.mdx
new file mode 100644
index 00000000..392211b9
--- /dev/null
+++ b/units/cn/unit5/pyramids.mdx
@@ -0,0 +1,39 @@
+# 金字塔环境
+
+这个环境的目标是训练我们的智能体**获取金字塔顶部的金砖。为了做到这一点,它需要按下按钮生成金字塔,导航到金字塔,将其推倒,并移动到顶部的金砖**。
+
+ +
+
+## 奖励函数
+
+奖励函数是:
+
+
+
+
+## 奖励函数
+
+奖励函数是:
+
+ +
+在代码方面,它看起来像这样
+
+
+在代码方面,它看起来像这样
+ +
+为了训练这个寻找按钮然后寻找金字塔以摧毁的新智能体,我们将使用两种类型奖励的组合:
+
+- 环境给予的*外部奖励*(上图所示)。
+- 还有一个称为**好奇心**的*内部奖励*。这第二个奖励将**推动我们的智能体变得好奇,或者换句话说,更好地探索其环境**。
+
+如果你想了解更多关于好奇心的信息,下一节(可选)将解释基础知识。
+
+## 观察空间
+
+在观察方面,我们**使用148个射线,每个射线都可以检测物体**(开关、砖块、金砖和墙壁)。
+
+
+
+为了训练这个寻找按钮然后寻找金字塔以摧毁的新智能体,我们将使用两种类型奖励的组合:
+
+- 环境给予的*外部奖励*(上图所示)。
+- 还有一个称为**好奇心**的*内部奖励*。这第二个奖励将**推动我们的智能体变得好奇,或者换句话说,更好地探索其环境**。
+
+如果你想了解更多关于好奇心的信息,下一节(可选)将解释基础知识。
+
+## 观察空间
+
+在观察方面,我们**使用148个射线,每个射线都可以检测物体**(开关、砖块、金砖和墙壁)。
+
+ +
+我们还使用一个**表示开关状态的布尔变量**(我们是否打开或关闭开关来生成金字塔)和一个**包含智能体速度的向量**。
+
+
+
+我们还使用一个**表示开关状态的布尔变量**(我们是否打开或关闭开关来生成金字塔)和一个**包含智能体速度的向量**。
+
+ +
+
+## 动作空间
+
+动作空间是**离散的**,有四种可能的动作:
+
+
+
+
+## 动作空间
+
+动作空间是**离散的**,有四种可能的动作:
+
+ diff --git a/units/cn/unit5/quiz.mdx b/units/cn/unit5/quiz.mdx
new file mode 100644
index 00000000..dcdd9bb4
--- /dev/null
+++ b/units/cn/unit5/quiz.mdx
@@ -0,0 +1,132 @@
+# 测验
+
+学习的最佳方式以及[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法**是测试自己**。这将帮助你找出**需要加强知识的地方**。
+
+### 问题1:以下哪些工具是专门为视频游戏开发设计的?
+
+
+
+### 问题2:关于Unity ML-Agents,以下哪些陈述是正确的?
+
+
+
+### 问题3:填写缺失的字母
+
+- 在Unity ML-Agents中,智能体的策略被称为b \_ \_ \_ n
+- 负责协调智能体的组件被称为\_ c \_ \_ \_ m \_
+
+
diff --git a/units/cn/unit5/quiz.mdx b/units/cn/unit5/quiz.mdx
new file mode 100644
index 00000000..dcdd9bb4
--- /dev/null
+++ b/units/cn/unit5/quiz.mdx
@@ -0,0 +1,132 @@
+# 测验
+
+学习的最佳方式以及[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法**是测试自己**。这将帮助你找出**需要加强知识的地方**。
+
+### 问题1:以下哪些工具是专门为视频游戏开发设计的?
+
+
+
+### 问题2:关于Unity ML-Agents,以下哪些陈述是正确的?
+
+
+
+### 问题3:填写缺失的字母
+
+- 在Unity ML-Agents中,智能体的策略被称为b \_ \_ \_ n
+- 负责协调智能体的组件被称为\_ c \_ \_ \_ m \_
+
+
+解决方案
+
+ - b r a i n
+ - a c a d e m y
+
+
+
+### 问题4:用你自己的话定义什么是`raycast`
+
+
+解决方案
+raycast(射线投射)是(大多数情况下)一种线性投射,如同一束"激光",旨在通过物体检测碰撞。
+
+
+### 问题5:使用`frames`(帧)或`raycasts`(射线投射)捕获环境有什么区别?
+
+
+
+
+### 问题6:列举在Snowball或Pyramid环境中用于训练智能体的几个环境和智能体输入变量
+
+
+解决方案
+- 从智能体生成的射线投射碰撞,检测方块、(不可见的)墙壁、石头、目标、开关等。
+- 描述智能体特征的传统输入,如其速度
+- 布尔变量,如Pyramids中的开关(开/关)或SnowballTarget中的"我能射击吗?"。
+
+
+
+恭喜你完成这个测验🥳,如果你错过了一些要素,请花时间再次阅读本章以加强(😏)你的知识。
diff --git a/units/cn/unit5/snowball-target.mdx b/units/cn/unit5/snowball-target.mdx
new file mode 100644
index 00000000..fbfecc36
--- /dev/null
+++ b/units/cn/unit5/snowball-target.mdx
@@ -0,0 +1,57 @@
+# SnowballTarget环境
+
+
+
+SnowballTarget是我们在Hugging Face使用[Kay Lousberg](https://kaylousberg.com/)的资源创建的环境。本单元末尾有一个可选部分,**如果你想学习使用Unity并创建自己的环境**。
+
+## 智能体的目标
+
+你将要训练的第一个智能体叫做Julien熊🐻。Julien被训练**用雪球击中目标**。
+
+这个环境中的目标是让Julien**在有限的时间内(1000个时间步)尽可能多地击中目标**。为此,它需要**正确地放置自己相对于目标的位置并射击**。
+
+此外,为了避免"雪球狂轰滥炸"(即每个时间步都发射一个雪球),**Julien有一个"冷却"系统**(它需要在射击后等待0.5秒才能再次射击)。
+
+
+ +智能体需要等待0.5秒才能再次发射雪球
+
+
+## 奖励函数和奖励工程问题
+
+奖励函数很简单。**每当智能体的雪球击中目标时,环境给予+1的奖励**。因为智能体的目标是最大化预期累积奖励,**它将尝试击中尽可能多的目标**。
+
+
+智能体需要等待0.5秒才能再次发射雪球
+
+
+## 奖励函数和奖励工程问题
+
+奖励函数很简单。**每当智能体的雪球击中目标时,环境给予+1的奖励**。因为智能体的目标是最大化预期累积奖励,**它将尝试击中尽可能多的目标**。
+
+ +
+我们可以有一个更复杂的奖励函数(例如,加入惩罚以促使智能体更快行动)。但当你设计一个环境时,你需要避免*奖励工程问题*,即使用过于复杂的奖励函数来强制你的智能体按照你希望的方式行动。
+为什么?因为这样做,**你可能会错过智能体用更简单的奖励函数找到的有趣策略**。
+
+在代码方面,它看起来像这样:
+
+
+
+我们可以有一个更复杂的奖励函数(例如,加入惩罚以促使智能体更快行动)。但当你设计一个环境时,你需要避免*奖励工程问题*,即使用过于复杂的奖励函数来强制你的智能体按照你希望的方式行动。
+为什么?因为这样做,**你可能会错过智能体用更简单的奖励函数找到的有趣策略**。
+
+在代码方面,它看起来像这样:
+
+ +
+
+## 观察空间
+
+关于观察,我们不使用普通视觉(帧),而是**使用射线投射(raycasts)**。
+
+把射线投射想象成激光,它们会检测是否穿过物体。
+
+
+
+
+
+## 观察空间
+
+关于观察,我们不使用普通视觉(帧),而是**使用射线投射(raycasts)**。
+
+把射线投射想象成激光,它们会检测是否穿过物体。
+
+
+ +来源:ML-Agents文档
+
+
+
+在这个环境中,我们的智能体有多组射线投射:
+
+来源:ML-Agents文档
+
+
+
+在这个环境中,我们的智能体有多组射线投射:
+ +
+除了射线投射外,智能体还获得一个"我能射击吗"的布尔值作为观察。
+
+
+
+除了射线投射外,智能体还获得一个"我能射击吗"的布尔值作为观察。
+
+ +
+## 动作空间
+
+动作空间是离散的:
+
+
+
+## 动作空间
+
+动作空间是离散的:
+
+ diff --git a/units/cn/unit6/additional-readings.mdx b/units/cn/unit6/additional-readings.mdx
new file mode 100644
index 00000000..08a8d46e
--- /dev/null
+++ b/units/cn/unit6/additional-readings.mdx
@@ -0,0 +1,17 @@
+# 额外阅读材料 [[additional-readings]]
+
+## 强化学习中的偏差-方差权衡
+
+如果你想深入了解深度强化学习中的方差和偏差权衡问题,可以查看以下两篇文章:
+
+- [理解(深度)强化学习中的偏差/方差权衡](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
+- [强化学习中的偏差-方差权衡](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
+
+## 优势函数
+
+- [优势函数,SpinningUp RL](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html?highlight=advantage%20functio#advantage-functions)
+
+## Actor Critic
+
+- [深度强化学习基础系列,L3策略梯度和优势估计,Pieter Abbeel主讲](https://www.youtube.com/watch?v=AKbX1Zvo7r8)
+- [A2C论文:深度强化学习的异步方法](https://arxiv.org/abs/1602.01783v2)
diff --git a/units/cn/unit6/advantage-actor-critic.mdx b/units/cn/unit6/advantage-actor-critic.mdx
new file mode 100644
index 00000000..240fc68d
--- /dev/null
+++ b/units/cn/unit6/advantage-actor-critic.mdx
@@ -0,0 +1,70 @@
+# 优势Actor-Critic (A2C) [[advantage-actor-critic]]
+
+## 使用Actor-Critic方法减少方差
+
+减少Reinforce算法方差并更快更好地训练我们的智能体的解决方案是使用基于策略和基于价值方法的组合:*Actor-Critic方法*。
+
+要理解Actor-Critic,想象你正在玩一个视频游戏。你可以和一个会给你提供反馈的朋友一起玩。你是Actor(演员),你的朋友是Critic(评论家)。
+
+
diff --git a/units/cn/unit6/additional-readings.mdx b/units/cn/unit6/additional-readings.mdx
new file mode 100644
index 00000000..08a8d46e
--- /dev/null
+++ b/units/cn/unit6/additional-readings.mdx
@@ -0,0 +1,17 @@
+# 额外阅读材料 [[additional-readings]]
+
+## 强化学习中的偏差-方差权衡
+
+如果你想深入了解深度强化学习中的方差和偏差权衡问题,可以查看以下两篇文章:
+
+- [理解(深度)强化学习中的偏差/方差权衡](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
+- [强化学习中的偏差-方差权衡](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
+
+## 优势函数
+
+- [优势函数,SpinningUp RL](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html?highlight=advantage%20functio#advantage-functions)
+
+## Actor Critic
+
+- [深度强化学习基础系列,L3策略梯度和优势估计,Pieter Abbeel主讲](https://www.youtube.com/watch?v=AKbX1Zvo7r8)
+- [A2C论文:深度强化学习的异步方法](https://arxiv.org/abs/1602.01783v2)
diff --git a/units/cn/unit6/advantage-actor-critic.mdx b/units/cn/unit6/advantage-actor-critic.mdx
new file mode 100644
index 00000000..240fc68d
--- /dev/null
+++ b/units/cn/unit6/advantage-actor-critic.mdx
@@ -0,0 +1,70 @@
+# 优势Actor-Critic (A2C) [[advantage-actor-critic]]
+
+## 使用Actor-Critic方法减少方差
+
+减少Reinforce算法方差并更快更好地训练我们的智能体的解决方案是使用基于策略和基于价值方法的组合:*Actor-Critic方法*。
+
+要理解Actor-Critic,想象你正在玩一个视频游戏。你可以和一个会给你提供反馈的朋友一起玩。你是Actor(演员),你的朋友是Critic(评论家)。
+
+ +
+一开始你不知道如何玩,**所以你随机尝试一些动作**。Critic观察你的动作并**提供反馈**。
+
+从这些反馈中学习,**你将更新你的策略并变得更擅长玩这个游戏。**
+
+另一方面,你的朋友(Critic)也会更新他们提供反馈的方式,使其下次能做得更好。
+
+这就是Actor-Critic背后的思想。我们学习两种函数近似:
+
+- *一个策略*,**控制我们的智能体如何行动**:\\( \pi_{\theta}(s) \\)
+
+- *一个价值函数*,通过衡量所采取动作的好坏来辅助策略更新:\\( \hat{q}_{w}(s,a) \\)
+
+## Actor-Critic过程
+现在我们已经了解了Actor Critic的大致情况,让我们深入了解Actor和Critic如何在训练过程中一起改进。
+
+如我们所见,使用Actor-Critic方法,有两种函数近似(两个神经网络):
+- *Actor*,一个由theta参数化的**策略函数**:\\( \pi_{\theta}(s) \\)
+- *Critic*,一个由w参数化的**价值函数**:\\( \hat{q}_{w}(s,a) \\)
+
+让我们看看训练过程,以了解Actor和Critic是如何优化的:
+- 在每个时间步t,我们从环境中获取当前状态\\( S_t\\),并**将其作为输入传递给我们的Actor和Critic**。
+
+- 我们的策略接收状态并**输出一个动作** \\( A_t \\)。
+
+
+
+一开始你不知道如何玩,**所以你随机尝试一些动作**。Critic观察你的动作并**提供反馈**。
+
+从这些反馈中学习,**你将更新你的策略并变得更擅长玩这个游戏。**
+
+另一方面,你的朋友(Critic)也会更新他们提供反馈的方式,使其下次能做得更好。
+
+这就是Actor-Critic背后的思想。我们学习两种函数近似:
+
+- *一个策略*,**控制我们的智能体如何行动**:\\( \pi_{\theta}(s) \\)
+
+- *一个价值函数*,通过衡量所采取动作的好坏来辅助策略更新:\\( \hat{q}_{w}(s,a) \\)
+
+## Actor-Critic过程
+现在我们已经了解了Actor Critic的大致情况,让我们深入了解Actor和Critic如何在训练过程中一起改进。
+
+如我们所见,使用Actor-Critic方法,有两种函数近似(两个神经网络):
+- *Actor*,一个由theta参数化的**策略函数**:\\( \pi_{\theta}(s) \\)
+- *Critic*,一个由w参数化的**价值函数**:\\( \hat{q}_{w}(s,a) \\)
+
+让我们看看训练过程,以了解Actor和Critic是如何优化的:
+- 在每个时间步t,我们从环境中获取当前状态\\( S_t\\),并**将其作为输入传递给我们的Actor和Critic**。
+
+- 我们的策略接收状态并**输出一个动作** \\( A_t \\)。
+
+ +
+- Critic也将该动作作为输入,并使用\\( S_t\\)和\\( A_t \\),**计算在该状态下采取该动作的价值:Q值**。
+
+
+
+- Critic也将该动作作为输入,并使用\\( S_t\\)和\\( A_t \\),**计算在该状态下采取该动作的价值:Q值**。
+
+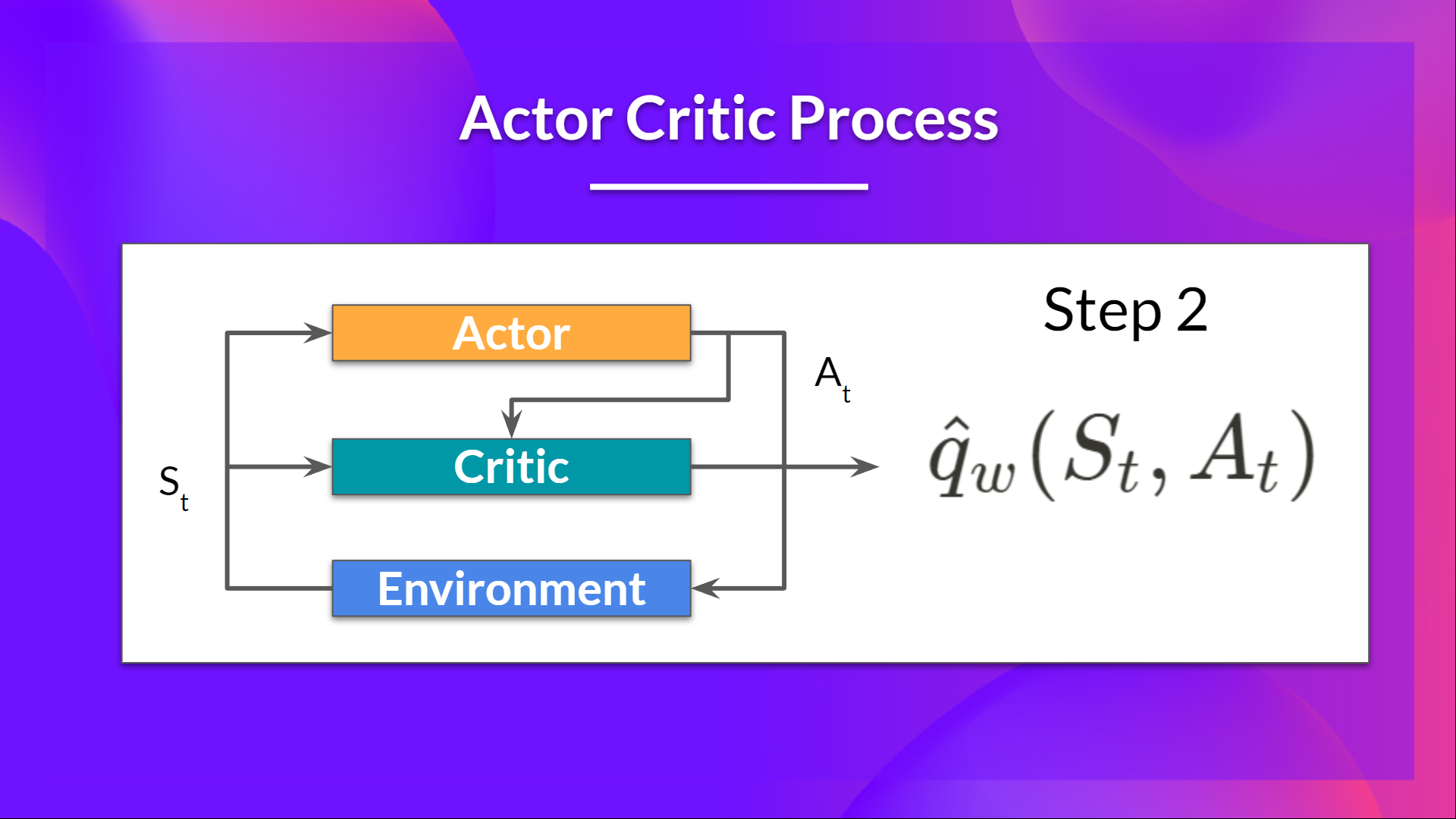 +
+- 在环境中执行的动作\\( A_t\\)输出一个新状态\\( S_{t+1}\\)和一个奖励\\( R_{t+1} \\)。
+
+
+
+- 在环境中执行的动作\\( A_t\\)输出一个新状态\\( S_{t+1}\\)和一个奖励\\( R_{t+1} \\)。
+
+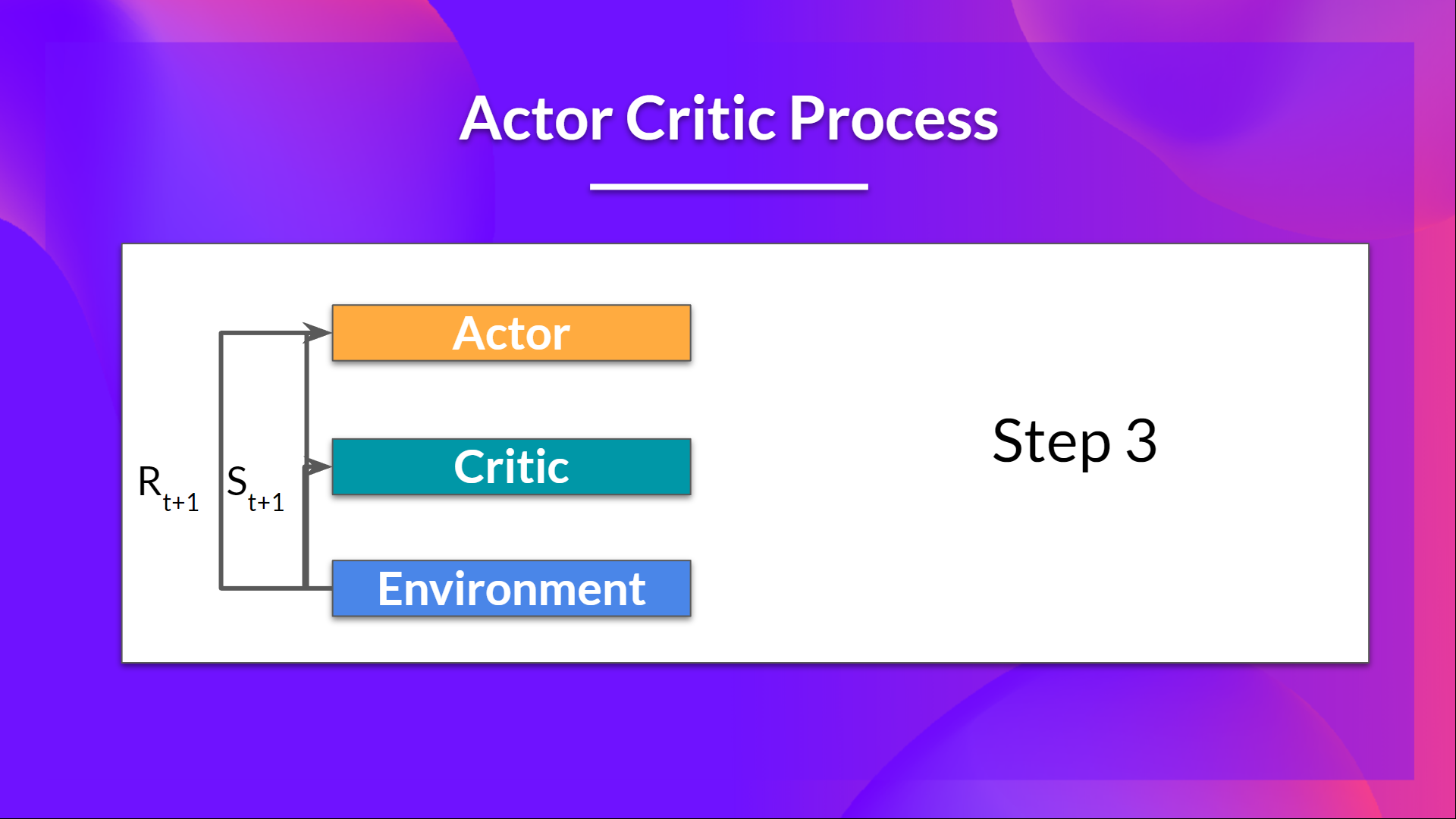 +
+- Actor使用Q值更新其策略参数。
+
+
+
+- Actor使用Q值更新其策略参数。
+
+ +
+- 通过其更新的参数,Actor产生下一个要在给定新状态\\( S_{t+1} \\)下采取的动作\\( A_{t+1} \\)。
+
+- 然后Critic更新其价值参数。
+
+
+
+- 通过其更新的参数,Actor产生下一个要在给定新状态\\( S_{t+1} \\)下采取的动作\\( A_{t+1} \\)。
+
+- 然后Critic更新其价值参数。
+
+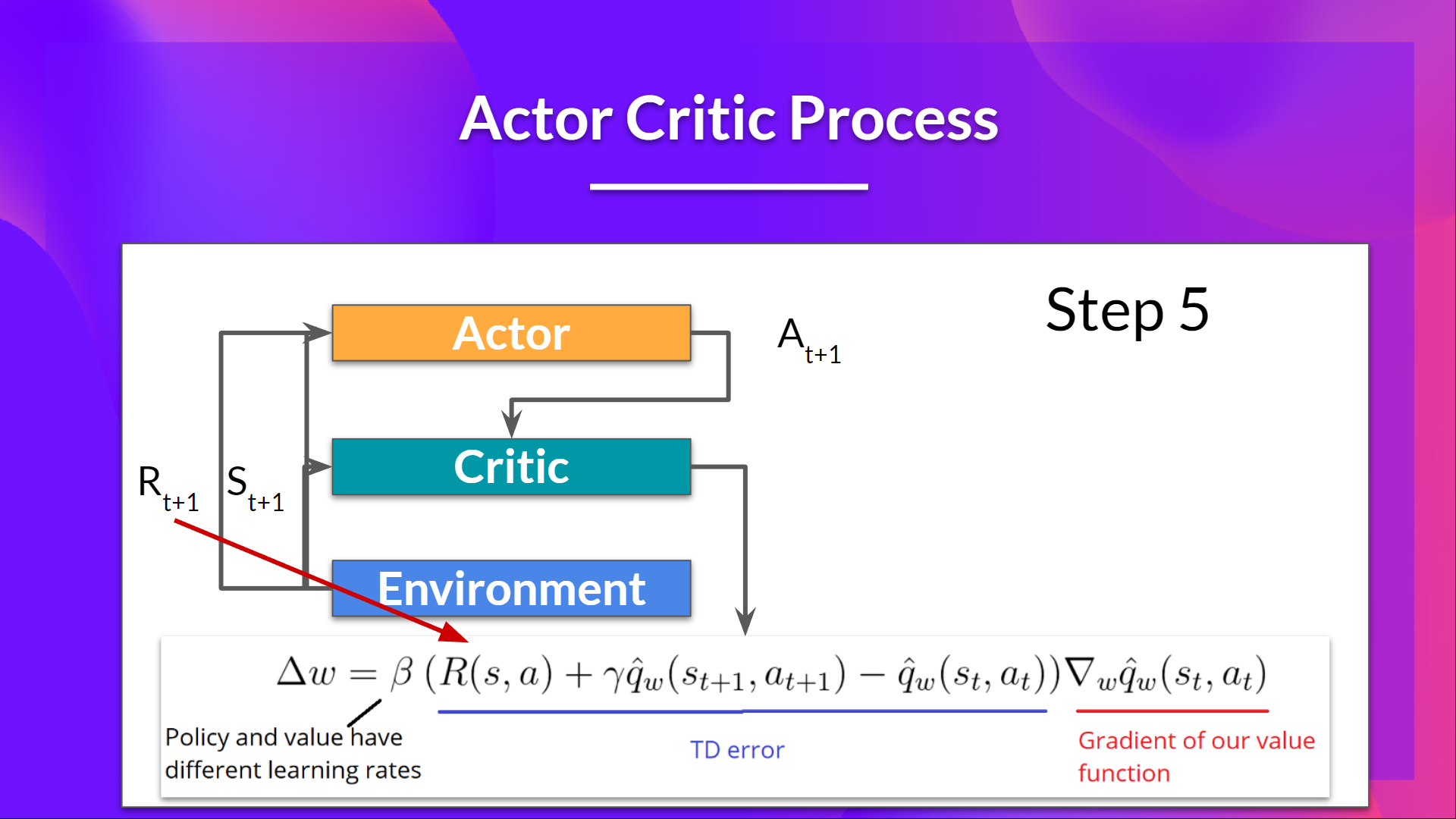 +
+## 在Actor-Critic中添加优势(A2C)
+我们可以通过**使用优势函数作为Critic而不是动作价值函数**来进一步稳定学习。
+
+这个想法是优势函数计算一个动作相对于在状态下可能的其他动作的相对优势:**在一个状态下采取该动作比该状态的平均价值好多少**。它从状态-动作对中减去状态的平均价值:
+
+
+
+## 在Actor-Critic中添加优势(A2C)
+我们可以通过**使用优势函数作为Critic而不是动作价值函数**来进一步稳定学习。
+
+这个想法是优势函数计算一个动作相对于在状态下可能的其他动作的相对优势:**在一个状态下采取该动作比该状态的平均价值好多少**。它从状态-动作对中减去状态的平均价值:
+
+ +
+换句话说,这个函数计算**如果我们在该状态下采取这个动作,相比于在该状态下获得的平均奖励,我们获得的额外奖励**。
+
+额外奖励是超出该状态预期价值的部分。
+- 如果A(s,a) > 0:我们的梯度**被推向那个方向**。
+- 如果A(s,a) < 0(我们的动作比该状态的平均价值差),**我们的梯度被推向相反方向**。
+
+实现这个优势函数的问题是它需要两个价值函数——\\( Q(s,a)\\)和\\( V(s)\\)。幸运的是,**我们可以使用TD误差作为优势函数的良好估计器。**
+
+
+
+换句话说,这个函数计算**如果我们在该状态下采取这个动作,相比于在该状态下获得的平均奖励,我们获得的额外奖励**。
+
+额外奖励是超出该状态预期价值的部分。
+- 如果A(s,a) > 0:我们的梯度**被推向那个方向**。
+- 如果A(s,a) < 0(我们的动作比该状态的平均价值差),**我们的梯度被推向相反方向**。
+
+实现这个优势函数的问题是它需要两个价值函数——\\( Q(s,a)\\)和\\( V(s)\\)。幸运的是,**我们可以使用TD误差作为优势函数的良好估计器。**
+
+ diff --git a/units/cn/unit6/conclusion.mdx b/units/cn/unit6/conclusion.mdx
new file mode 100644
index 00000000..43565a24
--- /dev/null
+++ b/units/cn/unit6/conclusion.mdx
@@ -0,0 +1,11 @@
+# 结论 [[conclusion]]
+
+恭喜你完成本单元和教程。你刚刚训练了你的第一个虚拟机器人🥳。
+
+**在继续之前,花时间理解这些材料**。你也可以查看我们在*额外阅读*部分提供的额外阅读材料。
+
+最后,我们很想**听听你对课程的看法以及我们如何改进它**。如果你有一些反馈,请👉 [填写这个表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+下个单元见!
+
+### 持续学习,保持精彩 🤗
diff --git a/units/cn/unit6/hands-on.mdx b/units/cn/unit6/hands-on.mdx
new file mode 100644
index 00000000..32a1e968
--- /dev/null
+++ b/units/cn/unit6/hands-on.mdx
@@ -0,0 +1,396 @@
+# 使用Panda-Gym机器人模拟环境的优势演员评论家算法(A2C) 🤖 [[hands-on]]
+
+
+
+
+
+现在你已经学习了优势演员评论家算法(A2C)背后的理论,**你已经准备好使用Stable-Baselines3在机器人环境中训练你的A2C智能体**。并训练:
+- 一个机器人手臂 🦾 移动到正确位置。
+
+我们将使用:
+- [panda-gym](https://github.com/qgallouedec/panda-gym)
+
+为了在认证过程中验证这个实践练习,你需要将你训练的两个模型推送到Hub并获得以下结果:
+
+- `PandaReachDense-v3` 获得 >= -3.5 的结果。
+
+要查找你的结果,[前往排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+**要开始实践,请点击"在Colab中打开"按钮** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit6/unit6.ipynb)
+
+
+# 单元6:使用Panda-Gym机器人模拟环境的优势演员评论家算法(A2C) 🤖
+
+### 🎮 环境:
+
+- [Panda-Gym](https://github.com/qgallouedec/panda-gym)
+
+### 📚 强化学习库:
+
+- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/)
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在完成本笔记本后,你将:
+
+- 能够使用**Panda-Gym**环境库。
+- 能够**使用A2C训练机器人**。
+- 理解**为什么我们需要对输入进行标准化**。
+- 能够**将你训练的智能体和代码推送到Hub**,并附带精美的视频回放和评估分数 🔥。
+
+## 先决条件 🏗️
+
+在深入学习本笔记本之前,你需要:
+
+🔲 📚 通过[阅读单元6](https://huggingface.co/deep-rl-course/unit6/introduction)学习演员评论家方法 🤗
+
+# 让我们训练我们的第一个机器人 🤖
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。要做到这一点,请转到`Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+## 创建虚拟显示器 🔽
+
+在笔记本中,我们需要生成回放视频。为此,在colab中,**我们需要有一个虚拟屏幕来能够渲染环境**(从而记录帧)。
+
+以下单元将安装库并创建并运行虚拟屏幕 🖥
+
+```python
+%%capture
+!apt install python-opengl
+!apt install ffmpeg
+!apt install xvfb
+!pip3 install pyvirtualdisplay
+```
+
+```python
+# 虚拟显示器
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+### 安装依赖项 🔽
+
+我们将安装多个依赖项:
+
+- `gymnasium`
+- `panda-gym`:包含机器人手臂环境。
+- `stable-baselines3`:SB3深度强化学习库。
+- `huggingface_sb3`:Stable-baselines3的附加代码,用于从Hugging Face 🤗 Hub加载和上传模型。
+- `huggingface_hub`:允许任何人使用Hub仓库的库。
+
+```bash
+!pip install stable-baselines3[extra]
+!pip install gymnasium
+!pip install huggingface_sb3
+!pip install huggingface_hub
+!pip install panda_gym
+```
+
+## 导入包 📦
+
+```python
+import os
+
+import gymnasium as gym
+import panda_gym
+
+from huggingface_sb3 import load_from_hub, package_to_hub
+
+from stable_baselines3 import A2C
+from stable_baselines3.common.evaluation import evaluate_policy
+from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
+from stable_baselines3.common.env_util import make_vec_env
+
+from huggingface_hub import notebook_login
+```
+
+## PandaReachDense-v3 🦾
+
+我们将要训练的智能体是一个需要进行控制(移动手臂和使用末端执行器)的机器人手臂。
+
+在机器人学中,*末端执行器*是机器人手臂末端的设备,设计用于与环境交互。
+
+在`PandaReach`中,机器人必须将其末端执行器放置在目标位置(绿色球)。
+
+我们将使用这个环境的密集版本。这意味着我们将获得一个*密集奖励函数*,它**将在每个时间步提供奖励**(智能体越接近完成任务,奖励越高)。与*稀疏奖励函数*相反,在稀疏奖励函数中,环境**当且仅当任务完成时才返回奖励**。
+
+此外,我们将使用*末端执行器位移控制*,这意味着**动作对应于末端执行器的位移**。我们不控制每个关节的个别运动(关节控制)。
+
+
diff --git a/units/cn/unit6/conclusion.mdx b/units/cn/unit6/conclusion.mdx
new file mode 100644
index 00000000..43565a24
--- /dev/null
+++ b/units/cn/unit6/conclusion.mdx
@@ -0,0 +1,11 @@
+# 结论 [[conclusion]]
+
+恭喜你完成本单元和教程。你刚刚训练了你的第一个虚拟机器人🥳。
+
+**在继续之前,花时间理解这些材料**。你也可以查看我们在*额外阅读*部分提供的额外阅读材料。
+
+最后,我们很想**听听你对课程的看法以及我们如何改进它**。如果你有一些反馈,请👉 [填写这个表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+下个单元见!
+
+### 持续学习,保持精彩 🤗
diff --git a/units/cn/unit6/hands-on.mdx b/units/cn/unit6/hands-on.mdx
new file mode 100644
index 00000000..32a1e968
--- /dev/null
+++ b/units/cn/unit6/hands-on.mdx
@@ -0,0 +1,396 @@
+# 使用Panda-Gym机器人模拟环境的优势演员评论家算法(A2C) 🤖 [[hands-on]]
+
+
+
+
+
+现在你已经学习了优势演员评论家算法(A2C)背后的理论,**你已经准备好使用Stable-Baselines3在机器人环境中训练你的A2C智能体**。并训练:
+- 一个机器人手臂 🦾 移动到正确位置。
+
+我们将使用:
+- [panda-gym](https://github.com/qgallouedec/panda-gym)
+
+为了在认证过程中验证这个实践练习,你需要将你训练的两个模型推送到Hub并获得以下结果:
+
+- `PandaReachDense-v3` 获得 >= -3.5 的结果。
+
+要查找你的结果,[前往排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+**要开始实践,请点击"在Colab中打开"按钮** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit6/unit6.ipynb)
+
+
+# 单元6:使用Panda-Gym机器人模拟环境的优势演员评论家算法(A2C) 🤖
+
+### 🎮 环境:
+
+- [Panda-Gym](https://github.com/qgallouedec/panda-gym)
+
+### 📚 强化学习库:
+
+- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/)
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在完成本笔记本后,你将:
+
+- 能够使用**Panda-Gym**环境库。
+- 能够**使用A2C训练机器人**。
+- 理解**为什么我们需要对输入进行标准化**。
+- 能够**将你训练的智能体和代码推送到Hub**,并附带精美的视频回放和评估分数 🔥。
+
+## 先决条件 🏗️
+
+在深入学习本笔记本之前,你需要:
+
+🔲 📚 通过[阅读单元6](https://huggingface.co/deep-rl-course/unit6/introduction)学习演员评论家方法 🤗
+
+# 让我们训练我们的第一个机器人 🤖
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。要做到这一点,请转到`Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+## 创建虚拟显示器 🔽
+
+在笔记本中,我们需要生成回放视频。为此,在colab中,**我们需要有一个虚拟屏幕来能够渲染环境**(从而记录帧)。
+
+以下单元将安装库并创建并运行虚拟屏幕 🖥
+
+```python
+%%capture
+!apt install python-opengl
+!apt install ffmpeg
+!apt install xvfb
+!pip3 install pyvirtualdisplay
+```
+
+```python
+# 虚拟显示器
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+### 安装依赖项 🔽
+
+我们将安装多个依赖项:
+
+- `gymnasium`
+- `panda-gym`:包含机器人手臂环境。
+- `stable-baselines3`:SB3深度强化学习库。
+- `huggingface_sb3`:Stable-baselines3的附加代码,用于从Hugging Face 🤗 Hub加载和上传模型。
+- `huggingface_hub`:允许任何人使用Hub仓库的库。
+
+```bash
+!pip install stable-baselines3[extra]
+!pip install gymnasium
+!pip install huggingface_sb3
+!pip install huggingface_hub
+!pip install panda_gym
+```
+
+## 导入包 📦
+
+```python
+import os
+
+import gymnasium as gym
+import panda_gym
+
+from huggingface_sb3 import load_from_hub, package_to_hub
+
+from stable_baselines3 import A2C
+from stable_baselines3.common.evaluation import evaluate_policy
+from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
+from stable_baselines3.common.env_util import make_vec_env
+
+from huggingface_hub import notebook_login
+```
+
+## PandaReachDense-v3 🦾
+
+我们将要训练的智能体是一个需要进行控制(移动手臂和使用末端执行器)的机器人手臂。
+
+在机器人学中,*末端执行器*是机器人手臂末端的设备,设计用于与环境交互。
+
+在`PandaReach`中,机器人必须将其末端执行器放置在目标位置(绿色球)。
+
+我们将使用这个环境的密集版本。这意味着我们将获得一个*密集奖励函数*,它**将在每个时间步提供奖励**(智能体越接近完成任务,奖励越高)。与*稀疏奖励函数*相反,在稀疏奖励函数中,环境**当且仅当任务完成时才返回奖励**。
+
+此外,我们将使用*末端执行器位移控制*,这意味着**动作对应于末端执行器的位移**。我们不控制每个关节的个别运动(关节控制)。
+
+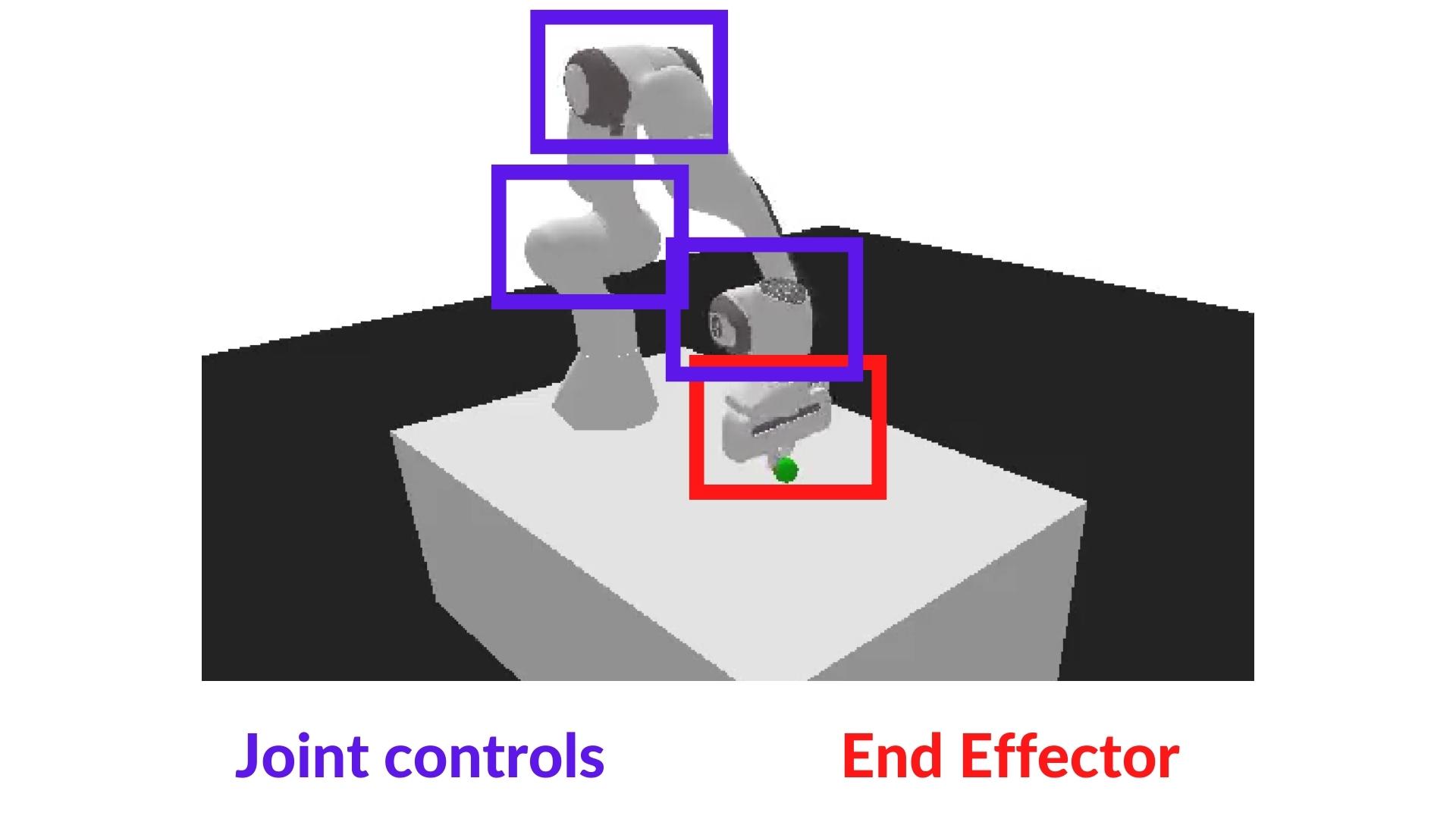 +
+这样**训练将更容易**。
+
+### 创建环境
+
+#### 环境 🎮
+
+在`PandaReachDense-v3`中,机器人手臂必须将其末端执行器放置在目标位置(绿色球)。
+
+```python
+env_id = "PandaReachDense-v3"
+
+# 创建环境
+env = gym.make(env_id)
+
+# 获取状态空间和动作空间
+s_size = env.observation_space.shape
+a_size = env.action_space
+```
+
+```python
+print("_____观察空间_____ \n")
+print("状态空间是:", s_size)
+print("观察样本", env.observation_space.sample()) # 获取随机观察
+```
+
+观察空间**是一个包含3个不同元素的字典**:
+
+- `achieved_goal`:目标的(x,y,z)位置。
+- `desired_goal`:目标位置与当前对象位置之间的(x,y,z)距离。
+- `observation`:末端执行器的位置(x,y,z)和速度(vx, vy, vz)。
+
+鉴于观察是一个字典,**我们需要使用MultiInputPolicy策略而不是MlpPolicy**。
+
+```python
+print("\n _____动作空间_____ \n")
+print("动作空间是:", a_size)
+print("动作空间样本", env.action_space.sample()) # 采取随机动作
+```
+
+动作空间是一个包含3个值的向量:
+- 控制x, y, z移动
+
+
+### 标准化观察和奖励
+
+强化学习中的一个良好实践是[标准化输入特征](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html)。
+
+为此,有一个包装器将计算输入特征的运行平均值和标准差。
+
+我们还通过添加`norm_reward = True`来使用这个相同的包装器标准化奖励
+
+[你应该查看文档来填写这个单元格](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
+
+```python
+env = make_vec_env(env_id, n_envs=4)
+
+# 添加这个包装器来标准化观察和奖励
+env = # TODO: 添加包装器
+```
+
+#### 解决方案
+
+```python
+env = make_vec_env(env_id, n_envs=4)
+
+env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
+```
+
+### 创建A2C模型 🤖
+
+有关使用StableBaselines3实现A2C的更多信息,请查看:https://stable-baselines3.readthedocs.io/en/master/modules/a2c.html#notes
+
+为了找到最佳参数,我查看了[Stable-Baselines3团队的官方训练智能体](https://huggingface.co/sb3)。
+
+```python
+model = # 创建A2C模型并尝试找到最佳参数
+```
+
+#### 解决方案
+
+```python
+model = A2C(policy = "MultiInputPolicy",
+ env = env,
+ verbose=1)
+```
+
+### 训练A2C智能体 🏃
+
+- 让我们训练我们的智能体1,000,000个时间步,不要忘记在Colab上使用GPU。这将花费大约~25-40分钟
+
+```python
+model.learn(1_000_000)
+```
+
+```python
+# 保存模型和VecNormalize统计数据
+model.save("a2c-PandaReachDense-v3")
+env.save("vec_normalize.pkl")
+```
+
+### 评估智能体 📈
+
+- 现在我们的智能体已经训练好了,我们需要**检查它的性能**。
+- Stable-Baselines3提供了一个方法来做到这一点:`evaluate_policy`
+
+```python
+from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
+
+# 加载保存的统计数据
+eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v3")])
+eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
+
+# 我们需要覆盖render_mode
+eval_env.render_mode = "rgb_array"
+
+# 测试时不更新统计数据
+eval_env.training = False
+# 测试时不需要奖励标准化
+eval_env.norm_reward = False
+
+# 加载智能体
+model = A2C.load("a2c-PandaReachDense-v3")
+
+mean_reward, std_reward = evaluate_policy(model, eval_env)
+
+print(f"平均奖励 = {mean_reward:.2f} +/- {std_reward:.2f}")
+```
+### 在Hub上发布你训练的模型 🔥
+
+现在我们看到训练后获得了良好的结果,我们可以用一行代码将我们训练的模型发布到Hub上。
+
+📚 库文档 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
+
+通过使用`package_to_hub`,正如我们在前面的单元中已经提到的,**你可以评估、记录回放、生成智能体的模型卡片并将其推送到hub**。
+
+这样:
+- 你可以**展示我们的工作** 🔥
+- 你可以**可视化你的智能体的游戏过程** 👀
+- 你可以**与社区分享一个其他人可以使用的智能体** 💾
+- 你可以**访问排行榜 🏆 查看你的智能体与同学相比表现如何** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+要能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果还没有完成)在HF创建一个账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录,然后,你需要从Hugging Face网站存储你的认证令牌。
+- 创建一个新令牌(https://huggingface.co/settings/tokens) **具有写入权限**
+
+
+
+- 复制令牌
+- 运行下面的单元格并粘贴令牌
+
+```python
+notebook_login()
+!git config --global credential.helper store
+```
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令代替:`huggingface-cli login`
+
+3️⃣ 我们现在准备好使用`package_to_hub()`函数将我们训练的智能体推送到🤗 Hub 🔥。
+对于这个环境,**运行这个单元格大约需要10分钟**
+
+```python
+from huggingface_sb3 import package_to_hub
+
+package_to_hub(
+ model=model,
+ model_name=f"a2c-{env_id}",
+ model_architecture="A2C",
+ env_id=env_id,
+ eval_env=eval_env,
+ repo_id=f"ThomasSimonini/a2c-{env_id}", # 更改用户名
+ commit_message="Initial commit",
+)
+```
+
+## 一些额外的挑战 🏆
+
+学习的最好方法**是自己尝试**!为什么不尝试`PandaPickAndPlace-v3`?
+
+如果你想尝试panda-gym的更高级任务,你需要查看使用**TQC或SAC**(一种更适合机器人任务的样本高效算法)所做的工作。在真实的机器人学中,你会使用更样本高效的算法,原因很简单:与模拟相反,**如果你过度移动你的机器人手臂,你有可能会损坏它**。
+
+PandaPickAndPlace-v1(这个模型使用环境的v1版本):https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
+
+不要犹豫,在这里查看panda-gym文档:https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html
+
+我们为你提供训练另一个智能体的步骤(可选):
+
+1. 定义名为"PandaPickAndPlace-v3"的环境
+2. 创建向量化环境
+3. 添加包装器来标准化观察和奖励。[查看文档](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
+4. 创建A2C模型(不要忘记verbose=1来打印训练日志)。
+5. 训练100万个时间步
+6. 保存模型和VecNormalize统计数据
+7. 评估你的智能体
+8. 使用`package_to_hub`在Hub上发布你训练的模型 🔥
+
+
+### 解决方案(可选)
+
+```python
+# 1 - 2
+env_id = "PandaPickAndPlace-v3"
+env = make_vec_env(env_id, n_envs=4)
+
+# 3
+env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
+
+# 4
+model = A2C(policy = "MultiInputPolicy",
+ env = env,
+ verbose=1)
+# 5
+model.learn(1_000_000)
+```
+
+```python
+# 6
+model_name = "a2c-PandaPickAndPlace-v3";
+model.save(model_name)
+env.save("vec_normalize.pkl")
+
+# 7
+from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
+
+# 加载保存的统计数据
+eval_env = DummyVecEnv([lambda: gym.make("PandaPickAndPlace-v3")])
+eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
+
+# 测试时不更新统计数据
+eval_env.training = False
+# 测试时不需要奖励标准化
+eval_env.norm_reward = False
+
+# 加载智能体
+model = A2C.load(model_name)
+
+mean_reward, std_reward = evaluate_policy(model, eval_env)
+
+print(f"平均奖励 = {mean_reward:.2f} +/- {std_reward:.2f}")
+
+# 8
+package_to_hub(
+ model=model,
+ model_name=f"a2c-{env_id}",
+ model_architecture="A2C",
+ env_id=env_id,
+ eval_env=eval_env,
+ repo_id=f"ThomasSimonini/a2c-{env_id}", # TODO: 更改用户名
+ commit_message="Initial commit",
+)
+```
+
+我们在单元7见!��
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit6/introduction.mdx b/units/cn/unit6/introduction.mdx
new file mode 100644
index 00000000..fdf54bf9
--- /dev/null
+++ b/units/cn/unit6/introduction.mdx
@@ -0,0 +1,22 @@
+# 介绍 [[introduction]]
+
+
+
+
+这样**训练将更容易**。
+
+### 创建环境
+
+#### 环境 🎮
+
+在`PandaReachDense-v3`中,机器人手臂必须将其末端执行器放置在目标位置(绿色球)。
+
+```python
+env_id = "PandaReachDense-v3"
+
+# 创建环境
+env = gym.make(env_id)
+
+# 获取状态空间和动作空间
+s_size = env.observation_space.shape
+a_size = env.action_space
+```
+
+```python
+print("_____观察空间_____ \n")
+print("状态空间是:", s_size)
+print("观察样本", env.observation_space.sample()) # 获取随机观察
+```
+
+观察空间**是一个包含3个不同元素的字典**:
+
+- `achieved_goal`:目标的(x,y,z)位置。
+- `desired_goal`:目标位置与当前对象位置之间的(x,y,z)距离。
+- `observation`:末端执行器的位置(x,y,z)和速度(vx, vy, vz)。
+
+鉴于观察是一个字典,**我们需要使用MultiInputPolicy策略而不是MlpPolicy**。
+
+```python
+print("\n _____动作空间_____ \n")
+print("动作空间是:", a_size)
+print("动作空间样本", env.action_space.sample()) # 采取随机动作
+```
+
+动作空间是一个包含3个值的向量:
+- 控制x, y, z移动
+
+
+### 标准化观察和奖励
+
+强化学习中的一个良好实践是[标准化输入特征](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html)。
+
+为此,有一个包装器将计算输入特征的运行平均值和标准差。
+
+我们还通过添加`norm_reward = True`来使用这个相同的包装器标准化奖励
+
+[你应该查看文档来填写这个单元格](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
+
+```python
+env = make_vec_env(env_id, n_envs=4)
+
+# 添加这个包装器来标准化观察和奖励
+env = # TODO: 添加包装器
+```
+
+#### 解决方案
+
+```python
+env = make_vec_env(env_id, n_envs=4)
+
+env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
+```
+
+### 创建A2C模型 🤖
+
+有关使用StableBaselines3实现A2C的更多信息,请查看:https://stable-baselines3.readthedocs.io/en/master/modules/a2c.html#notes
+
+为了找到最佳参数,我查看了[Stable-Baselines3团队的官方训练智能体](https://huggingface.co/sb3)。
+
+```python
+model = # 创建A2C模型并尝试找到最佳参数
+```
+
+#### 解决方案
+
+```python
+model = A2C(policy = "MultiInputPolicy",
+ env = env,
+ verbose=1)
+```
+
+### 训练A2C智能体 🏃
+
+- 让我们训练我们的智能体1,000,000个时间步,不要忘记在Colab上使用GPU。这将花费大约~25-40分钟
+
+```python
+model.learn(1_000_000)
+```
+
+```python
+# 保存模型和VecNormalize统计数据
+model.save("a2c-PandaReachDense-v3")
+env.save("vec_normalize.pkl")
+```
+
+### 评估智能体 📈
+
+- 现在我们的智能体已经训练好了,我们需要**检查它的性能**。
+- Stable-Baselines3提供了一个方法来做到这一点:`evaluate_policy`
+
+```python
+from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
+
+# 加载保存的统计数据
+eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v3")])
+eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
+
+# 我们需要覆盖render_mode
+eval_env.render_mode = "rgb_array"
+
+# 测试时不更新统计数据
+eval_env.training = False
+# 测试时不需要奖励标准化
+eval_env.norm_reward = False
+
+# 加载智能体
+model = A2C.load("a2c-PandaReachDense-v3")
+
+mean_reward, std_reward = evaluate_policy(model, eval_env)
+
+print(f"平均奖励 = {mean_reward:.2f} +/- {std_reward:.2f}")
+```
+### 在Hub上发布你训练的模型 🔥
+
+现在我们看到训练后获得了良好的结果,我们可以用一行代码将我们训练的模型发布到Hub上。
+
+📚 库文档 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
+
+通过使用`package_to_hub`,正如我们在前面的单元中已经提到的,**你可以评估、记录回放、生成智能体的模型卡片并将其推送到hub**。
+
+这样:
+- 你可以**展示我们的工作** 🔥
+- 你可以**可视化你的智能体的游戏过程** 👀
+- 你可以**与社区分享一个其他人可以使用的智能体** 💾
+- 你可以**访问排行榜 🏆 查看你的智能体与同学相比表现如何** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
+
+要能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果还没有完成)在HF创建一个账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录,然后,你需要从Hugging Face网站存储你的认证令牌。
+- 创建一个新令牌(https://huggingface.co/settings/tokens) **具有写入权限**
+
+
+
+- 复制令牌
+- 运行下面的单元格并粘贴令牌
+
+```python
+notebook_login()
+!git config --global credential.helper store
+```
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令代替:`huggingface-cli login`
+
+3️⃣ 我们现在准备好使用`package_to_hub()`函数将我们训练的智能体推送到🤗 Hub 🔥。
+对于这个环境,**运行这个单元格大约需要10分钟**
+
+```python
+from huggingface_sb3 import package_to_hub
+
+package_to_hub(
+ model=model,
+ model_name=f"a2c-{env_id}",
+ model_architecture="A2C",
+ env_id=env_id,
+ eval_env=eval_env,
+ repo_id=f"ThomasSimonini/a2c-{env_id}", # 更改用户名
+ commit_message="Initial commit",
+)
+```
+
+## 一些额外的挑战 🏆
+
+学习的最好方法**是自己尝试**!为什么不尝试`PandaPickAndPlace-v3`?
+
+如果你想尝试panda-gym的更高级任务,你需要查看使用**TQC或SAC**(一种更适合机器人任务的样本高效算法)所做的工作。在真实的机器人学中,你会使用更样本高效的算法,原因很简单:与模拟相反,**如果你过度移动你的机器人手臂,你有可能会损坏它**。
+
+PandaPickAndPlace-v1(这个模型使用环境的v1版本):https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
+
+不要犹豫,在这里查看panda-gym文档:https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html
+
+我们为你提供训练另一个智能体的步骤(可选):
+
+1. 定义名为"PandaPickAndPlace-v3"的环境
+2. 创建向量化环境
+3. 添加包装器来标准化观察和奖励。[查看文档](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
+4. 创建A2C模型(不要忘记verbose=1来打印训练日志)。
+5. 训练100万个时间步
+6. 保存模型和VecNormalize统计数据
+7. 评估你的智能体
+8. 使用`package_to_hub`在Hub上发布你训练的模型 🔥
+
+
+### 解决方案(可选)
+
+```python
+# 1 - 2
+env_id = "PandaPickAndPlace-v3"
+env = make_vec_env(env_id, n_envs=4)
+
+# 3
+env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
+
+# 4
+model = A2C(policy = "MultiInputPolicy",
+ env = env,
+ verbose=1)
+# 5
+model.learn(1_000_000)
+```
+
+```python
+# 6
+model_name = "a2c-PandaPickAndPlace-v3";
+model.save(model_name)
+env.save("vec_normalize.pkl")
+
+# 7
+from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
+
+# 加载保存的统计数据
+eval_env = DummyVecEnv([lambda: gym.make("PandaPickAndPlace-v3")])
+eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
+
+# 测试时不更新统计数据
+eval_env.training = False
+# 测试时不需要奖励标准化
+eval_env.norm_reward = False
+
+# 加载智能体
+model = A2C.load(model_name)
+
+mean_reward, std_reward = evaluate_policy(model, eval_env)
+
+print(f"平均奖励 = {mean_reward:.2f} +/- {std_reward:.2f}")
+
+# 8
+package_to_hub(
+ model=model,
+ model_name=f"a2c-{env_id}",
+ model_architecture="A2C",
+ env_id=env_id,
+ eval_env=eval_env,
+ repo_id=f"ThomasSimonini/a2c-{env_id}", # TODO: 更改用户名
+ commit_message="Initial commit",
+)
+```
+
+我们在单元7见!��
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit6/introduction.mdx b/units/cn/unit6/introduction.mdx
new file mode 100644
index 00000000..fdf54bf9
--- /dev/null
+++ b/units/cn/unit6/introduction.mdx
@@ -0,0 +1,22 @@
+# 介绍 [[introduction]]
+
+
+ +
+在第4单元中,我们学习了第一个基于策略的算法,称为**Reinforce**。
+
+在基于策略的方法中,**我们的目标是直接优化策略,而不使用价值函数**。更准确地说,Reinforce属于*基于策略的方法*的一个子类,称为*策略梯度方法*。这个子类通过**使用梯度上升估计最优策略的权重**来直接优化策略。
+
+我们看到Reinforce运行良好。然而,由于我们使用蒙特卡洛采样来估计回报(我们使用整个回合来计算回报),**我们在策略梯度估计中存在显著的方差**。
+
+请记住,策略梯度估计是**回报最陡增加方向**。换句话说,如何更新我们的策略权重,使得导致良好回报的动作有更高的概率被选择。蒙特卡洛方差,我们将在本单元中进一步研究,**导致训练速度变慢,因为我们需要大量样本来减轻它**。
+
+所以今天我们将学习**Actor-Critic方法**,这是一种结合了基于价值和基于策略方法的混合架构,通过以下方式帮助稳定训练并减少方差:
+- *一个Actor*,控制**我们的智能体如何行动**(基于策略的方法)
+- *一个Critic*,衡量**所采取的动作有多好**(基于价值的方法)
+
+
+我们将学习这些混合方法之一,优势Actor-Critic(A2C),**并使用Stable-Baselines3在机器人环境中训练我们的智能体**。我们将训练:
+- 一个机械臂🦾移动到正确位置。
+
+听起来很激动人心吧?让我们开始吧!
diff --git a/units/cn/unit6/quiz.mdx b/units/cn/unit6/quiz.mdx
new file mode 100644
index 00000000..6d34612b
--- /dev/null
+++ b/units/cn/unit6/quiz.mdx
@@ -0,0 +1,123 @@
+# 测验
+
+学习的最佳方式,也是[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法,**就是测试自己**。这将帮助你找出**需要加强知识的地方**。
+
+
+### 问题1:在强化学习领域中,以下哪种对偏差-方差权衡的解释最准确?
+
+
+
+### 问题2:在讨论强化学习中具有偏差和/或方差的模型时,以下哪些陈述是正确的?
+
+
+
+
+### 问题3:关于蒙特卡洛方法,以下哪些陈述是正确的?
+
+
+
+### 问题4:用你自己的话描述Actor-Critic方法(A2C)。
+
+
+
+在第4单元中,我们学习了第一个基于策略的算法,称为**Reinforce**。
+
+在基于策略的方法中,**我们的目标是直接优化策略,而不使用价值函数**。更准确地说,Reinforce属于*基于策略的方法*的一个子类,称为*策略梯度方法*。这个子类通过**使用梯度上升估计最优策略的权重**来直接优化策略。
+
+我们看到Reinforce运行良好。然而,由于我们使用蒙特卡洛采样来估计回报(我们使用整个回合来计算回报),**我们在策略梯度估计中存在显著的方差**。
+
+请记住,策略梯度估计是**回报最陡增加方向**。换句话说,如何更新我们的策略权重,使得导致良好回报的动作有更高的概率被选择。蒙特卡洛方差,我们将在本单元中进一步研究,**导致训练速度变慢,因为我们需要大量样本来减轻它**。
+
+所以今天我们将学习**Actor-Critic方法**,这是一种结合了基于价值和基于策略方法的混合架构,通过以下方式帮助稳定训练并减少方差:
+- *一个Actor*,控制**我们的智能体如何行动**(基于策略的方法)
+- *一个Critic*,衡量**所采取的动作有多好**(基于价值的方法)
+
+
+我们将学习这些混合方法之一,优势Actor-Critic(A2C),**并使用Stable-Baselines3在机器人环境中训练我们的智能体**。我们将训练:
+- 一个机械臂🦾移动到正确位置。
+
+听起来很激动人心吧?让我们开始吧!
diff --git a/units/cn/unit6/quiz.mdx b/units/cn/unit6/quiz.mdx
new file mode 100644
index 00000000..6d34612b
--- /dev/null
+++ b/units/cn/unit6/quiz.mdx
@@ -0,0 +1,123 @@
+# 测验
+
+学习的最佳方式,也是[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法,**就是测试自己**。这将帮助你找出**需要加强知识的地方**。
+
+
+### 问题1:在强化学习领域中,以下哪种对偏差-方差权衡的解释最准确?
+
+
+
+### 问题2:在讨论强化学习中具有偏差和/或方差的模型时,以下哪些陈述是正确的?
+
+
+
+
+### 问题3:关于蒙特卡洛方法,以下哪些陈述是正确的?
+
+
+
+### 问题4:用你自己的话描述Actor-Critic方法(A2C)。
+
+
+解决方案
+
+Actor-Critic背后的理念是我们学习两种函数近似:
+1. 一个`策略`,控制我们的智能体如何行动(π)
+2. 一个`价值`函数,通过衡量所采取的动作有多好来辅助策略更新(q)
+
+
+
+
+
+### 问题5:关于Actor-Critic方法,以下哪些陈述是正确的?
+
+
+
+
+
+### 问题6:A2C方法中的`优势`是什么?
+
+
+解决方案
+
+我们可以使用`优势`函数,而不是直接使用Critic的动作价值函数。优势函数背后的理念是我们计算一个动作相对于在某状态下其他可能动作的相对优势,对它们取平均值。
+
+换句话说:在某状态下采取该动作比该状态的平均价值好多少
+
+
+
+
+
+恭喜你完成这个测验🥳,如果你错过了一些要点,花时间再次阅读本章以加强(😏)你的知识。
diff --git a/units/cn/unit6/variance-problem.mdx b/units/cn/unit6/variance-problem.mdx
new file mode 100644
index 00000000..07f7c445
--- /dev/null
+++ b/units/cn/unit6/variance-problem.mdx
@@ -0,0 +1,31 @@
+# Reinforce中的方差问题 [[the-problem-of-variance-in-reinforce]]
+
+在Reinforce中,我们希望**增加轨迹中动作的概率,其比例与回报的高低成正比**。
+
+
+ +
+- 如果**回报很高**,我们将**提高**(状态,动作)组合的概率。
+- 否则,如果**回报很低**,它将**降低**(状态,动作)组合的概率。
+
+这个回报\\(R(\tau)\\)是使用*蒙特卡洛采样*计算的。我们收集一个轨迹并计算折扣回报,**并使用这个分数来增加或减少在该轨迹中采取的每个动作的概率**。如果回报很好,所有动作都将通过增加它们被采取的可能性而被"强化"。
+
+\\(R(\tau) = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ...\\)
+
+这种方法的优点是**它是无偏的。因为我们不估计回报**,我们只使用我们获得的真实回报。
+
+由于环境的随机性(回合期间的随机事件)和策略的随机性,**轨迹可能导致不同的回报,这可能导致高方差**。因此,相同的起始状态可能导致非常不同的回报。
+因此,**从相同状态开始的回报在不同回合之间可能有很大差异**。
+
+
+
+- 如果**回报很高**,我们将**提高**(状态,动作)组合的概率。
+- 否则,如果**回报很低**,它将**降低**(状态,动作)组合的概率。
+
+这个回报\\(R(\tau)\\)是使用*蒙特卡洛采样*计算的。我们收集一个轨迹并计算折扣回报,**并使用这个分数来增加或减少在该轨迹中采取的每个动作的概率**。如果回报很好,所有动作都将通过增加它们被采取的可能性而被"强化"。
+
+\\(R(\tau) = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ...\\)
+
+这种方法的优点是**它是无偏的。因为我们不估计回报**,我们只使用我们获得的真实回报。
+
+由于环境的随机性(回合期间的随机事件)和策略的随机性,**轨迹可能导致不同的回报,这可能导致高方差**。因此,相同的起始状态可能导致非常不同的回报。
+因此,**从相同状态开始的回报在不同回合之间可能有很大差异**。
+
+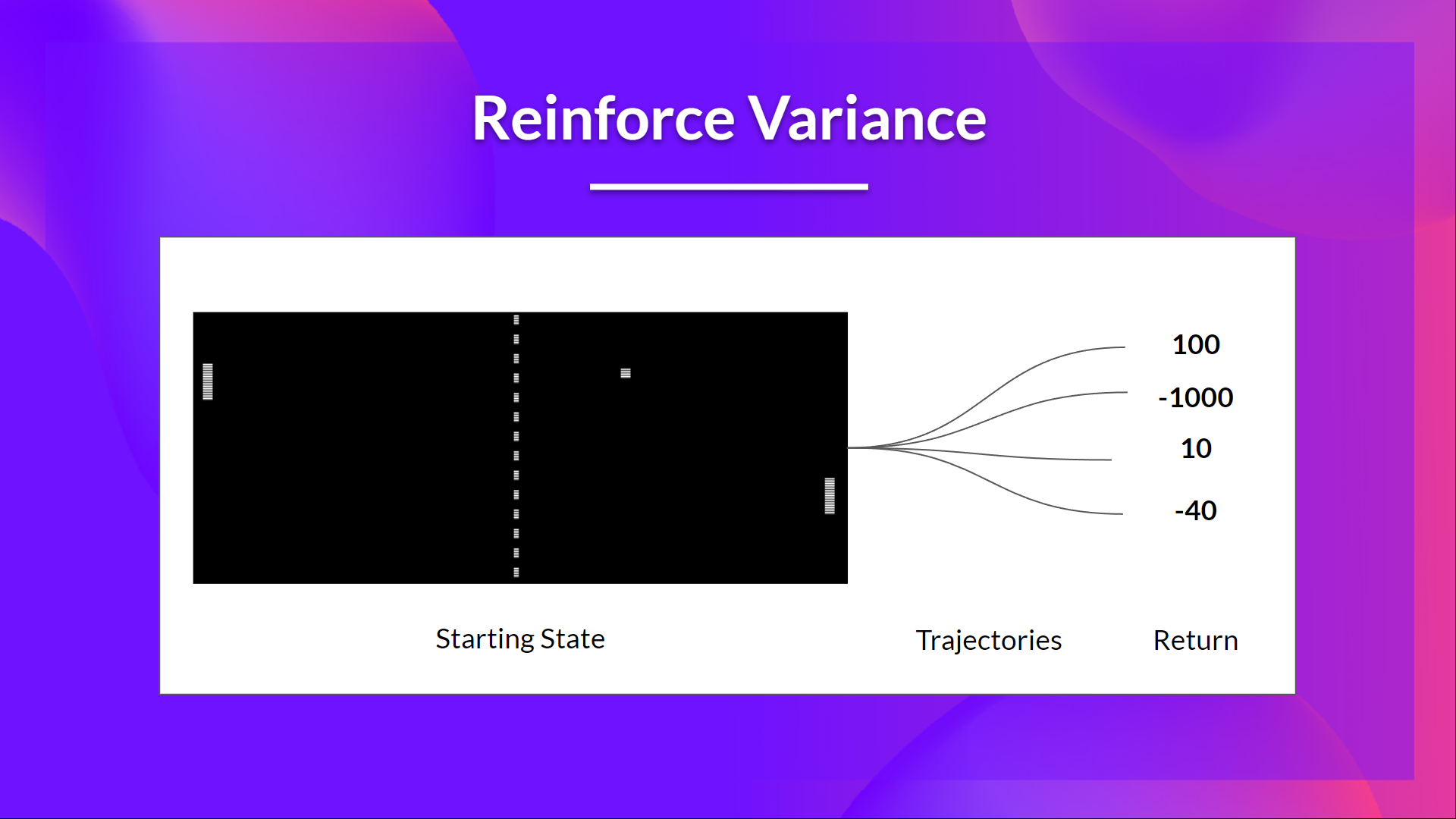 +
+解决方案是通过**使用大量轨迹来减轻方差,希望在任何一个轨迹中引入的方差在总体上会减少,并提供回报的"真实"估计。**
+
+然而,显著增加批量大小**降低了样本效率**。所以我们需要找到额外的机制来减少方差。
+
+---
+如果你想深入了解深度强化学习中方差和偏差权衡的问题,可以查看以下两篇文章:
+- [理解(深度)强化学习中的偏差/方差权衡](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
+- [强化学习中的偏差-方差权衡](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
+- [策略梯度中的高方差](https://balajiai.github.io/high_variance_in_policy_gradients)
+---
diff --git a/units/cn/unit7/additional-readings.mdx b/units/cn/unit7/additional-readings.mdx
new file mode 100644
index 00000000..a5f951dc
--- /dev/null
+++ b/units/cn/unit7/additional-readings.mdx
@@ -0,0 +1,17 @@
+# 额外阅读材料 [[additional-readings]]
+
+## 多智能体简介
+
+- [多智能体强化学习:概述](https://www.dcsc.tudelft.nl/~bdeschutter/pub/rep/10_003.pdf)
+- [多智能体强化学习,Marc Lanctot](https://rlss.inria.fr/files/2019/07/RLSS_Multiagent.pdf)
+- [多智能体环境示例](https://www.mathworks.com/help/reinforcement-learning/ug/train-3-agents-for-area-coverage.html?s_eid=PSM_15028)
+- [不同多智能体环境列表](https://agents.inf.ed.ac.uk/blog/multiagent-learning-environments/)
+- [多智能体强化学习:独立vs.合作智能体](https://bit.ly/3nVK7My)
+- [处理多智能体深度强化学习中的非平稳性](https://bit.ly/3v7LxaT)
+
+## 自我对弈和MA-POCA
+
+- [自我对弈理论与MLAgents](https://blog.unity.com/technology/training-intelligent-adversaries-using-self-play-with-ml-agents)
+- [使用MLAgents训练复杂行为](https://blog.unity.com/technology/ml-agents-v20-release-now-supports-training-complex-cooperative-behaviors)
+- [MLAgents玩躲避球](https://blog.unity.com/technology/ml-agents-plays-dodgeball)
+- [关于多智能体强化学习中吸收状态的使用和误用(MA-POCA)](https://arxiv.org/pdf/2111.05992.pdf)
diff --git a/units/cn/unit7/conclusion.mdx b/units/cn/unit7/conclusion.mdx
new file mode 100644
index 00000000..9eb290d8
--- /dev/null
+++ b/units/cn/unit7/conclusion.mdx
@@ -0,0 +1,11 @@
+# 结论
+
+今天的内容到此结束。恭喜你完成本单元和教程!
+
+学习的最佳方式是实践和尝试。**为什么不用不同的配置训练另一个智能体呢?**
+
+别忘了时不时地查看[排行榜](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos)
+
+我们第8单元见��
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit7/hands-on.mdx b/units/cn/unit7/hands-on.mdx
new file mode 100644
index 00000000..bef9b6d5
--- /dev/null
+++ b/units/cn/unit7/hands-on.mdx
@@ -0,0 +1,322 @@
+# 实践练习
+
+现在你已经学习了多智能体的基础知识,你已经准备好在多智能体系统中训练你的第一批智能体:**一个需要击败对手队伍的2对2足球队**。
+
+你将参与AI对抗AI的挑战,在这里你训练的智能体将**每天与其他同学的智能体竞争,并在新的排行榜上进行排名。**
+
+要在认证过程中验证这个实践练习,你只需要推送一个训练好的模型。**验证它不需要达到最低结果要求。**
+
+有关认证过程的更多信息,请查看此部分 👉 [https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process)
+
+这个实践练习会有所不同,因为**要获得正确的结果,你需要训练你的智能体4到8小时**。考虑到Colab超时的风险,我们建议你在自己的电脑上进行训练。你不需要超级计算机:一台普通的笔记本电脑对这个练习来说已经足够了。
+
+让我们开始吧!🔥
+
+## 什么是AI对抗AI?
+
+AI对抗AI是我们在Hugging Face开发的一个开源工具,用于让Hub上的智能体在多智能体环境中相互竞争。这些模型随后会在排行榜上进行排名。
+
+这个工具的理念是提供一个稳健的评估工具:**通过与许多其他智能体进行评估,你将对你的策略质量有一个很好的了解。**
+
+更准确地说,AI对抗AI包含三个工具:
+
+- 一个*匹配过程*,定义比赛(哪个模型对抗哪个)并使用Space中的后台任务运行模型对抗。
+- 一个*排行榜*,获取比赛历史结果并显示模型的ELO评分:[https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos)
+- 一个*Space演示*,用于可视化你的智能体与其他智能体的对抗:[https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos](https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos)
+
+除了这三个工具外,你的同学cyllum创建了一个🤗 SoccerTwos挑战分析工具,你可以在那里查看模型的详细比赛结果:[https://huggingface.co/spaces/cyllum/soccertwos-analytics](https://huggingface.co/spaces/cyllum/soccertwos-analytics)
+
+我们[写了一篇博客文章详细解释这个AI对抗AI工具](https://huggingface.co/blog/aivsai),但简单来说它的工作方式如下:
+
+- 每四小时,我们的算法**获取给定环境(在我们的例子中是ML-Agents-SoccerTwos)的所有可用模型。**
+- 它使用匹配算法**创建一个比赛队列。**
+- 我们在Unity无头进程中模拟比赛并**收集比赛结果**(如果第一个模型获胜则为1,如果平局则为0.5,如果第二个模型获胜则为0)到一个数据集中。
+- 然后,当比赛队列中的所有比赛完成后,**我们更新每个模型的ELO分数并更新排行榜。**
+
+### 比赛规则
+
+这第一个AI对抗AI比赛**是一个实验**:目标是根据你的反馈在未来改进这个工具。所以在挑战期间**可能会发生一些中断**。但不用担心,
+**所有结果都保存在数据集中,所以我们总是可以正确重新启动计算而不会丢失信息**。
+
+为了让你的模型能够正确地与其他模型进行评估,你需要遵循以下规则:
+
+1. **你不能更改智能体的观察空间或动作空间。** 这样做会导致你的模型在评估过程中无法工作。
+2. **目前你不能使用自定义训练器,** 你需要使用Unity MLAgents提供的训练器。
+3. 我们提供可执行文件来训练你的智能体。如果你愿意,也可以使用Unity编辑器,**但为了避免错误,我们建议你使用我们的可执行文件**。
+
+在这个挑战中,**你选择的超参数**将会产生差异。
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+### 在Discord上与你的同学聊天,分享建议并提问
+
+- 我们创建了一个名为`ai-vs-ai-challenge`的新频道,用于交流建议和提问。
+- 如果你还没有加入discord服务器,你可以[在这里加入](https://discord.gg/ydHrjt3WP5)
+
+## 步骤0:安装MLAgents并下载正确的可执行文件
+
+我们建议你使用[conda](https://docs.conda.io/en/latest/)作为包管理器并创建一个新环境。
+
+使用conda,我们创建一个名为rl的新环境,使用**Python 3.10.12**:
+
+```bash
+conda create --name rl python=3.10.12
+conda activate rl
+```
+
+为了能够正确训练我们的智能体并推送到Hub,我们需要安装ML-Agents
+
+```bash
+git clone https://github.com/Unity-Technologies/ml-agents
+```
+
+当克隆完成后(它占用2.63 GB),我们进入仓库并安装包
+
+```bash
+cd ml-agents
+pip install -e ./ml-agents-envs
+pip install -e ./ml-agents
+```
+
+ 使用Apple Silicon的Mac用户可能会遇到安装问题(例如ONNX wheel构建失败),你应该首先尝试安装grpcio:
+```bash
+conda install grpcio
+```
+[官方ml-agent仓库中的这个github issue](https://github.com/Unity-Technologies/ml-agents/issues/6019)也可能对你有所帮助。
+
+最后,你需要安装git-lfs:https://git-lfs.com/
+
+现在安装完成后,我们需要添加环境训练可执行文件。根据你的操作系统,你需要下载其中一个,解压缩并将其放在`ml-agents`内的一个新文件夹中,命名为`training-envs-executables`
+
+最终你的可执行文件应该位于`ml-agents/training-envs-executables/SoccerTwos`
+
+Windows:下载[这个可执行文件](https://drive.google.com/file/d/1sqFxbEdTMubjVktnV4C6ICjp89wLhUcP/view?usp=sharing)
+
+Linux (Ubuntu):下载[这个可执行文件](https://drive.google.com/file/d/1KuqBKYiXiIcU4kNMqEzhgypuFP5_45CL/view?usp=sharing)
+
+Mac:下载[这个可执行文件](https://drive.google.com/drive/folders/1h7YB0qwjoxxghApQdEUQmk95ZwIDxrPG?usp=share_link)
+⚠ 对于Mac,你还需要调用`xattr -cr training-envs-executables/SoccerTwos/SoccerTwos.app`才能运行SoccerTwos
+
+## 步骤1:理解环境
+
+这个环境叫做`SoccerTwos`。它是由Unity MLAgents团队制作的。你可以在[这里](https://github.com/Unity-Technologies/ml-agents/blob/develop/docs/Learning-Environment-Examples.md#soccer-twos)找到它的文档
+
+这个环境的目标**是将球送入对手的球门,同时防止球进入你自己的球门。**
+
+
+
+
+解决方案是通过**使用大量轨迹来减轻方差,希望在任何一个轨迹中引入的方差在总体上会减少,并提供回报的"真实"估计。**
+
+然而,显著增加批量大小**降低了样本效率**。所以我们需要找到额外的机制来减少方差。
+
+---
+如果你想深入了解深度强化学习中方差和偏差权衡的问题,可以查看以下两篇文章:
+- [理解(深度)强化学习中的偏差/方差权衡](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
+- [强化学习中的偏差-方差权衡](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
+- [策略梯度中的高方差](https://balajiai.github.io/high_variance_in_policy_gradients)
+---
diff --git a/units/cn/unit7/additional-readings.mdx b/units/cn/unit7/additional-readings.mdx
new file mode 100644
index 00000000..a5f951dc
--- /dev/null
+++ b/units/cn/unit7/additional-readings.mdx
@@ -0,0 +1,17 @@
+# 额外阅读材料 [[additional-readings]]
+
+## 多智能体简介
+
+- [多智能体强化学习:概述](https://www.dcsc.tudelft.nl/~bdeschutter/pub/rep/10_003.pdf)
+- [多智能体强化学习,Marc Lanctot](https://rlss.inria.fr/files/2019/07/RLSS_Multiagent.pdf)
+- [多智能体环境示例](https://www.mathworks.com/help/reinforcement-learning/ug/train-3-agents-for-area-coverage.html?s_eid=PSM_15028)
+- [不同多智能体环境列表](https://agents.inf.ed.ac.uk/blog/multiagent-learning-environments/)
+- [多智能体强化学习:独立vs.合作智能体](https://bit.ly/3nVK7My)
+- [处理多智能体深度强化学习中的非平稳性](https://bit.ly/3v7LxaT)
+
+## 自我对弈和MA-POCA
+
+- [自我对弈理论与MLAgents](https://blog.unity.com/technology/training-intelligent-adversaries-using-self-play-with-ml-agents)
+- [使用MLAgents训练复杂行为](https://blog.unity.com/technology/ml-agents-v20-release-now-supports-training-complex-cooperative-behaviors)
+- [MLAgents玩躲避球](https://blog.unity.com/technology/ml-agents-plays-dodgeball)
+- [关于多智能体强化学习中吸收状态的使用和误用(MA-POCA)](https://arxiv.org/pdf/2111.05992.pdf)
diff --git a/units/cn/unit7/conclusion.mdx b/units/cn/unit7/conclusion.mdx
new file mode 100644
index 00000000..9eb290d8
--- /dev/null
+++ b/units/cn/unit7/conclusion.mdx
@@ -0,0 +1,11 @@
+# 结论
+
+今天的内容到此结束。恭喜你完成本单元和教程!
+
+学习的最佳方式是实践和尝试。**为什么不用不同的配置训练另一个智能体呢?**
+
+别忘了时不时地查看[排行榜](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos)
+
+我们第8单元见��
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit7/hands-on.mdx b/units/cn/unit7/hands-on.mdx
new file mode 100644
index 00000000..bef9b6d5
--- /dev/null
+++ b/units/cn/unit7/hands-on.mdx
@@ -0,0 +1,322 @@
+# 实践练习
+
+现在你已经学习了多智能体的基础知识,你已经准备好在多智能体系统中训练你的第一批智能体:**一个需要击败对手队伍的2对2足球队**。
+
+你将参与AI对抗AI的挑战,在这里你训练的智能体将**每天与其他同学的智能体竞争,并在新的排行榜上进行排名。**
+
+要在认证过程中验证这个实践练习,你只需要推送一个训练好的模型。**验证它不需要达到最低结果要求。**
+
+有关认证过程的更多信息,请查看此部分 👉 [https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process)
+
+这个实践练习会有所不同,因为**要获得正确的结果,你需要训练你的智能体4到8小时**。考虑到Colab超时的风险,我们建议你在自己的电脑上进行训练。你不需要超级计算机:一台普通的笔记本电脑对这个练习来说已经足够了。
+
+让我们开始吧!🔥
+
+## 什么是AI对抗AI?
+
+AI对抗AI是我们在Hugging Face开发的一个开源工具,用于让Hub上的智能体在多智能体环境中相互竞争。这些模型随后会在排行榜上进行排名。
+
+这个工具的理念是提供一个稳健的评估工具:**通过与许多其他智能体进行评估,你将对你的策略质量有一个很好的了解。**
+
+更准确地说,AI对抗AI包含三个工具:
+
+- 一个*匹配过程*,定义比赛(哪个模型对抗哪个)并使用Space中的后台任务运行模型对抗。
+- 一个*排行榜*,获取比赛历史结果并显示模型的ELO评分:[https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos)
+- 一个*Space演示*,用于可视化你的智能体与其他智能体的对抗:[https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos](https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos)
+
+除了这三个工具外,你的同学cyllum创建了一个🤗 SoccerTwos挑战分析工具,你可以在那里查看模型的详细比赛结果:[https://huggingface.co/spaces/cyllum/soccertwos-analytics](https://huggingface.co/spaces/cyllum/soccertwos-analytics)
+
+我们[写了一篇博客文章详细解释这个AI对抗AI工具](https://huggingface.co/blog/aivsai),但简单来说它的工作方式如下:
+
+- 每四小时,我们的算法**获取给定环境(在我们的例子中是ML-Agents-SoccerTwos)的所有可用模型。**
+- 它使用匹配算法**创建一个比赛队列。**
+- 我们在Unity无头进程中模拟比赛并**收集比赛结果**(如果第一个模型获胜则为1,如果平局则为0.5,如果第二个模型获胜则为0)到一个数据集中。
+- 然后,当比赛队列中的所有比赛完成后,**我们更新每个模型的ELO分数并更新排行榜。**
+
+### 比赛规则
+
+这第一个AI对抗AI比赛**是一个实验**:目标是根据你的反馈在未来改进这个工具。所以在挑战期间**可能会发生一些中断**。但不用担心,
+**所有结果都保存在数据集中,所以我们总是可以正确重新启动计算而不会丢失信息**。
+
+为了让你的模型能够正确地与其他模型进行评估,你需要遵循以下规则:
+
+1. **你不能更改智能体的观察空间或动作空间。** 这样做会导致你的模型在评估过程中无法工作。
+2. **目前你不能使用自定义训练器,** 你需要使用Unity MLAgents提供的训练器。
+3. 我们提供可执行文件来训练你的智能体。如果你愿意,也可以使用Unity编辑器,**但为了避免错误,我们建议你使用我们的可执行文件**。
+
+在这个挑战中,**你选择的超参数**将会产生差异。
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+### 在Discord上与你的同学聊天,分享建议并提问
+
+- 我们创建了一个名为`ai-vs-ai-challenge`的新频道,用于交流建议和提问。
+- 如果你还没有加入discord服务器,你可以[在这里加入](https://discord.gg/ydHrjt3WP5)
+
+## 步骤0:安装MLAgents并下载正确的可执行文件
+
+我们建议你使用[conda](https://docs.conda.io/en/latest/)作为包管理器并创建一个新环境。
+
+使用conda,我们创建一个名为rl的新环境,使用**Python 3.10.12**:
+
+```bash
+conda create --name rl python=3.10.12
+conda activate rl
+```
+
+为了能够正确训练我们的智能体并推送到Hub,我们需要安装ML-Agents
+
+```bash
+git clone https://github.com/Unity-Technologies/ml-agents
+```
+
+当克隆完成后(它占用2.63 GB),我们进入仓库并安装包
+
+```bash
+cd ml-agents
+pip install -e ./ml-agents-envs
+pip install -e ./ml-agents
+```
+
+ 使用Apple Silicon的Mac用户可能会遇到安装问题(例如ONNX wheel构建失败),你应该首先尝试安装grpcio:
+```bash
+conda install grpcio
+```
+[官方ml-agent仓库中的这个github issue](https://github.com/Unity-Technologies/ml-agents/issues/6019)也可能对你有所帮助。
+
+最后,你需要安装git-lfs:https://git-lfs.com/
+
+现在安装完成后,我们需要添加环境训练可执行文件。根据你的操作系统,你需要下载其中一个,解压缩并将其放在`ml-agents`内的一个新文件夹中,命名为`training-envs-executables`
+
+最终你的可执行文件应该位于`ml-agents/training-envs-executables/SoccerTwos`
+
+Windows:下载[这个可执行文件](https://drive.google.com/file/d/1sqFxbEdTMubjVktnV4C6ICjp89wLhUcP/view?usp=sharing)
+
+Linux (Ubuntu):下载[这个可执行文件](https://drive.google.com/file/d/1KuqBKYiXiIcU4kNMqEzhgypuFP5_45CL/view?usp=sharing)
+
+Mac:下载[这个可执行文件](https://drive.google.com/drive/folders/1h7YB0qwjoxxghApQdEUQmk95ZwIDxrPG?usp=share_link)
+⚠ 对于Mac,你还需要调用`xattr -cr training-envs-executables/SoccerTwos/SoccerTwos.app`才能运行SoccerTwos
+
+## 步骤1:理解环境
+
+这个环境叫做`SoccerTwos`。它是由Unity MLAgents团队制作的。你可以在[这里](https://github.com/Unity-Technologies/ml-agents/blob/develop/docs/Learning-Environment-Examples.md#soccer-twos)找到它的文档
+
+这个环境的目标**是将球送入对手的球门,同时防止球进入你自己的球门。**
+
+
+ +
+这个环境由Unity MLAgents团队制作
+
+
+
+### 奖励函数
+
+奖励函数是:
+
+
+
+这个环境由Unity MLAgents团队制作
+
+
+
+### 奖励函数
+
+奖励函数是:
+
+ +
+### 观察空间
+
+观察空间由大小为336的向量组成:
+
+- 向前分布在120度范围内的11个射线投射(264个状态维度)
+- 向后分布在90度范围内的3个射线投射(72个状态维度)
+- 这些射线投射可以检测6种物体:
+ - 球
+ - 蓝色球门
+ - 紫色球门
+ - 墙
+ - 蓝色智能体
+ - 紫色智能体
+
+### 动作空间
+
+动作空间是三个离散分支:
+
+
+
+### 观察空间
+
+观察空间由大小为336的向量组成:
+
+- 向前分布在120度范围内的11个射线投射(264个状态维度)
+- 向后分布在90度范围内的3个射线投射(72个状态维度)
+- 这些射线投射可以检测6种物体:
+ - 球
+ - 蓝色球门
+ - 紫色球门
+ - 墙
+ - 蓝色智能体
+ - 紫色智能体
+
+### 动作空间
+
+动作空间是三个离散分支:
+
+ +
+## 步骤2:理解MA-POCA
+
+我们知道如何训练智能体与其他智能体对抗:**我们可以使用自我对弈。** 这对于1对1来说是一个完美的技术。
+
+但在我们的情况下是2对2,每个队伍有2个智能体。那么我们**如何为智能体组训练合作行为?**
+
+正如[Unity博客](https://blog.unity.com/technology/ml-agents-v20-release-now-supports-training-complex-cooperative-behaviors)中所解释的,智能体通常在团队进球时作为一个整体接收奖励(+1 - 惩罚)。这意味着**即使每个智能体对胜利的贡献不同,团队中的每个智能体都会得到奖励**,这使得独立学习该做什么变得困难。
+
+Unity MLAgents团队在一个名为*MA-POCA(多智能体事后信用分配,Multi-Agent POsthumous Credit Assignment)*的新多智能体训练器中开发了解决方案。
+
+这个想法简单但强大:一个中央评论家**处理团队中所有智能体的状态,以估计每个智能体的表现如何**。把这个评论家想象成一个教练。
+
+这允许每个智能体**仅基于其本地感知做出决策**,并**同时评估其行为在整个团队环境中的好坏**。
+
+
+
+
+
+## 步骤2:理解MA-POCA
+
+我们知道如何训练智能体与其他智能体对抗:**我们可以使用自我对弈。** 这对于1对1来说是一个完美的技术。
+
+但在我们的情况下是2对2,每个队伍有2个智能体。那么我们**如何为智能体组训练合作行为?**
+
+正如[Unity博客](https://blog.unity.com/technology/ml-agents-v20-release-now-supports-training-complex-cooperative-behaviors)中所解释的,智能体通常在团队进球时作为一个整体接收奖励(+1 - 惩罚)。这意味着**即使每个智能体对胜利的贡献不同,团队中的每个智能体都会得到奖励**,这使得独立学习该做什么变得困难。
+
+Unity MLAgents团队在一个名为*MA-POCA(多智能体事后信用分配,Multi-Agent POsthumous Credit Assignment)*的新多智能体训练器中开发了解决方案。
+
+这个想法简单但强大:一个中央评论家**处理团队中所有智能体的状态,以估计每个智能体的表现如何**。把这个评论家想象成一个教练。
+
+这允许每个智能体**仅基于其本地感知做出决策**,并**同时评估其行为在整个团队环境中的好坏**。
+
+
+
+ +
+这说明了MA-POCA的中央化学习和去中心化执行。来源:MLAgents Plays Dodgeball
+
+
+
+解决方案是使用带有MA-POCA训练器(称为poca)的自我对弈。poca训练器将帮助我们训练合作行为,而自我对弈则帮助我们战胜对手队伍。
+
+如果你想深入了解这个MA-POCA算法,你需要阅读他们在[这里](https://arxiv.org/pdf/2111.05992.pdf)发表的论文,以及我们在额外阅读部分提供的资源。
+
+## 步骤3:定义配置文件
+
+我们在[单元5](https://huggingface.co/deep-rl-course/unit5/introduction)中已经学习过,在ML-Agents中,你**在`config.yaml`文件中定义训练超参数。**
+
+有多种超参数。要更好地理解它们,你应该阅读**[文档](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md)**中对每个超参数的解释
+
+我们将在这里使用的配置文件位于`./config/poca/SoccerTwos.yaml`。它看起来像这样:
+
+```csharp
+behaviors:
+ SoccerTwos:
+ trainer_type: poca
+ hyperparameters:
+ batch_size: 2048
+ buffer_size: 20480
+ learning_rate: 0.0003
+ beta: 0.005
+ epsilon: 0.2
+ lambd: 0.95
+ num_epoch: 3
+ learning_rate_schedule: constant
+ network_settings:
+ normalize: false
+ hidden_units: 512
+ num_layers: 2
+ vis_encode_type: simple
+ reward_signals:
+ extrinsic:
+ gamma: 0.99
+ strength: 1.0
+ keep_checkpoints: 5
+ max_steps: 5000000
+ time_horizon: 1000
+ summary_freq: 10000
+ self_play:
+ save_steps: 50000
+ team_change: 200000
+ swap_steps: 2000
+ window: 10
+ play_against_latest_model_ratio: 0.5
+ initial_elo: 1200.0
+```
+
+与Pyramids或SnowballTarget相比,我们有新的超参数,包含自我对弈部分。你如何修改它们对获得好结果可能至关重要。
+
+我在这里给你的建议是查看**[文档](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md)**中对每个参数(特别是自我对弈参数)的解释和推荐值。
+
+现在你已经修改了我们的配置文件,你已经准备好训练你的智能体了。
+
+## 步骤4:开始训练
+
+要训练智能体,我们需要**启动mlagents-learn并选择包含环境的可执行文件。**
+
+我们定义四个参数:
+
+1. `mlagents-learn `:超参数配置文件的路径。
+2. `-env`:环境可执行文件的位置。
+3. `-run_id`:你想给训练运行ID起的名称。
+4. `-no-graphics`:在训练期间不启动可视化。
+
+根据你的硬件,5M时间步(推荐值,但你也可以尝试10M)将需要5到8小时的训练。你可以在此期间继续使用你的电脑,但我建议停用电脑待机模式,以防止训练被停止。
+
+根据你使用的可执行文件(windows、ubuntu、mac),训练命令将如下所示(你的可执行文件路径可能不同,所以运行前不要犹豫检查一下)。
+
+对于Windows,它可能看起来像这样:
+```bash
+mlagents-learn ./config/poca/SoccerTwos.yaml --env=./training-envs-executables/SoccerTwos.exe --run-id="SoccerTwos" --no-graphics
+```
+
+对于Mac,它可能看起来像这样:
+```bash
+mlagents-learn ./config/poca/SoccerTwos.yaml --env=./training-envs-executables/SoccerTwos/SoccerTwos.app --run-id="SoccerTwos" --no-graphics
+```
+
+该可执行文件包含8个SoccerTwos的副本。
+
+⚠️ 如果在2M时间步之前你没有看到ELO分数的大幅增加(甚至降至1200以下)是正常的,因为你的智能体在能够进球之前会花费大部分时间在场上随机移动。
+
+⚠️ 你可以用Ctrl + C停止训练,但要注意只输入一次这个命令来停止训练,因为MLAgents需要在关闭运行前生成最终的.onnx文件。
+
+## 步骤5:**将智能体推送到Hugging Face Hub**
+
+现在我们已经训练了我们的智能体,我们**准备将它们推送到Hub,以便能够参与AI对抗AI挑战并在浏览器中可视化它们的比赛🔥。**
+
+为了能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果还没有完成)创建一个HF账户 ➡ [https://huggingface.co/join](https://huggingface.co/join)
+
+2️⃣ 登录并从Hugging Face网站存储你的认证令牌。
+
+创建一个新令牌(https://huggingface.co/settings/tokens)**具有写入权限**
+
+
+
+复制令牌,运行以下命令,并粘贴令牌
+
+```bash
+huggingface-cli login
+```
+
+然后,我们需要运行`mlagents-push-to-hf`。
+
+我们定义四个参数:
+
+1. `-run-id`:训练运行ID的名称。
+2. `-local-dir`:智能体保存的位置,它是results/\,所以在我的例子中是results/First Training。
+3. `-repo-id`:你想创建或更新的Hugging Face仓库的名称。它总是\<你的huggingface用户名\>/\<仓库名称\>
+如果仓库不存在,**它将自动创建**
+4. `--commit-message`:由于HF仓库是git仓库,你需要提供一个提交消息。
+
+在我的例子中
+
+```bash
+mlagents-push-to-hf --run-id="SoccerTwos" --local-dir="./results/SoccerTwos" --repo-id="ThomasSimonini/poca-SoccerTwos" --commit-message="First Push"`
+```
+
+```bash
+mlagents-push-to-hf --run-id= # 添加你的运行ID --local-dir= # 你的本地目录 --repo-id= # 你的仓库ID --commit-message="First Push"
+```
+
+如果一切正常,你应该在过程结束时看到这个(但URL不同😆):
+
+你的模型已推送到Hub。你可以在这里查看你的模型:https://huggingface.co/ThomasSimonini/poca-SoccerTwos
+
+这是你模型的链接。它包含一个解释如何使用它的模型卡片,你的Tensorboard和你的配置文件。**最棒的是它是一个git仓库,这意味着你可以有不同的提交,用新的推送更新你的仓库等。**
+
+## 步骤6:验证你的模型已准备好参加AI对抗AI挑战
+
+现在你的模型已推送到Hub,**它将自动添加到AI对抗AI挑战模型池中。** 鉴于我们每4小时进行一次比赛,你的模型可能需要一点时间才能添加到排行榜中。
+
+但为了确保一切完美运行,你需要检查:
+
+1. 你的模型中有这个标签:ML-Agents-SoccerTwos。这是我们用来选择要添加到挑战池的模型的标签。为此,请转到你的模型并检查标签
+
+
+
+这说明了MA-POCA的中央化学习和去中心化执行。来源:MLAgents Plays Dodgeball
+
+
+
+解决方案是使用带有MA-POCA训练器(称为poca)的自我对弈。poca训练器将帮助我们训练合作行为,而自我对弈则帮助我们战胜对手队伍。
+
+如果你想深入了解这个MA-POCA算法,你需要阅读他们在[这里](https://arxiv.org/pdf/2111.05992.pdf)发表的论文,以及我们在额外阅读部分提供的资源。
+
+## 步骤3:定义配置文件
+
+我们在[单元5](https://huggingface.co/deep-rl-course/unit5/introduction)中已经学习过,在ML-Agents中,你**在`config.yaml`文件中定义训练超参数。**
+
+有多种超参数。要更好地理解它们,你应该阅读**[文档](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md)**中对每个超参数的解释
+
+我们将在这里使用的配置文件位于`./config/poca/SoccerTwos.yaml`。它看起来像这样:
+
+```csharp
+behaviors:
+ SoccerTwos:
+ trainer_type: poca
+ hyperparameters:
+ batch_size: 2048
+ buffer_size: 20480
+ learning_rate: 0.0003
+ beta: 0.005
+ epsilon: 0.2
+ lambd: 0.95
+ num_epoch: 3
+ learning_rate_schedule: constant
+ network_settings:
+ normalize: false
+ hidden_units: 512
+ num_layers: 2
+ vis_encode_type: simple
+ reward_signals:
+ extrinsic:
+ gamma: 0.99
+ strength: 1.0
+ keep_checkpoints: 5
+ max_steps: 5000000
+ time_horizon: 1000
+ summary_freq: 10000
+ self_play:
+ save_steps: 50000
+ team_change: 200000
+ swap_steps: 2000
+ window: 10
+ play_against_latest_model_ratio: 0.5
+ initial_elo: 1200.0
+```
+
+与Pyramids或SnowballTarget相比,我们有新的超参数,包含自我对弈部分。你如何修改它们对获得好结果可能至关重要。
+
+我在这里给你的建议是查看**[文档](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md)**中对每个参数(特别是自我对弈参数)的解释和推荐值。
+
+现在你已经修改了我们的配置文件,你已经准备好训练你的智能体了。
+
+## 步骤4:开始训练
+
+要训练智能体,我们需要**启动mlagents-learn并选择包含环境的可执行文件。**
+
+我们定义四个参数:
+
+1. `mlagents-learn `:超参数配置文件的路径。
+2. `-env`:环境可执行文件的位置。
+3. `-run_id`:你想给训练运行ID起的名称。
+4. `-no-graphics`:在训练期间不启动可视化。
+
+根据你的硬件,5M时间步(推荐值,但你也可以尝试10M)将需要5到8小时的训练。你可以在此期间继续使用你的电脑,但我建议停用电脑待机模式,以防止训练被停止。
+
+根据你使用的可执行文件(windows、ubuntu、mac),训练命令将如下所示(你的可执行文件路径可能不同,所以运行前不要犹豫检查一下)。
+
+对于Windows,它可能看起来像这样:
+```bash
+mlagents-learn ./config/poca/SoccerTwos.yaml --env=./training-envs-executables/SoccerTwos.exe --run-id="SoccerTwos" --no-graphics
+```
+
+对于Mac,它可能看起来像这样:
+```bash
+mlagents-learn ./config/poca/SoccerTwos.yaml --env=./training-envs-executables/SoccerTwos/SoccerTwos.app --run-id="SoccerTwos" --no-graphics
+```
+
+该可执行文件包含8个SoccerTwos的副本。
+
+⚠️ 如果在2M时间步之前你没有看到ELO分数的大幅增加(甚至降至1200以下)是正常的,因为你的智能体在能够进球之前会花费大部分时间在场上随机移动。
+
+⚠️ 你可以用Ctrl + C停止训练,但要注意只输入一次这个命令来停止训练,因为MLAgents需要在关闭运行前生成最终的.onnx文件。
+
+## 步骤5:**将智能体推送到Hugging Face Hub**
+
+现在我们已经训练了我们的智能体,我们**准备将它们推送到Hub,以便能够参与AI对抗AI挑战并在浏览器中可视化它们的比赛🔥。**
+
+为了能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果还没有完成)创建一个HF账户 ➡ [https://huggingface.co/join](https://huggingface.co/join)
+
+2️⃣ 登录并从Hugging Face网站存储你的认证令牌。
+
+创建一个新令牌(https://huggingface.co/settings/tokens)**具有写入权限**
+
+
+
+复制令牌,运行以下命令,并粘贴令牌
+
+```bash
+huggingface-cli login
+```
+
+然后,我们需要运行`mlagents-push-to-hf`。
+
+我们定义四个参数:
+
+1. `-run-id`:训练运行ID的名称。
+2. `-local-dir`:智能体保存的位置,它是results/\,所以在我的例子中是results/First Training。
+3. `-repo-id`:你想创建或更新的Hugging Face仓库的名称。它总是\<你的huggingface用户名\>/\<仓库名称\>
+如果仓库不存在,**它将自动创建**
+4. `--commit-message`:由于HF仓库是git仓库,你需要提供一个提交消息。
+
+在我的例子中
+
+```bash
+mlagents-push-to-hf --run-id="SoccerTwos" --local-dir="./results/SoccerTwos" --repo-id="ThomasSimonini/poca-SoccerTwos" --commit-message="First Push"`
+```
+
+```bash
+mlagents-push-to-hf --run-id= # 添加你的运行ID --local-dir= # 你的本地目录 --repo-id= # 你的仓库ID --commit-message="First Push"
+```
+
+如果一切正常,你应该在过程结束时看到这个(但URL不同😆):
+
+你的模型已推送到Hub。你可以在这里查看你的模型:https://huggingface.co/ThomasSimonini/poca-SoccerTwos
+
+这是你模型的链接。它包含一个解释如何使用它的模型卡片,你的Tensorboard和你的配置文件。**最棒的是它是一个git仓库,这意味着你可以有不同的提交,用新的推送更新你的仓库等。**
+
+## 步骤6:验证你的模型已准备好参加AI对抗AI挑战
+
+现在你的模型已推送到Hub,**它将自动添加到AI对抗AI挑战模型池中。** 鉴于我们每4小时进行一次比赛,你的模型可能需要一点时间才能添加到排行榜中。
+
+但为了确保一切完美运行,你需要检查:
+
+1. 你的模型中有这个标签:ML-Agents-SoccerTwos。这是我们用来选择要添加到挑战池的模型的标签。为此,请转到你的模型并检查标签
+
+ +
+
+如果不是这样,你只需要修改readme并添加它
+
+
+
+
+如果不是这样,你只需要修改readme并添加它
+
+ +
+2. 你有一个`SoccerTwos.onnx`文件
+
+
+
+2. 你有一个`SoccerTwos.onnx`文件
+
+ +
+如果你想再次训练它或训练新版本,我们强烈建议你在推送到Hub时创建一个新模型。
+
+## 步骤7:在我们的演示中可视化一些比赛
+
+现在你的模型已成为AI对抗AI挑战的一部分,**你可以可视化它与其他模型相比有多好**:https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
+
+为此,你只需要进入这个演示:
+
+- 选择你的模型作为蓝队(或者如果你喜欢的话,选择紫队)和另一个模型进行对抗。比较你的模型的最佳对手是排行榜上的顶级模型或[基准模型](https://huggingface.co/unity/MLAgents-SoccerTwos)
+
+你实时看到的比赛不会用于计算你的结果,**但它们是可视化你的智能体有多好的好方法**。
+
+不要犹豫在discord的#rl-i-made-this频道分享你的智能体获得的最佳分数🔥
diff --git a/units/cn/unit7/introduction-to-marl.mdx b/units/cn/unit7/introduction-to-marl.mdx
new file mode 100644
index 00000000..9ced2dff
--- /dev/null
+++ b/units/cn/unit7/introduction-to-marl.mdx
@@ -0,0 +1,55 @@
+# 多智能体强化学习(MARL)简介
+
+## 从单智能体到多智能体
+
+在第一单元中,我们学习了在单智能体系统中训练智能体。当我们的智能体在环境中是独立的时候:**它没有与其他智能体合作或协作**。
+
+
+
+
+如果你想再次训练它或训练新版本,我们强烈建议你在推送到Hub时创建一个新模型。
+
+## 步骤7:在我们的演示中可视化一些比赛
+
+现在你的模型已成为AI对抗AI挑战的一部分,**你可以可视化它与其他模型相比有多好**:https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
+
+为此,你只需要进入这个演示:
+
+- 选择你的模型作为蓝队(或者如果你喜欢的话,选择紫队)和另一个模型进行对抗。比较你的模型的最佳对手是排行榜上的顶级模型或[基准模型](https://huggingface.co/unity/MLAgents-SoccerTwos)
+
+你实时看到的比赛不会用于计算你的结果,**但它们是可视化你的智能体有多好的好方法**。
+
+不要犹豫在discord的#rl-i-made-this频道分享你的智能体获得的最佳分数🔥
diff --git a/units/cn/unit7/introduction-to-marl.mdx b/units/cn/unit7/introduction-to-marl.mdx
new file mode 100644
index 00000000..9ced2dff
--- /dev/null
+++ b/units/cn/unit7/introduction-to-marl.mdx
@@ -0,0 +1,55 @@
+# 多智能体强化学习(MARL)简介
+
+## 从单智能体到多智能体
+
+在第一单元中,我们学习了在单智能体系统中训练智能体。当我们的智能体在环境中是独立的时候:**它没有与其他智能体合作或协作**。
+
+
+ +
+自课程开始以来,你训练过的所有环境的拼贴画
+
+
+
+当我们进行多智能体强化学习(MARL)时,我们面对的是多个智能体**共享并在同一环境中交互**的情况。
+
+例如,你可以想象一个仓库,**多个机器人需要导航来装载和卸载包裹**。
+
+
+
+
+自课程开始以来,你训练过的所有环境的拼贴画
+
+
+
+当我们进行多智能体强化学习(MARL)时,我们面对的是多个智能体**共享并在同一环境中交互**的情况。
+
+例如,你可以想象一个仓库,**多个机器人需要导航来装载和卸载包裹**。
+
+
+ + [图片来源:upklyak](https://www.freepik.com/free-vector/robots-warehouse-interior-automated-machines_32117680.htm#query=warehouse robot&position=17&from_view=keyword) on Freepik
+
+
+或者一条有**多辆自动驾驶汽车**的道路。
+
+
+
+ [图片来源:upklyak](https://www.freepik.com/free-vector/robots-warehouse-interior-automated-machines_32117680.htm#query=warehouse robot&position=17&from_view=keyword) on Freepik
+
+
+或者一条有**多辆自动驾驶汽车**的道路。
+
+
+ +
+[图片来源:jcomp](https://www.freepik.com/free-vector/autonomous-smart-car-automatic-wireless-sensor-driving-road-around-car-autonomous-smart-car-goes-scans-roads-observe-distance-automatic-braking-system_26413332.htm#query=self driving cars highway&position=34&from_view=search&track=ais) on Freepik
+
+
+
+在这些例子中,我们有**多个智能体在环境中相互交互**。这意味着需要定义一个多智能体系统。但首先,让我们了解不同类型的多智能体环境。
+
+## 不同类型的多智能体环境
+
+鉴于在多智能体系统中,智能体与其他智能体交互,我们可以有不同类型的环境:
+
+- *合作环境*:你的智能体需要**最大化共同利益**。
+
+例如,在仓库中,**机器人必须协作以尽可能高效地(尽可能快地)装载和卸载包裹**。
+
+- *竞争/对抗环境*:在这种情况下,你的智能体**希望通过最小化对手的利益来最大化自己的利益**。
+
+例如,在网球比赛中,**每个智能体都想击败另一个智能体**。
+
+
+
+[图片来源:jcomp](https://www.freepik.com/free-vector/autonomous-smart-car-automatic-wireless-sensor-driving-road-around-car-autonomous-smart-car-goes-scans-roads-observe-distance-automatic-braking-system_26413332.htm#query=self driving cars highway&position=34&from_view=search&track=ais) on Freepik
+
+
+
+在这些例子中,我们有**多个智能体在环境中相互交互**。这意味着需要定义一个多智能体系统。但首先,让我们了解不同类型的多智能体环境。
+
+## 不同类型的多智能体环境
+
+鉴于在多智能体系统中,智能体与其他智能体交互,我们可以有不同类型的环境:
+
+- *合作环境*:你的智能体需要**最大化共同利益**。
+
+例如,在仓库中,**机器人必须协作以尽可能高效地(尽可能快地)装载和卸载包裹**。
+
+- *竞争/对抗环境*:在这种情况下,你的智能体**希望通过最小化对手的利益来最大化自己的利益**。
+
+例如,在网球比赛中,**每个智能体都想击败另一个智能体**。
+
+ +
+- *对抗和合作的混合*:就像我们的SoccerTwos环境一样,两个智能体是一个团队的一部分(蓝色或紫色):它们需要相互合作并击败对方团队。
+
+
+
+这个环境由Unity MLAgents团队制作
+
+
+所以现在我们可能会想:如何设计这些多智能体系统?换句话说,**如何在多智能体设置中训练智能体**?
diff --git a/units/cn/unit7/introduction.mdx b/units/cn/unit7/introduction.mdx
new file mode 100644
index 00000000..75d5e53d
--- /dev/null
+++ b/units/cn/unit7/introduction.mdx
@@ -0,0 +1,36 @@
+# 介绍 [[introduction]]
+
+
+
+- *对抗和合作的混合*:就像我们的SoccerTwos环境一样,两个智能体是一个团队的一部分(蓝色或紫色):它们需要相互合作并击败对方团队。
+
+
+
+这个环境由Unity MLAgents团队制作
+
+
+所以现在我们可能会想:如何设计这些多智能体系统?换句话说,**如何在多智能体设置中训练智能体**?
diff --git a/units/cn/unit7/introduction.mdx b/units/cn/unit7/introduction.mdx
new file mode 100644
index 00000000..75d5e53d
--- /dev/null
+++ b/units/cn/unit7/introduction.mdx
@@ -0,0 +1,36 @@
+# 介绍 [[introduction]]
+
+ +
+自本课程开始以来,我们学习了在*单智能体系统*中训练智能体,在这个系统中,我们的智能体在环境中是独立的:它**没有与其他智能体合作或协作**。
+
+这种方法效果很好,单智能体系统对许多应用都很有用。
+
+
+
+
+
+
+
+自课程开始以来,你训练过的所有环境的拼贴画
+
+
+
+但是,作为人类,**我们生活在一个多智能体的世界中**。我们的智能来源于与其他智能体的交互。因此,我们的**目标是创建能够与其他人类和其他智能体交互的智能体**。
+
+因此,我们必须研究如何在*多智能体系统*中训练深度强化学习智能体,以构建能够适应、协作或竞争的强大智能体。
+
+所以今天我们将**学习多智能体强化学习(MARL)这个迷人主题的基础知识**。
+
+最令人兴奋的部分是,在本单元中,你将在多智能体系统中训练你的第一个智能体:**一个需要击败对手团队的2对2足球队**。
+
+你将参加**AI对AI挑战**,你训练的智能体将每天与其他同学的智能体竞争,并在[新的排行榜](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos)上排名。
+
+
+
+
+这个环境由Unity MLAgents团队制作
+
+
+
+让我们开始吧!
diff --git a/units/cn/unit7/multi-agent-setting.mdx b/units/cn/unit7/multi-agent-setting.mdx
new file mode 100644
index 00000000..4283869d
--- /dev/null
+++ b/units/cn/unit7/multi-agent-setting.mdx
@@ -0,0 +1,57 @@
+# 设计多智能体系统
+
+在本节中,你将观看由Brian Douglas制作的关于多智能体的精彩介绍。
+
+
+
+
+在这个视频中,Brian讨论了如何设计多智能体系统。他特别以吸尘器的多智能体系统为例,并提出问题:**它们如何相互合作**?
+
+我们有两种解决方案来设计这种多智能体强化学习系统(MARL)。
+
+## 去中心化系统
+
+
+
+
+自本课程开始以来,我们学习了在*单智能体系统*中训练智能体,在这个系统中,我们的智能体在环境中是独立的:它**没有与其他智能体合作或协作**。
+
+这种方法效果很好,单智能体系统对许多应用都很有用。
+
+
+
+
+
+
+
+自课程开始以来,你训练过的所有环境的拼贴画
+
+
+
+但是,作为人类,**我们生活在一个多智能体的世界中**。我们的智能来源于与其他智能体的交互。因此,我们的**目标是创建能够与其他人类和其他智能体交互的智能体**。
+
+因此,我们必须研究如何在*多智能体系统*中训练深度强化学习智能体,以构建能够适应、协作或竞争的强大智能体。
+
+所以今天我们将**学习多智能体强化学习(MARL)这个迷人主题的基础知识**。
+
+最令人兴奋的部分是,在本单元中,你将在多智能体系统中训练你的第一个智能体:**一个需要击败对手团队的2对2足球队**。
+
+你将参加**AI对AI挑战**,你训练的智能体将每天与其他同学的智能体竞争,并在[新的排行榜](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos)上排名。
+
+
+
+
+这个环境由Unity MLAgents团队制作
+
+
+
+让我们开始吧!
diff --git a/units/cn/unit7/multi-agent-setting.mdx b/units/cn/unit7/multi-agent-setting.mdx
new file mode 100644
index 00000000..4283869d
--- /dev/null
+++ b/units/cn/unit7/multi-agent-setting.mdx
@@ -0,0 +1,57 @@
+# 设计多智能体系统
+
+在本节中,你将观看由Brian Douglas制作的关于多智能体的精彩介绍。
+
+
+
+
+在这个视频中,Brian讨论了如何设计多智能体系统。他特别以吸尘器的多智能体系统为例,并提出问题:**它们如何相互合作**?
+
+我们有两种解决方案来设计这种多智能体强化学习系统(MARL)。
+
+## 去中心化系统
+
+
+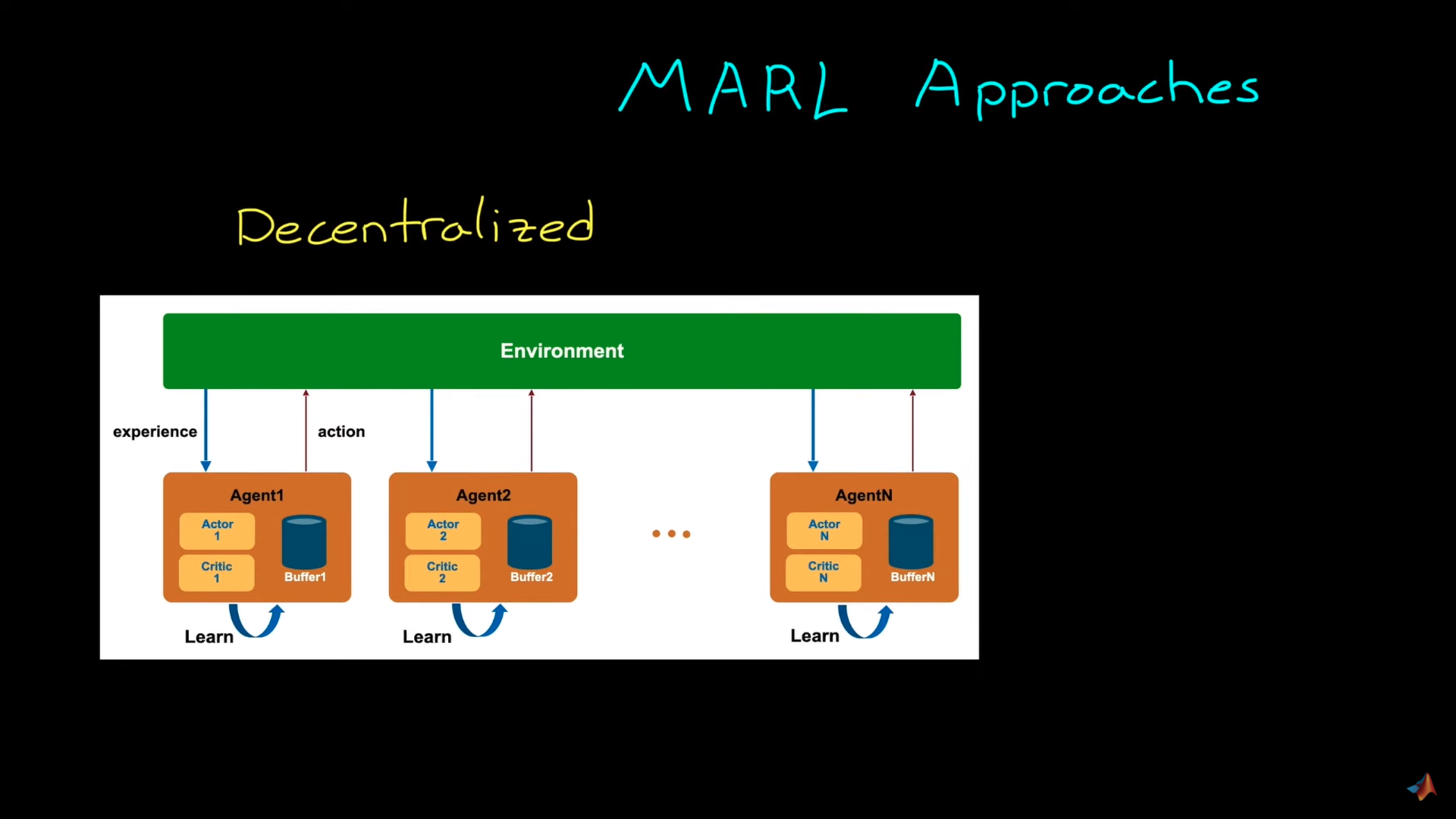 +
+来源:多智能体强化学习介绍
+
+
+
+在去中心化学习中,**每个智能体都是独立于其他智能体进行训练的**。在给出的例子中,每个吸尘器学习尽可能多地清洁地方,**而不关心其他吸尘器(智能体)在做什么**。
+
+好处是**由于智能体之间不共享信息,这些吸尘器可以像我们训练单个智能体一样被设计和训练**。
+
+这里的想法是**我们的训练智能体将其他智能体视为环境动态的一部分**。而不是作为智能体。
+
+然而,这种技术的一个很大的缺点是它会**使环境变得非平稳**,因为随着其他智能体也在环境中交互,底层的马尔可夫决策过程会随时间变化。
+这对许多强化学习算法来说是有问题的,**因为它们无法在非平稳环境中达到全局最优**。
+
+## 中心化方法
+
+
+
+
+来源:多智能体强化学习介绍
+
+
+
+在去中心化学习中,**每个智能体都是独立于其他智能体进行训练的**。在给出的例子中,每个吸尘器学习尽可能多地清洁地方,**而不关心其他吸尘器(智能体)在做什么**。
+
+好处是**由于智能体之间不共享信息,这些吸尘器可以像我们训练单个智能体一样被设计和训练**。
+
+这里的想法是**我们的训练智能体将其他智能体视为环境动态的一部分**。而不是作为智能体。
+
+然而,这种技术的一个很大的缺点是它会**使环境变得非平稳**,因为随着其他智能体也在环境中交互,底层的马尔可夫决策过程会随时间变化。
+这对许多强化学习算法来说是有问题的,**因为它们无法在非平稳环境中达到全局最优**。
+
+## 中心化方法
+
+
+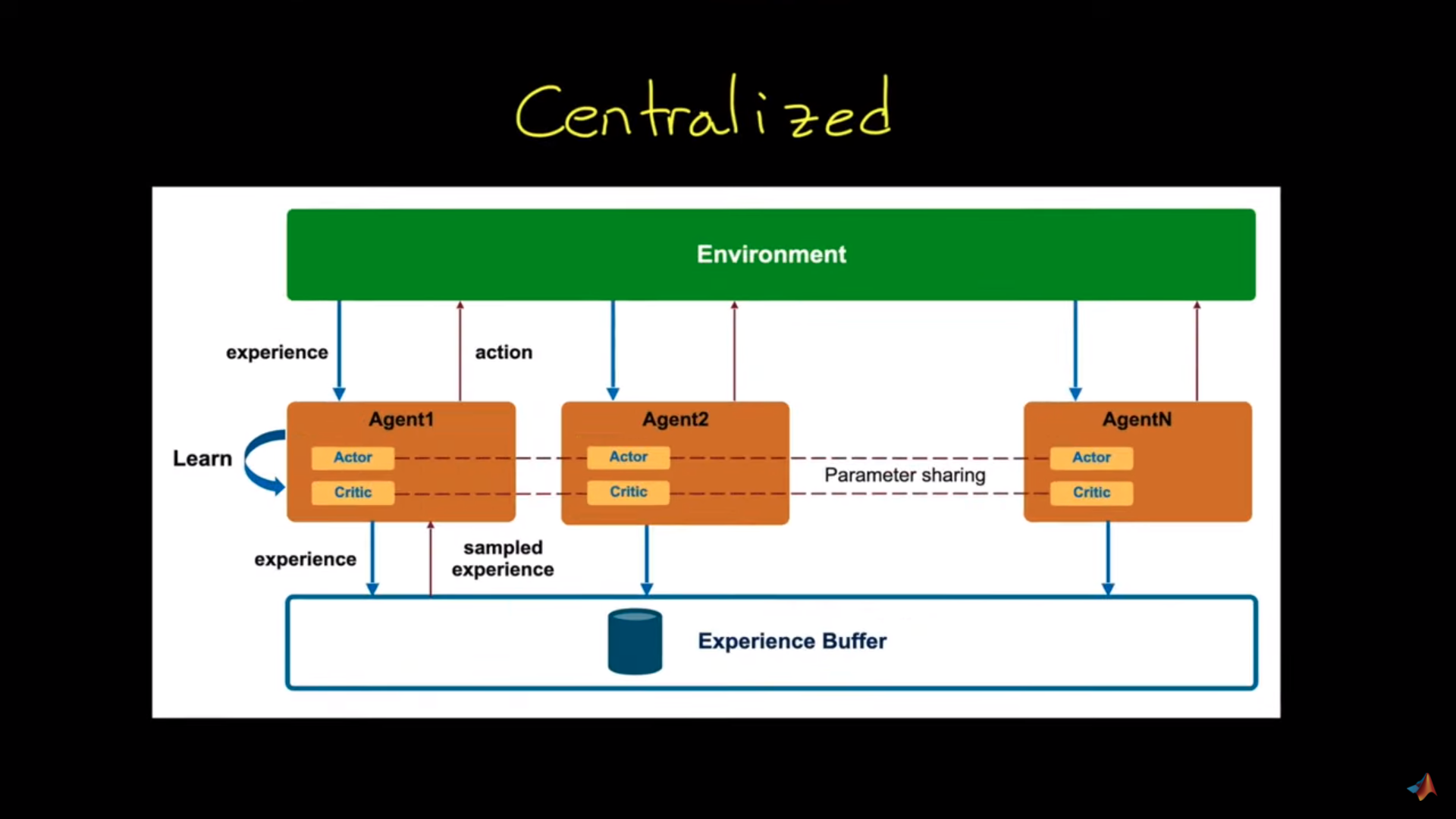 +
+来源:多智能体强化学习介绍
+
+
+
+在这种架构中,**我们有一个高级过程来收集智能体的经验**:经验缓冲区。我们将使用这些经验**来学习一个共同的策略**。
+
+例如,在吸尘器的例子中,观察将是:
+- 吸尘器的覆盖地图。
+- 所有吸尘器的位置。
+
+我们使用这种集体经验**来训练一个策略,该策略将以对整体最有利的方式移动所有三个机器人**。所以每个机器人都在从它们的共同经验中学习。
+我们现在有一个平稳的环境,因为所有的智能体都被视为一个更大的实体,并且它们知道其他智能体策略的变化(因为它与它们自己的相同)。
+
+如果我们总结一下:
+
+- 在*去中心化方法*中,我们**独立对待所有智能体,而不考虑其他智能体的存在**。
+ - 在这种情况下,所有智能体**将其他智能体视为环境的一部分**。
+ - **这是一个非平稳环境条件**,因此无法保证收敛。
+
+- 在*中心化方法*中:
+ - **从所有智能体中学习单一策略**。
+ - 以环境的当前状态作为输入,策略输出联合行动。
+ - 奖励是全局性的。
diff --git a/units/cn/unit7/quiz.mdx b/units/cn/unit7/quiz.mdx
new file mode 100644
index 00000000..89958911
--- /dev/null
+++ b/units/cn/unit7/quiz.mdx
@@ -0,0 +1,139 @@
+# 测验
+
+学习的最佳方式,也是[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法,**就是测试自己。** 这将帮助你找出**需要加强知识的地方**。
+
+
+### 问题1:在比较不同类型的多智能体环境时,选择最合适的选项
+
+- 你的智能体在____环境中旨在最大化共同利益
+- 你的智能体在____环境中旨在最大化共同利益的同时最小化对手的利益
+
+
+
+### 问题2:关于`去中心化`学习,以下哪些陈述是正确的?
+
+
+
+
+### 问题3:关于`中心化`学习,以下哪些陈述是正确的?
+
+
+
+### 问题4:用你自己的话解释什么是`自我对弈`方法
+
+
+
+来源:多智能体强化学习介绍
+
+
+
+在这种架构中,**我们有一个高级过程来收集智能体的经验**:经验缓冲区。我们将使用这些经验**来学习一个共同的策略**。
+
+例如,在吸尘器的例子中,观察将是:
+- 吸尘器的覆盖地图。
+- 所有吸尘器的位置。
+
+我们使用这种集体经验**来训练一个策略,该策略将以对整体最有利的方式移动所有三个机器人**。所以每个机器人都在从它们的共同经验中学习。
+我们现在有一个平稳的环境,因为所有的智能体都被视为一个更大的实体,并且它们知道其他智能体策略的变化(因为它与它们自己的相同)。
+
+如果我们总结一下:
+
+- 在*去中心化方法*中,我们**独立对待所有智能体,而不考虑其他智能体的存在**。
+ - 在这种情况下,所有智能体**将其他智能体视为环境的一部分**。
+ - **这是一个非平稳环境条件**,因此无法保证收敛。
+
+- 在*中心化方法*中:
+ - **从所有智能体中学习单一策略**。
+ - 以环境的当前状态作为输入,策略输出联合行动。
+ - 奖励是全局性的。
diff --git a/units/cn/unit7/quiz.mdx b/units/cn/unit7/quiz.mdx
new file mode 100644
index 00000000..89958911
--- /dev/null
+++ b/units/cn/unit7/quiz.mdx
@@ -0,0 +1,139 @@
+# 测验
+
+学习的最佳方式,也是[避免能力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的方法,**就是测试自己。** 这将帮助你找出**需要加强知识的地方**。
+
+
+### 问题1:在比较不同类型的多智能体环境时,选择最合适的选项
+
+- 你的智能体在____环境中旨在最大化共同利益
+- 你的智能体在____环境中旨在最大化共同利益的同时最小化对手的利益
+
+
+
+### 问题2:关于`去中心化`学习,以下哪些陈述是正确的?
+
+
+
+
+### 问题3:关于`中心化`学习,以下哪些陈述是正确的?
+
+
+
+### 问题4:用你自己的话解释什么是`自我对弈`方法
+
+
+解决方案
+
+`自我对弈`是一种方法,它实例化与你的策略相同的智能体副本作为对手,这样你的智能体就可以从具有相同训练水平的智能体中学习。
+
+
+
+### 问题5:在配置`自我对弈`时,有几个重要参数。你能通过它们的定义识别出我们在谈论哪个参数吗?
+
+- 与当前自我对弈与从池中选择对手的概率
+- 你可能面对的对手训练水平的多样性(分散度)
+- 在生成新对手之前的训练步骤数
+- 对手更换率
+
+
+
+### 问题6:使用ELO评分系统的主要动机是什么?
+
+
+
+恭喜你完成了这个测验 🥳,如果你错过了一些要点,请花时间再次阅读本章,以加强(😏)你的知识。
diff --git a/units/cn/unit7/self-play.mdx b/units/cn/unit7/self-play.mdx
new file mode 100644
index 00000000..b22b7c9f
--- /dev/null
+++ b/units/cn/unit7/self-play.mdx
@@ -0,0 +1,134 @@
+# 自我对弈:训练对抗性游戏中竞争性智能体的经典技术
+
+现在我们已经学习了多智能体的基础知识,我们准备深入研究。正如在介绍中提到的,我们将**在SoccerTwos这个2对2游戏的对抗性游戏中训练智能体**。
+
+
+
+
+这个环境由Unity MLAgents团队制作
+
+
+
+## 什么是自我对弈?
+
+在对抗性游戏中正确训练智能体可能**相当复杂**。
+
+一方面,我们需要找到如何获得一个训练良好的对手来与你的训练智能体对抗。另一方面,如果你找到一个非常好的训练对手,当对手太强时,你的智能体如何改进其策略?
+
+想想一个刚开始学习足球的孩子。与一个非常优秀的足球运动员对抗将毫无用处,因为这将太难获胜,或者至少偶尔获得球权。所以这个孩子将不断失败,没有时间学习一个好的策略。
+
+最好的解决方案是**拥有一个与智能体水平相当的对手,并随着智能体提升自己的水平而提升其水平**。因为如果对手太强,我们将学不到任何东西;如果对手太弱,我们将过度学习对抗更强对手时无用的行为。
+
+这种解决方案被称为*自我对弈*。在自我对弈中,**智能体使用自己的前一个副本(其策略的副本)作为对手**。这样,智能体将与同一水平的智能体对抗(具有挑战性但不会太多),有机会逐渐改进其策略,然后随着它变得更好而更新其对手。这是一种引导对手并逐步增加对手复杂性的方法。
+
+这与人类在竞争中学习的方式相同:
+
+- 我们开始与同等水平的对手训练
+- 然后我们从中学习,当我们获得一些技能后,我们可以与更强的对手进一步发展。
+
+我们在自我对弈中也做同样的事情:
+
+- 我们**以我们的智能体的副本作为对手开始**,这样,这个对手处于相似的水平。
+- 我们**从中学习**,当我们获得一些技能后,我们**用我们训练策略的更新版本更新我们的对手**。
+
+自我对弈背后的理论并不是什么新鲜事物。它已经在五十年代由Arthur Samuel的跳棋玩家系统和1995年由Gerald Tesauro的TD-Gammon使用。如果你想了解更多关于自我对弈的历史,[请查看Andrew Cohen的这篇非常好的博客文章](https://blog.unity.com/technology/training-intelligent-adversaries-using-self-play-with-ml-agents)
+
+## MLAgents中的自我对弈
+
+自我对弈已集成到MLAgents库中,并由我们将要研究的多个超参数管理。但正如文档中所解释的,主要关注点是**最终策略的技能水平和通用性与学习稳定性之间的权衡**。
+
+对抗一组缓慢变化或不变的对手,多样性低的训练**会导致更稳定的训练。但如果变化太慢,就有过拟合的风险。**
+
+所以我们需要控制:
+
+- **我们多久更换一次对手**,通过`swap_steps`和`team_change`参数。
+- **保存的对手数量**,通过`window`参数。`window`的较大值意味着智能体的对手池将包含更多样化的行为,因为它将包含来自训练运行早期的策略。
+- **与当前自我对弈与从池中抽样的对手对抗的概率**,通过`play_against_latest_model_ratio`参数。`play_against_latest_model_ratio`的较大值表示智能体将更频繁地与当前对手对抗。
+- **在保存新对手之前的训练步骤数**,通过`save_steps`参数。`save_steps`的较大值将产生一组覆盖更广泛技能水平和可能的游戏风格的对手,因为策略接收更多的训练。
+
+要获取有关这些超参数的更多详细信息,你绝对需要[查看文档的这部分](https://github.com/Unity-Technologies/ml-agents/blob/develop/docs/Training-Configuration-File.md#self-play)
+
+
+## ELO评分来评估我们的智能体
+
+### 什么是ELO评分?
+
+在对抗性游戏中,跟踪**累积奖励并不总是一个有意义的指标来跟踪学习进度:**因为这个指标**仅取决于对手的技能**。
+
+相反,我们使用***ELO评分系统***(以Arpad Elo命名),它计算零和游戏中给定人群中两个玩家之间的**相对技能水平**。
+
+在零和游戏中:一个智能体获胜,另一个智能体失败。这是一种数学表示,其中每个参与者的效用增益或损失**与其他参与者的效用增益或损失完全平衡**。我们之所以称之为零和游戏,是因为效用总和等于零。
+
+这个ELO(从特定分数开始:通常是1200)可能最初会下降,但应该在训练过程中逐渐增加。
+
+Elo系统是**从对其他玩家的失败和平局中推断出来的**。这意味着玩家的评分取决于**他们对手的评分以及对他们的得分结果**。
+
+Elo定义了一个Elo分数,它是玩家在零和游戏中的相对技能。**我们说相对是因为它取决于对手的表现**。
+
+核心思想是将玩家的表现视为**一个正态分布的随机变量**。
+
+两个玩家之间的评分差异作为**比赛结果的预测因子**。如果玩家获胜,但获胜的概率很高,它只会从对手那里赢得很少的分数,因为这意味着它比对手强得多。
+
+每场比赛后:
+
+- 获胜的玩家从失败的玩家那里**获取分数**。
+- 分数的数量**由两个玩家评分的差异决定(因此是相对的)**。
+ - 如果评分较高的玩家获胜 → 从评分较低的玩家那里获取很少的分数。
+ - 如果评分较低的玩家获胜 → 从评分较高的玩家那里获取大量分数。
+ - 如果是平局 → 评分较低的玩家从评分较高的玩家那里获得一些分数。
+
+所以如果A和B的评分分别为Ra和Rb,那么**预期分数**由以下公式给出:
+
+ +
+然后,在游戏结束时,我们需要更新玩家的实际Elo分数。我们使用**与玩家表现超出或不足的程度成比例的线性调整**。
+
+我们还定义了每场比赛的最大调整评分:K因子。
+
+- 对于大师级别,K=16。
+- 对于较弱的玩家,K=32。
+
+如果玩家A有Ea分但得到了Sa分,那么玩家的评分使用以下公式更新:
+
+
+
+然后,在游戏结束时,我们需要更新玩家的实际Elo分数。我们使用**与玩家表现超出或不足的程度成比例的线性调整**。
+
+我们还定义了每场比赛的最大调整评分:K因子。
+
+- 对于大师级别,K=16。
+- 对于较弱的玩家,K=32。
+
+如果玩家A有Ea分但得到了Sa分,那么玩家的评分使用以下公式更新:
+
+ +
+### 示例
+
+如果我们举个例子:
+
+玩家A的评分为2600
+
+玩家B的评分为2300
+
+- 我们首先计算预期分数:
+
+\(E_{A} = \frac{1}{1+10^{(2300-2600)/400}} = 0.849 \)
+
+\(E_{B} = \frac{1}{1+10^{(2600-2300)/400}} = 0.151 \)
+
+- 如果组织者确定K=16且A获胜,新的评分将是:
+
+\\(ELO_A = 2600 + 16*(1-0.849) = 2602 \\)
+
+\\(ELO_B = 2300 + 16*(0-0.151) = 2298 \\)
+
+- 如果组织者确定K=16且B获胜,新的评分将是:
+
+\\(ELO_A = 2600 + 16*(0-0.849) = 2586 \\)
+
+\\(ELO_B = 2300 + 16 *(1-0.151) = 2314 \\)
+
+
+### 优势
+
+使用ELO评分有多个优势:
+
+- 分数**始终平衡**(当出现意外结果时会交换更多分数,但总和始终相同)。
+- 这是一个**自我修正的系统**,因为如果一个玩家击败一个弱玩家,他们只会赢得很少的分数。
+- 它**适用于团队游戏**:我们计算每个团队的平均值并在Elo中使用它。
+
+### 缺点
+
+- ELO**不考虑团队中每个人的个人贡献**。
+- 评分通缩:**保持良好评分需要随着时间的推移保持技能**。
+- **无法比较历史上的评分**。
diff --git a/units/cn/unit8/additional-readings.mdx b/units/cn/unit8/additional-readings.mdx
new file mode 100644
index 00000000..830cee22
--- /dev/null
+++ b/units/cn/unit8/additional-readings.mdx
@@ -0,0 +1,21 @@
+# 额外阅读材料 [[additional-readings]]
+
+这些是**可选阅读材料**,如果你想深入了解可以参考。
+
+## PPO详解
+
+- [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization by Daniel Bick](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf)
+- [如何理解强化学习中的近端策略优化算法?](https://stackoverflow.com/questions/46422845/what-is-the-way-to-understand-proximal-policy-optimization-algorithm-in-rl)
+- [深度强化学习基础系列,L4 TRPO和PPO by Pieter Abbeel](https://youtu.be/KjWF8VIMGiY)
+- [OpenAI PPO博客文章](https://openai.com/blog/openai-baselines-ppo/)
+- [Spinning Up RL PPO](https://spinningup.openai.com/en/latest/algorithms/ppo.html)
+- [论文:近端策略优化算法](https://arxiv.org/abs/1707.06347)
+
+## PPO实现细节
+
+- [近端策略优化的37个实现细节](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
+- [近端策略优化实现第1部分(共3部分):11个核心实现细节](https://www.youtube.com/watch?v=MEt6rrxH8W4)
+
+## 重要性采样
+
+- [重要性采样解释](https://youtu.be/C3p2wI4RAi8)
diff --git a/units/cn/unit8/clipped-surrogate-objective.mdx b/units/cn/unit8/clipped-surrogate-objective.mdx
new file mode 100644
index 00000000..e43344c7
--- /dev/null
+++ b/units/cn/unit8/clipped-surrogate-objective.mdx
@@ -0,0 +1,69 @@
+# 引入裁剪替代目标函数
+## 回顾:策略目标函数
+
+让我们回顾一下Reinforce中要优化的目标:
+
+
+### 示例
+
+如果我们举个例子:
+
+玩家A的评分为2600
+
+玩家B的评分为2300
+
+- 我们首先计算预期分数:
+
+\(E_{A} = \frac{1}{1+10^{(2300-2600)/400}} = 0.849 \)
+
+\(E_{B} = \frac{1}{1+10^{(2600-2300)/400}} = 0.151 \)
+
+- 如果组织者确定K=16且A获胜,新的评分将是:
+
+\\(ELO_A = 2600 + 16*(1-0.849) = 2602 \\)
+
+\\(ELO_B = 2300 + 16*(0-0.151) = 2298 \\)
+
+- 如果组织者确定K=16且B获胜,新的评分将是:
+
+\\(ELO_A = 2600 + 16*(0-0.849) = 2586 \\)
+
+\\(ELO_B = 2300 + 16 *(1-0.151) = 2314 \\)
+
+
+### 优势
+
+使用ELO评分有多个优势:
+
+- 分数**始终平衡**(当出现意外结果时会交换更多分数,但总和始终相同)。
+- 这是一个**自我修正的系统**,因为如果一个玩家击败一个弱玩家,他们只会赢得很少的分数。
+- 它**适用于团队游戏**:我们计算每个团队的平均值并在Elo中使用它。
+
+### 缺点
+
+- ELO**不考虑团队中每个人的个人贡献**。
+- 评分通缩:**保持良好评分需要随着时间的推移保持技能**。
+- **无法比较历史上的评分**。
diff --git a/units/cn/unit8/additional-readings.mdx b/units/cn/unit8/additional-readings.mdx
new file mode 100644
index 00000000..830cee22
--- /dev/null
+++ b/units/cn/unit8/additional-readings.mdx
@@ -0,0 +1,21 @@
+# 额外阅读材料 [[additional-readings]]
+
+这些是**可选阅读材料**,如果你想深入了解可以参考。
+
+## PPO详解
+
+- [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization by Daniel Bick](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf)
+- [如何理解强化学习中的近端策略优化算法?](https://stackoverflow.com/questions/46422845/what-is-the-way-to-understand-proximal-policy-optimization-algorithm-in-rl)
+- [深度强化学习基础系列,L4 TRPO和PPO by Pieter Abbeel](https://youtu.be/KjWF8VIMGiY)
+- [OpenAI PPO博客文章](https://openai.com/blog/openai-baselines-ppo/)
+- [Spinning Up RL PPO](https://spinningup.openai.com/en/latest/algorithms/ppo.html)
+- [论文:近端策略优化算法](https://arxiv.org/abs/1707.06347)
+
+## PPO实现细节
+
+- [近端策略优化的37个实现细节](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
+- [近端策略优化实现第1部分(共3部分):11个核心实现细节](https://www.youtube.com/watch?v=MEt6rrxH8W4)
+
+## 重要性采样
+
+- [重要性采样解释](https://youtu.be/C3p2wI4RAi8)
diff --git a/units/cn/unit8/clipped-surrogate-objective.mdx b/units/cn/unit8/clipped-surrogate-objective.mdx
new file mode 100644
index 00000000..e43344c7
--- /dev/null
+++ b/units/cn/unit8/clipped-surrogate-objective.mdx
@@ -0,0 +1,69 @@
+# 引入裁剪替代目标函数
+## 回顾:策略目标函数
+
+让我们回顾一下Reinforce中要优化的目标:
+ +
+其思想是通过对这个函数进行梯度上升步骤(等同于对这个函数的负值进行梯度下降),我们将**推动我们的智能体采取能够获得更高奖励的行动并避免有害行动。**
+
+然而,问题来自于步长:
+- 太小,**训练过程太慢**
+- 太大,**训练中的变异性太大**
+
+在PPO中,思想是使用一个称为*裁剪替代目标函数*的新目标函数来约束我们的策略更新,**该函数将使用裁剪将策略变化限制在一个小范围内。**
+
+这个新函数**旨在避免破坏性的大权重更新**:
+
+
+
+其思想是通过对这个函数进行梯度上升步骤(等同于对这个函数的负值进行梯度下降),我们将**推动我们的智能体采取能够获得更高奖励的行动并避免有害行动。**
+
+然而,问题来自于步长:
+- 太小,**训练过程太慢**
+- 太大,**训练中的变异性太大**
+
+在PPO中,思想是使用一个称为*裁剪替代目标函数*的新目标函数来约束我们的策略更新,**该函数将使用裁剪将策略变化限制在一个小范围内。**
+
+这个新函数**旨在避免破坏性的大权重更新**:
+
+ +
+让我们研究每个部分以了解它是如何工作的。
+
+## 比率函数
+
+
+让我们研究每个部分以了解它是如何工作的。
+
+## 比率函数
+ +
+这个比率计算如下:
+
+
+
+这个比率计算如下:
+
+ +
+它是当前策略中在状态 \\( s_t \\) 下采取行动 \\( a_t \\) 的概率,除以前一个策略中相同情况的概率。
+
+如我们所见,\\( r_t(\theta) \\) 表示当前策略和旧策略之间的概率比率:
+
+- 如果 \\( r_t(\theta) > 1 \\),**在当前策略中,在状态 \\( s_t \\) 下采取行动 \\( a_t \\) 的可能性比旧策略更大。**
+- 如果 \\( r_t(\theta) \\) 在0和1之间,**该行动在当前策略中的可能性比旧策略小**。
+
+因此,这个概率比率是**估计旧策略和当前策略之间差异的简单方法。**
+
+## 裁剪替代目标函数的非裁剪部分
+
+
+它是当前策略中在状态 \\( s_t \\) 下采取行动 \\( a_t \\) 的概率,除以前一个策略中相同情况的概率。
+
+如我们所见,\\( r_t(\theta) \\) 表示当前策略和旧策略之间的概率比率:
+
+- 如果 \\( r_t(\theta) > 1 \\),**在当前策略中,在状态 \\( s_t \\) 下采取行动 \\( a_t \\) 的可能性比旧策略更大。**
+- 如果 \\( r_t(\theta) \\) 在0和1之间,**该行动在当前策略中的可能性比旧策略小**。
+
+因此,这个概率比率是**估计旧策略和当前策略之间差异的简单方法。**
+
+## 裁剪替代目标函数的非裁剪部分
+ +
+这个比率**可以替代我们在策略目标函数中使用的对数概率**。这给了我们新目标函数的左侧部分:将比率乘以优势。
+
+
+
+这个比率**可以替代我们在策略目标函数中使用的对数概率**。这给了我们新目标函数的左侧部分:将比率乘以优势。
+
+  + 近端策略优化算法
+
+
+然而,如果没有约束,如果在我们当前策略中采取的行动比我们以前的策略更有可能,**这将导致显著的策略梯度步骤**,因此,**过度的策略更新。**
+
+## 裁剪替代目标函数的裁剪部分
+
+
+ 近端策略优化算法
+
+
+然而,如果没有约束,如果在我们当前策略中采取的行动比我们以前的策略更有可能,**这将导致显著的策略梯度步骤**,因此,**过度的策略更新。**
+
+## 裁剪替代目标函数的裁剪部分
+
+ +
+因此,我们需要通过惩罚导致比率远离1的变化来约束这个目标函数(在论文中,比率只能从0.8变化到1.2)。
+
+**通过裁剪比率,我们确保不会有太大的策略更新,因为当前策略不能与旧策略相差太大。**
+
+为此,我们有两种解决方案:
+
+- *TRPO(信任区域策略优化)*在目标函数之外使用KL散度约束来约束策略更新。但这种方法**实现复杂,计算时间更长。**
+- *PPO*直接在目标函数中用其**裁剪替代目标函数**裁剪概率比率。
+
+
+
+这个裁剪部分是一个版本,其中 \\( r_t(\theta) \\) 被裁剪在 \\( [1 - \epsilon, 1 + \epsilon] \\) 之间。
+
+使用裁剪替代目标函数,我们有两个概率比率,一个非裁剪的和一个在 \\( [1 - \epsilon, 1 + \epsilon] \\) 范围内裁剪的,epsilon是一个超参数,帮助我们定义这个裁剪范围(在论文中 \\( \epsilon = 0.2 \\))。
+
+然后,我们取裁剪和非裁剪目标的最小值,**所以最终目标是非裁剪目标的下界(悲观界)。**
+
+取裁剪和非裁剪目标的最小值意味着**我们将根据比率和优势情况选择裁剪或非裁剪目标**。
diff --git a/units/cn/unit8/conclusion-sf.mdx b/units/cn/unit8/conclusion-sf.mdx
new file mode 100644
index 00000000..cb213deb
--- /dev/null
+++ b/units/cn/unit8/conclusion-sf.mdx
@@ -0,0 +1,13 @@
+# 结论
+
+今天的内容到此结束。恭喜你完成本单元和教程!⭐️
+
+现在你已经成功训练了你的Doom智能体,为什么不尝试死亡竞赛呢?请记住,这是一个比你刚刚训练的关卡复杂得多的关卡,**但这是一个很好的实验,我建议你尝试一下。**
+
+如果你做了,不要犹豫,在我们的[discord服务器](https://www.hf.co/join/discord)的`#rl-i-made-this`频道中分享你的模型。
+
+这结束了最后一个单元,但我们还没有完成!🤗 接下来的**奖励单元包含了深度强化学习中一些最有趣、最先进和最前沿的工作**。
+
+下次见 🔥
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit8/conclusion.mdx b/units/cn/unit8/conclusion.mdx
new file mode 100644
index 00000000..0abe7dbd
--- /dev/null
+++ b/units/cn/unit8/conclusion.mdx
@@ -0,0 +1,9 @@
+# 结论 [[Conclusion]]
+
+今天的内容到此结束。恭喜你完成本单元和教程!
+
+学习的最佳方式是实践和尝试。**为什么不改进实现以处理帧作为输入呢?**
+
+在本单元的第二部分再见 🔥
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit8/hands-on-cleanrl.mdx b/units/cn/unit8/hands-on-cleanrl.mdx
new file mode 100644
index 00000000..f6206602
--- /dev/null
+++ b/units/cn/unit8/hands-on-cleanrl.mdx
@@ -0,0 +1,1078 @@
+# 实践练习
+
+
+
+
+
+
+现在我们已经学习了PPO背后的理论,理解它如何工作的最佳方式**是从头开始实现它**。
+
+从头实现一个架构是理解它的最佳方式,这是一个好习惯。我们已经为基于价值的方法(Q-Learning)和基于策略的方法(Reinforce)做过这样的实践。
+
+因此,为了能够编写代码,我们将使用两个资源:
+- 由[Costa Huang](https://github.com/vwxyzjn)制作的教程。Costa是[CleanRL](https://github.com/vwxyzjn/cleanrl)的创建者,CleanRL是一个深度强化学习库,提供高质量的单文件实现,具有研究友好的特性。
+- 除了教程之外,为了更深入地理解,你可以阅读13个核心实现细节:[https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
+
+然后,为了测试其稳健性,我们将在以下环境中训练它:
+- [LunarLander-v2](https://www.gymlibrary.ml/environments/box2d/lunar_lander/)
+
+
+
+
+
+最后,我们将把训练好的模型推送到Hub上,以评估和可视化你的智能体的表现。
+
+LunarLander-v2是你在开始这门课程时使用的第一个环境。那时,你不知道它是如何工作的,而现在你可以从头开始编写代码并训练它。**这是多么令人难以置信啊🤩。**
+
+
+
+因此,我们需要通过惩罚导致比率远离1的变化来约束这个目标函数(在论文中,比率只能从0.8变化到1.2)。
+
+**通过裁剪比率,我们确保不会有太大的策略更新,因为当前策略不能与旧策略相差太大。**
+
+为此,我们有两种解决方案:
+
+- *TRPO(信任区域策略优化)*在目标函数之外使用KL散度约束来约束策略更新。但这种方法**实现复杂,计算时间更长。**
+- *PPO*直接在目标函数中用其**裁剪替代目标函数**裁剪概率比率。
+
+
+
+这个裁剪部分是一个版本,其中 \\( r_t(\theta) \\) 被裁剪在 \\( [1 - \epsilon, 1 + \epsilon] \\) 之间。
+
+使用裁剪替代目标函数,我们有两个概率比率,一个非裁剪的和一个在 \\( [1 - \epsilon, 1 + \epsilon] \\) 范围内裁剪的,epsilon是一个超参数,帮助我们定义这个裁剪范围(在论文中 \\( \epsilon = 0.2 \\))。
+
+然后,我们取裁剪和非裁剪目标的最小值,**所以最终目标是非裁剪目标的下界(悲观界)。**
+
+取裁剪和非裁剪目标的最小值意味着**我们将根据比率和优势情况选择裁剪或非裁剪目标**。
diff --git a/units/cn/unit8/conclusion-sf.mdx b/units/cn/unit8/conclusion-sf.mdx
new file mode 100644
index 00000000..cb213deb
--- /dev/null
+++ b/units/cn/unit8/conclusion-sf.mdx
@@ -0,0 +1,13 @@
+# 结论
+
+今天的内容到此结束。恭喜你完成本单元和教程!⭐️
+
+现在你已经成功训练了你的Doom智能体,为什么不尝试死亡竞赛呢?请记住,这是一个比你刚刚训练的关卡复杂得多的关卡,**但这是一个很好的实验,我建议你尝试一下。**
+
+如果你做了,不要犹豫,在我们的[discord服务器](https://www.hf.co/join/discord)的`#rl-i-made-this`频道中分享你的模型。
+
+这结束了最后一个单元,但我们还没有完成!🤗 接下来的**奖励单元包含了深度强化学习中一些最有趣、最先进和最前沿的工作**。
+
+下次见 🔥
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit8/conclusion.mdx b/units/cn/unit8/conclusion.mdx
new file mode 100644
index 00000000..0abe7dbd
--- /dev/null
+++ b/units/cn/unit8/conclusion.mdx
@@ -0,0 +1,9 @@
+# 结论 [[Conclusion]]
+
+今天的内容到此结束。恭喜你完成本单元和教程!
+
+学习的最佳方式是实践和尝试。**为什么不改进实现以处理帧作为输入呢?**
+
+在本单元的第二部分再见 🔥
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit8/hands-on-cleanrl.mdx b/units/cn/unit8/hands-on-cleanrl.mdx
new file mode 100644
index 00000000..f6206602
--- /dev/null
+++ b/units/cn/unit8/hands-on-cleanrl.mdx
@@ -0,0 +1,1078 @@
+# 实践练习
+
+
+
+
+
+
+现在我们已经学习了PPO背后的理论,理解它如何工作的最佳方式**是从头开始实现它**。
+
+从头实现一个架构是理解它的最佳方式,这是一个好习惯。我们已经为基于价值的方法(Q-Learning)和基于策略的方法(Reinforce)做过这样的实践。
+
+因此,为了能够编写代码,我们将使用两个资源:
+- 由[Costa Huang](https://github.com/vwxyzjn)制作的教程。Costa是[CleanRL](https://github.com/vwxyzjn/cleanrl)的创建者,CleanRL是一个深度强化学习库,提供高质量的单文件实现,具有研究友好的特性。
+- 除了教程之外,为了更深入地理解,你可以阅读13个核心实现细节:[https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
+
+然后,为了测试其稳健性,我们将在以下环境中训练它:
+- [LunarLander-v2](https://www.gymlibrary.ml/environments/box2d/lunar_lander/)
+
+
+
+
+
+最后,我们将把训练好的模型推送到Hub上,以评估和可视化你的智能体的表现。
+
+LunarLander-v2是你在开始这门课程时使用的第一个环境。那时,你不知道它是如何工作的,而现在你可以从头开始编写代码并训练它。**这是多么令人难以置信啊🤩。**
+
+via GIPHY
+
+让我们开始吧!🚀
+
+Colab笔记本:
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit8/unit8_part1.ipynb)
+
+# 单元8:使用PyTorch实现近端策略优化(PPO)🤖
+
+ +
+
+在本笔记本中,你将学习**使用CleanRL实现作为模型,从头开始用PyTorch编写PPO智能体**。
+
+为了测试其稳健性,我们将在以下环境中训练它:
+
+- [LunarLander-v2 🚀](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在完成本笔记本后,你将能够:
+
+- **使用PyTorch从头开始编写PPO智能体**。
+- **将你训练好的智能体和代码推送到Hub**,并附上精美的视频回放和评估分数 🔥。
+
+
+## 先决条件 🏗️
+
+在深入学习本笔记本之前,你需要:
+
+🔲 📚 通过[阅读单元8](https://huggingface.co/deep-rl-course/unit8/introduction)来学习PPO 🤗
+
+为了在[认证过程](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process)中验证这个实践练习,你需要推送一个模型,我们不要求最低结果,但我们**建议你尝试不同的超参数设置以获得更好的结果**。
+
+如果你找不到你的模型,**请转到页面底部并点击刷新按钮**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。为此,请转到`Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+## 创建虚拟显示器 🔽
+
+在本笔记本中,我们需要生成回放视频。为此,在colab中,**我们需要有一个虚拟屏幕才能渲染环境**(从而记录帧)。
+
+因此,以下单元将安装库并创建并运行虚拟屏幕 🖥
+
+```python
+apt install python-opengl
+apt install ffmpeg
+apt install xvfb
+pip install pyglet==1.5
+pip install pyvirtualdisplay
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## 安装依赖项 🔽
+对于这个练习,我们使用`gym==0.21`,因为视频是用Gym录制的。
+
+```python
+pip install gym==0.22
+pip install imageio-ffmpeg
+pip install huggingface_hub
+pip install gym[box2d]==0.22
+```
+
+## 让我们使用Costa Huang的教程从头开始编写PPO
+- 对于PPO的核心实现,我们将使用优秀的[Costa Huang](https://costa.sh/)教程。
+- 除了教程之外,为了更深入地理解,你可以阅读37个核心实现细节:https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
+
+👉 视频教程:https://youtu.be/MEt6rrxH8W4
+
+```python
+from IPython.display import HTML
+
+HTML(
+ ''
+)
+```
+
+## 添加Hugging Face集成 🤗
+- 为了将我们的模型推送到Hub,我们需要定义一个`package_to_hub`函数
+
+- 添加我们需要的依赖项,以将模型推送到Hub
+
+```python
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+```
+
+- Add new argument in `parse_args()` function to define the repo-id where we want to push the model.
+
+```python
+# Adding HuggingFace argument
+parser.add_argument(
+ "--repo-id",
+ type=str,
+ default="ThomasSimonini/ppo-CartPole-v1",
+ help="id of the model repository from the Hugging Face Hub {username/repo_name}",
+)
+```
+
+- Next, we add the methods needed to push the model to the Hub
+
+- These methods will:
+ - `_evalutate_agent()`: evaluate the agent.
+ - `_generate_model_card()`: generate the model card of your agent.
+ - `_record_video()`: record a video of your agent.
+
+```python
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+```
+
+- Finally, we call this function at the end of the PPO training
+
+```python
+# Create the evaluation environment
+eval_env = gym.make(args.env_id)
+
+package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+)
+```
+
+- Here's what the final ppo.py file looks like:
+
+```python
+# docs and experiment results can be found at https://docs.cleanrl.dev/rl-algorithms/ppo/#ppopy
+
+import argparse
+import os
+import random
+import time
+from distutils.util import strtobool
+
+import gym
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.optim as optim
+from torch.distributions.categorical import Categorical
+from torch.utils.tensorboard import SummaryWriter
+
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+
+
+def parse_args():
+ # fmt: off
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--exp-name", type=str, default=os.path.basename(__file__).rstrip(".py"),
+ help="the name of this experiment")
+ parser.add_argument("--seed", type=int, default=1,
+ help="seed of the experiment")
+ parser.add_argument("--torch-deterministic", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, `torch.backends.cudnn.deterministic=False`")
+ parser.add_argument("--cuda", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, cuda will be enabled by default")
+ parser.add_argument("--track", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="if toggled, this experiment will be tracked with Weights and Biases")
+ parser.add_argument("--wandb-project-name", type=str, default="cleanRL",
+ help="the wandb's project name")
+ parser.add_argument("--wandb-entity", type=str, default=None,
+ help="the entity (team) of wandb's project")
+ parser.add_argument("--capture-video", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="weather to capture videos of the agent performances (check out `videos` folder)")
+
+ # Algorithm specific arguments
+ parser.add_argument("--env-id", type=str, default="CartPole-v1",
+ help="the id of the environment")
+ parser.add_argument("--total-timesteps", type=int, default=50000,
+ help="total timesteps of the experiments")
+ parser.add_argument("--learning-rate", type=float, default=2.5e-4,
+ help="the learning rate of the optimizer")
+ parser.add_argument("--num-envs", type=int, default=4,
+ help="the number of parallel game environments")
+ parser.add_argument("--num-steps", type=int, default=128,
+ help="the number of steps to run in each environment per policy rollout")
+ parser.add_argument("--anneal-lr", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggle learning rate annealing for policy and value networks")
+ parser.add_argument("--gae", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Use GAE for advantage computation")
+ parser.add_argument("--gamma", type=float, default=0.99,
+ help="the discount factor gamma")
+ parser.add_argument("--gae-lambda", type=float, default=0.95,
+ help="the lambda for the general advantage estimation")
+ parser.add_argument("--num-minibatches", type=int, default=4,
+ help="the number of mini-batches")
+ parser.add_argument("--update-epochs", type=int, default=4,
+ help="the K epochs to update the policy")
+ parser.add_argument("--norm-adv", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles advantages normalization")
+ parser.add_argument("--clip-coef", type=float, default=0.2,
+ help="the surrogate clipping coefficient")
+ parser.add_argument("--clip-vloss", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles whether or not to use a clipped loss for the value function, as per the paper.")
+ parser.add_argument("--ent-coef", type=float, default=0.01,
+ help="coefficient of the entropy")
+ parser.add_argument("--vf-coef", type=float, default=0.5,
+ help="coefficient of the value function")
+ parser.add_argument("--max-grad-norm", type=float, default=0.5,
+ help="the maximum norm for the gradient clipping")
+ parser.add_argument("--target-kl", type=float, default=None,
+ help="the target KL divergence threshold")
+
+ # Adding HuggingFace argument
+ parser.add_argument("--repo-id", type=str, default="ThomasSimonini/ppo-CartPole-v1", help="id of the model repository from the Hugging Face Hub {username/repo_name}")
+
+ args = parser.parse_args()
+ args.batch_size = int(args.num_envs * args.num_steps)
+ args.minibatch_size = int(args.batch_size // args.num_minibatches)
+ # fmt: on
+ return args
+
+
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+
+
+def make_env(env_id, seed, idx, capture_video, run_name):
+ def thunk():
+ env = gym.make(env_id)
+ env = gym.wrappers.RecordEpisodeStatistics(env)
+ if capture_video:
+ if idx == 0:
+ env = gym.wrappers.RecordVideo(env, f"videos/{run_name}")
+ env.seed(seed)
+ env.action_space.seed(seed)
+ env.observation_space.seed(seed)
+ return env
+
+ return thunk
+
+
+def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
+ torch.nn.init.orthogonal_(layer.weight, std)
+ torch.nn.init.constant_(layer.bias, bias_const)
+ return layer
+
+
+class Agent(nn.Module):
+ def __init__(self, envs):
+ super().__init__()
+ self.critic = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 1), std=1.0),
+ )
+ self.actor = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),
+ )
+
+ def get_value(self, x):
+ return self.critic(x)
+
+ def get_action_and_value(self, x, action=None):
+ logits = self.actor(x)
+ probs = Categorical(logits=logits)
+ if action is None:
+ action = probs.sample()
+ return action, probs.log_prob(action), probs.entropy(), self.critic(x)
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ run_name = f"{args.env_id}__{args.exp_name}__{args.seed}__{int(time.time())}"
+ if args.track:
+ import wandb
+
+ wandb.init(
+ project=args.wandb_project_name,
+ entity=args.wandb_entity,
+ sync_tensorboard=True,
+ config=vars(args),
+ name=run_name,
+ monitor_gym=True,
+ save_code=True,
+ )
+ writer = SummaryWriter(f"runs/{run_name}")
+ writer.add_text(
+ "hyperparameters",
+ "|param|value|\n|-|-|\n%s" % ("\n".join([f"|{key}|{value}|" for key, value in vars(args).items()])),
+ )
+
+ # TRY NOT TO MODIFY: seeding
+ random.seed(args.seed)
+ np.random.seed(args.seed)
+ torch.manual_seed(args.seed)
+ torch.backends.cudnn.deterministic = args.torch_deterministic
+
+ device = torch.device("cuda" if torch.cuda.is_available() and args.cuda else "cpu")
+
+ # env setup
+ envs = gym.vector.SyncVectorEnv(
+ [make_env(args.env_id, args.seed + i, i, args.capture_video, run_name) for i in range(args.num_envs)]
+ )
+ assert isinstance(envs.single_action_space, gym.spaces.Discrete), "only discrete action space is supported"
+
+ agent = Agent(envs).to(device)
+ optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)
+
+ # ALGO Logic: Storage setup
+ obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape).to(device)
+ actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape).to(device)
+ logprobs = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ rewards = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ dones = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ values = torch.zeros((args.num_steps, args.num_envs)).to(device)
+
+ # TRY NOT TO MODIFY: start the game
+ global_step = 0
+ start_time = time.time()
+ next_obs = torch.Tensor(envs.reset()).to(device)
+ next_done = torch.zeros(args.num_envs).to(device)
+ num_updates = args.total_timesteps // args.batch_size
+
+ for update in range(1, num_updates + 1):
+ # Annealing the rate if instructed to do so.
+ if args.anneal_lr:
+ frac = 1.0 - (update - 1.0) / num_updates
+ lrnow = frac * args.learning_rate
+ optimizer.param_groups[0]["lr"] = lrnow
+
+ for step in range(0, args.num_steps):
+ global_step += 1 * args.num_envs
+ obs[step] = next_obs
+ dones[step] = next_done
+
+ # ALGO LOGIC: action logic
+ with torch.no_grad():
+ action, logprob, _, value = agent.get_action_and_value(next_obs)
+ values[step] = value.flatten()
+ actions[step] = action
+ logprobs[step] = logprob
+
+ # TRY NOT TO MODIFY: execute the game and log data.
+ next_obs, reward, done, info = envs.step(action.cpu().numpy())
+ rewards[step] = torch.tensor(reward).to(device).view(-1)
+ next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(done).to(device)
+
+ for item in info:
+ if "episode" in item.keys():
+ print(f"global_step={global_step}, episodic_return={item['episode']['r']}")
+ writer.add_scalar("charts/episodic_return", item["episode"]["r"], global_step)
+ writer.add_scalar("charts/episodic_length", item["episode"]["l"], global_step)
+ break
+
+ # bootstrap value if not done
+ with torch.no_grad():
+ next_value = agent.get_value(next_obs).reshape(1, -1)
+ if args.gae:
+ advantages = torch.zeros_like(rewards).to(device)
+ lastgaelam = 0
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ nextvalues = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ nextvalues = values[t + 1]
+ delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]
+ advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam
+ returns = advantages + values
+ else:
+ returns = torch.zeros_like(rewards).to(device)
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ next_return = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ next_return = returns[t + 1]
+ returns[t] = rewards[t] + args.gamma * nextnonterminal * next_return
+ advantages = returns - values
+
+ # flatten the batch
+ b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)
+ b_logprobs = logprobs.reshape(-1)
+ b_actions = actions.reshape((-1,) + envs.single_action_space.shape)
+ b_advantages = advantages.reshape(-1)
+ b_returns = returns.reshape(-1)
+ b_values = values.reshape(-1)
+
+ # Optimizing the policy and value network
+ b_inds = np.arange(args.batch_size)
+ clipfracs = []
+ for epoch in range(args.update_epochs):
+ np.random.shuffle(b_inds)
+ for start in range(0, args.batch_size, args.minibatch_size):
+ end = start + args.minibatch_size
+ mb_inds = b_inds[start:end]
+
+ _, newlogprob, entropy, newvalue = agent.get_action_and_value(
+ b_obs[mb_inds], b_actions.long()[mb_inds]
+ )
+ logratio = newlogprob - b_logprobs[mb_inds]
+ ratio = logratio.exp()
+
+ with torch.no_grad():
+ # calculate approx_kl http://joschu.net/blog/kl-approx.html
+ old_approx_kl = (-logratio).mean()
+ approx_kl = ((ratio - 1) - logratio).mean()
+ clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]
+
+ mb_advantages = b_advantages[mb_inds]
+ if args.norm_adv:
+ mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)
+
+ # Policy loss
+ pg_loss1 = -mb_advantages * ratio
+ pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)
+ pg_loss = torch.max(pg_loss1, pg_loss2).mean()
+
+ # Value loss
+ newvalue = newvalue.view(-1)
+ if args.clip_vloss:
+ v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2
+ v_clipped = b_values[mb_inds] + torch.clamp(
+ newvalue - b_values[mb_inds],
+ -args.clip_coef,
+ args.clip_coef,
+ )
+ v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2
+ v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)
+ v_loss = 0.5 * v_loss_max.mean()
+ else:
+ v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()
+
+ entropy_loss = entropy.mean()
+ loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef
+
+ optimizer.zero_grad()
+ loss.backward()
+ nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
+ optimizer.step()
+
+ if args.target_kl is not None:
+ if approx_kl > args.target_kl:
+ break
+
+ y_pred, y_true = b_values.cpu().numpy(), b_returns.cpu().numpy()
+ var_y = np.var(y_true)
+ explained_var = np.nan if var_y == 0 else 1 - np.var(y_true - y_pred) / var_y
+
+ # TRY NOT TO MODIFY: record rewards for plotting purposes
+ writer.add_scalar("charts/learning_rate", optimizer.param_groups[0]["lr"], global_step)
+ writer.add_scalar("losses/value_loss", v_loss.item(), global_step)
+ writer.add_scalar("losses/policy_loss", pg_loss.item(), global_step)
+ writer.add_scalar("losses/entropy", entropy_loss.item(), global_step)
+ writer.add_scalar("losses/old_approx_kl", old_approx_kl.item(), global_step)
+ writer.add_scalar("losses/approx_kl", approx_kl.item(), global_step)
+ writer.add_scalar("losses/clipfrac", np.mean(clipfracs), global_step)
+ writer.add_scalar("losses/explained_variance", explained_var, global_step)
+ print("SPS:", int(global_step / (time.time() - start_time)))
+ writer.add_scalar("charts/SPS", int(global_step / (time.time() - start_time)), global_step)
+
+ envs.close()
+ writer.close()
+
+ # Create the evaluation environment
+ eval_env = gym.make(args.env_id)
+
+ package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+ )
+```
+
+要与社区分享你的模型,需要遵循以下三个步骤:
+
+1️⃣ (如果你还没有完成) 创建一个HF账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录并从Hugging Face网站获取你的认证令牌。
+- 创建一个新令牌 (https://huggingface.co/settings/tokens) **并赋予写入权限**
+
+
+
+- 复制令牌
+- 运行下面的单元格并粘贴令牌
+
+```python
+from huggingface_hub import notebook_login
+notebook_login()
+!git config --global credential.helper store
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令代替:`huggingface-cli login`
+
+## 让我们开始训练 🔥
+
+⚠️ ⚠️ ⚠️ 不要使用**与单元1中相同的仓库ID**
+
+- 现在你已经从头编写了PPO并添加了Hugging Face集成,我们准备开始训练 🔥
+
+- 首先,你需要将所有代码复制到一个你创建的名为`ppo.py`的文件中
+
+
+
+
+在本笔记本中,你将学习**使用CleanRL实现作为模型,从头开始用PyTorch编写PPO智能体**。
+
+为了测试其稳健性,我们将在以下环境中训练它:
+
+- [LunarLander-v2 🚀](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在GitHub仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在完成本笔记本后,你将能够:
+
+- **使用PyTorch从头开始编写PPO智能体**。
+- **将你训练好的智能体和代码推送到Hub**,并附上精美的视频回放和评估分数 🔥。
+
+
+## 先决条件 🏗️
+
+在深入学习本笔记本之前,你需要:
+
+🔲 📚 通过[阅读单元8](https://huggingface.co/deep-rl-course/unit8/introduction)来学习PPO 🤗
+
+为了在[认证过程](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process)中验证这个实践练习,你需要推送一个模型,我们不要求最低结果,但我们**建议你尝试不同的超参数设置以获得更好的结果**。
+
+如果你找不到你的模型,**请转到页面底部并点击刷新按钮**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。为此,请转到`Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+## 创建虚拟显示器 🔽
+
+在本笔记本中,我们需要生成回放视频。为此,在colab中,**我们需要有一个虚拟屏幕才能渲染环境**(从而记录帧)。
+
+因此,以下单元将安装库并创建并运行虚拟屏幕 🖥
+
+```python
+apt install python-opengl
+apt install ffmpeg
+apt install xvfb
+pip install pyglet==1.5
+pip install pyvirtualdisplay
+```
+
+```python
+# Virtual display
+from pyvirtualdisplay import Display
+
+virtual_display = Display(visible=0, size=(1400, 900))
+virtual_display.start()
+```
+
+## 安装依赖项 🔽
+对于这个练习,我们使用`gym==0.21`,因为视频是用Gym录制的。
+
+```python
+pip install gym==0.22
+pip install imageio-ffmpeg
+pip install huggingface_hub
+pip install gym[box2d]==0.22
+```
+
+## 让我们使用Costa Huang的教程从头开始编写PPO
+- 对于PPO的核心实现,我们将使用优秀的[Costa Huang](https://costa.sh/)教程。
+- 除了教程之外,为了更深入地理解,你可以阅读37个核心实现细节:https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
+
+👉 视频教程:https://youtu.be/MEt6rrxH8W4
+
+```python
+from IPython.display import HTML
+
+HTML(
+ ''
+)
+```
+
+## 添加Hugging Face集成 🤗
+- 为了将我们的模型推送到Hub,我们需要定义一个`package_to_hub`函数
+
+- 添加我们需要的依赖项,以将模型推送到Hub
+
+```python
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+```
+
+- Add new argument in `parse_args()` function to define the repo-id where we want to push the model.
+
+```python
+# Adding HuggingFace argument
+parser.add_argument(
+ "--repo-id",
+ type=str,
+ default="ThomasSimonini/ppo-CartPole-v1",
+ help="id of the model repository from the Hugging Face Hub {username/repo_name}",
+)
+```
+
+- Next, we add the methods needed to push the model to the Hub
+
+- These methods will:
+ - `_evalutate_agent()`: evaluate the agent.
+ - `_generate_model_card()`: generate the model card of your agent.
+ - `_record_video()`: record a video of your agent.
+
+```python
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+```
+
+- Finally, we call this function at the end of the PPO training
+
+```python
+# Create the evaluation environment
+eval_env = gym.make(args.env_id)
+
+package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+)
+```
+
+- Here's what the final ppo.py file looks like:
+
+```python
+# docs and experiment results can be found at https://docs.cleanrl.dev/rl-algorithms/ppo/#ppopy
+
+import argparse
+import os
+import random
+import time
+from distutils.util import strtobool
+
+import gym
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.optim as optim
+from torch.distributions.categorical import Categorical
+from torch.utils.tensorboard import SummaryWriter
+
+from huggingface_hub import HfApi, upload_folder
+from huggingface_hub.repocard import metadata_eval_result, metadata_save
+
+from pathlib import Path
+import datetime
+import tempfile
+import json
+import shutil
+import imageio
+
+from wasabi import Printer
+
+msg = Printer()
+
+
+def parse_args():
+ # fmt: off
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--exp-name", type=str, default=os.path.basename(__file__).rstrip(".py"),
+ help="the name of this experiment")
+ parser.add_argument("--seed", type=int, default=1,
+ help="seed of the experiment")
+ parser.add_argument("--torch-deterministic", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, `torch.backends.cudnn.deterministic=False`")
+ parser.add_argument("--cuda", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="if toggled, cuda will be enabled by default")
+ parser.add_argument("--track", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="if toggled, this experiment will be tracked with Weights and Biases")
+ parser.add_argument("--wandb-project-name", type=str, default="cleanRL",
+ help="the wandb's project name")
+ parser.add_argument("--wandb-entity", type=str, default=None,
+ help="the entity (team) of wandb's project")
+ parser.add_argument("--capture-video", type=lambda x: bool(strtobool(x)), default=False, nargs="?", const=True,
+ help="weather to capture videos of the agent performances (check out `videos` folder)")
+
+ # Algorithm specific arguments
+ parser.add_argument("--env-id", type=str, default="CartPole-v1",
+ help="the id of the environment")
+ parser.add_argument("--total-timesteps", type=int, default=50000,
+ help="total timesteps of the experiments")
+ parser.add_argument("--learning-rate", type=float, default=2.5e-4,
+ help="the learning rate of the optimizer")
+ parser.add_argument("--num-envs", type=int, default=4,
+ help="the number of parallel game environments")
+ parser.add_argument("--num-steps", type=int, default=128,
+ help="the number of steps to run in each environment per policy rollout")
+ parser.add_argument("--anneal-lr", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggle learning rate annealing for policy and value networks")
+ parser.add_argument("--gae", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Use GAE for advantage computation")
+ parser.add_argument("--gamma", type=float, default=0.99,
+ help="the discount factor gamma")
+ parser.add_argument("--gae-lambda", type=float, default=0.95,
+ help="the lambda for the general advantage estimation")
+ parser.add_argument("--num-minibatches", type=int, default=4,
+ help="the number of mini-batches")
+ parser.add_argument("--update-epochs", type=int, default=4,
+ help="the K epochs to update the policy")
+ parser.add_argument("--norm-adv", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles advantages normalization")
+ parser.add_argument("--clip-coef", type=float, default=0.2,
+ help="the surrogate clipping coefficient")
+ parser.add_argument("--clip-vloss", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
+ help="Toggles whether or not to use a clipped loss for the value function, as per the paper.")
+ parser.add_argument("--ent-coef", type=float, default=0.01,
+ help="coefficient of the entropy")
+ parser.add_argument("--vf-coef", type=float, default=0.5,
+ help="coefficient of the value function")
+ parser.add_argument("--max-grad-norm", type=float, default=0.5,
+ help="the maximum norm for the gradient clipping")
+ parser.add_argument("--target-kl", type=float, default=None,
+ help="the target KL divergence threshold")
+
+ # Adding HuggingFace argument
+ parser.add_argument("--repo-id", type=str, default="ThomasSimonini/ppo-CartPole-v1", help="id of the model repository from the Hugging Face Hub {username/repo_name}")
+
+ args = parser.parse_args()
+ args.batch_size = int(args.num_envs * args.num_steps)
+ args.minibatch_size = int(args.batch_size // args.num_minibatches)
+ # fmt: on
+ return args
+
+
+def package_to_hub(
+ repo_id,
+ model,
+ hyperparameters,
+ eval_env,
+ video_fps=30,
+ commit_message="Push agent to the Hub",
+ token=None,
+ logs=None,
+):
+ """
+ Evaluate, Generate a video and Upload a model to Hugging Face Hub.
+ This method does the complete pipeline:
+ - It evaluates the model
+ - It generates the model card
+ - It generates a replay video of the agent
+ - It pushes everything to the hub
+ :param repo_id: id of the model repository from the Hugging Face Hub
+ :param model: trained model
+ :param eval_env: environment used to evaluate the agent
+ :param fps: number of fps for rendering the video
+ :param commit_message: commit message
+ :param logs: directory on local machine of tensorboard logs you'd like to upload
+ """
+ msg.info(
+ "This function will save, evaluate, generate a video of your agent, "
+ "create a model card and push everything to the hub. "
+ "It might take up to 1min. \n "
+ "This is a work in progress: if you encounter a bug, please open an issue."
+ )
+ # Step 1: Clone or create the repo
+ repo_url = HfApi().create_repo(
+ repo_id=repo_id,
+ token=token,
+ private=False,
+ exist_ok=True,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = Path(tmpdirname)
+
+ # Step 2: Save the model
+ torch.save(model.state_dict(), tmpdirname / "model.pt")
+
+ # Step 3: Evaluate the model and build JSON
+ mean_reward, std_reward = _evaluate_agent(eval_env, 10, model)
+
+ # First get datetime
+ eval_datetime = datetime.datetime.now()
+ eval_form_datetime = eval_datetime.isoformat()
+
+ evaluate_data = {
+ "env_id": hyperparameters.env_id,
+ "mean_reward": mean_reward,
+ "std_reward": std_reward,
+ "n_evaluation_episodes": 10,
+ "eval_datetime": eval_form_datetime,
+ }
+
+ # Write a JSON file
+ with open(tmpdirname / "results.json", "w") as outfile:
+ json.dump(evaluate_data, outfile)
+
+ # Step 4: Generate a video
+ video_path = tmpdirname / "replay.mp4"
+ record_video(eval_env, model, video_path, video_fps)
+
+ # Step 5: Generate the model card
+ generated_model_card, metadata = _generate_model_card(
+ "PPO", hyperparameters.env_id, mean_reward, std_reward, hyperparameters
+ )
+ _save_model_card(tmpdirname, generated_model_card, metadata)
+
+ # Step 6: Add logs if needed
+ if logs:
+ _add_logdir(tmpdirname, Path(logs))
+
+ msg.info(f"Pushing repo {repo_id} to the Hugging Face Hub")
+
+ repo_url = upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdirname,
+ path_in_repo="",
+ commit_message=commit_message,
+ token=token,
+ )
+
+ msg.info(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
+ return repo_url
+
+
+def _evaluate_agent(env, n_eval_episodes, policy):
+ """
+ Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
+ :param env: The evaluation environment
+ :param n_eval_episodes: Number of episode to evaluate the agent
+ :param policy: The agent
+ """
+ episode_rewards = []
+ for episode in range(n_eval_episodes):
+ state = env.reset()
+ step = 0
+ done = False
+ total_rewards_ep = 0
+
+ while done is False:
+ state = torch.Tensor(state).to(device)
+ action, _, _, _ = policy.get_action_and_value(state)
+ new_state, reward, done, info = env.step(action.cpu().numpy())
+ total_rewards_ep += reward
+ if done:
+ break
+ state = new_state
+ episode_rewards.append(total_rewards_ep)
+ mean_reward = np.mean(episode_rewards)
+ std_reward = np.std(episode_rewards)
+
+ return mean_reward, std_reward
+
+
+def record_video(env, policy, out_directory, fps=30):
+ images = []
+ done = False
+ state = env.reset()
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ while not done:
+ state = torch.Tensor(state).to(device)
+ # Take the action (index) that have the maximum expected future reward given that state
+ action, _, _, _ = policy.get_action_and_value(state)
+ state, reward, done, info = env.step(
+ action.cpu().numpy()
+ ) # We directly put next_state = state for recording logic
+ img = env.render(mode="rgb_array")
+ images.append(img)
+ imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
+
+
+def _generate_model_card(model_name, env_id, mean_reward, std_reward, hyperparameters):
+ """
+ Generate the model card for the Hub
+ :param model_name: name of the model
+ :env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ :hyperparameters: training arguments
+ """
+ # Step 1: Select the tags
+ metadata = generate_metadata(model_name, env_id, mean_reward, std_reward)
+
+ # Transform the hyperparams namespace to string
+ converted_dict = vars(hyperparameters)
+ converted_str = str(converted_dict)
+ converted_str = converted_str.split(", ")
+ converted_str = "\n".join(converted_str)
+
+ # Step 2: Generate the model card
+ model_card = f"""
+ # PPO Agent Playing {env_id}
+
+ This is a trained model of a PPO agent playing {env_id}.
+
+ # Hyperparameters
+ """
+ return model_card, metadata
+
+
+def generate_metadata(model_name, env_id, mean_reward, std_reward):
+ """
+ Define the tags for the model card
+ :param model_name: name of the model
+ :param env_id: name of the environment
+ :mean_reward: mean reward of the agent
+ :std_reward: standard deviation of the mean reward of the agent
+ """
+ metadata = {}
+ metadata["tags"] = [
+ env_id,
+ "ppo",
+ "deep-reinforcement-learning",
+ "reinforcement-learning",
+ "custom-implementation",
+ "deep-rl-course",
+ ]
+
+ # Add metrics
+ eval = metadata_eval_result(
+ model_pretty_name=model_name,
+ task_pretty_name="reinforcement-learning",
+ task_id="reinforcement-learning",
+ metrics_pretty_name="mean_reward",
+ metrics_id="mean_reward",
+ metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
+ dataset_pretty_name=env_id,
+ dataset_id=env_id,
+ )
+
+ # Merges both dictionaries
+ metadata = {**metadata, **eval}
+
+ return metadata
+
+
+def _save_model_card(local_path, generated_model_card, metadata):
+ """Saves a model card for the repository.
+ :param local_path: repository directory
+ :param generated_model_card: model card generated by _generate_model_card()
+ :param metadata: metadata
+ """
+ readme_path = local_path / "README.md"
+ readme = ""
+ if readme_path.exists():
+ with readme_path.open("r", encoding="utf8") as f:
+ readme = f.read()
+ else:
+ readme = generated_model_card
+
+ with readme_path.open("w", encoding="utf-8") as f:
+ f.write(readme)
+
+ # Save our metrics to Readme metadata
+ metadata_save(readme_path, metadata)
+
+
+def _add_logdir(local_path: Path, logdir: Path):
+ """Adds a logdir to the repository.
+ :param local_path: repository directory
+ :param logdir: logdir directory
+ """
+ if logdir.exists() and logdir.is_dir():
+ # Add the logdir to the repository under new dir called logs
+ repo_logdir = local_path / "logs"
+
+ # Delete current logs if they exist
+ if repo_logdir.exists():
+ shutil.rmtree(repo_logdir)
+
+ # Copy logdir into repo logdir
+ shutil.copytree(logdir, repo_logdir)
+
+
+def make_env(env_id, seed, idx, capture_video, run_name):
+ def thunk():
+ env = gym.make(env_id)
+ env = gym.wrappers.RecordEpisodeStatistics(env)
+ if capture_video:
+ if idx == 0:
+ env = gym.wrappers.RecordVideo(env, f"videos/{run_name}")
+ env.seed(seed)
+ env.action_space.seed(seed)
+ env.observation_space.seed(seed)
+ return env
+
+ return thunk
+
+
+def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
+ torch.nn.init.orthogonal_(layer.weight, std)
+ torch.nn.init.constant_(layer.bias, bias_const)
+ return layer
+
+
+class Agent(nn.Module):
+ def __init__(self, envs):
+ super().__init__()
+ self.critic = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 1), std=1.0),
+ )
+ self.actor = nn.Sequential(
+ layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, 64)),
+ nn.Tanh(),
+ layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),
+ )
+
+ def get_value(self, x):
+ return self.critic(x)
+
+ def get_action_and_value(self, x, action=None):
+ logits = self.actor(x)
+ probs = Categorical(logits=logits)
+ if action is None:
+ action = probs.sample()
+ return action, probs.log_prob(action), probs.entropy(), self.critic(x)
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ run_name = f"{args.env_id}__{args.exp_name}__{args.seed}__{int(time.time())}"
+ if args.track:
+ import wandb
+
+ wandb.init(
+ project=args.wandb_project_name,
+ entity=args.wandb_entity,
+ sync_tensorboard=True,
+ config=vars(args),
+ name=run_name,
+ monitor_gym=True,
+ save_code=True,
+ )
+ writer = SummaryWriter(f"runs/{run_name}")
+ writer.add_text(
+ "hyperparameters",
+ "|param|value|\n|-|-|\n%s" % ("\n".join([f"|{key}|{value}|" for key, value in vars(args).items()])),
+ )
+
+ # TRY NOT TO MODIFY: seeding
+ random.seed(args.seed)
+ np.random.seed(args.seed)
+ torch.manual_seed(args.seed)
+ torch.backends.cudnn.deterministic = args.torch_deterministic
+
+ device = torch.device("cuda" if torch.cuda.is_available() and args.cuda else "cpu")
+
+ # env setup
+ envs = gym.vector.SyncVectorEnv(
+ [make_env(args.env_id, args.seed + i, i, args.capture_video, run_name) for i in range(args.num_envs)]
+ )
+ assert isinstance(envs.single_action_space, gym.spaces.Discrete), "only discrete action space is supported"
+
+ agent = Agent(envs).to(device)
+ optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)
+
+ # ALGO Logic: Storage setup
+ obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape).to(device)
+ actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape).to(device)
+ logprobs = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ rewards = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ dones = torch.zeros((args.num_steps, args.num_envs)).to(device)
+ values = torch.zeros((args.num_steps, args.num_envs)).to(device)
+
+ # TRY NOT TO MODIFY: start the game
+ global_step = 0
+ start_time = time.time()
+ next_obs = torch.Tensor(envs.reset()).to(device)
+ next_done = torch.zeros(args.num_envs).to(device)
+ num_updates = args.total_timesteps // args.batch_size
+
+ for update in range(1, num_updates + 1):
+ # Annealing the rate if instructed to do so.
+ if args.anneal_lr:
+ frac = 1.0 - (update - 1.0) / num_updates
+ lrnow = frac * args.learning_rate
+ optimizer.param_groups[0]["lr"] = lrnow
+
+ for step in range(0, args.num_steps):
+ global_step += 1 * args.num_envs
+ obs[step] = next_obs
+ dones[step] = next_done
+
+ # ALGO LOGIC: action logic
+ with torch.no_grad():
+ action, logprob, _, value = agent.get_action_and_value(next_obs)
+ values[step] = value.flatten()
+ actions[step] = action
+ logprobs[step] = logprob
+
+ # TRY NOT TO MODIFY: execute the game and log data.
+ next_obs, reward, done, info = envs.step(action.cpu().numpy())
+ rewards[step] = torch.tensor(reward).to(device).view(-1)
+ next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(done).to(device)
+
+ for item in info:
+ if "episode" in item.keys():
+ print(f"global_step={global_step}, episodic_return={item['episode']['r']}")
+ writer.add_scalar("charts/episodic_return", item["episode"]["r"], global_step)
+ writer.add_scalar("charts/episodic_length", item["episode"]["l"], global_step)
+ break
+
+ # bootstrap value if not done
+ with torch.no_grad():
+ next_value = agent.get_value(next_obs).reshape(1, -1)
+ if args.gae:
+ advantages = torch.zeros_like(rewards).to(device)
+ lastgaelam = 0
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ nextvalues = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ nextvalues = values[t + 1]
+ delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]
+ advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam
+ returns = advantages + values
+ else:
+ returns = torch.zeros_like(rewards).to(device)
+ for t in reversed(range(args.num_steps)):
+ if t == args.num_steps - 1:
+ nextnonterminal = 1.0 - next_done
+ next_return = next_value
+ else:
+ nextnonterminal = 1.0 - dones[t + 1]
+ next_return = returns[t + 1]
+ returns[t] = rewards[t] + args.gamma * nextnonterminal * next_return
+ advantages = returns - values
+
+ # flatten the batch
+ b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)
+ b_logprobs = logprobs.reshape(-1)
+ b_actions = actions.reshape((-1,) + envs.single_action_space.shape)
+ b_advantages = advantages.reshape(-1)
+ b_returns = returns.reshape(-1)
+ b_values = values.reshape(-1)
+
+ # Optimizing the policy and value network
+ b_inds = np.arange(args.batch_size)
+ clipfracs = []
+ for epoch in range(args.update_epochs):
+ np.random.shuffle(b_inds)
+ for start in range(0, args.batch_size, args.minibatch_size):
+ end = start + args.minibatch_size
+ mb_inds = b_inds[start:end]
+
+ _, newlogprob, entropy, newvalue = agent.get_action_and_value(
+ b_obs[mb_inds], b_actions.long()[mb_inds]
+ )
+ logratio = newlogprob - b_logprobs[mb_inds]
+ ratio = logratio.exp()
+
+ with torch.no_grad():
+ # calculate approx_kl http://joschu.net/blog/kl-approx.html
+ old_approx_kl = (-logratio).mean()
+ approx_kl = ((ratio - 1) - logratio).mean()
+ clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]
+
+ mb_advantages = b_advantages[mb_inds]
+ if args.norm_adv:
+ mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)
+
+ # Policy loss
+ pg_loss1 = -mb_advantages * ratio
+ pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)
+ pg_loss = torch.max(pg_loss1, pg_loss2).mean()
+
+ # Value loss
+ newvalue = newvalue.view(-1)
+ if args.clip_vloss:
+ v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2
+ v_clipped = b_values[mb_inds] + torch.clamp(
+ newvalue - b_values[mb_inds],
+ -args.clip_coef,
+ args.clip_coef,
+ )
+ v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2
+ v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)
+ v_loss = 0.5 * v_loss_max.mean()
+ else:
+ v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()
+
+ entropy_loss = entropy.mean()
+ loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef
+
+ optimizer.zero_grad()
+ loss.backward()
+ nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
+ optimizer.step()
+
+ if args.target_kl is not None:
+ if approx_kl > args.target_kl:
+ break
+
+ y_pred, y_true = b_values.cpu().numpy(), b_returns.cpu().numpy()
+ var_y = np.var(y_true)
+ explained_var = np.nan if var_y == 0 else 1 - np.var(y_true - y_pred) / var_y
+
+ # TRY NOT TO MODIFY: record rewards for plotting purposes
+ writer.add_scalar("charts/learning_rate", optimizer.param_groups[0]["lr"], global_step)
+ writer.add_scalar("losses/value_loss", v_loss.item(), global_step)
+ writer.add_scalar("losses/policy_loss", pg_loss.item(), global_step)
+ writer.add_scalar("losses/entropy", entropy_loss.item(), global_step)
+ writer.add_scalar("losses/old_approx_kl", old_approx_kl.item(), global_step)
+ writer.add_scalar("losses/approx_kl", approx_kl.item(), global_step)
+ writer.add_scalar("losses/clipfrac", np.mean(clipfracs), global_step)
+ writer.add_scalar("losses/explained_variance", explained_var, global_step)
+ print("SPS:", int(global_step / (time.time() - start_time)))
+ writer.add_scalar("charts/SPS", int(global_step / (time.time() - start_time)), global_step)
+
+ envs.close()
+ writer.close()
+
+ # Create the evaluation environment
+ eval_env = gym.make(args.env_id)
+
+ package_to_hub(
+ repo_id=args.repo_id,
+ model=agent, # The model we want to save
+ hyperparameters=args,
+ eval_env=gym.make(args.env_id),
+ logs=f"runs/{run_name}",
+ )
+```
+
+要与社区分享你的模型,需要遵循以下三个步骤:
+
+1️⃣ (如果你还没有完成) 创建一个HF账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录并从Hugging Face网站获取你的认证令牌。
+- 创建一个新令牌 (https://huggingface.co/settings/tokens) **并赋予写入权限**
+
+
+
+- 复制令牌
+- 运行下面的单元格并粘贴令牌
+
+```python
+from huggingface_hub import notebook_login
+notebook_login()
+!git config --global credential.helper store
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令代替:`huggingface-cli login`
+
+## 让我们开始训练 🔥
+
+⚠️ ⚠️ ⚠️ 不要使用**与单元1中相同的仓库ID**
+
+- 现在你已经从头编写了PPO并添加了Hugging Face集成,我们准备开始训练 🔥
+
+- 首先,你需要将所有代码复制到一个你创建的名为`ppo.py`的文件中
+
+ +
+
+
+ +
+- 现在我们只需要使用`python .py`运行这个Python脚本,并加上我们使用`argparse`定义的额外参数
+
+- 你应该修改更多超参数,否则训练可能不会非常稳定。
+
+```python
+!python ppo.py --env-id="LunarLander-v2" --repo-id="YOUR_REPO_ID" --total-timesteps=50000
+```
+
+## 一些额外的挑战 🏆
+
+学习的最佳方式**是自己尝试**!为什么不尝试另一个环境?或者为什么不尝试修改实现以适用于Gymnasium?
+
+我们将在单元8的第2部分见面,那里我们将训练智能体玩Doom游戏 🔥
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit8/hands-on-sf.mdx b/units/cn/unit8/hands-on-sf.mdx
new file mode 100644
index 00000000..1154b833
--- /dev/null
+++ b/units/cn/unit8/hands-on-sf.mdx
@@ -0,0 +1,430 @@
+# 实践练习:高级深度强化学习。使用Sample Factory从像素级别玩Doom游戏
+
+
+
+Colab笔记本:
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit8/unit8_part2.ipynb)
+
+# 单元8 第2部分:高级深度强化学习。使用Sample Factory从像素级别玩Doom游戏
+
+
+
+- 现在我们只需要使用`python .py`运行这个Python脚本,并加上我们使用`argparse`定义的额外参数
+
+- 你应该修改更多超参数,否则训练可能不会非常稳定。
+
+```python
+!python ppo.py --env-id="LunarLander-v2" --repo-id="YOUR_REPO_ID" --total-timesteps=50000
+```
+
+## 一些额外的挑战 🏆
+
+学习的最佳方式**是自己尝试**!为什么不尝试另一个环境?或者为什么不尝试修改实现以适用于Gymnasium?
+
+我们将在单元8的第2部分见面,那里我们将训练智能体玩Doom游戏 🔥
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit8/hands-on-sf.mdx b/units/cn/unit8/hands-on-sf.mdx
new file mode 100644
index 00000000..1154b833
--- /dev/null
+++ b/units/cn/unit8/hands-on-sf.mdx
@@ -0,0 +1,430 @@
+# 实践练习:高级深度强化学习。使用Sample Factory从像素级别玩Doom游戏
+
+
+
+Colab笔记本:
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit8/unit8_part2.ipynb)
+
+# 单元8 第2部分:高级深度强化学习。使用Sample Factory从像素级别玩Doom游戏
+
+ +
+在本笔记本中,我们将学习如何训练一个深度神经网络,在基于Doom游戏的3D环境中收集物品,下面展示了最终策略的视频。我们使用[Sample Factory](https://www.samplefactory.dev/)(PPO算法的异步实现)来训练这个策略。
+
+请注意以下几点:
+
+* [Sample Factory](https://www.samplefactory.dev/)是一个高级强化学习框架,**仅在Linux和Mac上运行**(不支持Windows)。
+
+* 该框架在**具有多个CPU核心的GPU机器**上表现最佳,可以达到每秒10万次交互的速度。标准Colab笔记本上可用的资源**限制了这个库的性能**。因此,在这种设置下的速度**并不反映真实世界的性能**。
+* Sample Factory的基准测试在多种设置中都有提供,如果你想了解更多,请查看[示例](https://github.com/alex-petrenko/sample-factory/tree/master/sf_examples)。
+
+
+```python
+from IPython.display import HTML
+
+HTML(
+ """"""
+)
+```
+
+为了在[认证过程](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process)中验证这个实践练习,你需要推送一个模型:
+
+- `doom_health_gathering_supreme` 获得 >= 5 的结果。
+
+要查找你的结果,请前往[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+如果你找不到你的模型,**请转到页面底部并点击刷新按钮**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。为此,请转到`Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+在开始训练我们的智能体之前,让我们**研究一下我们将要使用的库和环境**。
+
+## Sample Factory
+
+[Sample Factory](https://www.samplefactory.dev/)是**最快的强化学习库之一,专注于策略梯度(PPO)的高效同步和异步实现**。
+
+Sample Factory经过**充分测试,被许多研究人员和实践者使用**,并且得到积极维护。我们的实现**在各种领域都能达到最先进的性能,同时最小化强化学习实验的训练时间和硬件需求**。
+
+
+
+在本笔记本中,我们将学习如何训练一个深度神经网络,在基于Doom游戏的3D环境中收集物品,下面展示了最终策略的视频。我们使用[Sample Factory](https://www.samplefactory.dev/)(PPO算法的异步实现)来训练这个策略。
+
+请注意以下几点:
+
+* [Sample Factory](https://www.samplefactory.dev/)是一个高级强化学习框架,**仅在Linux和Mac上运行**(不支持Windows)。
+
+* 该框架在**具有多个CPU核心的GPU机器**上表现最佳,可以达到每秒10万次交互的速度。标准Colab笔记本上可用的资源**限制了这个库的性能**。因此,在这种设置下的速度**并不反映真实世界的性能**。
+* Sample Factory的基准测试在多种设置中都有提供,如果你想了解更多,请查看[示例](https://github.com/alex-petrenko/sample-factory/tree/master/sf_examples)。
+
+
+```python
+from IPython.display import HTML
+
+HTML(
+ """"""
+)
+```
+
+为了在[认证过程](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process)中验证这个实践练习,你需要推送一个模型:
+
+- `doom_health_gathering_supreme` 获得 >= 5 的结果。
+
+要查找你的结果,请前往[排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard)并找到你的模型,**结果 = 平均奖励 - 奖励的标准差**
+
+如果你找不到你的模型,**请转到页面底部并点击刷新按钮**
+
+有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
+
+## 设置GPU 💪
+
+- 为了**加速智能体的训练,我们将使用GPU**。为此,请转到`Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+在开始训练我们的智能体之前,让我们**研究一下我们将要使用的库和环境**。
+
+## Sample Factory
+
+[Sample Factory](https://www.samplefactory.dev/)是**最快的强化学习库之一,专注于策略梯度(PPO)的高效同步和异步实现**。
+
+Sample Factory经过**充分测试,被许多研究人员和实践者使用**,并且得到积极维护。我们的实现**在各种领域都能达到最先进的性能,同时最小化强化学习实验的训练时间和硬件需求**。
+
+ +
+### 主要特点
+
+- 高度优化的算法[架构](https://www.samplefactory.dev/06-architecture/overview/),实现最大学习吞吐量
+- [同步和异步](https://www.samplefactory.dev/07-advanced-topics/sync-async/)训练模式
+- [串行(单进程)模式](https://www.samplefactory.dev/07-advanced-topics/serial-mode/)便于调试
+- 在基于CPU和[GPU加速环境](https://www.samplefactory.dev/09-environment-integrations/isaacgym/)中都能达到最佳性能
+- 单智能体和多智能体训练、自我对弈、支持在一个或多个GPU上[同时训练多个策略](https://www.samplefactory.dev/07-advanced-topics/multi-policy-training/)
+- 基于种群的训练([PBT](https://www.samplefactory.dev/07-advanced-topics/pbt/))
+- 离散、连续、混合动作空间
+- 基于向量、基于图像、字典观察空间
+- 通过解析动作/观察空间规范自动创建模型架构。支持[自定义模型架构](https://www.samplefactory.dev/03-customization/custom-models/)
+- 设计为可导入到其他项目中,[自定义环境](https://www.samplefactory.dev/03-customization/custom-environments/)是一等公民
+- 详细的[WandB和Tensorboard摘要](https://www.samplefactory.dev/05-monitoring/metrics-reference/),[自定义指标](https://www.samplefactory.dev/05-monitoring/custom-metrics/)
+- [HuggingFace 🤗 集成](https://www.samplefactory.dev/10-huggingface/huggingface/)(将训练好的模型和指标上传到Hub)
+- [多个](https://www.samplefactory.dev/09-environment-integrations/mujoco/)[示例](https://www.samplefactory.dev/09-environment-integrations/atari/)[环境](https://www.samplefactory.dev/09-environment-integrations/vizdoom/)[集成](https://www.samplefactory.dev/09-environment-integrations/dmlab/),带有调优参数和训练好的模型
+
+以上所有策略都可在🤗 hub上获取。搜索标签[sample-factory](https://huggingface.co/models?library=sample-factory&sort=downloads)
+
+### Sample-factory如何工作
+
+Sample-factory是**社区可用的最高度优化的强化学习实现之一**。
+
+它通过**生成多个进程来运行rollout工作器、推理工作器和学习工作器**。
+
+这些*工作器***通过共享内存进行通信,这降低了进程之间的通信成本**。
+
+*rollout工作器*与环境交互并将观察结果发送给*推理工作器*。
+
+*推理工作器*查询策略的固定版本并**将动作发送回rollout工作器**。
+
+在*k*步之后,rollout工作器将经验轨迹发送给学习工作器,**学习工作器使用这些经验来更新智能体的策略网络**。
+
+
+
+### 主要特点
+
+- 高度优化的算法[架构](https://www.samplefactory.dev/06-architecture/overview/),实现最大学习吞吐量
+- [同步和异步](https://www.samplefactory.dev/07-advanced-topics/sync-async/)训练模式
+- [串行(单进程)模式](https://www.samplefactory.dev/07-advanced-topics/serial-mode/)便于调试
+- 在基于CPU和[GPU加速环境](https://www.samplefactory.dev/09-environment-integrations/isaacgym/)中都能达到最佳性能
+- 单智能体和多智能体训练、自我对弈、支持在一个或多个GPU上[同时训练多个策略](https://www.samplefactory.dev/07-advanced-topics/multi-policy-training/)
+- 基于种群的训练([PBT](https://www.samplefactory.dev/07-advanced-topics/pbt/))
+- 离散、连续、混合动作空间
+- 基于向量、基于图像、字典观察空间
+- 通过解析动作/观察空间规范自动创建模型架构。支持[自定义模型架构](https://www.samplefactory.dev/03-customization/custom-models/)
+- 设计为可导入到其他项目中,[自定义环境](https://www.samplefactory.dev/03-customization/custom-environments/)是一等公民
+- 详细的[WandB和Tensorboard摘要](https://www.samplefactory.dev/05-monitoring/metrics-reference/),[自定义指标](https://www.samplefactory.dev/05-monitoring/custom-metrics/)
+- [HuggingFace 🤗 集成](https://www.samplefactory.dev/10-huggingface/huggingface/)(将训练好的模型和指标上传到Hub)
+- [多个](https://www.samplefactory.dev/09-environment-integrations/mujoco/)[示例](https://www.samplefactory.dev/09-environment-integrations/atari/)[环境](https://www.samplefactory.dev/09-environment-integrations/vizdoom/)[集成](https://www.samplefactory.dev/09-environment-integrations/dmlab/),带有调优参数和训练好的模型
+
+以上所有策略都可在🤗 hub上获取。搜索标签[sample-factory](https://huggingface.co/models?library=sample-factory&sort=downloads)
+
+### Sample-factory如何工作
+
+Sample-factory是**社区可用的最高度优化的强化学习实现之一**。
+
+它通过**生成多个进程来运行rollout工作器、推理工作器和学习工作器**。
+
+这些*工作器***通过共享内存进行通信,这降低了进程之间的通信成本**。
+
+*rollout工作器*与环境交互并将观察结果发送给*推理工作器*。
+
+*推理工作器*查询策略的固定版本并**将动作发送回rollout工作器**。
+
+在*k*步之后,rollout工作器将经验轨迹发送给学习工作器,**学习工作器使用这些经验来更新智能体的策略网络**。
+
+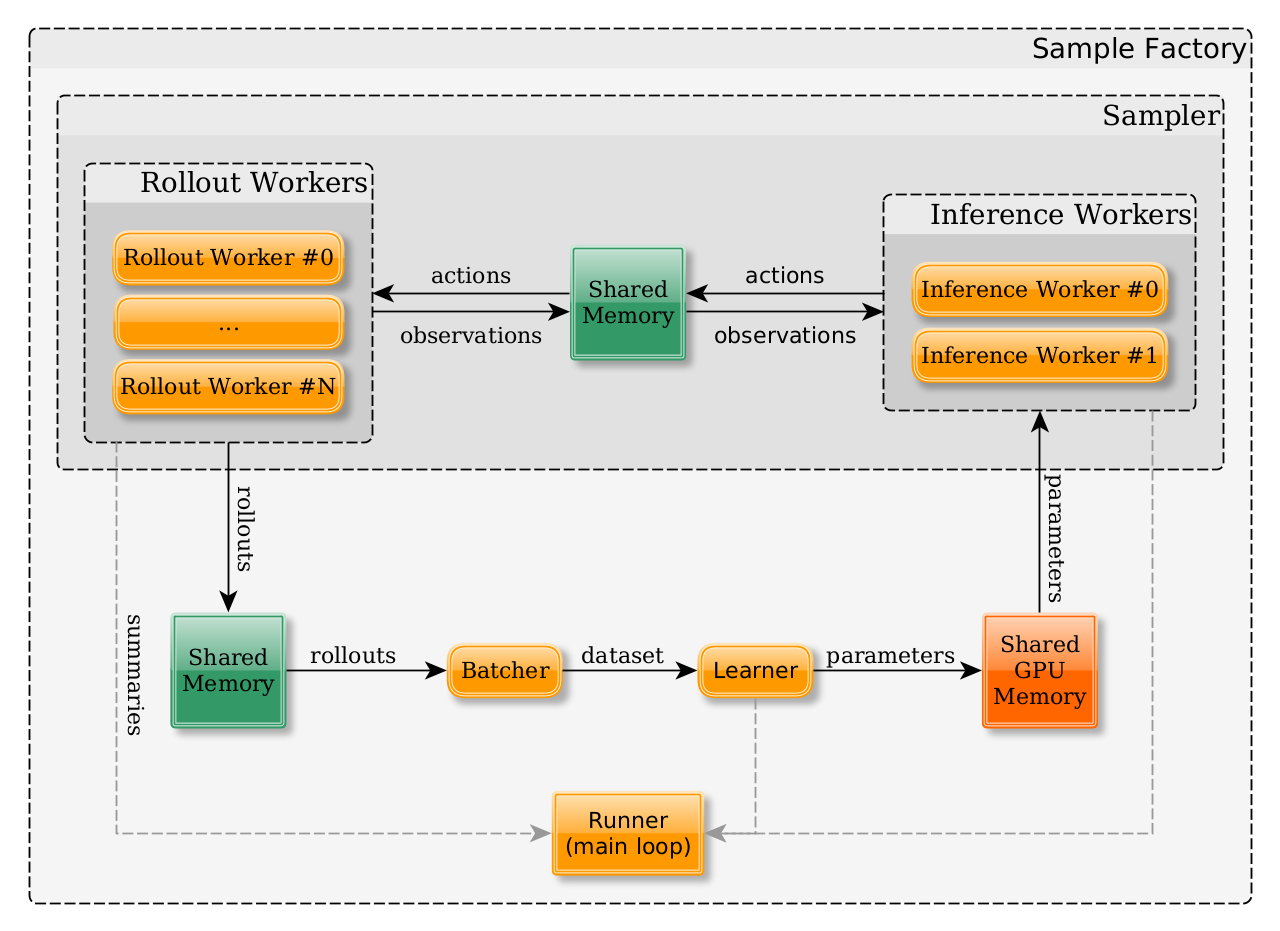 +
+### Sample-factory中的Actor Critic模型
+
+Sample Factory中的Actor Critic模型由三个组件组成:
+
+- **编码器(Encoder)** - 处理输入观察(图像、向量)并将其映射到向量。这是你最可能想要自定义的模型部分。
+- **核心(Core)** - 整合来自一个或多个编码器的向量,可以选择在基于记忆的智能体中包含单层或多层LSTM/GRU。
+- **解码器(Decoder)** - 在计算策略和价值输出之前,对模型核心的输出应用额外的层。
+
+该库被设计为自动支持任何观察和动作空间。用户可以轻松添加自定义模型。你可以在[文档](https://www.samplefactory.dev/03-customization/custom-models/#actor-critic-models-in-sample-factory)中了解更多信息。
+
+## ViZDoom
+
+[ViZDoom](https://vizdoom.cs.put.edu.pl/)是**Doom引擎的一个开源Python接口**。
+
+该库由波兹南理工大学计算机科学研究所的Marek Wydmuch和Michal Kempka于2016年创建。
+
+该库**支持在多种场景中直接从屏幕像素训练智能体**,包括团队死亡竞赛,如下面的视频所示。由于ViZDoom环境基于90年代创建的游戏,它可以在现代硬件上以加速速度运行,**使我们能够相当快速地学习复杂的AI行为**。
+
+该库包括以下功能:
+
+- 多平台(Linux、macOS、Windows)
+- Python和C++的API
+- [OpenAI Gym](https://www.gymlibrary.dev/)环境包装器
+- 易于创建自定义场景(提供可视化编辑器、脚本语言和示例)
+- 异步和同步的单人和多人模式
+- 轻量级(几MB)且快速(在同步模式下,单线程可达7000 fps)
+- 可自定义的分辨率和渲染参数
+- 访问深度缓冲区(3D视觉)
+- 自动标记帧中可见的游戏对象
+- 访问音频缓冲区
+- 访问角色/对象列表和地图几何
+- 离屏渲染和情节记录
+- 异步模式下的时间缩放
+
+## 我们首先需要安装ViZDoom环境所需的一些依赖项
+
+现在我们的Colab运行时已经设置好了,我们可以开始安装在Linux上运行ViZDoom所需的依赖项。
+
+如果你在Mac上的机器上跟进,你需要按照[github页面](https://github.com/Farama-Foundation/ViZDoom/blob/master/doc/Quickstart.md#-quickstart-for-macos-and-anaconda3-python-36)上的安装说明进行操作。
+
+```python
+# Install ViZDoom deps from
+# https://github.com/mwydmuch/ViZDoom/blob/master/doc/Building.md#-linux
+
+apt-get install build-essential zlib1g-dev libsdl2-dev libjpeg-dev \
+nasm tar libbz2-dev libgtk2.0-dev cmake git libfluidsynth-dev libgme-dev \
+libopenal-dev timidity libwildmidi-dev unzip ffmpeg
+
+# Boost libraries
+apt-get install libboost-all-dev
+
+# Lua binding dependencies
+apt-get install liblua5.1-dev
+```
+
+## Then we can install Sample Factory and ViZDoom
+
+- This can take 7min
+
+```bash
+pip install sample-factory
+pip install vizdoom
+```
+
+## Setting up the Doom Environment in sample-factory
+
+```python
+import functools
+
+from sample_factory.algo.utils.context import global_model_factory
+from sample_factory.cfg.arguments import parse_full_cfg, parse_sf_args
+from sample_factory.envs.env_utils import register_env
+from sample_factory.train import run_rl
+
+from sf_examples.vizdoom.doom.doom_model import make_vizdoom_encoder
+from sf_examples.vizdoom.doom.doom_params import add_doom_env_args, doom_override_defaults
+from sf_examples.vizdoom.doom.doom_utils import DOOM_ENVS, make_doom_env_from_spec
+
+
+# Registers all the ViZDoom environments
+def register_vizdoom_envs():
+ for env_spec in DOOM_ENVS:
+ make_env_func = functools.partial(make_doom_env_from_spec, env_spec)
+ register_env(env_spec.name, make_env_func)
+
+
+# Sample Factory allows the registration of a custom Neural Network architecture
+# See https://github.com/alex-petrenko/sample-factory/blob/master/sf_examples/vizdoom/doom/doom_model.py for more details
+def register_vizdoom_models():
+ global_model_factory().register_encoder_factory(make_vizdoom_encoder)
+
+
+def register_vizdoom_components():
+ register_vizdoom_envs()
+ register_vizdoom_models()
+
+
+# parse the command line args and create a config
+def parse_vizdoom_cfg(argv=None, evaluation=False):
+ parser, _ = parse_sf_args(argv=argv, evaluation=evaluation)
+ # parameters specific to Doom envs
+ add_doom_env_args(parser)
+ # override Doom default values for algo parameters
+ doom_override_defaults(parser)
+ # second parsing pass yields the final configuration
+ final_cfg = parse_full_cfg(parser, argv)
+ return final_cfg
+```
+
+现在设置已经完成,我们可以训练智能体了。我们在这里选择学习一个名为`Health Gathering Supreme`的ViZDoom任务。
+
+### 场景:Health Gathering Supreme(健康收集至尊版)
+
+
+
+### Sample-factory中的Actor Critic模型
+
+Sample Factory中的Actor Critic模型由三个组件组成:
+
+- **编码器(Encoder)** - 处理输入观察(图像、向量)并将其映射到向量。这是你最可能想要自定义的模型部分。
+- **核心(Core)** - 整合来自一个或多个编码器的向量,可以选择在基于记忆的智能体中包含单层或多层LSTM/GRU。
+- **解码器(Decoder)** - 在计算策略和价值输出之前,对模型核心的输出应用额外的层。
+
+该库被设计为自动支持任何观察和动作空间。用户可以轻松添加自定义模型。你可以在[文档](https://www.samplefactory.dev/03-customization/custom-models/#actor-critic-models-in-sample-factory)中了解更多信息。
+
+## ViZDoom
+
+[ViZDoom](https://vizdoom.cs.put.edu.pl/)是**Doom引擎的一个开源Python接口**。
+
+该库由波兹南理工大学计算机科学研究所的Marek Wydmuch和Michal Kempka于2016年创建。
+
+该库**支持在多种场景中直接从屏幕像素训练智能体**,包括团队死亡竞赛,如下面的视频所示。由于ViZDoom环境基于90年代创建的游戏,它可以在现代硬件上以加速速度运行,**使我们能够相当快速地学习复杂的AI行为**。
+
+该库包括以下功能:
+
+- 多平台(Linux、macOS、Windows)
+- Python和C++的API
+- [OpenAI Gym](https://www.gymlibrary.dev/)环境包装器
+- 易于创建自定义场景(提供可视化编辑器、脚本语言和示例)
+- 异步和同步的单人和多人模式
+- 轻量级(几MB)且快速(在同步模式下,单线程可达7000 fps)
+- 可自定义的分辨率和渲染参数
+- 访问深度缓冲区(3D视觉)
+- 自动标记帧中可见的游戏对象
+- 访问音频缓冲区
+- 访问角色/对象列表和地图几何
+- 离屏渲染和情节记录
+- 异步模式下的时间缩放
+
+## 我们首先需要安装ViZDoom环境所需的一些依赖项
+
+现在我们的Colab运行时已经设置好了,我们可以开始安装在Linux上运行ViZDoom所需的依赖项。
+
+如果你在Mac上的机器上跟进,你需要按照[github页面](https://github.com/Farama-Foundation/ViZDoom/blob/master/doc/Quickstart.md#-quickstart-for-macos-and-anaconda3-python-36)上的安装说明进行操作。
+
+```python
+# Install ViZDoom deps from
+# https://github.com/mwydmuch/ViZDoom/blob/master/doc/Building.md#-linux
+
+apt-get install build-essential zlib1g-dev libsdl2-dev libjpeg-dev \
+nasm tar libbz2-dev libgtk2.0-dev cmake git libfluidsynth-dev libgme-dev \
+libopenal-dev timidity libwildmidi-dev unzip ffmpeg
+
+# Boost libraries
+apt-get install libboost-all-dev
+
+# Lua binding dependencies
+apt-get install liblua5.1-dev
+```
+
+## Then we can install Sample Factory and ViZDoom
+
+- This can take 7min
+
+```bash
+pip install sample-factory
+pip install vizdoom
+```
+
+## Setting up the Doom Environment in sample-factory
+
+```python
+import functools
+
+from sample_factory.algo.utils.context import global_model_factory
+from sample_factory.cfg.arguments import parse_full_cfg, parse_sf_args
+from sample_factory.envs.env_utils import register_env
+from sample_factory.train import run_rl
+
+from sf_examples.vizdoom.doom.doom_model import make_vizdoom_encoder
+from sf_examples.vizdoom.doom.doom_params import add_doom_env_args, doom_override_defaults
+from sf_examples.vizdoom.doom.doom_utils import DOOM_ENVS, make_doom_env_from_spec
+
+
+# Registers all the ViZDoom environments
+def register_vizdoom_envs():
+ for env_spec in DOOM_ENVS:
+ make_env_func = functools.partial(make_doom_env_from_spec, env_spec)
+ register_env(env_spec.name, make_env_func)
+
+
+# Sample Factory allows the registration of a custom Neural Network architecture
+# See https://github.com/alex-petrenko/sample-factory/blob/master/sf_examples/vizdoom/doom/doom_model.py for more details
+def register_vizdoom_models():
+ global_model_factory().register_encoder_factory(make_vizdoom_encoder)
+
+
+def register_vizdoom_components():
+ register_vizdoom_envs()
+ register_vizdoom_models()
+
+
+# parse the command line args and create a config
+def parse_vizdoom_cfg(argv=None, evaluation=False):
+ parser, _ = parse_sf_args(argv=argv, evaluation=evaluation)
+ # parameters specific to Doom envs
+ add_doom_env_args(parser)
+ # override Doom default values for algo parameters
+ doom_override_defaults(parser)
+ # second parsing pass yields the final configuration
+ final_cfg = parse_full_cfg(parser, argv)
+ return final_cfg
+```
+
+现在设置已经完成,我们可以训练智能体了。我们在这里选择学习一个名为`Health Gathering Supreme`的ViZDoom任务。
+
+### 场景:Health Gathering Supreme(健康收集至尊版)
+
+ +
+
+
+这个场景的目标是**教会智能体如何在不知道什么能让它生存的情况下生存**。智能体只知道**生命是宝贵的**,死亡是不好的,所以**它必须学习什么能延长它的存在,以及它的健康与生存是相连的**。
+
+地图是一个包含墙壁的矩形,地面是绿色的酸性地板,**会定期伤害玩家**。最初,地图上均匀分布着一些医疗包。每隔一段时间,一个新的医疗包会从天空掉落。**医疗包可以恢复玩家健康的一部分**——为了生存,智能体需要拾取它们。在玩家死亡或超时后,回合结束。
+
+进一步配置:
+- 生存奖励 = 1
+- 3个可用按钮:向左转,向右转,向前移动
+- 1个可用游戏变量:HEALTH(健康值)
+- 死亡惩罚 = 100
+
+你可以在[这里](https://github.com/Farama-Foundation/ViZDoom/tree/master/scenarios)了解更多关于ViZDoom中可用场景的信息。
+
+还有一些为ViZDoom创建的更复杂的场景,比如[这个github页面](https://github.com/edbeeching/3d_control_deep_rl)上详述的场景。
+
+
+
+## 训练智能体
+
+- 我们将训练智能体4000000步。这将花费大约20分钟
+
+```python
+## Start the training, this should take around 15 minutes
+register_vizdoom_components()
+
+# The scenario we train on today is health gathering
+# other scenarios include "doom_basic", "doom_two_colors_easy", "doom_dm", "doom_dwango5", "doom_my_way_home", "doom_deadly_corridor", "doom_defend_the_center", "doom_defend_the_line"
+env = "doom_health_gathering_supreme"
+cfg = parse_vizdoom_cfg(
+ argv=[f"--env={env}", "--num_workers=8", "--num_envs_per_worker=4", "--train_for_env_steps=4000000"]
+)
+
+status = run_rl(cfg)
+```
+
+## 让我们看看训练好的策略的表现并输出智能体的视频
+
+```python
+from sample_factory.enjoy import enjoy
+
+cfg = parse_vizdoom_cfg(
+ argv=[f"--env={env}", "--num_workers=1", "--save_video", "--no_render", "--max_num_episodes=10"], evaluation=True
+)
+status = enjoy(cfg)
+```
+
+## 现在让我们可视化智能体的表现
+
+```python
+from base64 import b64encode
+from IPython.display import HTML
+
+mp4 = open("/content/train_dir/default_experiment/replay.mp4", "rb").read()
+data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
+HTML(
+ """
+
+"""
+ % data_url
+)
+```
+
+智能体已经学到了一些东西,但它的表现可以更好。我们显然需要训练更长时间。但让我们先将这个模型上传到Hub。
+
+## 现在让我们将你的检查点和视频上传到Hugging Face Hub
+
+
+
+
+要能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果还没有完成)创建一个HF账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录并从Hugging Face网站获取你的认证令牌。
+- 创建一个新令牌(https://huggingface.co/settings/tokens)**具有写入权限**
+
+
+
+- 复制令牌
+- 运行下面的单元格并粘贴令牌
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令代替:`huggingface-cli login`
+
+```python
+from huggingface_hub import notebook_login
+notebook_login()
+!git config --global credential.helper store
+```
+
+```python
+from sample_factory.enjoy import enjoy
+
+hf_username = "ThomasSimonini" # insert your HuggingFace username here
+
+cfg = parse_vizdoom_cfg(
+ argv=[
+ f"--env={env}",
+ "--num_workers=1",
+ "--save_video",
+ "--no_render",
+ "--max_num_episodes=10",
+ "--max_num_frames=100000",
+ "--push_to_hub",
+ f"--hf_repository={hf_username}/rl_course_vizdoom_health_gathering_supreme",
+ ],
+ evaluation=True,
+)
+status = enjoy(cfg)
+```
+
+## 让我们加载另一个模型
+
+
+
+
+这个智能体的表现很好,但我们可以做得更好!让我们从hub下载并可视化一个经过10B时间步训练的智能体。
+
+```bash
+#download the agent from the hub
+python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_health_gathering_supreme_2222 -d ./train_dir
+```
+
+```bash
+ls train_dir/doom_health_gathering_supreme_2222
+```
+
+```python
+env = "doom_health_gathering_supreme"
+cfg = parse_vizdoom_cfg(
+ argv=[
+ f"--env={env}",
+ "--num_workers=1",
+ "--save_video",
+ "--no_render",
+ "--max_num_episodes=10",
+ "--experiment=doom_health_gathering_supreme_2222",
+ "--train_dir=train_dir",
+ ],
+ evaluation=True,
+)
+status = enjoy(cfg)
+```
+
+```python
+mp4 = open("/content/train_dir/doom_health_gathering_supreme_2222/replay.mp4", "rb").read()
+data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
+HTML(
+ """
+
+"""
+ % data_url
+)
+```
+
+## 一些额外的挑战 🏆:Doom死亡竞赛
+
+训练一个智能体玩Doom死亡竞赛**需要在比Colab更强大的机器上花费很多小时**。
+
+幸运的是,我们**已经在这个场景中训练了一个智能体,它可以在🤗 Hub上获取!**让我们下载模型并可视化智能体的表现。
+
+```python
+# 从Hub下载智能体
+python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_deathmatch_bots_2222 -d ./train_dir
+```
+
+由于智能体需要很长时间,视频生成可能需要**10分钟**。
+
+```python
+from sample_factory.enjoy import enjoy
+
+register_vizdoom_components()
+env = "doom_deathmatch_bots"
+cfg = parse_vizdoom_cfg(
+ argv=[
+ f"--env={env}",
+ "--num_workers=1",
+ "--save_video",
+ "--no_render",
+ "--max_num_episodes=1",
+ "--experiment=doom_deathmatch_bots_2222",
+ "--train_dir=train_dir",
+ ],
+ evaluation=True,
+)
+status = enjoy(cfg)
+mp4 = open("/content/train_dir/doom_deathmatch_bots_2222/replay.mp4", "rb").read()
+data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
+HTML(
+ """
+
+"""
+ % data_url
+)
+```
+
+
+你**可以尝试在这个环境中训练你的智能体**,使用上面的代码,但不是在colab上。
+**祝你好运 🤞**
+
+如果你更喜欢简单一点的场景,**为什么不尝试在其他ViZDoom场景中训练,比如`doom_deadly_corridor`或`doom_defend_the_center`。**
+
+
+
+---
+
+
+这就结束了最后一个单元。但我们还没有完成!🤗 接下来的**奖励部分包含了深度强化学习中一些最有趣、最先进和最前沿的工作**。
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit8/introduction-sf.mdx b/units/cn/unit8/introduction-sf.mdx
new file mode 100644
index 00000000..cc679ebf
--- /dev/null
+++ b/units/cn/unit8/introduction-sf.mdx
@@ -0,0 +1,13 @@
+# 使用Sample-Factory的PPO介绍
+
+
+
+在第8单元的第二部分中,我们将通过使用[Sample-Factory](https://samplefactory.dev/)(**PPO算法的异步实现**)深入研究PPO优化,训练我们的智能体玩[vizdoom](https://vizdoom.cs.put.edu.pl/)(毁灭战士的开源版本)。
+
+在本次实践中,**你将训练你的智能体玩健康收集关卡**,智能体必须收集健康包以避免死亡。之后,你可以**训练你的智能体玩更复杂的关卡,比如死亡竞赛**。
+
+
+
+
+
+这个场景的目标是**教会智能体如何在不知道什么能让它生存的情况下生存**。智能体只知道**生命是宝贵的**,死亡是不好的,所以**它必须学习什么能延长它的存在,以及它的健康与生存是相连的**。
+
+地图是一个包含墙壁的矩形,地面是绿色的酸性地板,**会定期伤害玩家**。最初,地图上均匀分布着一些医疗包。每隔一段时间,一个新的医疗包会从天空掉落。**医疗包可以恢复玩家健康的一部分**——为了生存,智能体需要拾取它们。在玩家死亡或超时后,回合结束。
+
+进一步配置:
+- 生存奖励 = 1
+- 3个可用按钮:向左转,向右转,向前移动
+- 1个可用游戏变量:HEALTH(健康值)
+- 死亡惩罚 = 100
+
+你可以在[这里](https://github.com/Farama-Foundation/ViZDoom/tree/master/scenarios)了解更多关于ViZDoom中可用场景的信息。
+
+还有一些为ViZDoom创建的更复杂的场景,比如[这个github页面](https://github.com/edbeeching/3d_control_deep_rl)上详述的场景。
+
+
+
+## 训练智能体
+
+- 我们将训练智能体4000000步。这将花费大约20分钟
+
+```python
+## Start the training, this should take around 15 minutes
+register_vizdoom_components()
+
+# The scenario we train on today is health gathering
+# other scenarios include "doom_basic", "doom_two_colors_easy", "doom_dm", "doom_dwango5", "doom_my_way_home", "doom_deadly_corridor", "doom_defend_the_center", "doom_defend_the_line"
+env = "doom_health_gathering_supreme"
+cfg = parse_vizdoom_cfg(
+ argv=[f"--env={env}", "--num_workers=8", "--num_envs_per_worker=4", "--train_for_env_steps=4000000"]
+)
+
+status = run_rl(cfg)
+```
+
+## 让我们看看训练好的策略的表现并输出智能体的视频
+
+```python
+from sample_factory.enjoy import enjoy
+
+cfg = parse_vizdoom_cfg(
+ argv=[f"--env={env}", "--num_workers=1", "--save_video", "--no_render", "--max_num_episodes=10"], evaluation=True
+)
+status = enjoy(cfg)
+```
+
+## 现在让我们可视化智能体的表现
+
+```python
+from base64 import b64encode
+from IPython.display import HTML
+
+mp4 = open("/content/train_dir/default_experiment/replay.mp4", "rb").read()
+data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
+HTML(
+ """
+
+"""
+ % data_url
+)
+```
+
+智能体已经学到了一些东西,但它的表现可以更好。我们显然需要训练更长时间。但让我们先将这个模型上传到Hub。
+
+## 现在让我们将你的检查点和视频上传到Hugging Face Hub
+
+
+
+
+要能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果还没有完成)创建一个HF账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录并从Hugging Face网站获取你的认证令牌。
+- 创建一个新令牌(https://huggingface.co/settings/tokens)**具有写入权限**
+
+
+
+- 复制令牌
+- 运行下面的单元格并粘贴令牌
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令代替:`huggingface-cli login`
+
+```python
+from huggingface_hub import notebook_login
+notebook_login()
+!git config --global credential.helper store
+```
+
+```python
+from sample_factory.enjoy import enjoy
+
+hf_username = "ThomasSimonini" # insert your HuggingFace username here
+
+cfg = parse_vizdoom_cfg(
+ argv=[
+ f"--env={env}",
+ "--num_workers=1",
+ "--save_video",
+ "--no_render",
+ "--max_num_episodes=10",
+ "--max_num_frames=100000",
+ "--push_to_hub",
+ f"--hf_repository={hf_username}/rl_course_vizdoom_health_gathering_supreme",
+ ],
+ evaluation=True,
+)
+status = enjoy(cfg)
+```
+
+## 让我们加载另一个模型
+
+
+
+
+这个智能体的表现很好,但我们可以做得更好!让我们从hub下载并可视化一个经过10B时间步训练的智能体。
+
+```bash
+#download the agent from the hub
+python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_health_gathering_supreme_2222 -d ./train_dir
+```
+
+```bash
+ls train_dir/doom_health_gathering_supreme_2222
+```
+
+```python
+env = "doom_health_gathering_supreme"
+cfg = parse_vizdoom_cfg(
+ argv=[
+ f"--env={env}",
+ "--num_workers=1",
+ "--save_video",
+ "--no_render",
+ "--max_num_episodes=10",
+ "--experiment=doom_health_gathering_supreme_2222",
+ "--train_dir=train_dir",
+ ],
+ evaluation=True,
+)
+status = enjoy(cfg)
+```
+
+```python
+mp4 = open("/content/train_dir/doom_health_gathering_supreme_2222/replay.mp4", "rb").read()
+data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
+HTML(
+ """
+
+"""
+ % data_url
+)
+```
+
+## 一些额外的挑战 🏆:Doom死亡竞赛
+
+训练一个智能体玩Doom死亡竞赛**需要在比Colab更强大的机器上花费很多小时**。
+
+幸运的是,我们**已经在这个场景中训练了一个智能体,它可以在🤗 Hub上获取!**让我们下载模型并可视化智能体的表现。
+
+```python
+# 从Hub下载智能体
+python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_deathmatch_bots_2222 -d ./train_dir
+```
+
+由于智能体需要很长时间,视频生成可能需要**10分钟**。
+
+```python
+from sample_factory.enjoy import enjoy
+
+register_vizdoom_components()
+env = "doom_deathmatch_bots"
+cfg = parse_vizdoom_cfg(
+ argv=[
+ f"--env={env}",
+ "--num_workers=1",
+ "--save_video",
+ "--no_render",
+ "--max_num_episodes=1",
+ "--experiment=doom_deathmatch_bots_2222",
+ "--train_dir=train_dir",
+ ],
+ evaluation=True,
+)
+status = enjoy(cfg)
+mp4 = open("/content/train_dir/doom_deathmatch_bots_2222/replay.mp4", "rb").read()
+data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
+HTML(
+ """
+
+"""
+ % data_url
+)
+```
+
+
+你**可以尝试在这个环境中训练你的智能体**,使用上面的代码,但不是在colab上。
+**祝你好运 🤞**
+
+如果你更喜欢简单一点的场景,**为什么不尝试在其他ViZDoom场景中训练,比如`doom_deadly_corridor`或`doom_defend_the_center`。**
+
+
+
+---
+
+
+这就结束了最后一个单元。但我们还没有完成!🤗 接下来的**奖励部分包含了深度强化学习中一些最有趣、最先进和最前沿的工作**。
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unit8/introduction-sf.mdx b/units/cn/unit8/introduction-sf.mdx
new file mode 100644
index 00000000..cc679ebf
--- /dev/null
+++ b/units/cn/unit8/introduction-sf.mdx
@@ -0,0 +1,13 @@
+# 使用Sample-Factory的PPO介绍
+
+
+
+在第8单元的第二部分中,我们将通过使用[Sample-Factory](https://samplefactory.dev/)(**PPO算法的异步实现**)深入研究PPO优化,训练我们的智能体玩[vizdoom](https://vizdoom.cs.put.edu.pl/)(毁灭战士的开源版本)。
+
+在本次实践中,**你将训练你的智能体玩健康收集关卡**,智能体必须收集健康包以避免死亡。之后,你可以**训练你的智能体玩更复杂的关卡,比如死亡竞赛**。
+
+ +
+听起来很刺激吧?让我们开始吧!🚀
+
+本次实践由Hugging Face的机器学习研究科学家[Edward Beeching](https://twitter.com/edwardbeeching)制作。他曾参与开发Godot强化学习智能体,这是一个在Godot游戏引擎中开发环境和智能体的开源接口。
diff --git a/units/cn/unit8/introduction.mdx b/units/cn/unit8/introduction.mdx
new file mode 100644
index 00000000..6a0d9a5f
--- /dev/null
+++ b/units/cn/unit8/introduction.mdx
@@ -0,0 +1,23 @@
+# 介绍 [[introduction]]
+
+
+
+在第6单元中,我们学习了优势演员-评论家算法(Advantage Actor Critic, A2C),这是一种结合了基于价值和基于策略方法的混合架构,通过减少方差来帮助稳定训练:
+
+- *演员(Actor)* 控制**我们的智能体如何行动**(基于策略的方法)。
+- *评论家(Critic)* 衡量**所采取的行动有多好**(基于价值的方法)。
+
+今天我们将学习近端策略优化(Proximal Policy Optimization, PPO),这是一种**通过避免过大的策略更新来改善智能体训练稳定性的架构**。为此,我们使用一个比率来表示当前策略与旧策略之间的差异,并将这个比率裁剪到特定范围 \\( [1 - \epsilon, 1 + \epsilon] \\) 内。
+
+这样做将确保**我们的策略更新不会过大,使训练更加稳定。**
+
+本单元分为两部分:
+- 在第一部分中,你将学习PPO背后的理论,并使用[CleanRL](https://github.com/vwxyzjn/cleanrl)实现从头开始编写你的PPO智能体。为了测试其稳健性,你将使用LunarLander-v2。LunarLander-v2**是你开始这门课程时使用的第一个环境**。那时,你还不知道PPO是如何工作的,而现在,**你可以从头开始编写它并进行训练。这是多么令人难以置信啊🤩**。
+- 在第二部分中,我们将使用[Sample-Factory](https://samplefactory.dev/)深入研究PPO优化,并训练一个玩vizdoom(毁灭战士的开源版本)的智能体。
+
+
+
+这些是你将用来训练智能体的环境:VizDoom环境
+
+
+听起来很刺激吧?让我们开始吧!🚀
diff --git a/units/cn/unit8/intuition-behind-ppo.mdx b/units/cn/unit8/intuition-behind-ppo.mdx
new file mode 100644
index 00000000..5d69aa3e
--- /dev/null
+++ b/units/cn/unit8/intuition-behind-ppo.mdx
@@ -0,0 +1,16 @@
+# PPO背后的直觉 [[the-intuition-behind-ppo]]
+
+
+近端策略优化(PPO)的理念是,我们希望通过限制每个训练周期中对策略的改变来提高策略训练的稳定性:**我们希望避免策略更新过大。**
+
+这有两个原因:
+- 我们从经验上知道,训练期间较小的策略更新**更有可能收敛到最优解。**
+- 策略更新中过大的步骤可能导致"跌下悬崖"(得到一个糟糕的策略),**需要很长时间恢复,甚至可能无法恢复。**
+
+
+
+
+听起来很刺激吧?让我们开始吧!🚀
+
+本次实践由Hugging Face的机器学习研究科学家[Edward Beeching](https://twitter.com/edwardbeeching)制作。他曾参与开发Godot强化学习智能体,这是一个在Godot游戏引擎中开发环境和智能体的开源接口。
diff --git a/units/cn/unit8/introduction.mdx b/units/cn/unit8/introduction.mdx
new file mode 100644
index 00000000..6a0d9a5f
--- /dev/null
+++ b/units/cn/unit8/introduction.mdx
@@ -0,0 +1,23 @@
+# 介绍 [[introduction]]
+
+
+
+在第6单元中,我们学习了优势演员-评论家算法(Advantage Actor Critic, A2C),这是一种结合了基于价值和基于策略方法的混合架构,通过减少方差来帮助稳定训练:
+
+- *演员(Actor)* 控制**我们的智能体如何行动**(基于策略的方法)。
+- *评论家(Critic)* 衡量**所采取的行动有多好**(基于价值的方法)。
+
+今天我们将学习近端策略优化(Proximal Policy Optimization, PPO),这是一种**通过避免过大的策略更新来改善智能体训练稳定性的架构**。为此,我们使用一个比率来表示当前策略与旧策略之间的差异,并将这个比率裁剪到特定范围 \\( [1 - \epsilon, 1 + \epsilon] \\) 内。
+
+这样做将确保**我们的策略更新不会过大,使训练更加稳定。**
+
+本单元分为两部分:
+- 在第一部分中,你将学习PPO背后的理论,并使用[CleanRL](https://github.com/vwxyzjn/cleanrl)实现从头开始编写你的PPO智能体。为了测试其稳健性,你将使用LunarLander-v2。LunarLander-v2**是你开始这门课程时使用的第一个环境**。那时,你还不知道PPO是如何工作的,而现在,**你可以从头开始编写它并进行训练。这是多么令人难以置信啊🤩**。
+- 在第二部分中,我们将使用[Sample-Factory](https://samplefactory.dev/)深入研究PPO优化,并训练一个玩vizdoom(毁灭战士的开源版本)的智能体。
+
+
+
+这些是你将用来训练智能体的环境:VizDoom环境
+
+
+听起来很刺激吧?让我们开始吧!🚀
diff --git a/units/cn/unit8/intuition-behind-ppo.mdx b/units/cn/unit8/intuition-behind-ppo.mdx
new file mode 100644
index 00000000..5d69aa3e
--- /dev/null
+++ b/units/cn/unit8/intuition-behind-ppo.mdx
@@ -0,0 +1,16 @@
+# PPO背后的直觉 [[the-intuition-behind-ppo]]
+
+
+近端策略优化(PPO)的理念是,我们希望通过限制每个训练周期中对策略的改变来提高策略训练的稳定性:**我们希望避免策略更新过大。**
+
+这有两个原因:
+- 我们从经验上知道,训练期间较小的策略更新**更有可能收敛到最优解。**
+- 策略更新中过大的步骤可能导致"跌下悬崖"(得到一个糟糕的策略),**需要很长时间恢复,甚至可能无法恢复。**
+
+
+  + 采取较小的策略更新以提高训练稳定性
+ 修改自RL — 近端策略优化(PPO) 由Jonathan Hui解释
+
+
+**因此,使用PPO,我们保守地更新策略**。为此,我们需要使用当前策略与前一策略之间的比率计算来衡量当前策略相对于前一策略的变化程度。我们将这个比率裁剪在范围 \\( [1 - \epsilon, 1 + \epsilon] \\) 内,这意味着我们**消除了当前策略远离旧策略的激励(因此称为近端策略)。**
diff --git a/units/cn/unit8/visualize.mdx b/units/cn/unit8/visualize.mdx
new file mode 100644
index 00000000..42501efa
--- /dev/null
+++ b/units/cn/unit8/visualize.mdx
@@ -0,0 +1,68 @@
+# 可视化裁剪替代目标函数
+
+别担心。**如果现在这些看起来很复杂,这是正常的**。但我们将看看这个裁剪替代目标函数是什么样子的,这将帮助你更好地可视化正在发生的事情。
+
+
+
+ 采取较小的策略更新以提高训练稳定性
+ 修改自RL — 近端策略优化(PPO) 由Jonathan Hui解释
+
+
+**因此,使用PPO,我们保守地更新策略**。为此,我们需要使用当前策略与前一策略之间的比率计算来衡量当前策略相对于前一策略的变化程度。我们将这个比率裁剪在范围 \\( [1 - \epsilon, 1 + \epsilon] \\) 内,这意味着我们**消除了当前策略远离旧策略的激励(因此称为近端策略)。**
diff --git a/units/cn/unit8/visualize.mdx b/units/cn/unit8/visualize.mdx
new file mode 100644
index 00000000..42501efa
--- /dev/null
+++ b/units/cn/unit8/visualize.mdx
@@ -0,0 +1,68 @@
+# 可视化裁剪替代目标函数
+
+别担心。**如果现在这些看起来很复杂,这是正常的**。但我们将看看这个裁剪替代目标函数是什么样子的,这将帮助你更好地可视化正在发生的事情。
+
+
+ 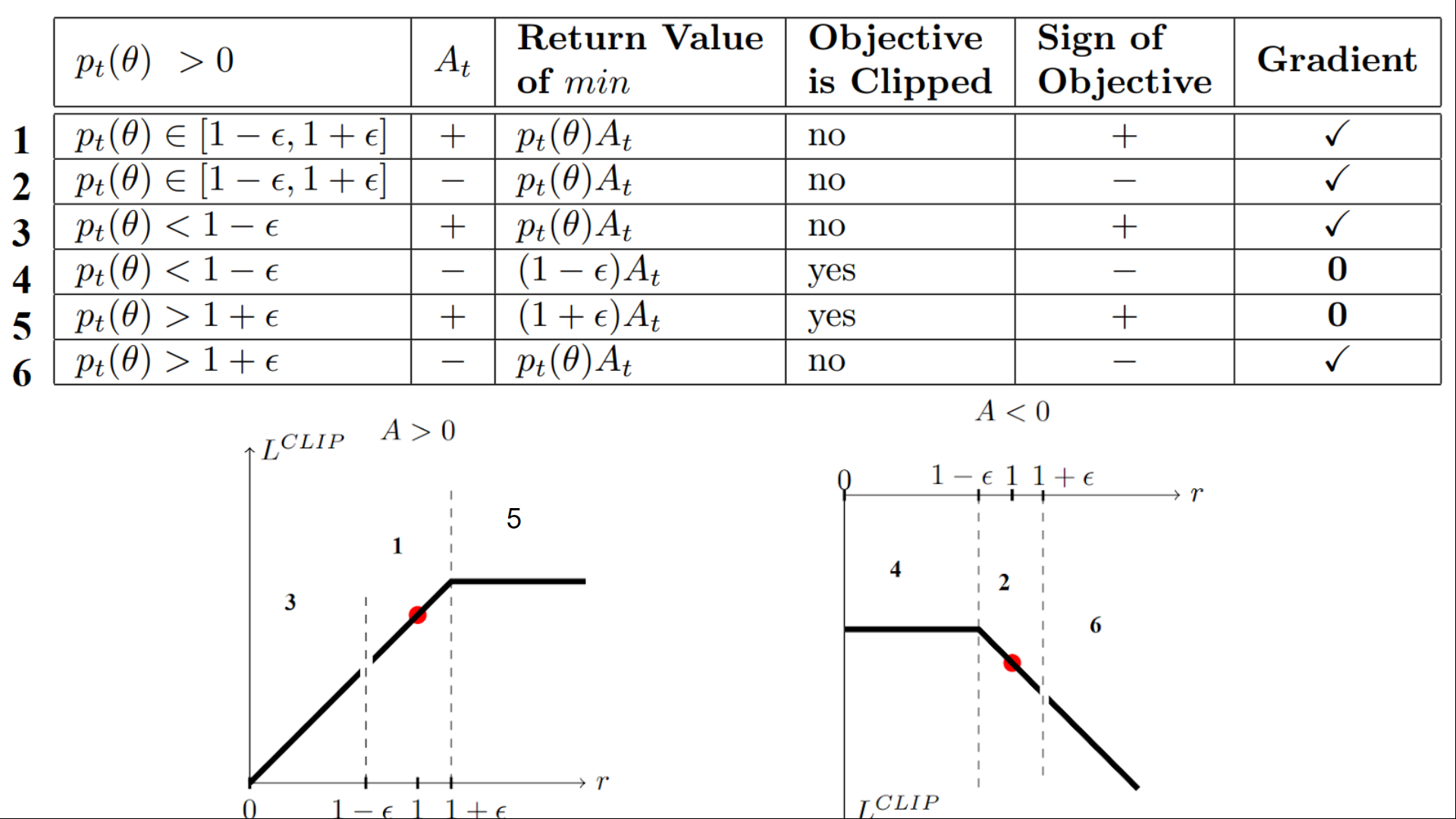 + 表格来自"Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization",作者Daniel Bick
+
+
+我们有六种不同的情况。首先记住,我们取裁剪和非裁剪目标之间的最小值。
+
+## 情况1和2:比率在范围内
+
+在情况1和2中,**由于比率在范围** \\( [1 - \epsilon, 1 + \epsilon] \\) **内,裁剪不适用**
+
+在情况1中,我们有一个正的优势:该**动作比该状态下所有动作的平均值更好**。因此,我们应该鼓励我们当前的策略增加在该状态下采取该动作的概率。
+
+由于比率在区间内,**我们可以增加我们策略在该状态下采取该动作的概率。**
+
+在情况2中,我们有一个负的优势:该动作比该状态下所有动作的平均值更差。因此,我们应该阻止我们当前的策略在该状态下采取该动作。
+
+由于比率在区间内,**我们可以降低我们策略在该状态下采取该动作的概率。**
+
+## 情况3和4:比率低于范围
+
+
+ 表格来自"Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization",作者Daniel Bick
+
+
+如果概率比率低于 \\( [1 - \epsilon] \\),则在该状态下采取该动作的概率比旧策略低得多。
+
+如果像情况3那样,优势估计为正(A>0),那么**你希望增加在该状态下采取该动作的概率。**
+
+但如果像情况4那样,优势估计为负,**我们不希望进一步降低**在该状态下采取该动作的概率。因此,梯度= 0(因为我们在一条平线上),所以我们不更新我们的权重。
+
+## 情况5和6:比率高于范围
+
+
+ 表格来自"Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization",作者Daniel Bick
+
+
+如果概率比率高于 \\( [1 + \epsilon] \\),则当前策略在该状态下采取该动作的概率**比前一策略高得多。**
+
+如果像情况5那样,优势为正,**我们不想变得太贪婪**。我们已经比前一策略有更高的概率在该状态下采取该动作。因此,梯度= 0(因为我们在一条平线上),所以我们不更新我们的权重。
+
+如果像情况6那样,优势为负,我们希望降低在该状态下采取该动作的概率。
+
+所以如果我们总结一下,**我们只用非裁剪目标部分更新策略**。当最小值是裁剪目标部分时,我们不更新我们的策略权重,因为梯度将等于0。
+
+所以我们只在以下情况更新我们的策略:
+- 我们的比率在范围 \\( [1 - \epsilon, 1 + \epsilon] \\) 内
+- 我们的比率在范围之外,但**优势导致更接近范围**
+ - 比率低于范围但优势> 0
+ - 比率高于范围但优势< 0
+
+**你可能想知道为什么当最小值是裁剪比率时,梯度为0。** 当比率被裁剪时,在这种情况下的导数将不是 \\( r_t(\theta) * A_t \\) 的导数,而是 \\( (1 - \epsilon)* A_t\\) 的导数或 \\( (1 + \epsilon)* A_t\\) 的导数,这两者都= 0。
+
+
+总结一下,通过这个裁剪替代目标,**我们限制了当前策略可以与旧策略变化的范围。** 因为我们消除了概率比率移出区间的激励,因为裁剪强制梯度为零。如果比率> \\( 1 + \epsilon \\) 或< \\( 1 - \epsilon \\),梯度将等于0。
+
+PPO Actor-Critic风格的最终裁剪替代目标损失看起来像这样,它是裁剪替代目标函数、价值损失函数和熵奖励的组合:
+
+
+ 表格来自"Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization",作者Daniel Bick
+
+
+我们有六种不同的情况。首先记住,我们取裁剪和非裁剪目标之间的最小值。
+
+## 情况1和2:比率在范围内
+
+在情况1和2中,**由于比率在范围** \\( [1 - \epsilon, 1 + \epsilon] \\) **内,裁剪不适用**
+
+在情况1中,我们有一个正的优势:该**动作比该状态下所有动作的平均值更好**。因此,我们应该鼓励我们当前的策略增加在该状态下采取该动作的概率。
+
+由于比率在区间内,**我们可以增加我们策略在该状态下采取该动作的概率。**
+
+在情况2中,我们有一个负的优势:该动作比该状态下所有动作的平均值更差。因此,我们应该阻止我们当前的策略在该状态下采取该动作。
+
+由于比率在区间内,**我们可以降低我们策略在该状态下采取该动作的概率。**
+
+## 情况3和4:比率低于范围
+
+
+ 表格来自"Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization",作者Daniel Bick
+
+
+如果概率比率低于 \\( [1 - \epsilon] \\),则在该状态下采取该动作的概率比旧策略低得多。
+
+如果像情况3那样,优势估计为正(A>0),那么**你希望增加在该状态下采取该动作的概率。**
+
+但如果像情况4那样,优势估计为负,**我们不希望进一步降低**在该状态下采取该动作的概率。因此,梯度= 0(因为我们在一条平线上),所以我们不更新我们的权重。
+
+## 情况5和6:比率高于范围
+
+
+ 表格来自"Towards Delivering a Coherent Self-Contained
+ Explanation of Proximal Policy Optimization",作者Daniel Bick
+
+
+如果概率比率高于 \\( [1 + \epsilon] \\),则当前策略在该状态下采取该动作的概率**比前一策略高得多。**
+
+如果像情况5那样,优势为正,**我们不想变得太贪婪**。我们已经比前一策略有更高的概率在该状态下采取该动作。因此,梯度= 0(因为我们在一条平线上),所以我们不更新我们的权重。
+
+如果像情况6那样,优势为负,我们希望降低在该状态下采取该动作的概率。
+
+所以如果我们总结一下,**我们只用非裁剪目标部分更新策略**。当最小值是裁剪目标部分时,我们不更新我们的策略权重,因为梯度将等于0。
+
+所以我们只在以下情况更新我们的策略:
+- 我们的比率在范围 \\( [1 - \epsilon, 1 + \epsilon] \\) 内
+- 我们的比率在范围之外,但**优势导致更接近范围**
+ - 比率低于范围但优势> 0
+ - 比率高于范围但优势< 0
+
+**你可能想知道为什么当最小值是裁剪比率时,梯度为0。** 当比率被裁剪时,在这种情况下的导数将不是 \\( r_t(\theta) * A_t \\) 的导数,而是 \\( (1 - \epsilon)* A_t\\) 的导数或 \\( (1 + \epsilon)* A_t\\) 的导数,这两者都= 0。
+
+
+总结一下,通过这个裁剪替代目标,**我们限制了当前策略可以与旧策略变化的范围。** 因为我们消除了概率比率移出区间的激励,因为裁剪强制梯度为零。如果比率> \\( 1 + \epsilon \\) 或< \\( 1 - \epsilon \\),梯度将等于0。
+
+PPO Actor-Critic风格的最终裁剪替代目标损失看起来像这样,它是裁剪替代目标函数、价值损失函数和熵奖励的组合:
+
+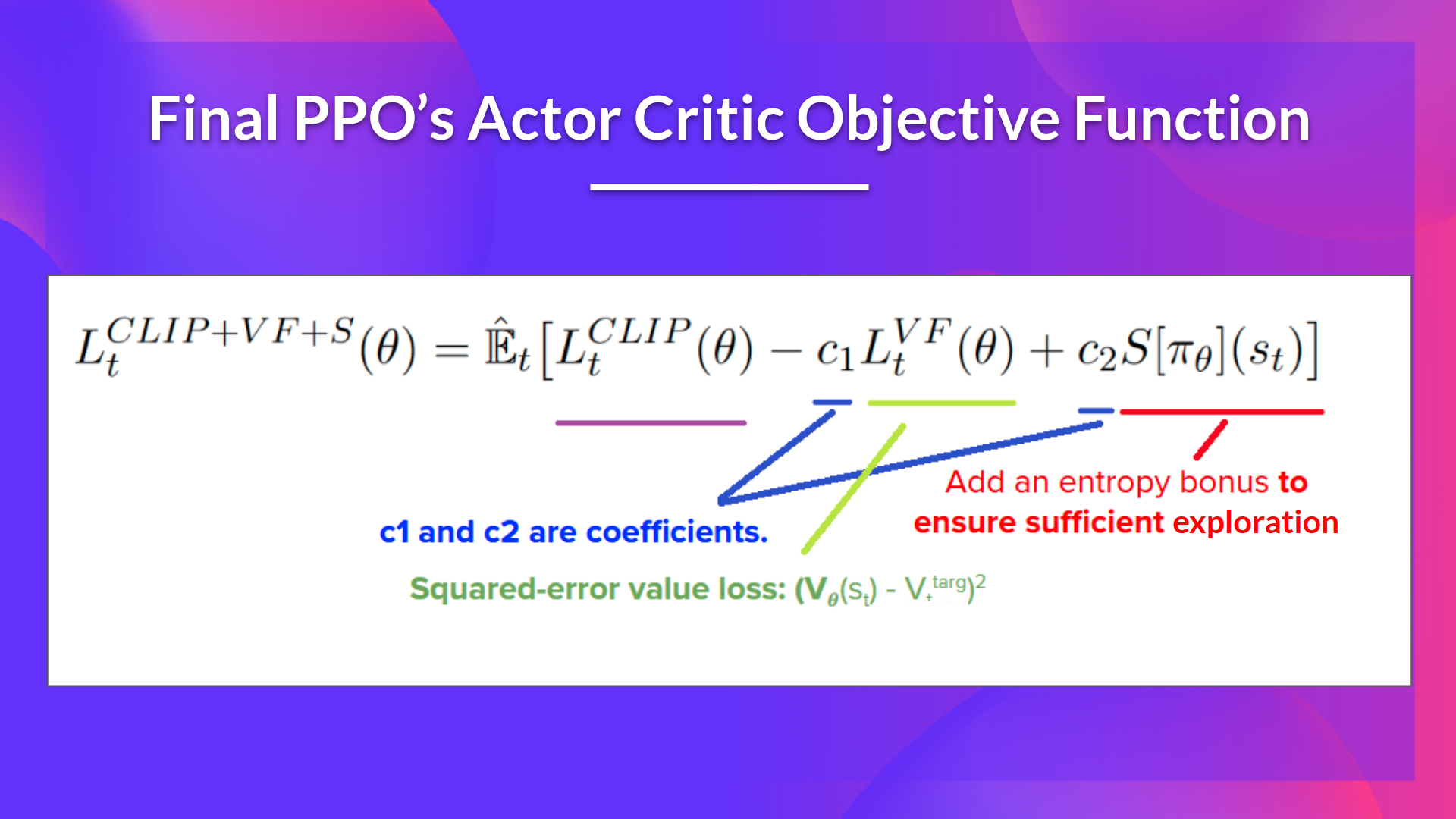 +
+这相当复杂。花时间通过查看表格和图表来理解这些情况。**你必须理解为什么这是有意义的。** 如果你想深入了解,最好的资源是Daniel Bick的文章["Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization",特别是3.4部分](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf)。
diff --git a/units/cn/unitbonus1/conclusion.mdx b/units/cn/unitbonus1/conclusion.mdx
new file mode 100644
index 00000000..a8b3d290
--- /dev/null
+++ b/units/cn/unitbonus1/conclusion.mdx
@@ -0,0 +1,12 @@
+# 结论 [[conclusion]]
+
+恭喜你完成这个奖励单元!
+
+现在你可以坐下来享受与你的Huggy🐶一起玩耍的乐趣。并且**不要忘记通过与朋友分享Huggy来传播爱🤗**。如果你在社交媒体上分享,**请标记我们@huggingface和我@simoninithomas**
+
+
+
+这相当复杂。花时间通过查看表格和图表来理解这些情况。**你必须理解为什么这是有意义的。** 如果你想深入了解,最好的资源是Daniel Bick的文章["Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization",特别是3.4部分](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf)。
diff --git a/units/cn/unitbonus1/conclusion.mdx b/units/cn/unitbonus1/conclusion.mdx
new file mode 100644
index 00000000..a8b3d290
--- /dev/null
+++ b/units/cn/unitbonus1/conclusion.mdx
@@ -0,0 +1,12 @@
+# 结论 [[conclusion]]
+
+恭喜你完成这个奖励单元!
+
+现在你可以坐下来享受与你的Huggy🐶一起玩耍的乐趣。并且**不要忘记通过与朋友分享Huggy来传播爱🤗**。如果你在社交媒体上分享,**请标记我们@huggingface和我@simoninithomas**
+
+ +
+最后,我们很想**听听你对这门课程的看法以及我们如何改进它**。如果你有一些反馈,请👉 [填写这个表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 持续学习,保持精彩 🤗
+
diff --git a/units/cn/unitbonus1/how-huggy-works.mdx b/units/cn/unitbonus1/how-huggy-works.mdx
new file mode 100644
index 00000000..63005103
--- /dev/null
+++ b/units/cn/unitbonus1/how-huggy-works.mdx
@@ -0,0 +1,66 @@
+# Huggy的工作原理 [[how-huggy-works]]
+
+Huggy是由Hugging Face创建的深度强化学习环境,基于[Unity MLAgents团队的项目Puppo the Corgi](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit)。
+这个环境是使用[Unity游戏引擎](https://unity.com/)和[MLAgents](https://github.com/Unity-Technologies/ml-agents)创建的。ML-Agents是Unity游戏引擎的工具包,允许我们**使用Unity创建环境或使用预制环境来训练我们的智能体**。
+
+
+
+在这个环境中,我们的目标是训练Huggy**去取我们扔出的棍子。这意味着他需要正确地向棍子移动**。
+
+## 状态空间,Huggy感知的内容 [[state-space]]
+Huggy并不"看见"他的环境。相反,我们提供给他关于环境的信息:
+
+- 目标(棍子)的位置
+- 他自己与目标之间的相对位置
+- 他腿部的方向
+
+有了所有这些信息,Huggy可以**使用他的策略来决定下一步采取什么行动来实现他的目标**。
+
+## 动作空间,Huggy可以执行的动作 [[action-space]]
+
+
+最后,我们很想**听听你对这门课程的看法以及我们如何改进它**。如果你有一些反馈,请👉 [填写这个表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 持续学习,保持精彩 🤗
+
diff --git a/units/cn/unitbonus1/how-huggy-works.mdx b/units/cn/unitbonus1/how-huggy-works.mdx
new file mode 100644
index 00000000..63005103
--- /dev/null
+++ b/units/cn/unitbonus1/how-huggy-works.mdx
@@ -0,0 +1,66 @@
+# Huggy的工作原理 [[how-huggy-works]]
+
+Huggy是由Hugging Face创建的深度强化学习环境,基于[Unity MLAgents团队的项目Puppo the Corgi](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit)。
+这个环境是使用[Unity游戏引擎](https://unity.com/)和[MLAgents](https://github.com/Unity-Technologies/ml-agents)创建的。ML-Agents是Unity游戏引擎的工具包,允许我们**使用Unity创建环境或使用预制环境来训练我们的智能体**。
+
+
+
+在这个环境中,我们的目标是训练Huggy**去取我们扔出的棍子。这意味着他需要正确地向棍子移动**。
+
+## 状态空间,Huggy感知的内容 [[state-space]]
+Huggy并不"看见"他的环境。相反,我们提供给他关于环境的信息:
+
+- 目标(棍子)的位置
+- 他自己与目标之间的相对位置
+- 他腿部的方向
+
+有了所有这些信息,Huggy可以**使用他的策略来决定下一步采取什么行动来实现他的目标**。
+
+## 动作空间,Huggy可以执行的动作 [[action-space]]
+ +
+**关节电机驱动Huggy的腿部**。这意味着要获取目标,Huggy需要**学会正确旋转他每条腿的关节电机,这样他才能移动**。
+
+## 奖励函数 [[reward-function]]
+
+奖励函数的设计使得**Huggy将实现他的目标**:取回棍子。
+
+记住强化学习的基础之一是*奖励假设*:目标可以被描述为**预期累积奖励的最大化**。
+
+在这里,我们的目标是让Huggy**朝着棍子前进,但不要旋转太多**。因此,我们的奖励函数必须转化这个目标。
+
+我们的奖励函数:
+
+
+
+**关节电机驱动Huggy的腿部**。这意味着要获取目标,Huggy需要**学会正确旋转他每条腿的关节电机,这样他才能移动**。
+
+## 奖励函数 [[reward-function]]
+
+奖励函数的设计使得**Huggy将实现他的目标**:取回棍子。
+
+记住强化学习的基础之一是*奖励假设*:目标可以被描述为**预期累积奖励的最大化**。
+
+在这里,我们的目标是让Huggy**朝着棍子前进,但不要旋转太多**。因此,我们的奖励函数必须转化这个目标。
+
+我们的奖励函数:
+
+ +
+- *方向奖励*:我们**奖励他接近目标**。
+- *时间惩罚*:每次行动都给予固定的时间惩罚,**迫使他尽快到达棍子**。
+- *旋转惩罚*:如果**他旋转太多并且转得太快**,我们会惩罚Huggy。
+- *到达目标奖励*:我们奖励Huggy**到达目标**。
+
+如果你想看看这个奖励函数在数学上是什么样子,请查看[Puppo the Corgi的介绍](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit)。
+
+## 训练Huggy
+
+Huggy的目标是**学习正确地跑动并尽可能快地朝向目标**。为此,在每一步,根据环境观察,他需要决定如何旋转他腿部的每个关节电机,以正确移动(不要旋转太多)并朝向目标。
+
+训练循环看起来像这样:
+
+
+
+- *方向奖励*:我们**奖励他接近目标**。
+- *时间惩罚*:每次行动都给予固定的时间惩罚,**迫使他尽快到达棍子**。
+- *旋转惩罚*:如果**他旋转太多并且转得太快**,我们会惩罚Huggy。
+- *到达目标奖励*:我们奖励Huggy**到达目标**。
+
+如果你想看看这个奖励函数在数学上是什么样子,请查看[Puppo the Corgi的介绍](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit)。
+
+## 训练Huggy
+
+Huggy的目标是**学习正确地跑动并尽可能快地朝向目标**。为此,在每一步,根据环境观察,他需要决定如何旋转他腿部的每个关节电机,以正确移动(不要旋转太多)并朝向目标。
+
+训练循环看起来像这样:
+
+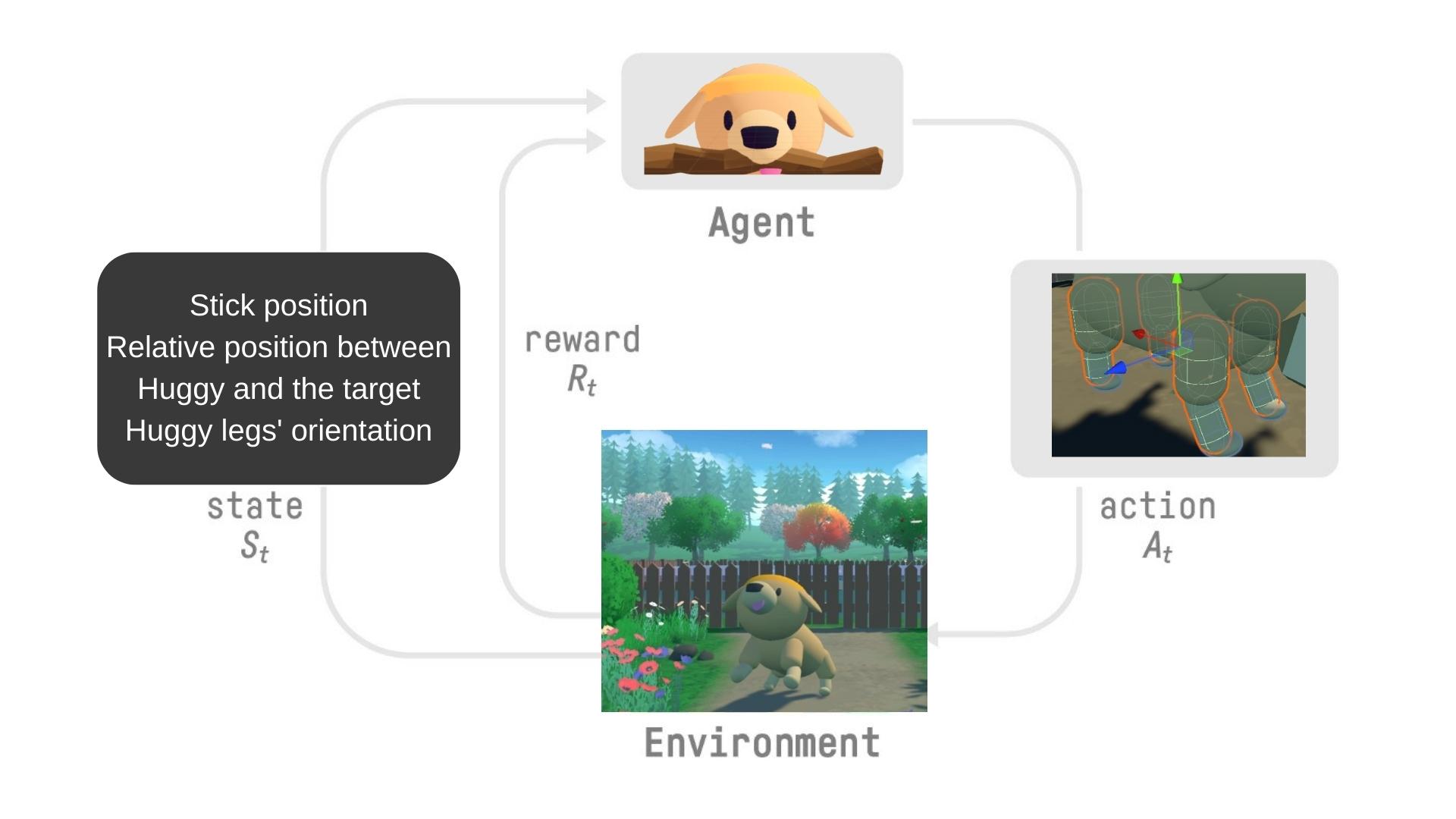 +
+
+训练环境看起来像这样:
+
+
+
+
+训练环境看起来像这样:
+
+ +
+
+这是一个**随机生成棍子**的地方。当Huggy到达棍子后,棍子会在其他地方重新生成。
+我们为训练**构建了环境的多个副本**。这通过提供更多样化的经验来帮助加速训练。
+
+
+
+现在你已经了解了环境的大致情况,你已经准备好训练Huggy去取棍子了。
+
+为此,我们将使用[MLAgents](https://github.com/Unity-Technologies/ml-agents)。如果你以前从未使用过它,不用担心。在这个单元中,我们将使用Google Colab来训练Huggy,然后你将能够加载你训练好的Huggy,并直接在浏览器中与他一起玩耍。
+
+在未来的单元中,我们将更深入地研究MLAgents,了解它是如何工作的。但现在,我们通过仅使用提供的实现来保持简单。
diff --git a/units/cn/unitbonus1/introduction.mdx b/units/cn/unitbonus1/introduction.mdx
new file mode 100644
index 00000000..1be57709
--- /dev/null
+++ b/units/cn/unitbonus1/introduction.mdx
@@ -0,0 +1,7 @@
+# 介绍 [[introduction]]
+
+在这个奖励单元中,我们将通过教导小狗Huggy捡回棍子来强化我们在第一单元中学到的知识,然后[直接在浏览器中与它互动](https://huggingface.co/spaces/ThomasSimonini/Huggy) 🐶
+
+
+
+
+这是一个**随机生成棍子**的地方。当Huggy到达棍子后,棍子会在其他地方重新生成。
+我们为训练**构建了环境的多个副本**。这通过提供更多样化的经验来帮助加速训练。
+
+
+
+现在你已经了解了环境的大致情况,你已经准备好训练Huggy去取棍子了。
+
+为此,我们将使用[MLAgents](https://github.com/Unity-Technologies/ml-agents)。如果你以前从未使用过它,不用担心。在这个单元中,我们将使用Google Colab来训练Huggy,然后你将能够加载你训练好的Huggy,并直接在浏览器中与他一起玩耍。
+
+在未来的单元中,我们将更深入地研究MLAgents,了解它是如何工作的。但现在,我们通过仅使用提供的实现来保持简单。
diff --git a/units/cn/unitbonus1/introduction.mdx b/units/cn/unitbonus1/introduction.mdx
new file mode 100644
index 00000000..1be57709
--- /dev/null
+++ b/units/cn/unitbonus1/introduction.mdx
@@ -0,0 +1,7 @@
+# 介绍 [[introduction]]
+
+在这个奖励单元中,我们将通过教导小狗Huggy捡回棍子来强化我们在第一单元中学到的知识,然后[直接在浏览器中与它互动](https://huggingface.co/spaces/ThomasSimonini/Huggy) 🐶
+
+ +
+让我们开始吧 🚀
diff --git a/units/cn/unitbonus1/play.mdx b/units/cn/unitbonus1/play.mdx
new file mode 100644
index 00000000..da661f20
--- /dev/null
+++ b/units/cn/unitbonus1/play.mdx
@@ -0,0 +1,18 @@
+# 与Huggy互动 [[play]]
+
+现在你已经训练了Huggy并将其推送到Hub。**你将能够与它互动 ❤️**
+
+这一步很简单:
+
+- 在浏览器中打开Huggy游戏:https://huggingface.co/spaces/ThomasSimonini/Huggy
+- 点击"Play with my Huggy model"(使用我的Huggy模型玩)
+
+
+
+让我们开始吧 🚀
diff --git a/units/cn/unitbonus1/play.mdx b/units/cn/unitbonus1/play.mdx
new file mode 100644
index 00000000..da661f20
--- /dev/null
+++ b/units/cn/unitbonus1/play.mdx
@@ -0,0 +1,18 @@
+# 与Huggy互动 [[play]]
+
+现在你已经训练了Huggy并将其推送到Hub。**你将能够与它互动 ❤️**
+
+这一步很简单:
+
+- 在浏览器中打开Huggy游戏:https://huggingface.co/spaces/ThomasSimonini/Huggy
+- 点击"Play with my Huggy model"(使用我的Huggy模型玩)
+
+ +
+1. 在第1步中,选择你的模型仓库,即模型ID(在我的例子中是ThomasSimonini/ppo-Huggy)。
+
+2. 在第2步中,**选择你想要回放的模型**:
+ - 我有多个模型,因为我们每500000个时间步保存一个模型。
+ - 但如果我想要最新的一个,我选择Huggy.onnx
+
+👉 **尝试不同的模型检查点来观察代理的改进情况**是很好的做法。
diff --git a/units/cn/unitbonus1/train.mdx b/units/cn/unitbonus1/train.mdx
new file mode 100644
index 00000000..e86a7e46
--- /dev/null
+++ b/units/cn/unitbonus1/train.mdx
@@ -0,0 +1,348 @@
+# 让我们训练并与Huggy互动 🐶 [[train]]
+
+
+
+
+
+
+
+
+我们强烈**建议学生使用Google Colab进行动手练习**,而不是在个人电脑上运行它们。
+
+通过使用Google Colab,**你可以专注于学习和实验,而不必担心设置环境的技术方面**。
+
+
+## 让我们训练Huggy 🐶
+
+**要开始训练Huggy,点击"Open In Colab"按钮** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/bonus-unit1/bonus-unit1.ipynb)
+
+
+
+在这个笔记本中,我们将通过**教导小狗Huggy捡回棍子,然后直接在浏览器中与它互动**来强化我们在第一单元中学到的知识
+
+
+
+### 环境 🎮
+
+- Huggy小狗,一个由[Thomas Simonini](https://twitter.com/ThomasSimonini)基于[Puppo The Corgi](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit)创建的环境
+
+### 使用的库 📚
+
+- [MLAgents](https://github.com/Unity-Technologies/ml-agents)
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在Github仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在完成本笔记本后,你将:
+
+- 理解**用于训练Huggy的状态空间、动作空间和奖励函数**。
+- **训练你自己的Huggy**去捡回棍子。
+- 能够**直接在浏览器中与你训练好的Huggy互动**。
+
+
+## 先决条件 🏗️
+
+在深入学习本笔记本之前,你需要:
+
+🔲 📚 通过完成第1单元**了解强化学习的基础知识**(MC、TD、奖励假设...)
+
+🔲 📚 通过完成奖励单元1**阅读Huggy的介绍**
+
+## 设置GPU 💪
+- 为了**加速代理的训练,我们将使用GPU**。要做到这一点,请转到`Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+## 克隆仓库 🔽
+
+- 我们需要克隆包含**ML-Agents**的仓库。
+
+```bash
+# 克隆仓库(可能需要3分钟)
+git clone --depth 1 https://github.com/Unity-Technologies/ml-agents
+```
+
+## 设置虚拟环境 🔽
+
+- 为了让**ML-Agents**在Colab中成功运行,Colab的Python版本必须满足库的Python要求。
+
+- 我们可以在`setup.py`文件的`python_requires`参数下检查支持的Python版本。这些文件是设置**ML-Agents**库所必需的,可以在以下位置找到:
+ - `/content/ml-agents/ml-agents/setup.py`
+ - `/content/ml-agents/ml-agents-envs/setup.py`
+
+- Colab当前的Python版本(可以使用`!python --version`检查)与库的`python_requires`参数不匹配,因此安装可能会悄无声息地失败,并在稍后执行相同命令时导致如下错误:
+ - `/bin/bash: line 1: mlagents-learn: command not found`
+ - `/bin/bash: line 1: mlagents-push-to-hf: command not found`
+
+- 为了解决这个问题,我们将创建一个与**ML-Agents**库兼容的Python版本的虚拟环境。
+
+`注意:` *为了未来的兼容性,请始终检查安装文件中的`python_requires`参数,如果Colab的Python版本不兼容,请在下面给出的脚本中将虚拟环境设置为支持的最大Python版本*
+
+```bash
+# Colab当前的Python版本(与ML-Agents不兼容)
+!python --version
+```
+
+```bash
+# 安装virtualenv并创建虚拟环境
+!pip install virtualenv
+!virtualenv myenv
+
+# 下载并安装Miniconda
+!wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
+!chmod +x Miniconda3-latest-Linux-x86_64.sh
+!./Miniconda3-latest-Linux-x86_64.sh -b -f -p /usr/local
+
+# 激活Miniconda并安装Python 3.10.12版本
+!source /usr/local/bin/activate
+!conda install -q -y --prefix /usr/local python=3.10.12 ujson # 在这里指定版本
+
+# 设置Python和conda路径的环境变量
+!export PYTHONPATH=/usr/local/lib/python3.10/site-packages/
+!export CONDA_PREFIX=/usr/local/envs/myenv
+```
+
+```bash
+# 新虚拟环境中的Python版本(与ML-Agents兼容)
+!python --version
+```
+
+## 安装依赖项 🔽
+
+```bash
+# 进入仓库并安装包(可能需要3分钟)
+%cd ml-agents
+pip3 install -e ./ml-agents-envs
+pip3 install -e ./ml-agents
+```
+
+## 下载环境zip文件并移动到`./trained-envs-executables/linux/`
+
+- 我们的环境可执行文件在一个zip文件中。
+- 我们需要下载它并将其放置到`./trained-envs-executables/linux/`
+
+```bash
+mkdir ./trained-envs-executables
+mkdir ./trained-envs-executables/linux
+```
+我们使用`wget`从https://github.com/huggingface/Huggy下载Huggy.zip文件
+
+```bash
+wget "https://github.com/huggingface/Huggy/raw/main/Huggy.zip" -O ./trained-envs-executables/linux/Huggy.zip
+```
+
+```bash
+%%capture
+unzip -d ./trained-envs-executables/linux/ ./trained-envs-executables/linux/Huggy.zip
+```
+
+确保你的文件可访问
+
+```bash
+chmod -R 755 ./trained-envs-executables/linux/Huggy
+```
+
+## 让我们回顾一下这个环境是如何工作的
+
+### 状态空间:Huggy感知到什么。
+
+Huggy并不"看到"他的环境。相反,我们提供给他关于环境的信息:
+
+- 目标(棍子)的位置
+- 他自己与目标之间的相对位置
+- 他腿部的方向。
+
+有了所有这些信息,Huggy**可以决定采取什么行动来实现他的目标**。
+
+
+
+
+### 动作空间:Huggy可以做哪些动作
+
+
+**关节电机驱动Huggy的腿部**。这意味着要获取目标,Huggy需要**学会正确旋转他每条腿的关节电机,这样他才能移动**。
+
+### 奖励函数
+
+奖励函数的设计使得**Huggy将实现他的目标**:捡回棍子。
+
+记住强化学习的基础之一是*奖励假设*:一个目标可以被描述为**预期累积奖励的最大化**。
+
+在这里,我们的目标是让Huggy**朝着棍子走去,但不要过度旋转**。因此,我们的奖励函数必须转化这个目标。
+
+我们的奖励函数:
+
+
+
+- *方向奖励*:我们**奖励他靠近目标**。
+- *时间惩罚*:每次行动都给予固定的时间惩罚,**迫使他尽快到达棍子**。
+- *旋转惩罚*:如果**他旋转过多并且转得太快**,我们会惩罚Huggy。
+- *到达目标奖励*:我们奖励Huggy**到达目标**。
+
+## 检查Huggy配置文件
+
+- 在ML-Agents中,你在config.yaml文件中**定义训练超参数**。
+
+- 在本笔记本的范围内,我们不会修改超参数,但如果你想尝试作为实验,Unity提供了非常[好的文档在这里解释每个参数](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md)。
+
+- 我们需要为Huggy创建一个配置文件。
+
+- 转到`/content/ml-agents/config/ppo`
+
+- 创建一个名为`Huggy.yaml`的新文件
+
+- 复制并粘贴下面的内容 🔽
+
+```
+behaviors:
+ Huggy:
+ trainer_type: ppo
+ hyperparameters:
+ batch_size: 2048
+ buffer_size: 20480
+ learning_rate: 0.0003
+ beta: 0.005
+ epsilon: 0.2
+ lambd: 0.95
+ num_epoch: 3
+ learning_rate_schedule: linear
+ network_settings:
+ normalize: true
+ hidden_units: 512
+ num_layers: 3
+ vis_encode_type: simple
+ reward_signals:
+ extrinsic:
+ gamma: 0.995
+ strength: 1.0
+ checkpoint_interval: 200000
+ keep_checkpoints: 15
+ max_steps: 2e6
+ time_horizon: 1000
+ summary_freq: 50000
+```
+
+- 不要忘记保存文件!
+
+- **如果你想修改超参数**,在Google Colab笔记本中,你可以点击这里打开config.yaml:`/content/ml-agents/config/ppo/Huggy.yaml`
+
+我们现在准备好训练我们的代理了 🔥。
+
+## 训练我们的代理
+
+要训练我们的代理,我们只需要**启动mlagents-learn并选择包含环境的可执行文件**。
+
+
+
+1. 在第1步中,选择你的模型仓库,即模型ID(在我的例子中是ThomasSimonini/ppo-Huggy)。
+
+2. 在第2步中,**选择你想要回放的模型**:
+ - 我有多个模型,因为我们每500000个时间步保存一个模型。
+ - 但如果我想要最新的一个,我选择Huggy.onnx
+
+👉 **尝试不同的模型检查点来观察代理的改进情况**是很好的做法。
diff --git a/units/cn/unitbonus1/train.mdx b/units/cn/unitbonus1/train.mdx
new file mode 100644
index 00000000..e86a7e46
--- /dev/null
+++ b/units/cn/unitbonus1/train.mdx
@@ -0,0 +1,348 @@
+# 让我们训练并与Huggy互动 🐶 [[train]]
+
+
+
+
+
+
+
+
+我们强烈**建议学生使用Google Colab进行动手练习**,而不是在个人电脑上运行它们。
+
+通过使用Google Colab,**你可以专注于学习和实验,而不必担心设置环境的技术方面**。
+
+
+## 让我们训练Huggy 🐶
+
+**要开始训练Huggy,点击"Open In Colab"按钮** 👇 :
+
+[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/bonus-unit1/bonus-unit1.ipynb)
+
+
+
+在这个笔记本中,我们将通过**教导小狗Huggy捡回棍子,然后直接在浏览器中与它互动**来强化我们在第一单元中学到的知识
+
+
+
+### 环境 🎮
+
+- Huggy小狗,一个由[Thomas Simonini](https://twitter.com/ThomasSimonini)基于[Puppo The Corgi](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit)创建的环境
+
+### 使用的库 📚
+
+- [MLAgents](https://github.com/Unity-Technologies/ml-agents)
+
+我们一直在努力改进我们的教程,所以**如果你在这个笔记本中发现一些问题**,请[在Github仓库上提出issue](https://github.com/huggingface/deep-rl-class/issues)。
+
+## 本笔记本的目标 🏆
+
+在完成本笔记本后,你将:
+
+- 理解**用于训练Huggy的状态空间、动作空间和奖励函数**。
+- **训练你自己的Huggy**去捡回棍子。
+- 能够**直接在浏览器中与你训练好的Huggy互动**。
+
+
+## 先决条件 🏗️
+
+在深入学习本笔记本之前,你需要:
+
+🔲 📚 通过完成第1单元**了解强化学习的基础知识**(MC、TD、奖励假设...)
+
+🔲 📚 通过完成奖励单元1**阅读Huggy的介绍**
+
+## 设置GPU 💪
+- 为了**加速代理的训练,我们将使用GPU**。要做到这一点,请转到`Runtime > Change Runtime type`
+
+
+
+- `Hardware Accelerator > GPU`
+
+
+
+## 克隆仓库 🔽
+
+- 我们需要克隆包含**ML-Agents**的仓库。
+
+```bash
+# 克隆仓库(可能需要3分钟)
+git clone --depth 1 https://github.com/Unity-Technologies/ml-agents
+```
+
+## 设置虚拟环境 🔽
+
+- 为了让**ML-Agents**在Colab中成功运行,Colab的Python版本必须满足库的Python要求。
+
+- 我们可以在`setup.py`文件的`python_requires`参数下检查支持的Python版本。这些文件是设置**ML-Agents**库所必需的,可以在以下位置找到:
+ - `/content/ml-agents/ml-agents/setup.py`
+ - `/content/ml-agents/ml-agents-envs/setup.py`
+
+- Colab当前的Python版本(可以使用`!python --version`检查)与库的`python_requires`参数不匹配,因此安装可能会悄无声息地失败,并在稍后执行相同命令时导致如下错误:
+ - `/bin/bash: line 1: mlagents-learn: command not found`
+ - `/bin/bash: line 1: mlagents-push-to-hf: command not found`
+
+- 为了解决这个问题,我们将创建一个与**ML-Agents**库兼容的Python版本的虚拟环境。
+
+`注意:` *为了未来的兼容性,请始终检查安装文件中的`python_requires`参数,如果Colab的Python版本不兼容,请在下面给出的脚本中将虚拟环境设置为支持的最大Python版本*
+
+```bash
+# Colab当前的Python版本(与ML-Agents不兼容)
+!python --version
+```
+
+```bash
+# 安装virtualenv并创建虚拟环境
+!pip install virtualenv
+!virtualenv myenv
+
+# 下载并安装Miniconda
+!wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
+!chmod +x Miniconda3-latest-Linux-x86_64.sh
+!./Miniconda3-latest-Linux-x86_64.sh -b -f -p /usr/local
+
+# 激活Miniconda并安装Python 3.10.12版本
+!source /usr/local/bin/activate
+!conda install -q -y --prefix /usr/local python=3.10.12 ujson # 在这里指定版本
+
+# 设置Python和conda路径的环境变量
+!export PYTHONPATH=/usr/local/lib/python3.10/site-packages/
+!export CONDA_PREFIX=/usr/local/envs/myenv
+```
+
+```bash
+# 新虚拟环境中的Python版本(与ML-Agents兼容)
+!python --version
+```
+
+## 安装依赖项 🔽
+
+```bash
+# 进入仓库并安装包(可能需要3分钟)
+%cd ml-agents
+pip3 install -e ./ml-agents-envs
+pip3 install -e ./ml-agents
+```
+
+## 下载环境zip文件并移动到`./trained-envs-executables/linux/`
+
+- 我们的环境可执行文件在一个zip文件中。
+- 我们需要下载它并将其放置到`./trained-envs-executables/linux/`
+
+```bash
+mkdir ./trained-envs-executables
+mkdir ./trained-envs-executables/linux
+```
+我们使用`wget`从https://github.com/huggingface/Huggy下载Huggy.zip文件
+
+```bash
+wget "https://github.com/huggingface/Huggy/raw/main/Huggy.zip" -O ./trained-envs-executables/linux/Huggy.zip
+```
+
+```bash
+%%capture
+unzip -d ./trained-envs-executables/linux/ ./trained-envs-executables/linux/Huggy.zip
+```
+
+确保你的文件可访问
+
+```bash
+chmod -R 755 ./trained-envs-executables/linux/Huggy
+```
+
+## 让我们回顾一下这个环境是如何工作的
+
+### 状态空间:Huggy感知到什么。
+
+Huggy并不"看到"他的环境。相反,我们提供给他关于环境的信息:
+
+- 目标(棍子)的位置
+- 他自己与目标之间的相对位置
+- 他腿部的方向。
+
+有了所有这些信息,Huggy**可以决定采取什么行动来实现他的目标**。
+
+
+
+
+### 动作空间:Huggy可以做哪些动作
+
+
+**关节电机驱动Huggy的腿部**。这意味着要获取目标,Huggy需要**学会正确旋转他每条腿的关节电机,这样他才能移动**。
+
+### 奖励函数
+
+奖励函数的设计使得**Huggy将实现他的目标**:捡回棍子。
+
+记住强化学习的基础之一是*奖励假设*:一个目标可以被描述为**预期累积奖励的最大化**。
+
+在这里,我们的目标是让Huggy**朝着棍子走去,但不要过度旋转**。因此,我们的奖励函数必须转化这个目标。
+
+我们的奖励函数:
+
+
+
+- *方向奖励*:我们**奖励他靠近目标**。
+- *时间惩罚*:每次行动都给予固定的时间惩罚,**迫使他尽快到达棍子**。
+- *旋转惩罚*:如果**他旋转过多并且转得太快**,我们会惩罚Huggy。
+- *到达目标奖励*:我们奖励Huggy**到达目标**。
+
+## 检查Huggy配置文件
+
+- 在ML-Agents中,你在config.yaml文件中**定义训练超参数**。
+
+- 在本笔记本的范围内,我们不会修改超参数,但如果你想尝试作为实验,Unity提供了非常[好的文档在这里解释每个参数](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md)。
+
+- 我们需要为Huggy创建一个配置文件。
+
+- 转到`/content/ml-agents/config/ppo`
+
+- 创建一个名为`Huggy.yaml`的新文件
+
+- 复制并粘贴下面的内容 🔽
+
+```
+behaviors:
+ Huggy:
+ trainer_type: ppo
+ hyperparameters:
+ batch_size: 2048
+ buffer_size: 20480
+ learning_rate: 0.0003
+ beta: 0.005
+ epsilon: 0.2
+ lambd: 0.95
+ num_epoch: 3
+ learning_rate_schedule: linear
+ network_settings:
+ normalize: true
+ hidden_units: 512
+ num_layers: 3
+ vis_encode_type: simple
+ reward_signals:
+ extrinsic:
+ gamma: 0.995
+ strength: 1.0
+ checkpoint_interval: 200000
+ keep_checkpoints: 15
+ max_steps: 2e6
+ time_horizon: 1000
+ summary_freq: 50000
+```
+
+- 不要忘记保存文件!
+
+- **如果你想修改超参数**,在Google Colab笔记本中,你可以点击这里打开config.yaml:`/content/ml-agents/config/ppo/Huggy.yaml`
+
+我们现在准备好训练我们的代理了 🔥。
+
+## 训练我们的代理
+
+要训练我们的代理,我们只需要**启动mlagents-learn并选择包含环境的可执行文件**。
+
+ +
+使用ML Agents,我们运行一个训练脚本。我们定义四个参数:
+
+1. `mlagents-learn `:超参数配置文件的路径。
+2. `--env`:环境可执行文件的位置。
+3. `--run-id`:你想给训练运行ID起的名字。
+4. `--no-graphics`:在训练期间不启动可视化。
+
+训练模型并使用`--resume`标志在中断的情况下继续训练。
+
+> 第一次使用`--resume`时会失败,尝试再次运行代码块以绕过错误。
+
+
+
+训练将根据你的机器需要30到45分钟(不要忘记**设置GPU**),去喝杯☕️,你值得 🤗。
+
+```bash
+mlagents-learn ./config/ppo/Huggy.yaml --env=./trained-envs-executables/linux/Huggy/Huggy --run-id="Huggy" --no-graphics
+```
+
+## 将代理推送到🤗 Hub
+
+- 现在我们已经训练了我们的代理,我们**准备将它推送到Hub,以便能够在浏览器上与Huggy互动🔥**。
+
+要能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果还没有完成)在HF创建一个账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录然后从Hugging Face网站获取你的令牌。
+- 创建一个新的令牌(https://huggingface.co/settings/tokens)**具有写入权限**
+
+
+
+- 复制令牌
+- 运行下面的单元格并粘贴令牌
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令代替:`huggingface-cli login`
+
+然后,我们只需要运行`mlagents-push-to-hf`。
+
+
+
+使用ML Agents,我们运行一个训练脚本。我们定义四个参数:
+
+1. `mlagents-learn `:超参数配置文件的路径。
+2. `--env`:环境可执行文件的位置。
+3. `--run-id`:你想给训练运行ID起的名字。
+4. `--no-graphics`:在训练期间不启动可视化。
+
+训练模型并使用`--resume`标志在中断的情况下继续训练。
+
+> 第一次使用`--resume`时会失败,尝试再次运行代码块以绕过错误。
+
+
+
+训练将根据你的机器需要30到45分钟(不要忘记**设置GPU**),去喝杯☕️,你值得 🤗。
+
+```bash
+mlagents-learn ./config/ppo/Huggy.yaml --env=./trained-envs-executables/linux/Huggy/Huggy --run-id="Huggy" --no-graphics
+```
+
+## 将代理推送到🤗 Hub
+
+- 现在我们已经训练了我们的代理,我们**准备将它推送到Hub,以便能够在浏览器上与Huggy互动🔥**。
+
+要能够与社区分享你的模型,还有三个步骤需要遵循:
+
+1️⃣ (如果还没有完成)在HF创建一个账户 ➡ https://huggingface.co/join
+
+2️⃣ 登录然后从Hugging Face网站获取你的令牌。
+- 创建一个新的令牌(https://huggingface.co/settings/tokens)**具有写入权限**
+
+
+
+- 复制令牌
+- 运行下面的单元格并粘贴令牌
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+如果你不想使用Google Colab或Jupyter Notebook,你需要使用这个命令代替:`huggingface-cli login`
+
+然后,我们只需要运行`mlagents-push-to-hf`。
+
+ +
+我们定义4个参数:
+
+1. `--run-id`:训练运行ID的名称。
+2. `--local-dir`:代理保存的位置,它是results/\,所以在我的例子中是results/First Training。
+3. `--repo-id`:你想创建或更新的Hugging Face仓库的名称。它总是\<你的huggingface用户名\>/\<仓库名称\>
+如果仓库不存在,**它将自动创建**
+4. `--commit-message`:由于HF仓库是git仓库,你需要提供一个提交消息。
+
+```bash
+mlagents-push-to-hf --run-id="HuggyTraining" --local-dir="./results/Huggy" --repo-id="ThomasSimonini/ppo-Huggy" --commit-message="Huggy"
+```
+
+如果一切正常,你应该在过程结束时看到这个(但URL不同 😆):
+
+
+
+```
+Your model is pushed to the hub. You can view your model here: https://huggingface.co/ThomasSimonini/ppo-Huggy
+```
+
+这是你的模型仓库的链接。该仓库包含一个解释如何使用模型的模型卡片,你的Tensorboard日志和你的配置文件。**最棒的是它是一个git仓库,这意味着你可以有不同的提交,用新的推送更新你的仓库,打开Pull Requests等**。
+
+
+
+我们定义4个参数:
+
+1. `--run-id`:训练运行ID的名称。
+2. `--local-dir`:代理保存的位置,它是results/\,所以在我的例子中是results/First Training。
+3. `--repo-id`:你想创建或更新的Hugging Face仓库的名称。它总是\<你的huggingface用户名\>/\<仓库名称\>
+如果仓库不存在,**它将自动创建**
+4. `--commit-message`:由于HF仓库是git仓库,你需要提供一个提交消息。
+
+```bash
+mlagents-push-to-hf --run-id="HuggyTraining" --local-dir="./results/Huggy" --repo-id="ThomasSimonini/ppo-Huggy" --commit-message="Huggy"
+```
+
+如果一切正常,你应该在过程结束时看到这个(但URL不同 😆):
+
+
+
+```
+Your model is pushed to the hub. You can view your model here: https://huggingface.co/ThomasSimonini/ppo-Huggy
+```
+
+这是你的模型仓库的链接。该仓库包含一个解释如何使用模型的模型卡片,你的Tensorboard日志和你的配置文件。**最棒的是它是一个git仓库,这意味着你可以有不同的提交,用新的推送更新你的仓库,打开Pull Requests等**。
+
+ +
+但现在是最好的部分:**能够在线与Huggy互动 👀**。
+
+## 与你的Huggy互动 🐕
+
+这一步是最简单的:
+
+- 在浏览器中打开Huggy游戏:https://huggingface.co/spaces/ThomasSimonini/Huggy
+
+- 点击"Play with my Huggy model"(使用我的Huggy模型玩)
+
+
+
+1. 在第1步中,输入你的用户名(你的用户名区分大小写:例如,我的用户名是ThomasSimonini而不是thomassimonini或ThOmasImoNInI)并点击搜索按钮。
+
+2. 在第2步中,选择你的模型仓库。
+
+3. 在第3步中,**选择你想要回放的模型**:
+ - 我有多个模型,因为我们每500000个时间步保存一个模型。
+ - 但由于我想要最新的一个,我选择`Huggy.onnx`
+
+👉 **尝试不同的模型步骤来观察代理的改进情况**是很好的做法。
+
+恭喜你完成这个奖励单元!
+
+你现在可以坐下来享受与你的Huggy互动的乐趣 🐶。不要**忘记通过与你的朋友分享Huggy来传播爱 🤗**。如果你在社交媒体上分享它,**请标记我们@huggingface和我@simoninithomas**
+
+
+
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unitbonus2/hands-on.mdx b/units/cn/unitbonus2/hands-on.mdx
new file mode 100644
index 00000000..52274a3d
--- /dev/null
+++ b/units/cn/unitbonus2/hands-on.mdx
@@ -0,0 +1,16 @@
+# 动手实践 [[hands-on]]
+
+现在你已经学会了使用Optuna,这里有一些应用你所学知识的想法:
+
+1️⃣ **通过使用Optuna找到更好的超参数集来超越你的LunarLander-v2代理结果**。你也可以尝试其他环境,如MountainCar-v0和CartPole-v1。
+
+2️⃣ **超越你的SpaceInvaders代理结果**。
+
+通过这样做,你将看到Optuna在训练更好的代理方面有多么有价值和强大。
+
+玩得开心!
+
+最后,我们很想**听听你对课程的看法以及我们如何改进它**。如果你有一些反馈,请 👉 [填写这个表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 持续学习,保持精彩 🤗
+
diff --git a/units/cn/unitbonus2/introduction.mdx b/units/cn/unitbonus2/introduction.mdx
new file mode 100644
index 00000000..48cb854d
--- /dev/null
+++ b/units/cn/unitbonus2/introduction.mdx
@@ -0,0 +1,7 @@
+# 介绍 [[introduction]]
+
+深度强化学习中最关键的任务之一是**找到一组好的训练超参数**。
+
+
+
+但现在是最好的部分:**能够在线与Huggy互动 👀**。
+
+## 与你的Huggy互动 🐕
+
+这一步是最简单的:
+
+- 在浏览器中打开Huggy游戏:https://huggingface.co/spaces/ThomasSimonini/Huggy
+
+- 点击"Play with my Huggy model"(使用我的Huggy模型玩)
+
+
+
+1. 在第1步中,输入你的用户名(你的用户名区分大小写:例如,我的用户名是ThomasSimonini而不是thomassimonini或ThOmasImoNInI)并点击搜索按钮。
+
+2. 在第2步中,选择你的模型仓库。
+
+3. 在第3步中,**选择你想要回放的模型**:
+ - 我有多个模型,因为我们每500000个时间步保存一个模型。
+ - 但由于我想要最新的一个,我选择`Huggy.onnx`
+
+👉 **尝试不同的模型步骤来观察代理的改进情况**是很好的做法。
+
+恭喜你完成这个奖励单元!
+
+你现在可以坐下来享受与你的Huggy互动的乐趣 🐶。不要**忘记通过与你的朋友分享Huggy来传播爱 🤗**。如果你在社交媒体上分享它,**请标记我们@huggingface和我@simoninithomas**
+
+
+
+
+## 持续学习,保持精彩 🤗
diff --git a/units/cn/unitbonus2/hands-on.mdx b/units/cn/unitbonus2/hands-on.mdx
new file mode 100644
index 00000000..52274a3d
--- /dev/null
+++ b/units/cn/unitbonus2/hands-on.mdx
@@ -0,0 +1,16 @@
+# 动手实践 [[hands-on]]
+
+现在你已经学会了使用Optuna,这里有一些应用你所学知识的想法:
+
+1️⃣ **通过使用Optuna找到更好的超参数集来超越你的LunarLander-v2代理结果**。你也可以尝试其他环境,如MountainCar-v0和CartPole-v1。
+
+2️⃣ **超越你的SpaceInvaders代理结果**。
+
+通过这样做,你将看到Optuna在训练更好的代理方面有多么有价值和强大。
+
+玩得开心!
+
+最后,我们很想**听听你对课程的看法以及我们如何改进它**。如果你有一些反馈,请 👉 [填写这个表单](https://forms.gle/BzKXWzLAGZESGNaE9)
+
+### 持续学习,保持精彩 🤗
+
diff --git a/units/cn/unitbonus2/introduction.mdx b/units/cn/unitbonus2/introduction.mdx
new file mode 100644
index 00000000..48cb854d
--- /dev/null
+++ b/units/cn/unitbonus2/introduction.mdx
@@ -0,0 +1,7 @@
+# 介绍 [[introduction]]
+
+深度强化学习中最关键的任务之一是**找到一组好的训练超参数**。
+
+ +
+[Optuna](https://optuna.org/)是一个帮助你自动化搜索的库。在这个单元中,我们将**学习一些自动超参数调整背后的理论**。我们首先会尝试手动优化上一单元中学习的DQN的参数。然后,我们将**学习如何使用Optuna自动化搜索**。
diff --git a/units/cn/unitbonus2/optuna.mdx b/units/cn/unitbonus2/optuna.mdx
new file mode 100644
index 00000000..8abc38d1
--- /dev/null
+++ b/units/cn/unitbonus2/optuna.mdx
@@ -0,0 +1,15 @@
+# Optuna教程 [[optuna]]
+
+以下内容来自[Antonin's Raffin的ICRA 2022演讲](https://araffin.github.io/tools-for-robotic-rl-icra2022/),他是Stable-Baselines和RL-Baselines3-Zoo的创始人之一。
+
+
+## 超参数调整背后的理论
+
+
+
+
+## Optuna教程
+
+
+
+笔记本 👉 [这里](https://colab.research.google.com/github/araffin/tools-for-robotic-rl-icra2022/blob/main/notebooks/optuna_lab.ipynb)
diff --git a/units/cn/unitbonus3/curriculum-learning.mdx b/units/cn/unitbonus3/curriculum-learning.mdx
new file mode 100644
index 00000000..0fd54ccf
--- /dev/null
+++ b/units/cn/unitbonus3/curriculum-learning.mdx
@@ -0,0 +1,53 @@
+# (自动)课程学习在强化学习中的应用
+
+虽然本课程中介绍的大多数强化学习方法在实践中表现良好,但在某些情况下单独使用它们会失败。例如,当:
+
+- 学习任务很困难,需要**渐进式技能获取**(例如,当想要让双足机器人学会穿越困难障碍物时,它必须先学会站立,然后行走,然后可能是跳跃...)
+- 环境中存在变化(影响难度),并且希望智能体对这些变化具有**鲁棒性**
+
+
+
+
+[Optuna](https://optuna.org/)是一个帮助你自动化搜索的库。在这个单元中,我们将**学习一些自动超参数调整背后的理论**。我们首先会尝试手动优化上一单元中学习的DQN的参数。然后,我们将**学习如何使用Optuna自动化搜索**。
diff --git a/units/cn/unitbonus2/optuna.mdx b/units/cn/unitbonus2/optuna.mdx
new file mode 100644
index 00000000..8abc38d1
--- /dev/null
+++ b/units/cn/unitbonus2/optuna.mdx
@@ -0,0 +1,15 @@
+# Optuna教程 [[optuna]]
+
+以下内容来自[Antonin's Raffin的ICRA 2022演讲](https://araffin.github.io/tools-for-robotic-rl-icra2022/),他是Stable-Baselines和RL-Baselines3-Zoo的创始人之一。
+
+
+## 超参数调整背后的理论
+
+
+
+
+## Optuna教程
+
+
+
+笔记本 👉 [这里](https://colab.research.google.com/github/araffin/tools-for-robotic-rl-icra2022/blob/main/notebooks/optuna_lab.ipynb)
diff --git a/units/cn/unitbonus3/curriculum-learning.mdx b/units/cn/unitbonus3/curriculum-learning.mdx
new file mode 100644
index 00000000..0fd54ccf
--- /dev/null
+++ b/units/cn/unitbonus3/curriculum-learning.mdx
@@ -0,0 +1,53 @@
+# (自动)课程学习在强化学习中的应用
+
+虽然本课程中介绍的大多数强化学习方法在实践中表现良好,但在某些情况下单独使用它们会失败。例如,当:
+
+- 学习任务很困难,需要**渐进式技能获取**(例如,当想要让双足机器人学会穿越困难障碍物时,它必须先学会站立,然后行走,然后可能是跳跃...)
+- 环境中存在变化(影响难度),并且希望智能体对这些变化具有**鲁棒性**
+
+
+ +
+ + TeachMyAgent
+
+
+在这些情况下,似乎有必要向我们的强化学习智能体提出不同的任务,并组织它们,使智能体能够逐步获取技能。这种方法被称为**课程学习**,通常涉及手动设计的课程(或以特定顺序组织的任务集)。在实践中,例如,可以控制环境的生成、初始状态,或使用自我对弈并控制提供给强化学习智能体的对手水平。
+
+由于设计这样的课程并不总是简单的,**自动课程学习(ACL)领域提出设计能够学习创建任务组织的方法,以最大化强化学习智能体的性能**。Portelas等人提出将ACL定义为:
+
+> ...一系列机制,通过学习调整学习情境的选择以适应强化学习智能体的能力,从而自动调整训练数据的分布。
+>
+
+例如,OpenAI使用**域随机化**(他们对环境应用随机变化)使机器人手能够解决魔方。
+
+
+
+ TeachMyAgent
+
+
+在这些情况下,似乎有必要向我们的强化学习智能体提出不同的任务,并组织它们,使智能体能够逐步获取技能。这种方法被称为**课程学习**,通常涉及手动设计的课程(或以特定顺序组织的任务集)。在实践中,例如,可以控制环境的生成、初始状态,或使用自我对弈并控制提供给强化学习智能体的对手水平。
+
+由于设计这样的课程并不总是简单的,**自动课程学习(ACL)领域提出设计能够学习创建任务组织的方法,以最大化强化学习智能体的性能**。Portelas等人提出将ACL定义为:
+
+> ...一系列机制,通过学习调整学习情境的选择以适应强化学习智能体的能力,从而自动调整训练数据的分布。
+>
+
+例如,OpenAI使用**域随机化**(他们对环境应用随机变化)使机器人手能够解决魔方。
+
+
+ + OpenAI - 用机器人手解魔方
+
+
+最后,你可以通过控制环境变化甚至绘制地形来体验在TeachMyAgent基准测试中训练的智能体的鲁棒性 👇
+
+
+
+ OpenAI - 用机器人手解魔方
+
+
+最后,你可以通过控制环境变化甚至绘制地形来体验在TeachMyAgent基准测试中训练的智能体的鲁棒性 👇
+
+
+ + https://huggingface.co/spaces/flowers-team/Interactive_DeepRL_Demo
+
+
+
+## 进一步阅读
+
+如需更多信息,我们建议你查看以下资源:
+
+### 领域概述
+
+- [深度强化学习的自动课程学习:简短综述](https://arxiv.org/pdf/2003.04664.pdf)
+- [强化学习的课程设计](https://lilianweng.github.io/posts/2020-01-29-curriculum-rl/)
+
+### 最新方法
+
+- [基于遗憾的环境设计进化课程](https://arxiv.org/abs/2203.01302)
+- [通过约束最优传输的课程强化学习](https://proceedings.mlr.press/v162/klink22a.html)
+- [优先级别重放](https://arxiv.org/abs/2010.03934)
+
+## 作者
+
+本节由Clément Romac撰写
diff --git a/units/cn/unitbonus3/decision-transformers.mdx b/units/cn/unitbonus3/decision-transformers.mdx
new file mode 100644
index 00000000..ed9353be
--- /dev/null
+++ b/units/cn/unitbonus3/decision-transformers.mdx
@@ -0,0 +1,31 @@
+# 决策Transformer
+
+决策Transformer模型由Chen L.等人在["决策Transformer:通过序列建模实现强化学习"](https://arxiv.org/abs/2106.01345)中提出。它将强化学习抽象为条件序列建模问题。
+
+主要思想是,不是使用强化学习方法(如拟合价值函数)来训练一个策略,告诉我们采取什么行动来最大化回报(累积奖励),**而是使用序列建模算法(Transformer),在给定期望回报、过去状态和行动的情况下,生成未来行动以实现这个期望回报**。
+这是一个自回归模型,以期望回报、过去状态和行动为条件,生成实现期望回报的未来行动。
+
+这是强化学习范式的一个完全转变,因为我们使用生成式轨迹建模(建模状态、行动和奖励序列的联合分布)来替代传统的强化学习算法。这意味着在决策Transformer中,我们不是最大化回报,而是生成一系列未来行动来实现期望的回报。
+
+🤗 Transformers团队将决策Transformer(一种离线强化学习方法)集成到了库中,并添加到了Hugging Face Hub。
+
+## 了解决策Transformers
+
+要了解更多关于决策Transformers的信息,你应该阅读我们写的博客文章[在Hugging Face上介绍决策Transformers](https://huggingface.co/blog/decision-transformers)
+
+## 训练你的第一个决策Transformers
+
+现在,通过[在Hugging Face上介绍决策Transformers](https://huggingface.co/blog/decision-transformers),你已经了解了决策Transformers的工作原理,你已经准备好学习从头开始训练你的第一个离线决策Transformer模型,使半猎豹机器人奔跑。
+
+在这里开始教程 👉 https://huggingface.co/blog/train-decision-transformers
+
+## 进一步阅读
+
+如需更多信息,我们建议你查看以下资源:
+
+- [决策Transformer:通过序列建模实现强化学习](https://arxiv.org/abs/2106.01345)
+- [在线决策Transformer](https://arxiv.org/abs/2202.05607)
+
+## 作者
+
+本节由Edward Beeching撰写
diff --git a/units/cn/unitbonus3/envs-to-try.mdx b/units/cn/unitbonus3/envs-to-try.mdx
new file mode 100644
index 00000000..d07d55bc
--- /dev/null
+++ b/units/cn/unitbonus3/envs-to-try.mdx
@@ -0,0 +1,88 @@
+# 值得尝试的有趣环境
+
+这里我们提供了一些你可以尝试训练智能体的有趣环境列表:
+
+## DIAMBRA Arena
+
+
+ https://huggingface.co/spaces/flowers-team/Interactive_DeepRL_Demo
+
+
+
+## 进一步阅读
+
+如需更多信息,我们建议你查看以下资源:
+
+### 领域概述
+
+- [深度强化学习的自动课程学习:简短综述](https://arxiv.org/pdf/2003.04664.pdf)
+- [强化学习的课程设计](https://lilianweng.github.io/posts/2020-01-29-curriculum-rl/)
+
+### 最新方法
+
+- [基于遗憾的环境设计进化课程](https://arxiv.org/abs/2203.01302)
+- [通过约束最优传输的课程强化学习](https://proceedings.mlr.press/v162/klink22a.html)
+- [优先级别重放](https://arxiv.org/abs/2010.03934)
+
+## 作者
+
+本节由Clément Romac撰写
diff --git a/units/cn/unitbonus3/decision-transformers.mdx b/units/cn/unitbonus3/decision-transformers.mdx
new file mode 100644
index 00000000..ed9353be
--- /dev/null
+++ b/units/cn/unitbonus3/decision-transformers.mdx
@@ -0,0 +1,31 @@
+# 决策Transformer
+
+决策Transformer模型由Chen L.等人在["决策Transformer:通过序列建模实现强化学习"](https://arxiv.org/abs/2106.01345)中提出。它将强化学习抽象为条件序列建模问题。
+
+主要思想是,不是使用强化学习方法(如拟合价值函数)来训练一个策略,告诉我们采取什么行动来最大化回报(累积奖励),**而是使用序列建模算法(Transformer),在给定期望回报、过去状态和行动的情况下,生成未来行动以实现这个期望回报**。
+这是一个自回归模型,以期望回报、过去状态和行动为条件,生成实现期望回报的未来行动。
+
+这是强化学习范式的一个完全转变,因为我们使用生成式轨迹建模(建模状态、行动和奖励序列的联合分布)来替代传统的强化学习算法。这意味着在决策Transformer中,我们不是最大化回报,而是生成一系列未来行动来实现期望的回报。
+
+🤗 Transformers团队将决策Transformer(一种离线强化学习方法)集成到了库中,并添加到了Hugging Face Hub。
+
+## 了解决策Transformers
+
+要了解更多关于决策Transformers的信息,你应该阅读我们写的博客文章[在Hugging Face上介绍决策Transformers](https://huggingface.co/blog/decision-transformers)
+
+## 训练你的第一个决策Transformers
+
+现在,通过[在Hugging Face上介绍决策Transformers](https://huggingface.co/blog/decision-transformers),你已经了解了决策Transformers的工作原理,你已经准备好学习从头开始训练你的第一个离线决策Transformer模型,使半猎豹机器人奔跑。
+
+在这里开始教程 👉 https://huggingface.co/blog/train-decision-transformers
+
+## 进一步阅读
+
+如需更多信息,我们建议你查看以下资源:
+
+- [决策Transformer:通过序列建模实现强化学习](https://arxiv.org/abs/2106.01345)
+- [在线决策Transformer](https://arxiv.org/abs/2202.05607)
+
+## 作者
+
+本节由Edward Beeching撰写
diff --git a/units/cn/unitbonus3/envs-to-try.mdx b/units/cn/unitbonus3/envs-to-try.mdx
new file mode 100644
index 00000000..d07d55bc
--- /dev/null
+++ b/units/cn/unitbonus3/envs-to-try.mdx
@@ -0,0 +1,88 @@
+# 值得尝试的有趣环境
+
+这里我们提供了一些你可以尝试训练智能体的有趣环境列表:
+
+## DIAMBRA Arena
+
+ +
+
+DIAMBRA Arena是一个软件包,提供了一系列高质量的环境,用于强化学习研究和实验。它为流行的街机模拟视频游戏提供了标准接口,提供完全兼容OpenAI Gym/Gymnasium格式的Python API,使其采用变得平滑和直接。
+
+它支持所有主要操作系统(Linux、Windows和MacOS),可以通过[Python PIP](https://pypi.org/project/diambra-arena/)轻松安装。它完全免费使用,用户只需在[官方网站](https://diambra.ai/register/)上注册。
+
+此外,其[GitHub仓库](https://github.com/diambra/)提供了涵盖主要用例的示例集合,只需几个步骤即可运行。
+
+#### 主要特点
+
+所有环境都是情节性强化学习任务,具有离散动作(游戏手柄按钮)和由屏幕像素加上额外数值数据(如角色生命条或角色舞台位置等RAM值)组成的观察。
+
+它们都支持单人(1P)和双人(2P)模式,使它们成为探索标准强化学习、竞争性多智能体、竞争性人机交互、自我对弈、模仿学习和人在环中学习的完美资源。
+
+[接口游戏](https://docs.diambra.ai/envs/games/)是从最流行的格斗复古游戏中选择的。虽然它们共享相同的基本机制,但提供了不同的挑战,具有特定功能,如不同类型和数量的角色、如何执行连击、生命条充能等。
+
+DIAMBRA Arena的构建目的是最大化与所有主要强化学习库的兼容性。它原生提供与两个最重要的包的接口:[Stable Baselines 3](https://stable-baselines3.readthedocs.io/en/master/)和[Ray RLlib](https://docs.ray.io/en/latest/rllib/index.html),而Stable Baselines也可用但已弃用。它们的使用在[官方文档](https://docs.diambra.ai/)和[DIAMBRA Agents示例仓库](https://github.com/diambra/agents)中有说明。它可以以类似的方式轻松地与任何其他包接口。
+
+### 竞赛平台
+
+DIAMBRA还提供了一个与Hugging Face Hub完全集成的竞赛平台,你可以在其中提交你训练的智能体,并与全球其他编码者在史诗级视频游戏锦标赛中竞争!
+
+它提供了一个公共排行榜,用户根据其智能体在我们不同环境中取得的最佳分数进行排名。
+
+它还提供了根据你的智能体表现解锁酷炫成就的可能性。
+
+提交的智能体会被评估,其游戏情节会在[DIAMBRA Twitch频道](https://www.twitch.tv/diambra_ai)上直播。
+
+#### 参考资料
+
+要开始使用这个环境,请查看这些资源:
+- [官方文档](https://docs.diambra.ai/)
+- [竞赛平台](https://diambra.ai)
+- [GitHub](https://github.com/diambra/)
+- [Discord](https://diambra.ai/discord)
+
+## MineRL
+
+
+
+
+DIAMBRA Arena是一个软件包,提供了一系列高质量的环境,用于强化学习研究和实验。它为流行的街机模拟视频游戏提供了标准接口,提供完全兼容OpenAI Gym/Gymnasium格式的Python API,使其采用变得平滑和直接。
+
+它支持所有主要操作系统(Linux、Windows和MacOS),可以通过[Python PIP](https://pypi.org/project/diambra-arena/)轻松安装。它完全免费使用,用户只需在[官方网站](https://diambra.ai/register/)上注册。
+
+此外,其[GitHub仓库](https://github.com/diambra/)提供了涵盖主要用例的示例集合,只需几个步骤即可运行。
+
+#### 主要特点
+
+所有环境都是情节性强化学习任务,具有离散动作(游戏手柄按钮)和由屏幕像素加上额外数值数据(如角色生命条或角色舞台位置等RAM值)组成的观察。
+
+它们都支持单人(1P)和双人(2P)模式,使它们成为探索标准强化学习、竞争性多智能体、竞争性人机交互、自我对弈、模仿学习和人在环中学习的完美资源。
+
+[接口游戏](https://docs.diambra.ai/envs/games/)是从最流行的格斗复古游戏中选择的。虽然它们共享相同的基本机制,但提供了不同的挑战,具有特定功能,如不同类型和数量的角色、如何执行连击、生命条充能等。
+
+DIAMBRA Arena的构建目的是最大化与所有主要强化学习库的兼容性。它原生提供与两个最重要的包的接口:[Stable Baselines 3](https://stable-baselines3.readthedocs.io/en/master/)和[Ray RLlib](https://docs.ray.io/en/latest/rllib/index.html),而Stable Baselines也可用但已弃用。它们的使用在[官方文档](https://docs.diambra.ai/)和[DIAMBRA Agents示例仓库](https://github.com/diambra/agents)中有说明。它可以以类似的方式轻松地与任何其他包接口。
+
+### 竞赛平台
+
+DIAMBRA还提供了一个与Hugging Face Hub完全集成的竞赛平台,你可以在其中提交你训练的智能体,并与全球其他编码者在史诗级视频游戏锦标赛中竞争!
+
+它提供了一个公共排行榜,用户根据其智能体在我们不同环境中取得的最佳分数进行排名。
+
+它还提供了根据你的智能体表现解锁酷炫成就的可能性。
+
+提交的智能体会被评估,其游戏情节会在[DIAMBRA Twitch频道](https://www.twitch.tv/diambra_ai)上直播。
+
+#### 参考资料
+
+要开始使用这个环境,请查看这些资源:
+- [官方文档](https://docs.diambra.ai/)
+- [竞赛平台](https://diambra.ai)
+- [GitHub](https://github.com/diambra/)
+- [Discord](https://diambra.ai/discord)
+
+## MineRL
+
+ +
+
+MineRL是一个Python库,提供了与Minecraft视频游戏交互的Gym接口,并附带人类游戏数据集。
+每年都有使用这个库的挑战。查看[网站](https://minerl.io/)
+
+要开始使用这个环境,请查看这些资源:
+- [什么是MineRL?](https://www.youtube.com/watch?v=z6PTrGifupU)
+- [MineRL的第一步](https://www.youtube.com/watch?v=8yIrWcyWGek)
+- [MineRL文档和教程](https://minerl.readthedocs.io/en/latest/)
+
+## DonkeyCar模拟器
+
+
+
+
+MineRL是一个Python库,提供了与Minecraft视频游戏交互的Gym接口,并附带人类游戏数据集。
+每年都有使用这个库的挑战。查看[网站](https://minerl.io/)
+
+要开始使用这个环境,请查看这些资源:
+- [什么是MineRL?](https://www.youtube.com/watch?v=z6PTrGifupU)
+- [MineRL的第一步](https://www.youtube.com/watch?v=8yIrWcyWGek)
+- [MineRL文档和教程](https://minerl.readthedocs.io/en/latest/)
+
+## DonkeyCar模拟器
+
+ +Donkey是一个用于业余遥控汽车的自动驾驶汽车平台。
+这个模拟器版本是基于Unity游戏平台构建的。它使用Unity内部的物理和图形系统,并连接到donkey Python进程,使用我们训练的模型来控制模拟的Donkey(汽车)。
+
+
+要开始使用这个环境,请查看这些资源:
+- [DonkeyCar模拟器文档](https://docs.donkeycar.com/guide/deep_learning/simulator/)
+- [学习平稳驾驶(Antonin Raffin的教程)第1部分](https://www.youtube.com/watch?v=ngK33h00iBE)
+- [学习平稳驾驶(Antonin Raffin的教程)第2部分](https://www.youtube.com/watch?v=DUqssFvcSOY)
+- [学习平稳驾驶(Antonin Raffin的教程)第3部分](https://www.youtube.com/watch?v=v8j2bpcE4Rg)
+
+- 预训练智能体:
+ - https://huggingface.co/araffin/tqc-donkey-mountain-track-v0
+ - https://huggingface.co/araffin/tqc-donkey-avc-sparkfun-v0
+ - https://huggingface.co/araffin/tqc-donkey-minimonaco-track-v0
+
+
+## 星际争霸II
+
+
+Donkey是一个用于业余遥控汽车的自动驾驶汽车平台。
+这个模拟器版本是基于Unity游戏平台构建的。它使用Unity内部的物理和图形系统,并连接到donkey Python进程,使用我们训练的模型来控制模拟的Donkey(汽车)。
+
+
+要开始使用这个环境,请查看这些资源:
+- [DonkeyCar模拟器文档](https://docs.donkeycar.com/guide/deep_learning/simulator/)
+- [学习平稳驾驶(Antonin Raffin的教程)第1部分](https://www.youtube.com/watch?v=ngK33h00iBE)
+- [学习平稳驾驶(Antonin Raffin的教程)第2部分](https://www.youtube.com/watch?v=DUqssFvcSOY)
+- [学习平稳驾驶(Antonin Raffin的教程)第3部分](https://www.youtube.com/watch?v=v8j2bpcE4Rg)
+
+- 预训练智能体:
+ - https://huggingface.co/araffin/tqc-donkey-mountain-track-v0
+ - https://huggingface.co/araffin/tqc-donkey-avc-sparkfun-v0
+ - https://huggingface.co/araffin/tqc-donkey-minimonaco-track-v0
+
+
+## 星际争霸II
+
+ +
+星际争霸II是一款著名的*即时战略游戏*。DeepMind使用这款游戏进行了他们的深度强化学习研究,开发了[Alphastar](https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii)
+
+要开始使用这个环境,请查看这些资源:
+- [星际争霸gym](http://starcraftgym.com/)
+- [A.I.学习玩星际争霸2(强化学习)教程](https://www.youtube.com/watch?v=q59wap1ELQ4)
+
+## 作者
+
+本节由Thomas Simonini撰写
diff --git a/units/cn/unitbonus3/generalisation.mdx b/units/cn/unitbonus3/generalisation.mdx
new file mode 100644
index 00000000..63ef3c9d
--- /dev/null
+++ b/units/cn/unitbonus3/generalisation.mdx
@@ -0,0 +1,12 @@
+# 强化学习中的泛化
+
+泛化在强化学习领域中扮演着关键角色。虽然**强化学习算法在受控环境中表现良好**,但现实世界由于其非静态和开放性质而提出了**独特的挑战**。
+
+因此,开发能够在环境变化面前保持稳健,同时具备向未知但类似的任务和设置转移和适应能力的强化学习算法,对于强化学习在现实世界中的应用变得至关重要。
+
+如果你有兴趣深入研究这个研究主题,我们建议探索以下资源:
+
+- [Robert Kirk的强化学习中的泛化](https://robertkirk.github.io/2022/01/17/generalisation-in-reinforcement-learning-survey.html):这篇全面的综述提供了对**强化学习中泛化概念的深刻见解**,使其成为你探索的绝佳起点。
+
+- [使用策略相似性嵌入改进强化学习中的泛化](https://blog.research.google/2021/09/improving-generalization-in.html?m=1)
+
diff --git a/units/cn/unitbonus3/godotrl.mdx b/units/cn/unitbonus3/godotrl.mdx
new file mode 100644
index 00000000..488b433c
--- /dev/null
+++ b/units/cn/unitbonus3/godotrl.mdx
@@ -0,0 +1,257 @@
+# Godot RL Agents
+
+[Godot RL Agents](https://github.com/edbeeching/godot_rl_agents)是一个开源包,允许视频游戏创作者、AI研究人员和爱好者有机会**为他们的非玩家角色或代理学习复杂行为**。
+
+该库提供:
+
+- 在[Godot引擎](https://godotengine.org/)中创建的游戏与在Python中运行的机器学习算法之间的接口
+- 四个知名rl框架的封装:[StableBaselines3](https://stable-baselines3.readthedocs.io/en/master/)、[CleanRL](https://docs.cleanrl.dev/)、[Sample Factory](https://www.samplefactory.dev/)和[Ray RLLib](https://docs.ray.io/en/latest/rllib-algorithms.html)
+- 支持基于LSTM或注意力机制接口的记忆型代理
+- 支持*2D和3D游戏*
+- 一套*AI传感器*,增强代理观察游戏世界的能力
+- Godot和Godot RL Agents**完全免费,在非常宽松的MIT许可下开源**。没有附加条件,没有版税,什么都没有。
+
+你可以在他们的[GitHub页面](https://github.com/edbeeching/godot_rl_agents)或AAAI-2022研讨会[论文](https://arxiv.org/abs/2112.03636)上了解更多关于Godot RL agents的信息。该库的创建者[Ed Beeching](https://edbeeching.github.io/)是Hugging Face的研究科学家。
+
+安装该库很简单:`pip install godot-rl`
+
+## 使用Godot RL Agents创建自定义RL环境
+
+在本节中,你将**学习如何在Godot游戏引擎中创建自定义环境**,然后实现一个使用深度强化学习学习游戏的AI控制器。
+
+我们今天创建的示例游戏很简单,**但展示了Godot引擎和Godot RL Agents库的许多功能**。然后你可以深入研究更复杂环境和行为的示例。
+
+我们今天要构建的环境叫做Ring Pong,这是一个乒乓球游戏,但球场是一个环形,球拍在环上移动。**目标是保持球在环内弹跳**。
+
+
+
+星际争霸II是一款著名的*即时战略游戏*。DeepMind使用这款游戏进行了他们的深度强化学习研究,开发了[Alphastar](https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii)
+
+要开始使用这个环境,请查看这些资源:
+- [星际争霸gym](http://starcraftgym.com/)
+- [A.I.学习玩星际争霸2(强化学习)教程](https://www.youtube.com/watch?v=q59wap1ELQ4)
+
+## 作者
+
+本节由Thomas Simonini撰写
diff --git a/units/cn/unitbonus3/generalisation.mdx b/units/cn/unitbonus3/generalisation.mdx
new file mode 100644
index 00000000..63ef3c9d
--- /dev/null
+++ b/units/cn/unitbonus3/generalisation.mdx
@@ -0,0 +1,12 @@
+# 强化学习中的泛化
+
+泛化在强化学习领域中扮演着关键角色。虽然**强化学习算法在受控环境中表现良好**,但现实世界由于其非静态和开放性质而提出了**独特的挑战**。
+
+因此,开发能够在环境变化面前保持稳健,同时具备向未知但类似的任务和设置转移和适应能力的强化学习算法,对于强化学习在现实世界中的应用变得至关重要。
+
+如果你有兴趣深入研究这个研究主题,我们建议探索以下资源:
+
+- [Robert Kirk的强化学习中的泛化](https://robertkirk.github.io/2022/01/17/generalisation-in-reinforcement-learning-survey.html):这篇全面的综述提供了对**强化学习中泛化概念的深刻见解**,使其成为你探索的绝佳起点。
+
+- [使用策略相似性嵌入改进强化学习中的泛化](https://blog.research.google/2021/09/improving-generalization-in.html?m=1)
+
diff --git a/units/cn/unitbonus3/godotrl.mdx b/units/cn/unitbonus3/godotrl.mdx
new file mode 100644
index 00000000..488b433c
--- /dev/null
+++ b/units/cn/unitbonus3/godotrl.mdx
@@ -0,0 +1,257 @@
+# Godot RL Agents
+
+[Godot RL Agents](https://github.com/edbeeching/godot_rl_agents)是一个开源包,允许视频游戏创作者、AI研究人员和爱好者有机会**为他们的非玩家角色或代理学习复杂行为**。
+
+该库提供:
+
+- 在[Godot引擎](https://godotengine.org/)中创建的游戏与在Python中运行的机器学习算法之间的接口
+- 四个知名rl框架的封装:[StableBaselines3](https://stable-baselines3.readthedocs.io/en/master/)、[CleanRL](https://docs.cleanrl.dev/)、[Sample Factory](https://www.samplefactory.dev/)和[Ray RLLib](https://docs.ray.io/en/latest/rllib-algorithms.html)
+- 支持基于LSTM或注意力机制接口的记忆型代理
+- 支持*2D和3D游戏*
+- 一套*AI传感器*,增强代理观察游戏世界的能力
+- Godot和Godot RL Agents**完全免费,在非常宽松的MIT许可下开源**。没有附加条件,没有版税,什么都没有。
+
+你可以在他们的[GitHub页面](https://github.com/edbeeching/godot_rl_agents)或AAAI-2022研讨会[论文](https://arxiv.org/abs/2112.03636)上了解更多关于Godot RL agents的信息。该库的创建者[Ed Beeching](https://edbeeching.github.io/)是Hugging Face的研究科学家。
+
+安装该库很简单:`pip install godot-rl`
+
+## 使用Godot RL Agents创建自定义RL环境
+
+在本节中,你将**学习如何在Godot游戏引擎中创建自定义环境**,然后实现一个使用深度强化学习学习游戏的AI控制器。
+
+我们今天创建的示例游戏很简单,**但展示了Godot引擎和Godot RL Agents库的许多功能**。然后你可以深入研究更复杂环境和行为的示例。
+
+我们今天要构建的环境叫做Ring Pong,这是一个乒乓球游戏,但球场是一个环形,球拍在环上移动。**目标是保持球在环内弹跳**。
+
+ +
+### 安装Godot游戏引擎
+
+[Godot游戏引擎](https://godotengine.org/)是一个开源工具,用于**创建视频游戏、工具和用户界面**。
+
+Godot引擎是一个功能丰富的跨平台游戏引擎,旨在从统一界面创建2D和3D游戏。它提供了一套全面的通用工具,因此用户**可以专注于制作游戏,而不必重新发明轮子**。游戏可以一键导出到多个平台,包括主要的桌面平台(Linux、macOS、Windows)以及移动(Android、iOS)和基于网络的(HTML5)平台。
+
+虽然我们将指导你完成实现代理的步骤,但你可能希望了解更多关于Godot游戏引擎的信息。他们的[文档](https://docs.godotengine.org/en/latest/index.html)非常详尽,YouTube上也有许多教程,我们也推荐[GDQuest](https://www.gdquest.com/)、[KidsCanCode](https://kidscancode.org/godot_recipes/4.x/)和[Bramwell](https://www.youtube.com/channel/UCczi7Aq_dTKrQPF5ZV5J3gg)作为信息来源。
+
+为了在Godot中创建游戏,**你必须首先下载编辑器**。Godot RL Agents支持最新版本的Godot,即Godot 4.0。
+
+可以在以下链接下载:
+
+- [Windows](https://downloads.tuxfamily.org/godotengine/4.0.1/Godot_v4.0.1-stable_win64.exe.zip)
+- [Mac](https://downloads.tuxfamily.org/godotengine/4.0.1/Godot_v4.0.1-stable_macos.universal.zip)
+- [Linux](https://downloads.tuxfamily.org/godotengine/4.0.1/Godot_v4.0.1-stable_linux.x86_64.zip)
+
+### 加载初始项目
+
+我们提供两个版本的代码库:
+- [初始项目,下载并跟随本教程](https://drive.google.com/file/d/1C7xd3TibJHlxFEJPBgBLpksgxrFZ3D8e/view?usp=share_link)
+- [项目的最终版本,用于比较和调试](https://drive.google.com/file/d/1k-b2Bu7uIA6poApbouX4c3sq98xqogpZ/view?usp=share_link)
+
+要加载项目,在Godot项目管理器中点击**导入**,导航到文件所在位置并加载**project.godot**文件。
+
+如果你按F5或在编辑器中播放,你应该能够在人类模式下玩游戏。有几个游戏实例在运行,这是因为我们想通过许多并行环境加速训练我们的AI代理。
+
+### 安装Godot RL Agents插件
+
+Godot RL Agents插件可以从Github仓库安装,也可以在编辑器中使用Godot Asset Lib安装。
+
+首先点击AssetLib并搜索"rl"
+
+
+
+### 安装Godot游戏引擎
+
+[Godot游戏引擎](https://godotengine.org/)是一个开源工具,用于**创建视频游戏、工具和用户界面**。
+
+Godot引擎是一个功能丰富的跨平台游戏引擎,旨在从统一界面创建2D和3D游戏。它提供了一套全面的通用工具,因此用户**可以专注于制作游戏,而不必重新发明轮子**。游戏可以一键导出到多个平台,包括主要的桌面平台(Linux、macOS、Windows)以及移动(Android、iOS)和基于网络的(HTML5)平台。
+
+虽然我们将指导你完成实现代理的步骤,但你可能希望了解更多关于Godot游戏引擎的信息。他们的[文档](https://docs.godotengine.org/en/latest/index.html)非常详尽,YouTube上也有许多教程,我们也推荐[GDQuest](https://www.gdquest.com/)、[KidsCanCode](https://kidscancode.org/godot_recipes/4.x/)和[Bramwell](https://www.youtube.com/channel/UCczi7Aq_dTKrQPF5ZV5J3gg)作为信息来源。
+
+为了在Godot中创建游戏,**你必须首先下载编辑器**。Godot RL Agents支持最新版本的Godot,即Godot 4.0。
+
+可以在以下链接下载:
+
+- [Windows](https://downloads.tuxfamily.org/godotengine/4.0.1/Godot_v4.0.1-stable_win64.exe.zip)
+- [Mac](https://downloads.tuxfamily.org/godotengine/4.0.1/Godot_v4.0.1-stable_macos.universal.zip)
+- [Linux](https://downloads.tuxfamily.org/godotengine/4.0.1/Godot_v4.0.1-stable_linux.x86_64.zip)
+
+### 加载初始项目
+
+我们提供两个版本的代码库:
+- [初始项目,下载并跟随本教程](https://drive.google.com/file/d/1C7xd3TibJHlxFEJPBgBLpksgxrFZ3D8e/view?usp=share_link)
+- [项目的最终版本,用于比较和调试](https://drive.google.com/file/d/1k-b2Bu7uIA6poApbouX4c3sq98xqogpZ/view?usp=share_link)
+
+要加载项目,在Godot项目管理器中点击**导入**,导航到文件所在位置并加载**project.godot**文件。
+
+如果你按F5或在编辑器中播放,你应该能够在人类模式下玩游戏。有几个游戏实例在运行,这是因为我们想通过许多并行环境加速训练我们的AI代理。
+
+### 安装Godot RL Agents插件
+
+Godot RL Agents插件可以从Github仓库安装,也可以在编辑器中使用Godot Asset Lib安装。
+
+首先点击AssetLib并搜索"rl"
+
+ +
+然后点击Godot RL Agents,点击下载并取消选择LICENSE和README .md文件。然后点击安装。
+
+
+
+然后点击Godot RL Agents,点击下载并取消选择LICENSE和README .md文件。然后点击安装。
+
+ +
+
+Godot RL Agents插件现已下载到你的机器上。现在点击项目→项目设置并启用插件:
+
+
+
+
+Godot RL Agents插件现已下载到你的机器上。现在点击项目→项目设置并启用插件:
+
+ +
+
+### 添加AI控制器
+
+我们现在想为我们的游戏添加一个AI控制器。打开player.tscn场景,在左侧你应该看到一个节点层次结构,如下所示:
+
+
+
+
+### 添加AI控制器
+
+我们现在想为我们的游戏添加一个AI控制器。打开player.tscn场景,在左侧你应该看到一个节点层次结构,如下所示:
+
+ +
+右键点击**Player**节点并点击**添加子节点**。这里列出了许多节点,搜索AIController3D并创建它。
+
+
+
+右键点击**Player**节点并点击**添加子节点**。这里列出了许多节点,搜索AIController3D并创建它。
+
+ +
+AI控制器节点应该已添加到场景树中,旁边有一个滚动条。点击它打开附加到AIController的脚本。Godot游戏引擎使用一种称为GDScript的脚本语言,其语法类似于python。该脚本包含需要实现的方法,以使我们的AI控制器工作。
+
+```python
+#-- Methods that need implementing using the "extend script" option in Godot --#
+func get_obs() -> Dictionary:
+ assert(false, "the get_obs method is not implemented when extending from ai_controller")
+ return {"obs":[]}
+
+func get_reward() -> float:
+ assert(false, "the get_reward method is not implemented when extending from ai_controller")
+ return 0.0
+
+func get_action_space() -> Dictionary:
+ assert(false, "the get get_action_space method is not implemented when extending from ai_controller")
+ return {
+ "example_actions_continous" : {
+ "size": 2,
+ "action_type": "continuous"
+ },
+ "example_actions_discrete" : {
+ "size": 2,
+ "action_type": "discrete"
+ },
+ }
+
+func set_action(action) -> void:
+ assert(false, "the get set_action method is not implemented when extending from ai_controller")
+# -----------------------------------------------------------------------------#
+```
+
+为了实现这些方法,我们需要创建一个继承自AIController3D的类。这在Godot中很容易做到,称为"扩展"一个类。
+
+右键点击AIController3D节点并点击"扩展脚本",将新脚本命名为`controller.gd`。你现在应该有一个几乎空的脚本文件,如下所示:
+
+```python
+extends AIController3D
+
+# Called when the node enters the scene tree for the first time.
+func _ready():
+ pass # Replace with function body.
+
+# Called every frame. 'delta' is the elapsed time since the previous frame.
+func _process(delta):
+ pass
+```
+
+我们现在将实现4个缺失的方法,删除这段代码,并用以下内容替换:
+
+```python
+extends AIController3D
+
+# Stores the action sampled for the agent's policy, running in python
+var move_action : float = 0.0
+
+func get_obs() -> Dictionary:
+ # get the balls position and velocity in the paddle's frame of reference
+ var ball_pos = to_local(_player.ball.global_position)
+ var ball_vel = to_local(_player.ball.linear_velocity)
+ var obs = [ball_pos.x, ball_pos.z, ball_vel.x/10.0, ball_vel.z/10.0]
+
+ return {"obs":obs}
+
+func get_reward() -> float:
+ return reward
+
+func get_action_space() -> Dictionary:
+ return {
+ "move_action" : {
+ "size": 1,
+ "action_type": "continuous"
+ },
+ }
+
+func set_action(action) -> void:
+ move_action = clamp(action["move_action"][0], -1.0, 1.0)
+```
+
+我们现在已经定义了代理的观察,即球在其局部坐标空间中的位置和速度。我们还定义了代理的动作空间,这是一个范围从-1到+1的单一连续值。
+
+下一步是更新Player的脚本以使用AIController的动作,通过点击player节点旁边的滚动条编辑Player的脚本,将`Player.gd`中的代码更新为以下内容:
+
+```python
+extends Node3D
+
+@export var rotation_speed = 3.0
+@onready var ball = get_node("../Ball")
+@onready var ai_controller = $AIController3D
+
+func _ready():
+ ai_controller.init(self)
+
+func game_over():
+ ai_controller.done = true
+ ai_controller.needs_reset = true
+
+func _physics_process(delta):
+ if ai_controller.needs_reset:
+ ai_controller.reset()
+ ball.reset()
+ return
+
+ var movement : float
+ if ai_controller.heuristic == "human":
+ movement = Input.get_axis("rotate_anticlockwise", "rotate_clockwise")
+ else:
+ movement = ai_controller.move_action
+ rotate_y(movement*delta*rotation_speed)
+
+func _on_area_3d_body_entered(body):
+ ai_controller.reward += 1.0
+```
+
+我们现在需要在Godot中运行的游戏和在Python中训练的神经网络之间进行同步。Godot RL agents提供了一个节点来完成这个任务。打开train.tscn场景,右键点击根节点,然后点击"添加子节点"。然后,搜索"sync"并添加一个Godot RL Agents Sync节点。这个节点通过TCP处理Python和Godot之间的通信。
+
+你可以通过首先使用`gdrl`启动python训练,在编辑器中实时运行训练。
+
+在这个简单的例子中,几分钟内就能学习到一个合理的策略。你可能希望加速训练,点击train场景中的Sync节点,你会看到编辑器中暴露了一个"Speed Up"属性:
+
+
+
+AI控制器节点应该已添加到场景树中,旁边有一个滚动条。点击它打开附加到AIController的脚本。Godot游戏引擎使用一种称为GDScript的脚本语言,其语法类似于python。该脚本包含需要实现的方法,以使我们的AI控制器工作。
+
+```python
+#-- Methods that need implementing using the "extend script" option in Godot --#
+func get_obs() -> Dictionary:
+ assert(false, "the get_obs method is not implemented when extending from ai_controller")
+ return {"obs":[]}
+
+func get_reward() -> float:
+ assert(false, "the get_reward method is not implemented when extending from ai_controller")
+ return 0.0
+
+func get_action_space() -> Dictionary:
+ assert(false, "the get get_action_space method is not implemented when extending from ai_controller")
+ return {
+ "example_actions_continous" : {
+ "size": 2,
+ "action_type": "continuous"
+ },
+ "example_actions_discrete" : {
+ "size": 2,
+ "action_type": "discrete"
+ },
+ }
+
+func set_action(action) -> void:
+ assert(false, "the get set_action method is not implemented when extending from ai_controller")
+# -----------------------------------------------------------------------------#
+```
+
+为了实现这些方法,我们需要创建一个继承自AIController3D的类。这在Godot中很容易做到,称为"扩展"一个类。
+
+右键点击AIController3D节点并点击"扩展脚本",将新脚本命名为`controller.gd`。你现在应该有一个几乎空的脚本文件,如下所示:
+
+```python
+extends AIController3D
+
+# Called when the node enters the scene tree for the first time.
+func _ready():
+ pass # Replace with function body.
+
+# Called every frame. 'delta' is the elapsed time since the previous frame.
+func _process(delta):
+ pass
+```
+
+我们现在将实现4个缺失的方法,删除这段代码,并用以下内容替换:
+
+```python
+extends AIController3D
+
+# Stores the action sampled for the agent's policy, running in python
+var move_action : float = 0.0
+
+func get_obs() -> Dictionary:
+ # get the balls position and velocity in the paddle's frame of reference
+ var ball_pos = to_local(_player.ball.global_position)
+ var ball_vel = to_local(_player.ball.linear_velocity)
+ var obs = [ball_pos.x, ball_pos.z, ball_vel.x/10.0, ball_vel.z/10.0]
+
+ return {"obs":obs}
+
+func get_reward() -> float:
+ return reward
+
+func get_action_space() -> Dictionary:
+ return {
+ "move_action" : {
+ "size": 1,
+ "action_type": "continuous"
+ },
+ }
+
+func set_action(action) -> void:
+ move_action = clamp(action["move_action"][0], -1.0, 1.0)
+```
+
+我们现在已经定义了代理的观察,即球在其局部坐标空间中的位置和速度。我们还定义了代理的动作空间,这是一个范围从-1到+1的单一连续值。
+
+下一步是更新Player的脚本以使用AIController的动作,通过点击player节点旁边的滚动条编辑Player的脚本,将`Player.gd`中的代码更新为以下内容:
+
+```python
+extends Node3D
+
+@export var rotation_speed = 3.0
+@onready var ball = get_node("../Ball")
+@onready var ai_controller = $AIController3D
+
+func _ready():
+ ai_controller.init(self)
+
+func game_over():
+ ai_controller.done = true
+ ai_controller.needs_reset = true
+
+func _physics_process(delta):
+ if ai_controller.needs_reset:
+ ai_controller.reset()
+ ball.reset()
+ return
+
+ var movement : float
+ if ai_controller.heuristic == "human":
+ movement = Input.get_axis("rotate_anticlockwise", "rotate_clockwise")
+ else:
+ movement = ai_controller.move_action
+ rotate_y(movement*delta*rotation_speed)
+
+func _on_area_3d_body_entered(body):
+ ai_controller.reward += 1.0
+```
+
+我们现在需要在Godot中运行的游戏和在Python中训练的神经网络之间进行同步。Godot RL agents提供了一个节点来完成这个任务。打开train.tscn场景,右键点击根节点,然后点击"添加子节点"。然后,搜索"sync"并添加一个Godot RL Agents Sync节点。这个节点通过TCP处理Python和Godot之间的通信。
+
+你可以通过首先使用`gdrl`启动python训练,在编辑器中实时运行训练。
+
+在这个简单的例子中,几分钟内就能学习到一个合理的策略。你可能希望加速训练,点击train场景中的Sync节点,你会看到编辑器中暴露了一个"Speed Up"属性:
+
+ +
+尝试将此属性设置为最高8以加速训练。这对更复杂的环境(如我们将在下一章学习的多人FPS)可能是一个很大的好处。
+
+### 导出模型
+
+[参考文档](https://github.com/edbeeching/godot_rl_agents/tree/main?tab=readme-ov-file#exporting-and-loading-your-trained-agent-in-onnx-format)
+
+现在让我们暂时放下Godot编辑器。我们需要使用终端运行一些命令来保存我们训练的模型。
+
+Godot RL库的最新版本为Stable Baselines 3、rllib和CleanRL训练框架提供了onnx模型的实验性支持。
+
+例如,让我们使用Stable Baselines 3作为框架。使用[sb3示例](https://github.com/edbeeching/godot_rl_agents/blob/main/examples/stable_baselines3_example.py)训练你的代理([使用脚本的说明](https://github.com/edbeeching/godot_rl_agents/blob/main/docs/ADV_STABLE_BASELINES_3.md#train-a-model-from-scratch)),启用选项`--onnx_export_path=model.onnx`
+
+以下是要执行的命令行示例:
+
+```bash
+cd <....> # 进入这个Godot项目目录
+python stable_baselines3_example.py --timesteps=100_000 --onnx_export_path=model.onnx --save_model_path=model.zip --save_checkpoint_frequency=20_000 --experiment_name=exp1
+```
+
+如果一切正常,你应该在终端中看到如下消息:
+
+```
+No game binary has been provided, please press PLAY in the Godot editor
+waiting for remote GODOT connection on port 11008
+```
+
+> 如果你在stable_baselines3_example脚本中遇到导入错误:"ImportError: cannot import name 'export_model_as_onnx' from 'godot_rl.wrappers.onnx.stable_baselines_export'",请参考[此问题](https://github.com/edbeeching/godot_rl_agents/issues/203)中的答案。
+
+现在是时候回到Godot编辑器,并点击右上角的PLAY。一旦你点击它,游戏场景将弹出显示AI训练。同时,终端将开始打印指标。等待训练完成,如果一切正常,你应该能够在Godot项目目录中找到文件`model.onnx`。
+
+### 在游戏中应用AI!
+
+现在让我们将这个训练好的模型应用到游戏中!
+
+在Godot编辑器中,找到`train.tscn`中的Sync节点:
+
+* 从下拉菜单中将控制模式更改为`Onnx Inference`
+* 将`Onnx Model Path`设置为模型文件名,在我们的例子中是`model.onnx`
+
+要运行这个游戏,我们需要mono版本(即.NET版本)的Godot编辑器,你可以从Godot官方页面下载。我们还需要安装[.NET](https://dotnet.microsoft.com/en-us/download)。
+
+在第一次尝试时,你很可能会遇到错误。以下是帮助你解决错误的场景。
+
+1. 关于`Invalid Call. Nonexistent function 'new' in base 'CSharpScript'`的问题:[解决方案](https://github.com/edbeeching/godot_rl_agents/blob/main/docs/TROUBLESHOOTING.md)
+2. 关于MacOS上`onnxruntime`的错误:[解决方案](https://github.com/microsoft/onnxruntime/issues/9707)
+
+
+### 还有更多!
+
+我们只是触及了Godot RL Agents可以实现的表面,该库包括自定义传感器和摄像机,以丰富代理可用的信息。查看[示例](https://github.com/edbeeching/godot_rl_agents_examples)了解更多!
+
+关于将训练好的模型导出为.onnx的能力,以便你可以直接从Godot运行推理而无需Python服务器,以及其他有用的训练选项,请查看[高级SB3教程](https://github.com/edbeeching/godot_rl_agents/blob/main/docs/ADV_STABLE_BASELINES_3.md)。
+
+## 作者
+
+本节由Edward Beeching撰写
diff --git a/units/cn/unitbonus3/introduction.mdx b/units/cn/unitbonus3/introduction.mdx
new file mode 100644
index 00000000..693722b2
--- /dev/null
+++ b/units/cn/unitbonus3/introduction.mdx
@@ -0,0 +1,11 @@
+# 介绍
+
+
+
+尝试将此属性设置为最高8以加速训练。这对更复杂的环境(如我们将在下一章学习的多人FPS)可能是一个很大的好处。
+
+### 导出模型
+
+[参考文档](https://github.com/edbeeching/godot_rl_agents/tree/main?tab=readme-ov-file#exporting-and-loading-your-trained-agent-in-onnx-format)
+
+现在让我们暂时放下Godot编辑器。我们需要使用终端运行一些命令来保存我们训练的模型。
+
+Godot RL库的最新版本为Stable Baselines 3、rllib和CleanRL训练框架提供了onnx模型的实验性支持。
+
+例如,让我们使用Stable Baselines 3作为框架。使用[sb3示例](https://github.com/edbeeching/godot_rl_agents/blob/main/examples/stable_baselines3_example.py)训练你的代理([使用脚本的说明](https://github.com/edbeeching/godot_rl_agents/blob/main/docs/ADV_STABLE_BASELINES_3.md#train-a-model-from-scratch)),启用选项`--onnx_export_path=model.onnx`
+
+以下是要执行的命令行示例:
+
+```bash
+cd <....> # 进入这个Godot项目目录
+python stable_baselines3_example.py --timesteps=100_000 --onnx_export_path=model.onnx --save_model_path=model.zip --save_checkpoint_frequency=20_000 --experiment_name=exp1
+```
+
+如果一切正常,你应该在终端中看到如下消息:
+
+```
+No game binary has been provided, please press PLAY in the Godot editor
+waiting for remote GODOT connection on port 11008
+```
+
+> 如果你在stable_baselines3_example脚本中遇到导入错误:"ImportError: cannot import name 'export_model_as_onnx' from 'godot_rl.wrappers.onnx.stable_baselines_export'",请参考[此问题](https://github.com/edbeeching/godot_rl_agents/issues/203)中的答案。
+
+现在是时候回到Godot编辑器,并点击右上角的PLAY。一旦你点击它,游戏场景将弹出显示AI训练。同时,终端将开始打印指标。等待训练完成,如果一切正常,你应该能够在Godot项目目录中找到文件`model.onnx`。
+
+### 在游戏中应用AI!
+
+现在让我们将这个训练好的模型应用到游戏中!
+
+在Godot编辑器中,找到`train.tscn`中的Sync节点:
+
+* 从下拉菜单中将控制模式更改为`Onnx Inference`
+* 将`Onnx Model Path`设置为模型文件名,在我们的例子中是`model.onnx`
+
+要运行这个游戏,我们需要mono版本(即.NET版本)的Godot编辑器,你可以从Godot官方页面下载。我们还需要安装[.NET](https://dotnet.microsoft.com/en-us/download)。
+
+在第一次尝试时,你很可能会遇到错误。以下是帮助你解决错误的场景。
+
+1. 关于`Invalid Call. Nonexistent function 'new' in base 'CSharpScript'`的问题:[解决方案](https://github.com/edbeeching/godot_rl_agents/blob/main/docs/TROUBLESHOOTING.md)
+2. 关于MacOS上`onnxruntime`的错误:[解决方案](https://github.com/microsoft/onnxruntime/issues/9707)
+
+
+### 还有更多!
+
+我们只是触及了Godot RL Agents可以实现的表面,该库包括自定义传感器和摄像机,以丰富代理可用的信息。查看[示例](https://github.com/edbeeching/godot_rl_agents_examples)了解更多!
+
+关于将训练好的模型导出为.onnx的能力,以便你可以直接从Godot运行推理而无需Python服务器,以及其他有用的训练选项,请查看[高级SB3教程](https://github.com/edbeeching/godot_rl_agents/blob/main/docs/ADV_STABLE_BASELINES_3.md)。
+
+## 作者
+
+本节由Edward Beeching撰写
diff --git a/units/cn/unitbonus3/introduction.mdx b/units/cn/unitbonus3/introduction.mdx
new file mode 100644
index 00000000..693722b2
--- /dev/null
+++ b/units/cn/unitbonus3/introduction.mdx
@@ -0,0 +1,11 @@
+# 介绍
+
+ +
+
+恭喜你完成本课程!**你现在已经具备了深度强化学习的坚实背景知识**。
+但这门课程只是你深度强化学习旅程的开始,还有很多子领域等待你去探索。在这个可选单元中,我们**为你提供资源,以探索强化学习中的多种概念和研究主题**。
+
+与其他单元不同,本单元是Hugging Face多位成员的集体作品。我们会在每个单元中提及作者。
+
+听起来很有趣吧?让我们开始吧🔥,
diff --git a/units/cn/unitbonus3/language-models.mdx b/units/cn/unitbonus3/language-models.mdx
new file mode 100644
index 00000000..3ea05681
--- /dev/null
+++ b/units/cn/unitbonus3/language-models.mdx
@@ -0,0 +1,45 @@
+# 强化学习中的语言模型
+## 语言模型为代理编码有用的知识
+
+**语言模型**(LMs)在处理文本时可以展现出令人印象深刻的能力,如问答甚至是逐步推理。此外,它们在海量文本语料库上的训练使它们**编码了各种类型的知识,包括关于我们世界物理规则的抽象知识**(例如可以用物体做什么,旋转物体时会发生什么等)。
+
+最近研究的一个自然问题是,这种知识是否可以使像机器人这样的代理在尝试解决日常任务时受益。虽然这些工作显示了有趣的结果,但所提出的代理缺乏任何学习方法。**这一限制阻止了这些代理适应环境(例如修正错误的知识)或学习新技能。**
+
+
+
+
+
+恭喜你完成本课程!**你现在已经具备了深度强化学习的坚实背景知识**。
+但这门课程只是你深度强化学习旅程的开始,还有很多子领域等待你去探索。在这个可选单元中,我们**为你提供资源,以探索强化学习中的多种概念和研究主题**。
+
+与其他单元不同,本单元是Hugging Face多位成员的集体作品。我们会在每个单元中提及作者。
+
+听起来很有趣吧?让我们开始吧🔥,
diff --git a/units/cn/unitbonus3/language-models.mdx b/units/cn/unitbonus3/language-models.mdx
new file mode 100644
index 00000000..3ea05681
--- /dev/null
+++ b/units/cn/unitbonus3/language-models.mdx
@@ -0,0 +1,45 @@
+# 强化学习中的语言模型
+## 语言模型为代理编码有用的知识
+
+**语言模型**(LMs)在处理文本时可以展现出令人印象深刻的能力,如问答甚至是逐步推理。此外,它们在海量文本语料库上的训练使它们**编码了各种类型的知识,包括关于我们世界物理规则的抽象知识**(例如可以用物体做什么,旋转物体时会发生什么等)。
+
+最近研究的一个自然问题是,这种知识是否可以使像机器人这样的代理在尝试解决日常任务时受益。虽然这些工作显示了有趣的结果,但所提出的代理缺乏任何学习方法。**这一限制阻止了这些代理适应环境(例如修正错误的知识)或学习新技能。**
+
+
+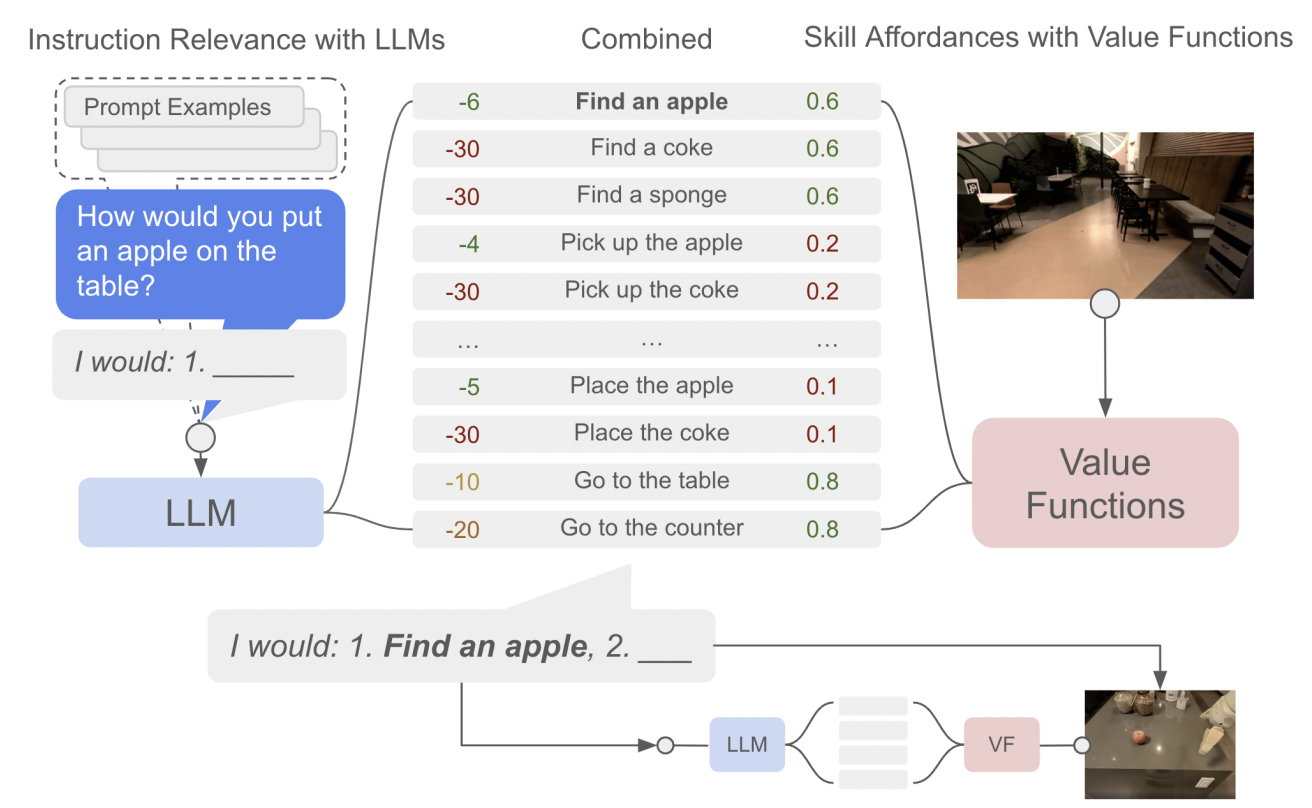 +来源:Towards Helpful Robots: Grounding Language in Robotic Affordances
+
+
+## 语言模型与强化学习
+
+因此,语言模型可以带来关于世界的知识,而强化学习可以通过与环境交互来调整和纠正这些知识,两者之间存在潜在的协同作用。从强化学习的角度来看,这尤其有趣,因为强化学习领域主要依赖于**白板设置**,即代理从头开始学习一切,这导致:
+
+1) 样本效率低下
+
+2) 从人类角度看出现意外行为
+
+作为第一次尝试,论文["Grounding Large Language Models with Online Reinforcement Learning"](https://arxiv.org/abs/2302.02662v1)解决了**使用PPO将语言模型适应或对齐到文本环境的问题**。他们表明,语言模型中编码的知识导致了对环境的快速适应(为样本高效的强化学习代理开辟了道路),而且这种知识一旦对齐,还允许语言模型更好地泛化到新任务。
+
+
+
+["Guiding Pretraining in Reinforcement Learning with Large Language Models"](https://arxiv.org/abs/2302.06692)研究的另一个方向是保持语言模型冻结,但利用其知识来**指导强化学习代理的探索**。这种方法允许强化学习代理被引导到对人类有意义且可能有用的行为,而无需在训练过程中有人类参与。
+
+
+
+来源:Towards Helpful Robots: Grounding Language in Robotic Affordances
+
+
+## 语言模型与强化学习
+
+因此,语言模型可以带来关于世界的知识,而强化学习可以通过与环境交互来调整和纠正这些知识,两者之间存在潜在的协同作用。从强化学习的角度来看,这尤其有趣,因为强化学习领域主要依赖于**白板设置**,即代理从头开始学习一切,这导致:
+
+1) 样本效率低下
+
+2) 从人类角度看出现意外行为
+
+作为第一次尝试,论文["Grounding Large Language Models with Online Reinforcement Learning"](https://arxiv.org/abs/2302.02662v1)解决了**使用PPO将语言模型适应或对齐到文本环境的问题**。他们表明,语言模型中编码的知识导致了对环境的快速适应(为样本高效的强化学习代理开辟了道路),而且这种知识一旦对齐,还允许语言模型更好地泛化到新任务。
+
+
+
+["Guiding Pretraining in Reinforcement Learning with Large Language Models"](https://arxiv.org/abs/2302.06692)研究的另一个方向是保持语言模型冻结,但利用其知识来**指导强化学习代理的探索**。这种方法允许强化学习代理被引导到对人类有意义且可能有用的行为,而无需在训练过程中有人类参与。
+
+
+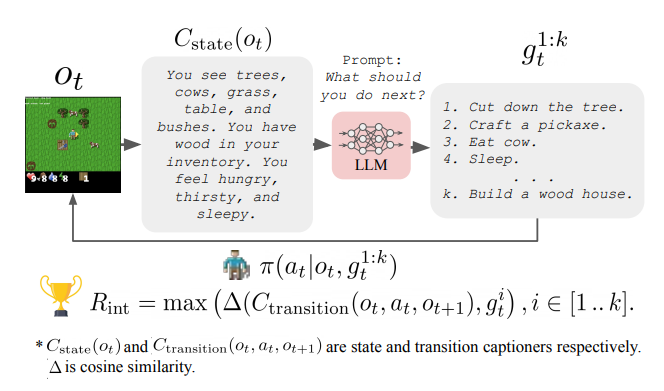 + 来源: Towards Helpful Robots: Grounding Language in Robotic Affordances
+
+
+几个限制使这些工作仍然非常初步,例如需要将代理的观察转换为文本后再给语言模型,以及与非常大的语言模型交互的计算成本。
+
+## 进一步阅读
+
+欲了解更多信息,我们建议你查看以下资源:
+
+- [Google Research, 2022 & beyond: Robotics](https://ai.googleblog.com/2023/02/google-research-2022-beyond-robotics.html)
+- [Pre-Trained Language Models for Interactive Decision-Making](https://arxiv.org/abs/2202.01771)
+- [Grounding Large Language Models with Online Reinforcement Learning](https://arxiv.org/abs/2302.02662v1)
+- [Guiding Pretraining in Reinforcement Learning with Large Language Models](https://arxiv.org/abs/2302.06692)
+
+## 作者
+
+本节由 Clément Romac 撰写
diff --git a/units/cn/unitbonus3/learning-agents.mdx b/units/cn/unitbonus3/learning-agents.mdx
new file mode 100644
index 00000000..ef6f2b25
--- /dev/null
+++ b/units/cn/unitbonus3/learning-agents.mdx
@@ -0,0 +1,37 @@
+# 虚幻引擎学习代理简介
+
+[学习代理](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction)是一个虚幻引擎(UE)插件,允许你**在虚幻引擎中使用机器学习(ML)训练AI角色**。
+
+这是一个令人兴奋的新插件,你可以使用虚幻引擎创建独特的环境并训练你的代理。
+
+让我们看看你如何**开始并训练一辆汽车在虚幻引擎环境中驾驶**。
+
+
+
+ 来源: Towards Helpful Robots: Grounding Language in Robotic Affordances
+
+
+几个限制使这些工作仍然非常初步,例如需要将代理的观察转换为文本后再给语言模型,以及与非常大的语言模型交互的计算成本。
+
+## 进一步阅读
+
+欲了解更多信息,我们建议你查看以下资源:
+
+- [Google Research, 2022 & beyond: Robotics](https://ai.googleblog.com/2023/02/google-research-2022-beyond-robotics.html)
+- [Pre-Trained Language Models for Interactive Decision-Making](https://arxiv.org/abs/2202.01771)
+- [Grounding Large Language Models with Online Reinforcement Learning](https://arxiv.org/abs/2302.02662v1)
+- [Guiding Pretraining in Reinforcement Learning with Large Language Models](https://arxiv.org/abs/2302.06692)
+
+## 作者
+
+本节由 Clément Romac 撰写
diff --git a/units/cn/unitbonus3/learning-agents.mdx b/units/cn/unitbonus3/learning-agents.mdx
new file mode 100644
index 00000000..ef6f2b25
--- /dev/null
+++ b/units/cn/unitbonus3/learning-agents.mdx
@@ -0,0 +1,37 @@
+# 虚幻引擎学习代理简介
+
+[学习代理](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction)是一个虚幻引擎(UE)插件,允许你**在虚幻引擎中使用机器学习(ML)训练AI角色**。
+
+这是一个令人兴奋的新插件,你可以使用虚幻引擎创建独特的环境并训练你的代理。
+
+让我们看看你如何**开始并训练一辆汽车在虚幻引擎环境中驾驶**。
+
+
+ +来源:[学习代理驾驶汽车教程](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive)
+
+
+## 情况1:我对虚幻引擎一无所知,是虚幻引擎的初学者
+如果你是虚幻引擎的新手,不要害怕!我们列出了两门你需要学习的课程,以便能够使用学习代理:
+
+1. 掌握基础知识:首先观看这门课程[在虚幻引擎5中的第一个小时](https://dev.epicgames.com/community/learning/courses/ZpX/your-first-hour-in-unreal-engine-5/E7L/introduction-to-your-first-hour-in-unreal-engine-5)。这门全面的课程将**奠定你使用虚幻引擎所需的基础知识**。
+
+2. 深入了解蓝图:探索虚幻引擎的视觉脚本组件——蓝图的世界。[这个视频课程](https://youtu.be/W0brCeJNMqk?si=zy4t4t1l6FMIzbpz)将使你熟悉这个基本工具。
+
+掌握了基础知识后,**你现在已准备好使用学习代理**:
+
+3. 通过[阅读这个信息概述](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction)了解学习代理的大局。
+
+4. [使用强化学习在学习代理中教汽车驾驶](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive)。
+
+5. [查看虚幻引擎5.3学习代理插件中的模仿学习](https://www.youtube.com/watch?v=NwYUNlFvajQ)
+
+## 情况2:我熟悉虚幻引擎
+
+对于已经熟悉虚幻引擎的人,你可以直接通过这两个教程开始使用学习代理:
+
+1. 通过[阅读这个信息概述](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction)了解学习代理的大局。
+
+2. [使用强化学习在学习代理中教汽车驾驶](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive)。
+
+3. [查看虚幻引擎5.3学习代理插件中的模仿学习](https://www.youtube.com/watch?v=NwYUNlFvajQ)
\ No newline at end of file
diff --git a/units/cn/unitbonus3/model-based.mdx b/units/cn/unitbonus3/model-based.mdx
new file mode 100644
index 00000000..cbcbecee
--- /dev/null
+++ b/units/cn/unitbonus3/model-based.mdx
@@ -0,0 +1,32 @@
+# 基于模型的强化学习 (MBRL)
+
+基于模型的强化学习与其无模型对应物的唯一区别在于学习一个*动态模型*,但这对决策方式产生了重大的下游影响。
+
+动态模型通常对环境转换动态进行建模,\\( s_{t+1} = f_\theta (s_t, a_t) \\),但在这个框架中也可以使用逆动态模型(从状态映射到动作)或奖励模型(预测奖励)等。
+
+
+## 简单定义
+
+- 有一个智能体反复尝试解决问题,**积累状态和动作数据**。
+- 利用这些数据,智能体创建一个结构化学习工具,*动态模型*,用于推理世界。
+- 通过动态模型,智能体**通过预测未来来决定如何行动**。
+- 通过这些行动,**智能体收集更多数据,改进模型,并有望改进未来的行动**。
+
+## 学术定义
+
+基于模型的强化学习(MBRL)遵循智能体在环境中交互的框架,**学习该环境的模型**,然后**利用该模型进行控制(做决策)**。
+
+具体来说,智能体在由转换函数\\( s_{t+1} = f (s_t , a_t) \\)控制的马尔可夫决策过程(MDP)中行动,并在每一步返回奖励\\( r(s_t, a_t) \\)。通过收集的数据集\\( D := \{s_i, a_i, s_{i+1}, r_i\} \\),智能体学习一个模型\\( s_{t+1} = f_\theta (s_t , a_t) \\) **以最小化转换的负对数似然**。
+
+我们使用基于学习的动态模型的基于样本的模型预测控制(MPC),该方法优化从均匀分布\\( U(a) \\)采样的一组动作在有限递归预测范围\\( \tau \\)上的期望奖励(参见[论文](https://arxiv.org/pdf/2002.04523)或[论文](https://arxiv.org/pdf/2012.09156.pdf)或[论文](https://arxiv.org/pdf/2009.01221.pdf))。
+
+## 进一步阅读
+
+有关MBRL的更多信息,我们建议您查看以下资源:
+
+- 一篇关于[调试MBRL的博客文章](https://www.natolambert.com/writing/debugging-mbrl)。
+- 一篇[关于MBRL的最新综述论文](https://arxiv.org/abs/2006.16712)。
+
+## 作者
+
+本节由 Nathan Lambert 撰写
diff --git a/units/cn/unitbonus3/offline-online.mdx b/units/cn/unitbonus3/offline-online.mdx
new file mode 100644
index 00000000..05d6d0b6
--- /dev/null
+++ b/units/cn/unitbonus3/offline-online.mdx
@@ -0,0 +1,37 @@
+# 离线与在线强化学习
+
+深度强化学习(RL)是一个**构建决策智能体的框架**。这些智能体旨在通过**尝试错误与环境交互并接收奖励作为唯一反馈**来学习最优行为(策略)。
+
+智能体的目标是**最大化其累积奖励**,称为回报。因为RL基于*奖励假设*:所有目标都可以描述为**期望累积奖励的最大化**。
+
+深度强化学习智能体**通过经验批次学习**。问题是,它们如何收集这些经验?:
+
+
+
+来源:[学习代理驾驶汽车教程](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive)
+
+
+## 情况1:我对虚幻引擎一无所知,是虚幻引擎的初学者
+如果你是虚幻引擎的新手,不要害怕!我们列出了两门你需要学习的课程,以便能够使用学习代理:
+
+1. 掌握基础知识:首先观看这门课程[在虚幻引擎5中的第一个小时](https://dev.epicgames.com/community/learning/courses/ZpX/your-first-hour-in-unreal-engine-5/E7L/introduction-to-your-first-hour-in-unreal-engine-5)。这门全面的课程将**奠定你使用虚幻引擎所需的基础知识**。
+
+2. 深入了解蓝图:探索虚幻引擎的视觉脚本组件——蓝图的世界。[这个视频课程](https://youtu.be/W0brCeJNMqk?si=zy4t4t1l6FMIzbpz)将使你熟悉这个基本工具。
+
+掌握了基础知识后,**你现在已准备好使用学习代理**:
+
+3. 通过[阅读这个信息概述](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction)了解学习代理的大局。
+
+4. [使用强化学习在学习代理中教汽车驾驶](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive)。
+
+5. [查看虚幻引擎5.3学习代理插件中的模仿学习](https://www.youtube.com/watch?v=NwYUNlFvajQ)
+
+## 情况2:我熟悉虚幻引擎
+
+对于已经熟悉虚幻引擎的人,你可以直接通过这两个教程开始使用学习代理:
+
+1. 通过[阅读这个信息概述](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction)了解学习代理的大局。
+
+2. [使用强化学习在学习代理中教汽车驾驶](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive)。
+
+3. [查看虚幻引擎5.3学习代理插件中的模仿学习](https://www.youtube.com/watch?v=NwYUNlFvajQ)
\ No newline at end of file
diff --git a/units/cn/unitbonus3/model-based.mdx b/units/cn/unitbonus3/model-based.mdx
new file mode 100644
index 00000000..cbcbecee
--- /dev/null
+++ b/units/cn/unitbonus3/model-based.mdx
@@ -0,0 +1,32 @@
+# 基于模型的强化学习 (MBRL)
+
+基于模型的强化学习与其无模型对应物的唯一区别在于学习一个*动态模型*,但这对决策方式产生了重大的下游影响。
+
+动态模型通常对环境转换动态进行建模,\\( s_{t+1} = f_\theta (s_t, a_t) \\),但在这个框架中也可以使用逆动态模型(从状态映射到动作)或奖励模型(预测奖励)等。
+
+
+## 简单定义
+
+- 有一个智能体反复尝试解决问题,**积累状态和动作数据**。
+- 利用这些数据,智能体创建一个结构化学习工具,*动态模型*,用于推理世界。
+- 通过动态模型,智能体**通过预测未来来决定如何行动**。
+- 通过这些行动,**智能体收集更多数据,改进模型,并有望改进未来的行动**。
+
+## 学术定义
+
+基于模型的强化学习(MBRL)遵循智能体在环境中交互的框架,**学习该环境的模型**,然后**利用该模型进行控制(做决策)**。
+
+具体来说,智能体在由转换函数\\( s_{t+1} = f (s_t , a_t) \\)控制的马尔可夫决策过程(MDP)中行动,并在每一步返回奖励\\( r(s_t, a_t) \\)。通过收集的数据集\\( D := \{s_i, a_i, s_{i+1}, r_i\} \\),智能体学习一个模型\\( s_{t+1} = f_\theta (s_t , a_t) \\) **以最小化转换的负对数似然**。
+
+我们使用基于学习的动态模型的基于样本的模型预测控制(MPC),该方法优化从均匀分布\\( U(a) \\)采样的一组动作在有限递归预测范围\\( \tau \\)上的期望奖励(参见[论文](https://arxiv.org/pdf/2002.04523)或[论文](https://arxiv.org/pdf/2012.09156.pdf)或[论文](https://arxiv.org/pdf/2009.01221.pdf))。
+
+## 进一步阅读
+
+有关MBRL的更多信息,我们建议您查看以下资源:
+
+- 一篇关于[调试MBRL的博客文章](https://www.natolambert.com/writing/debugging-mbrl)。
+- 一篇[关于MBRL的最新综述论文](https://arxiv.org/abs/2006.16712)。
+
+## 作者
+
+本节由 Nathan Lambert 撰写
diff --git a/units/cn/unitbonus3/offline-online.mdx b/units/cn/unitbonus3/offline-online.mdx
new file mode 100644
index 00000000..05d6d0b6
--- /dev/null
+++ b/units/cn/unitbonus3/offline-online.mdx
@@ -0,0 +1,37 @@
+# 离线与在线强化学习
+
+深度强化学习(RL)是一个**构建决策智能体的框架**。这些智能体旨在通过**尝试错误与环境交互并接收奖励作为唯一反馈**来学习最优行为(策略)。
+
+智能体的目标是**最大化其累积奖励**,称为回报。因为RL基于*奖励假设*:所有目标都可以描述为**期望累积奖励的最大化**。
+
+深度强化学习智能体**通过经验批次学习**。问题是,它们如何收集这些经验?:
+
+
+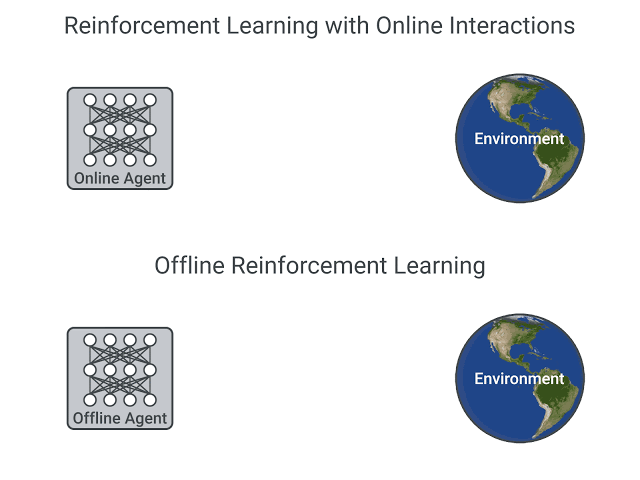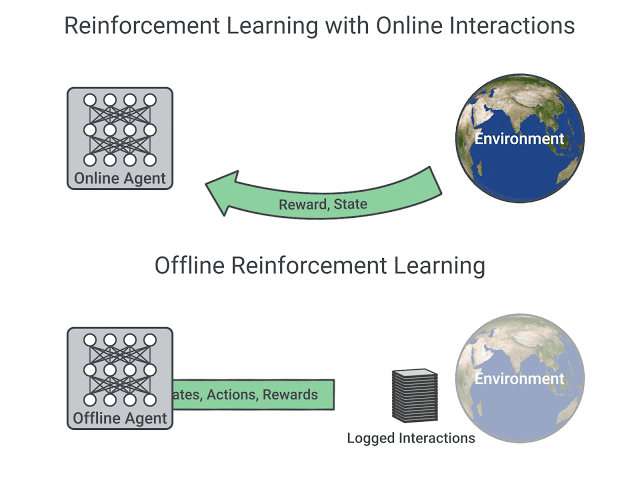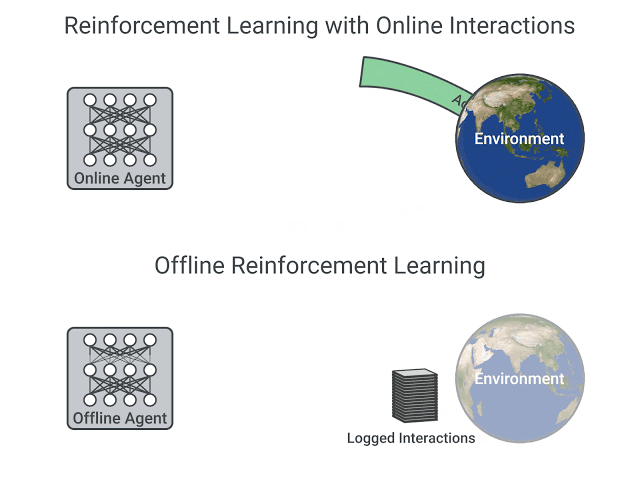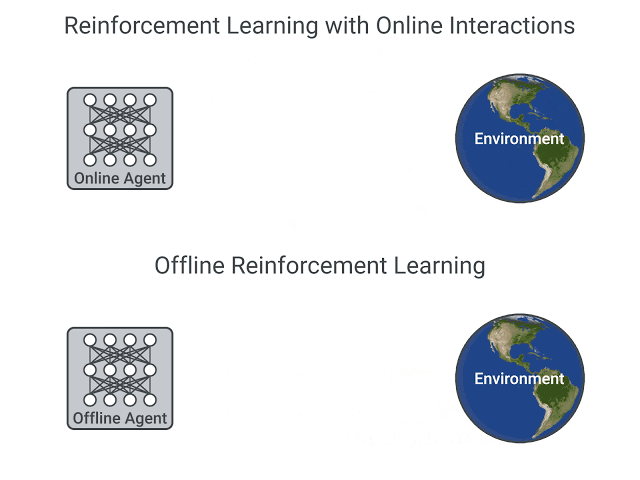 +在线和离线设置中强化学习的比较,图片来自这篇文章
+
+
+- 在*在线强化学习*中,也就是我们在本课程中学习的内容,智能体**直接收集数据**:它通过**与环境交互**收集一批经验。然后,它立即使用这些经验(或通过某种回放缓冲区)来学习(更新其策略)。
+
+但这意味着你要么**直接在真实世界中训练你的智能体,要么拥有一个模拟器**。如果你没有,你需要构建一个,这可能非常复杂(如何在环境中反映真实世界的复杂现实?),昂贵且不安全(如果模拟器有可能提供竞争优势的缺陷,智能体将利用它们)。
+
+- 另一方面,在*离线强化学习*中,智能体只**使用从其他智能体或人类示范中收集的数据**。它**不与环境交互**。
+
+过程如下:
+- **使用一个或多个策略和/或人类交互创建数据集**。
+- 在这个数据集上**运行离线RL**来学习策略
+
+这种方法有一个缺点:*反事实查询问题*。如果我们的智能体**决定做一些我们没有数据的事情,我们该怎么办?**例如,在十字路口向右转但我们没有这个轨迹。
+
+关于这个话题存在一些解决方案,但如果你想了解更多关于离线强化学习的信息,你可以[观看这个视频](https://www.youtube.com/watch?v=k08N5a0gG0A)
+
+## 进一步阅读
+
+欲了解更多信息,我们建议您查看以下资源:
+
+- [离线强化学习,Sergei Levine的演讲](https://www.youtube.com/watch?v=qgZPZREor5I)
+- [离线强化学习:教程、综述和开放问题的展望](https://arxiv.org/abs/2005.01643)
+
+## 作者
+
+本节由 Thomas Simonini撰写
diff --git a/units/cn/unitbonus3/rl-documentation.mdx b/units/cn/unitbonus3/rl-documentation.mdx
new file mode 100644
index 00000000..b0e14ac2
--- /dev/null
+++ b/units/cn/unitbonus3/rl-documentation.mdx
@@ -0,0 +1,51 @@
+# 强化学习文档简介
+
+在这个高级主题中,我们解决了这个问题:**我们应该如何监控和跟踪那些在真实世界中训练并与人类交互的强大强化学习智能体?**
+
+随着机器学习系统对现代生活的影响日益增加,**对这些系统进行文档记录的呼声也在增长**。
+
+这样的文档可以涵盖诸如使用的训练数据——存储位置、收集时间、参与人员等方面——或模型优化框架——架构、评估指标、相关论文等——以及更多内容。
+
+如今,模型卡片和数据表正变得越来越普及。例如,在Hub上
+(参见[此处](https://huggingface.co/docs/hub/model-cards)的文档)。
+
+如果你点击[Hub上的热门模型](https://huggingface.co/models),你可以了解其创建过程。
+
+这些特定于模型和数据的日志旨在在创建模型或数据集时完成,当这些模型在未来被构建到不断发展的系统中时,它们不会被更新。
+
+## 奖励报告的动机
+
+强化学习系统从根本上设计为基于奖励和时间的测量进行优化。
+虽然奖励函数的概念可以很好地映射到许多被充分理解的监督学习领域(通过损失函数),
+但对机器学习系统如何随时间演变的理解是有限的。
+
+为此,作者引入了[*强化学习的奖励报告*](https://www.notion.so/Brief-introduction-to-RL-documentation-b8cbda5a6f5242338e0756e6bef72af4)(这个简洁的命名旨在模仿流行的论文*模型卡片用于模型报告*和*数据集的数据表*)。
+目标是提出一种专注于**奖励的人为因素**和**随时间变化的反馈系统**的文档类型。
+
+基于Mitchell等人和Gebru等人提出的[模型卡片](https://arxiv.org/abs/1810.03993)和[数据表](https://arxiv.org/abs/1803.09010)的文档框架,我们主张AI系统需要奖励报告。
+
+**奖励报告**是为提议的RL部署划定设计选择的活文档。
+
+然而,关于这个框架对不同RL应用的适用性、系统可解释性的障碍,以及已部署的监督机器学习系统与RL中使用的顺序决策之间的共鸣,仍有许多问题。
+
+至少,奖励报告为RL从业者提供了一个机会,让他们深思这些问题,并开始决定如何在实践中解决它们。
+
+## 用文档捕捉时间行为
+
+专为RL和反馈驱动的ML系统设计的文档的核心部分是*变更日志*。变更日志更新来自设计者的信息(更改的训练参数、数据等)以及来自用户的注意到的变化(有害行为、意外响应等)。
+
+变更日志伴随着鼓励监控这些效果的更新触发器。
+
+## 贡献
+
+一些最具影响力的RL驱动系统本质上是多利益相关者的,并且在私人公司的闭门后面。
+这些公司在很大程度上没有监管,所以文档记录的负担落在了公众身上。
+
+如果你有兴趣贡献,我们正在为流行的机器学习系统构建奖励报告,并在[GitHub](https://github.com/RewardReports/reward-reports)上公开记录。
+
+欲了解更多信息,你可以访问奖励报告[论文](https://arxiv.org/abs/2204.10817)
+或查看[一个示例报告](https://github.com/RewardReports/reward-reports/tree/main/examples)。
+
+## 作者
+
+本节由 Nathan Lambert 撰写
diff --git a/units/cn/unitbonus3/rlhf.mdx b/units/cn/unitbonus3/rlhf.mdx
new file mode 100644
index 00000000..8b8c27e5
--- /dev/null
+++ b/units/cn/unitbonus3/rlhf.mdx
@@ -0,0 +1,50 @@
+# RLHF
+
+基于人类反馈的强化学习(RLHF)是一种**将人类数据标签整合到基于RL的优化过程中的方法**。
+它的动机是**建模人类偏好的挑战**。
+
+对于许多问题,即使你可以尝试写下一个理想的方程式,人类在偏好上也存在差异。
+
+**基于测量数据更新模型是尝试缓解这些固有人类ML问题的一种途径**。
+
+## 开始学习RLHF
+
+要开始学习RLHF:
+
+1. 阅读这个介绍:[图解基于人类反馈的强化学习(RLHF)](https://huggingface.co/blog/rlhf)。
+
+2. 观看我们几周前录制的直播,其中Nathan介绍了基于人类反馈的强化学习(RLHF)的基础知识,以及这项技术如何被用于支持像ChatGPT这样的最先进的ML工具。
+大部分讲座是对相互关联的ML模型的概述。它涵盖了自然语言处理和RL的基础知识,以及RLHF如何用于大型语言模型。然后我们以RLHF中的开放性问题结束。
+
+
+
+3. 阅读关于这个主题的其他博客,如[封闭API与开源的继续:RLHF、ChatGPT、数据护城河](https://robotic.substack.com/p/rlhf-chatgpt-data-moats)。如果你有更多喜欢的,请告诉我们!
+
+
+## 额外阅读
+
+*注意,这是从上面的图解RLHF博客文章中复制的*。
+以下是迄今为止关于RLHF的最流行论文列表。该领域最近随着DeepRL的出现(约2017年)而流行起来,并已发展成为许多大型科技公司对LLM应用的更广泛研究。
+以下是一些关于RLHF的论文,这些论文早于LM的关注:
+- [TAMER:通过评估性强化手动训练智能体](https://www.cs.utexas.edu/~pstone/Papers/bib2html-links/ICDL08-knox.pdf)(Knox和Stone 2008):提出了一种学习智能体,其中人类迭代地对所采取的行动提供分数,以学习奖励模型。
+- [从策略依赖的人类反馈中交互式学习](http://proceedings.mlr.press/v70/macglashan17a/macglashan17a.pdf)(MacGlashan等人2017):提出了一种演员-评论家算法COACH,其中人类反馈(正面和负面)用于调整优势函数。
+- [从人类偏好中深度强化学习](https://proceedings.neurips.cc/paper/2017/hash/d5e2c0adad503c91f91df240d0cd4e49-Abstract.html)(Christiano等人2017):RLHF应用于Atari轨迹之间的偏好。
+- [Deep TAMER:高维状态空间中的交互式智能体塑造](https://ojs.aaai.org/index.php/AAAI/article/view/11485)(Warnell等人2018):扩展了TAMER框架,其中使用深度神经网络来模拟奖励预测。
+
+以下是展示RLHF对LM性能的不断增长的论文集的快照:
+- [从人类偏好中微调语言模型](https://arxiv.org/abs/1909.08593)(Zieglar等人2019):一篇早期论文,研究了奖励学习对四个特定任务的影响。
+- [从人类反馈中学习总结](https://proceedings.neurips.cc/paper/2020/hash/1f89885d556929e98d3ef9b86448f951-Abstract.html)(Stiennon等人,2020):RLHF应用于文本总结任务。此外,[用人类反馈递归总结书籍](https://arxiv.org/abs/2109.10862)(OpenAI对齐团队2021),后续工作总结书籍。
+- [WebGPT:带有人类反馈的浏览器辅助问答](https://arxiv.org/abs/2112.09332)(OpenAI,2021):使用RLHF训练智能体导航网络。
+- InstructGPT:[通过人类反馈训练语言模型遵循指令](https://arxiv.org/abs/2203.02155)(OpenAI对齐团队2022):RLHF应用于通用语言模型[[关于InstructGPT的博客文章](https://openai.com/blog/instruction-following/)]。
+- GopherCite:[教语言模型用经过验证的引用支持答案](https://www.deepmind.com/publications/gophercite-teaching-language-models-to-support-answers-with-verified-quotes)(Menick等人2022):用RLHF训练LM返回带有特定引用的答案。
+- Sparrow:[通过有针对性的人类判断改进对话智能体的对齐](https://arxiv.org/abs/2209.14375)(Glaese等人2022):用RLHF微调对话智能体
+- [ChatGPT:优化用于对话的语言模型](https://openai.com/blog/chatgpt/)(OpenAI 2022):用RLHF训练LM,使其适合作为通用聊天机器人。
+- [奖励模型过度优化的缩放规律](https://arxiv.org/abs/2210.10760)(Gao等人2022):研究RLHF中学习的偏好模型的缩放特性。
+- [用人类反馈的强化学习训练有帮助且无害的助手](https://arxiv.org/abs/2204.05862)(Anthropic,2022):详细记录了用RLHF训练LM助手的过程。
+- [红队语言模型以减少危害:方法、缩放行为和经验教训](https://arxiv.org/abs/2209.07858)(Ganguli等人2022):详细记录了"发现、测量和尝试减少[语言模型]潜在有害输出"的努力。
+- [在开放式对话中使用强化学习进行动态规划](https://arxiv.org/abs/2208.02294)(Cohen等人2022):使用RL增强开放式对话智能体的对话技能。
+- [强化学习(不)适用于自然语言处理?:自然语言策略优化的基准、基线和构建块](https://arxiv.org/abs/2210.01241)(Ramamurthy和Ammanabrolu等人2022):讨论了RLHF中开源工具的设计空间,并提出了一种新算法NLPO(自然语言策略优化)作为PPO的替代方案。
+
+## 作者
+
+本节由 Nathan Lambert 撰写
diff --git a/units/cn/unitbonus3/student-works.mdx b/units/cn/unitbonus3/student-works.mdx
new file mode 100644
index 00000000..ba0b2c75
--- /dev/null
+++ b/units/cn/unitbonus3/student-works.mdx
@@ -0,0 +1,68 @@
+# 学生作品
+
+自深度强化学习课程推出以来,**许多学生创建了令人惊叹的项目,你应该查看并考虑参与其中**。
+
+如果你创建了一个有趣的项目,不要犹豫,[通过在GitHub仓库上开启拉取请求将其添加到此列表](https://github.com/huggingface/deep-rl-class)。
+
+这些项目**按照在本页面上的发布日期排列**。
+
+
+## 太空清道夫AI
+
+这个项目是一个带有经过训练的神经网络AI的太空游戏环境。
+
+AI通过基于UnityMLAgents和RLlib框架的强化学习算法进行训练。
+
+
+在线和离线设置中强化学习的比较,图片来自这篇文章
+
+
+- 在*在线强化学习*中,也就是我们在本课程中学习的内容,智能体**直接收集数据**:它通过**与环境交互**收集一批经验。然后,它立即使用这些经验(或通过某种回放缓冲区)来学习(更新其策略)。
+
+但这意味着你要么**直接在真实世界中训练你的智能体,要么拥有一个模拟器**。如果你没有,你需要构建一个,这可能非常复杂(如何在环境中反映真实世界的复杂现实?),昂贵且不安全(如果模拟器有可能提供竞争优势的缺陷,智能体将利用它们)。
+
+- 另一方面,在*离线强化学习*中,智能体只**使用从其他智能体或人类示范中收集的数据**。它**不与环境交互**。
+
+过程如下:
+- **使用一个或多个策略和/或人类交互创建数据集**。
+- 在这个数据集上**运行离线RL**来学习策略
+
+这种方法有一个缺点:*反事实查询问题*。如果我们的智能体**决定做一些我们没有数据的事情,我们该怎么办?**例如,在十字路口向右转但我们没有这个轨迹。
+
+关于这个话题存在一些解决方案,但如果你想了解更多关于离线强化学习的信息,你可以[观看这个视频](https://www.youtube.com/watch?v=k08N5a0gG0A)
+
+## 进一步阅读
+
+欲了解更多信息,我们建议您查看以下资源:
+
+- [离线强化学习,Sergei Levine的演讲](https://www.youtube.com/watch?v=qgZPZREor5I)
+- [离线强化学习:教程、综述和开放问题的展望](https://arxiv.org/abs/2005.01643)
+
+## 作者
+
+本节由 Thomas Simonini撰写
diff --git a/units/cn/unitbonus3/rl-documentation.mdx b/units/cn/unitbonus3/rl-documentation.mdx
new file mode 100644
index 00000000..b0e14ac2
--- /dev/null
+++ b/units/cn/unitbonus3/rl-documentation.mdx
@@ -0,0 +1,51 @@
+# 强化学习文档简介
+
+在这个高级主题中,我们解决了这个问题:**我们应该如何监控和跟踪那些在真实世界中训练并与人类交互的强大强化学习智能体?**
+
+随着机器学习系统对现代生活的影响日益增加,**对这些系统进行文档记录的呼声也在增长**。
+
+这样的文档可以涵盖诸如使用的训练数据——存储位置、收集时间、参与人员等方面——或模型优化框架——架构、评估指标、相关论文等——以及更多内容。
+
+如今,模型卡片和数据表正变得越来越普及。例如,在Hub上
+(参见[此处](https://huggingface.co/docs/hub/model-cards)的文档)。
+
+如果你点击[Hub上的热门模型](https://huggingface.co/models),你可以了解其创建过程。
+
+这些特定于模型和数据的日志旨在在创建模型或数据集时完成,当这些模型在未来被构建到不断发展的系统中时,它们不会被更新。
+
+## 奖励报告的动机
+
+强化学习系统从根本上设计为基于奖励和时间的测量进行优化。
+虽然奖励函数的概念可以很好地映射到许多被充分理解的监督学习领域(通过损失函数),
+但对机器学习系统如何随时间演变的理解是有限的。
+
+为此,作者引入了[*强化学习的奖励报告*](https://www.notion.so/Brief-introduction-to-RL-documentation-b8cbda5a6f5242338e0756e6bef72af4)(这个简洁的命名旨在模仿流行的论文*模型卡片用于模型报告*和*数据集的数据表*)。
+目标是提出一种专注于**奖励的人为因素**和**随时间变化的反馈系统**的文档类型。
+
+基于Mitchell等人和Gebru等人提出的[模型卡片](https://arxiv.org/abs/1810.03993)和[数据表](https://arxiv.org/abs/1803.09010)的文档框架,我们主张AI系统需要奖励报告。
+
+**奖励报告**是为提议的RL部署划定设计选择的活文档。
+
+然而,关于这个框架对不同RL应用的适用性、系统可解释性的障碍,以及已部署的监督机器学习系统与RL中使用的顺序决策之间的共鸣,仍有许多问题。
+
+至少,奖励报告为RL从业者提供了一个机会,让他们深思这些问题,并开始决定如何在实践中解决它们。
+
+## 用文档捕捉时间行为
+
+专为RL和反馈驱动的ML系统设计的文档的核心部分是*变更日志*。变更日志更新来自设计者的信息(更改的训练参数、数据等)以及来自用户的注意到的变化(有害行为、意外响应等)。
+
+变更日志伴随着鼓励监控这些效果的更新触发器。
+
+## 贡献
+
+一些最具影响力的RL驱动系统本质上是多利益相关者的,并且在私人公司的闭门后面。
+这些公司在很大程度上没有监管,所以文档记录的负担落在了公众身上。
+
+如果你有兴趣贡献,我们正在为流行的机器学习系统构建奖励报告,并在[GitHub](https://github.com/RewardReports/reward-reports)上公开记录。
+
+欲了解更多信息,你可以访问奖励报告[论文](https://arxiv.org/abs/2204.10817)
+或查看[一个示例报告](https://github.com/RewardReports/reward-reports/tree/main/examples)。
+
+## 作者
+
+本节由 Nathan Lambert 撰写
diff --git a/units/cn/unitbonus3/rlhf.mdx b/units/cn/unitbonus3/rlhf.mdx
new file mode 100644
index 00000000..8b8c27e5
--- /dev/null
+++ b/units/cn/unitbonus3/rlhf.mdx
@@ -0,0 +1,50 @@
+# RLHF
+
+基于人类反馈的强化学习(RLHF)是一种**将人类数据标签整合到基于RL的优化过程中的方法**。
+它的动机是**建模人类偏好的挑战**。
+
+对于许多问题,即使你可以尝试写下一个理想的方程式,人类在偏好上也存在差异。
+
+**基于测量数据更新模型是尝试缓解这些固有人类ML问题的一种途径**。
+
+## 开始学习RLHF
+
+要开始学习RLHF:
+
+1. 阅读这个介绍:[图解基于人类反馈的强化学习(RLHF)](https://huggingface.co/blog/rlhf)。
+
+2. 观看我们几周前录制的直播,其中Nathan介绍了基于人类反馈的强化学习(RLHF)的基础知识,以及这项技术如何被用于支持像ChatGPT这样的最先进的ML工具。
+大部分讲座是对相互关联的ML模型的概述。它涵盖了自然语言处理和RL的基础知识,以及RLHF如何用于大型语言模型。然后我们以RLHF中的开放性问题结束。
+
+
+
+3. 阅读关于这个主题的其他博客,如[封闭API与开源的继续:RLHF、ChatGPT、数据护城河](https://robotic.substack.com/p/rlhf-chatgpt-data-moats)。如果你有更多喜欢的,请告诉我们!
+
+
+## 额外阅读
+
+*注意,这是从上面的图解RLHF博客文章中复制的*。
+以下是迄今为止关于RLHF的最流行论文列表。该领域最近随着DeepRL的出现(约2017年)而流行起来,并已发展成为许多大型科技公司对LLM应用的更广泛研究。
+以下是一些关于RLHF的论文,这些论文早于LM的关注:
+- [TAMER:通过评估性强化手动训练智能体](https://www.cs.utexas.edu/~pstone/Papers/bib2html-links/ICDL08-knox.pdf)(Knox和Stone 2008):提出了一种学习智能体,其中人类迭代地对所采取的行动提供分数,以学习奖励模型。
+- [从策略依赖的人类反馈中交互式学习](http://proceedings.mlr.press/v70/macglashan17a/macglashan17a.pdf)(MacGlashan等人2017):提出了一种演员-评论家算法COACH,其中人类反馈(正面和负面)用于调整优势函数。
+- [从人类偏好中深度强化学习](https://proceedings.neurips.cc/paper/2017/hash/d5e2c0adad503c91f91df240d0cd4e49-Abstract.html)(Christiano等人2017):RLHF应用于Atari轨迹之间的偏好。
+- [Deep TAMER:高维状态空间中的交互式智能体塑造](https://ojs.aaai.org/index.php/AAAI/article/view/11485)(Warnell等人2018):扩展了TAMER框架,其中使用深度神经网络来模拟奖励预测。
+
+以下是展示RLHF对LM性能的不断增长的论文集的快照:
+- [从人类偏好中微调语言模型](https://arxiv.org/abs/1909.08593)(Zieglar等人2019):一篇早期论文,研究了奖励学习对四个特定任务的影响。
+- [从人类反馈中学习总结](https://proceedings.neurips.cc/paper/2020/hash/1f89885d556929e98d3ef9b86448f951-Abstract.html)(Stiennon等人,2020):RLHF应用于文本总结任务。此外,[用人类反馈递归总结书籍](https://arxiv.org/abs/2109.10862)(OpenAI对齐团队2021),后续工作总结书籍。
+- [WebGPT:带有人类反馈的浏览器辅助问答](https://arxiv.org/abs/2112.09332)(OpenAI,2021):使用RLHF训练智能体导航网络。
+- InstructGPT:[通过人类反馈训练语言模型遵循指令](https://arxiv.org/abs/2203.02155)(OpenAI对齐团队2022):RLHF应用于通用语言模型[[关于InstructGPT的博客文章](https://openai.com/blog/instruction-following/)]。
+- GopherCite:[教语言模型用经过验证的引用支持答案](https://www.deepmind.com/publications/gophercite-teaching-language-models-to-support-answers-with-verified-quotes)(Menick等人2022):用RLHF训练LM返回带有特定引用的答案。
+- Sparrow:[通过有针对性的人类判断改进对话智能体的对齐](https://arxiv.org/abs/2209.14375)(Glaese等人2022):用RLHF微调对话智能体
+- [ChatGPT:优化用于对话的语言模型](https://openai.com/blog/chatgpt/)(OpenAI 2022):用RLHF训练LM,使其适合作为通用聊天机器人。
+- [奖励模型过度优化的缩放规律](https://arxiv.org/abs/2210.10760)(Gao等人2022):研究RLHF中学习的偏好模型的缩放特性。
+- [用人类反馈的强化学习训练有帮助且无害的助手](https://arxiv.org/abs/2204.05862)(Anthropic,2022):详细记录了用RLHF训练LM助手的过程。
+- [红队语言模型以减少危害:方法、缩放行为和经验教训](https://arxiv.org/abs/2209.07858)(Ganguli等人2022):详细记录了"发现、测量和尝试减少[语言模型]潜在有害输出"的努力。
+- [在开放式对话中使用强化学习进行动态规划](https://arxiv.org/abs/2208.02294)(Cohen等人2022):使用RL增强开放式对话智能体的对话技能。
+- [强化学习(不)适用于自然语言处理?:自然语言策略优化的基准、基线和构建块](https://arxiv.org/abs/2210.01241)(Ramamurthy和Ammanabrolu等人2022):讨论了RLHF中开源工具的设计空间,并提出了一种新算法NLPO(自然语言策略优化)作为PPO的替代方案。
+
+## 作者
+
+本节由 Nathan Lambert 撰写
diff --git a/units/cn/unitbonus3/student-works.mdx b/units/cn/unitbonus3/student-works.mdx
new file mode 100644
index 00000000..ba0b2c75
--- /dev/null
+++ b/units/cn/unitbonus3/student-works.mdx
@@ -0,0 +1,68 @@
+# 学生作品
+
+自深度强化学习课程推出以来,**许多学生创建了令人惊叹的项目,你应该查看并考虑参与其中**。
+
+如果你创建了一个有趣的项目,不要犹豫,[通过在GitHub仓库上开启拉取请求将其添加到此列表](https://github.com/huggingface/deep-rl-class)。
+
+这些项目**按照在本页面上的发布日期排列**。
+
+
+## 太空清道夫AI
+
+这个项目是一个带有经过训练的神经网络AI的太空游戏环境。
+
+AI通过基于UnityMLAgents和RLlib框架的强化学习算法进行训练。
+
+ +
+在这里玩游戏 👉 https://swingshuffle.itch.io/spacescalvagerai
+
+在这里查看Unity项目 👉 https://github.com/HighExecutor/SpaceScalvagerAI
+
+
+## 神经氮气 🏎️
+
+
+
+在这里玩游戏 👉 https://swingshuffle.itch.io/spacescalvagerai
+
+在这里查看Unity项目 👉 https://github.com/HighExecutor/SpaceScalvagerAI
+
+
+## 神经氮气 🏎️
+
+ +
+在这个项目中,Sookeyy创建了一个低多边形赛车游戏并训练了一辆会驾驶的汽车。
+
+在这里查看演示 👉 https://sookeyy.itch.io/neuralnitro
+
+
+## 太空战争 🚀
+
+
+
+在这个项目中,Sookeyy创建了一个低多边形赛车游戏并训练了一辆会驾驶的汽车。
+
+在这里查看演示 👉 https://sookeyy.itch.io/neuralnitro
+
+
+## 太空战争 🚀
+
+ +
+在这个项目中,Eric Dong用Pygame重新创建了Bill Seiler 1985年版本的太空战争,并使用强化学习(RL)训练AI智能体。
+
+该项目目前正在开发中!
+
+### 演示
+
+开发/前沿版本:
+* https://e-dong.itch.io/spacewar-dev
+
+稳定版本:
+* https://e-dong.itch.io/spacewar
+* https://huggingface.co/spaces/EricofRL/SpaceWarRL
+
+### 社区博客文章
+
+待定
+
+### 其他链接
+
+在这里查看源代码 👉 https://github.com/e-dong/space-war-rl
+在这里查看他的博客 👉 https://dev.to/edong/space-war-rl-0-series-introduction-25dh
+
+
+## 用于交易的决策转换器
+
+在这个项目中,学生探索了为股票交易训练决策转换器。在第一阶段,实现了离线训练。他打算在下一个版本中加入在线微调。
+
+
+
+
+在这个项目中,Eric Dong用Pygame重新创建了Bill Seiler 1985年版本的太空战争,并使用强化学习(RL)训练AI智能体。
+
+该项目目前正在开发中!
+
+### 演示
+
+开发/前沿版本:
+* https://e-dong.itch.io/spacewar-dev
+
+稳定版本:
+* https://e-dong.itch.io/spacewar
+* https://huggingface.co/spaces/EricofRL/SpaceWarRL
+
+### 社区博客文章
+
+待定
+
+### 其他链接
+
+在这里查看源代码 👉 https://github.com/e-dong/space-war-rl
+在这里查看他的博客 👉 https://dev.to/edong/space-war-rl-0-series-introduction-25dh
+
+
+## 用于交易的决策转换器
+
+在这个项目中,学生探索了为股票交易训练决策转换器。在第一阶段,实现了离线训练。他打算在下一个版本中加入在线微调。
+
+
+ +来源: 斯坦福CS25:V1 I 决策转换器:通过序列建模进行强化学习
+
+
+在这里查看源代码 👉 https://github.com/ra9hur/Decision-Transformers-For-Trading
diff --git a/units/cn/unitbonus5/conclusion.mdx b/units/cn/unitbonus5/conclusion.mdx
new file mode 100644
index 00000000..12c1905b
--- /dev/null
+++ b/units/cn/unitbonus5/conclusion.mdx
@@ -0,0 +1,5 @@
+# 结论:
+
+**恭喜你完成这个奖励单元!** 你已经学习了记录专家示范和使用模仿学习训练智能体的过程,这在某些情况下可以作为使用强化学习训练游戏内智能体的替代方法。
+
+本教程由 [Ivan Dodic](https://github.com/Ivan-267) 编写。感谢 [Edward Beeching](https://twitter.com/edwardbeeching) 和 [Thomas Simonini](https://twitter.com/thomassimonini) 的审阅和反馈。
\ No newline at end of file
diff --git a/units/cn/unitbonus5/customize-the-environment.mdx b/units/cn/unitbonus5/customize-the-environment.mdx
new file mode 100644
index 00000000..0385e161
--- /dev/null
+++ b/units/cn/unitbonus5/customize-the-environment.mdx
@@ -0,0 +1,27 @@
+# (可选)如何自定义环境
+
+如果你想自定义游戏关卡,请打开关卡场景 `res://scenes/level.tscn`,然后在Godot文件系统中打开 `res://scenes/modules/` 文件夹:
+
+
+来源: 斯坦福CS25:V1 I 决策转换器:通过序列建模进行强化学习
+
+
+在这里查看源代码 👉 https://github.com/ra9hur/Decision-Transformers-For-Trading
diff --git a/units/cn/unitbonus5/conclusion.mdx b/units/cn/unitbonus5/conclusion.mdx
new file mode 100644
index 00000000..12c1905b
--- /dev/null
+++ b/units/cn/unitbonus5/conclusion.mdx
@@ -0,0 +1,5 @@
+# 结论:
+
+**恭喜你完成这个奖励单元!** 你已经学习了记录专家示范和使用模仿学习训练智能体的过程,这在某些情况下可以作为使用强化学习训练游戏内智能体的替代方法。
+
+本教程由 [Ivan Dodic](https://github.com/Ivan-267) 编写。感谢 [Edward Beeching](https://twitter.com/edwardbeeching) 和 [Thomas Simonini](https://twitter.com/thomassimonini) 的审阅和反馈。
\ No newline at end of file
diff --git a/units/cn/unitbonus5/customize-the-environment.mdx b/units/cn/unitbonus5/customize-the-environment.mdx
new file mode 100644
index 00000000..0385e161
--- /dev/null
+++ b/units/cn/unitbonus5/customize-the-environment.mdx
@@ -0,0 +1,27 @@
+# (可选)如何自定义环境
+
+如果你想自定义游戏关卡,请打开关卡场景 `res://scenes/level.tscn`,然后在Godot文件系统中打开 `res://scenes/modules/` 文件夹:
+
+ +
+关卡包含3个使用模块构建的房间、机器人以及一些额外的碰撞体,这些碰撞体防止通过在第一个房间爬墙并以这种方式到达钥匙来完成关卡。通过将模块添加到场景中,你可以添加新的房间和物品。
+
+如果你点击Key节点(它在`Room3`中,你也可以搜索它),然后点击`Node > Signals`,你会看到`collected`信号同时连接到机器人和宝箱。我们使用这个来跟踪机器人是否已收集钥匙,并解锁宝箱。同样的系统也应用于使用杠杆激活楼梯,如果你添加更多的杠杆/楼梯/钥匙,你可以使用信号连接它们。
+
+
+
+关卡包含3个使用模块构建的房间、机器人以及一些额外的碰撞体,这些碰撞体防止通过在第一个房间爬墙并以这种方式到达钥匙来完成关卡。通过将模块添加到场景中,你可以添加新的房间和物品。
+
+如果你点击Key节点(它在`Room3`中,你也可以搜索它),然后点击`Node > Signals`,你会看到`collected`信号同时连接到机器人和宝箱。我们使用这个来跟踪机器人是否已收集钥匙,并解锁宝箱。同样的系统也应用于使用杠杆激活楼梯,如果你添加更多的杠杆/楼梯/钥匙,你可以使用信号连接它们。
+
+ +
+如果你切换到`Groups`,你会看到钥匙是`resetable`组的成员。在同一组中,我们有木筏、杠杆、宝箱、玩家,并且可以添加任何在场景重置时需要重置的节点。
+
+
+
+如果你切换到`Groups`,你会看到钥匙是`resetable`组的成员。在同一组中,我们有木筏、杠杆、宝箱、玩家,并且可以添加任何在场景重置时需要重置的节点。
+
+ +
+为了使这个功能正常工作,`resetable`组中的每个对象都需要实现`reset()`方法,该方法负责重置该对象。
+
+因为我们有多个关卡场景实例用于训练,所以我们不会重置所有的`resetables`,而只重置同一场景内的对象。在`level_manager.gd`中,我们有一个方法`reset_all_resetables()`来处理这个问题,当需要重置时,它会被机器人脚本调用。
+
+更改关卡大小后,还需要更新`robot_ai_controller.gd`中的`level_size`变量。为此,只需粗略测量关卡的最长维度,并更新该变量。
+
+如果你更改了需要由`AIController`跟踪的对象数量(杠杆、木筏等),你将需要更新脚本中的相关代码,包括为这些对象添加导出属性,然后在关卡场景中的`AIController`检查器属性中连接它们:
+
+
+
+为了使这个功能正常工作,`resetable`组中的每个对象都需要实现`reset()`方法,该方法负责重置该对象。
+
+因为我们有多个关卡场景实例用于训练,所以我们不会重置所有的`resetables`,而只重置同一场景内的对象。在`level_manager.gd`中,我们有一个方法`reset_all_resetables()`来处理这个问题,当需要重置时,它会被机器人脚本调用。
+
+更改关卡大小后,还需要更新`robot_ai_controller.gd`中的`level_size`变量。为此,只需粗略测量关卡的最长维度,并更新该变量。
+
+如果你更改了需要由`AIController`跟踪的对象数量(杠杆、木筏等),你将需要更新脚本中的相关代码,包括为这些对象添加导出属性,然后在关卡场景中的`AIController`检查器属性中连接它们:
+
+ +
+完成此操作后,你可能还需要更新演示记录场景中`AIController`的相同属性。
\ No newline at end of file
diff --git a/units/cn/unitbonus5/getting-started.mdx b/units/cn/unitbonus5/getting-started.mdx
new file mode 100644
index 00000000..e02150e1
--- /dev/null
+++ b/units/cn/unitbonus5/getting-started.mdx
@@ -0,0 +1,266 @@
+# 入门指南:
+
+首先,从[这里](https://huggingface.co/ivan267/imitation-learning-tutorial-godot-project/tree/main)下载项目(点击`GDRL-IL-Project.zip`旁边的下载图标)。压缩文件包含"Starter"和"Complete"两个项目。
+
+入门项目中已经实现了游戏代码并配置了节点。我们将专注于:
+
+- 实现AIController节点的代码,
+- 记录专家示范,
+- 训练智能体并导出.onnx文件,以便在Godot中进行推理。
+
+### 在Godot中打开入门项目
+
+解压缩文件,打开Godot,点击"Import"并导航到解压缩档案的`Starter\Godot`文件夹。
+
+### 打开机器人场景
+
+
+你可以在文件系统搜索中搜索"robot"。
+
+
+这个场景包含几个不同的节点,包括`robot`节点(包含机器人的视觉形状),`CameraXRotation`节点(用于在人类控制模式下使用鼠标"上下"旋转摄像机)。AI智能体不控制这个节点,因为学习任务不需要它。`RaycastSensors`节点包含两个光线投射传感器,帮助智能体"感知"游戏世界的部分内容,包括墙壁、地板等。
+
+
+
+完成此操作后,你可能还需要更新演示记录场景中`AIController`的相同属性。
\ No newline at end of file
diff --git a/units/cn/unitbonus5/getting-started.mdx b/units/cn/unitbonus5/getting-started.mdx
new file mode 100644
index 00000000..e02150e1
--- /dev/null
+++ b/units/cn/unitbonus5/getting-started.mdx
@@ -0,0 +1,266 @@
+# 入门指南:
+
+首先,从[这里](https://huggingface.co/ivan267/imitation-learning-tutorial-godot-project/tree/main)下载项目(点击`GDRL-IL-Project.zip`旁边的下载图标)。压缩文件包含"Starter"和"Complete"两个项目。
+
+入门项目中已经实现了游戏代码并配置了节点。我们将专注于:
+
+- 实现AIController节点的代码,
+- 记录专家示范,
+- 训练智能体并导出.onnx文件,以便在Godot中进行推理。
+
+### 在Godot中打开入门项目
+
+解压缩文件,打开Godot,点击"Import"并导航到解压缩档案的`Starter\Godot`文件夹。
+
+### 打开机器人场景
+
+
+你可以在文件系统搜索中搜索"robot"。
+
+
+这个场景包含几个不同的节点,包括`robot`节点(包含机器人的视觉形状),`CameraXRotation`节点(用于在人类控制模式下使用鼠标"上下"旋转摄像机)。AI智能体不控制这个节点,因为学习任务不需要它。`RaycastSensors`节点包含两个光线投射传感器,帮助智能体"感知"游戏世界的部分内容,包括墙壁、地板等。
+
+ +
+### 点击AIController3D旁边的滚动图标以打开脚本进行编辑
+
+
+你可能需要折叠"robot"分支以更容易找到它,或者你可以在`Robot`节点上方的过滤框中输入`aicontroller`。
+
+
+### 用以下实现替换`get_obs()`和`get_reward()`方法:
+
+```python
+func get_obs() -> Dictionary:
+ var observations: Array[float] = []
+ for raycast_sensor in raycast_sensors:
+ observations.append_array(raycast_sensor.get_observation())
+
+ var level_size = 16.0
+
+ var chest_local = to_local(chest.global_position)
+ var chest_direction = chest_local.normalized()
+ var chest_distance = clampf(chest_local.length(), 0.0, level_size)
+
+ var lever_local = to_local(lever.global_position)
+ var lever_direction = lever_local.normalized()
+ var lever_distance = clampf(lever_local.length(), 0.0, level_size)
+
+ var key_local = to_local(key.global_position)
+ var key_direction = key_local.normalized()
+ var key_distance = clampf(key_local.length(), 0.0, level_size)
+
+ var raft_local = to_local(raft.global_position)
+ var raft_direction = raft_local.normalized()
+ var raft_distance = clampf(raft_local.length(), 0.0, level_size)
+
+ var player_speed = player.global_basis.inverse() * player.velocity.limit_length(5.0) / 5.0
+
+ (
+ observations
+ .append_array(
+ [
+ chest_direction.x,
+ chest_direction.y,
+ chest_direction.z,
+ chest_distance,
+ lever_direction.x,
+ lever_direction.y,
+ lever_direction.z,
+ lever_distance,
+ key_direction.x,
+ key_direction.y,
+ key_direction.z,
+ key_distance,
+ raft_direction.x,
+ raft_direction.y,
+ raft_direction.z,
+ raft_distance,
+ raft.movement_direction_multiplier,
+ float(player._is_lever_pulled),
+ float(player._is_chest_opened),
+ float(player._is_key_collected),
+ float(player.is_on_floor()),
+ player_speed.x,
+ player_speed.y,
+ player_speed.z,
+ ]
+ )
+ )
+ return {"obs": observations}
+
+func get_reward() -> float:
+ return reward
+```
+
+在`get_obs()`中,我们首先获取在检查器中添加到`AIController3D`节点的两个光线投射传感器的观测值,并将它们添加到观测中,然后我们获取到箱子、杠杆、钥匙和木筏的相对位置向量,将它们分为方向和距离,然后也将它们添加到观测中。
+
+我们还将其他游戏状态信息添加到观测中:
+
+- 杠杆是否已被拉动,
+- 钥匙是否已被收集,
+- 箱子是否已被打开,
+- 玩家是否在地面上(也决定玩家是否可以跳跃),
+- 玩家的归一化局部速度。
+
+我们将布尔值(如`_is_lever_pulled`)转换为浮点数(0或1)。
+
+在`get_reward()`中,我们只需要返回当前奖励。
+
+### 用以下实现替换`_physics_process()`和`reset()`方法:
+
+```python
+func _physics_process(delta: float) -> void:
+ # Reset on timeout, this is implemented in parent class to set needs_reset to true,
+ # we are re-implementing here to call player.game_over() that handles the game reset.
+ n_steps += 1
+ if n_steps > reset_after:
+ player.game_over()
+
+ # In training or onnx inference modes, this method will be called by sync node with actions provided,
+ # For expert demo recording mode, it will be called without any actions (as we set the actions based on human input),
+ # For human control mode the method will not be called, so we call it here without any actions provided.
+ if control_mode == ControlModes.HUMAN:
+ set_action()
+
+ # Reset the game faster if the lever is not pulled.
+ steps_without_lever_pulled += 1
+ if steps_without_lever_pulled > 200 and (not player._is_lever_pulled):
+ player.game_over()
+
+func reset():
+ super.reset()
+ steps_without_lever_pulled = 0
+```
+
+### **用以下实现替换`get_action_space()`、`get_action()`和`set_action()`方法:**
+
+```python
+# Defines the actions for the AI agent ("size": 2 means 2 floats for this action)
+func get_action_space() -> Dictionary:
+ return {
+ "movement": {"size": 2, "action_type": "continuous"},
+ "rotation": {"size": 1, "action_type": "continuous"},
+ "jump": {"size": 1, "action_type": "continuous"},
+ "use_action": {"size": 1, "action_type": "continuous"}
+ }
+
+# We return the action values in the same order as defined in get_action_space() (important), but all in one array
+# For actions of size 1, we return 1 float in the array, for size 2, 2 floats in the array, etc.
+# set_action is called just before get_action by the sync node, so we can read the newly set values
+func get_action():
+ return [
+ # "movement" action values
+ player.requested_movement.x,
+ player.requested_movement.y,
+ # "rotation" action value
+ player.requested_rotation.x,
+ # "jump" action value (-1 if not requested, 1 if requested)
+ -1.0 + 2.0 * float(player.jump_requested),
+ # "use_action" action value (-1 if not requested, 1 if requested)
+ -1.0 + 2.0 * float(player.use_action_requested)
+ ]
+
+# Here we set human control and AI control actions to the robot
+func set_action(action = null) -> void:
+ # If there's no action provided, it means that AI is not controlling the robot (human control),
+ if not action:
+ # Only rotate if the mouse has moved since the last set_action call
+ if previous_mouse_movement == mouse_movement:
+ mouse_movement = Vector2.ZERO
+
+ player.requested_movement = Input.get_vector(
+ "move_left", "move_right", "move_forward", "move_back"
+ )
+ player.requested_rotation = mouse_movement
+
+ var use_action = Input.is_action_pressed("requested_action")
+ var jump = Input.is_action_pressed("requested_jump")
+
+ player.use_action_requested = use_action
+ player.jump_requested = jump
+
+ previous_mouse_movement = mouse_movement
+ else:
+ # If there is action provided, we set the actions received from the AI agent
+ player.requested_movement = Vector2(action.movement[0], action.movement[1])
+ # The agent only rotates the robot along the Y axis, no need to rotate the camera along X axis
+ player.requested_rotation = Vector2(action.rotation[0], 0.0)
+ player.jump_requested = bool(action.jump[0] > 0)
+ player.use_action_requested = bool(action.use_action[0] > 0)
+```
+
+对于`get_action()`(仅在使用演示记录模式时需要),我们需要提供当智能体遇到相同状态时要发送的动作。重要的是值要在正确的范围内(`-1.0到1.0`),这就是为什么我们对布尔状态使用`-1 + 2 * 变量`,并且按照`get_action_space()`中定义的正确顺序。
+
+在演示记录模式下,`set_action()`被调用时不提供动作,因为我们需要根据人类输入设置动作值。在训练/推理模式下,该方法被调用时带有一个`action`参数,其中包含RL模型提供的所有动作的值,所以我们有一个`if/else`来处理这两种情况。
+
+更多信息包含在代码注释中。
+
+### 用以下实现替换`_input`方法:
+
+```python
+# Record mouse movement for human and demo_record modes
+# We don't directly rotate in input to allow for frame skipping (action_repeat setting) which
+# will also be applied to the AI agent in training/inference modes.
+func _input(event):
+ if not (heuristic == "human" or heuristic == "demo_record"):
+ return
+
+ if event is InputEventMouseMotion:
+ var movement_scale: float = 0.005
+ mouse_movement.y = clampf(event.relative.y * movement_scale, -1.0, 1.0)
+ mouse_movement.x = clampf(event.relative.x * movement_scale, -1.0, 1.0)
+```
+
+这部分代码在人类控制和演示记录模式下记录鼠标移动。
+
+**最后,保存脚本。我们准备进入下一步。**
+
+### 打开演示记录场景,并点击AIController3D节点
+
+
+你可以在文件系统搜索中搜索"demo",并在场景的过滤框中搜索"aicontroller"。
+
+
+
+
+### 点击AIController3D旁边的滚动图标以打开脚本进行编辑
+
+
+你可能需要折叠"robot"分支以更容易找到它,或者你可以在`Robot`节点上方的过滤框中输入`aicontroller`。
+
+
+### 用以下实现替换`get_obs()`和`get_reward()`方法:
+
+```python
+func get_obs() -> Dictionary:
+ var observations: Array[float] = []
+ for raycast_sensor in raycast_sensors:
+ observations.append_array(raycast_sensor.get_observation())
+
+ var level_size = 16.0
+
+ var chest_local = to_local(chest.global_position)
+ var chest_direction = chest_local.normalized()
+ var chest_distance = clampf(chest_local.length(), 0.0, level_size)
+
+ var lever_local = to_local(lever.global_position)
+ var lever_direction = lever_local.normalized()
+ var lever_distance = clampf(lever_local.length(), 0.0, level_size)
+
+ var key_local = to_local(key.global_position)
+ var key_direction = key_local.normalized()
+ var key_distance = clampf(key_local.length(), 0.0, level_size)
+
+ var raft_local = to_local(raft.global_position)
+ var raft_direction = raft_local.normalized()
+ var raft_distance = clampf(raft_local.length(), 0.0, level_size)
+
+ var player_speed = player.global_basis.inverse() * player.velocity.limit_length(5.0) / 5.0
+
+ (
+ observations
+ .append_array(
+ [
+ chest_direction.x,
+ chest_direction.y,
+ chest_direction.z,
+ chest_distance,
+ lever_direction.x,
+ lever_direction.y,
+ lever_direction.z,
+ lever_distance,
+ key_direction.x,
+ key_direction.y,
+ key_direction.z,
+ key_distance,
+ raft_direction.x,
+ raft_direction.y,
+ raft_direction.z,
+ raft_distance,
+ raft.movement_direction_multiplier,
+ float(player._is_lever_pulled),
+ float(player._is_chest_opened),
+ float(player._is_key_collected),
+ float(player.is_on_floor()),
+ player_speed.x,
+ player_speed.y,
+ player_speed.z,
+ ]
+ )
+ )
+ return {"obs": observations}
+
+func get_reward() -> float:
+ return reward
+```
+
+在`get_obs()`中,我们首先获取在检查器中添加到`AIController3D`节点的两个光线投射传感器的观测值,并将它们添加到观测中,然后我们获取到箱子、杠杆、钥匙和木筏的相对位置向量,将它们分为方向和距离,然后也将它们添加到观测中。
+
+我们还将其他游戏状态信息添加到观测中:
+
+- 杠杆是否已被拉动,
+- 钥匙是否已被收集,
+- 箱子是否已被打开,
+- 玩家是否在地面上(也决定玩家是否可以跳跃),
+- 玩家的归一化局部速度。
+
+我们将布尔值(如`_is_lever_pulled`)转换为浮点数(0或1)。
+
+在`get_reward()`中,我们只需要返回当前奖励。
+
+### 用以下实现替换`_physics_process()`和`reset()`方法:
+
+```python
+func _physics_process(delta: float) -> void:
+ # Reset on timeout, this is implemented in parent class to set needs_reset to true,
+ # we are re-implementing here to call player.game_over() that handles the game reset.
+ n_steps += 1
+ if n_steps > reset_after:
+ player.game_over()
+
+ # In training or onnx inference modes, this method will be called by sync node with actions provided,
+ # For expert demo recording mode, it will be called without any actions (as we set the actions based on human input),
+ # For human control mode the method will not be called, so we call it here without any actions provided.
+ if control_mode == ControlModes.HUMAN:
+ set_action()
+
+ # Reset the game faster if the lever is not pulled.
+ steps_without_lever_pulled += 1
+ if steps_without_lever_pulled > 200 and (not player._is_lever_pulled):
+ player.game_over()
+
+func reset():
+ super.reset()
+ steps_without_lever_pulled = 0
+```
+
+### **用以下实现替换`get_action_space()`、`get_action()`和`set_action()`方法:**
+
+```python
+# Defines the actions for the AI agent ("size": 2 means 2 floats for this action)
+func get_action_space() -> Dictionary:
+ return {
+ "movement": {"size": 2, "action_type": "continuous"},
+ "rotation": {"size": 1, "action_type": "continuous"},
+ "jump": {"size": 1, "action_type": "continuous"},
+ "use_action": {"size": 1, "action_type": "continuous"}
+ }
+
+# We return the action values in the same order as defined in get_action_space() (important), but all in one array
+# For actions of size 1, we return 1 float in the array, for size 2, 2 floats in the array, etc.
+# set_action is called just before get_action by the sync node, so we can read the newly set values
+func get_action():
+ return [
+ # "movement" action values
+ player.requested_movement.x,
+ player.requested_movement.y,
+ # "rotation" action value
+ player.requested_rotation.x,
+ # "jump" action value (-1 if not requested, 1 if requested)
+ -1.0 + 2.0 * float(player.jump_requested),
+ # "use_action" action value (-1 if not requested, 1 if requested)
+ -1.0 + 2.0 * float(player.use_action_requested)
+ ]
+
+# Here we set human control and AI control actions to the robot
+func set_action(action = null) -> void:
+ # If there's no action provided, it means that AI is not controlling the robot (human control),
+ if not action:
+ # Only rotate if the mouse has moved since the last set_action call
+ if previous_mouse_movement == mouse_movement:
+ mouse_movement = Vector2.ZERO
+
+ player.requested_movement = Input.get_vector(
+ "move_left", "move_right", "move_forward", "move_back"
+ )
+ player.requested_rotation = mouse_movement
+
+ var use_action = Input.is_action_pressed("requested_action")
+ var jump = Input.is_action_pressed("requested_jump")
+
+ player.use_action_requested = use_action
+ player.jump_requested = jump
+
+ previous_mouse_movement = mouse_movement
+ else:
+ # If there is action provided, we set the actions received from the AI agent
+ player.requested_movement = Vector2(action.movement[0], action.movement[1])
+ # The agent only rotates the robot along the Y axis, no need to rotate the camera along X axis
+ player.requested_rotation = Vector2(action.rotation[0], 0.0)
+ player.jump_requested = bool(action.jump[0] > 0)
+ player.use_action_requested = bool(action.use_action[0] > 0)
+```
+
+对于`get_action()`(仅在使用演示记录模式时需要),我们需要提供当智能体遇到相同状态时要发送的动作。重要的是值要在正确的范围内(`-1.0到1.0`),这就是为什么我们对布尔状态使用`-1 + 2 * 变量`,并且按照`get_action_space()`中定义的正确顺序。
+
+在演示记录模式下,`set_action()`被调用时不提供动作,因为我们需要根据人类输入设置动作值。在训练/推理模式下,该方法被调用时带有一个`action`参数,其中包含RL模型提供的所有动作的值,所以我们有一个`if/else`来处理这两种情况。
+
+更多信息包含在代码注释中。
+
+### 用以下实现替换`_input`方法:
+
+```python
+# Record mouse movement for human and demo_record modes
+# We don't directly rotate in input to allow for frame skipping (action_repeat setting) which
+# will also be applied to the AI agent in training/inference modes.
+func _input(event):
+ if not (heuristic == "human" or heuristic == "demo_record"):
+ return
+
+ if event is InputEventMouseMotion:
+ var movement_scale: float = 0.005
+ mouse_movement.y = clampf(event.relative.y * movement_scale, -1.0, 1.0)
+ mouse_movement.x = clampf(event.relative.x * movement_scale, -1.0, 1.0)
+```
+
+这部分代码在人类控制和演示记录模式下记录鼠标移动。
+
+**最后,保存脚本。我们准备进入下一步。**
+
+### 打开演示记录场景,并点击AIController3D节点
+
+
+你可以在文件系统搜索中搜索"demo",并在场景的过滤框中搜索"aicontroller"。
+
+
+ +
+
+你不需要做任何更改,因为一切都已预设好,但让我们回顾一下你在自己的环境中需要设置的内容:
+
+场景包含修改过的`Level > Robot > AIController3D`节点设置:
+
+- `Control Mode`设置为`Record Expert Demos`
+- `Expert Demo Save Path`已填写
+- `Action Repeat`设置为与`training_scene`和`onnx_inference_scene`中的`Sync`节点相同的值。这意味着智能体设置的每个动作都会在3个物理帧中重复。`AIController`中的设置为人类输入添加了相同的动作重复(这会引入一些延迟)以匹配相同的行为。这是一个相当低的值,不会引入太多延迟。如果你更改此值,请确保在所有3个地方都进行更改。
+- `Remove Last Episode`键允许我们在录制过程中使用一个键来删除失败的回合,而无需重新启动整个会话。例如,如果机器人掉入水中并且游戏重置,我们可以使用此键在录制下一个回合时删除之前录制的回合。它被设置为`R`,但你可以通过点击它,然后点击`Configure`按钮来将其更改为任何键。
+
+在具有挑战性的环境中使录制回合更容易的另一种方法是在录制过程中减慢环境速度。这可以通过点击场景中的`Sync`节点,并调整`Speed Up`属性(默认设置为1)来轻松完成。
+
+### 让我们记录一些演示:
+
+
+请注意,只有当我们至少录制了一个完整的回合并通过点击"X"或按ALT+F4关闭游戏窗口时,演示才会被保存。使用Godot编辑器中的停止按钮不会保存演示。最好先尝试录制一个回合,然后检查文件系统或Godot项目文件夹中是否看到"expert_demos.json"。
+
+
+确保你仍然在`demo_record_scene`中,`按F6`,演示录制将开始。
+
+控制:
+
+- 鼠标控制摄像机(如果你需要调整鼠标灵敏度,打开`robot`场景,点击`Robot`节点并调整`Rotation Speed`,在录制演示、训练和推理时保持相同的值),
+- `WASD`控制玩家移动,
+- `SPACE`跳跃,
+- `E`激活杠杆并打开箱子
+
+你可以先进行一些练习以熟悉环境。如果你希望跳过录制演示,你也可以在完成的项目中找到预先录制的演示,并使用那里的`expert_demos.json`文件。
+
+录制的演示应该包括至少22-24个完整成功的回合。在训练阶段也可以使用多个演示文件,所以你不必一次性录制所有演示(你可以使用前面提到的`Expert Demo Save Path`属性更改文件名)。
+
+录制23个回合花了我约10分钟(因为钥匙有2个交替的生成位置,22或24个回合将在演示中提供钥匙位置的均等分布,但这已经相当接近)。当接近杠杆或箱子时,我按住`E`键稍长一些,以确保在靠近这些物体时动作被记录多个步骤。我还通过在下一个回合中按`R`键删除了几个我没有成功完成的回合。
+
+以下是演示录制过程的加速视频:
+
+
+
+### 导出游戏进行训练:
+
+你可以使用`Project > Export`从Godot导出游戏。
diff --git a/units/cn/unitbonus5/introduction.mdx b/units/cn/unitbonus5/introduction.mdx
new file mode 100644
index 00000000..03bb4fe3
--- /dev/null
+++ b/units/cn/unitbonus5/introduction.mdx
@@ -0,0 +1,23 @@
+# 介绍:
+
+
+
+
+你不需要做任何更改,因为一切都已预设好,但让我们回顾一下你在自己的环境中需要设置的内容:
+
+场景包含修改过的`Level > Robot > AIController3D`节点设置:
+
+- `Control Mode`设置为`Record Expert Demos`
+- `Expert Demo Save Path`已填写
+- `Action Repeat`设置为与`training_scene`和`onnx_inference_scene`中的`Sync`节点相同的值。这意味着智能体设置的每个动作都会在3个物理帧中重复。`AIController`中的设置为人类输入添加了相同的动作重复(这会引入一些延迟)以匹配相同的行为。这是一个相当低的值,不会引入太多延迟。如果你更改此值,请确保在所有3个地方都进行更改。
+- `Remove Last Episode`键允许我们在录制过程中使用一个键来删除失败的回合,而无需重新启动整个会话。例如,如果机器人掉入水中并且游戏重置,我们可以使用此键在录制下一个回合时删除之前录制的回合。它被设置为`R`,但你可以通过点击它,然后点击`Configure`按钮来将其更改为任何键。
+
+在具有挑战性的环境中使录制回合更容易的另一种方法是在录制过程中减慢环境速度。这可以通过点击场景中的`Sync`节点,并调整`Speed Up`属性(默认设置为1)来轻松完成。
+
+### 让我们记录一些演示:
+
+
+请注意,只有当我们至少录制了一个完整的回合并通过点击"X"或按ALT+F4关闭游戏窗口时,演示才会被保存。使用Godot编辑器中的停止按钮不会保存演示。最好先尝试录制一个回合,然后检查文件系统或Godot项目文件夹中是否看到"expert_demos.json"。
+
+
+确保你仍然在`demo_record_scene`中,`按F6`,演示录制将开始。
+
+控制:
+
+- 鼠标控制摄像机(如果你需要调整鼠标灵敏度,打开`robot`场景,点击`Robot`节点并调整`Rotation Speed`,在录制演示、训练和推理时保持相同的值),
+- `WASD`控制玩家移动,
+- `SPACE`跳跃,
+- `E`激活杠杆并打开箱子
+
+你可以先进行一些练习以熟悉环境。如果你希望跳过录制演示,你也可以在完成的项目中找到预先录制的演示,并使用那里的`expert_demos.json`文件。
+
+录制的演示应该包括至少22-24个完整成功的回合。在训练阶段也可以使用多个演示文件,所以你不必一次性录制所有演示(你可以使用前面提到的`Expert Demo Save Path`属性更改文件名)。
+
+录制23个回合花了我约10分钟(因为钥匙有2个交替的生成位置,22或24个回合将在演示中提供钥匙位置的均等分布,但这已经相当接近)。当接近杠杆或箱子时,我按住`E`键稍长一些,以确保在靠近这些物体时动作被记录多个步骤。我还通过在下一个回合中按`R`键删除了几个我没有成功完成的回合。
+
+以下是演示录制过程的加速视频:
+
+
+
+### 导出游戏进行训练:
+
+你可以使用`Project > Export`从Godot导出游戏。
diff --git a/units/cn/unitbonus5/introduction.mdx b/units/cn/unitbonus5/introduction.mdx
new file mode 100644
index 00000000..03bb4fe3
--- /dev/null
+++ b/units/cn/unitbonus5/introduction.mdx
@@ -0,0 +1,23 @@
+# 介绍:
+
+ +
+欢迎来到这个奖励单元,在这里你将**使用模仿学习训练机器人智能体完成一个迷你游戏关卡。**
+
+在单元结束时,**你将拥有一个能够像视频中那样解决关卡的训练智能体**:
+
+
+
+
+## 目标:
+
+- 学习如何通过训练智能体使用人类记录的专家示范完成迷你游戏环境,从而将模仿学习与Godot RL Agents结合使用。
+
+## 先决条件和要求:
+
+- 建议你在开始本教程之前完成前一章([Godot RL Agents](https://huggingface.co/learn/deep-rl-course/unitbonus3/godotrl)),
+- 建议对Godot有一些熟悉,尽管完成本教程不需要任何gdscript编码知识,
+- 带有.NET支持的Godot(经测试可与[4.3.dev5 .NET](https://godotengine.org/article/dev-snapshot-godot-4-3-dev-5/)一起使用,也可能与更新版本一起使用),
+- Godot RL Agents(你可以在venv/conda环境中使用`pip install godot-rl`),
+- [Imitation库](https://huggingface.co/learn/deep-rl-course/unitbonus5/train-our-robot),
+- 时间:完成项目和训练约需1-2小时。根据使用的硬件,时间可能会有所不同。
diff --git a/units/cn/unitbonus5/the-environment.mdx b/units/cn/unitbonus5/the-environment.mdx
new file mode 100644
index 00000000..748f0b60
--- /dev/null
+++ b/units/cn/unitbonus5/the-environment.mdx
@@ -0,0 +1,9 @@
+# 环境
+
+
+
+欢迎来到这个奖励单元,在这里你将**使用模仿学习训练机器人智能体完成一个迷你游戏关卡。**
+
+在单元结束时,**你将拥有一个能够像视频中那样解决关卡的训练智能体**:
+
+
+
+
+## 目标:
+
+- 学习如何通过训练智能体使用人类记录的专家示范完成迷你游戏环境,从而将模仿学习与Godot RL Agents结合使用。
+
+## 先决条件和要求:
+
+- 建议你在开始本教程之前完成前一章([Godot RL Agents](https://huggingface.co/learn/deep-rl-course/unitbonus3/godotrl)),
+- 建议对Godot有一些熟悉,尽管完成本教程不需要任何gdscript编码知识,
+- 带有.NET支持的Godot(经测试可与[4.3.dev5 .NET](https://godotengine.org/article/dev-snapshot-godot-4-3-dev-5/)一起使用,也可能与更新版本一起使用),
+- Godot RL Agents(你可以在venv/conda环境中使用`pip install godot-rl`),
+- [Imitation库](https://huggingface.co/learn/deep-rl-course/unitbonus5/train-our-robot),
+- 时间:完成项目和训练约需1-2小时。根据使用的硬件,时间可能会有所不同。
diff --git a/units/cn/unitbonus5/the-environment.mdx b/units/cn/unitbonus5/the-environment.mdx
new file mode 100644
index 00000000..748f0b60
--- /dev/null
+++ b/units/cn/unitbonus5/the-environment.mdx
@@ -0,0 +1,9 @@
+# 环境
+
+ +
+教程环境中有一个机器人需要:
+
+- 拉动杠杆以升起通往第二个房间的楼梯,
+- 导航到钥匙🔑并收集它,同时避免掉入陷阱、水中或地图外,
+- 导航回到第一个房间的宝箱,并打开它。胜利!🏆
\ No newline at end of file
diff --git a/units/cn/unitbonus5/train-our-robot.mdx b/units/cn/unitbonus5/train-our-robot.mdx
new file mode 100644
index 00000000..a5da55ad
--- /dev/null
+++ b/units/cn/unitbonus5/train-our-robot.mdx
@@ -0,0 +1,53 @@
+# 训练我们的机器人
+
+
+为了开始训练,我们首先需要在安装Godot RL Agents的同一个venv / conda环境中安装imitation库,使用:
+
+教程环境中有一个机器人需要:
+
+- 拉动杠杆以升起通往第二个房间的楼梯,
+- 导航到钥匙🔑并收集它,同时避免掉入陷阱、水中或地图外,
+- 导航回到第一个房间的宝箱,并打开它。胜利!🏆
\ No newline at end of file
diff --git a/units/cn/unitbonus5/train-our-robot.mdx b/units/cn/unitbonus5/train-our-robot.mdx
new file mode 100644
index 00000000..a5da55ad
--- /dev/null
+++ b/units/cn/unitbonus5/train-our-robot.mdx
@@ -0,0 +1,53 @@
+# 训练我们的机器人
+
+
+为了开始训练,我们首先需要在安装Godot RL Agents的同一个venv / conda环境中安装imitation库,使用:pip install imitation
+
+
+### 从Godot RL仓库下载[模仿学习](https://github.com/edbeeching/godot_rl_agents/blob/main/examples/sb3_imitation.py)脚本的副本。
+
+### 使用以下参数运行训练:
+
+```python
+sb3_imitation.py --env_path="path_to_ILTutorial_executable" --bc_epochs=100 --gail_timesteps=1450000 --demo_files "path_to_expert_demos.json" --n_parallel=4 --speedup=20 --onnx_export_path=model.onnx --experiment_name=ILTutorial
+```
+
+**将env_path设置为导出的游戏路径,将demo_files路径设置为记录的演示。如果你有多个演示文件,请用空格分隔添加,例如`--demo_files demos.json demos2.json`。**
+
+你也可以为`--gail_timesteps`设置大量的时间步数,然后手动使用`CTRL+C`停止训练。我使用这种方法在奖励开始接近3时停止训练,这是在`total_timesteps | 1.38e+06`时。在我的电脑上使用CPU进行训练,这花了约41分钟,而BC预训练花了约5.5分钟。
+
+要在训练时观察环境,添加`--viz`参数。在BC训练期间,环境将被冻结,因为这个阶段不使用环境,除了获取关于观察和动作空间的一些信息。在GAIL训练阶段,环境渲染将更新。
+
+以下是使用[tensorboard](https://github.com/edbeeching/godot_rl_agents/blob/main/docs/TRAINING_STATISTICS.md)显示的日志中的`ep_rew_mean`和`ep_rew_wrapped_mean`统计数据,我们可以看到在这种情况下它们非常接近:
+
+ +
+
+
+你可以在相对于开始训练的路径的`logs/ILTutorial`中找到日志。如果进行多次运行,请在每次之间更改`--experiment_name`参数。
+
+
+尽管设置环境奖励不是必需的,也不用于这里的训练,但实现了一个简单的稀疏奖励来跟踪成功。掉出地图、掉入水中或陷阱设置`reward += -1`,而激活杠杆、收集钥匙和打开宝箱各设置`reward += 1`。如果`ep_rew_mean`接近3,我们就获得了一个好结果。`ep_rew_wrapped_mean`是来自GAIL判别器的奖励,它不直接告诉我们智能体在解决环境方面有多成功。
+
+### 让我们测试训练好的智能体
+
+训练后,你会在开始训练脚本的文件夹中找到一个`model.onnx`文件(你也可以在控制台的训练日志中找到`.onnx`文件的完整路径,接近结尾)。**将其复制到Godot游戏项目文件夹。**
+
+### 打开onnx推理场景
+
+这个场景,就像演示记录场景一样,只使用关卡的一个副本。它的`Sync`节点模式也设置为`Onnx Inference`。
+
+**点击`Sync`节点并将`Onnx Model Path`属性设置为`model.onnx`。**
+
+
+
+
+
+你可以在相对于开始训练的路径的`logs/ILTutorial`中找到日志。如果进行多次运行,请在每次之间更改`--experiment_name`参数。
+
+
+尽管设置环境奖励不是必需的,也不用于这里的训练,但实现了一个简单的稀疏奖励来跟踪成功。掉出地图、掉入水中或陷阱设置`reward += -1`,而激活杠杆、收集钥匙和打开宝箱各设置`reward += 1`。如果`ep_rew_mean`接近3,我们就获得了一个好结果。`ep_rew_wrapped_mean`是来自GAIL判别器的奖励,它不直接告诉我们智能体在解决环境方面有多成功。
+
+### 让我们测试训练好的智能体
+
+训练后,你会在开始训练脚本的文件夹中找到一个`model.onnx`文件(你也可以在控制台的训练日志中找到`.onnx`文件的完整路径,接近结尾)。**将其复制到Godot游戏项目文件夹。**
+
+### 打开onnx推理场景
+
+这个场景,就像演示记录场景一样,只使用关卡的一个副本。它的`Sync`节点模式也设置为`Onnx Inference`。
+
+**点击`Sync`节点并将`Onnx Model Path`属性设置为`model.onnx`。**
+
+ +
+**按F6启动场景,让我们看看智能体学到了什么!**
+
+训练好的智能体视频:
+
+
+看起来智能体能够从两个位置(左平台或右平台)收集钥匙,并很好地复制了记录的行为。**如果你获得了类似的结果,做得好,你已成功完成本教程!** 🏆👏
+
+如果你的结果有显著差异,请注意记录的演示的数量和质量可能会影响结果,调整BC/GAIL阶段的步数以及修改Python脚本中的超参数可能会有所帮助。运行之间也存在一些变化,所以即使使用相同的设置,结果有时也可能略有不同。
From 01f11db8068a9787dfe03eacb72159c160dedcb8 Mon Sep 17 00:00:00 2001
From: AmadeusGB <1069830494@qq.com>
Date: Tue, 11 Mar 2025 20:31:45 -0700
Subject: [PATCH 2/2] Translate course titles to Chinese in _toctree.yml
---
units/cn/_toctree.yml | 258 +++++++++++++++++++++---------------------
1 file changed, 129 insertions(+), 129 deletions(-)
diff --git a/units/cn/_toctree.yml b/units/cn/_toctree.yml
index f96d14cd..8d9d36eb 100644
--- a/units/cn/_toctree.yml
+++ b/units/cn/_toctree.yml
@@ -1,260 +1,260 @@
-- title: Unit 0. Welcome to the course
+- title: 单元 0. 欢迎来到课程
sections:
- local: unit0/introduction
- title: Welcome to the course 🤗
+ title: 欢迎来到课程 🤗
- local: unit0/setup
- title: Setup
+ title: 环境配置
- local: unit0/discord101
- title: Discord 101
-- title: Unit 1. Introduction to Deep Reinforcement Learning
+ title: Discord 使用指南
+- title: 单元 1. 深度强化学习简介
sections:
- local: unit1/introduction
- title: Introduction
+ title: 介绍
- local: unit1/what-is-rl
- title: What is Reinforcement Learning?
+ title: 什么是强化学习?
- local: unit1/rl-framework
- title: The Reinforcement Learning Framework
+ title: 强化学习框架
- local: unit1/tasks
- title: The type of tasks
+ title: 任务类型
- local: unit1/exp-exp-tradeoff
- title: The Exploration/ Exploitation tradeoff
+ title: 探索与利用的权衡
- local: unit1/two-methods
- title: The two main approaches for solving RL problems
+ title: 解决强化学习问题的两种主要方法
- local: unit1/deep-rl
- title: The “Deep” in Deep Reinforcement Learning
+ title: 深度强化学习中的"深度"
- local: unit1/summary
- title: Summary
+ title: 总结
- local: unit1/glossary
- title: Glossary
+ title: 术语表
- local: unit1/hands-on
- title: Hands-on
+ title: 实践练习
- local: unit1/quiz
- title: Quiz
+ title: 测验
- local: unit1/conclusion
- title: Conclusion
+ title: 结论
- local: unit1/additional-readings
- title: Additional Readings
-- title: Bonus Unit 1. Introduction to Deep Reinforcement Learning with Huggy
+ title: 扩展阅读
+- title: 奖励单元 1. 与Huggy一起深度强化学习入门
sections:
- local: unitbonus1/introduction
- title: Introduction
+ title: 介绍
- local: unitbonus1/how-huggy-works
- title: How Huggy works?
+ title: Huggy是如何工作的?
- local: unitbonus1/train
- title: Train Huggy
+ title: 训练Huggy
- local: unitbonus1/play
- title: Play with Huggy
+ title: 与Huggy互动
- local: unitbonus1/conclusion
- title: Conclusion
-- title: Live 1. How the course work, Q&A, and playing with Huggy
+ title: 结论
+- title: 直播 1. 课程工作方式,问答,以及与Huggy互动
sections:
- local: live1/live1
- title: Live 1. How the course work, Q&A, and playing with Huggy 🐶
-- title: Unit 2. Introduction to Q-Learning
+ title: 直播 1. 课程工作方式,问答,以及与Huggy互动 🐶
+- title: 单元 2. Q-Learning入门
sections:
- local: unit2/introduction
- title: Introduction
+ title: 介绍
- local: unit2/what-is-rl
- title: What is RL? A short recap
+ title: 什么是强化学习?简要回顾
- local: unit2/two-types-value-based-methods
- title: The two types of value-based methods
+ title: 基于价值的方法的两种类型
- local: unit2/bellman-equation
- title: The Bellman Equation, simplify our value estimation
+ title: Bellman方程,简化我们的价值估计
- local: unit2/mc-vs-td
- title: Monte Carlo vs Temporal Difference Learning
+ title: 蒙特卡洛与时序差分学习
- local: unit2/mid-way-recap
- title: Mid-way Recap
+ title: 中途回顾
- local: unit2/mid-way-quiz
- title: Mid-way Quiz
+ title: 中途测验
- local: unit2/q-learning
- title: Introducing Q-Learning
+ title: Q-Learning介绍
- local: unit2/q-learning-example
- title: A Q-Learning example
+ title: Q-Learning示例
- local: unit2/q-learning-recap
- title: Q-Learning Recap
+ title: Q-Learning回顾
- local: unit2/glossary
- title: Glossary
+ title: 术语表
- local: unit2/hands-on
- title: Hands-on
+ title: 实践练习
- local: unit2/quiz2
- title: Q-Learning Quiz
+ title: Q-Learning测验
- local: unit2/conclusion
- title: Conclusion
+ title: 结论
- local: unit2/additional-readings
- title: Additional Readings
-- title: Unit 3. Deep Q-Learning with Atari Games
+ title: 扩展阅读
+- title: 单元 3. 使用Atari游戏的深度Q-Learning
sections:
- local: unit3/introduction
- title: Introduction
+ title: 介绍
- local: unit3/from-q-to-dqn
- title: From Q-Learning to Deep Q-Learning
+ title: 从Q-Learning到深度Q-Learning
- local: unit3/deep-q-network
- title: The Deep Q-Network (DQN)
+ title: 深度Q网络(DQN)
- local: unit3/deep-q-algorithm
- title: The Deep Q Algorithm
+ title: 深度Q算法
- local: unit3/glossary
- title: Glossary
+ title: 术语表
- local: unit3/hands-on
- title: Hands-on
+ title: 实践练习
- local: unit3/quiz
- title: Quiz
+ title: 测验
- local: unit3/conclusion
- title: Conclusion
+ title: 结论
- local: unit3/additional-readings
- title: Additional Readings
-- title: Bonus Unit 2. Automatic Hyperparameter Tuning with Optuna
+ title: 扩展阅读
+- title: 奖励单元 2. 使用Optuna进行自动超参数调优
sections:
- local: unitbonus2/introduction
- title: Introduction
+ title: 介绍
- local: unitbonus2/optuna
title: Optuna
- local: unitbonus2/hands-on
- title: Hands-on
-- title: Unit 4. Policy Gradient with PyTorch
+ title: 实践练习
+- title: 单元 4. 使用PyTorch的策略梯度
sections:
- local: unit4/introduction
- title: Introduction
+ title: 介绍
- local: unit4/what-are-policy-based-methods
- title: What are the policy-based methods?
+ title: 什么是基于策略的方法?
- local: unit4/advantages-disadvantages
- title: The advantages and disadvantages of policy-gradient methods
+ title: 策略梯度方法的优缺点
- local: unit4/policy-gradient
- title: Diving deeper into policy-gradient
+ title: 深入策略梯度
- local: unit4/pg-theorem
- title: (Optional) the Policy Gradient Theorem
+ title: (可选) 策略梯度定理
- local: unit4/glossary
- title: Glossary
+ title: 术语表
- local: unit4/hands-on
- title: Hands-on
+ title: 实践练习
- local: unit4/quiz
- title: Quiz
+ title: 测验
- local: unit4/conclusion
- title: Conclusion
+ title: 结论
- local: unit4/additional-readings
- title: Additional Readings
-- title: Unit 5. Introduction to Unity ML-Agents
+ title: 扩展阅读
+- title: 单元 5. Unity ML-Agents入门
sections:
- local: unit5/introduction
- title: Introduction
+ title: 介绍
- local: unit5/how-mlagents-works
- title: How ML-Agents works?
+ title: ML-Agents是如何工作的?
- local: unit5/snowball-target
- title: The SnowballTarget environment
+ title: SnowballTarget环境
- local: unit5/pyramids
- title: The Pyramids environment
+ title: Pyramids环境
- local: unit5/curiosity
- title: (Optional) What is curiosity in Deep Reinforcement Learning?
+ title: (可选) 深度强化学习中的好奇心是什么?
- local: unit5/hands-on
- title: Hands-on
+ title: 实践练习
- local: unit5/bonus
- title: Bonus. Learn to create your own environments with Unity and MLAgents
+ title: 奖励. 学习使用Unity和MLAgents创建自己的环境
- local: unit5/quiz
- title: Quiz
+ title: 测验
- local: unit5/conclusion
- title: Conclusion
-- title: Unit 6. Actor Critic methods with Robotics environments
+ title: 结论
+- title: 单元 6. 使用机器人环境的Actor-Critic方法
sections:
- local: unit6/introduction
- title: Introduction
+ title: 介绍
- local: unit6/variance-problem
- title: The Problem of Variance in Reinforce
+ title: Reinforce中的方差问题
- local: unit6/advantage-actor-critic
- title: Advantage Actor Critic (A2C)
+ title: 优势Actor-Critic (A2C)
- local: unit6/hands-on
- title: Advantage Actor Critic (A2C) using Robotics Simulations with Panda-Gym 🤖
+ title: 使用Panda-Gym进行机器人模拟的优势Actor-Critic (A2C) 🤖
- local: unit6/quiz
- title: Quiz
+ title: 测验
- local: unit6/conclusion
- title: Conclusion
+ title: 结论
- local: unit6/additional-readings
- title: Additional Readings
-- title: Unit 7. Introduction to Multi-Agents and AI vs AI
+ title: 扩展阅读
+- title: 单元 7. 多智能体和AI对战AI入门
sections:
- local: unit7/introduction
- title: Introduction
+ title: 介绍
- local: unit7/introduction-to-marl
- title: An introduction to Multi-Agents Reinforcement Learning (MARL)
+ title: 多智能体强化学习(MARL)简介
- local: unit7/multi-agent-setting
- title: Designing Multi-Agents systems
+ title: 设计多智能体系统
- local: unit7/self-play
- title: Self-Play
+ title: 自我对弈
- local: unit7/hands-on
- title: Let's train our soccer team to beat your classmates' teams (AI vs. AI)
+ title: 训练我们的足球队击败你同学的队伍(AI对战AI)
- local: unit7/quiz
- title: Quiz
+ title: 测验
- local: unit7/conclusion
- title: Conclusion
+ title: 结论
- local: unit7/additional-readings
- title: Additional Readings
-- title: Unit 8. Part 1 Proximal Policy Optimization (PPO)
+ title: 扩展阅读
+- title: 单元 8. 第1部分 近端策略优化(PPO)
sections:
- local: unit8/introduction
- title: Introduction
+ title: 介绍
- local: unit8/intuition-behind-ppo
- title: The intuition behind PPO
+ title: PPO背后的直觉
- local: unit8/clipped-surrogate-objective
- title: Introducing the Clipped Surrogate Objective Function
+ title: 引入截断替代目标函数
- local: unit8/visualize
- title: Visualize the Clipped Surrogate Objective Function
+ title: 可视化截断替代目标函数
- local: unit8/hands-on-cleanrl
- title: PPO with CleanRL
+ title: 使用CleanRL实现PPO
- local: unit8/conclusion
- title: Conclusion
+ title: 结论
- local: unit8/additional-readings
- title: Additional Readings
-- title: Unit 8. Part 2 Proximal Policy Optimization (PPO) with Doom
+ title: 扩展阅读
+- title: 单元 8. 第2部分 使用Doom的近端策略优化(PPO)
sections:
- local: unit8/introduction-sf
- title: Introduction
+ title: 介绍
- local: unit8/hands-on-sf
- title: PPO with Sample Factory and Doom
+ title: 使用Sample Factory和Doom实现PPO
- local: unit8/conclusion-sf
- title: Conclusion
-- title: Bonus Unit 3. Advanced Topics in Reinforcement Learning
+ title: 结论
+- title: 奖励单元 3. 强化学习高级主题
sections:
- local: unitbonus3/introduction
- title: Introduction
+ title: 介绍
- local: unitbonus3/model-based
- title: Model-Based Reinforcement Learning
+ title: 基于模型的强化学习
- local: unitbonus3/offline-online
- title: Offline vs. Online Reinforcement Learning
+ title: 离线与在线强化学习
- local: unitbonus3/generalisation
- title: Generalisation Reinforcement Learning
+ title: 泛化强化学习
- local: unitbonus3/rlhf
- title: Reinforcement Learning from Human Feedback
+ title: 基于人类反馈的强化学习
- local: unitbonus3/decision-transformers
- title: Decision Transformers and Offline RL
+ title: 决策Transformers和离线强化学习
- local: unitbonus3/language-models
- title: Language models in RL
+ title: 强化学习中的语言模型
- local: unitbonus3/curriculum-learning
- title: (Automatic) Curriculum Learning for RL
+ title: 强化学习的(自动)课程学习
- local: unitbonus3/envs-to-try
- title: Interesting environments to try
+ title: 值得尝试的有趣环境
- local: unitbonus3/learning-agents
- title: An introduction to Unreal Learning Agents
+ title: Unreal Learning Agents简介
- local: unitbonus3/godotrl
- title: An Introduction to Godot RL
+ title: Godot RL简介
- local: unitbonus3/student-works
- title: Students projects
+ title: 学生项目
- local: unitbonus3/rl-documentation
- title: Brief introduction to RL documentation
-- title: Bonus Unit 5. Imitation Learning with Godot RL Agents
+ title: 强化学习文档简介
+- title: 奖励单元 5. 使用Godot RL Agents的模仿学习
sections:
- local: unitbonus5/introduction
- title: Introduction
+ title: 介绍
- local: unitbonus5/the-environment
- title: The environment
+ title: 环境
- local: unitbonus5/getting-started
- title: Getting started
+ title: 入门指南
- local: unitbonus5/train-our-robot
- title: Train our robot
+ title: 训练我们的机器人
- local: unitbonus5/customize-the-environment
- title: (Optional) Customize the environment
+ title: (可选) 自定义环境
- local: unitbonus5/conclusion
- title: Conclusion
-- title: Certification and congratulations
+ title: 结论
+- title: 认证与祝贺
sections:
- local: communication/conclusion
- title: Congratulations
+ title: 恭喜
- local: communication/certification
- title: Get your certificate of completion
+ title: 获取你的完成证书
+
+**按F6启动场景,让我们看看智能体学到了什么!**
+
+训练好的智能体视频:
+
+
+看起来智能体能够从两个位置(左平台或右平台)收集钥匙,并很好地复制了记录的行为。**如果你获得了类似的结果,做得好,你已成功完成本教程!** 🏆👏
+
+如果你的结果有显著差异,请注意记录的演示的数量和质量可能会影响结果,调整BC/GAIL阶段的步数以及修改Python脚本中的超参数可能会有所帮助。运行之间也存在一些变化,所以即使使用相同的设置,结果有时也可能略有不同。
From 01f11db8068a9787dfe03eacb72159c160dedcb8 Mon Sep 17 00:00:00 2001
From: AmadeusGB <1069830494@qq.com>
Date: Tue, 11 Mar 2025 20:31:45 -0700
Subject: [PATCH 2/2] Translate course titles to Chinese in _toctree.yml
---
units/cn/_toctree.yml | 258 +++++++++++++++++++++---------------------
1 file changed, 129 insertions(+), 129 deletions(-)
diff --git a/units/cn/_toctree.yml b/units/cn/_toctree.yml
index f96d14cd..8d9d36eb 100644
--- a/units/cn/_toctree.yml
+++ b/units/cn/_toctree.yml
@@ -1,260 +1,260 @@
-- title: Unit 0. Welcome to the course
+- title: 单元 0. 欢迎来到课程
sections:
- local: unit0/introduction
- title: Welcome to the course 🤗
+ title: 欢迎来到课程 🤗
- local: unit0/setup
- title: Setup
+ title: 环境配置
- local: unit0/discord101
- title: Discord 101
-- title: Unit 1. Introduction to Deep Reinforcement Learning
+ title: Discord 使用指南
+- title: 单元 1. 深度强化学习简介
sections:
- local: unit1/introduction
- title: Introduction
+ title: 介绍
- local: unit1/what-is-rl
- title: What is Reinforcement Learning?
+ title: 什么是强化学习?
- local: unit1/rl-framework
- title: The Reinforcement Learning Framework
+ title: 强化学习框架
- local: unit1/tasks
- title: The type of tasks
+ title: 任务类型
- local: unit1/exp-exp-tradeoff
- title: The Exploration/ Exploitation tradeoff
+ title: 探索与利用的权衡
- local: unit1/two-methods
- title: The two main approaches for solving RL problems
+ title: 解决强化学习问题的两种主要方法
- local: unit1/deep-rl
- title: The “Deep” in Deep Reinforcement Learning
+ title: 深度强化学习中的"深度"
- local: unit1/summary
- title: Summary
+ title: 总结
- local: unit1/glossary
- title: Glossary
+ title: 术语表
- local: unit1/hands-on
- title: Hands-on
+ title: 实践练习
- local: unit1/quiz
- title: Quiz
+ title: 测验
- local: unit1/conclusion
- title: Conclusion
+ title: 结论
- local: unit1/additional-readings
- title: Additional Readings
-- title: Bonus Unit 1. Introduction to Deep Reinforcement Learning with Huggy
+ title: 扩展阅读
+- title: 奖励单元 1. 与Huggy一起深度强化学习入门
sections:
- local: unitbonus1/introduction
- title: Introduction
+ title: 介绍
- local: unitbonus1/how-huggy-works
- title: How Huggy works?
+ title: Huggy是如何工作的?
- local: unitbonus1/train
- title: Train Huggy
+ title: 训练Huggy
- local: unitbonus1/play
- title: Play with Huggy
+ title: 与Huggy互动
- local: unitbonus1/conclusion
- title: Conclusion
-- title: Live 1. How the course work, Q&A, and playing with Huggy
+ title: 结论
+- title: 直播 1. 课程工作方式,问答,以及与Huggy互动
sections:
- local: live1/live1
- title: Live 1. How the course work, Q&A, and playing with Huggy 🐶
-- title: Unit 2. Introduction to Q-Learning
+ title: 直播 1. 课程工作方式,问答,以及与Huggy互动 🐶
+- title: 单元 2. Q-Learning入门
sections:
- local: unit2/introduction
- title: Introduction
+ title: 介绍
- local: unit2/what-is-rl
- title: What is RL? A short recap
+ title: 什么是强化学习?简要回顾
- local: unit2/two-types-value-based-methods
- title: The two types of value-based methods
+ title: 基于价值的方法的两种类型
- local: unit2/bellman-equation
- title: The Bellman Equation, simplify our value estimation
+ title: Bellman方程,简化我们的价值估计
- local: unit2/mc-vs-td
- title: Monte Carlo vs Temporal Difference Learning
+ title: 蒙特卡洛与时序差分学习
- local: unit2/mid-way-recap
- title: Mid-way Recap
+ title: 中途回顾
- local: unit2/mid-way-quiz
- title: Mid-way Quiz
+ title: 中途测验
- local: unit2/q-learning
- title: Introducing Q-Learning
+ title: Q-Learning介绍
- local: unit2/q-learning-example
- title: A Q-Learning example
+ title: Q-Learning示例
- local: unit2/q-learning-recap
- title: Q-Learning Recap
+ title: Q-Learning回顾
- local: unit2/glossary
- title: Glossary
+ title: 术语表
- local: unit2/hands-on
- title: Hands-on
+ title: 实践练习
- local: unit2/quiz2
- title: Q-Learning Quiz
+ title: Q-Learning测验
- local: unit2/conclusion
- title: Conclusion
+ title: 结论
- local: unit2/additional-readings
- title: Additional Readings
-- title: Unit 3. Deep Q-Learning with Atari Games
+ title: 扩展阅读
+- title: 单元 3. 使用Atari游戏的深度Q-Learning
sections:
- local: unit3/introduction
- title: Introduction
+ title: 介绍
- local: unit3/from-q-to-dqn
- title: From Q-Learning to Deep Q-Learning
+ title: 从Q-Learning到深度Q-Learning
- local: unit3/deep-q-network
- title: The Deep Q-Network (DQN)
+ title: 深度Q网络(DQN)
- local: unit3/deep-q-algorithm
- title: The Deep Q Algorithm
+ title: 深度Q算法
- local: unit3/glossary
- title: Glossary
+ title: 术语表
- local: unit3/hands-on
- title: Hands-on
+ title: 实践练习
- local: unit3/quiz
- title: Quiz
+ title: 测验
- local: unit3/conclusion
- title: Conclusion
+ title: 结论
- local: unit3/additional-readings
- title: Additional Readings
-- title: Bonus Unit 2. Automatic Hyperparameter Tuning with Optuna
+ title: 扩展阅读
+- title: 奖励单元 2. 使用Optuna进行自动超参数调优
sections:
- local: unitbonus2/introduction
- title: Introduction
+ title: 介绍
- local: unitbonus2/optuna
title: Optuna
- local: unitbonus2/hands-on
- title: Hands-on
-- title: Unit 4. Policy Gradient with PyTorch
+ title: 实践练习
+- title: 单元 4. 使用PyTorch的策略梯度
sections:
- local: unit4/introduction
- title: Introduction
+ title: 介绍
- local: unit4/what-are-policy-based-methods
- title: What are the policy-based methods?
+ title: 什么是基于策略的方法?
- local: unit4/advantages-disadvantages
- title: The advantages and disadvantages of policy-gradient methods
+ title: 策略梯度方法的优缺点
- local: unit4/policy-gradient
- title: Diving deeper into policy-gradient
+ title: 深入策略梯度
- local: unit4/pg-theorem
- title: (Optional) the Policy Gradient Theorem
+ title: (可选) 策略梯度定理
- local: unit4/glossary
- title: Glossary
+ title: 术语表
- local: unit4/hands-on
- title: Hands-on
+ title: 实践练习
- local: unit4/quiz
- title: Quiz
+ title: 测验
- local: unit4/conclusion
- title: Conclusion
+ title: 结论
- local: unit4/additional-readings
- title: Additional Readings
-- title: Unit 5. Introduction to Unity ML-Agents
+ title: 扩展阅读
+- title: 单元 5. Unity ML-Agents入门
sections:
- local: unit5/introduction
- title: Introduction
+ title: 介绍
- local: unit5/how-mlagents-works
- title: How ML-Agents works?
+ title: ML-Agents是如何工作的?
- local: unit5/snowball-target
- title: The SnowballTarget environment
+ title: SnowballTarget环境
- local: unit5/pyramids
- title: The Pyramids environment
+ title: Pyramids环境
- local: unit5/curiosity
- title: (Optional) What is curiosity in Deep Reinforcement Learning?
+ title: (可选) 深度强化学习中的好奇心是什么?
- local: unit5/hands-on
- title: Hands-on
+ title: 实践练习
- local: unit5/bonus
- title: Bonus. Learn to create your own environments with Unity and MLAgents
+ title: 奖励. 学习使用Unity和MLAgents创建自己的环境
- local: unit5/quiz
- title: Quiz
+ title: 测验
- local: unit5/conclusion
- title: Conclusion
-- title: Unit 6. Actor Critic methods with Robotics environments
+ title: 结论
+- title: 单元 6. 使用机器人环境的Actor-Critic方法
sections:
- local: unit6/introduction
- title: Introduction
+ title: 介绍
- local: unit6/variance-problem
- title: The Problem of Variance in Reinforce
+ title: Reinforce中的方差问题
- local: unit6/advantage-actor-critic
- title: Advantage Actor Critic (A2C)
+ title: 优势Actor-Critic (A2C)
- local: unit6/hands-on
- title: Advantage Actor Critic (A2C) using Robotics Simulations with Panda-Gym 🤖
+ title: 使用Panda-Gym进行机器人模拟的优势Actor-Critic (A2C) 🤖
- local: unit6/quiz
- title: Quiz
+ title: 测验
- local: unit6/conclusion
- title: Conclusion
+ title: 结论
- local: unit6/additional-readings
- title: Additional Readings
-- title: Unit 7. Introduction to Multi-Agents and AI vs AI
+ title: 扩展阅读
+- title: 单元 7. 多智能体和AI对战AI入门
sections:
- local: unit7/introduction
- title: Introduction
+ title: 介绍
- local: unit7/introduction-to-marl
- title: An introduction to Multi-Agents Reinforcement Learning (MARL)
+ title: 多智能体强化学习(MARL)简介
- local: unit7/multi-agent-setting
- title: Designing Multi-Agents systems
+ title: 设计多智能体系统
- local: unit7/self-play
- title: Self-Play
+ title: 自我对弈
- local: unit7/hands-on
- title: Let's train our soccer team to beat your classmates' teams (AI vs. AI)
+ title: 训练我们的足球队击败你同学的队伍(AI对战AI)
- local: unit7/quiz
- title: Quiz
+ title: 测验
- local: unit7/conclusion
- title: Conclusion
+ title: 结论
- local: unit7/additional-readings
- title: Additional Readings
-- title: Unit 8. Part 1 Proximal Policy Optimization (PPO)
+ title: 扩展阅读
+- title: 单元 8. 第1部分 近端策略优化(PPO)
sections:
- local: unit8/introduction
- title: Introduction
+ title: 介绍
- local: unit8/intuition-behind-ppo
- title: The intuition behind PPO
+ title: PPO背后的直觉
- local: unit8/clipped-surrogate-objective
- title: Introducing the Clipped Surrogate Objective Function
+ title: 引入截断替代目标函数
- local: unit8/visualize
- title: Visualize the Clipped Surrogate Objective Function
+ title: 可视化截断替代目标函数
- local: unit8/hands-on-cleanrl
- title: PPO with CleanRL
+ title: 使用CleanRL实现PPO
- local: unit8/conclusion
- title: Conclusion
+ title: 结论
- local: unit8/additional-readings
- title: Additional Readings
-- title: Unit 8. Part 2 Proximal Policy Optimization (PPO) with Doom
+ title: 扩展阅读
+- title: 单元 8. 第2部分 使用Doom的近端策略优化(PPO)
sections:
- local: unit8/introduction-sf
- title: Introduction
+ title: 介绍
- local: unit8/hands-on-sf
- title: PPO with Sample Factory and Doom
+ title: 使用Sample Factory和Doom实现PPO
- local: unit8/conclusion-sf
- title: Conclusion
-- title: Bonus Unit 3. Advanced Topics in Reinforcement Learning
+ title: 结论
+- title: 奖励单元 3. 强化学习高级主题
sections:
- local: unitbonus3/introduction
- title: Introduction
+ title: 介绍
- local: unitbonus3/model-based
- title: Model-Based Reinforcement Learning
+ title: 基于模型的强化学习
- local: unitbonus3/offline-online
- title: Offline vs. Online Reinforcement Learning
+ title: 离线与在线强化学习
- local: unitbonus3/generalisation
- title: Generalisation Reinforcement Learning
+ title: 泛化强化学习
- local: unitbonus3/rlhf
- title: Reinforcement Learning from Human Feedback
+ title: 基于人类反馈的强化学习
- local: unitbonus3/decision-transformers
- title: Decision Transformers and Offline RL
+ title: 决策Transformers和离线强化学习
- local: unitbonus3/language-models
- title: Language models in RL
+ title: 强化学习中的语言模型
- local: unitbonus3/curriculum-learning
- title: (Automatic) Curriculum Learning for RL
+ title: 强化学习的(自动)课程学习
- local: unitbonus3/envs-to-try
- title: Interesting environments to try
+ title: 值得尝试的有趣环境
- local: unitbonus3/learning-agents
- title: An introduction to Unreal Learning Agents
+ title: Unreal Learning Agents简介
- local: unitbonus3/godotrl
- title: An Introduction to Godot RL
+ title: Godot RL简介
- local: unitbonus3/student-works
- title: Students projects
+ title: 学生项目
- local: unitbonus3/rl-documentation
- title: Brief introduction to RL documentation
-- title: Bonus Unit 5. Imitation Learning with Godot RL Agents
+ title: 强化学习文档简介
+- title: 奖励单元 5. 使用Godot RL Agents的模仿学习
sections:
- local: unitbonus5/introduction
- title: Introduction
+ title: 介绍
- local: unitbonus5/the-environment
- title: The environment
+ title: 环境
- local: unitbonus5/getting-started
- title: Getting started
+ title: 入门指南
- local: unitbonus5/train-our-robot
- title: Train our robot
+ title: 训练我们的机器人
- local: unitbonus5/customize-the-environment
- title: (Optional) Customize the environment
+ title: (可选) 自定义环境
- local: unitbonus5/conclusion
- title: Conclusion
-- title: Certification and congratulations
+ title: 结论
+- title: 认证与祝贺
sections:
- local: communication/conclusion
- title: Congratulations
+ title: 恭喜
- local: communication/certification
- title: Get your certificate of completion
+ title: 获取你的完成证书