- Redis
Redis is a very fast non-relational (NoSQL) in-memory key-value database. It can store mappings between keys and five different types of values.
Keys can only be strings, while values support five data types: strings, lists, sets, hashes, and sorted sets.
Redis supports many features, such as persisting in-memory data to disk, using replication to scale read performance, and using sharding to scale write performance.
| Data Type | Values It Can Store | Operations |
|---|---|---|
| STRING | String, integer, or floating-point number | Perform operations on the whole string or part of it</br> Increment or decrement integers and floating-point numbers |
| LIST | List | Push or pop elements from both ends </br> Trim one or more elements,</br> keeping only elements within a range |
| SET | Unordered set | Add, get, or remove individual elements</br> Check whether an element exists in the set</br> Compute intersections, unions, and differences</br> Get random elements from the set |
| HASH | Unordered hash table containing key-value pairs | Add, get, or remove individual key-value pairs</br> Get all key-value pairs</br> Check whether a key exists |
| ZSET | Sorted set | Add, get, or remove elements</br> Get elements by score range or member</br> Compute the rank of a key |

> set hello world
OK
> get hello
"world"
> del hello
(integer) 1
> get hello
(nil)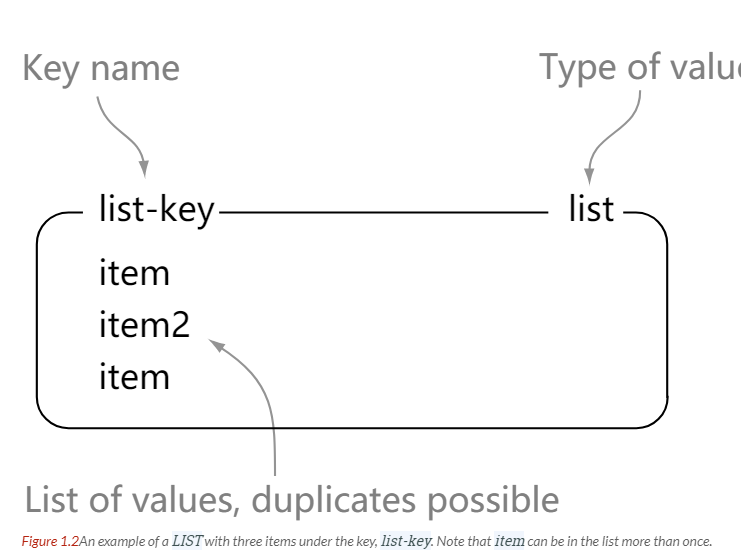
> rpush list-key item
(integer) 1
> rpush list-key item2
(integer) 2
> rpush list-key item
(integer) 3
> lrange list-key 0 -1
1) "item"
2) "item2"
3) "item"
> lindex list-key 1
"item2"
> lpop list-key
"item"
> lrange list-key 0 -1
1) "item2"
2) "item"
> sadd set-key item
(integer) 1
> sadd set-key item2
(integer) 1
> sadd set-key item3
(integer) 1
> sadd set-key item
(integer) 0
> smembers set-key
1) "item"
2) "item2"
3) "item3"
> sismember set-key item4
(integer) 0
> sismember set-key item
(integer) 1
> srem set-key item2
(integer) 1
> srem set-key item2
(integer) 0
> smembers set-key
1) "item"
2) "item3"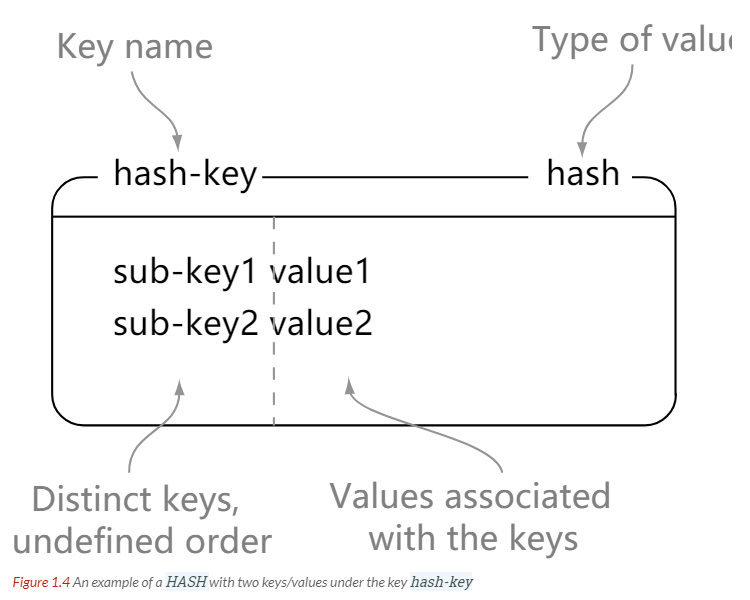
> hset hash-key sub-key1 value1
(integer) 1
> hset hash-key sub-key2 value2
(integer) 1
> hset hash-key sub-key1 value1
(integer) 0
> hgetall hash-key
1) "sub-key1"
2) "value1"
3) "sub-key2"
4) "value2"
> hdel hash-key sub-key2
(integer) 1
> hdel hash-key sub-key2
(integer) 0
> hget hash-key sub-key1
"value1"
> hgetall hash-key
1) "sub-key1"
2) "value1"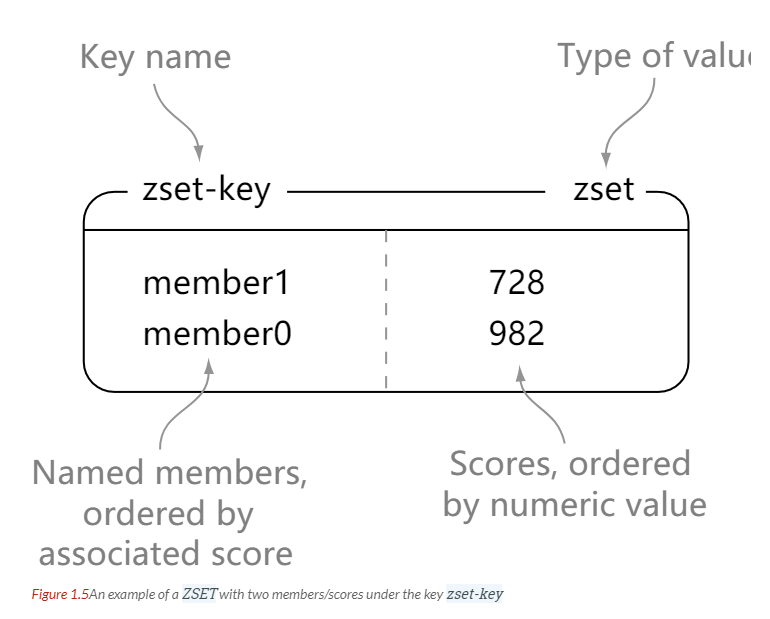
> zadd zset-key 728 member1
(integer) 1
> zadd zset-key 982 member0
(integer) 1
> zadd zset-key 982 member0
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member1"
2) "728"
3) "member0"
4) "982"
> zrangebyscore zset-key 0 800 withscores
1) "member1"
2) "728"
> zrem zset-key member1
(integer) 1
> zrem zset-key member1
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member0"
2) "982"dictht is a hash table structure that resolves hash collisions using separate chaining.
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;Redis dictionaries, dict, contain two dictht hash tables to make rehashing easier. During expansion, key-value pairs from one dictht are rehashed into the other dictht. After completion, space is released and the roles of the two dictht tables are swapped.
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;Rehashing is not completed all at once; it is incremental to avoid placing too much load on the server by doing too much rehashing in one step.
Incremental rehashing is done by recording rehashidx in dict. It starts at 0 and increments after each rehash step. For example, when rehashing dict[0] into dict[1], one step rehashes the key-value pairs in dict[0]'s table[rehashidx] into dict[1], sets dict[0]'s table[rehashidx] to null, and increments rehashidx.
During rehashing, every add, delete, lookup, or update operation on the dictionary also performs one incremental rehash step.
Incremental rehashing causes dictionary data to be spread across two dictht tables, so dictionary lookups must also search the corresponding dictht.
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
int empty_visits = n * 10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while (n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long) d->rehashidx);
while (d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while (de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}It is one of the underlying implementations of sorted sets.
A skip list is implemented based on ordered linked lists with multiple pointers and can be viewed as multiple ordered linked lists.

During lookup, search starts from the upper-level pointers. After finding the corresponding range, it continues to the next level. The figure below demonstrates the process of finding 22.
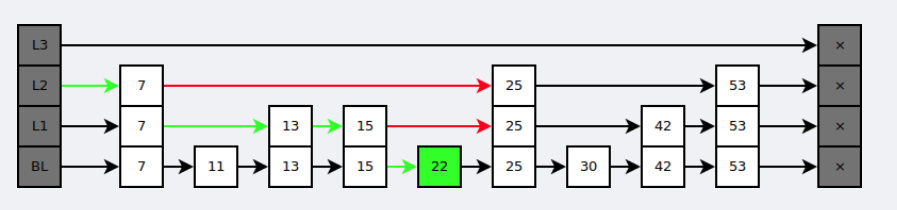
Compared with balanced trees such as red-black trees, skip lists have these advantages:
- Very fast insertion because no rotations or similar operations are needed to maintain balance;
- Easier to implement;
- Supports lock-free operations.
String values can be incremented and decremented to implement counters.
As an in-memory database, Redis has very high read/write performance and is well suited for storing frequently read and written counts.
Place hot data in memory and set the maximum memory usage and eviction policy to maintain the cache hit rate.
For example, DNS records are well suited for storage in Redis.
Lookup tables are similar to caches and also use Redis's fast lookup capability. However, lookup table contents cannot expire, while cached contents can expire because a cache is not a reliable source of data.
List is a doubly linked list, so messages can be written and read through lpush and rpop.
However, it is usually better to use message middleware such as Kafka or RabbitMQ.
Redis can be used to store session information for multiple application servers in one place.
When application servers no longer store user session information, they become stateless. A user can request any application server, making high availability and scalability easier to implement.
In distributed scenarios, locks from a single-machine environment cannot synchronize processes across multiple nodes.
Redis's built-in SETNX command can implement distributed locks. In addition, the official RedLock distributed lock implementation can be used.
Set can implement operations such as intersection and union, enabling features such as mutual friends.
ZSet can implement ordering operations, enabling features such as leaderboards.
Both are non-relational in-memory key-value databases. The main differences are:
Memcached supports only string values, while Redis supports five different data types and can solve problems more flexibly.
Redis supports two persistence strategies: RDB snapshots and AOF logs, while Memcached does not support persistence.
Memcached does not support distributed storage directly. It can only implement distributed storage through consistent hashing on the client side. This approach requires the client to compute the node where the data resides during both storage and lookup.
Redis Cluster provides distributed support.
-
In Redis, not all data is always stored in memory. Values that have not been used for a long time can be swapped to disk, while Memcached data always stays in memory.
-
Memcached divides memory into fixed-size blocks to store data, completely solving memory fragmentation. However, this approach reduces memory utilization. For example, if the block size is 128 bytes and only 100 bytes of data are stored, the remaining 28 bytes are wasted.
Redis can set an expiration time for each key. When a key expires, it is automatically deleted.
For container types such as hashes, expiration can only be set on the entire key, meaning the entire hash, not on individual elements inside the key.
The maximum memory usage can be configured. When memory usage exceeds it, an eviction policy is applied.
Redis has 6 specific eviction policies:
| Policy | Description |
|---|---|
| volatile-lru | Evict the least recently used data from the set of keys with expiration times |
| volatile-ttl | Evict data that is about to expire from the set of keys with expiration times |
| volatile-random | Randomly evict data from the set of keys with expiration times |
| allkeys-lru | Evict the least recently used data from all keys |
| allkeys-random | Randomly evict data from all keys |
| noeviction | Do not evict data |
As an in-memory database, Redis considers performance and memory consumption. In practice, its eviction algorithm does not inspect all keys; it samples a small subset and chooses keys to evict from that subset.
When using Redis to cache data, ensure cached data is hot data to improve the cache hit rate. The maximum memory usage can be set to the memory occupied by hot data, then the allkeys-lru eviction policy can be enabled to evict the least recently used data.
Redis 4.0 introduced the volatile-lfu and allkeys-lfu eviction policies. LFU evicts the key-value pairs with the lowest access frequency by tracking access frequency.
Redis is an in-memory database. To ensure data is not lost after power failure, in-memory data must be persisted to disk.
Store all data at a specific point in time on disk.
Snapshots can be copied to other servers to create server replicas with the same data.
If the system fails, data written after the last snapshot will be lost.
If the data volume is large, saving a snapshot takes a long time.
Append write commands to the end of the AOF file (Append Only File).
Using AOF persistence requires setting a synchronization option to determine when write commands are synchronized to the disk file. Writing to a file does not immediately synchronize contents to disk; data is first stored in a buffer, and the operating system decides when to synchronize it to disk. The synchronization options are:
| Option | Synchronization Frequency |
|---|---|
| always | Synchronize every write command |
| everysec | Synchronize once per second |
| no | Let the operating system decide when to synchronize |
- The always option severely reduces server performance;
- The everysec option is more appropriate. It guarantees that only about one second of data is lost during a system crash, and Redis synchronizing once per second has almost no effect on server performance;
- The no option does not significantly improve server performance and increases the amount of data lost during a system crash.
As server write requests increase, the AOF file grows larger. Redis provides an AOF rewrite feature that removes redundant write commands from the AOF file.
A transaction contains multiple commands. While executing a transaction, the server does not switch to executing command requests from other clients.
Multiple commands in a transaction are sent to the server all at once instead of one by one. This approach is called pipelining, and it improves performance by reducing network communication between client and server.
The simplest way to implement transactions in Redis is to wrap transaction operations with the MULTI and EXEC commands.
The Redis server is an event-driven program.
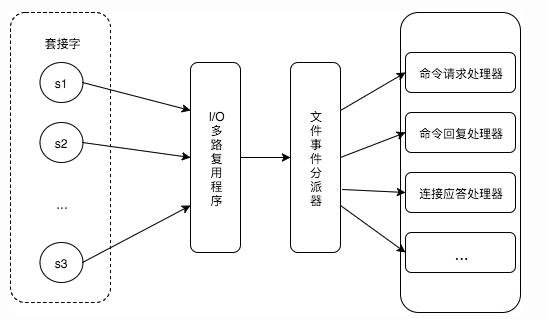
The server communicates with clients or other servers through sockets. File events are an abstraction over socket operations.
Redis developed its own network event processor based on the Reactor pattern. It uses I/O multiplexing to listen to multiple sockets at the same time and passes arriving events to the file event dispatcher. The dispatcher calls the corresponding event handler according to the type of event generated by the socket.
Some server operations need to run at specified times. Time events are an abstraction over these timed operations.
Time events are divided into:
- Timed events: run a piece of code once at a specified time;
- Periodic events: run a piece of code once every specified interval.
Redis stores all time events in an unordered linked list. It traverses the entire list to find time events that have arrived and calls the corresponding event handlers.
The server must continuously listen to sockets for file events to obtain pending file events, but it cannot listen indefinitely; otherwise, time events cannot execute at their scheduled times. Therefore, the listen duration should be determined by the nearest time event.
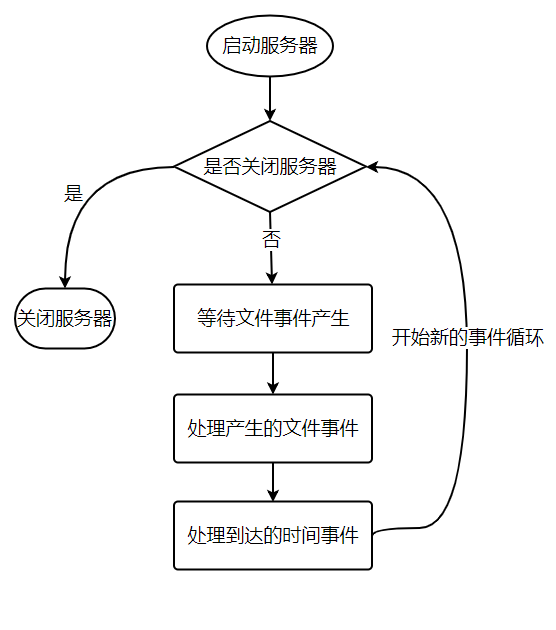
Event scheduling and execution are handled by the aeProcessEvents function. The pseudocode is:
def aeProcessEvents():
# Get the time event whose arrival time is closest to the current time
time_event = aeSearchNearestTimer()
# Calculate how many milliseconds remain before the nearest time event arrives
remaind_ms = time_event.when - unix_ts_now()
# If the event has already arrived, remaind_ms may be negative, so set it to 0
if remaind_ms < 0:
remaind_ms = 0
# Create timeval according to the value of remaind_ms
timeval = create_timeval_with_ms(remaind_ms)
# Block and wait for file events; the maximum blocking time is determined by timeval
aeApiPoll(timeval)
# Process all generated file events
procesFileEvents()
# Process all arrived time events
processTimeEvents()Put aeProcessEvents inside a loop, add initialization and cleanup functions, and this forms the main function of the Redis server. The pseudocode is:
def main():
# Initialize the server
init_server()
# Keep processing events until the server shuts down
while server_is_not_shutdown():
aeProcessEvents()
# The server has shut down; perform cleanup
clean_server()From the perspective of event handling, the server runs as follows:
Use the slaveof host port command to make one server become the slave of another server.
A slave server can have only one master server, and master-master replication is not supported.
-
The master server creates a snapshot file, sends it to the slave server, and records executed write commands in a buffer while sending. After the snapshot file is sent, it starts sending the buffered write commands to the slave server;
-
The slave server discards all old data, loads the snapshot file sent by the master server, and then starts accepting write commands from the master server;
-
Each time the master server executes a write command, it sends the same write command to the slave server.
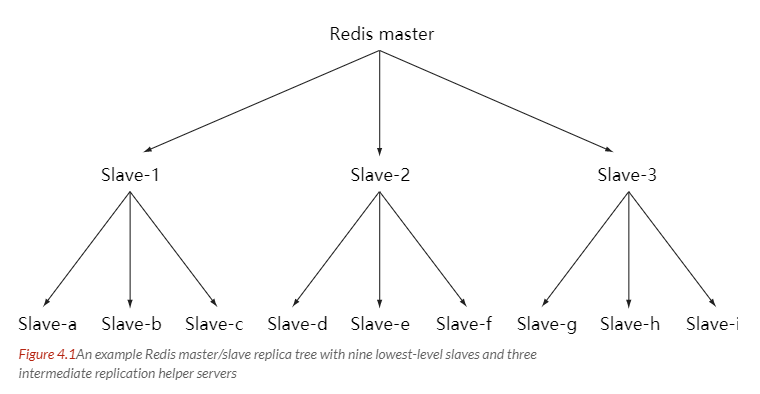
As load keeps increasing, the master server may be unable to update all slave servers quickly, or reconnecting and resynchronizing slave servers may overload the system. To solve this problem, an intermediate layer can be created to share the master's replication work. The intermediate server is a slave of the upper-level server and the master of the lower-level server.
Sentinel can monitor servers in a cluster and automatically elect a new master server from the slave servers when the master goes offline.
Sharding is a method of dividing data into multiple parts and storing it across multiple machines. For some problems, this approach can provide linear performance improvements.
Suppose there are 4 Redis instances, R0, R1, R2, and R3, and many keys representing users, such as user:1, user:2, and so on. There are different ways to choose which instance stores a specific key.
- The simplest approach is range sharding. For example, user IDs from 0~1000 are stored in instance R0, user IDs from 1001~2000 are stored in instance R1, and so on. However, this requires maintaining a range mapping table, which is costly to maintain.
- Another approach is hash sharding. Use the CRC32 hash function to convert a key into a number, then take the modulo by the number of instances to determine which instance should store it.
Based on where sharding is performed, it can be divided into three approaches:
- Client-side sharding: the client uses algorithms such as consistent hashing to decide which node a key should go to.
- Proxy sharding: client requests are sent to a proxy, which forwards each request to the correct node.
- Server-side sharding: Redis Cluster.
The forum system has the following features:
- Users can publish articles;
- Users can like articles;
- The home page can sort and display articles by publish time or like count.
An article includes information such as title, author, and like count. In a relational database, it is easy to create a table to store this information. In Redis, HASH can store the mapping between each field and its corresponding value.
Redis does not have the concept of tables from relational databases to store the same type of data together. Instead, it uses namespaces to achieve this. The front part of the key name stores the namespace, and the later part stores the ID, usually separated by :. For example, the HASH below has the key name article:92617, where article is the namespace and 92617 is the ID.

When a user likes an article, in addition to incrementing the article's votes field by 1, the system must record that the user has already liked the article to prevent more than one like from the same user. A set of users who have voted for the article can be created for this record.
To save memory, articles are no longer votable one week after publication, and the voted-user set for the article is also deleted. This rule can be implemented by setting a one-week expiration time on the article's voted-user set.

To sort by publish time and like count, create a sorted set for article publish times and another sorted set for article like counts. The score in the figure below is the like count mentioned here. The sorted-set scores shown below are not directly the time and like count, but are indirectly calculated from time and like count.

- Carlson J L. Redis in Action[J]. Media.johnwiley.com.au, 2013.
- Huang Jianhong. Redis Design and Implementation[M]. China Machine Press, 2014.
- REDIS IN ACTION
- Skip Lists: Done Right
- Discussion of the differences between Redis and Memcached
- Redis 3.0 Chinese edition - sharding
- Redis use cases
- Using Redis as an LRU cache