An input operation usually includes two stages:
- Waiting for data to be ready
- Copying data from the kernel to the process
For an input operation on a socket, the first step usually involves waiting for data to arrive from the network. When the awaited data arrives, it is copied into a buffer in the kernel. The second step is to copy the data from the kernel buffer into the application process buffer.
Unix has five I/O models:
- Blocking I/O
- Non-blocking I/O
- I/O multiplexing (select and poll)
- Signal-driven I/O (SIGIO)
- Asynchronous I/O (AIO)
The application process is blocked and returns only after data has been copied from the kernel buffer to the application process buffer.
Note that other application processes can still execute during the blocking period, so blocking does not mean the entire operating system is blocked. Because other application processes can still run, CPU time is not consumed by polling, so this model has relatively high CPU utilization.
In the figure below, recvfrom() receives data from a Socket and copies it into the application process buffer buf. Here recvfrom() is treated as a system call.
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);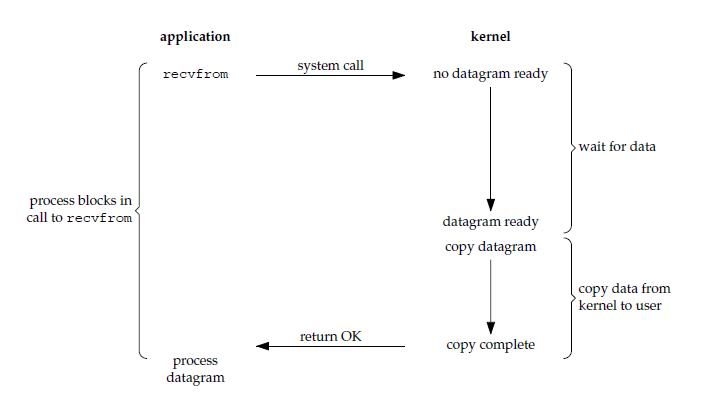
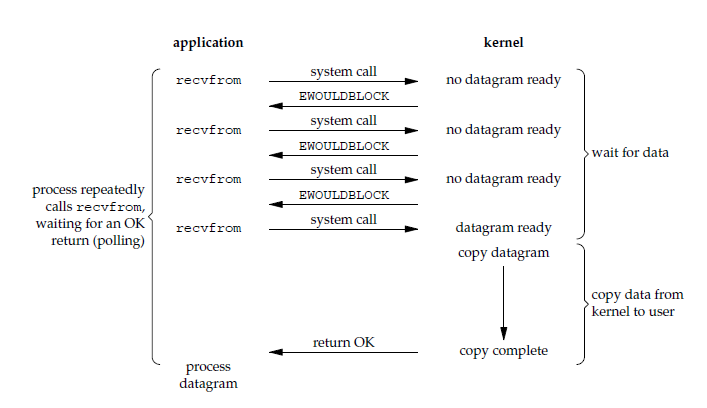
After the application process executes the system call, the kernel returns an error code. The application process can continue running, but it must repeatedly execute system calls to determine whether I/O is complete. This approach is called polling.
Because the CPU has to handle more system calls, this model has relatively low CPU utilization.
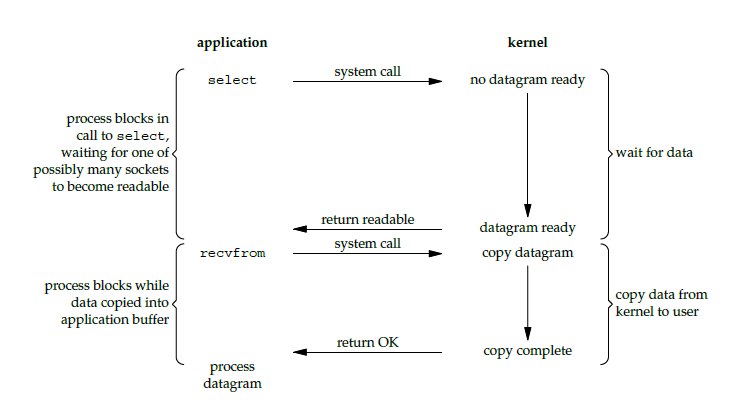
Use select or poll to wait for data, and wait until any one of multiple sockets becomes readable. This process blocks and returns when one socket is readable. Then recvfrom is used to copy the data from the kernel to the process.
It allows a single process to handle multiple I/O events. It is also called Event Driven I/O.
If a Web server does not use I/O multiplexing, each Socket connection needs a thread to handle it. If there are tens of thousands of simultaneous connections, the same number of threads must be created. Compared with multi-process and multi-thread techniques, I/O multiplexing avoids the overhead of process and thread creation and switching, so system overhead is lower.
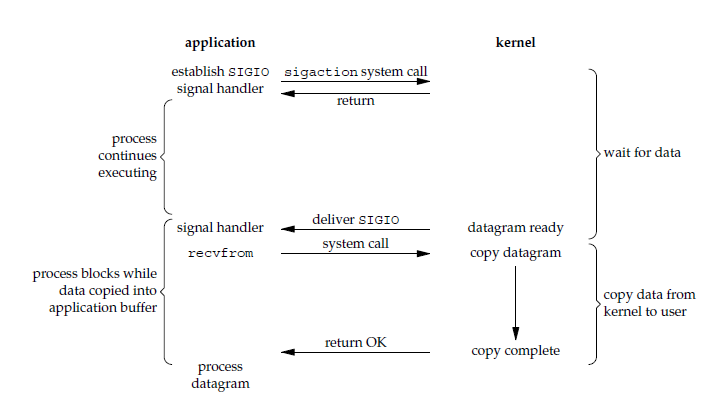
The application process uses the sigaction system call, and the kernel returns immediately. The application process can continue running, so it is non-blocking during the data-waiting stage. When data arrives, the kernel sends a SIGIO signal to the application process. After receiving it, the application process calls recvfrom in the signal handler to copy data from the kernel to the application process.
Compared with polling in non-blocking I/O, signal-driven I/O has higher CPU utilization.
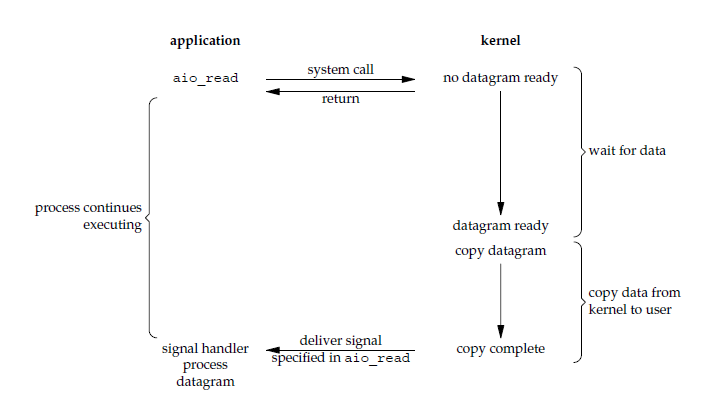
When the application process executes the aio_read system call, it returns immediately. The application process can continue executing and is not blocked. The kernel sends a signal to the application process after all operations are complete.
The difference between asynchronous I/O and signal-driven I/O is that the signal in asynchronous I/O notifies the application process that I/O is complete, while the signal in signal-driven I/O notifies the application process that I/O can begin.
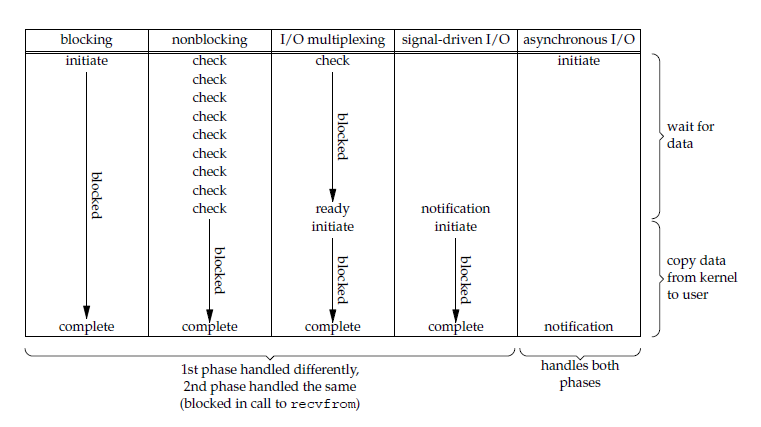
- Synchronous I/O: the application process blocks during the stage where data is copied from the kernel buffer to the application process buffer, which is the second stage.
- Asynchronous I/O: the application process does not block during the second stage.
Synchronous I/O includes blocking I/O, non-blocking I/O, I/O multiplexing, and signal-driven I/O. Their main differences are in the first stage.
Non-blocking I/O, signal-driven I/O, and asynchronous I/O do not block in the first stage.
select, poll, and epoll are concrete implementations of I/O multiplexing. select appeared first, followed by poll and then epoll.
int select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);select allows an application to monitor a set of file descriptors and wait until one or more descriptors become ready, thereby completing I/O operations.
-
fd_set is implemented with an array, and the array size is defined by FD_SETSIZE, so it can monitor only fewer than FD_SETSIZE descriptors. There are three descriptor sets: readset, writeset, and exceptset, corresponding to read, write, and exception conditions.
-
timeout is the timeout parameter. A select call blocks until a descriptor event arrives or the waiting time exceeds timeout.
-
A successful call returns a value greater than 0, an error returns -1, and a timeout returns 0.
fd_set fd_in, fd_out;
struct timeval tv;
// Reset the sets
FD_ZERO( &fd_in );
FD_ZERO( &fd_out );
// Monitor sock1 for input events
FD_SET( sock1, &fd_in );
// Monitor sock2 for output events
FD_SET( sock2, &fd_out );
// Find out which socket has the largest numeric value as select requires it
int largest_sock = sock1 > sock2 ? sock1 : sock2;
// Wait up to 10 seconds
tv.tv_sec = 10;
tv.tv_usec = 0;
// Call the select
int ret = select( largest_sock + 1, &fd_in, &fd_out, NULL, &tv );
// Check if select actually succeed
if ( ret == -1 )
// report error and abort
else if ( ret == 0 )
// timeout; no event detected
else
{
if ( FD_ISSET( sock1, &fd_in ) )
// input event on sock1
if ( FD_ISSET( sock2, &fd_out ) )
// output event on sock2
}int poll(struct pollfd *fds, unsigned int nfds, int timeout);poll is similar to select. It also waits for one descriptor in a set of descriptors to become ready.
The descriptors in poll are an array of pollfd. pollfd is defined as follows:
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};// The structure for two events
struct pollfd fds[2];
// Monitor sock1 for input
fds[0].fd = sock1;
fds[0].events = POLLIN;
// Monitor sock2 for output
fds[1].fd = sock2;
fds[1].events = POLLOUT;
// Wait 10 seconds
int ret = poll( &fds, 2, 10000 );
// Check if poll actually succeed
if ( ret == -1 )
// report error and abort
else if ( ret == 0 )
// timeout; no event detected
else
{
// If we detect the event, zero it out so we can reuse the structure
if ( fds[0].revents & POLLIN )
fds[0].revents = 0;
// input event on sock1
if ( fds[1].revents & POLLOUT )
fds[1].revents = 0;
// output event on sock2
}select and poll have basically the same functionality, but differ in some implementation details.
- select modifies descriptors, while poll does not.
- select uses an array for descriptor sets, and FD_SETSIZE defaults to 1024, so by default it can monitor fewer than 1024 descriptors. To monitor more descriptors, FD_SETSIZE must be modified and the program recompiled. poll has no descriptor count limit.
- poll provides more event types and has better descriptor reuse than select.
- If one thread calls select or poll on a descriptor and another thread closes that descriptor, the result is undefined.
select and poll are both relatively slow because every call needs to copy all descriptors from the application process buffer to the kernel buffer.
Almost all systems support select, but only relatively newer systems support poll.
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);epoll_ctl() registers new descriptors with the kernel or changes the state of a file descriptor. Registered descriptors are maintained in a red-black tree in the kernel. Through callbacks, the kernel adds descriptors whose I/O is ready to a linked list. The process can call epoll_wait() to obtain descriptors whose events have completed.
As the description above shows, epoll only needs to copy descriptors from the process buffer to the kernel buffer once, and the process does not need polling to obtain descriptors whose events have completed.
epoll applies only to Linux OS.
epoll is more flexible than select and poll and has no descriptor count limit.
epoll is friendlier to multithreaded programming. If one thread calls epoll_wait() and another thread closes the same descriptor, it does not produce the undefined behavior seen with select and poll.
// Create the epoll descriptor. Only one is needed per app, and is used to monitor all sockets.
// The function argument is ignored (it was not before, but now it is), so put your favorite number here
int pollingfd = epoll_create( 0xCAFE );
if ( pollingfd < 0 )
// report error
// Initialize the epoll structure in case more members are added in future
struct epoll_event ev = { 0 };
// Associate the connection class instance with the event. You can associate anything
// you want, epoll does not use this information. We store a connection class pointer, pConnection1
ev.data.ptr = pConnection1;
// Monitor for input, and do not automatically rearm the descriptor after the event
ev.events = EPOLLIN | EPOLLONESHOT;
// Add the descriptor into the monitoring list. We can do it even if another thread is
// waiting in epoll_wait - the descriptor will be properly added
if ( epoll_ctl( epollfd, EPOLL_CTL_ADD, pConnection1->getSocket(), &ev ) != 0 )
// report error
// Wait for up to 20 events (assuming we have added maybe 200 sockets before that it may happen)
struct epoll_event pevents[ 20 ];
// Wait for 10 seconds, and retrieve less than 20 epoll_event and store them into epoll_event array
int ready = epoll_wait( pollingfd, pevents, 20, 10000 );
// Check if epoll actually succeed
if ( ret == -1 )
// report error and abort
else if ( ret == 0 )
// timeout; no event detected
else
{
// Check if any events detected
for ( int i = 0; i < ready; i++ )
{
if ( pevents[i].events & EPOLLIN )
{
// Get back our connection pointer
Connection * c = (Connection*) pevents[i].data.ptr;
c->handleReadEvent();
}
}
}epoll descriptor events have two trigger modes: LT (level trigger) and ET (edge trigger).
When epoll_wait() detects that a descriptor event has arrived, it notifies the process. The process does not have to handle the event immediately; the next epoll_wait() call will notify the process again. This is the default mode and supports both blocking and non-blocking behavior.
Unlike LT mode, the process must handle the event immediately after being notified. The next epoll_wait() call will not receive another notification for the same event arrival.
This greatly reduces repeated triggering of epoll events, so it is more efficient than LT mode. It supports only non-blocking behavior to avoid starving the task that handles multiple file descriptors because of a blocking read or write on one file handle.
It is easy to think that epoll is always enough and that select and poll are obsolete, but each has its own use cases.
select's timeout parameter has microsecond precision, while poll and epoll use millisecond precision. Therefore, select is more suitable for scenarios with high real-time requirements, such as nuclear reactor control.
select has better portability and is supported by almost all mainstream platforms.
poll has no maximum descriptor count limit. If the platform supports it and real-time requirements are not high, use poll instead of select.
Use epoll when the program only needs to run on Linux, many descriptors need to be polled at the same time, and these connections are preferably long-lived.
If fewer than 1000 descriptors need to be monitored at the same time, epoll is unnecessary because its advantages do not show in this use case.
If the descriptors being monitored change state frequently and very briefly, epoll is also unnecessary. Because all descriptors in epoll are stored in the kernel, every descriptor state change requires an epoll_ctl() system call, and frequent system calls reduce efficiency. In addition, epoll descriptors are stored in the kernel, which makes debugging harder.
- Stevens W R, Fenner B, Rudoff A M. UNIX network programming[M]. Addison-Wesley Professional, 2004.
- http://man7.org/linux/man-pages/man2/select.2.html
- http://man7.org/linux/man-pages/man2/poll.2.html
- Boost application performance using asynchronous I/O
- Synchronous and Asynchronous I/O
- Linux IO Modes and Detailed Explanation of select, poll, and epoll
- poll vs select vs event-based
- select / poll / epoll: practical difference for system architects
- Browse the source code of userspace/glibc/sysdeps/unix/sysv/linux/ online