Application servers (nodes) in a cluster are usually designed to be stateless, so users can request any node.
A load balancer forwards user requests to appropriate nodes based on the load of each node in the cluster.
A load balancer can be used to achieve high availability and scalability:
- High availability: when a node fails, the load balancer forwards user requests to another node, ensuring that all services remain available.
- Scalability: nodes can be added or removed easily according to the overall system load.
The load balancer process includes two parts:
- Select the forwarding node according to the load balancing algorithm.
- Forward the request.
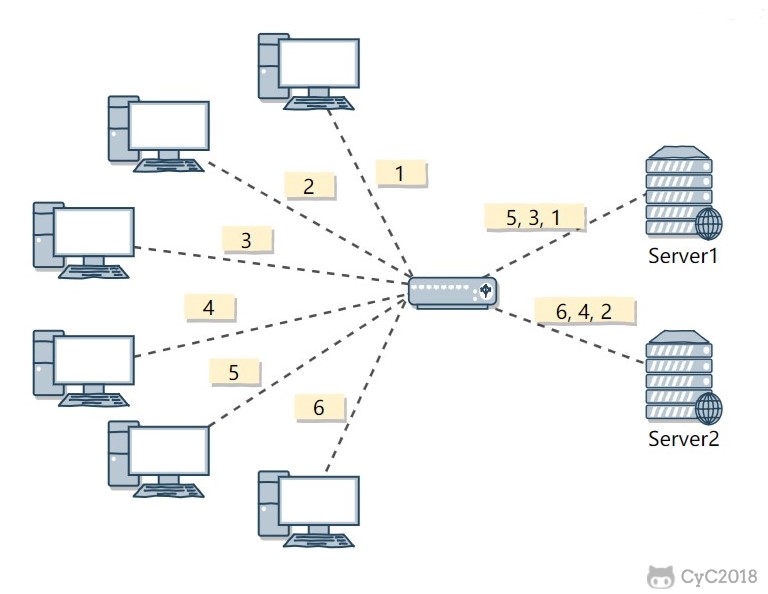
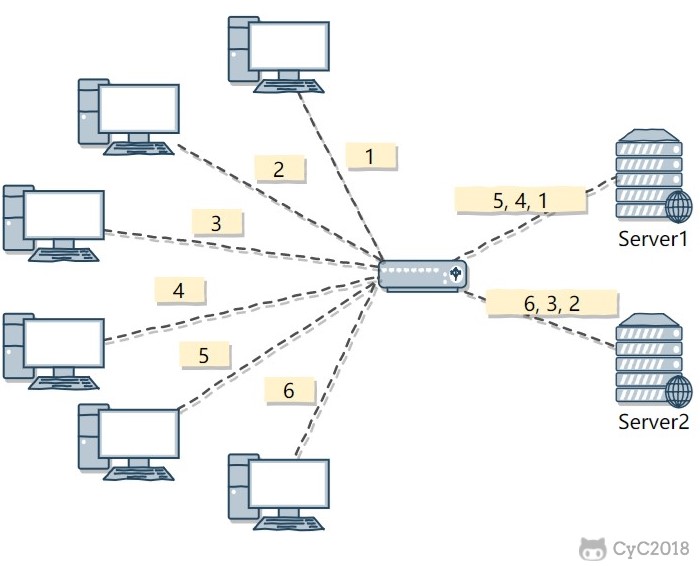
The round-robin algorithm sends each request to each server in turn.
In the figure below, six clients generate six requests, and the requests are sent in the order (1, 2, 3, 4, 5, 6). Requests (1, 3, 5) are sent to server 1, and requests (2, 4, 6) are sent to server 2.
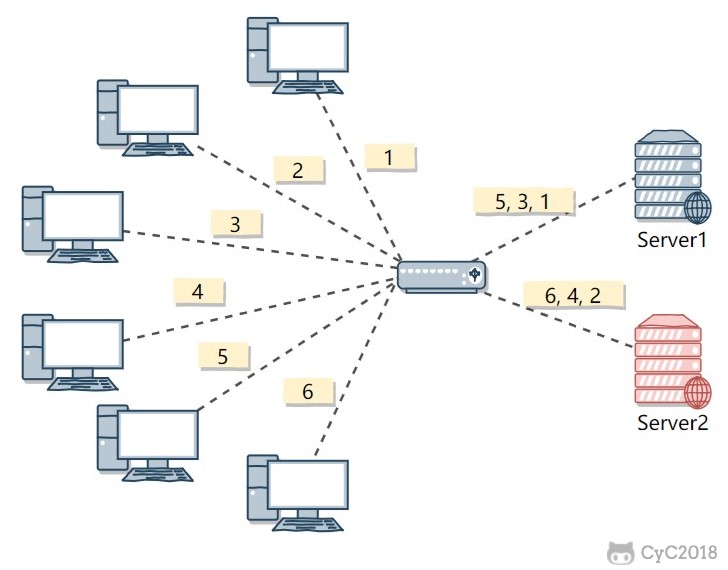
This algorithm is suitable when each server has similar performance. If server performance differs, a weaker server may be unable to handle excessive load, such as Server 2 in the figure below.
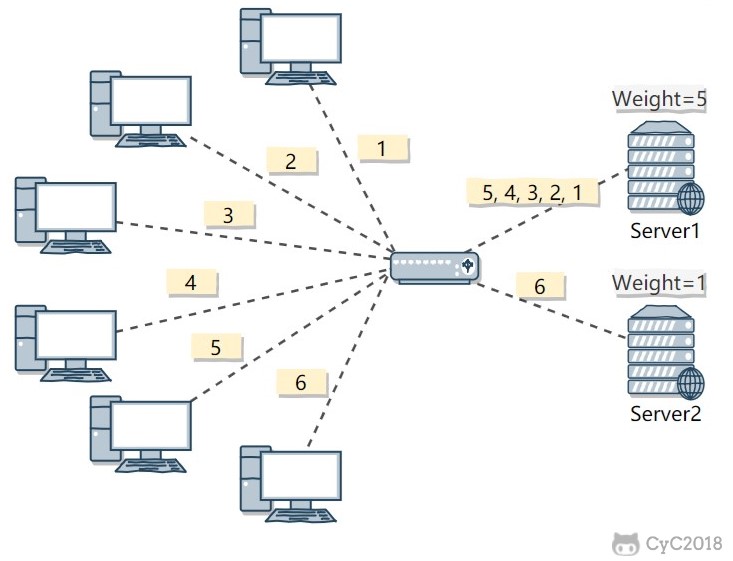
Weighted round robin assigns weights to servers based on their performance differences on top of round robin. Higher-performance servers receive higher weights.
For example, in the figure below, server 1 is assigned a weight of 5 and server 2 is assigned a weight of 1. Requests (1, 2, 3, 4, 5) are sent to server 1, and request (6) is sent to server 2.
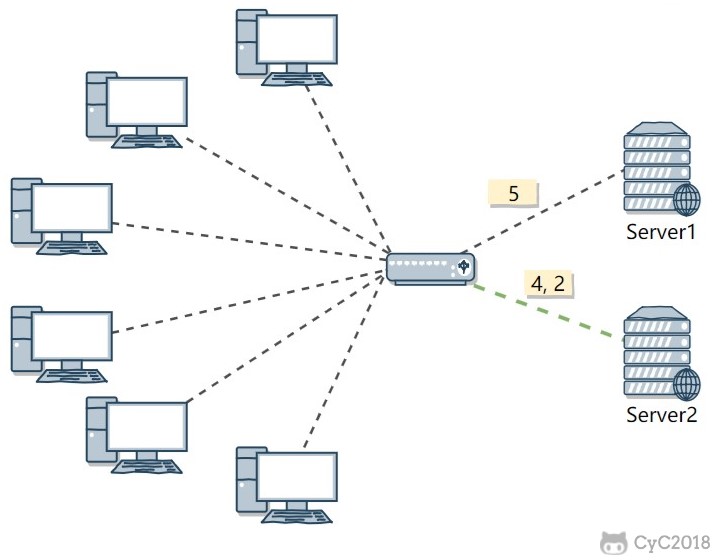
Because each request has a different connection duration, using round robin or weighted round robin may cause one server to have too many current connections while another has too few, creating load imbalance.
For example, in the figure below, requests (1, 3, 5) are sent to server 1, but (1, 3) disconnect quickly, so only request (5) remains connected to server 1. Requests (2, 4, 6) are sent to server 2, and only connection (2) disconnects, so requests (6, 4) remain connected to server 2. As the system continues running, server 2 bears excessive load.

The least-connections algorithm sends the request to the server with the fewest current connections.
For example, in the figure below, server 1 currently has the fewest connections, so the newly arrived request 6 is sent to server 1.
Based on least connections, each server is assigned a weight according to performance, and the number of connections each server can handle is calculated from that weight.
Send requests to servers randomly.
Like round robin, this algorithm is suitable when server performance is similar.
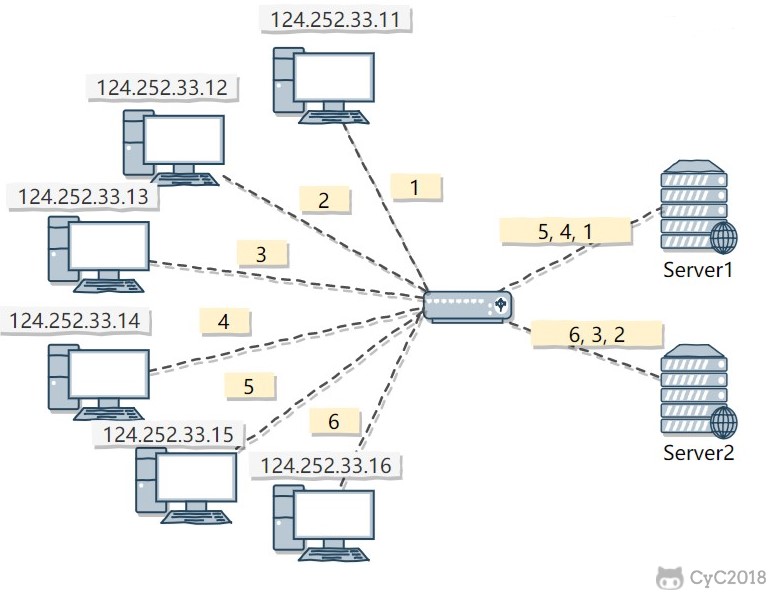
Source address hashing calculates a hash value from the client IP and then takes the modulus by the number of servers to obtain the target server number.
It ensures that requests from clients with the same IP are forwarded to the same server, which is used to implement Sticky Session.
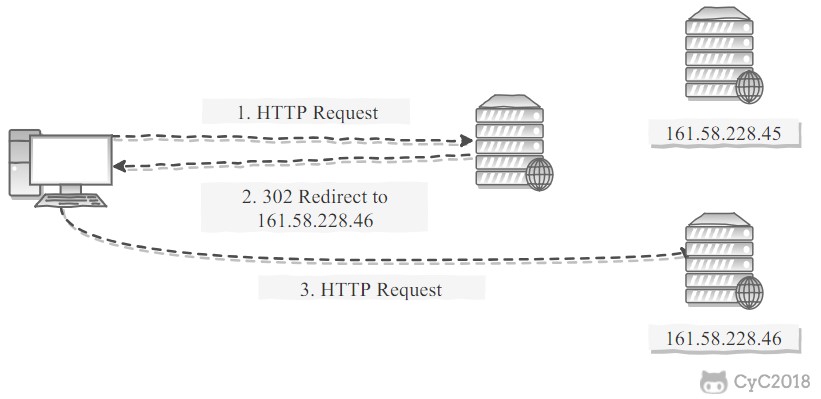
An HTTP redirect load balancer uses a load balancing algorithm to calculate the server IP address, writes that address into an HTTP redirect response, and returns status code 302. After the client receives the redirect response, it needs to initiate a new request to the server.
Disadvantages:
- Two requests are required, so access latency is relatively high.
- The processing capacity of an HTTP load balancer is limited, which restricts cluster size.
The disadvantages of this load balancing and forwarding approach are obvious, so it is rarely used in real scenarios.
When DNS resolves a domain name, it also uses a load balancing algorithm to calculate the server IP address.
Advantages:
- DNS can resolve domain names based on geographic location and return the server IP address closest to the user.
Disadvantages:
- Because DNS has a multi-level structure, domain records at each level may be cached. When a server is taken offline and DNS records need to be modified, it may take a long time for the change to take effect.
Large websites usually use DNS as the first level of load balancing and then use other methods internally as the second level of load balancing. In other words, domain resolution returns the IP address of an internal load balancing server.

A reverse proxy server sits in front of the origin server. User requests must pass through the reverse proxy before reaching the origin server. A reverse proxy can be used for caching, logging, and also as a load balancing server.
With this load balancing and forwarding method, the client does not request the origin server directly, so the origin server does not need an external IP address. The reverse proxy needs both internal and external IP addresses.
Advantages:
- It integrates with other functions and is simple to deploy.
Disadvantages:
- All requests and responses must pass through the reverse proxy server, which may become a performance bottleneck.
The operating system kernel process obtains network packets, calculates the origin server IP address according to the load balancing algorithm, modifies the destination IP address of the request packet, and then forwards it.
Responses returned by origin servers also need to pass through the load balancing server. This is usually implemented by making the load balancing server also act as the cluster's gateway server.
Advantages:
- Processing happens in the kernel process, so performance is relatively high.
Disadvantages:
- As with reverse proxying, all requests and responses pass through the load balancing server, which can become a performance bottleneck.
At the link layer, the origin server's MAC address is calculated according to the load balancing algorithm, the destination MAC address of the request packet is modified, and the packet is forwarded.
By configuring the origin server's virtual IP address to be the same as the load balancing server's IP address, forwarding can be performed without modifying the IP address. Because the IP addresses are the same, the origin server's response does not need to be forwarded back to the load balancing server and can be sent directly to the client, preventing the load balancing server from becoming a bottleneck.
This is a triangular transmission mode called direct routing. For websites that provide download and video services, direct routing avoids sending large amounts of network data through the load balancing server.
This is currently the most widely used load balancing forwarding method for large websites. On Linux, the available load balancing server is LVS (Linux Virtual Server).
References:
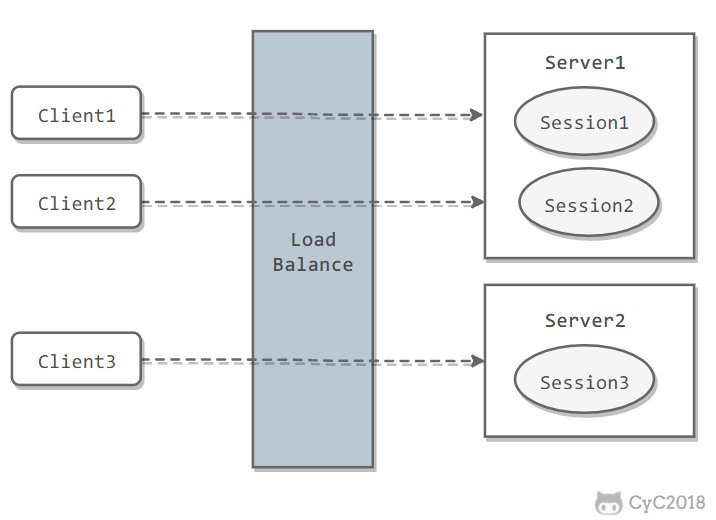
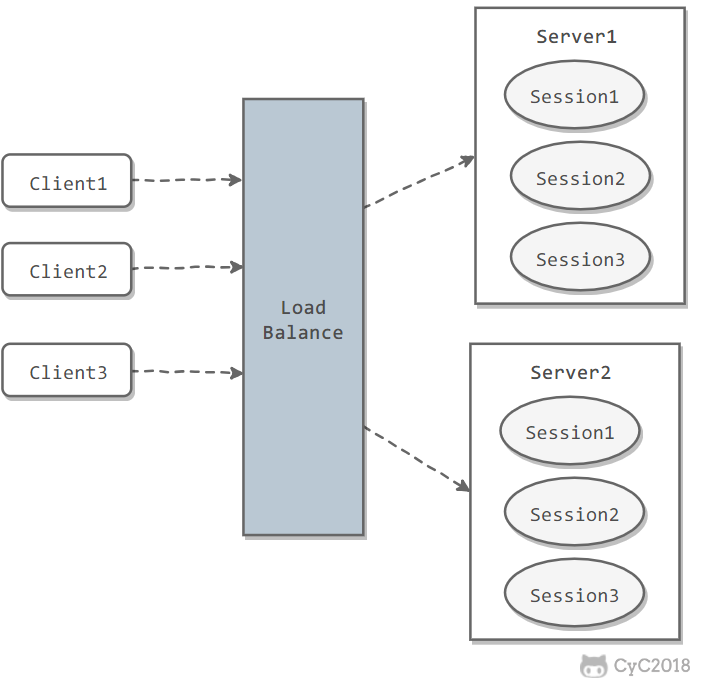
If a user's Session information is stored on one server, then when the load balancer forwards the user's next request to another server, that server does not have the user's Session information, so the user needs to log in again or perform similar operations.
The load balancer needs to be configured so that all requests from a user are routed to the same server. This allows the user's Session to be stored on that server.
Disadvantages:
- When the server goes down, all Sessions on that server are lost.
Session synchronization is performed between servers. Each server has Session information for all users, so users can send requests to any server.
Disadvantages:
- It consumes too much memory.
- Synchronization consumes network bandwidth and server CPU time.
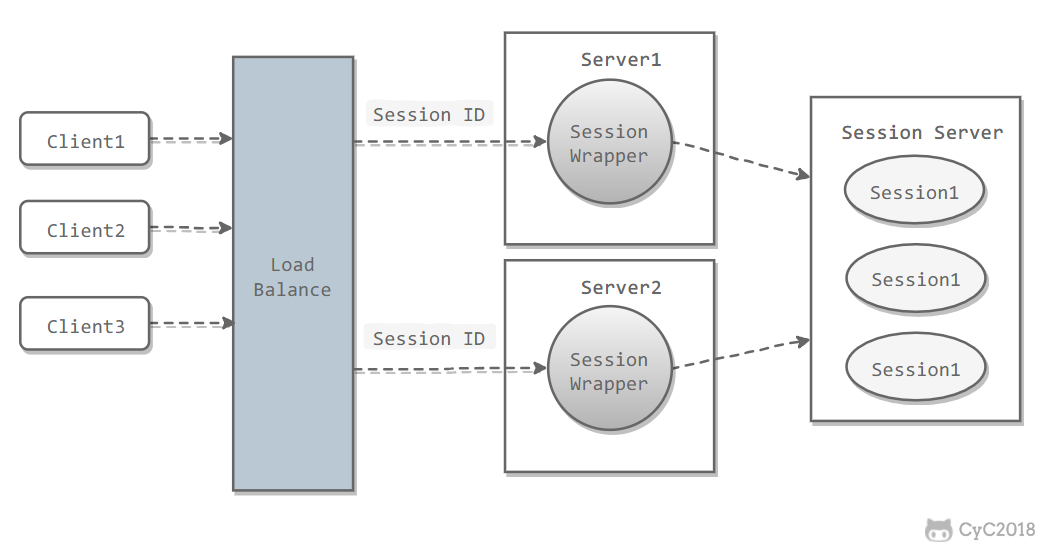
Use a separate server to store Session data. Traditional MySQL can be used, or in-memory databases such as Redis or Memcached can be used.
Advantages:
- To make large websites scalable, application servers in a cluster usually need to remain stateless, so application servers cannot store user session information. A Session Server stores user session information separately, ensuring that application servers remain stateless.
Disadvantages:
- Code for storing and retrieving Sessions needs to be implemented.
References: