Collections mainly include Collection and Map. Collection stores a collection of objects, while Map stores a mapping table of key-value pairs, or two objects.

-
TreeSet: implemented based on a red-black tree. It supports ordered operations, such as finding elements within a range. However, its lookup efficiency is lower than HashSet. HashSet lookup has time complexity O(1), while TreeSet is O(logN).
-
HashSet: implemented based on a hash table. It supports fast lookup but not ordered operations. It also loses insertion-order information, meaning the result of traversing a HashSet with an Iterator is uncertain.
-
LinkedHashSet: has the lookup efficiency of HashSet and internally uses a doubly linked list to maintain insertion order.
-
ArrayList: implemented based on a dynamic array and supports random access.
-
Vector: similar to ArrayList, but thread-safe.
-
LinkedList: implemented based on a doubly linked list. It supports only sequential access but can quickly insert and delete elements in the middle of the list. LinkedList can also be used as a stack, queue, or deque.
-
LinkedList: can be used to implement a deque.
-
PriorityQueue: implemented based on a heap structure and can be used to implement a priority queue.
-
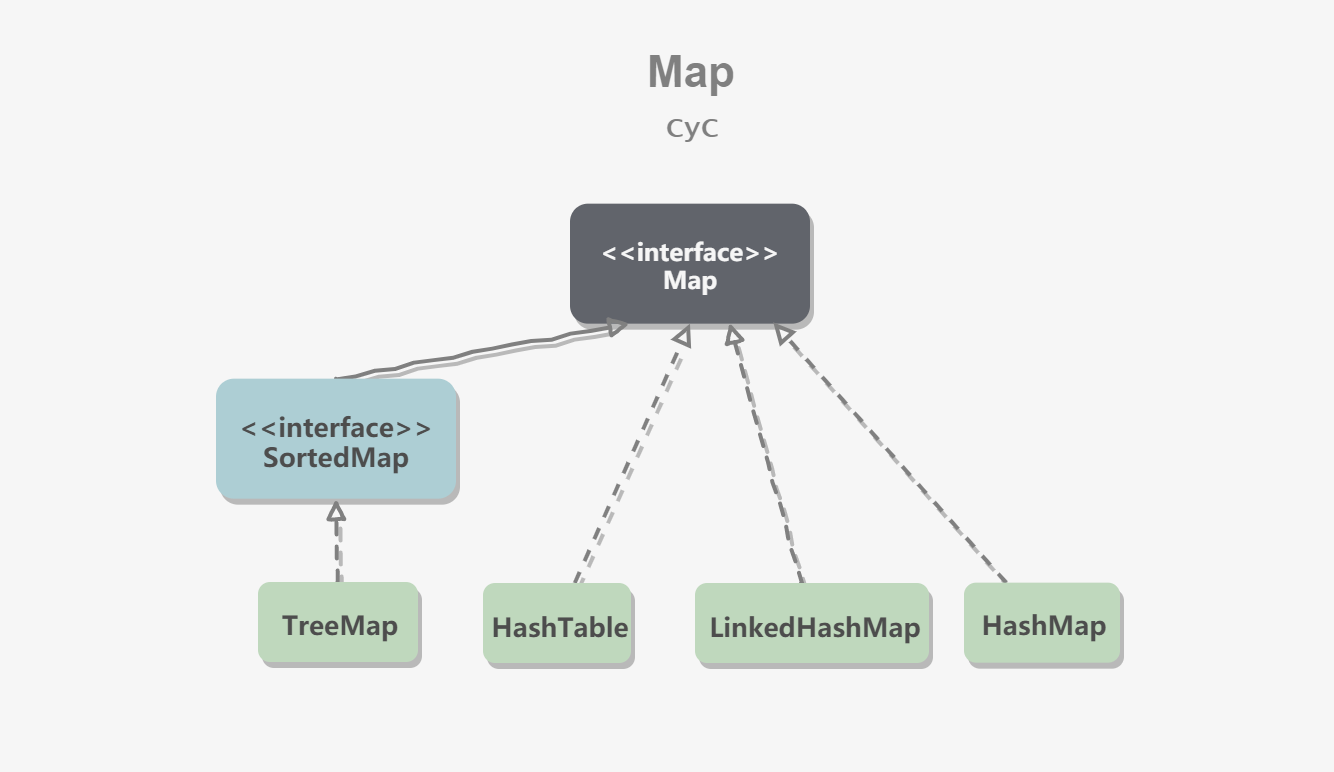
TreeMap: implemented based on a red-black tree.
-
HashMap: implemented based on a hash table.
-
HashTable: similar to HashMap, but thread-safe. This means multiple threads writing to HashTable at the same time will not cause data inconsistency. It is a legacy class and should not be used. Use ConcurrentHashMap for thread safety instead. ConcurrentHashMap is more efficient because it introduces segmented locks.
-
LinkedHashMap: uses a doubly linked list to maintain element order, either insertion order or least-recently-used (LRU) order.
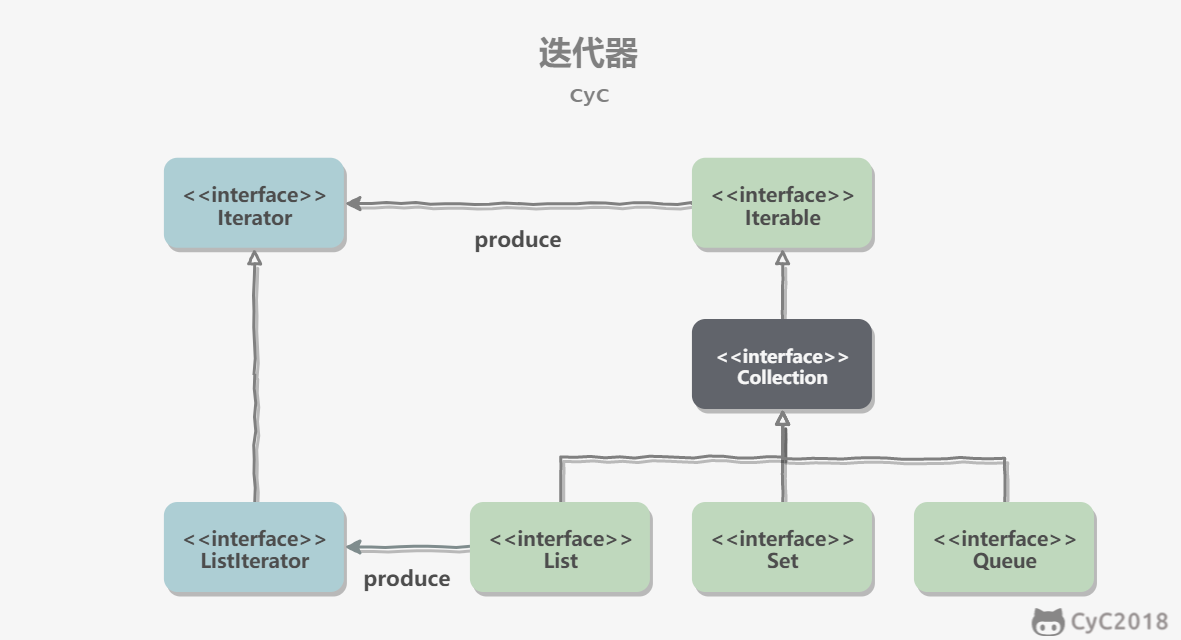
Collection extends the Iterable interface. Its iterator() method can produce an Iterator object, and this object can iterate through elements in the Collection.
Since JDK 1.5, foreach can be used to traverse aggregate objects that implement Iterable.
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
for (String item : list) {
System.out.println(item);
}java.util.Arrays#asList() can convert an array type to a List type.
@SafeVarargs
public static <T> List<T> asList(T... a)Note that the parameter of asList() is a generic varargs parameter. Primitive arrays cannot be used as parameters; only the corresponding wrapper type arrays can be used.
Integer[] arr = {1, 2, 3};
List list = Arrays.asList(arr);asList() can also be called as follows:
List list = Arrays.asList(1, 2, 3);Unless otherwise specified, the following source code analysis is based on JDK 1.8.
In IDEA, press double shift to open Search Everywhere, search for the source file, and read it after finding it.
Because ArrayList is implemented based on an array, it supports fast random access. The RandomAccess interface indicates that the class supports fast random access.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.SerializableThe default array size is 10.
private static final int DEFAULT_CAPACITY = 10;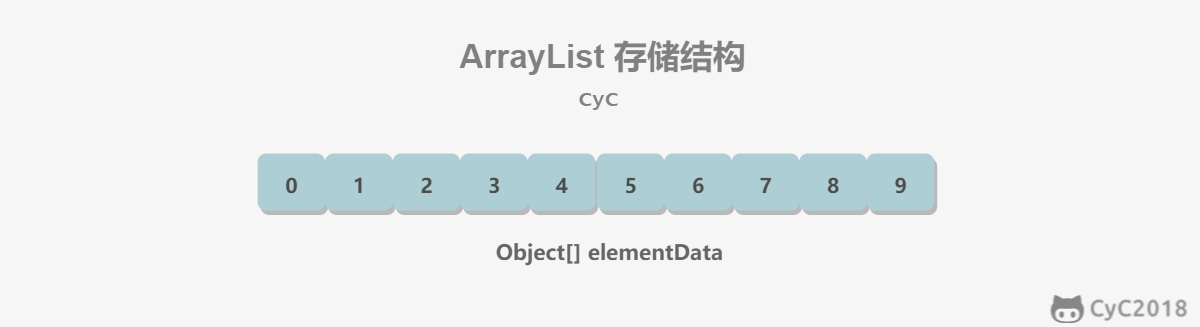
When adding elements, ensureCapacityInternal() is used to ensure sufficient capacity. If capacity is insufficient, grow() is used for expansion. The new capacity is oldCapacity + (oldCapacity >> 1), or oldCapacity + oldCapacity / 2. Since oldCapacity >> 1 is rounded down, the new capacity is about 1.5 times the old capacity. If oldCapacity is even, it is exactly 1.5 times; if odd, it is 1.5 times minus 0.5.
Expansion calls Arrays.copyOf() to copy the entire original array into a new array. This operation is expensive, so it is best to specify an approximate capacity when creating an ArrayList to reduce the number of expansions.
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}System.arraycopy() needs to be called to copy all elements after index+1 to the index position. This operation has time complexity O(N), so deleting elements from ArrayList is very costly.
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}ArrayList is implemented based on an array and supports dynamic expansion, so the array that stores elements may not be fully used. Therefore, there is no need to serialize the entire array.
The elementData array that stores elements is marked transient, which declares that the array is not serialized by default.
transient Object[] elementData; // non-private to simplify nested class accessArrayList implements writeObject() and readObject() to control serialization so that only the part of the array filled with elements is serialized.
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}Serialization uses ObjectOutputStream's writeObject() to convert an object to a byte stream and output it. If the passed object has a writeObject() method, writeObject() uses reflection to call that object's writeObject() to implement serialization. Deserialization uses ObjectInputStream's readObject(), with a similar principle.
ArrayList list = new ArrayList();
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(list);modCount records how many times the ArrayList structure changes. Structural changes include all operations that add or delete at least one element, or adjust the size of the internal array. Merely setting an element's value is not a structural change.
During serialization or iteration, modCount before and after the operation must be compared. If it changes, ConcurrentModificationException must be thrown. See the writeObject() method in the serialization section above for code.
Its implementation is similar to ArrayList, but it uses synchronized for synchronization.
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}Vector's constructor can accept the capacityIncrement parameter. Its role is to increase capacity by capacityIncrement during expansion. If this parameter is less than or equal to 0, capacity doubles each time expansion occurs.
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}When calling a constructor without capacityIncrement, capacityIncrement is set to 0. In other words, by default, Vector doubles its capacity each time it expands.
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
public Vector() {
this(10);
}- Vector is synchronized, so it has higher overhead and slower access than ArrayList. It is better to use ArrayList instead of Vector because synchronization can be fully controlled by the programmer;
- Vector requests 2 times its size on each expansion, although growth capacity can also be configured through the constructor, while ArrayList expands by 1.5 times.
Use Collections.synchronizedList(); to obtain a thread-safe ArrayList.
List<String> list = new ArrayList<>();
List<String> synList = Collections.synchronizedList(list);You can also use CopyOnWriteArrayList from the concurrent package.
List<String> list = new CopyOnWriteArrayList<>();Write operations are performed on a copied array, while read operations still use the original array. Reads and writes are separated and do not affect each other.
Write operations need locking to prevent data loss during concurrent writes.
After the write operation finishes, the original array must point to the new copied array.
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
final void setArray(Object[] a) {
array = a;
}@SuppressWarnings("unchecked")
private E get(Object[] a, int index) {
return (E) a[index];
}CopyOnWriteArrayList allows reads while writes occur, greatly improving read performance. It is well suited for read-heavy, write-light scenarios.
However, CopyOnWriteArrayList has drawbacks:
- Memory usage: write operations need to copy a new array, making memory usage about twice the original;
- Data inconsistency: read operations cannot read real-time data because some write data has not yet been synchronized to the read array.
Therefore, CopyOnWriteArrayList is not suitable for memory-sensitive scenarios or scenarios with high real-time requirements.
Implemented based on a doubly linked list, using Node to store linked-list node information.
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
}Each list stores first and last pointers:
transient Node<E> first;
transient Node<E> last;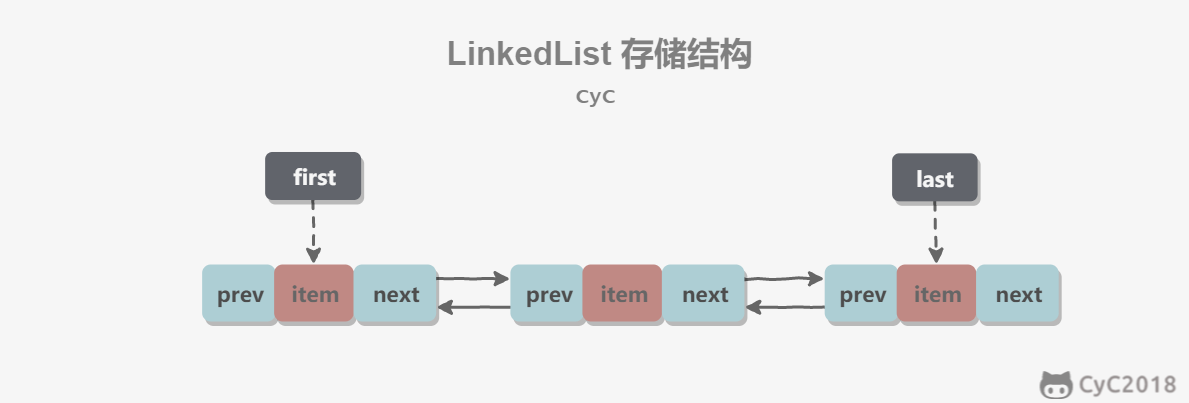
ArrayList is implemented based on a dynamic array, while LinkedList is implemented based on a doubly linked list. The difference between ArrayList and LinkedList can be summarized as the difference between arrays and linked lists:
- Arrays support random access, but insertion and deletion are expensive because many elements need to be moved;
- Linked lists do not support random access, but insertion and deletion only require changing pointers.
For easier understanding, the following source analysis is mainly based on JDK 1.7.
Internally, it contains an array table of Entry type. Entry stores key-value pairs. It contains four fields, and from the next field we can see that Entry forms a linked list. Each position in the array is treated as a bucket, and each bucket stores a linked list. HashMap uses separate chaining to resolve collisions. Entries with the same hash value and bucket index after modulo are stored in the same linked list.
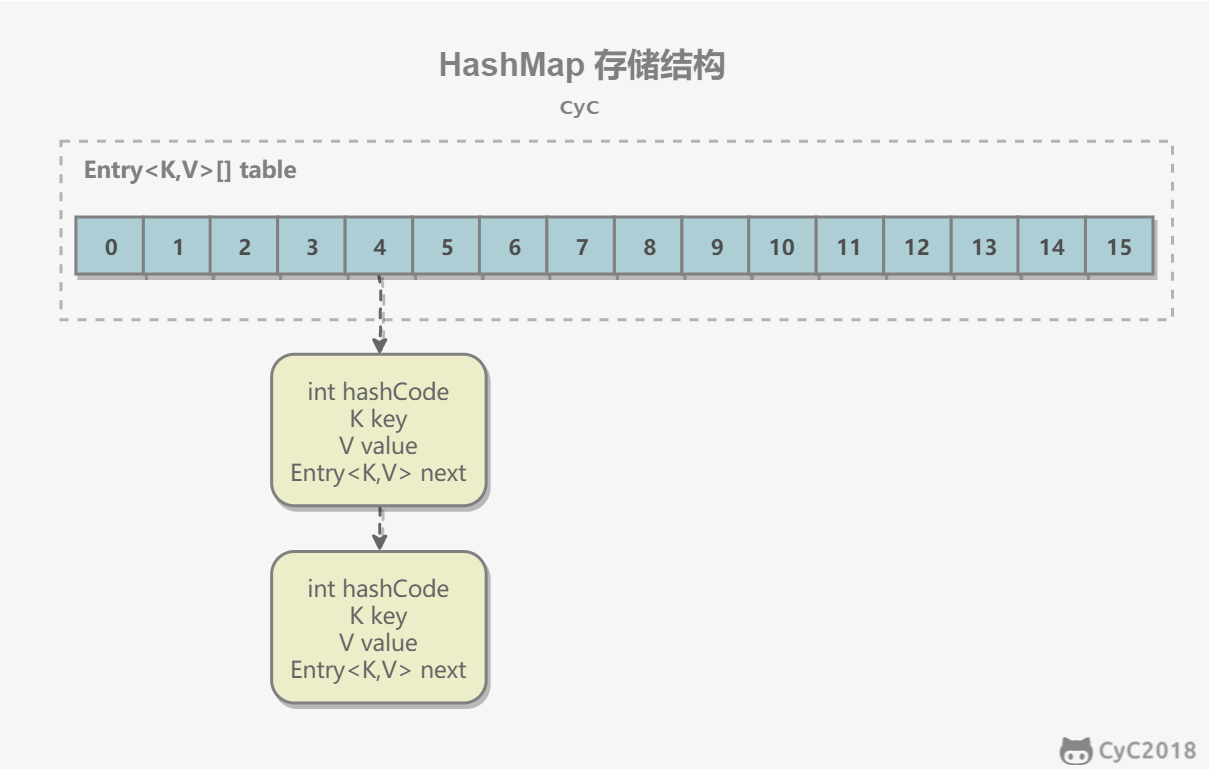
transient Entry[] table;static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
}HashMap<String, String> map = new HashMap<>();
map.put("K1", "V1");
map.put("K2", "V2");
map.put("K3", "V3");- Create a new HashMap with default size 16;
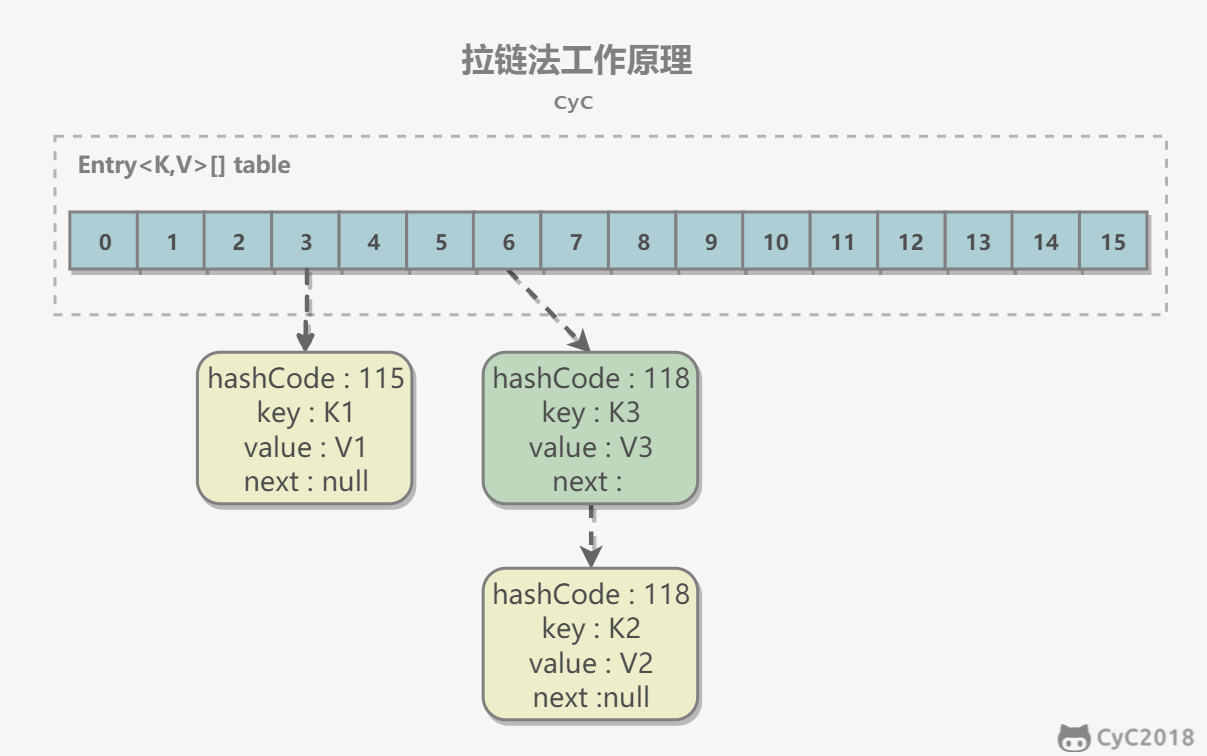
- Insert the <K1,V1> key-value pair. First compute K1's hashCode as 115, then use the division method to get bucket index 115%16=3.
- Insert the <K2,V2> key-value pair. First compute K2's hashCode as 118, then use the division method to get bucket index 118%16=6.
- Insert the <K3,V3> key-value pair. First compute K3's hashCode as 118, then use the division method to get bucket index 118%16=6, and insert it before <K2,V2>.
Note that linked-list insertion uses head insertion. For example, <K3,V3> above is not inserted after <K2,V2>; it is inserted at the head of the list.
Lookup has two steps:
- Compute the bucket containing the key-value pair;
- Search sequentially in the linked list. The time complexity is clearly proportional to the list length.
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// Handle null key separately
if (key == null)
return putForNullKey(value);
int hash = hash(key);
// Determine bucket index
int i = indexFor(hash, table.length);
// First check whether a key-value pair with key already exists; if so, update its value to value
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// Insert new key-value pair
addEntry(hash, key, value, i);
return null;
}HashMap allows inserting key-value pairs whose key is null. However, because null's hashCode() method cannot be called, the bucket index of this key-value pair cannot be determined normally and must be forcibly specified. HashMap uses bucket 0 to store key-value pairs whose key is null.
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}It uses linked-list head insertion, meaning the new key-value pair is inserted at the head of the list rather than the tail.
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
// Head insertion: the list head points to the new key-value pair
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}Many operations first need to determine the bucket index where a key-value pair belongs.
int hash = hash(key);
int i = indexFor(hash, table.length);4.1 Compute the hash value
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}4.2 Modulo
Let x = 1<<4, meaning x is 2 to the 4th power. It has the following property:
x : 00010000
x-1 : 00001111
Performing an AND operation between a number y and x-1 removes bits above the 4th bit in y's bit-level representation:
y : 10110010
x-1 : 00001111
y&(x-1) : 00000010
This property has the same effect as y modulo x:
y : 10110010
x : 00010000
y%x : 00000010
Bit operations are much cheaper than modulo operations, so using bit operations for this calculation can provide higher performance.
The final step in determining the bucket index is taking the key's hash value modulo the number of buckets: hash%capacity. If capacity is guaranteed to be a power of 2, this operation can be converted to a bit operation.
static int indexFor(int h, int length) {
return h & (length-1);
}Suppose the HashMap table length is M and the number of key-value pairs to store is N. If the hash function satisfies uniformity, each linked list has length about N/M, so lookup complexity is O(N/M).
To reduce lookup cost, N/M should be as small as possible, so M should be as large as possible, meaning the table should be as large as possible. HashMap uses dynamic expansion to adjust M according to the current N, ensuring both space efficiency and time efficiency.
Parameters related to expansion mainly include capacity, size, threshold, and load_factor.
| Parameter | Meaning |
|---|---|
| capacity | Capacity of table, default 16. Note that capacity must be a power of 2. |
| size | Number of key-value pairs. |
| threshold | Critical value of size. When size is greater than or equal to threshold, expansion must occur. |
| loadFactor | Load factor, the usable ratio of table. threshold = (int)(capacity* loadFactor). |
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
transient Entry[] table;
transient int size;
int threshold;
final float loadFactor;
transient int modCount;From the following element-addition code, when expansion is needed, capacity is doubled.
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}Expansion is implemented with resize(). Note that expansion also needs to reinsert all key-value pairs from oldTable into newTable, so this step is time-consuming.
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}During expansion, the bucket index of each key-value pair must be recomputed so it can be placed into the corresponding bucket. As mentioned earlier, HashMap uses hash%capacity to determine the bucket index. The fact that HashMap capacity is a power of 2 greatly reduces the complexity of recomputing bucket indexes.
Assume the original array capacity is 16 and the new capacity after expansion is 32:
capacity : 00010000
new capacity : 00100000For a key whose hash has a value at the 5th bit:
- If it is 0, then hash%00010000 = hash%00100000, and the bucket position stays the same;
- If it is 1, then hash%00010000 = hash%00100000 + 16, and the bucket position is the original position + 16.
HashMap constructors allow users to pass a capacity that is not a power of 2 because it can automatically convert the passed capacity to a power of 2.
First consider how to compute a number's mask. For 10010000, its mask is 11111111, which can be obtained as follows:
mask |= mask >> 1 11011000
mask |= mask >> 2 11111110
mask |= mask >> 4 11111111
mask+1 is the smallest power of 2 greater than the original number.
num 10010000
mask+1 100000000
The following is the code in HashMap for calculating array capacity:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}Starting from JDK 1.8, when the linked list stored in a bucket has length greater than or equal to 8, it is converted into a red-black tree.
- Hashtable uses synchronized for synchronization.
- HashMap can insert an Entry whose key is null.
- HashMap's iterator is a fail-fast iterator.
- HashMap does not guarantee that the order of elements in the Map remains unchanged over time.
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
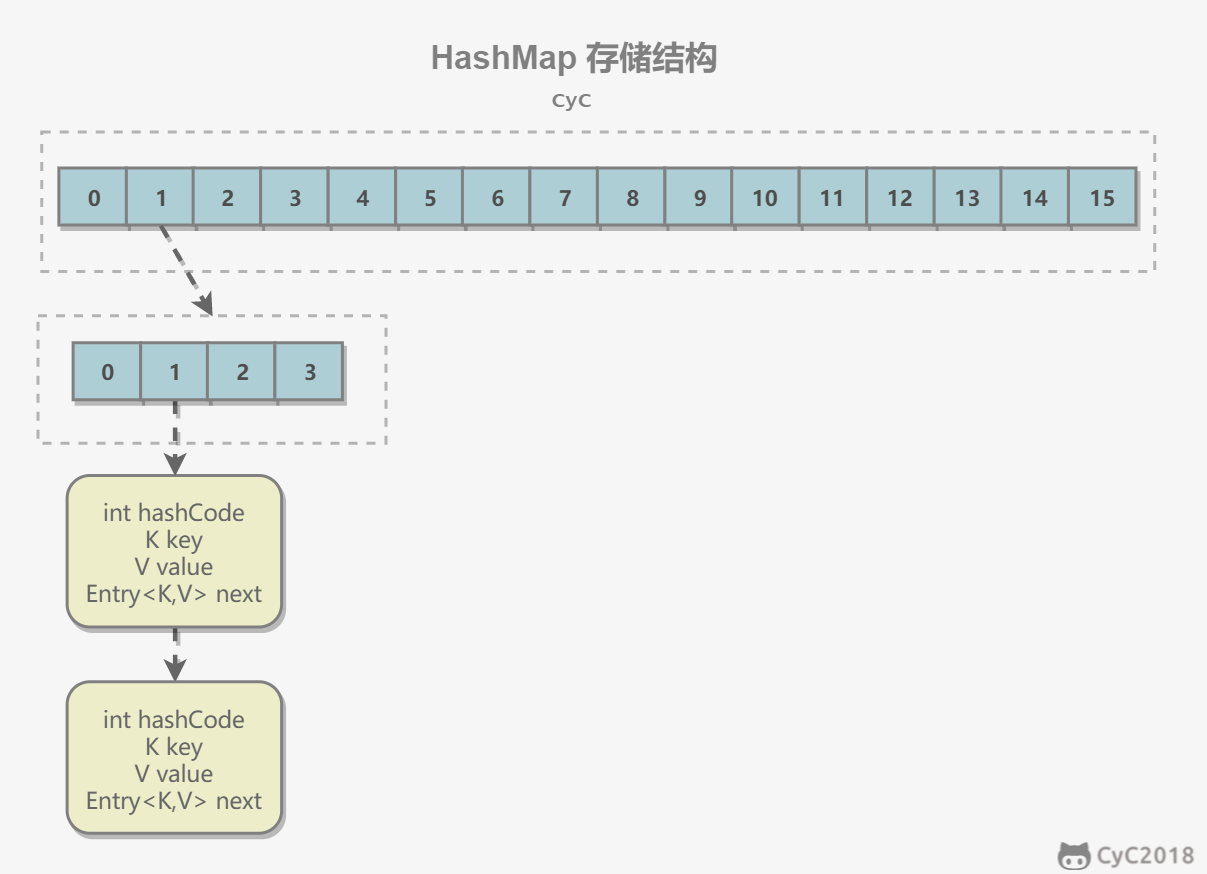
}ConcurrentHashMap and HashMap have similar implementations. The main difference is that ConcurrentHashMap uses segmented locks (Segment). Each segmented lock maintains several buckets (HashEntry). Multiple threads can access buckets on different segments at the same time, giving it higher concurrency. The concurrency level is the number of Segments.
Segment extends ReentrantLock.
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
}final Segment<K,V>[] segments;The default concurrency level is 16, meaning 16 Segments are created by default.
static final int DEFAULT_CONCURRENCY_LEVEL = 16;Each Segment maintains a count variable to count the number of key-value pairs in that Segment.
/**
* The number of elements. Accessed only either within locks
* or among other volatile reads that maintain visibility.
*/
transient int count;When executing size, all Segments must be traversed and their counts accumulated.
When executing size, ConcurrentHashMap first tries without locking. If two consecutive unlocked operations produce the same result, the result can be considered correct.
The number of attempts is defined by RETRIES_BEFORE_LOCK, whose value is 2. Since retries starts at -1, the number of attempts is 3.
If the number of attempts exceeds 3, every Segment needs to be locked.
/**
* Number of unsynchronized retries in size and containsValue
* methods before resorting to locking. This is used to avoid
* unbounded retries if tables undergo continuous modification
* which would make it impossible to obtain an accurate result.
*/
static final int RETRIES_BEFORE_LOCK = 2;
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
// If the retry count is exceeded, lock every Segment
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
// If two consecutive results are consistent, consider the result correct
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}JDK 1.7 uses a segmented locking mechanism to implement concurrent updates. The core class is Segment, which extends the reentrant lock ReentrantLock, and concurrency equals the number of Segments.
JDK 1.8 uses CAS operations to support higher concurrency and uses the built-in synchronized lock when CAS operations fail.
The JDK 1.8 implementation also converts a linked list into a red-black tree when the list becomes too long.
It extends HashMap, so it has the same fast lookup behavior as HashMap.
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>Internally, it maintains a doubly linked list to maintain insertion order or LRU order.
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;accessOrder determines the order. It defaults to false, meaning insertion order is maintained.
final boolean accessOrder;The most important parts of LinkedHashMap are the following functions for maintaining order. They are called in methods such as put and get.
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }When a node is accessed, if accessOrder is true, the node is moved to the tail of the linked list. In other words, after specifying LRU order, each time a node is accessed it is moved to the tail, ensuring that the tail is the most recently accessed node and the head is the least recently used node.
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}Executed after operations such as put. When removeEldestEntry() returns true, it removes the eldest node, which is the first node at the head of the linked list.
evict is false only when the Map is being constructed; here it is true.
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}removeEldestEntry() returns false by default. To make it return true, extend LinkedHashMap and override this method. This is especially useful for implementing LRU caches: by removing the least recently used node, cache space is kept sufficient and cached data remains hot.
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}The following is an LRU cache implemented with LinkedHashMap:
- Set the maximum cache size MAX_ENTRIES to 3;
- Use the LinkedHashMap constructor to set accessOrder to true, enabling LRU order;
- Override removeEldestEntry() so that when there are more than MAX_ENTRIES nodes, the least recently used data is removed.
class LRUCache<K, V> extends LinkedHashMap<K, V> {
private static final int MAX_ENTRIES = 3;
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_ENTRIES;
}
LRUCache() {
super(MAX_ENTRIES, 0.75f, true);
}
}public static void main(String[] args) {
LRUCache<Integer, String> cache = new LRUCache<>();
cache.put(1, "a");
cache.put(2, "b");
cache.put(3, "c");
cache.get(1);
cache.put(4, "d");
System.out.println(cache.keySet());
}[3, 1, 4]WeakHashMap's Entry extends WeakReference. Objects associated with WeakReference are reclaimed during the next garbage collection.
WeakHashMap is mainly used to implement caches. By using WeakHashMap to reference cached objects, the JVM can reclaim this part of the cache.
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V>Tomcat's ConcurrentCache uses WeakHashMap to implement caching.
ConcurrentCache uses generational caching:
- Frequently used objects are placed in eden. eden is implemented with ConcurrentHashMap, so there is no need to worry about reclamation;
- Infrequently used objects are placed in longterm. longterm is implemented with WeakHashMap, and these older objects are reclaimed by the garbage collector.
- When get() is called, eden is checked first. If not found, longterm is checked. If an object is found in longterm, it is placed into eden, ensuring frequently accessed nodes are less likely to be reclaimed.
- When put() is called, if the size of eden exceeds size, all objects in eden are moved into longterm, allowing the virtual machine to reclaim some infrequently used objects.
public final class ConcurrentCache<K, V> {
private final int size;
private final Map<K, V> eden;
private final Map<K, V> longterm;
public ConcurrentCache(int size) {
this.size = size;
this.eden = new ConcurrentHashMap<>(size);
this.longterm = new WeakHashMap<>(size);
}
public V get(K k) {
V v = this.eden.get(k);
if (v == null) {
v = this.longterm.get(k);
if (v != null)
this.eden.put(k, v);
}
return v;
}
public void put(K k, V v) {
if (this.eden.size() >= size) {
this.longterm.putAll(this.eden);
this.eden.clear();
}
this.eden.put(k, v);
}
}- Eckel B. Thinking in Java[M]. China Machine Press, 2002.
- Java Collection Framework
- Iterator pattern
- Java 8 series: rediscovering HashMap
- What is difference between HashMap and Hashtable in Java?
- Java Collections: HashMap
- The principle of ConcurrentHashMap analysis
- Exploring the implementation mechanism behind ConcurrentHashMap's high concurrency
- HashMap interview questions and answers
- Java collection details (2): limitations of asList
- Java Collection Framework – The LinkedList Class