This section focuses on understanding and leveraging TimescaleDB, a powerful time-series database extension for PostgreSQL. For definitions of terms used in this module, refer to our Glossary.
 with sleepy faces stack themselves automatically into neat rows. A felt temperature chart in the background shows a line graph made of heart beats. Continuous aggregates are represented by felt calculator characters doing group hugs. The scene includes a kawaii vacuum cleaner with eyes cleaning up old data chunks. Style: Kawaii, Hello Kitty-inspired, handmade felt craft aesthetic, time-themed pastels")
Before starting this module, ensure you understand:
Hypertables are the foundation of TimescaleDB's time-series optimization. They automatically partition your data into chunks based on time intervals, providing several benefits:
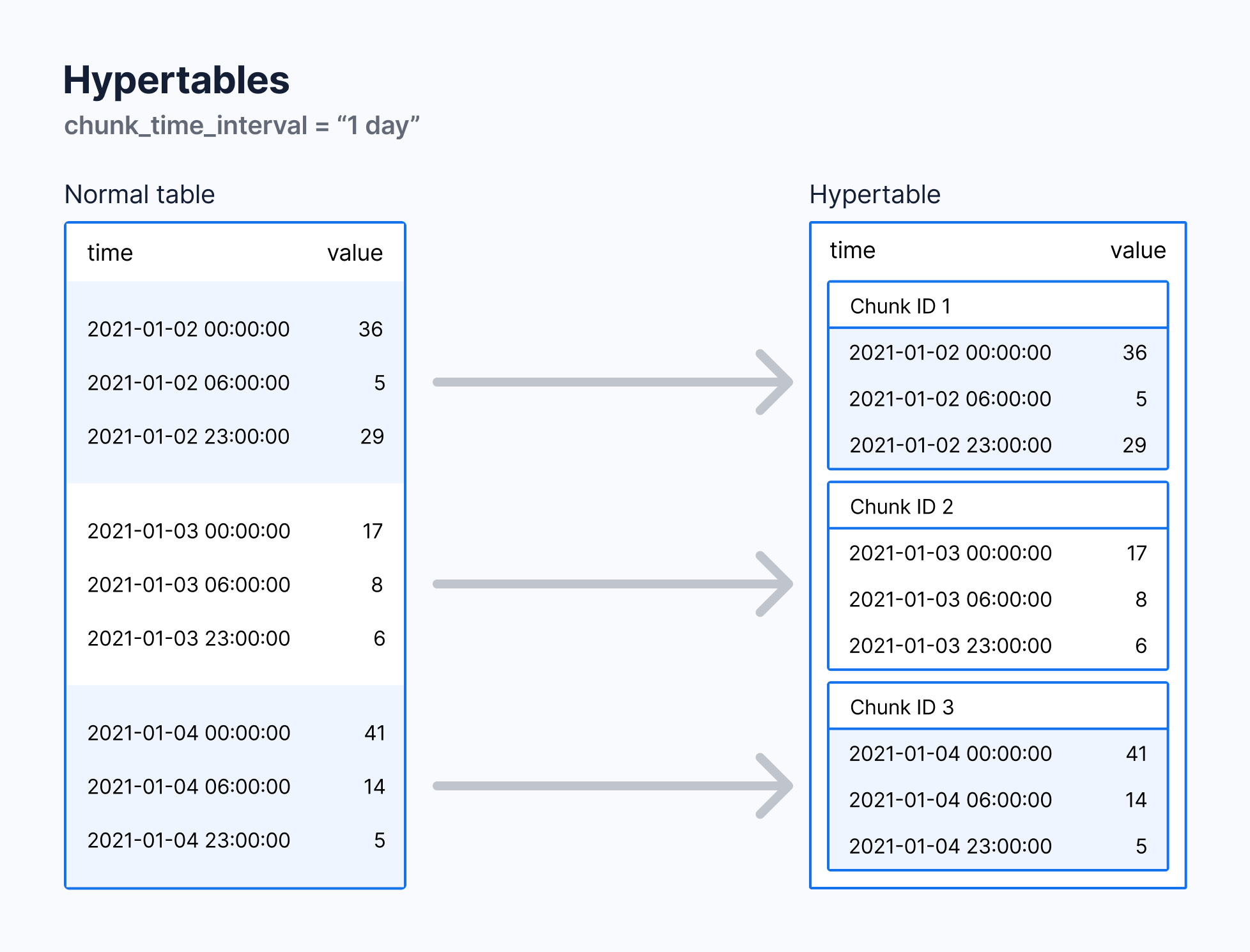
-
Automatic Partitioning
- Time-based chunking for efficient data management
- Transparent query optimization
- Automatic chunk creation and management
-
Query Performance
- Chunk exclusion for faster time-range queries
- Parallel query execution across chunks
- Optimized index usage per chunk
-
Data Management
- Efficient compression of older data
- Automated retention policies
- Easy backup and maintenance
This workshop consists of the following files:
-
- Sets up TimescaleDB extension and tables
- Creates hypertables and continuous aggregates
- Generates sample IoT sensor data
- Implements compression and retention policies
-
- Time-bucket query examples
- Continuous Aggregate demonstrations
- Chunk management and compression
- Query performance analysis
Start with timescale_setup.rb to understand:
- Hypertable creation and configuration
- Continuous aggregate setup
- Compression policies
- Data retention strategies
Work through practice_timescale.rb:
- Execute time-bucket queries
- Analyze query performance with EXPLAIN
- Work with continuous aggregates
- Manage chunks and compression
- Implement advanced time-series analytics
class Measurement < ActiveRecord::Base
acts_as_hypertable time_column: 'time',
value_column: 'temperature',
segment_by: 'device_id',
chunk_time_interval: '1 day'
endKey configuration options:
time_column: Primary time dimensionsegment_by: Additional partitioning dimensionchunk_time_interval: Time interval for chunkscompress_after: When to compress older chunks
continuous_aggregates scopes: [:avg_temperature],
timeframes: [:hour, :day],
refresh_policy: {
hour: {
start_offset: '3 hours',
end_offset: '1 hour',
schedule_interval: '1 hour'
}
}Benefits:
- Pre-computed aggregates for faster queries
- Automatic refresh policies
- Materialized view-like functionality
- Efficient memory usage
# Basic time bucketing
Measurement.today.avg_temperature
# Advanced time series analytics
Measurement.where(time: 1.week.ago..Time.current)
.avg_temperatureFeatures:
- Automatic chunk exclusion
- Parallel query execution
- Efficient index usage
- Time-based optimization
# Compression configuration
hypertable_options = {
compress_segmentby: 'device_id',
compress_orderby: 'time DESC',
compress_after: '7 days'
}
# Retention policy
SELECT add_retention_policy('measurements', INTERVAL '3 months');Benefits:
- Significant storage savings
- Automated data lifecycle management
- Maintained query performance
- Efficient resource utilization
# Compression Configuration
hypertable_options = {
compress_segmentby: 'device_id',
compress_orderby: 'time DESC',
compress_after: '7 days'
}
# Compression Analysis
compression_stats = Measurement.hypertable.compression_stats
puts "Compression ratio: #{compression_stats.compression_ratio}%"Key Factors for Optimal Compression:
-
Data Patterns
- Gradual changes in measurements
- Consistent value ranges
- Monotonic changes
-
Chunk Management
- Default chunk interval: 1 day
- Compression threshold: 7 days
- Automatic chunk creation and compression
-
Optimization Strategies
- Segment by high-cardinality columns
- Order by time for efficient queries
- Balance compression and query performance
-- Refresh Policy Analysis
SELECT view_name,
refresh_interval,
start_offset,
end_offset
FROM timescaledb_information.continuous_aggregate_policies
-- Manual Refresh
CALL refresh_continuous_aggregate('avg_temperature_per_hour', NULL, NULL);Considerations:
- Real-time vs. batch updates
- Resource utilization
- Data freshness requirements
- Query performance impact
-- Chunk Analysis
SELECT chunk_schema || '.' || chunk_name as chunk_full_name,
range_start,
range_end,
is_compressed,
pg_size_pretty(total_bytes) as total_size
FROM timescaledb_information.chunks
WHERE hypertable_name = 'measurements'Optimization Areas:
- Chunk interval selection
- Compression timing
- Retention policies
- Space management
TimescaleDB extends PostgreSQL with powerful time-series capabilities. Here's how to implement efficient real-time analytics:
First, create the migration for your measurements table:
# db/migrate/YYYYMMDDHHMMSS_create_measurements.rb
class CreateMeasurements < ActiveRecord::Migration[7.0]
def change
# Enable TimescaleDB extension if not already enabled
enable_extension 'timescaledb' unless extension_enabled?('timescaledb')
# Create the measurements table as a hypertable
hypertable_options = {
time_column: 'time',
chunk_time_interval: '1 day',
compress_segmentby: 'device_id',
compress_orderby: 'time DESC',
compress_after: '7 days'
}
create_table :measurements, id: false, hypertable: hypertable_options do |t|
t.timestamptz :time, null: false
t.text :device_id, null: false
t.float :temperature
t.float :humidity
t.float :battery_level
end
end
endThen define your model with TimescaleDB features:
class Measurement < ActiveRecord::Base
extend Timescaledb::ActsAsHypertable
acts_as_hypertable time_column: 'time',
segment_by: 'device_id',
value_column: 'temperature',
chunk_time_interval: '1 day'
scope :avg_temperature, -> { select('device_id, avg(temperature) as temperature').group('device_id') }
scope :avg_humidity, -> { select('device_id, avg(humidity) as humidity').group('device_id') }
scope :battery_stats, -> { select('device_id, min(battery_level) as min_battery, avg(battery_level) as battery_level').group('device_id') }
endYou can use the continuous_aggregates helper to create continuous aggregates hierarchies using declared scopes:
continuous_aggregates scopes: [:avg_temperature, :avg_humidity, :battery_stats],
timeframes: [:hour, :day],
refresh_policy: {
hour: {
start_offset: '3 hours',
end_offset: '1 hour',
schedule_interval: '1 hour'
},
day: {
start_offset: '3 days',
end_offset: '1 day',
schedule_interval: '1 day'
}
}Query from raw data and mix scopes to filter out the data you need:
Measurement.today.avg_temperature # average temperature per device
Measurement.last_hour.avg_humidity # average humidity per device
Measurement.last_minute.battery_stats # min and avg battery level per deviceUsing the macro in the model, you can query the continuous aggregate directly from generated class:
Measurement::AvgTemperatureByHour.today.all
Measurement::AvgTemperatureByDay.last_week.allMatch common query intervals
# Define chunk intervals that match your most common queries
class Measurement < ActiveRecord::Base
acts_as_hypertable time_column: 'time',
chunk_time_interval: '1 day' # If most queries are daily aggregates
end
# Common query patterns will be efficient
Measurement.where(time: 1.day.ago..Time.current).avg_temperatureConsider data retention needs
# Set up retention policy based on your data lifecycle
class AddRetentionPolicyToMeasurements < ActiveRecord::Migration[7.0]
def change
add_retention_policy 'measurements', INTERVAL '90 days'
end
endBalance storage vs. query speed
Default chunk time interval is 7 days.
# Larger chunks = better compression ratios, slower queries
# Smaller chunks = faster queries, more overhead
class CreateMeasurementsHypertable < ActiveRecord::Migration[7.0]
def change
set_chunk_time_interval 'measurements', '1 day'
end
endCompress older chunks
class AddCompressionToMeasurements < ActiveRecord::Migration[7.0]
def change
add_compression_policy 'measurements', compress_after: '7 days'
end
endChoose effective segment columns
class EnableCompressionWithSegmentBy < ActiveRecord::Migration[7.0]
def change
add_compression_policy 'measurements', compress_after: '7 days',
compress_segmentby: 'device_id, sensor_type',
compress_orderby: 'time DESC'
end
end
# Example of efficient query using segmented columns
scope :by_device_and_type, ->(device_id, type) {
where(device_id: device_id, sensor_type: type)
}
endMonitor compression ratios
Measurement.hypertable.compression_statsIdentify common aggregations
class Measurement < ActiveRecord::Base
scope :avg_temperature, -> {
select('avg(temperature) as avg_temp')
}
scope :avg_humidity, -> {
select('avg(humidity) as avg_humidity')
}
continuous_aggregates scopes: [:avg_temperature, :avg_humidity],
timeframes: [:hour, :day],
refresh_policy: {
hour: { schedule_interval: '1 hour' },
day: { schedule_interval: '1 day' }
}
endSet appropriate refresh intervals
Refresh policy is defined in the continuous aggregate macro:
class Measurement < ActiveRecord::Base
continuous_aggregates scopes: [:avg_temperature],
timeframes: [:hour, :day],
refresh_policy: {
hour: {
start_offset: '3 hours',
end_offset: '1 hour',
schedule_interval: '1 hour'
},
day: {
start_offset: '2 days',
end_offset: '1 day',
schedule_interval: '1 day'
}
}
endUse hierarchy of continuous aggregates
class Measurement < ActiveRecord::Base
# Create a hierarchy of aggregates for different time scales
continuous_aggregates scopes: [:avg_temperature],
timeframes: [:minute, :hour, :day],
refresh_policy: {
minute: {
schedule_interval: '1 minute',
start_offset: '5 minutes'
},
hour: {
schedule_interval: '1 hour',
start_offset: '3 hours'
},
day: {
schedule_interval: '1 day',
start_offset: '2 days'
}
}
endLeverage chunk exclusion
class Measurement < ActiveRecord::Base
# Queries that allow chunk exclusion
scope :recent_data, -> {
where(time: 1.day.ago..Time.current)
}
end
Measurement.recent_data.avg_temperature.explain(analyze: true)Use appropriate indexes
class CreateMeasurements < ActiveRecord::Migration[7.0]
def change
# Create optimized indexes for time-series data
add_index :measurements, [:time, :device_id],
using: :brin,
name: 'idx_measurements_time_device'
add_index :measurements, :device_id,
where: "time >= now() - INTERVAL '7 days'"
end
endImplement efficient partitioning
In case you have a model with a partitioning column, you can use it to partition the data:
class Measurement < ActiveRecord::Base
scope :device_metrics, ->(device_id) {
where(device_id: device_id)
.where(time: 1.week.ago..Time.current)
.select('time_bucket(\'1 hour\', time) as hour,
avg(temperature) as avg_temp')
.group('hour')
}
endThe migration will look like this:
class CreateMeasurements < ActiveRecord::Migration[7.0]
def change
hypertable_options = {
time_column: 'time',
chunk_time_interval: '1 day',
partitioning_column: 'device_id',
number_partitions: 4
}
create_table :measurements, id: false, hypertable: hypertable_options do |t|
t.timestamptz :time, null: false
t.text :device_id, null: false
t.float :temperature
end
end
endBalance memory usage
# Configure memory settings in postgresql.conf
# shared_buffers = '4GB' # 25% of RAM for dedicated DB server
# maintenance_work_mem = '1GB' # For maintenance operations
# work_mem = '50MB' # Per-operation memory
# Monitor memory usage in your application
def self.monitor_memory_usage
connection.execute(<<-SQL)
SELECT * FROM pg_stat_activity
WHERE datname = current_database()
ORDER BY state_change DESC;
SQL
endMonitor disk space
class Measurement < ActiveRecord::Base
acts_as_hypertable time_column: 'time', # ...
end
Measurement.hypertable.compression_statsOptimize parallel execution
# Configure parallel execution settings
class Measurement < ActiveRecord::Base
def self.configure_parallel_execution
connection.execute(<<-SQL)
ALTER DATABASE your_database
SET max_parallel_workers_per_gather = 4;
ALTER DATABASE your_database
SET max_parallel_workers = 8;
SQL
end
# Query using parallel execution
scope :parallel_query, -> {
from('measurements').select('*')
.where(time: 1.month.ago..Time.current)
.optimizer_hints('enable_parallel_append ON')
}
end- Choose appropriate time columns
- Select effective segmentation columns
- Plan compression strategies
- Design efficient indexes
- Use time-bucket functions effectively
- Leverage continuous aggregates
- Implement proper retention policies
- Monitor and optimize query performance
- Regular compression checks
- Continuous aggregate refresh monitoring
- Performance metric tracking
- Capacity planning
- High-frequency data collection
- Real-time analytics
- Historical trend analysis
- Device-specific queries
- System performance data
- Application metrics
- User activity logs
- Resource utilization tracking
- Time-series market data
- Trading analytics
- Performance metrics
- Historical analysis
-
Query Performance
- Check chunk interval size
- Verify continuous aggregate usage
- Monitor compression status
- Analyze query patterns
-
Resource Usage
- Review chunk size
- Check compression settings
- Monitor aggregate refreshes
- Optimize memory configuration
- Merge chunks to reduce the number of chunks
-
Data Management
- Implement retention policies
- Monitor compression ratios
- Track chunk growth
- Plan capacity needs
- TimescaleDB Documentation
- Continuous Aggregates Guide
- Compression Documentation
- Query Optimization Tips
After completing this module, next step is to learn about Ruby Performance.