Kafka Exactly Once Semantics Implementation: Idempotence and Transactional Messages
In modern distributed systems, ensuring the accuracy and consistency of data processing is crucial. Apache Kafka®, a widely-used streaming platform, provides robust capabilities for message queuing and streaming. With the increasing demands of businesses, Kafka has introduced a transactional messaging feature that allows applications to process messages atomically—either all messages are correctly handled, or none are processed. This article delves into the principles behind Kafka's Exactly-Once semantics, including the key concepts of idempotence and transactional messages, and their implementation within Kafka. We will explore the Kafka transaction process, the ACID guarantees provided by transactions, and some limitations that might be encountered in real-world applications. Whether you are new to Kafka or an experienced developer, this article will offer valuable insights and guidance.
Kafka's current use in streaming scenarios resembles a Directed Acyclic Graph (DAG), where each node is a Kafka Topic, and each edge represents a stream processing operation. In such scenarios, there are two operations:
-
Consuming upstream messages and committing offsets
-
Processing messages and sending them to downstream Topics
For a set of processing flows constituted by these two operations, transaction semantics are essential, allowing us to handle upstream messages exactly once and reliably store the results in downstream Topics.
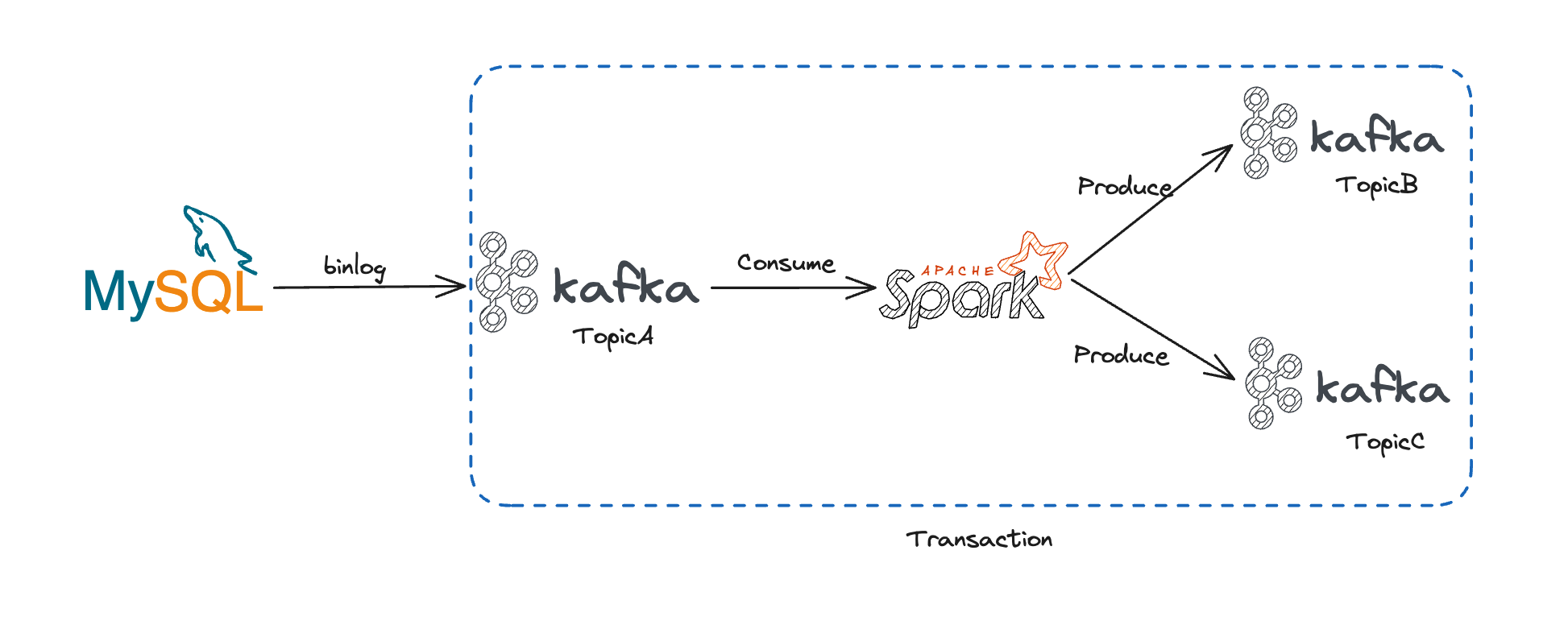
The above figure illustrates a typical Kafka transaction process. As seen:
MySQL's binlog, as an upstream data source, writes data into Kafka. Spark Streaming reads data from Kafka and processes it, eventually writing the results into two other Topics (all three Topics are within the same cluster). The operations of consuming Topic A and writing to Topics B and C are transactional.
From the scenario described above, it is clear that the primary driver for transactional messages is to achieve Exactly Once semantics in stream processing, which is divided into:
-
Send Only Once: This involves ensuring single-partition sends through producer idempotence and multi-partition sends through the transaction mechanism.
-
Consume Only Once: Kafka manages the consumption tracking by committing consumer offsets, effectively turning it into a message sent to a system topic. This approach harmonizes the actions of sending and consuming, and addressing the consistency issues in multi-partition message sends culminates in Exactly Once semantics.
When configuring a Kafka producer, the enable.idempotence parameter is activated to ensure producer idempotence.
val props = new Properties()
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true")
val producer = new KafkaProducer(props)
Kafka's send idempotence is maintained by using a sequencing method; each message is tagged with a sequence number that increases sequentially, maintaining the order of messages. When a producer dispatches a message, it logs the sequence number and content of the message. If a message arrives with an unexpected sequence number, an OutOfOrderSequenceException is generated.
Upon setting the enable.idempotence parameter, the producer verifies the validity of the next three parameters (ProducerConfig#postProcessAndValidateIdempotenceConfigs).
-
`max.in.flight.requests.per.connection` must be set to less than 5
-
`retries` must be configured to be more than 0
-
`acks` should be configured to `all`
Kafka records message sequence information per partition in a .snapshot file, outlined as follows (ProducerStateManager#ProducerSnapshotEntrySchema):
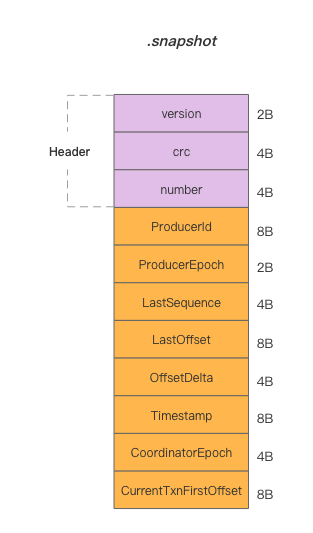
The file captures ProducerId, ProducerEpoch, and LastSequence. Therefore, the idempotence condition is: for identical partitions and the same Producer (ID and epoch), message sequence numbers must be sent in an increasing order. This demonstrates that Kafka's producer idempotence is only valid within a single connection and partition. Idempotence is compromised if the Producer restarts or if messages are directed to a different partition.
The .snapshot file is refreshed upon log segment turnover, and after a restart, the Producer’s state is restored from the .snapshot file along with the most current log file. Broker restarts or partition reassignments do not impact idempotence.
Let’s begin with a Demo to explore how to execute a transaction using a Kafka client:
// Initialize the transaction
val props = new Properties()
// ...
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionalId)
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true")
val producer = new KafkaProducer(props)
producer.initTransactions()
producer.beginTransaction()
// Send messages
producer.send(RecordUtils.create(topic1, partition1, "message1"))
producer.send(RecordUtils.create(topic2, partition2, "message2"))
// Commit or abort the transaction
producer.commitTransaction()
After launching the Kafka Producer, we use two APIs to initialize transactions: `initTransactions` and `beginTransaction`.
To revisit our Demo, when sending messages, they are dispatched to two different partitions, which may reside on different Brokers, thus necessitating a global coordinator, `TransactionCoordinator`, to log the transaction's status.
Therefore, in `initTransactions`, the Producer first sends a `ApiKeys.FIND_COORDINATOR` request to obtain the `TransactionCoordinator`.
Subsequently, it can send `ApiKeys.INIT_PRODUSER_ID` requests to acquire `ProducerId` and `ProducerEpoch` (also the field used for idempotence as mentioned earlier). The generated id and epoch are recorded in the internal Topic `__transaction_state`, setting the transaction state to Empty.
`__transaction_state` is a compaction Topic, where the message key is the client-set `transactional.id` (see `TransactionStateManager#appendTransactionToLog` for more details).
Unlike `ProducerId`, which is a server-generated internal attribute; `TransactionId` is set by the user, representing what the business considers as "the same application." Initiating a new Producer with the same `TransactionId` will cause the incomplete transactions to be rolled back, and requests from the old Producer (with a smaller epoch) to be rejected.
Subsequent `beginTransaction` is used to start a transaction, creating an internal transaction state within the Producer, marking the beginning of this transaction, without generating any RPC.
As outlined in the preceding section, initiating a transaction with `beginTransaction` only alters the internal state of the Producer. It's only when the first message is dispatched that the transaction officially commences:
Initially, the Producer issues an `ApiKeys.ADD_PARTITIONS_TO_TXN` request to the TransactionCoordinator. The TransactionCoordinator then incorporates this partition into the transaction and shifts the transaction state to Ongoing; this update is recorded in `__transaction_state`.
Subsequently, the Producer typically sends messages to the designated partition via the `ApiKeys.PRODUCE` request. The visibility control of these messages will be explored in depth in the upcoming section on message consumption.
Once all messages have been dispatched, the Producer has the option to either commit or rollback the transaction, at which point:
-
TransactionCoordinator: possesses details regarding all the partitions involved in the current transaction
-
Other Brokers: have successfully saved the messages in the log files
Subsequently, the Producer executes `commitTransaction`, which sends an `ApiKeys.END_TXN` request to transition the transaction state to `PrepareCommit` (with the corresponding rollback state being `PrepareAbort`) and records it in `__transaction_protected`. From the Producer's perspective, the transaction is effectively complete.
The `TransactionCoordinator` then asynchronously dispatches `ApiKeys.WRITE_TXN_MARKERS` requests to all the Brokers involved in the transaction. After receiving successful responses from these Brokers, the `TransactionCoordinator` updates the transaction state to `CompleteCommit` (with the rollback state being `CompleteAbort`) and logs this state in `__transaction_state`.
Messages within a specific partition may consist of both transactional and non-transactional types, as depicted below:
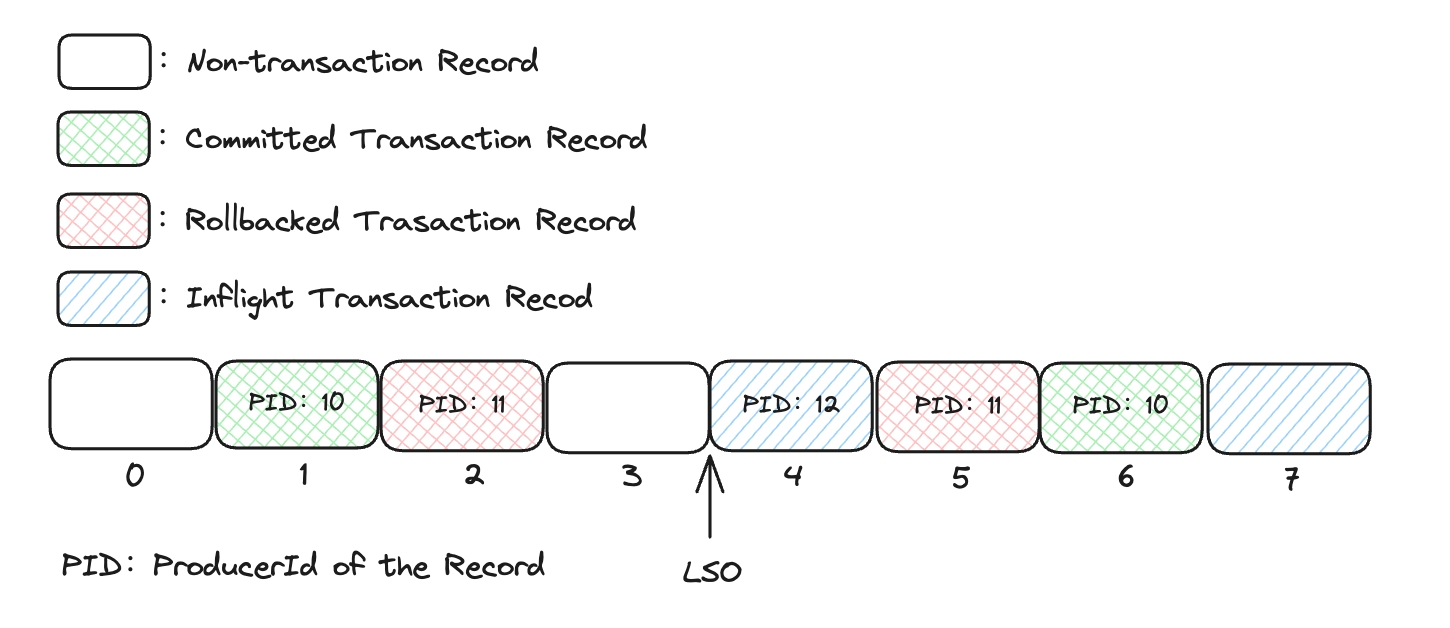
When a Broker handles an `ApiKeys.PRODUCE` request, it adjusts the LSO (Log Stable Offset) to the position of the first uncommitted transactional message. This modification enables consumers to ascertain message visibility based on the LSO: if the `isolation.level` is set to `read_committed`, only messages preceding the LSO will be accessible.
LSO (log stable offset): It denotes the highest offset of messages that have been successfully replicated across all replicas and are deemed safe for consumption by consumers.
However, it's notable that there are messages that have been rolled back prior to the LSO (as indicated by the red rectangle in the diagram), which ought to be excluded: when a Broker processes an `ApiKeys.WRITE_TXN_MARKERS` request, it logs the indices of these rolled-back messages into the `.txnindex` file (`LogSegmentKafka#updateTxnIndex`).
Subsequently, when the Consumer processes messages, they will also retrieve a list of canceled transaction messages for the specified range. The list depicted includes:
| ProducerId |
StartOffset |
EndOffset |
|---|---|---|
| 11 |
2 |
5 |
Messages sent by the Producer with ID 11 and offsets between [2, 5] have been canceled.
Previously, we explored how the implementation of __transaction_state ensures that at any given time, only one transaction is active per TransactionId. Consequently, using the ProducerId and the offset range to identify the canceled messages avoids conflicts.
- Atomicity
Kafka manages transaction state transitions through entries in the __transaction_state Topic, ensuring that transactions are either fully committed or entirely rolled back at the same time.
- Consistency
During the PrepareCommit or PrepareAbort phases, the TransactionCoordinator asynchronously commits or aborts transactions across all Brokers involved. This arrangement prevents Kafka from achieving strong consistency, instead relying on continuous retries to ensure eventual consistency.
- Isolation
Apache Kafka® avoids dirty reads and achieves a Read Committed isolation level through the LSO mechanism and the .txnindex file.
- Durability
Kafka ensures durability by writing the transaction state to the __transaction_state Topic and recording messages in log files.
Functionally, Kafka transactions do not support business-level transactions, and they strictly require that both the consumption upstream and the writing downstream occur within the same Kafka cluster to ensure atomicity.
From a performance perspective, the main cost of Kafka transactions is incurred on the production side:
-
Initiating a transaction requires additional RPC requests to locate the TransactionCoordinator and initialize data.
-
Message sending requires synchronizing a request to add a partition to the TransactionCoordinator before sending the message, and logging the transaction state changes to the __transaction_state Topic.
-
When committing or rolling back a transaction, requests must be sent to all Brokers involved in the transaction.
For transactions that involve fewer partitions but a larger number of messages, the overhead of the transaction can be distributed; conversely, the overhead from numerous synchronous RPCs can significantly impact performance. Additionally, each producer can only have one active transaction, which means that the transaction throughput is limited.
On the consumption side, there is also an impact: consumers can only see messages below the LSO and require additional index files to filter out rolled-back messages, which undoubtedly increases end-to-end latency.
Through the in-depth analysis in this article, we have learned how Apache Kafka's transactional messaging feature provides Exactly-Once semantics in stream processing scenarios. Kafka achieves atomicity, eventual consistency, isolation, and durability in message sending through its transactional API and internal mechanisms, although there may be some performance and functionality limitations in practical applications. Developers and architects should fully understand these concepts and consider how to effectively utilize Kafka's transactional features when designing systems to build more robust and reliable data processing workflows.
AutoMQ is a cloud-native Kafka fork built on top of object storage, and is fully compatible with Kafka while addressing cost and scalability issues inherent in Kafka. As a dedicated supporter of the Kafka ecosystem in China, AutoMQ continuously brings high-quality Kafka technical content to Kafka enthusiasts. Follow us for more updates.