


I build AI agent systems, browser automation tools, and local-first developer workflows.
Local flight recorder for AI browser agents.
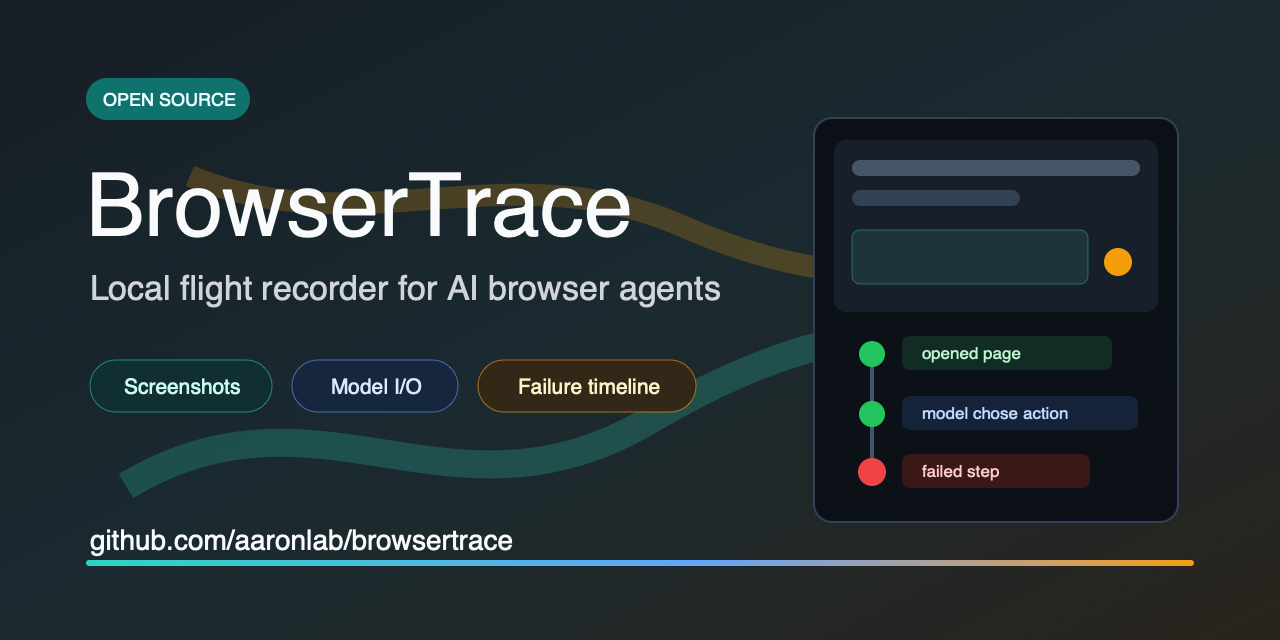
BrowserTrace helps Browser Use, Stagehand, Skyvern, Playwright + LLM, and custom computer-use builders debug failed browser-agent runs with local step timelines.
- Records screenshots, URLs, actions, model input/output, status, and errors.
- Opens failed runs in a local web UI.
- Exports standalone HTML traces.
- Supports public-safe exports that omit prompts, model I/O, screenshots, and URLs.
- MIT licensed and local-first.
Repo: https://github.com/aaronlab/browsertrace
Live demo: https://aaronlab.github.io/browsertrace/
Try locally before PyPI publishing is enabled:
uvx --from "browsertrace[ui] @ git+https://github.com/aaronlab/browsertrace@v0.1.14" browsertrace doctor
uvx --from "browsertrace[ui] @ git+https://github.com/aaronlab/browsertrace@v0.1.14" browsertrace demoComputer-use guide: https://aaronlab.github.io/browsertrace/computer-use-agent-debugging.html
Runnable examples: https://github.com/aaronlab/browsertrace/tree/main/examples
Roadmap: https://github.com/aaronlab/browsertrace/blob/main/ROADMAP.md
Launch feedback: aaronlab/browsertrace#3
Good first issue: aaronlab/browsertrace#221
First PR Recipe: https://github.com/aaronlab/browsertrace/blob/main/CONTRIBUTING.md#first-pr-recipe keeps the first contribution small and reviewable.
Public-safe demo export: https://github.com/aaronlab/browsertrace/releases/download/v0.1.14/browsertrace-demo-public.html
For profile-reader follow-up, local first-run issues, CI failures, or AI/coding-agent troubleshooting replies, ask for debugging/workflow details plus JSON CLI diagnostics when safe to share:
browsertrace doctor --json
browsertrace list --status failed --json
browsertrace show <run_id> --json- AI browser-agent debugging
- Browser automation and computer-use agents
- LLM observability for local workflows
- Agent evaluation and tool reliability
| Project | Focus |
|---|---|
| browsertrace | Local traces for failed AI browser-agent runs |
| claude-code-source-analysis | Claude Code source analysis and learning notes |
| agent-bench-lite | Lightweight AI agent evaluation benchmark |
| mcp-shield | MCP server security audit tooling |
| openclaw | Personal AI assistant experiments |
If you build browser agents, the most useful BrowserTrace feedback is:
- Which framework do you use?
- What context is missing when a run fails?
- Are local HTML exports enough, or do you need hosted share links?
- Which adapter should be improved first?
Launch discussion: aaronlab/browsertrace#6