{kind=link}
This is a project I did for my "Parallel and High-Performance Computing" course at EPFL. The goal was to optimize the conjugate gradient algorithm using CUDA and MPI in C++. The CG algorithm solves the system: Ax = b, where A is a full, real, symmetric, positive-definite matrix. The algorithm is as follows:
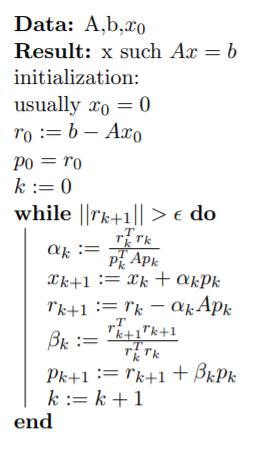
The code for the solve method for the parallelized MPI version is:
void CGSolver::solve(std::vector<double> & x) {
int prank, psize;
MPI_Comm_rank(MPI_COMM_WORLD, &prank);
MPI_Comm_size(MPI_COMM_WORLD, &psize);
if(psize > 1) {
std::vector<double> r(m_m);
std::vector<double> smaller_r(m_m/psize);
std::vector<double> smaller_p(m_m/psize);
std::vector<double> p(m_m);
std::vector<double> Ap(m_m/psize);
std::vector<double> tmp(m_m/psize);
std::vector<double> smaller_x(m_m/psize);
std::vector<double> smaller_m_b(m_m/psize);
std::fill_n(Ap.begin(), Ap.size(), 0.);
Matrix smaller_m_A(m_m/psize, m_n);
for(int i = 0; i < m_m/psize; i++) {
for(int j = 0; j < m_n; j++) {
smaller_m_A(i,j) = m_A(prank*(m_m/psize) + i,j);
}
}
for(int i=0; i < m_m/psize; i++) {
smaller_x[i] = x[prank*(m_m/psize)+i];
}
for(int i=0; i < m_m/psize; i++) {
smaller_m_b[i] = m_b[prank*(m_m/psize)+i];
}
cblas_dgemv(CblasRowMajor, CblasNoTrans, m_m/psize, m_n, 1., smaller_m_A.data(), m_n, x.data(), 1, 0., Ap.data(), 1);
smaller_r = smaller_m_b;
// Calculating r = b - A*x on smaller set of rows
cblas_daxpy(m_m/psize, -1., Ap.data(), 1, smaller_r.data(), 1);
// Setting p = r on smaller set of rows
smaller_p = smaller_r;
// Gathering all the rows together
MPI_Allgather(&smaller_r[0], m_m/psize, MPI_DOUBLE, &r[0], m_m/psize, MPI_DOUBLE, MPI_COMM_WORLD);
MPI_Allgather(&smaller_p[0], m_m/psize, MPI_DOUBLE, &p[0], m_m/psize, MPI_DOUBLE, MPI_COMM_WORLD);
// r' * r;
auto rold = cblas_ddot(m_m, r.data(), 1, r.data(), 1);
// for i = 1:length(b)
int k = 0;
for (; k < m_m/psize ; ++k) {
// Ap = A * p;
std::fill_n(Ap.begin(), Ap.size(), 0.);
cblas_dgemv(CblasRowMajor, CblasNoTrans, m_m/psize, m_n, 1., smaller_m_A.data(), m_n, p.data(), 1, 0., Ap.data(), 1);
// alpha = rold / (p' * Ap);
auto alpha = rold / std::max(cblas_ddot(m_m/psize, smaller_p.data(), 1, Ap.data(), 1), rold * NEARZERO);
// x = x + alpha * p;
cblas_daxpy(m_m/psize, alpha, smaller_p.data(), 1, smaller_x.data(), 1);
// r = r - alpha * Ap;
cblas_daxpy(m_m/psize, -alpha, Ap.data(), 1, smaller_r.data(), 1);
// prank*m_n/psize
MPI_Allgather(&smaller_r[0], m_m/psize, MPI_DOUBLE, &r[0], m_m/psize, MPI_DOUBLE, MPI_COMM_WORLD);
// rnew = r' * r;
auto rnew = cblas_ddot(m_m, r.data(), 1, r.data(), 1);
if (std::sqrt(rnew) < m_tolerance) break;
auto beta = rnew / rold;
// p = r + (rnew / rold) * p;
tmp = smaller_r;
cblas_daxpy(m_m/psize, beta, smaller_p.data(), 1, tmp.data(), 1);
smaller_p = tmp;
MPI_Allgather(&smaller_p[0], m_m/psize, MPI_DOUBLE, &p[0], m_m/psize, MPI_DOUBLE, MPI_COMM_WORLD);
// rsold = rsnew;
rold = rnew;
if (DEBUG) {
std::cout << " [STEP " << k << "] residual = " << std::scientific
<< std::sqrt(rold) << " " << std::flush;
}
}
MPI_Allgather(&smaller_x[0], m_m/psize, MPI_DOUBLE, &x[0], m_m/psize, MPI_DOUBLE, MPI_COMM_WORLD);
if (DEBUG) {
std::fill_n(r.begin(), r.size(), 0.);
cblas_dgemv(CblasRowMajor, CblasNoTrans, m_m, m_n, 1., m_A.data(), m_n, x.data(), 1, 0., r.data(), 1);
cblas_daxpy(m_n, -1., m_b.data(), 1, r.data(), 1);
auto res = std::sqrt(cblas_ddot(m_n, r.data(), 1, r.data(), 1)) /
std::sqrt(cblas_ddot(m_n, m_b.data(), 1, m_b.data(), 1));
auto nx = std::sqrt(cblas_ddot(m_n, x.data(), 1, x.data(), 1));
std::cout << " [STEP " << k << "] residual = " << std::scientific
<< std::sqrt(rold) << ", ||x|| = " << nx
<< ", ||Ax - b||/||b|| = " << res << std::endl;
}
}
if (psize == 1) {
std::vector<double> r(m_n);
std::vector<double> p(m_n);
std::vector<double> Ap(m_n);
std::vector<double> tmp(m_n);
// r = b - A * x;
std::fill_n(Ap.begin(), Ap.size(), 0.);
cblas_dgemv(CblasRowMajor, CblasNoTrans, m_m, m_n, 1., m_A.data(), m_n, x.data(), 1, 0., Ap.data(), 1);
r = m_b;
cblas_daxpy(m_n, -1., Ap.data(), 1, r.data(), 1);
// p = r;
p = r;
// rsold = r' * r;
auto rsold = cblas_ddot(m_n, r.data(), 1, p.data(), 1);
// for i = 1:length(b)
int k = 0;
for (; k < m_n; ++k) {
// Ap = A * p;
std::fill_n(Ap.begin(), Ap.size(), 0.);
cblas_dgemv(CblasRowMajor, CblasNoTrans, m_m, m_n, 1., m_A.data(), m_n, p.data(), 1, 0., Ap.data(), 1);
// alpha = rsold / (p' * Ap);
auto alpha = rsold / std::max(cblas_ddot(m_n, p.data(), 1, Ap.data(), 1), rsold * NEARZERO);
// x = x + alpha * p;
cblas_daxpy(m_n, alpha, p.data(), 1, x.data(), 1);
// r = r - alpha * Ap;
cblas_daxpy(m_n, -alpha, Ap.data(), 1, r.data(), 1);
// rsnew = r' * r;
auto rsnew = cblas_ddot(m_n, r.data(), 1, r.data(), 1);
if (std::sqrt(rsnew) < m_tolerance)
break; // Convergence test
auto beta = rsnew / rsold;
// p = r + (rsnew / rsold) * p;
tmp = r;
cblas_daxpy(m_n, beta, p.data(), 1, tmp.data(), 1);
p = tmp;
// rsold = rsnew;
rsold = rsnew;
if (DEBUG) {
std::cout << " [STEP " << k << "] residual = " << std::scientific
<< std::sqrt(rsold) << " " << std::flush;
}
}
if (DEBUG) {
std::fill_n(r.begin(), r.size(), 0.);
cblas_dgemv(CblasRowMajor, CblasNoTrans, m_m, m_n, 1., m_A.data(), m_n, x.data(), 1, 0., r.data(), 1);
cblas_daxpy(m_n, -1., m_b.data(), 1, r.data(), 1);
auto res = std::sqrt(cblas_ddot(m_n, r.data(), 1, r.data(), 1)) /
std::sqrt(cblas_ddot(m_n, m_b.data(), 1, m_b.data(), 1));
auto nx = std::sqrt(cblas_ddot(m_n, x.data(), 1, x.data(), 1));
std::cout << " [STEP " << k << "] residual = " << std::scientific
<< std::sqrt(rsold) << ", ||x|| = " << nx
<< ", ||Ax - b||/||b|| = " << res << std::endl;
}
}
}
The code for the solve method designed to be run on a GPU with CUDA is:
__global__ void initialization(double *x_device, double *r_device, double *p_device, double *tmp_device, double *m_A_device, double *m_b_device, int *m_n_device) {
// Find the blockId, we know it is between 0 and 9
// Each block is in charge of 1000 rows
int blockId = blockIdx.x;
// Find the threadId
// In each block you may have a different number of threads, and this number must divide 1000
int threadId = threadIdx.x;
// Number of rows each thread must consider
int numRowsForEachThread = (int) 1000/blockDim.x;
// Begining row index
int beginningRowIndex = blockId*1000 + threadId*numRowsForEachThread;
// Creating A*x for the specific rows
for(int i = beginningRowIndex; i < beginningRowIndex + numRowsForEachThread; i++){
int m_n_device_int = *m_n_device;
for(int j = 0; j < *m_n_device; j++) {
tmp_device[i] = tmp_device[i] + x_device[j]*m_A_device[i*m_n_device_int + j];
}
}
for(int i = 0; i < numRowsForEachThread; i++) {
r_device[beginningRowIndex + i] = m_b_device[beginningRowIndex + i] - tmp_device[beginningRowIndex + i];
}
// Synchronize after this kernel
*p_device = *r_device;
}
__global__ void computeAlphaNumerator(double *r_device, double *p_device, double *Ap_device, double *m_A_device, int *m_m_device, int *m_n_device, double *numerator_alpha) {
int blockId = blockIdx.x;
int threadId = threadIdx.x;
int numRowsForEachThread = (int) 1000/blockDim.x;
int beginningRowIndex = blockId*1000 + threadId*numRowsForEachThread;
for(int j = 0; j < *m_m_device; j++) {
*numerator_alpha = *numerator_alpha + r_device[j]*r_device[j];
}
for(int i = beginningRowIndex; i < beginningRowIndex + numRowsForEachThread; i++){
int m_n_device_int = *m_n_device;
for(int j = 0; j < m_n_device_int; j++) {
Ap_device[i] = Ap_device[i] + p_device[j]*m_A_device[i*m_n_device_int + j];
}
}
// Synchronize after this kernel
}
__global__ void computeAlphaDenominator(double *x_device, double *r_device, double *p_device,double *Ap_device, int *m_m_device, double *numerator_alpha, double *denominator_alpha) {
int blockId = blockIdx.x;
int threadId = threadIdx.x;
int numRowsForEachThread = (int) 1000/blockDim.x;
int beginningRowIndex = blockId*1000 + threadId*numRowsForEachThread;
for(int j = 0; j < *m_m_device; j++) {
*denominator_alpha = *denominator_alpha + p_device[j]*Ap_device[j];
}
double alpha;
if(*denominator_alpha != 0) {
alpha = *numerator_alpha/ *denominator_alpha;
} else {
alpha = 0.1;
}
for(int i = 0; i < numRowsForEachThread; i++) {
x_device[beginningRowIndex + i] = x_device[beginningRowIndex + i] + alpha*p_device[beginningRowIndex + i];
r_device[beginningRowIndex + i] = r_device[beginningRowIndex + i] - alpha*Ap_device[beginningRowIndex + i];
}
// Synchronize after this kernel
}
__global__ void computeBeta(double *r_device, double *p_device, int *m_m_device, double *numerator_alpha, double *beta) {
int blockId = blockIdx.x;
int threadId = threadIdx.x;
int numRowsForEachThread = (int) 1000/blockDim.x;
int beginningRowIndex = blockId*1000 + threadId*numRowsForEachThread;
for(int j = 0; j < *m_m_device; j++) {
*beta = *beta + r_device[j]*r_device[j];
}
*beta = *beta/ *numerator_alpha;
for(int i=0; i < numRowsForEachThread; i++) {
p_device[beginningRowIndex + i] = r_device[beginningRowIndex + i] + (*beta)*p_device[beginningRowIndex + i];
}
// Synchronize after this kernel
}
void CGSolver::solve(std::vector<double> & x) {
// CUDA parameters
// --- CAN BE CHANGED ---
int grid_size = 10;
int block_size = 10;
// Arrays allocated
std::vector<double> r(m_m);
double *r_device;
std::vector<double> p(m_m);
double *p_device;
std::vector<double> Ap(m_m);
std::fill_n(Ap.begin(), Ap.size(), 0.);
double *Ap_device;
std::vector<double> tmp(m_m);
std::fill_n(tmp.begin(), tmp.size(), 0.);
double *tmp_device;
double *x_device;
cudaMalloc((void **) &r_device, m_m*sizeof(double));
cudaMemcpy(r_device, &r[0], m_m*sizeof(double), cudaMemcpyHostToDevice);
cudaMalloc((void **) &p_device, m_m*sizeof(double));
cudaMemcpy(p_device, &p[0], m_m*sizeof(double), cudaMemcpyHostToDevice);
cudaMalloc((void **) &Ap_device, m_m*sizeof(double));
cudaMemcpy(Ap_device, &Ap[0], m_m*sizeof(double), cudaMemcpyHostToDevice);
cudaMalloc((void **) &tmp_device, m_m*sizeof(double));
cudaMemcpy(tmp_device, &tmp[0], m_m*sizeof(double), cudaMemcpyHostToDevice);
cudaMalloc((void **) &x_device, m_m*sizeof(double));
cudaMemcpy(x_device, &x[0], m_m*sizeof(double), cudaMemcpyHostToDevice);
double *m_A_device;
cudaMalloc((void **) &m_A_device, m_m*m_n*sizeof(double));
cudaMemcpy(m_A_device, &m_A.data()[0], m_m*m_n*sizeof(double), cudaMemcpyHostToDevice);
double *m_b_device;
cudaMalloc((void **) &m_b_device, m_m*sizeof(double));
cudaMemcpy(m_b_device, &m_b.data()[0], m_m*sizeof(double), cudaMemcpyHostToDevice);
// Scalars allocated
int *m_m_device, *m_n_device;
double numerator_alpha = 0.0;
double denominator_alpha = 0.0;
double beta = 0.0;
double *numerator_alpha_device, *denominator_alpha_device, *beta_device;
cudaMalloc((void **)&m_m_device, sizeof(int));
cudaMemcpy(m_m_device, &m_m, sizeof(int), cudaMemcpyHostToDevice);
cudaMalloc((void **)&m_n_device, sizeof(int));
cudaMemcpy(m_n_device, &m_n, sizeof(int), cudaMemcpyHostToDevice);
cudaMalloc((void **)&numerator_alpha_device, sizeof(int));
cudaMemcpy(numerator_alpha_device, &numerator_alpha, sizeof(int), cudaMemcpyHostToDevice);
cudaMalloc((void **)&denominator_alpha_device, sizeof(int));
cudaMemcpy(denominator_alpha_device, &denominator_alpha, sizeof(int), cudaMemcpyHostToDevice);
cudaMalloc((void **)&beta_device, sizeof(int));
cudaMemcpy(beta_device, &beta, sizeof(int), cudaMemcpyHostToDevice);
double m_tolerance{1e-10};
double stopping_criterion = 0.0;
initialization<<<grid_size, block_size>>>(x_device, r_device, p_device, tmp_device, m_A_device, m_b_device, m_n_device);
cudaDeviceSynchronize();
cudaMemcpy(&r[0], &r_device, m_m*sizeof(double), cudaMemcpyDeviceToHost);
for (int i = 0; i < m_m; i++) {
stopping_criterion += r[i];
}
while(stopping_criterion > m_tolerance) {
computeAlphaNumerator<<<grid_size, block_size>>>(r_device, p_device, Ap_device, m_A_device, m_m_device, m_n_device, numerator_alpha_device);
cudaDeviceSynchronize();
computeAlphaDenominator<<<grid_size, block_size>>>(x_device, r_device, p_device, Ap_device, m_m_device, numerator_alpha_device, denominator_alpha_device);
cudaDeviceSynchronize();
computeBeta<<<grid_size, block_size>>>(r_device, p_device, m_m_device, numerator_alpha_device, beta_device);
cudaDeviceSynchronize();
cudaMemcpy(&r[0], &r_device, m_m*sizeof(double), cudaMemcpyDeviceToHost);
stopping_criterion = 0.0;
for (int i = 0; i < m_m; i++) {
stopping_criterion += r[i];
}
}
// When the iterations are finished, copy the final answer from the device to the host variable x
cudaMemcpy(&x[0], &x_device, m_m*sizeof(double), cudaMemcpyDeviceToHost);
}