- 爬取并处理Java文档中约5万条API数据
- 对数据进行预处理和分析,根据分析的数据设计知识图谱的实体和关系
- 使用SpaCy搭建基于语法语义依存树的数据标注模型,自动的从数据中抽取实体和关系
- 利用 Neo4j 图数据库构建API知识图谱
数据来源:java document
| 字段名 | 详细介绍 |
|---|---|
| qualified_name | java api method全称 |
| functionality_description | java api method的功能性描述,取api描述的第一句话 |

| 实体类型 | 详细描述 |
|---|---|
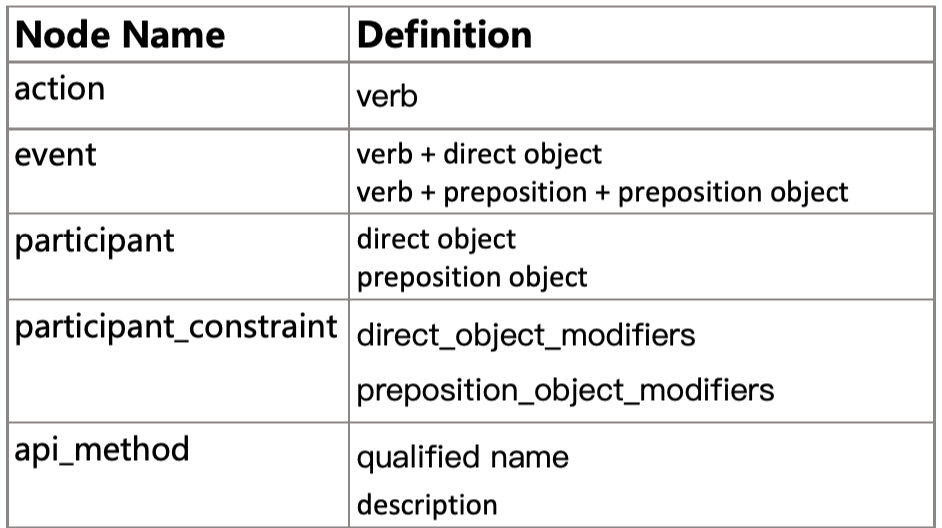
| api_method | api method实体 |
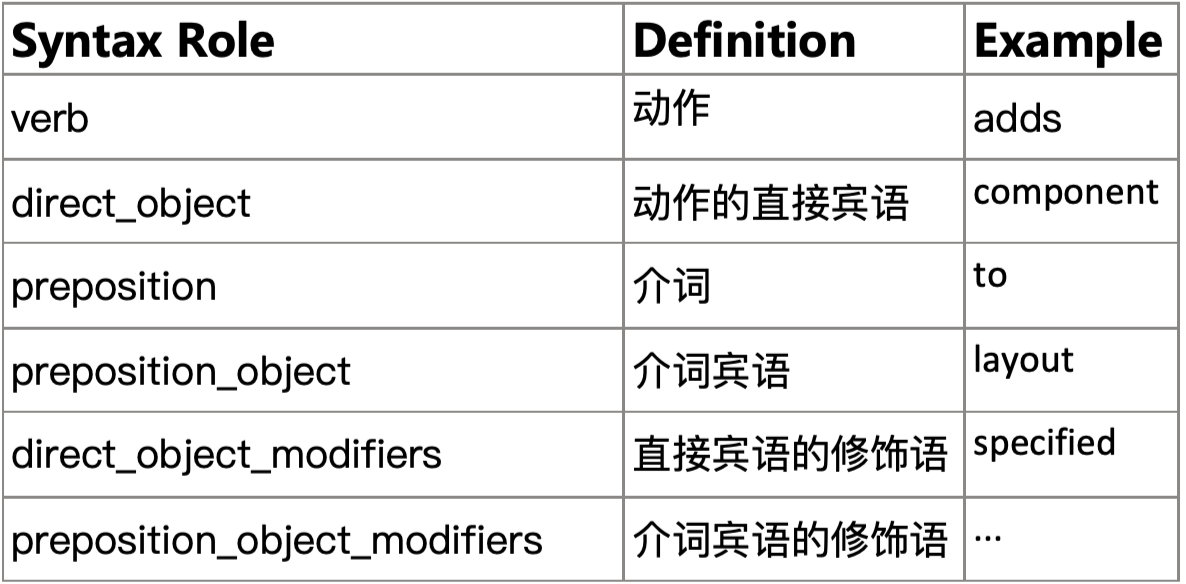
| action | 功能性描述的主要动作 |
| participant | 功能性描述的参与者,分别为直接宾语和介词宾语 |
| event | action+participant |
| event_constraint | event实体的约束 |
| participant_constraint | participant实体的约束 |
| 前序实体类型 | 关系 | 后继实体类型 |
|---|---|---|
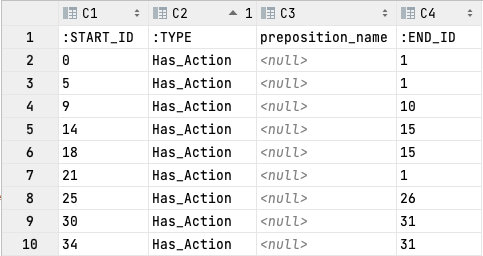
| api_method | Has_Action | action |
| api_method | Has_Event | event |
| api_method | Has_Event | action_event |
| event | Has_Direct_Object | participant |
| event | Has_Preposition_Object | participant |
-
使用Allennlp的semantic role labeling模型对功能性描述进行标注,输入句子,输出语义标注结果
-
将V+ARG1+ARG2...ARG4组成新的句子(称作api描述的主要功能),ARGM-...则构成event_constraint实体

-
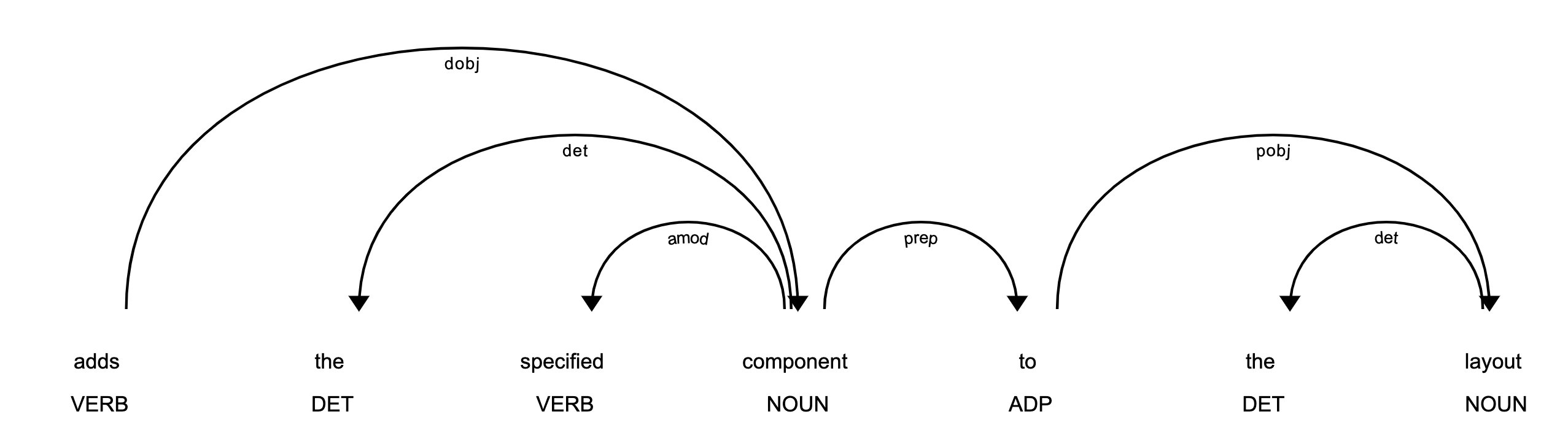
基于Spacy对主要功能进行语法角色标注,得到至多6种语法角色
-
将提取到的语法角色与定义的实体进行对应
-
参考论文1 | SpCy工具
 |
 |
|---|
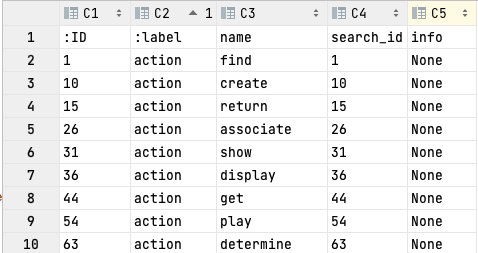
- 实体在上述信息抽取过程已经对应完毕
- 接着根据Step2提到的三元组构建关系,最终得到node.csv和relation.csv
 |
 |
|---|
./bin/neo4j-admin import --nodes "node.csv" --relationships "relation.csv"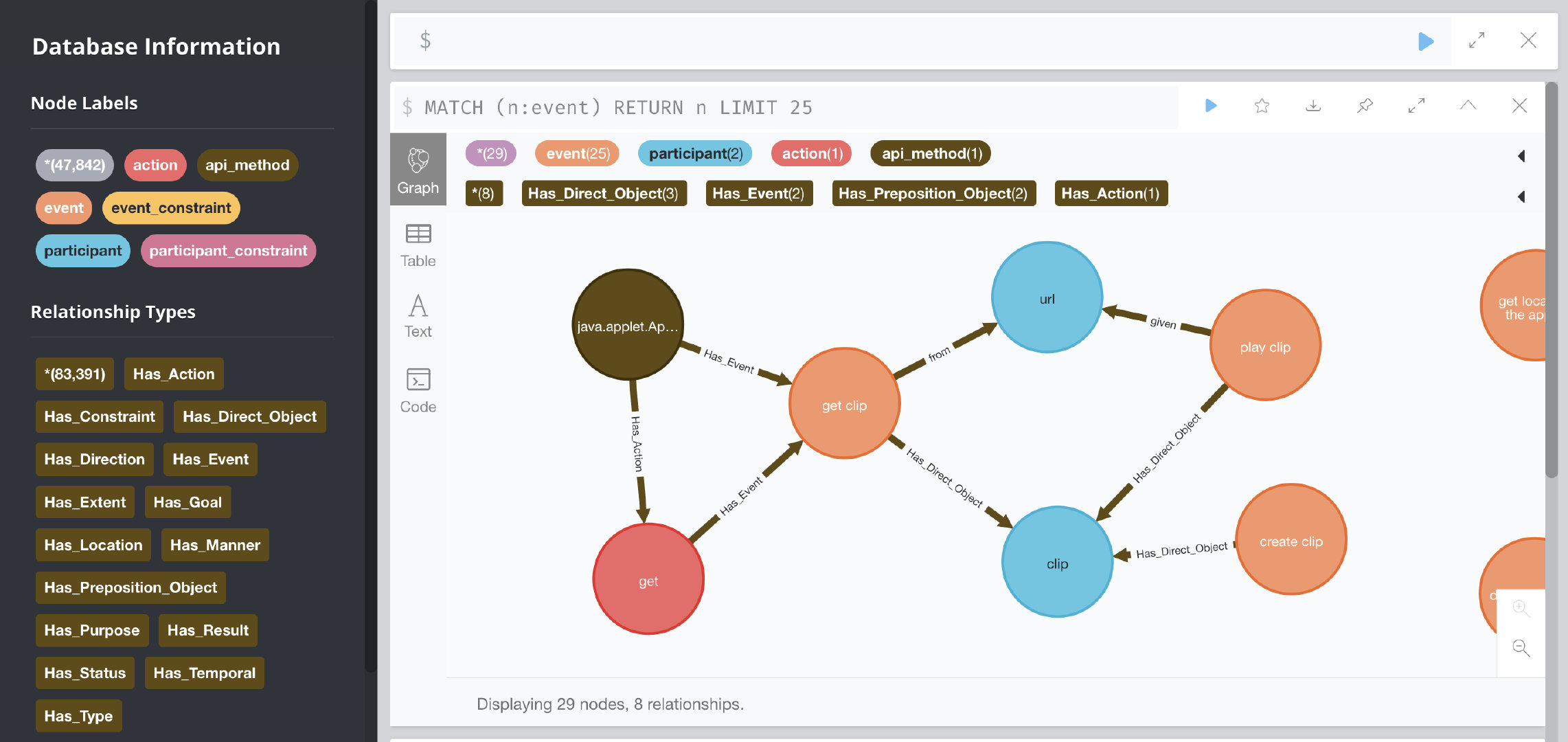
├── LICENSE
├── README.md
├── data
├── definitions.py #定义路径
├── import2neo4j #将数据导入到neo4j
│ └── neo4j-import
│ ├── bin
│ ├── import
│ ├── import.report
│ ├── import.sh #将输入导入到neo4j脚本
│ ├── lib
│ ├── logs
│ ├── run
│ └── run.sh #打开neo4j脚本
├── main #构建KG代码
│ ├── entity_relation_build.py #将抽取到的信息对应到实体与关系
│ ├── pipeline.py #从句子中抽取信息的代码
│ ├── run.py #入口
│ └── util.py #数据读取相关的函数
├── output
│ ├── build_kg_data #存储kg相关的数据
│ └── crawl_data #存储原始数据
├── requirements.txt
└── util_model #使用的semantic role labeling模型
└── structured-prediction-srl-bert.2020.12.15- Treude, C., Robillard, M. P. & Dagenais, B. Extracting Development Tasks to Navigate Software Documentation. Ieee T Software Eng 41, 565–581 (2014).