Proyecto de Archivomex Estadísticas históricas de México. CIDE-INEGI-CentroGEO
La versión más actualizada (v1.1.1) de nuestra herramienta open-source de extracción para exportar información númerica de los tomos en PDF de las Estadísticas Históricas de México a tablas en xls. Esta versión solo corre en maquinas Windows10, una futura versión para macOS está en desarrollo. Con este enlace puedes descargar directamente la herramienta ejecutable en formato zip.
https://drive.google.com/file/d/1IRNFwpq8jTKwjv4e9d0BNQ-TGOygRF7v/view?usp=sharing
Uso directamente desde Python
Para poder utilizar la versión de Python es necesario tener los siguientes paquetes con sus respectivas versiones:
Openpyxl 3.0.3
TK-tools 0.12.0
PyMuPDF 1.17.3
opencv-python 4.3.0.36
pytesseract 0.3.4
Pillow 7.2.0
Se puede utilizar el archivo librerias.py ubicado en cualquiera de las subcarpetas para instalar los paquetes.
Es necesario instalar una versión de Python igual o superior a 3.6.
Es necesario hacer la instalación de Tesseract-OCR para el correcto funcionamiento de la herramienta. La ubicación de Tesseract-OCR debe de ser la misma en la que se encuentra el archivo .py del Xtractor que se esté utilizando o se deben de actualizar las rutas con la referencia correcta.
Para más información sobre la primera instalación, revisar el "Manual de Instalación Xtractor" que se encuentra dentro de la carpeta Xtractor EHM 2014.
Xtractor EHM 2014
Esta versión de la herramienta es exclusiva para la extracción de tablas de las Estadísticas Históricas de México de 2014.
Se recomienda comenzar por este Xtractor para tener la instalación adecuada para el uso de las adicionales herramientas disponibles. Revisar el "Manual de Instalación Xtractor" que se encuentra dentro de la carpeta Xtractor EHM 2014.
Para verificar si la instalación fue satisfactoria y conocer el funcionamiento de la herramienta, se deben de realizar los siguientes pasos:
- Correr el script de Python ArchivoMex_Extractor.py, la siguiente ventana deberá de aparecer en la pantalla:
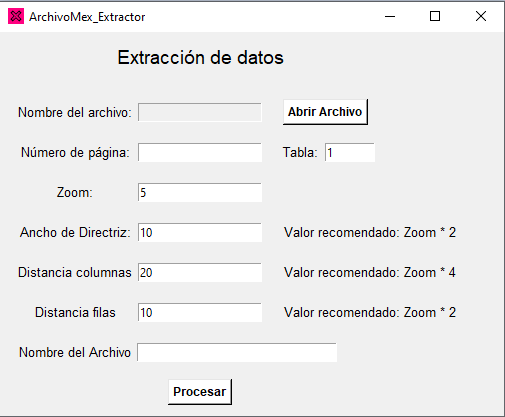
- Seleccionar de la carpeta EHM2014 el anuario estadístico de su interés y la página donde se encuentra la tabla que desea extraer. Indicar el índice de la tabla dentro de la página seleccionada, se debe de contar de arriba para abajo comenzando con el índice 1. En caso de que la extracción sea errónea y presente texto o números que no corresponden a los de la tabla, incremente el valor del zoom en 1 y ajuste los demás parámetros de acuerdo a la fórmula. Para este ejemplo se seleccionó el anuario estadístico número 18 (Precios), con la página 130 y la tabla número 2.
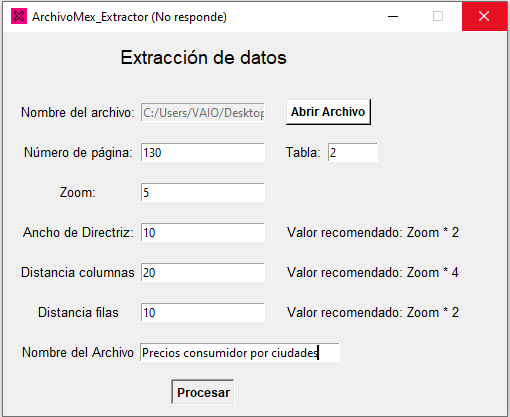
- Una vez se llenan los campos, se da click en el botón de procesar. Una vez que el procesamiento termine deberá de aparecer un mensaje indicando el fin del proceso. El archivo de Excel se encontrará en la misma ubicación del script de Python.

Resultado

*Es importante destacar que el Xtractor está limitado a extraer únicamente el contenido de la tabla, el título y los encabezados se ignoran.
Censo Hospitales
Esta versión de la herramienta es exclusiva para la extracción de tablas del Censo y Planificación de hospitales de 1959.
En el siguiente enlace se encuentra el Censo y Planificación de hospitales de 1959: https://drive.google.com/file/d/15EFbzDvc8BgYMi1zHzNbatozrkC_sAYT/view?usp=sharing
Los prerrequisitos para el uso de esta herramienta son los mismos que se utilizan en el Xtractor EHM 2014.
Para verificar si la instalación fue satisfactoria y conocer el funcionamiento de la herramienta, se deben de realizar los siguientes pasos:
- Correr el script de Python CensoHospitalesExtrator_GUI.py, la siguiente ventana deberá de aparecer en la pantalla:

- Seleccionar el PDF del censo y planificación de hospitales, el número de página del PDF y el número de página del censo (1 o 2). Dejar el campo de rotar en "0" y dar click en Procesar. Para este ejemplo se seleccionó la página 16 del PDF y la página 2 del Censo.

- Se van a generar imagenes de cada tabla segmentada y puede que en algunos casos una imagen de ruido. Deberá de aparecer el mensaje de completado.

Resultado

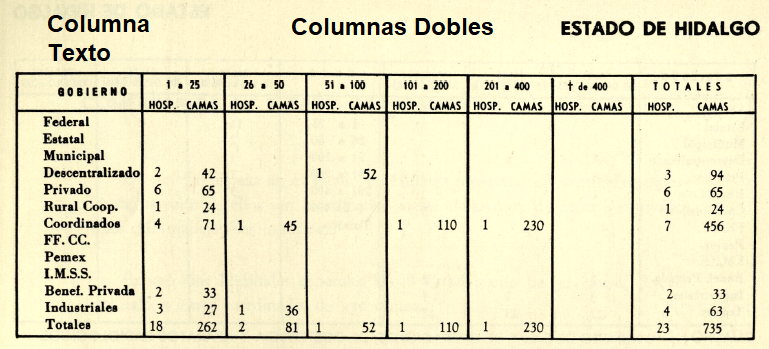
- En la sección derecha de la ventana del Xtractor se debe de cargar la imagen de la tabla de interés. Se deben de indicar que columnas son dobles (aquellas que tienen 2 valores numéricos) y cuales tienen únicamente texto. Seleccionar la casilla de Extracción 2 para mejores resultados. Para este ejemplo se seleccionó la tabla "0__hospital".
Ejemplo de columnas

- Dar click en procesar. Esperar a que el mensaje de completado aparezca. El archivo generado se encuentra en la misma ubicación en la que se encuentra el script de Python.

Resultado

Xtractor EHM 1970
Está versión de la herramienta es exclusiva para la extracción de tablas de las Estadísticas Históricas de México de 1970.
Para el uso de esta herramienta es necesario entrenar un modelo de clasificación de caracteres del 0-9 para la extracción de los datos numéricos de la tabla. En la carpeta CNN se encuentra el dataset utilizado para el entrenamiento de la red, así como un algoritmo de segmentación de caracteres para generar un dataset propio.
*Para obtener mejores resultados, procesar imagenes de las columnas individuales (ColumnaLista.png), segmentadas manualmente de la imagen original (Original.png). También es posible procesar toda la imagen generada.
Una vez que se genera el modelo de clasificación, es posible utilizar el Xtracor CNN.py para la extracción de tablas.
*Es necesario actualizar las rutas de acceso a archivos. Las rutas que se encuentran definidas quedan como ejemplo para obtener un correcto funcionamiento de la herramienta.
Dataset
Para poder crear la red neuronal convolucional es necesario tener un dataset con imágenes del 0-9. Para esto, se incluye en el repositorio el dataset utilizado para entrenar el modelo. Sin embargo, a continuación se explica el procedimiento para crear un dataset propio.
-
El script SegmentarCaracteres.py se compone de 2 funciones. "escalar" funciona para crear una imagen en alta resolución de una página del anuario estadístico de 1970 que se desee.
-
Posteriormente se debe de segmentar manualmente una columna de la imagen generada o procesar toda la imagen con la función "dividir".
-
Finalizado el proceso se van a generar imagenes de los caracteres dentro de la imagen procesada.
Imagen Original con escala
Columna segmentada manualmente

Imágenes generadas

- Se debe de hacer el etiquetado manualmente.
Entrenamiento
Antes de comenzar con el entrenamiento es necesario instalar "tensorflow". https://www.tensorflow.org/install/pip?hl=es-419
Para el entrenamiento es necesario organizar las imagenes del dataset. Para esto se utiliza la función "Normalizar" del script Entrenamiento.py. Esta función se encarga de escalar las imágenes de imágenes de 15x30 pixeles.
Posteriormente se debe de utilizar la función "CNN" para crear la red neuronal.
Es importante actualizar las rutas que se utilizan.
Cuando se finaliza el entrenamiento se generará un archivo con la terminación "h5", esta es la red obtenida.
Xtractor EHM 1970
Para el uso de este Xtractor es necesario utilizar la red generada previamente, ya que esta se encarga de la clasificación de los números dentro de la imagen.
El funcionamiento es el siguiente:
- Correr el script Xtractor CNN.py. La siguiente ventana deberá de aparecer en la pantalla.

- Seleccionar el anuario estadístico, indicar el número de la página a procesar y dar click en procesar. En este primer paso se desplegará una imagen con las filas encontradas. Si las filas indicadas no aparecen se debe de decrementar el valor de sensibilidad, en caso contrario, si aparecen filas que no corresponden y obstruyen las indicadas, se decrementa el valor.
Para este ejemplo se utilizó el archivo "702825140564_1.pdf" con la página 28.


- Cerrar la imagen y el mensaje de completado. Del lado derecho del Xtractor especificar el índice donde comienzan los datos de la tabla y el índice donde termina, y dar click en procesar.
- Esperar a que el mensaje de completado aparezca en pantalla. El archivo generado se encontrará en la misma carpeta donde se encuentre el script.
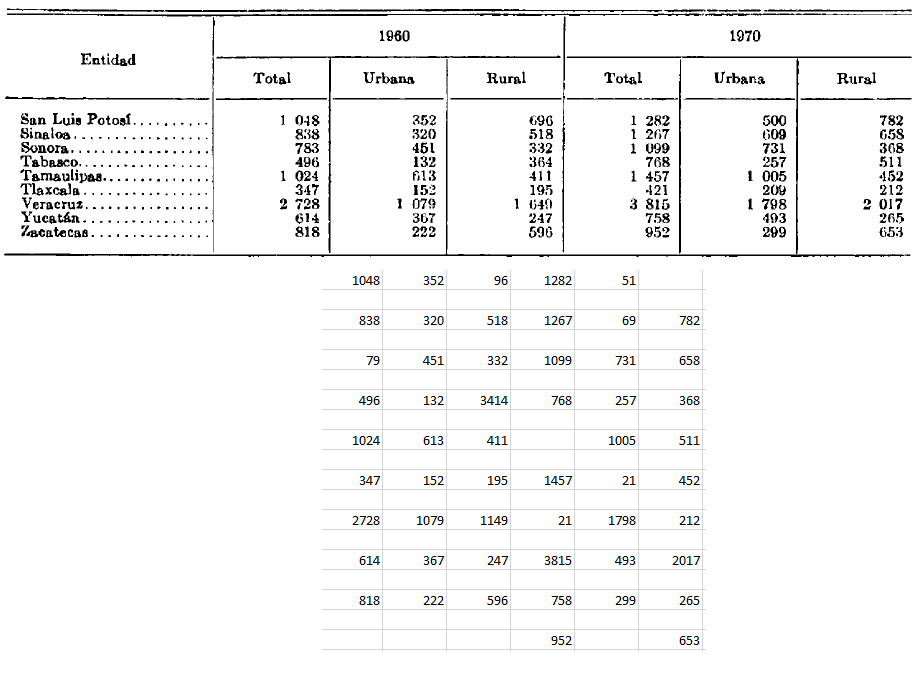
Esta versión se encuentra en fase de experimentación. Aún se necesita refinar el procesamiento de la imagen y segmentación.