🧠 Fused Multi-Branch Multi-Domain Residual Multi-Scale CNN BiLSTM Multi-Head Attention Swin Transformer for End-to-End Language Decoding from MEG: Application for BCI Systems
A Hybrid End-to-End Deep Learning Architecture for Decoding Language from Brain Activity, with Specific Applications in BCI Systems.
This repository details the implementation of a hybrid Deep Learning (DL) architecture designed for Magnetoencephalography (MEG) signal (LibriBrain dataset) processing and decoding in the LibriBrain Competition 2025, which addresses the complex challenge of mapping non-invasive brain recordings to speech events. The model, referred to as the Fused Multi-Path/Branch Multi-Domain (temporal/spectral/temporal-spectral, ...) Residual Multi-Scale Convolutional Neural Network (CNN) Bidirectional Long Short-Term Memory (BiLSTM) Multi-Head with Dual Attention (spatial/temporal) Swin Transformer Encoder (to extract embeddings from Time-Freq representations), is built for signal processing and decoding tasks with substantial societal impact on Brain-Computer Interface (BCI) systems. The model's primary objective in the LibriBrain Competition 2025 is to decode language from MEG recordings of brain activity during a listening session, addressing core BCI tasks such as:
-
Speech Detection: speech vs. non-speech (silence) events (binary task);
-
Phoneme Classification: 39 Phonems (multi-class task).
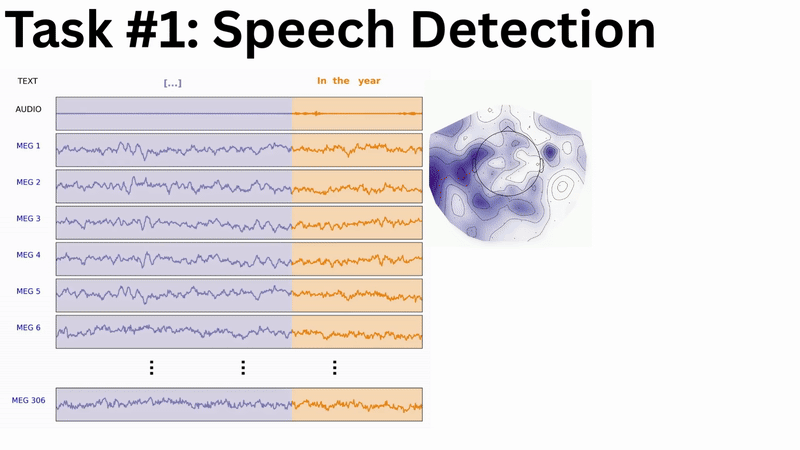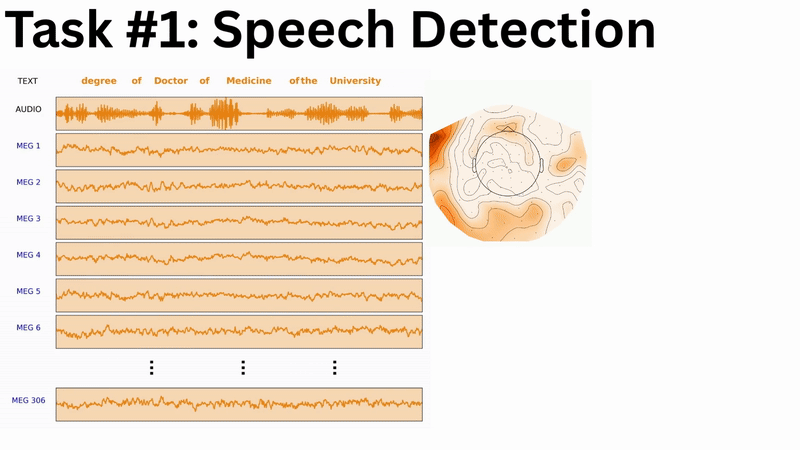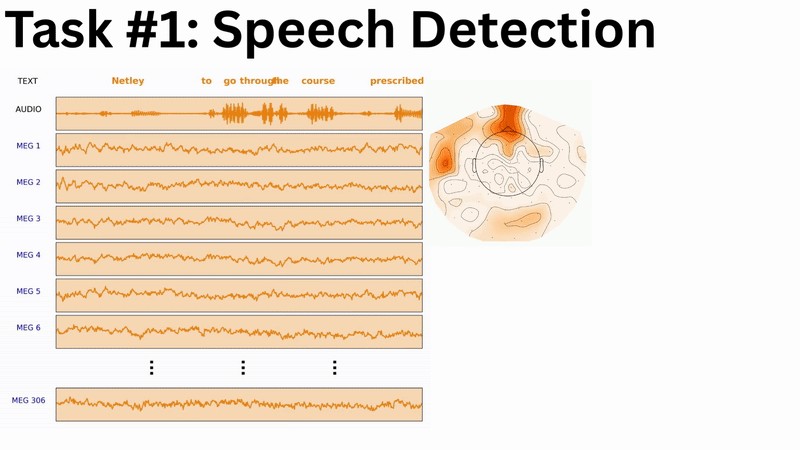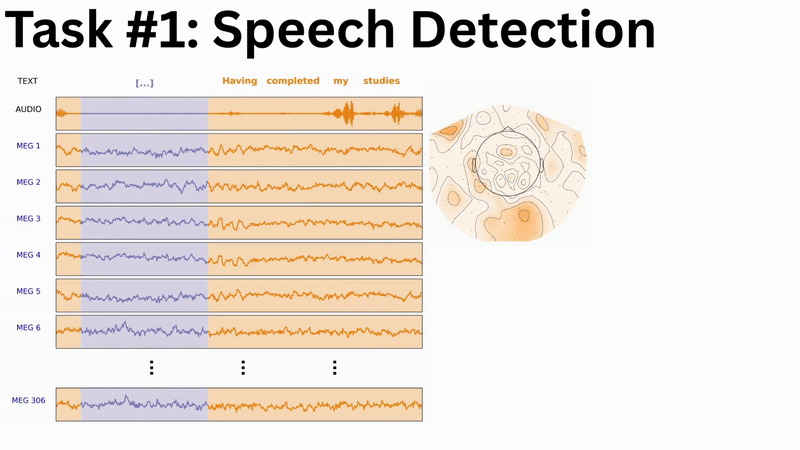
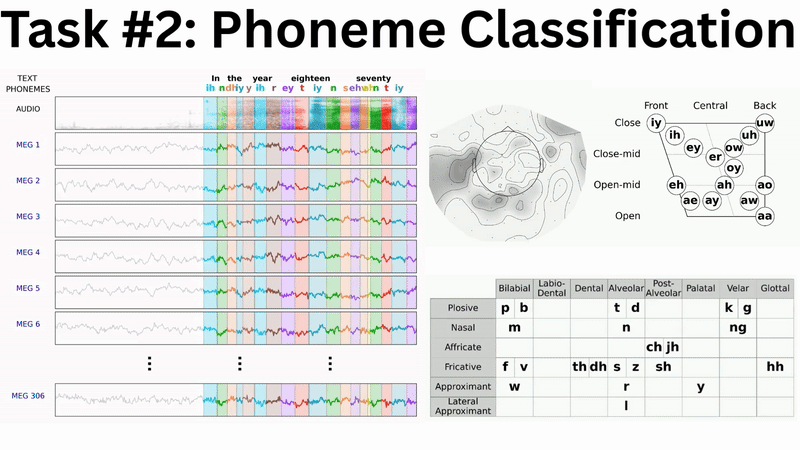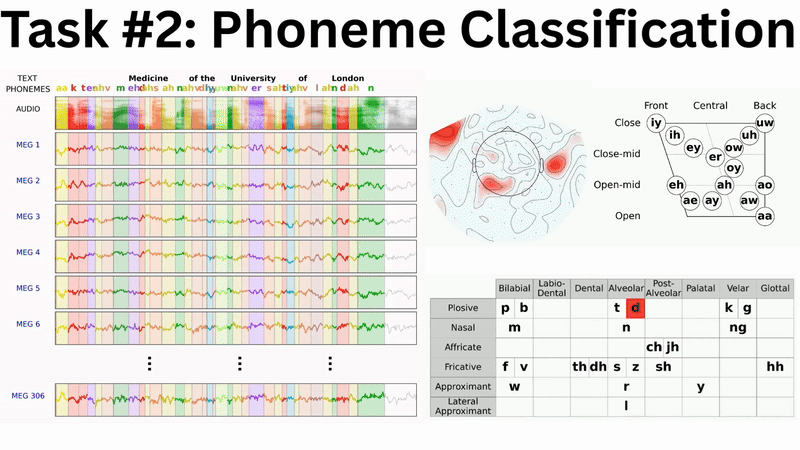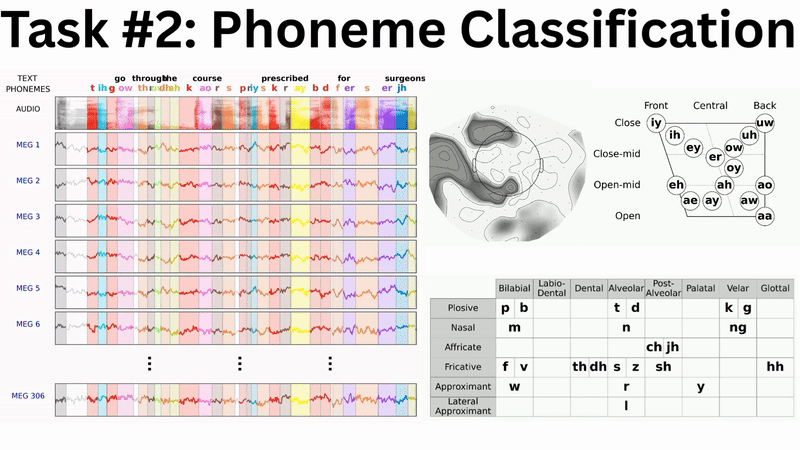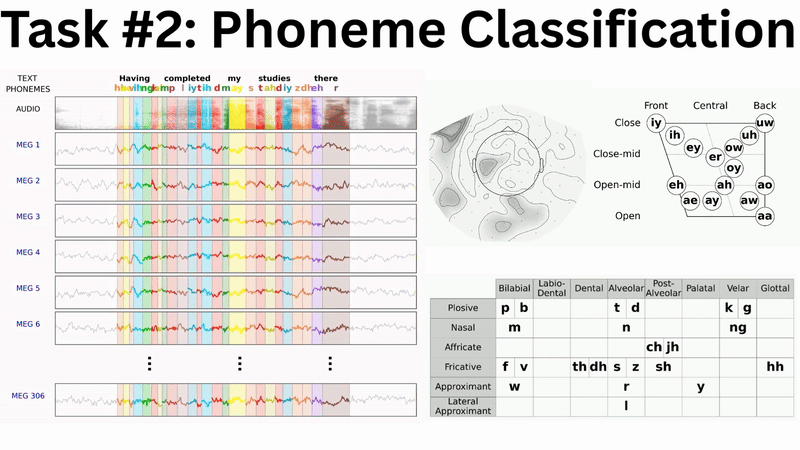
While the complete multi-branch architecture is actively being engineered and tuned, a subcomponent has yielded the following preliminary results at the LibriBrain Competition 2025:
- Place 27/53 in Speech Detection
- Place 18/30 in Phoneme Classification
🏗️ Multi-Branch Residual Multi-Scale CNN BiLSTM Multi-Head with Dual Attention Network (ResMS-CNN-BiLSTM-MH-DANet) + Time-Freq Swin Transformer Encoder Network (TF-STENet) + Filter Bank Dual-Branch Attention-based Frequency Domain Network (FB-DB-AFDNet)
The model fuses distinct, highly specialized following branches of neural networks into a unified decision framework:
graph LR
meg[MEG]
subgraph "Temporal"
A[ResMS-CNN-BiLSTM-MH-DANet]
end
subgraph "Time-Frequency"
tmpfreq[TF-STENet]
end
subgraph "Frequency"
freq[FB-DB-AFDNet]
end
meg --> A & tmpfreq & freq
A & tmpfreq & freq --> F[Fusion]
F --> clf[Classifier]
This branch is designed to capture linguistic units of varying lengths.
- Multi-Scale Extraction: Utilizes parallel convolution branches with different kernel sizes.
- Dual Attention:
- Spatial Attention: Identifies informative MEG sensors (Squeeze-and-Excitation).
- Temporal Attention: Multi-head self-attention to focus on relevant segments.
- Long Residual Connections: Preserves gradient flow across deep layers to prevent vanishing gradients.
This branch leverages Transfer Learning by treating the MEG signal as a visual problem.
- Superlets Transform: Applies Fractional Adaptive Superlet Transform (FASLT) to generate high-resolution time-frequency representations.
- Vision Transformer: Uses a pre-trained Swin Transformer V2 Tiny to extract hierarchical visual features from the spectrograms.
- Dual-Branch Processing: Separates Real and Imaginary (or Magnitude and Phase) components of the FFT.
- Constraint Learning: Applies Orthogonality Constraints (to disentangle unique features) and Similarity Constraints between the dual branches.

This model combines residual multi-scale CNN with BiLSTM and multi-head dual attention mechanisms:

graph LR
A[MEG Input<br/>B,C,T] --> B[Spatial Attention<br/>B,C,T]
B --> C[MS-CNN Block 1<br/>B,D₁,T]
C --> D[MS-CNN Block 2<br/>B,D₂,T]
D --> E[...]
E --> F[MS-CNN Block N<br/>B,D_N,T]
F --> G((+))
B -.Long Residual.-> G
G --> H[Permute<br/>B,T,D_N]
H --> I[Layer Norm<br/>B,T,D_N]
I --> J[Bi-LSTM<br/>B,T,D_N]
J --> K[Temporal Attention<br/>B,T,D_N]
K --> L[Global Avg Pool<br/>B,D_N]
L --> M[Classifier<br/>B,1]
M --> N[Output<br/>Speech/No-Speech]
- Input Shape:
(Batch, Channels, Time)where:Batch: Number of samplesChannels: Number of MEG sensors (e.g., 306 for Neuromag/Elekta systems)Time: Temporal sequence length (e.g., 200 time points)
- Purpose: Identify and focus on the most relevant MEG channels for speech detection (improves SNR)
- Function: Learns channel-wise importance weights/scores
- Output: Weighted MEG signals emphasizing informative sensors
- Architecture: Uses Squeeze-and-Excitation (SE) blocks with Global Average Pooling (GAP)
- Why it matters: Not all MEG sensors are equally informative for speech - some are positioned over motor cortex, others over auditory cortex, etc.
Each Multi-Scale CNN block contains some (here three) parallel processing scales with different temporal receptive fields (kernel sizes):
Scale 1 (K=5): Conv1d(kernel=5) → BatchNorm1d → GELU
Scale 2 (K=13): Conv1d(kernel=13) → BatchNorm1d → GELU
Scale 3 (K=25): Conv1d(kernel=25) → BatchNorm1d → GELU
- K=5 (~20ms): Captures phonetic features - short-term acoustic patterns
- K=13 (~52ms): Captures syllabic patterns - medium-term linguistic units
- K=25 (~100ms): Captures prosodic information - longer-term intonation patterns
- Parallel Processing: Input is processed simultaneously through all three scales
- Concatenation: Scale outputs are concatenated along the channel dimension:
[B, D/3, T] + [B, D/3, T] + [B, D/3, T] → [B, D, T]
- Dropout Regularization: Applied after concatenation (rate = 0.15 for CNN layers)
- Output: Multi-scale feature representation flows to the next block
Blocks progressively expand feature dimensions:
Block 1: D₁ = model_dim / 2^(N-1)
Block 2: D₂ = model_dim / 2^(N-2)
...
Block N: D_N = model_dim
For example, with model_dim=128 and N=3:
- Block 1: 32 dimensions
- Block 2: 64 dimensions
- Block 3: 128 dimensions
A critical skip connection that:
- Starts: After Spatial Attention output
- Ends: At the addition operation after Block N
- Purpose:
- Preserves gradient flow during backpropagation
- Training Stabilization: Enables deeper networks without vanishing gradients
- Maintains direct path for information from input to deep layers
- Adaptive Projection: If dimensions mismatch, a 1×1 convolution projects the residual to match
- Permute: Transforms from CNN format
(B, C, T)to RNN format(B, T, C) - Layer Normalization: Stabilizes activations before temporal processing
- Purpose: Model temporal sequential dependencies in both forward and backward directions
- Architecture:
- Multiple stacked layers (typically 2-3)
- Hidden size:
D_N/2per direction (total output:D_N) - Dropout between layers for regularization
- Why bidirectional: Speech context flows both ways - future phonemes influence current perception
- Purpose: Learn which time steps are most important for classification
- Configuration: 8 attention heads
- Mechanism: Computes attention weights across the time dimension
- Benefit: Adaptively focuses on informative temporal segments (e.g., speech onset, vowels)
- Function: Converts
(B, T, D_N)to(B, D_N) - Advantage: More robust
- Operation:
output = mean(sequence, dim=time)
A Fully Connected (FC) network with progressive dimension reduction, non-linearity, and regularization (to prevent overfitting):
Input (B, D_N)
↓
Linear(D_N → D_N/2) + Dropout(0.3)
↓
GELU activation
↓
Dropout(0.15)
↓
Linear(D_N/2 → 1)
↓
Output (B, 1) - Single logit for binary classification
- Binary Classification: Speech vs No-Speech
- Format: Single logit per sample (apply sigmoid for probability)
This model architecture combines adaptive time-frequency representations with pre-trained vision transformer encoders:

graph LR
A[MEG Signals<br/>B, C, T] --> B[Superlets Transform<br/>FASLT 0.5-30 Hz]
B --> C[Power Spectrogram<br/>B, C, F, T]
C --> D[RGB Conversion<br/>B×C, 3, 256, 256]
D --> E[Swin V2 Encoder<br/>Frozen Backbone]
E --> F[Visual Features<br/>B×C, 768]
F --> G[Feature Projection<br/>768 → 256 → 128]
G --> H[Projected Features<br/>B×C, 128]
H --> I[Channel Aggregation<br/>Average Pooling]
I --> J[Unified Embedding<br/>B, 128]
J --> K[Classification Head<br/>Dropout + FC Layers]
K --> L[Output Logits<br/>B, 1]
L --> M[Speech / No-Speech<br/>Binary Prediction]
Converts raw MEG signals into adaptive time-frequency representations using Superlets, which applies the Fractional Adaptive Superlet Transform (FASLT).
- Frequency range: 0.5-30 Hz (covering delta, theta, alpha, and beta bands)
- Adaptive resolution: Low frequencies (0.5-8 Hz) use high frequency resolution to capture slow oscillations, while high frequencies (8-30 Hz) use high temporal resolution for fast dynamics
- Multi-order analysis: Orders 1-16 provide multi-scale spectral decomposition
- Output: Log-power spectrograms preserving both spatial (channel) and spectral information
The model leverages a pretrained Swin Transformer V2 (Tiny variant) originally trained on ImageNet-1K to process MEG spectrograms as visual data to extracts hierarchical visual features from spectrograms using transfer learning.
- Frozen backbone: The Swin V2 model weights remain fixed, utilizing learned visual representations
- Input preprocessing: Grayscale spectrograms are converted to RGB format (256×256 pixels)
- Feature extraction: Produces 768-dimensional embeddings per channel
- Trainable projection: Maps 768 → 256 → 128 dimensions with GELU activation and dropout (0.1)
- Channel aggregation: Average pooling across all MEG sensors produces a unified 128-dimensional representation
Filter Bank Dual-Branch Attention-based Frequency Domain Network (FB-DB-AFDNet)
This model architecture incorporates a filter bank approach to process multiple frequency subbands, using DB-AFDNets, in parallel. The DB-AFDNet processes complex frequency-domain representations of neural signals, obtained using FFT Transform, through a dual-branch framework, treating the real and imaginary (or magnitude and phase) components separately in different branches, rather than concatenating them in a single branch. The DB-AFDNet uses inter-branch attentional similarity, intra-branch orthogonality, and attention (spatial and multi-scale adaptive) modules to extract shared and unique features of the spectral components and assigns spatial and temporal attention:

graph LR
A[Raw MEG Signals<br/>Multi-channel Time Series] --> B[Filter Bank Decomposition]
B --> C1[Subband 1<br/>f₁-f₂ Hz]
B --> C2[Subband 2<br/>f₃-f₄ Hz]
B --> C3[...]
B --> CN[Subband N<br/>fₙ₋₁-fₙ Hz]
C1 --> D1[DB-AFDNet 1<br/>Subnetwork]
C2 --> D2[DB-AFDNet 2<br/>Subnetwork]
C3 --> D3[...]
CN --> DN[DB-AFDNet N<br/>Subnetwork]
D1 --> F[Fusion]
D2 --> F
D3 --> F
DN --> F
F --> G[Multi-layer Decision Network<br/>FC + Dropout + LayerNorm]
graph LR
A[Subband MEG Signal] --> B[FFT]
B --> C[Complex Frequency Features]
C --> D1[Real Part]
C --> D2[Imaginary Part]
D1 --> E1[Attention 1<br/>Channel-wise + Multi-scale]
D2 --> E2[Attention 2<br/>Channel-wise + Multi-scale]
E1 --> F1[Orthogonality Constraint 1]
E1 --> F2[Similarity Constraint]
E2 --> F3[Orthogonality Constraint 2]
E2 --> F2[Similarity Constraint]
F2 --> F1[Orthogonality Constraint 1]
F2 --> F3[Orthogonality Constraint 2]
F1 --> G[Fusion]
F3 --> G[Fusion]
G --> H[Multi-layer Decision Network<br/>FC + Dropout + LayerNorm]
- Adaptively focuses on spatially and spectrally important features
- Channel-wise Attention: Recalibrates multi-channel data to improve signal-to-noise ratio by learning spatial/channel importance weights/scores
- Multi-scale Adaptive Attention: Captures frequency responses across multiple scales using grouped convolutions with varying kernel sizes (receptive fields)
- Effectively utilizes both real and imaginary (or magnitude and phase) components of frequency representations
- Similarity Constraint: Enforces consistency between branches to learn shared features.
- Orthogonality Constraint: Disentangles shared (inter-branch) and unique (branch-specific) information within each branch.
- Multi-band Processing: Captures frequency-specific neural patterns across different brain rhythms by applying multiple DB-AFDNet subnetworks to different frequency subbands.
Performance logs on Weights & Biases (an AI developer platform):




With B=32, C=306, T=200, model_dim=128, N=3:
MEG Input: [32, 306, 200]
Spatial Attention: [32, 306, 200]
CNN Block 1: [32, 32, 200] # D₁ = 128/4 = 32
CNN Block 2: [32, 64, 200] # D₂ = 128/2 = 64
CNN Block 3: [32, 128, 200] # D₃ = 128
Residual Added: [32, 128, 200]
Permuted: [32, 200, 128]
Bi-LSTM: [32, 200, 128]
Temporal Attention: [32, 200, 128]
Global Pooled: [32, 128]
Classifier Layer 1: [32, 64]
Final Output: [32, 1]
Inspired by EEGNet and recent MEG research, parallel convolutions with different kernel sizes capture neural patterns at multiple temporal scales simultaneously.
- Spatial: Focus on relevant brain regions
- Temporal: Focus on important time points
- Both improve interpretability and performance
Long skip connections enable:
- Deeper networks (prevents vanishing gradients)
- Faster convergence
- Better gradient flow
- Dropout: Higher rates (0.3) in classifier, lower (0.15) in feature extractors
- Batch Normalization: After each convolution
- Layer Normalization: Before recurrent processing
- Weight Initialization: Xavier for linear, Kaiming for conv, Orthogonal for LSTM
- GELU: Preferred over ReLU for neural signal processing (smoother, better for small signals)
- Superlets provide optimal resolution across different frequency bands relevant to neural processing
- Leveraging powerful visual feature extractors trained on large-scale image datasets (pretrained vision transformers) reduces training requirements and improves generalization
- Adapt efficiently to MEG data with limited training samples
- Capture complex spatiotemporal patterns in neural signals
| Parameter | Default | Range | Description |
|---|---|---|---|
input_dim |
306 | - | Number of MEG channels |
model_dim |
128 | 64-256 | Hidden dimension size |
dropout_rate |
0.3 | 0.2-0.5 | Dropout probability |
lstm_layers |
2 | 2-3 | Number of LSTM layers |
cnn_layers |
3 | 3-6 | Number of MS-CNN blocks (N) |
kernel_sizes |
[5,13,25] | [[5,25], [5,13,25]] | Multi-scale kernel sizes |
use_attention |
True | [True, False] | Enable spatial attention |
use_residual |
True | [True, False] | Enable residual connections |
bi_directional |
True | [True, False] | Bidirectional LSTM |
smoothing |
0.1 | - | Label smoothing |
Binary Cross-Entropy (BCE) for speech/no-speech classification
Adam optimizer recommended with:
- Learning rate: 1e-3 to 1e-4
- Weight decay: 1e-5 to 1e-2
- Warmup for first 5-10% of training
- Cosine annealing or ReduceLROnPlateau
- Temporal cropping/shifting
- Channel dropout
- Gaussian noise injection
- Time warping
- Batch Size: Start with 32-64, increase if memory permits
- Gradient Clipping: Use value of 1.0 to prevent exploding gradients
- Mixed Precision: Use FP16 training for speed (careful with numerical stability)
- Preprocessing:
- Bandpass filter MEG signals (e.g., 0.5-40 Hz)
- Z-score normalization per channel
- Remove bad channels/sensors
- LibriBrain Competition 2025
- EEGNet
- Attention is All You Need
- Deep Residual Learning
- Time-frequency super-resolution with superlets
- Filter Bank Dual-Branch Attention-based Frequency Domain Network (FB-DB-AFDNet)
- F. Afdideh, et al., “Fused Multi-Branch Multi-Domain Residual Multi-Scale CNN BiLSTM Multi-Head Attention Swin Transformer for Language Decoding from MEG: Application for BCI Systems,” in preparation.