Local LLM-assisted text completion for Qt Creator.
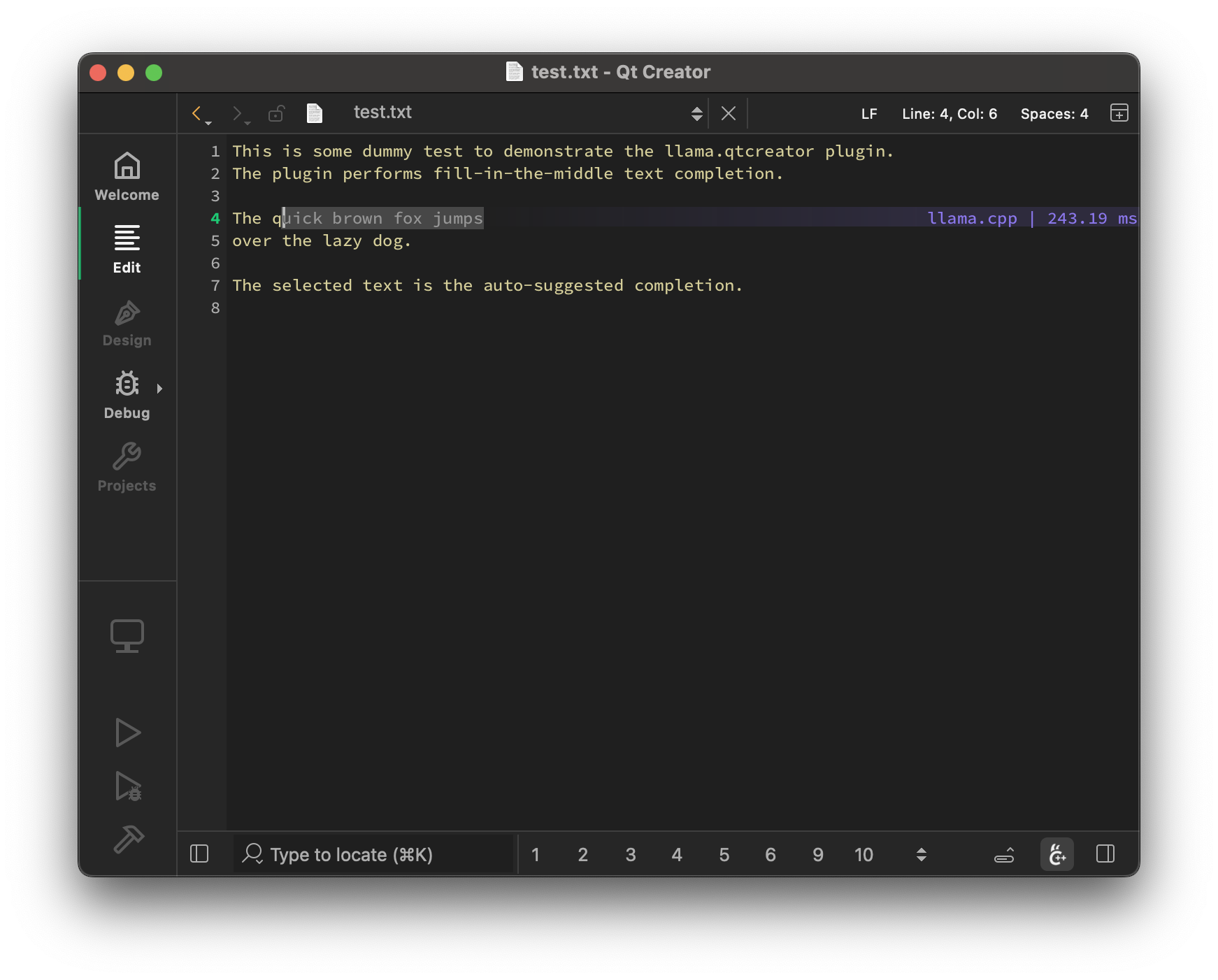
- Auto-suggest on cursor movement. Toggle enable / disable with
Ctrl+Shift+G - Trigger the suggestion manually by pressing
Ctrl+G - Accept a suggestion with
Tab - Accept the first line of a suggestion with
Shift+Tab - Control max text generation time
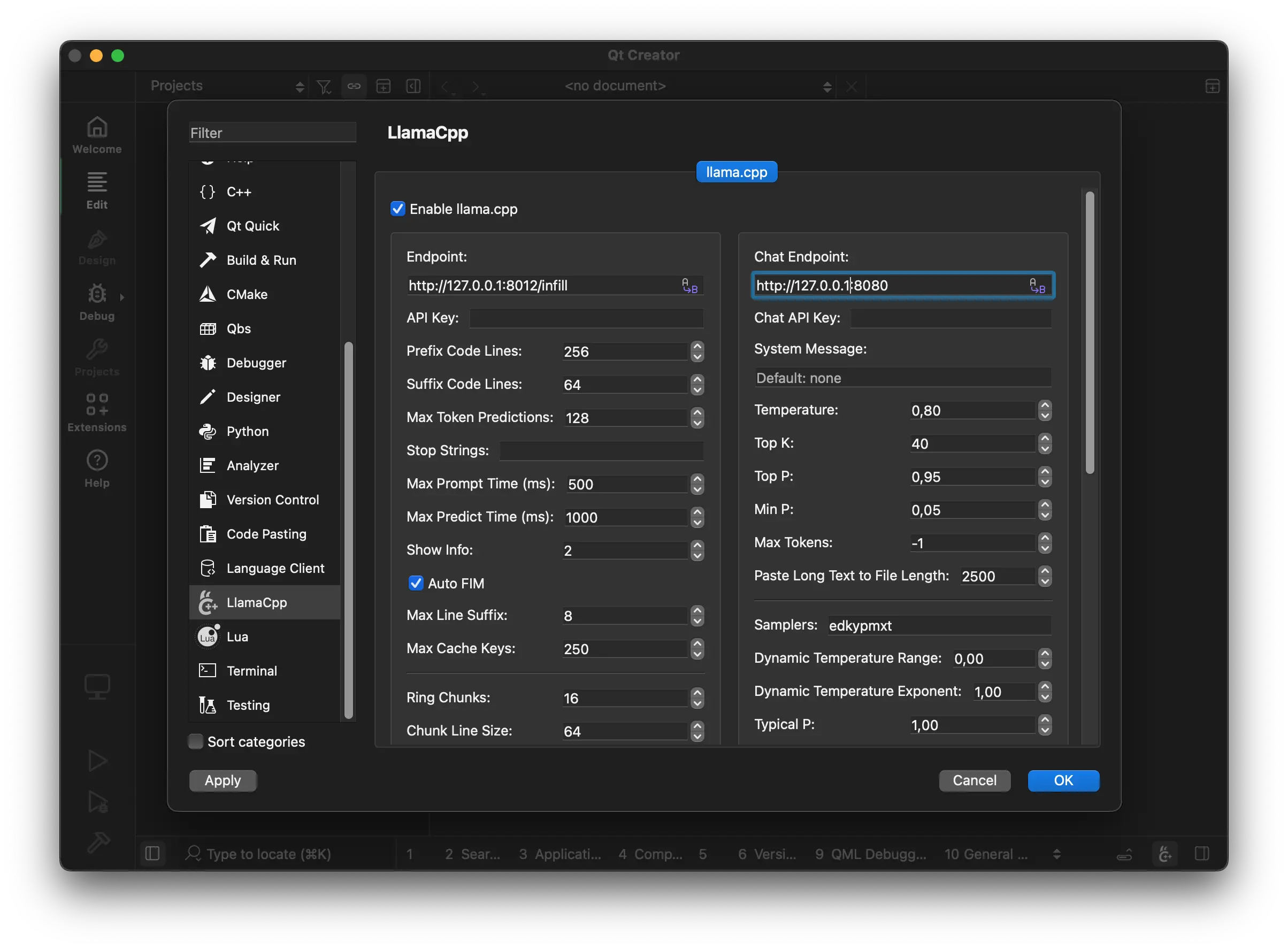
- Configure scope of context around the cursor
- Ring context with chunks from open and edited files and yanked text
- Supports very large contexts even on low-end hardware via smart context reuse
- Speculative FIM support
- Speculative Decoding support
- Display performance stats
The plugin requires a llama.cpp server instance to be running at:
brew install llama.cppwinget install llama.cppEither build from source or use the latest binaries: https://github.com/ggml-org/llama.cpp/releases
Here are recommended settings, depending on the amount of VRAM that you have:
-
More than 16GB VRAM:
llama-server --fim-qwen-7b-default
-
Less than 16GB VRAM:
llama-server --fim-qwen-3b-default
-
Less than 8GB VRAM:
llama-server --fim-qwen-1.5b-default
Use llama-server --help for more details.
The plugin requires FIM-compatible models: HF collection
The plugin aims to be very simple and lightweight and at the same time to provide high-quality and performant local FIM completions, even on consumer-grade hardware.
- Vim/Neovim: https://github.com/ggml-org/llama.vim
- VS Code: https://github.com/ggml-org/llama.vscode