
These are parallel coordinates, one of the best ways I know to visualize data in an understandable way.
The problem starts with larger datasets and the available height on the display and its resolution, which determines how many lines can be drawn. Click on the animations for full screen.

This can be seen on the used credit card fraud detection dataset with nearly 300,000 samples, 30 features and 2 labels. Here is only a partial view of the data possible. Blue lines show transactions and gold lines show fraud. But drawing all the data would take a very long time, and then the latest data lines would simply overdraw the previous data. Even 1% of the data can't be drawn properly here, and every look into a quantum of data ends up in very different impressions.
It may seem better to count the data for each height pixel and align the bar on the highest pixel value for that feature. This would make completely underrepresented data just as visible as overrepresented data. The result: parallel coordinates distribution count (pcdc) - may correct me

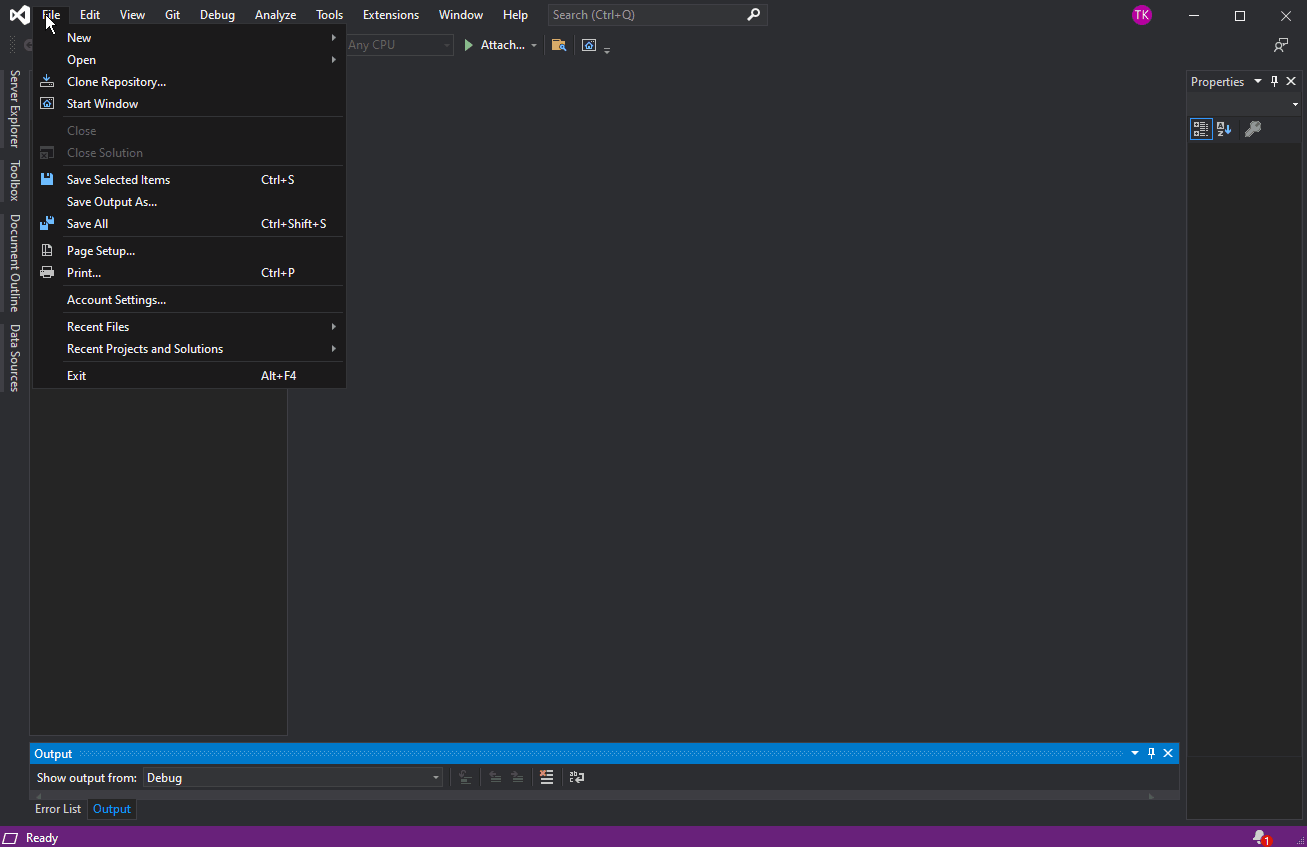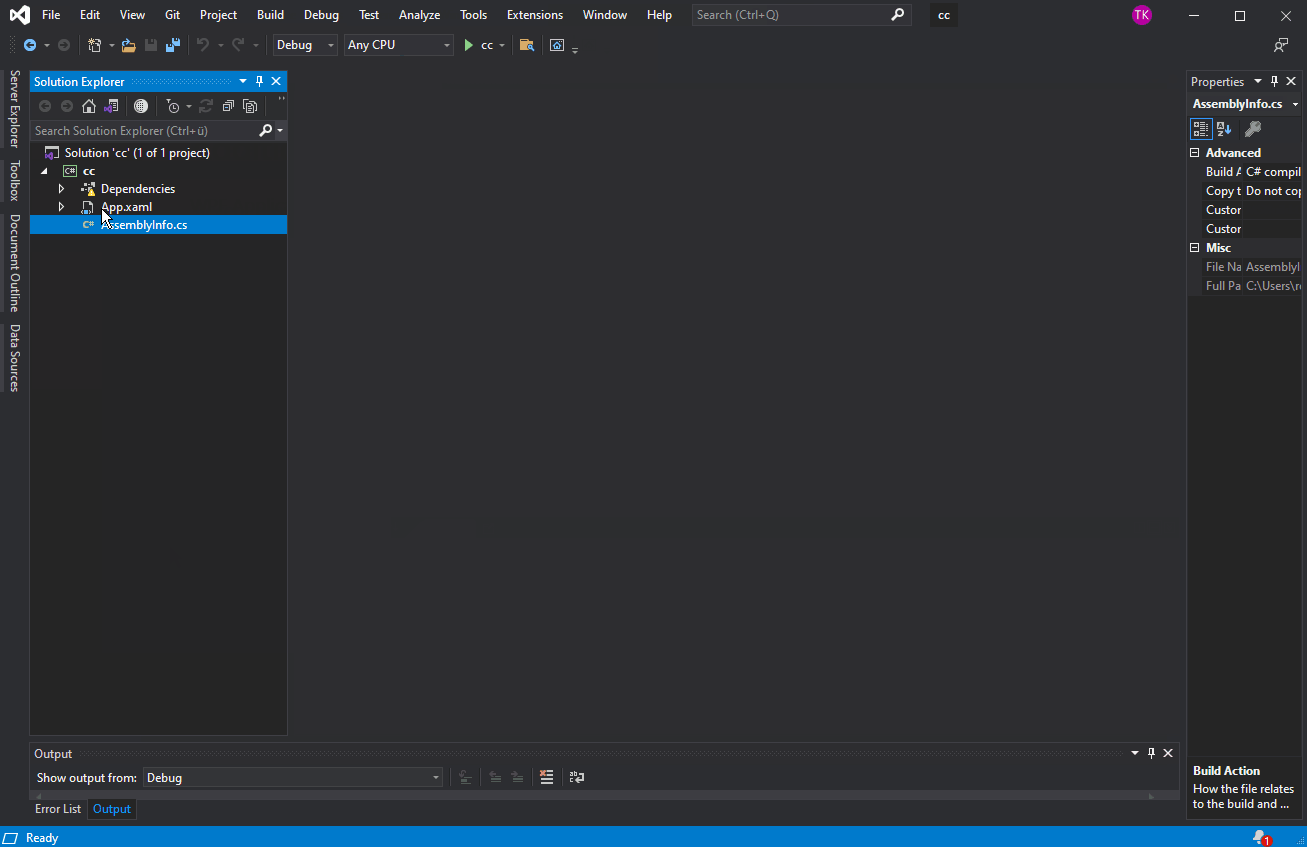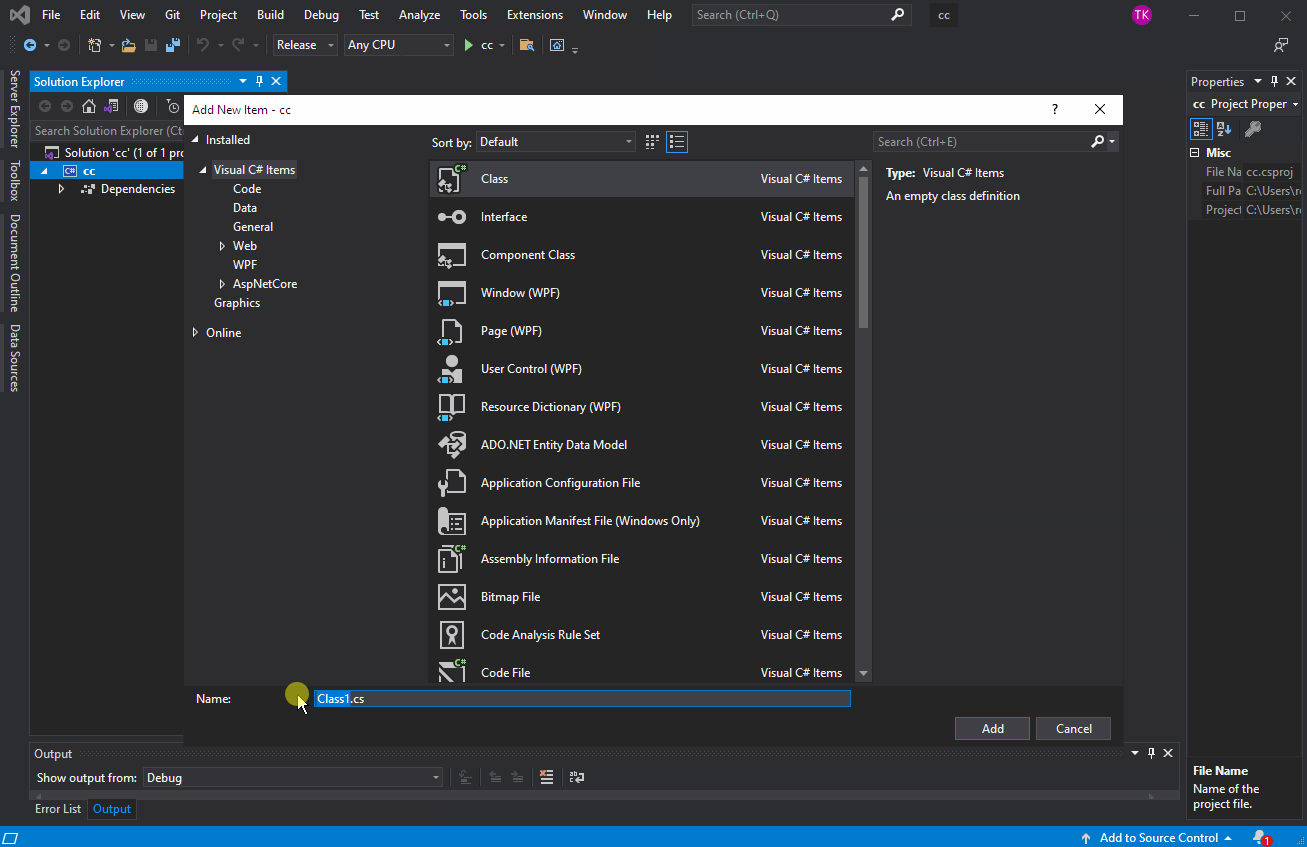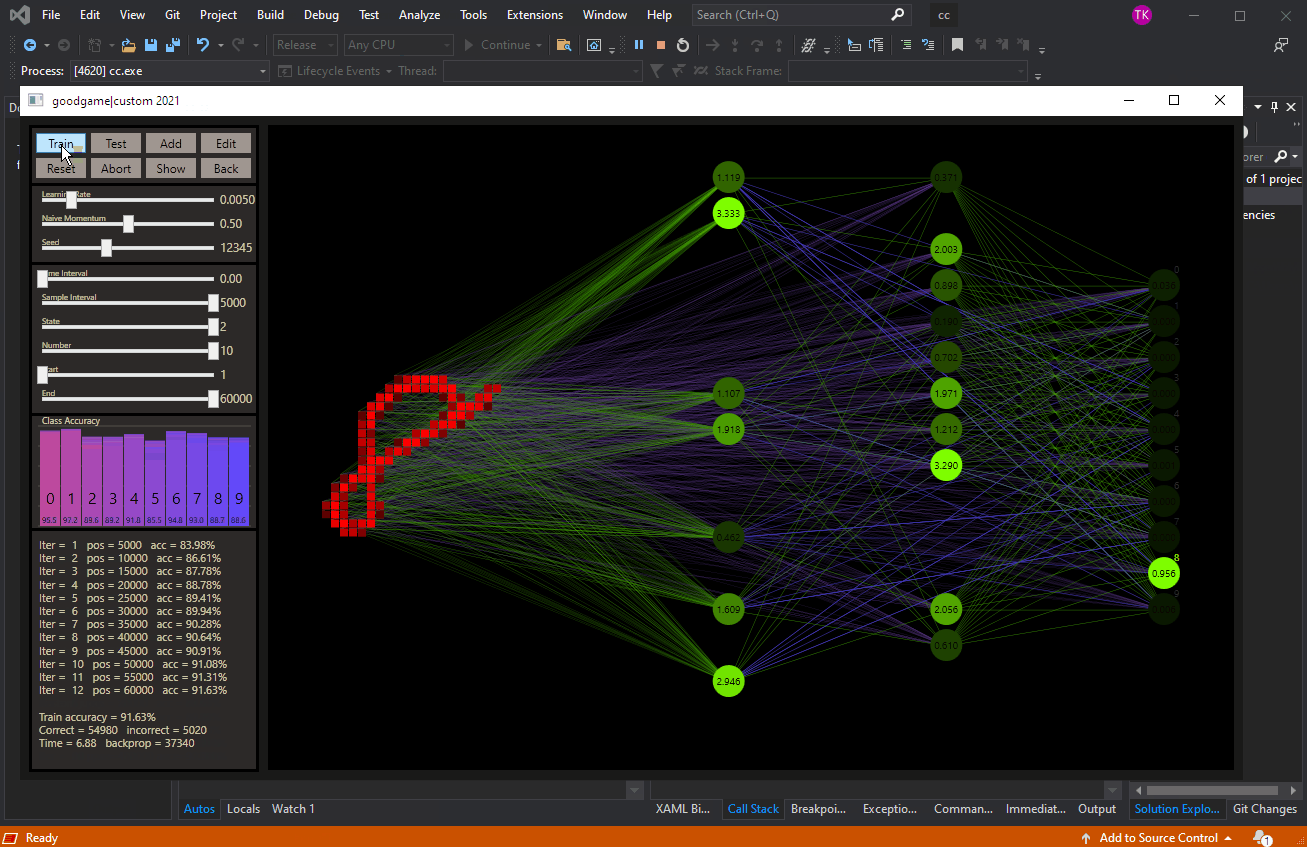
Here is the ruler in action, simple rules that can be set for each feature. In further examples about 25% of the data can be pre-classified just with simple rules. Or, in other words, if we always see fraud in the data in certain areas, it seems wise to look there. After playing around, I was able to achieve the quality of good prediction systems with about 130 rules.
The rules can be saved. A right mouse click on the coordinates deletes all rules. Or we can load the rules again. To predict with the ruler is nice, but only in a naive way, it actually works as a tool. The paradigm is: you get what you see.

The dataset consists of 2 days of transaction data provided by a bank. An alternative dataset link With the new tool, we can quickly create a training dataset for the first day with the desired features. Or simply to create enough space for feature engineering.

You can create a new feature by clicking on the lonely square in the upper right corner. Then simply click on the respective feature on the light blue colored square. The data and the new filled feature can then be adapted to the pixel range and normalized. This feature can be added, subtracted or multiplied with a new feature. When you are done, simply click on the equal sign.
Now new rules can be created based on this, or new datasets or features, just repeat the process and get better insights into the dataset.
To install just take the code and follow this guide with the latest Visual Studio version. The demo uses auto download, the directory for the demo can be changed and is located at the top of the 975 lines of code.
{kind=link}
For illustration only, but not yet supported in the current code.

The Higgs boson (particle) vs. background noise dataset, available here. Be beware of 11,000,000 examples, the file has 8 GB. Here I was more concerned about the question of where the limits are. Much more data should probably not be actively processed on my medium skilled pc.
I don't really know anything about particle accelerators and what happens there. But after the first look at the data it seems to be helpful to cut the last 8 features to stretch the data. It appears that these are the features that offer the greatest differentiation for prediction systems. Assuming we have normalized the dataset already, then all data would be distributed between 0 and 1. The code to cap could look like this: feature = valueFeature > 0.5 ? 1.0 : valueFeature / 0.5;

Here I take the year 2021 to show different ways in which the data can be viewed. The EURUSDM1 dataset 2000-2022 is from kaggle.
The dataset seems independent and identically distributed (iid). Which means that any value can result in the price being higher, the same, or lower in the next minute, which represents the label for us. Forex prediction of how the price will turn out in the next period is very difficult.In reality you would rather look at how many pips the price will move. As a simple example, it is interesting to have all the data for neural network predictions. Which was able to achieve 50.5% accuracy so far, not great but okay actually with 3 labels for entire data. With pcdc it was possible to find some simple rules to reach 55% with a little part of the data. But probably it is more interesting to build a system that can predict based on equality instead of the difference. No matter how you divide the forex data, the picture always seems to converge. Otherwise the difference would have to show up more. At least that was my first naive impression.

Normalization by feeling. But why all this? Actually, pcdc is a kind of glasses, adaptable, and there to provide a neural network improved data. Basically, my main focus lies on neural networks, or what can evolve out of them. Connected to this is also NN visualization. Thinking further, we could combine NNs and hyperparameters and predictions with pcdc to maybe build something more cool.
This is just one example of how pcdc can be used in ways that may seem unusual, but can be extremely effective. In any case, a challenge in the future development of pcdc remains the correct linking between normalization, feature engineering, the prediction system and its training and inference.

Even regression with one single numeric value as label is possible, here still as ordinary parallel coordinates. The highest gold shows the highest house price.
All this is inspired by: Tools to Improve Training Data - Vincent Warmerdam - Talking Language AI Ep#2
From minute 12 on, things get really exciting and data are shown as parallel coordinates. My solution can perhaps be seen as an upgrade for dealing with Big Data. Great video with nice ending.

This tweet was cool, quite a lot of information in a small space, even if I don't completely agree. But pcdc doesn't fit in there, just like the comment about limiting ChatGPT to RL, which was actually RLHF. Nevertheless, it is worth following Sebastian Raschka, especially if you are interested in the latest transformer development topics.
So if there is such a category, then perhaps it is human feedback (HF) learning. Hope you liked the introduction to PCDC.
