{kind=link}
A Study in Parallel Algorithms : Stream Compaction
Comparison of CPU and GPU version for part 2 and part 3:
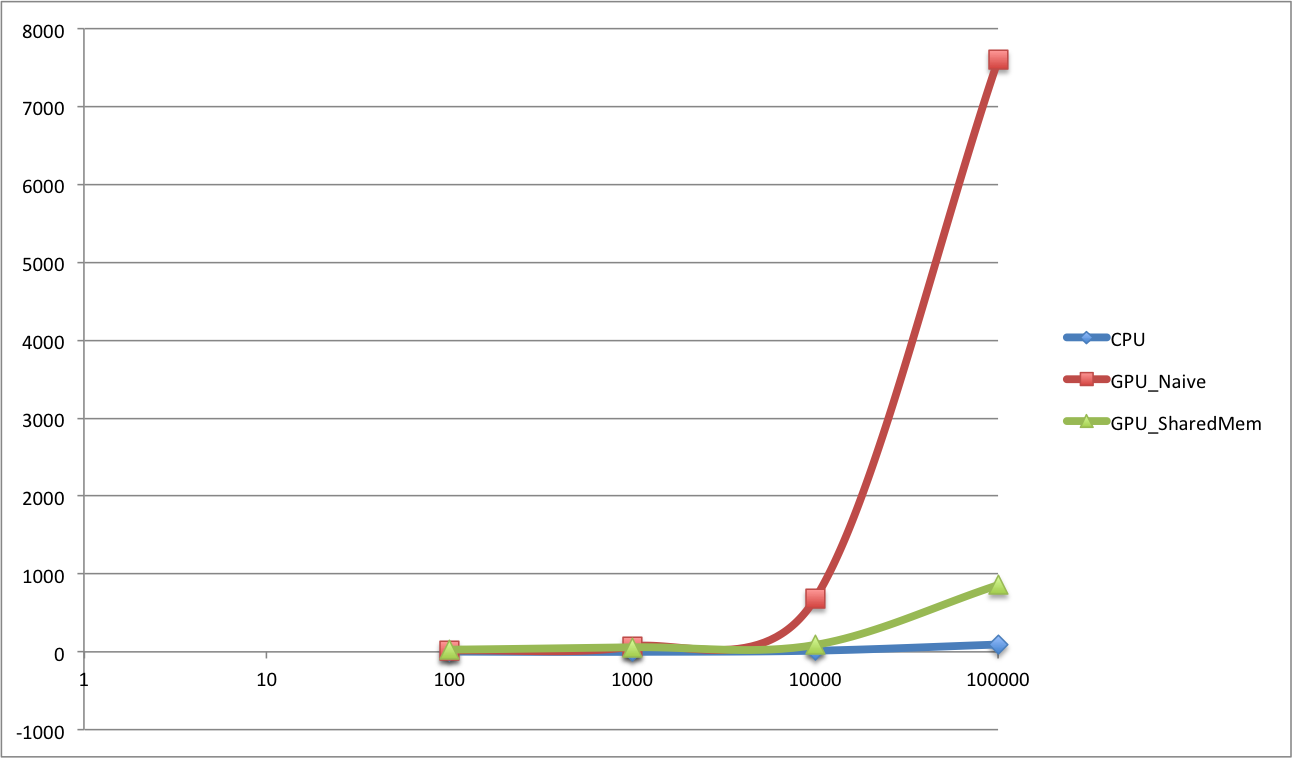
Analysis: The CPU version of scan is actually very fast. I think me implementation of GPU version is not optimal at all.Still the one with shared memory works better than naive implementation when input size increases. And there are lots of bank conflicts. My function has wired behavior. With same input, it returns different output. Half times it gets the right answer, other time it just goes wrong from some points. I am still trying to figure out why. For naive implementation this only happens when input size is larger than the block size. I think this is caused by the threads cannot synchronize across blocks. But for the one using shared memory, even with input size smaller than block size, it still only working half time...
Since my scan is not always working, I cannot verify my scatter. But I think scatter itself is not hard if you have implemented scan. I haven't be able to use thrust, but I guess thrust's stream compact should be better. For my code, I would start optimize it from fix bank conflicts and implement the balanced tree algorithm.
Please answer all the questions in each of the subsections above and write your answers in the README by overwriting the README file. In future projects, we expect your analysis to be similar to the one we have led you through in this project. Like other projects, please open a pull request and email Harmony.
"Parallel Prefix Sum (Scan) with CUDA." GPU Gems 3.