![]()
An automatic differentiation library for generalized meta-learning and multilevel optimization
Docs |
Tutorials |
Examples |
Paper |
Citation |
CASL


pip install betty-ml[Sep 22 2023] "SAMA: Making Scalable Meta Learning Practical" got accepted at NeurIPS 2023!
[Jan 21 2023] Betty got accepted as a notable-top-5% (oral) paper at ICLR 2023!
[Jan 12 2023] We release Betty v0.2 with new distributed training support for meta-learning! Currently available features are:
- Distributed Data Parallel (DDP)
- ZeRO Redundancy Optimizer (ZeRO)
- (experimental) Fully Sharded Data Parallel (FSDP)
You can now easily scale up meta-learning (or even meta-meta-learning) with one-liner change!
- Example: Meta-Weight-Net with RoBERTa
- Tutorial: link
Betty is a PyTorch library for generalized meta-learning (GML) and multilevel optimization (MLO) that allows a simple and modular programming interface for a number of large-scale applications including meta-learning, hyperparameter optimization, neural architecture search, data reweighting, and many more.
With Betty, users simply need to do two things to implement any GML/MLO programs:
- Define each level's optimization problem using the Problem class.
- Define the hierarchical problem structure using the Engine class.
Each level problem can be defined with seven components: (1) module, (2) optimizer, (3)
data loader, (4) loss function, (5) problem configuration, (6) name, and (7) other
optional components (e.g. learning rate scheduler). The loss function (4) can be
defined via the training_step method, while all other components can be provided
through the class constructor. For example, an image classification problem can be
defined as follows:
from betty.problems import ImplicitProblem
from betty.configs import Config
# set up module, optimizer, data loader (i.e. (1)-(3))
cls_module, cls_optimizer, cls_data_loader = setup_classification()
class Classifier(ImplicitProblem):
# set up loss function
def training_step(self, batch):
inputs, labels = batch
outputs = self.module(inputs)
loss = F.cross_entropy(outputs, labels)
return loss
# set up problem configuration
cls_config = Config(type='darts', unroll_steps=1, log_step=100)
# Classifier problem class instantiation
cls_prob = Classifier(name='classifier',
module=cls_module,
optimizer=cls_optimizer,
train_data_loader=cls_data_loader,
config=cls_config)In GML/MLO, each problem will often need to access modules from other problems to
define its loss function. This can be achieved by using the name attribute as
follows:
class HPO(ImplicitProblem):
def training_step(self, batch):
# set up hyperparameter optimization loss
...
# HPO problem class instantiation
hpo_prob = HPO(name='hpo', module=...)
class Classifier(ImplicitProblem):
def training_step(self, batch):
inputs, labels = batch
outputs = self.module(inputs)
loss = F.cross_entropy(outputs, labels)
"""
accessing weight decay hyperparameter from another
problem HPO can be achieved by its name 'hpo'
"""
weight_decay = self.hpo()
reg_loss = weight_decay * sum(
[p.norm().pow(2) for p in self.module.parameters()]
)
return loss + reg_loss
cls_prob = Classifier(name='classifier', module=...)The Engine class handles the hierarchical dependencies between problems. In GML/MLO,
there are two types of dependencies: upper-to-lower (u2l) and lower-to-upper (l2u).
Both types of dependencies can be defined with a Python dictionary, where the key is
the starting node and the value is the list of destination nodes.
from betty import Engine
from betty.configs import EngineConfig
# set up all involved problems
problems = [cls_prob, hpo_prob]
# set up upper-to-lower and lower-to-upper dependencies
u2l = {hpo_prob: [cls_prob]}
l2u = {cls_prob: [hpo_prob]}
dependencies = {'u2l': u2l, 'l2u': l2u}
# set up Engine configuration
engine_config = EngineConfig(train_iters=10000, valid_step=100)
# instantiate Engine class
engine = Engine(problems=problems,
dependencies=dependencies,
config=engine_config)
# execute multilevel optimization
engine.run()Since Engine manages the whole GML/MLO program, you can also perform a global validation
stage within it. All problems that comprise the GML/MLO program can again be accessed with
their names.
class HPOEngine(Engine):
# set up global validation
@torch.no_grad()
def validation(self):
loss = 0
for inputs, labels in test_loader:
outputs = self.classifer(inputs)
loss += F.cross_entropy(outputs, targets)
# Returned dict will be automatically logged after each validation
return {'loss': loss}
...
engine = HPOEngine(problems=problems,
dependencies=dependencies,
config=engine_config)
engine.run()Once we define all optimization problems and the hierarchical dependencies between them
with, respectively, the Problem class and the Engine class, all complicated internal
mechanisms of GML/MLO such as gradient calculation and optimization execution order will
be handled by Betty. For more details and advanced features, users can check out our
Documentation and
Tutorials.
Happy multilevel optimization programming!
We provide reference implementations of several GML/MLO applications, including:
- Hyperparameter Optimization
- Neural Architecture Search
- Data Reweighting
- Domain Adaptation for Pretraining & Finetuning
- (Implicit) Model-Agnostic Meta-Learning
While each of the above examples traditionally has a distinct implementation style, note that our implementations share the same code structure thanks to Betty. More examples are on the way!
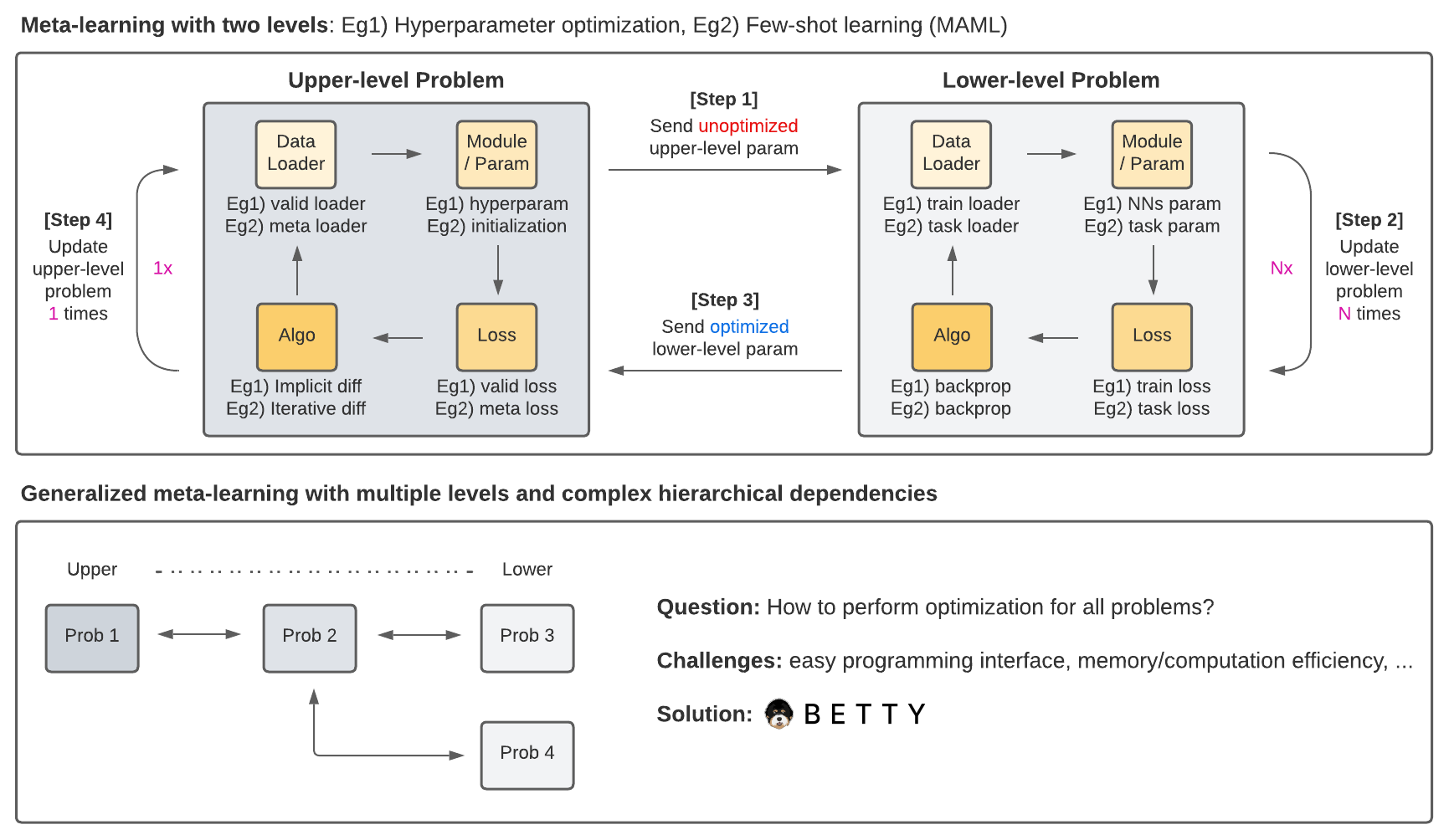
- Implicit Differentiation
- Finite Difference (or T1-T2) (DARTS: Differentiable Architecture Search)
- Neumann Series (Optimizing Millions of Hyperparameters by Implicit Differentiation)
- Conjugate Gradient (Meta-Learning with Implicit Gradients)
- Iterative Differentiation
- Reverse-mode Automatic Differentiation (Model-Agnostic Meta-Learning (MAML))
- Gradient accumulation
- FP16/BF16 training
- Distributed data-parallel training
- Gradient clipping
We welcome contributions from the community! Please see our contributing guidelines for details on how to contribute to Betty.
If you use Betty in your research, please cite our paper with the following Bibtex entry.
@inproceedings{
choe2023betty,
title={Betty: An Automatic Differentiation Library for Multilevel Optimization},
author={Sang Keun Choe and Willie Neiswanger and Pengtao Xie and Eric Xing},
booktitle={The Eleventh International Conference on Learning Representations },
year={2023},
url={https://openreview.net/forum?id=LV_MeMS38Q9}
}
Betty is licensed under the Apache 2.0 License.