有时我们通过sparkSQL来分析数据,当使用Join操作时,最让人头疼的莫过于数据倾斜了,如果你是大表关联小表的情况, 那情况还不是很糟糕,可以使用MAPJOIN来破解一下,spark使用spark.sql.autoBroadcastJoinThreshold参数来自动 开启MAPJOIN; BUT,如果两张表数据量都很大的话,MAPJOIN就无能为力了。
处理Join导致的数据倾斜常规方式是对导致倾斜的keys做单独处理,最后在做union, 但问题来了,使用SQL如何处理? 这时我们自定义hint就派上用场了,自定义hint需要扩展ResolveHints解析器的逻辑,修改也比较简单,详细请参见GitHub上源码 我这边自定义的hint为SKEWED_JOIN。 用法如下:
SKEWED_JOIN(join_key(leftTB.field, rightTB.field), skewed_values('value1', 'value2'))
假如我们有SQL:
SELECT f1, f2, f3, f4 FROM leftTB t1 LEFT JOIN rightTB t2 on t1.id=t2.id
leftTB数据量:1亿
rightTB数据量:5000万
关联key: leftTB.id = rightTB.id
解析后的plan:
Project [f1#1, f2#2, f3#4, f4#5]
+- Join LeftOuter, (id#0 = id#3)
:- SubqueryAlias t1
: +- SubqueryAlias leftTB
: +- Relation[id#0,f1#1,f2#2] parquet
+- SubqueryAlias t2
+- SubqueryAlias rightTB
+- Relation[id#3,f3#4,f4#5] parquet
由于 leftTB.id列的数值 5和6非常多,这样就会导致数据处理倾斜(注:rightTB.id列的数值分布正常,如果不正常是另一种场景, 数据膨胀) 这是我们使用自定义hint来处理数据倾斜
现在SQL:
SELECT /*+ SKEWED_JOIN(join_key(leftTB.id,rightTB.id),skewed_values(5,6)) */ f1, f2, f3, f4 FROM leftTB t1 LEFT JOIN rightTB t2 on t1.id=t2.id
解析后的plan:
Project [f1#1, f2#2, f3#4, f4#5]
+- ResolvedHint none
+- Union
:- Join LeftOuter, (id#0 = id#3)
: :- Filter NOT id#0 IN (5, 6)
: : +- SubqueryAlias t1
: : +- SubqueryAlias leftTB
: : +- Relation[id#0,f1#1,f2#2] parquet
: +- Filter NOT id#3 IN (5, 6)
: +- SubqueryAlias t2
: +- SubqueryAlias rightTB
: +- Relation[id#3,f3#4,f4#5] parquet
+- Join Inner, (id#0 = id#3)
:- ResolvedHint (broadcast)
: +- Filter id#0 IN (5, 6)
: +- SubqueryAlias t1
: +- SubqueryAlias leftTB
: +- Relation[id#0,f1#1,f2#2] parquet
+- ResolvedHint (broadcast)
+- Filter id#3 IN (5, 6)
+- SubqueryAlias t2
+- SubqueryAlias rightTB
+- Relation[id#3,f3#4,f4#5] parquet
从plan我们可以看到SKEWED_JOIN hint帮我们把语法树拆解成两Join,并且把导致倾斜的值过滤出来单独做MAPJOIN,最后再做了Union
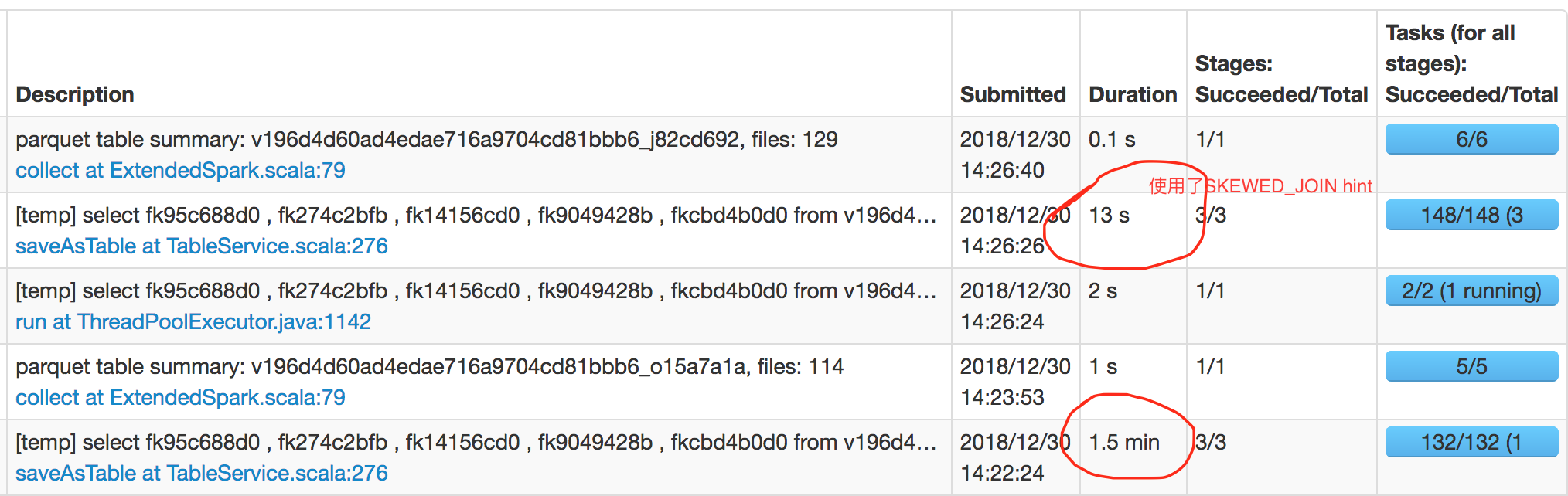
A: 这种拆解Join最终的执行结果与原Join的结果一致吗?
Q: SKEWED_JOIN hint只是把导致倾斜的某几个value单独过滤出来做Inner Join, 最后再做Union,理论上不会影响执行结果